Part I:
The awk Language ¶
- Getting Started with
awk - Running
awkandgawk - Regular Expressions
- Reading Input Files
- Printing Output
- Expressions
- Patterns, Actions, and Variables
- Arrays in
awk - Functions
1 Getting Started with awk ¶
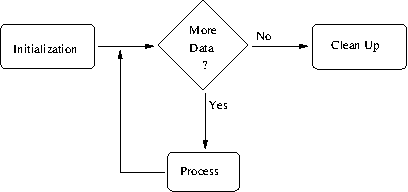
The basic function of awk is to search files for lines (or other
units of text) that contain certain patterns. When a line matches one
of the patterns, awk performs specified actions on that line.
awk continues to process input lines in this way until it reaches
the end of the input files.
Programs in awk are different from programs in most other languages,
because awk programs are data driven (i.e., you describe
the data you want to work with and then what to do when you find it).
Most other languages are procedural; you have to describe, in great
detail, every step the program should take. When working with procedural
languages, it is usually much
harder to clearly describe the data your program will process.
For this reason, awk programs are often refreshingly easy to
read and write.
When you run awk, you specify an awk program that
tells awk what to do. The program consists of a series of
rules (it may also contain function definitions,
an advanced feature that we will ignore for now;
see User-Defined Functions). Each rule specifies one
pattern to search for and one action to perform
upon finding the pattern.
Syntactically, a rule consists of a pattern followed by an
action. The action is enclosed in braces to separate it from the
pattern. Newlines usually separate rules. Therefore, an awk
program looks like this:
pattern { action }
pattern { action }
...
- How to Run
awkPrograms - Data files for the Examples
- Some Simple Examples
- An Example with Two Rules
- A More Complex Example
awkStatements Versus Lines- Other Features of
awk - When to Use
awk - Summary
1.1 How to Run awk Programs ¶
There are several ways to run an awk program. If the program is
short, it is easiest to include it in the command that runs awk,
like this:
awk 'program' input-file1 input-file2 ...
When the program is long, it is usually more convenient to put it in a file and run it with a command like this:
awk -f program-file input-file1 input-file2 ...
This section discusses both mechanisms, along with several variations of each.
- One-Shot Throwaway
awkPrograms - Running
awkWithout Input Files - Running Long Programs
- Executable
awkPrograms - Comments in
awkPrograms - Shell Quoting Issues
1.1.1 One-Shot Throwaway awk Programs ¶
Once you are familiar with awk, you will often type in simple
programs the moment you want to use them. Then you can write the
program as the first argument of the awk command, like this:
awk 'program' input-file1 input-file2 ...
where program consists of a series of patterns and actions, as described earlier.
This command format instructs the shell, or command interpreter,
to start awk and use the program to process records in the
input file(s). There are single quotes around program so
the shell won’t interpret any awk characters as special shell
characters. The quotes also cause the shell to treat all of program as
a single argument for awk, and allow program to be more
than one line long.
This format is also useful for running short or medium-sized awk
programs from shell scripts, because it avoids the need for a separate
file for the awk program. A self-contained shell script is more
reliable because there are no other files to misplace.
Later in this chapter, in Some Simple Examples, we’ll see examples of several short, self-contained programs.
1.1.2 Running awk Without Input Files ¶
You can also run awk without any input files. If you type the
following command line:
awk 'program'
awk applies the program to the standard input,
which usually means whatever you type on the keyboard. This continues
until you indicate end-of-file by typing Ctrl-d.
(On non-POSIX operating systems, the end-of-file character may be different.)
As an example, the following program prints a friendly piece of advice (from Douglas Adams’s The Hitchhiker’s Guide to the Galaxy), to keep you from worrying about the complexities of computer programming:
$ awk 'BEGIN { print "Don\47t Panic!" }'
-| Don't Panic!
awk executes statements associated with BEGIN before
reading any input. If there are no other statements in your program,
as is the case here, awk just stops, instead of trying to read
input it doesn’t know how to process.
The ‘\47’ is a magic way (explained later) of getting a single quote into
the program, without having to engage in ugly shell quoting tricks.
NOTE: If you use Bash as your shell, you should execute the command ‘set +H’ before running this program interactively, to disable the C shell-style command history, which treats ‘!’ as a special character. We recommend putting this command into your personal startup file.
This next simple awk program
emulates the cat utility; it copies whatever you type on the
keyboard to its standard output (why this works is explained shortly):
$ awk '{ print }'
Now is the time for all good men
-| Now is the time for all good men
to come to the aid of their country.
-| to come to the aid of their country.
Four score and seven years ago, ...
-| Four score and seven years ago, ...
What, me worry?
-| What, me worry?
Ctrl-d
1.1.3 Running Long Programs ¶
Sometimes awk programs are very long. In these cases, it is
more convenient to put the program into a separate file. In order to tell
awk to use that file for its program, you type:
awk -f source-file input-file1 input-file2 ...
The -f instructs the awk utility to get the
awk program from the file source-file (see Command-Line Options).
Any file name can be used for source-file. For example, you
could put the program:
BEGIN { print "Don't Panic!" }
into the file advice. Then this command:
awk -f advice
does the same thing as this one:
awk 'BEGIN { print "Don\47t Panic!" }'
This was explained earlier
(see Running awk Without Input Files).
Note that you don’t usually need single quotes around the file name that you
specify with -f, because most file names don’t contain any of the shell’s
special characters. Notice that in advice, the awk
program did not have single quotes around it. The quotes are only needed
for programs that are provided on the awk command line.
(Also, placing the program in a file allows us to use a literal single quote in the program
text, instead of the magic ‘\47’.)
If you want to clearly identify an awk program file as such,
you can add the extension .awk to the file name. This doesn’t
affect the execution of the awk program but it does make
“housekeeping” easier.
1.1.4 Executable awk Programs ¶
Once you have learned awk, you may want to write self-contained
awk scripts, using the ‘#!’ script mechanism. You can do
this on many systems.8
For example, you could update the file advice to look like this:
#! /bin/awk -f
BEGIN { print "Don't Panic!" }
After making this file executable (with the chmod utility),
simply type ‘advice’
at the shell and the system arranges to run awk as if you had
typed ‘awk -f advice’:
$ chmod +x advice $ ./advice -| Don't Panic!
Self-contained awk scripts are useful when you want to write a
program that users can invoke without their having to know that the program is
written in awk.
| Understanding ‘#!’ |
|---|
|
The line beginning with ‘#!’ lists the full file name of an
interpreter to run and a single optional initial command-line argument
to pass to that interpreter. The operating system then runs the
interpreter with the given argument and the full argument list of the
executed program. The first argument in the list is the full file name
of the Some systems limit the length of the interpreter name to 32 characters. Often, this can be dealt with by using a symbolic link. You should not put more than one argument on the ‘#!’
line after the path to Finally, the value of |
1.1.5 Comments in awk Programs ¶
A comment is some text that is included in a program for the sake of human readers; it is not really an executable part of the program. Comments can explain what the program does and how it works. Nearly all programming languages have provisions for comments, as programs are typically hard to understand without them.
In the awk language, a comment starts with the number sign
character (‘#’) and continues to the end of the line.
The ‘#’ does not have to be the first character on the line. The
awk language ignores the rest of a line following a number sign.
For example, we could have put the following into advice:
# This program prints a nice, friendly message. It helps
# keep novice users from being afraid of the computer.
BEGIN { print "Don't Panic!" }
You can put comment lines into keyboard-composed throwaway awk
programs, but this usually isn’t very useful; the purpose of a
comment is to help you or another person understand the program
when reading it at a later time.
CAUTION: As mentioned in One-Shot Throwaway
awkPrograms, you can enclose short to medium-sized programs in single quotes, in order to keep your shell scripts self-contained. When doing so, don’t put an apostrophe (i.e., a single quote) into a comment (or anywhere else in your program). The shell interprets the quote as the closing quote for the entire program. As a result, usually the shell prints a message about mismatched quotes, and ifawkactually runs, it will probably print strange messages about syntax errors. For example, look at the following:$ awk 'BEGIN { print "hello" } # let's be cute' >The shell sees that the first two quotes match, and that a new quoted object begins at the end of the command line. It therefore prompts with the secondary prompt, waiting for more input. With Unix
awk, closing the quoted string produces this result:$ awk '{ print "hello" } # let's be cute' > ' error→ awk: can't open file be error→ source line number 1Putting a backslash before the single quote in ‘let's’ wouldn’t help, because backslashes are not special inside single quotes. The next subsection describes the shell’s quoting rules.
1.1.6 Shell Quoting Issues ¶
For short to medium-length awk programs, it is most convenient
to enter the program on the awk command line.
This is best done by enclosing the entire program in single quotes.
This is true whether you are entering the program interactively at
the shell prompt, or writing it as part of a larger shell script:
awk 'program text' input-file1 input-file2 ...
Once you are working with the shell, it is helpful to have a basic knowledge of shell quoting rules. The following rules apply only to POSIX-compliant, Bourne-style shells (such as Bash, the GNU Bourne-Again Shell). If you use the C shell, you’re on your own.
Before diving into the rules, we introduce a concept that appears throughout this Web page, which is that of the null, or empty, string.
The null string is character data that has no value.
In other words, it is empty. It is written in awk programs
like this: "". In the shell, it can be written using single
or double quotes: "" or ''. Although the null string has
no characters in it, it does exist. For example, consider this command:
$ echo ""
Here, the echo utility receives a single argument, even
though that argument has no characters in it. In the rest of this
Web page, we use the terms null string and empty string
interchangeably. Now, on to the quoting rules:
- Quoted items can be concatenated with nonquoted items as well as with other quoted items. The shell turns everything into one argument for the command.
- Preceding any single character with a backslash (‘\’) quotes that character. The shell removes the backslash and passes the quoted character on to the command.
-
Single quotes protect everything between the opening and closing quotes.
The shell does no interpretation of the quoted text, passing it on verbatim
to the command.
It is impossible to embed a single quote inside single-quoted text.
Refer back to
Comments in
awkPrograms for an example of what happens if you try. -
Double quotes protect most things between the opening and closing quotes.
The shell does at least variable and command substitution on the quoted text.
Different shells may do additional kinds of processing on double-quoted text.
Because certain characters within double-quoted text are processed by the shell, they must be escaped within the text. Of note are the characters ‘$’, ‘`’, ‘\’, and ‘"’, all of which must be preceded by a backslash within double-quoted text if they are to be passed on literally to the program. (The leading backslash is stripped first.) Thus, the example seen previously in Running
awkWithout Input Files:awk 'BEGIN { print "Don\47t Panic!" }'could instead be written this way:
$ awk "BEGIN { print \"Don't Panic!\" }" -| Don't Panic!Note that the single quote is not special within double quotes.
- Null strings are removed when they occur as part of a non-null
command-line argument, while explicit null objects are kept.
For example, to specify that the field separator
FSshould be set to the null string, use:awk -F "" 'program' files # correct
Don’t use this:
awk -F"" 'program' files # wrong!
In the second case,
awkattempts to use the text of the program as the value ofFS, and the first file name as the text of the program! This results in syntax errors at best, and confusing behavior at worst.
Mixing single and double quotes is difficult. You have to resort to shell quoting tricks, like this:
$ awk 'BEGIN { print "Here is a single quote <'"'"'>" }'
-| Here is a single quote <'>
This program consists of three concatenated quoted strings. The first and the third are single-quoted, and the second is double-quoted.
This can be “simplified” to:
$ awk 'BEGIN { print "Here is a single quote <'\''>" }'
-| Here is a single quote <'>
Judge for yourself which of these two is the more readable.
Another option is to use double quotes, escaping the embedded, awk-level
double quotes:
$ awk "BEGIN { print \"Here is a single quote <'>\" }"
-| Here is a single quote <'>
This option is also painful, because double quotes, backslashes, and dollar signs
are very common in more advanced awk programs.
A third option is to use the octal escape sequence equivalents (see Escape Sequences) for the single- and double-quote characters, like so:
$ awk 'BEGIN { print "Here is a single quote <\47>" }'
-| Here is a single quote <'>
$ awk 'BEGIN { print "Here is a double quote <\42>" }'
-| Here is a double quote <">
This works nicely, but you should comment clearly what the escape sequences mean.
A fourth option is to use command-line variable assignment, like this:
$ awk -v sq="'" 'BEGIN { print "Here is a single quote <" sq ">" }'
-| Here is a single quote <'>
(Here, the two string constants and the value of sq are concatenated
into a single string that is printed by print.)
If you really need both single and double quotes in your awk
program, it is probably best to move it into a separate file, where
the shell won’t be part of the picture and you can say what you mean.
1.1.6.1 Quoting in MS-Windows Batch Files ¶
Although this Web page generally only worries about POSIX systems and the POSIX shell, the following issue arises often enough for many users that it is worth addressing.
The “shells” on Microsoft Windows systems use the double-quote character for quoting, and make it difficult or impossible to include an escaped double-quote character in a command-line script. The following example, courtesy of Jeroen Brink, shows how to escape the double quotes from this one liner script that prints all lines in a file surrounded by double quotes:
{ print "\"" $0 "\"" }
In an MS-Windows command-line the one-liner script above may be passed as follows:
gawk "{ print \"\042\" $0 \"\042\" }" file
In this example the ‘\042’ is the octal code for a double-quote;
gawk converts it into a real double-quote for output by
the print statement.
In MS-Windows escaping double-quotes is a little tricky because you use backslashes to escape double-quotes, but backslashes themselves are not escaped in the usual way; indeed they are either duplicated or not, depending upon whether there is a subsequent double-quote. The MS-Windows rule for double-quoting a string is the following:
- For each double quote in the original string, let N be the number of backslash(es) before it, N might be zero. Replace these N backslash(es) by 2*N+1 backslash(es)
- Let N be the number of backslash(es) tailing the original string, N might be zero. Replace these N backslash(es) by 2*N backslash(es)
- Surround the resulting string by double-quotes.
So to double-quote the one-liner script ‘{ print "\"" $0 "\"" }’ from the previous example you would do it this way:
gawk "{ print \"\\\"\" $0 \"\\\"\" }" file
However, the use of ‘\042’ instead of ‘\\\"’ is also possible and easier to read, because backslashes that are not followed by a double-quote don’t need duplication.
1.2 Data files for the Examples ¶
Many of the examples in this Web page take their input from two sample data files. The first, mail-list, represents a list of peoples’ names together with their email addresses and information about those people. The second data file, called inventory-shipped, contains information about monthly shipments. In both files, each line is considered to be one record.
In mail-list, each record contains the name of a person, his/her phone number, his/her email address, and a code for his/her relationship with the author of the list. The columns are aligned using spaces. An ‘A’ in the last column means that the person is an acquaintance. An ‘F’ in the last column means that the person is a friend. An ‘R’ means that the person is a relative:
Amelia 555-5553 amelia.zodiacusque@gmail.com F Anthony 555-3412 anthony.asserturo@hotmail.com A Becky 555-7685 becky.algebrarum@gmail.com A Bill 555-1675 bill.drowning@hotmail.com A Broderick 555-0542 broderick.aliquotiens@yahoo.com R Camilla 555-2912 camilla.infusarum@skynet.be R Fabius 555-1234 fabius.undevicesimus@ucb.edu F Julie 555-6699 julie.perscrutabor@skeeve.com F Martin 555-6480 martin.codicibus@hotmail.com A Samuel 555-3430 samuel.lanceolis@shu.edu A Jean-Paul 555-2127 jeanpaul.campanorum@nyu.edu R
The data file inventory-shipped represents information about shipments during the year. Each record contains the month, the number of green crates shipped, the number of red boxes shipped, the number of orange bags shipped, and the number of blue packages shipped, respectively. There are 16 entries, covering the 12 months of last year and the first four months of the current year. An empty line separates the data for the two years:
Jan 13 25 15 115 Feb 15 32 24 226 Mar 15 24 34 228 Apr 31 52 63 420 May 16 34 29 208 Jun 31 42 75 492 Jul 24 34 67 436 Aug 15 34 47 316 Sep 13 55 37 277 Oct 29 54 68 525 Nov 20 87 82 577 Dec 17 35 61 401 Jan 21 36 64 620 Feb 26 58 80 652 Mar 24 75 70 495 Apr 21 70 74 514
The sample files are included in the gawk distribution,
in the directory awklib/eg/data.
1.3 Some Simple Examples ¶
The following command runs a simple awk program that searches the
input file mail-list for the character string ‘li’ (a
grouping of characters is usually called a string;
the term string is based on similar usage in English, such
as “a string of pearls” or “a string of cars in a train”):
awk '/li/ { print $0 }' mail-list
When lines containing ‘li’ are found, they are printed because ‘print $0’ means print the current line. (Just ‘print’ by itself means the same thing, so we could have written that instead.)
You will notice that slashes (‘/’) surround the string ‘li’
in the awk program. The slashes indicate that ‘li’
is the pattern to search for. This type of pattern is called a
regular expression, which is covered in more detail later
(see Regular Expressions).
The pattern is allowed to match parts of words.
There are
single quotes around the awk program so that the shell won’t
interpret any of it as special shell characters.
Here is what this program prints:
$ awk '/li/ { print $0 }' mail-list
-| Amelia 555-5553 amelia.zodiacusque@gmail.com F
-| Broderick 555-0542 broderick.aliquotiens@yahoo.com R
-| Julie 555-6699 julie.perscrutabor@skeeve.com F
-| Samuel 555-3430 samuel.lanceolis@shu.edu A
In an awk rule, either the pattern or the action can be omitted,
but not both. If the pattern is omitted, then the action is performed
for every input line. If the action is omitted, the default
action is to print all lines that match the pattern.
Thus, we could leave out the action (the print statement and the
braces) in the previous example and the result would be the same:
awk prints all lines matching the pattern ‘li’. By comparison,
omitting the print statement but retaining the braces makes an
empty action that does nothing (i.e., no lines are printed).
Many practical awk programs are just a line or two long. Following is a
collection of useful, short programs to get you started. Some of these
programs contain constructs that haven’t been covered yet. (The description
of the program will give you a good idea of what is going on, but you’ll
need to read the rest of the Web page to become an awk expert!)
Most of the examples use a data file named data. This is just a
placeholder; if you use these programs yourself, substitute
your own file names for data.
Some of the following examples use the output of ‘ls -l’ as input.
ls is a system command that gives you a listing of the files in a
directory. With the -l option, this listing includes each file’s
size and the date the file was last modified. Its output looks like this:
-rw-r--r-- 1 arnold user 1933 Nov 7 13:05 Makefile -rw-r--r-- 1 arnold user 10809 Nov 7 13:03 awk.h -rw-r--r-- 1 arnold user 983 Apr 13 12:14 awk.tab.h -rw-r--r-- 1 arnold user 31869 Jun 15 12:20 awkgram.y -rw-r--r-- 1 arnold user 22414 Nov 7 13:03 awk1.c -rw-r--r-- 1 arnold user 37455 Nov 7 13:03 awk2.c -rw-r--r-- 1 arnold user 27511 Dec 9 13:07 awk3.c -rw-r--r-- 1 arnold user 7989 Nov 7 13:03 awk4.c
The first field contains read-write permissions, the second field contains the number of links to the file, and the third field identifies the file’s owner. The fourth field identifies the file’s group. The fifth field contains the file’s size in bytes. The sixth, seventh, and eighth fields contain the month, day, and time, respectively, that the file was last modified. Finally, the ninth field contains the file name.
For future reference, note that there is often more than
one way to do things in awk. At some point, you may want
to look back at these examples and see if
you can come up with different ways to do the same things shown here:
- Print every line that is longer than 80 characters:
awk 'length($0) > 80' data
The sole rule has a relational expression as its pattern and has no action—so it uses the default action, printing the record.
- Print the length of the longest input line:
awk '{ if (length($0) > max) max = length($0) } END { print max }' dataThe code associated with
ENDexecutes after all input has been read; it’s the other side of the coin toBEGIN. -
Print the length of the longest line in data:
expand data | awk '{ if (x < length($0)) x = length($0) } END { print "maximum line length is " x }'This example differs slightly from the previous one: the input is processed by the
expandutility to change TABs into spaces, so the widths compared are actually the right-margin columns, as opposed to the number of input characters on each line. - Print every line that has at least one field:
awk 'NF > 0' data
This is an easy way to delete blank lines from a file (or rather, to create a new file similar to the old file but from which the blank lines have been removed).
- Print seven random numbers from 0 to 100, inclusive:
awk 'BEGIN { for (i = 1; i <= 7; i++) print int(101 * rand()) }' - Print the total number of bytes used by files:
ls -l files | awk '{ x += $5 } END { print "total bytes: " x }' - Print the total number of kilobytes used by files:
ls -l files | awk '{ x += $5 } END { print "total K-bytes:", x / 1024 }' - Print a sorted list of the login names of all users:
awk -F: '{ print $1 }' /etc/passwd | sort - Count the lines in a file:
awk 'END { print NR }' data - Print the even-numbered lines in the data file:
awk 'NR % 2 == 0' data
If you used the expression ‘NR % 2 == 1’ instead, the program would print the odd-numbered lines.
1.4 An Example with Two Rules ¶
The awk utility reads the input files one line at a
time. For each line, awk tries the patterns of each rule.
If several patterns match, then several actions execute in the order in
which they appear in the awk program. If no patterns match, then
no actions run.
After processing all the rules that match the line (and perhaps there are none),
awk reads the next line. (However,
see The next Statement
and also see The nextfile Statement.)
This continues until the program reaches the end of the file.
For example, the following awk program contains two rules:
/12/ { print $0 }
/21/ { print $0 }
The first rule has the string ‘12’ as the pattern and ‘print $0’ as the action. The second rule has the string ‘21’ as the pattern and also has ‘print $0’ as the action. Each rule’s action is enclosed in its own pair of braces.
This program prints every line that contains the string ‘12’ or the string ‘21’. If a line contains both strings, it is printed twice, once by each rule.
This is what happens if we run this program on our two sample data files, mail-list and inventory-shipped:
$ awk '/12/ { print $0 }
> /21/ { print $0 }' mail-list inventory-shipped
-| Anthony 555-3412 anthony.asserturo@hotmail.com A
-| Camilla 555-2912 camilla.infusarum@skynet.be R
-| Fabius 555-1234 fabius.undevicesimus@ucb.edu F
-| Jean-Paul 555-2127 jeanpaul.campanorum@nyu.edu R
-| Jean-Paul 555-2127 jeanpaul.campanorum@nyu.edu R
-| Jan 21 36 64 620
-| Apr 21 70 74 514
Note how the line beginning with ‘Jean-Paul’ in mail-list was printed twice, once for each rule.
1.5 A More Complex Example ¶
Now that we’ve mastered some simple tasks, let’s look at
what typical awk
programs do. This example shows how awk can be used to
summarize, select, and rearrange the output of another utility. It uses
features that haven’t been covered yet, so don’t worry if you don’t
understand all the details:
ls -l | awk '$6 == "Nov" { sum += $5 }
END { print sum }'
This command prints the total number of bytes in all the files in the current directory that were last modified in November (of any year).
As a reminder, the output of ‘ls -l’ gives you a listing of the files in a directory, including each file’s size and the date the file was last modified. The first field contains read-write permissions, the second field contains the number of links to the file, and the third field identifies the file’s owner. The fourth field identifies the file’s group. The fifth field contains the file’s size in bytes. The sixth, seventh, and eighth fields contain the month, day, and time, respectively, that the file was last modified. Finally, the ninth field contains the file name.
The ‘$6 == "Nov"’ in our awk program is an expression that
tests whether the sixth field of the output from ‘ls -l’
matches the string ‘Nov’. Each time a line has the string
‘Nov’ for its sixth field, awk performs the action
‘sum += $5’. This adds the fifth field (the file’s size) to the variable
sum. As a result, when awk has finished reading all the
input lines, sum is the total of the sizes of the files whose
lines matched the pattern. (This works because awk variables
are automatically initialized to zero.)
After the last line of output from ls has been processed, the
END rule executes and prints the value of sum.
In this example, the value of sum is 80600.
These more advanced awk techniques are covered in later
sections
(see Actions). Before you can move on to more
advanced awk programming, you have to know how awk interprets
your input and displays your output. By manipulating fields and using
print statements, you can produce some very useful and
impressive-looking reports.
1.6 awk Statements Versus Lines ¶
Most often, each line in an awk program is a separate statement or
separate rule, like this:
awk '/12/ { print $0 }
/21/ { print $0 }' mail-list inventory-shipped
However, gawk ignores newlines after any of the following
symbols and keywords:
, { ? : || && do else
A newline at any other point is considered the end of the statement.9
If you would like to split a single statement into two lines at a point where a newline would terminate it, you can continue it by ending the first line with a backslash character (‘\’). The backslash must be the final character on the line in order to be recognized as a continuation character. A backslash followed by a newline is allowed anywhere in the statement, even in the middle of a string or regular expression. For example:
awk '/This regular expression is too long, so continue it\
on the next line/ { print $1 }'
We have generally not used backslash continuation in our sample programs.
gawk places no limit on the
length of a line, so backslash continuation is never strictly necessary;
it just makes programs more readable. For this same reason, as well as
for clarity, we have kept most statements short in the programs
presented throughout the Web page.
Backslash continuation is
most useful when your awk program is in a separate source file
instead of entered from the command line. You should also note that
many awk implementations are more particular about where you
may use backslash continuation. For example, they may not allow you to
split a string constant using backslash continuation. Thus, for maximum
portability of your awk programs, it is best not to split your
lines in the middle of a regular expression or a string.
CAUTION: Backslash continuation does not work as described with the C shell. It works for
awkprograms in files and for one-shot programs, provided you are using a POSIX-compliant shell, such as the Unix Bourne shell or Bash. But the C shell behaves differently! There you must use two backslashes in a row, followed by a newline. Note also that when using the C shell, every newline in yourawkprogram must be escaped with a backslash. To illustrate:% awk 'BEGIN { \ ? print \\ ? "hello, world" \ ? }' -| hello, worldHere, the ‘%’ and ‘?’ are the C shell’s primary and secondary prompts, analogous to the standard shell’s ‘$’ and ‘>’.
Compare the previous example to how it is done with a POSIX-compliant shell:
$ awk 'BEGIN { > print \ > "hello, world" > }' -| hello, world
awk is a line-oriented language. Each rule’s action has to
begin on the same line as the pattern. To have the pattern and action
on separate lines, you must use backslash continuation; there
is no other option.
Another thing to keep in mind is that backslash continuation and
comments do not mix. As soon as awk sees the ‘#’ that
starts a comment, it ignores everything on the rest of the
line. For example:
$ gawk 'BEGIN { print "dont panic" # a friendly \
> BEGIN rule
> }'
error→ gawk: cmd. line:2: BEGIN rule
error→ gawk: cmd. line:2: ^ syntax error
In this case, it looks like the backslash would continue the comment onto the
next line. However, the backslash-newline combination is never even
noticed because it is “hidden” inside the comment. Thus, the
BEGIN is noted as a syntax error.
Backslash continuation comes into play in an additional, unexpected situation. Consider:
gawk -F'\ a' '...'
This command line assigns a value to FS. But what value?
There are several possibilities, and in fact different versions of
awk do different things. gawk treats this as
if it were written:
BEGIN { FS = "\
a"
}
...
In short, the backslash and newline are removed, assigning "a"
to FS. This same treatment applies to variable assignments
made with the -v option (see Command-Line Options)
and to regular command-line variable assignments (see Assigning Variables on the Command Line).
If you’re interested, see
https://lists.gnu.org/archive/html/bug-gawk/2022-10/msg00025.html
for a source code patch that allows lines to be continued when inside
parentheses. This patch was not added to gawk since it would
quietly decrease the portability of awk programs.
When awk statements within one rule are short, you might want to put
more than one of them on a line. This is accomplished by separating the statements
with a semicolon (‘;’).
This also applies to the rules themselves.
Thus, the program shown at the start of this section
could also be written this way:
/12/ { print $0 } ; /21/ { print $0 }
NOTE: The requirement that states that rules on the same line must be separated with a semicolon was not in the original
awklanguage; it was added for consistency with the treatment of statements within an action.
1.7 Other Features of awk ¶
The awk language provides a number of predefined, or
built-in, variables that your programs can use to get information
from awk. There are other variables your program can set
as well to control how awk processes your data.
In addition, awk provides a number of built-in functions for doing
common computational and string-related operations.
gawk provides built-in functions for working with timestamps,
performing bit manipulation, for runtime string translation (internationalization),
determining the type of a variable,
and array sorting.
As we develop our presentation of the awk language, we will introduce
most of the variables and many of the functions. They are described
systematically in Predefined Variables and in
Built-in Functions.
1.8 When to Use awk ¶
Now that you’ve seen some of what awk can do,
you might wonder how awk could be useful for you. By using
utility programs, advanced patterns, field separators, arithmetic
statements, and other selection criteria, you can produce much more
complex output. The awk language is very useful for producing
reports from large amounts of raw data, such as summarizing information
from the output of other utility programs like ls.
(See A More Complex Example.)
Programs written with awk are usually much smaller than they would
be in other languages. This makes awk programs easy to compose and
use. Often, awk programs can be quickly composed at your keyboard,
used once, and thrown away. Because awk programs are interpreted, you
can avoid the (usually lengthy) compilation part of the typical
edit-compile-test-debug cycle of software development.
Complex programs have been written in awk, including a complete
retargetable assembler for
eight-bit microprocessors (see Glossary, for more information),
and a microcode assembler for a special-purpose Prolog
computer.
The original awk’s capabilities were strained by tasks
of such complexity, but modern versions are more capable.
If you find yourself writing awk scripts of more than, say,
a few hundred lines, you might consider using a different programming
language. The shell is good at string and pattern matching; in addition,
it allows powerful use of the system utilities. Python offers a nice
balance between high-level ease of programming and access to system
facilities.10
1.9 Summary ¶
- Programs in
awkconsist of pattern–action pairs. - An action without a pattern always runs. The default action for a pattern without one is ‘{ print $0 }’.
- Use either
‘awk 'program' files’
or
‘awk -f program-file files’
to run
awk. - You may use the special ‘#!’ header line to create
awkprograms that are directly executable. - Comments in
awkprograms start with ‘#’ and continue to the end of the same line. - Be aware of quoting issues when writing
awkprograms as part of a larger shell script (or MS-Windows batch file). - You may use backslash continuation to continue a source line.
Lines are automatically continued after
a comma, open brace, question mark, colon,
‘||’, ‘&&’,
do, andelse.
2 Running awk and gawk ¶
This chapter covers how to run awk, both POSIX-standard
and gawk-specific command-line options, and what
awk and
gawk do with nonoption arguments.
It then proceeds to cover how gawk searches for source files,
reading standard input along with other files, gawk’s
environment variables, gawk’s exit status, using include files,
and obsolete and undocumented options and/or features.
Many of the options and features described here are discussed in more detail later in the Web page; feel free to skip over things in this chapter that don’t interest you right now.
- Invoking
awk - Command-Line Options
- Other Command-Line Arguments
- Naming Standard Input
- The Environment Variables
gawkUses gawk’s Exit Status- Including Other Files into Your Program
- Loading Dynamic Extensions into Your Program
- Obsolete Options and/or Features
- Undocumented Options and Features
- Summary
2.1 Invoking awk ¶
There are two ways to run awk—with an explicit program or with
one or more program files. Here are templates for both of them; items
enclosed in […] in these templates are optional:
awk[options] -f progfile [--] file ...awk[options] [--]'program'file ...
In addition to traditional one-letter POSIX-style options, gawk also
supports GNU long options.
It is possible to invoke awk with an empty program:
awk '' datafile1 datafile2
Doing so makes little sense, though; awk exits
silently when given an empty program.
(d.c.)
If --lint has
been specified on the command line, gawk issues a
warning that the program is empty.
2.2 Command-Line Options ¶
Options begin with a dash and consist of a single character. GNU-style long options consist of two dashes and a keyword. The keyword can be abbreviated, as long as the abbreviation allows the option to be uniquely identified. If the option takes an argument, either the keyword is immediately followed by an equals sign (‘=’) and the argument’s value, or the keyword and the argument’s value are separated by whitespace (spaces or TABs). If a particular option with a value is given more than once, it is (usually) the last value that counts.
Each long option for gawk has a corresponding
POSIX-style short option.
The long and short options are
interchangeable in all contexts.
The following list describes options mandated by the POSIX standard:
-
-F fs¶ --field-separator fsSet the
FSvariable to fs (see Specifying How Fields Are Separated).-
-f source-file¶ --file source-fileRead the
awkprogram source from source-file instead of in the first nonoption argument. This option may be given multiple times; theawkprogram consists of the concatenation of the contents of each specified source-file.Files named with -f are treated as if they had ‘@namespace "awk"’ at their beginning. See Changing The Namespace, for more information on this advanced feature.
-
-v var=val¶ --assign var=valSet the variable var to the value val before execution of the program begins. Such variable values are available inside the
BEGINrule (see Other Command-Line Arguments).The -v option can only set one variable, but it can be used more than once, setting another variable each time, like this: ‘awk -v foo=1 -v bar=2 …’.
CAUTION: Using -v to set the values of the built-in variables may lead to surprising results.
awkwill reset the values of those variables as it needs to, possibly ignoring any initial value you may have given.-W gawk-opt¶Provide an implementation-specific option. This is the POSIX convention for providing implementation-specific options. These options also have corresponding GNU-style long options. Note that the long options may be abbreviated, as long as the abbreviations remain unique. The full list of
gawk-specific options is provided next.--¶-
Signal the end of the command-line options. The following arguments are not treated as options even if they begin with ‘-’. This interpretation of -- follows the POSIX argument parsing conventions.
This is useful if you have file names that start with ‘-’, or in shell scripts, if you have file names that will be specified by the user that could start with ‘-’. It is also useful for passing options on to the
awkprogram; see Processing Command-Line Options.
The following list describes gawk-specific options:
- -b ¶
- --characters-as-bytes
Cause
gawkto treat all input data as single-byte characters. In addition, all output written withprintorprintfis treated as single-byte characters.Normally,
gawkfollows the POSIX standard and attempts to process its input data according to the current locale (see Where You Are Makes a Difference). This can often involve converting multibyte characters into wide characters (internally), and can lead to problems or confusion if the input data does not contain valid multibyte characters. This option is an easy way to tellgawk, “Hands off my data!”- -c ¶
- --traditional
Specify compatibility mode, in which the GNU extensions to the
awklanguage are disabled, so thatgawkbehaves just like BWKawk. See Extensions ingawkNot in POSIXawk, which summarizes the extensions. Also see Downward Compatibility and Debugging.- -C ¶
- --copyright
Print the short version of the General Public License and then exit.
- -d[file] ¶
- --dump-variables[
=file] -
Print a sorted list of global variables, their types, and final values to file. If no file is provided, print this list to a file named awkvars.out in the current directory. No space is allowed between the -d and file, if file is supplied.
Having a list of all global variables is a good way to look for typographical errors in your programs. You would also use this option if you have a large program with a lot of functions, and you want to be sure that your functions don’t inadvertently use global variables that you meant to be local. (This is a particularly easy mistake to make with simple variable names like
i,j, etc.) - -D[file] ¶
- --debug[
=file] Enable debugging of
awkprograms (see Introduction to thegawkDebugger). By default, the debugger reads commands interactively from the keyboard (standard input). The optional file argument allows you to specify a file with a list of commands for the debugger to execute noninteractively. No space is allowed between the -D and file, if file is supplied.- -e program-text ¶
- --source program-text
Provide program source code in the program-text. This option allows you to mix source code in files with source code that you enter on the command line. This is particularly useful when you have library functions that you want to use from your command-line programs (see The
AWKPATHEnvironment Variable).Note that
gawktreats each string as if it ended with a newline character (even if it doesn’t). This makes building the total program easier.CAUTION: Prior to version 5.0, there was no requirement that each program-text be a full syntactic unit. I.e., the following worked:
$ gawk -e 'BEGIN { a = 5 ;' -e 'print a }' -| 5However, this is no longer true. If you have any scripts that rely upon this feature, you should revise them.
This is because each program-text is treated as if it had ‘@namespace "awk"’ at its beginning. See Changing The Namespace, for more information.
- -E file ¶
- --exec file
-
Similar to -f, read
awkprogram text from file. There are two differences from -f:- This option terminates option processing; anything
else on the command line is passed on directly to the
awkprogram. - Command-line variable assignments of the form ‘var=value’ are disallowed.
This option is particularly necessary for World Wide Web CGI applications that pass arguments through the URL; using this option prevents a malicious (or other) user from passing in options, assignments, or
awksource code (via -e) to the CGI application.11 This option should be used with ‘#!’ scripts (see ExecutableawkPrograms), like so:#! /usr/local/bin/gawk -E awk program here ...
- This option terminates option processing; anything
else on the command line is passed on directly to the
- -g ¶
- --gen-pot
-
Analyze the source program and generate a GNU
gettextportable object template file on standard output for all string constants that have been marked for translation. See Internationalization withgawk, for information about this option. - -h ¶
- --help
-
Print a “usage” message summarizing the short- and long-style options that
gawkaccepts and then exit. - -i source-file ¶
- --include source-file
Read an
awksource library from source-file. This option is completely equivalent to using the@includedirective inside your program. It is very similar to the -f option, but there are two important differences. First, when -i is used, the program source is not loaded if it has been previously loaded, whereas with -f,gawkalways loads the file. Second, because this option is intended to be used with code libraries,gawkdoes not recognize such files as constituting main program input. Thus, after processing an -i argument,gawkstill expects to find the main source code via the -f option or on the command line.Files named with -i are treated as if they had ‘@namespace "awk"’ at their beginning. See Changing The Namespace, for more information.
- -I ¶
- --trace
Print the internal byte code names as they are executed when running the program. The trace is printed to standard error. Each “op code” is preceded by a
+sign in the output.- -k ¶
- --csv
-
Enable special processing for files with comma separated values (CSV). See Working With Comma Separated Value Files. This option cannot be used with --posix. Attempting to do causes a fatal error.
- -l ext ¶
- --load ext
Load a dynamic extension named ext. Extensions are stored as system shared libraries. This option searches for the library using the
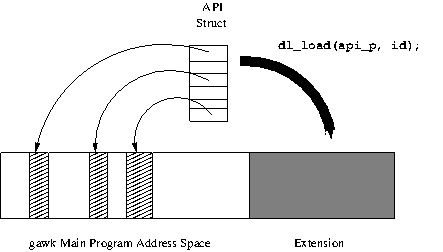
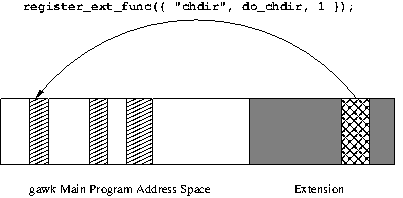
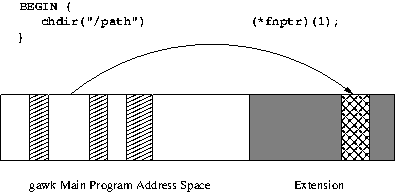
AWKLIBPATHenvironment variable. The correct library suffix for your platform will be supplied by default, so it need not be specified in the extension name. The extension initialization routine should be nameddl_load(). An alternative is to use the@loadkeyword inside the program to load a shared library. This advanced feature is described in detail in Writing Extensions forgawk.- -L[value] ¶
- --lint[
=value] -
Warn about constructs that are dubious or nonportable to other
awkimplementations. No space is allowed between the -L and value, if value is supplied. Some warnings are issued whengawkfirst reads your program. Others are issued at runtime, as your program executes. The optional argument may be one of the following:fatalCause lint warnings become fatal errors. This may be drastic, but its use will certainly encourage the development of cleaner
awkprograms.invalidOnly issue warnings about things that are actually invalid are issued. (This is not fully implemented yet.)
no-extDisable warnings about
gawkextensions.
Some warnings are only printed once, even if the dubious constructs they warn about occur multiple times in your
awkprogram. Thus, when eliminating problems pointed out by --lint, you should take care to search for all occurrences of each inappropriate construct. Asawkprograms are usually short, doing so is not burdensome. - -M ¶
- --bignum
Select arbitrary-precision arithmetic on numbers. This option has no effect if
gawkis not compiled to use the GNU MPFR and MP libraries (see Arithmetic and Arbitrary-Precision Arithmetic withgawk).As of version 5.2, the arbitrary precision arithmetic features in
gawkare “on parole.” The primary maintainer is no longer willing to support this feature, but another member of the development team has stepped up to take it over. As long as this situation remains stable, MPFR will be supported. If it changes, the MPFR support will be removed fromgawk.- -n ¶
- --non-decimal-data
Enable automatic interpretation of octal and hexadecimal values in input data (see Allowing Nondecimal Input Data).
CAUTION: This option can severely break old programs. Use with care. Also note that this option may disappear in a future version of
gawk.- -N ¶
- --use-lc-numeric
Force the use of the locale’s decimal point character when parsing numeric input data (see Where You Are Makes a Difference).
- -o[file] ¶
- --pretty-print[
=file] Enable pretty-printing of
awkprograms. Implies --no-optimize. By default, the output program is created in a file named awkprof.out (see Profiling YourawkPrograms). The optional file argument allows you to specify a different file name for the output. No space is allowed between the -o and file, if file is supplied.NOTE: In the past, this option would also execute your program. This is no longer the case.
- -O ¶
- --optimize
Enable
gawk’s default optimizations on the internal representation of the program. At the moment, this includes just simple constant folding.Optimization is enabled by default. This option remains primarily for backwards compatibility. However, it may be used to cancel the effect of an earlier -s option (see later in this list).
- -p[file] ¶
- --profile[
=file] Enable profiling of
awkprograms (see Profiling YourawkPrograms). Implies --no-optimize. By default, profiles are created in a file named awkprof.out. The optional file argument allows you to specify a different file name for the profile file. No space is allowed between the -p and file, if file is supplied.The profile contains execution counts for each statement in the program in the left margin, and function call counts for each function.
- -P ¶
- --posix
Operate in strict POSIX mode. This disables all
gawkextensions (just like --traditional) and disables all extensions not allowed by POSIX. See Common Extensions Summary for a summary of the extensions ingawkthat are disabled by this option. Also, the following additional restrictions apply:- Newlines are not allowed after ‘?’ or ‘:’ (see Conditional Expressions).
- Specifying ‘-Ft’ on the command line does not set the value
of
FSto be a single TAB character (see Specifying How Fields Are Separated). - The locale’s decimal point character is used for parsing input data (see Where You Are Makes a Difference).
If you supply both --traditional and --posix on the command line, --posix takes precedence.
gawkissues a warning if both options are supplied.- -r ¶
- --re-interval
Allow interval expressions (see Regular Expression Operators) in regexps. This is now
gawk’s default behavior. Nevertheless, this option remains for backward compatibility.- -s ¶
- --no-optimize
Disable
gawk’s default optimizations on the internal representation of the program.- -S ¶
- --sandbox
Disable the
system()function, input redirections withgetline, output redirections withprintandprintf, and dynamic extensions. Also, disallow adding file names toARGVthat were not there whengawkstarted running. This is particularly useful when you want to runawkscripts from questionable sources and need to make sure the scripts can’t access your system (other than the specified input data files).- -t ¶
- --lint-old
Warn about constructs that are not available in the original version of
awkfrom Version 7 Unix (see Major Changes Between V7 and SVR3.1).- -V ¶
- --version
Print version information for this particular copy of
gawk. This allows you to determine if your copy ofgawkis up to date with respect to whatever the Free Software Foundation is currently distributing. It is also useful for bug reports (see Reporting Problems and Bugs).--Mark the end of all options. Any command-line arguments following
--are placed inARGV, even if they start with a minus sign.
In compatibility mode, as long as program text has been supplied, any other options are flagged as invalid with a warning message but are otherwise ignored.
In compatibility mode, as a special case, if the value of fs supplied
to the -F option is ‘t’, then FS is set to the TAB
character ("\t"). This is true only for --traditional and not
for --posix
(see Specifying How Fields Are Separated).
The -f option may be used more than once on the command line.
If it is, awk reads its program source from all of the named files, as
if they had been concatenated together into one big file. This is
useful for creating libraries of awk functions. These functions
can be written once and then retrieved from a standard place, instead
of having to be included in each individual program.
The -i option is similar in this regard.
(As mentioned in
Function Definition Syntax,
function names must be unique.)
With standard awk, library functions can still be used, even
if the program is entered at the keyboard,
by specifying ‘-f /dev/tty’. After typing your program,
type Ctrl-d (the end-of-file character) to terminate it.
(You may also use ‘-f -’ to read program source from the standard
input, but then you will not be able to also use the standard input as a
source of data.)
Because it is clumsy using the standard awk mechanisms to mix
source file and command-line awk programs, gawk
provides the -e option. This does not require you to
preempt the standard input for your source code, and it allows you to easily
mix command-line and library source code (see The AWKPATH Environment Variable).
As with -f, the -e and -i
options may also be used multiple times on the command line.
If no -f option (or -e option for gawk)
is specified, then awk uses the first nonoption command-line
argument as the text of the program source code. Arguments on
the command line that follow the program text are entered into the
ARGV array; awk does not continue to parse the
command line looking for options.
If the environment variable POSIXLY_CORRECT exists,
then gawk behaves in strict POSIX mode, exactly as if
you had supplied --posix.
Many GNU programs look for this environment variable to suppress
extensions that conflict with POSIX, but gawk behaves
differently: it suppresses all extensions, even those that do not
conflict with POSIX, and behaves in
strict POSIX mode. If --lint is supplied on the command line
and gawk turns on POSIX mode because of POSIXLY_CORRECT,
then it issues a warning message indicating that POSIX
mode is in effect.
You would typically set this variable in your shell’s startup file.
For a Bourne-compatible shell (such as Bash), you would add these
lines to the .profile file in your home directory:
POSIXLY_CORRECT=true export POSIXLY_CORRECT
For a C shell-compatible shell,12 you would add this line to the .login file in your home directory:
setenv POSIXLY_CORRECT true
Having POSIXLY_CORRECT set is not recommended for daily use,
but it is good for testing the portability of your programs to other
environments.
2.3 Other Command-Line Arguments ¶
Any additional arguments on the command line are normally treated as
input files to be processed in the order specified. However, an
argument that has the form var=value, assigns
the value value to the variable var—it does not specify a
file at all. (See Assigning Variables on the Command Line.) In the following example,
‘count=1’ is a variable assignment, not a file name:
awk -f program.awk file1 count=1 file2
As a side point, should you really need to have awk
process a file named count=1 (or any file whose name looks like
a variable assignment), precede the file name with ‘./’, like so:
awk -f program.awk file1 ./count=1 file2
All the command-line arguments are made available to your awk program in the
ARGV array (see Predefined Variables). Command-line options
and the program text (if present) are omitted from ARGV.
All other arguments, including variable assignments, are
included. As each element of ARGV is processed, gawk
sets ARGIND to the index in ARGV of the
current element. (gawk makes the full command line,
including program text and options, available in PROCINFO["argv"];
see Built-in Variables That Convey Information.)
Changing ARGC and ARGV in your awk program lets
you control how awk processes the input files; this is described
in more detail in Using ARGC and ARGV.
The distinction between file name arguments and variable-assignment
arguments is made when awk is about to open the next input file.
At that point in execution, it checks the file name to see whether
it is really a variable assignment; if so, awk sets the variable
instead of reading a file.
Therefore, the variables actually receive the given values after all
previously specified files have been read. In particular, the values of
variables assigned in this fashion are not available inside a
BEGIN rule
(see The BEGIN and END Special Patterns),
because such rules are run before awk begins scanning the argument list.
The variable values given on the command line are processed for escape sequences (see Escape Sequences). (d.c.)
In some very early implementations of awk, when a variable assignment
occurred before any file names, the assignment would happen before
the BEGIN rule was executed. awk’s behavior was thus
inconsistent; some command-line assignments were available inside the
BEGIN rule, while others were not. Unfortunately,
some applications came to depend
upon this “feature.” When awk was changed to be more consistent,
the -v option was added to accommodate applications that depended
upon the old behavior.
The variable assignment feature is most useful for assigning to variables
such as RS, OFS, and ORS, which control input and
output formats, before scanning the data files. It is also useful for
controlling state if multiple passes are needed over a data file. For
example:
awk 'pass == 1 { pass 1 stuff }
pass == 2 { pass 2 stuff }' pass=1 mydata pass=2 mydata
Given the variable assignment feature, the -F option for setting
the value of FS is not
strictly necessary. It remains for historical compatibility.
2.4 Naming Standard Input ¶
Often, you may wish to read standard input together with other files. For example, you may wish to read one file, read standard input coming from a pipe, and then read another file.
The way to name the standard input, with all versions of awk,
is to use a single, standalone minus sign or dash, ‘-’. For example:
some_command | awk -f myprog.awk file1 - file2
Here, awk first reads file1, then it reads
the output of some_command, and finally it reads
file2.
You may also use "-" to name standard input when reading
files with getline (see Using getline from a File).
And, you can even use "-" with the -f option
to read program source code from standard input (see Command-Line Options).
In addition, gawk allows you to specify the special
file name /dev/stdin, both on the command line and
with getline.
Some other versions of awk also support this, but it
is not standard.
(Some operating systems provide a /dev/stdin file
in the filesystem; however, gawk always processes
this file name itself.)
2.5 The Environment Variables gawk Uses ¶
A number of environment variables influence how gawk
behaves.
2.5.1 The AWKPATH Environment Variable ¶
In most awk
implementations, you must supply a precise pathname for each program
file, unless the file is in the current directory.
But with gawk, if the file name supplied to the -f
or -i options
does not contain a directory separator ‘/’, then gawk searches a list of
directories (called the search path) one by one, looking for a
file with the specified name.
The search path is a string consisting of directory names
separated by colons.13
gawk gets its search path from the
AWKPATH environment variable. If that variable does not exist,
or if it has an empty value,
gawk uses a default path (described shortly).
The search path feature is particularly helpful for building libraries
of useful awk functions. The library files can be placed in a
standard directory in the default path and then specified on
the command line with a short file name. Otherwise, you would have to
type the full file name for each file.
By using the -i or -f options, your command-line
awk programs can use facilities in awk library files
(see A Library of awk Functions).
Path searching is not done if gawk is in compatibility mode.
This is true for both --traditional and --posix.
See Command-Line Options.
If the source code file is not found after the initial search, the path is searched again after adding the suffix ‘.awk’ to the file name.
gawk’s path search mechanism is similar
to the shell’s.
(See The Bourne-Again SHell manual.)
It treats a null entry in the path as indicating the current
directory.
(A null entry is indicated by starting or ending the path with a
colon or by placing two colons next to each other [‘::’].)
NOTE: To include the current directory in the path, either place . as an entry in the path or write a null entry in the path.
