Next: Introducción, Up: (dir) [Contents][Index]
GNU Guix
Este documento describe GNU Guix versión 1.4.0, una herramienta funcional de gestión de paquetes escrita para el sistema GNU.
This manual is also available in Simplified Chinese (see GNU Guix参考手册), French (see Manuel de référence de GNU Guix), German (see Referenzhandbuch zu GNU Guix), Spanish (see Manual de referencia de GNU Guix), Brazilian Portuguese (see Manual de referência do GNU Guix), and Russian (see Руководство GNU Guix). If you would like to translate it in your native language, consider joining Weblate (see Traduciendo Guix).
Table of Contents
- 1 Introducción
- 2 Instalación
- 3 Instalación del sistema
- 3.1 Limitaciones
- 3.2 Consideraciones sobre el hardware
- 3.3 Instalación desde memoria USB y DVD
- 3.4 Preparación para la instalación
- 3.5 Instalación gráfica guiada
- 3.6 Instalación manual
- 3.7 Tras la instalación del sistema
- 3.8 Instalación de Guix en una máquina virtual
- 3.9 Construcción de la imagen de instalación
- 3.10 Construcción de la imagen de instalación para placas ARM
- 4 System Troubleshooting Tips
- 5 Empezando
- 6 Gestión de paquetes
- 7 Canales
- 7.1 Especificación de canales adicionales
- 7.2 Uso de un canal de Guix personalizado
- 7.3 Replicación de Guix
- 7.4 Verificación de canales
- 7.5 Channels with Substitutes
- 7.6 Creación de un canal
- 7.7 Módulos de paquetes en un subdirectorio
- 7.8 Declaración de dependencias de canales
- 7.9 Especificación de autorizaciones del canal
- 7.10 URL primaria
- 7.11 Escribir de noticias del canal
- 8 Desarrollo
- 9 Interfaz programática
- 9.1 Módulos de paquetes
- 9.2 Definición de paquetes
- 9.3 Definición de variantes de paquetes
- 9.4 Writing Manifests
- 9.5 Sistemas de construcción
- 9.6 Fases de construcción
- 9.7 Utilidades de construcción
- 9.8 Search Paths
- 9.9 El almacén
- 9.10 Derivaciones
- 9.11 La mónada del almacén
- 9.12 Expresiones-G
- 9.13 Invocación de
guix repl - 9.14 Using Guix Interactively
- 10 Utilidades
- 10.1 Invocación de
guix build - 10.2 Invocación de
guix edit - 10.3 Invocación de
guix download - 10.4 Invocación de
guix hash - 10.5 Invocación de
guix import - 10.6 Invocación de
guix refresh - 10.7 Invoking
guix style - 10.8 Invocación de
guix lint - 10.9 Invocación de
guix size - 10.10 Invocación de
guix graph - 10.11 Invocación de
guix publish - 10.12 Invocación de
guix challenge - 10.13 Invocación de
guix copy - 10.14 Invocación de
guix container - 10.15 Invocación de
guix weather - 10.16 Invocación de
guix processes
- 10.1 Invocación de
- 11 Foreign Architectures
- 12 Configuración del sistema
- 12.1 Uso de la configuración del sistema
- 12.2 Referencia de
operating-system - 12.3 Sistemas de archivos
- 12.4 Dispositivos traducidos
- 12.5 Swap Space
- 12.6 Cuentas de usuaria
- 12.7 Distribución de teclado
- 12.8 Localizaciones
- 12.9 Servicios
- 12.9.1 Servicios base
- 12.9.2 Ejecución de tareas programadas
- 12.9.3 Rotación del registro de mensajes
- 12.9.4 Networking Setup
- 12.9.5 Servicios de red
- 12.9.6 Actualizaciones no-atendidas
- 12.9.7 Sistema X Window
- 12.9.8 Servicios de impresión
- 12.9.9 Servicios de escritorio
- 12.9.10 Servicios de sonido
- 12.9.11 Servicios de bases de datos
- 12.9.12 Servicios de correo
- 12.9.13 Servicios de mensajería
- 12.9.14 Servicios de telefonía
- 12.9.15 File-Sharing Services
- 12.9.16 Servicios de monitorización
- 12.9.17 Servicios Kerberos
- 12.9.18 Servicios LDAP
- 12.9.19 Servicios Web
- 12.9.20 Servicios de certificados
- 12.9.21 Servicios DNS
- 12.9.22 VNC Services
- 12.9.23 Servicios VPN
- 12.9.24 Sistema de archivos en red
- 12.9.25 Samba Services
- 12.9.26 Integración continua
- 12.9.27 Servicios de gestión de energía
- 12.9.28 Servicios de audio
- 12.9.29 Servicios de virtualización
- 12.9.30 Servicios de control de versiones
- 12.9.31 Servicios de juegos
- 12.9.32 Servicio PAM Mount
- 12.9.33 Servicios de Guix
- 12.9.34 Servicios de Linux
- 12.9.35 Servicios de Hurd
- 12.9.36 Servicios misceláneos
- 12.10 Programas con setuid
- 12.11 Certificados X.509
- 12.12 Selector de servicios de nombres
- 12.13 Disco en RAM inicial
- 12.14 Configuración del gestor de arranque
- 12.15 Invoking
guix system - 12.16 Invoking
guix deploy - 12.17 Ejecución de Guix en una máquina virtual
- 12.18 Definición de servicios
- 13 Home Configuration
- 14 Documentación
- 15 Platforms
- 16 Creating System Images
- 17 Instalación de archivos de depuración
- 18 Using TeX and LaTeX
- 19 Actualizaciones de seguridad
- 20 Lanzamiento inicial
- 21 Transportar a una nueva plataforma
- 22 Contribuir
- 22.1 Construcción desde Git
- 22.2 Ejecución de Guix antes de estar instalado
- 22.3 La configuración perfecta
- 22.4 Pautas de empaquetamiento
- 22.5 Estilo de codificación
- 22.6 Envío de parches
- 22.7 Seguimiento de errores y parches
- 22.8 Acceso al repositorio
- 22.9 Actualizar el paquete Guix
- 22.10 Writing Documentation
- 22.11 Traduciendo Guix
- 23 Reconocimientos
- Appendix A Licencia de documentación libre GNU
- Índice de conceptos
- Índice programático
Next: Instalación, Previous: GNU Guix, Up: GNU Guix [Contents][Index]
1 Introducción
GNU Guix1 es una herramienta de gestión de paquetes y una distribución del sistema GNU. Guix facilita a usuarias sin privilegios la instalación, actualización o borrado de paquetes de software, la vuelta a un conjunto de paquetes previo atómicamente, la construcción de paquetes desde las fuentes, y ayuda de forma general en la creación y mantenimiento de entornos software.
Puede instalar GNU Guix sobre un sistema GNU/Linux existente, donde complementará las herramientas disponibles sin interferencias (see Instalación), o puede usarse como un sistema operativo en sí mismo, el sistema Guix2. See Distribución GNU.
Next: Distribución GNU, Up: Introducción [Contents][Index]
1.1 Gestión de software con Guix
Guix provides a command-line package management interface (see Gestión de paquetes), tools to help with software development (see Desarrollo), command-line utilities for more advanced usage (see Utilidades), as well as Scheme programming interfaces (see Interfaz programática). Su daemon de construcción es responsable de la construcción de paquetes en delegación de las usuarias (see Preparación del daemon) y de la descarga de binarios preconstruidos de fuentes autorizadas (see Sustituciones)
Guix incluye definiciones de paquetes para muchos paquetes GNU y no-GNU, todos los cuales respetan la libertad de computación de la usuaria. Es extensible: las usuarias pueden escribir sus propias definiciones de paquetes (see Definición de paquetes) y hacerlas disponibles como módulos independientes de paquetes (see Módulos de paquetes). También es personalizable: las usuarias pueden derivar definiciones de paquetes especializadas de las existentes, inclusive desde la línea de órdenes (see Opciones de transformación de paquetes).
En su implementación, Guix utiliza la disciplina de gestión de paquetes funcional en la que Nix fue pionero (see Reconocimientos). En Guix, el proceso de construcción e instalación es visto como una función, en el sentido matemático. Dicha función toma entradas, como los guiones de construcción, un compilador, unas bibliotecas y devuelve el paquete instalado. Como función pura, su resultado únicamente depende de sus entradas—por ejemplo, no puede hacer referencia a software o guiones que no fuesen pasados explícitamente como entrada. Una función de construcción siempre produce el mismo resultado cuando se le proporciona un conjunto de entradas dado. No puede modificar el entorno del sistema que la ejecuta de ninguna forma; por ejemplo, no puede crear, modificar o borrar archivos fuera de sus directorios de construcción e instalación. Esto se consigue ejecutando los procesos de construcción en entornos aislados (o contenedores), donde únicamente sus entradas explícitas son visibles.
El resultado de las funciones de construcción de paquetes es almacenado en la caché en el sistema de archivos, en un directorio especial llamado el almacén (see El almacén). Cada paquete se instala en un directorio propio en el almacén—por defecto, bajo /gnu/store. El nombre del directorio contiene el hash de todas las entradas usadas para construir el paquete; por tanto, cambiar una entrada resulta en un nombre de directorio distinto.
Esta aproximación es el cimiento de las avanzadas características de Guix: capacidad para la actualización transaccional y vuelta-atrás de paquetes, instalación en el ámbito de la usuaria y recolección de basura de paquetes (see Características).
Previous: Gestión de software con Guix, Up: Introducción [Contents][Index]
1.2 Distribución GNU
Guix viene con una distribución del sistema GNU consistente en su totalidad de software libre3. La distribución puede instalarse independientemente (see Instalación del sistema), pero también es posible instalar Guix como un gestor de paquetes sobre un sistema GNU/Linux existente (see Instalación). Para distinguir entre las dos opciones, nos referimos a la distribución independiente como el sistema Guix.
La distribución proporciona paquetes principales de GNU como GNU libc, GCC y
Binutils, así como muchas aplicaciones GNU y no-GNU. La lista completa de
paquetes disponibles se puede explorar
en línea o ejecutando
guix package (see Invocación de guix package):
guix package --list-available
Nuestro objetivo es proporcionar una distribución práctica con 100% software libre basada en Linux y otras variantes de GNU, con un enfoque en la promoción y la alta integración de componentes GNU, y un énfasis en programas y herramientas que ayuden a las usuarias a ejercitar esa libertad.
Actualmente hay paquetes disponibles para las siguientes plataformas:
x86_64-linuxArquitectura
x86_64de Intel/AMD, con núcleo Linux-Libre.i686-linuxArquitectura de 32-bits Intel (IA32), con núcleo Linux-Libre.
armhf-linuxArquitectura ARMv7-A con coma flotante hardware, Thumb-2 y NEON, usando la interfaz binaria de aplicaciones (ABI) EABI con coma flotante hardware, y con el núcleo Linux-Libre.
aarch64-linuxprocesadores ARMv8-A de 64 bits little-endian, con el núcleo Linux-Libre.
i586-gnuGNU/Hurd en la arquitectura Intel de 32 bits (IA32).
Esta configuración es experimental y se encuentra en desarrollo. La forma más fácil de probarla es configurando una instancia del servicio
hurd-vm-service-typeen su máquina GNU/Linux (seehurd-vm-service-type). ¡See Contribuir para informarse sobre cómo ayudar!mips64el-linux (unsupported)little-endian 64-bit MIPS processors, specifically the Loongson series, n32 ABI, and Linux-Libre kernel. This configuration is no longer fully supported; in particular, there is no ongoing work to ensure that this architecture still works. Should someone decide they wish to revive this architecture then the code is still available.
powerpc-linux (unsupported)big-endian 32-bit PowerPC processors, specifically the PowerPC G4 with AltiVec support, and Linux-Libre kernel. This configuration is not fully supported and there is no ongoing work to ensure this architecture works.
powerpc64le-linuxlittle-endian 64-bit Power ISA processors, Linux-Libre kernel. This includes POWER9 systems such as the RYF Talos II mainboard. This platform is available as a "technology preview": although it is supported, substitutes are not yet available from the build farm (see Sustituciones), and some packages may fail to build (see Seguimiento de errores y parches). That said, the Guix community is actively working on improving this support, and now is a great time to try it and get involved!
riscv64-linuxlittle-endian 64-bit RISC-V processors, specifically RV64GC, and Linux-Libre kernel. This platform is available as a "technology preview": although it is supported, substitutes are not yet available from the build farm (see Sustituciones), and some packages may fail to build (see Seguimiento de errores y parches). That said, the Guix community is actively working on improving this support, and now is a great time to try it and get involved!
Con el sistema Guix, declara todos los aspectos de la configuración del sistema y Guix se hace cargo de instanciar la configuración de manera transaccional, reproducible y sin estado global (see Configuración del sistema). El sistema Guix usa el núcleo Linux-libre, el sistema de inicialización Shepherd (see Introduction in The GNU Shepherd Manual), las conocidas utilidades y herramientas de compilación GNU, así como el entorno gráfico o servicios del sistema de su elección.
Guix System is available on all the above platforms except
mips64el-linux, powerpc-linux, powerpc64le-linux and
riscv64-linux.
Para información sobre el transporte a otras arquitecturas o núcleos, see Transportar a una nueva plataforma.
La construcción de esta distribución es un esfuerzo cooperativo, ¡y esta invitada a unirse! See Contribuir, para información sobre cómo puede ayudar.
Next: Instalación del sistema, Previous: Introducción, Up: GNU Guix [Contents][Index]
2 Instalación
Nota: Recomendamos el uso de este guión de instalación para instalar Guix sobre un sistema GNU/Linux en ejecución, de aquí en adelante referido como una distribución distinta.4 El guión automatiza la descarga, instalación y configuración inicial de Guix. Debe ejecutarse como la usuaria de administración root.
Cuando está instalado sobre una distribución distinta, GNU Guix complementa las herramientas disponibles sin interferencias. Sus datos radican exclusivamente en dos directorios, normalmente /gnu/store y /var/guix; otros archivos en su sistema, como /etc, permanecen intactos.
Una vez instalado, Guix puede ser actualizado ejecutando guix pull
(see Invocación de guix pull.
Si prefiere realizar los pasos de instalación manualmente o desea personalizarlos, puede encontrar útiles las siguientes instrucciones. Describen los requisitos de software de Guix, así como su instalación manual y la preparación para su uso.
- Instalación binaria
- Requisitos
- Ejecución de la batería de pruebas
- Preparación del daemon
- Invocación de
guix-daemon - Configuración de la aplicación
- Actualizar Guix
Next: Requisitos, Up: Instalación [Contents][Index]
2.1 Instalación binaria
Esta sección describe cómo instalar Guix en un sistema arbitrario desde un archivador autocontenido que proporciona los binarios para Guix y todas sus dependencias. Esto es normalmente más rápido que una instalación desde las fuentes, la cual es descrita en las siguientes secciones. El único requisito es tener GNU tar y Xz.
Nota: Le recomendamos el uso de este guión de instalación. Automatiza la descarga, instalación y los pasos iniciales de configuración descritos a continuación. Debe ser ejecutarse como root. Mediante el uso de dicha cuenta puede ejecutar esto:
cd /tmp wget https://git.savannah.gnu.org/cgit/guix.git/plain/etc/guix-install.sh chmod +x guix-install.sh ./guix-install.shIf you’re running Debian or a derivative such as Ubuntu, you can instead install the package (it might be a version older than 1.4.0 but you can update it afterwards by running ‘guix pull’):
sudo apt install guixLikewise on openSUSE:
sudo zypper install guixCuando haya terminado, see Configuración de la aplicación para obtener información adicional que pueda necesitar, ¡y Empezando para sus primeros pasos!
La instalación consiste más o menos en los siguientes pasos:
-
Descargue el archivador con los binarios de
‘
https://ftp.gnu.org/gnu/guix/guix-binary-1.4.0.x86_64-linux.tar.xz’, donde, por ejemplo,x86_64-linuxpuede sustituirse pori686-linuxpara una máquinai686(32 bits) que ejecute el núcleo Linux (see Distribución GNU).Asegúrese de descargar el archivo .sig asociado y de verificar la autenticidad del archivador con él, más o menos así:
$ wget https://ftp.gnu.org/gnu/guix/guix-binary-1.4.0.x86_64-linux.tar.xz.sig $ gpg --verify guix-binary-1.4.0.x86_64-linux.tar.xz.sig
Si la orden falla porque no dispone de la clave pública necesaria, entonces ejecute esta otra orden para importarla:
$ wget 'https://sv.gnu.org/people/viewgpg.php?user_id=15145' \ -qO - | gpg --import -y vuelva a ejecutar la orden
gpg --verify.Tenga en cuenta que un aviso del tipo “Esta clave no esta certificada con una firma de confianza” es normal.
- Ahora necesita convertirse en la usuaria
root. Dependiendo de su distribución, puede que tenga que ejecutarsu -osudo -i. Comoroot, ejecute:# cd /tmp # tar --warning=no-timestamp -xf \ /ruta/a/guix-binary-1.4.0.x86_64-linux.tar.xz # mv var/guix /var/ && mv gnu /Esto crea /gnu/store (see El almacén) y /var/guix. El último contiene un perfil listo para usar para
root(véase el siguiente paso).No extraiga el archivador en un sistema Guix ya funcionando ya que sobreescribiría sus propios archivos esenciales.
La opción --warning=no-timestamp asegura que GNU tar no emite avisos sobre “marcas de tiempo imposibles” (dichos avisos eran emitidos por GNU tar 1.26 y anteriores; las versiones recientes están bien). Parten del hecho de que todos los archivos en el archivador tienen su tiempo de modificación con valor uno (que significa el 1 de enero de 1970). Esto se hace de manera voluntaria para asegurarse de que el contenido del archivador es independiente de su fecha de creación, haciendolo por tanto reproducible.
- Ponga disponible el perfil en ~root/.config/guix/current, que es
donde
guix pullinstalará las actualizaciones (see Invocación deguix pull):# mkdir -p ~root/.config/guix # ln -sf /var/guix/profiles/per-user/root/current-guix \ ~root/.config/guix/currentCargue etc/profile para aumentar
PATHy otras variables de entorno relevantes:# GUIX_PROFILE="`echo ~root`/.config/guix/current" ; \ source $GUIX_PROFILE/etc/profile
- Cree el grupo y las cuentas de usuaria para las usuarias de construcción como se explica a continuación (see Configuración del entorno de construcción).
- Ejecute el daemon, y configure su inicio automático durante el arranque.
Si su distribución anfitriona usa el sistema de inicio systemd, puede hacerlo con las siguientes órdenes:
# cp ~root/.config/guix/current/lib/systemd/system/gnu-store.mount \ ~root/.config/guix/current/lib/systemd/system/guix-daemon.service \ /etc/systemd/system/ # systemctl enable --now gnu-store.mount guix-daemonYou may also want to arrange for
guix gcto run periodically:# cp ~root/.config/guix/current/lib/systemd/system/guix-gc.service \ ~root/.config/guix/current/lib/systemd/system/guix-gc.timer \ /etc/systemd/system/ # systemctl enable --now guix-gc.timerYou may want to edit guix-gc.service to adjust the command line options to fit your needs (see Invocación de
guix gc).Si su distribución anfitriona usa el sistema de inicio Upstart:
# initctl reload-configuration # cp ~root/.config/guix/current/lib/upstart/system/guix-daemon.conf \ /etc/init/ # start guix-daemonEn otro caso, todavía puede iniciar el daemon manualmente con:
# ~root/.config/guix/current/bin/guix-daemon \ --build-users-group=guixbuild - Haga accesible la orden
guixa otras usuarias de la máquina, por ejemplo con:# mkdir -p /usr/local/bin # cd /usr/local/bin # ln -s /var/guix/profiles/per-user/root/current-guix/bin/guix
Es también una buena idea poner disponible la versión Info de este manual ahí:
# mkdir -p /usr/local/share/info # cd /usr/local/share/info # for i in /var/guix/profiles/per-user/root/current-guix/share/info/* ; do ln -s $i ; done
De este modo, asumiendo que /usr/local/share/info está en la ruta de búsqueda, ejecutar
info guix.esabrirá este manual (see Other Info Directories in GNU Texinfo, para más detalles sobre cómo cambiar la ruta de búsqueda de Info). -
To use substitutes from
ci.guix.gnu.org,bordeaux.guix.gnu.orgor a mirror (see Sustituciones), authorize them:# guix archive --authorize < \ ~root/.config/guix/current/share/guix/ci.guix.gnu.org.pub # guix archive --authorize < \ ~root/.config/guix/current/share/guix/bordeaux.guix.gnu.org.pubNota: If you do not enable substitutes, Guix will end up building everything from source on your machine, making each installation and upgrade very expensive. See Sobre la confianza en binarios, for a discussion of reasons why one might want do disable substitutes.
- Cada usuaria puede necesitar dar algunos pasos adicionales para preparar su entorno de Guix para el uso diario, see Configuración de la aplicación.
Voilà, ¡la instalación está completa!
Puede confirmar que Guix está funcionando instalando un paquete de ejemplo en su perfil de root:
# guix install hello
El archivador de la instalación binaria puede ser (re)producido y verificado simplemente ejecutando la siguiente orden en el árbol de fuentes de Guix:
make guix-binary.sistema.tar.xz
... que a su vez ejecuta:
guix pack -s sistema --localstatedir \ --profile-name=current-guix guix
See Invocación de guix pack, para más información sobre esta útil herramienta.
