GNU APL
June 29, 2024 This manual briefly documents GNU APL, an interpreter for APL as described in ISO standard 13751, aka. "Programming Language APL, Extended".
This manual for GNU APL can be distributed under the terms of the GNU Free Documentation License, *Note Chapter 6::.
This manual does NOT describe APL itself; there exist a number of good books and texts about APL. We would like to refer the reader to the following:
ISO Standard for APL:
www.math.uwaterloo.ca/~ljdickey/apl-rep/docs/is13751.pdf
Note that the file is13751.pdf above is compressed with gzip, therefore it must be expanded with e.g. gunzip before it can be read.
More pointers to APL resources on the Web:
ftp://rtfm.mit.edu/pub/usenet-by-group/comp.lang.apl/APL_language_FAQ
Table of Contents
- 1 Installing and Starting GNU APL
- 2 Non-standard GNU APL Features
- 2.1 APL Scripting
- 2.2 Axis argument in defined functions
- 2.3 Colored Output
- 2.4 Comparison Rules
- 2.5 Complex Numbers
- 2.6 Debug Commands
- 2.7 Direct Functions (Lambdas)
- 2.8 ]DOXY Command
- 2.9 Commands )COPY_ONCE, )DUMP, and DUMP-HTML
- 2.10 ]NEXTFILE and ]PUSHFILE Commands
- 2.11 History and TAB completion
- 2.12 Logging Facilities
- 2.13 Rational Numbers
- 2.14 Hex Numbers
- 2.15 User-defined Commands
- 2.16 Structured Variables and Associative Arrays
- 2.17 Monadic ⊢ and ⊣, dyadic ⊢ with Axis
- 2.18 Bit-wise Logical Functions ⊤∧, ⊤∨, ⊤⍲, ⊤⍱, ⊤≠, and ⊤=
- 2.19 Generalized ⍳
- 2.20 ⌹[X] - QR Factorization
- 2.21 Dyadic ⎕CR
- 2.22 Dyadic ⎕FX (Native Functions)
- 2.23 ⎕ARG - Interpreter command line arguments
- 2.24 ⎕DLX - Knuth’s Dancing Links Algorithm
- 2.25 ⎕ENV - Environment Variables
- 2.26 ⎕FIO - File I/O Functions
- 2.27 ⎕FFT - Fast Fourier Transform
- 2.28 ⎕GTK - GTK Interface
- 2.29 ⎕JSON - JSON Parsing
- 2.30 ⎕MAP - Map Value
- 2.31 ⎕PLOT - Plot Data
- 2.32 ⎕PNG - Portable Network Graphics
- 2.33 ⎕PS - Print Style
- 2.34 ⎕RE - Regular Expressions
- 2.35 ⎕RVAL - Random APL value
- 2.36 ⎕SQL - SQL Database Interface
- 2.36.1 ⎕SQL[0] : display subfunctions
- 2.36.2 ref ← A ⎕SQL[1] B : open database
- 2.36.3 ⎕SQL[2] B : close database
- 2.36.4 Z ← A ⎕SQL[3, ref] B : database query (with result)
- 2.36.5 Z ← A ⎕SQL[4, ref] B : database query (w/o result)
- 2.36.6 ⎕SQL[5] B : start transaction
- 2.36.7 ⎕SQL[6] B : commit transaction
- 2.36.8 ⎕SQL[7] B : rollback transaction
- 2.36.9 Z←⎕SQL[8] B : table names
- 2.36.10 Z←⎕SQL[9] B : column names
- 2.36.11 Z ← ⎕SQL[10] B : library version number
- 2.36.12 Z ← ⎕SQL[11] B : library version string
- 2.37 ⎕SI - State Indicator
- 2.38 ⎕SYL - System limits
- 2.39 ⎕XML - XML Parsing
- 2.40 Conditionals
- 2.41 Matrix Product
- 3 Limitations and Missing Features
- 4 Internationalization
- 5 Project Structure
- 6 Libraries Contributed by GNU APL Users
- 7 Licenses for this GNU APL Manual and for GNU APL
Next: Non-standard GNU APL Features, Previous: GNU APL, Up: GNU APL [Contents]
1 Installing and Starting GNU APL
- Installing APL
- Starting APL
- Command Line Options
- Configuration File for GNU APL
- File Names and Paths
1.1 Installing APL
APL is built and installed like this:
- download the tar file containing GNU APL, from ftp://ftp.gnu.org/gnu/apl or from one of its mirrors (see http://www.gnu.org/prep/ftp.html), and un-tar the file.
- read (and follow) the instructions given in file README in the unpacked directory
For the experienced, but impatient reader: it is the usual sequence
- ./configure
- make
- make install
On success, an executable file named ’apl’ will have been produced in the sub-directory ’src’.
File README contains further instructions about the installation GNU APL.
1.2 Starting APL
Last things first: before explaining how to start APL, it is important to remember how to stop (i.e. exit) it. Neither ^C nor ^D will stop APL - they serve other purposes. Instead, you leave APL with the command )OFF (on a separate line) like this:
)OFF
If APL is computing a function (and possibly caught in an endless loop), then you may have to press ^C (this is called ATTENTION in APL) to return to APL’s command mode so that the )OFF command can be entered. In some circumstances it may be necessary to press ^C twice within a short time interval (this is called INTERRUPT in APL).
Having that said, APL is started like every other program - by entering its name and optional command line parameters, for example:
$ apl
or:
$ apl -id 1001
GNU APL is script-able; a text file whose first line looks like this (assuming the APL interpreter binary is called ’apl’ and is located in the current directory):
#! ./apl
or (if the APL interpreter binary is not in the current directory but in /mypath/apl):
#! /mypath/apl
The path to the ’apl’ binary can be missing (like in the first example), relative, or absolute (second example). The exact details of how the first line of a GNU APL script shall look vary slightly among operating systems. Please consult the info (or man) pages for ’path_resolution’ and/or ’execve’ on your operating system. After the name of the binary, optional GNU APL command line options, usually –script, can be provided.
The text file must, of course, have execute permission, and should be ASCII or, more likely, UTF-8 encoded. The APL characters in the script shall be those defined in the Unicode character set (most of them in the U+2200 - U+23FF range).
1.3 Command Line Options
GNU APL understands the following command line options:
- -C new_root
perform chroot("new_root") followed by chdir("/"). This restricts the access of the process running GNU APL to files in or below directory new_root, and it also changes the current directory (which could have resided above new_root before the chroot() was executed).
The -C option is intended to be a security feature for GNU APL interpreters that are facing a hostile environment like the public internet.
NOTES:
- For -C to work, new_root needs to contain a minimal set of binaries, in particular a shell, and possibly libraries needed by the shell. Consult ’info chroot invocation’ for issues to consider and common pitfalls.
- GNU APL processes the -C option (i.e. it calls chroot("new_root")) before all other command line options. As a consequence, file names in other command line options of GNU APL are also affected by -C. That means that the file names in command line options are being interpreted relative to new_root and not relative to the current directory of the process that had started GNU APL.
- GNU APL may automatically start other processes such as APserver and friends after processing the -C option. These processes (and the libraries that they depend on) should reside in the proper directory below new_root. For example, with the default configuration of GNU APL, GNU APL installs itself in /usr/local/bin and also expects APserver in the same directory. After -C new_root, however, /usr/local/bin is no longer accessible and one would need to copy /usr/local/bin/APserver to new_root/usr/local/bin/APserver
- Depending on your platform, the process using -C may need root privileges.
- --cfg
show ./configure options that were used to configure GNU APL, and exit.
- --[no]Color
start with ]COLOR ON [OFF].
- -d
run the APL interpreter (or APL script) in the background (i.e. as a daemon). For this to work you need to provide some input to the background process, e.g. via the -f option.
- --emacs
run in (old) Emacs mode.
- --emacs_arg arg
run in (new) Emacs mode with argument arg.
- --eval line
evaluate one APL line and exit. This option can be given several times; in that case several lines are being executed before GNU apl exits. Keep in mind that command line options are normally processed by your shell before being passed to apl. Therefore sometimes quoting the argument of –eval may be needed and common wisdom has it to always quote the argument of –eval.
- -f file
read input from file rather than from the keyboard. When the end of the file is reached, input is switched back to the keyboard. If you want to terminate the APL interpreter after executing the file, then use )OFF as last line in the file.
- --gpl
show GNU APL license (GPL) and exit.
- -L wsname
)LOAD wsname on start-up.
- --LX expr
execute expr first. The workspace behaves as if ⎕LX (latent expression) were set to expr in the workspace. This can be used, for example, to start the same workspace with different start-up values.
- -h, --help
print all command line options with a brief hint about what they do.
- --id proc
use processor ID proc for this interpreter. If no ID is provided, then the first unused ID > 1000 is taken by this interpreter and the ID becomes used as long as the interpreter runs. Processor IDs are used by shared variables to identify share partners.
- -l num
turn logging facility num ON (provided that dynamic logging was ./configure’d). The logging facility 37 (start-up messages) is of particular importance for troubleshooting and it works even if dynamic logging was not ./configure’d.
- --mem [memory-limit]
tell the interpreter not to use more than memory-limit bytes of RAM. By using this option, the user is fully responsible for ensuring that the specified amount of memory will always be available. The following rules should be observed.
The interpreter will exit at start-up if --mem is used and:
- the platform on which the interpreter runs has no /proc/meminfo, or
- the platform has no /proc/sys/vm/overcommit_memory, or
- /proc/sys/vm/overcommit_memory is not 2 (aka. ’never overcommit’)
On GNU/Linux systems these conditions are normally satisfied, but the root user has to set /proc/sys/vm/overcommit_memory to 2 which differs from the default value 0 (aka. overcommit allowed).
If no memory-limit is given, then a memory-limit of 50% is used.
If a memory-limit is provided then it must have a unit of %, kB, MB, or GB. If the unit is % then the limit is computed as that percentage (between 5% and 95%) of parameter ’MemFree:’ in /proc/meminfo. Otherwise the limit is the given amount in kB, MB, or GB.
For example:
- --mem (50% of MemFree: in /proc/meminfo are guaranteed)
- --mem 80% (80% of MemFree: in /proc/meminfo are guaranteed)
- --mem 5G (5 GB are guaranteed)
WARNING: The memory-limit is checked against parameter ’MemFree’ in /proc/meminfo when GNU APL starts, but this does not protect against other processes consuming the free memory at a later point in time.
If that happens (and according to the rules above the user has the responsibility to prevent it), then ⎕WA becomes unreliable and the interpreter may crash badly (i.e. without a WS FULL error, and without any chance to )SAVE the workspace) when the available memory is exhausted.
- --echoCIN copy the input line (after editing) to stdout. For creating session logs.
- --noCIN
do not echo stdin to stdout. Almost a must for scripting (unless you intend to troubleshoot a script).
- --to_COUT
normally GNU APL writes its output to stderr (i.e. file descriptor 2) so that, when GNU APL is started in a script, the output of the script appears on stdout (i.e. file descriptor 1) while the output of GNU APL appears on stderr.
This option redirects the stderr output of GNU APL to stdout. The same effect can be achieved with the option "OUTPUT-TO-COUT Yes" in a preferences file.
- --tcp_port PORT
this option starts GNU APL as a server that listens on TCP port PORT. Every TCP connection accepted by the server forks a new GNU APL instance which has its stdin, stdout, and stderr redirected to the TCP connection.
WARNING: This option is dangerous if PORT is directly exposed to the internet!
- --noCONT
do not load a SETUP or CONTINUE workspace on start-up.
- --OFF
This option causes GNU APL to perform an automatic )OFF command after the last line of the last input file (as per -f option) was executed.
- --PW COLS
set the initial value of ⎕PW to COLS (min. 30, max. 10000)
- --[no]SV
do [not] start APserver (a shared variable server) on start-up. This disables communication with other workspaces or auxiliary processors through shared variables.
- -p N
use profile number N in preferences files. A preference file may contain several sets of settings for different purposes; the profile number selects one of these sets.
- --par pproc
use processor parent ID pproc (default: no parent ID).
- --rawCIN
do not emit ESC sequences. Normally ESC sequences are emitted for colored output and during line editing. In scripts, however, ESC sequences usually are not wanted and can be turned off with this option.
- -s, --script
this option is an abbreviation for: --silent --noCIN --noCONT -f - which is a typical combination of options for APL scripts.
- -q, --silent
suppress printing of the GNU APL welcome message. Useful for scripts.
- --safe
disable shared variables and native functions
- --show_bin_dir
display the binary directory (where, according to ./configure, the programs apl, APserver, AP100, and AP210 are supposed to be installed. Then exit.
- --show_doc_dir
display the directory where, according to ./configure, documentation files for GNU APL are installed. Then exit.
- --show_etc_dir
display the system configuration directory where, according to ./configure, the preferences file for GNU APL is installed. Then exit.
- --show_lib_dir
display the library directory where, according to ./configure, shared library files and the workspaces shipped with GNU APL are installed. Then exit.
- --show_src_dir
display the source directory where, according to ./configure, GNU APL was compiled. Then exit. This can be used, for example, by native functions that are built outside the GNU APL source tree to find GNU APL header files that are needed to compile the native function.
- --show_all_dirs
display all the directories above. Then exit.
- -T testcases ... run testcases. Testcases are text files that contain both input to the APL interpreter and the expected response from the interpreter. The output from the interpreter is compared with the expected output in the testcase file(s) and differences are marked. In addition a summary file is created that tells whether or not each of the testcases was successful.
- --TM mode
test mode. This option specifies how the interpreter shall behave when running a number of testcases (as specified with the -T option)
--TM 0 (default) run all testcases and exit after the last testcase.
--TM 1 like --TM 0 if no error was detected. However, if one of the testcases has failed, then the interpreter does not exit so that the user can investigate the state of APL (SI, variable values, etc.).
--TM 2 like --TM 1, but stay in the interpreter even if all testcases have passed. This can be useful for quickly bringing the interpreter into a specific state and continue manual troubleshooting from that state.
--TM 3 like --TM 1, but stop testcase execution after the first failed testcase (i.e. do not exit).
--TM 4 like --TM 3, but exit after the first failed testcase. This is useful for automatic regression tests, where no errors are expected.
- --TR
executes test case files in random order.
- --TS
Normally, when the interpreter is run with the -T option, an existing summary.log file is overwritten without notice. This option causes new test results to be appended to a possibly existing summary.log instead of overwriting it.
- -v, --version,
show version information and exit.
- -u UID
run as user with UID 0. This option can only be used by the root user (who then wants to run as a different user).
- -w milli
wait milli milliseconds at start-up. Useful to give other programs that are started together with this interpreter time to initialize themselves.
- +APPOPT
- ++APPOPT ARG1
- +++APPOPT ARG1 ARG2
- ...
Those command line options above that start with - are understood by the GNU APL binary and their arguments must follow the description given for them. In addition the interpreter also accepts command line options that start with +. However, these options are not checked by the interpreter in any way, but are merely copied to ⎕ARG (see below). In these options, APPOPT, ARG1, ARG2, ... are arbitrary strings that should not contain any whitespace characters. The purpose of these options is to control aspects of the APL application from the command line.
- --
end of command line options for the interpreter. GNU APL provides the system variable ⎕ARG that returns all command line options with which the GNU APL interpreter was invoked (similar to variable argv in main(int argc, char * argv[]) in C/C++). Option -- can be used to separate command line options for the APL interpreter from command line options understood by APL applications.
Thus,
(⎕ARG ⍳ ⊂'--') ↑ ⎕ARGreturns the options for the APL interpreter, while(⎕ARG ⍳ ⊂'--') ↓ ⎕ARGreturns the options for the APL application.All command line options after -- are ignored by the interpreter (except for including them in ⎕ARG).
1.4 Configuration File for GNU APL
The default values for some of the command line options discussed in the previous section can be set in a configuration file for GNU APL. The name of the configuration file is ’preferences’ and it should live in one of the following directories:
- in the sub-directory gnu-apl.d of the system configuration directory, or
- in the sub-directory .config/gnu-apl of the user’s home directory (as per $HOME).
The system configuration directory is usually /etc or /usr/local/etc and is configurable via ./configure --sysconfdir. An empty (i.e. most settings commented out) preferences file is also installed in the system configuration directory when GNU APL is installed. You can edit it, use it as a template or read it to see which options can be controlled.
If file ’preferences’ exists in both directories, the settings in $HOME/.config/gnu-apl/preferences override settings in, for example, /etc/gnu-apl.d/preferences.
Command line options in turn override settings in ’preferences’ files.
1.5 File Names and Paths
The GNU APL interpreter is a binary file named ’apl’. It is usually installed in directory /usr/bin/ or in /usr/local/bin/. The location where ’apl’ is installed can be changed via ./configure options (see file INSTALL).
GNU APL understands 4 file types:
- APL workspaces that can be manipulated with the )LOAD, )SAVE, )COPY, and )DROP commands. APL workspaces are XML files and must have a file extension of .xml to be accepted by GNU APL. APL workspaces can only be exchanged between machines that all run GNU APL.
- APL exchange files can be manipulated with the )IN and )OUT commands. APL exchange files are text files in ⎕TF format defined by IBM (basically APL expressions that create variables or functions) and must have a file extension of .atf to be accepted by GNU APL. APL exchange files can be exchanged between machines running APL interpreters from different vendors. The ⎕TF format can be easily emulated on machines not providing compatible )IN and )OUT commands.
- APL scripts consist of APL commands and APL expressions (including function definition via ∇) like they would be entered by the user. APL scripts should have a file extension of .apl but other extensions are also accepted by GNU APL. APL scripts are, for example, the files expected for the -f command line option. A workspace can be written in this format with the )DUMP command.
- APL testcase files are similar to APL scripts, but in addition to the APL commands and expressions they also contain the expected output from the commands. APL testcase files normally have a file extension of .tc for normal (functional) testcases and .pt for performance testcases. APL testcase files are, for example, the files expected for the -T command line option.
The following APL commands are related to file names:
)LOAD [lib] name[.xml]
)SAVE [lib] [name[.xml]]
)COPY [lib] [name[.xml]]
)PCOPY [lib] [name[.xml]]
)DROP [lib] [name[.xml]]
)IN [lib] name[.atf]
)PIN [lib] name[.atf]
)OUT [lib] name[.atf]
)DUMP [lib] [name[.apl]]
)LIB [lib]
)LIBS [new-lib-root]
)WSID [name]
The rules for how file names are constructed from the argument(s) of an APL command are:
- command arguments shown in brackets are optional.
- lib is a number from 0 to 9. If lib is not present then 0 is taken as default.
- if the name is optional and missing then the workspace ID (the name set with the )WSID command) is used.
- if the file extension (i.e. .xml or .atf) is missing then it is appended automatically to name.
If the name starts with ’/’ then it is taken as an absolute path to the file (an absolute file name) and no further computation is done with the name.
Otherwise name is a relative path which is relative to some directory library-root and a sub-directory of library-root that is determined by the lib number. The library numbers 0-9 correspond to the following directories:
0: library-root/workspaces/
1: library-root/wslib1/
2: library-root/wslib2/
...
9: library-root/wslib9/
The command )LIBS without arguments shows the mapping between library numbers and paths. The command )LIBS with an argument sets a new lib-root.
The command )LIB [lib] shows the files in library (i.e. directory) lib.
The directory library-root is computed as follows when the interpreter starts:
If an environment variable APL_LIB_ROOT is defined, then its value is used as library-root. Otherwise the path from the current directory (".") up to the root directory ("/") is searched until a directory containing two files ’workspaces’ and ’wslib1’ is found. Normally ’workspaces’ and ’wslib1’ are directories, but for the computation of library-root files suffice.
If such a directory is found, then it is used as library-root; otherwise the current directory (i.e. ".") is used and converted to an absolute path.
For example, if library-root is "." then the command
)LOAD 2 test
will try to load the workspace file
./wslib2/test.xml
Using a library root implies that all 10 library directories are contained in the same directory. This is good enough for single-user environments but is often not adequate for multi-user environments where some directories are not writable by users and different users have different home directories.
For that reason the above library root scheme can be overridden by the GNU APL configuration files (preferences). In these files you can un-comment any of the LIBREF-0 to LIBREF-9 settings (which correspond to library numbers 0 to 9) and provide your own paths. The library numbers NOT overridden in a ’preferences’ file still follow the library root scheme.
Next: Limitations and Missing Features, Previous: Installing and Starting GNU APL, Up: GNU APL [Contents]
2 Non-standard GNU APL Features
There are a few hopefully useful features in GNU APL:
- APL Scripting
- Axis argument in defined functions
- Colored Output
- Comparison Rules
- Complex Numbers
- Debug Commands
- Direct Functions (Lambdas)
- ]DOXY Command
- Commands )COPY_ONCE, )DUMP, and DUMP-HTML
- ]NEXTFILE and ]PUSHFILE Commands
- History and TAB completion
- Logging Facilities
- Rational Numbers
- Hex Numbers
- User-defined Commands
- Structured Variables and Associative Arrays
- Monadic ⊢ and ⊣, dyadic ⊢ with Axis
- Bit-wise Logical Functions ⊤∧, ⊤∨, ⊤⍲, ⊤⍱, ⊤≠, and ⊤=
- Generalized ⍳
- ⌹[X] - QR Factorization
- Dyadic ⎕CR
- Dyadic ⎕FX (Native Functions)
- ⎕ARG - Interpreter command line arguments
- ⎕DLX - Knuth’s Dancing Links Algorithm
- ⎕ENV - Environment Variables
- ⎕FIO - File I/O Functions
- ⎕FFT - Fast Fourier Transform
- ⎕GTK - GTK Interface
- ⎕JSON - JSON Parsing
- ⎕MAP - Map Value
- ⎕PLOT - Plot Data
- ⎕PNG - Portable Network Graphics
- ⎕PS - Print Style
- ⎕RE - Regular Expressions
- ⎕RVAL - Random APL value
- ⎕SQL - SQL Database Interface
- ⎕SI - State Indicator
- ⎕SYL - System limits
- ⎕XML - XML Parsing
- Conditionals
- Matrix Product
2.1 APL Scripting
As already mentioned, it is possible to write APL scripts. Similar to other script languages, an APL script is a text file whose first line is a "shebang line", i.e. a line starting with #!, followed by the absolute path to the interpreter (in our case the GNU APL binary), followed by command line arguments that are passed on to the interpreter. In our case the shebang line could be, for example:
#! /usr/local/bin/apl --id 1010
There are essentially two ways to run an APL script: redirecting the script file to stdin of the interpreter or making the script executable and indicate apl as the script interpreter (followed by some command line arguments for apl).
- Redirect the script file to the stdin of the GNU APL interpreter
- Make the script file executable
- How command line arguments are handled
- Helpful Features for Scripting
- Double-quoted Strings
- Multi-Line Strings
- Automatic )MORE
- Script Example
Next: Make the script file executable, Up: APL Scripting [Contents]
2.1.1 Redirect the script file to the stdin of the GNU APL interpreter
A file, say SCRIPT.apl, can be redirected to apl by redirection of the shell:
apl < SCRIPT.apl
Alternatively, the command line option -f of apl can be used:
apl -f SCRIPT.apl
Both ways of redirecting the file are almost identical; in the first case redirection was performed by the shell running apl, while in the second case the redirecting of the file was performed by apl itself.
Next: How command line arguments are handled, Previous: Redirect the script file to the stdin of the GNU APL interpreter, Up: APL Scripting [Contents]
2.1.2 Make the script file executable
Alternatively the script can be made executable, mentioning apl as the interpreter for the script (see also 'man 2 execve'). For this to work, the first line of the script must have a special format
#! /usr/local/bin/apl --script
--script prevents: printing of a welcome banner, echoing of stdin to stdout, automatic loading of a )CONTINUE workspace, and prevents starting of a thread for shared variable communication.
If the path to the interpreter is relative (which might be useful if you do not know in advance where the APL interpreter will be installed) then it must be in $PATH of the shell that runs the script.
Next: Helpful Features for Scripting, Previous: Make the script file executable, Up: APL Scripting [Contents]
2.1.3 How command line arguments are handled
As we have seen, GNU APL can be started directly (by entering the name of the GNU APL binary on the command line of a shell, or indirectly by entering the name of a script that provides the name of the GNU APL binary on the first line of the script. In the latter case, the shell uses function execve() to start APL, and one can provide additional arguments that are passed on to APL. We briefly discuss both cases:
0. General Remark
There is a convention in (not only) GNU APL, that the command line options (and possibly an optional option argument) that occur left of -- are options directed to (and understood by) the APL interpreter while the options right of -- are passed to the APL application (and their exact format is then defined by the APL application). All command line options that were used to start APL can later be retrieved with the system variable ⎕ARG in APL.
Example 1: APL started directly
We start APL with some command line options and display them with ⎕ARG. The command line options for the interpreter are –silent, -l, and 37, while the options app1 and app2 are for the APL application:
$ apl --silent -l 37 -- app1 app2
⊃⎕ARG
apl
--silent
-l
37
--
app1
app2
Example 2: APL started indirectly
A script is a text file which has execute permissions. The first line of a script, commonly known as the shebang of the script, has a special format which specifies how the subsequent lines of the script file shall be processed, see man execve for details.
A GNU APL script is then a script whose shebang indicates the apl binary as the interpreter for the subsequent lines where those subsequent lines are either APL commands or APL statements. With some limitations, executing such an APL script yields the same result as entering the subsequent lines in immediate execution mode.
When APL is started directly, there is only one (possibly empty) set of command line options, which are processed by the shell and then passed to the apl binary.
Starting APL indirectly refers to executing an APL script. In this case there are two sets of command line options:
- those passed to the script as command line arguments, and
- those on the shebang line of the script
When the APL script is started, possibly with command line arguments, the command line arguments entered by the user are combined with the arguments on the shebang line of the script in a way that is described in ’man 2 execve’.
Assume the script file SCRIPT.apl contains this (the file is shipped with GNU APL):
#! /usr/local/bin/apl --id 1010 --script
⊃⎕ARG ⍝ show command line options
)OFF ⍝ leave the interpreter
Assume further that the script is started like this:
$ ./SCRIPT.apl sarg1 sarg2
Then the following output, which shows the order of command line options as seen by ⎕ARG, is produced:
⊃⎕ARG /usr/local/bin/apl --script ./SCRIPT.apl sarg1 sarg2
This suggests that the options and option arguments are constructed by execve() (the function that is eventually responsible for processing scripts in shells and other executables) in the following order:
1. Interpreter name (the first name in the shebang, here: /usr/local/bin/apl)
2. Optional Interpreter arguments (here: –script)
3. Script filename (here: ./SCRIPT.apl)
4. Script arguments (here: sarg1 sarg2)
CAUTION: as discussed in ’man 2 execve’ the interpretation of the optional interpreter arguments (2. above) is system specific and possibly not portable. For that reason the optional interpreter argument should not be missing (you can use – to provide at least one argument) and also not more than one argument. On GNU/Linux systems the following shebang lines of the script are understood:
/usr/local/bin/apl /usr/local/bin/apl -- /usr/local/bin/apl -s /usr/local/bin/apl --script /usr/local/bin/apl -s -- /usr/local/bin/apl --script --
The recommended form is: /usr/local/bin/apl --script.
Note that -- and any options that follow it on the shebang line MAY OR MAY NOT be included in ⎕ARG (this depends on the platform used). In contrast, options that follow -- on the script command line WILL BE shown since this is controlled by GNU APL and not by the platform. There is normally no point in passing any application options on the shebang line to APL because such parameters can more easily be provided directly further down in the script. However, in cases where the script has only application options it may be convenient to make -- the last option of the shebang so that the user of the script need not specify it manually.
Using -- on the shebang line of the script file usually prevents subsequent options on the shebang line from being interpreted as APL options (and, more importantly, from causing unknown option errors when GNU APL starts). At least under GNU/Linux with bash the subsequent options will be passed to the APL application via ⎕ARG.
Depending on this exact behavior cannot be recommended. A cleaner approach is to use options starting with - or -- only for the interpreter options, and options starting with + for application options. This should work on all platforms because for strings, say, APLOPT, ARG1, ARG2, ..., which contain no whitespace:
- +APLOPT is ignored, although shown in ⎕ARG,
- ++APLOPT ARG1 is ignored, although shown in ⎕ARG,
- +++APLOPT ARG1 ARG2 is ignored, although shown in ⎕ARG,
- ...
Next: Double-quoted Strings, Previous: How command line arguments are handled, Up: APL Scripting [Contents]
2.1.4 Helpful Features for Scripting
GNU APL provides three system variables and functions that are particularly useful for scripting:
- ⎕ARG: access to the command line arguments given to the interpreter,
- ⎕ENV: access to the environment variables of the process running the interpreter, and
- ⎕INP: Here-Document-alike function for creating large text variables
2.1.4.1 ⎕ARG
The system variable ⎕ARG contains all command line arguments passed to the interpreter. In the initial example above this would be a nested 3-element vector:
/usr/local/bin/apl --id 1010
2.1.4.2 ⎕ENV
There are usually at least two ways of passing parameters to a script:
- as command line options, and/or
- by means of environment variables
Just as the system variable ⎕ARG makes the command line options used available to APL, so does the system function ⎕ENV make the environment variables available to APL. Since there normally exist far more environment variables than command line options, ⎕ENV is a monadic function whose argument is a filter for the name(s) of the variable(s) to be retrieved.
⎕ENV B returns all environment variables whose name starts with B. If ⍴B is 0, like:
⎕ENV ''
then all environment variables of the process running GNU APL are returned.
The result of ⎕ENV is a (possibly empty) N×2 matrix. The first column contains the name(s) of the environment variable(s), while the second column contains their value(s). The name and the value are both strings.
The number N of environment variables returned by ⎕ENV obviously depends on the number of environment variables whose name begins with the prefix given in B; shorter prefixes B therefore result in higher counts N. B is case sensitive; by convention the names of environment variables are all uppercase. Note the subtle difference between shell variables and environment variables in shells like bash: ⎕ENV returns only environment variables (which are set with command setenv in bash), but not shell variables (which are set with command set in bash). For a shell variable to occur in ⎕ENV it must be exported into the environment of the process before the GNU APL interpreter is started.
2.1.4.3 ⎕INP
If you need to create a longer static text, like the body of a web page, then you would normally construct it in APL like this:
BODY ← ⊂ 'First line' BODY ← BODY , ⊂ 'Second line' BODY ← BODY , ⊂ 'Third line' ...
The above is obviously not very handy for longer texts. Instead you may write the following in a GNU APL script:
BODY←⎕INP 'END-OF-⎕INP' First line Second line Third line ... END-OF-⎕INP
This works like "Here documents" in bash. The right argument of ⎕INP is the end of text marker.
⎕INP also has a dyadic form where the left argument specifies an escape sequence from text to APL and back to the text, similar to PHP scripts. For example:
Z←'<?apl' '?>' ⎕INP 'END-OF-⎕INP' First line Time is now: <?apl ⍕⎕TS ?> Third line ... END-OF-⎕INP
This creates a mainly static text with a small dynamic plug-in computed by APL:
⊃Z First line Time is now: 2022 8 4 15 15 2 177 Third line ...
It should be noted that, while ⎕INP simplifies the construction of multi-line strings compared to standard APL, it has come of age and these days an even simpler feature - Multi-line strings as described below - is provided for the same purpose. The monadic ⎕INP has therefore become obsolete.
Next: Multi-Line Strings, Previous: Helpful Features for Scripting, Up: APL Scripting [Contents]
2.1.5 Double-quoted Strings
Standard APL literals (aka. strings) such as ’Hello’ are single quoted. As a matter of convenience, GNU APL also provides double-quoted strings which differ from single quoted strings in two ways:
- A standard single quoted APL string is a vector if its length ≠ 1 but a scalar if its length = 1. This is sometimes inconvenient and therefore double-quoted strings are more consistent in always being vectors regardless of their length. In other words, ’A’ is a scalar while "A" is a vector.
- Double-quoted strings understand the standard C escape sequences for control character, such as \n for ASCII line feed, \t for ASCII TAB, etc.