Different past versions of
gawkwould also look explicitly in the current directory, either before or after the path search. As of version 4.1.2, this no longer happens; if you wish to look in the current directory, you must include . either as a separate entry or as a null entry in the search path.
The default value for AWKPATH is
‘.:/usr/local/share/awk’.14 Since . is included at the beginning, gawk
searches first in the current directory and then in /usr/local/share/awk.
In practice, this means that you will rarely need to change the
value of AWKPATH.
See Shell Startup Files, for information on functions that help to
manipulate the AWKPATH variable.
gawk places the value of the search path that it used into
ENVIRON["AWKPATH"]. This provides access to the actual search
path value from within an awk program.
Although you can change ENVIRON["AWKPATH"] within your awk
program, this has no effect on the running program’s behavior. This makes
sense: the AWKPATH environment variable is used to find the program
source files. Once your program is running, all the files have been
found, and gawk no longer needs to use AWKPATH.
2.5.2 The AWKLIBPATH Environment Variable ¶
The AWKLIBPATH environment variable is similar to the AWKPATH
variable, but it is used to search for loadable extensions (stored as
system shared libraries) specified with the -l option rather
than for source files. If the extension is not found, the path is
searched again after adding the appropriate shared library suffix for
the platform. For example, on GNU/Linux systems, the suffix ‘.so’
is used. The search path specified is also used for extensions loaded
via the @load keyword (see Loading Dynamic Extensions into Your Program).
If AWKLIBPATH does not exist in the environment, or if it has
an empty value, gawk uses a default path; this
is typically ‘/usr/local/lib/gawk’, although it can vary depending
upon how gawk was built.15
See Shell Startup Files, for information on functions that help to
manipulate the AWKLIBPATH variable.
gawk places the value of the search path that it used into
ENVIRON["AWKLIBPATH"]. This provides access to the actual search
path value from within an awk program.
Although you can change ENVIRON["AWKLIBPATH"] within your
awk program, this has no effect on the running program’s
behavior. This makes sense: the AWKLIBPATH environment variable
is used to find any requested extensions, and they are loaded before
the program starts to run. Once your program is running, all the
extensions have been found, and gawk no longer needs to use
AWKLIBPATH.
2.5.3 Other Environment Variables ¶
A number of other environment variables affect gawk’s
behavior, but they are more specialized. Those in the following
list are meant to be used by regular users:
GAWK_MSEC_SLEEPSpecifies the interval between connection retries, in milliseconds. On systems that do not support the
usleep()system call, the value is rounded up to an integral number of seconds.GAWK_PERSIST_FILESpecifies the backing file to use for persistent storage of
gawk’s variables and arrays. See Preserving Data Between Runs.GAWK_READ_TIMEOUTSpecifies the time, in milliseconds, for
gawkto wait for input before returning with an error. See Reading Input with a Timeout.GAWK_SOCK_RETRIESControls the number of times
gawkattempts to retry a two-way TCP/IP (socket) connection before giving up. See Usinggawkfor Network Programming. Note that when nonfatal I/O is enabled (see Enabling Nonfatal Output),gawkonly tries to open a TCP/IP socket once.PMA_VERBOSITYControls the verbosity of the persistent memory allocator. See Preserving Data Between Runs.
POSIXLY_CORRECTCauses
gawkto switch to POSIX-compatibility mode, disabling all traditional and GNU extensions. See Command-Line Options.
The environment variables in the following list are meant
for use by the gawk developers for testing and tuning.
They are subject to change. The variables are:
AWKBUFSIZEThis variable only affects
gawkon POSIX-compliant systems. With a value of ‘exact’,gawkuses the size of each input file as the size of the memory buffer to allocate for I/O. Otherwise, the value should be a number, andgawkuses that number as the size of the buffer to allocate. (When this variable is not set,gawkuses the smaller of the file’s size and the “default” blocksize, which is usually the filesystem’s I/O blocksize.)AWK_HASHIf this variable exists with a value of ‘gst’,
gawkswitches to using the hash function from GNU Smalltalk for managing arrays. With a value of ‘fnv1a’,gawkuses the FNV1-A hash function. These functions may be marginally faster than the standard function.AWKREADFUNCIf this variable exists,
gawkswitches to reading source files one line at a time, instead of reading in blocks. This exists for debugging problems on filesystems on non-POSIX operating systems where I/O is performed in records, not in blocks.GAWK_MSG_SRCIf this variable exists,
gawkincludes the file name and line number within thegawksource code from which warning and/or fatal messages are generated. Its purpose is to help isolate the source of a message, as there are multiple places that produce the same warning or error message.GAWK_LOCALE_DIRSpecifies the location of compiled message object files for
gawkitself. This is passed to thebindtextdomain()function whengawkstarts up.GAWK_NO_DFAIf this variable exists,
gawkdoes not use the DFA regexp matcher for “does it match” kinds of tests. This can causegawkto be slower. Its purpose is to help isolate differences between the two regexp matchers thatgawkuses internally. (There aren’t supposed to be differences, but occasionally theory and practice don’t coordinate with each other.)GAWK_STACKSIZEThis specifies the amount by which
gawkshould grow its internal evaluation stack, when needed.INT_CHAIN_MAXThis specifies intended maximum number of items
gawkwill maintain on a hash chain for managing arrays indexed by integers.STR_CHAIN_MAXThis specifies intended maximum number of items
gawkwill maintain on a hash chain for managing arrays indexed by strings.TIDYMEMIf this variable exists,
gawkuses themtrace()library calls from the GNU C library to help track down possible memory leaks. This cannot be used together with the persistent memory allocator.
2.6 gawk’s Exit Status ¶
If the exit statement is used with a value
(see The exit Statement), then gawk exits with
the numeric value given to it.
Otherwise, if there were no problems during execution,
gawk exits with the value of the C constant
EXIT_SUCCESS. This is usually zero.
If an error occurs, gawk exits with the value of
the C constant EXIT_FAILURE. This is usually one.
If gawk exits because of a fatal error, the exit
status is two. On non-POSIX systems, this value may be mapped
to EXIT_FAILURE.
2.7 Including Other Files into Your Program ¶
This section describes a feature that is specific to gawk.
The @include keyword can be used to read external awk source
files. This gives you the ability to split large awk source files
into smaller, more manageable pieces, and also lets you reuse common awk
code from various awk scripts. In other words, you can group
together awk functions used to carry out specific tasks
into external files. These files can be used just like function libraries,
using the @include keyword in conjunction with the AWKPATH
environment variable. Note that source files may also be included
using the -i option.
Let’s see an example.
We’ll start with two (trivial) awk scripts, namely
test1 and test2. Here is the test1 script:
BEGIN {
print "This is script test1."
}
and here is test2:
@include "test1"
BEGIN {
print "This is script test2."
}
Running gawk with test2
produces the following result:
$ gawk -f test2 -| This is script test1. -| This is script test2.
gawk runs the test2 script, which includes test1
using the @include
keyword. So, to include external awk source files, you just
use @include followed by the name of the file to be included,
enclosed in double quotes.
NOTE: Keep in mind that this is a language construct and the file name cannot be a string variable, but rather just a literal string constant in double quotes.
The files to be included may be nested; e.g., given a third script, namely test3:
@include "test2"
BEGIN {
print "This is script test3."
}
Running gawk with the test3 script produces the
following results:
$ gawk -f test3 -| This is script test1. -| This is script test2. -| This is script test3.
The file name can, of course, be a pathname. For example:
@include "../io_funcs"
and:
@include "/usr/awklib/network"
are both valid. The AWKPATH environment variable can be of great
value when using @include. The same rules for the use
of the AWKPATH variable in command-line file searches
(see The AWKPATH Environment Variable) apply to
@include also.
This is very helpful in constructing gawk function libraries.
If you have a large script with useful, general-purpose awk
functions, you can break it down into library files and put those files
in a special directory. You can then include those “libraries,”
either by using the full pathnames of the files, or by setting the AWKPATH
environment variable accordingly and then using @include with
just the file part of the full pathname. Of course,
you can keep library files in more than one directory;
the more complex the working
environment is, the more directories you may need to organize the files
to be included.
Given the ability to specify multiple -f options, the
@include mechanism is not strictly necessary.
However, the @include keyword
can help you in constructing self-contained gawk programs,
thus reducing the need for writing complex and tedious command lines.
In particular, @include is very useful for writing CGI scripts
to be run from web pages.
The @include directive and the -i/--include
command line option are completely equivalent. An included program
source is not loaded if it has been previously loaded.
The rules for finding a source file described in The AWKPATH Environment Variable also
apply to files loaded with @include.
Finally, files included with @include
are treated as if they had ‘@namespace "awk"’
at their beginning. See Changing The Namespace, for more information.
2.9 Obsolete Options and/or Features ¶
This section describes features and/or command-line options from
previous releases of gawk that either are not available in the
current version or are still supported but deprecated (meaning that
they will not be in a future release).
As of
gawk version 5.2.
the arbitrary precision arithmetic feature is “on parole.”
This feature is now being
supported by a volunteer in the development team and not by the primary
maintainer. If this situation changes, then the feature will be removed.
For more information see Arbitrary Precision Arithmetic is On Parole!.
2.10 Undocumented Options and Features ¶
Use the Source, Luke!
This section intentionally left blank.
2.11 Summary ¶
gawkparses arguments on the command line, left to right, to determine if they should be treated as options or as non-option arguments.gawkrecognizes several options which control its operation, as described in Command-Line Options. All options begin with ‘-’.- Any argument that is not recognized as an option is treated as a
non-option argument, even if it begins with ‘-’.
- However, when an option itself requires an argument, and the option is separated from that argument on the command line by at least one space, the space is ignored, and the argument is considered to be related to the option. Thus, in the invocation, ‘gawk -F x’, the ‘x’ is treated as belonging to the -F option, not as a separate non-option argument.
- Once
gawkfinds a non-option argument, it stops looking for options. Therefore, all following arguments are also non-option arguments, even if they resemble recognized options. - If no -e or -f options are present,
gawkexpects the program text to be in the first non-option argument. - All non-option arguments, except program text provided in the first
non-option argument, are placed in
ARGVas explained in UsingARGCandARGV, and are processed as described in Other Command-Line Arguments. AdjustingARGCandARGVaffects howawkprocesses input. - The three standard options for all versions of
awkare -f, -F, and -v.gawksupplies these and many others, as well as corresponding GNU-style long options. - Nonoption command-line arguments are usually treated as file names, unless they have the form ‘var=value’, in which case they are taken as variable assignments to be performed at that point in processing the input.
- You can use a single minus sign (‘-’) to refer to standard input
on the command line.
gawkalso lets you use the special file name /dev/stdin. -
gawkpays attention to a number of environment variables.AWKPATH,AWKLIBPATH, andPOSIXLY_CORRECTare the most important ones. gawk’s exit status conveys information to the program that invoked it. Use theexitstatement from within anawkprogram to set the exit status.gawkallows you to include otherawksource files into your program using the@includestatement and/or the -i and -f command-line options.gawkallows you to load additional functions written in C or C++ using the@loadstatement and/or the -l option. (This advanced feature is described later, in Writing Extensions forgawk.)
3 Regular Expressions ¶
A regular expression, or regexp, is a way of describing a
set of strings.
Because regular expressions are such a fundamental part of awk
programming, their format and use deserve a separate chapter.
A regular expression enclosed in slashes (‘/’)
is an awk pattern that matches every input record whose text
belongs to that set.
The simplest regular expression is a sequence of letters, numbers, or
both. Such a regexp matches any string that contains that sequence.
Thus, the regexp ‘foo’ matches any string containing ‘foo’.
Thus, the pattern /foo/ matches any input record containing
the three adjacent characters ‘foo’ anywhere in the record. Other
kinds of regexps let you specify more complicated classes of strings.
Initially, the examples in this chapter are simple. As we explain more about how regular expressions work, we present more complicated instances.
- How to Use Regular Expressions
- Escape Sequences
- Regular Expression Operators
- Using Bracket Expressions
- How Much Text Matches?
- Using Dynamic Regexps
gawk-Specific Regexp Operators- Case Sensitivity in Matching
- Summary
3.1 How to Use Regular Expressions ¶
A regular expression can be used as a pattern by enclosing it in slashes. Then the regular expression is tested against the entire text of each record. (Normally, it only needs to match some part of the text in order to succeed.) For example, the following prints the second field of each record where the string ‘li’ appears anywhere in the record:
$ awk '/li/ { print $2 }' mail-list
-| 555-5553
-| 555-0542
-| 555-6699
-| 555-3430
Regular expressions can also be used in matching expressions. These
expressions allow you to specify the string to match against; it need
not be the entire current input record. The two operators ‘~’
and ‘!~’ perform regular expression comparisons. Expressions
using these operators can be used as patterns, or in if,
while, for, and do statements.
(See Control Statements in Actions.)
For example, the following is true if the expression exp (taken
as a string) matches regexp:
exp ~ /regexp/
This example matches, or selects, all input records with the uppercase letter ‘J’ somewhere in the first field:
$ awk '$1 ~ /J/' inventory-shipped -| Jan 13 25 15 115 -| Jun 31 42 75 492 -| Jul 24 34 67 436 -| Jan 21 36 64 620
So does this:
awk '{ if ($1 ~ /J/) print }' inventory-shipped
This next example is true if the expression exp (taken as a character string) does not match regexp:
exp !~ /regexp/
The following example matches, or selects, all input records whose first field does not contain the uppercase letter ‘J’:
$ awk '$1 !~ /J/' inventory-shipped -| Feb 15 32 24 226 -| Mar 15 24 34 228 -| Apr 31 52 63 420 -| May 16 34 29 208 ...
When a regexp is enclosed in slashes, such as /foo/, we call it
a regexp constant, much like 5.27 is a numeric constant and
"foo" is a string constant.
3.2 Escape Sequences ¶
Some characters cannot be included literally in string constants
("foo") or regexp constants (/foo/).
Instead, they should be represented with escape sequences,
which are character sequences beginning with a backslash (‘\’).
One use of an escape sequence is to include a double-quote character in
a string constant. Because a plain double quote ends the string, you
must use ‘\"’ to represent an actual double-quote character as a
part of the string. For example:
$ awk 'BEGIN { print "He said \"hi!\" to her." }'
-| He said "hi!" to her.
The backslash character itself is another character that cannot be
included normally; you must write ‘\\’ to put one backslash in the
string or regexp. Thus, the string whose contents are the two characters
‘"’ and ‘\’ must be written "\"\\".
Other escape sequences represent unprintable characters such as TAB or newline. There is nothing to stop you from entering most unprintable characters directly in a string constant or regexp constant, but they may look ugly.
The following list presents
all the escape sequences used in awk and
what they represent. Unless noted otherwise, all these escape
sequences apply to both string constants and regexp constants:
\\A literal backslash, ‘\’.
\aThe “alert” character, Ctrl-g, ASCII code 7 (BEL). (This often makes some sort of audible noise.)
\bBackspace, Ctrl-h, ASCII code 8 (BS).
\fFormfeed, Ctrl-l, ASCII code 12 (FF).
\nNewline, Ctrl-j, ASCII code 10 (LF).
\rCarriage return, Ctrl-m, ASCII code 13 (CR).
\tHorizontal TAB, Ctrl-i, ASCII code 9 (HT).
\vVertical TAB, Ctrl-k, ASCII code 11 (VT).
\nnnThe octal value nnn, where nnn stands for 1 to 3 digits between ‘0’ and ‘7’. For example, the code for the ASCII ESC (escape) character is ‘\033’.
\xhh…The hexadecimal value hh, where hh stands for a sequence of hexadecimal digits (‘0’–‘9’, and either ‘A’–‘F’ or ‘a’–‘f’). A maximum of two digits are allowed after the ‘\x’. Any further hexadecimal digits are treated as simple letters or numbers. (c.e.) (The ‘\x’ escape sequence is not allowed in POSIX awk.)
CAUTION: In ISO C, the escape sequence continues until the first nonhexadecimal digit is seen. For many years,
gawkwould continue incorporating hexadecimal digits into the value until a non-hexadecimal digit or the end of the string was encountered. However, using more than two hexadecimal digits produced undefined results. As of version 4.2, only two digits are processed.\uhh…The hexadecimal value hh, where hh stands for a sequence of one or more hexadecimal digits (‘0’–‘9’, and either ‘A’–‘F’ or ‘a’–‘f’). A maximum of eight digits are allowed after the ‘\u’. Any further hexadecimal digits are treated as simple letters or numbers. (c.e.) (The ‘\u’ escape sequence is not allowed in POSIX awk.)
This escape sequence is intended for designating a character in the current locale’s character set.16
gawkfirst converts the given digits into an integer and then translates the given “wide character” value into the current locale’s multibyte encoding. If the wide character value does not represent a valid character, or if the character is valid but cannot be encoded into the current locale’s multibyte encoding, the value becomes"?".gawkissues a warning message when this happens.\/A literal slash (should be used for regexp constants only). This sequence is used when you want to write a regexp constant that contains a slash (such as
/.*:\/home\/[[:alnum:]]+:.*/; the ‘[[:alnum:]]’ notation is discussed in Using Bracket Expressions). Because the regexp is delimited by slashes, you need to escape any slash that is part of the pattern, in order to tellawkto keep processing the rest of the regexp.\"A literal double quote (should be used for string constants only). This sequence is used when you want to write a string constant that contains a double quote (such as
"He said \"hi!\" to her."). Because the string is delimited by double quotes, you need to escape any quote that is part of the string, in order to tellawkto keep processing the rest of the string.
In gawk, a number of additional two-character sequences that begin
with a backslash have special meaning in regexps.
See gawk-Specific Regexp Operators.
In a regexp, a backslash before any character that is not in the previous list
and not listed in
gawk-Specific Regexp Operators
means that the next character should be taken literally, even if it would
normally be a regexp operator. For example, /a\+b/ matches the three
characters ‘a+b’.
For complete portability, do not use a backslash before any character not shown in the previous list or that is not an operator.
| Backslash Before Regular Characters |
|---|
|
If you place a backslash in a string constant before something that is
not one of the characters previously listed, POSIX
|
To summarize:
- The escape sequences in the preceding list are always processed first,
for both string constants and regexp constants. This happens very early,
as soon as
awkreads your program. gawkprocesses both regexp constants and dynamic regexps (see Using Dynamic Regexps), for the special operators listed ingawk-Specific Regexp Operators.- A backslash before any other character means to treat that character literally.
| Escape Sequences for Metacharacters |
|---|
|
Suppose you use an octal or hexadecimal
escape to represent a regexp metacharacter.
(See Regular Expression Operators.)
Does Historically, such characters were taken literally.
(d.c.)
However, the POSIX standard indicates that they should be treated
as real metacharacters, which is what |
3.3 Regular Expression Operators ¶
You can combine regular expressions with special characters, called regular expression operators or metacharacters, to increase the power and versatility of regular expressions.
3.3.1 Regexp Operators in awk ¶
The escape sequences described earlier in Escape Sequences are valid inside a regexp. They are introduced by a ‘\’ and are recognized and converted into corresponding real characters as the very first step in processing regexps.
Here is a list of metacharacters. All characters that are not escape sequences and that are not listed here stand for themselves:
\This suppresses the special meaning of a character when matching. For example, ‘\$’ matches the character ‘$’.
^This matches the beginning of a string. ‘^@chapter’ matches ‘@chapter’ at the beginning of a string, for example, and can be used to identify chapter beginnings in Texinfo source files. The ‘^’ is known as an anchor, because it anchors the pattern to match only at the beginning of the string.
It is important to realize that ‘^’ does not match the beginning of a line (the point right after a ‘\n’ newline character) embedded in a string. The condition is not true in the following example:
if ("line1\nLINE 2" ~ /^L/) ...$This is similar to ‘^’, but it matches only at the end of a string. For example, ‘p$’ matches a record that ends with a ‘p’. The ‘$’ is an anchor and does not match the end of a line (the point right before a ‘\n’ newline character) embedded in a string. The condition in the following example is not true:
if ("line1\nLINE 2" ~ /1$/) ...-
.(period) ¶ This matches any single character, including the newline character. For example, ‘.P’ matches any single character followed by a ‘P’ in a string. Using concatenation, we can make a regular expression such as ‘U.A’, which matches any three-character sequence that begins with ‘U’ and ends with ‘A’.
In strict POSIX mode (see Command-Line Options), ‘.’ does not match the NUL character, which is a character with all bits equal to zero. Otherwise, NUL is just another character. Other versions of
awkmay not be able to match the NUL character.-
[…]¶ This is called a bracket expression.17 It matches any one of the characters that are enclosed in the square brackets. For example, ‘[MVX]’ matches any one of the characters ‘M’, ‘V’, or ‘X’ in a string. A full discussion of what can be inside the square brackets of a bracket expression is given in Using Bracket Expressions.
[^…]This is a complemented bracket expression. The first character after the ‘[’ must be a ‘^’. It matches any characters except those in the square brackets. For example, ‘[^awk]’ matches any character that is not an ‘a’, ‘w’, or ‘k’.
-
|¶ This is the alternation operator and it is used to specify alternatives. The ‘|’ has the lowest precedence of all the regular expression operators. For example, ‘^P|[aeiouy]’ matches any string that matches either ‘^P’ or ‘[aeiouy]’. This means it matches any string that starts with ‘P’ or contains (anywhere within it) a lowercase English vowel.
The alternation applies to the largest possible regexps on either side.
(…)Parentheses are used for grouping in regular expressions, as in arithmetic. They can be used to concatenate regular expressions containing the alternation operator, ‘|’. For example, ‘@(samp|code)\{[^}]+\}’ matches both ‘@code{foo}’ and ‘@samp{bar}’. (These are Texinfo formatting control sequences. The ‘+’ is explained further on in this list.)
The left or opening parenthesis is always a metacharacter; to match one literally, precede it with a backslash. However, the right or closing parenthesis is only special when paired with a left parenthesis; an unpaired right parenthesis is (silently) treated as a regular character.
*This symbol means that the preceding regular expression should be repeated as many times as necessary to find a match. For example, ‘ph*’ applies the ‘*’ symbol to the preceding ‘h’ and looks for matches of one ‘p’ followed by any number of ‘h’s. This also matches just ‘p’ if no ‘h’s are present.
There are two subtle points to understand about how ‘*’ works. First, the ‘*’ applies only to the single preceding regular expression component (e.g., in ‘ph*’, it applies just to the ‘h’). To cause ‘*’ to apply to a larger subexpression, use parentheses: ‘(ph)*’ matches ‘ph’, ‘phph’, ‘phphph’, and so on.
Second, ‘*’ finds as many repetitions as possible. If the text to be matched is ‘phhhhhhhhhhhhhhooey’, ‘ph*’ matches all of the ‘h’s.
+This symbol is similar to ‘*’, except that the preceding expression must be matched at least once. This means that ‘wh+y’ would match ‘why’ and ‘whhy’, but not ‘wy’, whereas ‘wh*y’ would match all three.
?This symbol is similar to ‘*’, except that the preceding expression can be matched either once or not at all. For example, ‘fe?d’ matches ‘fed’ and ‘fd’, but nothing else.
{n}¶{n,}{n,m}One or two numbers inside braces denote an interval expression. If there is one number in the braces, the preceding regexp is repeated n times. If there are two numbers separated by a comma, the preceding regexp is repeated n to m times. If there is one number followed by a comma, then the preceding regexp is repeated at least n times:
wh{3}yMatches ‘whhhy’, but not ‘why’ or ‘whhhhy’.
wh{3,5}yMatches ‘whhhy’, ‘whhhhy’, or ‘whhhhhy’ only.
wh{2,}yMatches ‘whhy’, ‘whhhy’, and so on.
In regular expressions, the ‘*’, ‘+’, and ‘?’ operators, as well as the braces ‘{’ and ‘}’, have the highest precedence, followed by concatenation, and finally by ‘|’. As in arithmetic, parentheses can change how operators are grouped.
According to the POSIX specification, when ‘*’, ‘+’, ‘?’,
or ‘{’ are not preceded by a character, the behavior is
“undefined.”
In practice, for gawk, the ‘*’, ‘+’, ‘?’ and
‘{’ operators stand for themselves when there is nothing in the
regexp that precedes them. For example, /+/ matches a literal
plus sign. However, many other versions of awk treat such a
usage as a syntax error.
| What About The Empty Regexp? |
|---|
|
We describe here an advanced regexp usage. Feel free to skip it upon first reading. You can supply an empty regexp constant (‘//’) in all places where a regexp is expected. Is this useful? What does it match? It is useful. It matches the (invisible) empty string at the start
and end of a string of characters, as well as the empty string
between characters. This is best illustrated with the $ awk '
> BEGIN {
> x = "ABC_CBA"
> gsub(/B/, "bb", x)
> print x
> }'
-| AbbC_CbbA
We can use $ awk '
> BEGIN {
> x = "ABC"
> gsub(//, "x", x)
> print x
> }'
-| xAxBxCx
|
3.3.2 Some Notes On Interval Expressions ¶
Interval expressions were not traditionally available in awk.
They were added as part of the POSIX standard to make awk
and egrep consistent with each other.
Initially, because old programs may use ‘{’ and ‘}’ in regexp
constants,
gawk did not match interval expressions
in regexps.
However, beginning with version 4.0,
gawk does match interval expressions by default.
This is because compatibility with POSIX has become more
important to most gawk users than compatibility with
old programs.
For programs that use ‘{’ and ‘}’ in regexp constants,
it is good practice to always escape them with a backslash. Then the
regexp constants are valid and work the way you want them to, using
any version of awk.18
When ‘{’ and ‘}’ appear in regexp constants
in a way that cannot be interpreted as an interval expression
(such as /q{a}/), then they stand for themselves.
As mentioned, interval expressions were not traditionally available
in awk. In March of 2019, BWK awk (finally) acquired them.
Starting with version 5.2, gawk’s
--traditional option no longer disables interval
expressions in regular expressions.
POSIX says that interval expressions containing repetition counts greater than 255 produce unspecified results.
In the manual for GNU grep, Paul Eggert notes the following:
Interval expressions may be implemented internally via repetition. For example, ‘^(a|bc){2,4}$’ might be implemented as ‘^(a|bc)(a|bc)((a|bc)(a|bc)?)?$’. A large repetition count may exhaust memory or greatly slow matching. Even small counts can cause problems if cascaded; for example, ‘grep -E ".*{10,}{10,}{10,}{10,}{10,}"’ is likely to overflow a stack. Fortunately, regular expressions like these are typically artificial, and cascaded repetitions do not conform to POSIX so cannot be used in portable programs anyway.
This same caveat applies to gawk.
3.4 Using Bracket Expressions ¶
As mentioned earlier, a bracket expression matches any character among those listed between the opening and closing square brackets.
Within a bracket expression, a range expression consists of two
characters separated by a hyphen. It matches any single character that
sorts between the two characters, based upon the system’s native character
set. For example, ‘[0-9]’ is equivalent to ‘[0123456789]’.
(See Regexp Ranges and Locales: A Long Sad Story for an explanation of how the POSIX
standard and gawk have changed over time. This is mainly
of historical interest.)
With the increasing popularity of the Unicode character standard, there is an additional wrinkle to consider. Octal and hexadecimal escape sequences inside bracket expressions are taken to represent only single-byte characters (characters whose values fit within the range 0–256). To match a range of characters where the endpoints of the range are larger than 256, enter the multibyte encodings of the characters directly.
To include one of the characters ‘\’, ‘]’, ‘-’, or ‘^’ in a bracket expression, put a ‘\’ in front of it. For example:
[d\]]
matches either ‘d’ or ‘]’. Additionally, if you place ‘]’ right after the opening ‘[’, the closing bracket is treated as one of the characters to be matched.
The treatment of ‘\’ in bracket expressions
is compatible with other awk
implementations and is also mandated by POSIX.
The regular expressions in awk are a superset
of the POSIX specification for Extended Regular Expressions (EREs).
POSIX EREs are based on the regular expressions accepted by the
traditional egrep utility.
Character classes are a feature introduced in the POSIX standard. A character class is a special notation for describing lists of characters that have a specific attribute, but the actual characters can vary from country to country and/or from character set to character set. For example, the notion of what is an alphabetic character differs between the United States and France.
A character class is only valid in a regexp inside the brackets of a bracket expression. Character classes consist of ‘[:’, a keyword denoting the class, and ‘:]’. Table 3.1 lists the character classes defined by the POSIX standard.
| Class | Meaning |
|---|---|
[:alnum:] | Alphanumeric characters |
[:alpha:] | Alphabetic characters |
[:blank:] | Space and TAB characters |
[:cntrl:] | Control characters |
[:digit:] | Numeric characters |
[:graph:] | Characters that are both printable and visible (a space is printable but not visible, whereas an ‘a’ is both) |
[:lower:] | Lowercase alphabetic characters |
[:print:] | Printable characters (characters that are not control characters) |
[:punct:] | Punctuation characters (characters that are not letters, digits, control characters, or space characters) |
[:space:] | Space characters (these are: space, TAB, newline, carriage return, formfeed and vertical tab) |
[:upper:] | Uppercase alphabetic characters |
[:xdigit:] | Characters that are hexadecimal digits |
Table 3.1: POSIX character classes
For example, before the POSIX standard, you had to write /[A-Za-z0-9]/
to match alphanumeric characters. If your
character set had other alphabetic characters in it, this would not
match them.
With the POSIX character classes, you can write
/[[:alnum:]]/ to match the alphabetic
and numeric characters in your character set.
Some utilities that match regular expressions provide a nonstandard
‘[:ascii:]’ character class; awk does not. However, you
can simulate such a construct using ‘[\x00-\x7F]’. This matches
all values numerically between zero and 127, which is the defined
range of the ASCII character set. Use a complemented character list
(‘[^\x00-\x7F]’) to match any single-byte characters that are not
in the ASCII range.
NOTE: Some older versions of Unix
awktreat[:blank:]like[:space:], incorrectly matching more characters than they should. Caveat Emptor.
Two additional special sequences can appear in bracket expressions. These apply to non-ASCII character sets, which can have single symbols (called collating elements) that are represented with more than one character. They can also have several characters that are equivalent for collating, or sorting, purposes. (For example, in French, a plain “e” and a grave-accented “è” are equivalent.) These sequences are:
- Collating symbols ¶
Multicharacter collating elements enclosed between ‘[.’ and ‘.]’. For example, if ‘ch’ is a collating element, then ‘[[.ch.]]’ is a regexp that matches this collating element, whereas ‘[ch]’ is a regexp that matches either ‘c’ or ‘h’.
- Equivalence classes
Locale-specific names for a list of characters that are equal. The name is enclosed between ‘[=’ and ‘=]’. For example, the name ‘e’ might be used to represent all of “e,” “ê,” “è,” and “é.” In this case, ‘[[=e=]]’ is a regexp that matches any of ‘e’, ‘ê’, ‘é’, or ‘è’.
These features are very valuable in non-English-speaking locales.
CAUTION: The library functions that
gawkuses for regular expression matching currently recognize only POSIX character classes; they do not recognize collating symbols or equivalence classes.
Inside a bracket expression, an opening bracket (‘[’) that does not start a character class, collating element or equivalence class is taken literally. This is also true of ‘.’ and ‘*’.
3.5 How Much Text Matches? ¶
Consider the following:
echo aaaabcd | awk '{ sub(/a+/, "<A>"); print }'
This example uses the sub() function to make a change to the input
record. (sub() replaces the first instance of any text matched
by the first argument with the string provided as the second argument;
see String-Manipulation Functions.) Here, the regexp /a+/ indicates “one
or more ‘a’ characters,” and the replacement text is ‘<A>’.
The input contains four ‘a’ characters.
awk (and POSIX) regular expressions always match
the leftmost, longest sequence of input characters that can
match. Thus, all four ‘a’ characters are
replaced with ‘<A>’ in this example:
$ echo aaaabcd | awk '{ sub(/a+/, "<A>"); print }'
-| <A>bcd
For simple match/no-match tests, this is not so important. But when doing
text matching and substitutions with the match(), sub(), gsub(),
and gensub() functions, it is very important.
Understanding this principle is also important for regexp-based record
and field splitting (see How Input Is Split into Records,
and also see Specifying How Fields Are Separated).
3.6 Using Dynamic Regexps ¶
The righthand side of a ‘~’ or ‘!~’ operator need not be a regexp constant (i.e., a string of characters between slashes). It may be any expression. The expression is evaluated and converted to a string if necessary; the contents of the string are then used as the regexp. A regexp computed in this way is called a dynamic regexp or a computed regexp:
BEGIN { digits_regexp = "[[:digit:]]+" }
$0 ~ digits_regexp { print }
This sets digits_regexp to a regexp that describes one or more digits,
and tests whether the input record matches this regexp.
NOTE: When using the ‘~’ and ‘!~’ operators, be aware that there is a difference between a regexp constant enclosed in slashes and a string constant enclosed in double quotes. If you are going to use a string constant, you have to understand that the string is, in essence, scanned twice: the first time when
awkreads your program, and the second time when it goes to match the string on the lefthand side of the operator with the pattern on the right. This is true of any string-valued expression (such asdigits_regexp, shown in the previous example), not just string constants.
What difference does it make if the string is scanned twice? The answer has to do with escape sequences, and particularly with backslashes. To get a backslash into a regular expression inside a string, you have to type two backslashes.
For example, /\*/ is a regexp constant for a literal ‘*’.
Only one backslash is needed. To do the same thing with a string,
you have to type "\\*". The first backslash escapes the
second one so that the string actually contains the
two characters ‘\’ and ‘*’.
Given that you can use both regexp and string constants to describe regular expressions, which should you use? The answer is “regexp constants,” for several reasons:
- String constants are more complicated to write and more difficult to read. Using regexp constants makes your programs less error-prone. Not understanding the difference between the two kinds of constants is a common source of errors.
- It is more efficient to use regexp constants.
awkcan note that you have supplied a regexp and store it internally in a form that makes pattern matching more efficient. When using a string constant,awkmust first convert the string into this internal form and then perform the pattern matching. - Using regexp constants is better form; it shows clearly that you intend a regexp match.
3.7 gawk-Specific Regexp Operators ¶
GNU software that deals with regular expressions provides a number of
additional regexp operators. These operators are described in this
section and are specific to gawk;
they are not available in other awk implementations.
Most of the additional operators deal with word matching.
For our purposes, a word is a sequence of one or more letters, digits,
or underscores (‘_’):
\sMatches any space character as defined by the current locale. Think of it as shorthand for ‘[[:space:]]’.
\SMatches any character that is not a space, as defined by the current locale. Think of it as shorthand for ‘[^[:space:]]’.
\wMatches any word-constituent character—that is, it matches any letter, digit, or underscore. Think of it as shorthand for ‘[[:alnum:]_]’.
\WMatches any character that is not word-constituent. Think of it as shorthand for ‘[^[:alnum:]_]’.
\<Matches the empty string at the beginning of a word. For example,
/\<away/matches ‘away’ but not ‘stowaway’.\>Matches the empty string at the end of a word. For example,
/stow\>/matches ‘stow’ but not ‘stowaway’.\y¶Matches the empty string at either the beginning or the end of a word (i.e., the word boundary). For example, ‘\yballs?\y’ matches either ‘ball’ or ‘balls’, as a separate word.
\BMatches the empty string that occurs between two word-constituent characters. For example,
/\Brat\B/matches ‘crate’, but it does not match ‘dirty rat’. ‘\B’ is essentially the opposite of ‘\y’. Another way to think of this is that ‘\B’ matches the empty string provided it’s not at the edge of a word.
There are two other operators that work on buffers. In Emacs, a
buffer is, naturally, an Emacs buffer.
Other GNU programs, including gawk,
consider the entire string to match as the buffer.
The operators are:
\`-
Matches the empty string at the beginning of a buffer (string)
\'Matches the empty string at the end of a buffer (string)
Because ‘^’ and ‘$’ always work in terms of the beginning
and end of strings, these operators don’t add any new capabilities
for awk. They are provided for compatibility with other
GNU software.
In other GNU software, the word-boundary operator is ‘\b’. However,
that conflicts with the awk language’s definition of ‘\b’
as backspace, so gawk uses a different letter.
An alternative method would have been to require two backslashes in the
GNU operators, but this was deemed too confusing. The current
method of using ‘\y’ for the GNU ‘\b’ appears to be the
lesser of two evils.
The various command-line options
(see Command-Line Options)
control how gawk interprets characters in regexps:
- No options
In the default case,
gawkprovides all the facilities of POSIX regexps and the previously described GNU regexp operators. GNU regexp operators described in Regular Expression Operators.- --posix
Match only POSIX regexps; the GNU operators are not special (e.g., ‘\w’ matches a literal ‘w’). Interval expressions are allowed.
- --traditional ¶
Match traditional Unix
awkregexps. The GNU operators are not special. Because BWKawksupports them, the POSIX character classes (‘[[:alnum:]]’, etc.) are available. So too, interval expressions are allowed. Characters described by octal and hexadecimal escape sequences are treated literally, even if they represent regexp metacharacters.- --re-interval
This option remains for backwards compatibility but no longer has any real effect.
3.8 Case Sensitivity in Matching ¶
Case is normally significant in regular expressions, both when matching ordinary characters (i.e., not metacharacters) and inside bracket expressions. Thus, a ‘w’ in a regular expression matches only a lowercase ‘w’ and not an uppercase ‘W’.
The simplest way to do a case-independent match is to use a bracket expression—for example, ‘[Ww]’. However, this can be cumbersome if you need to use it often, and it can make the regular expressions harder to read. There are two alternatives that you might prefer.
One way to perform a case-insensitive match at a particular point in the
program is to convert the data to a single case, using the
tolower() or toupper() built-in string functions (which we
haven’t discussed yet;
see String-Manipulation Functions).
For example:
tolower($1) ~ /foo/ { ... }
converts the first field to lowercase before matching against it.
This works in any POSIX-compliant awk.
Another method, specific to gawk, is to set the variable
IGNORECASE to a nonzero value (see Predefined Variables).
When IGNORECASE is not zero, all regexp and string
operations ignore case.
Changing the value of IGNORECASE dynamically controls the
case sensitivity of the program as it runs. Case is significant by
default because IGNORECASE (like most variables) is initialized
to zero:
x = "aB" if (x ~ /ab/) ... # this test will fail IGNORECASE = 1 if (x ~ /ab/) ... # now it will succeed
In general, you cannot use IGNORECASE to make certain rules
case insensitive and other rules case sensitive, as there is no
straightforward way
to set IGNORECASE just for the pattern of
a particular rule.19
To do this, use either bracket expressions or tolower(). However, one
thing you can do with IGNORECASE only is dynamically turn
case sensitivity on or off for all the rules at once.
IGNORECASE can be set on the command line or in a BEGIN rule
(see Other Command-Line Arguments; also
see Startup and Cleanup Actions).
Setting IGNORECASE from the command line is a way to make
a program case insensitive without having to edit it.
In multibyte locales, the equivalences between upper- and lowercase characters are tested based on the wide-character values of the locale’s character set. Prior to version 5.0, single-byte characters were tested based on the ISO-8859-1 (ISO Latin-1) character set. However, as of version 5.0, single-byte characters are also tested based on the values of the locale’s character set.20
The value of IGNORECASE has no effect if gawk is in
compatibility mode (see Command-Line Options).
Case is always significant in compatibility mode.
3.9 Summary ¶
- Regular expressions describe sets of strings to be matched.
In
awk, regular expression constants are written enclosed between slashes:/…/. - Regexp constants may be used standalone in patterns and in conditional expressions, or as part of matching expressions using the ‘~’ and ‘!~’ operators.
- Escape sequences let you represent nonprintable characters and also let you represent regexp metacharacters as literal characters to be matched.
- Regexp operators provide grouping, alternation, and repetition.
- Bracket expressions give you a shorthand for specifying sets of characters that can match at a particular point in a regexp. Within bracket expressions, POSIX character classes let you specify certain groups of characters in a locale-independent fashion.
- Regular expressions match the leftmost longest text in the string being matched. This matters for cases where you need to know the extent of the match, such as for text substitution and when the record separator is a regexp.
- Matching expressions may use dynamic regexps (i.e., string values treated as regular expressions).
gawk’sIGNORECASEvariable lets you control the case sensitivity of regexp matching. In otherawkversions, usetolower()ortoupper().
4 Reading Input Files ¶
In the typical awk program,
awk reads all input either from the
standard input (by default, this is the keyboard, but often it is a pipe from another
command) or from files whose names you specify on the awk
command line. If you specify input files, awk reads them
in order, processing all the data from one before going on to the next.
The name of the current input file can be found in the predefined variable
FILENAME
(see Predefined Variables).
The input is read in units called records, and is processed by the rules of your program one record at a time. By default, each record is one line. Each record is automatically split into chunks called fields. This makes it more convenient for programs to work on the parts of a record.
On rare occasions, you may need to use the getline command.
The getline command is valuable both because it
can do explicit input from any number of files, and because the files
used with it do not have to be named on the awk command line
(see Explicit Input with getline).
- How Input Is Split into Records
- Examining Fields
- Nonconstant Field Numbers
- Changing the Contents of a Field
- Specifying How Fields Are Separated
- Reading Fixed-Width Data
- Defining Fields by Content
- Checking How
gawkIs Splitting Records - Multiple-Line Records
- Explicit Input with
getline - Reading Input with a Timeout
- Retrying Reads After Certain Input Errors
- Directories on the Command Line
- Summary
- Exercises
4.1 How Input Is Split into Records ¶
awk divides the input for your program into records and fields.
It keeps track of the number of records that have been read so far from
the current input file. This value is stored in a predefined variable
called FNR, which is reset to zero every time a new file is started.
Another predefined variable, NR, records the total number of input
records read so far from all data files. It starts at zero, but is
never automatically reset to zero.
Normally, records are separated by newline characters. You can control how
records are separated by assigning values to the built-in variable RS.
If RS is any single character, that character separates records.
Otherwise (in gawk), RS is treated as a regular expression.
This mechanism is explained in greater detail shortly.
NOTE: When
gawkis invoked with the --csv option, nothing in this section applies. See Working With Comma Separated Value Files, for the details.
4.1.1 Record Splitting with Standard awk ¶
Records are separated by a character called the record separator.
By default, the record separator is the newline character.
This is why records are, by default, single lines.
To use a different character for the record separator,
simply assign that character to the predefined variable RS.
Like any other variable,
the value of RS can be changed in the awk program
with the assignment operator, ‘=’
(see Assignment Expressions).
The new record-separator character should be enclosed in quotation marks,
which indicate a string constant. Often, the right time to do this is
at the beginning of execution, before any input is processed,
so that the very first record is read with the proper separator.
To do this, use the special BEGIN pattern
(see The BEGIN and END Special Patterns).
For example:
awk 'BEGIN { RS = "u" }
{ print $0 }' mail-list
changes the value of RS to ‘u’, before reading any input.
The new value is a string whose first character is the letter “u”; as a result, records
are separated by the letter “u”. Then the input file is read, and the second
rule in the awk program (the action with no pattern) prints each
record. Because each print statement adds a newline at the end of
its output, this awk program copies the input
with each ‘u’ changed to a newline. Here are the results of running
the program on mail-list:
$ awk 'BEGIN { RS = "u" }
> { print $0 }' mail-list
-| Amelia 555-5553 amelia.zodiac -| sq -| e@gmail.com F -| Anthony 555-3412 anthony.assert -| ro@hotmail.com A -| Becky 555-7685 becky.algebrar -| m@gmail.com A -| Bill 555-1675 bill.drowning@hotmail.com A -| Broderick 555-0542 broderick.aliq -| otiens@yahoo.com R -| Camilla 555-2912 camilla.inf -| sar -| m@skynet.be R -| Fabi -| s 555-1234 fabi -| s. -| ndevicesim -| s@ -| cb.ed -| F -| J -| lie 555-6699 j -| lie.perscr -| tabor@skeeve.com F -| Martin 555-6480 martin.codicib -| s@hotmail.com A -| Sam -| el 555-3430 sam -| el.lanceolis@sh -| .ed -| A -| Jean-Pa -| l 555-2127 jeanpa -| l.campanor -| m@ny -| .ed -| R -|
Note that the entry for the name ‘Bill’ is not split. In the original data file (see Data files for the Examples), the line looks like this:
Bill 555-1675 bill.drowning@hotmail.com A
It contains no ‘u’, so there is no reason to split the record,
unlike the others, which each have one or more occurrences of the ‘u’.
In fact, this record is treated as part of the previous record;
the newline separating them in the output
is the original newline in the data file, not the one added by
awk when it printed the record!
Another way to change the record separator is on the command line, using the variable-assignment feature (see Other Command-Line Arguments):
awk '{ print $0 }' RS="u" mail-list
This sets RS to ‘u’ before processing mail-list.
Using an alphabetic character such as ‘u’ for the record separator is highly likely to produce strange results. Using an unusual character such as ‘/’ is more likely to produce correct behavior in the majority of cases, but there are no guarantees. The moral is: Know Your Data.
gawk allows RS to be a full regular expression
(discussed shortly; see Record Splitting with gawk). Even so, using
a regular expression metacharacter, such as ‘.’ as the single
character in the value of RS has no special effect: it is
treated literally. This is required for backwards compatibility with
both Unix awk and with POSIX.
Reaching the end of an input file terminates the current input record,
even if the last character in the file is not the character in RS.
(d.c.)
The empty string "" (a string without any characters)
has a special meaning
as the value of RS. It means that records are separated
by one or more blank lines and nothing else.
See Multiple-Line Records for more details.
If you change the value of RS in the middle of an awk run,
the new value is used to delimit subsequent records, but the record
currently being processed, as well as records already processed, are not
affected.
After the end of the record has been determined, gawk
sets the variable RT to the text in the input that matched
RS.
4.1.2 Record Splitting with gawk ¶
When using gawk, the value of RS is not limited to a
one-character string. If it contains more than one character, it is
treated as a regular expression
(see Regular Expressions). (c.e.)
In general, each record
ends at the next string that matches the regular expression; the next
record starts at the end of the matching string. This general rule is
actually at work in the usual case, where RS contains just a
newline: a record ends at the beginning of the next matching string (the
next newline in the input), and the following record starts just after
the end of this string (at the first character of the following line).
The newline, because it matches RS, is not part of either record.
When RS is a single character, RT
contains the same single character. However, when RS is a
regular expression, RT contains
the actual input text that matched the regular expression.
If the input file ends without any text matching RS,
gawk sets RT to the null string.
The following example illustrates both of these features.
It sets RS equal to a regular expression that
matches either a newline or a series of one or more uppercase letters
with optional leading and/or trailing whitespace:
$ echo record 1 AAAA record 2 BBBB record 3 |
> gawk 'BEGIN { RS = "\n|( *[[:upper:]]+ *)" }
> { print "Record =", $0,"and RT = [" RT "]" }'
-| Record = record 1 and RT = [ AAAA ] -| Record = record 2 and RT = [ BBBB ] -| Record = record 3 and RT = [ -| ]
The square brackets delineate the contents of RT, letting you
see the leading and trailing whitespace. The final value of
RT is a newline.
See A Simple Stream Editor for a more useful example
of RS as a regexp and RT.
If you set RS to a regular expression that allows optional
trailing text, such as ‘RS = "abc(XYZ)?"’, it is possible, due
to implementation constraints, that gawk may match the leading
part of the regular expression, but not the trailing part, particularly
if the input text that could match the trailing part is fairly long.
gawk attempts to avoid this problem, but currently, there’s
no guarantee that this will never happen.
Caveats When Using Regular Expressions for RS |
|---|
|
Remember that in Record splitting with regular expressions works differently than
regexp matching with the |
The use of RS as a regular expression and the RT
variable are gawk extensions; they are not available in
compatibility mode
(see Command-Line Options).
In compatibility mode, only the first character of the value of
RS determines the end of the record.
mawk has allowed RS to be a regexp for decades.
As of October, 2019, BWK awk also supports it. Neither
version supplies RT, however.
RS = "\0" Is Not Portable |
|---|
|
There are times when you might want to treat an entire data file as a
single record. The only way to make this happen is to give You might think that for text files, the NUL character, which
consists of a character with all bits equal to zero, is a good
value to use for BEGIN { RS = "\0" } # whole file becomes one record?
Almost all other It happens that recent versions of See Reading a Whole File at Once for an interesting way to read
whole files. If you are using |
4.2 Examining Fields ¶
When awk reads an input record, the record is
automatically parsed or separated by the awk utility into chunks
called fields. By default, fields are separated by whitespace,
like words in a line.
Whitespace in awk means any string of one or more spaces,
TABs, or newlines; other characters
that are considered whitespace by other languages
(such as formfeed, vertical tab, etc.) are not considered
whitespace by awk.
The purpose of fields is to make it more convenient for you to refer to
these pieces of the record. You don’t have to use them—you can
operate on the whole record if you want—but fields are what make
simple awk programs so powerful.
You use a dollar sign (‘$’)
to refer to a field in an awk program,
followed by the number of the field you want. Thus, $1
refers to the first field, $2 to the second, and so on.
(Unlike in the Unix shells, the field numbers are not limited to single digits.
$127 is the 127th field in the record.)
For example, suppose the following is a line of input:
This seems like a pretty nice example.
Here the first field, or $1, is ‘This’, the second field, or
$2, is ‘seems’, and so on. Note that the last field,
$7, is ‘example.’. Because there is no space between the
‘e’ and the ‘.’, the period is considered part of the seventh
field.
NF is a predefined variable whose value is the number of fields
in the current record. awk automatically updates the value
of NF each time it reads a record. No matter how many fields
there are, the last field in a record can be represented by $NF.
So, $NF is the same as $7, which is ‘example.’.
If you try to reference a field beyond the last
one (such as $8 when the record has only seven fields), you get
the empty string. If used in a numeric operation, you get zero.22
The use of $0, which looks like a reference to the “zeroth” field, is
a special case: it represents the whole input record. Use it
when you are not interested in specific fields.
Here are some more examples:
$ awk '$1 ~ /li/ { print $0 }' mail-list
-| Amelia 555-5553 amelia.zodiacusque@gmail.com F
-| Julie 555-6699 julie.perscrutabor@skeeve.com F
This example prints each record in the file mail-list whose first field contains the string ‘li’.
By contrast, the following example looks for ‘li’ in the entire record and prints the first and last fields for each matching input record:
$ awk '/li/ { print $1, $NF }' mail-list
-| Amelia F
-| Broderick R
-| Julie F
-| Samuel A
4.3 Nonconstant Field Numbers ¶
A field number need not be a constant. Any expression in
the awk language can be used after a ‘$’ to refer to a
field. The value of the expression specifies the field number. If the
value is a string, rather than a number, it is converted to a number.
Consider this example:
awk '{ print $NR }'
Recall that NR is the number of records read so far: one in the
first record, two in the second, and so on. So this example prints the first
field of the first record, the second field of the second record, and so
on. For the twentieth record, field number 20 is printed; most likely,
the record has fewer than 20 fields, so this prints a blank line.