Next: Ejecución de la batería de pruebas, Previous: Instalación binaria, Up: Instalación [Contents][Index]
2.2 Requisitos
Esta sección enumera los requisitos para construir Guix desde las fuentes. El procedimiento de construcción de Guix es el mismo que el de otro software GNU, y no está cubierto aquí. Por favor, eche un vistazo a los archivos README y INSTALL en el árbol de fuentes de Guix para obtener detalles adicionales.
GNU Guix está disponible para descarga desde su sitio web en http://www.gnu.org/software/guix/.
GNU Guix depende de los siguientes paquetes:
- GNU Guile, version 3.0.x, version 3.0.3 or later;
- Guile-Gcrypt, versión 0.1.0 o posterior;
- Guile-GnuTLS (see how to install the GnuTLS bindings for Guile in GnuTLS-Guile)5;
- Guile-SQLite3, versión 0.1.0 o posterior;
- Guile-zlib, version 0.1.0 or later;
- Guile-lzlib;
- Guile-Avahi;
- Guile-Git, version 0.5.0 or later;
- Guile-JSON 4.3.0 o posterior;
- GNU Make.
Las siguientes dependencias son opcionales:
- La delegación de construcciones (see Uso de la facilidad de delegación de trabajo) y
guix copy(see Invocación deguix copy) dependen de Guile-SSH, versión 0.13.0 o posterior. - Guile-zstd, for zstd
compression and decompression in
guix publishand for substitutes (see Invocación deguix publish). - Guile-Semver for the
crateimporter (see Invocación deguix import). - Guile-Lib for the
goimporter (see Invocación deguix import) and for some of the “updaters” (see Invocación deguix refresh). - Cuando libbz2 está disponible,
guix daemonpuede usarla para comprimir los registros de construcción.
Si no se ha proporcionado --disable-daemon a configure,
los siguientes paquetes también son necesarios:
- GNU libgcrypt;
- SQLite 3;
- g++ de GCC, con implementación del estándar C++11
Cuando se configura Guix en un sistema que ya tiene una instalación de Guix,
asegúrese de especificar el mismo directorio de estado que el de la
instalación existente usando la opción --localstatedir al guión
configure (see localstatedir in GNU Coding Standards). Habitualmente, esta opción
localstatedir tiene el valor /var. El guión configure
le proteje ante una mala configuración no deseada de localstatedir de
modo que no pueda corromper inadvertidamente su almacén (see El almacén).
Next: Preparación del daemon, Previous: Requisitos, Up: Instalación [Contents][Index]
2.3 Ejecución de la batería de pruebas
Después de una ejecución exitosa de configure y make, es
una buena idea ejecutar la batería de pruebas. Puede ayudar a encontrar
problemas con la configuración o el entorno, o errores en el mismo Guix—e
informar de fallos en las pruebas es realmente una buena forma de ayudar a
mejorar el software. Para ejecutar la batería de pruebas, teclee:
make check
Los casos de prueba pueden ejecutarse en paralelo: puede usar la opción
-j de GNU make para acelerar las cosas. La primera ejecución
puede tomar algunos minutos en una máquina reciente; las siguientes
ejecuciones serán más rápidas puesto que el almacén creado para las pruebas
ya tendrá varias cosas en la caché.
También es posible ejecutar un subconjunto de las pruebas definiendo la
variable de makefile TESTS como en el ejemplo:
make check TESTS="tests/store.scm tests/cpio.scm"
Por defecto, los resultados de las pruebas se muestran a nivel de
archivo. Para ver los detalles de cada caso de prueba individual, es posible
definir la variable de makefile SCM_LOG_DRIVER_FLAGS como en el
ejemplo:
make check TESTS="tests/base64.scm" SCM_LOG_DRIVER_FLAGS="--brief=no"
The underlying SRFI 64 custom Automake test driver used for the ’check’ test suite (located at build-aux/test-driver.scm) also allows selecting which test cases to run at a finer level, via its --select and --exclude options. Here’s an example, to run all the test cases from the tests/packages.scm test file whose names start with “transaction-upgrade-entry”:
export SCM_LOG_DRIVER_FLAGS="--select=^transaction-upgrade-entry" make check TESTS="tests/packages.scm"
Those wishing to inspect the results of failed tests directly from the
command line can add the --errors-only=yes option to the
SCM_LOG_DRIVER_FLAGS makefile variable and set the VERBOSE
Automake makefile variable, as in:
make check SCM_LOG_DRIVER_FLAGS="--brief=no --errors-only=yes" VERBOSE=1
The --show-duration=yes option can be used to print the duration of the individual test cases, when used in combination with --brief=no:
make check SCM_LOG_DRIVER_FLAGS="--brief=no --show-duration=yes"
See Parallel Test Harness in GNU Automake for more information about the Automake Parallel Test Harness.
En caso de fallo, le rogamos que envíe un correo a bug-guix@gnu.org y adjunte el archivo test-suite.log. Por favor, especifique la versión de Guix usada así como los números de versión de las dependencias (see Requisitos) en su mensaje.
Guix también viene como una batería de pruebas del sistema completo que prueban instancias completas del sistema Guix. Se puede ejecutar únicamente en sistemas donde Guix ya está instalado, usando:
make check-system
o, de nuevo, definiendo TESTS para seleccionar un subconjunto de las
pruebas a ejecutar:
make check-system TESTS="basic mcron"
Estas pruebas de sistema están definidas en los módulos (gnu tests
…). Funcionan ejecutando el sistema operativo con una instrumentación
ligera en una máquina virtual (VM). Pueden ser computacionalmente intensivas
o bastante baratas, dependiendo de si hay sustituciones disponibles para sus
dependencias (see Sustituciones). Algunas requieren mucho espacio de
almacenamiento para alojar las imágenes de la máquina virtual.
De nuevo, en caso de fallos en las pruebas, le rogamos que envíe a bug-guix@gnu.org todos los detalles.
Next: Invocación de guix-daemon, Previous: Ejecución de la batería de pruebas, Up: Instalación [Contents][Index]
2.4 Preparación del daemon
Operaciones como la construcción de un paquete o la ejecución del recolector
de basura son realizadas por un proceso especializado, el daemon de
construcción, en delegación de sus clientes. Únicamente el daemon puede
acceder al almacén y su base de datos asociada. Por tanto, cualquier
operación que manipula el almacén se realiza a través del daemon. Por
ejemplo, las herramientas de línea de órdenes como guix package y
guix build se comunican con el daemon (via llamadas a
procedimientos remotos) para indicarle qué hacer.
Las siguientes secciones explican cómo preparar el entorno del daemon de construcción. Véase también Sustituciones, para información sobre cómo permitir al daemon descargar binarios pre-construidos.
- Configuración del entorno de construcción
- Uso de la facilidad de delegación de trabajo
- Soporte de SELinux
2.4.1 Configuración del entorno de construcción
En una configuración multiusuaria estándar, Guix y su daemon—el programa
guix-daemon—son instalados por la administradora del sistema;
/gnu/store pertenece a root y guix-daemon se ejecuta
como root. Usuarias sin privilegios pueden usar las herramientas de
Guix para construir paquetes o acceder al almacén de otro modo, y el daemon
lo hará en delegación suya, asegurando que el almacén permanece en un estado
consistente, y permitiendo compartir entre usuarias los paquetes
construidos.
Mientras que guix-daemon se ejecuta como root, puede que no
desee que los procesos de construcción de paquetes se ejecuten como
root también, por razones de seguridad obvias. Para evitarlo, una
reserva especial de usuarias de construcción debe ser creada para ser
usada por los procesos de construcción iniciados por el daemon. Estas
usuarias de construcción no necesitan tener un intérprete ni un directorio
home: simplemente serán usadas cuando el daemon se deshaga de los
privilegios de root en los procesos de construcción. Tener varias de
dichas usuarias permite al daemon lanzar distintos procesos de construcción
bajo UID separados, lo que garantiza que no interferirán entre ellos—una
característica esencial ya que las construcciones se caracterizan como
funciones puras (see Introducción).
En un sistema GNU/Linux, una reserva de usuarias de construcción puede ser
creada así (usando la sintaxis de Bash y las órdenes de shadow):
# groupadd --system guixbuild
# for i in $(seq -w 1 10);
do
useradd -g guixbuild -G guixbuild \
-d /var/empty -s $(which nologin) \
-c "Guix build user $i" --system \
guixbuilder$i;
done
El número de usuarias de construcción determina cuantos trabajos de
construcción se pueden ejecutar en paralelo, especificado por la opción
--max-jobs (see --max-jobs). Para usar guix system vm y las órdenes
relacionadas, puede necesitar añadir las usuarias de construcción al grupo
kvm para que puedan acceder a /dev/kvm, usando -G
guixbuild,kvm en vez de -G guixbuild (see Invoking guix system).
The guix-daemon program may then be run as root with the
following command6:
# guix-daemon --build-users-group=guixbuild
De este modo, el daemon inicia los procesos de construcción en un
“chroot”, bajo una de las usuarias guixbuilder. En GNU/Linux, por
defecto, el entorno “chroot” contiene únicamente:
- un directorio
/devmínimo, creado en su mayor parte independientemente del/devdel sistema anfitrión7; - el directorio
/proc; únicamente muestra los procesos del contenedor ya que se usa un espacio de nombres de PID separado; - /etc/passwd con una entrada para la usuaria actual y una entrada para la usuaria nobody;
- /etc/groups con una entrada para el grupo de la usuaria;
- /etc/hosts con una entrada que asocia
localhosta127.0.0.1; - un directorio /tmp con permisos de escritura.
The chroot does not contain a /home directory, and the HOME
environment variable is set to the non-existent /homeless-shelter.
This helps to highlight inappropriate uses of HOME in the build
scripts of packages.
Puede influir en el directorio que el daemon utiliza para almacenar los
árboles de construcción a través de la variable de entorno TMPDIR. No
obstante, el árbol de construcción en el “chroot” siempre se llama
/tmp/guix-build-nombre.drv-0, donde nombre es el nombre
de la derivación—por ejemplo, coreutils-8.24. De este modo, el
valor de TMPDIR no se escapa a los entornos de construcción, lo que
evita discrepancias en caso de que los procesos de construcción capturen el
nombre de su árbol de construcción.
El daemon también respeta la variable de entorno http_proxy y
https_proxy para las descargas HTTP y HTTPS que realiza, ya sea para
derivaciones de salida fija (see Derivaciones) o para sustituciones
(see Sustituciones).
Si está instalando Guix como una usuaria sin privilegios, es posible todavía
ejecutar guix-daemon siempre que proporcione el parámetro
--disable-chroot. No obstante, los procesos de construcción no
estarán aislados entre sí ni del resto del sistema. Por tanto, los procesos
de construcción pueden interferir entre ellos y pueden acceder a programas,
bibliotecas y otros archivos disponibles en el sistema—haciendo mucho más
difícil verlos como funciones puras.
Next: Soporte de SELinux, Previous: Configuración del entorno de construcción, Up: Preparación del daemon [Contents][Index]
2.4.2 Uso de la facilidad de delegación de trabajo
Cuando así se desee, el daemon de construcción puede delegar
construcciones de derivación a otras máquinas ejecutando Guix, usando el
procedimiento de extensión de construcción
offload8. Cuando dicha característica es activada se lee una lista de
máquinas de construcción especificadas por la usuaria desde
/etc/guix/machines.scm; cada vez que se solicita una construcción,
por ejemplo via guix build, el daemon intenta su delegación a una de
las máquinas que satisfaga las condiciones de la derivación, en particular
su tipo de sistema—por ejemplo, x86_64-linux. Una única máquina
puede usarse para múltiples tipos de sistema, ya sea porque los implemente
su arquitectura de manera nativa, a través de emulación
(see Transparent Emulation with QEMU), o
ambas. Los prerrequisitos restantes para la construcción se copian a través
de SSH a la máquina seleccionada, la cual procede con la construcción; con
un resultado satisfactorio la o las salidas de la construcción son copiadas
de vuelta a la máquina inicial. La facilidad de descarga de trabajo
incorpora una planificación básica que intenta seleccionar la mejor máquina,
la cual es seleccionada entre las máquinas disponibles en base a criterios
como los siguientes:
- La disponibilidad de un puesto de construcción. Una máquina de construcción
tiene el número de puestos de construcción (conexiones) que indique el valor
de
parallel-buildsen su objetobuild-machine. - Su velocidad relativa, a través del campo
speedde su objetobuild-machine. - Su carga de trabajo. El valor normalizado de carga debe ser menor aun valor
límite, configurable a través del campo
overload-thresholdde su objetobuild-machine. - El espacio disponible en el disco. Debe haber más de 100 MiB disponibles.
El archivo /etc/guix/machines.scm normalmente tiene un contenido de este estilo:
(list (build-machine
(name "ochentayseis.example.org")
(systems (list "x86_64-linux" "i686-linux"))
(host-key "ssh-ed25519 AAAAC3Nza…")
(user "rober")
(speed 2.)) ;¡increíblemente rápida!
(build-machine
(name "armeight.example.org")
(systems (list "aarch64-linux"))
(host-key "ssh-rsa AAAAB3Nza…")
(user "alice")
;; Remember 'guix offload' is spawned by
;; 'guix-daemon' as root.
(private-key "/root/.ssh/identity-for-guix")))
En el ejemplo anterior se especifica una lista de dos máquinas de
construcción, una para las arquitecturas x86_64 y i686, y otra
para la arquitectura aarch64.
De hecho, este archivo es—¡sin sorpresa ninguna!—un archivo Scheme que
se evalúa cuando el procedimiento de extensión offload se inicia. El
valor que devuelve debe ser una lista de objetos
build-machine. Mientras que este ejemplo muestra una lista fija de
máquinas de construcción, una puede imaginarse, digamos, el uso de DNS-SD
para devolver una lista de máquinas de construcción potenciales descubierta
en la red local (see Guile-Avahi in Using Avahi
in Guile Scheme Programs). El tipo de datos build-machine se detalla
a continuación.
- Tipo de datos: build-machine
Este tipo de datos representa las máquinas de construcción a las cuales el daemon puede delegar construcciones. Los campos importantes son:
nameEl nombre de red de la máquina remota.
systemsLos tipos de sistema implementados por la máquina remota—por ejemplo,
(list "x86_64-linux" "i686-linux").userLa cuenta de usuaria usada para la conexión a la máquina remota por SSH. Tenga en cuenta que el par de claves SSH no debe estar protegido por contraseña, para permitir ingresos al sistema no interactivos.
host-keyEste campo debe contener la clave pública de la máquina de SSH en formato OpenSSH. Es usado para autentificar la máquina cuando nos conectamos a ella. Es una cadena larga más o menos así:
ssh-ed25519 AAAAC3NzaC…mde+UhL recordatorio@example.org
Si la máquina está ejecutando el daemon OpenSSH,
sshd, la clave pública de la máquina puede encontrarse en un archivo como /etc/ssh/ssh_host_ed25519_key.pub.Si la máquina está ejecutando el daemon SSH GNU lsh,
lshd, la clave de la máquina está en /etc/lsh/host-key.pub o un archivo similar. Puede convertirse a formato OpenSSH usandolsh-export-key(see Converting keys in LSH Manual):$ lsh-export-key --openssh < /etc/lsh/host-key.pub ssh-rsa AAAAB3NzaC1yc2EAAAAEOp8FoQAAAQEAs1eB46LV…
Ciertos número de campos opcionales pueden ser especificados:
port(predeterminado:22)Número de puerto del servidor SSH en la máquina.
private-key(predeterminada: ~root/.ssh/id_rsa)El archivo de clave privada SSH usado para conectarse a la máquina, en formato OpenSSH. Esta clave no debe estar protegida con una contraseña.
Tenga en cuenta que el valor predeterminado es la clave privada de la cuenta de root. Asegúrese de que existe si usa el valor predeterminado.
compression(predeterminado:"zlib@openssh.com,zlib")compression-level(predeterminado:3)Los métodos de compresión y nivel de compresión a nivel SSH solicitados.
Tenga en cuenta que la delegación de carga depende de la compresión SSH para reducir el ancho de banda usado cuando se transfieren archivos hacia y desde máquinas de construcción.
daemon-socket(predeterminado:"/var/guix/daemon-socket/socket")Nombre de archivo del socket de dominio Unix en el que
guix-daemonescucha en esa máquina.overload-threshold(default:0.8)El límite superior de carga, el cual se usa en la planificación de delegación de tareas para descartar potenciales máquinas si superan dicho límite. Dicho valor más o menos representa el uso del procesador de la máquina, con un rango de 0.0 (0%) a 1.0 (100%). También se puede desactivar si se proporciona el valor
#fenoverload-threshold.parallel-builds(predeterminadas:1)El número de construcciones que pueden ejecutarse en paralelo en la máquina.
speed(predeterminado:1.0)Un “factor de velocidad relativa”. El planificador de delegaciones tenderá a preferir máquinas con un factor de velocidad mayor.
features(predeterminadas:'())Una lista de cadenas denotando las características específicas permitidas por la máquina. Un ejemplo es
"kvm"para máquinas que tienen los módulos KVM de Linux y las correspondientes características hardware. Las derivaciones pueden solicitar las características por nombre, y entonces se planificarán en las máquinas adecuadas.
El ejecutable guix debe estar en la ruta de búsqueda de las máquinas
de construcción. Puede comprobar si es el caso ejecutando:
ssh build-machine guix repl --version
Hay una última cosa por hacer una vez machines.scm está en su
lugar. Como se ha explicado anteriormente, cuando se delega, los archivos se
transfieren en ambas direcciones entre los almacenes de las máquinas. Para
que esto funcione, primero debe generar un par de claves en cada máquina
para permitir al daemon exportar los archivos firmados de archivos en el
almacén (see Invocación de guix archive):
# guix archive --generate-key
Cada máquina de construcción debe autorizar a la clave de la máquina maestra para que acepte elementos del almacén que reciba de la maestra:
# guix archive --authorize < clave-publica-maestra.txt
La máquina maestra debe autorizar la clave de cada máquina de construcción de la misma manera.
Todo este lío con claves está ahí para expresar las mutuas relaciones de confianza entre pares de la máquina maestra y las máquinas de construcción. Concretamente, cuando la maestra recibe archivos de una máquina de construcción (y vice versa), su daemon de construcción puede asegurarse de que son genuinos, no han sido modificados, y que están firmados por una clave autorizada.
Para comprobar si su configuración es operacional, ejecute esta orden en el nodo maestro:
# guix offload test
This will attempt to connect to each of the build machines specified in /etc/guix/machines.scm, make sure Guix is available on each machine, attempt to export to the machine and import from it, and report any error in the process.
Si quiere probar un archivo de máquinas diferente, simplemente lo debe especificar en la línea de órdenes:
# guix offload test otras-maquinas.scm
Por último, puede probar un subconjunto de máquinas cuyos nombres coincidan con una expresión regular así:
# guix offload test maquinas.scm '\.gnu\.org$'
Para mostrar la carga actual de todas las máquinas de construcción, ejecute esta orden en el nodo principal:
# guix offload status
Previous: Uso de la facilidad de delegación de trabajo, Up: Preparación del daemon [Contents][Index]
2.4.3 Soporte de SELinux
Guix incluye un archivo de política SELinux en etc/guix-daemon.cil que puede ser instalado en un sistema donde SELinux está activado, para etiquetar los archivos Guix y especificar el comportamiento esperado del daemon. Ya que el sistema Guix no proporciona una política base de SELinux, la política del daemon no puede usarse en el sistema Guix.
2.4.3.1 Instalación de la política de SELinux
Para instalar la política ejecute esta orden como root:
semodule -i etc/guix-daemon.cil
Una vez hecho, vuelva a etiquetar el sistema de archivos con
restorecon o con un mecanismo distinto que proporcione su sistema.
Una vez la política está instalada, el sistema de archivos ha sido
re-etiquetado, y el daemon ha sido reiniciado, debería ejecutarse en el
contexto guix_daemon_t. Puede confirmarlo con la siguiente orden:
ps -Zax | grep guix-daemon
Monitorice los archivos de log de SELinux mientras ejecuta una orden como
guix build hello para convencerse que SELinux permite todas las
operaciones necesarias.
2.4.3.2 Limitaciones
Esta política no es perfecta. Aquí está una lista de limitaciones o comportamientos extraños que deben ser considerados al desplegar la política SELinux provista para el daemon Guix.
-
guix_daemon_socket_tisn’t actually used. None of the socket operations involve contexts that have anything to do withguix_daemon_socket_t. It doesn’t hurt to have this unused label, but it would be preferable to define socket rules for only this label. -
guix gcno puede acceder enlaces arbitrarios a los perfiles. Por diseño, la etiqueta del archivo del destino de un enlace simbólico es independiente de la etiqueta de archivo del archivo en sí. Aunque todos los perfiles bajo $localstatedir se etiquetan, los enlaces para estos perfiles heredan la etiqueta del directorio en el que están. Para enlaces en el directorio de la usuaria esto seráuser_home_t. Pero para los enlaces del directorio de root, o /tmp, o del directorio del servidor HTTP, etc., esto no funcionará.guix gcse verá incapacitado para leer y seguir dichos enlaces. - La característica del daemon de esperar conexiones TCP puede que no funcione más. Esto puede requerir reglas adicionales, ya que SELinux trata los sockets de red de forma diferente a los archivos.