Next: Automatic )MORE, Previous: Double-quoted Strings, Up: APL Scripting [Contents]
2.1.6 Multi-Line Strings
A substantial disadvantage of ⎕INP is that it only works in immediate execution mode (and consequently also in .apl scripts), but not the bodies of defined functions. Multi-line strings fill this gap for string literals that span several lines of text inside the body of defined functions. Multi-Line strings have become more and more advanced (and elegant) over time. For this reason they currently come in different flavors (of which the older ones will eventually disappear).
2.1.6.1 Old-style Multi-Line Strings
Old-style multi-line strings were the first attempt to provide long strings for defined functions. The idea for the old-style multi-line strings was adopted from shells like bash where, for example,
echo "Line1 Line2"
prints:
Line1 Line2
In simple terms this means that as long as the number of " characters is odd, the string remains open until the closing " is found (which makes the number even again).
Old-style multi-line strings are not allowed in immediate execution mode because they could easily be entered by mistake (by simply forgetting the terminating " or ’ of a standard string) and that would have obscured the familiar behavior of immediate execution mode. In function definition mode, the total number of function lines is known and it can therefore check if a multi-line string inside the function is properly terminated. Immediate execution mode, however, is open-ended and therefore a forgotten closing " can lead to a fatal misinterpretation of (intended) string content as (unintended) APL code, with lots of nonsense error messages.
Like in bash and also other shells, an old-style multi-line string starts at the last " on a line of a defined function that has an an odd number of " characters. The string continues over the subsequent function lines until the next " is found. The result is a nested APL value containing one nested string per line involved.
In immediate execution mode an old-style multi-line string yields, like in standard APL:
No string end found+
For example:
∇Z←FOO Z←"ABC DEF GHIJK" ∇ 4 ⎕CR FOO ┏→━━━━━━━━━━━━━━━━━━━━┓ ┃┏→━━┓ ┏→━━━┓ ┏→━━━━━┓┃ ┃┃ABC┃ ┃ DEF┃ ┃ GHIJK┃┃ ┃┗━━━┛ ┗━━━━┛ ┗━━━━━━┛┃ ┗∊━━━━━━━━━━━━━━━━━━━━┛
If the first string is empty then the nested value starts with an empty string, but completely empty lines in defined functions are ignored:
∇Z←FOO Z←" ABC DEF GHIJK" ∇ 4 ⎕CR FOO ┏→━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃┏⊖┓ ┏→━━┓ ┏→━━━┓ ┏→━━━━━━┓┃ ┃┃ ┃ ┃ABC┃ ┃ DEF┃ ┃ GHIJK┃┃ ┃┗━┛ ┗━━━┛ ┗━━━━┛ ┗━━━━━━━┛┃ ┗∊━━━━━━━━━━━━━━━━━━━━━━━━━┛
2.1.6.2 New-style Multi-Line Strings
The combination of ⎕INP for immediate execution mode and multi-line strings for defined functions achieved, at least in principle, the goal of specifying large amounts of text in a simpler manner than in standard APL. However, having different methods for creating multi-line string literals in different APL modes could not convince entirely.
The search for a more intuitive and more consistent solution then led to new-style multi-line strings. These strings adopted the triple quote (""") syntax known from e.g. the Python language. The syntax of new-style multi-line strings is cleaner: empty lines are handled more consistently and the string lines are completely separated from the APL code lines. More importantly, new-style multi-line strings work alike in immediate execution mode, in scripts, and in defined functions. New-style strings are a little different and syntactically stricter than their old-style companions:
- the starting """ must be placed at the end of an APL code line, i.e. there is no more mixing of APL code and string content on the same line. An old-style string starts with APL code and ends with the first line of the string, while a new-style string starts with an APL code line and the string itself begins at the following line.
- the ending """ must be placed at the end of a separate line with only spaces allowed before the """ (to horizontally indent-align it with the leading """ if so desired). In old-style strings the text up to the termination " is part of the string while in new-style strings it is not.
- Neither the starting nor the ending line become nested strings of the result, and every line can be clearly identified as being either APL code or else string text.
Example:
4 ⎕CR """
ABC
DEF
GHIJK
"""
┏→━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃┏→━━┓ ┏→━━━┓ ┏⊖┓ ┏→━━━━━━┓┃
┃┃ABC┃ ┃ DEF┃ ┃ ┃ ┃ GHIJK┃┃
┃┗━━━┛ ┗━━━━┛ ┗━┛ ┗━━━━━━━┛┃
┗∊━━━━━━━━━━━━━━━━━━━━━━━━━┛
When entering new-style multi-line strings, the prompt is prefixed by → to indicate that a Multi-Line String is being entered.
⎕INP and old-style strings will coexist for a while, but may eventually disappear at some point in time.
2.1.6.3 « » Strings
When new-style multi-line strings are used in scripts the related error reporting (if the syntax is used incorrectly) can become cumbersome. For example, if one forgets the closing """ of a multi-line string then the next """ (which was meant as the start of a new multi-line string) is mistaken as the (forgotten) end of the previous one. The often long content of the new string is then parsed as APL code and will usually produce many error messages, all of them nonsense. Things get worse if the script itself is long because the odd/even nature of the quotes will then persist until the end of the string (or at least until the next forgotten quote, if any).
To deal with this problem, GNU APL also allows strings whose contents are enclosed in double angle quotation marks « and ». In inline strings ’...’ and "...", as well as in multi-line strings """ ... """, there is no general (and reliable) way to decide if a user has forgotten the ending quote(s), which leads to the problems above.
For this reason, GNU APL now also allows inline and multi-line strings like, for example:
«Hello world»
Hello world
8 ⎕CR «««
→ Line 1
→ Line 2
→ »»»
┌→──────────────────┐
│┌→─────┐ ┌→───────┐│
││Line 1│ │ Line 2││
│└──────┘ └────────┘│
└ϵ──────────────────┘
⍝ provoke an error...
8 ⎕CR «««
→ Line 1
→ Line 2
→ «««
*** WARNING: see (second) ««« when expecting the closing »»»
┌→──────────────────┐
│┌→─────┐ ┌→───────┐│
││Line 1│ │ Line 2││
│└──────┘ └────────┘│
└ϵ──────────────────┘
Another advantage of ««« ... »»» over """ ... """ is that a decent text editor (read: vi/vim) may jump back and forth between the corresponding opening « and closing » with a single key stroke (character % in vi/vim). For this to work, add the following line to /etc/vim/vimrc (or ~/.vimrc):
set matchpairs+=«:»
Next: Script Example, Previous: Multi-Line Strings, Up: APL Scripting [Contents]
2.1.7 Automatic )MORE
The GNU APL command )MORE provides, in some cases, additional information about a prior APL error. The availability of such additional information is indicated by a + at the end of the error message. The additional information is automatically discarded when the next non-empty line is entered. For example:
"ABC"[4]
INDEX ERROR+
'ABC'[4]
^ ^
)MORE
min index=⎕IO (=1), offending index=4, max index=⎕IO+2 (=3)
◊ ⍝ clears )MORE
)MORE
NO )MORE ERROR INFO
This is rather useful in purely interactive mode where the user can issue the )MORE command directly after an APL error has occurred to help figure out what exactly went wrong. In a script, however, the standard )MORE command (as inherited from IBM APL2) is fairly useless for two reasons:
- A human user has a chance to issue the )MORE command interactively after an error has occurred, while a script continues after displaying the error message, and
- It is rather difficult to predict where the next errors will occur, i.e. where to place the )MORE command in the script.
To make the )MORE command more useful for scripts, in GNU APL it can be augmented with an optional argument AUTO like this:
)MORE AUTO ON
Automatic )MORE is now: ON
"ABC"[4]
min index=⎕IO (=1), offending index=4, max index=⎕IO+2 (=3)
INDEX ERROR+
'ABC'[4]
^ ^
If ON/OFF is omitted then the automatic )MORE mode is toggled. The additional )MORE information is displayed before the standard 3-line APL error message.
Previous: Automatic )MORE, Up: APL Scripting [Contents]
2.1.8 Script Example
Note that the two different ways of running an APL script have an impact on how ⎕ARG looks like. If stdin is redirected then there is only one (possibly empty) set of command line options. Otherwise there are two sets of command line options: command line options for the apl interpreter and command line options for the script.
Consider the following simple script called SCRIPT.apl in directory workspaces:
#! /usr/local/bin/apl --script ⊃⎕ARG ⍝ show command line options )OFF ⍝ leave the interpreter
If SCRIPT.apl is redirected to stdin of the APL interpreter:
/usr/local/bin/apl --silent < ../workspaces/SCRIPT.apl or /usr/local/bin/apl --silent -f ../workspaces/SCRIPT.apl
then the first line #! /usr/local/bin/apl --script of file SCRIPT.apl is merely a comment (GNU APL accepts both the traditional APL character ⍝ and the character # as start of a comment). The --script option is therefore ignored and the following mix of input and output is shown on the screen. The input from the script is indented by the usual APL prompt of 6 blanks, while the output of the APL interpreter is not indented.
#! /usr/local/bin/apl --script
⊃⎕ARG ⍝ show command line options
)OFF ⍝ leave the interpreter
If we run the same script directly:
../workspaces/SCRIPT.apl
Then we get:
/usr/local/bin/apl --script ../workspaces/SCRIPT.apl
The --script implies --noCIN so that the input lines for the interpreter are no longer echoed to the output. This is most likely what you want when writing a script.
Also, the first line of the script is no longer ignored as a comment, but controls the command line argument (and thus ⎕ARG) of the interpreter. The additional command line argument ../workspaces/SCRIPT.apl comes from function execve (see ’man 2 execve’).
If we provide an argument, say SCRIPTARG, to SCRIPT.apl:
../workspaces/SCRIPT.apl SCRIPTARG
then it shows up at the end of ⎕ARG:
/usr/local/bin/apl --script ../workspaces/SCRIPT.apl SCRIPTARG
A final note on scripting in GNU APL is that the ∇-editor works slightly differently when it is used in a script. If a user edits an APL function interactively then an attempt to open an existing function with a full header gives a DEFN ERROR:
∇Z←FOO B
[1] ∇
∇Z←FOO B
DEFN ERROR+
∇Z←FOO B
^
)MORE
attempt to ∇-open existing function with new function header
In contrast to a user who can react to the DEFN ERROR, a script cannot detect this situation and would continue to push lines (which were intended to be the body of the defined function) into the APL interpreter. That would most likely cause fairly undesirable behavior. For example, if the lines of a defined function start with line numbers (like [1], [2], ...) then every such line would give a SYNTAX ERROR, and other errors can be expected as well.
For that reason, if the ∇-editor is used in a script and attempts to redefine an existing defined function then the existing function is simply overwritten with the new one and no DEFN ERROR is raised.
Next: Colored Output, Previous: APL Scripting, Up: Non-standard GNU APL Features [Contents]
2.2 Axis argument in defined functions
Defined functions and operators (including lambdas) accept an axis argument. For example:
∇Z←Average[X] B
Z←(+/[X]B) ÷ (⍴B)[X]
∇
Average[1] 5 5⍴⍳25
11 12 13 14 15
Average[2] 5 5⍴⍳25
3 8 13 18 23
Syntactically, the axis is used in the same way as for primitive functions and operators.
There are no constraints on the axis such as being integers. Therefore you can use an axis as a third function argument. Keep in mind, however, that doing so will make your APL code incompatible with other APL interpreters. Use this feature carefully!
Next: Comparison Rules, Previous: Axis argument in defined functions, Up: Non-standard GNU APL Features [Contents]
2.3 Colored Output
The APL interpreter gets its input from the standard input (stdin), which is normally connected to the user’s keyboard, but can also be a file if APL scripting, the -f option, or the -T option is used.
The APL interpreter prints its results on either the standard output (stdout) for normal APL output, or to the error output (stderr) for additional trouble-shooting information.
You can print the 3 channels stdin, stdout, and stderr in different colors by means of the debug command ]XTERM. Command ]XTERM ON enables colored output while ]XTERM OFF disables it (for example to avoid annoying ANSI Escape sequences when forwarding stdout or stderr to a file).
By default colored output assumes a terminal (-emulation) that understands ANSI (or VT100) Escape sequences. The xterm that comes with most recent GNU/Linux distributions is a perfect choice supporting both colors and UTF-8 (Unicode) encoded character I/O.
Non-ANSI terminals, as well as other colors than the default ones, can be configured in the ’preferences’ file. The ’preferences’ file also contains a description of all possible color settings.
Next: Complex Numbers, Previous: Colored Output, Up: Non-standard GNU APL Features [Contents]
2.4 Comparison Rules
Both IBM APL2 and the ISO standard require that the arguments of <, ≤, ≥, and > (but not of = or ≠) are integer or real numbers. As a consequence, the argument(s) of ⍋ or ⍒ (which require comparison) must also be a vector of integer or real numbers.
In contrast, GNU APL also allows the comparison of characters and numbers or the comparison of complex numbers according to the following, more general, rules.
Let A and B be two APL values to be compared. The final result of comparing A and B is the first verdict (i.e. either A < B, or A > B, or A = B) obtained when following the rules below in the indicated order:
- Comparison by rank: if (⍴⍴A) < (⍴⍴B) then A < B and vice versa.
- Comparison by shape: if (⍴A) < (⍴B) then A < B and vice versa. The first differing shape item (from the left) decides.
- Comparison of ravel elements: at this point (⍴A) ≡ (⍴B). If all
corresponding ravel elements of A and B are equal (i.e. tolerantly equal
within ⎕CT as defined in the ISO standard) then A = B.
Otherwise let A1 and B1 be the first corresponding ravel elements of A and B with A1 ≠ B1. If A1 < B1 then A < B and vice versa. The comparison A1 < B1 is made according to the following rules 4 - 8 below.
- Comparison by depth:
- If A1 and B1 are both nested: the rules 1 - 3 above are (recursively) applied to corresponding ravel elements of ⊃A1 and ⊃B1 until a verdict is obtained.
- if A1 is simple and B1 is nested then A < B and vice versa.
- otherwise (i.e. A1 and B1 are both simple): A < B if A1 < B1 according to rules 5 - 8 below and vice versa.
- Comparison by Unicode: if A1 and B1 are both character values and (⎕UCS A1) < (⎕UCS B1) then A < B and vice versa.
- Comparison by type: If A1 is a character and B1 is numeric, then A < B and vice versa.
- Comparison by numeric value: if A1 and B1 are both numeric values then:
- Comparison by real part: if (9○A1) < (9○B1) then A < B and vice versa.
- Comparison by imaginary part: otherwise if (11○A1) < (11○B1) then A < B and vice versa.
- Otherwise: A = B.
Another way of describing the rules above is that the comparison of two values is comprised of sub-comparisons of certain properties of the values in the following order:
- the ranks of the values,
- the shapes of the values,
- the first differing ravel element (in row-major order) of the values,
- the depths of the differing ravel elements,
- the types (character vs. numeric) of the differing ravel elements,
- the Unicodes of the differing ravel elements (if applicable)
- the real parts of numeric values,
- the imaginary parts of numeric values,
Note: Rules 1 and 2 above are only relevant for comparisons made in the context of sorting (i.e. for ⍋ or ⍒). This is because for =, ≠, <, ≤, ≥, or > either a RANK ERROR or a LENGTH ERROR is raised if the ranks or shapes of A and B do not match:
(9 8) < (1 2 3)
LENGTH ERROR
9 8<1 2 3
^ ^
⍋(9 8) (1 2 3)
1 2
The reason for comparing complex numbers first by their real parts and then by their imaginary part and not, for example, first by their magnitude and then by their angle is that the chosen order gives more consistent results when comparing near-complex numbers or their true real companions. For example, a magnitude first comparison of complex numbers would make ¯2 < ¯1 < ¯2J1E¯20 for the near-complex number ¯2J1E¯20.
CAUTION: The comparison of two strings (i.e. nested character vectors) may give unexpected results because shorter strings come before longer strings. For example, ’Zoo’ comes before ’Adam’ even though one might expect the opposite.
Z[⍋Z ← 'Adam' 'Zoo']
Zoo Adam
Z[⍋Z ← 'Adam' 'Zora']
Adam Zora
This pitfall can be avoided by enforcing the same length for all strings being compared or sorted. A simple way to achieve that is the use of ⊂[2]⊃ like this (assuming IO←1):
Z[⍋Z ← ⊂[2]⊃ 'Adam' 'Zoo']
Adam Zoo
Z[⍋Z ← ⊂[2]⊃ 'Adam' 'Zora']
Adam Zora
Next: Debug Commands, Previous: Comparison Rules, Up: Non-standard GNU APL Features [Contents]
2.5 Complex Numbers
Complex numbers are fully supported.
Next: Direct Functions (Lambdas), Previous: Complex Numbers, Up: Non-standard GNU APL Features [Contents]
2.6 Debug Commands
In addition to the classical APL commands like )LOAD or )SAVE, GNU APL has a number of debug commands for debugging purposes. Regular APL commands start with ) and print their output on stdout. Debug commands start with ] and print their output on stderr. Normally you cannot easily distinguish between stdout and stderr, but another GNU APL feature, colored output, uses different colors for stdout and stderr.
Type )HELP or ]HELP in the interpreter for a list of all commands available.
Next: ]DOXY Command, Previous: Debug Commands, Up: Non-standard GNU APL Features [Contents]
2.7 Direct Functions (Lambdas)
GNU APL supports direct functions (aka. lambdas), but only in a rather limited form.
2.7.1 Named Lambdas
A statement of the form
FUN ← { body_statement }
creates a named lambda. A body_statement can contain variable names ⍺ and ⍵ as well as function names ⍶ and ⍹ which are replaced by the actual arguments of the lambda. If both ⍺ and ⍵ are present in body_statement then the lambda is dyadic. If only ⍵ is present then it is monadic, and if neither ⍺ nor ⍵ is present then the lambda is niladic.
Likewise, if ⍶ and ⍹ are present then the lambda is a dyadic operator. If only ⍶ is present then it is a monadic operator, and if neither ⍶ nor ⍹ is present then the lambda is a normal function.
GNU APL supports an axis argument in normal user defined functions and operators. In lambda expressions the Greek letter χ (Chi) is the variable name for an axis argument.
The way a named lambda is implemented in GNU APL is that the expression
FUN ← { body_expression }
is translated to a two-line function ⎕FX ’lambda_header’ ’body_expression’.
For example:
)FNS
SUM ← { ⍺ + ⍵ }
)FNS
SUM
∇SUM[⎕]∇
[0] λ←⍺ SUM ⍵
[1] λ← ⍺ + ⍵
The lambda_header is automatically deduced from the presence or absence of the variable names (⍺, ⍵, and χ) and function names (⍶ and ⍹) in the body_expression and from whether the body_expression is empty (no λ←) or not (with λ←).
It is possible to specify local variables that work exactly like their companions in normal defined functions. Please note that this is different from some other APL interpreters which treat all variables in lambda bodies as local variables. The syntax for specifying local variables is the same as for the header in normal defined functions: they are added at the end with semicolons as separators. In the above example one could add local variables C and D like this:
SUM ← { ⍺ + ⍵ ;C;D }
⎕CR 'SUM'
λ←⍺ λ1 ⍵;C;D
λ← ⍺ + ⍵
If a named lambda is created inside a function, then the name of the lambda (i.e. the name left of ← { ... }) can be made a local variable of the function in which the named lambda is created. This creates a lambda with local scope.
Please note that the above only describes the current implementation of named lambda in GNU APL. A consequence of that implementation is that the symbols ⍺, ⍵, χ, ⍶, ⍹, and λ are pretty much behaving like user defined variables. In particular, they can be used outside named or unnamed lambdas. However, that may change in the future and therefore such use of ⍺, ⍵, χ, ⍶, ⍹, and λ outside is certainly a bad idea.
2.7.2 Unnamed Lambdas
An unnamed lambda is an expression inside { } but without assigning it to a name. This is often used together with the EACH operator. For example:
{ ⍴ , ⍵ } ¨ 'a' 'ab' 'abc'
1 2 3
Unnamed lambdas are automatically local in scope (similar to labels). They can be passed as function arguments to operators. However, unnamed lambdas are NOT inserted into the symbol table of the interpreter. They are therefore not visible to functions like ⎕CR or by the ∇-editor. Occasionally the names λ1, λ2, ... may show up in commands like )SIS. These names are automatically generated for unnamed lambdas in order to provide a name in places where a function name is needed.
2.7.3 Limitations of Lambdas
There are a number of features related to lambdas that are present in other APL interpreters but that are NOT implemented in GNU APL. This includes multiple statements, guards, lexical scoping, and probably more.
Next: Commands )COPY_ONCE, )DUMP, and DUMP-HTML, Previous: Direct Functions (Lambdas), Up: Non-standard GNU APL Features [Contents]
2.8 ]DOXY Command
A particularly useful debug command is ]Doxy. It dumps the current workspace in brows-able HTML format with listings of defined functions and hyperlinks between them.
]DOXY ⍝ write documentation to /tmp/WSNAME/* ]DOXY dest ⍝ write documentation to dest/WSNAME/*
The starting point for browsing the documentation are the files:
/tmp/WSNAME/index.html ⍝ for ]DOXY without arguments, or dest/WSNAME/index.html ⍝ for e.g. ]DOXY dest
The index.html files above usually correspond to the following URIs in your browser:
file:///tmp/WSNAME or file:///absolute-path-to-dest/WSNAME respectively.
In the above examples WSNAME is the )WSID of the workspace in which the ]DOXY command was executed.
One can (and should make it a habit to) insert special comments into defined functions which are copied into proper places inside the documentation that is generated by the ]DOXY command. These "Doxy" comments begin with ⍝⍝ (as opposed to "normal" APL comments that start with a single ⍝. Doxy comments are typically one-liners that briefly explain what a function is supposed to do.
For example:
∇Z←A SUM B ⍝⍝ Return the sum of A and B ← ]DOXY comment: (double ⍝) ⍝ A: numeric ← "normal" APL comments (single ⍝) ... ⍝ B: numeric Z←A + B ∇
But please note the following: in the original doxygen program (for C, C++, or other languages) source code lines may be a mix of code and comments (including doxygen comments). In the ]DOXY command of GNU APL a line of a defined function shall be either APL code or else a doxygen comment (i.e. starting with ⍝⍝). Doxygen comments indented with blanks are allowed (for the sake of readability).
Since a doxygen comment is also a valid APL comment, it is perfectly legal to put a doxygen comment at the end of a line that starts with APL code. However, such lines will be ignored by the ]DOXY command.
The parser generates no extra code from the doxygen comments, and therefore the use of many doxygen comments causes no performance problem (and nor do regular APL comments).
Next: ]NEXTFILE and ]PUSHFILE Commands, Previous: ]DOXY Command, Up: Non-standard GNU APL Features [Contents]
2.9 Commands )COPY_ONCE, )DUMP, and DUMP-HTML
In standard APL, workspaces are processed with the standard commands )LOAD, )COPY, and )SAVE. GNU APL provides additional commands to process workspaces.
2.9.1 )DUMP Command
GNU APL has a command )DUMP that saves a workspace to disk, similar to the )OUT command. The difference between them is the file format being produced. While )OUT produces a file in IBM’s workspace interchange format (aka. an .atf file), )DUMP produces a file in GNU APL’s script format (i.e. readable APL statements). Files written with )DUMP can be edited with normal text editors (vi, Emacs), read back with "apl -f", or made executable (see scripting).
2.9.2 )DUMP-HTML Command
The )DUMP-HTML command is similar to the )DUMP command. The output format is similar to the )DUMP command, the difference is that those characters that need HTML-escaping (e.g. ’<’ becomes <, ’>’ becomes ’>) are being HTML-escaped. The output of the )DUMP-HTML command can therefore be directly used by a web server to display workspace listings (to share the code).
The files written with command )DUMP-HTML have the extension .html.
In addition to the APL code, the .html files produced have a short HTML <head> section template. The user should replace the fields marked with ?????? with proper values (for the author, the copyright owner, and a short description) before publishing the page.
2.9.3 )COPY_ONCE Command
Command )COPY_ONCE copies all objects (variables, functions and operators) from some other workspace into the current workspace similar to )COPY. However, )COPY_ONCE does this only once; a second invocation of )COPY_ONCE with the same workspace (and the same library reference number) is silently ignored. This speeds up the )COPYing of libraries that occur in several )DUMP-ed or )SAVE-ed workspaces.
Next: History and TAB completion, Previous: Commands )COPY_ONCE, )DUMP, and DUMP-HTML, Up: Non-standard GNU APL Features [Contents]
2.10 ]NEXTFILE and ]PUSHFILE Commands
2.10.1 ]NEXTFILE
The debug command ]NEXTFILE, when used in an APL script file, terminates the processing of that file and continues processing in the next script file (if any) or else enters immediate execution mode. Unlike )OFF (which terminates the interpreter), ]NEXTFILE does not terminate the interpreter but only changes its input source to the next script file (if there is one remaining) and enters immediate execution only if all scripts were processed.
The user may, for example, want to use the space near the end of the script to add longer comments (as to what the script does, how it works, how it is used, etc.) without the need to prepend every line with ⍝ or #.
For example:
#/usr/local/bin/apl ⍝ see documentation at the end of this file <APL CODE...> ]NEXTFILE This workspace does the following...
2.10.2 ]PUSHFILE
The debug command ]PUSHFILE is similar to ]NEXTFILE in that it terminates the processing of the current script file. Unlike ]NEXTFILE, ]PUSHFILE does not proceed to the next script file but enters a new immediate execution context in which the user can interact with the interpreter. This context processes user input until a ]NEXTFILE command is given. After a ]NEXTFILE command, the immediate execution context processing proceeds at the next line after the ]PUSHFILE command.
Next: Logging Facilities, Previous: ]NEXTFILE and ]PUSHFILE Commands, Up: Non-standard GNU APL Features [Contents]
2.11 History and TAB completion
Until GNU APL 1.4 / SVN 465, GNU APL used libreadline for interactive user input. libreadline did provide two useful features: tab expansion (the tab key would expand file names) and history (the cursor up/down keys would recall previously entered lines).
Since SVN 465 libreadline was removed and the standard TAB expansion and history of libreadline were replaced by more context sensitive (i.e. APL aware) implementations:
1. Instead of simply recalling the last line entered by the user, there are now different histories for different input contexts:
1a. The input history in immediate execution recalls the last line entered in immediate execution (and not, for example, lines entered in function editing mode or ⍞ input.
1b. Likewise, ⍞ recalls the last line entered for ⍞-input
1c. ⎕ recalls the last line entered for ⎕-input
1d. In the ∇-editor, the other function lines of the function being edited can be recalled. This is far more handy than the ∇-editor commands for recalling function lines (and which are not fully supported in GNU APL).
2. Instead of always TAB-completing file names, the tab character now understands different TAB-completion contexts:
2a. Input starting with . or / is completed as a filename like readline did.
2b. Input starting with ) or ] is completed as command name name or, to some extent, as command arguments.
2c. Input starting with ⎕ is completed as a system function name or a system variable name.
2d. Input starting with letters, ∆, or ⍙ is completed as a user defined function or variable name.
Next: Rational Numbers, Previous: History and TAB completion, Up: Non-standard GNU APL Features [Contents]
2.12 Logging Facilities
The APL interpreter has over 30 logging facilities. Each logging facility can be ON (and then produces some logging output on stderr) or OFF. The decision which logging facility shall be ON and which shall be OFF can be made at compile time (of the APL interpreter) or at run-time.
If the decision is made at compile time - we call that static logging - then it cannot be changed later on. Otherwise - we call that dynamic logging - there is a debug command ]LOG that allows logging facilities to be turned ON or OFF.
2.12.1 Static Logging
By default the logging facilities that shall be turned ON are defined statically. To change the logging facilities that shall be turned ON, you can edit the file src/Logging.def which defines the different logging facilities. The first argument of macro log_def() specifies that the indicated logging facility shall be ON (1) or OFF (0).
Static logging results in a faster interpreter than dynamic logging because the decision to log something is made at compile time and not at run-time.
If you benchmark the APL interpreter, then ./configure Static Logging by NOT setting DYNAMIC_LOG_WANTED=yes.
2.12.2 Dynamic Logging
Dynamic Logging is intended for trouble-shooters of GNU APL, but also for those who are interested in the internals of GNU APL. Dynamic Logging is enabled by setting DYNAMIC_LOG_WANTED=yes when running ./configure.
If Dynamic Logging is enabled, then the already mentioned file src/Logging.def determines the initial setting of each logging facility.
The command
]LOG
(without arguments) then shows all logging facilities and their current state. The command
]LOG N
toggles the state of logging facility N from OFF to ON and back.
Next: Hex Numbers, Previous: Logging Facilities, Up: Non-standard GNU APL Features [Contents]
2.13 Rational Numbers
GNU APL has limited support for rational numbers. Instead of dividing integers (and possibly causing rounding errors), integer quotients are kept undivided internally until some function requires a conversion to a floating point (double) value.
Currently only +, -, ×, and ÷ preserve rational numbers where possible, but this list may grow in the future. Monadic + (a no-op for non-complex numbers) explicitly converts rational numbers to floating point numbers.
A quotient is internally stored as a 64-bit numerator and a 64-bit denominator. In some cases arithmetic with rational numbers is faster than with doubles, but in most cases it is slower.
For that reason support for rational numbers is disabled by default and must be enabled via ./configure (see README-2-configure).
Next: User-defined Commands, Previous: Rational Numbers, Up: Non-standard GNU APL Features [Contents]
2.14 Hex Numbers
GNU APL supports sedecimal numbers. They start with $ and can be uppercase or lowercase:
$2a
42
$2A
42
Next: Structured Variables and Associative Arrays, Previous: Hex Numbers, Up: Non-standard GNU APL Features [Contents]
2.15 User-defined Commands
There is a simple mechanism to define additional APL commands. This mechanism is intended to introduce new commands by APL libraries. Like system commands, user-define commands can only be executed in immediate execution mode and not from user-defined functions or from ⍎. It is not intended to extend the functionality of user-defined commands beyond what is being described in the following.
A user-defined command ]NEW_COMMAND is created with the debug command ]USERCMD like this:
]USERCMD ]NEW_COMMAND APL_FUNCTION [mode]
APL_FUNCTION is an APL function that will be called when the command is entered in immediate execution mode. The entire line entered by the user, starting at ]NEW_COMMAND, is the right argument of APL_FUNCTION. If mode is missing (or 0) then APL_FUNCTION is called monadically. If mode is 1 then APL_FUNCTION is called dyadically; the left argument is a vector of strings that is the left argument broken down into individual argument strings.
The function APL_FUNCTION that implements a command need not exist when the command is created.
A single user-defined command ]UCMD, or all user-defined commands can be deleted like this:
]USERCMD REMOVE ]UCMD
]USERCMD REMOVE-ALL
Next: Monadic ⊢ and ⊣, dyadic ⊢ with Axis, Previous: User-defined Commands, Up: Non-standard GNU APL Features [Contents]
2.16 Structured Variables and Associative Arrays
GNU APL has implemented two features that are closely related because, under the hood, they share the same implementation: structured variables and associative arrays.
2.16.1 Structured Variables
A structured variable is an APL variable that contains several related but otherwise independent sub-variables aka. members. Such structured variables can be convenient for passing many related arguments to a function, or for returning multiple results from a function.
The different sub-variables of a structured variable are accessed by the (top-level) name of the variable followed by a non-empty sequence of member names, separated by ’.’. In the following we will use uppercase names for structured variables and lowercase names for their members. For example:
PERSON.address.street
is a structured variable PERSON, which has a member address, and PERSON.address is a structured (sub-)variable of PERSON which has a member street.
For a structured variable and all its sub-variables, the usual rules for normal variables apply. They can be created, erased, and even passed as arguments to functions. Nota bene: Some GNU APL operators are implemented as macros (i.e. internal defined APL functions). The macros may call APL primitives that invalidate the fact that a value is structured and, as a consequence, the operator results may become plain APL values. If this happens, the structured nature of a plain APL value can be restored with 38 ⎕CR.