Here is another example of using expressions as field numbers:
awk '{ print $(2*2) }' mail-list
awk evaluates the expression ‘(2*2)’ and uses
its value as the number of the field to print. The ‘*’
represents multiplication, so the expression ‘2*2’ evaluates to four.
The parentheses are used so that the multiplication is done before the
‘$’ operation; they are necessary whenever there is a binary
operator23
in the field-number expression. This example, then, prints the
type of relationship (the fourth field) for every line of the file
mail-list. (All of the awk operators are listed, in
order of decreasing precedence, in
Operator Precedence (How Operators Nest).)
If the field number you compute is zero, you get the entire record.
Thus, ‘$(2-2)’ has the same value as $0. Negative field
numbers are not allowed; trying to reference one usually terminates
the program. (The POSIX standard does not define
what happens when you reference a negative field number. gawk
notices this and terminates your program. Other awk
implementations may behave differently.)
As mentioned in Examining Fields,
awk stores the current record’s number of fields in the built-in
variable NF (also see Predefined Variables). Thus, the expression
$NF is not a special feature—it is the direct consequence of
evaluating NF and using its value as a field number.
4.4 Changing the Contents of a Field ¶
The contents of a field, as seen by awk, can be changed within an
awk program; this changes what awk perceives as the
current input record. (The actual input is untouched; awk never
modifies the input file.)
Consider the following example and its output:
$ awk '{ nboxes = $3 ; $3 = $3 - 10
> print nboxes, $3 }' inventory-shipped
-| 25 15
-| 32 22
-| 24 14
...
The program first saves the original value of field three in the variable
nboxes.
The ‘-’ sign represents subtraction, so this program reassigns
field three, $3, as the original value of field three minus ten:
‘$3 - 10’. (See Arithmetic Operators.)
Then it prints the original and new values for field three.
(Someone in the warehouse made a consistent mistake while inventorying
the red boxes.)
For this to work, the text in $3 must make sense
as a number; the string of characters must be converted to a number
for the computer to do arithmetic on it. The number resulting
from the subtraction is converted back to a string of characters that
then becomes field three.
See Conversion of Strings and Numbers.
When the value of a field is changed (as perceived by awk), the
text of the input record is recalculated to contain the new field where
the old one was. In other words, $0 changes to reflect the altered
field. Thus, this program
prints a copy of the input file, with 10 subtracted from the second
field of each line:
$ awk '{ $2 = $2 - 10; print $0 }' inventory-shipped
-| Jan 3 25 15 115
-| Feb 5 32 24 226
-| Mar 5 24 34 228
...
It is also possible to assign contents to fields that are out of range. For example:
$ awk '{ $6 = ($5 + $4 + $3 + $2)
> print $6 }' inventory-shipped
-| 168
-| 297
-| 301
...
We’ve just created $6, whose value is the sum of fields
$2, $3, $4, and $5. The ‘+’ sign
represents addition. For the file inventory-shipped, $6
represents the total number of parcels shipped for a particular month.
Creating a new field changes awk’s internal copy of the current
input record, which is the value of $0. Thus, if you do ‘print $0’
after adding a field, the record printed includes the new field, with
the appropriate number of field separators between it and the previously
existing fields.
This recomputation affects and is affected by
NF (the number of fields; see Examining Fields).
For example, the value of NF is set to the number of the highest
field you create.
The exact format of $0 is also affected by a feature that has not been discussed yet:
the output field separator, OFS,
used to separate the fields (see Output Separators).
Note, however, that merely referencing an out-of-range field
does not change the value of either $0 or NF.
Referencing an out-of-range field only produces an empty string. For
example:
if ($(NF+1) != "")
print "can't happen"
else
print "everything is normal"
should print ‘everything is normal’, because NF+1 is certain
to be out of range. (See The if-else Statement
for more information about awk’s if-else statements.
See Variable Typing and Comparison Expressions
for more information about the ‘!=’ operator.)
It is important to note that making an assignment to an existing field
changes the
value of $0 but does not change the value of NF,
even when you assign the empty string to a field. For example:
$ echo a b c d | awk '{ OFS = ":"; $2 = ""
> print $0; print NF }'
-| a::c:d
-| 4
The field is still there; it just has an empty value, delimited by the two colons between ‘a’ and ‘c’. This example shows what happens if you create a new field:
$ echo a b c d | awk '{ OFS = ":"; $2 = ""; $6 = "new"
> print $0; print NF }'
-| a::c:d::new
-| 6
The intervening field, $5, is created with an empty value
(indicated by the second pair of adjacent colons),
and NF is updated with the value six.
Decrementing NF throws away the values of the fields
after the new value of NF and recomputes $0.
(d.c.)
Here is an example:
$ echo a b c d e f | awk '{ print "NF =", NF;
> NF = 3; print $0 }'
-| NF = 6
-| a b c
CAUTION: Some versions of
awkdon’t rebuild$0whenNFis decremented. Until August, 2018, this included BWKawk; fortunately his version now handles this correctly.
Finally, there are times when it is convenient to force
awk to rebuild the entire record, using the current
values of the fields and OFS. To do this, use the
seemingly innocuous assignment:
$1 = $1 # force record to be reconstituted print $0 # or whatever else with $0
This forces awk to rebuild the record. It does help
to add a comment, as we’ve shown here.
There is a flip side to the relationship between $0 and
the fields. Any assignment to $0 causes the record to be
reparsed into fields using the current value of FS.
This also applies to any built-in function that updates $0,
such as sub() and gsub()
(see String-Manipulation Functions).
Understanding $0 |
|---|
|
It is important to remember that It is a common error to try to change the field separators
in a record simply by setting But this does not work, because nothing was done to change the record itself. Instead, you must force the record to be rebuilt, typically with a statement such as ‘$1 = $1’, as described earlier. |
4.5 Specifying How Fields Are Separated ¶
The field separator, which is either a single character or a regular
expression, controls the way awk splits an input record into fields.
awk scans the input record for character sequences that
match the separator; the fields themselves are the text between the matches.
In the examples that follow, we use the bullet symbol (•) to represent spaces in the output. If the field separator is ‘oo’, then the following line:
moo goo gai pan
is split into three fields: ‘m’, ‘•g’, and ‘•gai•pan’. Note the leading spaces in the values of the second and third fields.
The field separator is represented by the predefined variable FS.
Shell programmers take note: awk does not use the
name IFS that is used by the POSIX-compliant shells (such as
the Unix Bourne shell, sh, or Bash).
The value of FS can be changed in the awk program with the
assignment operator, ‘=’ (see Assignment Expressions).
Often, the right time to do this is at the beginning of execution
before any input has been processed, so that the very first record
is read with the proper separator. To do this, use the special
BEGIN pattern
(see The BEGIN and END Special Patterns).
For example, here we set the value of FS to the string
":":
awk 'BEGIN { FS = ":" } ; { print $2 }'
Given the input line:
John Q. Smith: 29 Oak St.: Walamazoo: MI 42139
this awk program extracts and prints the string
‘•29•Oak•St.’.
Sometimes the input data contains separator characters that don’t separate fields the way you thought they would. For instance, the person’s name in the example we just used might have a title or suffix attached, such as:
John Q. Smith: LXIX: 29 Oak St.: Walamazoo: MI 42139
The same program would extract ‘•LXIX’ instead of
‘•29•Oak•St.’.
If you were expecting the program to print the
address, you would be surprised. The moral is to choose your data layout and
separator characters carefully to prevent such problems.
(If the data is not in a form that is easy to process, perhaps you
can massage it first with a separate awk program.)
- Whitespace Normally Separates Fields
- Using Regular Expressions to Separate Fields
- Making Each Character a Separate Field
- Working With Comma Separated Value Files
- Setting
FSfrom the Command Line - Making the Full Line Be a Single Field
- Field-Splitting Summary
4.5.1 Whitespace Normally Separates Fields ¶
Fields are normally separated by whitespace sequences
(spaces, TABs, and newlines), not by single spaces. Two spaces in a row do not
delimit an empty field. The default value of the field separator FS
is a string containing a single space, " ". If awk
interpreted this value in the usual way, each space character would separate
fields, so two spaces in a row would make an empty field between them.
The reason this does not happen is that a single space as the value of
FS is a special case—it is taken to specify the default manner
of delimiting fields.
If FS is any other single character, such as ",", then
each occurrence of that character separates two fields. Two consecutive
occurrences delimit an empty field. If the character occurs at the
beginning or the end of the line, that too delimits an empty field. The
space character is the only single character that does not follow these
rules.
4.5.2 Using Regular Expressions to Separate Fields ¶
The previous subsection
discussed the use of single characters or simple strings as the
value of FS.
More generally, the value of FS may be a string containing any
regular expression. In this case, each match in the record for the regular
expression separates fields. For example, the assignment:
FS = ", \t"
makes every area of an input line that consists of a comma followed by a space and a TAB into a field separator.
For a less trivial example of a regular expression, try using
single spaces to separate fields the way single commas are used.
FS can be set to "[ ]" (left bracket, space, right
bracket). This regular expression matches a single space and nothing else
(see Regular Expressions).
There is an important difference between the two cases of ‘FS = " "’
(a single space) and ‘FS = "[ \t\n]+"’
(a regular expression matching one or more spaces, TABs, or newlines).
For both values of FS, fields are separated by runs
(multiple adjacent occurrences) of spaces, TABs,
and/or newlines. However, when the value of FS is " ",
awk first strips leading and trailing whitespace from
the record and then decides where the fields are.
For example, the following pipeline prints ‘b’:
$ echo ' a b c d ' | awk '{ print $2 }'
-| b
However, this pipeline prints ‘a’ (note the extra spaces around each letter):
$ echo ' a b c d ' | awk 'BEGIN { FS = "[ \t\n]+" }
> { print $2 }'
-| a
In this case, the first field is null, or empty.
The stripping of leading and trailing whitespace also comes into
play whenever $0 is recomputed. For instance, study this pipeline:
$ echo ' a b c d' | awk '{ print; $2 = $2; print }'
-| a b c d
-| a b c d
The first print statement prints the record as it was read,
with leading whitespace intact. The assignment to $2 rebuilds
$0 by concatenating $1 through $NF together,
separated by the value of OFS (which is a space by default).
Because the leading whitespace was ignored when finding $1,
it is not part of the new $0. Finally, the last print
statement prints the new $0.
There is an additional subtlety to be aware of when using regular expressions
for field splitting.
It is not well specified in the POSIX standard, or anywhere else, what ‘^’
means when splitting fields. Does the ‘^’ match only at the beginning of
the entire record? Or is each field separator a new string? It turns out that
different awk versions answer this question differently, and you
should not rely on any specific behavior in your programs.
(d.c.)
As a point of information, BWK awk allows ‘^’
to match only at the beginning of the record. gawk
also works this way. For example:
$ echo 'xxAA xxBxx C' |
> gawk -F '(^x+)|( +)' '{ for (i = 1; i <= NF; i++)
> printf "-->%s<--\n", $i }'
-| --><--
-| -->AA<--
-| -->xxBxx<--
-| -->C<--
Finally, field splitting with regular expressions works differently than
regexp matching with the sub(), gsub(), and gensub()
(see String-Manipulation Functions). Those functions allow a regexp to match the
empty string; field splitting does not. Thus, for example ‘FS =
"()"’ does not split fields between characters.
4.5.3 Making Each Character a Separate Field ¶
There are times when you may want to examine each character
of a record separately. This can be done in gawk by
simply assigning the null string ("") to FS. (c.e.)
In this case,
each individual character in the record becomes a separate field.
For example:
$ echo a b | gawk 'BEGIN { FS = "" }
> {
> for (i = 1; i <= NF; i = i + 1)
> print "Field", i, "is", $i
> }'
-| Field 1 is a
-| Field 2 is
-| Field 3 is b
Traditionally, the behavior of FS equal to "" was not defined.
In this case, most versions of Unix awk simply treat the entire record
as only having one field.
(d.c.)
In compatibility mode
(see Command-Line Options),
if FS is the null string, then gawk also
behaves this way.
4.5.4 Working With Comma Separated Value Files ¶
Many commonly-used tools use a comma to separate fields, instead of whitespace. This is particularly true of popular spreadsheet programs. There is no universally accepted standard for the format of these files, although RFC 4180 lists the common practices.
For decades, anyone wishing to work with CSV files and awk
had to “roll their own” solution.
(For an example, see Defining Fields by Content).
In 2023, Brian Kernighan decided to add CSV support to his version of
awk. In order to keep up, gawk too provides the same
support as his version.
To use CSV data, invoke gawk with either of the
-k or --csv options.
Fields in CSV files are separated by commas. In order to allow a comma to appear inside a field (i.e., as data), the field may be quoted by beginning and ending it with double quotes. In order to allow a double quote inside a field, the field must be quoted, and two double quotes represent an actual double quote. The double quote that starts a quoted field must be the first character after the comma. Table 4.1 shows some examples.
| Input | Field Contents |
|---|---|
abc def | abc def |
"quoted data" | quoted data |
"quoted, data" | quoted, data |
"She said ""Stop!""." | She said "Stop!". |
Table 4.1: Examples of CSV data
Additionally, and here’s where it gets messy, newlines are also
allowed inside double-quoted fields!
In order to deal with such things, when processing CSV files,
gawk scans the input data looking for newlines that
are not enclosed in double quotes. Thus, use of the --csv option
totally overrides normal record processing with RS (see How Input Is Split into Records),
as well as field splitting with any of FS, FIELDWIDTHS,
or FPAT.
| Carriage-Return–Line-Feed Line Endings In CSV Files |
|---|
— Brian Kernighan
Many CSV files are imported from systems where the line terminator
for text files is a carriage-return–line-feed pair
(CR-LF, ‘\r’ followed by ‘\n’).
For ease of use, when processing CSV files, This occurs only when a CR is paired with an LF; a standalone CR
is left alone. This behavior is consistent with Windows systems
which automatically convert CR-LF in files into a plain LF in memory,
and also with the commonly available |
The behavior of the split() function (not formally discussed
yet, see String-Manipulation Functions) differs slightly when processing CSV
files. When called with two arguments
(‘split(string, array)’), split()
does CSV-based splitting. Otherwise, it behaves normally.
If --csv has been used, PROCINFO["CSV"] will
exist. Otherwise, it will not. See Built-in Variables That Convey Information.
Finally, if --csv has been used, assigning a value
to any of FS, FIELDWIDTHS, FPAT, or
RS generates a warning message.
To be clear, gawk takes
RFC 4180 as its
specification for CSV input data. There are no mechanisms
for accepting nonstandard CSV data, such as files that use
a semicolon instead of a comma as the separator.
4.5.5 Setting FS from the Command Line ¶
FS can be set on the command line. Use the -F option to
do so. For example:
awk -F, 'program' input-files
sets FS to the ‘,’ character. Notice that the option uses
an uppercase ‘F’ instead of a lowercase ‘f’. The latter
option (-f) specifies a file containing an awk program.
The value used for the argument to -F is processed in exactly the
same way as assignments to the predefined variable FS.
Any special characters in the field separator must be escaped
appropriately. For example, to use a ‘\’ as the field separator
on the command line, you would have to type:
# same as FS = "\\" awk -F\\\\ '...' files ...
Because ‘\’ is used for quoting in the shell, awk sees
‘-F\\’. Then awk processes the ‘\\’ for escape
characters (see Escape Sequences), finally yielding
a single ‘\’ to use for the field separator.
As a special case, in compatibility mode
(see Command-Line Options),
if the argument to -F is ‘t’, then FS is set to
the TAB character. If you type ‘-F\t’ at the
shell, without any quotes, the ‘\’ gets deleted, so awk
figures that you really want your fields to be separated with TABs and
not ‘t’s. Use ‘-v FS="t"’ or ‘-F"[t]"’ on the command line
if you really do want to separate your fields with ‘t’s.
Use ‘-F '\t'’ when not in compatibility mode to specify that TABs
separate fields.
As an example, let’s use an awk program file called edu.awk
that contains the pattern /edu/ and the action ‘print $1’:
/edu/ { print $1 }
Let’s also set FS to be the ‘-’ character and run the
program on the file mail-list. The following command prints a
list of the names of the people that work at or attend a university, and
the first three digits of their phone numbers:
$ awk -F- -f edu.awk mail-list -| Fabius 555 -| Samuel 555 -| Jean
Note the third line of output. The third line in the original file looked like this:
Jean-Paul 555-2127 jeanpaul.campanorum@nyu.edu R
The ‘-’ as part of the person’s name was used as the field separator, instead of the ‘-’ in the phone number that was originally intended. This demonstrates why you have to be careful in choosing your field and record separators.
Perhaps the most common use of a single character as the field separator occurs when processing the Unix system password file. On many Unix systems, each user has a separate entry in the system password file, with one line per user. The information in these lines is separated by colons. The first field is the user’s login name and the second is the user’s encrypted or shadow password. (A shadow password is indicated by the presence of a single ‘x’ in the second field.) A password file entry might look like this:
arnold:x:2076:10:Arnold Robbins:/home/arnold:/bin/bash
The following program searches the system password file and prints the entries for users whose full name is not indicated:
awk -F: '$5 == ""' /etc/passwd
4.5.6 Making the Full Line Be a Single Field ¶
Occasionally, it’s useful to treat the whole input line as a
single field. This can be done easily and portably simply by
setting FS to "\n" (a newline):24
awk -F'\n' 'program' files ...
When you do this, $1 is the same as $0.
Changing FS Does Not Affect the Fields |
|---|
|
According to the POSIX standard, However, many older implementations of sed 1q /etc/passwd | awk '{ FS = ":" ; print $1 }'
which usually prints: root on an incorrect implementation of root:x:0:0:Root:/: (The |
4.5.7 Field-Splitting Summary ¶
It is important to remember that when you assign a string constant
as the value of FS, it undergoes normal awk string
processing. For example, with Unix awk and gawk,
the assignment ‘FS = "\.."’ assigns the character string ".."
to FS (the backslash is stripped). This creates a regexp meaning
“fields are separated by occurrences of any two characters.”
If instead you want fields to be separated by a literal period followed
by any single character, use ‘FS = "\\.."’.
The following list summarizes how fields are split, based on the value
of FS (‘==’ means “is equal to”):
gawkwas invoked with --csvField splitting follows the rules given in Working With Comma Separated Value Files. The value of
FSis ignored.FS == " "Fields are separated by runs of whitespace. Leading and trailing whitespace are ignored. This is the default.
FS == any other single characterFields are separated by each occurrence of the character. Multiple successive occurrences delimit empty fields, as do leading and trailing occurrences. The character can even be a regexp metacharacter; it does not need to be escaped.
FS == regexpFields are separated by occurrences of characters that match regexp. Leading and trailing matches of regexp delimit empty fields.
FS == ""Each individual character in the record becomes a separate field. (This is a common extension; it is not specified by the POSIX standard.)
FS and IGNORECASE |
|---|
|
The FS = "c" IGNORECASE = 1 $0 = "aCa" print $1 The output is ‘aCa’. If you really want to split fields on an
alphabetic character while ignoring case, use a regexp that will
do it for you (e.g., ‘FS = "[c]"’). In this case, |
4.6 Reading Fixed-Width Data ¶
This section discusses an advanced
feature of gawk. If you are a novice awk user,
you might want to skip it on the first reading.
gawk provides a facility for dealing with fixed-width fields
with no distinctive field separator. We discuss this feature in
the following subsections.
- Processing Fixed-Width Data
- Skipping Intervening Fields
- Capturing Optional Trailing Data
- Field Values With Fixed-Width Data
4.6.1 Processing Fixed-Width Data ¶
An example of fixed-width data would be the input for old Fortran programs where numbers are run together, or the output of programs that did not anticipate the use of their output as input for other programs.
An example of the latter is a table where all the columns are lined up
by the use of a variable number of spaces and empty fields are
just spaces. Clearly, awk’s normal field splitting based
on FS does not work well in this case. Although a portable
awk program can use a series of substr() calls on
$0 (see String-Manipulation Functions), this is awkward and inefficient
for a large number of fields.
The splitting of an input record into fixed-width fields is specified by
assigning a string containing space-separated numbers to the built-in
variable FIELDWIDTHS. Each number specifies the width of the
field, including columns between fields. If you want to ignore
the columns between fields, you can specify the width as a separate
field that is subsequently ignored. It is a fatal error to supply a
field width that has a negative value.
The following data is the output of the Unix w utility. It is useful
to illustrate the use of FIELDWIDTHS:
10:06pm up 21 days, 14:04, 23 users User tty login idle JCPU PCPU what hzuo ttyV0 8:58pm 9 5 vi p24.tex hzang ttyV3 6:37pm 50 -csh eklye ttyV5 9:53pm 7 1 em thes.tex dportein ttyV6 8:17pm 1:47 -csh gierd ttyD3 10:00pm 1 elm dave ttyD4 9:47pm 4 4 w brent ttyp0 26Jun91 4:46 26:46 4:41 bash dave ttyq4 26Jun9115days 46 46 wnewmail
The following program takes this input, converts the idle time to number of seconds, and prints out the first two fields and the calculated idle time:
BEGIN { FIELDWIDTHS = "9 6 10 6 7 7 35" }
NR > 2 {
idle = $4
sub(/^ +/, "", idle) # strip leading spaces
if (idle == "")
idle = 0
if (idle ~ /:/) { # hh:mm
split(idle, t, ":")
idle = t[1] * 60 + t[2]
}
if (idle ~ /days/)
idle *= 24 * 60 * 60
print $1, $2, idle
}
NOTE: The preceding program uses a number of
awkfeatures that haven’t been introduced yet.
Running the program on the data produces the following results:
hzuo ttyV0 0 hzang ttyV3 50 eklye ttyV5 0 dportein ttyV6 107 gierd ttyD3 1 dave ttyD4 0 brent ttyp0 286 dave ttyq4 1296000
Another (possibly more practical) example of fixed-width input data
is the input from a deck of balloting cards. In some parts of
the United States, voters mark their choices by punching holes in computer
cards. These cards are then processed to count the votes for any particular
candidate or on any particular issue. Because a voter may choose not to
vote on some issue, any column on the card may be empty. An awk
program for processing such data could use the FIELDWIDTHS feature
to simplify reading the data. (Of course, getting gawk to run on
a system with card readers is another story!)
4.6.2 Skipping Intervening Fields ¶
Starting in version 4.2, each field width may optionally be
preceded by a colon-separated value specifying the number of characters
to skip before the field starts. Thus, the preceding program could be
rewritten to specify FIELDWIDTHS like so:
BEGIN { FIELDWIDTHS = "8 1:5 4:7 6 1:6 1:6 2:33" }
This strips away some of the white space separating the fields. With such a change, the program produces the following results:
hzang ttyV3 50 eklye ttyV5 0 dportein ttyV6 107 gierd ttyD3 1 dave ttyD4 0 brent ttyp0 286 dave ttyq4 1296000
4.6.3 Capturing Optional Trailing Data ¶
There are times when fixed-width data may be followed by additional data
that has no fixed length. Such data may or may not be present, but if
it is, it should be possible to get at it from an awk program.
Starting with version 4.2, in order to provide a way to say “anything
else in the record after the defined fields,” gawk
allows you to add a final ‘*’ character to the value of
FIELDWIDTHS. There can only be one such character, and it must
be the final non-whitespace character in FIELDWIDTHS.
For example:
$ cat fw.awk Show the program
-| BEGIN { FIELDWIDTHS = "2 2 *" }
-| { print NF, $1, $2, $3 }
$ cat fw.in Show sample input
-| 1234abcdefghi
$ gawk -f fw.awk fw.in Run the program
-| 3 12 34 abcdefghi
4.6.4 Field Values With Fixed-Width Data ¶
So far, so good. But what happens if there isn’t as much data as there
should be based on the contents of FIELDWIDTHS? Or, what happens
if there is more data than expected?
For many years, what happens in these cases was not well defined. Starting with version 4.2, the rules are as follows:
- Enough data for some fields
For example, if
FIELDWIDTHSis set to"2 3 4"and the input record is ‘aabbb’. In this case,NFis set to two.- Not enough data for a field
For example, if
FIELDWIDTHSis set to"2 3 4"and the input record is ‘aab’. In this case,NFis set to two and$2has the value"b". The idea is that even though there aren’t as many characters as were expected, there are some, so the data should be made available to the program.- Too much data
For example, if
FIELDWIDTHSis set to"2 3 4"and the input record is ‘aabbbccccddd’. In this case,NFis set to three and the extra characters (‘ddd’) are ignored. If you wantgawkto capture the extra characters, supply a final ‘*’ in the value ofFIELDWIDTHS.- Too much data, but with ‘*’ supplied
For example, if
FIELDWIDTHSis set to"2 3 4 *"and the input record is ‘aabbbccccddd’. In this case,NFis set to four, and$4has the value"ddd".
4.7 Defining Fields by Content ¶
NOTE: This whole section needs rewriting now that
gawkhas built-in CSV parsing. Sigh.
This section discusses an advanced
feature of gawk. If you are a novice awk user,
you might want to skip it on the first reading.
Normally, when using FS, gawk defines the fields as the
parts of the record that occur in between each field separator. In other
words, FS defines what a field is not, instead of what a field
is.
However, there are times when you really want to define the fields by
what they are, and not by what they are not.
The most notorious such case is comma-separated values (CSV) data. Many spreadsheet programs, for example, can export their data into text files, where each record is terminated with a newline, and fields are separated by commas. If commas only separated the data, there wouldn’t be an issue. The problem comes when one of the fields contains an embedded comma. In such cases, most programs embed the field in double quotes.26 So, we might have data like this:
Robbins,Arnold,"1234 A Pretty Street, NE",MyTown,MyState,12345-6789,USA
The FPAT variable offers a solution for cases like this.
The value of FPAT should be a string that provides a regular expression.
This regular expression describes the contents of each field.
In the case of CSV data as presented here, each field is either “anything that
is not a comma,” or “a double quote, anything that is not a double quote, and a
closing double quote.” (There are more complicated definitions of CSV data,
treated shortly.)
If written as a regular expression constant
(see Regular Expressions),
we would have /([^,]+)|("[^"]+")/.
Writing this as a string requires us to escape the double quotes, leading to:
FPAT = "([^,]+)|(\"[^\"]+\")"
Putting this to use, here is a simple program to parse the data:
BEGIN {
FPAT = "([^,]+)|(\"[^\"]+\")"
}
{
print "NF = ", NF
for (i = 1; i <= NF; i++) {
printf("$%d = <%s>\n", i, $i)
}
}
When run, we get the following:
$ gawk -f simple-csv.awk addresses.csv NF = 7 $1 = <Robbins> $2 = <Arnold> $3 = <"1234 A Pretty Street, NE"> $4 = <MyTown> $5 = <MyState> $6 = <12345-6789> $7 = <USA>
Note the embedded comma in the value of $3.
A straightforward improvement when processing CSV data of this sort would be to remove the quotes when they occur, with something like this:
if (substr($i, 1, 1) == "\"") {
len = length($i)
$i = substr($i, 2, len - 2) # Get text within the two quotes
}
NOTE: Some programs export CSV data that contains embedded newlines between the double quotes.
gawkprovides no way to deal with this. Even though a formal specification for CSV data exists, there isn’t much more to be done; theFPATmechanism provides an elegant solution for the majority of cases, and thegawkdevelopers are satisfied with that.
As written, the regexp used for FPAT requires that each field
contain at least one character. A straightforward modification
(changing the first ‘+’ to ‘*’) allows fields to be empty:
FPAT = "([^,]*)|(\"[^\"]+\")"
As with FS, the IGNORECASE variable (see Built-in Variables That Control awk)
affects field splitting with FPAT.
Assigning a value to FPAT overrides field splitting
with FS and with FIELDWIDTHS.
Finally, the patsplit() function makes the same functionality
available for splitting regular strings (see String-Manipulation Functions).
NOTE: Given that
gawknow has built-in CSV parsing (see Working With Comma Separated Value Files), the examples presented here are obsolete. Nonetheless, it remains useful as an example of whatFPAT-based field parsing can do.
4.7.1 More on CSV Files ¶
Manuel Collado notes that in addition to commas, a CSV field can also
contains quotes, that have to be escaped by doubling them. The previously
described regexps fail to accept quoted fields with both commas and
quotes inside. He suggests that the simplest FPAT expression that
recognizes this kind of fields is /([^,]*)|("([^"]|"")+")/. He
provides the following input data to test these variants:
p,"q,r",s p,"q""r",s p,"q,""r",s p,"",s p,,s
And here is his test program:
BEGIN {
fp[0] = "([^,]+)|(\"[^\"]+\")"
fp[1] = "([^,]*)|(\"[^\"]+\")"
fp[2] = "([^,]*)|(\"([^\"]|\"\")+\")"
FPAT = fp[fpat+0]
}
{
print "<" $0 ">"
printf("NF = %s ", NF)
for (i = 1; i <= NF; i++) {
printf("<%s>", $i)
}
print ""
}
When run on the third variant, it produces:
$ gawk -v fpat=2 -f test-csv.awk sample.csv -| <p,"q,r",s> -| NF = 3 <p><"q,r"><s> -| <p,"q""r",s> -| NF = 3 <p><"q""r"><s> -| <p,"q,""r",s> -| NF = 3 <p><"q,""r"><s> -| <p,"",s> -| NF = 3 <p><""><s> -| <p,,s> -| NF = 3 <p><><s>
In general, using FPAT to do your own CSV parsing is like having
a bed with a blanket that’s not quite big enough. There’s always a corner
that isn’t covered. We recommend, instead, that you use Manuel Collado’s
CSVMODE library for gawk.
4.7.2 FS Versus FPAT: A Subtle Difference ¶
As we discussed earlier, FS describes the data between fields (“what fields are not”)
and FPAT describes the fields themselves (“what fields are”).
This leads to a subtle difference in how fields are found when using regexps as the value
for FS or FPAT.
In order to distinguish one field from another, there must be a non-empty separator between each field. This makes intuitive sense—otherwise one could not distinguish fields from separators.
Thus, regular expression matching as done when splitting fields with FS is not
allowed to match the null string; it must always match at least one character, in order
to be able to proceed through the entire record.
On the other hand, regular expression matching with FPAT can match the null
string, and the non-matching intervening characters function as the separators.
This same difference is reflected in how matching is done with the split()
and patsplit() functions (see String-Manipulation Functions).
4.8 Checking How gawk Is Splitting Records ¶
As we’ve seen, gawk provides three independent methods to split
input records into fields. The mechanism used is based on which of the
three variables—FS, FIELDWIDTHS, or FPAT—was
last assigned to. In addition, an API input parser may choose to override
the record parsing mechanism; please refer to Customized Input Parsers for
further information about this feature.
To restore normal field splitting after using FIELDWIDTHS
and/or FPAT, simply assign a value to FS.
You can use ‘FS = FS’ to do this,
without having to know the current value of FS.
In order to tell which kind of field splitting is in effect,
use PROCINFO["FS"] (see Built-in Variables That Convey Information).
The value is "FS" if regular field splitting is being used,
"FIELDWIDTHS" if fixed-width field splitting is being used,
or "FPAT" if content-based field splitting is being used:
if ("CSV" in PROCINFO)
CSV-based field splitting ...
else if (PROCINFO["FS"] == "FS")
regular field splitting ...
else if (PROCINFO["FS"] == "FIELDWIDTHS")
fixed-width field splitting ...
else if (PROCINFO["FS"] == "FPAT")
content-based field splitting ...
else
API input parser field splitting ... (advanced feature)
This information is useful when writing a function that needs to
temporarily change FS, FIELDWIDTHS, or FPAT, read some records,
and then restore the original settings (see Reading the User Database for an
example of such a function).
4.9 Multiple-Line Records ¶
In some databases, a single line cannot conveniently hold all the information in one entry. In such cases, you can use multiline records. The first step in doing this is to choose your data format.
One technique is to use an unusual character or string to separate
records. For example, you could use the formfeed character (written
‘\f’ in awk, as in C) to separate them, making each record
a page of the file. To do this, just set the variable RS to
"\f" (a string containing the formfeed character). Any
other character could equally well be used, as long as it won’t be part
of the data in a record.
Another technique is to have blank lines separate records. By a special
dispensation, an empty string as the value of RS indicates that
records are separated by one or more blank lines. When RS is set
to the empty string, each record always ends at the first blank line
encountered. The next record doesn’t start until the first nonblank
line that follows. No matter how many blank lines appear in a row, they
all act as one record separator.
(Blank lines must be completely empty; lines that contain only
whitespace do not count.)
You can achieve the same effect as ‘RS = ""’ by assigning the
string "\n\n+" to RS. This regexp matches the newline
at the end of the record and one or more blank lines after the record.
In addition, a regular expression always matches the longest possible
sequence when there is a choice
(see How Much Text Matches?).
So, the next record doesn’t start until
the first nonblank line that follows—no matter how many blank lines
appear in a row, they are considered one record separator.
However, there is an important difference between ‘RS = ""’ and ‘RS = "\n\n+"’. In the first case, leading newlines in the input data file are ignored, and if a file ends without extra blank lines after the last record, the final newline is removed from the record. In the second case, this special processing is not done. (d.c.)
Now that the input is separated into records, the second step is to
separate the fields in the records. One way to do this is to divide each
of the lines into fields in the normal manner. This happens by default
as the result of a special feature. When RS is set to the empty
string and FS is set to a single character,
the newline character always acts as a field separator.
This is in addition to whatever field separations result from
FS.
NOTE: When
FSis the null string ("") or a regexp, this special feature ofRSdoes not apply. It does apply to the default field separator of a single space: ‘FS = " "’.Note that language in the POSIX specification implies that this special feature should apply when
FSis a regexp. However, Unixawkhas never behaved that way, nor hasgawk. This is essentially a bug in POSIX.
The original motivation for this special exception was probably to provide
useful behavior in the default case (i.e., FS is equal
to " "). This feature can be a problem if you really don’t
want the newline character to separate fields, because there is no way to
prevent it. However, you can work around this by using the split()
function to break up the record manually
(see String-Manipulation Functions).
If you have a single-character field separator, you can work around
the special feature in a different way, by making FS into a
regexp for that single character. For example, if the field
separator is a percent character, instead of
‘FS = "%"’, use ‘FS = "[%]"’.
Another way to separate fields is to
put each field on a separate line: to do this, just set the
variable FS to the string "\n".
(This single-character separator matches a single newline.)
A practical example of a data file organized this way might be a mailing
list, where blank lines separate the entries. Consider a mailing
list in a file named addresses, which looks like this:
Jane Doe 123 Main Street Anywhere, SE 12345-6789 John Smith 456 Tree-lined Avenue Smallville, MW 98765-4321 ...
A simple program to process this file is as follows:
# addrs.awk --- simple mailing list program
# Records are separated by blank lines.
# Each line is one field.
BEGIN { RS = "" ; FS = "\n" }
{
print "Name is:", $1
print "Address is:", $2
print "City and State are:", $3
print ""
}
Running the program produces the following output:
$ awk -f addrs.awk addresses -| Name is: Jane Doe -| Address is: 123 Main Street -| City and State are: Anywhere, SE 12345-6789 -| -| Name is: John Smith -| Address is: 456 Tree-lined Avenue -| City and State are: Smallville, MW 98765-4321 -| ...
See Printing Mailing Labels for a more realistic program dealing with
address lists. The following list summarizes how records are split,
based on the value of
RS:
RS == "\n"Records are separated by the newline character (‘\n’). In effect, every line in the data file is a separate record, including blank lines. This is the default.
RS == any single characterRecords are separated by each occurrence of the character. Multiple successive occurrences delimit empty records.
RS == ""Records are separated by runs of blank lines. When
FSis a single character, then the newline character always serves as a field separator, in addition to whatever valueFSmay have. Leading and trailing newlines in a file are ignored.RS == regexpRecords are separated by occurrences of characters that match regexp. Leading and trailing matches of regexp delimit empty records. (This is a
gawkextension; it is not specified by the POSIX standard.)
If not in compatibility mode (see Command-Line Options), gawk sets
RT to the input text that matched the value specified by RS.
But if the input file ended without any text that matches RS,
then gawk sets RT to the null string.
4.10 Explicit Input with getline ¶
So far we have been getting our input data from awk’s main
input stream—either the standard input (usually your keyboard, sometimes
the output from another program) or the
files specified on the command line. The awk language has a
special built-in command called getline that
can be used to read input under your explicit control.
The getline command is used in several different ways and should
not be used by beginners.
The examples that follow the explanation of the getline command
include material that has not been covered yet. Therefore, come back
and study the getline command after you have reviewed the
rest of
this Web page
and have a good knowledge of how awk works.
The getline command returns 1 if it finds a record and 0 if
it encounters the end of the file. If there is some error in getting
a record, such as a file that cannot be opened, then getline
returns −1. In this case, gawk sets the variable
ERRNO to a string describing the error that occurred.
If ERRNO indicates that the I/O operation may be
retried, and PROCINFO["input", "RETRY"] is set,
then getline returns −2
instead of −1, and further calls to getline
may be attempted. See Retrying Reads After Certain Input Errors for further information about
this feature.
In the following examples, command stands for a string value that represents a shell command.
NOTE: When --sandbox is specified (see Command-Line Options), reading lines from files, pipes, and coprocesses is disabled.
- Using
getlinewith No Arguments - Using
getlineinto a Variable - Using
getlinefrom a File - Using
getlineinto a Variable from a File - Using
getlinefrom a Pipe - Using
getlineinto a Variable from a Pipe - Using
getlinefrom a Coprocess - Using
getlineinto a Variable from a Coprocess - Points to Remember About
getline - Summary of
getlineVariants
4.10.1 Using getline with No Arguments ¶
The getline command can be used without arguments to read input
from the current input file. All it does in this case is read the next
input record and split it up into fields. This is useful if you’ve
finished processing the current record, but want to do some special
processing on the next record right now. For example:
# Remove text between /* and */, inclusive
{
while ((start = index($0, "/*")) != 0) {
out = substr($0, 1, start - 1) # leading part of the string
rest = substr($0, start + 2) # ... */ ...
while ((end = index(rest, "*/")) == 0) { # is */ in trailing part?
# get more text
if (getline <= 0) {
print("unexpected EOF or error:", ERRNO) > "/dev/stderr"
exit
}
# build up the line using string concatenation
rest = rest $0
}
rest = substr(rest, end + 2) # remove comment
# build up the output line using string concatenation
$0 = out rest
}
print $0
}
This awk program deletes C-style comments (‘/* …
*/’) from the input.
It uses a number of features we haven’t covered yet, including
string concatenation
(see String Concatenation)
and the index() and substr() built-in
functions
(see String-Manipulation Functions).
By replacing the ‘print $0’ with other
statements, you could perform more complicated processing on the
decommented input, such as searching for matches of a regular
expression.
Here is some sample input:
mon/*comment*/key rab/*commen t*/bit horse /*comment*/more text part 1 /*comment*/part 2 /*comment*/part 3 no comment
When run, the output is:
$ awk -f strip_comments.awk example_text -| monkey -| rabbit -| horse more text -| part 1 part 2 part 3 -| no comment
This form of the getline command sets NF,
NR, FNR, RT, and the value of $0.
NOTE: The new value of
$0is used to test the patterns of any subsequent rules. The original value of$0that triggered the rule that executedgetlineis lost. By contrast, thenextstatement reads a new record but immediately begins processing it normally, starting with the first rule in the program. See ThenextStatement.
4.10.2 Using getline into a Variable ¶
You can use ‘getline var’ to read the next record from
awk’s input into the variable var. No other processing is
done.
For example, suppose the next line is a comment or a special string,
and you want to read it without triggering
any rules. This form of getline allows you to read that line
and store it in a variable so that the main
read-a-line-and-check-each-rule loop of awk never sees it.
The following example swaps every two lines of input:
{
if ((getline tmp) > 0) {
print tmp
print $0
} else
print $0
}
It takes the following list:
wan tew free phore
and produces these results:
tew wan phore free
The getline command used in this way sets only the variables
NR, FNR, and RT (and, of course, var).
The record is not
split into fields, so the values of the fields (including $0) and
the value of NF do not change.
4.10.3 Using getline from a File ¶
Use ‘getline < file’ to read the next record from file. Here, file is a string-valued expression that specifies the file name. ‘< file’ is called a redirection because it directs input to come from a different place. For example, the following program reads its input record from the file secondary.input when it encounters a first field with a value equal to 10 in the current input file:
{
if ($1 == 10) {
getline < "secondary.input"
print
} else
print
}
Because the main input stream is not used, the values of NR and
FNR are not changed. However, the record it reads is split into fields in
the normal manner, so the values of $0 and the other fields are
changed, resulting in a new value of NF.
RT is also set.
According to POSIX, ‘getline < expression’ is ambiguous if
expression contains unparenthesized operators other than
‘$’; for example, ‘getline < dir "/" file’ is ambiguous
because the concatenation operator (not discussed yet; see String Concatenation)
is not parenthesized. You should write it as ‘getline < (dir "/" file)’ if
you want your program to be portable to all awk implementations.
4.10.4 Using getline into a Variable from a File ¶
Use ‘getline var < file’ to read input from the file file, and put it in the variable var. As earlier, file is a string-valued expression that specifies the file from which to read.
In this version of getline, none of the predefined variables are
changed and the record is not split into fields. The only variable
changed is var.27
For example, the following program copies all the input files to the
output, except for records that say ‘@include filename’.
Such a record is replaced by the contents of the file
filename:
{
if (NF == 2 && $1 == "@include") {
while ((getline line < $2) > 0)
print line
close($2)
} else
print
}
Note here how the name of the extra input file is not built into
the program; it is taken directly from the data, specifically from the second field on
the @include line.
The close() function is called to ensure that if two identical
@include lines appear in the input, the entire specified file is
included twice.
See Closing Input and Output Redirections.
One deficiency of this program is that it does not process nested
@include statements
(i.e., @include statements in included files)
the way a true macro preprocessor would.
See An Easy Way to Use Library Functions for a program
that does handle nested @include statements.
4.10.5 Using getline from a Pipe ¶
Omniscience has much to recommend it. Failing that, attention to details would be useful.
The output of a command can also be piped into getline, using
‘command | getline’. In
this case, the string command is run as a shell command and its output
is piped into awk to be used as input. This form of getline
reads one record at a time from the pipe.
For example, the following program copies its input to its output, except for
lines that begin with ‘@execute’, which are replaced by the output
produced by running the rest of the line as a shell command:
{
if ($1 == "@execute") {
tmp = substr($0, 10) # Remove "@execute"
while ((tmp | getline) > 0)
print
close(tmp)
} else
print
}
The close() function is called to ensure that if two identical
‘@execute’ lines appear in the input, the command is run for
each one.
See Closing Input and Output Redirections.
Given the input:
foo bar baz @execute who bletch
the program might produce:
foo bar baz arnold ttyv0 Jul 13 14:22 miriam ttyp0 Jul 13 14:23 (murphy:0) bill ttyp1 Jul 13 14:23 (murphy:0) bletch
Notice that this program ran the command who and printed the result.
(If you try this program yourself, you will of course get different results,
depending upon who is logged in on your system.)
This variation of getline splits the record into fields, sets the
value of NF, and recomputes the value of $0. The values of
NR and FNR are not changed.
RT is set.
According to POSIX, ‘expression | getline’ is ambiguous if
expression contains unparenthesized operators other than
‘$’—for example, ‘"echo " "date" | getline’ is ambiguous
because the concatenation operator is not parenthesized. You should
write it as ‘("echo " "date") | getline’ if you want your program
to be portable to all awk implementations.
NOTE: Unfortunately,
gawkhas not been consistent in its treatment of a construct like ‘"echo " "date" | getline’. Most versions, including the current version, treat it as ‘("echo " "date") | getline’. (This is also how BWKawkbehaves.) Some versions instead treat it as ‘"echo " ("date" | getline)’. (This is howmawkbehaves.) In short, always use explicit parentheses, and then you won’t have to worry.
4.10.6 Using getline into a Variable from a Pipe ¶
When you use ‘command | getline var’, the
output of command is sent through a pipe to
getline and into the variable var. For example, the
following program reads the current date and time into the variable
current_time, using the date utility, and then
prints it:
BEGIN {
"date" | getline current_time
close("date")
print "Report printed on " current_time
}
In this version of getline, none of the predefined variables are
changed and the record is not split into fields. However, RT is set.
4.10.7 Using getline from a Coprocess ¶
Reading input into getline from a pipe is a one-way operation.
The command that is started with ‘command | getline’ only
sends data to your awk program.
On occasion, you might want to send data to another program
for processing and then read the results back.
gawk allows you to start a coprocess, with which two-way
communications are possible. This is done with the ‘|&’
operator.
Typically, you write data to the coprocess first and then
read the results back, as shown in the following:
print "some query" |& "db_server" "db_server" |& getline
which sends a query to db_server and then reads the results.
The values of NR and
FNR are not changed,
because the main input stream is not used.
However, the record is split into fields in
the normal manner, thus changing the values of $0, of the other fields,
and of NF and RT.
Coprocesses are an advanced feature. They are discussed here only because
this is the section on getline.
See Two-Way Communications with Another Process,
where coprocesses are discussed in more detail.
4.10.8 Using getline into a Variable from a Coprocess ¶
When you use ‘command |& getline var’, the output from
the coprocess command is sent through a two-way pipe to getline
and into the variable var.
In this version of getline, none of the predefined variables are
changed and the record is not split into fields. The only variable
changed is var.
However, RT is set.
4.10.9 Points to Remember About getline ¶
Here are some miscellaneous points about getline that
you should bear in mind:
- When
getlinechanges the value of$0andNF,awkdoes not automatically jump to the start of the program and start testing the new record against every pattern. However, the new record is tested against any subsequent rules. - Some very old
awkimplementations limit the number of pipelines that anawkprogram may have open to just one. Ingawk, there is no such limit. You can open as many pipelines (and coprocesses) as the underlying operating system permits. - An interesting side effect occurs if you use
getlinewithout a redirection inside aBEGINrule. Because an unredirectedgetlinereads from the command-line data files, the firstgetlinecommand causesawkto set the value ofFILENAME. Normally,FILENAMEdoes not have a value insideBEGINrules, because you have not yet started to process the command-line data files. (d.c.) (See TheBEGINandENDSpecial Patterns; also see Built-in Variables That Convey Information.) - Using
FILENAMEwithgetline(‘getline < FILENAME’) is likely to be a source of confusion.awkopens a separate input stream from the current input file. However, by not using a variable,$0andNFare still updated. If you’re doing this, it’s probably by accident, and you should reconsider what it is you’re trying to accomplish. - Summary of
getlineVariants, presents a table summarizing thegetlinevariants and which variables they can affect. It is worth noting that those variants that do not use redirection can causeFILENAMEto be updated if they causeawkto start reading a new input file. -
If the variable being assigned is an expression with side effects,
different versions of
awkbehave differently upon encountering end-of-file. Some versions don’t evaluate the expression; many versions (includinggawk) do. Here is an example, courtesy of Duncan Moore:BEGIN { system("echo 1 > f") while ((getline a[++c] < "f") > 0) { } print c }Here, the side effect is the ‘++c’. Is
cincremented if end-of-file is encountered before the element inais assigned?gawktreatsgetlinelike a function call, and evaluates the expression ‘a[++c]’ before attempting to read from f. However, some versions ofawkonly evaluate the expression once they know that there is a string value to be assigned.
4.10.10 Summary of getline Variants ¶
Table 4.2
summarizes the eight variants of getline,
listing which predefined variables are set by each one,
and whether the variant is standard or a gawk extension.
Note: for each variant, gawk sets the RT predefined variable.
| Variant | Effect | awk / gawk |
|---|---|---|
getline | Sets $0, NF, FNR, NR, and RT | awk |
getline var | Sets var, FNR, NR, and RT | awk |
getline < file | Sets $0, NF, and RT | awk |
getline var < file | Sets var and RT | awk |
command | getline | Sets $0, NF, and RT | awk |
command | getline var | Sets var and RT | awk |
command |& getline | Sets $0, NF, and RT | gawk |
command |& getline var | Sets var and RT | gawk |
Table 4.2: getline variants and what they set
4.11 Reading Input with a Timeout ¶
This section describes a feature that is specific to gawk.
You may specify a timeout in milliseconds for reading input from the keyboard,
a pipe, or two-way communication, including TCP/IP sockets. This can be done
on a per-input, per-command, or per-connection basis, by setting a special
element in the PROCINFO array (see Built-in Variables That Convey Information):
PROCINFO["input_name", "READ_TIMEOUT"] = timeout in milliseconds
When set, this causes gawk to time out and return failure
if no data is available to read within the specified timeout period.
For example, a TCP client can decide to give up on receiving
any response from the server after a certain amount of time:
Service = "/inet/tcp/0/localhost/daytime"
PROCINFO[Service, "READ_TIMEOUT"] = 100
if ((Service |& getline) > 0)
print $0
else if (ERRNO != "")
print ERRNO
Here is how to read interactively from the user28 without waiting for more than five seconds:
PROCINFO["/dev/stdin", "READ_TIMEOUT"] = 5000
while ((getline < "/dev/stdin") > 0)
print $0
gawk terminates the read operation if input does not
arrive after waiting for the timeout period, returns failure,
and sets ERRNO to an appropriate string value.
A negative or zero value for the timeout is the same as specifying
no timeout at all.
A timeout can also be set for reading from the keyboard in the implicit loop that reads input records and matches them against patterns, like so:
$ gawk 'BEGIN { PROCINFO["-", "READ_TIMEOUT"] = 5000 }
> { print "You entered: " $0 }'
gawk
-| You entered: gawk
In this case, failure to respond within five seconds results in the following error message:
error→ gawk: cmd. line:2: (FILENAME=- FNR=1) fatal: error reading input file `-': Connection timed out
The timeout can be set or changed at any time, and will take effect on the next attempt to read from the input device. In the following example, we start with a timeout value of one second, and progressively reduce it by one-tenth of a second until we wait indefinitely for the input to arrive:
PROCINFO[Service, "READ_TIMEOUT"] = 1000
while ((Service |& getline) > 0) {
print $0
PROCINFO[Service, "READ_TIMEOUT"] -= 100
}
NOTE: You should not assume that the read operation will block exactly after the tenth record has been printed. It is possible that
gawkwill read and buffer more than one record’s worth of data the first time. Because of this, changing the value of timeout like in the preceding example is not very useful.
If the PROCINFO element is not present and the
GAWK_READ_TIMEOUT environment variable exists,
gawk uses its value to initialize the timeout value.
The exclusive use of the environment variable to specify timeout
has the disadvantage of not being able to control it
on a per-command or per-connection basis.
gawk considers a timeout event to be an error even though
the attempt to read from the underlying device may
succeed in a later attempt. This is a limitation, and it also
means that you cannot use this to multiplex input from
two or more sources. See Retrying Reads After Certain Input Errors for a way to enable
later I/O attempts to succeed.