- Actualmente todos los archivos con un nombre coincidente con la expresión
regular
/gnu/store.+-(gux-.+|profile)/bin/guix-daemontienen asignada la etiquetaguix_daemon_exec_t; esto significa que cualquier archivo con ese nombre en cualquier perfil tendrá permitida la ejecución en el dominioguix_daemon_t. Esto no es ideal. Una atacante podría construir un paquete que proporcione este ejecutable y convencer a la usuaria para instalarlo y ejecutarlo, lo que lo eleva al dominioguix_daemon_t. Llegadas a este punto, SELinux no puede prevenir que acceda a los archivos permitidos para los procesos en dicho dominio.You will need to relabel the store directory after all upgrades to guix-daemon, such as after running
guix pull. Assuming the store is in /gnu, you can do this withrestorecon -vR /gnu, or by other means provided by your operating system.Podríamos generar una política mucho más restrictiva en tiempo de instalación, de modo que solo el nombre exacto del archivo del ejecutable de
guix-daemonactualmente instalado sea marcado comoguix_daemon_exec_t, en vez de usar una expresión regular amplia. La desventaja es que root tendría que instalar o actualizar la política en tiempo de instalación cada vez que se actualizase el paquete de Guix que proporcione el ejecutable deguix-daemonrealmente en ejecución.
Next: Configuración de la aplicación, Previous: Preparación del daemon, Up: Instalación [Contents][Index]
2.5 Invocación de guix-daemon
El programa guix-daemon implementa toda la funcionalidad para
acceder al almacén. Esto incluye iniciar procesos de construcción, ejecutar
el recolector de basura, comprobar la disponibilidad de un resultado de
construcción, etc. Normalmente se ejecuta como root así:
# guix-daemon --build-users-group=guixbuild
This daemon can also be started following the systemd “socket activation”
protocol (see make-systemd-constructor in The GNU Shepherd Manual).
Para detalles obre como configurarlo, see Preparación del daemon.
Por defecto, guix-daemon inicia los procesos de construcción bajo
distintos UIDs, tomados del grupo de construcción especificado con
--build-users-group. Además, cada proceso de construcción se
ejecuta en un entorno “chroot” que únicamente contiene el subconjunto del
almacén del que depende el proceso de construcción, como especifica su
derivación (see derivación), más un conjunto
específico de directorios del sistema. Por defecto, estos directorios
contienen /dev y /dev/pts. Es más, sobre GNU/Linux, el entorno
de construcción es un contenedor: además de tener su propio árbol del
sistema de archivos, tiene un espacio de nombres de montado separado, su
propio espacio de nombres de PID, de red, etc. Esto ayuda a obtener
construcciones reproducibles (see Características).
Cuando el daemon realiza una construcción en delegación de la usuaria, crea
un directorio de construcción bajo /tmp o bajo el directorio
especificado por su variable de entorno TMPDIR. Este directorio se
comparte con el contenedor durante toda la construcción, aunque dentro del
contenedor el árbol de construcción siempre se llama
/tmp/guix-build-nombre.drv-0.
The build directory is automatically deleted upon completion, unless the build failed and the client specified --keep-failed (see --keep-failed).
El daemon espera conexiones y lanza un subproceso por sesión iniciada por
cada cliente (una de las sub-órdenes de guix). La orden
guix processes le permite tener una visión general de la actividad
de su sistema mostrando clientes y sesiones activas. See Invocación de guix processes, para más información.
Se aceptan las siguientes opciones de línea de ordenes:
--build-users-group=grupoToma las usuarias de grupo para ejecutar los procesos de construcción (see build users).
--no-substitutes¶No usa sustituciones para la construcción de productos. Esto es, siempre realiza las construcciones localmente en vez de permitir la descarga de binarios pre-construidos (see Sustituciones).
Cuando el daemon se está ejecutando con la opción --no-substitutes, los clientes aún pueden activar explícitamente las sustituciones a través de la llamada de procedimiento remoto
set-build-options(see El almacén).--substitute-urls=urlsConsider urls the default whitespace-separated list of substitute source URLs. When this option is omitted, ‘
https://ci.guix.gnu.org https://bordeaux.guix.gnu.org’ is used.Esto significa que las sustituciones puede ser descargadas de urls, mientras estén firmadas por una firma de confianza (see Sustituciones).
See Obtención de sustiticiones desde otros servidores para obtener más información sobre cómo configurar el daemon para obtener sustituciones de otros servidores.
--no-offloadNo usa la delegación de construcciones en otras máquinas (see Uso de la facilidad de delegación de trabajo). Es decir, siempre realiza las construcciones de manera local en vez de delegar construcciones a máquinas remotas.
--cache-failuresAlmacena en la caché los fallos de construcción. Por defecto, únicamente las construcciones satisfactorias son almacenadas en la caché.
Cuando se usa esta opción,
guix gc --list-failurespuede usarse para consultar el conjunto de elementos del almacén marcados como fallidos;guix gc --clear-failuresborra los elementos del almacén del conjunto de fallos existentes en la caché. See Invocación deguix gc.--cores=n-c nUsa n núcleos de la CPU para construir cada derivación;
0significa tantos como haya disponibles.El valor predeterminado es
0, pero puede ser sobreescrito por los clientes, como la opción --cores deguix build(see Invocación deguix build).El efecto es definir la variable de entorno
NIX_BUILD_CORESen el proceso de construcción, el cual puede usarla para explotar el paralelismo interno—por ejemplo, ejecutandomake -j$NIX_BUILD_CORES.--max-jobs=n-M nPermite como máximo n trabajos de construcción en paralelo. El valor predeterminado es
1. Fijarlo a0significa que ninguna construcción se realizará localmente; en vez de eso, el daemon delegará las construcciones (see Uso de la facilidad de delegación de trabajo), o simplemente fallará.--max-silent-time=segundosCuando la construcción o sustitución permanece en silencio más de segundos, la finaliza e informa de un fallo de construcción.
El valor predeterminado es
0, que desactiva los plazos.El valor especificado aquí puede ser sobreescrito por clientes (see --max-silent-time).
--timeout=segundosDel mismo modo, cuando el proceso de construcción o sustitución dura más de segundos, lo termina e informa un fallo de construcción.
El valor predeterminado es
0, que desactiva los plazos.El valor especificado aquí puede ser sobreescrito por los clientes (see --timeout).
--rounds=NConstruye cada derivación n veces seguidas, y lanza un error si los resultados de las construcciones consecutivas no son idénticos bit-a-bit. Fíjese que esta configuración puede ser sobreescrita por clientes como
guix build(see Invocación deguix build).Cuando se usa conjuntamente con --keep-failed, la salida que difiere se mantiene en el almacén, bajo /gnu/store/…-check. Esto hace fácil buscar diferencias entre los dos resultados.
--debugProduce salida de depuración.
Esto es útil para depurar problemas en el arranque del daemon, pero su comportamiento puede cambiarse en cada cliente, por ejemplo con la opción --verbosity de
guix build(see Invocación deguix build).--chroot-directory=dirAñade dir al chroot de construcción.
Hacer esto puede cambiar el resultado del proceso de construcción—por ejemplo si usa dependencias opcionales, que se encuentren en dir, cuando están disponibles, y no de otra forma. Por esa razón, no se recomienda hacerlo. En vez de eso, asegúrese que cada derivación declara todas las entradas que necesita.
--disable-chrootDesactiva la construcción en un entorno chroot.
No se recomienda el uso de esta opción ya que, de nuevo, podría permitir a los procesos de construcción ganar acceso a dependencias no declaradas. Es necesario, no obstante, cuando
guix-daemonse ejecuta bajo una cuenta de usuaria sin privilegios.--log-compression=tipoComprime los logs de construcción de acuerdo a tipo, que puede ser
gzip,bzip2onone.Unless --lose-logs is used, all the build logs are kept in the localstatedir. To save space, the daemon automatically compresses them with gzip by default.
--discover[=yes|no]Whether to discover substitute servers on the local network using mDNS and DNS-SD.
This feature is still experimental. However, here are a few considerations.
- It might be faster/less expensive than fetching from remote servers;
- There are no security risks, only genuine substitutes will be used (see Verificación de sustituciones);
- An attacker advertising
guix publishon your LAN cannot serve you malicious binaries, but they can learn what software you’re installing; - Servers may serve substitute over HTTP, unencrypted, so anyone on the LAN can see what software you’re installing.
It is also possible to enable or disable substitute server discovery at run-time by running:
herd discover guix-daemon on herd discover guix-daemon off
--disable-deduplication¶Desactiva la “deduplicación” automática en el almacén.
Por defecto, los archivos se añaden al almacén “deduplicados” automáticamente: si un nuevo archivo añadido es idéntico a otro que ya se encuentra en el almacén, el daemon introduce el nuevo archivo como un enlace duro al otro archivo. Esto puede reducir notablemente el uso del disco, a expensas de una carga de entrada/salida ligeramente incrementada al finalizar un proceso de construcción. Esta opción desactiva dicha optimización.
--gc-keep-outputs[=yes|no]Determina si el recolector de basura (GC) debe mantener salidas de las derivaciones vivas.
Cuando se usa
yes, el recolector de basura mantendrá las salidas de cualquier derivación viva disponible en el almacén—los archivos.drv. El valor predeterminado esno, lo que significa que las salidas de las derivaciones se mantienen únicamente si son alcanzables desde alguna raíz del recolector de basura. See Invocación deguix gc, para más información sobre las raíces del recolector de basura.--gc-keep-derivations[=yes|no]Determina si el recolector de basura (GC) debe mantener derivaciones correspondientes a salidas vivas.
Cuando se usa
yes, como es el caso predeterminado, el recolector de basura mantiene derivaciones—es decir, archivos.drv—mientras al menos una de sus salidas está viva. Esto permite a las usuarias seguir la pista de los orígenes de los elementos en el almacén. El uso denoaquí ahorra un poco de espacio en disco.De este modo, usar --gc-keep-derivations con valor
yesprovoca que la vitalidad fluya de salidas a derivaciones, y usar --gc-keep-outputs con valoryesprovoca que la vitalidad fluya de derivaciones a salidas. Cuando ambas tienen valoryes, el efecto es mantener todos los prerrequisitos de construcción (las fuentes, el compilador, las bibliotecas y otras herramientas de tiempo de construcción) de los objetos vivos del almacén, independientemente de que esos prerrequisitos sean alcanzables desde una raíz del recolector de basura. Esto es conveniente para desarrolladoras ya que evita reconstrucciones o descargas.--impersonate-linux-2.6En sistemas basados en Linux, suplanta a Linux 2.6. Esto significa que la llamada del sistema
unamedel núcleo indicará 2.6 como el número de versión de la publicación.Esto puede ser útil para construir programas que (habitualmente de forma incorrecta) dependen en el número de versión del núcleo.
--lose-logsNo guarda logs de construcción. De manera predeterminada se almacenan en el directorio localstatedir/guix/log.
--system=sistemaAsume sistema como el tipo actual de sistema. Por defecto es el par de arquitectura/núcleo encontrado durante la configuración, como
x86_64-linux.--listen=destinoEspera conexiones en destino. destino se interpreta como el nombre del archivo del socket de dominio Unix si comienza on
/(barra a la derecha). En otro caso, destino se interpreta como un nombre de máquina o un nombre de máquina y puerto a escuchar. Aquí van unos pocos ejemplos:--listen=/gnu/var/daemonEspera conexiones en el socket de dominio Unix /gnu/var/daemon, se crea si es necesario.
--listen=localhost¶-
Espera conexiones TCP en la interfaz de red correspondiente a
localhost, en el puerto 44146. --listen=128.0.0.42:1234Espera conexiones TCP en la interfaz de red correspondiente a
128.0.0.42, en el puerto 1234.
Esta opción puede repetirse múltiples veces, en cuyo caso
guix-daemonacepta conexiones en todos los destinos especificados. Las usuarias pueden indicar a los clientes a qué destino conectarse proporcionando el valor deseado a la variable de entornoGUIX_DAEMON_SOCKET(seeGUIX_DAEMON_SOCKET).Nota: El protocolo del daemon
no está autentificado ni cifrado. El uso de --listen=dirección es aceptable en redes locales, como clusters, donde únicamente los nodos de confianza pueden conectarse al daemon de construcción. En otros casos donde el acceso remoto al daemon es necesario, recomendamos usar sockets de dominio Unix junto a SSH.Cuando se omite --listen,
guix-daemonescucha conexiones en el socket de dominio Unix que se encuentra en localstatedir/guix/daemon-socket/socket.
Next: Actualizar Guix, Previous: Invocación de guix-daemon, Up: Instalación [Contents][Index]
2.6 Configuración de la aplicación
Cuando se usa Guix sobre una distribución GNU/Linux distinta al sistema Guix—una distribución distinta—unos pocos pasos adicionales son necesarios para tener todo preparado. Aquí están algunos de ellos.
2.6.1 Localizaciones
Los paquetes instalados a través de Guix no usarán los datos de localización
del sistema anfitrión. En vez de eso, debe instalar primero uno de los
paquetes de localización disponibles con Guix y después definir la variable
de entorno GUIX_LOCPATH:
$ guix install glibc-locales $ export GUIX_LOCPATH=$HOME/.guix-profile/lib/locale
Note that the glibc-locales package contains data for all the locales
supported by the GNU libc and weighs in at around
930 MiB9. If
you only need a few locales, you can define your custom locales package via
the make-glibc-utf8-locales procedure from the (gnu packages
base) module. The following example defines a package containing the
various Canadian UTF-8 locales known to the GNU libc, that weighs
around 14 MiB:
(use-modules (gnu packages base)) (define my-glibc-locales (make-glibc-utf8-locales glibc #:locales (list "en_CA" "fr_CA" "ik_CA" "iu_CA" "shs_CA") #:name "glibc-canadian-utf8-locales"))
La variable GUIX_LOCPATH juega un rol similar a LOCPATH
(see LOCPATH in The GNU C Library Reference
Manual). No obstante, hay dos diferencias importantes:
-
GUIX_LOCPATHes respetada únicamente por la libc dentro de Guix, y no por la libc que proporcionan las distribuciones distintas. Por tanto, usarGUIX_LOCPATHle permite asegurarse de que los programas de la distribución distinta no cargarán datos de localización incompatibles. - libc añade un sufijo a cada entrada de
GUIX_LOCPATHcon/X.Y, dondeX.Yes la versión de libc—por ejemplo,2.22. Esto significa que, en caso que su perfil Guix contenga una mezcla de programas enlazados contra diferentes versiones de libc, cada versión de libc únicamente intentará cargar datos de localización en el formato correcto.
Esto es importante porque el formato de datos de localización usado por diferentes versiones de libc puede ser incompatible.
2.6.2 Selector de servicios de nombres
Cuando se usa Guix en una distribución distinta, recomendamos
encarecidamente que el sistema ejecute el daemon de caché del servicio
de nombres de la biblioteca de C de GNU, ncsd, que debe escuchar
en el socket /var/run/nscd/socket. En caso de no hacerlo, las
aplicaciones instaladas con Guix pueden fallar al buscar nombres de máquinas
o cuentas de usuaria, o incluso pueden terminar abruptamente. Los siguientes
párrafos explican por qué.
La biblioteca de C de GNU implementa un selector de servicios de nombres (NSS), que es un mecanismo extensible para “búsquedas de nombres” en general: resolución de nombres de máquinas, cuentas de usuaria y más (see Name Service Switch in The GNU C Library Reference Manual).
Al ser extensible, NSS permite el uso de módulos, los cuales
proporcionan nuevas implementaciones de búsqueda de nombres: por ejemplo, el
módulo nss-mdns permite la resolución de nombres de máquina
.local, el módulo nis permite la búsqueda de cuentas de
usuaria usando el servicio de información de red (NIS), etc. Estos
“servicios de búsqueda” extra se configuran para todo el sistema en
/etc/nsswitch.conf, y todos los programas en ejecución respetan esta
configuración (see NSS Configuration File in The GNU C Reference
Manual).
Cuando se realiza una búsqueda de nombres—por ejemplo, llamando a la
función getaddrinfo en C—las aplicaciones primero intentarán
conectar con nscd; en caso satisfactorio, nscd realiza la búsqueda de
nombres en delegación suya. Si nscd no está ejecutándose, entonces realizan
la búsqueda por ellas mismas, cargando los servicios de búsqueda de nombres
en su propio espacio de direcciones y ejecutándola. Estos servicios de
búsqueda de nombres—los archivos libnss_*.so—son abiertos con
dlopen, pero pueden venir de la biblioteca de C del sistema, en vez
de la biblioteca de C contra la que la aplicación está enlazada (la
biblioteca de C que viene en Guix).
Y aquí es donde está el problema: si su aplicación está enlazada contra la
biblioteca de C de Guix (digamos, glibc 2.24) e intenta cargar módulos de
otra biblioteca de C (digamos, libnss_mdns.so para glibc 2.22),
probablemente terminará abruptamente o sus búsquedas de nombres fallarán
inesperadamente.
Ejecutar nscd en el sistema, entre otras ventajas, elimina este
problema de incompatibilidad binaria porque esos archivos libnss_*.so
se cargan en el proceso nscd, no en la aplicación misma.
2.6.3 Tipografías X11
The majority of graphical applications use Fontconfig to locate and load
fonts and perform X11-client-side rendering. The fontconfig package
in Guix looks for fonts in $HOME/.guix-profile by default. Thus, to
allow graphical applications installed with Guix to display fonts, you have
to install fonts with Guix as well. Essential font packages include
font-ghostscript, font-dejavu, and font-gnu-freefont.
Una vez que haya instalado o borrado tipografías, o cuando se de cuenta de que una aplicación no encuentra las tipografías, puede que necesite instalar Fontconfig y forzar una actualización de su caché de tipografías ejecutando:
guix install fontconfig fc-cache -rv
Para mostrar texto escrito en lenguas chinas, Japonés o Coreano en
aplicaciones gráficas, considere instalar font-adobe-source-han-sans
o font-wqy-zenhei. La anterior tiene múltiples salidas, una por
familia de lengua (see Paquetes con múltiples salidas). Por ejemplo, la
siguiente orden instala tipografías para lenguas chinas:
guix install font-adobe-source-han-sans:cn
Programas más antiguos como xterm no usan Fontconfig sino que
dependen en el lado del servidor para realizar el renderizado de
tipografías. Dichos programas requieren especificar un nombre completo de
tipografía usando XLFD (Descripción lógica de tipografías X), como esta:
-*-dejavu sans-medium-r-normal-*-*-100-*-*-*-*-*-1
Para ser capaz de usar estos nombres completos para las tipografías TrueType instaladas en su perfil Guix, necesita extender la ruta de fuentes del servidor X:
xset +fp $(dirname $(readlink -f ~/.guix-profile/share/fonts/truetype/fonts.dir))
Después de eso, puede ejecutar xlsfonts (del paquete xlsfonts)
para asegurarse que sus tipografías TrueType se enumeran aquí.
2.6.4 Certificados X.509
El paquete nss-certs proporciona certificados X.509, que permiten a
los programas verificar los servidores accedidos por HTTPS.
Cuando se usa Guix en una distribución distinta, puede instalar este paquete y definir las variables de entorno relevantes de modo que los paquetes sepan dónde buscar los certificados. See Certificados X.509, para información detallada.
2.6.5 Paquetes Emacs
Cuando instale paquetes de Emacs con Guix los archivos de Elisp se
encuentran en el directorio share/emacs/site-lisp/ del perfil en el
que se instalen. Las bibliotecas de Elisp se ponen a disposición de Emacs a
través de la variable de entorno EMACSLOADPATH, a la cual se le asigna
un valor cuando se instale el propio Emacs.
De manera adicional, las definiciones de carga automática se evaluan de
manera automática en la inicialización de Emacs, mediante el procedimiento
guix-emacs-autoload-packages específico de Guix. Si, por alguna
razón, desea evitar la carga automática de paquetes Emacs instalados con
Guix, puede hacerlo ejecutando Emacs con la opción --no-site-file
(see Init File in The GNU Emacs Manual).
Nota: Emacs can now compile packages natively. Under the default configuration, this means that Emacs packages will now be just-in-time (JIT) compiled as you use them, and the results stored in a subdirectory of your
user-emacs-directory.Furthermore, the build system for Emacs packages transparently supports native compilation, but note, that
emacs-minimal—the default Emacs for building packages—has been configured without native compilation. To natively compile your emacs packages ahead of time, use a transformation like --with-input=emacs-minimal=emacs.
Previous: Configuración de la aplicación, Up: Instalación [Contents][Index]
2.7 Actualizar Guix
Para actualizar Guix ejecute:
guix pull
See Invocación de guix pull, para más información.
En una distribución distinta puede actualizar el daemon de construcción ejecutando:
sudo -i guix pull
seguido de (asumiendo que su distribución usa la herramienta de gestión de servicios systemd):
systemctl restart guix-daemon.service
En el Sistema Guix, la actualización del daemon se lleva a cabo con la
reconfiguración el sistema (see guix system
reconfigure).
Next: System Troubleshooting Tips, Previous: Instalación, Up: GNU Guix [Contents][Index]
3 Instalación del sistema
Esta sección explica cómo instalar el sistema Guix en una máquina. Guix, como gestor de paquetes, puede instalarse sobre un sistema GNU/Linux en ejecución, see Instalación.