A structured variable is created by assigning a value to one of its members. For example:
PERSON.firstname ← 'Jane' ⍝ create variable PERSON with member 'firstname'
PERSON.lastname ← 'Doe' ⍝ add a second member 'lastname' to PERSON
The depth of a newly created member can be more than one. In this case the intermediate members are created automatically. For example:
PERSON.address.street ← '42 Main Street' ⍝ implicitly creates PERSON.address
Empty structured variables can be created with 38 ⎕CR:
EMPTY ← 38 ⎕CR CAPACITY ← 32
Note: A structured variable is automatically expanded when new members are added to it. From time to time this expansion exceeds the space allocated for the members of the variable and then the existing members need to be copied into a new, larger structure. The overhead caused by this reorganization can be avoided by specifying a sufficiently large capacity when the structure is created (with 38 ⎕CR).
An entire structured variable can be erased with ⎕EX or with )ERASE just like other variables. They erase the variable along with all its members. In addition to erasing an entire structured variable, individual members at any depth can also be erased with ⎕EX or )ERASE:
)ERASE PERSON.address ⍝ OK, PERSON.address exists
)ERASE PERSON.address ⍝ error: PERSON.address does not exist anymore
NOT ERASED: PERSON.address
After having been created, the members of a structured variable can be referenced and overwritten just like normal variables:
PERSON.address.street ← '42 Main Street' ⍝ create member address.street
PERSON.address.street ⍝ reference member address.street of PERSON
42 Main Street
PERSON.address.street ← '44 Main Street' ⍝ overwrite address.street
PERSON.address.street
44 Main Street
The members of a structured variable form a tree of (sub-) variables, similar to the file system on a computer. This tree has:
- one root (which is the structured variable itself),
- zero or more non-leafs (like sub-directories of the top-level root directory), and
- zero or more leafs. The case of zero non-leafs occurs, for example, directly after a new empty variable was created with 38 ⎕CR.
Due to their tree-like structure, structured variables need to be printed somewhat differently than normal APL variables. For example:
PERSON
.firstname: ┌→───┐
│Jane│
└────┘
.lastname: ┌→──┐
│Doe│
└───┘
.address:
.address.street: ┌→─────────────┐
│44 Main Street│
└──────────────┘
Only the leafs of a deeply structured variable can have values and, as a precaution, assigning a value to a non-leaf (including the root) raises a DOMAIN ERROR:
B.b.c←'leaf-Abc' ⍝ OK, since B.b.c will be a leaf
B.b←42 ⍝ will fail since B.b is not a leaf
DOMAIN ERROR+
B.b←42
^ ^
)MORE
member access: cannot override non-leaf member A.b
)ERASE or ⎕EX that member first.
)ERASE B.b
B.b ← 'leaf-Ab' ⍝ now OK, since B.b will now become a (new) leaf
)SIC
On the other hand, assigning a structured variable to the leaf of another structured variable is valid and concatenates the members:
)ERASE A
A.b.c ← 'leaf-Abc' ⍝ variable A with leaf A.b.c
C.d.e ← 'leaf-cde' ⍝ variable C with leaf C.d.e
A.b.c ← C ⍝ overwrite leaf A.b.c of A
A.b.c.d.e
leaf-cde
The file src/testcases/Structured_variable.tc contains the examples above (and more)
2.16.2 Associative Arrays
APL arrays are primarily indexed with numbers (or arrays of numbers), which is also the most efficient method. Many other languages provide, either in addition or else alternatively, a method to index arrays by keys, where the keys are frequently character strings. Such arrays are commonly referred to as associative arrays.
APL has no associative array per se, but the structured variables in GNU APL can be used for the same purpose. The only limitation is (currently) that the keys need to be character strings (as opposed to arbitrary APL values).
That is, in GNU APL an associative array
- is a structured variable, and
- can be indexed with arbitrary (!) strings
As long as the strings that are used as keys follow the same rules as APL variable names (no leading digit, no ’.’ etc.), a structured variable can also be indexed with a string. That can be useful if keys are being computed or passed as function arguments. However, unlike indexing of APL arrays with numbers, only one key per (bracket-) index is permitted.
A.key ← 42
A.key
42
A['key']
42
A['key']←24
A.key
24
A['key' 'key'] ⍝ not allowed even though 'key' is a valid member
DOMAIN ERROR
D['key' 'key']
Strings that do not follow the rules for variable names can be used with bracket index, but not with the .member syntax:
ASSOC ← 38 ⎕CR 8
KEY←'key.dot' ⍝ works, but avoid such keys
ASSOC[KEY]←42
ASSOC[KEY]
42
ASSOC[KEY]←43
ASSOC[KEY]
43
ASSOC.key.dot ⍝ won't work: 'key.dot' is a single key, but key.dot is 2 keys
VALUE ERROR+
ASSOC.key.dot
^
)MORE
member access: structure ASSOC has no member key
ASSOC.key.dot←44 ⍝ works: 2 (nested) keys
ASSOC.key.dot
44
ASSOC['key.dot'] ⍝ works: one key containing '.'
43
This is because ASSOC.key.dot above is being tokenized by the APL parser into [ASSOC] [key] [dot], while ’key.dot’ is a single key. The example above (with different values for ASSOC.key.dot and for ASSOC[’key.dot’] demonstrates why such keys are better avoided.
Even though (one) bracket index can only access the top-level members of a structured variable, repeated bracket index (or dyadic PICK) can be used to access deeper nesting levels:
D.b.c←42
D['b.c'] ⍝ will fail
INDEX ERROR+
D['b.c']
^^
)MORE
member access: member b.c was not found. The valid members are:
b
D['b']['c'] ⍝ will work
42
⍝ alternatively: use PICK
⍝
'b' 'c' ⊃ D ⍝ fails: 'b' 'c' is 'bc'
"b" "c" ⊃ D ⍝ works
42
In the above examples each bracket index (or each element of PICK) discards the current top-level structure and descends into the structured sub-variable of the chosen member. In this case PICK is more efficient since repeated bracket index creates copies of the intermediate structured sub-variables.
If a variable is used as a structured variable then the number of its members is typically small (since every member name occurs explicitly in the APL code that uses it). If a variable is used as an associative array, then the member names are typically being computed and the number of members can become rather large (like the different key values in a database). When such a variable (i.e. with many members) reaches its capacity, then finding a member (when the array is indexed), or finding an unused place in the variable (when a new member is added) becomes slower and slower. The GNU APL implementation has addressed this by hashing into the variable (based on the member name) instead of, for example, sequentially allocating the members. This is very fast under normal circumstances, but becomes as slow as sequential allocation when the number of members in the variable reaches its current capacity. For this reason, if a structured variable is used as an associative array, e.g. as a database, then it is better to not rely on the (automatic) reorganization of the variable, but to create the variable with a large enough (with 38 ⎕CR) from the beginning.
If that is not possible (because the (performance-) problem has occurred after the variable was created, then one can manually increase the capacity like this:
TMP ← 39 ⎕CR ASSOC_ARRAY ⍝ save ASSOC_ARRAY as normal APL array
⊣ ⎕EX 'ASSOC_ARRAY' ⍝ erase it so that it can be assigned
ASSOC_ARRAY ← 38 ⎕CR TMP ⍝ new associative array with ≥ twice the size
As a rule of thumb, associative arrays will be fast as long their capacity is more than twice the number of their members. The expression ASSOC_ARRAY[;1] returns all keys (= members) of ASSOC_ARRAY, therefore the number of members is ⍴ASSOC_ARRAY[;1] and the capacity is ↑⍴ASSOC_ARRAY.
Next: Bit-wise Logical Functions ⊤∧, ⊤∨, ⊤⍲, ⊤⍱, ⊤≠, and ⊤=, Previous: Structured Variables and Associative Arrays, Up: Non-standard GNU APL Features [Contents]
2.17 Monadic ⊢ and ⊣, dyadic ⊢ with Axis
Monadic ⊢ is the identity function. It returns its (committed or non-committed) right argument as a non-committed value.
Conversely, monadic ⊣ (called Hide in GNU APL) discards its (committed or non-committed) right argument and returns a committed integer scalar 0.
For the most part there is no difference between a committed value (= a value that was assigned to a variable, including ⎕ and ⍞) and a non-committed value. The point where it does make a difference is when the value is the final result of a statement (as opposed to an intermediate result inside a statement). In that situation (and only there) a non-committed value is being printed while a committed value is not.
You can use ⊢ in a similar fashion as ⎕← at the left end of a statement, to print a value even though it was previously assigned to a variable.
The main motivation for ⊣ is that, at least in GNU APL, lambdas always return a value. However, if a lambda is used only for the sake of its side effects, say to print something, then the value returned by the lambda is often of no interest and only messes up the APL output. In that situation ⊣ can be used to suppress the printing of undesired return values from lambdas.
In earlier GNU APL versions, ⊣B and ⊢B would both return B; with ⊣ as committed value and with ⊢ as non-committed value. But since the only real-life purpose of ⊣ is to suppress the printing of B, the implementation of ⊣ was changed to returning a committed integer scalar 0 instead of committed B. That reduced the run-time of ⊣B from O(,B) to O(1). Also, ⊢B is marginally faster than ⎕←B.
Dyadic ⊢ with axis is a selection function that generalizes ⊣ and ⊢.
Let Z←A ⊣[X] B. Then:
- if X is a one-element vector and ↑X is 0 then Z ≡ A,
- if X is a one-element vector and ↑X is 1 then Z ≡ B,
- otherwise X selects items of A or B if the corresponding elements of X are 0 or 1 respectively. In that case, the shapes of A and B must match the shape of X, but one-element A or B are scalar extended to the shape of X.
Example:
A←2 3⍴'abcdef'
B←2 3⍴⍳6
X←2 3⍴0 1 0 1 0 1
A ⊢[X] B
a 2 c
4 e 6
A ⊢[X] '*'
a*c
*e*
'*' ⊢[X] B
* 2 *
4 * 6
Next: Generalized ⍳, Previous: Monadic ⊢ and ⊣, dyadic ⊢ with Axis, Up: Non-standard GNU APL Features [Contents]
2.18 Bit-wise Logical Functions ⊤∧, ⊤∨, ⊤⍲, ⊤⍱, ⊤≠, and ⊤=
The APL functions And (∧), Or (∨), Nand (⍲), and Nor (⍱) operate primarily on Boolean integers. Primarily means that the LCM variant for ∧ and the GCD variant for ∨ are not considered in this context. (The LCM and GCD variants are defined in the ISO standard and supported in GNU APL but not in IBM APL2).
However, probably more often than not one needs to compute Boolean functions between the bits of arbitrary (non-Boolean) integers and not between entire Boolean integers 0 or 1. Although that is possible to do in standard APL, the procedure is fairly awkward and, more importantly, inefficient:
- convert every integer argument X to a 64-item Boolean vector X←(64⍴2)⊤X,
- call the Boolean function ∧, ∨, ⍲, ⍱, =, or ≠ with the converted arguments, and
- convert the Boolean result vector R back to the integer result Z←2⊥R
Note: for Boolean arguments the APL functions ≠ and = can be used to compute the more customary Boolean functions XOR and XNOR respectively. In this context = and ≠ are treated as Boolean functions even though they accept non-Boolean arguments,
For example, using 5 ⎕CR (4⍴256)⊤X to display X in hex:
5 ⎕CR (4⍴256)⊤ A←$ABBADEAD
ABBADEAD
5 ⎕CR (4⍴256)⊤ B←$00FF00FF
00FF00FF
5 ⎕CR (4⍴256)⊤ 2⊥ ((64⍴2)⊤A) ∧ (64⍴2)⊤B
00BA00AD
With the bit-wise And (⊤∧) the same can be achieved in a simpler fashion and far more efficiently:
⍝ Traditional AND
5 ⎕CR (4⍴256)⊤ A←$ABBADEAD
ABBADEAD
5 ⎕CR (4⍴256)⊤ B←$00FF00FF
00FF00FF
⍝ bit-wise AND
5 ⎕CR (4⍴256)⊤ A ⊤∧ B
00BA00AD
- Dyadic ⊤∧, ⊤∨, ⊤⍲, ⊤⍱, ⊤=, and ⊤≠
- Monadic ⊤∨ and ⊤⍱
- Monadic ⊤∧
- Character Arguments for Monadic ⊤⍱ and Dyadic ⊤∧, ⊤∨, ==, and ≠≠
2.18.1 Dyadic ⊤∧, ⊤∨, ⊤⍲, ⊤⍱, ⊤=, and ⊤≠
The dyadic forms of ⊤∧, ⊤∨, ⊤⍲, and ⊤⍱ are simply the bit-wise variants of their Boolean counterparts:
A ⊤∧ B ←→ 2⊥ ((64⍴2)⊤A) ∧ (64⍴2)⊤B ⍝ aka. AND
A ⊤∨ B ←→ 2⊥ ((64⍴2)⊤A) ∨ (64⍴2)⊤B ⍝ aka. OR
A ⊤⍲ B ←→ 2⊥ ((64⍴2)⊤A) ⍲ (64⍴2)⊤B ⍝ aka. NAND
A ⊤⍱ B ←→ 2⊥ ((64⍴2)⊤A) ⍱ (64⍴2)⊤B ⍝ aka. NOR
A ⊤≠ B ←→ 2⊥ ((64⍴2)⊤A) ≠ (64⍴2)⊤B ⍝ aka. XOR
A ⊤= B ←→ 2⊥ ((64⍴2)⊤A) = (64⍴2)⊤B ⍝ aka. NXOR or XNOR
2.18.2 Monadic ⊤∨ and ⊤⍱
⊤=, ⊤≠, and ⊤⍲ do not have a monadic form, but ⊤∧, ⊤∨, and ⊤⍱ do. Formally monadic ⊤∨ and ⊤⍱ are dyadic ⊤∨ and ⊤⍱ with a left argument of 0:
⊤∨ B ←→ 0 ⊤∨ B ⍝ real B to nearby integer
⊤⍱ B ←→ 0 ⊤⍱ B ⍝ bit-wise Not
Even though Or-ing a Boolean vector with 0 itself has no effect, the monadic ⊤∨ and ⊤⍱ are still useful due to their side effects: conversion from near-integer float values to integers (monadic ⊤∨ and inversion of the bits (monadic ⊤⍱, The latter is needed since ∼ has a monadic form and, as a consequence, ⊤∼ was not an option for a bit-wise Not function.
Monadic ⊤⍱ B is the bit-wise Not function of its argument:
⊤⍱ B ←→ 2⊥ ~(64⍴2)⊤B
Monadic ⊤∨ B converts near-integer values B into true integers:
26 ⎕CR 1 ⍝ integer
16
26 ⎕CR 1.1 ⍝ real
32
26 ⎕CR 1÷1 ⍝ integer
16
26 ⎕CR 1.1÷1.1 ⍝ real
32
26 ⎕CR ⊤∨ 1.1÷1.1 ⍝ integer
16
That also works for complex numbers with a near-zero imaginary part:
26 ⎕CR 1.1J0÷1.1 ⍝ real
32
26 ⎕CR ⊤∨ 1.1J0÷1.1 ⍝ integer
16
As a matter of fact, ⊤∨ works for all near-Gaussian complex numbers, but the effect is not visible with 26 ⎕CR since Gaussian and non-Gaussian complex numbers have the same cell type in GNU APL.
2.18.3 Monadic ⊤∧
The ISO standard defines two different concepts to decide if a real number R is close to an integer I,
- the real number R is said to be near to integer I if the absolute value of I-R is smaller than some small constant called the integer tolerance in ISO and system tolerance in IBM APL2. The integer tolerance is typically platform dependent (1E¯10 in GNU APL).
- the real number R is said to be equal to integer I within ⎕CT if the absolute value of (I-R)/I is smaller than ⎕CT.
The first concept is an absolute distance from a real R to a nearby integer I while the second concept is a relative distance (larger numbers are allowed to be farther away from a nearby integer than smaller numbers). The two concepts differ in the same way that absolute and relative errors do.
Now, all bit-wise functions described so far use the first concept, i,e, if their arguments are real or complex, then the smallest distance to a (nearby) integer must not exceed the integer tolerance. In some contexts that could be difficult to achieve and for that reason GNU APL provides monadic ⊤∧ which works like ⊤∨ except that the permitted distance from a nearby integer is now controlled by ⎕CT rather than by the integer tolerance.
All bit-wise logical functions throw a DOMAIN ERROR if an argument is not close enough to an integer. The integer tolerance is typically smaller than ⎕CT and in that case ⊤∧ is a little more tolerant than ⊤∨ regarding the distance to nearby integers. In addition ⊤∧ gives the user (via ⎕CT) more control over the permitted tolerance for real numbers in the neighborhood of integers.
2.18.4 Character Arguments for Monadic ⊤⍱ and Dyadic ⊤∧, ⊤∨, ==, and ≠≠
Some of the bit-wise operations are allowed to have characters as their right argument. If the right argument is a character then the result is a character as well. This can be useful for masking purposes such as extracting the lower 7 bits of 8-bit bytes containing ASCII characters.
The characters involved are treated as 32 bit quantities:
5⎕CR 'A'
41
5⎕CR ⊤⍱'A' ⍝ Note that 5⎕CR aka. ⎕CR.to_HEX ANDs with $FF
BE
256 256 256 256⊤ ⎕UCS ⊤⍱ 'A' ⍝ ⊤⍱ 'A' is FFFFFFBE
255 255 255 190
256 256 256 256⊤$FFFFFFBE
255 255 255 190
Next: ⌹[X] - QR Factorization, Previous: Bit-wise Logical Functions ⊤∧, ⊤∨, ⊤⍲, ⊤⍱, ⊤≠, and ⊤=, Up: Non-standard GNU APL Features [Contents]
2.19 Generalized ⍳
2.19.1 Generalized monadic ⍳
The standard function Interval (Z←⍳B) requires its argument B to be a scalar or a length 1 vector. The result Z←⍳B then contains all possible indices of values which have shape B.
Generalized monadic ⍳ extends this concept to integer vectors B with more than 1 element. The result Z←⍳B again contains all possible indices of a value which has shape B, but the rank of B can now be more than 1. The items of Z are nested integer vectors as opposed to integer scalars in the standard case.
2.19.2 Generalized dyadic ⍳
The standard function Index Of (Z←A⍳B) requires its left argument A to be a scalar or a vector of rank 1. The items of the result Z are the (first) positions (= indices) of the corresponding items of B in A (for the items found in A) or else ⎕IO+⍴A (which is an invalid index of A) for the items of B that are not found in A.
Generalized dyadic ⍳ extends this concept to find the (first) indices of the corresponding items of B in A (in ravel order) where the rank of A is > 1. Each item of the result Z is then either a nested integer vector (if the item was found) or - different from the standard case (!) - the empty vector ⍬ if the item was not found).
Next: Dyadic ⎕CR, Previous: Generalized ⍳, Up: Non-standard GNU APL Features [Contents]
2.20 ⌹[X] - QR Factorization
Z←⌹[X] B computes a QR factorization of the real or complex matrix B. The axis argument X is used to clear near-0 matrix items to exactly 0.0 during the computation. Set X←⎕CT if unsure.
The result Z is a triple (QT R Ri)←Z with the following properties. Let ⍴B=(M, N).
* QT is an orthogonal M×M matrix, i.e QT-1 = QTT, and QT +.× ⍉QT is the M×M identity matrix IM (with IM←∘.=⍨⍳M).
* R is an upper triangular M×N matrix, i.e. R[m;n] = 0 for n < m, and
* Ri is the inverse of R, i.e. Ri +.× R is the identity matrix IN.
* (⍉QT) +.× R = B.
Note that, unlike in standard QR factorizations, the matrix QT returned by ⌹[X] is already inverted (i.e. transposed since QT is orthogonal). The reason is that the algorithm used can transpose Q with no extra cost and usually the first step after a QR factorization is to transpose the returned Q matrix. This first transpose step is therefore not needed.
Example 1 (real B)
⎕←B←3 3⍴ 1 1 3 2 4 2 4 8 7
1 1 3
2 4 2
4 8 7
(QT R Ri)←⌹[⎕CT]B
Q←⍉QT ⍝ recover the non-transposed Q
4 ⎕CR 0 4⍕ Q
┏→━━━━━━━━━━━━━━━━━━━┓
↓ .2182 .9759 ¯.0000┃
┃ .4364 ¯.0976 ¯.8944┃
┃ .8729 ¯.1952 .4472┃
┗━━━━━━━━━━━━━━━━━━━━┛
⍝ verify that Q is orthogonal
4 ⎕CR 0 4⍕ Q +.×⍉Q
┏→━━━━━━━━━━━━━━━━━━━━┓
↓ 1.0000 ¯.0000 .0000┃
┃ ¯.0000 1.0000 .0000┃
┃ .0000 .0000 1.0000┃
┗━━━━━━━━━━━━━━━━━━━━━┛
⍝ verify that R is upper triangle
4 ⎕CR 0 4⍕ R
┏→━━━━━━━━━━━━━━━━━━━━┓
↓ 4.5826 8.9469 7.6376┃
┃ .0000 ¯.9759 1.3663┃
┃ ¯.0000 ¯.0000 1.3416┃
┗━━━━━━━━━━━━━━━━━━━━━┛
⍝ verify that B is Q +.× R i.e. B is (⍉Q) +.× R
Q +.× R
1 1 3
2 4 2
4 8 7
⍝ verify that Ri is the inverse of R
4 ⎕CR 0 4⍕ Ri +.×R
┏→━━━━━━━━━━━━━━━━━━━━┓
↓ 1.0000 ¯.0000 .0000┃
┃ .0000 1.0000 .0000┃
┃ .0000 .0000 1.0000┃
┗━━━━━━━━━━━━━━━━━━━━━┛
Example 2 (complex over-determined B)
⎕←B←5 4⍴4J6 6J3 5J10 3J2 8J10 3J4 5J10 5J8 3J1 2J3 4J5 1J3 1J4 9J9 9J6 2J7 2J10 7J6 9J8 10J10
(QT R)←⌹[⎕CT]B
Q←⍉QT ⍝ recover the non-transposed Q
4 ⎕CR 0 4⍕ Q
┏→━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
↓ .4107J¯.0310 .0621J¯.1742 .9124J¯.1121 .3710J.3755 ¯.2148J.0626 ┃
┃ .7219J¯.1180 ¯.5950J.0697 ¯.2629J.4735 ¯.7179J¯.4253 ¯.1979J.2738 ┃
┃ .1338J¯.1213 .0880J.2603 .3667J¯.0282 ¯.1833J.3784 1.0188J.0717 ┃
┃ .2271J.0623 .9071J.0968 .0575J.2496 ¯.5003J.2494 ¯.1208J¯.0703┃
┃ .5538J.1806 .1779J¯.3283 ¯.6232J¯.3575 .8260J¯.3033 .0605J¯.2291┃
┗━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┛
⍝ verify that Q is orthogonal
4 ⎕CR 0 4⍕ Q +.×⍉Q
┏→━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
↓ 1.0000J.0000 .0000J¯.0000 ¯.0000J¯.0000 ¯.0000J¯.0000 .0000J.0000 ┃
┃ .0000J¯.0000 1.0000J.0000 .0000J.0000 .0000J.0000 .0000J¯.0000┃
┃ ¯.0000J¯.0000 .0000J.0000 1.0000J¯.0000 .0000J¯.0000 ¯.0000J.0000 ┃
┃ ¯.0000J¯.0000 .0000J.0000 .0000J¯.0000 1.0000J.0000 ¯.0000J.0000 ┃
┃ .0000J.0000 .0000J¯.0000 ¯.0000J.0000 ¯.0000J.0000 1.0000J.0000 ┃
┗━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┛
⍝ verify that R is upper triangle...
4 ⎕CR 0 4⍕ R
┏→━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
↓ 8.5870J15.2557 10.1036J10.9309 13.5055J18.7452 10.0961J15.2530┃
┃ .0000J.0000 8.7353J5.5589 9.2429J.4120 2.5086J.7539 ┃
┃ ¯.0000J.0000 .0000J.0000 ¯2.4869J4.4115 ¯5.9788J¯6.0801┃
┃ ¯.0000J.0000 ¯.0000J.0000 ¯.0000J.0000 7.4038J¯3.9492┃
┃ .0000J.0000 .0000J.0000 .0000J.0000 ¯.0000J.0000 ┃
┗━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┛
⍝ verify that B is Q +.× R i.e. B is (⍉Q) +.× R
Q +.× R
4J6 6J3 5J10 3J2
8J10 3J4 5J10 5J8
3J1 2J3 4J5 1J3
1J4 9J9 9J6 2J7
2J10 7J6 9J8 10J10
Please note as well that QR factorization is currently experimental. So please double-check its results before using it in production code.
2.20.1 The Impact of ⎕CT for ⌹
Due to the lack of a better place we describe here how ⎕CT is used in the various ⌹ functions.
2.20.1.1 A⌹B and ⌹B
The first step in the computation of A⌹B or ⌹B is the estimation of the number of linearly independent columns of B. If that number is smaller than the total number of columns (IOW some columns of B are linearly dependent) then a DOMAIN ERROR is raised before the computation of ⌹B starts. Although B may be over-determined (so it may have more rows than columns and in that case the rows of B cannot be linearly independent) it may not have linearly dependent columns.
Now, for every real or complex number ⍺ does ⎕CT define a range of nearby numbers that are considered equal to ⍺ even though they are, strictly speaking, different.
In the same fashion, let B be a matrix with linearly dependent columns. For every such B does ⎕CT define a range of nearby matrices that are also considered linearly dependent even though they are, strictly speaking, linearly independent. As a matter of fact, the probability that the columns of B are strictly linearly independent decreases as the size of the matrix grows. If a matrix has linearly dependent columns, then every new row added to the matrix can make it linearly independent, but not the other way around.
The consequence for the user of GNU APL is the following. If GNU APL raises a DOMAIN ERROR caused by the supposedly linearly dependent columns of some matrix B then there are two possibilities:
- the columns of B are indeed linearly dependent, e.g. ⌹B←2 2⍴3 4. In this case there is no way to compute ⌹B.
- the columns of B are only close (as controlled by ⎕CT) to some other strictly linearly dependent matrix. In this case (which is far more likely than the other), one may decrease ⎕CT until the matrix becomes linearly independent. For example, ⌹B may raise a DOMAIN ERROR with the default ⎕CT←1E¯13 but not with ⎕CT←1E¯15. However, one should use this technique with great care because matrices that are nearly linearly dependent tend to produce significant rounding errors in the result.
2.20.1.2 ⌹[X] B
The integer scalar X chooses one of currently two different algorithms that compute a QR factorization of a matrix B:
- ⌹[1]B uses the algorithm published by Garry Helzer in APL Quote Quad in 1990.
- ⌹[2]B uses a LApack algorithm (xGELSY). This algorithm uses ⎕CT in the same way as described above for ⌹B and A⌹B.
- for backward compatibility with older versions of GNU APL, a real scalar X in ⌹[X]B uses ⌹[1]B if X < 0.1 and ⌹[2]B otherwise. The scalar X is used instead of ⎕CT. Do not use this case in new code.
The Helzer algorithm recursively factors a N×N matrix, a (N-1)×(N-1) matrix, a (N-2)×(N-2) matrix, and so forth. After every step of that recursion, all matrix items close to 0.0 are set to exactly 0.0.
GNU APL uses ⎕CT in the same way as the Helzer alogrithm, i.e. to decide if a matrix item close to 0.0 shall be set to 0.0 or not (APL functions A TOL X and A CPR B, where Helzer leaves it open how to implement A TOL X and A CPR B). GNU APL uses the example implementation given in the Helzer paper. The TOL and CPR functions seem to be related to what is elsewhere known as the condition number of the matrix that is being factorized. In the LApack case, the parameter RCOND of FORTRAN function xcDGELSY is set to ⎕CT.
Next: Dyadic ⎕FX (Native Functions), Previous: ⌹[X] - QR Factorization, Up: Non-standard GNU APL Features [Contents]
2.21 Dyadic ⎕CR
The ⎕CR function has an optional left argument that selects one of several formatting styles and conversion functions in addition to the well-known monadic form.
Calling ⎕CR monadically without an axis and with an empty right argument shows a list of all functions provided by ⎕CR:
⎕CR ''
Say a byte vector is an integer vector with numbers having a (signed or unsigned) 8-bit value (i.e. a value from -128 to 255 inclusive). Such byte vectors are frequently used arguments and results of ⎕FIO functions.
Let Z←A ⎕CR B.
Then the left argument A of ⎕CR selects one of several sub-functions of ⎕CR:
A=0-4 or 7-9, or 29: various formatting styles (boxed, APL input/output, etc.). Just try them out.
A=5 or 6: convert byte vector B to a string of uppercase or lowercase hex digits respectively. Every byte in B becomes 2 characters in Z.
A=10: convert variable named in B to an APL expression producing it.
A=11: convert value B to byte vector Z in CDR ("Common Data Representation", an IBM standard) format (similar to 3 ⎕TF).
A=12: convert byte vector Z in CDR format to value Z.
A=13: convert hex string B to byte vector Z.
If a conversion has an inverse conversion (like 12 being the inverse of 11) then the inverse conversion can be expressed as the negative of the conversion number. For example, 12 ⎕CR B is the same as ¯11 ⎕CR B.
A=14: conversion 11 followed by conversion 13 (Value to hex string in CDR format)
A=15: conversion 13 followed by conversion 12 (hex string in CDR format to Value)
A=16: encode byte vector B into Z (base64 encoding, RFC 4648)
A=17: decode base64 vector B into byte vector Z (base64 encoding, RFC 4648)
A=18: convert text vector B into byte vector Z (UTF8 encoding, RFC 3629)
A=19: convert byte vector B into text vector Z (UTF8 encoding, RFC 3629)
A=20-25: like 3,4,7-9 but using a formatting similar to NARS APL ⎕FMT (showing the axis lengths as numbers instead of → and ↓)
A=26: Z is the cell types of the ravel elements of B (2: character, 16: integer, 32: real number, 64: complex number.
A=27: Z[I] is the primary data representation (for example the real part of a complex number, or the numerator of a rational number) of B[I].
A=28: Z[I] is the additional data representation (for example the imaginary part of a complex number, or the denominator of a rational number) of B[I].
A=30: Z is B with all top-level elements conformed to a common rank and shape (as required by the ⍤ operator). This conversion is primarily used internally by the GNU APL interpreter.
A=31 or A=32: These conversions are used internally by ⎕INP.
A=33: convert tagged byte vector to a TLV (Tag/Length/Value) buffer. The TLV buffer can be sent over a byte stream (socket) and easily decoded at the other end. Say B = B[1], B[2], ..., B[n] such that B1 is an Integer (the tag) and B[j] is a character in the range 0-255 for j > 1. Let Z←33 ⎕CR B with Z = Z[1], Z[2], ... Z[m]. Then Z[1 2 3 4] is the 4 byte tag, Z[5 6 7 8] is the 4 byte data length (n-1) == (m - 8) and 1↓B == 8 ↓ Z. In other words, the first 4 bytes of Z are the tag in big endian byte order, the next 4 bytes are the length of B except the tag, and the rest of Z is B except the tag.
Example:
Tag←55 ⍝ hex 37
5 ⎕CR 33 ⎕CR Tag,'Value'
000000370000000556616C7565
A=34: this is the inverse of 33 ⎕CR. The intended use for 33 ⎕CR and 34 ⎕CR is the transmission of a tagged byte vector over e.g a TCP socket:
Sender Receiver —— ——– T,Data →→→ 33 ⎕CR T,Data →→→TCP connection→→→ 34 ⎕CR T,Data →→→ T,Data
Example:
34 ⎕CR ¯5 ⎕CR '000000370000000556616C7565' 55 Value
The TLVs constructed by 33 ⎕CR can be sent back-to-back over a TCP connection or similar in such a way that the receiver knows exactly after which byte a TLV ends, which is perfect for connections over which data is sent sporadically. 33 ⎕CR and 34 ⎕CR are particularly useful for encoding and decoding TLV byte buffers exchanged between GNU APL and processes that were forked by GNU APL with ⎕FIO[57] (aka. fork() and execve()).