Assigning a timeout value prevents read operations from being
blocked indefinitely. But bear in mind that there are other ways
gawk can stall waiting for an input device to be ready.
A network client can sometimes take a long time to establish
a connection before it can start reading any data,
or the attempt to open a FIFO special file for reading can be blocked
indefinitely until some other process opens it for writing.
4.12 Retrying Reads After Certain Input Errors ¶
This section describes a feature that is specific to gawk.
When gawk encounters an error while reading input, by
default getline returns −1, and subsequent attempts to
read from that file result in an end-of-file indication. However, you
may optionally instruct gawk to allow I/O to be retried when
certain errors are encountered by setting a special element in
the PROCINFO array (see Built-in Variables That Convey Information):
PROCINFO["input_name", "RETRY"] = 1
When this element exists, gawk checks the value of the system
(C language)
errno variable when an I/O error occurs. If errno indicates
a subsequent I/O attempt may succeed, getline instead returns
−2 and
further calls to getline may succeed. This applies to the errno
values EAGAIN, EWOULDBLOCK, EINTR, or ETIMEDOUT.
This feature is useful in conjunction with
PROCINFO["input_name", "READ_TIMEOUT"] or situations where a file
descriptor has been configured to behave in a non-blocking fashion.
4.13 Directories on the Command Line ¶
According to the POSIX standard, files named on the awk
command line must be text files; it is a fatal error if they are not.
Most versions of awk treat a directory on the command line as
a fatal error.
By default, gawk produces a warning for a directory on the
command line, but otherwise ignores it. This makes it easier to use
shell wildcards with your awk program:
$ gawk -f whizprog.awk * Directories could kill this program
If either of the --posix
or --traditional options is given, then gawk reverts
to treating a directory on the command line as a fatal error.
See Reading Directories for a way to treat directories
as usable data from an awk program.
4.14 Summary ¶
- Input is split into records based on the value of
RS. The possibilities are as follows:Value of RSRecords are split on … awk/gawkAny single character That character awkThe empty string ( "")Runs of two or more newlines awkA regexp Text that matches the regexp gawk FNRindicates how many records have been read from the current input file;NRindicates how many records have been read in total.gawksetsRTto the text matched byRS.- After splitting the input into records,
awkfurther splits the records into individual fields, named$1,$2, and so on.$0is the whole record, andNFindicates how many fields there are. The default way to split fields is between whitespace characters. - Fields may be referenced using a variable, as in
$NF. Fields may also be assigned values, which causes the value of$0to be recomputed when it is later referenced. Assigning to a field with a number greater thanNFcreates the field and rebuilds the record, usingOFSto separate the fields. IncrementingNFdoes the same thing. DecrementingNFthrows away fields and rebuilds the record. - Field splitting is more complicated than record splitting:
Field separator value Fields are split … awk/gawkFS == " "On runs of whitespace awkFS == any single characterOn that character awkFS == regexpOn text matching the regexp awkFS == ""Such that each individual character is a separate field gawkFIELDWIDTHS == list of columnsBased on character position gawkFPAT == regexpOn the text surrounding text matching the regexp gawk - Using ‘FS = "\n"’ causes the entire record to be a single field (assuming that newlines separate records).
FSmay be set from the command line using the -F option. This can also be done using command-line variable assignment.- Use
PROCINFO["FS"]to see how fields are being split. - Use
getlinein its various forms to read additional records from the default input stream, from a file, or from a pipe or coprocess. - Use
PROCINFO[file, "READ_TIMEOUT"]to cause reads to time out for file. -
Directories on the command line are fatal for standard
awk;gawkignores them if not in POSIX mode.
4.15 Exercises ¶
- Using the
FIELDWIDTHSvariable (see Reading Fixed-Width Data), write a program to read election data, where each record represents one voter’s votes. Come up with a way to define which columns are associated with each ballot item, and print the total votes, including abstentions, for each item.
5 Printing Output ¶
One of the most common programming actions is to print, or output,
some or all of the input. Use the print statement
for simple output, and the printf statement
for fancier formatting.
The print statement is not limited when
computing which values to print. However, with two exceptions,
you cannot specify how to print them—how many
columns, whether to use exponential notation or not, and so on.
(For the exceptions, see Output Separators and
Controlling Numeric Output with print.)
For printing with specifications, you need the printf statement
(see Using printf Statements for Fancier Printing).
Besides basic and formatted printing, this chapter
also covers I/O redirections to files and pipes, introduces
the special file names that gawk processes internally,
and discusses the close() built-in function.
- The
printStatement printStatement Examples- Output Separators
- Controlling Numeric Output with
print - Using
printfStatements for Fancier Printing - Redirecting Output of
printandprintf - Special Files for Standard Preopened Data Streams
- Special File names in
gawk - Closing Input and Output Redirections
- Speeding Up Pipe Output
- Enabling Nonfatal Output
- Summary
- Exercises
5.1 The print Statement ¶
Use the print statement to produce output with simple, standardized
formatting. You specify only the strings or numbers to print, in a
list separated by commas. They are output, separated by single spaces,
followed by a newline. The statement looks like this:
print item1, item2, ...
The entire list of items may be optionally enclosed in parentheses. The
parentheses are necessary if any of the item expressions uses the ‘>’
relational operator; otherwise it could be confused with an output redirection
(see Redirecting Output of print and printf).
The items to print can be constant strings or numbers, fields of the
current record (such as $1), variables, or any awk
expression. Numeric values are converted to strings and then printed.
The simple statement ‘print’ with no items is equivalent to
‘print $0’: it prints the entire current record. To print a blank
line, use ‘print ""’.
To print a fixed piece of text, use a string constant, such as
"Don't Panic", as one item. If you forget to use the
double-quote characters, your text is taken as an awk
expression, and you will probably get an error. Keep in mind that a
space is printed between any two items.
Note that the print statement is a statement and not an
expression—you can’t use it in the pattern part of a
pattern–action statement, for example.
5.2 print Statement Examples ¶
Each print statement makes at least one line of output. However, it
isn’t limited to only one line. If an item value is a string containing a
newline, the newline is output along with the rest of the string. A
single print statement can make any number of lines this way.
The following is an example of printing a string that contains embedded newlines (the ‘\n’ is an escape sequence, used to represent the newline character; see Escape Sequences):
$ awk 'BEGIN { print "line one\nline two\nline three" }'
-| line one
-| line two
-| line three
The next example, which is run on the inventory-shipped file, prints the first two fields of each input record, with a space between them:
$ awk '{ print $1, $2 }' inventory-shipped
-| Jan 13
-| Feb 15
-| Mar 15
...
A common mistake in using the print statement is to omit the comma
between two items. This often has the effect of making the items run
together in the output, with no space. The reason for this is that
juxtaposing two string expressions in awk means to concatenate
them. Here is the same program, without the comma:
$ awk '{ print $1 $2 }' inventory-shipped
-| Jan13
-| Feb15
-| Mar15
...
To someone unfamiliar with the inventory-shipped file, neither
example’s output makes much sense. A heading line at the beginning
would make it clearer. Let’s add some headings to our table of months
($1) and green crates shipped ($2). We do this using
a BEGIN rule (see The BEGIN and END Special Patterns) so that the headings are only
printed once:
awk 'BEGIN { print "Month Crates"
print "----- ------" }
{ print $1, $2 }' inventory-shipped
When run, the program prints the following:
Month Crates ----- ------ Jan 13 Feb 15 Mar 15 ...
The only problem, however, is that the headings and the table data don’t line up! We can fix this by printing some spaces between the two fields:
awk 'BEGIN { print "Month Crates"
print "----- ------" }
{ print $1, " ", $2 }' inventory-shipped
Lining up columns this way can get pretty
complicated when there are many columns to fix. Counting spaces for two
or three columns is simple, but any more than this can take up
a lot of time. This is why the printf statement was
created (see Using printf Statements for Fancier Printing);
one of its specialties is lining up columns of data.
NOTE: You can continue either a
printfstatement simply by putting a newline after any comma (seeawkStatements Versus Lines).
5.3 Output Separators ¶
As mentioned previously, a print statement contains a list
of items separated by commas. In the output, the items are normally
separated by single spaces. However, this doesn’t need to be the case;
a single space is simply the default. Any string of
characters may be used as the output field separator by setting the
predefined variable OFS. The initial value of this variable
is the string " " (i.e., a single space).
The output from an entire print statement is called an output
record. Each print statement outputs one output record, and
then outputs a string called the output record separator (or
ORS). The initial value of ORS is the string "\n"
(i.e., a newline character). Thus, each print statement normally
makes a separate line.
In order to change how output fields and records are separated, assign
new values to the variables OFS and ORS. The usual
place to do this is in the BEGIN rule
(see The BEGIN and END Special Patterns), so
that it happens before any input is processed. It can also be done
with assignments on the command line, before the names of the input
files, or using the -v command-line option
(see Command-Line Options).
The following example prints the first and second fields of each input
record, separated by a semicolon, with a blank line added after each
newline:
$ awk 'BEGIN { OFS = ";"; ORS = "\n\n" }
> { print $1, $2 }' mail-list
-| Amelia;555-5553
-|
-| Anthony;555-3412
-|
-| Becky;555-7685
-|
-| Bill;555-1675
-|
-| Broderick;555-0542
-|
-| Camilla;555-2912
-|
-| Fabius;555-1234
-|
-| Julie;555-6699
-|
-| Martin;555-6480
-|
-| Samuel;555-3430
-|
-| Jean-Paul;555-2127
-|
If the value of ORS does not contain a newline, the program’s output
runs together on a single line.
5.4 Controlling Numeric Output with print ¶
When printing numeric values with the print statement,
awk internally converts each number to a string of characters
and prints that string. awk uses the sprintf() function
to do this conversion
(see String-Manipulation Functions).
For now, it suffices to say that the sprintf()
function accepts a format specification that tells it how to format
numbers (or strings), and that there are a number of different ways in which
numbers can be formatted. The different format specifications are discussed
more fully in
Format-Control Letters.
The predefined variable OFMT contains the format specification
that print uses with sprintf() when it wants to convert a
number to a string for printing.
The default value of OFMT is "%.6g".
The way print prints numbers can be changed
by supplying a different format specification
for the value of OFMT, as shown in the following example:
$ awk 'BEGIN {
> OFMT = "%.0f" # print numbers as integers (rounds)
> print 17.23, 17.54 }'
-| 17 18
More detail on how awk converts numeric values into
strings is provided in How awk Converts Between Strings and Numbers. In particular, for
print, awk uses the value of OFMT instead of
that of CONVFMT, but otherwise behaves exactly the same
as described in that section.
According to the POSIX standard, awk’s behavior is undefined
if OFMT contains anything but a floating-point conversion specification.
(d.c.)
5.5 Using printf Statements for Fancier Printing ¶
For more precise control over the output format than what is
provided by print, use printf.
With printf you can
specify the width to use for each item, as well as various
formatting choices for numbers (such as what output base to use, whether to
print an exponent, whether to print a sign, and how many digits to print
after the decimal point).
- Introduction to the
printfStatement - Format-Control Letters
- Modifiers for
printfFormats - Examples Using
printf
5.5.1 Introduction to the printf Statement ¶
A simple printf statement looks like this:
printf format, item1, item2, ...
As for print, the entire list of arguments may optionally be
enclosed in parentheses. Here too, the parentheses are necessary if any
of the item expressions uses the ‘>’ relational operator; otherwise,
it can be confused with an output redirection (see Redirecting Output of print and printf).
The difference between printf and print is the format
argument. This is an expression whose value is taken as a string; it
specifies how to output each of the other arguments. It is called the
format string.
The format string is very similar to that in the ISO C library function
printf(). Most of format is text to output verbatim.
Scattered among this text are format specifiers—one per item.
Each format specifier says to output the next item in the argument list
at that place in the format.
The printf statement does not automatically append a newline
to its output. It outputs only what the format string specifies.
So if a newline is needed, you must include one in the format string.
The output separator variables OFS and ORS have no effect
on printf statements. For example:
$ awk 'BEGIN {
> ORS = "\nOUCH!\n"; OFS = "+"
> msg = "Don\47t Panic!"
> printf "%s\n", msg
> }'
-| Don't Panic!
Here, neither the ‘+’ nor the ‘OUCH!’ appears in the output message.
5.5.2 Format-Control Letters ¶
A format specifier starts with the character ‘%’ and ends with
a format-control letter—it tells the printf statement
how to output one item. The format-control letter specifies what kind
of value to print. The rest of the format specifier is made up of
optional modifiers that control how to print the value, such as
the field width. Here is a list of the format-control letters:
%a,%AA floating point number of the form [
-]0xh.hhhhp+-dd(C99 hexadecimal floating point format). For%A, uppercase letters are used instead of lowercase ones.NOTE: The current POSIX standard requires support for
%aand%Ainawk. As far as we know, besidesgawk, the only other version ofawkthat actually implements it is BWKawk. It’s use is thus highly nonportable!Furthermore, these formats are not available on any system where the underlying C library
printf()function does not support them. As of this writing, among current systems, only OpenVMS is known to not support them.%cPrint a number as a character; thus, ‘printf "%c", 65’ outputs the letter ‘A’. The output for a string value is the first character of the string.
NOTE: The POSIX standard says the first character of a string is printed. In locales with multibyte characters,
gawkattempts to convert the leading bytes of the string into a valid wide character and then to print the multibyte encoding of that character. Similarly, when printing a numeric value,gawkallows the value to be within the numeric range of values that can be held in a wide character. If the conversion to multibyte encoding fails,gawkuses the low eight bits of the value as the character to print.Other
awkversions generally restrict themselves to printing the first byte of a string or to numeric values within the range of a single byte (0–255). (d.c.)%d,%iPrint a decimal integer. The two control letters are equivalent. (The ‘%i’ specification is for compatibility with ISO C.)
%e,%EPrint a number in scientific (exponential) notation. For example:
printf "%4.3e\n", 1950
prints ‘1.950e+03’, with a total of four significant figures, three of which follow the decimal point. (The ‘4.3’ represents two modifiers, discussed in the next subsection.) ‘%E’ uses ‘E’ instead of ‘e’ in the output.
%fPrint a number in floating-point notation. For example:
printf "%4.3f", 1950
prints ‘1950.000’, with a minimum of four significant figures, three of which follow the decimal point. (The ‘4.3’ represents two modifiers, discussed in the next subsection.)
On systems supporting IEEE 754 floating-point format, values representing negative infinity are formatted as ‘-inf’ or ‘-infinity’, and positive infinity as ‘inf’ or ‘infinity’. The special “not a number” value formats as ‘-nan’ or ‘nan’ (see Floating Point Values They Didn’t Talk About In School).
%FLike ‘%f’, but the infinity and “not a number” values are spelled using uppercase letters.
The ‘%F’ format is a POSIX extension to ISO C; not all systems support it. On those that don’t,
gawkuses ‘%f’ instead.%g,%GPrint a number in either scientific notation or in floating-point notation, whichever uses fewer characters; if the result is printed in scientific notation, ‘%G’ uses ‘E’ instead of ‘e’.
%oPrint an unsigned octal integer (see Octal and Hexadecimal Numbers).
%sPrint a string.
%uPrint an unsigned decimal integer. (This format is of marginal use, because all numbers in
awkare floating point; it is provided primarily for compatibility with C.)%x,%XPrint an unsigned hexadecimal integer; ‘%X’ uses the letters ‘A’ through ‘F’ instead of ‘a’ through ‘f’ (see Octal and Hexadecimal Numbers).
%%Print a single ‘%’. This does not consume an argument and it ignores any modifiers.
NOTE: When using the integer format-control letters for values that are outside the range of the widest C integer type,
gawkswitches to the ‘%g’ format specifier. If --lint is provided on the command line (see Command-Line Options),gawkwarns about this. Other versions ofawkmay print invalid values or do something else entirely. (d.c.)
NOTE: The IEEE 754 standard for floating-point arithmetic allows for special values that represent “infinity” (positive and negative) and values that are “not a number” (NaN).
Input and output of these values occurs as text strings. This is somewhat problematic for the
awklanguage, which predates the IEEE standard. Further details are provided in Standards Versus Existing Practice; please see there.
5.5.3 Modifiers for printf Formats ¶
A format specification can also include modifiers that can control how much of the item’s value is printed, as well as how much space it gets. The modifiers come between the ‘%’ and the format-control letter. We use the bullet symbol “•” in the following examples to represent spaces in the output. Here are the possible modifiers, in the order in which they may appear:
N$¶An integer constant followed by a ‘$’ is a positional specifier. Normally, format specifications are applied to arguments in the order given in the format string. With a positional specifier, the format specification is applied to a specific argument, instead of what would be the next argument in the list. Positional specifiers begin counting with one. Thus:
printf "%s %s\n", "don't", "panic" printf "%2$s %1$s\n", "panic", "don't"
prints the famous friendly message twice.
At first glance, this feature doesn’t seem to be of much use. It is in fact a
gawkextension, intended for use in translating messages at runtime. See RearrangingprintfArguments, which describes how and why to use positional specifiers. For now, we ignore them.-(Minus)The minus sign, used before the width modifier (see later on in this list), says to left-justify the argument within its specified width. Normally, the argument is printed right-justified in the specified width. Thus:
printf "%-4s", "foo"
prints ‘foo•’.
- space
For numeric conversions, prefix positive values with a space and negative values with a minus sign.
+The plus sign, used before the width modifier (see later on in this list), says to always supply a sign for numeric conversions, even if the data to format is positive. The ‘+’ overrides the space modifier.
#Use an “alternative form” for certain control letters. For ‘%o’, supply a leading zero. For ‘%x’ and ‘%X’, supply a leading ‘0x’ or ‘0X’ for a nonzero result. For ‘%e’, ‘%E’, ‘%f’, and ‘%F’, the result always contains a decimal point. For ‘%g’ and ‘%G’, trailing zeros are not removed from the result.
0A leading ‘0’ (zero) acts as a flag indicating that output should be padded with zeros instead of spaces. This applies only to the numeric output formats. This flag only has an effect when the field width is wider than the value to print.
'A single quote or apostrophe character is a POSIX extension to ISO C. It indicates that the integer part of a floating-point value, or the entire part of an integer decimal value, should have a thousands-separator character in it. This only works in locales that support such characters. For example:
$ cat thousands.awk Show source program -| BEGIN { printf "%'d\n", 1234567 } $ LC_ALL=C gawk -f thousands.awk -| 1234567 Results in "C" locale $ LC_ALL=en_US.UTF-8 gawk -f thousands.awk -| 1,234,567 Results in US English UTF localeFor more information about locales and internationalization issues, see Where You Are Makes a Difference.
NOTE: The ‘'’ flag is a nice feature, but its use complicates things: it becomes difficult to use it in command-line programs. For information on appropriate quoting tricks, see Shell Quoting Issues.
- width
This is a number specifying the desired minimum width of a field. Inserting any number between the ‘%’ sign and the format-control character forces the field to expand to this width. The default way to do this is to pad with spaces on the left. For example:
printf "%4s", "foo"
prints ‘•foo’.
The value of width is a minimum width, not a maximum. If the item value requires more than width characters, it can be as wide as necessary. Thus, the following:
printf "%4s", "foobar"
prints ‘foobar’.
Preceding the width with a minus sign causes the output to be padded with spaces on the right, instead of on the left.
.precA period followed by an integer constant specifies the precision to use when printing. The meaning of the precision varies by control letter:
%d,%i,%o,%u,%x,%XMinimum number of digits to print.
%e,%E,%f,%FNumber of digits to the right of the decimal point.
%g,%GMaximum number of significant digits.
%sMaximum number of characters from the string that should print.
Thus, the following:
printf "%.4s", "foobar"
prints ‘foob’.
The C library printf’s dynamic width and prec
capability (e.g., "%*.*s") is supported. Instead of
supplying explicit width and/or prec values in the format
string, they are passed in the argument list. For example:
w = 5 p = 3 s = "abcdefg" printf "%*.*s\n", w, p, s
is exactly equivalent to:
s = "abcdefg" printf "%5.3s\n", s
Both programs output ‘••abc’.
Earlier versions of awk did not support this capability.
If you must use such a version, you may simulate this feature by using
concatenation to build up the format string, like so:
w = 5 p = 3 s = "abcdefg" printf "%" w "." p "s\n", s
This is not particularly easy to read, but it does work.
C programmers may be used to supplying additional modifiers (‘h’,
‘j’, ‘l’, ‘L’, ‘t’, and ‘z’) in printf
format strings. These are not valid in awk. Most awk
implementations silently ignore them. If --lint is provided
on the command line (see Command-Line Options), gawk warns about their
use. If --posix is supplied, their use is a fatal error.
5.5.4 Examples Using printf ¶
The following simple example shows
how to use printf to make an aligned table:
awk '{ printf "%-10s %s\n", $1, $2 }' mail-list
This command
prints the names of the people ($1) in the file
mail-list as a string of 10 characters that are left-justified. It also
prints the phone numbers ($2) next on the line. This
produces an aligned two-column table of names and phone numbers,
as shown here:
$ awk '{ printf "%-10s %s\n", $1, $2 }' mail-list
-| Amelia 555-5553
-| Anthony 555-3412
-| Becky 555-7685
-| Bill 555-1675
-| Broderick 555-0542
-| Camilla 555-2912
-| Fabius 555-1234
-| Julie 555-6699
-| Martin 555-6480
-| Samuel 555-3430
-| Jean-Paul 555-2127
In this case, the phone numbers had to be printed as strings because the numbers are separated by dashes. Printing the phone numbers as numbers would have produced just the first three digits: ‘555’. This would have been pretty confusing.
It wasn’t necessary to specify a width for the phone numbers because they are last on their lines. They don’t need to have spaces after them.
The table could be made to look even nicer by adding headings to the
tops of the columns. This is done using a BEGIN rule
(see The BEGIN and END Special Patterns)
so that the headers are only printed once, at the beginning of
the awk program:
awk 'BEGIN { print "Name Number"
print "---- ------" }
{ printf "%-10s %s\n", $1, $2 }' mail-list
The preceding example mixes print and printf statements in
the same program. Using just printf statements can produce the
same results:
awk 'BEGIN { printf "%-10s %s\n", "Name", "Number"
printf "%-10s %s\n", "----", "------" }
{ printf "%-10s %s\n", $1, $2 }' mail-list
Printing each column heading with the same format specification used for the column elements ensures that the headings are aligned just like the columns.
The fact that the same format specification is used three times can be emphasized by storing it in a variable, like this:
awk 'BEGIN { format = "%-10s %s\n"
printf format, "Name", "Number"
printf format, "----", "------" }
{ printf format, $1, $2 }' mail-list
5.6 Redirecting Output of print and printf ¶
So far, the output from print and printf has gone
to the standard
output, usually the screen. Both print and printf can
also send their output to other places.
This is called redirection.
NOTE: When --sandbox is specified (see Command-Line Options), redirecting output to files, pipes, and coprocesses is disabled.
A redirection appears after the print or printf statement.
Redirections in awk are written just like redirections in shell
commands, except that they are written inside the awk program.
There are four forms of output redirection: output to a file, output
appended to a file, output through a pipe to another command, and output
to a coprocess. We show them all for the print statement,
but they work identically for printf:
print items > output-fileThis redirection prints the items into the output file named output-file. The file name output-file can be any expression. Its value is changed to a string and then used as a file name (see Expressions).
When this type of redirection is used, the output-file is erased before the first output is written to it. Subsequent writes to the same output-file do not erase output-file, but append to it. (This is different from how you use redirections in shell scripts.) If output-file does not exist, it is created. For example, here is how an
awkprogram can write a list of peoples’ names to one file named name-list, and a list of phone numbers to another file named phone-list:$ awk '{ print $2 > "phone-list" > print $1 > "name-list" }' mail-list $ cat phone-list -| 555-5553 -| 555-3412 ... $ cat name-list -| Amelia -| Anthony ...Each output file contains one name or number per line.
print items >> output-fileThis redirection prints the items into the preexisting output file named output-file. The difference between this and the single-‘>’ redirection is that the old contents (if any) of output-file are not erased. Instead, the
awkoutput is appended to the file. If output-file does not exist, then it is created.print items | commandIt is possible to send output to another program through a pipe instead of into a file. This redirection opens a pipe to command, and writes the values of items through this pipe to another process created to execute command.
The redirection argument command is actually an
awkexpression. Its value is converted to a string whose contents give the shell command to be run. For example, the following produces two files, one unsorted list of peoples’ names, and one list sorted in reverse alphabetical order:awk '{ print $1 > "names.unsorted" command = "sort -r > names.sorted" print $1 | command }' mail-listThe unsorted list is written with an ordinary redirection, while the sorted list is written by piping through the
sortutility.The next example uses redirection to mail a message to the mailing list
bug-system. This might be useful when trouble is encountered in anawkscript run periodically for system maintenance:report = "mail bug-system" print("Awk script failed:", $0) | report print("at record number", FNR, "of", FILENAME) | report close(report)The
close()function is called here because it’s a good idea to close the pipe as soon as all the intended output has been sent to it. See Closing Input and Output Redirections for more information.This example also illustrates the use of a variable to represent a file or command—it is not necessary to always use a string constant. Using a variable is generally a good idea, because (if you mean to refer to that same file or command)
awkrequires that the string value be written identically every time.print items |& commandThis redirection prints the items to the input of command. The difference between this and the single-‘|’ redirection is that the output from command can be read with
getline. Thus, command is a coprocess, which works together with but is subsidiary to theawkprogram.This feature is a
gawkextension, and is not available in POSIXawk. See Usinggetlinefrom a Coprocess, for a brief discussion. See Two-Way Communications with Another Process, for a more complete discussion.
Redirecting output using ‘>’, ‘>>’, ‘|’, or ‘|&’
asks the system to open a file, pipe, or coprocess only if the particular
file or command you specify has not already been written
to by your program or if it has been closed since it was last written to.
In other words, files, pipes, and coprocesses remain open until
explicitly closed. All further print and printf statements
continue to write to the same open file, pipe, or coprocess.
In the shell, when you are building up a file a line at a time, you first use ‘>’ to create the file, and then you use ‘>>’ for subsequent additions to it, like so:
echo Name: Arnold Robbins > data echo Street Address: 1234 A Pretty Street, NE >> data echo City and State: MyTown, MyState 12345-6789 >> data
In awk, the ‘>’ and ‘>>’ operators are subtly
different. The operator you use the first time you write to a
file determines how awk will open (or create) the file.
If you use ‘>’, the file is truncated, and then all subsequent
output appends data to the file, even if additional print or
printf statements continue to use ‘>’. If you use ‘>>’
the first time, then existing data is not truncated, and all subsequent
print or printf statements append data to the file.
You should be consistent and always use the same operator for all output
to the same file. (You can mix ‘>’ and ‘>>’, and nothing bad
will happen, but mixing the operators is considered to be bad style in
awk. If invoked with the --lint option, gawk
issues a warning when it encounters both operators being used for the
same open file.)
As mentioned earlier
(see Points to Remember About getline),
many
Many
older
awk implementations limit the number of pipelines that an awk
program may have open to just one! In gawk, there is no such limit.
gawk allows a program to
open as many pipelines as the underlying operating system permits.
Piping into sh |
|---|
|
A particularly powerful way to use redirection is to build command lines
and pipe them into the shell, { printf("mv %s %s\n", $0, tolower($0)) | "sh" }
END { close("sh") }
The See Quoting Strings to Pass to the Shell for a function that can help in generating command lines to be fed to the shell. |
5.7 Special Files for Standard Preopened Data Streams ¶
Running programs conventionally have three input and output streams already available to them for reading and writing. These are known as the standard input, standard output, and standard error output. These open streams (and any other open files or pipes) are often referred to by the technical term file descriptors.
These streams are, by default, connected to your keyboard and screen, but they are often redirected with the shell, via the ‘<’, ‘<<’, ‘>’, ‘>>’, ‘>&’, and ‘|’ operators. Standard error is typically used for writing error messages; the reason there are two separate streams, standard output and standard error, is so that they can be redirected separately.
In traditional implementations of awk, the only way to write an error
message to standard error in an awk program is as follows:
print "Serious error detected!" | "cat 1>&2"
This works by opening a pipeline to a shell command that can access the
standard error stream that it inherits from the awk process.
This is far from elegant, and it also requires a
separate process. So people writing awk programs often
don’t do this. Instead, they send the error messages to the
screen, like this:
print "Serious error detected!" > "/dev/tty"
(/dev/tty is a special file supplied by the operating system
that is connected to your keyboard and screen. It represents the
“terminal,”29 which on modern systems is a keyboard
and screen, not a serial console.)
This generally has the same effect, but not always: although the
standard error stream is usually the screen, it can be redirected; when
that happens, writing to the screen is not correct. In fact, if
awk is run from a background job, it may not have a
terminal at all.
Then opening /dev/tty fails.
gawk, BWK awk, and mawk provide
special file names for accessing the three standard streams.
If the file name matches one of these special names when gawk
(or one of the others) redirects input or output, then it directly uses
the descriptor that the file name stands for. These special
file names work for all operating systems that gawk
has been ported to, not just those that are POSIX-compliant:
- /dev/stdin
The standard input (file descriptor 0).
- /dev/stdout
The standard output (file descriptor 1).
- /dev/stderr
The standard error output (file descriptor 2).
With these facilities, the proper way to write an error message then becomes:
print "Serious error detected!" > "/dev/stderr"
Note the use of quotes around the file name. Like with any other redirection, the value must be a string. It is a common error to omit the quotes, which leads to confusing results.
gawk does not treat these file names as special when
in POSIX-compatibility mode. However, because BWK awk
supports them, gawk does support them even when
invoked with the --traditional option (see Command-Line Options).
5.8 Special File names in gawk ¶
Besides access to standard input, standard output, and standard error,
gawk provides access to any open file descriptor.
Additionally, there are special file names reserved for
TCP/IP networking.
- Accessing Other Open Files with
gawk - Special Files for Network Communications
- Special File name Caveats
5.8.1 Accessing Other Open Files with gawk ¶
Besides the /dev/stdin, /dev/stdout, and /dev/stderr
special file names mentioned earlier, gawk provides syntax
for accessing any other inherited open file:
- /dev/fd/N
The file associated with file descriptor N. Such a file must be opened by the program initiating the
awkexecution (typically the shell). Unless special pains are taken in the shell from whichgawkis invoked, only descriptors 0, 1, and 2 are available.
The file names /dev/stdin, /dev/stdout, and /dev/stderr are essentially aliases for /dev/fd/0, /dev/fd/1, and /dev/fd/2, respectively. However, those names are more self-explanatory.
Note that using close() on a file name of the
form "/dev/fd/N", for file descriptor numbers
above two, does actually close the given file descriptor.
5.8.2 Special Files for Network Communications ¶
gawk programs
can open a two-way
TCP/IP connection, acting as either a client or a server.
This is done using a special file name of the form:
/net-type/protocol/local-port/remote-host/remote-port
The net-type is one of ‘inet’, ‘inet4’, or ‘inet6’.
The protocol is one of ‘tcp’ or ‘udp’,
and the other fields represent the other essential pieces of information
for making a networking connection.
These file names are used with the ‘|&’ operator for communicating
with a coprocess
(see Two-Way Communications with Another Process).
This is an advanced feature, mentioned here only for completeness.
Full discussion is delayed until
Using gawk for Network Programming.
5.8.3 Special File name Caveats ¶
Here are some things to bear in mind when using the
special file names that gawk provides:
- Recognition of the file names for the three standard preopened files is disabled only in POSIX mode.
- Recognition of the other special file names is disabled if
gawkis in compatibility mode (either --traditional or --posix; see Command-Line Options). gawkalways interprets these special file names. For example, using ‘/dev/fd/4’ for output actually writes on file descriptor 4, and not on a new file descriptor that isdup()ed from file descriptor 4. Most of the time this does not matter; however, it is important to not close any of the files related to file descriptors 0, 1, and 2. Doing so results in unpredictable behavior.
5.9 Closing Input and Output Redirections ¶
If the same file name or the same shell command is used with getline
more than once during the execution of an awk program
(see Explicit Input with getline),
the file is opened (or the command is executed) the first time only.
At that time, the first record of input is read from that file or command.
The next time the same file or command is used with getline,
another record is read from it, and so on.
Similarly, when a file or pipe is opened for output, awk remembers
the file name or command associated with it, and subsequent
writes to the same file or command are appended to the previous writes.
The file or pipe stays open until awk exits.
This implies that special steps are necessary in order to read the same
file again from the beginning, or to rerun a shell command (rather than
reading more output from the same command). The close() function
makes these things possible:
close(filename)
or:
close(command)
The argument filename or command can be any expression. Its value must exactly match the string that was used to open the file or start the command (spaces and other “irrelevant” characters included). For example, if you open a pipe with this:
"sort -r names" | getline foo
then you must close it with this:
close("sort -r names")
Once this function call is executed, the next getline from that
file or command, or the next print or printf to that
file or command, reopens the file or reruns the command.
Because the expression that you use to close a file or pipeline must
exactly match the expression used to open the file or run the command,
it is good practice to use a variable to store the file name or command.
The previous example becomes the following:
sortcom = "sort -r names" sortcom | getline foo
... close(sortcom)
This helps avoid hard-to-find typographical errors in your awk
programs. Here are some of the reasons for closing an output file:
- To write a file and read it back later on in the same
awkprogram. Close the file after writing it, then begin reading it withgetline. - To write numerous files, successively, in the same
awkprogram. If the files aren’t closed, eventuallyawkmay exceed a system limit on the number of open files in one process. It is best to close each one when the program has finished writing it. - To make a command finish. When output is redirected through a pipe,
the command reading the pipe normally continues to try to read input
as long as the pipe is open. Often this means the command cannot
really do its work until the pipe is closed. For example, if
output is redirected to the
mailprogram, the message is not actually sent until the pipe is closed. - To run the same program a second time, with the same arguments.
This is not the same thing as giving more input to the first run!
For example, suppose a program pipes output to the
mailprogram. If it outputs several lines redirected to this pipe without closing it, they make a single message of several lines. By contrast, if the program closes the pipe after each line of output, then each line makes a separate message.
If you use more files than the system allows you to have open,
gawk attempts to multiplex the available open files among
your data files. gawk’s ability to do this depends upon the
facilities of your operating system, so it may not always work. It is
therefore both good practice and good portability advice to always
use close() on your files when you are done with them.
In fact, if you are using a lot of pipes, it is essential that
you close commands when done. For example, consider something like this:
{
...
command = ("grep " $1 " /some/file | my_prog -q " $3)
while ((command | getline) > 0) {
process output of command
}
# need close(command) here
}
This example creates a new pipeline based on data in each record.
Without the call to close() indicated in the comment, awk
creates child processes to run the commands, until it eventually
runs out of file descriptors for more pipelines.
Even though each command has finished (as indicated by the end-of-file
return status from getline), the child process is not
terminated;30
more importantly, the file descriptor for the pipe
is not closed and released until close() is called or
awk exits.
close() silently does nothing if given an argument that
does not represent a file, pipe, or coprocess that was opened with
a redirection. In such a case, it returns a negative value,
indicating an error. In addition, gawk sets ERRNO
to a string indicating the error.
Note also that ‘close(FILENAME)’ has no “magic” effects on the
implicit loop that reads through the files named on the command line.
It is, more likely, a close of a file that was never opened with a
redirection, so awk silently does nothing, except return
a negative value.
When using the ‘|&’ operator to communicate with a coprocess,
it is occasionally useful to be able to close one end of the two-way
pipe without closing the other.
This is done by supplying a second argument to close().
As in any other call to close(),
the first argument is the name of the command or special file used
to start the coprocess.
The second argument should be a string, with either of the values
"to" or "from". Case does not matter.
As this is an advanced feature, discussion is
delayed until
Two-Way Communications with Another Process,
which describes it in more detail and gives an example.
5.9.1 Using close()’s Return Value ¶
In many older versions of Unix awk, the close() function
is actually a statement.
(d.c.)
It is a syntax error to try and use the return
value from close():
command = "..." command | getline info retval = close(command) # syntax error in many Unix awks
gawk treats close() as a function.
The return value is −1 if the argument names something
that was never opened with a redirection, or if there is
a system problem closing the file or process.
In these cases, gawk sets the predefined variable
ERRNO to a string describing the problem.
In gawk, starting with version 4.2, when closing a pipe or
coprocess (input or output), the return value is the exit status of the
command, as described in Table 5.1.31 Otherwise, it is the return value from the system’s close()
or fclose() C functions when closing input or output files,
respectively. This value is zero if the close succeeds, or −1
if it fails.
Recent versions of BWK awk also return the same values
from close().
| Situation | Return value from close() |
|---|---|
| Normal exit of command | Command’s exit status |
| Death by signal of command | 256 + number of murderous signal |
| Death by signal of command with core dump | 512 + number of murderous signal |
| Some kind of error | −1 |
Table 5.1: Return values from close() of a pipe
The POSIX standard is very vague; it says that close()
returns zero on success and a nonzero value otherwise. In general,
different implementations vary in what they report when closing
pipes; thus, the return value cannot be used portably.
(d.c.)
In POSIX mode (see Command-Line Options), gawk just returns zero
when closing a pipe.
5.10 Speeding Up Pipe Output ¶
This section describes a gawk-specific feature.
Normally, when you send data down a pipeline to a command with
print or printf, gawk flushes the
output down the pipe. That is, output is not buffered, but
written directly. This assures, that pipeline output
intermixed with gawk’s output comes out in the
expected order:
print "something" # goes to standard output print "something else" | "some-command" # also to standard output print "more stuff" # and this too
There can be a price to pay for this; flushing data down the pipeline uses more CPU time, and in certain environments this can become expensive.
You can tell gawk not to flush buffered data in
one of two ways:
- Set
PROCINFO["BUFFERPIPE"]to any value. When this is done,gawkwill buffer data for all pipelines. - Set
PROCINFO["command", "BUFFERPIPE"]to any value. In this case, only command’s data will be fully buffered.
You must create one or the other of these elements
in PROCINFO before the first print or
printf to the pipeline. Doing so after output has
already been sent is too late.
Be aware that using this feature may change the output behavior of your programs, so exercise caution.
5.11 Enabling Nonfatal Output ¶
This section describes a gawk-specific feature.
In standard awk, output with print or printf
to a nonexistent file, or some other I/O error (such as filling up the
disk) is a fatal error.
$ gawk 'BEGIN { print "hi" > "/no/such/file" }'
error→ gawk: cmd. line:1: fatal: can't redirect to `/no/such/file' (No
error→ such file or directory)
gawk makes it possible to detect that an error has
occurred, allowing you to possibly recover from the error, or
at least print an error message of your choosing before exiting.
You can do this in one of two ways:
- For all output files, by assigning any value to
PROCINFO["NONFATAL"]. - On a per-file basis, by assigning any value to
PROCINFO[filename, "NONFATAL"]. Here, filename is the name of the file to which you wish output to be nonfatal.
Once you have enabled nonfatal output, you must check ERRNO
after every relevant print or printf statement to
see if something went wrong. It is also a good idea to initialize
ERRNO to zero before attempting the output. For example:
$ gawk '
> BEGIN {
> PROCINFO["NONFATAL"] = 1
> ERRNO = 0
> print "hi" > "/no/such/file"
> if (ERRNO) {
> print("Output failed:", ERRNO) > "/dev/stderr"
> exit 1
> }
> }'
error→ Output failed: No such file or directory
Here, gawk did not produce a fatal error; instead
it let the awk program code detect the problem and handle it.
This mechanism works also for standard output and standard error.
For standard output, you may use PROCINFO["-", "NONFATAL"]
or PROCINFO["/dev/stdout", "NONFATAL"]. For standard error, use
PROCINFO["/dev/stderr", "NONFATAL"].
When attempting to open a TCP/IP socket (see Using gawk for Network Programming),
gawk tries multiple times. The GAWK_SOCK_RETRIES
environment variable (see Other Environment Variables) allows you to
override gawk’s builtin default number of attempts. However,
once nonfatal I/O is enabled for a given socket, gawk only
retries once, relying on awk-level code to notice that there
was a problem.
5.12 Summary ¶
- The
printstatement prints comma-separated expressions. Each expression is separated by the value ofOFSand terminated by the value ofORS.OFMTprovides the conversion format for numeric values for theprintstatement. - The
printfstatement provides finer-grained control over output, with format-control letters for different data types and various flags that modify the behavior of the format-control letters. - Output from both
printandprintfmay be redirected to files, pipes, and coprocesses. gawkprovides special file names for access to standard input, output, and error, and for network communications.- Use
close()to close open file, pipe, and coprocess redirections. For coprocesses, it is possible to close only one direction of the communications. - Normally errors with
printorprintfare fatal.gawklets you make output errors be nonfatal either for all files or on a per-file basis. You must then check for errors after every relevant output statement.
5.13 Exercises ¶
- Rewrite the program:
awk 'BEGIN { print "Month Crates" print "----- ------" } { print $1, " ", $2 }' inventory-shippedfrom Output Separators, by using a new value of
OFS. - Use the
printfstatement to line up the headings and table data for the inventory-shipped example that was covered in TheprintStatement. - What happens if you forget the double quotes when redirecting
output, as follows:
BEGIN { print "Serious error detected!" > /dev/stderr }
6 Expressions ¶
Expressions are the basic building blocks of awk patterns
and actions. An expression evaluates to a value that you can print, test,
or pass to a function. Additionally, an expression
can assign a new value to a variable or a field by using an assignment operator.
An expression can serve as a pattern or action statement on its own.
Most other kinds of
statements contain one or more expressions that specify the data on which to
operate. As in other languages, expressions in awk can include
variables, array references, constants, and function calls, as well as
combinations of these with various operators.
- Constants, Variables, and Conversions
- Operators: Doing Something with Values
- Truth Values and Conditions
- Function Calls
- Operator Precedence (How Operators Nest)
- Where You Are Makes a Difference
- Summary
6.1 Constants, Variables, and Conversions ¶
Expressions are built up from values and the operations performed upon them. This section describes the elementary objects that provide the values used in expressions.
6.1.1 Constant Expressions ¶
The simplest type of expression is the constant, which always has the same value. There are three types of constants: numeric, string, and regular expression.
Each is used in the appropriate context when you need a data value that isn’t going to change. Numeric constants can have different forms, but are internally stored in an identical manner.
6.1.1.1 Numeric and String Constants ¶
A numeric constant stands for a number. This number can be an integer, a decimal fraction, or a number in scientific (exponential) notation.32 Here are some examples of numeric constants that all have the same value:
105 1.05e+2 1050e-1
A string constant consists of a sequence of characters enclosed in double quotation marks. For example:
"parrot"
represents the string whose contents are ‘parrot’. Strings in
gawk can be of any length, and they can contain any of the possible
eight-bit ASCII characters, including ASCII NUL (character code zero).
Other awk
implementations may have difficulty with some character codes.
Some languages allow you to continue long strings across multiple lines by ending the line with a backslash. For example in C:
#include <stdio.h>
int main()
{
printf("hello, \
world\n");
return 0;
}
In such a case, the C compiler removes both the backslash and the newline, producing a string as if it had been typed ‘"hello, world\n"’. This is useful when a single string needs to contain a large amount of text.
The POSIX standard says explicitly that newlines are not allowed inside string
constants. And indeed, all awk implementations report an error
if you try to do so. For example:
$ gawk 'BEGIN { print "hello,
> world" }'
-| gawk: cmd. line:1: BEGIN { print "hello,
-| gawk: cmd. line:1: ^ unterminated string
-| gawk: cmd. line:1: BEGIN { print "hello,
-| gawk: cmd. line:1: ^ syntax error
Although POSIX doesn’t define what happens if you use an escaped
newline, as in the previous C example, all known versions of
awk allow you to do so. Unfortunately, what each one
does with such a string varies. (d.c.) gawk,
mawk, and the OpenSolaris POSIX awk
(see Other Freely Available awk Implementations) elide the backslash and newline, as in C:
$ gawk 'BEGIN { print "hello, \
> world" }'
-| hello, world
In POSIX mode (see Command-Line Options), gawk does not
allow escaped newlines. Otherwise, it behaves as just described.
BWK awk33 and BusyBox awk
remove the backslash but leave the newline
intact, as part of the string:
$ nawk 'BEGIN { print "hello, \
> world" }'
-| hello,
-| world
6.1.1.2 Octal and Hexadecimal Numbers ¶
In awk, all numbers are in decimal (i.e., base 10). Many other
programming languages allow you to specify numbers in other bases, often
octal (base 8) and hexadecimal (base 16).
In octal, the numbers go 0, 1, 2, 3, 4, 5, 6, 7, 10, 11, 12, and so on.
Just as ‘11’ in decimal is 1 times 10 plus 1, so
‘11’ in octal is 1 times 8 plus 1. This equals 9 in decimal.
In hexadecimal, there are 16 digits. Because the everyday decimal
number system only has ten digits (‘0’–‘9’), the letters
‘a’ through ‘f’ represent the rest.
(Case in the letters is usually irrelevant; hexadecimal ‘a’ and ‘A’
have the same value.)
Thus, ‘11’ in
hexadecimal is 1 times 16 plus 1, which equals 17 in decimal.
Just by looking at plain ‘11’, you can’t tell what base it’s in. So, in C, C++, and other languages derived from C, there is a special notation to signify the base. Octal numbers start with a leading ‘0’, and hexadecimal numbers start with a leading ‘0x’ or ‘0X’:
11Decimal value 11
011Octal 11, decimal value 9
0x11Hexadecimal 11, decimal value 17
This example shows the difference:
$ gawk 'BEGIN { printf "%d, %d, %d\n", 011, 11, 0x11 }'
-| 9, 11, 17
Being able to use octal and hexadecimal constants in your programs is most useful when working with data that cannot be represented conveniently as characters or as regular numbers, such as binary data of various sorts.
gawk allows the use of octal and hexadecimal
constants in your program text. However, such numbers in the input data
are not treated differently; doing so by default would break old
programs.
(If you really need to do this, use the --non-decimal-data
command-line option;
see Allowing Nondecimal Input Data.)
If you have octal or hexadecimal data,
you can use the strtonum() function
(see String-Manipulation Functions)
to convert the data into a number.
Most of the time, you will want to use octal or hexadecimal constants
when working with the built-in bit-manipulation functions;
see Bit-Manipulation Functions
for more information.
Unlike in some early C implementations, ‘8’ and ‘9’ are not
valid in octal constants. For example, gawk treats ‘018’
as decimal 18:
$ gawk 'BEGIN { print "021 is", 021 ; print 018 }'
-| 021 is 17
-| 18
Octal and hexadecimal source code constants are a gawk extension.
If gawk is in compatibility mode
(see Command-Line Options),
they are not available.
| A Constant’s Base Does Not Affect Its Value |
|---|
|
Once a numeric constant has
been converted internally into a number,
$ gawk 'BEGIN { printf "0x11 is <%s>\n", 0x11 }'
-| 0x11 is <17>
|
6.1.1.3 Regular Expression Constants ¶
A regexp constant is a regular expression description enclosed in
slashes, such as /^beginning and end$/. Most regexps used in
awk programs are constant, but the ‘~’ and ‘!~’
matching operators can also match computed or dynamic regexps
(which are typically just ordinary strings or variables that contain a regexp,
but could be more complex expressions).
6.1.2 Using Regular Expression Constants ¶
Regular expression constants consist of text describing
a regular expression enclosed in slashes (such as /the +answer/).
This section describes how such constants work in
POSIX awk and gawk, and then goes on to describe
strongly typed regexp constants, which are a gawk extension.
6.1.2.1 Standard Regular Expression Constants ¶
When used on the righthand side of the ‘~’ or ‘!~’
operators, a regexp constant merely stands for the regexp that is to be
matched.
However, regexp constants (such as /foo/) may be used like simple expressions.
When a
regexp constant appears by itself, it has the same meaning as if it appeared
in a pattern (i.e., ‘($0 ~ /foo/)’).
(d.c.)
See Expressions as Patterns.
This means that the following two code segments:
if ($0 ~ /barfly/ || $0 ~ /camelot/)
print "found"
and:
if (/barfly/ || /camelot/)
print "found"
are exactly equivalent. One rather bizarre consequence of this rule is that the following Boolean expression is valid, but does not do what its author probably intended:
# Note that /foo/ is on the left of the ~ if (/foo/ ~ $1) print "found foo"
This code is “obviously” testing $1 for a match against the regexp
/foo/. But in fact, the expression ‘/foo/ ~ $1’ really means
‘($0 ~ /foo/) ~ $1’. In other words, first match the input record
against the regexp /foo/. The result is either zero or one,
depending upon the success or failure of the match. That result
is then matched against the first field in the record.
Because it is unlikely that you would ever really want to make this kind of
test, gawk issues a warning when it sees this construct in
a program.
Another consequence of this rule is that the assignment statement:
matches = /foo/
assigns either zero or one to the variable matches, depending
upon the contents of the current input record.
Constant regular expressions are also used as the first argument for
the gensub(), sub(), and gsub() functions, as the
second argument of the match() function,
and as the third argument of the split() and patsplit() functions
(see String-Manipulation Functions).
Modern implementations of awk, including gawk, allow
the third argument of split() to be a regexp constant, but some
older implementations do not.
(d.c.)
Because some built-in functions accept regexp constants as arguments,
confusion can arise when attempting to use regexp constants as arguments
to user-defined functions (see User-Defined Functions). For example:
function mysub(pat, repl, str, global)
{
if (global)
gsub(pat, repl, str)
else
sub(pat, repl, str)
return str
}
{
...
text = "hi! hi yourself!"
mysub(/hi/, "howdy", text, 1)
...
}
In this example, the programmer wants to pass a regexp constant to the
user-defined function mysub(), which in turn passes it on to
either sub() or gsub(). However, what really happens is that
the pat parameter is assigned a value of either one or zero, depending upon whether
or not $0 matches /hi/.
gawk issues a warning when it sees a regexp constant used as
a parameter to a user-defined function, because passing a truth value in
this way is probably not what was intended.
6.1.2.2 Strongly Typed Regexp Constants ¶
This section describes a gawk-specific feature.
As we saw in the previous section,
regexp constants (/…/) hold a strange position in the
awk language. In most contexts, they act like an expression:
‘$0 ~ /…/’. In other contexts, they denote only a regexp to
be matched. In no case are they really a “first class citizen” of the
language. That is, you cannot define a scalar variable whose type is
“regexp” in the same sense that you can define a variable to be a
number or a string:
num = 42 Numeric variable str = "hi" String variable re = /foo/ Wrong! re is the result of $0 ~ /foo/
For a number of more advanced use cases, it would be nice to have regexp constants that are strongly typed; in other words, that denote a regexp useful for matching, and not an expression.
gawk provides this feature. A strongly typed regexp constant
looks almost like a regular regexp constant, except that it is preceded
by an ‘@’ sign:
re = @/foo/ Regexp variable
Strongly typed regexp constants cannot be used everywhere that a regular regexp constant can, because this would make the language even more confusing. Instead, you may use them only in certain contexts:
- On the righthand side of the ‘~’ and ‘!~’ operators: ‘some_var ~ @/foo/’ (see How to Use Regular Expressions).