- Limitaciones
- Consideraciones sobre el hardware
- Instalación desde memoria USB y DVD
- Preparación para la instalación
- Instalación gráfica guiada
- Instalación manual
- Tras la instalación del sistema
- Instalación de Guix en una máquina virtual
- Construcción de la imagen de instalación
- Construcción de la imagen de instalación para placas ARM
3.1 Limitaciones
Consideramos que el sistema Guix está listo para un amplio rango de casos de uso, tanto de servidor como de escritorio. Las garantías que proporciona—actualizaciones transaccionales y vuelta atrás atómica, reproducibilidad—lo convierten en un cimiento sólido.
No obstante, antes de que proceda con la instalación, sea consciente de las siguientes limitaciones apreciables que se conocen en la versión 1.4.0:
- Se proporcionan más y más servicios del sistema (see Servicios), pero pueden faltar algunos.
- Están disponibles GNOME, Xfce, LXDE y Enlightenment (see Servicios de escritorio), así como un número de gestores de ventanas X11. No obstante, actualmente falta KDE.
Más que una descarga de responsabilidades es una invitación a informar de problemas (¡e historias satisfactorias!), y para unirse a nosotras en su mejora. See Contribuir, para más información.
Next: Instalación desde memoria USB y DVD, Previous: Limitaciones, Up: Instalación del sistema [Contents][Index]
3.2 Consideraciones sobre el hardware
GNU Guix se enfoca en respetar la libertad de computación de las usuarias. Se construye sobre el núcleo Linux-libre, lo que significa que únicamente funciona hardware para el que existen controladores y firmware libres. Hoy en día, un amplio rango del hardware común funciona con GNU/Linux-libre—desde teclados a tarjetas gráficas a escáneres y controladoras Ethernet. Desafortunadamente, todavía hay áreas donde los fabricantes de hardware deniegan a las usuarias el control de su propia computación, y dicho hardware no funciona en el sistema Guix.
Una de las áreas principales donde faltan controladores o firmware libre son
los dispositivos WiFi. Los dispositivos WiFi que se sabe que funcionan
incluyen aquellos que usan los chips Atheros (AR9271 y AR7010), que
corresponden al controlador ath9k de Linux-libre, y aquellos que usan
los chips Broadcom/AirForce (BCM43xx con Wireless-Core Revisión 5), que
corresponden al controlador b43-open de Linux-libre. Existe firmware
libre para ambos, y está disponible por defecto en el sistema Guix, como
parte de %base-firmware (see firmware).
The installer warns you early on if it detects devices that are known not to work due to the lack of free firmware or free drivers.
La Fundación del Software Libre patrocina Respeta Su Libertad (RYF), un programa de certificación para productos hardware que respetan su libertad y su privacidad y se aseguran de que usted tenga el control sobre su dispositivo. Le recomendamos que compruebe la lista de dispositivos certificados RYF.
Otro recurso útil es el sitio web H-Node. Contiene un catálogo de dispositivos hardware con información acerca su funcionalidad con GNU/Linux.
Next: Preparación para la instalación, Previous: Consideraciones sobre el hardware, Up: Instalación del sistema [Contents][Index]
3.3 Instalación desde memoria USB y DVD
Se puede descargar una imagen de instalación ISO-9660 que puede ser escrita
en una memoria USB o grabada en un DVD desde
‘https://ftp.gnu.org/gnu/guix/guix-system-install-1.4.0.x86_64-linux.iso’,
donde puede sustituir x86_64-linux con uno de los siguientes valores:
x86_64-linuxpara un sistema GNU/Linux en CPUs compatibles con la arquitectura de 64-bits de Intel/AMD;
i686-linuxpara un sistema GNU/Linux en CPUs compatibles con la arquitectura de 32-bits de Intel.
Asegúrese de descargar el archivo .sig asociado y de verificar la autenticidad de la imagen contra él, más o menos así:
$ wget https://ftp.gnu.org/gnu/guix/guix-system-install-1.4.0.x86_64-linux.iso.sig $ gpg --verify guix-system-install-1.4.0.x86_64-linux.iso.sig
Si la orden falla porque no dispone de la clave pública necesaria, entonces ejecute esta otra orden para importarla:
$ wget https://sv.gnu.org/people/viewgpg.php?user_id=15145 \
-qO - | gpg --import -
y vuelva a ejecutar la orden gpg --verify.
Tenga en cuenta que un aviso del tipo “Esta clave no esta certificada con una firma de confianza” es normal.
Esta imagen contiene las herramientas necesarias para una instalación. Está pensada ara ser copiada tal cual a una memoria USB o DVD con espacio suficiente.
Copiado en una memoria USB
Conecte una memoria USB de 1 GiB o más a su máquina, y determine su nombre de dispositivo. Asumiendo que la memoria USB es /dev/sdX copie la imagen con:
dd if=guix-system-install-1.4.0.x86_64-linux.iso of=/dev/sdX sync
El acceso a /dev/sdX normalmente necesita privilegios de root.
Grabación en un DVD
Introduzca un DVD en su máquina para grabarlo, y determine el nombre del dispositivo. Asumiendo que la unidad DVD es /dev/srX, copie la imagen con:
growisofs -dvd-compat -Z /dev/srX=guix-system-install-1.4.0.x86_64-linux.iso
El acceso a /dev/srX normalmente necesita privilegios de root.
Arranque
Once this is done, you should be able to reboot the system and boot from the
USB stick or DVD. The latter usually requires you to get in the BIOS or
UEFI boot menu, where you can choose to boot from the USB stick. In order
to boot from Libreboot, switch to the command mode by pressing the c
key and type search_grub usb.
See Instalación de Guix en una máquina virtual, si, en vez de esto, desea instalar el sistema Guix en una máquina virtual (VM).
Next: Instalación gráfica guiada, Previous: Instalación desde memoria USB y DVD, Up: Instalación del sistema [Contents][Index]
3.4 Preparación para la instalación
Una vez que haya arrancado, puede usar el instalador gráfico guiado, el cual facilita la introducción al sistema (see Instalación gráfica guiada). Alternativamente, si ya es está familiarizada con GNU/Linux y desea más control que el que proporciona el instalador gráfico, puede seleccionar el proceso de instalación “manual” (see Instalación manual).
El instalador gráfico está disponible en TTY1. Puede obtener consolas de administración (“root”) en los TTY 3 a 6 pulsando ctrl-alt-f3, ctrl-alt-f4, etc. TTY2 muestra esta documentación y se puede cambiar a dicha consola con ctrl-alt-f2. La documentación es explorable usando las órdenes del lector Info (see Stand-alone GNU Info). El sistema de instalación ejecuta el daemon GPM para ratones, el cual le permite seleccionar texto con el botón izquierdo y pegarlo con el botón central.
Nota: La instalación requiere acceso a Internet de modo que cualquier dependencia de su configuración de sistema no encontrada pueda ser descargada. Véase la sección “Red” más adelante.
Next: Instalación manual, Previous: Preparación para la instalación, Up: Instalación del sistema [Contents][Index]
3.5 Instalación gráfica guiada
El instalador gráfico es una interfaz de usuaria basada en texto. Le guiará, con cajas de diálogo, a través de los pasos necesarios para instalar el sistema GNU Guix.
Las primeras cajas de diálogo le permiten configurar el sistema mientras lo usa durante la instalación: puede seleccionar el idioma, la distribución del teclado y configurar la red, la cual se usará durante la instalación. La siguiente imagen muestra el diálogo de configuración de red.
Los siguientes pasos le permitirán particionar su disco duro, como se muestra en la siguiente imagen, elegir si se usarán o no sistemas de archivos cifrados, introducir el nombre de la máquina, la contraseña de root y crear cuentas adicionales, entre otras cosas.
Tenga en cuenta que, en cualquier momento, el instalador le permite salir de la instalación actual y retomarla en un paso previo, como se muestra en la siguiente imagen.
Una vez haya finalizado, el instalador produce una configuración de sistema operativo y la muestra (see Uso de la configuración del sistema). En este punto puede pulsar “OK” y la instalación procederá. En caso de finalización satisfactoria, puede reiniciar con el nuevo sistema y disfrutarlo. ¡See Tras la instalación del sistema para ver cómo proceder a continuación!
Next: Tras la instalación del sistema, Previous: Instalación gráfica guiada, Up: Instalación del sistema [Contents][Index]
3.6 Instalación manual
Esta sección describe como podría instalar “manualmente” el sistema GNU Guix en su máquina. Esta opción requiere familiaridad con GNU/Linux, con el intérprete y con las herramientas de administración comunes. Si piensa que no es para usted, considere el uso del instalador gráfico guiado (see Instalación gráfica guiada).
The installation system provides root shells on TTYs 3 to 6; press
ctrl-alt-f3, ctrl-alt-f4, and so on to reach them. It includes
many common tools needed to install the system, but is also a full-blown
Guix System. This means that you can install additional packages, should
you need it, using guix package (see Invocación de guix package).
Next: Procedimiento de instalación, Up: Instalación manual [Contents][Index]
3.6.1 Distribución de teclado, red y particionado
Antes de instalar el sistema, puede desear ajustar la distribución del teclado, configurar la red y particionar el disco duro deseado. Esta sección le guiará durante este proceso.
3.6.1.1 Distribución de teclado
La imagen de instalación usa la distribución de teclado QWERTY de los
EEUU. Si desea cambiarla, puede usar la orden loadkeys. Por
ejemplo, la siguiente orden selecciona la distribución de teclado para el
castellano:
loadkeys es
Véanse los archivos bajo /run/current-system/profile/share/keymaps
para la obtención de una lista de distribuciones de teclado
disponibles. Ejecute man loadkeys para más información.
3.6.1.2 Red
Ejecute la siguiente orden para ver los nombres asignados a sus interfaces de red:
ifconfig -a
… o, usando la orden específica de GNU/Linux ip:
ip address
El nombre de las interfaces de cable comienza con ‘e’; por ejemplo, la interfaz que corresponde a la primera controladora Ethernet en la placa se llama ‘eno1’. El nombre de las interfaces inalámbricas comienza con ‘w’, como ‘w1p2s0’.
- Conexión por cable
Para configurar una red por cable ejecute la siguiente orden, substituyendo interfaz con el nombre de la interfaz de cable que desea usar.
ifconfig interfaz up
… o, usando la orden específica de GNU/Linux
ip:ip link set interfaz up
- Conexión sin cable ¶
-
Para configurar una red inalámbrica, puede crear un archivo de configuración para la herramienta de configuración
wpa_supplicant(su ruta no es importante) usando uno de los editores de texto disponibles comonano:nano wpa_supplicant.conf
Como un ejemplo, la siguiente plantilla puede colocarse en este archivo y funcionará para muchas redes inalámbricas, siempre que se proporcione el SSID y la contraseña reales de la red a la que se va a conectar:
network={ ssid="mi-ssid" key_mgmt=WPA-PSK psk="la contraseña de la red" }Inicie el servicio inalámbrico y lance su ejecución en segundo plano con la siguiente orden (sustituya interfaz por el nombre de la interfaz de red que desea usar):
wpa_supplicant -c wpa_supplicant.conf -i interfaz -B
Ejecute
man wpa_supplicantpara más información.
En este punto, necesita obtener una dirección IP. En una red donde las direcciones IP se asignan automáticamente mediante DHCP, puede ejecutar:
dhclient -v interfaz
Intente hacer ping a un servidor para comprobar si la red está funcionando correctamente:
ping -c 3 gnu.org
Configurar el acceso por red es casi siempre un requisito debido a que la imagen no contiene todo el software y las herramientas que puedan ser necesarias.
Si necesita que el acceso a HTTP y HTTPS se produzca a través de una pasarela (“proxy”), ejecute la siguiente orden:
herd set-http-proxy guix-daemon URL
donde URL es la URL de la pasarela, por ejemplo
http://example.org:8118.
Si lo desea, puede continuar la instalación de forma remota iniciando un servidor SSH:
herd start ssh-daemon
Asegúrese de establecer una contraseña con passwd, o configure la
verificación de clave pública de OpenSSH antes de ingresar al sistema.
3.6.1.3 Particionado de discos
A menos que se haya realizado previamente, el siguiente paso es el particionado, y después dar formato a la/s partición/es deseadas.
La imagen de instalación contiene varias herramientas de particionado,
incluyendo Parted (see Overview in GNU Parted User Manual),
fdisk y cfdisk. Invoque su ejecución y configure el mapa
de particiones deseado en su disco:
cfdisk
Si su disco usa el formato de tabla de particiones GUID (GPT) y tiene pensado instalar GRUB basado en BIOS (la opción predeterminada), asegúrese de tener una partición de arranque BIOS disponible (see BIOS installation in GNU GRUB manual).
Si en vez de eso desea GRUB basado en EFI, se requiere una Partición
del Sistema EFI (ESP) con formato FAT32. Esta partición puede montarse en
/boot/efi y debe tener la opción esp activa. Por ejemplo, en
parted:
parted /dev/sda set 1 esp on
Nota: ¿No esta segura si usar GRUB basado en EFI o en BIOS? Si el directorio /sys/firmware/efi existe en la imagen de instalación, probablemente debería realizar una instalación EFI, usando
grub-efi-bootloader. En otro caso, debe usar GRUB basado en BIOS, conocido comogrub-bootloader. See Configuración del gestor de arranque, para más información sobre cargadores de arranque.
Once you are done partitioning the target hard disk drive, you have to create a file system on the relevant partition(s)10. For the ESP, if you have one and assuming it is /dev/sda1, run:
mkfs.fat -F32 /dev/sda1
El formato de sistema de archivos ext4 es el formato más ampliamente usado para el sistema de archivos raíz. Otros sistemas de archivos, como por ejemplo Btrfs, implementan compresión, la cual complementa adecuadamente la deduplicación de archivos que el daemon realiza de manera independiente al sistema de archivos(see deduplicación).
Preferentemente, asigne una etiqueta a los sistemas de archivos de modo que
pueda referirse a ellos de forma fácil y precisa en las declaraciones
file-system (see Sistemas de archivos). Esto se consigue habitualmente
con la opción -L de mkfs.ext4 y las ordenes
relacionadas. Por tanto, asumiendo que la partición de la raíz es
/dev/sda2, se puede crear un sistema de archivos con la etiqueta
mi-raiz de esta manera:
mkfs.ext4 -L mi-raiz /dev/sda2
If you are instead planning to encrypt the root partition, you can use the
Cryptsetup/LUKS utilities to do that (see man cryptsetup for more information).
Aviso: Note that GRUB can unlock LUKS2 devices since version 2.06, but only supports the PBKDF2 key derivation function, which is not the default for
cryptsetup luksFormat. You can check which key derivation function is being used by a device by runningcryptsetup luksDump device, and looking for the PBKDF field of your keyslots.
Assuming you want to store the root partition on /dev/sda2, the command sequence to format it as a LUKS2 partition would be along these lines:
cryptsetup luksFormat --type luks2 --pbkdf pbkdf2 /dev/sda2 cryptsetup open /dev/sda2 my-partition mkfs.ext4 -L my-root /dev/mapper/my-partition
Una vez hecho esto, monte el sistema de archivos deseado bajo /mnt
con una orden como (de nuevo, asumiendo que mi-raiz es la etiqueta
del sistema de archivos raíz):
mount LABEL=mi-raiz /mnt
Monte también cualquier otro sistema de archivos que desee usar en el
sistema resultante relativamente a esta ruta. Si ha optado por
/boot/efi como el punto de montaje de EFI, por ejemplo, ahora debe
ser montada en /mnt/boot/efi para que guix system init pueda
encontrarla más adelante.
Finally, if you plan to use one or more swap partitions (see Swap Space), make sure to initialize them with mkswap. Assuming you
have one swap partition on /dev/sda3, you would run:
mkswap /dev/sda3 swapon /dev/sda3
De manera alternativa, puede usar un archivo de intercambio. Por ejemplo, asumiendo que en el nuevo sistema desea usar el archivo /archivo-de-intercambio como tal, ejecutaría11:
# Esto son 10GiB de espacio de intercambio. Ajuste "count" para # cambiar el tamaño. dd if=/dev/zero of=/mnt/swapfile bs=1MiB count=10240 # Por seguridad, se le conceden permisos de lectura y escritura # únicamente a root. chmod 600 /mnt/swapfile mkswap /mnt/swapfile swapon /mnt/swapfile
Fíjese que si ha cifrado la partición raíz y creado un archivo de intercambio en su sistema de archivos como se ha descrito anteriormente, el cifrado también protege al archivo de intercambio, como a cualquier archivo en dicho sistema de archivos.
Previous: Distribución de teclado, red y particionado, Up: Instalación manual [Contents][Index]
3.6.2 Procedimiento de instalación
Con las particiones deseadas listas y la raíz deseada montada en /mnt, estamos preparadas para empezar. Primero, ejecute:
herd start cow-store /mnt
Esto activa la copia-durante-escritura en /gnu/store, de modo que los
paquetes que se añadan durante la fase de instalación se escriban en el
disco montado en /mnt en vez de permanecer en memoria. Esto es
necesario debido a que la primera fase de la orden guix system
init (vea más adelante) implica descargas o construcciones en
/gnu/store, el cual, inicialmente, está un sistema de archivos en
memoria.
Next, you have to edit a file and provide the declaration of the operating
system to be installed. To that end, the installation system comes with
three text editors. We recommend GNU nano (see GNU nano
Manual), which supports syntax highlighting and parentheses matching; other
editors include mg (an Emacs clone), and nvi (a clone of the original BSD
vi editor). We strongly recommend storing that file on the target
root file system, say, as /mnt/etc/config.scm. Failing to do that,
you will have lost your configuration file once you have rebooted into the
newly-installed system.
See Uso de la configuración del sistema, para hacerse una idea del archivo de configuración. Las configuraciones de ejemplo mencionadas en esa sección están disponibles bajo /etc/configuration en la imagen de instalación. Por tanto, para empezar con una configuración del sistema que proporcione un servidor gráfico (un sistema de “escritorio”), puede ejecutar algo parecido a estas órdenes:
# mkdir /mnt/etc # cp /etc/configuration/desktop.scm /mnt/etc/config.scm # nano /mnt/etc/config.scm
Debe prestar atención a lo que su archivo de configuración contiene, y en particular:
- Make sure the
bootloader-configurationform refers to the targets you want to install GRUB on. It should mentiongrub-bootloaderif you are installing GRUB in the legacy way, orgrub-efi-bootloaderfor newer UEFI systems. For legacy systems, thetargetsfield contain the names of the devices, like(list "/dev/sda"); for UEFI systems it names the paths to mounted EFI partitions, like(list "/boot/efi"); do make sure the paths are currently mounted and afile-systementry is specified in your configuration. - Asegúrese que las etiquetas de su sistema de archivos corresponden con el
valor de sus campos
devicerespectivos en su configuraciónfile-system, asumiendo que su configuraciónfile-systemusa el procedimientofile-system-labelen su campodevice. - Si hay particiones cifradas o en RAID, asegúrese de añadir un campo
mapped-devicespara describirlas (see Dispositivos traducidos).
Una vez haya terminado de preparar el archivo de configuración, el nuevo sistema debe ser inicializado (recuerde que el sistema de archivos raíz deseado está montado bajo /mnt):
guix system init /mnt/etc/config.scm /mnt
Esto copia todos los archivos necesarios e instala GRUB en /dev/sdX,
a menos que proporcione la opción --no-bootloader. Para más
información, see Invoking guix system. Esta orden puede desencadenar
descargas o construcciones de paquetes no encontrados, lo cual puede tomar
algún tiempo.
Una vez que la orden se complete—¡y, deseablemente, de forma
satisfactoria!—puede ejecutar reboot y arrancar con el nuevo
sistema. La contraseña de root en el nuevo sistema está vacía
inicialmente; otras contraseñas de usuarias tienen que ser inicializadas
ejecutando la orden passwd como root, a menos que en su
configuración se especifique de otra manera (see contraseñas de cuentas de usuaria). ¡See Tras la instalación del sistema para
proceder a continuación!
Next: Instalación de Guix en una máquina virtual, Previous: Instalación manual, Up: Instalación del sistema [Contents][Index]
3.7 Tras la instalación del sistema
¡Éxito! ¡Ha arrancado en el sistema Guix! De ahora en adelante, puede actualizar el sistema cuando quiera mediante la ejecución de, digamos:
guix pull sudo guix system reconfigure /etc/config.scm
Esto construye una nueva generación del sistema con los últimos paquetes y
servicios (see Invoking guix system). Recomendamos realizarlo de manera
regular de modo que su sistema incluya las últimas actualizaciones de
seguridad (see Actualizaciones de seguridad).
Nota: Tenga en cuenta que
sudo guixejecuta el ejecutableguixde su usuaria y no el de root, ya quesudono alteraPATH. Para ejecutar explícitamente el ejecutableguixde root, escribasudo -i guix ….The difference matters here, because
guix pullupdates theguixcommand and package definitions only for the user it is run as. This means that if you choose to useguix system reconfigurein root’s login shell, you’ll need toguix pullseparately.
Now, see Empezando, and join us on #guix on the Libera Chat
IRC network or on guix-devel@gnu.org to share your experience!
Next: Construcción de la imagen de instalación, Previous: Tras la instalación del sistema, Up: Instalación del sistema [Contents][Index]
3.8 Instalación de Guix en una máquina virtual
Si desea instalar el sistema Guix en una máquina virtual (VM) o en un servidor privado virtual (VPS) en vez de en su preciada máquina, esta sección es para usted.