Most dyadic ⎕CR variants whose argument B is expected to be a byte vector throw:
- RANK ERROR if 1≠⍴⍴B
- DOMAIN ERROR if one of the B[j] is not a proper byte value
A proper byte value is either an integer in the range -128...255 including, or a (Unicode) character with a code point between U+FF80 and U+FFFF (including, corresponding to a negative signed char in C/C++) or between U+0000...U+00FF (including, corresponding to an unsigned char or to a signed positive char in C/C++). Real, Complex, or rational numbers are never proper byte values even if their value is close to an integer. Nor are nested APL values or values being assigned.
Next: ⎕ARG - Interpreter command line arguments, Previous: Dyadic ⎕CR, Up: Non-standard GNU APL Features [Contents]
2.22 Dyadic ⎕FX (Native Functions)
A Native Function is a function that can be called in APL like a normal user defined APL function, but is implemented in C++.
A native function is created with A ⎕FX B. A is a string that is the path of a shared library and B is the name of the function in APL.
The GNU APL package contains a shared library file_io.so that contains the implementation of a native function for reading and writing files (fopen(), fclose(), ...), For example:
⍝ fix native function in lib_file_io.so as FILE_IO
⍝
'lib_file_io.so' ⎕FX 'FILE_IO'
FILE_IO
⍝ show overview of sub-functions in FILE_IO
⍝
FILE_IO ''
Functions provided by this library.
Assumes 'lib_file_io.so' ⎕FX 'FUN'
Legend: e - error code
i - integer
h - file handle (integer)
s - string
A1, A2, ... nested vector with elements A1, A2, ...
FUN '' print this text on stderr
'' FUN '' print this text on stdout
FUN[ 0] '' print this text on stderr
'' FUN[ 0] '' print this text on stdout
Zi ← FUN[ 1] '' errno (of last call)
Zs ← FUN[ 2] Be strerror(Be)
Zh ← As FUN[ 3] Bs fopen(Bs, As) filename Bs mode As
Zh ← FUN[ 3] Bs fopen(Bs, "r") filename Bs
...
Recent versions of GNU APL have replaced the native FILE_IO function above by the system function ⎕FIO. ⎕FIO need not be ⎕FX’ed and is otherwise backward compatible to the native function. New function numbers are, however, only added to ⎕FIO and not to the old native function FILE_IO. The parameters of the functions are described in the man pages for, e.g. strerror, fopen, ... and are fairly obvious.
Many functions in FILE_IO have byte vectors as arguments or return byte vectors. A byte vector is an integer vector whose numbers fit into a byte (so they are integers between -128 and 255). Often ⎕UCS and the functions in dyadic ⎕CR are used to convert such byte vectors to/from, for example, Unicode strings.
The GNU APL package also contains other shared libraries as templates for your own native functions. Copy one of the files src/native/template_F0.cc (for niladic native functions), src/native/template_F12.cc (for nomadic native functions), src/native/template_OP1.cc (for monadic native operators), or src/native/template_OP2/cc (for dyadic native operators) to your own .cc file and adjust src/native/Makefile.am accordingly.
Note: The )IN and )OUT commands of GNU APL support native functions, but to do so they have to use dyadic ⎕FX. This renders the workspace interchange file (.atf files) written by )OUT incompatible with all other APL interpreters if the workspace contains native functions. The )OUT command prints a warning when it is used with a workspace that contains native functions.
Note: As of GNU APL 1.6, the native function FILE_IO has been turned into the system function ⎕FIO. The syntax of ⎕FIO is the same as for FILE_IO. The )CLEAR workspace command will close all open files.
Next: ⎕DLX - Knuth’s Dancing Links Algorithm, Previous: Dyadic ⎕FX (Native Functions), Up: Non-standard GNU APL Features [Contents]
2.23 ⎕ARG - Interpreter command line arguments
⎕ARG contains the command line arguments with which GNU APL was invoked. See APL Scripting.
Next: ⎕ENV - Environment Variables, Previous: ⎕ARG - Interpreter command line arguments, Up: Non-standard GNU APL Features [Contents]
2.24 ⎕DLX - Knuth’s Dancing Links Algorithm
⎕DLX is an implementation of Donald Knuth’s Dancing Links Algorithm (called DLX by Knuth himself, but is sometimes also referred to as Knuth’s Algorithm X). ⎕DLX is a generic backtracking machine that can be used to dramatically simplify problems like the 8 queens problem on a chess board or sudokus.
The monadic form of ⎕DLX, i.e. ⎕DLX B, is a shortcut for 0 ⎕DLX B. It computes the first solution for the constraint matrix B.
The dyadic form of ⎕DLX, i.e. A ⎕DLX B, has an integer scalar A as left argument which determines the details of the computation as follows:
A > 0: The algorithm tries to find all solutions, but stops when A solutions have been found. This is handy while debugging code using ⎕DLX. The result is a nested vector with one vector item per solution.
A = 0: The algorithm stops when the first solution was found. In this case the solution is a simple (non-nested) numeric vector.
A = ¯1: like A > 0 but finding all solutions
A = ¯2: like A = 0 but instead of returning the first solution, the number of solutions (i.e. 0 or 1), the number of backtracks, and the number of link dances is returned as a 3-element numeric vector.
A = ¯3: like A = ¯1 but instead of returning all solutions, the number of solutions, the number of backtracks, and the number of link dances is returned as a 3-element numeric vector.
A = ¯4: A number of single steps in Knuth’s Algorithm are performed. Let e.g. A←¯4 r1 r2 r3. Then Z←A ⎕DLX B is the matrix B after 3 steps r1, r2, and r3 have been performed. r1, r2, and r3 are valid (as per ⎕IO) row numbers of B, and a step with a given row changes B as follows:
- the given row is set to 0 (this row becomes part of the final result),
- all other rows that have a 1 or a 2 in the same column as B are set to 0 (these 1s or 2s in the other rows conflict with the 1 or 2 in the given row and are therefore removed from B), and
- all columns that have no 1s or 2s left are removed from B (these columns have a 1 or 2 in B and the constraint is therefore satisfied).
The purpose of ¯4 ⎕DLX is:
- To demonstrate how Knuth’s algorithm works, and/or
- To preset some initial values in B. For example, one can first initialize the constraints for an empty Sudoku (which is the same matrix for all Sudokus) and then enter the initial digits of a particular Sudoku using 4 ⎕DLX. If there are, say, 20 initial digits in the Sudoku then A has 21 elements (¯4 plus the 20 rows representing the 20 initial digits. The result of ¯4 ⎕DLX B has the same number of rows as B (with some rows now cleared), but fewer columns than B.
The right argument B of ⎕DLX B or A ⎕DLX B is a constraints matrix whose columns consist of either 0s and 1s (called a primary column) or 0s and 2s (called secondary columns). The 0s, 1s and 2s can be the integers 0, 1, or 2, characters ’0’, ’1’, or ’2’ respectively, or ’ ’ meaning ’0’. The character representation is useful when B becomes large and shall be printed because the spaces in the numerical variant will not be printed. In the following, B is assumed to be numeric.
Let Z←A ⎕DLX B, and let R be a solution in Z, that is, Z itself (A = 0) or R is Z[k] for some k if A ≠ 0. And let S←+⌿B[R].
Then S = s1 s2 s3, ... sN where N is the number of columns in B and sj=1 if j is a primary column of B and sj∈0 1 if j is a secondary column of B.
In other words, ⎕DLX B computes a subset of the rows of B in such a way that for every column j of B exactly one (for primary column j) or at most one (for a secondary column) of the rows in a solution has its j’th element set to 1 and all other words set their j’th element set to 0.
In yet other words, for every solution returned by ⎕DLX B, a 1 in one row prevents all other rows that also have a 1 in that column, and all rows together have exactly one 1 in every primary column and at most one 1 in every secondary column. In the absence of secondary columns, the problem solved by ⎕DLX is also known as the "exact cover problem"
If all that sounds weird and useless, consider the following APL program for finding all solutions of the 8 Queens problem on a chess board (which probably every programmer has programmed at some point in time):
RC←8↑'1' ◊ D←15↑¯8↑'2' ⍝ helpers for constructing Q8
⍝ rows cols diag1 diag2
Q8←⊃{(R⌽RC),(C⌽RC),((C-R)⌽D),((¯7-R+C)⌽D)⊣(R C)←-8 8⊤⍵-⎕IO} ¨ ⍳64
Z←¯1 ⎕DLX Q8
{⎕UCS (65+⌊⍵÷8)(49+8∣⍵←⍵-⎕IO)} ¨ ⊃Z[1 2 3 92] ⍝ solutions 1, 2, 3, and 92
A1 B5 C8 D6 G2 E3 F7 H4
A1 B6 C8 D3 E7 F4 G2 H5
A1 B7 C4 E8 D6 G5 F2 H3
A8 B4 C1 D3 G7 E6 F2 H5
8 8⍴("+" "Q")[⎕IO+(⍳64)∈⊃Z[1]] ⍝ visualize solution Z[1]
Q + + + + + + +
+ + + + Q + + +
+ + + + + + + Q
+ + + + + Q + +
+ + Q + + + + +
+ + + + + + Q +
+ Q + + + + + +
+ + + Q + + + +
Obviously Z contains solutions for the 8 Queens problem; the total number of solutions is well known to be 92 and we showed only the first two and the last solution above.
The constraint matrix Q8 is the key to success. The matrix has 64 rows - one row for every field of the chess board. And it has 8 + 8 + 15 + 15 columns. The first 8 columns of Q8 are constraints that prevent more than one Queen from being placed in the same row of the chess board (the argument ⍵ is the field number counting from left to right and from bottom to top). The next 8 columns of Q8 are constraints that prevent more than one Queen from being placed in the same column of the chess board.
If we would call ⎕DLX with only these constraints, i.e. ⎕DLX T8←64 16↑Q8, then we would get the solutions of the 8 tower problem. However, we continue and add 15 more constraints for each of the two diagonals. The resulting constraint matrix Q8 is this:
Q8
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
11 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
To see what, for example, the first solution looks like and how it relates to the constraints matrix Q8:
⍝ the rows in Q8 of the first solution
⍝
Z[1]
1 14 24 27 39 44 50 61
⍝ the first solution translated back into the problem domain
⍝
{⎕UCS (65+⌊⍵÷8)(49+8∣⍵←⍵-⎕IO)} ¨ ⊃Z[1]
A1 B6 C8 D3 E7 F4 G2 H5
⍝ the constraints of the rows of the first solution
⍝
Q8[⊃Z[1];]
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
1 1 2 2
⍝ all primary constraints met?
⍝
+⌿ ' '≠ Q8[⊃Z[1];]
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 1 0 1 1 1 1 0 1 0 1 1 0 0 0 0 0 1 1 1 1 1 1
1 0 0 0 0 1
And that’s it: call ⎕DLX to get the solution(s). In general all problems that can be solved by ⎕DLX contain 3 steps:
- translate the problem into a constraints matrix B,
- Z←⎕DLX B, and
- translate the result Z back into the problem domain.
Another application of ⎕DLX is solving sudokus. The constraints matrix is a little more complicated, but the principle is the same. GNU APL is shipped with two workspaces: sudoku.apl (which solves sudokus without using ⎕DLX) and sudoku_DLX.apl (which solves sudokus using ⎕DLX).
Next: ⎕FIO - File I/O Functions, Previous: ⎕DLX - Knuth’s Dancing Links Algorithm, Up: Non-standard GNU APL Features [Contents]
2.25 ⎕ENV - Environment Variables
⎕ENV contains the environment variables of the process that is running GNU APL. See APL Scripting.
Next: ⎕FFT - Fast Fourier Transform, Previous: ⎕ENV - Environment Variables, Up: Non-standard GNU APL Features [Contents]
2.26 ⎕FIO - File I/O Functions
As of GNU APL 1.6, the native function FILE_IO has been replaced by the system function ⎕FIO. ⎕FIO normally takes a numeric axis argument which selects one of many different functions, most of which are contained in the standard C library. The arguments for these functions are usually the same as the corresponding C functions and the man page for each function describes the meaning of the arguments.
For example, ⎕FIO[3] corresponds to fopen() and ’man fopen’ explains what fopen does (opening a file).
Calling ⎕FIO monadically without an axis and with an empty right argument shows a list of all functions provided by ⎕FIO:
⎕FIO ''
Functions provided by ⎕FIO...
Legend: a - address family, IPv4 address, port (or errno)
d - table of dirent structs
e - error code (integer as per errno.h)
h - file handle (integer)
i - integer
n - names (nested vector of strings)
s - string
u - time divisor: 1 - second
1000 - milli second
1000000 - micro second
y4 - seconds, wday, yday, dst (
y67- year, mon, day, hour, minute, second, [dst]
y9 - year, mon, day, hour, minute, second, wday, yday, dst
A1, A2, ... nested vector with elements A1, A2, ...
⎕FIO '' print this text on stderr
'' ⎕FIO '' print this text on stdout
⎕FIO[ 0] '' print this text on stderr
'' ⎕FIO[ 0] '' print this text on stdout
Zi ← ⎕FIO[ 1] '' errno (of last call)
Zs ← ⎕FIO[ 2] Be strerror(Be)
Zh ← As ⎕FIO[ 3] Bs fopen(Bs, As) filename Bs mode As
Zh ← ⎕FIO[ 3] Bs fopen(Bs, "r") filename Bs
File I/O functions:
Ze ← ⎕FIO[ 4] Bh fclose(Bh)
Ze ← ⎕FIO[ 5] Bh errno (of last call on Bh)
Zi ← ⎕FIO[ 6] Bh fread(Zi, 1, 5000, Bh) 1 byte per Zi
Zi ← Ai ⎕FIO[ 6] Bh fread(Zi, 1, Ai, Bh) 1 byte per Zi
Zi ← Ai ⎕FIO[ 7] Bh fwrite(Ai, 1, ⍴Ai, Bh) 1 byte per Ai
Zi ← ⎕FIO[ 8] Bh fgets(Zi, 5000, Bh) 1 byte per Zi
Zi ← Ai ⎕FIO[ 8] Bh fgets(Zi, Ai, Bh) 1 byte per Zi
Zi ← ⎕FIO[ 9] Bh fgetc(Zi, Bh) 1 byte
Zi ← ⎕FIO[10] Bh feof(Bh)
Zi ← ⎕FIO[11] Bh ferror(Bh)
Zi ← ⎕FIO[12] Bh ftell(Bh)
Zi ← Ai ⎕FIO[13] Bh fseek(Bh, Ai, SEEK_SET)
Zi ← Ai ⎕FIO[14] Bh fseek(Bh, Ai, SEEK_CUR)
Zi ← Ai ⎕FIO[15] Bh fseek(Bh, Ai, SEEK_END)
Zi ← ⎕FIO[16] Bh fflush(Bh)
Zi ← ⎕FIO[17] Bh fsync(Bh)
Zi ← ⎕FIO[18] Bh fstat(Bh)
Zi ← ⎕FIO[19] Bh unlink(Bc)
Zi ← ⎕FIO[20] Bh mkdir(Bc, 0777)
Zi ← Ai ⎕FIO[20] Bh mkdir(Bc, AI)
Zi ← ⎕FIO[21] Bh rmdir(Bc)
Zi ← A ⎕FIO[22] 1 printf( A1, A2...) format A1
Zi ← A ⎕FIO[22] 2 fprintf(stderr, A1, A2...) format A1
Zi ← A ⎕FIO[22] Bh fprintf(Bh, A1, A2...) format A1
Zi ← Ac ⎕FIO[23] Bh fwrite(Ac, 1, ⍴Ac, Bh) 1 Unicode per Ac, Output UTF8
Zh ← As ⎕FIO[24] Bs popen(Bs, As) command Bs mode As
Zh ← ⎕FIO[24] Bs popen(Bs, "r") command Bs
Ze ← ⎕FIO[25] Bh pclose(Bh)
Zs ← ⎕FIO[26] Bs return entire file Bs as byte vector
Zs ← As ⎕FIO[27] Bs rename file As to Bs
Zd ← ⎕FIO[28] Bs return content of directory Bs
Zn ← ⎕FIO[29] Bs return file names in directory Bs
Zs ← ⎕FIO 30 getcwd()
Zn ← As ⎕FIO[31] Bs access(As, Bs) As ∈ 'RWXF'
Zh ← ⎕FIO[32] Bi socket(Bi=AF_INET, SOCK_STREAM, 0)
Ze ← Aa ⎕FIO[33] Bh bind(Bh, Aa)
Ze ← ⎕FIO[34] Bh listen(Bh, 10)
Ze ← Ai ⎕FIO[34] Bh listen(Bh, Ai)
Za ← ⎕FIO[35] Bh accept(Bh)
Ze ← Aa ⎕FIO[36] Bh connect(Bh, Aa)
Zi ← ⎕FIO[37] Bh recv(Bh, Zi, 5000, 0) 1 byte per Zi
Zi ← Ai ⎕FIO[37] Bh recv(Bh, Zi, Ai, 0) 1 byte per Zi
Zi ← Ai ⎕FIO[38] Bh send(Bh, Ai, ⍴Ai, 0) 1 byte per Ai
Zi ← Ac ⎕FIO[39] Bh send(Bh, Ac, ⍴Ac, 0) 1 Unicode per Ac, Output UTF8
Zi ← ⎕FIO[40] B select(B_read, B_write, B_exception, B_timeout)
Zi ← ⎕FIO[41] Bh read(Bh, Zi, 5000) 1 byte per Zi
Zi ← Ai ⎕FIO[41] Bh read(Bh, Zi, Ai) 1 byte per Zi
Zi ← Ai ⎕FIO[42] Bh write(Bh, Ai, ⍴Ai) 1 byte per Ai
Zi ← Ac ⎕FIO[43] Bh write(Bh, Ac, ⍴Ac) 1 Unicode per Ac, Output UTF8
Za ← ⎕FIO[44] Bh getsockname(Bh)
Za ← ⎕FIO[45] Bh getpeername(Bh)
Zi ← Ai ⎕FIO[46] Bh getsockopt(Bh, A_level, A_optname, Zi)
Ze ← Ai ⎕FIO[47] Bh setsockopt(Bh, A_level, A_optname, A_optval)
Ze ← As ⎕FIO[48] Bh fscanf(Bh, As)
Zs ← ⎕FIO[49] Bs return entire file Bs as nested lines
Zs ← LO ⎕FIO[49] Bs ⎕FIO[49] Bs and pipe each line through LO.
Zi ← ⎕FIO[50] Bu gettimeofday()
Zy4← ⎕FIO[51] By67 mktime(By67) Note: Jan 2, 2017 is: 2017 1 2 ...
Zy9← ⎕FIO[52] Bi localtime(Bi) Note: Jan 2, 2017 is: 2017 1 2 ...
Zy9← ⎕FIO[53] Bi gmtime(Bi) Note: Jan 2, 2017 is: 2017 1 2 ...
Zi ← ⎕FIO[54] Bs chdir(Bs)
Ze ← As ⎕FIO[55] Bh sscanf(Bs, As) As is the format string
Zs ← As ⎕FIO[56] Bs write nested lines As to file named Bs
Benchmarking functions:
⎕FIO[200] Bi clear statistics with ID Bi
Zn ← ⎕FIO[201] Bi get statistics with ID Bi
⎕FIO[202] Bs get monadic parallel threshold for primitive Bs
Ai ⎕FIO[202] Bs set monadic parallel threshold for primitive Bs
⎕FIO[203] Bs get dyadic parallel threshold for primitive Bs
Ai ⎕FIO[203] Bs set dyadic parallel threshold for primitive Bs
A new feature of ⎕FIO (which is not available with the native function FILE_IO) is ⎕FIO[49]. ⎕FIO[49] is a monadic operator which takes a monadic conversion function as function argument. For example:
Z←F ⎕FIO[49] 'filename'
reads the file named filename line by line. For every line read, the conversion function F is called and the result returned by F is enclosed and stored in Z. In other words,
Z←F ⎕FIO[49] 'filename'
does:
Z F¨Z←⎕FIO[49] 'filename'
Next: ⎕GTK - GTK Interface, Previous: ⎕FIO - File I/O Functions, Up: Non-standard GNU APL Features [Contents]
2.27 ⎕FFT - Fast Fourier Transform
For those interested in signal processing and the like, GNU APL provides ⎕FFT:
The monadic form ⎕FFT B is a shortcut for the dyadic form 0 ⎕FFT B. It computes the FFT of complex or real B without applying a window function.
The dyadic form A ⎕FFT B provides more control over what ⎕FFT computes. A is an integer scalar which falls into one of three ranges.
The first range from ¯15 to ¯10 does not compute an FFT, but returns the result of multiplying B with one of several window functions, that are frequently used in the context of FFTs. The result has same shape as B and can be used for analyzing or troubleshooting FFTs:
- A=¯10: no FFT, return the Hann window applied to B
- A=¯11: no FFT, return the Hamming window applied to B
- A=¯12: no FFT, return the Blackman window applied to B
- A=¯13: no FFT, return the Blackman-Harris window applied to B
- A=¯14: no FFT, return the Blackman-Nuttal window applied to B
- A=¯15: no FFT, return the Flat-Top window applied to B
The second range around 0 contains the computation of the forward and inverse FFTs:
- 0 ⎕FFT B returns the "normal" (aka. forward) FFT of the numeric array B.
- ¯1 ⎕FFT B returns the inverse FFT of the numeric array B.
The third range from 10 to 15 corresponds to the first range and first multiplies B with a window function and then computes the FFT:
- A=10: FFT(B × Hann window)
- A=11: FFT(B × Hamming window)
- A=12: FFT(B × Blackman window)
- A=13: FFT(B × Blackman-Harris window)
- A=14: FFT(B × Blackman-Nuttal window)
- A=15: FFT(B × Flat-Top window)
⍴⍴B can be 1 (one-dimensional FFT, the most common case) or more. The implementation of ⎕FFT uses libfftw3, aka. "The fastest Fourier Transform in the West." GNU APL checks the presence of libfftw3 when it is ./configure’d. If libfftw3 is present then ⎕FFT will hopefully return the expected result; if not then a DOMAIN ERROR will be raised when ⎕FFT is being used.
⎕FFT honors the presence of /etc/fftw/wisdom (see man fftw-wisdom) to speed up the computations performed by ⎕FFT. Creating /etc/fftw/wisdom will take a few hours, though, so that creating it will not pay off for most mortals.
Next: ⎕JSON - JSON Parsing, Previous: ⎕FFT - Fast Fourier Transform, Up: Non-standard GNU APL Features [Contents]
2.28 ⎕GTK - GTK Interface
GTK (Gimp ToolKit) is a rather powerful library for creating graphical user interfaces (GUIs). ⎕GTK makes a subset of the almost 10000 functions in the different GTK libraries available to GNU APL programs. With ⎕GTK a GNU APL program can, for example, replace the somewhat crude ⎕ or ⍞ input methods of standard APL with a more intuitive GUI.
The details of using ⎕GTK would go far beyond the scope of this info manual and has therefore been put into a separate document. See: HOWTOs/Quad-GTK.html.
Next: ⎕MAP - Map Value, Previous: ⎕GTK - GTK Interface, Up: Non-standard GNU APL Features [Contents]
2.29 ⎕JSON - JSON Parsing
GNU APL provides ⎕JSON for decoding and encoding JSON strings and files. A (valid) JSON string is mapped to an APL value as follows:
- JSON value ←→ structured or non-structured APL value
- JSON number ←→ APL number
- JSON string ←→ APL string
- JSON literal ←→ enclosed APL string (one of either ⊂’null’, ⊂’true’, or ⊂’false’ )
- JSON array ←→ APL vector
- JSON object ←→ structured APL value (associative array)
2.29.1 Monadic ⎕JSON
Z←⎕JSON B converts the string B into an APL value according to the mapping above. If that fails then command )MORE provides information about the error and where in B the error was detected.
2.29.2 Dyadic ⎕JSON
Z←A ⎕JSON B performs one of the following conversions:
- Z←0 ⎕JSON B is the same as monadic Z←⎕JSON B.
- Z←1 ⎕JSON B is like Z←0 ⎕XML B, except that B is not the JSON string itself but the name of a file from which a JSON string is read.
- Z←2 ⎕JSON B is the inverse of Z←0 ⎕XML B. It converts an APL value to a JSON string.
- Z←3 ⎕JSON B is like 2 ⎕JSON B, except that the member names (keys) of all JSON objects are sorted alphabetically. That is of little use (but costs performance) if Z is not displayed but processed further, but it could help troubleshooting when Z is displayed and the number of keys in Z is large.
Next: ⎕PLOT - Plot Data, Previous: ⎕JSON - JSON Parsing, Up: Non-standard GNU APL Features [Contents]
2.30 ⎕MAP - Map Value
⎕MAP changes the ravel items of its right argument according to a mapping table provided as its left argument. Let Z←A ⎕MAP B.
The left argument A of Z←A ⎕MAP B shall be a N×2 matrix. Each 2-element row of A, say A[J;], specifies a separate mapping A[J;1] → A[J;2]. The result Z has the same shape as the right argument B. The items Z[...] of their result are constructed from their corresponding items B[...] in B as follows:
- if B[...] ≡ A[J;1] for some J then Z[...] is A[J;2].
- otherwise B[...] is different from all A[1;J] and then Z[...] is B[...]
In other words, Z is B, but with items of B found in A[;1] replaced by their mapped item A[;2].
In practice the left argument A is frequently created from a literal APL value such as 5 2⍴’eEwWaAzZ92’ in the example below. To simplify these cases, A ⎕MAP B also accepts a vector instead of a N×2 matrix:
A ⎕MAP B ←→ ((N 2)⍴A) ⎕MAP B if (2×N) ←→ ⍴A
Examples:
⍝ the map A
⊢A←5 2⍴'eEwWaAzZ92'
eE ⍝ map 'e' → 'E'
wW ⍝ map 'w' → 'W'
aA ⍝ map 'a' → 'A'
zZ ⍝ map 'z' → 'Z'
92 ⍝ map '9' → '2'
⍝ the value B being mapped
⊢B←'Halloween'
Halloween
⍝ the result of A ⎕MAP B
A ⎕MAP B
HAlloWEEn
A←'eEwWaAzZ92' ⍝ vector A instead of N×2 matrix
A ⎕MAP B
HAlloWEEn
NOTES:
- The keys of the mapping A (i.e. the elements in column A[;1]) must be unique. If they are not then the mapping is ambiguous and a DOMAIN ERROR is raised.
- Nested items in B: if an item of B is nested, then it is either equal to some (also nested) key, say A[N;1], (in that case it is being mapped to A[N;2] in the result), or it is different from all keys in A[;1] (and in that case the corresponding item in the result is the item in B.
- Nested items in A: if a key, say A[N;1], is nested and matches an equal (hence also nested) item in B, then the corresponding item in the result will be A[N;2] (which may or may not be nested). If a (nested or not nested) key A[N;1] is equal to an item in B, then the corresponding item in the result will be nested if A[N;2] is nested. If, for some N, the depths of A[N;1] and A[N;2] differ, then depths of B and A ⎕MAP B may differ as well. That is, ⎕MAP conserves the shape of B, but not necessarily the depth of B.
- By default the mapping of B is non-recursive, i.e. the top-level items of
B are compared with the top-level keys A[;1], and nested keys and items of B
are handled as described above.
Sometimes, however, it is desirable to recursively descend into the nested sub-values of B (though never of A). This can be achieved by enclosing A as shown in the examples below.
A←5 2⍴'eEwWaAzZ92'
B←'Hal' 'low' 'een' ⍝ nested B
4 ⎕CR A ⎕MAP B ⍝ non-recursive (none of the keys in A[;1] matches)
┏→━━━━━━━━━━━━━━━━┓
┃┏→━━┓ ┏→━━┓ ┏→━━┓┃
┃┃Hal┃ ┃low┃ ┃een┃┃
┃┗━━━┛ ┗━━━┛ ┗━━━┛┃
┗∊━━━━━━━━━━━━━━━━┛
4 ⎕CR (⊂A) ⎕MAP B ⍝ recursive (some simple keys in A[;1] match)
┏→━━━━━━━━━━━━━━━━┓
┃┏→━━┓ ┏→━━┓ ┏→━━┓┃
┃┃HAl┃ ┃loW┃ ┃EEn┃┃
┃┗━━━┛ ┗━━━┛ ┗━━━┛┃
┗∊━━━━━━━━━━━━━━━━┛
Next: ⎕PNG - Portable Network Graphics, Previous: ⎕MAP - Map Value, Up: Non-standard GNU APL Features [Contents]
2.31 ⎕PLOT - Plot Data
⎕PLOT is a function for visualizing numerical APL values. The values to be plotted are provided as the right argument of ⎕PLOT while the optional left argument controls details of the output, such as the plot window size, colors for plot lines, points, and grids, etc.
The general syntax of ⎕PLOT is:
⎕PLOT ⍬ ⍝ show a list of attributes and their default values H←⎕PLOT B ⍝ plot B with all attributes set to their default values H←A ⎕PLOT B ⍝ plot B with some of the default attributes overridden ⎕PLOT H ⍝ close the plot window with handle H ⎕PLOT 0 ⍝ verbosity: OFF (no debug output) ⎕PLOT ¯1 ⍝ verbosity: ON (print attribute values before plotting) ⎕PLOT ¯2 ⍝ verbosity: DEBUG (also print debug information) ⎕PLOT ¯3 ⍝ close all plot windows ⎕PLOT ¯6 ⍝ return all open plot window handles H
2.31.1 The Plot Data B
The plot data B can be a vector (for a single plot line to be drawn) or a matrix (in that case one plot line per matrix row is being drawn, by default in different colors). Each data item has to be numeric and represents one point in the plot. The points that are adjacent in a row of the matrix are connected by lines. By default plotted points are black and the lines connecting them are green (for the first plot line). However, all colors used, all diameters of points, and all thicknesses of the lines can be fine-tuned by overriding the default values (see dyadic A ⎕PLOT B below).
2.31.1.1 Complex Plot Data B
If a data item B[N] or B[row;N] is complex, say B[N] = x + iy. then it is placed (after some scaling) at position (x, y) of the plot. The X-range [Xmin ... Xmax] of the plot is then determined by the real parts of B, and the Y-range [Ymin ... Ymax] of the plot is determined by the imaginary parts of B. That is:
Xmin ← ⌊/,9○B ⍝ smallest real part of B Xmax ← ⌈/,9○B ⍝ largest real part of B Ymin ← ⌊/,11○B ⍝ smallest imaginary part of B Ymax ← ⌈/,11○B ⍝ largest imaginary part of B
Example (plot a circle (actually: a regular 20-gon)):
⎕PLOT +⌿1 0J1×[1]1 2 ∘.○ (0,⍳2×N) × ○÷N←10
produces this plot window (only visible in the HTML version of this document; in text mode see file doc/PLOT_circle.png):
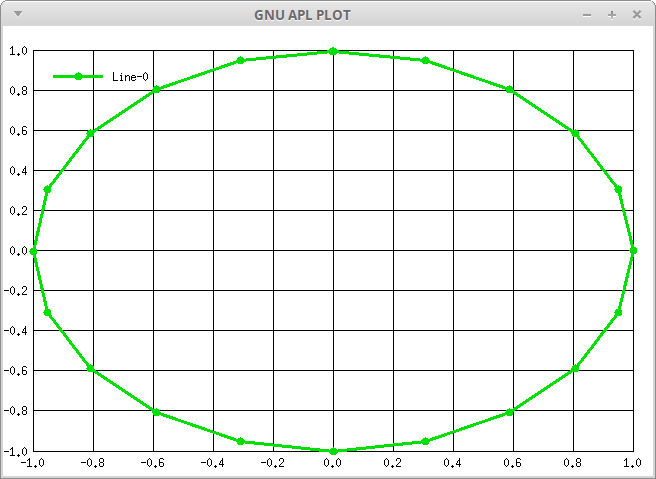
2.31.1.2 Real Plot Data B
On the other hand, if a data item B[N] or B[row;N] is real, then it is placed at position (N, x) of the plot. The X-range is then [⎕IO ... ⎕IO + ¯1↑⍴B] and the Y-range [Ymin ... Ymax] of the plot is determined by the values of B. That is:
Xmin ← ⎕IO ⍝ smallest real part of B Xmax ← ¯1 + ⎕IO + ⍴B ⍝ largest real part of B Ymin ← ⌊/,B ⍝ smallest value in B Ymax ← ⌈/,B ⍝ largest value in B
Example:
⎕PLOT 0 1 ¯1 2 ¯2 3 ¯3
produces this plot window (only visible in the HTML version of this document; in text mode see file doc/PLOT_zigzag.png):
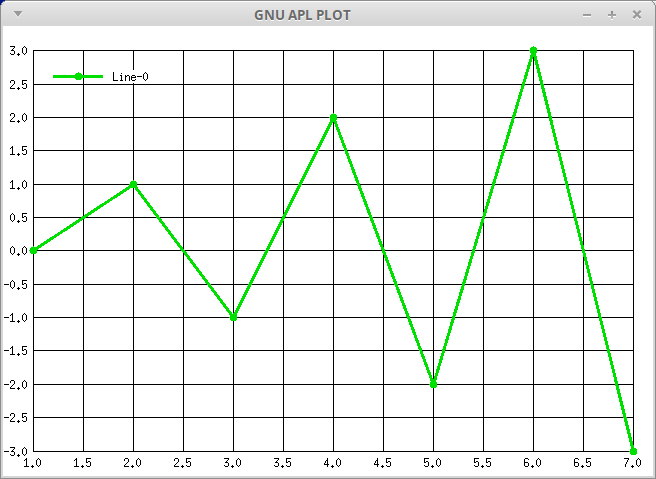
NOTE: In theory one can also mix real and complex values, even though doing so makes little sense. If at least one item of the plot data B is complex, then all real items in B are taken as complex with imaginary part 0.