- In the
casepart of aswitchstatement (see TheswitchStatement). - As an argument to one of the built-in functions that accept regexp constants:
gensub(),gsub(),match(),patsplit(),split(), andsub()(see String-Manipulation Functions). - As a parameter in a call to a user-defined function (see User-Defined Functions).
- As the return value of a user-defined function.
- On the righthand side of an assignment to a variable: ‘some_var = @/foo/’.
In this case, the type of
some_varis regexp. Additionally,some_varcan be used with ‘~’ and ‘!~’, passed to one of the built-in functions listed above, or passed as a parameter to a user-defined function.
You may use the -v option (see Command-Line Options) to assign a strongly-typed regexp constant to a variable on the command line, like so:
gawk -v pattern='@/something(interesting)+/' ...
You may also make such assignments as regular command-line arguments (see Other Command-Line Arguments).
You may use the typeof() built-in function
(see Getting Type Information)
to determine if a variable or function parameter is
a regexp variable.
The true power of this feature comes from the ability to create variables that have regexp type. Such variables can be passed on to user-defined functions, without the confusing aspects of computed regular expressions created from strings or string constants. They may also be passed through indirect function calls (see Indirect Function Calls) and on to the built-in functions that accept regexp constants.
When used in numeric conversions, strongly typed regexp variables convert to zero. When used in string conversions, they convert to the string value of the original regexp text.
There is an additional, interesting corner case. When used as the third
argument to sub() or gsub(), they retain their type. Thus,
if you have something like this:
re = @/don't panic/ sub(/don't/, "do", re) print typeof(re), re
then re retains its type, but now attempts to match the string
‘do panic’. This provides a (very indirect) way to create regexp-typed
variables at runtime.
6.1.3 Variables ¶
Variables are ways of storing values at one point in your program for
use later in another part of your program. They can be manipulated
entirely within the program text, and they can also be assigned values
on the awk command line.
6.1.3.1 Using Variables in a Program ¶
Variables let you give names to values and refer to them later. Variables
have already been used in many of the examples. The name of a variable
must be a sequence of letters, digits, or underscores, and it may not begin
with a digit.
Here, a letter is any one of the 52 upper- and lowercase
English letters. Other characters that may be defined as letters
in non-English locales are not valid in variable names.
Case is significant in variable names; a and A
are distinct variables.
A variable name is a valid expression by itself; it represents the
variable’s current value. Variables are given new values with
assignment operators, increment operators, and
decrement operators
(see Assignment Expressions).
In addition, the sub() and gsub() functions can
change a variable’s value, and the match(), split(),
and patsplit() functions can change the contents of their
array parameters (see String-Manipulation Functions).
A few variables have special built-in meanings, such as FS (the
field separator) and NF (the number of fields in the current input
record). See Predefined Variables for a list of the predefined variables.
These predefined variables can be used and assigned just like all other
variables, but their values are also used or changed automatically by
awk. All predefined variables’ names are entirely uppercase.
Variables in awk can be assigned either numeric or string values.
The kind of value a variable holds can change over the life of a program.
By default, variables are initialized to the empty string, which
is zero if converted to a number. There is no need to explicitly
initialize a variable in awk,
which is what you would do in C and in most other traditional languages.
6.1.3.2 Assigning Variables on the Command Line ¶
Any awk variable can be set by including a variable assignment
among the arguments on the command line when awk is invoked
(see Other Command-Line Arguments).
Such an assignment has the following form:
variable=text
With it, a variable is set either at the beginning of the
awk run or in between input files.
When the assignment is preceded with the -v option,
as in the following:
-v variable=text
the variable is set at the very beginning, even before the
BEGIN rules execute. The -v option and its assignment
must precede all the file name arguments, as well as the program text.
(See Command-Line Options for more information about
the -v option.)
Otherwise, the variable assignment is performed at a time determined by
its position among the input file arguments—after the processing of the
preceding input file argument. For example:
awk '{ print $n }' n=4 inventory-shipped n=2 mail-list
prints the value of field number n for all input records. Before
the first file is read, the command line sets the variable n
equal to four. This causes the fourth field to be printed in lines from
inventory-shipped. After the first file has finished,
but before the second file is started, n is set to two, so that the
second field is printed in lines from mail-list:
$ awk '{ print $n }' n=4 inventory-shipped n=2 mail-list
-| 15
-| 24
...
-| 555-5553
-| 555-3412
...
Command-line arguments are made available for explicit examination by
the awk program in the ARGV array
(see Using ARGC and ARGV).
awk processes the values of command-line assignments for escape
sequences
(see Escape Sequences).
(d.c.)
Normally, variables assigned on the command line (with or without the
-v option) are treated as strings. When such variables are
used as numbers, awk’s normal automatic conversion of strings
to numbers takes place, and everything “just works.”
However, gawk supports variables whose types are “regexp”.
You can assign variables of this type using the following syntax:
gawk -v 're1=@/foo|bar/' '...' /path/to/file1 're2=@/baz|quux/' /path/to/file2
Strongly typed regexps are an advanced feature (see Strongly Typed Regexp Constants). We mention them here only for completeness.
6.1.4 Conversion of Strings and Numbers ¶
Number-to-string and string-to-number conversion are generally
straightforward. There can be subtleties to be aware of;
this section discusses this important facet of awk.
6.1.4.1 How awk Converts Between Strings and Numbers ¶
Strings are converted to numbers and numbers are converted to strings, if the context
of the awk program demands it. For example, if the value of
either foo or bar in the expression ‘foo + bar’
happens to be a string, it is converted to a number before the addition
is performed. If numeric values appear in string concatenation, they
are converted to strings. Consider the following:
two = 2; three = 3 print (two three) + 4
This prints the (numeric) value 27. The numeric values of
the variables two and three are converted to strings and
concatenated together. The resulting string is converted back to the
number 23, to which 4 is then added.
If, for some reason, you need to force a number to be converted to a
string, concatenate that number with the empty string, "".
To force a string to be converted to a number, add zero to that string.
A string is converted to a number by interpreting any numeric prefix
of the string as numerals:
"2.5" converts to 2.5, "1e3" converts to 1,000, and "25fix"
has a numeric value of 25.
Strings that can’t be interpreted as valid numbers convert to zero.
The exact manner in which numbers are converted into strings is controlled
by the awk predefined variable CONVFMT (see Predefined Variables).
Numbers are converted using the sprintf() function
with CONVFMT as the format
specifier
(see String-Manipulation Functions).
CONVFMT’s default value is "%.6g", which creates a value with
at most six significant digits. For some applications, you might want to
change it to specify more precision.
On most modern machines,
17 digits is usually enough to capture a floating-point number’s
value exactly.34
Strange results can occur if you set CONVFMT to a string that doesn’t
tell sprintf() how to format floating-point numbers in a useful way.
For example, if you forget the ‘%’ in the format, awk converts
all numbers to the same constant string.
As a special case, if a number is an integer, then the result of converting
it to a string is always an integer, no matter what the value of
CONVFMT may be. Given the following code fragment:
CONVFMT = "%2.2f" a = 12 b = a ""
b has the value "12", not "12.00".
(d.c.)
Pre-POSIX awk Used OFMT for String Conversion |
|---|
|
Prior to the POSIX standard, |
6.1.4.2 Locales Can Influence Conversion ¶
Where you are can matter when it comes to converting between numbers and
strings. The local character set and language—the locale—can
affect numeric formats. In particular, for awk programs,
it affects the decimal point character and the thousands-separator
character. The "C" locale, and most English-language locales,
use the period character (‘.’) as the decimal point and don’t
have a thousands separator. However, many (if not most) European and
non-English locales use the comma (‘,’) as the decimal point
character. European locales often use either a space or a period as
the thousands separator, if they have one.
The POSIX standard says that awk always uses the period as the decimal
point when reading the awk program source code, and for
command-line variable assignments (see Other Command-Line Arguments). However,
when interpreting input data, for print and printf output,
and for number-to-string conversion, the local decimal point character
is used. (d.c.) In all cases, numbers in source code and
in input data cannot have a thousands separator. Here are some examples
indicating the difference in behavior, on a GNU/Linux system:
$ export POSIXLY_CORRECT=1 Force POSIX behavior
$ gawk 'BEGIN { printf "%g\n", 3.1415927 }'
-| 3.14159
$ LC_ALL=en_DK.utf-8 gawk 'BEGIN { printf "%g\n", 3.1415927 }'
-| 3,14159
$ echo 4,321 | gawk '{ print $1 + 1 }'
-| 5
$ echo 4,321 | LC_ALL=en_DK.utf-8 gawk '{ print $1 + 1 }'
-| 5,321
The en_DK.utf-8 locale is for English in Denmark, where the comma acts as
the decimal point separator. In the normal "C" locale, gawk
treats ‘4,321’ as 4, while in the Danish locale, it’s treated
as the full number including the fractional part, 4.321.
Some earlier versions of gawk fully complied with this aspect
of the standard. However, many users in non-English locales complained
about this behavior, because their data used a period as the decimal
point, so the default behavior was restored to use a period as the
decimal point character. You can use the --use-lc-numeric
option (see Command-Line Options) to force gawk to use the locale’s
decimal point character. (gawk also uses the locale’s decimal
point character when in POSIX mode, either via --posix or the
POSIXLY_CORRECT environment variable, as shown previously.)
Table 6.1 describes the cases in which the locale’s decimal point character is used and when a period is used. Some of these features have not been described yet.
| Feature | Default | --posix or --use-lc-numeric |
|---|---|---|
%'g | Use locale | Use locale |
%g | Use period | Use locale |
| Input | Use period | Use locale |
strtonum() | Use period | Use locale |
Table 6.1: Locale decimal point versus a period
Finally, modern-day formal standards and the IEEE standard floating-point
representation can have an unusual but important effect on the way
gawk converts some special string values to numbers. The details
are presented in Standards Versus Existing Practice.
6.2 Operators: Doing Something with Values ¶
This section introduces the operators that make use of the values provided by constants and variables.
6.2.1 Arithmetic Operators ¶
The awk language uses the common arithmetic operators when
evaluating expressions. All of these arithmetic operators follow normal
precedence rules and work as you would expect them to.
The following example uses a file named grades, which contains a list of student names as well as three test scores per student (it’s a small class):
Pat 100 97 58 Sandy 84 72 93 Chris 72 92 89
This program takes the file grades and prints the average of the scores:
$ awk '{ sum = $2 + $3 + $4 ; avg = sum / 3
> print $1, avg }' grades
-| Pat 85
-| Sandy 83
-| Chris 84.3333
The following list provides the arithmetic operators in awk,
in order from the highest precedence to the lowest:
x ^ yx ** yExponentiation; x raised to the y power. ‘2 ^ 3’ has the value eight; the character sequence ‘**’ is equivalent to ‘^’. (c.e.)
- xNegation.
+ xUnary plus; the expression is converted to a number.
x * yMultiplication.
x / y¶Division; because all numbers in
awkare floating-point numbers, the result is not rounded to an integer—‘3 / 4’ has the value 0.75. (It is a common mistake, especially for C programmers, to forget that all numbers inawkare floating point, and that division of integer-looking constants produces a real number, not an integer.)x % yRemainder; further discussion is provided in the text, just after this list.
x + yAddition.
x - ySubtraction.
Unary plus and minus have the same precedence, the multiplication operators all have the same precedence, and addition and subtraction have the same precedence.
When computing the remainder of ‘x % y’, the quotient is rounded toward zero to an integer and multiplied by y. This result is subtracted from x; this operation is sometimes known as “trunc-mod.” The following relation always holds:
b * int(a / b) + (a % b) == a
One possibly undesirable effect of this definition of remainder is that ‘x % y’ is negative if x is negative. Thus:
-17 % 8 = -1
This definition is compliant with the POSIX standard, which says that the %
operator produces results equivalent to using the standard C
fmod() function, and that function in turn works as just
described.
In other awk implementations, the signedness of the remainder
may be machine-dependent.
NOTE: The POSIX standard only specifies the use of ‘^’ for exponentiation. For maximum portability, do not use the ‘**’ operator.
6.2.2 String Concatenation ¶
It seemed like a good idea at the time.
There is only one string operation: concatenation. It does not have a specific operator to represent it. Instead, concatenation is performed by writing expressions next to one another, with no operator. For example:
$ awk '{ print "Field number one: " $1 }' mail-list
-| Field number one: Amelia
-| Field number one: Anthony
...
Without the space in the string constant after the ‘:’, the line runs together. For example:
$ awk '{ print "Field number one:" $1 }' mail-list
-| Field number one:Amelia
-| Field number one:Anthony
...
Because string concatenation does not have an explicit operator, it is
often necessary to ensure that it happens at the right time by using
parentheses to enclose the items to concatenate. For example,
you might expect that the
following code fragment concatenates file and name:
file = "file" name = "name" print "something meaningful" > file name
This produces a syntax error with some versions of Unix
awk.35
It is necessary to use the following:
print "something meaningful" > (file name)
Parentheses should be used around concatenation in all but the
most common contexts, such as on the righthand side of ‘=’.
Be careful about the kinds of expressions used in string concatenation.
In particular, the order of evaluation of expressions used for concatenation
is undefined in the awk language. Consider this example:
BEGIN {
a = "don't"
print (a " " (a = "panic"))
}
It is not defined whether the second assignment to a happens
before or after the value of a is retrieved for producing the
concatenated value. The result could be either ‘don't panic’,
or ‘panic panic’.
The precedence of concatenation, when mixed with other operators, is often counter-intuitive. Consider this example:
$ awk 'BEGIN { print -12 " " -24 }'
-| -12-24
This “obviously” is concatenating −12, a space, and −24.
But where did the space disappear to?
The answer lies in the combination of operator precedences and
awk’s automatic conversion rules. To get the desired result,
write the program this way:
$ awk 'BEGIN { print -12 " " (-24) }'
-| -12 -24
This forces awk to treat the ‘-’ on the ‘-24’ as unary.
Otherwise, it’s parsed as follows:
−12 (" " − 24)
⇒ −12 (0 − 24)
⇒ −12 (−24)
⇒ −12−24
As mentioned earlier, when mixing concatenation with other operators, parenthesize. Otherwise, you’re never quite sure what you’ll get.
6.2.3 Assignment Expressions ¶
An assignment is an expression that stores a (usually different)
value into a variable. For example, let’s assign the value one to the variable
z:
z = 1
After this expression is executed, the variable z has the value one.
Whatever old value z had before the assignment is forgotten.
Assignments can also store string values. For example, the
following stores
the value "this food is good" in the variable message:
thing = "food" predicate = "good" message = "this " thing " is " predicate
This also illustrates string concatenation. The ‘=’ sign is called an assignment operator. It is the simplest assignment operator because the value of the righthand operand is stored unchanged. Most operators (addition, concatenation, and so on) have no effect except to compute a value. If the value isn’t used, there’s no reason to use the operator. An assignment operator is different; it does produce a value, but even if you ignore it, the assignment still makes itself felt through the alteration of the variable. We call this a side effect.
The lefthand operand of an assignment need not be a variable
(see Variables); it can also be a field
(see Changing the Contents of a Field) or
an array element (see Arrays in awk).
These are all called lvalues,
which means they can appear on the lefthand side of an assignment operator.
The righthand operand may be any expression; it produces the new value
that the assignment stores in the specified variable, field, or array
element. (Such values are called rvalues.)
It is important to note that variables do not have permanent types.
A variable’s type is simply the type of whatever value was last assigned
to it. In the following program fragment, the variable
foo has a numeric value at first, and a string value later on:
foo = 1 print foo
foo = "bar" print foo
When the second assignment gives foo a string value, the fact that
it previously had a numeric value is forgotten.
String values that do not begin with a digit have a numeric value of
zero. After executing the following code, the value of foo is five:
foo = "a string" foo = foo + 5
NOTE: Using a variable as a number and then later as a string can be confusing and is poor programming style. The previous two examples illustrate how
awkworks, not how you should write your programs!
An assignment is an expression, so it has a value—the same value that is assigned. Thus, ‘z = 1’ is an expression with the value one. One consequence of this is that you can write multiple assignments together, such as:
x = y = z = 5
This example stores the value five in all three variables
(x, y, and z).
It does so because the
value of ‘z = 5’, which is five, is stored into y and then
the value of ‘y = z = 5’, which is five, is stored into x.
Assignments may be used anywhere an expression is called for. For
example, it is valid to write ‘x != (y = 1)’ to set y to one,
and then test whether x equals one. But this style tends to make
programs hard to read; such nesting of assignments should be avoided,
except perhaps in a one-shot program.
Aside from ‘=’, there are several other assignment operators that
do arithmetic with the old value of the variable. For example, the
operator ‘+=’ computes a new value by adding the righthand value
to the old value of the variable. Thus, the following assignment adds
five to the value of foo:
foo += 5
This is equivalent to the following:
foo = foo + 5
Use whichever makes the meaning of your program clearer.
There are situations where using ‘+=’ (or any assignment operator) is not the same as simply repeating the lefthand operand in the righthand expression. For example:
# Thanks to Pat Rankin for this example
BEGIN {
foo[rand()] += 5
for (x in foo)
print x, foo[x]
bar[rand()] = bar[rand()] + 5
for (x in bar)
print x, bar[x]
}
The indices of bar are practically guaranteed to be different, because
rand() returns different values each time it is called.
(Arrays and the rand() function haven’t been covered yet.
See Arrays in awk,
and
see Numeric Functions
for more information.)
This example illustrates an important fact about assignment
operators: the lefthand expression is only evaluated once.
It is up to the implementation as to which expression is evaluated first, the lefthand or the righthand. Consider this example:
i = 1 a[i += 2] = i + 1
The value of a[3] could be either two or four.
Table 6.2 lists the arithmetic assignment operators. In each case, the righthand operand is an expression whose value is converted to a number.
Table 6.2: Arithmetic assignment operators
NOTE: Only the ‘^=’ operator is specified by POSIX. For maximum portability, do not use the ‘**=’ operator.
6.2.4 Increment and Decrement Operators ¶
Increment and decrement operators increase or decrease the value of
a variable by one. An assignment operator can do the same thing, so
the increment operators add no power to the awk language; however, they
are convenient abbreviations for very common operations.
The operator used for adding one is written ‘++’. It can be used to increment
a variable either before or after taking its value.
To pre-increment a variable v, write ‘++v’. This adds
one to the value of v—that new value is also the value of the
expression. (The assignment expression ‘v += 1’ is completely equivalent.)
Writing the ‘++’ after the variable specifies post-increment. This
increments the variable value just the same; the difference is that the
value of the increment expression itself is the variable’s old
value. Thus, if foo has the value four, then the expression ‘foo++’
has the value four, but it changes the value of foo to five.
In other words, the operator returns the old value of the variable,
but with the side effect of incrementing it.
The post-increment ‘foo++’ is nearly the same as writing ‘(foo
+= 1) - 1’. It is not perfectly equivalent because all numbers in
awk are floating point—in floating point, ‘foo + 1 - 1’ does
not necessarily equal foo. But the difference is minute as
long as you stick to numbers that are fairly small (less than
1012).
Fields and array elements are incremented just like variables. (Use ‘$(i++)’ when you want to do a field reference and a variable increment at the same time. The parentheses are necessary because of the precedence of the field reference operator ‘$’.)
The decrement operator ‘--’ works just like ‘++’, except that it subtracts one instead of adding it. As with ‘++’, it can be used before the lvalue to pre-decrement or after it to post-decrement. Following is a summary of increment and decrement expressions:
++lvalueIncrement lvalue, returning the new value as the value of the expression.
lvalue++Increment lvalue, returning the old value of lvalue as the value of the expression.
--lvalueDecrement lvalue, returning the new value as the value of the expression. (This expression is like ‘++lvalue’, but instead of adding, it subtracts.)
lvalue--Decrement lvalue, returning the old value of lvalue as the value of the expression. (This expression is like ‘lvalue++’, but instead of adding, it subtracts.)
6.3 Truth Values and Conditions ¶
In certain contexts, expression values also serve as “truth values”; i.e.,
they determine what should happen next as the program runs. This
section describes how awk defines “true” and “false”
and how values are compared.
- True and False in
awk - Variable Typing and Comparison Expressions
- Boolean Expressions
- Conditional Expressions
6.3.1 True and False in awk ¶
Many programming languages have a special representation for the concepts
of “true” and “false.” Such languages usually use the special
constants true and false, or perhaps their uppercase
equivalents.
However, awk is different.
It borrows a very simple concept of true and
false from C. In awk, any nonzero numeric value or any
nonempty string value is true. Any other value (zero or the null
string, "") is false. The following program prints ‘A strange
truth value’ three times:
BEGIN {
if (3.1415927)
print "A strange truth value"
if ("Four Score And Seven Years Ago")
print "A strange truth value"
if (j = 57)
print "A strange truth value"
}
There is a surprising consequence of the “nonzero or non-null” rule:
the string constant "0" is actually true, because it is non-null.
(d.c.)
6.3.2 Variable Typing and Comparison Expressions ¶
The Guide is definitive. Reality is frequently inaccurate.
Unlike in other programming languages, in awk variables do not have a
fixed type. Instead, they can be either a number or a string, depending
upon the value that is assigned to them.
We look now at how variables are typed, and how awk
compares variables.
- String Type versus Numeric Type
- Comparison Operators
- String Comparison Based on Locale Collating Order
6.3.2.1 String Type versus Numeric Type ¶
Scalar objects in awk (variables, array elements, and fields)
are dynamically typed. This means their type can change as the
program runs, from untyped before any use,36 to string
or number, and then from string to number or number to string, as the
program progresses. (gawk also provides regexp-typed scalars,
but let’s ignore that for now; see Strongly Typed Regexp Constants.)
You can’t do much with untyped variables, other than tell that they
are untyped. The following program tests a against ""
and 0; the test succeeds when a has never been assigned
a value. It also uses the built-in typeof() function
(not presented yet; see Getting Type Information) to show a’s type:
$ gawk 'BEGIN { print (a == "" && a == 0 ?
> "a is untyped" : "a has a type!") ; print typeof(a) }'
-| a is untyped
-| unassigned
A scalar has numeric type when assigned a numeric value, such as from a numeric constant, or from another scalar with numeric type:
$ gawk 'BEGIN { a = 42 ; print typeof(a)
> b = a ; print typeof(b) }'
number
number
Similarly, a scalar has string type when assigned a string value, such as from a string constant, or from another scalar with string type:
$ gawk 'BEGIN { a = "forty two" ; print typeof(a)
> b = a ; print typeof(b) }'
string
string
So far, this is all simple and straightforward. What happens, though,
when awk has to process data from a user? Let’s start with
field data. What should the following command produce as output?
echo hello | awk '{ printf("%s %s < 42\n", $1,
($1 < 42 ? "is" : "is not")) }'
Since ‘hello’ is alphabetic data, awk can only do a string
comparison. Internally, it converts 42 into "42" and compares
the two string values "hello" and "42". Here’s the result:
$ echo hello | awk '{ printf("%s %s < 42\n", $1,
> ($1 < 42 ? "is" : "is not")) }'
-| hello is not < 42
However, what happens when data from a user looks like a number?
On the one hand, in reality, the input data consists of characters, not
binary numeric
values. But, on the other hand, the data looks numeric, and awk
really ought to treat it as such. And indeed, it does:
$ echo 37 | awk '{ printf("%s %s < 42\n", $1,
> ($1 < 42 ? "is" : "is not")) }'
-| 37 is < 42
Here are the rules for when awk
treats data as a number, and for when it treats data as a string.
The POSIX standard uses the term numeric string for input data that looks numeric. The ‘37’ in the previous example is a numeric string. So what is the type of a numeric string? Answer: numeric.
The type of a variable is important because the types of two variables determine how they are compared. Variable typing follows these definitions and rules:
- A numeric constant or the result of a numeric operation has the numeric attribute.
- A string constant or the result of a string operation has the string attribute.
- Fields,
getlineinput,FILENAME,ARGVelements,ENVIRONelements, and the elements of an array created bymatch(),split(), andpatsplit()that are numeric strings have the strnum attribute.37 Otherwise, they have the string attribute. Uninitialized variables also have the strnum attribute. - Attributes propagate across assignments but are not changed by any use.
The last rule is particularly important. In the following program,
a has numeric type, even though it is later used in a string
operation:
BEGIN {
a = 12.345
b = a " is a cute number"
print b
}
When two operands are compared, either string comparison or numeric comparison may be used. This depends upon the attributes of the operands, according to the following symmetric matrix:
+----------------------------------------------
| STRING NUMERIC STRNUM
--------+----------------------------------------------
|
STRING | string string string
|
NUMERIC | string numeric numeric
|
STRNUM | string numeric numeric
--------+----------------------------------------------
The basic idea is that user input that looks numeric—and only
user input—should be treated as numeric, even though it is actually
made of characters and is therefore also a string.
Thus, for example, the string constant " +3.14",
when it appears in program source code,
is a string—even though it looks numeric—and
is never treated as a number for comparison
purposes.
In short, when one operand is a “pure” string, such as a string
constant, then a string comparison is performed. Otherwise, a
numeric comparison is performed.
(The primary difference between a number and a strnum is that
for strnums gawk preserves the original string value that
the scalar had when it came in.)
This point bears additional emphasis: Input that looks numeric is numeric. All other input is treated as strings.
Thus, the six-character input string ‘ +3.14’ receives the
strnum attribute. In contrast, the eight characters
" +3.14" appearing in program text comprise a string constant.
The following examples print ‘1’ when the comparison between
the two different constants is true, and ‘0’ otherwise:
$ echo ' +3.14' | awk '{ print($0 == " +3.14") }' True
-| 1
$ echo ' +3.14' | awk '{ print($0 == "+3.14") }' False
-| 0
$ echo ' +3.14' | awk '{ print($0 == "3.14") }' False
-| 0
$ echo ' +3.14' | awk '{ print($0 == 3.14) }' True
-| 1
$ echo ' +3.14' | awk '{ print($1 == " +3.14") }' False
-| 0
$ echo ' +3.14' | awk '{ print($1 == "+3.14") }' True
-| 1
$ echo ' +3.14' | awk '{ print($1 == "3.14") }' False
-| 0
$ echo ' +3.14' | awk '{ print($1 == 3.14) }' True
-| 1
You can see the type of an input field (or other user input)
using typeof():
$ echo hello 37 | gawk '{ print typeof($1), typeof($2) }'
-| string strnum
6.3.2.2 Comparison Operators ¶
Comparison expressions compare strings or numbers for relationships such as equality. They are written using relational operators, which are a superset of those in C. Table 6.3 describes them.
| Expression | Result |
|---|---|
x < y | True if x is less than y |
x <= y | True if x is less than or equal to y |
x > y | True if x is greater than y |
x >= y | True if x is greater than or equal to y |
x == y | True if x is equal to y |
x != y | True if x is not equal to y |
x ~ y | True if the string x matches the regexp denoted by y |
x !~ y | True if the string x does not match the regexp denoted by y |
subscript in array | True if the array array has an element with the subscript subscript |
Table 6.3: Relational operators
Comparison expressions have the value one if true and zero if false.
When comparing operands of mixed types, numeric operands are converted
to strings using the value of CONVFMT
(see Conversion of Strings and Numbers).
Strings are compared
by comparing the first character of each, then the second character of each,
and so on. Thus, "10" is less than "9". If there are two
strings where one is a prefix of the other, the shorter string is less than
the longer one. Thus, "abc" is less than "abcd".
It is very easy to accidentally mistype the ‘==’ operator and
leave off one of the ‘=’ characters. The result is still valid
awk code, but the program does not do what is intended:
if (a = b) # oops! should be a == b ... else ...
Unless b happens to be zero or the null string, the if
part of the test always succeeds. Because the operators are
so similar, this kind of error is very difficult to spot when
scanning the source code.
The following list of expressions illustrates the kinds of comparisons
awk performs, as well as what the result of each comparison is:
1.5 <= 2.0Numeric comparison (true)
"abc" >= "xyz"String comparison (false)
1.5 != " +2"String comparison (true)
"1e2" < "3"String comparison (true)
a = 2; b = "2"a == bString comparison (true)
a = 2; b = " +2"a == bString comparison (false)
In this example:
$ echo 1e2 3 | awk '{ print ($1 < $2) ? "true" : "false" }'
-| false
the result is ‘false’ because both $1 and $2
are user input. They are numeric strings—therefore both have
the strnum attribute, dictating a numeric comparison.
The purpose of the comparison rules and the use of numeric strings is
to attempt to produce the behavior that is “least surprising,” while
still “doing the right thing.”
String comparisons and regular expression comparisons are very different. For example:
x == "foo"
has the value one, or is true if the variable x
is precisely ‘foo’. By contrast:
x ~ /foo/
has the value one if x contains ‘foo’, such as
"Oh, what a fool am I!".
The righthand operand of the ‘~’ and ‘!~’ operators may be
either a regexp constant (/…/) or an ordinary
expression. In the latter case, the value of the expression as a string is used as a
dynamic regexp (see How to Use Regular Expressions; also
see Using Dynamic Regexps).
A constant regular
expression in slashes by itself is also an expression.
/regexp/ is an abbreviation for the following comparison expression:
$0 ~ /regexp/
One special place where /foo/ is not an abbreviation for
‘$0 ~ /foo/’ is when it is the righthand operand of ‘~’ or
‘!~’.
See Using Regular Expression Constants,
where this is discussed in more detail.
6.3.2.3 String Comparison Based on Locale Collating Order ¶
The POSIX standard used to say that all string comparisons are performed based on the locale’s collating order. This is the order in which characters sort, as defined by the locale (for more discussion, see Where You Are Makes a Difference). This order is usually very different from the results obtained when doing straight byte-by-byte comparison.38
Because this behavior differs considerably from existing practice,
gawk only implemented it when in POSIX mode (see Command-Line Options).
Here is an example to illustrate the difference, in an en_US.UTF-8
locale:
$ gawk 'BEGIN { printf("ABC < abc = %s\n",
> ("ABC" < "abc" ? "TRUE" : "FALSE")) }'
-| ABC < abc = TRUE
$ gawk --posix 'BEGIN { printf("ABC < abc = %s\n",
> ("ABC" < "abc" ? "TRUE" : "FALSE")) }'
-| ABC < abc = FALSE
Fortunately, as of August 2016, comparison based on locale
collating order is no longer required for the == and !=
operators.39 However, comparison based on locales is still
required for <, <=, >, and >=. POSIX thus
recommends as follows:
Since the
==operator checks whether strings are identical, not whether they collate equally, applications needing to check whether strings collate equally can use:a <= b && a >= b
As of version 4.2, gawk continues to use locale
collating order for <, <=, >, and >= only
in POSIX mode.
6.3.3 Boolean Expressions ¶
A Boolean expression is a combination of comparison expressions or matching expressions, using the Boolean operators “or” (‘||’), “and” (‘&&’), and “not” (‘!’), along with parentheses to control nesting. The truth value of the Boolean expression is computed by combining the truth values of the component expressions. Boolean expressions are also referred to as logical expressions. The terms are equivalent.
Boolean expressions can be used wherever comparison and matching
expressions can be used. They can be used in if, while,
do, and for statements
(see Control Statements in Actions).
They have numeric values (one if true, zero if false) that come into play
if the result of the Boolean expression is stored in a variable or
used in arithmetic.
In addition, every Boolean expression is also a valid pattern, so you can use one as a pattern to control the execution of rules. The Boolean operators are:
boolean1 && boolean2True if both boolean1 and boolean2 are true. For example, the following statement prints the current input record if it contains both ‘edu’ and ‘li’:
if ($0 ~ /edu/ && $0 ~ /li/) print
The subexpression boolean2 is evaluated only if boolean1 is true. This can make a difference when boolean2 contains expressions that have side effects. In the case of ‘$0 ~ /foo/ && ($2 == bar++)’, the variable
baris not incremented if there is no substring ‘foo’ in the record.boolean1 || boolean2True if at least one of boolean1 or boolean2 is true. For example, the following statement prints all records in the input that contain either ‘edu’ or ‘li’:
if ($0 ~ /edu/ || $0 ~ /li/) print
The subexpression boolean2 is evaluated only if boolean1 is false. This can make a difference when boolean2 contains expressions that have side effects. (Thus, this test never really distinguishes records that contain both ‘edu’ and ‘li’—as soon as ‘edu’ is matched, the full test succeeds.)
! booleanTrue if boolean is false. For example, the following program prints ‘no home!’ in the unusual event that the
HOMEenvironment variable is not defined:BEGIN { if (! ("HOME" in ENVIRON)) print "no home!" }(The
inoperator is described in Referring to an Array Element.)
The ‘&&’ and ‘||’ operators are called short-circuit operators because of the way they work. Evaluation of the full expression is “short-circuited” if the result can be determined partway through its evaluation.
Statements that end with ‘&&’ or ‘||’ can be continued simply
by putting a newline after them. But you cannot put a newline in front
of either of these operators without using backslash continuation
(see awk Statements Versus Lines).
The actual value of an expression using the ‘!’ operator is either one or zero, depending upon the truth value of the expression it is applied to. The ‘!’ operator is often useful for changing the sense of a flag variable from false to true and back again. For example, the following program is one way to print lines in between special bracketing lines:
$1 == "START" { interested = ! interested; next }
interested { print }
$1 == "END" { interested = ! interested; next }
The variable interested, as with all awk variables, starts
out initialized to zero, which is also false. When a line is seen whose
first field is ‘START’, the value of interested is toggled
to true, using ‘!’. The next rule prints lines as long as
interested is true. When a line is seen whose first field is
‘END’, interested is toggled back to false.40
Most commonly, the ‘!’ operator is used in the conditions of
if and while statements, where it often makes more
sense to phrase the logic in the negative:
if (! some condition || some other condition) {
... do whatever processing ...
}
NOTE: The
nextstatement is discussed in ThenextStatement.nexttellsawkto skip the rest of the rules, get the next record, and start processing the rules over again at the top. The reason it’s there is to avoid printing the bracketing ‘START’ and ‘END’ lines.
6.3.4 Conditional Expressions ¶
A conditional expression is a special kind of expression that has
three operands. It allows you to use one expression’s value to select
one of two other expressions.
The conditional expression in awk is the same as in the C
language, as shown here:
selector ? if-true-exp : if-false-exp
There are three subexpressions. The first, selector, is always
computed first. If it is “true” (not zero or not null), then
if-true-exp is computed next, and its value becomes the value of
the whole expression. Otherwise, if-false-exp is computed next,
and its value becomes the value of the whole expression.
For example, the following expression produces the absolute value of x:
x >= 0 ? x : -x
Each time the conditional expression is computed, only one of
if-true-exp and if-false-exp is used; the other is ignored.
This is important when the expressions have side effects. For example,
this conditional expression examines element i of either array
a or array b, and increments i:
x == y ? a[i++] : b[i++]
This is guaranteed to increment i exactly once, because each time
only one of the two increment expressions is executed
and the other is not.
See Arrays in awk,
for more information about arrays.
As a minor gawk extension,
a statement that uses ‘?:’ can be continued simply
by putting a newline after either character.
However, putting a newline in front
of either character does not work without using backslash continuation
(see awk Statements Versus Lines).
If --posix is specified
(see Command-Line Options), this extension is disabled.
6.4 Function Calls ¶
A function is a name for a particular calculation.
This enables you to
ask for it by name at any point in the program. For
example, the function sqrt() computes the square root of a number.
A fixed set of functions are built in, which means they are
available in every awk program. The sqrt() function is one
of these. See Built-in Functions for a list of built-in
functions and their descriptions. In addition, you can define
functions for use in your program.
See User-Defined Functions
for instructions on how to do this.
Finally, gawk lets you write functions in C or C++
that may be called from your program (see Writing Extensions for gawk).
The way to use a function is with a function call expression, which consists of the function name followed immediately by a list of arguments in parentheses. The arguments are expressions that provide the raw materials for the function’s calculations. When there is more than one argument, they are separated by commas. If there are no arguments, just write ‘()’ after the function name. The following examples show function calls with and without arguments:
sqrt(x^2 + y^2) one argument atan2(y, x) two arguments rand() no arguments
CAUTION: Do not put any space between the function name and the opening parenthesis! A user-defined function name looks just like the name of a variable—a space would make the expression look like concatenation of a variable with an expression inside parentheses. With built-in functions, space before the parenthesis is harmless, but it is best not to get into the habit of using space to avoid mistakes with user-defined functions.
Each function expects a particular number
of arguments. For example, the sqrt() function must be called with
a single argument, the number of which to take the square root:
sqrt(argument)
Some of the built-in functions have one or more optional arguments. If those arguments are not supplied, the functions use a reasonable default value. See Built-in Functions for full details. If arguments are omitted in calls to user-defined functions, then those arguments are treated as local variables. Such local variables act like the empty string if referenced where a string value is required, and like zero if referenced where a numeric value is required (see User-Defined Functions).
As an advanced feature, gawk provides indirect function calls,
which is a way to choose the function to call at runtime, instead of
when you write the source code to your program. We defer discussion of
this feature until later; see Indirect Function Calls.
Like every other expression, the function call has a value, often called the return value, which is computed by the function based on the arguments you give it. In this example, the return value of ‘sqrt(argument)’ is the square root of argument. The following program reads numbers, one number per line, and prints the square root of each one:
$ awk '{ print "The square root of", $1, "is", sqrt($1) }'
1
-| The square root of 1 is 1
3
-| The square root of 3 is 1.73205
5
-| The square root of 5 is 2.23607
Ctrl-d
A function can also have side effects, such as assigning
values to certain variables or doing I/O.
This program shows how the match() function
(see String-Manipulation Functions)
changes the variables RSTART and RLENGTH:
{
if (match($1, $2))
print RSTART, RLENGTH
else
print "no match"
}
Here is a sample run:
$ awk -f matchit.awk aaccdd c+ -| 3 2 foo bar -| no match abcdefg e -| 5 1
6.5 Operator Precedence (How Operators Nest) ¶
Operator precedence determines how operators are grouped when
different operators appear close by in one expression. For example,
‘*’ has higher precedence than ‘+’; thus, ‘a + b * c’
means to multiply b and c, and then add a to the
product (i.e., ‘a + (b * c)’).
The normal precedence of the operators can be overruled by using parentheses. Think of the precedence rules as saying where the parentheses are assumed to be. In fact, it is wise to always use parentheses whenever there is an unusual combination of operators, because other people who read the program may not remember what the precedence is in this case. Even experienced programmers occasionally forget the exact rules, which leads to mistakes. Explicit parentheses help prevent any such mistakes.
When operators of equal precedence are used together, the leftmost operator groups first, except for the assignment, conditional, and exponentiation operators, which group in the opposite order. Thus, ‘a - b + c’ groups as ‘(a - b) + c’ and ‘a = b = c’ groups as ‘a = (b = c)’.
Normally the precedence of prefix unary operators does not matter, because there is only one way to interpret them: innermost first. Thus, ‘$++i’ means ‘$(++i)’ and ‘++$x’ means ‘++($x)’. However, when another operator follows the operand, then the precedence of the unary operators can matter. ‘$x^2’ means ‘($x)^2’, but ‘-x^2’ means ‘-(x^2)’, because ‘-’ has lower precedence than ‘^’, whereas ‘$’ has higher precedence. Also, operators cannot be combined in a way that violates the precedence rules; for example, ‘$$0++--’ is not a valid expression because the first ‘$’ has higher precedence than the ‘++’; to avoid the problem the expression can be rewritten as ‘$($0++)--’.
This list presents awk’s operators, in order of highest
to lowest precedence:
(…)Grouping.
$Field reference.
++ --Increment, decrement.
^ **Exponentiation. These operators group right to left.
+ - !Unary plus, minus, logical “not.”
* / %Multiplication, division, remainder.
+ -Addition, subtraction.
- String concatenation
There is no special symbol for concatenation. The operands are simply written side by side (see String Concatenation).
< <= == != > >= >> | |&Relational and redirection. The relational operators and the redirections have the same precedence level. Characters such as ‘>’ serve both as relationals and as redirections; the context distinguishes between the two meanings.
Note that the I/O redirection operators in
printandprintfstatements belong to the statement level, not to expressions. The redirection does not produce an expression that could be the operand of another operator. As a result, it does not make sense to use a redirection operator near another operator of lower precedence without parentheses. Such combinations (e.g., ‘print foo > a ? b : c’) result in syntax errors. The correct way to write this statement is ‘print foo > (a ? b : c)’.~ !~Matching, nonmatching.
in¶Array membership.
&&Logical “and.”
||Logical “or.”
?:Conditional. This operator groups right to left.
= += -= *= /= %= ^= **=Assignment. These operators group right to left.
NOTE: The ‘|&’, ‘**’, and ‘**=’ operators are not specified by POSIX. For maximum portability, do not use them.
6.6 Where You Are Makes a Difference ¶
Modern systems support the notion of locales: a way to tell the
system about the local character set and language. The ISO C standard
defines a default "C" locale, which is an environment that is
typical of what many C programmers are used to.
Once upon a time, the locale setting used to affect regexp matching, but this is no longer true (see Regexp Ranges and Locales: A Long Sad Story).
Locales can affect record splitting. For the normal case of ‘RS =
"\n"’, the locale is largely irrelevant. For other single-character
record separators, setting ‘LC_ALL=C’ in the environment will
give you much better performance when reading records. Otherwise,
gawk has to make several function calls, per input
character, to find the record terminator.
Locales can affect how dates and times are formatted (see Time Functions). For example, a common way to abbreviate the date September
4, 2015, in the United States is “9/4/15.” In many countries in
Europe, however, it is abbreviated “4.9.15.” Thus, the ‘%x’
specification in a "US" locale might produce ‘9/4/15’,
while in a "EUROPE" locale, it might produce ‘4.9.15’.
According to POSIX, string comparison is also affected by locales (similar to regular expressions). The details are presented in String Comparison Based on Locale Collating Order.
Finally, the locale affects the value of the decimal point character
used when gawk parses input data. This is discussed in detail
in Conversion of Strings and Numbers.
6.7 Summary ¶
- Expressions are the basic elements of computation in programs. They are built from constants, variables, function calls, and combinations of the various kinds of values with operators.
awksupplies three kinds of constants: numeric, string, and regexp.gawklets you specify numeric constants in octal and hexadecimal (bases 8 and 16) as well as decimal (base 10). In certain contexts, a standalone regexp constant such as/foo/has the same meaning as ‘$0 ~ /foo/’.- Variables hold values between uses in computations. A number of built-in
variables provide information to your
awkprogram, and a number of others let you control howawkbehaves. - Numbers are automatically converted to strings, and strings to numbers,
as needed by
awk. Numeric values are converted as if they were formatted withsprintf()using the format inCONVFMT. Locales can influence the conversions. awkprovides the usual arithmetic operators (addition, subtraction, multiplication, division, modulus), and unary plus and minus. It also provides comparison operators, Boolean operators, an array membership testing operator, and regexp matching operators. String concatenation is accomplished by placing two expressions next to each other; there is no explicit operator. The three-operand ‘?:’ operator provides an “if-else” test within expressions.- Assignment operators provide convenient shorthands for common arithmetic operations.
- In
awk, a value is considered to be true if it is nonzero or non-null. Otherwise, the value is false. - A variable’s type is set upon each assignment and may change over its lifetime. The type determines how it behaves in comparisons (string or numeric).
- Function calls return a value that may be used as part of a larger
expression. Expressions used to pass parameter values are fully
evaluated before the function is called.
awkprovides built-in and user-defined functions; this is described in Functions. - Operator precedence specifies the order in which operations are performed,
unless explicitly overridden by parentheses.
awk’s operator precedence is compatible with that of C. - Locales can affect the format of data as output by an
awkprogram, and occasionally the format for data read as input.
7 Patterns, Actions, and Variables ¶
As you have already seen, each awk statement consists of
a pattern with an associated action. This chapter describes how
you build patterns and actions, what kinds of things you can do within
actions, and awk’s predefined variables.
The pattern–action rules and the statements available for use
within actions form the core of awk programming.
In a sense, everything covered
up to here has been the foundation
that programs are built on top of. Now it’s time to start
building something useful.
- Pattern Elements
- Using Shell Variables in Programs
- Actions
- Control Statements in Actions
- Predefined Variables
- Summary
7.1 Pattern Elements ¶
Patterns in awk control the execution of rules—a rule is
executed when its pattern matches the current input record.
The following is a summary of the types of awk patterns:
/regular expression/A regular expression. It matches when the text of the input record fits the regular expression. (See Regular Expressions.)
expressionA single expression. It matches when its value is nonzero (if a number) or non-null (if a string). (See Expressions as Patterns.)
begpat, endpatA pair of patterns separated by a comma, specifying a range of records. The range includes both the initial record that matches begpat and the final record that matches endpat. (See Specifying Record Ranges with Patterns.)
BEGINENDSpecial patterns for you to supply startup or cleanup actions for your
awkprogram. (See TheBEGINandENDSpecial Patterns.)BEGINFILEENDFILESpecial patterns for you to supply startup or cleanup actions to be done on a per-file basis. (See The
BEGINFILEandENDFILESpecial Patterns.)emptyThe empty pattern matches every input record. (See The Empty Pattern.)
- Regular Expressions as Patterns
- Expressions as Patterns
- Specifying Record Ranges with Patterns
- The
BEGINandENDSpecial Patterns - The
BEGINFILEandENDFILESpecial Patterns - The Empty Pattern
7.1.1 Regular Expressions as Patterns ¶
Regular expressions are one of the first kinds of patterns presented in this book. This kind of pattern is simply a regexp constant in the pattern part of a rule. Its meaning is ‘$0 ~ /pattern/’. The pattern matches when the input record matches the regexp. For example:
/foo|bar|baz/ { buzzwords++ }
END { print buzzwords, "buzzwords seen" }
7.1.2 Expressions as Patterns ¶
Any awk expression is valid as an awk pattern.
The pattern matches if the expression’s value is nonzero (if a
number) or non-null (if a string).
The expression is reevaluated each time the rule is tested against a new
input record. If the expression uses fields such as $1, the
value depends directly on the new input record’s text; otherwise, it
depends on only what has happened so far in the execution of the
awk program.
Comparison expressions, using the comparison operators described in
Variable Typing and Comparison Expressions,
are a very common kind of pattern.
Regexp matching and nonmatching are also very common expressions.
The left operand of the ‘~’ and ‘!~’ operators is a string.
The right operand is either a constant regular expression enclosed in
slashes (/regexp/), or any expression whose string value
is used as a dynamic regular expression
(see Using Dynamic Regexps).
The following example prints the second field of each input record
whose first field is precisely ‘li’:
$ awk '$1 == "li" { print $2 }' mail-list
(There is no output, because there is no person with the exact name ‘li’.) Contrast this with the following regular expression match, which accepts any record with a first field that contains ‘li’:
$ awk '$1 ~ /li/ { print $2 }' mail-list
-| 555-5553
-| 555-6699
A regexp constant as a pattern is also a special case of an expression
pattern. The expression /li/ has the value one if ‘li’
appears in the current input record. Thus, as a pattern, /li/
matches any record containing ‘li’.
Boolean expressions are also commonly used as patterns. Whether the pattern matches an input record depends on whether its subexpressions match. For example, the following command prints all the records in mail-list that contain both ‘edu’ and ‘li’:
$ awk '/edu/ && /li/' mail-list -| Samuel 555-3430 samuel.lanceolis@shu.edu A
The following command prints all records in mail-list that contain either ‘edu’ or ‘li’ (or both, of course):
$ awk '/edu/ || /li/' mail-list -| Amelia 555-5553 amelia.zodiacusque@gmail.com F -| Broderick 555-0542 broderick.aliquotiens@yahoo.com R -| Fabius 555-1234 fabius.undevicesimus@ucb.edu F -| Julie 555-6699 julie.perscrutabor@skeeve.com F -| Samuel 555-3430 samuel.lanceolis@shu.edu A -| Jean-Paul 555-2127 jeanpaul.campanorum@nyu.edu R
The following command prints all records in mail-list that do not contain the string ‘li’:
$ awk '! /li/' mail-list -| Anthony 555-3412 anthony.asserturo@hotmail.com A -| Becky 555-7685 becky.algebrarum@gmail.com A -| Bill 555-1675 bill.drowning@hotmail.com A -| Camilla 555-2912 camilla.infusarum@skynet.be R -| Fabius 555-1234 fabius.undevicesimus@ucb.edu F
-| Martin 555-6480 martin.codicibus@hotmail.com A -| Jean-Paul 555-2127 jeanpaul.campanorum@nyu.edu R
The subexpressions of a Boolean operator in a pattern can be constant regular
expressions, comparisons, or any other awk expressions. Range
patterns are not expressions, so they cannot appear inside Boolean
patterns. Likewise, the special patterns BEGIN, END,
BEGINFILE, and ENDFILE,
which never match any input record, are not expressions and cannot
appear inside Boolean patterns.
The precedence of the different operators that can appear in patterns is described in Operator Precedence (How Operators Nest).
7.1.3 Specifying Record Ranges with Patterns ¶
A range pattern is made of two patterns separated by a comma, in the form ‘begpat, endpat’. It is used to match ranges of consecutive input records. The first pattern, begpat, controls where the range begins, while endpat controls where the pattern ends. For example, the following:
awk '$1 == "on", $1 == "off"' myfile
prints every record in myfile between ‘on’/‘off’ pairs, inclusive.
A range pattern starts out by matching begpat against every input record. When a record matches begpat, the range pattern is turned on, and the range pattern matches this record as well. As long as the range pattern stays turned on, it automatically matches every input record read. The range pattern also matches endpat against every input record; when this succeeds, the range pattern is turned off again for the following record. Then the range pattern goes back to checking begpat against each record.
The record that turns on the range pattern and the one that turns it
off both match the range pattern. If you don’t want to operate on
these records, you can write if statements in the rule’s action
to distinguish them from the records you are interested in.
It is possible for a pattern to be turned on and off by the same
record. If the record satisfies both conditions, then the action is
executed for just that record.
For example, suppose there is text between two identical markers (e.g.,
the ‘%’ symbol), each on its own line, that should be ignored.
A first attempt would be to
combine a range pattern that describes the delimited text with the
next statement
(not discussed yet, see The next Statement).