Si quiere arrancar una VM QEMU para instalar el sistema Guix en una imagen de disco, siga estos pasos:
- Primero, obtenga y descomprima la imagen de instalación del sistema Guix como se ha descrito previamente (see Instalación desde memoria USB y DVD).
- Cree una imagen de disco que contendrá el sistema instalado. Para crear una
imagen de disco con formato qcow2, use la orden
qemu-img:qemu-img create -f qcow2 guix-system.img 50G
El archivo que obtenga será mucho menor de 50GB (típicamente menos de 1MB), pero crecerá cuando el dispositivo de almacenamiento virtualizado se vaya llenando.
- Arranque la imagen de instalación USB en una máquina virtual:
qemu-system-x86_64 -m 1024 -smp 1 -enable-kvm \ -nic user,model=virtio-net-pci -boot menu=on,order=d \ -drive file=guix-system.img \ -drive media=cdrom,file=guix-system-install-1.4.0.sistema.iso
-enable-kvmes opcional, pero mejora el rendimiento significativamente, see Ejecución de Guix en una máquina virtual. - Ahora es root en la VM, prosiga con el procedimiento de instalación. See Preparación para la instalación, y siga las instrucciones.
Una vez complete la instalación, puede arrancar el sistema que está en la imagen guix-system.img. See Ejecución de Guix en una máquina virtual, para información sobre cómo hacerlo.
Previous: Instalación de Guix en una máquina virtual, Up: Instalación del sistema [Contents][Index]
3.9 Construcción de la imagen de instalación
La imagen de instalación descrita anteriormente se construyó usando la orden
guix system, específicamente:
guix system image -t iso9660 gnu/system/install.scm
Eche un vistazo a gnu/system/install.scm en el árbol de fuentes, y
vea también Invoking guix system para más información acerca de la
imagen de instalación.
3.10 Construcción de la imagen de instalación para placas ARM
Muchos dispositivos con procesador ARM necesitan una variante específica del cargador de arranque U-Boot.
Si construye una imagen de disco y el cargador de arranque no está disponible de otro modo (en otra unidad de arranque, etc.), es recomendable construir una imagen que incluya el cargador, específicamente:
guix system image --system=armhf-linux -e '((@ (gnu system install) os-with-u-boot) (@ (gnu system install) installation-os) "A20-OLinuXino-Lime2")'
A20-OLinuXino-Lime2 es el nombre de la placa. Si especifica una placa
no válida, una lista de placas posibles será mostrada.
Next: Empezando, Previous: Instalación del sistema, Up: GNU Guix [Contents][Index]
4 System Troubleshooting Tips
Guix System allows rebooting into a previous generation should the last one be malfunctioning, which makes it quite robust against being broken irreversibly. This feature depends on GRUB being correctly functioning though, which means that if for whatever reasons your GRUB installation becomes corrupted during a system reconfiguration, you may not be able to easily boot into a previous generation. A technique that can be used in this case is to chroot into your broken system and reconfigure it from there. Such technique is explained below.
4.1 Chrooting into an existing system
This section details how to chroot to an already installed Guix System with the aim of reconfiguring it, for example to fix a broken GRUB installation. The process is similar to how it would be done on other GNU/Linux systems, but there are some Guix System particularities such as the daemon and profiles that make it worthy of explaining here.
- Obtain a bootable image of Guix System. It is recommended the latest development snapshot so the kernel and the tools used are at least as as new as those of your installed system; it can be retrieved from the https://ci.guix.gnu.org URL. Follow the see Instalación desde memoria USB y DVD section for copying it to a bootable media.
- Boot the image, and proceed with the graphical text-based installer until your network is configured. Alternatively, you could configure the network manually by following the manual-installation-networking section. If you get the error ‘RTNETLINK answers: Operation not possible due to RF-kill’, try ‘rfkill list’ followed by ‘rfkill unblock 0’, where ‘0’ is your device identifier (ID).
- Switch to a virtual console (tty) if you haven’t already by pressing
simultaneously the Control + Alt + F4 keys. Mount your file system at
/mnt. Assuming your root partition is /dev/sda2, you would
do:
mount /dev/sda2 /mnt
- Mount special block devices and Linux-specific directories:
mount --bind /proc /mnt/proc mount --bind /sys /mnt/sys mount --bind /dev /mnt/dev
If your system is EFI-based, you must also mount the ESP partition. Assuming it is /dev/sda1, you can do so with:
mount /dev/sda1 /mnt/boot/efi
- Enter your system via chroot:
chroot /mnt /bin/sh
- Source the system profile as well as your user profile to setup the
environment, where user is the user name used for the Guix System you
are attempting to repair:
source /var/guix/profiles/system/profile/etc/profile source /home/user/.guix-profile/etc/profile
To ensure you are working with the Guix revision you normally would as your normal user, also source your current Guix profile:
source /home/user/.config/guix/current/etc/profile
- Start a minimal
guix-daemonin the background:guix-daemon --build-users-group=guixbuild --disable-chroot &
- Edit your Guix System configuration if needed, then reconfigure with:
guix system reconfigure your-config.scm
- Finally, you should be good to reboot the system to test your fix.
Next: Gestión de paquetes, Previous: System Troubleshooting Tips, Up: GNU Guix [Contents][Index]
5 Empezando
Es probable que haya llegado a esta sección o bien porque haya instalado Guix sobre otra distribución (see Instalación), o bien porque haya instalado el sistema Guix completo (see Instalación del sistema). Es hora de dar sus primeros pasos con Guix; esta sección intenta ser de ayuda con estos primeros pasos y proporcionar una primera impresión sobre Guix.
Guix está orientado a instalar software, por lo que probablemente la primera cosa que deseará hacer es mirar el software disponible. Digamos, por ejemplo, que busca un editor de texto. Para ello puede ejecutar:
guix search texto editor
Esta orden le muestra cierto número de paquetes asociados a dicha búsqueda, mostrando con cada uno de ellos su nombre, versión, una descripción e información adicional. Una vez que ha encontrado el que quiere usar, digamos Emacs (je je je), puede seguir adelante e instalarlo (ejecute esta orden con su cuenta de usuaria habitual, ¡no necesita privilegios de administración o usar la cuenta “root”!):
guix install emacs
You’ve installed your first package, congrats! The package is now visible in your default profile, $HOME/.guix-profile—a profile is a directory containing installed packages. In the process, you’ve probably noticed that Guix downloaded pre-built binaries; or, if you explicitly chose to not use pre-built binaries, then probably Guix is still building software (see Sustituciones, for more info).
Si no está usando el sistema Guix, la orden guix install debe
haber mostrado este consejo:
consejo: Considere proporcionar valor a las variables de entorno necesarias ejecutando:
GUIX_PROFILE="$HOME/.guix-profile"
. "$GUIX_PROFILE/etc/profile"
Alternativamente, véase `guix package --search-paths -p "$HOME/.guix-profile"'.
Indeed, you must now tell your shell where emacs and other
programs installed with Guix are to be found. Pasting the two lines above
will do just that: it will add $HOME/.guix-profile/bin—which is
where the installed package is—to the PATH environment variable.
You can paste these two lines in your shell so they take effect right away,
but more importantly you should add them to ~/.bash_profile (or
equivalent file if you do not use Bash) so that environment variables are
set next time you spawn a shell. You only need to do this once and other
search paths environment variables will be taken care of similarly—e.g.,
if you eventually install python and Python libraries,
GUIX_PYTHONPATH will be defined.
Puede continuar instalando paquetes cuando quiera. Para enumerar los paquetes instalados, ejecute:
guix package --list-installed
Para borrar un paquete, deberá ejecutar guix remove. Una
característica distintiva es la capacidad de revertir cualquier
operación que haya realizado—instalación, borrado,
actualización—simplemente escribiendo:
guix package --roll-back
Esto es debido al hecho de que cada operación en realidad es una transacción que crea una nueva generación. Estas generaciones y la diferencia entre ellas puede ser visualizada mediante la ejecución de:
guix package --list-generations
¡Ahora ya conoce lo básico sobre gestión de paquetes!
Más allá: See Gestión de paquetes, para más información sobre gestión de paquetes. Puede que le guste la gestión declarativa de paquetes con
guix package --manifest, la gestión de distintos perfiles con --profile, el borrado de generaciones antiguas, la recolección de basura y otras interesantes características que le serán útiles una vez que se familiarice con Guix. Si es desarrolladora, see Desarrollo para herramientas adicionales. Y si simplemente tiene curiosidad, see Características, para echar un vistazo a su funcionamiento interno.
Una vez que haya instalado un conjunto de paquetes, deseará actualizarlos periódicamente a la última y mejor versión. Para hacerlo, primero debe obtener la última revisión de Guix y su colección de paquetes:
guix pull
El resultado final es un nuevo ejecutable guix, que se encuentra
en ~/.config/guix/current/bin. A menos que use el sistema Guix,
asegúrese de seguir el consejo que la orden muestra y, al igual que vimos
previamente, pegue estas dos líneas en su terminal y en
.bash_profile:
GUIX_PROFILE="$HOME/.config/guix/current" . "$GUIX_PROFILE/etc/profile"
También le debe indicar a su intérprete que haga referencia a este nuevo
guix:
hash guix
En este momento ya está ejecutando una nueva instalación de Guix. Por lo tanto puede continuar y actualizar todos los paquetes que haya instalado previamente:
guix upgrade
Mientras se ejecuta esta orden verá que se descargan binarios (o quizá que algunos paquetes se construyen) y tras cierto tiempo obtendrá los paquetes actualizados. ¡Recuerde que siempre puede revertir esta acción en caso de que uno de los paquetes no sea de su agrado!
Puede mostrar la revisión exacta de Guix que está ejecutando mediante la orden:
guix describe
La información que muestra contiene todo lo necesario para reproducir exactamente el mismo Guix, ya sea en otro momento o en una máquina diferente.
Más allá: See Invocación de
guix pull, para más información. See Canales, para saber cómo especificar canales adicionales de los que obtener paquetes, cómo replicar Guix y más información. La ordentime-machinetambién le puede ser de utilidad (see Invocación deguix time-machine).
Si ha instalado el sistema Guix, una de las primeras cosas que probablemente
desee hacer es actualizar su sistema. Una vez que haya ejecutado
guix pull con la última versión de Guix, puede actualizar su
sistema de este modo:
sudo guix system reconfigure /etc/config.scm
Tras su finalización, el sistema ejecuta las últimas versiones de sus paquetes de software. Cuando reinicie el sistema verá un menú en el cargador de arranque que dice “GNU system, old configurations...”: es lo que le permite arrancar una generación anterior de su sistema, en caso de que la generación actual falle o resulte insatisfactoria de algún otro modo. Al igual que con los paquetes, siempre puede revertir el sistema completo a una generación previa:
sudo guix system roll-back
Habrá muchas cosas que probablemente quiera modificar su sistema para que se adapte a sus necesidades: añadir nuevas cuentas de acceso, nuevos servicios del sistema, modificar la configuración de esos servicios, etcétera. La configuración del sistema se describe al completo en el archivo /etc/config.scm. See Uso de la configuración del sistema para aprender cómo cambiarla.
¡Ya sabe lo suficiente para empezar!
Recursos: El resto de este manual proporciona una referencia para Guix al completo. Esta es una lista de recursos adicionales que le pueden resultar útiles:
- See The GNU Guix Cookbook, que contiene una lista de recetas tipo “cómo se hace” para una variedad de casos.
- La tarjeta de referencia de GNU Guix enumera en dos páginas la mayor parte de las órdenes y opciones que pueda necesitar en cualquier momento.
- La página web contiene medios audiovisuales instructivos sobre temas como el uso diario de Guix, cómo obtener ayuda y cómo contribuir.
- See Documentación para aprender cómo acceder a la documentación en su máquina.
¡Esperamos que disfrute Guix tanto como la comunidad disfruta en su construcción!
6 Gestión de paquetes
El propósito de GNU Guix es permitir a las usuarias instalar, actualizar y borrar fácilmente paquetes de software, sin tener que conocer acerca de sus procedimientos de construcción o dependencias. Guix también va más allá de este conjunto obvio de características.
Este capítulo describe las principales características de Guix, así como las
herramientas de gestión de paquetes que ofrece. Junto a la interfaz de línea
de órdenes descrita a continuación (see guix
package, también puede usar la interfaz Emacs-Guix (see The Emacs Guix Reference Manual), tras la instalación del
paquete emacs-guix (ejecute la orden M-x guix-help para
iniciarse en su uso):
guix install emacs-guix
- Características
- Invocación de
guix package - Sustituciones
- Paquetes con múltiples salidas
- Invocación de
guix gc - Invocación de
guix pull - Invocación de
guix time-machine - Inferiores
- Invocación de
guix describe - Invocación de
guix archive
Next: Invocación de guix package, Up: Gestión de paquetes [Contents][Index]
6.1 Características
Se asume que ya ha dado sus primeros pasos con Guix (see Empezando) y desea obtener información general sobre cómo funciona la implementación internamente.
Cuando se usa Guix, cada paquete se encuentra en el almacén de
paquetes, en su propio directorio—algo que se asemeja a
/gnu/store/xxx-paquete-1.2, donde xxx es una cadena en base32.
En vez de referirse a estos directorios, las usuarias tienen su propio
perfil, el cual apunta a los paquetes que realmente desean usar. Estos
perfiles se almacenan en el directorio de cada usuaria, en
$HOME/.guix-profile.
Por ejemplo, alicia instala GCC 4.7.2. Como resultado,
/home/alicia/.guix-profile/bin/gcc apunta a
/gnu/store/…-gcc-4.7.2/bin/gcc. Ahora, en la misma máquina,
rober ha instalado ya GCC 4.8.0. El perfil de rober
simplemente sigue apuntando a
/gnu/store/…-gcc-4.8.0/bin/gcc—es decir, ambas versiones de
GCC pueden coexistir en el mismo sistema sin ninguna interferencia.
La orden guix package es la herramienta central para gestión de
paquetes (see Invocación de guix package). Opera en los perfiles de usuaria,
y puede ser usada con privilegios de usuaria normal.
La orden proporciona las operaciones obvias de instalación, borrado y
actualización. Cada invocación es en realidad una transacción: o bien
la operación especificada se realiza satisfactoriamente, o bien nada
sucede. Por tanto, si el proceso guix package es finalizado
durante una transacción, o un fallo eléctrico ocurre durante la transacción,
el perfil de usuaria permanece en su estado previo, y permanece usable.
Además, cualquier transacción de paquetes puede ser vuelta atrás. Si, por ejemplo, una actualización instala una nueva versión de un paquete que resulta tener un error importante, las usuarias pueden volver a la instancia previa de su perfil, de la cual se tiene constancia que funcionaba bien. De igual modo, la configuración global del sistema en Guix está sujeta a actualizaciones transaccionales y vuelta atrás (see Uso de la configuración del sistema).
Todos los paquetes en el almacén de paquetes pueden ser eliminados por
el recolector de basura. Guix puede determinar a qué paquetes hacen
referencia todavía los perfiles de usuarias, y eliminar aquellos que, de
forma demostrable, no se haga referencia en ningún perfil (see Invocación de guix gc). Las usuarias pueden también borrar explícitamente generaciones
antiguas de su perfil para que los paquetes a los que hacen referencia
puedan ser recolectados.
Guix toma una aproximación puramente funcional en la gestión de paquetes, como se describe en la introducción (see Introducción). Cada nombre de directorio de paquete en /gnu/store contiene un hash de todas las entradas que fueron usadas para construir el paquete—compilador, bibliotecas, guiones de construcción, etc. Esta correspondencia directa permite a las usuarias asegurarse que una instalación dada de un paquete corresponde al estado actual de su distribución. Esto también ayuda a maximizar la reproducibilidad de la construcción: gracias al uso de entornos aislados de construcción, una construcción dada probablemente generará archivos idénticos bit-a-bit cuando se realice en máquinas diferentes (see container).
Estos cimientos permiten a Guix ofrecer despliegues transparentes de
binarios/fuentes. Cuando un binario pre-construido para un elemento de
/gnu/store está disponible para descarga de una fuente externa—una
sustitución, Guix simplemente lo descarga y desempaqueta; en otro caso
construye el paquete de las fuentes, localmente
(see Sustituciones). Debido a que los resultados de construcción son
normalmente reproducibles bit-a-bit, las usuarias no tienen que confiar en
los servidores que proporcionan sustituciones: pueden forzar una
construcción local y retar a las proveedoras (see Invocación de guix challenge).
Control over the build environment is a feature that is also useful for
developers. The guix shell command allows developers of a package
to quickly set up the right development environment for their package,
without having to manually install the dependencies of the package into
their profile (see Invoking guix shell).
Todo Guix y sus definiciones de paquetes están bajo control de versiones, y
guix pull le permite “viajar en el tiempo” por la historia del
mismo Guix (see Invocación de guix pull). Esto hace posible replicar una
instancia de Guix en una máquina diferente o en un punto posterior del
tiempo, lo que a su vez le permite replicar entornos de software
completos, mientras que mantiene un preciso seguimiento de la
procedencia del software.
Next: Sustituciones, Previous: Características, Up: Gestión de paquetes [Contents][Index]
6.2 Invocación de guix package
The guix package command is the tool that allows users to install,
upgrade, and remove packages, as well as rolling back to previous
configurations. These operations work on a user profile—a directory
of installed packages. Each user has a default profile in
$HOME/.guix-profile. The command operates only on the user’s own
profile, and works with normal user privileges (see Características). Its
syntax is:
guix package opciones
Primariamente, opciones especifica las operaciones a ser realizadas durante la transacción. Al completarse, un nuevo perfil es creado, pero las generaciones previas del perfil permanecen disponibles, en caso de que la usuaria quisiera volver atrás.
Por ejemplo, para borrar lua e instalar guile y
guile-cairo en una única transacción:
guix package -r lua -i guile guile-cairo
Para su conveniencia, también se proporcionan los siguientes alias:
-
guix searches un alias deguix package -s, -
guix installes un alias deguix package -i, -
guix removees un alias deguix package -r, -
guix upgradees un alias deguix package -u - y
guix showes un alias deguix package --show=.
Estos alias tienen menos capacidad expresiva que guix package y
proporcionan menos opciones, por lo que en algunos casos es probable que
desee usar guix package directamente.
guix package también proporciona una aproximación
declarativa, donde la usuaria especifica el conjunto exacto de paquetes a
poner disponibles y la pasa a través de la opción --manifest
(see --manifest).
Para cada usuaria, un enlace simbólico al perfil predeterminado de la
usuaria es creado en $HOME/.guix-profile. Este enlace simbólico
siempre apunta a la generación actual del perfil predeterminado de la
usuaria. Por lo tanto, las usuarias pueden añadir
$HOME/.guix-profile/bin a su variable de entorno PATH,
etcétera.
Si no está usando el sistema Guix, considere la adición de las siguientes
líneas en su ~/.bash_profile (see Bash Startup Files in The
GNU Bash Reference Manual) de manera que los nuevos intérpretes que ejecute
obtengan todas las definiciones correctas de las variables de entorno:
GUIX_PROFILE="$HOME/.guix-profile" ; \ source "$GUIX_PROFILE/etc/profile"
En una configuración multiusuaria, los perfiles de usuaria se almacenan en
un lugar registrado como una raíz del sistema de archivos, a la que
apunta $HOME/.guix-profile (see Invocación de guix gc). Ese directorio
normalmente es
localstatedir/guix/profiles/per-user/usuaria, donde
localstatedir es el valor pasado a configure como
--localstatedir y usuaria es el nombre de usuaria. El
directorio per-user se crea cuando se lanza guix-daemon, y
el subdirectorio usuaria es creado por guix package.
Las opciones pueden ser las siguientes:
--install=paquete …-i paquete …Instala los paquetes especificados.
Each package may specify a simple package name, such as
guile, optionally followed by an at-sign and version number, such asguile@3.0.7or simplyguile@3.0. In the latter case, the newest version prefixed by3.0is selected.If no version number is specified, the newest available version will be selected. In addition, such a package specification may contain a colon, followed by the name of one of the outputs of the package, as in
gcc:docorbinutils@2.22:lib(see Paquetes con múltiples salidas).Packages with a corresponding name (and optionally version) are searched for among the GNU distribution modules (see Módulos de paquetes).
Alternatively, a package can directly specify a store file name such as /gnu/store/...-guile-3.0.7, as produced by, e.g.,
guix build.A veces los paquetes tienen entradas propagadas: estas son las dependencias que se instalan automáticamente junto al paquete requerido (see
propagated-inputsinpackageobjects, para información sobre las entradas propagadas en las definiciones de paquete).Un ejemplo es la biblioteca GNU MPC: sus archivos de cabecera C hacen referencia a los de la biblioteca GNU MPFR, que a su vez hacen referencia a los de la biblioteca GMP. Por tanto, cuando se instala MPC, las bibliotecas MPFR y GMP también se instalan en el perfil; borrar MPC también borra MPFR y GMP—a menos que también se hayan instalado explícitamente por la usuaria.
Por otra parte, los paquetes a veces dependen de la definición de variables de entorno para sus rutas de búsqueda (véase a continuación la explicación de --seach-paths). Cualquier definición de variable de entorno que falte o sea posiblemente incorrecta se informa aquí.