2.31.2 The Plot Attributes A
There are a number of attributes like colors, point sizes, line widths, etc. that control how the resulting plot will look.
Similar to ⎕CR and ⎕FIO, an empty argument B in ⎕PLOT B displays a list of the arguments. The list of arguments grows over time and therefore the list displayed by ⎕PLOT ⍬ may be more up-to-date than this description. For example:
⎕PLOT Usage:
⎕PLOT B plot B with default attribute values
A ⎕PLOT B plot B with attributes specified by A
A is a nested vector of strings.
Each string A[i] has the form "Attribute: Value"
Colors are specified either as #RGB or as #RRGGBB or as RR GG BB)
The attributes understood by ⎕PLOT and their default values are:
1. Global (plot window) Attributes:
caption: ⎕PLOT (plot window caption)
output_filename: (output file name)
auto_close: 0 (= do not close X window automatically)
(1) (= close if file was written successfully)
(2) (= always close X window automatically)
with_border: 1 (= write plot area and window borders)
(0) (= write only plot area to output file)
pw_pos_X: 50 pixel (plot window position X)
pw_pos_Y: 50 pixel (plot window position Y)
border_width: 10 pixel (width of the window border)
pa_width: 600 pixel (plotarea width)
pa_height: 400 pixel (plotarea height)
pa_border_L: 50 pixel (pixels left of the plotarea)
pa_border_R: 20 pixel (pixels right of the plotarea)
pa_border_T: 25 pixel (pixels above the plotarea)
pa_border_B: 25 pixel (pixels below the plotarea)
gridX_style: 1 (X grid style = ──────── )
(2) ( = ╴╴╴╴╴╴╴╴ )
(3) ( = ─╴─╴─╴─╴ )
axisX_arrow: 0 (X-axis arrow)
axisX_label: X (X-axis label)
axisY_arrow: 0 (Yaxis arrow)
axisY_label: Y (Y-axis label)
axisZ_arrow: 0 (Z-axis arrow)
axisZ_label: Z (Z-axis label)
gridX_pixels: 44 pixel (pixels between X grid lines)
gridX_variable: 0 (draw X grid (only) at plot points)
gridX_line_width: 1 pixel (thickness of the X-grid lines)
gridX_color: #000000 (color of the X-grid lines)
gridY_style: 1 (Y grid style, see gridX_style above)
gridY_pixels: 33 pixel (pixels between Y grid lines)
gridY_line_width: 1 pixel (thickness of the Y-grid lines)
gridY_color: #000000 (color of the Y-grid lines)
gridZ_style: 1 (Z grid style, see gridX_style above)
gridZ_pixels: 33 pixel (pixels between Z grid lines)
gridZ_line_width: 1 pixel (thickness of the Z-grid lines)
gridZ_color: #000000 (color of the Z-grid lines)
canvas_color: #FFFFFF (background color of the plot window)
legend_color: #F0F0F0 (background color of the legend)
legend_X: 50 pixel (the X position of the legend)
legend_Y: 50 pixel (the Y position of the legend)
legend_dY: 15 pixel (the distance between legend lines)
legend_lX: 50 pixel (the length of the legend lines)
rangeX_min: 0.0 (the start of the X range to be plotted)
rangeX_max: 0.0 (the end of the X range to be plotted)
rangeY_min: 0.0 (the start of the Y range to be plotted)
rangeY_max: 0.0 (the end of the Y range to be plotted)
rangeZ_min: 0.0 (the start of the Z range to be plotted)
rangeZ_max: 0.0 (the end of the Z range to be plotted)
origin_X: 100 pixel (X position offset of the origin)
origin_Y: 100 pixel (Y position offset of the origin)
format_X: (none) (format for X-axis ticks (GTK only))
%sT1%T2...%Tn (static texts for ticks)
%G, %g grid line number (starting at 1 or )
%v value
%S (seconds SS)
%I (minutes MM)
%H, %h (hours HH or h/hh)
%D, %d (day DD or d/dd)
%M, %m (month MM or m/mm)
%q (quarter 0..3)
%Q (quarter 1..4)
%Y, %y (year YYYY or yy)
format_Y: (format for Y-axis (dito))
format_Z: (format for Z-axis (dito))
color_level-P: (none) (color gradient at P% (surface plots only))
2. Local (plot line N) Attributes:
line_color-N: #00FF00 (the color of plot line N)
line_style-N: 1 (line style, see gridX_style above)
line_width-N: 3 pixel (the thickness of plot line N)
point_color-N: #000000 (the color of the plot points)
point_style-N: 1 (= plot_points: ● )
(2) (= plot_points: ▲ )
(3) (= plot_points: ▼ )
(4) (= plot_points: ◆ )
(5) (= plot_points: ■ )
(6) (= plot_points: 🞤 (GTK only)
(7) (= plot_points: 🞫 (GTK only)
point_size-N: 8 pixel (the outer diameter of the plot points)
point_size2-N: 0 pixel (the inner diameter of the plot points)
legend_name-N: (the name of plot line N in the legend)
There are 2 kinds of attributes: global attributes that affect the entire plot, and local (per-line) attributes that affect one of the plot lines (which corresponds to one row of B). One way to specify multiple attributes in one go is to use multi-line strings.
For example (plot 2 lines of 10 random numbers each, named "random row 1" and "random row 2"):
Data ← ?2 10⍴10 ⍝ two rows of random data
Attributes ← """
legend_name-1: Random Row 1
legend_name-2: Random Row 2
"""
Attributes ⎕PLOT Data
While specifying the plot attributes A in one place is most convenient for a single plot window or when the attributes are read from some external test file, its is sometimes simpler to specify the plot attributes individually. This can be done by using a structured APL variable as left argument A:
Attributes.legend_name_1 ← "Random Row 1"
Attributes.legend_name_2 ← "Random Row 2"
Attributes ⎕PLOT Data
Note that (for syntactical reasons) the separation between the line attribute and the line number is _ (underscore) if A is specified as a structured APL value and - (minus) if A is specified as a string of lines.
If the global attribute output_filename is given, then the plot is not only being displayed in a window on the screen, but also written to a file with the name of the file provided as attribute value. See Output File Format below.
For example:
⊣ ( ⊂ "output_filename: /tmp/bitmap.png" ) ⎕PLOT 1 3 1 4 2
writes the plot of a a zigzag curve to file /tmp/bitmap.png.
Caution: ⎕PLOT with attribute output_filename overwrites existing files without any warning). Errors, most likely lack of permissions to write the output file, raises a DOMAIN ERROR with )MORE possibly providing details as to why the file could not be written.
Some line attributes such as line_width or point_size are frequently the same for several or even all plot lines. In that case one can use the line attribute without a -N or _N suffix which is then used as the default for all lines (unless overridden by the same attribute with -N or _N suffix.
For example:
Attributes.line_width ← 2 ⍝ all plot lines: 2 pixels thick, Attributes.line_width_2 ← 4 ⍝ except plot line 2: 4 pixels thick
2.31.2.1 Tick formatting (GTK only)
By default, the ticks on the X, Y, and Z axes show the naked value of their corresponding coordinates. Sometimes you may want them to look a little different, e.g. by adding units to the numbers. This can be achieved with window properties format_X/Y/Z, possibly accompanied by property gridX_variable.
The properties format_X/Y/Z may be set to a format string that allows the value that is being displayed at the ticks. The format is a string that is a mix of static text and tick items. A tick item is computed from the displayed value or from its position on the axis. There are two different types of tick items: static and dynamic.
A static tick item starts with %s, followed by one or more texts, separated by %. The texts are displayed in the same order starting from the origin and proceeding along the axis. For example:
ATT.format_X ← ’%sT1%T2%T3’
will name X-axis ticks T1, T2, and T3, regardless of the X coordinate. static tick items are the fallbacks for those cases where dynamic tick items cannot produce the desired result. In other words, static tick items must be constructed in APL beforehand.
In contrast, dynamic tick items are computed from the value at the axis, which is often simpler than computing them beforehand in APL. A format string may contain 0 or more tick items which are used in a printf() like manner.
Most of the dynamic tick items (see ⎕PLOT ⍬ for a complete list) are related to points in time (years, quarters, months, days, hours, minutes, and seconds). For them the X coordinate (time) is, according to the *nix time conventions, seconds since midnight 1970. Since this number of seconds is not easy to compute in APL, ⎕FIO.secs_epoch comes to rescue:
Q1 ← ⎕FIO.secs_epoch 2023 2 15 ⍝ Feb. 15 (middle of Q1) 00:00:00
An example for plotting the quarterly values 1 3 4 2 is:
)CLEAR SPQ ← 91×24×60×60 ⍝ seconds per quarter Q1 ← ⎕FIO.secs_epoch 2023 2 15 ⍝ Feb. 15 (middle of Q1) 00:00:00 X ← Q1 + SPQ×0 1 2 3 ⍝ middles of Q1, Q2, Q3, and Q4 Y ← 1 3 2 4 ⍝ values for Q1, Q2, Q3, and Q4 ATT.format_X ← "Q-%Q/%y" ⍝ X-axis ticks: quarter and year ATT ⎕PLOT X + 0J1×Y
Sometimes it is more convenient to display the exact X coordinates of the plot points along the X axis instead of drawing an X-grid and visually guessing the X-values between the vertical grid lines. This can be achieved with setting gridX_variable to 1. Usually the X-coordinates are evenly distributed along their axis while the Y and Z-coordinates are not. For this reason there is no gridY_variable or gridZ_variable.
2.31.3 Plot Window Handling
Each call of ⎕PLOT with some plot data B opens a separate window in the X server (which implies that ⎕PLOT requires X). That window runs in its own thread until it is closed. A plot window can be closed in different ways:
- interactively by clicking on the close button (often located near the top-right corner) of the plot window,
- interactively by opening the drop down menu (if any) of the window (near the top left-of the window) and selecting the menu option named Close,
- programmatically from APL by calling ⎕PLOT ¯3 (which closes all open plot windows), or
- programmatically from APL by calling ⎕PLOT H (which closes a specific plot window), where H is the plot window handle returned by monadic ⎕PLOT B, or by dyadic A ⎕PLOT B with plot attributes A and plot data B.
Note that the exact method for closing a plot window interactively with the mouse or the keyboard (as opposed to programmatically with ⎕PLOT ¯3 or ⎕PLOT H from APL) differs between different window managers. The above corresponds to the typical method(s) for closing windows on most systems.
Up: ⎕PLOT - Plot Data [Contents]
2.31.4 Output File Format
Early versions of ⎕PLOT were using libxcb to display the results of ⎕PLOT while recent versions use libgtk-3. The primary driver for this change was the lack of full Unicode support in libxcb which made it, for example, difficult to properly display APL characters in window captions or in plot line legends.
Writing the pixels of a plot to a file uses functions provided by either libxcb or libgtk-3, and these functions generate different file formats.
libxcb is the older of the two libraries and it therefore produces the older file format .bmp (bitmaps). libgtk-3 is the newer library and it produces the somewhat newer file format .png (portable network graphics). There are tools like convert from package imagemagick that can be used to convert different image file formats into each other and therefore this incompatibility should not cause too much trouble.
For backward compatibility, the libxcb option for ⎕PLOT will continue to exist for some time, but bug fixes and new features will only be made for the libgtk-3 option.
Next: ⎕PS - Print Style, Previous: ⎕PLOT - Plot Data, Up: Non-standard GNU APL Features [Contents]
2.32 ⎕PNG - Portable Network Graphics
Portable Network Graphics is a file format for images, defined in RFC 2083. To quote the RFC:
The PNG format provides a portable, legally unencumbered, well-compressed, well-specified standard for lossless bitmapped image files.
2.32.1 The GNU APL Color Model
An image is a rectangular matrix of Pixels which makes APL the perfect language for manipulating images. In GNU APL (and also in the PNG standard) a single pixel may have one, two, three, or four color components, or short colors, as follows:
- a pixel with one color defines an uncolored (grayscale) pixel between black and white,
- a pixel with two colors defines a grayscale pixel between black and white, and its opacity (see below),
- a pixel with three colors defines a colored pixel whose colors are red, green and blue (or RGB for short), and
- a pixel with four colors defines an RGB pixel and its opacity (RGBA for short).
The opacity (sometimes called the "alpha channel" and abbreviated A in the RGBA format) defines how transparent a pixel is; lower values cause the background of a pixel to shine through while larger values make the pixel more opaque. One important use of the alpha channel is images that shall not appear rectangular (even though their underlying color matrix is). For example, to display a red circle on top of something else, one can set the opacity of the pixels inside the circle to their maximum (as to making them fully opaque and completely hiding the background or some other image below) and the pixels outside the circle to 0 (making them fully transparent).
Since every pixel of an image may have 1, 2, 3, or 4 color components, the representation of an image in APL is a three dimensional array Image where:
- (COLORS HEIGHT WIDTH) ← ⍴ IMAGE,
- COLORS is a number that determines general
format of the image (and, by chance, the number of its color components):
- COLORS = 1: a grayscale image,
- COLORS = 2: a grayscale image with an alpha channel,
- COLORS = 3: a colored RGB (red/green/blue) image, or
- COLORS = 4: a colored RGB image with an alpha channel, aka. RGBA)
- Height is the number of pixels of the image in the vertical direction, and
- Width is the number of pixels of the image in the horizontal direction.
Above is: WIDTH the number of pixels in the horizontal direction, HEIGHT the number of the pixels in the vertical direction, and COLORS the number of color components as above. For simplicity we can treat the opacity as yet another color although, strictly speaking, it is not.
For an image I, the horizontal pixel position I[;;x] increases from left to right and the vertical pixel position I[;y;] increases from top to bottom.
In addition to the 4 general image formats above, the PNG standard allows each format to have different resolutions (of 1-bit, 2-bit, 4-bit, 8-bit, and 16-bit, even though not all combinations of image format and resolution are permitted. For example, the lower resolutions (of 1-bit, 2-bit, or 4-bit) are only permitted for grayscale images without alpha channel, 16-bit is allowed for all images except those with a color table, and so on.
In theory there are 20 different combinations of 4 general image formats and 5 resolutions of the color components. However, the PNG standard allows only 15 of them, in particular by permitting 1-bit, 2-bit, 4-bit resolutions only for grayscale images without alpha channel. The GNU APL color model reduces these 15 combinations further to the 4 general types with the following rules:
- On input, i.e. when reading a PNG image file and producing the APL array described above, the different resolutions allowed by the PNG standard are normalized to a single range of real numbers between 0.0 and 1.0 (this is by chance also the range used in the GTK standard used in ⎕PNG and ⎕PLOT).
- Also on input, images that use color tables (for compressing the image to reduce the file size) are automatically expanded. The resulting APL value is therefore independent of the use of color tables.
- On output, i.e. when storing the APL array in a PNG file, the resolution is 8-bit by default. 8-bit is the only resolution which is valid for all image formats in the PNG standard.
- Also on output, one may optionally specify a different resolution.
In GNU APL, integers and floating point numbers take the same space in memory. The advantage of smaller PNG files with lower resolutions would therefore disappear as soon as converted to APL. On the other hand, the disadvantage (primarily different max. values for different resolutions) would remain. In the GNU APL color model a purely red RGB pixel has the same value I[;y[x] ← 1.0 0.0 0.0 regardless of resolution, which simplifies matters considerably. In a PNG file that same red RGB pixel would instead have either:
- the value $01 0 0 in a 1-bit RGB image, or
- the value $03 0 0 in a 2-bit RGB image, or
- the value $07 0 0 in a 4-bit RGB image, or
- the value $FF 0 0 in a 8-bit RGB image, or
- the value $FFFF 0 0 in a 16-bit RGB image.
It may be useful to note that the human eye can only distinguish around 120 different colors, i.e. about 7 bits (for all color planes together). For this reason 16-bit color components are quite an overkill and the 8-bit default therefore should be more than sufficient for most purposes.
2.32.2 Monadic ⎕PNG
Monadic ⎕PNG, i.e. ⎕PNG B is used for 3 purposes:
- Conversion of PNG files into the GNU APL color model,
- Display of an APL array (in the GNU APL color model) in a window on the screen (interactive use of PNG), and
- Controlling of ⎕PNG itself.
The desired purpose is dictated by the properties of B:
- Any APL text vector (i.e. a string) B is taken as the name of a file that supposedly contains an image in the PNG format. ⎕PNG will read the file and return the pixels in it as a numeric APL array of rank 3. The array contains the color components of the image in the file as described above.
- Any array B with rank 3 must be numeric (with values from 0.0 to 1.0) and is then assumed to be an array in the GNU APL color model (such as the result of the case above). This image is displayed in a new window on the screen; the window survives even after ⎕PNG has returned. The result returned by ⎕PNG is a window handle (a positive integer identifying the window) which may later be used (in the case described below) to close the window programmatically from APL. Alternatively the window can also be closed interactively by the user via its close button.
- Finally, if B is a numeric scalar it fine-tunes the ⎕PNG
behaviour:
- ⎕PNG N with N ≥ 1 (as returned in the case above) closes the window with handle N programmatically.
- ⎕PNG 0 disables all debug printouts related to ⎕PNG.
- ⎕PNG ¯1 turns on a debug printout related to ⎕PNG (X events).
- ⎕PNG ¯2 turns on a debug printout related to ⎕PNG (image data).
- ⎕PNG ¯3 closes all open ⎕PNG windows.
- ⎕PNG ¯4 turns on a debug printout related to ⎕PNG (GTK drawing).
- ⎕PNG ¯5 turns on a debug printout related to ⎕PNG (function calls).
- ⎕PNG ¯6 returns a vector of all all open ⎕PNG window handles.
2.32.3 Dyadic ⎕PNG
Dyadic A ⎕PNG B has only one purpose: to store an APL array in the GNU APL color model into a PNG file.
- If A is a text vector then it is taken as the name of a PNG file into which the image B shall be written. In this case the resolution is 8 bits for each color component.
- If A is a 2-element vector, say (A1 A2) ← A, then the nested A1 is the name of a PNG file as before and A2 is the resolution (1, 2, 4, 8, or 16) to be used for the output file. In this case the combination of the general image format (as implied by ↑⍴B) and resolution A2 must be a valid one in the PNG standard.
2.32.4 APL Examples
⍝ load PNG file image.png
Image ← ⎕PNG 'image.png'
⍝ display the image
Handle ← ⎕PNG Image
⍝ close the window that displays the image
⎕PNG Handle
⍝ display PNG file image.png without storing it in a variable
⎕PNG ⎕PNG 'image.png'
⍝ Simple color conversions...
⍝ convert a monochrome image into the equivalent RGB image
RGB_Gray ← 3 ⌿ Mono
⍝ paint all pixels of a monochrome image red
RGB_Red ← 1 0 0 ⍀ Mono
⍝ paint all pixels of a monochrome image green
RGB_Green ← 0 1 0 ⍀ Mono
⍝ paint all pixels of a monochrome image blue
RGB_Blue ← 0 0 1 ⍀ Mono
Next: ⎕RE - Regular Expressions, Previous: ⎕PNG - Portable Network Graphics, Up: Non-standard GNU APL Features [Contents]
2.33 ⎕PS - Print Style
⎕PS is an integer vector that currently (read: as of SVN 982) contains two integers which control some details of how APL values are being printed. The default value of ⎕PS is 0 0. ⎕PS is a session variable which survives the )LOADing of workspaces.
⎕PS[1] = 0: print rational quotients as normal floating point numbers (digits, fractional point, possibly an exponent).
⎕PS[1] = 1: print rational quotients as Numerator÷Denominator÷
Note: ⎕PS[1] has no effect if rational numbers were not ./configure’d.
⎕PS[2] = 0: no "boxing" of APL values
⎕PS[2] > 0: "boxing" of APL values according to ⎕PS[2].
Setting ⎕PS[2] has the same effect as the debug command ]BOXING and uses the same values.
Note: For compatibility with older workspaces, assigning a single value to ⎕PS assigns that value to ⎕PS[2] and sets ⎕PS[1] to 0.
Next: ⎕RVAL - Random APL value, Previous: ⎕PS - Print Style, Up: Non-standard GNU APL Features [Contents]
2.34 ⎕RE - Regular Expressions
⎕RE is a function that provides access to a subset of libpcre2, which is a powerful regular expression matching library. "pcre" is an acronym for "Perl compatible regular expressions". libpcre2 is Copyright (c) 1997-2017 University of Cambridge, England.
- Preconditions
- Syntax
- The Regular Expression A
- The String(s) B Being Matched
- The Flags X
- Complex Matches
2.34.1 Preconditions
libpcre2 is NOT shipped with GNU APL but must be installed before the GNU APL ./configure script is executed. The ./configure script tries to locate libpcre2 and enables ⎕RE if the library (and its header files) are found.
If ./configure does not find libpcre2, then ⎕RE will raise a SYNTAX ERROR when ⎕RE is used in an APL program.
2.34.2 Syntax
⎕RE has two forms. The short form (without an axis argument) is intended to cover the most likely use cases of ⎕RE, while the long form gives more control over the format of the result produced by ⎕RE:
Z ← A ⎕RE B (short form, no axis) Z ← A ⎕RE[X] B (long form, with axis X)
The short form is equivalent to the long form with an empty axis:
A ⎕RE B ←→ A ⎕RE[''] B
It therefore suffices to explain the long form. The long form has 3 different arguments A, B, and X.
2.34.3 The Regular Expression A
A is a simple character vector which is expected to be a regular expression as defined for the libpcre2 library. ⎕RE passes its left argument A unmodified to libpcre2. The format of A ranges from very simple REs to very complex REs. In fact, regular expressions are a language of their own, and it is unnecessary to describe them here. The user of ⎕RE is referred to the description that comes with libpcre2.
See in particular: man pcre2pattern
2.34.4 The String(s) B Being Matched
B is either:
- a simple character vector (which is then also passed unmodified to libpcre2), or
- a (nested) APL array consisting of simple character vectors.
In the second case above, the result of ⎕RE is conceptually the same as if the EACH operator had been applied to ⎕RE:
A ⎕RE B ←→ A ⎕RE ¨ B
The libpcre2 first compiles A into an internal representation that improves the matching (of B) speed. As a consequence, if several strings shall be matched with the same regular expression A, then it is (sometimes considerably) faster to A ⎕RE B once with several items of a nested B, than to A ⎕RE B multiple times with the same A but different Bs. This is especially true when longer text files with many lines will be matched.
If multiple (nested) strings B are used then A is compiled once and after that the different ⊃B[i] in B are passed unmodified to libpcre2. In that case the result Z is nested and (⍴B) ≡ (⍴Z←A ⎕RE[X] B). We can therefore limit the description to the case where B is a simple character vector.
Any string B that is passed to libpcre2 is called "Subject" in the libpcre2 documentation.
2.34.5 The Flags X
By default, i.e. without an axis argument X or - equivalently - with an empty string X←"" as axis argument, ⎕RE returns the first match of the regular expression A in the string B as an APL string.
By means of the optional axis argument X ≢ "" (in the following called flags) one may override the default behavior to adapt various aspects of the matching to satisfy the requirements that the user of ⎕RE may have.
The X argument of A⎕RE[X] B is a character vector where each character is a flag. Each flag is either understood by (and then passed unmodified to) libpcre2 or else understood by ⎕RE itself (and then not passed to libpcre2).
- The libpcre2 flags: i, m, s, and x
- The ⎕RE (APL output format) flags ↓, ⊂, and /
- the ⎕RE global flag g
- the ⎕RE error flag E
2.34.5.1 The libpcre2 flags: i, m, s, and x
The libpcre2 flags accepted by ⎕RE are: i, m, s, and x. They correspond to the following libpcre2 flags:
- i: PCRE2_CASELESS (perform case insensitive matching)
- m: PCRE2_MULTILINE (perform matching across multiple lines)
- s: PCRE2_DOTALL (dot (.) in A also matches CR/LF)
- x: PCRE2_EXTENDED (see ’man pcre2pattern’)
Please consult the libpcre2 documentation for a more detailed description of these flags.
2.34.5.2 The ⎕RE (APL output format) flags ↓, ⊂, and /
⎕RE provides different output formats, some of which are tailored to different APL functions, so that these other APL functions can use the result of ⎕RE without major conversions. There are currently 4 different output formats:
- no ⎕RE flag: ⎕RE returns the matching sub-string(s) of B.
- ↓ flag: ⎕RE returns the position(s) and the length(s) of the matched sub-string of B, Like other left arguments of ↑ or ↓, the string position(s) in the result start at 0 (i.e. not at ⎕IO) and can therefore be used directly by dyadic ↓ and ↑. For instance to cut out the matched pieces.
- ⊂ flag: ⎕RE returns an integer vector suitable as the left argument of partition (dyadic ⊂).
- / flag: ⎕RE returns a Boolean vector suitable as the left argument of compress (dyadic /).
The following examples may better explain the nature of the output flags:
⍝ return (first) matched string
4 ⎕CR 'f..' ⎕RE[''] '__foo___fun____fox'
┏→━━┓
┃foo┃
┗━━━┛
⍝ return (first) pair (position, length)
4 ⎕CR 'f..' ⎕RE['↓'] '__foo___fun____fox'
┏→━━┓
┃2 3┃
┗━━━┛
⍝ return left argument A of A ⊂ B
4 ⎕CR 'f..' ⎕RE['⊂'] '__foo___fun____fox'
┏→━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃0 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0┃
┗━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┛
⍝ return left argument A of A / B
4 ⎕CR 'f..' ⎕RE['/'] '__foo___fun____fox'
┏→━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃0 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0┃
┗━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┛
In the absence of a ’g’ flag (see below) the results of output formats ⊂ and / are identical; if ’g’ is present, however, then they may differ.
2.34.5.3 the ⎕RE global flag g
The default behavior of ⎕RE is to return only the first match of A in B. The ’g’ flag causes ⎕RE to return all matches instead. For example:
⍝ return first match as string
4 ⎕CR 'f..' ⎕RE[''] '__foo___fun____fox'
┏→━━┓
┃foo┃
┗━━━┛
⍝ return all matches as strings
4 ⎕CR 'f..' ⎕RE['g'] '__foo___fun____fox'
┏→━━━━━k━━━━━━━━━━━┓
┃┏→━━┓ ┏→━━┓ ┏→━━┓┃
┃┃foo┃ ┃fun┃ ┃fox┃┃
┃┗━━━┛ ┗━━━┛ ┗━━━┛┃
┗∊━━━━━━━━━━━━━━━━┛
⍝ return first match as pair (position, length)
4 ⎕CR 'f..' ⎕RE['↓'] '__foo___fun____fox'
┏→━━┓
┃2 3┃
┗━━━┛
⍝ return all matches as pair (position, length)
4 ⎕CR 'f..' ⎕RE['↓g'] '__foo___fun____fox'
┏→━━━━━━━━━━━━━━━━━┓
┃┏→━━┓ ┏→━━┓ ┏→━━━┓┃
┃┃2 3┃ ┃8 3┃ ┃15 3┃┃
┃┗━━━┛ ┗━━━┛ ┗━━━━┛┃
┗∊━━━━━━━━━━━━━━━━━┛
⍝ return first match as left argument of ⊂ (aka. partition)
4 ⎕CR 'f..' ⎕RE['⊂'] '__foo___fun____fox'
┏→━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃0 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0┃
┗━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┛
⍝ return all matches as left argument of ⊂ (aka. partition)
4 ⎕CR 'f..' ⎕RE['⊂g'] '__foo___fun____fox'
┏→━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃0 0 1 1 1 0 0 0 2 2 2 0 0 0 0 3 3 3┃
┗━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┛
⍝ return first match as left argument of / (aka. compress)
4 ⎕CR 'f..' ⎕RE['/'] '__foo___fun____fox'
┏→━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃0 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0┃
┗━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┛
⍝ return all matches as left argument of / (aka. compress)
4 ⎕CR 'f..' ⎕RE['/g'] '__foo___fun____fox'
┏→━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃0 0 1 1 1 0 0 0 1 1 1 0 0 0 0 1 1 1┃
┗━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┛
Please note that the ’g’ flag increments the depth of the result of the output formats ’string’ and ’position/length’, but not of the result of output formats ’partition’ and ’compress’.
The output formats ⊂ and / are related like this:
A ⌷RE['/'] B ←→ 0 ≠ A A ⌷RE['⊂'] B
2.34.5.4 the ⎕RE error flag E
The default behavior of ⎕RE is to return an empty result if no match of the regular expression A is found in B. It is sometimes more convenient to raise an error if no match is found. This can be achieved with the E flag:
4 ⎕CR 'g..' ⎕RE[''] '__foo___fun____fox'
┏⊖┓
┃0┃
┗━┛
'g..' ⎕RE['E'] '__foo___fun____fox'
DOMAIN ERROR+
'g..' ⎕RE['E']'__foo___fun____fox'
^ ^
)MORE
No match
The ’E’ flag has no effect if the ’g’ flag is also given because in that case it is natural to check the length of the result:
4 ⎕CR 'g..' ⎕RE['Eg'] '__foo___fun____fox' ┏⊖┓ ┃0┃ ┗━┛
2.34.6 Complex Matches
The regular expressions considered so far were simple, which means that they did not have (regular) sub-expressions. In other words, the regular expression A did not contain non-literal (unquoted) parentheses. However, the libpcre2 allows sub-expressions and ⎕RE follows suit to a certain extent. If A contains sub-expressions, the result of A ⎕RE B becomes deeper and the structure of the result is determined by the structure of the parentheses in A.
The result of a general regular expression A is recursively constructed by ⎕RE as follows:
1. If A contains no sub-expressions then the result is constructed as described in the previous sections.
2. If A contains sub-expressions, say A1, ... An, then the result is a (nested) vector with N+1 elements where the first element is the entire match (which contains the sub-matches) and the following elements are the next-level sub-matches.
Since the sub-matches are contained in their parent matches, it makes no sense to handle sub-matches in the partition and compress output formats. For the string and pos+len formats, the following examples may give some insight into how the results look.