This causes awk to skip any further processing of the current
record and start over again with the next input record. Such a program
looks like this:
/^%$/,/^%$/ { next }
{ print }
This program fails because the range pattern is both turned on and turned off by the first line, which just has a ‘%’ on it. To accomplish this task, write the program in the following manner, using a flag:
/^%$/ { skip = ! skip; next }
skip == 1 { next } # skip lines with `skip' set
In a range pattern, the comma (‘,’) has the lowest precedence of all the operators (i.e., it is evaluated last). Thus, the following program attempts to combine a range pattern with another, simpler test:
echo Yes | awk '/1/,/2/ || /Yes/'
The intent of this program is ‘(/1/,/2/) || /Yes/’.
However, awk interprets this as ‘/1/, (/2/ || /Yes/)’.
This cannot be changed or worked around; range patterns do not combine
with other patterns:
$ echo Yes | gawk '(/1/,/2/) || /Yes/' error→ gawk: cmd. line:1: (/1/,/2/) || /Yes/ error→ gawk: cmd. line:1: ^ syntax error
As a minor point of interest, although it is poor style, POSIX allows you to put a newline after the comma in a range pattern. (d.c.)
7.1.4 The BEGIN and END Special Patterns ¶
All the patterns described so far are for matching input records.
The BEGIN and END special patterns are different.
They supply startup and cleanup actions for awk programs.
BEGIN and END rules must have actions; there is no default
action for these rules because there is no current record when they run.
BEGIN and END rules are often referred to as
“BEGIN and END blocks” by longtime awk
programmers.
7.1.4.1 Startup and Cleanup Actions ¶
A BEGIN rule is executed once only, before the first input record
is read. Likewise, an END rule is executed once only, after all the
input is read. For example:
$ awk '
> BEGIN { print "Analysis of \"li\"" }
> /li/ { ++n }
> END { print "\"li\" appears in", n, "records." }' mail-list
-| Analysis of "li"
-| "li" appears in 4 records.
This program finds the number of records in the input file mail-list
that contain the string ‘li’. The BEGIN rule prints a title
for the report. There is no need to use the BEGIN rule to
initialize the counter n to zero, as awk does this
automatically (see Variables).
The second rule increments the variable n every time a
record containing the pattern ‘li’ is read. The END rule
prints the value of n at the end of the run.
The special patterns BEGIN and END cannot be used in ranges
or with Boolean operators (indeed, they cannot be used with any operators).
An awk program may have multiple BEGIN and/or END
rules. They are executed in the order in which they appear: all the BEGIN
rules at startup and all the END rules at termination.
BEGIN and END rules may be intermixed with other rules.
This feature was added in the 1987 version of awk and is included
in the POSIX standard.
The original (1978) version of awk
required the BEGIN rule to be placed at the beginning of the
program, the END rule to be placed at the end, and only allowed one of
each.
This is no longer required, but it is a good idea to follow this template
in terms of program organization and readability.
Multiple BEGIN and END rules are useful for writing
library functions, because each library file can have its own BEGIN and/or
END rule to do its own initialization and/or cleanup.
The order in which library functions are named on the command line
controls the order in which their BEGIN and END rules are
executed. Therefore, you have to be careful when writing such rules in
library files so that the order in which they are executed doesn’t matter.
See Command-Line Options for more information on
using library functions.
See A Library of awk Functions,
for a number of useful library functions.
If an awk program has only BEGIN rules and no
other rules, then the program exits after the BEGIN rules are
run.41 However, if an
END rule exists, then the input is read, even if there are
no other rules in the program. This is necessary in case the END
rule checks the FNR and NR variables, or the fields.
7.1.4.2 Input/Output from BEGIN and END Rules ¶
There are several (sometimes subtle) points to be aware of when doing I/O
from a BEGIN or END rule.
The first has to do with the value of $0 in a BEGIN
rule. Because BEGIN rules are executed before any input is read,
there simply is no input record, and therefore no fields, when
executing BEGIN rules. References to $0 and the fields
yield a null string or zero, depending upon the context. One way
to give $0 a real value is to execute a getline command
without a variable (see Explicit Input with getline).
Another way is simply to assign a value to $0.
The second point is similar to the first, but from the other direction.
Traditionally, due largely to implementation issues, $0 and
NF were undefined inside an END rule.
The POSIX standard specifies that NF is available in an END
rule. It contains the number of fields from the last input record.
Most probably due to an oversight, the standard does not say that $0
is also preserved, although logically one would think that it should be.
In fact, all of BWK awk, mawk, and gawk
preserve the value of $0 for use in END rules. Be aware,
however, that some other implementations and many older versions
of Unix awk do not.
The third point follows from the first two. The meaning of ‘print’
inside a BEGIN or END rule is the same as always:
‘print $0’. If $0 is the null string, then this prints an
empty record. Many longtime awk programmers use an unadorned
‘print’ in BEGIN and END rules to mean ‘print ""’,
relying on $0 being null. Although one might generally get away with
this in BEGIN rules, it is a very bad idea in END rules,
at least in gawk. It is also poor style, because if an empty
line is needed in the output, the program should print one explicitly.
Finally, the next and nextfile statements are not allowed
in a BEGIN rule, because the implicit
read-a-record-and-match-against-the-rules loop has not started yet. Similarly, those statements
are not valid in an END rule, because all the input has been read.
(See The next Statement and
see The nextfile Statement.)
7.1.5 The BEGINFILE and ENDFILE Special Patterns ¶
This section describes a gawk-specific feature.
Two special kinds of rule, BEGINFILE and ENDFILE, give
you “hooks” into gawk’s command-line file processing loop.
As with the BEGIN and END rules
(see The BEGIN and END Special Patterns),
BEGINFILE rules in a program execute in the order they are
read by gawk. Similarly, all ENDFILE rules also execute in
the order they are read.
The bodies of the BEGINFILE rules execute just before
gawk reads the first record from a file. FILENAME
is set to the name of the current file, and FNR is set to zero.
Prior to version 5.1.1 of gawk, as an accident of the
implementation, $0 and the fields retained any previous values
they had in BEGINFILE rules. Starting with version
5.1.1, $0 and the fields are cleared, since no record has been
read yet from the file that is about to be processed.
The BEGINFILE rule provides you the opportunity to accomplish two tasks
that would otherwise be difficult or impossible to perform:
- You can test if the file is readable. Normally, it is a fatal error if a
file named on the command line cannot be opened for reading. However,
you can bypass the fatal error and move on to the next file on the
command line.
You do this by checking if the
ERRNOvariable is not the empty string; if so, thengawkwas not able to open the file. In this case, your program can execute thenextfilestatement (see ThenextfileStatement). This causesgawkto skip the file entirely. Otherwise,gawkexits with the usual fatal error. - If you have written extensions that modify the record handling (by
inserting an “input parser”; see Customized Input Parsers), you can invoke
them at this point, before
gawkhas started processing the file. (This is a very advanced feature, currently used only by thegawkextlibproject.)
The ENDFILE rule is called when gawk has finished processing
the last record in an input file. For the last input file,
it will be called before any END rules.
The ENDFILE rule is executed even for empty input files.
Normally, when an error occurs when reading input in the normal
input-processing loop, the error is fatal. However, if a BEGINFILE
rule is present, the error becomes non-fatal, and instead ERRNO
is set. This makes it possible to catch and process I/O errors at the
level of the awk program.
The next statement (see The next Statement) is not allowed inside
either a BEGINFILE or an ENDFILE rule. The nextfile
statement is allowed only inside a
BEGINFILE rule, not inside an ENDFILE rule.
The getline statement (see Explicit Input with getline) is restricted inside
both BEGINFILE and ENDFILE: only redirected
forms of getline are allowed.
BEGINFILE and ENDFILE are gawk extensions.
In most other awk implementations, or if gawk is in
compatibility mode (see Command-Line Options), they are not special.
7.1.6 The Empty Pattern ¶
An empty (i.e., nonexistent) pattern is considered to match every input record. For example, the program:
awk '{ print $1 }' mail-list
prints the first field of every record.
7.2 Using Shell Variables in Programs ¶
awk programs are often used as components in larger
programs written in shell.
For example, it is very common to use a shell variable to
hold a pattern that the awk program searches for.
There are two ways to get the value of the shell variable
into the body of the awk program.
A common method is to use shell quoting to substitute the variable’s value into the program inside the script. For example, consider the following program:
printf "Enter search pattern: "
read pattern
awk "/$pattern/ "'{ nmatches++ }
END { print nmatches, "found" }' /path/to/data
The awk program consists of two pieces of quoted text
that are concatenated together to form the program.
The first part is double-quoted, which allows substitution of
the pattern shell variable inside the quotes.
The second part is single-quoted.
Variable substitution via quoting works, but can potentially be messy. It requires a good understanding of the shell’s quoting rules (see Shell Quoting Issues), and it’s often difficult to correctly match up the quotes when reading the program.
A better method is to use awk’s variable assignment feature
(see Assigning Variables on the Command Line)
to assign the shell variable’s value to an awk variable.
Then use dynamic regexps to match the pattern
(see Using Dynamic Regexps).
The following shows how to redo the
previous example using this technique:
printf "Enter search pattern: "
read pattern
awk -v pat="$pattern" '$0 ~ pat { nmatches++ }
END { print nmatches, "found" }' /path/to/data
Now, the awk program is just one single-quoted string.
The assignment ‘-v pat="$pattern"’ still requires double quotes,
in case there is whitespace in the value of $pattern.
The awk variable pat could be named pattern
too, but that would be more confusing. Using a variable also
provides more flexibility, as the variable can be used anywhere inside
the program—for printing, as an array subscript, or for any other
use—without requiring the quoting tricks at every point in the program.
7.3 Actions ¶
An awk program or script consists of a series of
rules and function definitions interspersed. (Functions are
described later. See User-Defined Functions.)
A rule contains a pattern and an action, either of which (but not
both) may be omitted. The purpose of the action is to tell
awk what to do once a match for the pattern is found. Thus,
in outline, an awk program generally looks like this:
[pattern]{ action }pattern [{ action }] ...function name(args) { ... }...
An action consists of one or more awk statements, enclosed
in braces (‘{…}’). Each statement specifies one
thing to do. The statements are separated by newlines or semicolons.
The braces around an action must be used even if the action
contains only one statement, or if it contains no statements at
all. However, if you omit the action entirely, omit the braces as
well. An omitted action is equivalent to ‘{ print $0 }’:
/foo/ { } match foo, do nothing --- empty action
/foo/ match foo, print the record --- omitted action
The following types of statements are supported in awk:
- Expressions
Call functions or assign values to variables (see Expressions). Executing this kind of statement simply computes the value of the expression. This is useful when the expression has side effects (see Assignment Expressions).
- Control statements
Specify the control flow of
awkprograms. Theawklanguage gives you C-like constructs (if,for,while, anddo) as well as a few special ones (see Control Statements in Actions).- Compound statements
Enclose one or more statements in braces. A compound statement is used in order to put several statements together in the body of an
if,while,do, orforstatement.- Input statements
Use the
getlinecommand (see Explicit Input withgetline). Also supplied inawkare thenextstatement (see ThenextStatement) and thenextfilestatement (see ThenextfileStatement).- Output statements
Such as
printandprintf. See Printing Output.- Deletion statements
For deleting array elements. See The
deleteStatement.
7.4 Control Statements in Actions ¶
Control statements, such as if, while, and so on,
control the flow of execution in awk programs. Most of awk’s
control statements are patterned after similar statements in C.
All the control statements start with special keywords, such as if
and while, to distinguish them from simple expressions.
Many control statements contain other statements. For example, the
if statement contains another statement that may or may not be
executed. The contained statement is called the body.
To include more than one statement in the body, group them into a
single compound statement with braces, separating them with
newlines or semicolons.
- The
if-elseStatement - The
whileStatement - The
do-whileStatement - The
forStatement - The
switchStatement - The
breakStatement - The
continueStatement - The
nextStatement - The
nextfileStatement - The
exitStatement
7.4.1 The if-else Statement ¶
The if-else statement is awk’s decision-making
statement. It looks like this:
if (condition) then-body[else else-body]
The condition is an expression that controls what the rest of the
statement does. If the condition is true, then-body is
executed; otherwise, else-body is executed.
The else part of the statement is
optional. The condition is considered false if its value is zero or
the null string; otherwise, the condition is true.
Refer to the following:
if (x % 2 == 0)
print "x is even"
else
print "x is odd"
In this example, if the expression ‘x % 2 == 0’ is true (i.e.,
if the value of x is evenly divisible by two), then the first
print statement is executed; otherwise, the second print
statement is executed.
If the else keyword appears on the same line as then-body and
then-body is not a compound statement (i.e., not surrounded by
braces), then a semicolon must separate then-body from
the else.
To illustrate this, the previous example can be rewritten as:
if (x % 2 == 0) print "x is even"; else
print "x is odd"
If the ‘;’ is left out, awk can’t interpret the statement and
it produces a syntax error. Don’t actually write programs this way,
because a human reader might fail to see the else if it is not
the first thing on its line.
7.4.2 The while Statement ¶
In programming, a loop is a part of a program that can
be executed two or more times in succession.
The while statement is the simplest looping statement in
awk. It repeatedly executes a statement as long as a condition is
true. For example:
while (condition) body
body is a statement called the body of the loop,
and condition is an expression that controls how long the loop
keeps running.
The first thing the while statement does is test the condition.
If the condition is true, it executes the statement body.
After body has been executed,
condition is tested again, and if it is still true, body
executes again. This process repeats until the condition is no longer
true. If the condition is initially false, the body of the loop
never executes and awk continues with the statement following
the loop.
This example prints the first three fields of each record, one per line:
awk '
{
i = 1
while (i <= 3) {
print $i
i++
}
}' inventory-shipped
The body of this loop is a compound statement enclosed in braces,
containing two statements.
The loop works in the following manner: first, the value of i is set to one.
Then, the while statement tests whether i is less than or equal to
three. This is true when i equals one, so the ith
field is printed. Then the ‘i++’ increments the value of i
and the loop repeats. The loop terminates when i reaches four.
A newline is not required between the condition and the body; however, using one makes the program clearer unless the body is a compound statement or else is very simple. The newline after the open brace that begins the compound statement is not required either, but the program is harder to read without it.
7.4.3 The do-while Statement ¶
The do loop is a variation of the while looping statement.
The do loop executes the body once and then repeats the
body as long as the condition is true. It looks like this:
do body while (condition)
Even if the condition is false at the start, the body
executes at least once (and only once, unless executing body
makes condition true). Contrast this with the corresponding
while statement:
while (condition)
body
This statement does not execute the body even once if the
condition is false to begin with. The following is an example of
a do statement:
{
i = 1
do {
print $0
i++
} while (i <= 10)
}
This program prints each input record 10 times. However, it isn’t a very
realistic example, because in this case an ordinary while would do
just as well. This situation reflects actual experience; only
occasionally is there a real use for a do statement.
7.4.4 The for Statement ¶
The for statement makes it more convenient to count iterations of a
loop. The general form of the for statement looks like this:
for (initialization; condition; increment) body
The initialization, condition, and increment parts are
arbitrary awk expressions, and body stands for any
awk statement.
The for statement starts by executing initialization.
Then, as long
as the condition is true, it repeatedly executes body and then
increment. Typically, initialization sets a variable to
either zero or one, increment adds one to it, and condition
compares it against the desired number of iterations.
For example:
awk '
{
for (i = 1; i <= 3; i++)
print $i
}' inventory-shipped
This prints the first three fields of each input record, with one input field per output line.
C and C++ programmers might expect to be able to use the comma
operator to set more than one variable in the initialization
part of the for loop, or to increment multiple variables in the
increment part of the loop, like so:
for (i = 0, j = length(a); i < j; i++, j--) ... C/C++, not awk!
You cannot do this; the comma operator is not supported in awk.
There are workarounds, but they are nonobvious and can lead to
code that is difficult to read and understand. It is best, therefore,
to simply write additional initializations as separate statements
preceding the for loop and to place additional increment statements
at the end of the loop’s body.
Most often, increment is an increment expression, as in the earlier example. But this is not required; it can be any expression whatsoever. For example, the following statement prints all the powers of two between 1 and 100:
for (i = 1; i <= 100; i *= 2)
print i
If there is nothing to be done, any of the three expressions in the
parentheses following the for keyword may be omitted. Thus,
‘for (; x > 0;)’ is equivalent to ‘while (x > 0)’. If the
condition is omitted, it is treated as true, effectively
yielding an infinite loop (i.e., a loop that never terminates).
In most cases, a for loop is an abbreviation for a while
loop, as shown here:
initialization
while (condition) {
body
increment
}
The only exception is when the continue statement
(see The continue Statement) is used
inside the loop. Changing a for statement to a while
statement in this way can change the effect of the continue
statement inside the loop.
The awk language has a for statement in addition to a
while statement because a for loop is often both less work to
type and more natural to think of. Counting the number of iterations is
very common in loops. It can be easier to think of this counting as part
of looping rather than as something to do inside the loop.
There is an alternative version of the for loop, for iterating over
all the indices of an array:
for (i in array)
do something with array[i]
See Scanning All Elements of an Array
for more information on this version of the for loop.
7.4.5 The switch Statement ¶
This section describes a gawk-specific feature.
If gawk is in compatibility mode (see Command-Line Options),
it is not available.
The switch statement allows the evaluation of an expression and
the execution of statements based on a case match. Case statements
are checked for a match in the order they are defined. If no suitable
case is found, the default section is executed, if supplied.
Each case contains a single constant, be it numeric, string,
or regexp. The switch expression is evaluated, and then each
case’s constant is compared against the result in turn. The
type of constant determines the comparison: numeric or string do the
usual comparisons. A regexp constant (either regular, /foo/, or
strongly typed, @/foo/) does a regular expression match against
the string value of the original expression. The general form of the
switch statement looks like this:
switch (expression) {
case value or regular expression:
case-body
default:
default-body
}
Control flow in
the switch statement works as it does in C. Once a match to a given
case is made, the case statement bodies execute until a break,
continue, next, nextfile, or exit is encountered,
or the end of the switch statement itself. For example:
while ((c = getopt(ARGC, ARGV, "aksx")) != -1) {
switch (c) {
case "a":
# report size of all files
all_files = TRUE;
break
case "k":
BLOCK_SIZE = 1024 # 1K block size
break
case "s":
# do sums only
sum_only = TRUE
break
case "x":
# don't cross filesystems
fts_flags = or(fts_flags, FTS_XDEV)
break
case "?":
default:
usage()
break
}
}
Note that if none of the statements specified here halt execution
of a matched case statement, execution falls through to the
next case until execution halts. In this example, the
case for "?" falls through to the default
case, which is to call a function named usage().
(The getopt() function being called here is
described in Processing Command-Line Options.)
7.4.6 The break Statement ¶
The break statement jumps out of the innermost for,
while, or do loop that encloses it. The following example
finds the smallest divisor of any integer, and also identifies prime
numbers:
# find smallest divisor of num
{
num = $1
for (divisor = 2; divisor * divisor <= num; divisor++) {
if (num % divisor == 0)
break
}
if (num % divisor == 0)
printf "Smallest divisor of %d is %d\n", num, divisor
else
printf "%d is prime\n", num
}
When the remainder is zero in the first if statement, awk
immediately breaks out of the containing for loop. This means
that awk proceeds immediately to the statement following the loop
and continues processing. (This is very different from the exit
statement, which stops the entire awk program.
See The exit Statement.)
The following program illustrates how the condition of a for
or while statement could be replaced with a break inside
an if:
# find smallest divisor of num
{
num = $1
for (divisor = 2; ; divisor++) {
if (num % divisor == 0) {
printf "Smallest divisor of %d is %d\n", num, divisor
break
}
if (divisor * divisor > num) {
printf "%d is prime\n", num
break
}
}
}
The break statement is also used to break out of the
switch statement.
This is discussed in The switch Statement.
The break statement has no meaning when
used outside the body of a loop or switch.
However, although it was never documented,
historical implementations of awk treated the break
statement outside of a loop as if it were a next statement
(see The next Statement).
(d.c.)
Recent versions of BWK awk no longer allow this usage,
nor does gawk.
7.4.7 The continue Statement ¶
Similar to break, the continue statement is used only inside
for, while, and do loops. It skips
over the rest of the loop body, causing the next cycle around the loop
to begin immediately. Contrast this with break, which jumps out
of the loop altogether.
The continue statement in a for loop directs awk to
skip the rest of the body of the loop and resume execution with the
increment-expression of the for statement. The following program
illustrates this fact:
BEGIN {
for (x = 0; x <= 20; x++) {
if (x == 5)
continue
printf "%d ", x
}
print ""
}
This program prints all the numbers from 0 to 20—except for 5, for
which the printf is skipped. Because the increment ‘x++’
is not skipped, x does not remain stuck at 5. Contrast the
for loop from the previous example with the following while loop:
BEGIN {
x = 0
while (x <= 20) {
if (x == 5)
continue
printf "%d ", x
x++
}
print ""
}
This program loops forever once x reaches 5, because
the increment (‘x++’) is never reached.
The continue statement has no special meaning with respect to the
switch statement, nor does it have any meaning when used outside the
body of a loop. Historical versions of awk treated a continue
statement outside a loop the same way they treated a break
statement outside a loop: as if it were a next
statement
(see The next Statement).
(d.c.)
Recent versions of BWK awk no longer work this way, nor
does gawk.
7.4.8 The next Statement ¶
The next statement forces awk to immediately stop processing
the current record and go on to the next record. This means that no
further rules are executed for the current record, and the rest of the
current rule’s action isn’t executed.
Contrast this with the effect of the getline function
(see Explicit Input with getline). That also causes
awk to read the next record immediately, but it does not alter the
flow of control in any way (i.e., the rest of the current action executes
with a new input record).
At the highest level, awk program execution is a loop that reads
an input record and then tests each rule’s pattern against it. If you
think of this loop as a for statement whose body contains the
rules, then the next statement is analogous to a continue
statement. It skips to the end of the body of this implicit loop and
executes the increment (which reads another record).
For example, suppose an awk program works only on records
with four fields, and it shouldn’t fail when given bad input. To avoid
complicating the rest of the program, write a “weed out” rule near
the beginning, in the following manner:
NF != 4 {
printf("%s:%d: skipped: NF != 4\n", FILENAME, FNR) > "/dev/stderr"
next
}
Because of the next statement,
the program’s subsequent rules won’t see the bad record. The error
message is redirected to the standard error output stream, as error
messages should be.
For more detail, see
Special File names in gawk.
If the next statement causes the end of the input to be reached,
then the code in any END rules is executed.
See The BEGIN and END Special Patterns.
The next statement is not allowed inside BEGINFILE and
ENDFILE rules. See The BEGINFILE and ENDFILE Special Patterns.
According to the POSIX standard, the behavior is undefined if the
next statement is used in a BEGIN or END rule.
gawk treats it as a syntax error. Although POSIX does not disallow it,
most other awk implementations don’t allow the next
statement inside function bodies (see User-Defined Functions). Just as with any
other next statement, a next statement inside a function
body reads the next record and starts processing it with the first rule
in the program.
7.4.9 The nextfile Statement ¶
The nextfile statement
is similar to the next statement.
However, instead of abandoning processing of the current record, the
nextfile statement instructs awk to stop processing the
current data file.
Upon execution of the nextfile statement,
FILENAME is
updated to the name of the next data file listed on the command line,
FNR is reset to one,
and processing
starts over with the first rule in the program.
If the nextfile statement causes the end of the input to be reached,
then the code in any END rules is executed. An exception to this is
when nextfile is invoked during execution of any statement in an
END rule; in this case, it causes the program to stop immediately.
See The BEGIN and END Special Patterns.
The nextfile statement is useful when there are many data files
to process but it isn’t necessary to process every record in every file.
Without nextfile,
in order to move on to the next data file, a program
would have to continue scanning the unwanted records. The nextfile
statement accomplishes this much more efficiently.
In gawk, execution of nextfile causes additional things
to happen: any ENDFILE rules are executed if gawk is
not currently in an END rule, ARGIND is
incremented, and any BEGINFILE rules are executed. (ARGIND
hasn’t been introduced yet. See Predefined Variables.)
There is an additional, special, use case
with gawk. nextfile is useful inside a BEGINFILE
rule to skip over a file that would otherwise cause gawk
to exit with a fatal error. In this special case, ENDFILE rules are not
executed. See The BEGINFILE and ENDFILE Special Patterns.
Although it might seem that ‘close(FILENAME)’ would accomplish
the same as nextfile, this isn’t true. close() is
reserved for closing files, pipes, and coprocesses that are
opened with redirections. It is not related to the main processing that
awk does with the files listed in ARGV.
NOTE: For many years,
nextfilewas a common extension. In September 2012, it was accepted for inclusion into the POSIX standard. See the Austin Group website.
The current version of BWK awk and mawk
also support nextfile. However, they don’t allow the
nextfile statement inside function bodies (see User-Defined Functions).
gawk does; a nextfile inside a function body reads the
first record from the next file and starts processing it with the first
rule in the program, just as any other nextfile statement.
7.4.10 The exit Statement ¶
The exit statement causes awk to immediately stop
executing the current rule and to stop processing input; any remaining input
is ignored. The exit statement is written as follows:
exit [return code]
When an exit statement is executed from a BEGIN rule, the
program stops processing everything immediately. No input records are
read. However, if an END rule is present,
as part of executing the exit statement,
the END rule is executed
(see The BEGIN and END Special Patterns).
If exit is used in the body of an END rule, it causes
the program to stop immediately.
An exit statement that is not part of a BEGIN or END
rule stops the execution of any further automatic rules for the current
record, skips reading any remaining input records, and executes the
END rule if there is one. gawk also skips
any ENDFILE rules; they do not execute.
In such a case,
if you don’t want the END rule to do its job, set a variable
to a nonzero value before the exit statement and check that variable in
the END rule.
See Assertions
for an example that does this.
If an argument is supplied to exit, its value is used as the exit
status code for the awk process. If no argument is supplied,
exit causes awk to return a “success” status.
In the case where an argument
is supplied to a first exit statement, and then exit is
called a second time from an END rule with no argument,
awk uses the previously supplied exit value. (d.c.)
See gawk’s Exit Status for more information.
For example, suppose an error condition occurs that is difficult or
impossible to handle. Conventionally, programs report this by
exiting with a nonzero status. An awk program can do this
using an exit statement with a nonzero argument, as shown
in the following example:
BEGIN {
if (("date" | getline date_now) <= 0) {
print "Can't get system date" > "/dev/stderr"
exit 1
}
print "current date is", date_now
close("date")
}
NOTE: For full portability, exit values should be between zero and 126, inclusive. Negative values, and values of 127 or greater, may not produce consistent results across different operating systems.
7.5 Predefined Variables ¶
Most awk variables are available to use for your own
purposes; they never change unless your program assigns values to
them, and they never affect anything unless your program examines them.
However, a few variables in awk have special built-in meanings.
awk examines some of these automatically, so that they enable you
to tell awk how to do certain things. Others are set
automatically by awk, so that they carry information from the
internal workings of awk to your program.
This section documents all of gawk’s predefined variables,
most of which are also documented in the chapters describing
their areas of activity.
7.5.1 Built-in Variables That Control awk ¶
The following is an alphabetical list of variables that you can change to
control how awk does certain things.
The variables that are specific to gawk are marked with a pound
sign (‘#’). These variables are gawk extensions. In other
awk implementations or if gawk is in compatibility
mode (see Command-Line Options), they are not special. (Any exceptions are noted
in the description of each variable.)
BINMODE #On non-POSIX systems, this variable specifies use of binary mode for all I/O. Numeric values of one, two, or three specify that input files, output files, or all files, respectively, should use binary I/O. A numeric value less than zero is treated as zero, and a numeric value greater than three is treated as three. Alternatively, string values of
"r"or"w"specify that input files and output files, respectively, should use binary I/O. A string value of"rw"or"wr"indicates that all files should use binary I/O. Any other string value is treated the same as"rw", but causesgawkto generate a warning message.BINMODEis described in more detail in Usinggawkon PC Operating Systems.mawk(see Other Freely AvailableawkImplementations) also supports this variable, but only using numeric values.CONVFMTA string that controls the conversion of numbers to strings (see Conversion of Strings and Numbers). It works by being passed, in effect, as the first argument to the
sprintf()function (see String-Manipulation Functions). Its default value is"%.6g".CONVFMTwas introduced by the POSIX standard.FIELDWIDTHS #A space-separated list of columns that tells
gawkhow to split input with fixed columnar boundaries. Starting in version 4.2, each field width may optionally be preceded by a colon-separated value specifying the number of characters to skip before the field starts. Assigning a value toFIELDWIDTHSoverrides the use ofFSandFPATfor field splitting. See Reading Fixed-Width Data for more information.FPAT #A regular expression (as a string) that tells
gawkto create the fields based on text that matches the regular expression. Assigning a value toFPAToverrides the use ofFSandFIELDWIDTHSfor field splitting. See Defining Fields by Content for more information.FS¶The input field separator (see Specifying How Fields Are Separated). The value is a single-character string or a multicharacter regular expression that matches the separations between fields in an input record. If the value is the null string (
""), then each character in the record becomes a separate field. (This behavior is agawkextension. POSIXawkdoes not specify the behavior whenFSis the null string. Nonetheless, some other versions ofawkalso treat""specially.)The default value is
" ", a string consisting of a single space. As a special exception, this value means that any sequence of spaces, TABs, and/or newlines is a single separator. It also causes spaces, TABs, and newlines at the beginning and end of a record to be ignored.You can set the value of
FSon the command line using the -F option:awk -F, 'program' input-files
If
gawkis usingFIELDWIDTHSorFPATfor field splitting, assigning a value toFScausesgawkto return to the normal,FS-based field splitting. An easy way to do this is to simply say ‘FS = FS’, perhaps with an explanatory comment.IGNORECASE #If
IGNORECASEis nonzero or non-null, then all string comparisons and all regular expression matching are case-independent. This applies to regexp matching with ‘~’ and ‘!~’, thegensub(),gsub(),index(),match(),patsplit(),split(), andsub()functions, record termination withRS, and field splitting withFSandFPAT. However, the value ofIGNORECASEdoes not affect array subscripting and it does not affect field splitting when using a single-character field separator. See Case Sensitivity in Matching.LINT #¶When this variable is true (nonzero or non-null),
gawkbehaves as if the --lint command-line option is in effect (see Command-Line Options). With a value of"fatal", lint warnings become fatal errors. With a value of"invalid", only warnings about things that are actually invalid are issued. (This is not fully implemented yet.) Any other true value prints nonfatal warnings. Assigning a false value toLINTturns off the lint warnings.This variable is a
gawkextension. It is not special in otherawkimplementations. Unlike with the other special variables, changingLINTdoes affect the production of lint warnings, even ifgawkis in compatibility mode. Much as the --lint and --traditional options independently control different aspects ofgawk’s behavior, the control of lint warnings during program execution is independent of the flavor ofawkbeing executed.OFMTA string that controls conversion of numbers to strings (see Conversion of Strings and Numbers) for printing with the
printstatement. It works by being passed as the first argument to thesprintf()function (see String-Manipulation Functions). Its default value is"%.6g". Earlier versions ofawkusedOFMTto specify the format for converting numbers to strings in general expressions; this is now done byCONVFMT.OFS¶The output field separator (see Output Separators). It is output between the fields printed by a
printstatement. Its default value is" ", a string consisting of a single space.ORS¶The output record separator. It is output at the end of every
printstatement. Its default value is"\n", the newline character. (See Output Separators.)PREC #¶The working precision of arbitrary-precision floating-point numbers, 53 bits by default (see Setting the Precision).
ROUNDMODE #¶The rounding mode to use for arbitrary-precision arithmetic on numbers, by default
"N"(roundTiesToEvenin the IEEE 754 standard; see Setting the Rounding Mode).RSThe input record separator. Its default value is a string containing a single newline character, which means that an input record consists of a single line of text. It can also be the null string, in which case records are separated by runs of blank lines. If it is a regexp, records are separated by matches of the regexp in the input text. (See How Input Is Split into Records.)
The ability for
RSto be a regular expression is agawkextension. In most otherawkimplementations, or ifgawkis in compatibility mode (see Command-Line Options), just the first character ofRS’s value is used.SUBSEPThe subscript separator. It has the default value of
"\034"and is used to separate the parts of the indices of a multidimensional array. Thus, the expression ‘foo["A", "B"]’ really accessesfoo["A\034B"](see Multidimensional Arrays).TEXTDOMAIN #Used for internationalization of programs at the
awklevel. It sets the default text domain for specially marked string constants in the source text, as well as for thedcgettext(),dcngettext(), andbindtextdomain()functions (see Internationalization withgawk). The default value ofTEXTDOMAINis"messages".
7.5.2 Built-in Variables That Convey Information ¶
The following is an alphabetical list of variables that awk
sets automatically on certain occasions in order to provide
information to your program.
The variables that are specific to gawk are marked with a pound
sign (‘#’). These variables are gawk extensions. In other
awk implementations or if gawk is in compatibility
mode (see Command-Line Options), they are not special:
ARGC,ARGVThe command-line arguments available to
awkprograms are stored in an array calledARGV.ARGCis the number of command-line arguments present. See Other Command-Line Arguments. Unlike mostawkarrays,ARGVis indexed from 0 toARGC− 1. In the following example:$ awk 'BEGIN { > for (i = 0; i < ARGC; i++) > print ARGV[i] > }' inventory-shipped mail-list -| awk -| inventory-shipped -| mail-listARGV[0]contains ‘awk’,ARGV[1]contains ‘inventory-shipped’, andARGV[2]contains ‘mail-list’. The value ofARGCis three, one more than the index of the last element inARGV, because the elements are numbered from zero.The names
ARGCandARGV, as well as the convention of indexing the array from 0 toARGC− 1, are derived from the C language’s method of accessing command-line arguments.The value of
ARGV[0]can vary from system to system. Also, you should note that the program text is not included inARGV, nor are any ofawk’s command-line options. See UsingARGCandARGVfor information about howawkuses these variables. (d.c.)ARGIND #The index in
ARGVof the current file being processed. Every timegawkopens a new data file for processing, it setsARGINDto the index inARGVof the file name. Whengawkis processing the input files, ‘FILENAME == ARGV[ARGIND]’ is always true.This variable is useful in file processing; it allows you to tell how far along you are in the list of data files as well as to distinguish between successive instances of the same file name on the command line.
While you can change the value of
ARGINDwithin yourawkprogram,gawkautomatically sets it to a new value when it opens the next file.ENVIRONAn associative array containing the values of the environment. The array indices are the environment variable names; the elements are the values of the particular environment variables. For example,
ENVIRON["HOME"]might be/home/arnold.For POSIX
awk, changing this array does not affect the environment passed on to any programs thatawkmay spawn via redirection or thesystem()function.However, beginning with version 4.2, if not in POSIX compatibility mode,
gawkdoes update its own environment whenENVIRONis changed, thus changing the environment seen by programs that it creates. You should therefore be especially careful if you modifyENVIRON["PATH"], which is the search path for finding executable programs.This can also affect the running
gawkprogram, since some of the built-in functions may pay attention to certain environment variables. The most notable instance of this ismktime()(see Time Functions), which pays attention the value of theTZenvironment variable on many systems.Some operating systems may not have environment variables. On such systems, the
ENVIRONarray is empty (except forENVIRON["AWKPATH"]andENVIRON["AWKLIBPATH"]; see TheAWKPATHEnvironment Variable and see TheAWKLIBPATHEnvironment Variable).ERRNO #If a system error occurs during a redirection for
getline, during a read forgetline, or during aclose()operation, thenERRNOcontains a string describing the error.In addition,
gawkclearsERRNObefore opening each command-line input file. This enables checking if the file is readable inside aBEGINFILEpattern (see TheBEGINFILEandENDFILESpecial Patterns).Otherwise,
ERRNOworks similarly to the C variableerrno. Except for the case just mentioned,gawknever clears it (sets it to zero or""). Thus, you should only expect its value to be meaningful when an I/O operation returns a failure value, such asgetlinereturning −1. You are, of course, free to clear it yourself before doing an I/O operation.If the value of
ERRNOcorresponds to a system error in the Cerrnovariable, thenPROCINFO["errno"]will be set to the value oferrno. For non-system errors,PROCINFO["errno"]will be zero.FILENAMEThe name of the current input file. When no data files are listed on the command line,
awkreads from the standard input andFILENAMEis set to"-".FILENAMEchanges each time a new file is read (see Reading Input Files). Inside aBEGINrule, the value ofFILENAMEis"", because there are no input files being processed yet.42 (d.c.) Note, though, that usinggetline(see Explicit Input withgetline) inside aBEGINrule can giveFILENAMEa value.FNR¶The current record number in the current file.
awkincrementsFNReach time it reads a new record (see How Input Is Split into Records).awkresetsFNRto zero each time it starts a new input file.NF¶The number of fields in the current input record.
NFis set each time a new record is read, when a new field is created, or when$0changes (see Examining Fields).Unlike most of the variables described in this subsection, assigning a value to
NFhas the potential to affectawk’s internal workings. In particular, assignments toNFcan be used to create fields in or remove fields from the current record. See Changing the Contents of a Field.FUNCTAB #An array whose indices and corresponding values are the names of all the built-in, user-defined, and extension functions in the program.
NOTE: Attempting to use the
deletestatement with theFUNCTABarray causes a fatal error. Any attempt to assign to an element ofFUNCTABalso causes a fatal error.NR¶The number of input records
awkhas processed since the beginning of the program’s execution (see How Input Is Split into Records).awkincrementsNReach time it reads a new record.PROCINFO #The elements of this array provide access to information about the running
awkprogram. The following elements (listed alphabetically) are guaranteed to be available:PROCINFO["argv"]¶The
PROCINFO["argv"]array contains all of the command-line arguments (after glob expansion and redirection processing on platforms where that must be done manually by the program) with subscripts ranging from 0 throughargc− 1. For example,PROCINFO["argv"][0]will contain the name by whichgawkwas invoked. Here is an example of how this feature may be used:gawk ' BEGIN { for (i = 0; i < length(PROCINFO["argv"]); i++) print i, PROCINFO["argv"][i] }'Please note that this differs from the standard
ARGVarray which does not include command-line arguments that have already been processed bygawk(see UsingARGCandARGV).PROCINFO["egid"]¶The value of the
getegid()system call.PROCINFO["errno"]The value of the C
errnovariable whenERRNOis set to the associated error message.PROCINFO["euid"]¶The value of the
geteuid()system call.PROCINFO["FS"]This is
"FS"if field splitting withFSis in effect,"FIELDWIDTHS"if field splitting withFIELDWIDTHSis in effect,"FPAT"if field matching withFPATis in effect, or"API"if field splitting is controlled by an API input parser.PROCINFO["gid"]¶The value of the
getgid()system call.PROCINFO["identifiers"]¶A subarray, indexed by the names of all identifiers used in the text of the
awkprogram. An identifier is simply the name of a variable (be it scalar or array), built-in function, user-defined function, or extension function. For each identifier, the value of the element is one of the following:"array"The identifier is an array.
"builtin"The identifier is a built-in function.
"extension"The identifier is an extension function loaded via
@loador -l."scalar"The identifier is a scalar.
"untyped"The identifier is untyped (could be used as a scalar or an array;
gawkdoesn’t know yet)."user"The identifier is a user-defined function.
The values indicate what
gawkknows about the identifiers after it has finished parsing the program; they are not updated while the program runs.-
PROCINFO["platform"]¶ This element gives a string indicating the platform for which
gawkwas compiled. The value will be one of the following:"mingw"Microsoft Windows, using MinGW.
"os390"OS/390 (also known as z/OS).
"posix"GNU/Linux, Cygwin, macOS, and legacy Unix systems.
"vms"OpenVMS.
PROCINFO["pgrpid"]¶The process group ID of the current process.
PROCINFO["pid"]¶The process ID of the current process.
PROCINFO["pma"]¶-
The version of the PMA memory allocator compiled into
gawk. This element will not be present if the PMA allocator is not available for use. See Preserving Data Between Runs. PROCINFO["ppid"]¶The parent process ID of the current process.
PROCINFO["strftime"]The default time format string for
strftime(). Assigning a new value to this element changes the default. See Time Functions.PROCINFO["uid"]The value of the
getuid()system call.PROCINFO["version"]¶-
The version of
gawk.
The following additional elements in the array are available to provide information about the MPFR and GMP libraries if your version of
gawksupports arbitrary-precision arithmetic (see Arithmetic and Arbitrary-Precision Arithmetic withgawk):PROCINFO["gmp_version"]¶The version of the GNU MP library.
PROCINFO["mpfr_version"]The version of the GNU MPFR library.
PROCINFO["prec_max"]¶The maximum precision supported by MPFR.
PROCINFO["prec_min"]¶The minimum precision required by MPFR.
The following additional elements in the array are available to provide information about the version of the extension API, if your version of
gawksupports dynamic loading of extension functions (see Writing Extensions forgawk):PROCINFO["api_major"]¶-
The major version of the extension API.
PROCINFO["api_minor"]The minor version of the extension API.
On some systems, there may be elements in the array,
"group1"through"groupN"for some N. N is the number of supplementary groups that the process has. Use theinoperator to test for these elements (see Referring to an Array Element).The following elements allow you to change
gawk’s behavior:PROCINFO["BUFFERPIPE"]If this element exists, all output to pipelines becomes buffered. See Speeding Up Pipe Output.
PROCINFO["command", "BUFFERPIPE"]Make output to command buffered. See Speeding Up Pipe Output.
PROCINFO["NONFATAL"]If this element exists, then I/O errors for all redirections become nonfatal. See Enabling Nonfatal Output.
PROCINFO["name", "NONFATAL"]Make I/O errors for name be nonfatal. See Enabling Nonfatal Output.
PROCINFO["command", "pty"]For two-way communication to command, use a pseudo-tty instead of setting up a two-way pipe. See Two-Way Communications with Another Process for more information.
PROCINFO["input_name", "READ_TIMEOUT"]Set a timeout for reading from input redirection input_name. See Reading Input with a Timeout for more information.
PROCINFO["input_name", "RETRY"]If an I/O error that may be retried occurs when reading data from input_name, and this array entry exists, then
getlinereturns −2 instead of following the default behavior of returning −1 and configuring input_name to return no further data. An I/O error that may be retried is one whereerrnohas the valueEAGAIN,EWOULDBLOCK,EINTR, orETIMEDOUT. This may be useful in conjunction withPROCINFO["input_name", "READ_TIMEOUT"]or situations where a file descriptor has been configured to behave in a non-blocking fashion. See Retrying Reads After Certain Input Errors for more information.PROCINFO["sorted_in"]If this element exists in
PROCINFO, its value controls the order in which array indices will be processed by ‘for (indx in array)’ loops. This is an advanced feature, so we defer the full description until later; see Using Predefined Array Scanning Orders withgawk.
RLENGTH¶The length of the substring matched by the
match()function (see String-Manipulation Functions).RLENGTHis set by invoking thematch()function. Its value is the length of the matched string, or −1 if no match is found.RSTART¶The start index in characters of the substring that is matched by the
match()function (see String-Manipulation Functions).RSTARTis set by invoking thematch()function. Its value is the position of the string where the matched substring starts, or zero if no match was found.RT #The input text that matched the text denoted by
RS, the record separator. It is set every time a record is read.SYMTAB #An array whose indices are the names of all defined global variables and arrays in the program.
SYMTABmakesgawk’s symbol table visible to theawkprogrammer. It is built asgawkparses the program and is complete before the program starts to run.The array may be used for indirect access to read or write the value of a variable:
foo = 5 SYMTAB["foo"] = 4 print foo # prints 4
The
isarray()function (see Getting Type Information) may be used to test if an element inSYMTABis an array. Also, you may not use thedeletestatement with theSYMTABarray.Prior to version 5.0 of
gawk, you could use an index forSYMTABthat was not a predefined identifier:SYMTAB["xxx"] = 5 print SYMTAB["xxx"]
This no longer works, instead producing a fatal error, as it led to rampant confusion.
The
SYMTABarray is more interesting than it looks. Andrew Schorr points out that it effectively givesawkdata pointers. Consider his example:# Indirect multiply of any variable by amount, return result function multiply(variable, amount) { return SYMTAB[variable] *= amount }You would use it like this:
BEGIN { answer = 10.5 multiply("answer", 4) print "The answer is", answer }When run, this produces:
$ gawk -f answer.awk -| The answer is 42
NOTE: In order to avoid severe time-travel paradoxes,43 neither
FUNCTABnorSYMTABis available as an element within theSYMTABarray.
Changing NR and FNR |
|---|
|
$ echo '1
> 2
> 3
> 4' | awk 'NR == 2 { NR = 17 }
> { print NR }'
-| 1
-| 17
-| 18
-| 19
Before |
7.5.3 Using ARGC and ARGV ¶
Built-in Variables That Convey Information
presented the following program describing the information contained in ARGC
and ARGV:
$ awk 'BEGIN {
> for (i = 0; i < ARGC; i++)
> print ARGV[i]
> }' inventory-shipped mail-list
-| awk
-| inventory-shipped
-| mail-list
In this example, ARGV[0] contains ‘awk’, ARGV[1]
contains ‘inventory-shipped’, and ARGV[2] contains
‘mail-list’.
Notice that the awk program is not entered in ARGV. The
other command-line options, with their arguments, are also not
entered. This includes variable assignments done with the -v
option (see Command-Line Options).
Normal variable assignments on the command line are
treated as arguments and do show up in the ARGV array.
Given the following program in a file named showargs.awk:
BEGIN {
printf "A=%d, B=%d\n", A, B
for (i = 0; i < ARGC; i++)
printf "\tARGV[%d] = %s\n", i, ARGV[i]
}
END { printf "A=%d, B=%d\n", A, B }
Running it produces the following:
$ awk -v A=1 -f showargs.awk B=2 /dev/null -| A=1, B=0 -| ARGV[0] = awk -| ARGV[1] = B=2 -| ARGV[2] = /dev/null -| A=1, B=2
A program can alter ARGC and the elements of ARGV.
Each time awk reaches the end of an input file, it uses the next
element of ARGV as the name of the next input file. By storing a
different string there, a program can change which files are read.
Use "-" to represent the standard input. Storing
additional elements and incrementing ARGC causes
additional files to be read.
If the value of ARGC is decreased, that eliminates input files
from the end of the list. By recording the old value of ARGC
elsewhere, a program can treat the eliminated arguments as
something other than file names.
To eliminate a file from the middle of the list, store the null string
("") into ARGV in place of the file’s name. As a
special feature, awk ignores file names that have been
replaced with the null string.
Another option is to
use the delete statement to remove elements from
ARGV (see The delete Statement).
All of these actions are typically done in the BEGIN rule,
before actual processing of the input begins.
See Splitting a Large File into Pieces and
see Duplicating Output into Multiple Files
for examples
of each way of removing elements from ARGV.
To actually get options into an awk program,
end the awk options with -- and then supply
the awk program’s options, in the following manner:
awk -f myprog.awk -- -v -q file1 file2 ...
The following fragment processes ARGV in order to examine, and
then remove, the previously mentioned command-line options:
BEGIN {
for (i = 1; i < ARGC; i++) {
if (ARGV[i] == "-v")
verbose = 1
else if (ARGV[i] == "-q")
debug = 1
else if (ARGV[i] ~ /^-./) {
e = sprintf("%s: unrecognized option -- %c",
ARGV[0], substr(ARGV[i], 2, 1))
print e > "/dev/stderr"
} else
break
delete ARGV[i]
}
}
Ending the awk options with -- isn’t
necessary in gawk. Unless --posix has
been specified, gawk silently puts any unrecognized options
into ARGV for the awk program to deal with. As soon
as it sees an unknown option, gawk stops looking for other
options that it might otherwise recognize. The previous command line with
gawk would be:
gawk -f myprog.awk -q -v file1 file2 ...
Because -q is not a valid gawk option, it and the
following -v are passed on to the awk program.
(See Processing Command-Line Options for an awk library function that
parses command-line options.)
When designing your program, you should choose options that don’t
conflict with gawk’s, because it will process any options
that it accepts before passing the rest of the command line on to
your program. Using ‘#!’ with the -E option may help
(see Executable awk Programs
and
see Command-Line Options).
7.6 Summary ¶
- Pattern–action pairs make up the basic elements of an
awkprogram. Patterns are either normal expressions, range expressions, or regexp constants; one of the special keywordsBEGIN,END,BEGINFILE, orENDFILE; or empty. The action executes if the current record matches the pattern. Empty (missing) patterns match all records. - I/O from
BEGINandENDrules has certain constraints. This is also true, only more so, forBEGINFILEandENDFILErules. The latter two give you “hooks” intogawk’s file processing, allowing you to recover from a file that otherwise would cause a fatal error (such as a file that cannot be opened). - Shell variables can be used in
awkprograms by careful use of shell quoting. It is easier to pass a shell variable intoawkby using the -v option and anawkvariable. - Actions consist of statements enclosed in curly braces. Statements are built up from expressions, control statements, compound statements, input and output statements, and deletion statements.
- The control statements in
awkareif-else,while,for, anddo-while.gawkadds theswitchstatement. There are two flavors offorstatement: one for performing general looping, and the other for iterating through an array. breakandcontinuelet you exit early or start the next iteration of a loop (or get out of aswitch).nextandnextfilelet you read the next record and start over at the top of your program or skip to the next input file and start over, respectively.- The
exitstatement terminates your program. When executed from an action (or function body), it transfers control to theENDstatements. From anENDstatement body, it exits immediately. You may pass an optional numeric value to be used asawk’s exit status. - Some predefined variables provide control over
awk, mainly for I/O. Other variables convey information fromawkto your program. ARGCandARGVmake the command-line arguments available to your program. Manipulating them from aBEGINrule lets you control howawkwill process the provided data files.
8 Arrays in awk ¶
An array is a table of values called elements. The elements of an array are distinguished by their indices. Indices may be either numbers or strings.
This chapter describes how arrays work in awk,
how to use array elements, how to scan through every element in an array,
and how to remove array elements.
It also describes how awk simulates multidimensional
arrays, as well as some of the less obvious points about array usage.
The chapter moves on to discuss gawk’s facility
for sorting arrays, and ends with a brief description of gawk’s
ability to support true arrays of arrays.
- The Basics of Arrays
- Using Numbers to Subscript Arrays
- Using Uninitialized Variables as Subscripts
- The
deleteStatement - Multidimensional Arrays
- Arrays of Arrays
- Summary
8.1 The Basics of Arrays ¶
This section presents the basics: working with elements in arrays one at a time, and traversing all of the elements in an array.
- Introduction to Arrays
- Referring to an Array Element
- Assigning Array Elements
- Basic Array Example
- Scanning All Elements of an Array
- Using Predefined Array Scanning Orders with
gawk
8.1.1 Introduction to Arrays ¶
Doing linear scans over an associative array is like trying to club someone to death with a loaded Uzi.
The awk language provides one-dimensional arrays
for storing groups of related strings or numbers.
Every awk array must have a name. Array names have the same
syntax as variable names; any valid variable name would also be a valid
array name. But one name cannot be used in both ways (as an array and
as a variable) in the same awk program.