--install-from-expression=exp-e expInstala el paquete al que exp evalúa.
exp debe ser una expresión Scheme que evalúe a un objeto
<package>. Esta opción es notablemente útil para diferenciar entre variantes con el mismo nombre de paquete, con expresiones como(@ (gnu packages base) guile-final).Fíjese que esta opción instala la primera salida del paquete especificado, lo cual puede ser insuficiente cuando se necesita una salida específica de un paquete con múltiples salidas.
--install-from-file=archivo-f archivoInstala el paquete que resulta de evaluar el código en archivo.
Como un ejemplo, archivo puede contener una definición como esta (see Definición de paquetes):
(use-modules (guix) (guix build-system gnu) (guix licenses)) (package (name "hello") (version "2.10") (source (origin (method url-fetch) (uri (string-append "mirror://gnu/hello/hello-" version ".tar.gz")) (sha256 (base32 "0ssi1wpaf7plaswqqjwigppsg5fyh99vdlb9kzl7c9lng89ndq1i")))) (build-system gnu-build-system) (synopsis "Hello, GNU world: An example GNU package") (description "Guess what GNU Hello prints!") (home-page "http://www.gnu.org/software/hello/") (license gpl3+))
Developers may find it useful to include such a guix.scm file in the root of their project source tree that can be used to test development snapshots and create reproducible development environments (see Invoking
guix shell).El archivo puede contener también una representación en JSON de una o más definiciones de paquetes. Ejecutar
guix package -fen hello.json con el contenido mostrado a continuación provocará la instalación del paquetegreetertras la construcción demyhello:[ { "name": "myhello", "version": "2.10", "source": "mirror://gnu/hello/hello-2.10.tar.gz", "build-system": "gnu", "arguments": { "tests?": false } "home-page": "https://www.gnu.org/software/hello/", "synopsis": "Hello, GNU world: An example GNU package", "description": "GNU Hello prints a greeting.", "license": "GPL-3.0+", "native-inputs": ["gettext"] }, { "name": "greeter", "version": "1.0", "source": "https://example.com/greeter-1.0.tar.gz", "build-system": "gnu", "arguments": { "test-target": "foo", "parallel-build?": false, }, "home-page": "https://example.com/", "synopsis": "Greeter using GNU Hello", "description": "This is a wrapper around GNU Hello.", "license": "GPL-3.0+", "inputs": ["myhello", "hello"] } ]--remove=paquete …-r paquete …Borra los paquetes especificados.
Como en --install, cada paquete puede especificar un número de versión y/o un nombre de salida además del nombre del paquete. Por ejemplo,
-r glibc:debugeliminaría la salidadebugdeglibc.--upgrade[=regexp …]¶-u [regexp …]Actualiza todos los paquetes instalados. Si se especifica una o más expresiones regular regexp, actualiza únicamente los paquetes instalados cuyo nombre es aceptado por regexp. Véase también la opción --do-not-upgrade más adelante.
Tenga en cuenta que esto actualiza los paquetes a la última versión encontrada en la distribución instalada actualmente. Para actualizar su distribución, debe ejecutar regularmente
guix pull(see Invocación deguix pull).Al actualizar, las transformaciones que se aplicaron originalmente al crear el perfil se aplican de nuevo de manera automática (see Opciones de transformación de paquetes). Por ejemplo, asumiendo que hubiese instalado Emacs a partir de la última revisión de su rama de desarrollo con:
guix install emacs-next --with-branch=emacs-next=master
La próxima vez que ejecute
guix upgradeGuix obtendrá de nuevo la última revisión de la rama de desarrollo de Emacs y construiráemacs-nexta partir de ese código.Tenga en cuenta que las opciones de transformación, como por ejemplo --with-branch y --with-source, dependen de un estado externo; es su responsabilidad asegurarse de que funcionen de la manera esperada. También puede deshacer las transformaciones aplicadas a un paquete con la siguiente orden:
guix install paquete
--do-not-upgrade[=regexp …]Cuando se usa junto a la opción --upgrade, no actualiza ningún paquete cuyo nombre sea aceptado por regexp. Por ejemplo, para actualizar todos los paquetes en el perfil actual excepto aquellos que contengan la cadena “emacs”:
$ guix package --upgrade . --do-not-upgrade emacs
--manifest=archivo¶-m archivo-
Crea una nueva generación del perfil desde el objeto de manifiesto devuelto por el código Scheme en archivo. Esta opción puede repetirse varias veces, en cuyo caso los manifiestos se concatenan.
Esto le permite declarar los contenidos del perfil en vez de construirlo a través de una secuencia de --install y órdenes similares. La ventaja es que archivo puede ponerse bajo control de versiones, copiarse a máquinas diferentes para reproducir el mismo perfil, y demás.
archivo debe devolver un objeto manifest, que es básicamente una lista de paquetes:
(use-package-modules guile emacs) (packages->manifest (list emacs guile-2.0 ;; Usa una salida específica del paquete. (list guile-2.0 "debug")))
See Writing Manifests, for information on how to write a manifest. See --export-manifest, to learn how to obtain a manifest file from an existing profile.
--roll-back¶-
Vuelve a la generación previa del perfil—es decir, revierte la última transacción.
Cuando se combina con opciones como --install, la reversión atrás ocurre antes que cualquier acción.
Cuando se vuelve atrás en la primera generación que realmente contiene paquetes instalados, se hace que el perfil apunte a la generación cero, la cual no contiene ningún archivo a excepción de sus propios metadatos.
Después de haber vuelto atrás, instalar, borrar o actualizar paquetes sobreescribe las generaciones futuras previas. Por tanto, la historia de las generaciones en un perfil es siempre linear.
--switch-generation=patrón¶-S patrónCambia a una generación particular definida por el patrón.
patrón puede ser tanto un número de generación como un número prefijado con “+” o “-”. Esto último significa: mueve atrás/hacia delante el número especificado de generaciones. Por ejemplo, si quiere volver a la última generación antes de --roll-back, use --switch-generation=+1.
La diferencia entre --roll-back y --switch-generation=-1 es que --switch-generation no creará una generación cero, así que si la generación especificada no existe, la generación actual no se verá cambiada.
--search-paths[=tipo]¶Informa de variables de entorno, en sintaxis Bash, que pueden necesitarse para usar el conjunto de paquetes instalado. Estas variables de entorno se usan para especificar las rutas de búsqueda para archivos usadas por algunos de los paquetes.
For example, GCC needs the
CPATHandLIBRARY_PATHenvironment variables to be defined so it can look for headers and libraries in the user’s profile (see Environment Variables in Using the GNU Compiler Collection (GCC)). If GCC and, say, the C library are installed in the profile, then --search-paths will suggest setting these variables to profile/include and profile/lib, respectively (see Search Paths, for info on search path specifications associated with packages.)El caso de uso típico es para definir estas variables de entorno en el intérprete de consola:
$ eval $(guix package --search-paths)
tipo puede ser
exact,prefixosuffix, lo que significa que las definiciones de variables de entorno devueltas serán respectivamente las configuraciones exactas, prefijos o sufijos del valor actual de dichas variables. Cuando se omite, el valor predeterminado de tipo esexact.Esta opción puede usarse para calcular las rutas de búsqueda combinadas de varios perfiles. Considere este ejemplo:
$ guix package -p foo -i guile $ guix package -p bar -i guile-json $ guix package -p foo -p bar --search-paths
La última orden informa sobre la variable
GUILE_LOAD_PATH, aunque, tomada individualmente, ni foo ni bar hubieran llevado a esa recomendación.--profile=perfil-p perfilUsa perfil en vez del perfil predeterminado de la usuaria.
perfil debe ser el nombre de un archivo que se creará tras completar las tareas. Concretamente, perfil sera simplemente un enlace simbólico (“symlink”) que apunta al verdadero perfil en el que se instalan los paquetes:
$ guix install hello -p ~/código/mi-perfil … $ ~/código/mi-perfil/bin/hello ¡Hola mundo!
Todo lo necesario para deshacerse del perfil es borrar dicho enlace simbólico y sus enlaces relacionados que apuntan a generaciones específicas:
$ rm ~/código/mi-perfil ~/código/mi-perfil-*-link
--list-profilesEnumera los perfiles de la usuaria:
$ guix package --list-profiles /home/carlos/.guix-profile /home/carlos/código/mi-perfil /home/carlos/código/perfil-desarrollo /home/carlos/tmp/prueba
Cuando se ejecuta como root, enumera todos los perfiles de todas las usuarias.
--allow-collisionsPermite colisiones de paquetes en el nuevo perfil. ¡Úselo bajo su propio riesgo!
Por defecto,
guix packageinforma como un error las colisiones en el perfil. Las colisiones ocurren cuando dos o más versiones diferentes o variantes de un paquete dado se han seleccionado para el perfil.--bootstrapUse el Guile usado para el lanzamiento para construir el perfil. Esta opción es util únicamente a las desarrolladoras de la distribución.
Además de estas acciones, guix package acepta las siguientes
opciones para consultar el estado actual de un perfil, o la disponibilidad
de paquetes:
- --search=regexp
- -s regexp
-
Enumera los paquetes disponibles cuyo nombre, sinopsis o descripción corresponde con regexp (sin tener en cuenta la capitalización), ordenados por relevancia. Imprime todos los metadatos de los paquetes coincidentes en formato
recutils(see GNU recutils databases in GNU recutils manual).Esto permite extraer campos específicos usando la orden
recsel, por ejemplo:$ guix package -s malloc | recsel -p name,version,relevance name: jemalloc version: 4.5.0 relevance: 6 name: glibc version: 2.25 relevance: 1 name: libgc version: 7.6.0 relevance: 1
De manera similar, para mostrar el nombre de todos los paquetes disponibles bajo los términos de la GNU LGPL versión 3:
$ guix package -s "" | recsel -p name -e 'license ~ "LGPL 3"' name: elfutils name: gmp …
También es posible refinar los resultados de búsqueda mediante el uso de varias opciones
-s, o varios parámetros aguix search. Por ejemplo, la siguiente orden devuelve un lista de juegos de mesa12 (esta vez mediante el uso del aliasguix search:$ guix search '\<board\>' game | recsel -p name name: gnubg …
Si omitimos
-s game, también obtendríamos paquetes de software que tengan que ver con placas de circuitos impresos ("circuit board" en inglés); borrar los signos mayor y menor alrededor deboardañadiría paquetes que tienen que ver con teclados (keyboard en inglés).Y ahora para un ejemplo más elaborado. La siguiente orden busca bibliotecas criptográficas, descarta bibliotecas Haskell, Perl, Python y Ruby, e imprime el nombre y la sinopsis de los paquetes resultantes:
$ guix search crypto library | \ recsel -e '! (name ~ "^(ghc|perl|python|ruby)")' -p name,synopsisSee Selection Expressions in GNU recutils manual, para más información en expresiones de selección para
recsel -e. - --show=paquete
Muestra los detalles del paquete, tomado de la lista disponible de paquetes, en formato
recutils(see GNU recutils databases in GNU recutils manual).$ guix package --show=guile | recsel -p name,version name: guile version: 3.0.5 name: guile version: 3.0.2 name: guile version: 2.2.7 …
También puede especificar el nombre completo de un paquete para únicamente obtener detalles sobre una versión específica (esta vez usando el alias
guix show):$ guix show guile@3.0.5 | recsel -p name,version name: guile version: 3.0.5
- --list-installed[=regexp]
- -I [regexp]
Enumera los paquetes actualmente instalados en el perfil especificado, con los últimos paquetes instalados mostrados al final. Cuando se especifica regexp, enumera únicamente los paquetes instalados cuyos nombres son aceptados por regexp.
Por cada paquete instalado, imprime los siguientes elementos, separados por tabuladores: el nombre del paquete, la cadena de versión, la parte del paquete que está instalada (por ejemplo,
outpara la salida predeterminada,includepara sus cabeceras, etc.), y la ruta de este paquete en el almacén.- --list-available[=regexp]
- -A [regexp]
Enumera los paquetes disponibles actualmente en la distribución para este sistema (see Distribución GNU). Cuando se especifica regexp, enumera únicamente paquetes disponibles cuyo nombre coincide con regexp.
Por cada paquete, imprime los siguientes elementos separados por tabuladores: su nombre, su cadena de versión, las partes del paquete (see Paquetes con múltiples salidas) y la dirección de las fuentes de su definición.
- --list-generations[=patrón] ¶
- -l [patrón]
Devuelve una lista de generaciones junto a sus fechas de creación; para cada generación, muestra los paquetes instalados, con los paquetes instalados más recientemente mostrados los últimos. Fíjese que la generación cero nunca se muestra.
Por cada paquete instalado, imprime los siguientes elementos, separados por tabuladores: el nombre de un paquete, su cadena de versión, la parte del paquete que está instalada (see Paquetes con múltiples salidas), y la ruta de este paquete en el almacén.
Cuando se usa patrón, la orden devuelve únicamente las generaciones que se ajustan al patrón. Entre los patrones adecuados se encuentran:
- Enteros y enteros separados por comas. Ambos patrones denotan
números de generación. Por ejemplo, --list-generations=1 devuelve
la primera.
Y --list-generations=1,8,2 devuelve las tres generaciones en el orden especificado. No se permiten ni espacios ni una coma al final.
- Rangos. --list-generations=2..9 imprime
las generaciones especificadas y todas las intermedias. Fíjese que el inicio
de un rango debe ser menor a su fin.
También es posible omitir el destino final. Por ejemplo, --list-generations=2.. devuelve todas las generaciones empezando por la segunda.
- Duraciones. Puede también obtener los últimos N días, semanas, o meses pasando un entero junto a la primera letra de la duración. Por ejemplo, --list-generations=20d enumera las generaciones que tienen hasta 20 días de antigüedad.
- Enteros y enteros separados por comas. Ambos patrones denotan
números de generación. Por ejemplo, --list-generations=1 devuelve
la primera.
- --delete-generations[=patrón]
- -d [patrón]
Cuando se omite patrón, borra todas las generaciones excepto la actual.
Esta orden acepta los mismos patrones que --list-generations. Cuando se especifica un patrón, borra las generaciones coincidentes. Cuando el patrón especifica una duración, las generaciones más antiguas que la duración especificada son las borradas. Por ejemplo, --delete-generations=1m borra las generaciones de más de un mes de antigüedad.
Si la generación actual entra en el patrón, no es borrada. Tampoco la generación cero es borrada nunca.
Preste atención a que el borrado de generaciones previas impide la reversión a su estado. Consecuentemente esta orden debe ser usada con cuidado.
- --export-manifest
Write to standard output a manifest suitable for --manifest corresponding to the chosen profile(s).
This option is meant to help you migrate from the “imperative” operating mode—running
guix install,guix upgrade, etc.—to the declarative mode that --manifest offers.Be aware that the resulting manifest approximates what your profile actually contains; for instance, depending on how your profile was created, it can refer to packages or package versions that are not exactly what you specified.
Keep in mind that a manifest is purely symbolic: it only contains package names and possibly versions, and their meaning varies over time. If you wish to “pin” channels to the revisions that were used to build the profile(s), see --export-channels below.
- --export-channels
Write to standard output the list of channels used by the chosen profile(s), in a format suitable for
guix pull --channelsorguix time-machine --channels(see Canales).Together with --export-manifest, this option provides information allowing you to replicate the current profile (see Replicación de Guix).
However, note that the output of this command approximates what was actually used to build this profile. In particular, a single profile might have been built from several different revisions of the same channel. In that case, --export-manifest chooses the last one and writes the list of other revisions in a comment. If you really need to pick packages from different channel revisions, you can use inferiors in your manifest to do so (see Inferiores).
Together with --export-manifest, this is a good starting point if you are willing to migrate from the “imperative” model to the fully declarative model consisting of a manifest file along with a channels file pinning the exact channel revision(s) you want.
Finally, since guix package may actually start build processes, it
supports all the common build options (see Opciones comunes de construcción). It
also supports package transformation options, such as
--with-source, and preserves them across upgrades (see Opciones de transformación de paquetes).
Next: Paquetes con múltiples salidas, Previous: Invocación de guix package, Up: Gestión de paquetes [Contents][Index]
6.3 Sustituciones
Guix permite despliegues transparentes de fuentes/binarios, lo que significa que puede tanto construir cosas localmente, como descargar elementos preconstruidos de un servidor, o ambas. Llamamos a esos elementos preconstruidos sustituciones—son sustituciones de los resultados de construcciones locales. En muchos casos, descargar una sustitución es mucho más rápido que construirla localmente.
Las sustituciones pueden ser cualquier cosa que resulte de una construcción de una derivación (see Derivaciones). Por supuesto, en el caso común, son paquetes binarios preconstruidos, pero los archivos de fuentes, por ejemplo, que también resultan de construcciones de derivaciones, pueden estar disponibles como sustituciones.
- Official Substitute Servers
- Autorización de servidores de sustituciones
- Obtención de sustiticiones desde otros servidores
- Verificación de sustituciones
- Configuración de la pasarela.
- Fallos en las sustituciones
- Sobre la confianza en binarios
6.3.1 Official Substitute Servers
ci.guix.gnu.org and bordeaux.guix.gnu.org
are both front-ends to official build farms that build packages from Guix
continuously for some architectures, and make them available as
substitutes. These are the default source of substitutes; which can be
overridden by passing the --substitute-urls option either to
guix-daemon (see guix-daemon
--substitute-urls) or to client tools such as guix package
(see client --substitute-urls option).
Las URLs de sustituciones pueden ser tanto HTTP como HTTPS. Se recomienda HTTPS porque las comunicaciones están cifradas; de modo contrario, usar HTTP hace visibles todas las comunicaciones para alguien que las intercepte, quien puede usar la información obtenida para determinar, por ejemplo, si su sistema tiene vulnerabilidades de seguridad sin parchear.
Substitutes from the official build farms are enabled by default when using Guix System (see Distribución GNU). However, they are disabled by default when using Guix on a foreign distribution, unless you have explicitly enabled them via one of the recommended installation steps (see Instalación). The following paragraphs describe how to enable or disable substitutes for the official build farm; the same procedure can also be used to enable substitutes for any other substitute server.
Next: Obtención de sustiticiones desde otros servidores, Previous: Official Substitute Servers, Up: Sustituciones [Contents][Index]
6.3.2 Autorización de servidores de sustituciones
To allow Guix to download substitutes from
ci.guix.gnu.org, bordeaux.guix.gnu.org or a
mirror, you must add the relevant public key to the access control list
(ACL) of archive imports, using the guix archive command
(see Invocación de guix archive). Doing so implies that you trust the
substitute server to not be compromised and to serve genuine substitutes.
Nota: If you are using Guix System, you can skip this section: Guix System authorizes substitutes from
ci.guix.gnu.organdbordeaux.guix.gnu.orgby default.
The public keys for each of the project maintained substitute servers are
installed along with Guix, in prefix/share/guix/, where
prefix is the installation prefix of Guix. If you installed Guix from
source, make sure you checked the GPG signature of
guix-1.4.0.tar.gz, which contains this public key file.
Then, you can run something like this:
# guix archive --authorize < prefix/share/guix/ci.guix.gnu.org.pub # guix archive --authorize < prefix/share/guix/bordeaux.guix.gnu.org.pub
Una vez esté autorizada, la salida de una orden como guix build
debería cambiar de algo como:
$ guix build emacs --dry-run Se construirían las siguientes derivaciones: /gnu/store/yr7bnx8xwcayd6j95r2clmkdl1qh688w-emacs-24.3.drv /gnu/store/x8qsh1hlhgjx6cwsjyvybnfv2i37z23w-dbus-1.6.4.tar.gz.drv /gnu/store/1ixwp12fl950d15h2cj11c73733jay0z-alsa-lib-1.0.27.1.tar.bz2.drv /gnu/store/nlma1pw0p603fpfiqy7kn4zm105r5dmw-util-linux-2.21.drv …
a algo así:
$ guix build emacs --dry-run Se descargarían 112.3 MB: /gnu/store/pk3n22lbq6ydamyymqkkz7i69wiwjiwi-emacs-24.3 /gnu/store/2ygn4ncnhrpr61rssa6z0d9x22si0va3-libjpeg-8d /gnu/store/71yz6lgx4dazma9dwn2mcjxaah9w77jq-cairo-1.12.16 /gnu/store/7zdhgp0n1518lvfn8mb96sxqfmvqrl7v-libxrender-0.9.7 …
The text changed from “The following derivations would be built” to “112.3 MB would be downloaded”. This indicates that substitutes from the configured substitute servers are usable and will be downloaded, when possible, for future builds.
El mecanismo de sustituciones puede ser desactivado globalmente ejecutando
guix-daemon con --no-subsitutes (see Invocación de guix-daemon). También puede ser desactivado temporalmente pasando la opción
--no-substitutes a guix package, guix build y
otras herramientas de línea de órdenes.
Next: Verificación de sustituciones, Previous: Autorización de servidores de sustituciones, Up: Sustituciones [Contents][Index]
6.3.3 Obtención de sustiticiones desde otros servidores
Guix puede buscar y obtener sustituciones a partir de varios servidores. Esto es útil cuando se usan paquetes de canales adicionales para los que el servidor oficial no proporciona sustituciones pero otros servidores sí. Otra situación donde puede esta característica puede ser útil es en el caso de que prefiera realizar las descargas desde el servidor de sustituciones de su organización, accediendo al servidor oficial únicamente como mecanismo de salvaguarda o no usándolo en absoluto.