The regular expression A ← ’f(.)(.)’ used in the example below is a top-level regular expression which contains two 1-character sub-expressions (.). The result is therefore the top-level match plus two 1-character sub-matches:
4 ⎕CR 'f(.)(.)' ⎕RE[''] '__foo___fun____fox' ┏→━━━━━━━━━━━━┓ ┃┏→━━┓ ┏→┓ ┏→┓┃ ┃┃foo┃ ┃o┃ ┃o┃┃ ┃┗━━━┛ ┗━┛ ┗━┛┃ ┗∊━━━━━━━━━━━━┛
Matching all instead of only the first then gives:
4 ⎕CR 'f(.)(.)' ⎕RE['g'] '__foo___fun____fox' ┏→━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃┏→━━━━━━━━━━━━┓ ┏→━━━━━━━━━━━━┓ ┏→━━━━━━━━━━━━┓┃ ┃┃┏→━━┓ ┏→┓ ┏→┓┃ ┃┏→━━┓ ┏→┓ ┏→┓┃ ┃┏→━━┓ ┏→┓ ┏→┓┃┃ ┃┃┃foo┃ ┃o┃ ┃o┃┃ ┃┃fun┃ ┃u┃ ┃n┃┃ ┃┃fox┃ ┃o┃ ┃x┃┃┃ ┃┃┗━━━┛ ┗━┛ ┗━┛┃ ┃┗━━━┛ ┗━┛ ┗━┛┃ ┃┗━━━┛ ┗━┛ ┗━┛┃┃ ┃┗∊━━━━━━━━━━━━┛ ┗∊━━━━━━━━━━━━┛ ┗∊━━━━━━━━━━━━┛┃ ┗∊∊━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┛
The same for the pos+len output format:
4 ⎕CR 'f(.)(.)' ⎕RE['↓'] '__foo___fun____fox'
┏→━━━━━━━━━━━━━━┓
┃2 3 ┏→━━┓ ┏→━━┓┃
┃ ┃3 1┃ ┃4 1┃┃
┃ ┗━━━┛ ┗━━━┛┃
┗∊━━━━━━━━━━━━━━┛
4 ⎕CR 'f(.)(.)' ⎕RE['↓g'] '__foo___fun____fox'
┏→━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃┏→━━━━━━━━━━━━━━┓ ┏→━━━━━━━━━━━━━━━┓ ┏→━━━━━━━━━━━━━━━━━┓┃
┃┃2 3 ┏→━━┓ ┏→━━┓┃ ┃8 3 ┏→━━┓ ┏→━━━┓┃ ┃15 3 ┏→━━━┓ ┏→━━━┓┃┃
┃┃ ┃3 1┃ ┃4 1┃┃ ┃ ┃9 1┃ ┃10 1┃┃ ┃ ┃16 1┃ ┃17 1┃┃┃
┃┃ ┗━━━┛ ┗━━━┛┃ ┃ ┗━━━┛ ┗━━━━┛┃ ┃ ┗━━━━┛ ┗━━━━┛┃┃
┃┗∊━━━━━━━━━━━━━━┛ ┗∊━━━━━━━━━━━━━━━┛ ┗∊━━━━━━━━━━━━━━━━━┛┃
┗∊∊━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┛
Next: ⎕SQL - SQL Database Interface, Previous: ⎕RE - Regular Expressions, Up: Non-standard GNU APL Features [Contents]
2.35 ⎕RVAL - Random APL value
The standard way to produce random numbers is the primitive function ? aka. Roll. Roll returns a simple random array whose ravel elements are positive integers chosen in a (pseudo-) random fashion. While this is sufficient for many applications, one sometimes needs APL values whose randomness not only affects the ravel elements themselves, but also other aspects like:
- the rank of the value,
- the shape of the value,
- the data type of the ravel elements, and
- the depth (nesting) of the values.
Such values can be produced with system function ⎕RVAL. The main use case for ⎕RVAL is the production of test data for the interpreter, but ⎕RVAL might be useful for other purposes as well.
2.35.1 General
In general, monadic ⎕RVAL B, returns a single random APL value Z, while dyadic A RVAL B is used to control the properties of subsequently generated random APL values returned by monadic ⎕RVAL.
The typical use of ⎕RVAL is to first call A ⎕RVAL B zero or more times to override individual default properties of the subsequently produced values, followed by one or more calls of monadic ⎕RVAL B.
The default properties, i.e. the properties used unless they were overridden by dyadic A ⎕RVAL B, are:
Rank: 0 Shape: 1 1 1 1 1 1 1 1 (initially irrelevant since Rank = 0) Type: 0 1 0 0 0 (only integer random values) Max. Depth: 4 (initially irrelevant since type = 0 1 0 0 0)
With these default properties, every call of monadic ⎕RVAL B returns an integer scalar.
2.35.2 Dyadic ⎕RVAL
The left argument A of A ⎕RVAL B determines which aspect of the subsequent random APL values shall be controlled. A is an integer scalar:
- A=0 controls the state of the underlying random number generator,
- A=1 controls the ranks of the subsequent random APL values,
- A=2 controls the shapes of the subsequent random APL values,
- A=3 controls the data types in the ravels of the subsequent random APL values, and
- A=4 controls a maximum depth of the subsequent random APL values.
- Control of the underlying random number generator: 0 ⎕RVAL B
- Control of the ranks: 1 ⎕RVAL B
- Control of the shapes: 2 ⎕RVAL B
- Control of the data types: 3 ⎕RVAL B
- Control of a maximum depth: 4 ⎕RVAL B
- monadic ⎕RVAL B: Return a new random value
2.35.2.1 Control of the underlying random number generator: 0 ⎕RVAL B
⎕RVAL uses the standard C function random_r(). For this reason ⎕RVAL is only available on platforms which use glibc, for example all GNU/Linux systems.
Every random number generator has a state (similar to ⎕RL for ’?’). While the primitive ? keeps its state in ⎕RL, i.e. in the workspace, ⎕RVAL has no associated system variable like ⎕RL which keeps its state. Instead, the user needs to store the state of ⎕RVAL in a workspace variable if the workspace shall be stored and continued at a later point. This rarely happens, therefore no effort was spent for implementing another system variable. For the same reason, the state of ⎕RVAL survives )CLEAR.
The current state of ⎕RVAL’s random number generator can be retrieved with:
STATE ← 0 ⎕RVAL ''
The state changes with every call of monadic ⎕RVAL. The random number generator can later be restored to the same state like this:
0 ⎕RVAL STATE
Restoring the state is needed when the same sequence of random values shall be generated again. The random number generators of ? and ⎕RVAL are independent; generating a random number or random value with one does not change the state of the other.
2.35.2.2 Control of the ranks: 1 ⎕RVAL B
The rank of subsequently generated random values can be controlled with 1 ⎕RVAL B as follows:
- If B is a non-negative scalar with 0 ≤ B < MAX_RANK then the subsequently generated random values will have the fixed rank B. MAX_RANK is a ./configurable constant with a default of 8.
- If B is a negative scalar with 0 > B > -MAX_RANK then the ranks of the subsequently generated random values will be chosen at random between 0 and -B (inclusive). All possible ranks 0 ... B will have the same probability P = 100÷1-B %.
- Otherwise B must be a vector of positive integers. The integers are the relative frequencies of the ranks 0, 1, ... MAX_RANK respectively. Too many integers (i.e. MAX_RANK > ⍴B) will raise a LENGTH ERROR while fewer (than MAX_RANK) are set to 0.
1 ⎕RVAL always returns its previous setting (i.e. before applying B). An empty B, e.g. 1 ⎕RVAL ⍬ will not change anything and can be used to query the current setting for 1 ⎕RVAL.
Examples:
- 1 ⎕RVAL 2 will produce only matrices,
- 1 ⎕RVAL ¯2 will produce scalars, vectors or matrices, each with a probability of 100÷3 %, and
- 1 ⎕RVAL 50 30 20 will produce scalars with probability 50%, vectors with probability 30%, and matrices with probability 20%. The numbers need not add up to 100, but will be scaled accordingly.
2.35.2.3 Control of the shapes: 2 ⎕RVAL B
The shapes of subsequently generated random values can be controlled with 2 ⎕RVAL B as follows.
B must be a vector of positive or negative integers. Vectors longer than MAX_RANK + 1 will give a LENGTH ERROR while vectors shorter than MAX_RANK + 1 will be filled with 1 until the length of B becomes MAX_RANK + 1.
If an element Bi of the resulting shape B = B1 ... BMAXRANK is ≥ 0 then the corresponding axis i will have a fixed length of Bi. If Bi < 0 then the length of that axis will be chosen at random with a probability of 1÷Bi. Note that the same B can still produce different shapes even if all Bi are ≥ 0 (i.e. if the rank is also chosen at random).
2 ⎕RVAL always returns its previous setting (i.e. before applying B). An empty B, e.g. 2 ⎕RVAL ⍬, will not change anything and can be used to query the current setting for 2 ⎕RVAL.
Example:
1 ⎕RVAL 2 ⍝ produce matrices
2 ⎕RVAL 3 ¯10 ⍝ the first axis of every matrix will have length 3, and
⍝ the last axis of every matrix will vary between 0 and 10
This will produce scalars, vectors with a fixed length of 3 and matrices with 3 rows and between 0 and 10 columns.
2.35.2.4 Control of the data types: 3 ⎕RVAL B
The types (i.e. CHARACTER, INTEGER, REAL, COMPLEX, or NESTED) of subsequently generated random values can be controlled with 3 ⎕RVAL B as follows.
B must be a vector with up to 5 positive numbers, corresponding to the types. Shorter vectors are filled with 0 (the corresponding types will not occur) and longer vectors will raise a LENGTH error.
Once the type was chosen, the ravel item will be:
- for type CHARACTER: a random character with ⎕UCS between 0 and $3000 (exclusive). Larger Unicodes typically cause display problems. If you need larger Unicodes, use ⎕UCS with random integers.
- for type INTEGER: a random integer with ⎕UCS between -$80000000 and $7FFFFFFF.
- for type REAL: a floating point number between 0.0 and 1.0 (exclusive)
- for type COMPLEX: a complex point number with real and imaginaty part between 0.0 and 1.0 (exclusive), and
- for type NESTED: a nested APL value with the same properties (rank, shape, and type) as their parent.
3 ⎕RVAL always returns its previous setting (i.e. before applying B). An empty B, e.g. 3 ⎕RVAL ⍬ will not change anything and can be used to query the current setting for 3 ⎕RVAL.
Example:
1 ⎕RVAL 2 ⍝ produce matrices
2 ⎕RVAL 3 3 ⍝ produce 3×3 matrices
3 ⎕RVAL 0 50 50 ⍝ produce a mix of integer and real values
⎕RVAL ''
¯975954163190248487 0.5892132425
7677327503669503253 2152001972871424768
2.35.2.5 Control of a maximum depth: 4 ⎕RVAL B
If the probability of generating a nested value is > 0 then the depth of random values can become arbitrarily large and could therefore exceed the system limit for the depth of the random value being produced. This can be prevented by setting a maximum depth for every value generated. ⎕RVAL sets the probability of the deepest allowed depth to 0.
4 ⎕RVAL B expects B to be a positive integer which is deepest allowed depth;
An empty B, e.g. 4 ⎕RVAL ⍬, will not change anything and can be used to query the current setting for 4 ⎕RVAL.
2.35.2.6 monadic ⎕RVAL B: Return a new random value
Calling ⎕RVAL monadically produces one new random APL value.
The properties of that next value can be controlled by the dyadic calls of ⎕RVAL as described above. If no prior dyadic call of ⎕RVAL was made then the properties have the following defaults:
1 ⎕RVAL ⍬ ⍝ rank (scalar)
0
2 ⎕RVAL ⍬ ⍝ shape (not used since rank = 0)
1 1 1 1 1 1 1 1
3 ⎕RVAL ⍬ ⍝ types (integer)
0 1 0 0 0
4 ⎕RVAL ⍬ ⍝ max. depth (not used since probability of NESTED = 0)
4
That is, by default, ⎕RVAL ⍬ produces random integer scalars.
It is sometimes convenient to be able to change the properties of the next random value without modifying (and later restoring) the properties with dyadic ⎕RVAL. This can be achieved with monadic ⎕RVAL with non-empty B.
Let 4=⍴B. Then
Z←⎕RVAL B does essentially: B[1]←1 ⎕RVAL B[1] B[2]←2 ⎕RVAL B[2] B[3]←3 ⎕RVAL B[3] B[4]←4 ⎕RVAL B[4] Z←⎕RVAL '' B[1]←1 ⎕RVAL B[1] B[2]←2 ⎕RVAL B[2] B[3]←3 ⎕RVAL B[3] B[4]←4 ⎕RVAL B[4]
If 4>⍴B then the missing properties are not changed.
Examples:
⎕RVAL 1 (,¯4) (0 1) ⍝ return a random 0-4 element integer vector ⎕RVAL 2 (2 2) (1 0) ⍝ return a random 2×2 character array
Next: ⎕SI - State Indicator, Previous: ⎕RVAL - Random APL value, Up: Non-standard GNU APL Features [Contents]
2.36 ⎕SQL - SQL Database Interface
As of GNU APL 1.6, the native function SQL has been replaced by the system function ⎕SQL, described below. ⎕SQL has an axis argument that selects a sub-function of ⎕SQL.
- ⎕SQL[0] : display subfunctions
- ref ← A ⎕SQL[1] B : open database
- ⎕SQL[2] B : close database
- Z ← A ⎕SQL[3, ref] B : database query (with result)
- Z ← A ⎕SQL[4, ref] B : database query (w/o result)
- ⎕SQL[5] B : start transaction
- ⎕SQL[6] B : commit transaction
- ⎕SQL[7] B : rollback transaction
- Z←⎕SQL[8] B : table names
- Z←⎕SQL[9] B : column names
- Z ← ⎕SQL[10] B : library version number
- Z ← ⎕SQL[11] B : library version string
2.36.1 ⎕SQL[0] : display subfunctions
⎕SQL[0]''
Available function numbers:
type ⎕SQL[1] file - open a database file, return reference ID for it
⎕SQL[2] ref - close database
query ⎕SQL[3,db] params - send SQL query
query ⎕SQL[4,db] params - send SQL update
⎕SQL[5] ref - begin a transaction
⎕SQL[6] ref - commit current transaction
⎕SQL[7] ref - rollback current transaction
⎕SQL[8] ref - list tables
ref ⎕SQL[9] table - list columns for table
⎕SQL[10] type - return the library version number
⎕SQL[11] type - return the library version string
2.36.2 ref ← A ⎕SQL[1] B : open database
type ⎕SQL[1] file
Connect to database of type A using connection arguments B. The result is a database handle ref to be used in the other ⎕SQL functions.
A must be a string indicating the database type. Currently supported values are ’postgresql’ and ’sqlite’.
B is the connection parameters which depends on the type of database:
- For type≡’sqlite’: the argument is string pointing to the database file.
- For type≡’postgresql’, the argument is a standard connect string as described in the PostgreSQL documentation.
This function returns a database handle that should be used when using other SQL functions. This value should be seen as an opaque handle. It is, however, guaranteed that the handle is a scalar value.
2.36.3 ⎕SQL[2] B : close database
⎕SQL[2] ref
Disconnect from database ref.
B is the database handle that should be disconnected. After this function has been called, no further operations are to be performed on this handle. Future calls to ⎕SQL[1] may reuse previously disconnected handles.
2.36.4 Z ← A ⎕SQL[3, ref] B : database query (with result)
query ⎕SQL[3, ref] params
Execute a select statement and return the result table.
The axis parameter indicates the database handle.
A is a select statement to be executed. Positional parameters can be supplied by specifying a question mark "?" in the statement.
B is an array containing the values for the positional parameters. If the array is of rank 2, the statement will be executed multiple times with each row being the values for each call.
The return value Z is a rank-2 array representing the result of the select statement. Null values are returned as ⍬ and empty strings are returned as ”.
2.36.5 Z ← A ⎕SQL[4, ref] B : database query (w/o result)
query ⎕SQL[4, ref] params
Execute an SQL statement that does not return a result.
This function is identical to SQL∆Select with the exception that it is used on statements which do not return a result table.
2.36.6 ⎕SQL[5] B : start transaction
⎕SQL[5] ref
Begin a transaction.
2.36.7 ⎕SQL[6] B : commit transaction
⎕SQL[6] ref
Commit a transaction.
2.36.8 ⎕SQL[7] B : rollback transaction
⎕SQL[7] ref
Rolls back the current transaction.
2.36.9 Z←⎕SQL[8] B : table names
⎕SQL[8] ref
Return an array containing the name of all tables.
2.36.10 Z←⎕SQL[9] B : column names
ref ⎕SQL[9] table
Return an array containing information about the columns in the given table. Currently, the column layout is as follows:
Name Type
More columns containing additional information may be added in a future release.
2.36.11 Z ← ⎕SQL[10] B : library version number
Return the version number (integer scalar) of the library that was used to implement the database type B.
2.36.12 Z ← ⎕SQL[11] B : library version string
Return the version string of the library that was used to implement the database type B.
Next: ⎕SYL - System limits, Previous: ⎕SQL - SQL Database Interface, Up: Non-standard GNU APL Features [Contents]
2.37 ⎕SI - State Indicator
⎕SI returns aspects of the current State Indicator, similar to the standard command )SI. This can be used, for example, to create debug functions similar to the assert() macro in C/C++:
∇Assert B;COND;LOC;VAR
→(1≡B)⍴0
' '
COND←7↓,¯2 ⎕SI 4
LOC←,¯2 ⎕SI 3
'************************************************'
' '
'*** Assertion (', COND, ') failed at ',LOC
''
⍝ show stack
⍝
' '
'Stack:'
7 ⎕CR ⊃¯1↓⎕SI 3
' '
'************************************************</pre>'
→
∇
The right argument of ⎕SI specifies which aspect of the State Indicator shall be returned:
- ⎕SI 1: The name of the context. That name is either:
- the name of a defined function, or
- ◊ for an immediate execution context, or
- ⍎ for an execute context.
- ⎕SI 2: The line number (of a defined function) or 0 for immediate execution and execute contexts.
- ⎕SI 3: The function name and line number in square brackets, for example: "FOO[3]"
- ⎕SI 4: Either the statement text of the function line or the error text of an error that has occurred on the line
- ⎕SI 5: The program counter (= token number counted from the start of the function text)
- ⎕SI 6: the parse mode of the context (immediate execution, execute, or defined function).
If no left argument is provided then the result of ⎕SI is a vector with one entry per State Indicator level (and hence ⍴⎕SI B is the depth of the SI stack).
If the optional left argument A is provided then it specifies a particular level of the SI instead of the entire SI. A should be an integer scalar. If A is positive then the level is counted from the oldest entry to the latest, while negative A counts from the latest to the oldest level.
For example, ¯1 ⎕SI refers to the currently executing context, ¯2 ⎕SI is the caller, and so on.
Next: ⎕XML - XML Parsing, Previous: ⎕SI - State Indicator, Up: Non-standard GNU APL Features [Contents]
2.38 ⎕SYL - System limits
System variable ⎕SYL shows a number of system limits when referenced:
⎕SYL SI depth limit (0 = no limit) 0 number of values limit (0 = no limit) 0 total ravel bytes limit (0 = no limit) 0 current SI depth 1 current number of values 54 current total ravel bytes 9072 max. rank for APL values 8 min. ⎕PW 30 max. ⎕PW 1000 min. ⎕PP 1 max. ⎕PP 16 max. input line length 2000 hash table size (obsolete) 65536 max. shared variable name length 64 max. length of filenames (paths) 4096 max. # of shared variables (obsolete) 64 max. number of APs 16 max. operators per statement 16 largest integer 9000000000000000000 smallest integer ¯9000000000000000000 largest numeric exponent 308 max. shared variable size (bytes) 65000 max. cores (per ./configure) 0 max. cores (per max_cores()) 1 current cores (per core_count()) 1 print length limit (0 = no limit) 0
Most system limits are read-only; attempting to assign ⎕SYL will result in a SYNTAX ERROR. Indexed assignment to ⎕SYL will result in an INDEX ERROR unless the limit is writable. Some read-only limits can be changed at compile-time via ./configure
2.38.1 ⎕SYL[1 2 3 4 5 6;]
The first three limits are writable; their purpose is to stop execution if:
- The SI stack of the interpreter reaches a limit, or
- The number of APL values created reaches a limit, or
- The memory size of APL values created reaches a limit.
Whenever a writable limit is reached, a corresponding LIMIT ERROR is reported and the limit is reset to 0 (meaning no limit) in order to prevent the interpreter from locking up.
The main use of ⎕SYL is to troubleshoot infinite recursion in user-defined function that would otherwise cause the machine to start swapping or to become non-responding.
Example (stop execution if function call stack exceeds 20):
⎕SYL[1;2]←20
Note that small APL values (up to a configurable number of ravel elements) count as values (in the number of values limit), but not in the total ravel bytes limit (the ravel does not allocate memory in addition to the space already in the number of values limit). It is therefore typical to set the number of values limit and the total ravel bytes limit together.
An attempt to set a too small limit, for example one that is close to the current value, is rejected with a DOMAIN ERROR.
2.38.2 ⎕SYL[7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23;]
These system limits are read-only. Some of them can be changed at compile time via ./configure. Most others can be changed in the source code of GNU APL, but doing so is not recommended.
2.38.3 ⎕SYL[24 25 26;]
These system limits have been added in preparation for multi-core GNU APL. They are currently not used.
2.38.4 ⎕SYL[27;]
This is not a limit that raises a limit error. Instead it limits the size of APL values when printed as statement results. It is fairly easy in APL to create huge APL values by mistake. During development it can be useful to limit the amount of data printed. If the ravel length of, say, VALUE exceeds ⎕SYL[27;2] (i.e. if ⎕SYL[27;2] ≤ ⍴,VALUE) then SH↑VALUE is printed instead of VALUE. The shape SH is computed like this:
SH←⍴VALUE
while (ravel-length(SH) ≥ ⎕SYL[27;2]) { divide longest axis in SH by 2 }
Next: Conditionals, Previous: ⎕SYL - System limits, Up: Non-standard GNU APL Features [Contents]
2.39 ⎕XML - XML Parsing
- Purpose
- Some XML Terminology
- How ⎕XML maps XML documents to APL Values
- Monadic ⎕XML
- Dyadic ⎕XML
- XML Queries
2.39.1 Purpose
GNU APL provides ⎕XML as a means of performing elementary manipulations of APL character strings that are formatted according to the XML standard. The anticipated procedure for such modifications is something like:
XML_string ← "<A><B><C>Hello</C></B></A>" ⍝ input data (usually from an .xml file)
APL ← ⎕XML XML_string ⍝ convert XML_string to associative array APL
ABC ← APL.a.b.c ⍝ retrieve node a.b.c in APL
APL.a.b.c ← ABC, " World" ⍝ modify node a.b.c in APL
Z ← ⎕XML APL ⍝ convert associative array APL to XML string Z
ABC ⍝ the original value of XML.a.b.c
Hello
Z ⍝ the modified XML string
<A><B><C>Hello World</C></B></A>"
The scope (functionality) of ⎕XML is then:
- Conversion of (valid) XML strings to associative APL arrays that can be more easily processed in APL than the XML strings,
- Conversion of associative APL arrays back to valid XML strings,
- Simple (at APL level) access to the data contained in XML strings, and
- Transparent access to those (mostly XML specific) portions of the XML string that are not (yet) handled by ⎕XML; this means that the user of ⎕XML shall be able to handle advanced XML aspects (like document type declarations (DTDs), document validation, etc.) in APL without much overhead.
2.39.2 Some XML Terminology
An XML document is a character string with a standardized format. The characters must be valid XML characters as defined in the XML standard (almost all Unicode characters except most of the ASCII control characters). GNU APL raises a DOMAIN ERROR when an XML document contains invalid XML characters.
The XML document is a sequence of adjacent sub-strings, where each sub-string is:
- either markup (-string),
- or non-markup (-string).
A markup (sub-)string:
- starts with character ’<’, and
- ends with character ’>’, and
- all other characters in the markup string differ from ’<’ and ’>’.
A non-markup (sub-)string:
- starts either at the beginning of the XML document or else directly after a markup string,
- end at the end of the document or else directly before a markup string, and therefore
- cannot be adjacent to another non-markup string.
Non-markup is sometimes referred to as "unstructured text". The producer of an XML document has a principal choice about where to locate the information that the document contains: in the unstructured text or in the attribute values inside the tags. For that reason the XML standard is somewhat picky about keeping the unstructured text as well as attribute values intact and requires that whitespace in non-markup (the only allowed whitespace characters in XML being TAB, CR, LF, and SPACE) is preserved in non-markup strings.
As a consequence, many non-markup strings begin with LF because the preceeding markup was on the previous line and therefore the LF after the preceeding markup is whitespace of the non-markup and therefore needs to be preserved.
Every markup belongs to one of 4 categories:
- Processing instructions: "<? ... ?>",
- Comments: "<!— ... —>",
- Declarations "<! ... !>", and
- Tags, which are either:
- Empty tags (leaf tags): "<tagname attributes... />
- Start tags: "<tagname attributes... >, or
- End tags: "</tagname>
The XML tags recursively define a tree structure where:
- the nodes of the trees are either Empty Tags or else a start tag, followed by a (possibly empty) sequence of non-markup, comments, and sub-nodes (of the tree), followed by an end tag (with the same name as the start tag),
- the leafs of the trees are either Empty Tags or else a start tag, followed by a (possibly empty) sequence of non-markup and comments, followed by an end tag (with the same name as the start tag). The difference between a leaf node and a non-leaf is therefore the absence of sub-nodes between a start and an end tag.
- optionally non-markup and comments before, after, and between the nodes.
Processing instructions and declarations are typically located at the beginning of the XML document and at the same level as the root of the tree. defined by the document. Document type declarations are being preserved (so that they can be processed in APL), but are currently ignored by ⎕XML. As a consequence, entity declarations have no effect and only the predefined XML entities (i.e. &, <, >, ’, and ") are recognized (and translated) by ⎕XML.
2.39.3 How ⎕XML maps XML documents to APL Values
The principal mapping between XML strings and APL values is:
- XML document ←→ structured (top-level) APL value or variable (= an associative array)
- XML node ←→ structured APL (sub-) value (= an associative (sub-) array of either the top-level value or of another XML node)
- XML name ←→ name of a member in a structured APL value
- Other ←→ member value
Every valid name in XML is also a valid name for an APL variable or structure member. Unfortunately, mapping XML names directly to APL member names cannot work because:
- In any associative array the names of the members are necessarily
distinct. Assigning a value to an already existing member of a structured
value overwrites the current value of that member instead of creating a
second member with that value. On the other hand, in XML nodes tags may (and
frequently do) occur repeatedly. If an XML document contains several nodes
with the same tag, then the applications usually knows how to interpret the
order in which the tags occur, but this order may not be detectable at the XML
level (i.e. the nodes may not only have the same tag names, but also the same
attributes and attribute values).
The applications that use the XML document frequently require that the order of XML nodes with the same name remain intact when the document is modified. For example, the entries of a telephone book may be sorted alphabetically without XML being aware of that. Reading, modifying, and writing back the data in the telephone book must therefore not destroy that order.
- Likewise, at least for readability reasons, the order of node attributes should not be changed. XML documents are frequently processed with text tools like diff which would incorrectly show differences between XML documents that are equivalent from an XML perspective.
- Conflicts between tag names and attribute names. In XML, the same name can designate an attribute in one node and a tag in another node. ⎕XML keeps all information from the < of a start tag to the > of an end tag in a single associative array, therefore the attribute names must somehow differ from the (sub-) tag names.
- Every XML node has a tag name that can be used to derive a corresponding APL member name. However, the text segments between an XML tag and its corresponding end tag, are a mixture of unstructured text, XML subnodes and comments of which only the XML subnodes have tags of their own. These untagged segments may, however, contain relevant information and, from an XML standard perspective, both their content and their order must be preserved.
⎕XML solves these issues with a simple naming convention for all member names in the (recursive) associative array that is produced by monadic ⎕XML. Every member name consists of 3 components that together yield a valid APL variable name (and therefore a valid member name that is understood by the APL parser):
- A single character ⍙, ∆, or _, that indicates the role of the name in
the XML document as follows:
- the character ⍙ characterizes an attribute name, i.e. a name that was used inside (i.e. between < and >) of an XML start or leaf tag. The character ⍙ alone is the name of a special member which is present in every associative array below the top-level and whose value is the original XML tag name of a tag, or
- the character ∆ characterizes a name that was synthesized by ⎕XML itself in order to tag a text (sub-) segment that has no tag of its own. The corresponding XML entity was not a tag (and therefore had no tag name), or
- the character _ characterizes the name of an XML entity, i.e. a CML name that occurred between the start tag and the corresponding end tag (if any: leaf tags have no such entities)
- a position prefix of the form NN, where NN is the position of the member in relation to the tag to which it belongs. The numbering starts at ⎕IO and restarts at every XML start or leaf tag.
- the attribute name or tag name. For those parts of an XML entity that
do not have a tag name, the member name is being synthesized by ⎕XML and the
member value will be the text in the XML document with predefined XML
entities replaced by their single characters, i.e.:
- & for &,
- < for <,
- > for >,
- ’ for &apos,
- " for ",
- ⎕UCS nnn for &#nnn, and
- ⎕UCS $xxx for &#xxx
Let NN be a sequence of decimal digits. Then only the following 4 synthesized names are produced by ⎕XML:
- ∆NNcomment for XML comments, i.e. <!— ... —> in XML,
- ∆NNdeclaration for XML declarations, i.e. <? ... ?> in XML,
- ∆NNdoctype for document type declarations, i.e. <!DOCTYPE ... > in XML
- ∆NNtext for unstructured (and hence untagged) text segements in XML.
Every XML name (of a tag or attribute) is also a valid APL name, but valid APL names may also contain the characters ¯, ∆, and ⍙ which are not valid in XML and used in the naming convention above to clearly separate the member names used in APL from the names used in the XML document.
The essence of all this is that everything that belongs to an XML node or document, i.e. the attributes inside a tag, the sub-nodes between a start tag and its corresponding end tag (if any), declarations, etc. will be contained in a single associative array.
Examples of APL member names (assuming ⎕IO←1):
⍙1 ⍝ the first member in every XML node. Its value is the node tag.
∆1declaration ⍝ the first member in most XML documents. E.g. <?xml version= ...>
∆2text ⍝ whitespace (LF) between _1∆declaration and _3∆doctype
∆3doctype ⍝ DTD in XML documents that have one. E.g. <!DOCTYPE ...
_6Workspace ⍝ Sub-array for <Workspace ... at position 6.
⍙1wsid ⍝ first attribute wsid from e.g. <Workspace wsid=...
⍙2year ⍝ second attribute year
2.39.4 Monadic ⎕XML
Z ← ⎕XML B converts APL string B that contains a valid XML document to an associative APL array Z and vice versa.
Note: If you convert an associative APL array back to a an XML document, the result is a possibly very long string containing several linefeed characters. That is OK if the string is written to a file, but causes problems when the string is being displayed and longer than ⎕PW. The standard APL folding of output near ⎕PW make the string then look somewhat garbled. This effect can be suppressed in 2 ways:
- set ⎕PW large enough, or
- prefix the string with ⊃35⎕CR as in the examples below.
2.39.5 Dyadic ⎕XML
Z ← A ⎕XML B provides a number of convenience functions. Its left argument A is an integer function number, possibly followed by arguments of the function number ↑A.
In the following examples, let
XML←36 ⎕CR """
<?xml version='1.0' encoding='UTF-8'?>
<Document>
<Tag1 name='tag1'> <!-- first tag -->
TEXT1
<Subtag name='subag1.1'> <!-- first subtag -->
SUBTEXT1_1
</Subtag>
</Tag1>
</Document>
"""
APL←⎕XML XML
Then
- Z←0 ⎕XML B is the same as monadic Z←⎕XML B.
- Z←1 ⎕XML B is like 0 ⎕XML B, except that B is not the XML document (string) itself but the name of a file from which an XML document is read.
- Z←2 ⎕XML B splits an APL member path (a sequence of member names) into a vector P of (nested) member names. This vector P is understood by the APL primitive PICK (i.e. Z←P⊃APL or (P⊃APL←value) and can be used to address the data in an XML node.