Arrays in awk superficially resemble arrays in other programming
languages, but there are fundamental differences. In awk, it
isn’t necessary to specify the size of an array before starting to use it.
Additionally, any number or string, not just consecutive integers,
may be used as an array index.
In most other languages, arrays must be declared before use, including a specification of how many elements or components they contain. In such languages, the declaration causes a contiguous block of memory to be allocated for that many elements. Usually, an index in the array must be a nonnegative integer. For example, the index zero specifies the first element in the array, which is actually stored at the beginning of the block of memory. Index one specifies the second element, which is stored in memory right after the first element, and so on. It is impossible to add more elements to the array, because it has room only for as many elements as given in the declaration. (Some languages allow arbitrary starting and ending indices—e.g., ‘15 .. 27’—but the size of the array is still fixed when the array is declared.)
A contiguous array of four elements might look like
Figure 8.1,
conceptually, if the element values are eight, "foo",
"", and 30.

Figure 8.1: A contiguous array
Only the values are stored; the indices are implicit from the order of the values. Here, eight is the value at index zero, because eight appears in the position with zero elements before it.
Arrays in awk are different—they are associative. This means
that each array is a collection of pairs—an index and its corresponding
array element value:
| Index | Value | |
|---|---|---|
3 | 30 | |
1 | "foo" | |
0 | 8 | |
2 | "" |
The pairs are shown in jumbled order because their order is irrelevant.44
One advantage of associative arrays is that new pairs can be added
at any time. For example, suppose a tenth element is added to the array
whose value is "number ten". The result is:
| Index | Value | |
|---|---|---|
10 | "number ten" | |
3 | 30 | |
1 | "foo" | |
0 | 8 | |
2 | "" |
Now the array is sparse, which just means some indices are missing. It has elements 0–3 and 10, but doesn’t have elements 4, 5, 6, 7, 8, or 9.
Another consequence of associative arrays is that the indices don’t have to be nonnegative integers. Any number, or even a string, can be an index. For example, the following is an array that translates words from English to French:
| Index | Value | |
|---|---|---|
"dog" | "chien" | |
"cat" | "chat" | |
"one" | "un" | |
1 | "un" |
Here we decided to translate the number one in both spelled-out and
numeric form—thus illustrating that a single array can have both
numbers and strings as indices.
(In fact, array subscripts are always strings.
There are some subtleties to how numbers work when used as
array subscripts; this is discussed in more detail in
Using Numbers to Subscript Arrays.)
Here, the number 1 isn’t double-quoted, because awk
automatically converts it to a string.
The value of IGNORECASE has no effect upon array subscripting.
The identical string value used to store an array element must be used
to retrieve it.
When awk creates an array (e.g., with the split()
built-in function),
that array’s indices are consecutive integers starting at one.
(See String-Manipulation Functions.)
awk’s arrays are efficient—the time to access an element
is independent of the number of elements in the array.
8.1.2 Referring to an Array Element ¶
The principal way to use an array is to refer to one of its elements. An array reference is an expression as follows:
array[index-expression]
Here, array is the name of an array. The expression index-expression is the index of the desired element of the array.
The value of the array reference is the current value of that array
element. For example, foo[4.3] is an expression referencing the element
of array foo at index ‘4.3’.
A reference to an array element that has no recorded value yields a value of
"", the null string. This includes elements
that have not been assigned any value as well as elements that have been
deleted (see The delete Statement).
NOTE: A reference to an element that does not exist automatically creates that array element, with the null string as its value. (In some cases, this is unfortunate, because it might waste memory inside
awk.)Novice
awkprogrammers often make the mistake of checking if an element exists by checking if the value is empty:# Check if "foo" exists in a: Incorrect! if (a["foo"] != "") ...This is incorrect for two reasons. First, it creates
a["foo"]if it didn’t exist before! Second, it is valid (if a bit unusual) to set an array element equal to the empty string.
To determine whether an element exists in an array at a certain index, use the following expression:
indx in array
This expression tests whether the particular index indx exists,
without the side effect of creating that element if it is not present.
The expression has the value one (true) if array[indx]
exists and zero (false) if it does not exist.
(We use indx here, because ‘index’ is the name of a built-in
function.)
For example, this statement tests whether the array frequencies
contains the index ‘2’:
if (2 in frequencies)
print "Subscript 2 is present."
Note that this is not a test of whether the array
frequencies contains an element whose value is two.
There is no way to do that except to scan all the elements. Also, this
does not create frequencies[2], while the following
(incorrect) alternative does:
if (frequencies[2] != "")
print "Subscript 2 is present."
8.1.3 Assigning Array Elements ¶
Array elements can be assigned values just like
awk variables:
array[index-expression] = value
array is the name of an array. The expression index-expression is the index of the element of the array that is assigned a value. The expression value is the value to assign to that element of the array.
8.1.4 Basic Array Example ¶
The following program takes a list of lines, each beginning with a line number, and prints them out in order of line number. The line numbers are not in order when they are first read—instead, they are scrambled. This program sorts the lines by making an array using the line numbers as subscripts. The program then prints out the lines in sorted order of their numbers. It is a very simple program and gets confused upon encountering repeated numbers, gaps, or lines that don’t begin with a number:
{
if ($1 > max)
max = $1
arr[$1] = $0
}
END {
for (x = 1; x <= max; x++)
print arr[x]
}
The first rule keeps track of the largest line number seen so far;
it also stores each line into the array arr, at an index that
is the line’s number.
The second rule runs after all the input has been read, to print out
all the lines.
When this program is run with the following input:
5 I am the Five man 2 Who are you? The new number two! 4 . . . And four on the floor 1 Who is number one? 3 I three you.
Its output is:
1 Who is number one? 2 Who are you? The new number two! 3 I three you. 4 . . . And four on the floor 5 I am the Five man
If a line number is repeated, the last line with a given number overrides
the others.
Gaps in the line numbers can be handled with an easy improvement to the
program’s END rule, as follows:
END {
for (x = 1; x <= max; x++)
if (x in arr)
print arr[x]
}
As mentioned, the program is simplistic. It can be easily confused; for example, by using negative or nonalphabetic line numbers. The point here is merely to demonstrate basic array usage.
8.1.5 Scanning All Elements of an Array ¶
In programs that use arrays, it is often necessary to use a loop that
executes once for each element of an array. In other languages, where
arrays are contiguous and indices are limited to nonnegative integers,
this is easy: all the valid indices can be found by counting from
the lowest index up to the highest. This technique won’t do the job
in awk, because any number or string can be an array index.
So awk has a special kind of for statement for scanning
an array:
for (var in array)
body
This loop executes body once for each index in array that the program has previously used, with the variable var set to that index.
The following program uses this form of the for statement. The
first rule scans the input records and notes which words appear (at
least once) in the input, by storing a one into the array used with
the word as the index. The second rule scans the elements of used to
find all the distinct words that appear in the input. It prints each
word that is more than 10 characters long and also prints the number of
such words.
See String-Manipulation Functions
for more information on the built-in function length().
# Record a 1 for each word that is used at least once
{
for (i = 1; i <= NF; i++)
used[$i] = 1
}
# Find number of distinct words more than 10 characters long
END {
for (x in used) {
if (length(x) > 10) {
++num_long_words
print x
}
}
print num_long_words, "words longer than 10 characters"
}
See Generating Word-Usage Counts for a more detailed example of this type.
The order in which elements of the array are accessed by this statement
is determined by the internal arrangement of the array elements within
awk and in standard awk cannot be controlled
or changed. This can lead to problems if new elements are added to
array by statements in the loop body; it is not predictable whether
the for loop will reach them. Similarly, changing var inside
the loop may produce strange results. It is best to avoid such things.
As a point of information, gawk sets up the list of elements
to be iterated over before the loop starts, and does not change it.
But not all awk versions do so. Consider this program, named
loopcheck.awk:
BEGIN {
a["here"] = "here"
a["is"] = "is"
a["a"] = "a"
a["loop"] = "loop"
for (i in a) {
j++
a[j] = j
print i
}
}
Here is what happens when run with gawk (and mawk):
$ gawk -f loopcheck.awk -| here -| loop -| a -| is
Contrast this to BWK awk:
$ nawk -f loopcheck.awk -| loop -| here -| is -| a -| 1
8.1.6 Using Predefined Array Scanning Orders with gawk ¶
This subsection describes a feature that is specific to gawk.
By default, when a for loop traverses an array, the order
is undefined, meaning that the awk implementation
determines the order in which the array is traversed.
This order is usually based on the internal implementation of arrays
and will vary from one version of awk to the next.
Often, though, you may wish to do something simple, such as
“traverse the array by comparing the indices in ascending order,”
or “traverse the array by comparing the values in descending order.”
gawk provides two mechanisms that give you this control:
- Set
PROCINFO["sorted_in"]to one of a set of predefined values. We describe this now. - Set
PROCINFO["sorted_in"]to the name of a user-defined function to use for comparison of array elements. This advanced feature is described later in Controlling Array Traversal and Array Sorting.
The following special values for PROCINFO["sorted_in"] are available:
"@unsorted"Array elements are processed in arbitrary order, which is the default
awkbehavior."@ind_str_asc"Order by indices in ascending order compared as strings; this is the most basic sort. (Internally, array indices are always strings, so with ‘a[2*5] = 1’ the index is
"10"rather than numeric 10.)"@ind_num_asc"Order by indices in ascending order but force them to be treated as numbers in the process. Any index with a non-numeric value will end up positioned as if it were zero.
"@val_type_asc"Order by element values in ascending order (rather than by indices). Ordering is by the type assigned to the element (see Variable Typing and Comparison Expressions). All numeric values come before all string values, which in turn come before all subarrays. (Subarrays have not been described yet; see Arrays of Arrays.)
If you choose to use this feature in traversing
FUNCTAB(see Built-in Variables That Convey Information), then the order is built-in functions first (see Built-in Functions), then user-defined functions (see User-Defined Functions) next, and finally functions loaded from an extension (see Writing Extensions forgawk)."@val_str_asc"Order by element values in ascending order (rather than by indices). Scalar values are compared as strings. If the string values are identical, the index string values are compared instead. When comparing non-scalar values,
"@val_type_asc"sort ordering is used, so subarrays, if present, come out last."@val_num_asc"Order by element values in ascending order (rather than by indices). Scalar values are compared as numbers. Non-scalar values are compared using
"@val_type_asc"sort ordering, so subarrays, if present, come out last. When numeric values are equal, the string values are used to provide an ordering: this guarantees consistent results across different versions of the Cqsort()function,45 whichgawkuses internally to perform the sorting. If the string values are also identical, the index string values are compared instead."@ind_str_desc"Like
"@ind_str_asc", but the string indices are ordered from high to low."@ind_num_desc"Like
"@ind_num_asc", but the numeric indices are ordered from high to low."@val_type_desc"Like
"@val_type_asc", but the element values, based on type, are ordered from high to low. Subarrays, if present, come out first."@val_str_desc"Like
"@val_str_asc", but the element values, treated as strings, are ordered from high to low. If the string values are identical, the index string values are compared instead. When comparing non-scalar values,"@val_type_desc"sort ordering is used, so subarrays, if present, come out first."@val_num_desc"Like
"@val_num_asc", but the element values, treated as numbers, are ordered from high to low. If the numeric values are equal, the string values are compared instead. If they are also identical, the index string values are compared instead. Non-scalar values are compared using"@val_type_desc"sort ordering, so subarrays, if present, come out first.
The array traversal order is determined before the for loop
starts to run. Changing PROCINFO["sorted_in"] in the loop body
does not affect the loop.
For example:
$ gawk '
> BEGIN {
> a[4] = 4
> a[3] = 3
> for (i in a)
> print i, a[i]
> }'
-| 4 4
-| 3 3
$ gawk '
> BEGIN {
> PROCINFO["sorted_in"] = "@ind_str_asc"
> a[4] = 4
> a[3] = 3
> for (i in a)
> print i, a[i]
> }'
-| 3 3
-| 4 4
When sorting an array by element values, if a value happens to be a subarray then it is considered to be greater than any string or numeric value, regardless of what the subarray itself contains, and all subarrays are treated as being equal to each other. Their order relative to each other is determined by their index strings.
Here are some additional things to bear in mind about sorted array traversal:
- The value of
PROCINFO["sorted_in"]is global. That is, it affects all array traversalforloops. If you need to change it within your own code, you should see if it’s defined and save and restore the value:... if ("sorted_in" in PROCINFO) save_sorted = PROCINFO["sorted_in"] PROCINFO["sorted_in"] = "@val_str_desc" # or whatever ... if (save_sorted) PROCINFO["sorted_in"] = save_sorted - As already mentioned, the default array traversal order is represented by
"@unsorted". You can also get the default behavior by assigning the null string toPROCINFO["sorted_in"]or by just deleting the"sorted_in"element from thePROCINFOarray with thedeletestatement. (Thedeletestatement hasn’t been described yet; see ThedeleteStatement.)
In addition, gawk provides built-in functions for
sorting arrays; see Sorting Array Values and Indices with gawk.
8.2 Using Numbers to Subscript Arrays ¶
An important aspect to remember about arrays is that array subscripts
are always strings. When a numeric value is used as a subscript,
it is converted to a string value before being used for subscripting
(see Conversion of Strings and Numbers).
This means that the value of the predefined variable CONVFMT can
affect how your program accesses elements of an array. For example:
xyz = 12.153
data[xyz] = 1
CONVFMT = "%2.2f"
if (xyz in data)
printf "%s is in data\n", xyz
else
printf "%s is not in data\n", xyz
This prints ‘12.15 is not in data’. The first statement gives
xyz a numeric value. Assigning to
data[xyz] subscripts data with the string value "12.153"
(using the default conversion value of CONVFMT, "%.6g").
Thus, the array element data["12.153"] is assigned the value one.
The program then changes
the value of CONVFMT. The test ‘(xyz in data)’ generates a new
string value from xyz—this time "12.15"—because the value of
CONVFMT only allows two significant digits. This test fails,
because "12.15" is different from "12.153".
According to the rules for conversions
(see Conversion of Strings and Numbers), integer
values always convert to strings as integers, no matter what the
value of CONVFMT may happen to be. So the usual case of
the following works:
for (i = 1; i <= maxsub; i++)
do something with array[i]
The “integer values always convert to strings as integers” rule
has an additional consequence for array indexing.
Octal and hexadecimal constants
(see Octal and Hexadecimal Numbers)
are converted internally into numbers, and their original form
is forgotten. This means, for example, that array[17],
array[021], and array[0x11] all refer to the same element!
As with many things in awk, the majority of the time
things work as you would expect them to. But it is useful to have a precise
knowledge of the actual rules, as they can sometimes have a subtle
effect on your programs.
8.3 Using Uninitialized Variables as Subscripts ¶
Suppose it’s necessary to write a program to print the input data in reverse order. A reasonable attempt to do so (with some test data) might look like this:
$ echo 'line 1
> line 2
> line 3' | awk '{ l[lines] = $0; ++lines }
> END {
> for (i = lines - 1; i >= 0; i--)
> print l[i]
> }'
-| line 3
-| line 2
Unfortunately, the very first line of input data did not appear in the output!
Upon first glance, we would think that this program should have worked.
The variable lines
is uninitialized, and uninitialized variables have the numeric value zero.
So, awk should have printed the value of l[0].
The issue here is that subscripts for awk arrays are always
strings. Uninitialized variables, when used as strings, have the
value "", not zero. Thus, ‘line 1’ ends up stored in
l[""].
The following version of the program works correctly:
{ l[lines++] = $0 }
END {
for (i = lines - 1; i >= 0; i--)
print l[i]
}
Here, the ‘++’ forces lines to be numeric, thus making
the “old value” numeric zero. This is then converted to "0"
as the array subscript.
Even though it is somewhat unusual, the null string
("") is a valid array subscript.
(d.c.)
gawk warns about the use of the null string as a subscript
if --lint is provided
on the command line (see Command-Line Options).
8.4 The delete Statement ¶
To remove an individual element of an array, use the delete
statement:
delete array[index-expression]
Once an array element has been deleted, any value the element once had is no longer available. It is as if the element had never been referred to or been given a value. The following is an example of deleting elements in an array:
for (i in frequencies)
delete frequencies[i]
This example removes all the elements from the array frequencies.
Once an element is deleted, a subsequent for statement to scan the array
does not report that element and using the in operator to check for
the presence of that element returns zero (i.e., false):
delete foo[4]
if (4 in foo)
print "This will never be printed"
It is important to note that deleting an element is not the
same as assigning it a null value (the empty string, "").
For example:
foo[4] = "" if (4 in foo) print "This is printed, even though foo[4] is empty"
It is not an error to delete an element that does not exist.
However, if --lint is provided on the command line
(see Command-Line Options),
gawk issues a warning message when an element that
is not in the array is deleted.
All the elements of an array may be deleted with a single statement
by leaving off the subscript in the delete statement,
as follows:
delete array
Using this version of the delete statement is about three times
more efficient than the equivalent loop that deletes each element one
at a time.
This form of the delete statement is also supported
by BWK awk and mawk, as well as
by a number of other implementations.
NOTE: For many years, using
deletewithout a subscript was a common extension. In September 2012, it was accepted for inclusion into the POSIX standard. See the Austin Group website.
The following statement provides a portable but nonobvious way to clear out an array:46
split("", array)
The split() function
(see String-Manipulation Functions)
clears out the target array first. This call asks it to split
apart the null string. Because there is no data to split out, the
function simply clears the array and then returns.
CAUTION: Deleting all the elements from an array does not change its type; you cannot clear an array and then use the array’s name as a scalar (i.e., a regular variable). For example, the following does not work:
a[1] = 3 delete a a = 3
8.5 Multidimensional Arrays ¶
A multidimensional array is an array in which an element is identified
by a sequence of indices instead of a single index. For example, a
two-dimensional array requires two indices. The usual way (in many
languages, including awk) to refer to an element of a
two-dimensional array named grid is with
grid[x,y].
Multidimensional arrays are supported in awk through
concatenation of indices into one string.
awk converts the indices into strings
(see Conversion of Strings and Numbers) and
concatenates them together, with a separator between them. This creates
a single string that describes the values of the separate indices. The
combined string is used as a single index into an ordinary,
one-dimensional array. The separator used is the value of the built-in
variable SUBSEP.
For example, suppose we evaluate the expression ‘foo[5,12] = "value"’
when the value of SUBSEP is "@". The numbers 5 and 12 are
converted to strings and
concatenated with an ‘@’ between them, yielding "5@12"; thus,
the array element foo["5@12"] is set to "value".
Once the element’s value is stored, awk has no record of whether
it was stored with a single index or a sequence of indices. The two
expressions ‘foo[5,12]’ and ‘foo[5 SUBSEP 12]’ are always
equivalent.
The default value of SUBSEP is the string "\034",
which contains a nonprinting character that is unlikely to appear in an
awk program or in most input data.
The usefulness of choosing an unlikely character comes from the fact
that index values that contain a string matching SUBSEP can lead to
combined strings that are ambiguous. Suppose that SUBSEP is
"@"; then ‘foo["a@b", "c"]’ and ‘foo["a", "b@c"]’ are indistinguishable because both are actually
stored as ‘foo["a@b@c"]’.
To test whether a particular index sequence exists in a
multidimensional array, use the same operator (in) that is
used for single-dimensional arrays. Write the whole sequence of indices
in parentheses, separated by commas, as the left operand:
if ((subscript1, subscript2, ...) in array)
...
Here is an example that treats its input as a two-dimensional array of fields; it rotates this array 90 degrees clockwise and prints the result. It assumes that all lines have the same number of elements:
{
if (max_nf < NF)
max_nf = NF
max_nr = NR
for (x = 1; x <= NF; x++)
vector[x, NR] = $x
}
END {
for (x = 1; x <= max_nf; x++) {
for (y = max_nr; y >= 1; --y)
printf("%s ", vector[x, y])
printf("\n")
}
}
When given the input:
1 2 3 4 5 6 2 3 4 5 6 1 3 4 5 6 1 2 4 5 6 1 2 3
the program produces the following output:
4 3 2 1 5 4 3 2 6 5 4 3 1 6 5 4 2 1 6 5 3 2 1 6
8.5.1 Scanning Multidimensional Arrays ¶
There is no special for statement for scanning a
“multidimensional” array. There cannot be one, because, in truth,
awk does not have
multidimensional arrays or elements—there is only a
multidimensional way of accessing an array.
However, if your program has an array that is always accessed as
multidimensional, you can get the effect of scanning it by combining
the scanning for statement
(see Scanning All Elements of an Array) with the
built-in split() function
(see String-Manipulation Functions).
It works in the following manner:
for (combined in array) {
split(combined, separate, SUBSEP)
...
}
This sets the variable combined to
each concatenated combined index in the array, and splits it
into the individual indices by breaking it apart where the value of
SUBSEP appears. The individual indices then become the elements of
the array separate.
Thus, if a value is previously stored in array[1, "foo"], then
an element with index "1\034foo" exists in array. (Recall
that the default value of SUBSEP is the character with code 034.)
Sooner or later, the for statement finds that index and does an
iteration with the variable combined set to "1\034foo".
Then the split() function is called as follows:
split("1\034foo", separate, "\034")
The result is to set separate[1] to "1" and
separate[2] to "foo". Presto! The original sequence of
separate indices is recovered.
8.6 Arrays of Arrays ¶
gawk goes beyond standard awk’s multidimensional
array access and provides true arrays of
arrays. Elements of a subarray are referred to by their own indices
enclosed in square brackets, just like the elements of the main array.
For example, the following creates a two-element subarray at index 1
of the main array a:
a[1][1] = 1 a[1][2] = 2
This simulates a true two-dimensional array. Each subarray element can
contain another subarray as a value, which in turn can hold other arrays
as well. In this way, you can create arrays of three or more dimensions.
The indices can be any awk expressions, including scalars
separated by commas (i.e., a regular awk simulated
multidimensional subscript). So the following is valid in
gawk:
a[1][3][1, "name"] = "barney"
Each subarray and the main array can be of different length. In fact, the
elements of an array or its subarray do not all have to have the same
type. This means that the main array and any of its subarrays can be
nonrectangular, or jagged in structure. You can assign a scalar value to
the index 4 of the main array a, even though a[1]
is itself an array and not a scalar:
a[4] = "An element in a jagged array"
The terms dimension, row, and column are
meaningless when applied
to such an array, but we will use “dimension” henceforth to imply the
maximum number of indices needed to refer to an existing element. The
type of any element that has already been assigned cannot be changed
by assigning a value of a different type. You have to first delete the
current element, which effectively makes gawk forget about
the element at that index:
delete a[4] a[4][5][6][7] = "An element in a four-dimensional array"
This removes the scalar value from index 4 and then inserts a
three-level nested subarray
containing a scalar. You can also
delete an entire subarray or subarray of subarrays:
delete a[4][5] a[4][5] = "An element in subarray a[4]"
But recall that you can not delete the main array a and then use it
as a scalar.
The built-in functions that take array arguments can also be used
with subarrays. For example, the following code fragment uses length()
(see String-Manipulation Functions)
to determine the number of elements in the main array a and
its subarrays:
print length(a), length(a[1]), length(a[1][3])
This results in the following output for our main array a:
2, 3, 1
The ‘subscript in array’ expression
(see Referring to an Array Element) works similarly for both
regular awk-style
arrays and arrays of arrays. For example, the tests ‘1 in a’,
‘3 in a[1]’, and ‘(1, "name") in a[1][3]’ all evaluate to
one (true) for our array a.
The ‘for (item in array)’ statement (see Scanning All Elements of an Array) can be nested to scan all the elements of an array of arrays if it is rectangular in structure. In order to print the contents (scalar values) of a two-dimensional array of arrays (i.e., in which each first-level element is itself an array, not necessarily of the same length), you could use the following code:
for (i in array)
for (j in array[i])
print array[i][j]
The isarray() function (see Getting Type Information)
lets you test if an array element is itself an array:
for (i in array) {
if (isarray(array[i])) {
for (j in array[i]) {
print array[i][j]
}
}
else
print array[i]
}
If the structure of a jagged array of arrays is known in advance,
you can often devise workarounds using control statements. For example,
the following code prints the elements of our main array a:
for (i in a) {
for (j in a[i]) {
if (j == 3) {
for (k in a[i][j])
print a[i][j][k]
} else
print a[i][j]
}
}
See Traversing Arrays of Arrays for a user-defined function that “walks” an arbitrarily dimensioned array of arrays.
8.7 Summary ¶
- Standard
awkprovides one-dimensional associative arrays (arrays indexed by string values). All arrays are associative; numeric indices are converted automatically to strings. - Array elements are referenced as
array[indx]. Referencing an element creates it if it did not exist previously. - The proper way to see if an array has an element with a given index
is to use the
inoperator: ‘indx in array’. - Use ‘for (indx in array) …’ to scan through all the individual elements of an array. In the body of the loop, indx takes on the value of each element’s index in turn.
- The order in which a ‘for (indx in array)’ loop
traverses an array is undefined in POSIX
awkand varies among implementations.gawklets you control the order by assigning special predefined values toPROCINFO["sorted_in"]. - Use ‘delete array[indx]’ to delete an individual element.
To delete all of the elements in an array,
use ‘delete array’.
This latter feature has been a common extension for many
years and is now standard, but may not be supported by all commercial
versions of
awk. - Standard
awksimulates multidimensional arrays by separating subscript values with commas. The values are concatenated into a single string, separated by the value ofSUBSEP. The fact that such a subscript was created in this way is not retained; thus, changingSUBSEPmay have unexpected consequences. You can use ‘(sub1, sub2, …) in array’ to see if such a multidimensional subscript exists in array. gawkprovides true arrays of arrays. You use a separate set of square brackets for each dimension in such an array:data[row][col], for example. Array elements may thus be either scalar values (number or string) or other arrays.- Use the
isarray()built-in function to determine if an array element is itself a subarray.
9 Functions ¶
This chapter describes awk’s built-in functions,
which fall into three categories: numeric, string, and I/O.
gawk provides additional groups of functions
to work with values that represent time, do
bit manipulation, sort arrays,
provide type information, and internationalize and localize programs.
Besides the built-in functions, awk has provisions for
writing new functions that the rest of a program can use.
The second half of this chapter describes these
user-defined functions.
Finally, we explore indirect function calls, a gawk-specific
extension that lets you determine at runtime what function is to
be called.
9.1 Built-in Functions ¶
Built-in functions are always available for your awk
program to call. This section defines all the built-in functions
in awk; some of these are mentioned in other sections
but are summarized here for your convenience.
- Calling Built-in Functions
- Generating Boolean Values
- Numeric Functions
- String-Manipulation Functions
- Input/Output Functions
- Time Functions
- Bit-Manipulation Functions
- Getting Type Information
- String-Translation Functions
9.1.1 Calling Built-in Functions ¶
To call one of awk’s built-in functions, write the name of
the function followed
by arguments in parentheses. For example, ‘atan2(y + z, 1)’
is a call to the function atan2() and has two arguments.
Whitespace is ignored between the built-in function name and the opening parenthesis, but nonetheless it is good practice to avoid using whitespace there. User-defined functions do not permit whitespace in this way, and it is easier to avoid mistakes by following a simple convention that always works—no whitespace after a function name.
Each built-in function accepts a certain number of arguments.
In some cases, arguments can be omitted. The defaults for omitted
arguments vary from function to function and are described under the
individual functions. In some awk implementations, extra
arguments given to built-in functions are ignored. However, in gawk,
it is a fatal error to give extra arguments to a built-in function.
When a function is called, expressions that create the function’s actual parameters are evaluated completely before the call is performed. For example, in the following code fragment:
i = 4 j = sqrt(i++)
the variable i is incremented to the value five before sqrt()
is called with a value of four for its actual parameter.
The order of evaluation of the expressions used for the function’s
parameters is undefined. Thus, avoid writing programs that
assume that parameters are evaluated from left to right or from
right to left. For example:
i = 5 j = atan2(++i, i *= 2)
If the order of evaluation is left to right, then i first becomes
six, and then 12, and atan2() is called with the two arguments six
and 12. But if the order of evaluation is right to left, i
first becomes 10, then 11, and atan2() is called with the
two arguments 11 and 10.
9.1.2 Generating Boolean Values ¶
This function is specific to gawk. It is not
available in compatibility mode (see Command-Line Options):
mkbool(expression)¶Return a Boolean-typed value based on the regular Boolean value of expression. Boolean “true” values have numeric value one. Boolean “false” values have numeric zero. This is discussed in more detail in Boolean Typed Values.
9.1.3 Numeric Functions ¶
The following list describes all of the built-in functions that work with numbers. Optional parameters are enclosed in square brackets ([ ]):
-
atan2(y, x)¶ Return the arctangent of
y / xin radians. You can use ‘pi = atan2(0, -1)’ to retrieve the value of pi.-
cos(x)¶ Return the cosine of x, with x in radians.
-
exp(x)¶ Return the exponential of x (
e ^ x) or report an error if x is out of range. The range of values x can have depends on your machine’s floating-point representation.-
int(x)¶ Return the nearest integer to x, located between x and zero and truncated toward zero. For example,
int(3)is 3,int(3.9)is 3,int(-3.9)is −3, andint(-3)is −3 as well.-
log(x)¶ Return the natural logarithm of x, if x is positive; otherwise, return NaN (“not a number”) on IEEE 754 systems. Additionally,
gawkprints a warning message whenxis negative.-
rand()¶ Return a random number. The values of
rand()are uniformly distributed between zero and one. The value could be zero but is never one.47Often random integers are needed instead. Following is a user-defined function that can be used to obtain a random nonnegative integer less than n:
function randint(n) { return int(n * rand()) }The multiplication produces a random number greater than or equal to zero and less than
n. Usingint(), this result is made into an integer between zero andn− 1, inclusive.The following example uses a similar function to produce random integers between one and n. This program prints a new random number for each input record:
# Function to roll a simulated die. function roll(n) { return 1 + int(rand() * n) } # Roll 3 six-sided dice and # print total number of points. { printf("%d points\n", roll(6) + roll(6) + roll(6)) }CAUTION: In most
awkimplementations, includinggawk,rand()starts generating numbers from the same starting number, or seed, each time you runawk.48 Thus, a program generates the same results each time you run it. The numbers are random within oneawkrun but predictable from run to run. This is convenient for debugging, but if you want a program to do different things each time it is used, you must change the seed to a value that is different in each run. To do this, usesrand().-
sin(x)¶ Return the sine of x, with x in radians.
-
sqrt(x)¶ Return the positive square root of x.
gawkprints a warning message if x is negative. Thus,sqrt(4)is 2.srand([x])¶Set the starting point, or seed, for generating random numbers to the value x.
Each seed value leads to a particular sequence of random numbers.49 Thus, if the seed is set to the same value a second time, the same sequence of random numbers is produced again.
CAUTION: Different
awkimplementations use different random-number generators internally. Don’t expect the sameawkprogram to produce the same series of random numbers when executed by different versions ofawk.If the argument x is omitted, as in ‘srand()’, then the current date and time of day are used for a seed. This is the way to get random numbers that are truly unpredictable.
The return value of
srand()is the previous seed. This makes it easy to keep track of the seeds in case you need to consistently reproduce sequences of random numbers.POSIX does not specify the initial seed; it differs among
awkimplementations.
9.1.4 String-Manipulation Functions ¶
The functions in this section look at or change the text of one or more strings.
gawk understands locales (see Where You Are Makes a Difference) and does all
string processing in terms of characters, not bytes.
This distinction is particularly important to understand for locales
where one character may be represented by multiple bytes. Thus, for
example, length() returns the number of characters in a string,
and not the number of bytes used to represent those characters. Similarly,
index() works with character indices, and not byte indices.
CAUTION: A number of functions deal with indices into strings. For these functions, the first character of a string is at position (index) one. This is different from C and the languages descended from it, where the first character is at position zero. You need to remember this when doing index calculations, particularly if you are used to C.
In the following list, optional parameters are enclosed in square brackets ([ ]).
Several functions perform string substitution; the full discussion is
provided in the description of the sub() function, which comes
toward the end, because the list is presented alphabetically.
Those functions that are specific to gawk are marked with a
pound sign (‘#’). They are not available in compatibility mode
(see Command-Line Options):
-
asort(source [,dest [,how ] ]) #¶ asorti(source [,dest [,how ] ]) #-
These two functions are similar in behavior, so they are described together.
NOTE: The following description ignores the third argument, how, as it requires understanding features that we have not discussed yet. Thus, the discussion here is a deliberate simplification. (We do provide all the details later on; see Sorting Array Values and Indices with
gawkfor the full story.)Both functions return the number of elements in the array source. For
asort(),gawksorts the values of source and replaces the indices of the sorted values of source with sequential integers starting with one. If the optional array dest is specified, then source is duplicated into dest. dest is then sorted, leaving the indices of source unchanged.When comparing strings,
IGNORECASEaffects the sorting (see Sorting Array Values and Indices withgawk). If the source array contains subarrays as values (see Arrays of Arrays), they will come last, after all scalar values. Subarrays are not recursively sorted.For example, if the contents of
aare as follows:a["last"] = "de" a["first"] = "sac" a["middle"] = "cul"
A call to
asort():asort(a)
results in the following contents of
a:a[1] = "cul" a[2] = "de" a[3] = "sac"
The
asorti()function works similarly toasort(); however, the indices are sorted, instead of the values. Thus, in the previous example, starting with the same initial set of indices and values ina, calling ‘asorti(a)’ would yield:a[1] = "first" a[2] = "last" a[3] = "middle"
NOTE: You may not use either
SYMTABorFUNCTABas the second argument to these functions. Attempting to do so produces a fatal error. You may use them as the first argument, but only if providing a second array to use for the actual sorting.You are allowed to use the same array for both the source and dest arguments, but doing so only makes sense if you’re also supplying the third argument.
-
gensub(regexp, replacement, how[, target]) #¶ Search the target string target for matches of the regular expression regexp. If how is a string beginning with ‘g’ or ‘G’ (short for “global”), then replace all matches of regexp with replacement. Otherwise, treat how as a number indicating which match of regexp to replace. Treat numeric values less than one as if they were one. If no target is supplied, use
$0. Return the modified string as the result of the function. The original target string is not changed.The returned value is always a string, even if the original target was a number or a regexp value.
gensub()is a general substitution function. Its purpose is to provide more features than the standardsub()andgsub()functions.gensub()provides an additional feature that is not available insub()orgsub(): the ability to specify components of a regexp in the replacement text. This is done by using parentheses in the regexp to mark the components and then specifying ‘\N’ in the replacement text, where N is a digit from 1 to 9. For example:$ gawk ' > BEGIN { > a = "abc def" > b = gensub(/(.+) (.+)/, "\\2 \\1", "g", a) > print b > }' -| def abcAs with
sub(), you must type two backslashes in order to get one into the string. In the replacement text, the sequence ‘\0’ represents the entire matched text, as does the character ‘&’.The following example shows how you can use the third argument to control which match of the regexp should be changed:
$ echo a b c a b c | > gawk '{ print gensub(/a/, "AA", 2) }' -| a b c AA b cIn this case,
$0is the default target string.gensub()returns the new string as its result, which is passed directly toprintfor printing.If the how argument is a string that does not begin with ‘g’ or ‘G’, or if it is a number that is less than or equal to zero, only one substitution is performed. If how is zero,
gawkissues a warning message.If regexp does not match target,
gensub()’s return value is the original unchanged value of target. Note that, as mentioned above, the returned value is a string, even if target was not.In the replacement string, a backslash before a non-digit character is simply elided. For example, ‘\q’ becomes ‘q’ in the result. If the final character in the replacement string is a backslash, it is left alone.
gsub(regexp, replacement[, target])¶Search target for all of the longest, leftmost, nonoverlapping matching substrings it can find and replace them with replacement. The ‘g’ in
gsub()stands for “global,” which means replace everywhere. For example:{ gsub(/Britain/, "United Kingdom"); print }replaces all occurrences of the string ‘Britain’ with ‘United Kingdom’ for all input records.
The
gsub()function returns the number of substitutions made. If the variable to search and alter (target) is omitted, then the entire input record ($0) is used. As insub(), the characters ‘&’ and ‘\’ are special, and the third argument must be assignable.-
index(in, find)¶ Search the string in for the first occurrence of the string find, and return the position in characters where that occurrence begins in the string in. Consider the following example:
$ awk 'BEGIN { print index("peanut", "an") }' -| 3If find is not found,
index()returns zero.With BWK
awkandgawk, it is a fatal error to use a regexp constant for find. Other implementations allow it, simply treating the regexp constant as an expression meaning ‘$0 ~ /regexp/’. (d.c.)-
length([string])¶ -
Return the number of characters in string. If string is a number, the length of the digit string representing that number is returned. For example,
length("abcde")is five. By contrast,length(15 * 35)works out to three. In this example, 15 * 35 = 525, and 525 is then converted to the string"525", which has three characters.If no argument is supplied,
length()returns the length of$0.NOTE: In older versions of
awk, thelength()function could be called without any parentheses. Doing so is considered poor practice, although the 2008 POSIX standard explicitly allows it, to support historical practice. For programs to be maximally portable, always supply the parentheses.If
length()is called with a variable that has not been used,gawkforces the variable to be a scalar. Other implementations ofawkleave the variable without a type. (d.c.) Consider:$ gawk 'BEGIN { print length(x) ; x[1] = 1 }' -| 0 error→ gawk: fatal: attempt to use scalar `x' as array $ nawk 'BEGIN { print length(x) ; x[1] = 1 }' -| 0If --lint has been specified on the command line,
gawkissues a warning about this.With
gawkand several otherawkimplementations, when given an array argument, thelength()function returns the number of elements in the array. (c.e.) This is less useful than it might seem at first, as the array is not guaranteed to be indexed from one to the number of elements in it. If --lint is provided on the command line (see Command-Line Options),gawkwarns that passing an array argument is not portable. If --posix is supplied, using an array argument is a fatal error (see Arrays inawk). -
match(string, regexp[, array])¶ -
Search string for the longest, leftmost substring matched by the regular expression regexp and return the character position (index) at which that substring begins (one, if it starts at the beginning of string). If no match is found, return zero.
The regexp argument may be either a regexp constant (
/…/) or a string constant ("…"). In the latter case, the string is treated as a regexp to be matched. See Using Dynamic Regexps for a discussion of the difference between the two forms, and the implications for writing your program correctly.The order of the first two arguments is the opposite of most other string functions that work with regular expressions, such as
sub()andgsub(). It might help to remember that formatch(), the order is the same as for the ‘~’ operator: ‘string ~ regexp’.The
match()function sets the predefined variableRSTARTto the index. It also sets the predefined variableRLENGTHto the length in characters of the matched substring. If no match is found,RSTARTis set to zero, andRLENGTHto −1.For example:
{ if ($1 == "FIND") regex = $2 else { where = match($0, regex) if (where != 0) print "Match of", regex, "found at", where, "in", $0 } }This program looks for lines that match the regular expression stored in the variable
regex. This regular expression can be changed. If the first word on a line is ‘FIND’,regexis changed to be the second word on that line. Therefore, if given:FIND ru+n My program runs but not very quickly FIND Melvin JF+KM This line is property of Reality Engineering Co. Melvin was here.
awkprints:Match of ru+n found at 12 in My program runs Match of Melvin found at 1 in Melvin was here.
If array is present, it is cleared, and then the zeroth element of array is set to the entire portion of string matched by regexp. If regexp contains parentheses, the integer-indexed elements of array are set to contain the portion of string matching the corresponding parenthesized subexpression. For example:
$ echo foooobazbarrrrr | > gawk '{ match($0, /(fo+).+(bar*)/, arr) > print arr[1], arr[2] }' -| foooo barrrrrIn addition, multidimensional subscripts are available providing the start index and length of each matched subexpression:
$ echo foooobazbarrrrr | > gawk '{ match($0, /(fo+).+(bar*)/, arr) > print arr[1], arr[2] > print arr[1, "start"], arr[1, "length"] > print arr[2, "start"], arr[2, "length"] > }' -| foooo barrrrr -| 1 5 -| 9 7There may not be subscripts for the start and index for every parenthesized subexpression, because they may not all have matched text; thus, they should be tested for with the
inoperator (see Referring to an Array Element).The array argument to
match()is agawkextension. In compatibility mode (see Command-Line Options), using a third argument is a fatal error. -
patsplit(string, array[, fieldpat[, seps] ]) #¶ Divide string into pieces (or “fields”) defined by fieldpat and store the pieces in array and the separator strings in the seps array. The first piece is stored in
array[1], the second piece inarray[2], and so forth. The third argument, fieldpat, is a regexp describing the fields in string (just asFPATis a regexp describing the fields in input records). It may be either a regexp constant or a string. If fieldpat is omitted, the value ofFPATis used.patsplit()returns the number of elements created.seps[i]is the possibly null separator string afterarray[i]. The possibly null leading separator will be inseps[0]. So a non-null string with n fields will have n+1 separators. A null string has no fields or separators.The
patsplit()function splits strings into pieces in a manner similar to the way input lines are split into fields usingFPAT(see Defining Fields by Content).Before splitting the string,
patsplit()deletes any previously existing elements in the arrays array and seps.split(string, array[, fieldsep[, seps] ])¶Divide string into pieces separated by fieldsep and store the pieces in array and the separator strings in the seps array. The first piece is stored in
array[1], the second piece inarray[2], and so forth. The string value of the third argument, fieldsep, is a regexp describing where to split string (much asFScan be a regexp describing where to split input records). If fieldsep is omitted, the value ofFSis used.split()returns the number of elements created. seps is agawkextension, withseps[i]being the separator string betweenarray[i]andarray[i+1]. If fieldsep is a single space, then any leading whitespace goes intoseps[0]and any trailing whitespace goes intoseps[n], where n is the return value ofsplit()(i.e., the number of elements in array).The
split()function splits strings into pieces in the same way that input lines are split into fields. For example:split("cul-de-sac", a, "-", seps)splits the string
"cul-de-sac"into three fields using ‘-’ as the separator. It sets the contents of the arrayaas follows:a[1] = "cul" a[2] = "de" a[3] = "sac"
and sets the contents of the array
sepsas follows:seps[1] = "-" seps[2] = "-"
The value returned by this call to
split()is three.If
gawkis invoked with --csv, then a two-argument call tosplit()splits the string using the CSV parsing rules as described in Working With Comma Separated Value Files. With three and four arguments,split()works as just described. The four-argument call makes no sense, since each element of seps would simply consist of a string containing a comma.As with input field-splitting, when the value of fieldsep is
" ", leading and trailing whitespace is ignored in values assigned to the elements of array but not in seps, and the elements are separated by runs of whitespace. Also, as with input field splitting, if fieldsep is the null string, each individual character in the string is split into its own array element. (c.e.) Additionally, if fieldsep is a single-character string, that string acts as the separator, even if its value is a regular expression metacharacter.Note, however, that
RShas no effect on the waysplit()works. Even though ‘RS = ""’ causes the newline character to also be an input field separator, this does not affect howsplit()splits strings.Modern implementations of
awk, includinggawk, allow the third argument to be a regexp constant (/…/) as well as a string. (d.c.) The POSIX standard allows this as well. See Using Dynamic Regexps for a discussion of the difference between using a string constant or a regexp constant, and the implications for writing your program correctly.Before splitting the string,
split()deletes any previously existing elements in the arrays array and seps.If string is null, the array has no elements. (So this is a portable way to delete an entire array with one statement. See The
deleteStatement.)If string does not match fieldsep at all (but is not null), array has one element only. The value of that element is the original string.
In POSIX mode (see Command-Line Options), the fourth argument is not allowed.
-
sprintf(format, expression1, …)¶ Return (without printing) the string that
printfwould have printed out with the same arguments (see UsingprintfStatements for Fancier Printing). For example:pival = sprintf("pi = %.2f (approx.)", 22/7)assigns the string ‘pi = 3.14 (approx.)’ to the variable
pival.strtonum(str) #Examine str and return its numeric value. If str begins with a leading ‘0’,
strtonum()assumes that str is an octal number. If str begins with a leading ‘0x’ or ‘0X’,strtonum()assumes that str is a hexadecimal number. For example:$ echo 0x11 | > gawk '{ printf "%d\n", strtonum($1) }' -| 17Using the
strtonum()function is not the same as adding zero to a string value; the automatic coercion of strings to numbers works only for decimal data, not for octal or hexadecimal.50Note also that
strtonum()uses the current locale’s decimal point for recognizing numbers (see Where You Are Makes a Difference).-
sub(regexp, replacement[, target])¶ Search target, which is treated as a string, for the leftmost, longest substring matched by the regular expression regexp. Modify the entire string by replacing the matched text with replacement. The modified string becomes the new value of target. Return the number of substitutions made (zero or one).
The regexp argument may be either a regexp constant (
/…/) or a string constant ("…"). In the latter case, the string is treated as a regexp to be matched. See Using Dynamic Regexps for a discussion of the difference between the two forms, and the implications for writing your program correctly.This function is peculiar because target is not simply used to compute a value, and not just any expression will do—it must be a variable, field, or array element so that
sub()can store a modified value there. If this argument is omitted, then the default is to use and alter$0.51 For example:str = "water, water, everywhere" sub(/at/, "ith", str)
sets
strto ‘wither, water, everywhere’, by replacing the leftmost longest occurrence of ‘at’ with ‘ith’.If the special character ‘&’ appears in replacement, it stands for the precise substring that was matched by regexp. (If the regexp can match more than one string, then this precise substring may vary.) For example:
{ sub(/candidate/, "& and his wife"); print }changes the first occurrence of ‘candidate’ to ‘candidate and his wife’ on each input line. Here is another example:
$ awk 'BEGIN { > str = "daabaaa" > sub(/a+/, "C&C", str) > print str > }' -| dCaaCbaaaThis shows how ‘&’ can represent a nonconstant string and also illustrates the “leftmost, longest” rule in regexp matching (see How Much Text Matches?).
The effect of this special character (‘&’) can be turned off by putting a backslash before it in the string. As usual, to insert one backslash in the string, you must write two backslashes. Therefore, write ‘\\&’ in a string constant to include a literal ‘&’ in the replacement. For example, the following shows how to replace the first ‘|’ on each line with an ‘&’:
{ sub(/\|/, "\\&"); print }As mentioned, the third argument to
sub()must be a variable, field, or array element. Some versions ofawkallow the third argument to be an expression that is not an lvalue. In such a case,sub()still searches for the pattern and returns zero or one, but the result of the substitution (if any) is thrown away because there is no place to put it. Such versions ofawkaccept expressions like the following:sub(/USA/, "United States", "the USA and Canada")
For historical compatibility,
gawkaccepts such erroneous code. However, using any other nonchangeable object as the third parameter causes a fatal error and your program will not run.Finally, if the regexp is not a regexp constant, it is converted into a string, and then the value of that string is treated as the regexp to match.
-
substr(string, start[, length])¶ Return a length-character-long substring of string, starting at character number start. The first character of a string is character number one.52 For example,
substr("washington", 5, 3)returns"ing".If length is not present,
substr()returns the whole suffix of string that begins at character number start. For example,substr("washington", 5)returns"ington". The whole suffix is also returned if length is greater than the number of characters remaining in the string, counting from character start.If start is less than one,
substr()treats it as if it was one. (POSIX doesn’t specify what to do in this case: BWKawkacts this way, and thereforegawkdoes too.) If start is greater than the number of characters in the string,substr()returns the null string. Similarly, if length is present but less than or equal to zero, the null string is returned.The string returned by
substr()cannot be assigned. Thus, it is a mistake to attempt to change a portion of a string, as shown in the following example:string = "abcdef" # try to get "abCDEf", won't work substr(string, 3, 3) = "CDE"
It is also a mistake to use
substr()as the third argument ofsub()orgsub():gsub(/xyz/, "pdq", substr($0, 5, 20)) # WRONG
(Some commercial versions of
awktreatsubstr()as assignable, but doing so is not portable.)If you need to replace bits and pieces of a string, combine
substr()with string concatenation, in the following manner:string = "abcdef" ... string = substr(string, 1, 2) "CDE" substr(string, 6)
-
tolower(string)¶ Return a copy of string, with each uppercase character in the string replaced with its corresponding lowercase character. Nonalphabetic characters are left unchanged. For example,
tolower("MiXeD cAsE 123")returns"mixed case 123".-
toupper(string)¶ Return a copy of string, with each lowercase character in the string replaced with its corresponding uppercase character. Nonalphabetic characters are left unchanged. For example,
toupper("MiXeD cAsE 123")returns"MIXED CASE 123".
At first glance, the split() and patsplit() functions appear to be
mirror images of each other. But there are differences:
split()treats its third argument likeFS, with all the special rules involved forFS.- Matching of null strings differs. This is discussed in
FSVersusFPAT: A Subtle Difference.
9.1.4.1 More about ‘\’ and ‘&’ with sub(), gsub(), and gensub() ¶
I collect spores, molds, and fungus.
CAUTION: This subsubsection has been reported to cause headaches. You might want to skip it upon first reading.
When using sub(), gsub(), or gensub(), and trying to get literal
backslashes and ampersands into the replacement text, you need to remember
that there are several levels of escape processing going on.
First, there is the lexical level, which is when awk reads
your program
and builds an internal copy of it to execute.
Then there is the runtime level, which is when awk actually scans the
replacement string to determine what to generate.
At both levels, awk looks for a defined set of characters that
can come after a backslash. At the lexical level, it looks for the
escape sequences listed in Escape Sequences.
Thus, for every ‘\’ that awk processes at the runtime
level, you must type two backslashes at the lexical level.
When a character that is not valid for an escape sequence follows the
‘\’, BWK awk and gawk both simply remove the initial
‘\’ and put the next character into the string. Thus, for
example, "a\qb" is treated as "aqb".
At the runtime level, the various functions handle sequences of
‘\’ and ‘&’ differently. The situation is (sadly) somewhat complex.
Historically, the sub() and gsub() functions treated the
two-character sequence ‘\&’ specially; this sequence was replaced in
the generated text with a single ‘&’. Any other ‘\’ within
the replacement string that did not precede an ‘&’ was passed
through unchanged. This is illustrated in Table 9.1.
You typesub()seessub()generates ——– ———- —————\&&The matched text\\&\&A literal ‘&’\\\&\&A literal ‘&’\\\\&\\&A literal ‘\&’\\\\\&\\&A literal ‘\&’\\\\\\&\\\&A literal ‘\\&’\\q\qA literal ‘\q’
Table 9.1: Historical escape sequence processing for sub() and gsub()
This table shows the lexical-level processing, where
an odd number of backslashes becomes an even number at the runtime level,
as well as the runtime processing done by sub().
(For the sake of simplicity, the rest of the following tables only show the
case of even numbers of backslashes entered at the lexical level.)