Puede proporcionarle a Guix una lista de URL de servidores de los que obtener sustituciones y las comprobará en el orden especificado. También es necesario que autorice explícitamente las claves públicas de los servidores de sustituciones para que Guix acepte las sustituciones firmadas por dichos claves.
En el sistema Guix esto se consigue modificando la configuración del
servicio guix. Puesto que el servicio guix es parte de las
listas de servicios predeterminadas, %base-services y
%desktop-services, puede usar modify-services para cambiar su
configuración y añadir las URL y claves para sustituciones que desee
(see modify-services).
As an example, suppose you want to fetch substitutes from
guix.example.org and to authorize the signing key of that server, in
addition to the default ci.guix.gnu.org and
bordeaux.guix.gnu.org. The resulting operating system
configuration will look something like:
(operating-system
;; …
(services
;; Se asume que se parte de '%desktop-services'. Debe sustituirse
;; por la lista de servicios que use en realidad.
(modify-services %desktop-services
(guix-service-type config =>
(guix-configuration
(inherit config)
(substitute-urls
(append (list "https://guix.example.org")
%default-substitute-urls))
(authorized-keys
(append (list (local-file "./clave.pub"))
%default-authorized-guix-keys)))))))
Esto asume que el archivo clave.pub contiene la clave de firma de
guix.example.org. Cuando haya realizado este cambio en el archivo de
configuración de su sistema operativo (digamos /etc/config.scm),
puede reconfigurar y reiniciar el servicio guix-daemon o reiniciar la
máquina para que los cambios se hagan efectivos:
$ sudo guix system reconfigure /etc/config.scm $ sudo herd restart guix-daemon
Si por el contrario ejecuta Guix sobre una distribución distinta, deberá llevar a cabo los siguientes pasos para obtener sustituciones de servidores adicionales:
- Edite el archivo de configuración para el servicio de
guix-daemon; cuando use systemd normalmente se trata de /etc/systemd/system/guix-daemon.service. Añada la opción --substitute-urls en la línea de ordenes deguix-daemony la lista de URL que desee (seeguix-daemon --substitute-urls):… --substitute-urls='https://guix.example.org https://ci.guix.gnu.org https://bordeaux.guix.gnu.org'
- Reinicie el daemon. Con systemd estos son los pasos:
systemctl daemon-reload systemctl restart guix-daemon.service
- Autorice la clave del nuevo servidor (see Invocación de
guix archive):guix archive --authorize < clave.pub
De nuevo se asume que clave.pub contiene la clave pública usada por
guix.example.orgpara firmar las sustituciones.
Now you’re all set! Substitutes will be preferably taken from
https://guix.example.org, using ci.guix.gnu.org
then bordeaux.guix.gnu.org as fallback options. Of course you
can list as many substitute servers as you like, with the caveat that
substitute lookup can be slowed down if too many servers need to be
contacted.
Tenga en cuenta que existen situaciones en las que se puede desear añadir la URL de un servidor de sustitucines sin autorizar su clave. See Verificación de sustituciones para entender este caso específico.
Next: Configuración de la pasarela., Previous: Obtención de sustiticiones desde otros servidores, Up: Sustituciones [Contents][Index]
6.3.4 Verificación de sustituciones
Guix detecta y emite errores cuando se intenta usar una sustitución que ha sido adulterado. Del mismo modo, ignora las sustituciones que no están firmadas, o que no están firmadas por una de las firmas enumeradas en la ACL.
No obstante hay una excepción: si un servidor no autorizado proporciona sustituciones que son idénticas bit-a-bit a aquellas proporcionadas por un servidor autorizado, entonces el servidor no autorizado puede ser usado para descargas. Por ejemplo, asumiendo que hemos seleccionado dos servidores de sustituciones con esta opción:
--substitute-urls="https://a.example.org https://b.example.org"
Si la ACL contiene únicamente la clave para ‘b.example.org’, y si ‘a.example.org’ resulta que proporciona exactamente las mismas sustituciones, Guix descargará sustituciones de ‘a.example.org’ porque viene primero en la lista y puede ser considerado un espejo de ‘b.example.org’. En la práctica, máquinas de construcción independientes producen habitualmente los mismos binarios, gracias a las construcciones reproducibles bit-a-bit (véase a continuación).
Cuando se usa HTTPS, el certificado X.509 del servidor no se valida (en otras palabras, el servidor no está verificado), lo contrario del comportamiento habitual de los navegadores Web. Esto es debido a que Guix verifica la información misma de las sustituciones, como se ha explicado anteriormente, lo cual nos concierne (mientras que los certificados X.509 tratan de verificar las conexiones entre nombres de dominio y claves públicas).
Next: Fallos en las sustituciones, Previous: Verificación de sustituciones, Up: Sustituciones [Contents][Index]
6.3.5 Configuración de la pasarela.
Substitutes are downloaded over HTTP or HTTPS. The http_proxy and
https_proxy environment variables can be set in the environment of
guix-daemon and are honored for downloads of substitutes. Note
that the value of those environment variables in the environment where
guix build, guix package, and other client commands are
run has absolutely no effect.
Next: Sobre la confianza en binarios, Previous: Configuración de la pasarela., Up: Sustituciones [Contents][Index]
6.3.6 Fallos en las sustituciones
Incluso cuando una sustitución de una derivación está disponible, a veces el intento de sustitución puede fallar. Esto puede suceder por varias razones: el servidor de sustituciones puede estar desconectado, la sustitución puede haber sido borrada, la conexión puede interrumpirse, etc.
Cuando las sustituciones están activadas y una sustitución para una derivación está disponible, pero el intento de sustitución falla, Guix intentará construir la derivación localmente dependiendo si se proporcionó la opción --fallback (see opción común de construcción --fallback). Específicamente, si no se pasó --fallback, no se realizarán construcciones locales, y la derivación se considera se considera fallida. No obstante, si se pasó --fallback, Guix intentará construir la derivación localmente, y el éxito o fracaso de la derivación depende del éxito o fracaso de la construcción local. Fíjese que cuando las sustituciones están desactivadas o no hay sustituciones disponibles para la derivación en cuestión, la construcción local se realizará siempre, independientemente de si se pasó la opción --fallback.
Para hacerse una idea de cuantas sustituciones hay disponibles en este
momento, puede intentar ejecutar la orden guix weather
(see Invocación de guix weather). Esta orden proporciona estadísticas de las
sustituciones proporcionadas por un servidor.
Previous: Fallos en las sustituciones, Up: Sustituciones [Contents][Index]
6.3.7 Sobre la confianza en binarios
Today, each individual’s control over their own computing is at the mercy of
institutions, corporations, and groups with enough power and determination
to subvert the computing infrastructure and exploit its weaknesses. While
using substitutes can be convenient, we encourage users to also build on
their own, or even run their own build farm, such that the project run
substitute servers are less of an interesting target. One way to help is by
publishing the software you build using guix publish so that
others have one more choice of server to download substitutes from
(see Invocación de guix publish).
Guix tiene los cimientos para maximizar la reproducibilidad de las
construcciones (see Características). En la mayor parte de los casos,
construcciones independientes de un paquete o derivación dada deben emitir
resultados idénticos bit a bit. Por tanto, a través de un conjunto diverso
de construcciones independientes de paquetes, podemos reforzar la integridad
de nuestros sistemas. La orden guix challenge intenta ayudar a las
usuarias en comprobar servidores de sustituciones, y asiste a las
desarrolladoras encontrando construcciones no deterministas de paquetes
(see Invocación de guix challenge). Similarmente, la opción --check
de guix build permite a las usuarias si las sustituciones
previamente instaladas son genuinas mediante su reconstrucción local
(see guix build --check).
En el futuro, queremos que Guix permita la publicación y obtención de binarios hacia/desde otras usuarias, entre pares (P2P). En caso de interesarle hablar sobre este proyecto, unase a nosotras en guix-devel@gnu.org.
Next: Invocación de guix gc, Previous: Sustituciones, Up: Gestión de paquetes [Contents][Index]
6.4 Paquetes con múltiples salidas
Habitualmente, los paquetes definidos en Guix tienen una salida
única—es decir, el paquete de fuentes proporcionará exactamente un
directorio en el almacén. Cuando se ejecuta guix install glibc, se
instala la salida predeterminada del paquete GNU libc; la salida
predeterminada se llama out, pero su nombre puede omitirse como se
mostró en esta orden. En este caso particular, la salida predeterminada de
glibc contiene todos archivos de cabecera C, bibliotecas dinámicas,
bibliotecas estáticas, documentación Info y otros archivos auxiliares.
A veces es más apropiado separar varios tipos de archivos producidos por un
paquete único de fuentes en salidas separadas. Por ejemplo, la biblioteca C
GLib (usada por GTK+ y paquetes relacionados) instala más de 20 MiB de
documentación de referencia como páginas HTML. Para ahorrar espacio para
usuarias que no la necesiten, la documentación va a una salida separada,
llamada doc. Para instalar la salida principal de GLib, que contiene
todo menos la documentación, se debe ejecutar:
guix install glib
La orden que instala su documentación es:
guix install glib:doc
Algunos paquetes instalan programas con diferentes “huellas de
dependencias”. Por ejemplo, el paquete WordNet instala tanto herramientas
de línea de órdenes como interfaces gráficas de usuaria (IGU). Las primeras
dependen únicamente de la biblioteca de C, mientras que las últimas dependen
en Tcl/Tk y las bibliotecas de X subyacentes. En este caso, dejamos las
herramientas de línea de órdenes en la salida predeterminada, mientras que
las IGU están en una salida separada. Esto permite a las usuarias que no
necesitan una IGU ahorrar espacio. La orden guix size puede ayudar
a exponer estas situaciones (see Invocación de guix size). guix
graph también puede ser útil (see Invocación de guix graph).
Hay varios de estos paquetes con salida múltiple en la distribución
GNU. Otros nombres de salida convencionales incluyen lib para
bibliotecas y posiblemente archivos de cabecera, bin para programas
independientes y debug para información de depuración
(see Instalación de archivos de depuración). La salida de los paquetes se enumera
en la tercera columna del resultado de guix package
--list-available (see Invocación de guix package).
Next: Invocación de guix pull, Previous: Paquetes con múltiples salidas, Up: Gestión de paquetes [Contents][Index]
6.5 Invocación de guix gc
Los paquetes instalados, pero no usados, pueden ser recolectados. La
orden guix gc permite a las usuarias ejecutar explícitamente el
recolector de basura para reclamar espacio del directorio
/gnu/store—¡borrar archivos o directorios manualmente puede dañar
el almacén sin reparación posible!
El recolector de basura tiene un conjunto de raíces conocidas:
cualquier archivo en /gnu/store alcanzable desde una raíz se
considera vivo y no puede ser borrado; cualquier otro archivo se
considera muerto y puede ser borrado. El conjunto de raíces del
recolector de basura (“raíces del GC” para abreviar) incluye los perfiles
predeterminados de las usuarias; por defecto los enlaces bajo
/var/guix/gcroots representan dichas raíces. Por ejemplo, nuevas
raíces del GC pueden añadirse con guix build --root
(see Invocación de guix build). La orden guix gc --list-roots las
enumera.
Antes de ejecutar guix gc --collect-garbage para liberar espacio,
habitualmente es útil borrar generaciones antiguas de los perfiles de
usuaria; de ese modo, las construcciones antiguas de paquetes a las que
dichas generaciones hacen referencia puedan ser reclamadas. Esto se consigue
ejecutando guix package --delete-generations (see Invocación de guix package).
Nuestra recomendación es ejecutar una recolección de basura periódicamente, o cuando tenga poco espacio en el disco. Por ejemplo, para garantizar que al menos 5 GB están disponibles en su disco, simplemente ejecute:
guix gc -F 5G
Es completamente seguro ejecutarla como un trabajo periódico no-interactivo
(see Ejecución de tareas programadas, para la configuración de un trabajo de ese
tipo). La ejecución de guix gc sin ningún parámetro recolectará
tanta basura como se pueda, pero eso es no es normalmente conveniente: puede
encontrarse teniendo que reconstruir o volviendo a bajar software que está
“muerto” desde el punto de vista del recolector pero que es necesario para
construir otras piezas de software—por ejemplo, la cadena de herramientas
de compilación.
La orden guix gc tiene tres modos de operación: puede ser usada
para recolectar archivos muertos (predeterminado), para borrar archivos
específicos (la opción --delete), para mostrar información sobre la
recolección de basura o para consultas más avanzadas. Las opciones de
recolección de basura son las siguientes:
--collect-garbage[=min]-C [min]Recolecta basura—es decir, archivos no alcanzables de /gnu/store y subdirectorios. Esta operación es la predeterminada cuando no se especifican opciones.
Cuando se proporciona min, para una vez que min bytes han sido recolectados. min puede ser un número de bytes, o puede incluir una unidad como sufijo, como
MiBpara mebibytes yGBpara gigabytes (see size specifications in GNU Coreutils).Cuando se omite min, recolecta toda la basura.
--free-space=libre-F libreRecolecta basura hasta que haya espacio libre bajo /gnu/store, si es posible: libre denota espacio de almacenamiento, por ejemplo
500MiB, como se ha descrito previamente.Cuando libre o más está ya disponible en /gnu/store, no hace nada y sale inmediatamente.
--delete-generations[=duración]-d [duración]Before starting the garbage collection process, delete all the generations older than duration, for all the user profiles and home environment generations; when run as root, this applies to all the profiles of all the users.
Por ejemplo, esta orden borra todas las generaciones de todos sus perfiles que tengan más de 2 meses de antigüedad (excepto generaciones que sean las actuales), y una vez hecho procede a liberar espacio hasta que al menos 10 GiB estén disponibles:
guix gc -d 2m -F 10G
--delete-DIntenta borrar todos los archivos del almacén y directorios especificados como parámetros. Esto falla si alguno de los archivos no están en el almacén, o todavía están vivos.
--list-failuresEnumera los elementos del almacén correspondientes a construcciones fallidas existentes en la caché.
Esto no muestra nada a menos que el daemon se haya ejecutado pasando --cache-failures (see --cache-failures).
--list-rootsEnumera las raíces del recolector de basura poseídas por la usuaria; cuando se ejecuta como root, enumera todas las raíces del recolector de basura.
--list-busyEnumera los elementos del almacén que actualmente están siendo usados por procesos en ejecución. Estos elementos del almacén se consideran de manera efectiva raíces del recolector de basura: no pueden borrarse.
--clear-failuresBorra los elementos especificados del almacén de la caché de construcciones fallidas.
De nuevo, esta opción únicamente tiene sentido cuando el daemon se inicia con --cache-failures. De otro modo, no hace nada.
--list-deadMuestra la lista de archivos y directorios muertos todavía presentes en el almacén—es decir, archivos y directorios que ya no se pueden alcanzar desde ninguna raíz.
--list-liveMuestra la lista de archivos y directorios del almacén vivos.
Además, las referencias entre los archivos del almacén pueden ser consultadas:
--references¶--referrersEnumera las referencias (o, respectivamente, los referentes) de los archivos del almacén pasados como parámetros.
--requisites¶-REnumera los requisitos los archivos del almacén pasados como parámetros. Los requisitos incluyen los mismos archivos del almacén, sus referencias, las referencias de estas, recursivamente. En otras palabras, la lista devuelta es la clausura transitiva de los archivos del almacén.
See Invocación de
guix size, para una herramienta que perfila el tamaño de la clausura de un elemento. See Invocación deguix graph, para una herramienta de visualización del grafo de referencias.--derivers¶Devuelve la/s derivación/es que conducen a los elementos del almacén dados (see Derivaciones).
Por ejemplo, esta orden:
guix gc --derivers $(guix package -I ^emacs$ | cut -f4)
devuelve el/los archivo/s .drv que conducen al paquete
emacsinstalado en su perfil.Fíjese que puede haber cero archivos .drv encontrados, por ejemplo porque estos archivos han sido recolectados. Puede haber más de un archivo .drv encontrado debido a derivaciones de salida fija.
Por último, las siguientes opciones le permiten comprobar la integridad del almacén y controlar el uso del disco.
- --verify[=opciones] ¶
-
Verifica la integridad del almacén.
Por defecto, comprueba que todos los elementos del almacén marcados como válidos en la base de datos del daemon realmente existen en /gnu/store.
Cuando se proporcionan, opciones debe ser una lista separada por comas que contenga uno o más valores
contentsandrepair.Cuando se usa --verify=contents, el daemon calcula el hash del contenido de cada elemento del almacén y lo compara contra el hash de su base de datos. Las incongruencias se muestran como corrupciones de datos. Debido a que recorre todos los archivos del almacén, esta orden puede tomar mucho tiempo, especialmente en sistemas con una unidad de disco lenta.
El uso de --verify=repair o --verify=contents,repair hace que el daemon intente reparar elementos corruptos del almacén obteniendo sustituciones para dichos elementos (see Sustituciones). Debido a que la reparación no es atómica, y por tanto potencialmente peligrosa, está disponible únicamente a la administradora del sistema. Una alternativa ligera, cuando sabe exactamente qué elementos del almacén están corruptos, es
guix build --repair(see Invocación deguix build). - --optimize ¶
Optimiza el almacén sustituyendo archivos idénticos por enlaces duros—esto es la deduplicación.
El daemon realiza la deduplicación después de cada construcción satisfactoria o importación de archivos, a menos que se haya lanzado con la opción --disable-deduplication (see --disable-deduplication). Por tanto, esta opción es útil principalmente cuando el daemon se estaba ejecutando con --disable-deduplication.
- --vacuum-database ¶
Guix uses an sqlite database to keep track of the items in (see El almacén). Over time it is possible that the database may grow to a large size and become fragmented. As a result, one may wish to clear the freed space and join the partially used pages in the database left behind from removed packages or after running the garbage collector. Running
sudo guix gc --vacuum-databasewill lock the database andVACUUMthe store, defragmenting the database and purging freed pages, unlocking the database when it finishes.
Next: Invocación de guix time-machine, Previous: Invocación de guix gc, Up: Gestión de paquetes [Contents][Index]
6.6 Invocación de guix pull
Packages are installed or upgraded to the latest version available in the
distribution currently available on your local machine. To update that
distribution, along with the Guix tools, you must run guix pull:
the command downloads the latest Guix source code and package descriptions,
and deploys it. Source code is downloaded from a
Git repository, by default the official
GNU Guix repository, though this can be customized. guix
pull ensures that the code it downloads is authentic by verifying
that commits are signed by Guix developers.
Específicamente, guix pull descarga código de los canales
(see Canales) especificados en una de las posibilidades siguientes, en
este orden:
- la opción --channels;
- el archivo ~/.config/guix/channels.scm de la usuaria;
- el archivo /etc/guix/channels.scm común al sistema;
- los canales predeterminados en código especificados en la variable
%default-channels.
Una vez completada, guix package usará paquetes y versiones de
paquetes de esta copia recién obtenida de Guix. No solo eso, sino que todas
las órdenes de Guix y los módulos Scheme también se tomarán de la última
versión. Nuevas sub-órdenes guix incorporadas por la actualización
también estarán disponibles.
Cualquier usuaria puede actualizar su copia de Guix usando guix
pull, y el efecto está limitado a la usuaria que ejecute guix
pull. Por ejemplo, cuando la usuaria root ejecuta guix
pull, dicha acción no produce ningún efecto en la versión del Guix que la
usuaria alicia ve, y viceversa.
El resultado de ejecutar guix pull es un perfil disponible
bajo ~/.config/guix/current conteniendo el último Guix. Por tanto,
asegúrese de añadirlo al inicio de sus rutas de búsqueda de modo que use la
última versión, de modo similar para el manual Info(see Documentación).
export PATH="$HOME/.config/guix/current/bin:$PATH" export INFOPATH="$HOME/.config/guix/current/share/info:$INFOPATH"
Las opciones --list-generations o -l enumeran las
generaciones pasadas producidas por guix pull, junto a detalles de
su procedencia:
$ guix pull -l
Generación 1 10 jun 2018 00:18:18
guix 65956ad
URL del repositorio: https://git.savannah.gnu.org/git/guix.git
rama: origin/master
revisión: 65956ad3526ba09e1f7a40722c96c6ef7c0936fe
Generation 2 Jun 11 2018 11:02:49
guix e0cc7f6
repository URL: https://git.savannah.gnu.org/git/guix.git
branch: origin/master
commit: e0cc7f669bec22c37481dd03a7941c7d11a64f1d
Generation 3 Jun 13 2018 23:31:07 (current)
guix 844cc1c
repository URL: https://git.savannah.gnu.org/git/guix.git
branch: origin/master
commit: 844cc1c8f394f03b404c5bb3aee086922373490c
guix describe, para otras formas de
describir el estado actual de Guix.