- Z←3 ⎕XML B splits an APL member name (as produced by e.g.
monadic ⎕XML into a 3-item vector Z. Z[1] is a single character indicating
the category (i.e. a character scalar ∆, ⍙, or _). Z[2] is the position (an
integer scalar ≥ ⎕IO). Z[3] is a (nested) APL string. 3 ⎕XML has an
inverse function ¯3 ⎕XML which converts a 3-item vector as produced by 3 ⎕XML
back into an APL member name indicating the category (i.e. _, ∆, or ⍙)
and the name from the XML tag:
8 ⎕CR (C P N)←3 ⎕XML "∆2comment" ┌→────────────┐ │∆ 2 ┌→──────┐│ │ │comment││ │ └───────┘│ └∊────────────┘ C ⍝ category ∆ P ⍝ position 2 N ⍝ (XML-) name comment ¯3 ⎕XML C P N ⍝ inverse of 3 ⎕XML ∆2comment - Z←4 ⎕XML B is a string that shows the member names of the
associative array B in a tree-like fashion. For example:
⊃35⎕CR 4 ⎕XML APL XML │ └─── Document │ └─── Tag1 │ └─── Subtag - Z←5 ⎕XML B is like 4 ⎕XML but displays not only the XML tags but
also other XML nodes (declarations, attributes, etc.):
⊃35⎕CR 5 ⎕XML APL XML │ ├─── _1∆declaration ├─── _2∆text └─── _3_Document │ ├─── _1∆text ├─── _2_Tag1 │ │ │ ├─── _1∆text │ ├─── _2∆comment │ ├─── _3∆text │ ├─── _4_Subtag │ │ │ │ │ ├─── _1∆text │ │ ├─── _2∆comment │ │ └─── _3∆text │ └─── _5∆text └─── _3∆text - Z←6 ⎕XML B is like 4 ⎕XML but displays not only the member
name but the entire path to the member:
⊃35⎕CR 6 ⎕XML APL XML │ └─── ._3_Document │ └─── ._3_Document._2_Tag1 │ └─── ._3_Document._2_Tag1._4_Subtag - Z←7 ⎕XML B returns a list of all members in a depth-first order.
This list can be used as an iterator to traverse the entire tree (and possibly
filter out items along the way).
⊃7 ⎕XML APL ._1∆declaration ._2∆text ._18∆text ._3_Document ._3_Document._1⍙ ._3_Document._1∆text ._3_Document._3∆text ._3_Document._2_Tag1 ._3_Document._2_Tag1._1⍙ ._3_Document._2_Tag1._2⍙name ._3_Document._2_Tag1._1∆text ._3_Document._2_Tag1._2∆comment ._3_Document._2_Tag1._3∆text ._3_Document._2_Tag1._5∆text ._3_Document._2_Tag1._4_Subtag ._3_Document._2_Tag1._4_Subtag._1⍙ ._3_Document._2_Tag1._4_Subtag._2⍙name ._3_Document._2_Tag1._4_Subtag._1∆text ._3_Document._2_Tag1._4_Subtag._2∆comment ._3_Document._2_Tag1._4_Subtag._3∆text
- Z←8 ⎕XML B is like Z←7 ⎕XML B, except that only the subset of
those members that are related to tags (the tag name ⍙ and tag attributes)
are returned:
⊃8 ⎕XML APL ⍝ all tag related member names (tag names and attributes) ._3Document.⍙1···················· ._3Document._2Tag1.⍙1············· ._3Document._2Tag1.⍙2name········· ._3Document._2Tag1._4Subtag.⍙1···· ._3Document._2Tag1._4Subtag.⍙2name
- Z←9 ⎕XML B is like Z←7 ⎕XML B, except that only the subset of
synthesized members other than ∆text are returned:
⊃9 ⎕XML APL ⍝ all synthetic member names (except unstructured text) .∆1declaration······················· ._3Document._2Tag1.∆2comment········· ._3Document._2Tag1._4Subtag.∆2comment
- Z←10 ⎕XML B is like Z←7 ⎕XML B, except that only the subset of
synthesized ∆text members are returned:
.∆2text··························· ._3Document.∆1text················ ._3Document._2Tag1.∆1text········· ._3Document._2Tag1.∆3text········· ._3Document._2Tag1._4Subtag.∆1text ._3Document._2Tag1._4Subtag.∆3text ._3Document._2Tag1.∆5text········· ._3Document.∆3text················ .∆18text··························
- Z←11 ⎕XML B is like Z←7 ⎕XML B, except that only the tag
names are returned:
⊃11 ⎕XML APL ⍝ all tag member names ._3Document················ ._3Document._2Tag1········· ._3Document._2Tag1._4Subtag
- Z←12 ⎕XML B is like Z←7 ⎕XML B, except that all member
names of B are returned without descending into the sub-tree:
⊃12 ⎕XML APL ⍝ all member names (7 ⎕XML, but non-recursive) .∆1declaration .∆2text······· ._3Document··· .∆18text······
This variant may also be useful for structured variables that were not created by ⎕XML.
- Z←13 ⎕XML B shows the (flat) tag names in B, but but does
not descend into any sub-tree of B.
⊃13 ⎕XML APL ⍝ all tag members (8 ⎕XML, but non-recursive) ._3Document
- Z←(14 "member-name") ⎕XML B shows the next member in B
after "member-name". It can be used as an iterator that walks through
the tags. An empty member name returns the first member:
APL ← ⎕XML XML←"<ROOT><A/><B/><C/></ROOT>" (14 "") ⎕XML APL._1ROOT ⍝ get first member in APL._1ROOT ⍙1 (14 "⍙1") ⎕XML APL._1ROOT ⍝ next member after APL._1ROOT.⍙1 _1A (14 "_1A") ⎕XML APL._1ROOT ⍝ next member after APL._1ROOT._1A _2B (14 "_2B") ⎕XML APL._1ROOT ⍝ next member after APL._1ROOT._2B _3C (14 "_3C") ⎕XML APL._1ROOT ⍝ last member: will be empty4786
2.39.6 XML Queries
The different functions in dyadic ⎕XML are intended to construct XML queries. An XML query extracts information from, or modifies information in, an XML document. XML queries may differ considerably in their details, but usually follow these top-level steps:
- Read an XML document into, say, APL (APL←0 ⎕XML B or APL←1 ⎕XML B)
- Optionally, display the structure of the document (3, 4, or 5 ⎕XML)
- Select a subset of XML nodes (= GNU APL member names, 6 ⎕XML APL)
- retrieve or modify the data in the selected XML nodes (with something like MEMBERS←(⊂APL) FUN¨6⎕XML APL←⎕XML followed by MEMBER⊃ )
- Optionally, convert the modified XML document back to XML (0 ⎕XML
Next: Matrix Product, Previous: ⎕XML - XML Parsing, Up: Non-standard GNU APL Features [Contents]
2.40 Conditionals
WARNING: GNU APL conditionals are experimental. Use them with care and avoid them, wherever possible, in favour of portability. Neither the ISO APL standard, nor IBM APL2 provide conditionals.
2.40.1 Design considerations.
The author of GNU APL has, for a long time, hesitated to implement conditionals in GNU APL. Primarily for the following reasons:
- the lack of standardization of conditionals,
- the lack of an elegant syntax that fits well into the typical (brief) APL programming style, and in particular
- the large number of keywords for flow control used in some other APL interpreters. See below.
The C language has 6 keywords for flow control: if, else, for, do, Two of them (do and while) are redundant and rarely used, leaving only 4 base cases. A quick grep -c over the 90000 top-level C++ source code lines of GNU APL reveals the following statistics:
- 7000 if statements, 1600 of them two-sided if-then-else-endif, the others one-sided if-then-endif,
- 2000 for statements, 1200 of them trivial iterations over some array (aka. for (int i = 0; i < size; ++i) ... ,
- 200 switch statements with an averge of 8 case clauses per switch,
- 250 while statements, and
- 70 do while statements
In contrast, a popular non-free APL interpreter came up with a zoo of 30 or so keywords for the purpose of flow control in one way or the other:
:If :While :Repeat :For :In :InEach :Select :With :Trap :Hold :Disposable :Else :ElseIf :AndIf :OrIf :Until :Case :CaseList :EndIf :EndWhile :EndRepeat :EndFor :EndSelect :EndWith :EndTrap :EndHold :EndDisposable :GoTo, :Return, :Leave :Continue
This approach, its implementation, and its constraints raise a number of serious problems. To name a few:
- A rather common APL design practice has it to first debug non-trivial APL statements in immediate execution mode and only transfer them into the body of defined functions when they work properly. However, the keywords above seem to work only in the bodies of defined functions but not in immediate execution mode. The reason seems to be that their implementation depends on labels which are not available in immediate execution.
- Another rather common design practice is to limit the length of lines to less than 80 characters (e.g. in the GNU coding conventions, https://gcc.gnu.org/codingconventions.html#Line). Even if it were possible to squeeze an :If :Then :Else :Endif into an 80 character line, and using a single whitespace around the keywords for readability, wastes almost 1/3 of the precious 80 characters for keywords. In this example, each of the COND, THEN, and ELSE parts must then be < 20 characters on average. Not to talk about indentation to clarify the code.
- Each of the keywords has rather specific constraints as to how and
where it can be used. For example (to quote a simple one from a reference
manual):
Control words, including qualifiers such as :Else and :ElseIf, may occur only at the beginning of a line or expression in a diamond-separated statement. The only exceptions are :In and :InEach which must appear on the same line within a :For expression.
These constraints suggest that the keywords mentioned are merely syntactic sugar that covers the underlying APL structure, i.e. labels and computed branches. GNU APL does not claim to be fundamentally different in that regard, but the syntax of the syntactic sugar is somewhat simpler.
Learning from the above, the conclusions for the syntax of GNU APL condionals were these:
- the syntax shall be easy to understand and consistent,
- the syntax shall work in immediate execution mode (as long as the entire conditional is provided on a single input line),
- to support 2., lengthy keywords shall be avoided in favour of the original APL style, and
- the syntax needs to only support those cases where the standard APL flow control (i.e. →N) becomes cumbersome. There is absolutely no benefit in introducing a new (and redundant) syntax when the standard APL mechanism is already completely adequate.
As to the last point, almost every flow control case (in a standards compliant APL program) falls into one of the following categories (sorted by increasing complexity):
- one-sided if: if COND then THEN endif
- two-sided if/else: if COND then THEN else ELSE endif
- loop: while COND do BODY (or its less frequently used twin do BODY while COND)
- switch/case: switch ARG case CASE1 case CASE2 case ... CASEn endswitch
where THEN, ELSE, CASE1, CASE2, CASEn, and BODY are a sequence of one or more statements, while COND or ARG control which of these sequences (if any) shall be executed.
Interestingly, the complexity of the above cases, when coded in APL, increases in amost the reverse order (compared to other languages). For example,
- switch/case:
→(ARG) / L1 L2 ... Ln ⍝ switch(ARG) L1: CASE1 ◊ →L_endcase ⍝ case 1: L2: CASE2 ◊ →L_endcase ⍝ case 2: ... LN: CASEn ⍝ case N: L_endcase:
- loop:
Loop: BODY ◊ →(COND) / Loop ⍝ repeat BODY while COND
- one-sided if:
→(!COND) / L_endif ⍝ jump over the THEN clause THEN L_endif:
or, not uncommon and shorter, but less portable and less readable:
→(!COND) / ↑1+⎕LC ◊ THEN ⍝ jump over the THEN clause to the next line
- two-sided if/else:
→COND ↓ L_else L_then L_then: THEN ◊ →L_endif L_else: ELSE L_endif:
A closer look at these case reveals that there is not much room for syntax improvements in cases 1. (switch) and 2. (loop). The introduction of a new syntax like :Select / :Case for switches or :For / :Endfor for loops would therefore only make matters different and incompatible, but not better.
In case 3. (one-sided if) there is also not much to gain. However, case 3. can be seen as a special case of case 4. (with an empty ELSE clause). As a matter of consistency, a new syntax for case 4. should also cover case 3.
The only cases where a new syntax could improve matters are therefore cases 3. and 4.
Another consideration relates to the end marker L_endif (and would likewise relate to L_endcase if we hadn’t already ruled that case out). There are two reasonable syntax alternatives to handle the branch to the end of the conditional:
- allow multiple statements in the THEN and ELSE clauses and mark the end of the ELSE clause (or, in the one-sided case 3 of the THEN clause with some ENDIF marker, or
- allow only single statement clauses (which implies the ENDIF and makes it obsolete.
The design decision made in GNU APL was to go for multiple statements because the advantage in 2. (shorter code) looks much smaller than the advantages of 1. (e.g. insertion of debug printouts into a clause).
2.40.2 Syntax
With the above considerations in mind, GNU APL decided for the following syntax:
- one-sided if/else:
COND →→ THEN ←←
- two-sided if/else:
COND →→ THEN ←→ ELSE ←←
For this syntax to work, the following rules must be followed:
- The →→, ←→, and ←← markers must be single tokens (2 adjacent Unicode characters) That is, no whitespace (and in particular no line feed) is permitted between the first and the second arrow. A single → is a valid APL statement (named Escape). A linefeed between two → turns the single token →→ into two valid (though most of the time useless) Escape statements.
- The →→, ←→, and ←← tokens are end-of statement markers (as opposed to beginning-of statement markers). Each marker binds to the non-empty statement left of it. APL is parsed line by line, so there can never be a valid non-empty APL statement left of the first token of a line. As a consequence, a →→ token, a ←→ token, or a ←← token at the beginning of a line is a SYNTAX ERROR.
- The COND, THEN, and ELSE clauses shall be non-empty (!) sequences of
valid APL statements. In particular:
- The condition COND shall be a single statement that evaluates to a 1-item Boolean array (of any rank). The statement result of COND is a committed value (and therefore not displayed).
- The THEN clause shall be one or more valid statements, separated by ◊ for more than one statement.
- The ELSE clause (if present) shall be one or more valid statements, separated by ◊ for more than one statement.
Examples:
⍝ short format. Valid in immediate execution and in defined functions
⍝
X←5 ◊ X≥0 →→ X 'is positive' ←→ X 'is negative' ←←
5 is positive
⍝ long format. Only possible in defined functions because immediate
⍝ execution works line by line (and parsing the first line would fail).
⍝ valid split into several lines (in a defined function)
⍝
∇FOO X
X≥0 →→
X 'is positive' ←→
X 'is negative' ←←
∇
FOO 5
5 is positive
FOO ¯5
¯5 is negative
⍝ invalid split into several lines: ←→ spread over 2 lines.
⍝ FOO can be properly parsed, but calling FOO fails.
⍝
∇FOO X
X≥0 →→ X 'is positive' ←
→ X 'is negative' ←←
∇
FOO 5
SYNTAX ERROR
FOO[1] X 'is positive'←
⍝ invalid split into several lines: ←→ is first token in line).
⍝ FOO is invalid and the ∇-editor complains when closing FOO.
⍝
∇FOO X
X≥0 →→ X 'is positive'
←→ X 'is negative' ←←
∇
NOTE: Invalid ←→ at start of line 2
Error in function body in function line [2] of:
[0] FOO X
[1] X≥0 →→ X 'is positive'
[2] ←→ X 'is negative' ←←
Fatal error in defined function line [2]. You may now:
change the faulty line with: [2] ..., or
delete the faulty line with: [∆2], or
cancel editing with: [→]∇.
The recommended usage of corresponding →→, ←→, and ←← token is to:
- either put them on the same line (short format), or else
- align all of them on the same column (long form), but
- never mix the short and long forms
Like shown in the examples above.
Previous: Conditionals, Up: Non-standard GNU APL Features [Contents]
2.41 Matrix Product
In standard APL, the inner product Z of two matrices A and B as known from linear algebra, is:
Z←A +.× B ⍝ the most frequent special case of A f.g B
However, the inner product in APL is more generic than the inner product in linear algebra. In the general case A f.g B may the functions f and b also be non-scalar APL primitives or even defined functions. This generality is occasionally helpful, but comes with a performance penalty since many argument checks are duplicated. At the same time A +.× B is by far the most frequent case of operator ’.’.
For this reason GNU APL also provides a more efficient dyadic function ∘ (Matrix Product) for the special case +.× of the dyadic operator ’.’. This function ∘ has been optimized for numeric arguments and computes the matrix product as known from linear algebra.
For two-dimensional matrices A and B function ∘ is the same as +.×:
A∘B ←→ A +.× B
Otherwise there are some subtle differences between ∘ and +.×:
- A +.× B allows A and B to be of any rank, while A∘B raises a RANK ERROR if the rank of A or B is more than 2.
- With operator +.× the product of e.g. a vector and a matrix (or
vice versa) is a vector, usually understood as row-vector.
In contrast (and more similar to linear algebra) A∘B is always a matrix,
to preserve the distinction between row vectors and column vectors:
M←2 2⍴1 2 3 4 ⍝ a matrix V←10 11 ⍝ a vector M +.× V 32 74 M∘V 32 74 V +.× M 43 64 V∘M 43 64 ⍴M +.× V ⍝ vector 2 ⍴V +.× M ⍝ vector 2 ⍴V∘M ⍝ row vector 1 2 ⍴M∘V ⍝ column vector 2 1
Next: Internationalization, Previous: Non-standard GNU APL Features, Up: GNU APL [Contents]
3 Limitations and Missing Features
GNU APL is an almost full implementation of the ISO standard 13751. However, a few limitations exist. See file README-4-compliance for an up-to-date descriptions of limitations.
3.1 System Limits
APL floating point values are 64-bit wide, thus ranging from -8.98E307 to 8.98E307.
GNU APL integers have a guaranteed range from -9200000000000000000 to 9200000000000000000, which is a slighly smaller range.
A 64-bit integer represents a value between -9223372036854775808 and 9223372036854775807.
If the result of a computation is integer by nature, for example +, -, or × with integer arguments, and falls into the guaranteed range, then the result will be an APL integer. If the result is too large for a 64-bit signed integer then the result will be automatically converted to an APL floating point value. However, if the result is outside the guaranteed range but still within the 64-bit integer range, e.g. between 9200000000000000000 and 9223372036854775807 (exclusive), then GNU APL gives no guarantees as to whether the result will be a 64-bit integer or a 64-bit floating point (with the resulting loss of precision). This decision is usually function-specific and driven by performance considerations.
APL values have a maximum rank of 8. However, the maximum range can be set by means of ./configure (see README-2-configure).
Next: Project Structure, Previous: Limitations and Missing Features, Up: GNU APL [Contents]
4 Internationalization
GNU APL used to be internationalized by means of GNU gettext, but is not anymore.
For APL characters to work properly with keyboards and terminal emulators (see also README-3-keyboard) it is essential that your LANG environment variable is correctly set. For German, that would be "de_DE.utf8", like:
$export LANG=de_DE.utf8
A misspelling of the language can cause APL characters to become unavailable, even if your xmodmap is correct. You can check your setting by executing the program ’locale’. If it shows warnings like these:
locale: Cannot set LC_CTYPE to default locale: No such file or directory locale: Cannot set LC_MESSAGES to default locale: No such file or directory locale: Cannot set LC_ALL to default locale: No such file or directory
then something is wrong and you should check your LANG setting and installed locales.
As far as xterm is concerned, the xterm command line options –u8, –lc, and –en might solve problems related to the terminal.
Next: Libraries Contributed by GNU APL Users, Previous: Internationalization, Up: GNU APL [Contents]
5 Project Structure
The top-level directory of the GNU APL project has a structure like this:
apl-1.9/
├── autom4te.cache
├── build
├── debian
├── debian_tmp
├── devel_doc
├── doc
├── erlang
├── gnu-apl.d
├── HOWTOs
├── html
├── m4
├── rpm
├── src
├── support-files
├── tools
├── websock
├── workspaces
├── wslib2
├── wslib3
├── wslib4
└── wslib5
Most of these directories are contained in the project tar file (e.g. apl-1.9.tar.gz) and some are created during the build of GNU APL. Only the directories in the top-level are shown above.
The GNU APL project follows the standard layout for autoconf/automake projects. The top-level itself contains the files needed by autoconf/automake and a handful of README-XXX files that might be of interest when building GNU APL.
The subdirectories are (in order of decreasing relevance):
- The subdirectory src
- The subdirectory support-files
- The subdirectory doc
- The subdirectory HOWTOs
- The subdirectories workspaces and wslib2 ... wslib5
- The subdirectory m4
- The subdirectories debian and debian_tmp
- The subdirectory tools
Next: The subdirectory support-files, Up: Project Structure [Contents]
5.1 The subdirectory src
The subdirectory src contains all C++ source files that are needed to build either the GNU APL interpreter itself, or libapl (a library that contains the essential part of GNU APL, but without the interactive REPL loop of the interpreter). During the build, the object files produced by the compiler are also placed in this directory.
The subdirectory src contains further subdirectories for components of GNU APL that are optional and typically require the installation of additional libraries on the build machine. The ./configure script in the top-level directory determines, which optional components shall be included in the build.
apl-1.9/
├── src
├── APs APs for ⎕SVO and friends
├── emacs_mode dito
├── Gtk ⎕GTK (graphical user interface)
├── native templates for native functions
├── sql ⎕SQL
├── testcases dito
GNU APL comes with an automated test suite, the testcases are contained in subdirectory src/testcases
Next: The subdirectory doc, Previous: The subdirectory src, Up: Project Structure [Contents]
5.2 The subdirectory support-files
The subdirectory support-file contains a number of configuration files that aim at making a standard keyboard produce APL characters. Details are explained in top-level file README-3-keyboard.
Next: The subdirectory HOWTOs, Previous: The subdirectory support-files, Up: Project Structure [Contents]
5.3 The subdirectory doc
The subdirectory doc is used to create this info file in different file formats (.info, .html).
Next: The subdirectories workspaces and wslib2 ... wslib5, Previous: The subdirectory doc, Up: Project Structure [Contents]
5.4 The subdirectory HOWTOs
The subdirectory HOWTOs contains some documents that try to explain how some of the non-standard features of GNU APL are intended to be used. These documents were written for two different audiences: APL programmers and GNU APL hackers. The documents for APL programmers are, by default, installed in directory /usr/local/share/doc/apl by make install while the documents for GNU APL hackers (i.e. C++ programmers or trouble-shooters) are not installed by make install, but rather remain in the source tree.
Next: The subdirectory m4, Previous: The subdirectory HOWTOs, Up: Project Structure [Contents]
5.5 The subdirectories workspaces and wslib2 ... wslib5
These directories (and their content) are, by default, copied to /usr/local/lib/apl by make install. Some subdirectories are empty while others contain small workspaces or libraries for various purposes (mostly demonstrating the use of some non-standard APL features).
Next: The subdirectories debian and debian_tmp, Previous: The subdirectories workspaces and wslib2 ... wslib5, Up: Project Structure [Contents]
5.6 The subdirectory m4
The subdirectory m4 contains macros used by autoconf and automake. In most cases the top-level ./configure script can be used as is. If a platform on which GNU APL shall be built differs too much from the platform on which the GNU APL project tar file (e.g. apl-1.9.tar.gz) was created, then it might be necessary to re-create the ./configure script on the platform.
Re-creating the ./configure script requires:
- the installation of autoconf,
- the installation of automake,
- the installation of libtool,
- maybe running aclocal, libtoolize, and other scripts, and finally
- running autoreconf
Next: The subdirectory tools, Previous: The subdirectory m4, Up: Project Structure [Contents]
5.7 The subdirectories debian and debian_tmp
These subdirectories are templates for building Debian packages that contain GNU APL. Subdirectory debian_tmp is initially empty and acts as a scratch directory inside which the interpreter is being compiled when a Debian package is built.
Previous: The subdirectories debian and debian_tmp, Up: Project Structure [Contents]
5.8 The subdirectory tools
GNU APL uses generated C++ code. The subdirectory tools contains the source code for the code generator (phrase_gen) and also some other small tools for various purposes. These tools are typically used by GNU APL hackers and are therefore not installed by make install.
Next: Licenses for this GNU APL Manual and for GNU APL, Previous: Project Structure, Up: GNU APL [Contents]
6 Libraries Contributed by GNU APL Users
Since the first release of GNU APL, a number of libraries, but also other developments, have been made by users of GNU APL. Below are links to these contributions.
Next: Core Libraries, Up: Libraries Contributed by GNU APL Users [Contents]
6.1 The GNU APL Community Webpage
The GNU APL project maintains a web page that lists contributions made by GNU APL users:
http://www.gnu.org/software/apl/Community.html
The contributions listed there were collected from emails sent to bug-apl@gnu.org
Since the list was started long after bug-apl@gnu.org was created. It is therefore quite possible that your contribution is missing. That does not mean that your contribution was not considered worthwhile to be listed but more likely that it was overlooked. Just send an email to bug-apl@gnu.org to fix that.
Previous: The GNU APL Community Webpage, Up: Libraries Contributed by GNU APL Users [Contents]
6.2 Core Libraries
There is a small number of libraries that are considered "core" APL because, for example, the ISO standard requires their functionality, or because other APL interpreters normally support them.
These libraries are linked via the GNU APL Community web page. In addition they are stored in the GNU APL SVN repository and also included in the GNU APL packages that follows their contribution.
Currently the following core libraries exist:
GNU APL Emacs mode (for Emacs users) by Elias Mårtenson
SQL interface (SQLite and Postgres) by Elias Mårtenson
Component File System (as required by ISO 13751) by David B. Lamkins
Component File System (as required by ISO 13751) by Blake McBride
SQL
Previous: Libraries Contributed by GNU APL Users, Up: GNU APL [Contents]
7 Licenses for this GNU APL Manual and for GNU APL
This manual for GNU APL is licensed under the GNU Free Documentation License, *Note Section 7.1:: below.
GNU APL itself is licensed under the GNU Public License version 3 or later (aka GPLv3+), *Note Section 7.2:: below.
Next: The GNU GENERAL PUBLIC LICENSE, Up: Licenses for this GNU APL Manual and for GNU APL [Contents]
7.1 The GNU Free Documentation License
Copyright © 2000, 2001, 2002, 2007, 2008 Free Software Foundation, Inc. http://fsf.org/ Everyone is permitted to copy and distribute verbatim copies of this license document, but changing it is not allowed.
- PREAMBLE
The purpose of this License is to make a manual, textbook, or other functional and useful document free in the sense of freedom: to assure everyone the effective freedom to copy and redistribute it, with or without modifying it, either commercially or non-commercially. Secondarily, this License preserves for the author and publisher a way to get credit for their work, while not being considered responsible for modifications made by others.
This License is a kind of “copyleft”, which means that derivative works of the document must themselves be free in the same sense. It complements the GNU General Public License, which is a copyleft license designed for free software.
We have designed this License in order to use it for manuals for free software, because free software needs free documentation: a free program should come with manuals providing the same freedoms that the software does. But this License is not limited to software manuals; it can be used for any textual work, regardless of subject matter or whether it is published as a printed book. We recommend this License principally for works whose purpose is instruction or reference.
- APPLICABILITY AND DEFINITIONS
This License applies to any manual or other work, in any medium, that contains a notice placed by the copyright holder saying it can be distributed under the terms of this License. Such a notice grants a world-wide, royalty-free license, unlimited in duration, to use that work under the conditions stated herein. The “Document”, below, refers to any such manual or work. Any member of the public is a licensee, and is addressed as “you”. You accept the license if you copy, modify or distribute the work in a way requiring permission under copyright law.
A “Modified Version” of the Document means any work containing the Document or a portion of it, either copied verbatim, or with modifications and/or translated into another language.
A “Secondary Section” is a named appendix or a front-matter section of the Document that deals exclusively with the relationship of the publishers or authors of the Document to the Document’s overall subject (or to related matters) and contains nothing that could fall directly within that overall subject. (Thus, if the Document is in part a textbook of mathematics, a Secondary Section may not explain any mathematics.) The relationship could be a matter of historical connection with the subject or with related matters, or of legal, commercial, philosophical, ethical or political position regarding them.
The “Invariant Sections” are certain Secondary Sections whose titles are designated, as being those of Invariant Sections, in the notice that says that the Document is released under this License. If a section does not fit the above definition of Secondary then it is not allowed to be designated as Invariant. The Document may contain zero Invariant Sections. If the Document does not identify any Invariant Sections then there are none.
The “Cover Texts” are certain short passages of text that are listed, as Front-Cover Texts or Back-Cover Texts, in the notice that says that the Document is released under this License. A Front-Cover Text may be at most 5 words, and a Back-Cover Text may be at most 25 words.
A “Transparent” copy of the Document means a machine-readable copy, represented in a format whose specification is available to the general public, that is suitable for revising the document straightforwardly with generic text editors or (for images composed of pixels) generic paint programs or (for drawings) some widely available drawing editor, and that is suitable for input to text formatters or for automatic translation to a variety of formats suitable for input to text formatters. A copy made in an otherwise Transparent file format whose markup, or absence of markup, has been arranged to thwart or discourage subsequent modification by readers is not Transparent. An image format is not Transparent if used for any substantial amount of text. A copy that is not “Transparent” is called “Opaque”.
Examples of suitable formats for Transparent copies include plain ASCII without markup, Texinfo input format, LaTeX input format, SGML or XML using a publicly available DTD, and standard-conforming simple HTML, PostScript or PDF designed for human modification. Examples of transparent image formats include PNG, XCF and JPG. Opaque formats include proprietary formats that can be read and edited only by proprietary word processors, SGML or XML for which the DTD and/or processing tools are not generally available, and the machine-generated HTML, PostScript or PDF produced by some word processors for output purposes only.
The “Title Page” means, for a printed book, the title page itself, plus such following pages as are needed to hold, legibly, the material this License requires to appear in the title page. For works in formats which do not have any title page as such, “Title Page” means the text near the most prominent appearance of the work’s title, preceding the beginning of the body of the text.
The “publisher” means any person or entity that distributes copies of the Document to the public.
A section “Entitled XYZ” means a named subunit of the Document whose title either is precisely XYZ or contains XYZ in parentheses following text that translates XYZ in another language. (Here XYZ stands for a specific section name mentioned below, such as “Acknowledgements”, “Dedications”, “Endorsements”, or “History”.) To “Preserve the Title” of such a section when you modify the Document means that it remains a section “Entitled XYZ” according to this definition.
The Document may include Warranty Disclaimers next to the notice which states that this License applies to the Document. These Warranty Disclaimers are considered to be included by reference in this License, but only as regards disclaiming warranties: any other implication that these Warranty Disclaimers may have is void and has no effect on the meaning of this License.
- VERBATIM COPYING
You may copy and distribute the Document in any medium, either commercially or noncommercially, provided that this License, the copyright notices, and the license notice saying this License applies to the Document are reproduced in all copies, and that you add no other conditions whatsoever to those of this License. You may not use technical measures to obstruct or control the reading or further copying of the copies you make or distribute. However, you may accept compensation in exchange for copies. If you distribute a large enough number of copies you must also follow the conditions in section 3.
You may also lend copies, under the same conditions stated above, and you may publicly display copies.
- COPYING IN QUANTITY
If you publish printed copies (or copies in media that commonly have printed covers) of the Document, numbering more than 100, and the Document’s license notice requires Cover Texts, you must enclose the copies in covers that carry, clearly and legibly, all these Cover Texts: Front-Cover Texts on the front cover, and Back-Cover Texts on the back cover. Both covers must also clearly and legibly identify you as the publisher of these copies. The front cover must present the full title with all words of the title equally prominent and visible. You may add other material on the covers in addition. Copying with changes limited to the covers, as long as they preserve the title of the Document and satisfy these conditions, can be treated as verbatim copying in other respects.
If the required texts for either cover are too voluminous to fit legibly, you should put the first ones listed (as many as fit reasonably) on the actual cover, and continue the rest onto adjacent pages.
If you publish or distribute Opaque copies of the Document numbering more than 100, you must either include a machine-readable Transparent copy along with each Opaque copy, or state in or with each Opaque copy a computer-network location from which the general network-using public has access to download using public-standard network protocols a complete Transparent copy of the Document, free of added material. If you use the latter option, you must take reasonably prudent steps, when you begin distribution of Opaque copies in quantity, to ensure that this Transparent copy will remain thus accessible at the stated location until at least one year after the last time you distribute an Opaque copy (directly or through your agents or retailers) of that edition to the public.
It is requested, but not required, that you contact the authors of the Document well before redistributing any large number of copies, to give them a chance to provide you with an updated version of the Document.