The problem with the historical approach is that there is no way to get a literal ‘\’ followed by the matched text.
Several editions of the POSIX standard attempted to fix this problem but weren’t successful. The details are irrelevant at this point in time.
At one point, the gawk maintainer submitted
proposed text for a revised standard that
reverts to rules that correspond more closely to the original existing
practice. The proposed rules have special cases that make it possible
to produce a ‘\’ preceding the matched text.
This is shown in
Table 9.2.
You typesub()seessub()generates ——– ———- —————\\\\\\&\\\&A literal ‘\&’\\\\&\\&A literal ‘\’, followed by the matched text\\&\&A literal ‘&’\\q\qA literal ‘\q’\\\\\\\\
Table 9.2: gawk rules for sub() and backslash
In a nutshell, at the runtime level, there are now three special sequences of characters (‘\\\&’, ‘\\&’, and ‘\&’) whereas historically there was only one. However, as in the historical case, any ‘\’ that is not part of one of these three sequences is not special and appears in the output literally.
gawk 3.0 and 3.1 follow these rules for sub() and
gsub(). The POSIX standard took much longer to be revised than
was expected. In addition, the gawk maintainer’s proposal was
lost during the standardization process. The final rules are
somewhat simpler. The results are similar except for one case.
The POSIX rules state that ‘\&’ in the replacement string produces a literal ‘&’, ‘\\’ produces a literal ‘\’, and ‘\’ followed by anything else is not special; the ‘\’ is placed straight into the output. These rules are presented in Table 9.3.
You typesub()seessub()generates ——– ———- —————\\\\\\&\\\&A literal ‘\&’\\\\&\\&A literal ‘\’, followed by the matched text\\&\&A literal ‘&’\\q\qA literal ‘\q’\\\\\\\
Table 9.3: POSIX rules for sub() and gsub()
The only case where the difference is noticeable is the last one: ‘\\\\’ is seen as ‘\\’ and produces ‘\’ instead of ‘\\’.
Starting with version 3.1.4, gawk followed the POSIX rules
when --posix was specified (see Command-Line Options). Otherwise,
it continued to follow the proposed rules, as
that had been its behavior for many years.
When version 4.0.0 was released, the gawk maintainer
made the POSIX rules the default, breaking well over a decade’s worth
of backward compatibility.53 Needless to say, this was a bad idea,
and as of version 4.0.1, gawk resumed its historical
behavior, and only follows the POSIX rules when --posix is given.
The rules for gensub() are considerably simpler. At the runtime
level, whenever gawk sees a ‘\’, if the following character
is a digit, then the text that matched the corresponding parenthesized
subexpression is placed in the generated output. Otherwise,
no matter what character follows the ‘\’, it
appears in the generated text and the ‘\’ does not,
as shown in Table 9.4.
You typegensub()seesgensub()generates ——– ————- ——————&&The matched text\\&\&A literal ‘&’\\\\\\A literal ‘\’\\\\&\\&A literal ‘\’, then the matched text\\\\\\&\\\&A literal ‘\&’\\q\qA literal ‘q’
Table 9.4: Escape sequence processing for gensub()
Because of the complexity of the lexical- and runtime-level processing
and the special cases for sub() and gsub(),
we recommend the use of gawk and gensub() when you have
to do substitutions.
9.1.5 Input/Output Functions ¶
The following functions relate to input/output (I/O). Optional parameters are enclosed in square brackets ([ ]):
-
close(filename [,how])¶ -
Close the file filename for input or output. Alternatively, the argument may be a shell command that was used for creating a coprocess, or for redirecting to or from a pipe; then the coprocess or pipe is closed. See Closing Input and Output Redirections for more information.
When closing a coprocess, it is occasionally useful to first close one end of the two-way pipe and then to close the other. This is done by providing a second argument to
close(). This second argument (how) should be one of the two string values"to"or"from", indicating which end of the pipe to close. Case in the string does not matter. See Two-Way Communications with Another Process, which discusses this feature in more detail and gives an example.Note that the second argument to
close()is agawkextension; it is not available in compatibility mode (see Command-Line Options). -
fflush([filename])¶ Flush any buffered output associated with filename, which is either a file opened for writing or a shell command for redirecting output to a pipe or coprocess.
Many utility programs buffer their output (i.e., they save information to write to a disk file or the screen in memory until there is enough for it to be worthwhile to send the data to the output device). This is often more efficient than writing every little bit of information as soon as it is ready. However, sometimes it is necessary to force a program to flush its buffers (i.e., write the information to its destination, even if a buffer is not full). This is the purpose of the
fflush()function—gawkalso buffers its output, and thefflush()function forcesgawkto flush its buffers.Brian Kernighan added
fflush()to hisawkin April 1992. For two decades, it was a common extension. In December 2012, it was accepted for inclusion into the POSIX standard. See the Austin Group website.POSIX standardizes
fflush()as follows: if there is no argument, or if the argument is the null string (""), thenawkflushes the buffers for all open output files and pipes.NOTE: Prior to version 4.0.2,
gawkwould flush only the standard output if there was no argument, and flush all output files and pipes if the argument was the null string. This was changed in order to be compatible with BWKawk, in the hope that standardizing this feature in POSIX would then be easier (which indeed proved to be the case).With
gawk, you can use ‘fflush("/dev/stdout")’ if you wish to flush only the standard output.fflush()returns zero if the buffer is successfully flushed; otherwise, it returns a nonzero value. (gawkreturns −1.) In the case where all buffers are flushed, the return value is zero only if all buffers were flushed successfully. Otherwise, it is −1, andgawkwarns about the problem filename.gawkalso issues a warning message if you attempt to flush a file or pipe that was opened for reading (such as withgetline), or if filename is not an open file, pipe, or coprocess. In such a case,fflush()returns −1, as well.
| Interactive Versus Noninteractive Buffering |
|---|
|
As a side point, buffering issues can be even more confusing if your program is interactive (i.e., communicating with a user sitting at a keyboard).54 Interactive programs generally line buffer their output (i.e., they write out every line). Noninteractive programs wait until they have a full buffer, which may be many lines of output. Here is an example of the difference: $ awk '{ print $1 + $2 }'
1 1
-| 2
2 3
-| 5
Ctrl-d
Each line of output is printed immediately. Compare that behavior with this example: $ awk '{ print $1 + $2 }' | cat
1 1
2 3
Ctrl-d
-| 2
-| 5
Here, no output is printed until after the Ctrl-d is typed, because
it is all buffered and sent down the pipe to |
-
system(command)¶ Execute the operating system command command and then return to the
awkprogram. Return command’s exit status (see further on).For example, if the following fragment of code is put in your
awkprogram:END { system("date | mail -s 'awk run done' root") }the system administrator is sent mail when the
awkprogram finishes processing input and begins its end-of-input processing.Note that redirecting
printorprintfinto a pipe is often enough to accomplish your task. If you need to run many commands, it is more efficient to simply print them down a pipeline to the shell:while (more stuff to do) print command | "/bin/sh" close("/bin/sh")However, if your
awkprogram is interactive,system()is useful for running large self-contained programs, such as a shell or an editor. Some operating systems cannot implement thesystem()function.system()causes a fatal error if it is not supported.NOTE: When --sandbox is specified, the
system()function is disabled (see Command-Line Options).On POSIX systems, a command’s exit status is a 16-bit number. The exit value passed to the C
exit()function is held in the high-order eight bits. The low-order bits indicate if the process was killed by a signal (bit 7) and if so, the guilty signal number (bits 0–6).Traditionally,
awk’ssystem()function has simply returned the exit status value divided by 256. In the normal case this gives the exit status but in the case of death-by-signal it yields a fractional floating-point value.55 POSIX states thatawk’ssystem()should return the full 16-bit value.gawksteers a middle ground. The return values are summarized in Table 9.5.Situation Return value from system()--traditional C system()’s value divided by 256--posix C system()’s valueNormal exit of command Command’s exit status Death by signal of command 256 + number of murderous signal Death by signal of command with core dump 512 + number of murderous signal Some kind of error −1 Table 9.5: Return values from
system()
As of August, 2018, BWK awk now follows gawk’s behavior
for the return value of system().
9.1.6 Time Functions ¶
awk programs are commonly used to process log files
containing timestamp information, indicating when a
particular log record was written. Many programs log their timestamps
in the form returned by the time() system call, which is the
number of seconds since a particular epoch. On POSIX-compliant systems,
it is the number of seconds since
1970-01-01 00:00:00 UTC, not counting leap
seconds.56
All known POSIX-compliant systems support timestamps from 0 through
231 − 1,
which is sufficient to represent times through
2038-01-19 03:14:07 UTC. Many systems support a wider range of timestamps,
including negative timestamps that represent times before the
epoch.
In order to make it easier to process such log files and to produce
useful reports, gawk provides the following functions for
working with timestamps. They are gawk extensions; they are
not specified in the POSIX standard.57
However, recent versions
of mawk (see Other Freely Available awk Implementations) also support these functions.
Optional parameters are enclosed in square brackets ([ ]):
-
mktime(datespec[, utc-flag])¶ Turn datespec into a timestamp in the same form as is returned by
systime(). It is similar to the function of the same name in ISO C. The argument, datespec, is a string of the form"YYYY MM DD HH MM SS [DST]". The string consists of six or seven numbers representing, respectively, the full year including century, the month from 1 to 12, the day of the month from 1 to 31, the hour of the day from 0 to 23, the minute from 0 to 59, the second from 0 to 60,58 and an optional daylight-savings flag.The values of these numbers need not be within the ranges specified; for example, an hour of −1 means 1 hour before midnight. The origin-zero Gregorian calendar is assumed, with year 0 preceding year 1 and year −1 preceding year 0. If utc-flag is present and is either nonzero or non-null, the time is assumed to be in the UTC time zone; otherwise, the time is assumed to be in the local time zone. If the DST daylight-savings flag is positive, the time is assumed to be daylight savings time; if zero, the time is assumed to be standard time; and if negative (the default),
mktime()attempts to determine whether daylight savings time is in effect for the specified time.If datespec does not contain enough elements or if the resulting time is out of range,
mktime()returns −1.-
strftime([format [,timestamp [,utc-flag] ] ])¶ Format the time specified by timestamp based on the contents of the format string and return the result. It is similar to the function of the same name in ISO C. If utc-flag is present and is either nonzero or non-null, the value is formatted as UTC (Coordinated Universal Time, formerly GMT or Greenwich Mean Time). Otherwise, the value is formatted for the local time zone. The timestamp is in the same format as the value returned by the
systime()function. If no timestamp argument is supplied,gawkuses the current time of day as the timestamp. Without a format argument,strftime()uses the value ofPROCINFO["strftime"]as the format string (see Predefined Variables). The default string value is"%a %b %e %H:%M:%S %Z %Y". This format string produces output that is equivalent to that of thedateutility. You can assign a new value toPROCINFO["strftime"]to change the default format; see the following list for the various format directives.-
systime()¶ Return the current time as the number of seconds since the system epoch. On POSIX systems, this is the number of seconds since 1970-01-01 00:00:00 UTC, not counting leap seconds. It may be a different number on other systems.
The systime() function allows you to compare a timestamp from a
log file with the current time of day. In particular, it is easy to
determine how long ago a particular record was logged. It also allows
you to produce log records using the “seconds since the epoch” format.
The mktime() function allows you to convert a textual representation
of a date and time into a timestamp. This makes it easy to do before/after
comparisons of dates and times, particularly when dealing with date and
time data coming from an external source, such as a log file.
The strftime() function allows you to easily turn a timestamp
into human-readable information. It is similar in nature to the sprintf()
function
(see String-Manipulation Functions),
in that it copies nonformat specification characters verbatim to the
returned string, while substituting date and time values for format
specifications in the format string.
strftime() is guaranteed by the 1999 ISO C
standard59
to support the following date format specifications:
%aThe locale’s abbreviated weekday name.
%AThe locale’s full weekday name.
%bThe locale’s abbreviated month name.
%BThe locale’s full month name.
%cThe locale’s “appropriate” date and time representation. (This is ‘%A %B %d %T %Y’ in the
"C"locale.)%CThe century part of the current year. This is the year divided by 100 and truncated to the next lower integer.
%dThe day of the month as a decimal number (01–31).
%DEquivalent to specifying ‘%m/%d/%y’.
%eThe day of the month, padded with a space if it is only one digit.
%FEquivalent to specifying ‘%Y-%m-%d’. This is the ISO 8601 date format.
%gThe year modulo 100 of the ISO 8601 week number, as a decimal number (00–99). For example, January 1, 2012, is in week 53 of 2011. Thus, the year of its ISO 8601 week number is 2011, even though its year is 2012. Similarly, December 31, 2012, is in week 1 of 2013. Thus, the year of its ISO week number is 2013, even though its year is 2012.
%GThe full year of the ISO week number, as a decimal number.
%hEquivalent to ‘%b’.
%HThe hour (24-hour clock) as a decimal number (00–23).
%IThe hour (12-hour clock) as a decimal number (01–12).
%jThe day of the year as a decimal number (001–366).
%mThe month as a decimal number (01–12).
%MThe minute as a decimal number (00–59).
%nA newline character (ASCII LF).
%pThe locale’s equivalent of the AM/PM designations associated with a 12-hour clock.
%rThe locale’s 12-hour clock time. (This is ‘%I:%M:%S %p’ in the
"C"locale.)%REquivalent to specifying ‘%H:%M’.
%SThe second as a decimal number (00–60).
%tA TAB character.
%TEquivalent to specifying ‘%H:%M:%S’.
%uThe weekday as a decimal number (1–7). Monday is day one.
%UThe week number of the year (with the first Sunday as the first day of week one) as a decimal number (00–53).
%VThe week number of the year (with the first Monday as the first day of week one) as a decimal number (01–53). The method for determining the week number is as specified by ISO 8601. (To wit: if the week containing January 1 has four or more days in the new year, then it is week one; otherwise it is the last week [52 or 53] of the previous year and the next week is week one.)
%wThe weekday as a decimal number (0–6). Sunday is day zero.
%WThe week number of the year (with the first Monday as the first day of week one) as a decimal number (00–53).
%xThe locale’s “appropriate” date representation. (This is ‘%A %B %d %Y’ in the
"C"locale.)%XThe locale’s “appropriate” time representation. (This is ‘%T’ in the
"C"locale.)%yThe year modulo 100 as a decimal number (00–99).
%YThe full year as a decimal number (e.g., 2015).
%zThe time zone offset in a ‘+HHMM’ format (e.g., the format necessary to produce RFC 822/RFC 1036 date headers).
%ZThe time zone name or abbreviation; no characters if no time zone is determinable.
%Ec %EC %Ex %EX %Ey %EY %Od %Oe %OH%OI %Om %OM %OS %Ou %OU %OV %Ow %OW %Oy“Alternative representations” for the specifications that use only the second letter (‘%c’, ‘%C’, and so on).60 (These facilitate compliance with the POSIX
dateutility.)%%A literal ‘%’.
If a conversion specifier is not one of those just listed, the behavior is undefined.61
For systems that are not yet fully standards-compliant,
gawk supplies a copy of
strftime() from the GNU C Library.
It supports all of the just-listed format specifications.
If that version is
used to compile gawk (see Installing gawk),
then the following additional format specifications are available:
%kThe hour (24-hour clock) as a decimal number (0–23). Single-digit numbers are padded with a space.
%lThe hour (12-hour clock) as a decimal number (1–12). Single-digit numbers are padded with a space.
%sThe time as a decimal timestamp in seconds since the epoch.
Additionally, the alternative representations are recognized but their normal representations are used.
The following example is an awk implementation of the POSIX
date utility. Normally, the date utility prints the
current date and time of day in a well-known format. However, if you
provide an argument to it that begins with a ‘+’, date
copies nonformat specifier characters to the standard output and
interprets the current time according to the format specifiers in
the string. For example:
$ date '+Today is %A, %B %d, %Y.' -| Today is Monday, September 22, 2014.
Here is the gawk version of the date utility.
It has a shell “wrapper” to handle the -u option,
which requires that date run as if the time zone
is set to UTC:
#! /bin/sh
#
# date --- approximate the POSIX 'date' command
case $1 in
-u) TZ=UTC0 # use UTC
export TZ
shift ;;
esac
gawk 'BEGIN {
format = PROCINFO["strftime"]
exitval = 0
if (ARGC > 2)
exitval = 1
else if (ARGC == 2) {
format = ARGV[1]
if (format ~ /^\+/)
format = substr(format, 2) # remove leading +
}
print strftime(format)
exit exitval
}' "$@"
9.1.7 Bit-Manipulation Functions ¶
I can explain it for you, but I can’t understand it for you.
Many languages provide the ability to perform bitwise operations on two integer numbers. In other words, the operation is performed on each successive pair of bits in the operands. Three common operations are bitwise AND, OR, and XOR. The operations are described in Table 9.6.
Bit operator
| AND | OR | XOR
|---+---+---+---+---+---
Operands | 0 | 1 | 0 | 1 | 0 | 1
----------+---+---+---+---+---+---
0 | 0 0 | 0 1 | 0 1
1 | 0 1 | 1 1 | 1 0
Table 9.6: Bitwise operations
As you can see, the result of an AND operation is 1 only when both bits are 1. The result of an OR operation is 1 if either bit is 1. The result of an XOR operation is 1 if either bit is 1, but not both. The next operation is the complement; the complement of 1 is 0 and the complement of 0 is 1. Thus, this operation “flips” all the bits of a given value.
Finally, two other common operations are to shift the bits left or right.
For example, if you have a bit string ‘10111001’ and you shift it
right by three bits, you end up with ‘00010111’.62
If you start over again with ‘10111001’ and shift it left by three
bits, you end up with ‘11001000’. The following list describes
gawk’s built-in functions that implement the bitwise operations.
Optional parameters are enclosed in square brackets ([ ]):
and(v1,v2 [,…])Return the bitwise AND of the arguments. There must be at least two.
compl(val)Return the bitwise complement of val.
lshift(val, count)¶Return the value of val, shifted left by count bits.
or(v1,v2 [,…])Return the bitwise OR of the arguments. There must be at least two.
rshift(val, count)¶Return the value of val, shifted right by count bits.
xor(v1,v2 [,…])Return the bitwise XOR of the arguments. There must be at least two.
CAUTION: Beginning with
gawkversion 4.2, negative operands are not allowed for any of these functions. A negative operand produces a fatal error. See the sidebar “Beware The Smoke and Mirrors!” for more information as to why.
Here is a user-defined function (see User-Defined Functions) that illustrates the use of these functions:
# bits2str --- turn an integer into readable ones and zeros
function bits2str(bits, data, mask)
{
if (bits == 0)
return "0"
mask = 1
for (; bits != 0; bits = rshift(bits, 1))
data = (and(bits, mask) ? "1" : "0") data
while ((length(data) % 8) != 0)
data = "0" data
return data
}
BEGIN {
printf "123 = %s\n", bits2str(123)
printf "0123 = %s\n", bits2str(0123)
printf "0x99 = %s\n", bits2str(0x99)
comp = compl(0x99)
printf "compl(0x99) = %#x = %s\n", comp, bits2str(comp)
shift = lshift(0x99, 2)
printf "lshift(0x99, 2) = %#x = %s\n", shift, bits2str(shift)
shift = rshift(0x99, 2)
printf "rshift(0x99, 2) = %#x = %s\n", shift, bits2str(shift)
}
This program produces the following output when run:
$ gawk -f testbits.awk -| 123 = 01111011 -| 0123 = 01010011 -| 0x99 = 10011001 -| compl(0x99) = 0x3fffffffffff66 = -| 00111111111111111111111111111111111111111111111101100110 -| lshift(0x99, 2) = 0x264 = 0000001001100100 -| rshift(0x99, 2) = 0x26 = 00100110
The bits2str() function turns a binary number into a string.
Initializing mask to one creates
a binary value where the rightmost bit
is set to one. Using this mask,
the function repeatedly checks the rightmost bit.
ANDing the mask with the value indicates whether the
rightmost bit is one or not. If so, a "1" is concatenated onto the front
of the string.
Otherwise, a "0" is added.
The value is then shifted right by one bit and the loop continues
until there are no more one bits.
If the initial value is zero, it returns a simple "0".
Otherwise, at the end, it pads the value with zeros to represent multiples
of 8-bit quantities. This is typical in modern computers.
The main code in the BEGIN rule shows the difference between the
decimal and octal values for the same numbers
(see Octal and Hexadecimal Numbers),
and then demonstrates the
results of the compl(), lshift(), and rshift() functions.
| Beware The Smoke and Mirrors! |
|---|
|
It other languages, bitwise operations are performed on integer values, not floating-point values. As a general statement, such operations work best when performed on unsigned integers.
In normal operation, for all of these functions, first the
double-precision floating-point value is converted to the widest C
unsigned integer type, then the bitwise operation is performed. If the
result cannot be represented exactly as a C However, when using arbitrary precision arithmetic with the -M
option (see Arithmetic and Arbitrary-Precision Arithmetic with $ gawk 'BEGIN { print compl(42) }'
-| 9007199254740949
$ gawk -M 'BEGIN { print compl(42) }'
-| -43
What’s going on becomes clear when printing the results in hexadecimal: $ gawk 'BEGIN { printf "%#x\n", compl(42) }'
-| 0x1fffffffffffd5
$ gawk -M 'BEGIN { printf "%#x\n", compl(42) }'
-| 0xffffffffffffffd5
When using the -M option, under the hood, In short, using |
9.1.8 Getting Type Information ¶
gawk provides two functions that let you distinguish
the type of a variable.
This is necessary for writing code
that traverses every element of an array of arrays
(see Arrays of Arrays), and in other contexts.
-
isarray(x)¶ Return a true value if x is an array. Otherwise, return false.
typeof(x)Return one of the following strings, depending upon the type of x:
"array"x is an array.
"regexp"x is a strongly typed regexp (see Strongly Typed Regexp Constants).
"number"x is a number.
"number|bool"x is a Boolean typed value (see Boolean Typed Values).
"string"x is a string.
"strnum"x is a number that started life as user input, such as a field or the result of calling
split(). (I.e., x has the strnum attribute; see String Type versus Numeric Type.)"unassigned"x is a scalar variable that has not been assigned a value yet. For example:
BEGIN { # creates a[1] but it has no assigned value a[1] print typeof(a[1]) # unassigned }"untyped"x has not yet been used yet at all; it can become a scalar or an array. The typing could even conceivably differ from run to run of the same program! For example:
BEGIN { print "initially, typeof(v) = ", typeof(v) if ("FOO" in ENVIRON) make_scalar(v) else make_array(v) print "typeof(v) =", typeof(v) } function make_scalar(p, l) { l = p } function make_array(p) { p[1] = 1 }
isarray() is meant for use in two circumstances. The first is when
traversing a multidimensional array: you can test if an element is itself
an array or not. The second is inside the body of a user-defined function
(not discussed yet; see User-Defined Functions), to test if a parameter is an
array or not.
NOTE: While you can use
isarray()at the global level to test variables, doing so makes no sense. Because you are the one writing the program, you are supposed to know if your variables are arrays or not.
The typeof() function is general; it allows you to determine
if a variable or function parameter is a scalar (number, string,
or strongly typed regexp) or an array.
Normally, passing a variable that has never been used to a built-in
function causes it to become a scalar variable (unassigned).
However, isarray() and typeof() are different; they do
not change their arguments from untyped to unassigned.
This applies to both variables denoted by simple identifiers and array elements that come into existence simply by referencing them. Consider:
$ gawk 'BEGIN { print typeof(x) }'
-| untyped
$ gawk 'BEGIN { print typeof(x["foo"]) }'
-| untyped
Note that prior to version 5.2, array elements that come into existence simply by referencing them were different, they were automatically forced to be scalars:
$ gawk-5.1.1 'BEGIN { print typeof(x) }'
-| untyped
$ gawk-5.1.1 'BEGIN { print typeof(x["foo"]) }'
-| unassigned
9.1.9 String-Translation Functions ¶
gawk provides facilities for internationalizing awk programs.
These include the functions described in the following list.
The descriptions here are purposely brief.
See Internationalization with gawk,
for the full story.
Optional parameters are enclosed in square brackets ([ ]):
-
bindtextdomain(directory[,domain])¶ Set the directory in which
gawkwill look for message translation files, in case they will not or cannot be placed in the “standard” locations (e.g., during testing). It returns the directory in which domain is “bound.”The default domain is the value of
TEXTDOMAIN. If directory is the null string (""), thenbindtextdomain()returns the current binding for the given domain.-
dcgettext(string[,domain [,category] ])¶ Return the translation of string in text domain domain for locale category category. The default value for domain is the current value of
TEXTDOMAIN. The default value for category is"LC_MESSAGES".dcngettext(string1, string2, number[,domain [,category] ])¶Return the plural form used for number of the translation of string1 and string2 in text domain domain for locale category category. string1 is the English singular variant of a message, and string2 is the English plural variant of the same message. The default value for domain is the current value of
TEXTDOMAIN. The default value for category is"LC_MESSAGES".
9.2 User-Defined Functions ¶
Complicated awk programs can often be simplified by defining
your own functions. User-defined functions can be called just like
built-in ones (see Function Calls), but it is up to you to define
them (i.e., to tell awk what they should do).
- Function Definition Syntax
- Function Definition Examples
- Calling User-Defined Functions
- The
returnStatement - Functions and Their Effects on Variable Typing
9.2.1 Function Definition Syntax ¶
It’s entirely fair to say that the awk syntax for local variable definitions is appallingly awful.
Definitions of functions can appear anywhere between the rules of an
awk program. Thus, the general form of an awk program is
extended to include sequences of rules and user-defined function
definitions.
There is no need to put the definition of a function
before all uses of the function. This is because awk reads the
entire program before starting to execute any of it.
The definition of a function named name looks like this:
functionname([parameter-list]){body-of-function}
Here, name is the name of the function to define. A valid function
name is like a valid variable name: a sequence of letters, digits, and
underscores that doesn’t start with a digit.
Here too, only the 52 upper- and lowercase English letters may
be used in a function name.
Within a single awk program, any particular name can only be
used as a variable, array, or function.
parameter-list is an optional list of the function’s arguments and local variable names, separated by commas. When the function is called, the argument names are used to hold the argument values given in the call.
A function cannot have two parameters with the same name, nor may it have a parameter with the same name as the function itself.
CAUTION: According to the POSIX standard, function parameters cannot have the same name as one of the special predefined variables (see Predefined Variables), nor may a function parameter have the same name as another function.
Not all versions of
awkenforce these restrictions. (d.c.)gawkalways enforces the first restriction. With --posix (see Command-Line Options), it also enforces the second restriction.
Local variables act like the empty string if referenced where a string value is required, and like zero if referenced where a numeric value is required. This is the same as the behavior of regular variables that have never been assigned a value. (There is more to understand about local variables; see Functions and Their Effects on Variable Typing.)
The body-of-function consists of awk statements. It is the
most important part of the definition, because it says what the function
should actually do. The argument names exist to give the body a
way to talk about the arguments; local variables exist to give the body
places to keep temporary values.
Argument names are not distinguished syntactically from local variable names. Instead, the number of arguments supplied when the function is called determines how many argument variables there are. Thus, if three argument values are given, the first three names in parameter-list are arguments and the rest are local variables.
It follows that if the number of arguments is not the same in all calls to the function, some of the names in parameter-list may be arguments on some occasions and local variables on others. Another way to think of this is that omitted arguments default to the null string.
Usually when you write a function, you know how many names you intend to use for arguments and how many you intend to use as local variables. It is conventional to place some extra space between the arguments and the local variables, in order to document how your function is supposed to be used.
During execution of the function body, the arguments and local variable
values hide, or shadow, any variables of the same names used in the
rest of the program. The shadowed variables are not accessible in the
function definition, because there is no way to name them while their
names have been taken away for the arguments and local variables. All other variables
used in the awk program can be referenced or set normally in the
function’s body.
The arguments and local variables last only as long as the function body is executing. Once the body finishes, you can once again access the variables that were shadowed while the function was running.
The function body can contain expressions that call functions. They can even call this function, either directly or by way of another function. When this happens, we say the function is recursive. The act of a function calling itself is called recursion.
All the built-in functions return a value to their caller.
User-defined functions can do so also, using the return statement,
which is described in detail in The return Statement.
Many of the subsequent examples in this section use
the return statement.
In many awk implementations, including gawk,
the keyword function may be
abbreviated func. (c.e.)
However, POSIX only specifies the use of
the keyword function. This actually has some practical implications.
If gawk is in POSIX-compatibility mode
(see Command-Line Options), then the following
statement does not define a function:
func foo() { a = sqrt($1) ; print a }
Instead, it defines a rule that, for each record, concatenates the value
of the variable ‘func’ with the return value of the function ‘foo’.
If the resulting string is non-null, the action is executed.
This is probably not what is desired. (awk accepts this input as
syntactically valid, because functions may be used before they are defined
in awk programs.64)
To ensure that your awk programs are portable, always use the
keyword function when defining a function.
9.2.2 Function Definition Examples ¶
Here is an example of a user-defined function, called myprint(), that
takes a number and prints it in a specific format:
function myprint(num)
{
printf "%6.3g\n", num
}
To illustrate, here is an awk rule that uses our myprint()
function:
$3 > 0 { myprint($3) }
This program prints, in our special format, all the third fields that contain a positive number in our input. Therefore, when given the following input:
1.2 3.4 5.6 7.8 9.10 11.12 -13.14 15.16 17.18 19.20 21.22 23.24
this program, using our function to format the results, prints:
5.6 21.2
This function deletes all the elements in an array (recall that the extra whitespace signifies the start of the local variable list):
function delarray(a, i)
{
for (i in a)
delete a[i]
}
When working with arrays, it is often necessary to delete all the elements
in an array and start over with a new list of elements
(see The delete Statement).
Instead of having
to repeat this loop everywhere that you need to clear out
an array, your program can just call delarray().
(This guarantees portability. The use of ‘delete array’ to delete
the contents of an entire array is a relatively recent65
addition to the POSIX standard.)
The following is an example of a recursive function. It takes a string as an input parameter and returns the string in reverse order. Recursive functions must always have a test that stops the recursion. In this case, the recursion terminates when the input string is already empty:
function rev(str)
{
if (str == "")
return ""
return (rev(substr(str, 2)) substr(str, 1, 1))
}
If this function is in a file named rev.awk, it can be tested this way:
$ echo "Don't Panic!" |
> gawk -e '{ print rev($0) }' -f rev.awk
-| !cinaP t'noD
The C ctime() function takes a timestamp and returns it as a string,
formatted in a well-known fashion.
The following example uses the built-in strftime() function
(see Time Functions)
to create an awk version of ctime():
# ctime.awk
#
# awk version of C ctime(3) function
function ctime(ts, format)
{
format = "%a %b %e %H:%M:%S %Z %Y"
if (ts == 0)
ts = systime() # use current time as default
return strftime(format, ts)
}
You might think that ctime() could use PROCINFO["strftime"]
for its format string. That would be a mistake, because ctime() is
supposed to return the time formatted in a standard fashion, and user-level
code could have changed PROCINFO["strftime"].
9.2.3 Calling User-Defined Functions ¶
Calling a function means causing the function to run and do its job. A function call is an expression and its value is the value returned by the function.
- Writing a Function Call
- Controlling Variable Scope
- Passing Function Arguments by Value Or by Reference
- Other Points About Calling Functions
9.2.3.1 Writing a Function Call ¶
A function call consists of the function name followed by the arguments
in parentheses. awk expressions are what you write in the
call for the arguments. Each time the call is executed, these
expressions are evaluated, and the values become the actual arguments. For
example, here is a call to foo() with three arguments (the first
being a string concatenation):
foo(x y, "lose", 4 * z)
CAUTION: Whitespace characters (spaces and TABs) are not allowed between the function name and the opening parenthesis of the argument list. If you write whitespace by mistake,
awkmight think that you mean to concatenate a variable with an expression in parentheses. However, it notices that you used a function name and not a variable name, and reports an error.
9.2.3.2 Controlling Variable Scope ¶
Unlike in many languages,
there is no way to make a variable local to a { … } block in
awk, but you can make a variable local to a function. It is
good practice to do so whenever a variable is needed only in that
function.
To make a variable local to a function, simply declare the variable as
an argument after the actual function arguments
(see Function Definition Syntax).
Look at the following example, where variable
i is a global variable used by both functions foo() and
bar():
function bar()
{
for (i = 0; i < 3; i++)
print "bar's i=" i
}
function foo(j)
{
i = j + 1
print "foo's i=" i
bar()
print "foo's i=" i
}
BEGIN {
i = 10
print "top's i=" i
foo(0)
print "top's i=" i
}
Running this script produces the following, because the i in
functions foo() and bar() and at the top level refer to the same
variable instance:
top's i=10 foo's i=1 bar's i=0 bar's i=1 bar's i=2 foo's i=3 top's i=3
If you want i to be local to both foo() and bar(), do as
follows (the extra space before i is a coding convention to
indicate that i is a local variable, not an argument):
function bar( i)
{
for (i = 0; i < 3; i++)
print "bar's i=" i
}
function foo(j, i)
{
i = j + 1
print "foo's i=" i
bar()
print "foo's i=" i
}
BEGIN {
i = 10
print "top's i=" i
foo(0)
print "top's i=" i
}
Running the corrected script produces the following:
top's i=10 foo's i=1 bar's i=0 bar's i=1 bar's i=2 foo's i=1 top's i=10
Besides scalar values (strings and numbers), you may also have
local arrays. By using a parameter name as an array, awk
treats it as an array, and it is local to the function.
In addition, recursive calls create new arrays.
Consider this example:
function some_func(p1, a)
{
if (p1++ > 3)
return
a[p1] = p1
some_func(p1)
printf("At level %d, index %d %s found in a\n",
p1, (p1 - 1), (p1 - 1) in a ? "is" : "is not")
printf("At level %d, index %d %s found in a\n",
p1, p1, p1 in a ? "is" : "is not")
print ""
}
BEGIN {
some_func(1)
}
When run, this program produces the following output:
At level 4, index 3 is not found in a At level 4, index 4 is found in a At level 3, index 2 is not found in a At level 3, index 3 is found in a At level 2, index 1 is not found in a At level 2, index 2 is found in a
9.2.3.3 Passing Function Arguments by Value Or by Reference ¶
In awk, when you declare a function, there is no way to
declare explicitly whether the arguments are passed by value or
by reference.
Instead, the passing convention is determined at runtime when the function is called, according to the following rule: if the argument is an array variable, then it is passed by reference. Otherwise, the argument is passed by value.
Passing an argument by value means that when a function is called, it is given a copy of the value of this argument. The caller may use a variable as the expression for the argument, but the called function does not know this—it only knows what value the argument had. For example, if you write the following code:
foo = "bar" z = myfunc(foo)
then you should not think of the argument to myfunc() as being
“the variable foo.” Instead, think of the argument as the
string value "bar".
If the function myfunc() alters the values of its local variables,
this has no effect on any other variables. Thus, if myfunc()
does this:
function myfunc(str)
{
print str
str = "zzz"
print str
}
to change its first argument variable str, it does not
change the value of foo in the caller. The role of foo in
calling myfunc() ended when its value ("bar") was computed.
If str also exists outside of myfunc(), the function body
cannot alter this outer value, because it is shadowed during the
execution of myfunc() and cannot be seen or changed from there.
However, when arrays are the parameters to functions, they are not copied. Instead, the array itself is made available for direct manipulation by the function. This is usually termed call by reference. Changes made to an array parameter inside the body of a function are visible outside that function.
NOTE: Changing an array parameter inside a function can be very dangerous if you do not watch what you are doing. For example:
function changeit(array, ind, nvalue) { array[ind] = nvalue } BEGIN { a[1] = 1; a[2] = 2; a[3] = 3 changeit(a, 2, "two") printf "a[1] = %s, a[2] = %s, a[3] = %s\n", a[1], a[2], a[3] }prints ‘a[1] = 1, a[2] = two, a[3] = 3’, because
changeit()stores"two"in the second element ofa.
9.2.3.4 Other Points About Calling Functions ¶
Some awk implementations allow you to call a function that
has not been defined. They only report a problem at runtime, when the
program actually tries to call the function. For example:
BEGIN {
if (0)
foo()
else
bar()
}
function bar() { ... }
# note that `foo' is not defined
Because the ‘if’ statement will never be true, it is not really a
problem that foo() has not been defined. Usually, though, it is a
problem if a program calls an undefined function.
If --lint is specified
(see Command-Line Options),
gawk reports calls to undefined functions.
Some awk implementations generate a runtime
error if you use either the next statement
or the nextfile statement
(see The next Statement, and
see The nextfile Statement)
inside a user-defined function.
gawk does not have this limitation.
You can call a function and pass it more parameters than it was declared with, like so:
function foo(p1, p2)
{
...
}
BEGIN {
foo(1, 2, 3, 4)
}
Doing so is bad practice, however. The called function cannot do
anything with the additional values being passed to it, so awk
evaluates the expressions but then just throws them away.
More importantly, such a call is confusing for whoever will next read your program.66 Function parameters generally are input items that influence the computation performed by the function. Calling a function with more parameters than it accepts gives the false impression that those values are important to the function, when in fact they are not.
Because this is such a bad practice, gawk unconditionally
issues a warning whenever it executes such a function call. (If you
don’t like the warning, fix your code! It’s incorrect, after all.)
9.2.4 The return Statement ¶
As seen in several earlier examples,
the body of a user-defined function can contain a return statement.
This statement returns control to the calling part of the awk program. It
can also be used to return a value for use in the rest of the awk
program. It looks like this:
return [expression]
The expression part is optional.
Due most likely to an oversight, POSIX does not define what the return
value is if you omit the expression. Technically speaking, this
makes the returned value undefined, and therefore, unpredictable.
In practice, though, all versions of awk simply return the
null string, which acts like zero if used in a numeric context.
A return statement without an expression is assumed at the end of
every function definition. So, if control reaches the end of the function
body, then technically the function returns an unpredictable value.
In practice, it returns the empty string. awk
does not warn you if you use the return value of such a function.
Sometimes, you want to write a function for what it does, not for
what it returns. Such a function corresponds to a void function
in C, C++, or Java, or to a procedure in Ada. Thus, it may be appropriate to not
return any value; simply bear in mind that you should not be using the
return value of such a function.
The following is an example of a user-defined function that returns a value for the largest number among the elements of an array:
function maxelt(vec, i, ret)
{
for (i in vec) {
if (ret == "" || vec[i] > ret)
ret = vec[i]
}
return ret
}
You call maxelt() with one argument, which is an array name. The local
variables i and ret are not intended to be arguments;
there is nothing to stop you from passing more than one argument
to maxelt() but the results would be strange. The extra space before
i in the function parameter list indicates that i and
ret are local variables.
You should follow this convention when defining functions.
The following program uses the maxelt() function. It loads an
array, calls maxelt(), and then reports the maximum number in that
array:
function maxelt(vec, i, ret)
{
for (i in vec) {
if (ret == "" || vec[i] > ret)
ret = vec[i]
}
return ret
}
# Load all fields of each record into nums.
{
for(i = 1; i <= NF; i++)
nums[NR, i] = $i
}
END {
print maxelt(nums)
}
Given the following input:
1 5 23 8 16 44 3 5 2 8 26 256 291 1396 2962 100 -6 467 998 1101 99385 11 0 225
the program reports (predictably) that 99,385 is the largest value in the array.
9.2.5 Functions and Their Effects on Variable Typing ¶
It’s a desert topping!
It’s a floor wax!
awk is a very fluid language.
It is possible that awk can’t tell if an identifier
represents a scalar variable or an array until runtime.
Here is an annotated sample program:
function foo(a)
{
a[1] = 1 # parameter is an array
}
BEGIN {
b = 1
foo(b) # invalid: fatal type mismatch
foo(x) # x uninitialized, becomes an array dynamically
x = 1 # now not allowed, runtime error
}
In this example, the first call to foo() generates
a fatal error, so awk will not report the second
error. If you comment out that call, though, then awk
does report the second error.
Here is a more extreme example:
BEGIN {
funky(a)
if (A == 0)
print "<" a ">"
else
print a[1]
}
function funky(arr)
{
if (A == 0)
arr = 1
else
arr[1] = 1
}
Here, the function uses its parameter differently depending upon the
value of the global variable A. If A is zero, the
parameter arr is treated as a scalar. Otherwise it’s treated
as an array.
There are two ways this program might behave. awk could notice
that in the main program, a is subscripted, and so mark it as
an array before the program even begins to run. BWK awk, mawk,
and possibly others do this:
$ nawk -v A=0 -f funky.awk error→ nawk: can't assign to a; it's an array name. error→ source line number 11 $ nawk -v A=1 -f funky.awk -| 1
Or awk could wait until runtime to set the type of a.
In this case, since a was never used before being
passed to the function, how the function uses it forces the type to
be resolved to either scalar or array. gawk
and the MKS awk do this:
$ gawk -v A=0 -f funky.awk -| <> $ gawk -v A=1 -f funky.awk -| 1
POSIX does not specify the correct behavior, so be aware that different implementations work differently.
9.3 Indirect Function Calls ¶
This section describes an advanced, gawk-specific extension.
Often, you may wish to defer the choice of function to call until runtime. For example, you may have different kinds of records, each of which should be processed differently.
Normally, you would have to use a series of if-else
statements to decide which function to call. By using indirect
function calls, you can specify the name of the function to call as a
string variable, and then call the function. Let’s look at an example.
Suppose you have a file with your test scores for the classes you are taking, and you wish to get the sum and the average of your test scores. The first field is the class name. The following fields are the functions to call to process the data, up to a “marker” field ‘data:’. Following the marker, to the end of the record, are the various numeric test scores.
Here is the initial file:
Biology_101 sum average data: 87.0 92.4 78.5 94.9 Chemistry_305 sum average data: 75.2 98.3 94.7 88.2 English_401 sum average data: 100.0 95.6 87.1 93.4
To process the data, you might write initially:
{
class = $1
for (i = 2; $i != "data:"; i++) {
if ($i == "sum")
sum() # processes the whole record
else if ($i == "average")
average()
... # and so on
}
}
This style of programming works, but can be awkward. With indirect
function calls, you tell gawk to use the value of a
variable as the name of the function to call.
The syntax is similar to that of a regular function call: an identifier immediately followed by an opening parenthesis, any arguments, and then a closing parenthesis, with the addition of a leading ‘@’ character:
the_function = "sum" result = @the_function() # calls the sum() function
Here is a full program that processes the previously shown data, using indirect function calls:
# indirectcall.awk --- Demonstrate indirect function calls
# average --- return the average of the values in fields $first - $last
function average(first, last, sum, i)
{
sum = 0;
for (i = first; i <= last; i++)
sum += $i
return sum / (last - first + 1)
}
# sum --- return the sum of the values in fields $first - $last
function sum(first, last, ret, i)
{
ret = 0;
for (i = first; i <= last; i++)
ret += $i
return ret
}
These two functions expect to work on fields; thus, the parameters
first and last indicate where in the fields to start and end.
Otherwise, they perform the expected computations and are not unusual:
# For each record, print the class name and the requested statistics
{
class_name = $1
gsub(/_/, " ", class_name) # Replace _ with spaces
# find start
for (i = 1; i <= NF; i++) {
if ($i == "data:") {
start = i + 1
break
}
}
printf("%s:\n", class_name)
for (i = 2; $i != "data:"; i++) {
the_function = $i
printf("\t%s: <%s>\n", $i, @the_function(start, NF) "")
}
print ""
}
This is the main processing for each record. It prints the class name (with
underscores replaced with spaces). It then finds the start of the actual data,
saving it in start.
The last part of the code loops through each function name (from $2 up to
the marker, ‘data:’), calling the function named by the field. The indirect
function call itself occurs as a parameter in the call to printf.
(The printf format string uses ‘%s’ as the format specifier so that we
can use functions that return strings, as well as numbers. Note that the result
from the indirect call is concatenated with the empty string, in order to force
it to be a string value.)
Here is the result of running the program:
$ gawk -f indirectcall.awk class_data1 -| Biology 101: -| sum: <352.8> -| average: <88.2> -| -| Chemistry 305: -| sum: <356.4> -| average: <89.1> -| -| English 401: -| sum: <376.1> -| average: <94.025>
The ability to use indirect function calls is more powerful than you may
think at first. The C and C++ languages provide “function pointers,” which
are a mechanism for calling a function chosen at runtime. One of the most
well-known uses of this ability is the C qsort() function, which sorts
an array using the famous “quicksort” algorithm
(see the Wikipedia article
for more information). To use this function, you supply a pointer to a comparison
function. This mechanism allows you to sort arbitrary data in an arbitrary
fashion.
We can do something similar using gawk, like this:
# quicksort.awk --- Quicksort algorithm, with user-supplied
# comparison function
# quicksort --- C.A.R. Hoare's quicksort algorithm. See Wikipedia
# or almost any algorithms or computer science text.
function quicksort(data, left, right, less_than, i, last)
{
if (left >= right) # do nothing if array contains fewer
return # than two elements
quicksort_swap(data, left, int((left + right) / 2))
last = left
for (i = left + 1; i <= right; i++)
if (@less_than(data[i], data[left]))
quicksort_swap(data, ++last, i)
quicksort_swap(data, left, last)
quicksort(data, left, last - 1, less_than)
quicksort(data, last + 1, right, less_than)
}
# quicksort_swap --- helper function for quicksort, should really be inline
function quicksort_swap(data, i, j, temp)
{
temp = data[i]
data[i] = data[j]
data[j] = temp
}
The quicksort() function receives the data array, the starting and ending
indices to sort (left and right), and the name of a function that
performs a “less than” comparison. It then implements the quicksort algorithm.
To make use of the sorting function, we return to our previous example. The first thing to do is write some comparison functions:
# num_lt --- do a numeric less than comparison
function num_lt(left, right)
{
return ((left + 0) < (right + 0))
}
# num_ge --- do a numeric greater than or equal to comparison
function num_ge(left, right)
{
return ((left + 0) >= (right + 0))
}
The num_ge() function is needed to perform a descending sort; when used
to perform a “less than” test, it actually does the opposite (greater than
or equal to), which yields data sorted in descending order.
Next comes a sorting function. It is parameterized with the starting and
ending field numbers and the comparison function. It builds an array with
the data and calls quicksort() appropriately, and then formats the
results as a single string:
# do_sort --- sort the data according to `compare'
# and return it as a string
function do_sort(first, last, compare, data, i, retval)
{
delete data
for (i = 1; first <= last; first++) {
data[i] = $first
i++
}
quicksort(data, 1, i-1, compare)
retval = data[1]
for (i = 2; i in data; i++)
retval = retval " " data[i]
return retval
}
Finally, the two sorting functions call do_sort(), passing in the
names of the two comparison functions:
# sort --- sort the data in ascending order and return it as a string
function sort(first, last)
{
return do_sort(first, last, "num_lt")
}
# rsort --- sort the data in descending order and return it as a string
function rsort(first, last)
{
return do_sort(first, last, "num_ge")
}
Here is an extended version of the data file:
Biology_101 sum average sort rsort data: 87.0 92.4 78.5 94.9 Chemistry_305 sum average sort rsort data: 75.2 98.3 94.7 88.2 English_401 sum average sort rsort data: 100.0 95.6 87.1 93.4
Finally, here are the results when the enhanced program is run:
$ gawk -f quicksort.awk -f indirectcall.awk class_data2 -| Biology 101: -| sum: <352.8> -| average: <88.2> -| sort: <78.5 87.0 92.4 94.9> -| rsort: <94.9 92.4 87.0 78.5> -| -| Chemistry 305: -| sum: <356.4> -| average: <89.1> -| sort: <75.2 88.2 94.7 98.3> -| rsort: <98.3 94.7 88.2 75.2> -| -| English 401: -| sum: <376.1> -| average: <94.025> -| sort: <87.1 93.4 95.6 100.0> -| rsort: <100.0 95.6 93.4 87.1>
Another example where indirect functions calls are useful can be found in processing arrays. This is described in Traversing Arrays of Arrays.
Remember that you must supply a leading ‘@’ in front of an indirect function call.
Starting with version 4.1.2 of gawk, indirect function
calls may also be used with built-in functions and with extension functions
(see Writing Extensions for gawk). There are some limitations when calling
built-in functions indirectly, as follows.
- You cannot pass a regular expression constant to a built-in function
through an indirect function call. This applies to the
sub(),gsub(),gensub(),match(),split()andpatsplit()functions. However, you can pass a strongly typed regexp constant (see Strongly Typed Regexp Constants). - If calling
sub()orgsub(), you may only pass two arguments, since those functions are unusual in that they update their third argument. This means that$0will be updated. - You cannot indirectly call built-in functions that can take
$0as a default parameter; you must supply an argument instead. For example, you must pass an argument tolength()if calling it indirectly. - Calling a built-in function indirectly with the wrong number of arguments
for that function causes a fatal error. For example, calling
length()with two arguments. These errors are found at runtime instead of whengawkparses your program, sincegawkdoesn’t know until runtime if you have passed the correct number of arguments or not.
gawk does its best to make indirect function calls efficient.
For example, in the following case:
for (i = 1; i <= n; i++)
@the_function()
gawk looks up the actual function to call only once.
9.4 Summary ¶
awkprovides built-in functions and lets you define your own functions.- POSIX
awkprovides three kinds of built-in functions: numeric, string, and I/O.gawkprovides functions that sort arrays, work with values representing time, do bit manipulation, determine variable type (array versus scalar), and internationalize and localize programs.gawkalso provides several extensions to some of standard functions, typically in the form of additional arguments. - Functions accept zero or more arguments and return a value. The expressions that provide the argument values are completely evaluated before the function is called. Order of evaluation is not defined. The return value can be ignored.
- The handling of backslash in
sub()andgsub()is not simple. It is more straightforward ingawk’sgensub()function, but that function still requires care in its use. - User-defined functions provide important capabilities but come with some syntactic inelegancies. In a function call, there cannot be any space between the function name and the opening left parenthesis of the argument list. Also, there is no provision for local variables, so the convention is to add extra parameters, and to separate them visually from the real parameters by extra whitespace.
- User-defined functions may call other user-defined (and built-in)
functions and may call themselves recursively. Function parameters
“hide” any global variables of the same names.
You cannot use the name of a reserved variable (such as
ARGC) as the name of a parameter in user-defined functions. - Scalar values are passed to user-defined functions by value. Array parameters are passed by reference; any changes made by the function to array parameters are thus visible after the function has returned.
- Use the
returnstatement to return from a user-defined function. An optional expression becomes the function’s return value. Only scalar values may be returned by a function. - If a variable that has never been used is passed to a user-defined function, how that function treats the variable can set its nature: either scalar or array.
gawkprovides indirect function calls using a special syntax. By setting a variable to the name of a function, you can determine at runtime what function will be called at that point in the program. This is equivalent to function pointers in C and C++.