- MODIFICATIONS
You may copy and distribute a Modified Version of the Document under the conditions of sections 2 and 3 above, provided that you release the Modified Version under precisely this License, with the Modified Version filling the role of the Document, thus licensing distribution and modification of the Modified Version to whoever possesses a copy of it. In addition, you must do these things in the Modified Version:
- Use in the Title Page (and on the covers, if any) a title distinct from that of the Document, and from those of previous versions (which should, if there were any, be listed in the History section of the Document). You may use the same title as a previous version if the original publisher of that version gives permission.
- List on the Title Page, as authors, one or more persons or entities responsible for authorship of the modifications in the Modified Version, together with at least five of the principal authors of the Document (all of its principal authors, if it has fewer than five), unless they release you from this requirement.
- State on the Title page the name of the publisher of the Modified Version, as the publisher.
- Preserve all the copyright notices of the Document.
- Add an appropriate copyright notice for your modifications adjacent to the other copyright notices.
- Include, immediately after the copyright notices, a license notice giving the public permission to use the Modified Version under the terms of this License, in the form shown in the Addendum below.
- Preserve in that license notice the full lists of Invariant Sections and required Cover Texts given in the Document’s license notice.
- Include an unaltered copy of this License.
- Preserve the section Entitled “History”, Preserve its Title, and add to it an item stating at least the title, year, new authors, and publisher of the Modified Version as given on the Title Page. If there is no section Entitled “History” in the Document, create one stating the title, year, authors, and publisher of the Document as given on its Title Page, then add an item describing the Modified Version as stated in the previous sentence.
- Preserve the network location, if any, given in the Document for public access to a Transparent copy of the Document, and likewise the network locations given in the Document for previous versions it was based on. These may be placed in the “History” section. You may omit a network location for a work that was published at least four years before the Document itself, or if the original publisher of the version it refers to gives permission.
- For any section Entitled “Acknowledgements” or “Dedications”, Preserve the Title of the section, and preserve in the section all the substance and tone of each of the contributor acknowledgements and/or dedications given therein.
- Preserve all the Invariant Sections of the Document, unaltered in their text and in their titles. Section numbers or the equivalent are not considered part of the section titles.
- Delete any section Entitled “Endorsements”. Such a section may not be included in the Modified Version.
- Do not retitle any existing section to be Entitled “Endorsements” or to conflict in title with any Invariant Section.
- Preserve any Warranty Disclaimers.
If the Modified Version includes new front-matter sections or appendices that qualify as Secondary Sections and contain no material copied from the Document, you may at your option designate some or all of these sections as invariant. To do this, add their titles to the list of Invariant Sections in the Modified Version’s license notice. These titles must be distinct from any other section titles.
You may add a section Entitled “Endorsements”, provided it contains nothing but endorsements of your Modified Version by various parties—for example, statements of peer review or that the text has been approved by an organization as the authoritative definition of a standard.
You may add a passage of up to five words as a Front-Cover Text, and a passage of up to 25 words as a Back-Cover Text, to the end of the list of Cover Texts in the Modified Version. Only one passage of Front-Cover Text and one of Back-Cover Text may be added by (or through arrangements made by) any one entity. If the Document already includes a cover text for the same cover, previously added by you or by arrangement made by the same entity you are acting on behalf of, you may not add another; but you may replace the old one, on explicit permission from the previous publisher that added the old one.
The author(s) and publisher(s) of the Document do not by this License give permission to use their names for publicity for or to assert or imply endorsement of any Modified Version.
- COMBINING DOCUMENTS
You may combine the Document with other documents released under this License, under the terms defined in section 4 above for modified versions, provided that you include in the combination all of the Invariant Sections of all of the original documents, unmodified, and list them all as Invariant Sections of your combined work in its license notice, and that you preserve all their Warranty Disclaimers.
The combined work need only contain one copy of this License, and multiple identical Invariant Sections may be replaced with a single copy. If there are multiple Invariant Sections with the same name but different contents, make the title of each such section unique by adding at the end of it, in parentheses, the name of the original author or publisher of that section if known, or else a unique number. Make the same adjustment to the section titles in the list of Invariant Sections in the license notice of the combined work.
In the combination, you must combine any sections Entitled “History” in the various original documents, forming one section Entitled “History”; likewise combine any sections Entitled “Acknowledgements”, and any sections Entitled “Dedications”. You must delete all sections Entitled “Endorsements.”
- COLLECTIONS OF DOCUMENTS
You may make a collection consisting of the Document and other documents released under this License, and replace the individual copies of this License in the various documents with a single copy that is included in the collection, provided that you follow the rules of this License for verbatim copying of each of the documents in all other respects.
You may extract a single document from such a collection, and distribute it individually under this License, provided you insert a copy of this License into the extracted document, and follow this License in all other respects regarding verbatim copying of that document.
- AGGREGATION WITH INDEPENDENT WORKS
A compilation of the Document or its derivatives with other separate and independent documents or works, in or on a volume of a storage or distribution medium, is called an “aggregate” if the copyright resulting from the compilation is not used to limit the legal rights of the compilation’s users beyond what the individual works permit. When the Document is included in an aggregate, this License does not apply to the other works in the aggregate which are not themselves derivative works of the Document.
If the Cover Text requirement of section 3 is applicable to these copies of the Document, then if the Document is less than one half of the entire aggregate, the Document’s Cover Texts may be placed on covers that bracket the Document within the aggregate, or the electronic equivalent of covers if the Document is in electronic form. Otherwise they must appear on printed covers that bracket the whole aggregate.
- TRANSLATION
Translation is considered a kind of modification, so you may distribute translations of the Document under the terms of section 4. Replacing Invariant Sections with translations requires special permission from their copyright holders, but you may include translations of some or all Invariant Sections in addition to the original versions of these Invariant Sections. You may include a translation of this License, and all the license notices in the Document, and any Warranty Disclaimers, provided that you also include the original English version of this License and the original versions of those notices and disclaimers. In case of a disagreement between the translation and the original version of this License or a notice or disclaimer, the original version will prevail.
If a section in the Document is Entitled “Acknowledgements”, “Dedications”, or “History”, the requirement (section 4) to Preserve its Title (section 1) will typically require changing the actual title.
- TERMINATION
You may not copy, modify, sublicense, or distribute the Document except as expressly provided under this License. Any attempt otherwise to copy, modify, sublicense, or distribute it is void, and will automatically terminate your rights under this License.
However, if you cease all violation of this License, then your license from a particular copyright holder is reinstated (a) provisionally, unless and until the copyright holder explicitly and finally terminates your license, and (b) permanently, if the copyright holder fails to notify you of the violation by some reasonable means prior to 60 days after the cessation.
Moreover, your license from a particular copyright holder is reinstated permanently if the copyright holder notifies you of the violation by some reasonable means, this is the first time you have received notice of violation of this License (for any work) from that copyright holder, and you cure the violation prior to 30 days after your receipt of the notice.
Termination of your rights under this section does not terminate the licenses of parties who have received copies or rights from you under this License. If your rights have been terminated and not permanently reinstated, receipt of a copy of some or all of the same material does not give you any rights to use it.
- FUTURE REVISIONS OF THIS LICENSE
The Free Software Foundation may publish new, revised versions of the GNU Free Documentation License from time to time. Such new versions will be similar in spirit to the present version, but may differ in detail to address new problems or concerns. See http://www.gnu.org/copyleft/.
Each version of the License is given a distinguishing version number. If the Document specifies that a particular numbered version of this License “or any later version” applies to it, you have the option of following the terms and conditions either of that specified version or of any later version that has been published (not as a draft) by the Free Software Foundation. If the Document does not specify a version number of this License, you may choose any version ever published (not as a draft) by the Free Software Foundation. If the Document specifies that a proxy can decide which future versions of this License can be used, that proxy’s public statement of acceptance of a version permanently authorizes you to choose that version for the Document.
- RELICENSING
“Massive Multiauthor Collaboration Site” (or “MMC Site”) means any World Wide Web server that publishes copyrightable works and also provides prominent facilities for anybody to edit those works. A public wiki that anybody can edit is an example of such a server. A “Massive Multiauthor Collaboration” (or “MMC”) contained in the site means any set of copyrightable works thus published on the MMC site.
“CC-BY-SA” means the Creative Commons Attribution-Share Alike 3.0 license published by Creative Commons Corporation, a not-for-profit corporation with a principal place of business in San Francisco, California, as well as future copyleft versions of that license published by that same organization.
“Incorporate” means to publish or republish a Document, in whole or in part, as part of another Document.
An MMC is “eligible for relicensing” if it is licensed under this License, and if all works that were first published under this License somewhere other than this MMC, and subsequently incorporated in whole or in part into the MMC, (1) had no cover texts or invariant sections, and (2) were thus incorporated prior to November 1, 2008.
The operator of an MMC Site may republish an MMC contained in the site under CC-BY-SA on the same site at any time before August 1, 2009, provided the MMC is eligible for relicensing.
ADDENDUM: How to use this License for your documents
To use this License in a document you have written, include a copy of the License in the document and put the following copyright and license notices just after the title page:
Copyright (C) year your name. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.3 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the section entitled ``GNU Free Documentation License''.
If you have Invariant Sections, Front-Cover Texts and Back-Cover Texts, replace the “with…Texts.” line with this:
with the Invariant Sections being list their titles, with
the Front-Cover Texts being list, and with the Back-Cover Texts
being list.
If you have Invariant Sections without Cover Texts, or some other combination of the three, merge those two alternatives to suit the situation.
If your document contains nontrivial examples of program code, we recommend releasing these examples in parallel under your choice of free software license, such as the GNU General Public License, to permit their use in free software.
Previous: The GNU Free Documentation License, Up: Licenses for this GNU APL Manual and for GNU APL [Contents]
7.2 The GNU GENERAL PUBLIC LICENSE
GNU GENERAL PUBLIC LICENSE Version 3, 29 June 2007
Copyright (C) 2007 Free Software Foundation, Inc. <http://fsf.org/> Everyone is permitted to copy and distribute verbatim copies of this license document, but changing it is not allowed.
Preamble
The GNU General Public License is a free, copyleft license for software and other kinds of works.
The licenses for most software and other practical works are designed to take away your freedom to share and change the works. By contrast, the GNU General Public License is intended to guarantee your freedom to share and change all versions of a program–to make sure it remains free software for all its users. We, the Free Software Foundation, use the GNU General Public License for most of our software; it applies also to any other work released this way by its authors. You can apply it to your programs, too.
When we speak of free software, we are referring to freedom, not price. Our General Public Licenses are designed to make sure that you have the freedom to distribute copies of free software (and charge for them if you wish), that you receive source code or can get it if you want it, that you can change the software or use pieces of it in new free programs, and that you know you can do these things.
To protect your rights, we need to prevent others from denying you these rights or asking you to surrender the rights. Therefore, you have certain responsibilities if you distribute copies of the software, or if you modify it: responsibilities to respect the freedom of others.
For example, if you distribute copies of such a program, whether gratis or for a fee, you must pass on to the recipients the same freedoms that you received. You must make sure that they, too, receive or can get the source code. And you must show them these terms so they know their rights.
Developers that use the GNU GPL protect your rights with two steps: (1) assert copyright on the software, and (2) offer you this License giving you legal permission to copy, distribute and/or modify it.
For the developers’ and authors’ protection, the GPL clearly explains that there is no warranty for this free software. For both users’ and authors’ sake, the GPL requires that modified versions be marked as changed, so that their problems will not be attributed erroneously to authors of previous versions.
Some devices are designed to deny users access to install or run modified versions of the software inside them, although the manufacturer can do so. This is fundamentally incompatible with the aim of protecting users’ freedom to change the software. The systematic pattern of such abuse occurs in the area of products for individuals to use, which is precisely where it is most unacceptable. Therefore, we have designed this version of the GPL to prohibit the practice for those products. If such problems arise substantially in other domains, we stand ready to extend this provision to those domains in future versions of the GPL, as needed to protect the freedom of users.
Finally, every program is threatened constantly by software patents. States should not allow patents to restrict development and use of software on general-purpose computers, but in those that do, we wish to avoid the special danger that patents applied to a free program could make it effectively proprietary. To prevent this, the GPL assures that patents cannot be used to render the program non-free.
The precise terms and conditions for copying, distribution and modification follow.
TERMS AND CONDITIONS
0. Definitions.
"This License" refers to version 3 of the GNU General Public License.
"Copyright" also means copyright-like laws that apply to other kinds of works, such as semiconductor masks.
"The Program" refers to any copyrightable work licensed under this License. Each licensee is addressed as "you". "Licensees" and "recipients" may be individuals or organizations.
To "modify" a work means to copy from or adapt all or part of the work in a fashion requiring copyright permission, other than the making of an exact copy. The resulting work is called a "modified version" of the earlier work or a work "based on" the earlier work.
A "covered work" means either the unmodified Program or a work based on the Program.
To "propagate" a work means to do anything with it that, without permission, would make you directly or secondarily liable for infringement under applicable copyright law, except executing it on a computer or modifying a private copy. Propagation includes copying, distribution (with or without modification), making available to the public, and in some countries other activities as well.
To "convey" a work means any kind of propagation that enables other parties to make or receive copies. Mere interaction with a user through a computer network, with no transfer of a copy, is not conveying.
An interactive user interface displays "Appropriate Legal Notices" to the extent that it includes a convenient and prominently visible feature that (1) displays an appropriate copyright notice, and (2) tells the user that there is no warranty for the work (except to the extent that warranties are provided), that licensees may convey the work under this License, and how to view a copy of this License. If the interface presents a list of user commands or options, such as a menu, a prominent item in the list meets this criterion.
1. Source Code.
The "source code" for a work means the preferred form of the work for making modifications to it. "Object code" means any non-source form of a work.
A "Standard Interface" means an interface that either is an official standard defined by a recognized standards body, or, in the case of interfaces specified for a particular programming language, one that is widely used among developers working in that language.
The "System Libraries" of an executable work include anything, other than the work as a whole, that (a) is included in the normal form of packaging a Major Component, but which is not part of that Major Component, and (b) serves only to enable use of the work with that Major Component, or to implement a Standard Interface for which an implementation is available to the public in source code form. A "Major Component", in this context, means a major essential component (kernel, window system, and so on) of the specific operating system (if any) on which the executable work runs, or a compiler used to produce the work, or an object code interpreter used to run it.
The "Corresponding Source" for a work in object code form means all the source code needed to generate, install, and (for an executable work) run the object code and to modify the work, including scripts to control those activities. However, it does not include the work’s System Libraries, or general-purpose tools or generally available free programs which are used unmodified in performing those activities but which are not part of the work. For example, Corresponding Source includes interface definition files associated with source files for the work, and the source code for shared libraries and dynamically linked subprograms that the work is specifically designed to require, such as by intimate data communication or control flow between those subprograms and other parts of the work.
The Corresponding Source need not include anything that users can regenerate automatically from other parts of the Corresponding Source.
The Corresponding Source for a work in source code form is that same work.
2. Basic Permissions.
All rights granted under this License are granted for the term of copyright on the Program, and are irrevocable provided the stated conditions are met. This License explicitly affirms your unlimited permission to run the unmodified Program. The output from running a covered work is covered by this License only if the output, given its content, constitutes a covered work. This License acknowledges your rights of fair use or other equivalent, as provided by copyright law.
You may make, run and propagate covered works that you do not convey, without conditions so long as your license otherwise remains in force. You may convey covered works to others for the sole purpose of having them make modifications exclusively for you, or provide you with facilities for running those works, provided that you comply with the terms of this License in conveying all material for which you do not control copyright. Those thus making or running the covered works for you must do so exclusively on your behalf, under your direction and control, on terms that prohibit them from making any copies of your copyrighted material outside their relationship with you.
Conveying under any other circumstances is permitted solely under the conditions stated below. Sublicensing is not allowed; section 10 makes it unnecessary.
3. Protecting Users’ Legal Rights From Anti-Circumvention Law.
No covered work shall be deemed part of an effective technological measure under any applicable law fulfilling obligations under article 11 of the WIPO copyright treaty adopted on 20 December 1996, or similar laws prohibiting or restricting circumvention of such measures.
When you convey a covered work, you waive any legal power to forbid circumvention of technological measures to the extent such circumvention is effected by exercising rights under this License with respect to the covered work, and you disclaim any intention to limit operation or modification of the work as a means of enforcing, against the work’s users, your or third parties’ legal rights to forbid circumvention of technological measures.
4. Conveying Verbatim Copies.
You may convey verbatim copies of the Program’s source code as you receive it, in any medium, provided that you conspicuously and appropriately publish on each copy an appropriate copyright notice; keep intact all notices stating that this License and any non-permissive terms added in accord with section 7 apply to the code; keep intact all notices of the absence of any warranty; and give all recipients a copy of this License along with the Program.
You may charge any price or no price for each copy that you convey, and you may offer support or warranty protection for a fee.
5. Conveying Modified Source Versions.
You may convey a work based on the Program, or the modifications to produce it from the Program, in the form of source code under the terms of section 4, provided that you also meet all of these conditions:
a) The work must carry prominent notices stating that you modified it, and giving a relevant date.
b) The work must carry prominent notices stating that it is released under this License and any conditions added under section 7. This requirement modifies the requirement in section 4 to "keep intact all notices".
c) You must license the entire work, as a whole, under this License to anyone who comes into possession of a copy. This License will therefore apply, along with any applicable section 7 additional terms, to the whole of the work, and all its parts, regardless of how they are packaged. This License gives no permission to license the work in any other way, but it does not invalidate such permission if you have separately received it.
d) If the work has interactive user interfaces, each must display Appropriate Legal Notices; however, if the Program has interactive interfaces that do not display Appropriate Legal Notices, your work need not make them do so.
A compilation of a covered work with other separate and independent works, which are not by their nature extensions of the covered work, and which are not combined with it such as to form a larger program, in or on a volume of a storage or distribution medium, is called an "aggregate" if the compilation and its resulting copyright are not used to limit the access or legal rights of the compilation’s users beyond what the individual works permit. Inclusion of a covered work in an aggregate does not cause this License to apply to the other parts of the aggregate.
6. Conveying Non-Source Forms.
You may convey a covered work in object code form under the terms of sections 4 and 5, provided that you also convey the machine-readable Corresponding Source under the terms of this License, in one of these ways:
a) Convey the object code in, or embodied in, a physical product (including a physical distribution medium), accompanied by the Corresponding Source fixed on a durable physical medium customarily used for software interchange.
b) Convey the object code in, or embodied in, a physical product (including a physical distribution medium), accompanied by a written offer, valid for at least three years and valid for as long as you offer spare parts or customer support for that product model, to give anyone who possesses the object code either (1) a copy of the Corresponding Source for all the software in the product that is covered by this License, on a durable physical medium customarily used for software interchange, for a price no more than your reasonable cost of physically performing this conveying of source, or (2) access to copy the Corresponding Source from a network server at no charge.
c) Convey individual copies of the object code with a copy of the written offer to provide the Corresponding Source. This alternative is allowed only occasionally and noncommercially, and only if you received the object code with such an offer, in accord with subsection 6b.
d) Convey the object code by offering access from a designated place (gratis or for a charge), and offer equivalent access to the Corresponding Source in the same way through the same place at no further charge. You need not require recipients to copy the Corresponding Source along with the object code. If the place to copy the object code is a network server, the Corresponding Source may be on a different server (operated by you or a third party) that supports equivalent copying facilities, provided you maintain clear directions next to the object code saying where to find the Corresponding Source. Regardless of what server hosts the Corresponding Source, you remain obligated to ensure that it is available for as long as needed to satisfy these requirements.
e) Convey the object code using peer-to-peer transmission, provided you inform other peers where the object code and Corresponding Source of the work are being offered to the general public at no charge under subsection 6d.
A separable portion of the object code, whose source code is excluded from the Corresponding Source as a System Library, need not be included in conveying the object code work.
A "User Product" is either (1) a "consumer product", which means any tangible personal property which is normally used for personal, family, or household purposes, or (2) anything designed or sold for incorporation into a dwelling. In determining whether a product is a consumer product, doubtful cases shall be resolved in favor of coverage. For a particular product received by a particular user, "normally used" refers to a typical or common use of that class of product, regardless of the status of the particular user or of the way in which the particular user actually uses, or expects or is expected to use, the product. A product is a consumer product regardless of whether the product has substantial commercial, industrial or non-consumer uses, unless such uses represent the only significant mode of use of the product.
"Installation Information" for a User Product means any methods, procedures, authorization keys, or other information required to install and execute modified versions of a covered work in that User Product from a modified version of its Corresponding Source. The information must suffice to ensure that the continued functioning of the modified object code is in no case prevented or interfered with solely because modification has been made.
If you convey an object code work under this section in, or with, or specifically for use in, a User Product, and the conveying occurs as part of a transaction in which the right of possession and use of the User Product is transferred to the recipient in perpetuity or for a fixed term (regardless of how the transaction is characterized), the Corresponding Source conveyed under this section must be accompanied by the Installation Information. But this requirement does not apply if neither you nor any third party retains the ability to install modified object code on the User Product (for example, the work has been installed in ROM).
The requirement to provide Installation Information does not include a requirement to continue to provide support service, warranty, or updates for a work that has been modified or installed by the recipient, or for the User Product in which it has been modified or installed. Access to a network may be denied when the modification itself materially and adversely affects the operation of the network or violates the rules and protocols for communication across the network.
Corresponding Source conveyed, and Installation Information provided, in accord with this section must be in a format that is publicly documented (and with an implementation available to the public in source code form), and must require no special password or key for unpacking, reading or copying.
7. Additional Terms.
"Additional permissions" are terms that supplement the terms of this License by making exceptions from one or more of its conditions. Additional permissions that are applicable to the entire Program shall be treated as though they were included in this License, to the extent that they are valid under applicable law. If additional permissions apply only to part of the Program, that part may be used separately under those permissions, but the entire Program remains governed by this License without regard to the additional permissions.
When you convey a copy of a covered work, you may at your option remove any additional permissions from that copy, or from any part of it. (Additional permissions may be written to require their own removal in certain cases when you modify the work.) You may place additional permissions on material, added by you to a covered work, for which you have or can give appropriate copyright permission.
Notwithstanding any other provision of this License, for material you add to a covered work, you may (if authorized by the copyright holders of that material) supplement the terms of this License with terms:
a) Disclaiming warranty or limiting liability differently from the terms of sections 15 and 16 of this License; or
b) Requiring preservation of specified reasonable legal notices or author attributions in that material or in the Appropriate Legal Notices displayed by works containing it; or
c) Prohibiting misrepresentation of the origin of that material, or requiring that modified versions of such material be marked in reasonable ways as different from the original version; or
d) Limiting the use for publicity purposes of names of licensors or authors of the material; or
e) Declining to grant rights under trademark law for use of some trade names, trademarks, or service marks; or
f) Requiring indemnification of licensors and authors of that material by anyone who conveys the material (or modified versions of it) with contractual assumptions of liability to the recipient, for any liability that these contractual assumptions directly impose on those licensors and authors.
All other non-permissive additional terms are considered "further restrictions" within the meaning of section 10. If the Program as you received it, or any part of it, contains a notice stating that it is governed by this License along with a term that is a further restriction, you may remove that term. If a license document contains a further restriction but permits relicensing or conveying under this License, you may add to a covered work material governed by the terms of that license document, provided that the further restriction does not survive such relicensing or conveying.
If you add terms to a covered work in accord with this section, you must place, in the relevant source files, a statement of the additional terms that apply to those files, or a notice indicating where to find the applicable terms.
Additional terms, permissive or non-permissive, may be stated in the form of a separately written license, or stated as exceptions; the above requirements apply either way.
8. Termination.
You may not propagate or modify a covered work except as expressly provided under this License. Any attempt otherwise to propagate or modify it is void, and will automatically terminate your rights under this License (including any patent licenses granted under the third paragraph of section 11).
However, if you cease all violation of this License, then your license from a particular copyright holder is reinstated (a) provisionally, unless and until the copyright holder explicitly and finally terminates your license, and (b) permanently, if the copyright holder fails to notify you of the violation by some reasonable means prior to 60 days after the cessation.
Moreover, your license from a particular copyright holder is reinstated permanently if the copyright holder notifies you of the violation by some reasonable means, this is the first time you have received notice of violation of this License (for any work) from that copyright holder, and you cure the violation prior to 30 days after your receipt of the notice.
Termination of your rights under this section does not terminate the licenses of parties who have received copies or rights from you under this License. If your rights have been terminated and not permanently reinstated, you do not qualify to receive new licenses for the same material under section 10.
9. Acceptance Not Required for Having Copies.
You are not required to accept this License in order to receive or run a copy of the Program. Ancillary propagation of a covered work occurring solely as a consequence of using peer-to-peer transmission to receive a copy likewise does not require acceptance. However, nothing other than this License grants you permission to propagate or modify any covered work. These actions infringe copyright if you do not accept this License. Therefore, by modifying or propagating a covered work, you indicate your acceptance of this License to do so.
10. Automatic Licensing of Downstream Recipients.
Each time you convey a covered work, the recipient automatically receives a license from the original licensors, to run, modify and propagate that work, subject to this License. You are not responsible for enforcing compliance by third parties with this License.
An "entity transaction" is a transaction transferring control of an organization, or substantially all assets of one, or subdividing an organization, or merging organizations. If propagation of a covered work results from an entity transaction, each party to that transaction who receives a copy of the work also receives whatever licenses to the work the party’s predecessor in interest had or could give under the previous paragraph, plus a right to possession of the Corresponding Source of the work from the predecessor in interest, if the predecessor has it or can get it with reasonable efforts.
You may not impose any further restrictions on the exercise of the rights granted or affirmed under this License. For example, you may not impose a license fee, royalty, or other charge for exercise of rights granted under this License, and you may not initiate litigation (including a cross-claim or counterclaim in a lawsuit) alleging that any patent claim is infringed by making, using, selling, offering for sale, or importing the Program or any portion of it.
11. Patents.
A "contributor" is a copyright holder who authorizes use under this License of the Program or a work on which the Program is based. The work thus licensed is called the contributor’s "contributor version".
A contributor’s "essential patent claims" are all patent claims owned or controlled by the contributor, whether already acquired or hereafter acquired, that would be infringed by some manner, permitted by this License, of making, using, or selling its contributor version, but do not include claims that would be infringed only as a consequence of further modification of the contributor version. For purposes of this definition, "control" includes the right to grant patent sublicenses in a manner consistent with the requirements of this License.
Each contributor grants you a non-exclusive, worldwide, royalty-free patent license under the contributor’s essential patent claims, to make, use, sell, offer for sale, import and otherwise run, modify and propagate the contents of its contributor version.
In the following three paragraphs, a "patent license" is any express agreement or commitment, however denominated, not to enforce a patent (such as an express permission to practice a patent or covenant not to sue for patent infringement). To "grant" such a patent license to a party means to make such an agreement or commitment not to enforce a patent against the party.
If you convey a covered work, knowingly relying on a patent license, and the Corresponding Source of the work is not available for anyone to copy, free of charge and under the terms of this License, through a publicly available network server or other readily accessible means, then you must either (1) cause the Corresponding Source to be so available, or (2) arrange to deprive yourself of the benefit of the patent license for this particular work, or (3) arrange, in a manner consistent with the requirements of this License, to extend the patent license to downstream recipients. "Knowingly relying" means you have actual knowledge that, but for the patent license, your conveying the covered work in a country, or your recipient’s use of the covered work in a country, would infringe one or more identifiable patents in that country that you have reason to believe are valid.
If, pursuant to or in connection with a single transaction or arrangement, you convey, or propagate by procuring conveyance of, a covered work, and grant a patent license to some of the parties receiving the covered work authorizing them to use, propagate, modify or convey a specific copy of the covered work, then the patent license you grant is automatically extended to all recipients of the covered work and works based on it.
A patent license is "discriminatory" if it does not include within the scope of its coverage, prohibits the exercise of, or is conditioned on the non-exercise of one or more of the rights that are specifically granted under this License. You may not convey a covered work if you are a party to an arrangement with a third party that is in the business of distributing software, under which you make payment to the third party based on the extent of your activity of conveying the work, and under which the third party grants, to any of the parties who would receive the covered work from you, a discriminatory patent license (a) in connection with copies of the covered work conveyed by you (or copies made from those copies), or (b) primarily for and in connection with specific products or compilations that contain the covered work, unless you entered into that arrangement, or that patent license was granted, prior to 28 March 2007.
Nothing in this License shall be construed as excluding or limiting any implied license or other defenses to infringement that may otherwise be available to you under applicable patent law.
12. No Surrender of Others’ Freedom.
If conditions are imposed on you (whether by court order, agreement or otherwise) that contradict the conditions of this License, they do not excuse you from the conditions of this License. If you cannot convey a covered work so as to satisfy simultaneously your obligations under this License and any other pertinent obligations, then as a consequence you may not convey it at all. For example, if you agree to terms that obligate you to collect a royalty for further conveying from those to whom you convey the Program, the only way you could satisfy both those terms and this License would be to refrain entirely from conveying the Program.
13. Use with the GNU Affero General Public License.
Notwithstanding any other provision of this License, you have permission to link or combine any covered work with a work licensed under version 3 of the GNU Affero General Public License into a single combined work, and to convey the resulting work. The terms of this License will continue to apply to the part which is the covered work, but the special requirements of the GNU Affero General Public License, section 13, concerning interaction through a network will apply to the combination as such.
14. Revised Versions of this License.
The Free Software Foundation may publish revised and/or new versions of the GNU General Public License from time to time. Such new versions will be similar in spirit to the present version, but may differ in detail to address new problems or concerns.
Each version is given a distinguishing version number. If the Program specifies that a certain numbered version of the GNU General Public License "or any later version" applies to it, you have the option of following the terms and conditions either of that numbered version or of any later version published by the Free Software Foundation. If the Program does not specify a version number of the GNU General Public License, you may choose any version ever published by the Free Software Foundation.
If the Program specifies that a proxy can decide which future versions of the GNU General Public License can be used, that proxy’s public statement of acceptance of a version permanently authorizes you to choose that version for the Program.
Later license versions may give you additional or different permissions. However, no additional obligations are imposed on any author or copyright holder as a result of your choosing to follow a later version.
15. Disclaimer of Warranty.
THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
16. Limitation of Liability.
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS), EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
17. Interpretation of Sections 15 and 16.
If the disclaimer of warranty and limitation of liability provided above cannot be given local legal effect according to their terms, reviewing courts shall apply local law that most closely approximates an absolute waiver of all civil liability in connection with the Program, unless a warranty or assumption of liability accompanies a copy of the Program in return for a fee.
END OF TERMS AND CONDITIONS
How to Apply These Terms to Your New Programs
If you develop a new program, and you want it to be of the greatest possible use to the public, the best way to achieve this is to make it free software which everyone can redistribute and change under these terms.
To do so, attach the following notices to the program. It is safest to attach them to the start of each source file to most effectively state the exclusion of warranty; and each file should have at least the "copyright" line and a pointer to where the full notice is found.
<one line to give the program’s name and a brief idea of what it does.> Copyright (C) <year> <name of author>
This program is free software: you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version.
This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with this program. If not, see <http://www.gnu.org/licenses/>.
Also add information on how to contact you by electronic and paper mail.
If the program does terminal interaction, make it output a short notice like this when it starts in an interactive mode:
<program> Copyright (C) <year> <name of author> This program comes with ABSOLUTELY NO WARRANTY; for details type ‘show w’. This is free software, and you are welcome to redistribute it under certain conditions; type ‘show c’ for details.
The hypothetical commands ‘show w’ and ‘show c’ should show the appropriate parts of the General Public License. Of course, your program’s commands might be different; for a GUI interface, you would use an "about box".
You should also get your employer (if you work as a programmer) or school, if any, to sign a "copyright disclaimer" for the program, if necessary. For more information on this, and how to apply and follow the GNU GPL, see <http://www.gnu.org/licenses/>.
The GNU General Public License does not permit incorporating your program into proprietary programs. If your program is a subroutine library, you may consider it more useful to permit linking proprietary applications with the library. If this is what you want to do, use the GNU Lesser General Public License instead of this License. But first, please read <http://www.gnu.org/philosophy/why-not-lgpl.html>.