This ~/.config/guix/current profile works exactly like the profiles
created by guix package (see Invocación de guix package). That is,
you can list generations, roll back to the previous generation—i.e., the
previous Guix—and so on:
$ guix pull --roll-back se pasó de la generación 3 a la 2 $ guix pull --delete-generations=1 borrando /var/guix/profiles/per-user/carlos/current-guix-1-link
También puede usar guix package (see Invocación de guix package)
para gestionar el perfil proporcionando su nombre de manera específica:
$ guix package -p ~/.config/guix/current --roll-back se pasó de la generación 3 a la 2 $ guix package -p ~/.config/guix/current --delete-generations=1 borrando /var/guix/profiles/per-user/carlos/current-guix-1-link
La orden guix pull se invoca habitualmente sin parámetros, pero
permite las siguientes opciones:
--url=url--commit=revisión--branch=ramaDownload code for the
guixchannel from the specified url, at the given commit (a valid Git commit ID represented as a hexadecimal string or the name of a tag), or branch.Estas opciones se proporcionan por conveniencia, pero también puede especificar su configuración en el archivo ~/.config/guix/channels.scm o usando la opción --channels (vea más adelante).
--channels=archivo-C archivoLee la lista de canales de archivo en vez de ~/.config/guix/channels.scm o /etc/guix/channels.scm. archivo debe contener código Scheme que evalúe a una lista de objetos “channel”. See Canales, para más información.
--news-NDisplay news written by channel authors for their users for changes made since the previous generation (see Writing Channel News). When --details is passed, additionally display new and upgraded packages.
You can view that information for previous generations with
guix pull -l.--list-generations[=patrón]-l [patrón]Enumera todas las generaciones de ~/.config/guix/current o, si se proporciona un patrón, el subconjunto de generaciones que correspondan con el patrón. La sintaxis de patrón es la misma que
guix package --list-generations(see Invocación deguix package).By default, this prints information about the channels used in each revision as well as the corresponding news entries. If you pass --details, it will also print the list of packages added and upgraded in each generation compared to the previous one.
--detailsInstruct --list-generations or --news to display more information about the differences between subsequent generations—see above.
--roll-back¶-
Vuelve a la generación previa de ~/.config/guix/current—es decir, deshace la última transacción.
--switch-generation=patrón¶-S patrónCambia a una generación particular definida por el patrón.
patrón puede ser tanto un número de generación como un número prefijado con “+” o “-”. Esto último significa: mueve atrás/hacia delante el número especificado de generaciones. Por ejemplo, si quiere volver a la última generación antes de --roll-back, use --switch-generation=+1.
--delete-generations[=patrón]-d [patrón]Cuando se omite patrón, borra todas las generaciones excepto la actual.
Esta orden acepta los mismos patrones que --list-generations. Cuando se especifica un patrón, borra las generaciones coincidentes. Cuando el patrón especifica una duración, las generaciones más antiguas que la duración especificada son las borradas. Por ejemplo, --delete-generations=1m borra las generaciones de más de un mes de antigüedad.
Si la generación actual entra en el patrón, no será borrada.
Preste atención a que el borrado de generaciones previas impide la reversión a su estado. Consecuentemente esta orden debe ser usada con cuidado.
Invocación de
guix describe, para una forma de mostrar información sobre únicamente la generación actual.--profile=perfil-p perfilUsa perfil en vez de ~/.config/guix/current.
--dry-run-nMuestra qué revisión/es del canal serían usadas y qué se construiría o sustituiría, sin efectuar ninguna acción real.
--allow-downgradesPermite obtener revisiones de los canales más antiguas o no relacionadas con aquellas que se encuentran en uso actualmente.
De manera predeterminada
guix pullproteje contra los llamados “ataques de versión anterior” en los que el repositorio Git de un canal se reinicia a una revisión anterior o no relacionada de sí mismo, provocando potencialmente la instalación de versiones más antiguas y con vulnerabilidades conocidas de paquetes de software.Nota: Asegúrese de entender las implicaciones de seguridad antes de usar la opción --allow-downgrades.
--disable-authenticationPermite obtener código de un canal sin verificarlo.
De manera predeterminada,
guix pullvalida el código que descarga de los canales verificando que sus revisiones están firmadas por desarrolladoras autorizadas, y emite un error si no es el caso. Esta opción le indica que no debe realizar ninguna de esas verificaciones.Nota: Asegúrese de entender las implicaciones de seguridad antes de usar la opción --disable-authentication.
--system=sistema-s sistemaIntenta construir paquetes para sistema—por ejemplo,
x86_64-linux—en vez del tipo de sistema de la máquina de construcción.--bootstrapUse el Guile usado para el lanzamiento para construir el último Guix. Esta opción es útil para las desarrolladoras de Guix únicamente.
El mecanismo de canales le permite instruir a guix pull de
qué repositorio y rama obtener los datos, así como repositorios
adicionales que contengan módulos de paquetes que deben ser
desplegados. See Canales, para más información.
Además, guix pull acepta todas las opciones de construcción
comunes (see Opciones comunes de construcción).
Next: Inferiores, Previous: Invocación de guix pull, Up: Gestión de paquetes [Contents][Index]
6.7 Invocación de guix time-machine
La orden guix time-machine proporciona acceso a otras revisiones
de Guix, por ejemplo para instalar versiones antiguas de un paquete, o para
reproducir una computación en un entorno idéntico. La revisión de Guix que
se usará se define por el identificador de una revisión o por un archivo de
descripción de canales creado con guix describe (see Invocación de guix describe).
Let’s assume that you want to travel to those days of November 2020 when
version 1.2.0 of Guix was released and, once you’re there, run the
guile of that time:
guix time-machine --commit=v1.2.0 -- \ environment -C --ad-hoc guile -- guile
The command above fetches Guix 1.2.0 and runs its guix
environment command to spawn an environment in a container running
guile (guix environment has since been subsumed by
guix shell; see Invoking guix shell). It’s like driving a
DeLorean13! The first guix time-machine invocation can
be expensive: it may have to download or even build a large number of
packages; the result is cached though and subsequent commands targeting the
same commit are almost instantaneous.
Nota: The history of Guix is immutable and
guix time-machineprovides the exact same software as they are in a specific Guix revision. Naturally, no security fixes are provided for old versions of Guix or its channels. A careless use ofguix time-machineopens the door to security vulnerabilities. See --allow-downgrades.
La sintaxis general es:
guix time-machine opciones… -- orden param…
donde orden and param… se proporcionan sin modificar a la
orden guix de la revisión especificada. Las opciones que
definen esta revisión son las mismas que se usan con guix pull
(see Invocación de guix pull):
--url=url--commit=revisión--branch=ramaUse the
guixchannel from the specified url, at the given commit (a valid Git commit ID represented as a hexadecimal string or the name of a tag), or branch.--channels=archivo-C archivoLee la lista de canales de archivo. archivo debe contener código Scheme que evalúe a una lista de objetos “channel”. See Canales, para más información.
As for guix pull, the absence of any options means that the latest
commit on the master branch will be used. The command
guix time-machine -- build hello
construirá el paquete hello como esté definido en la rama master, que
en general es la última revisión de Guix que haya instalado. ¡Los viajes
temporales funcionan en ambas direcciones!
Tenga en cuenta que guix time-machine puede desencadenar
construcciones de canales y sus dependencias, y que pueden controlarse
mediante las opciones de construcción estándar (see Opciones comunes de construcción).
Next: Invocación de guix describe, Previous: Invocación de guix time-machine, Up: Gestión de paquetes [Contents][Index]
6.8 Inferiores
Nota: La funcionalidad descrita aquí es una “versión de evaluación tecnológica” en la versión 1.4.0. Como tal, la interfaz está sujeta a cambios.
A veces necesita mezclar paquetes de revisiones de la revisión de Guix que está ejecutando actualmente con paquetes disponibles en una revisión diferente. Los inferiores de Guix le permiten conseguirlo componiendo diferentes revisiones de Guix de modo arbitrario.
Técnicamente, un “inferior” es esencialmente un proceso Guix separado
conectado con su Guix principal a través de una sesión interactiva
(see Invocación de guix repl). El módulo (guix inferior) le permite
crear inferiores y comunicarse con ellos. También proporciona una interfaz
de alto nivel para buscar y manipular los paquetes que un inferior
proporciona—paquetes de inferiores.
When combined with channels (see Canales), inferiors provide a simple
way to interact with a separate revision of Guix. For example, let’s assume
you want to install in your profile the current guile package, along
with the guile-json as it existed in an older revision of
Guix—perhaps because the newer guile-json has an incompatible API
and you want to run your code against the old API. To do that, you could
write a manifest for use by guix package --manifest (see Writing Manifests); in that manifest, you would create an inferior for that old
Guix revision you care about, and you would look up the guile-json
package in the inferior:
(use-modules (guix inferior) (guix channels) (srfi srfi-1)) ;para 'first' (define channels ;; Esta es la revisión antigua de donde queremos ;; extraer guile-json. (list (channel (name 'guix) (url "https://git.savannah.gnu.org/git/guix.git") (commit "65956ad3526ba09e1f7a40722c96c6ef7c0936fe")))) (define inferior ;; Un inferior que representa la revisión previa. (inferior-for-channels channels)) ;; Ahora crea un manifiesto con el paquete "guile" actual ;; y el antiguo paquete "guile-json". (packages->manifest (list (first (lookup-inferior-packages inferior "guile-json")) (specification->package "guile")))
En su primera ejecución, guix package --manifest puede tener que
construir el canal que especificó antes de crear el inferior; las siguientes
ejecuciones serán mucho más rápidas porque la revisión de Guix estará en la
caché.
El módulo (guix inferior) proporciona los siguientes procedimientos
para abrir un inferior:
- Procedimiento Scheme: inferior-for-channels canales [#:cache-directory] [#:ttl]
Devuelve un inferior para canales, una lista de canales. Usa la caché en cache-directory, donde las entradas pueden ser reclamadas después de ttl segundos. Este procedimiento abre una nueva conexión al daemon de construcción.
Como efecto secundario, este procedimiento puede construir o sustituir binarios para canales, lo cual puede tomar cierto tiempo.
- Procedimiento Scheme: open-inferior directorio [#:command "bin/guix"]
Abre el Guix inferior en directorio, ejecutando
directorio/command replo su equivalente. Devuelve#fsi el inferior no pudo ser ejecutado.
Los procedimientos enumerados a continuación le permiten obtener y manipular paquetes de inferiores.
- Procedimiento Scheme: inferior-packages inferior
Devuelve la lista de paquetes conocida por inferior.
- Procedimiento Scheme: lookup-inferior-packages inferior nombre [versión]
Devuelve la lista ordenada de paquetes del inferior que corresponden con nombre en inferior, con los números de versión más altos primero. Si versión tiene un valor verdadero, devuelve únicamente paquetes con un número de versión cuyo prefijo es versión.
- Procedimiento Scheme: inferior-package? obj
Devuelve verdadero si obj es un paquete inferior.
- Procedimiento Scheme: inferior-package-name paquete
- Procedimiento Scheme: inferior-package-version paquete
- Procedimiento Scheme: inferior-package-synopsis paquete
- Procedimiento Scheme: inferior-package-description paquete
- Procedimiento Scheme: inferior-package-home-page paquete
- Procedimiento Scheme: inferior-package-location paquete
- Procedimiento Scheme: inferior-package-inputs paquete
- Procedimiento Scheme: inferior-package-native-inputs paquete
- Procedimiento Scheme: inferior-package-propagated-inputs paquete
- Procedimiento Scheme: inferior-package-transitive-propagated-inputs paquete
- Procedimiento Scheme: inferior-package-native-search-paths paquete
- Procedimiento Scheme: inferior-package-transitive-native-search-paths paquete
- Procedimiento Scheme: inferior-package-search-paths paquete
Estos procedimientos son la contraparte de los accesos a los registros de paquete (see Referencia de
package). La mayor parte funcionan interrogando al inferior del que paquete viene, por lo que el inferior debe estar vivo cuando llama a dichos procedimientos.
Inferior packages can be used transparently like any other package or
file-like object in G-expressions (see Expresiones-G). They are also
transparently handled by the packages->manifest procedure, which is
commonly used in manifests (see the
--manifest option of guix package). Thus you can insert
an inferior package pretty much anywhere you would insert a regular package:
in manifests, in the packages field of your operating-system
declaration, and so on.
Next: Invocación de guix archive, Previous: Inferiores, Up: Gestión de paquetes [Contents][Index]
6.9 Invocación de guix describe
A menudo desea responder a preguntas como: “¿Qué revisión de Guix estoy
usando?” o “¿Qué canales estoy usando?” Esto es una información muy útil
en muchas situaciones: si quiere replicar un entorno en una máquina
diferente o cuenta de usuaria, si desea informar de un error o determinar
qué cambio en los canales que usa lo causó, o si quiere almacenar el estado
de su sistema por razones de reproducibilidad. La orden guix
describe responde a estas preguntas.
Cuando se ejecuta desde un guix bajado con guix pull,
guix describe muestra el/los canal/es desde el/los que se
construyó, incluyendo la URL de su repositorio y los IDs de las revisiones
(see Canales):
$ guix describe
Generation 10 Sep 03 2018 17:32:44 (current)
guix e0fa68c
repository URL: https://git.savannah.gnu.org/git/guix.git
branch: master
commit: e0fa68c7718fffd33d81af415279d6ddb518f727
Si está familiarizado con el sistema de control de versiones Git, esto es
similar a git describe; la salida también es similar a la de
guix pull --list-generations, pero limitada a la generación actual
(see the --list-generations option). Debido
a que el ID de revisión Git mostrado antes refiere sin ambigüedades al
estado de Guix, esta información es todo lo necesario para describir la
revisión de Guix que usa, y también para replicarla.
Para facilitar la replicación de Guix, también se le puede solicitar a
guix describe devolver una lista de canales en vez de la
descripción legible por humanos mostrada antes:
$ guix describe -f channels
(list (channel
(name 'guix)
(url "https://git.savannah.gnu.org/git/guix.git")
(commit
"e0fa68c7718fffd33d81af415279d6ddb518f727")
(introduction
(make-channel-introduction
"9edb3f66fd807b096b48283debdcddccfea34bad"
(openpgp-fingerprint
"BBB0 2DDF 2CEA F6A8 0D1D E643 A2A0 6DF2 A33A 54FA")))))
Puede almacenar esto en un archivo y se lo puede proporcionar a
guix pull -C en otra máquina o en un momento futuro, lo que
instanciará esta revisión exacta de Guix (see the -C option). De aquí en adelante, ya que puede desplegar la
misma revisión de Guix, puede también replicar un entorno completo de
software. Nosotras humildemente consideramos que esto es
impresionante, ¡y esperamos que le guste a usted también!
Los detalles de las opciones aceptadas por guix describe son las
siguientes:
--format=formato-f formatoProduce salida en el formato especificado, uno de:
humanproduce salida legible por humanos;
channelsproduce una lista de especificaciones de canales que puede ser pasada a
guix pull -Co instalada como ~/.config/guix/channels.scm (see Invocación deguix pull);channels-sans-introcomo
channels, pero se omite el campointroduction; se puede usar para producir una especificación de canal adecuada para la versión 1.1.0 de Guix y versiones anteriores—el campointroductionestá relacionado con la verificación de canales (see Verificación de canales) y no está implementado en dichas versiones;json¶produce una lista de especificaciones de canales en formato JSON;
recutilsproduce una lista de especificaciones de canales en formato Recutils.
--list-formatsMuestra los formatos disponibles para la opción --format.
--profile=perfil-p perfilMuestra información acerca del perfil.
Previous: Invocación de guix describe, Up: Gestión de paquetes [Contents][Index]
6.10 Invocación de guix archive
La orden guix archive permite a las usuarias exportar
archivos del almacén en un único archivador, e importarlos
posteriormente en una máquina que ejecute Guix. En particular, permite que
los archivos del almacén sean transferidos de una máquina al almacén de otra
máquina.
Nota: Si está buscando una forma de producir archivos en un formato adecuado para herramientas distintas a Guix, see Invocación de
guix pack.
Para exportar archivos del almacén como un archivo por la salida estándar, ejecute:
guix archive --export opciones especificaciones...
especificaciones deben ser o bien nombres de archivos del almacén o
especificaciones de paquetes, como las de guix package
(see Invocación de guix package). Por ejemplo, la siguiente orden crea un
archivo que contiene la salida gui del paquete git y la salida
principal de emacs:
guix archive --export git:gui /gnu/store/...-emacs-24.3 > great.nar
Si los paquetes especificados no están todavía construidos, guix
archive los construye automáticamente. El proceso de construcción puede
controlarse mediante las opciones de construcción comunes (see Opciones comunes de construcción).
Para transferir el paquete emacs a una máquina conectada por SSH, se
ejecutaría:
guix archive --export -r emacs | ssh otra-maquina guix archive --import
De manera similar, un perfil de usuaria completo puede transferirse de una máquina a otra de esta manera:
guix archive --export -r $(readlink -f ~/.guix-profile) | \ ssh otra-maquina guix archive --import
No obstante, fíjese que, en ambos ejemplos, todo emacs y el perfil
como también todas sus dependencias son transferidas (debido a la
-r), independiente de lo que estuviese ya disponible en el almacén
de la máquina objetivo. La opción --missing puede ayudar a
esclarecer qué elementos faltan en el almacén objetivo. La orden
guix copy simplifica y optimiza este proceso completo, así que
probablemente es lo que debería usar en este caso (see Invocación de guix copy).
Cada elemento del almacén se escribe en formato de archivo normalizado
o nar (descrito a continuación), y la salida de guix archive
--export (y entrada de guix archive --import) es un
empaquetado nar.
El formato “nar” es comparable a ‘tar’ en el espíritu, pero con diferencias que lo hacen más apropiado para nuestro propósito. Primero, en vez de almacenar todos los metadatos Unix de cada archivo, el formato nar solo menciona el tipo de archivo (normal, directorio o enlace simbólico); los permisos Unix y el par propietario/grupo se descartan. En segundo lugar, el orden en el cual las entradas de directorios se almacenan siempre siguen el orden de los nombres de archivos de acuerdo a la ordenación de cadenas en la localización C. Esto hace la producción del archivo completamente determinista.
El formato del empaquetado nar es esencialmente una concatenación de cero o más nar junto a metadatos para cada elemento del almacén que contiene: su nombre de archivo, referencias, derivación correspondiente y firma digital.
Durante la exportación, el daemon firma digitalmente los contenidos del archivo, y la firma digital se adjunta. Durante la importación, el daemon verifica la firma y rechaza la importación en caso de una firma inválida o si la clave firmante no está autorizada.
Las opciones principales son:
--exportExporta los archivos del almacén o paquetes (véase más adelante). Escribe el archivo resultante a la salida estándar.
Las dependencias no están incluidas en la salida, a menos que se use --recursive.
-r--recursiveCuando se combina con --export, instruye a
guix archivepara incluir las dependencias de los elementos dados en el archivo. Por tanto, el archivo resultante está auto-contenido: contiene la clausura de los elementos exportados del almacén.--importLee un archivo de la entrada estándar, e importa los archivos enumerados allí en el almacén. La operación se aborta si el archivo tiene una firma digital no válida, o si está firmado por una clave pública que no está entre las autorizadas (vea --authorize más adelante).
--missingLee una lista de nombres de archivos del almacén de la entrada estándar, uno por línea, y escribe en la salida estándar el subconjunto de estos archivos que faltan en el almacén.
--generate-key[=parámetros]¶Genera un nuevo par de claves para el daemon. Esto es un prerrequisito antes de que los archivos puedan ser exportados con --export. Esta operación es habitualmente instantánea pero puede tomar tiempo si la piscina de entropía necesita tiene que rellenarse. En el sistema Guix
guix-service-typese encarga de generar este par de claves en el primer arranque.El par de claves generado se almacena típicamente bajo /etc/guix, en signing-key.pub (clave pública) y signing-key.sec (clave privada, que se debe mantener secreta). Cuando parámetros se omite, se genera una clave ECDSA usando la curva Ed25519, o, en versiones de Libgcrypt previas a la 1.6.0, es una clave RSA de 4096 bits. De manera alternativa, los parámetros pueden especificar parámetros
genkeyadecuados para Libgcrypt (seegcry_pk_genkeyin The Libgcrypt Reference Manual).--authorize¶Autoriza importaciones firmadas con la clave pública pasada por la entrada estándar. La clave pública debe estar en el “formato avanzado de expresiones-s”—es decir, el mismo formato que el archivo signing-key.pub.
La lista de claves autorizadas se mantiene en el archivo editable por personas /etc/guix/acl. El archivo contiene “expresiones-s en formato avanzado” y está estructurado como una lista de control de acceso en el formato Infraestructura Simple de Clave Pública (SPKI).
--extract=directorio-x directorioLee un único elemento del archivo como es ofrecido por los servidores de sustituciones (see Sustituciones) y lo extrae a directorio. Esta es una operación de bajo nivel necesitada únicamente para casos muy concretos; véase a continuación.
For example, the following command extracts the substitute for Emacs served by
ci.guix.gnu.orgto /tmp/emacs:$ wget -O - \ https://ci.guix.gnu.org/nar/gzip/…-emacs-24.5 \ | gunzip | guix archive -x /tmp/emacs
Los archivos de un único elemento son diferentes de los archivos de múltiples elementos producidos por
guix archive --export; contienen un único elemento del almacén, y no embeben una firma. Por tanto esta operación no verifica la firma y su salida debe considerarse insegura.El propósito primario de esta operación es facilitar la inspección de los contenidos de un archivo que provenga probablemente de servidores de sustituciones en los que no se confía (see Invocación de
guix challenge).--list-tLee un único elemento del archivo como es ofrecido por los servidores de sustituciones (see Sustituciones) e imprime la lista de archivos que contiene, como en este ejemplo:
$ wget -O - \ https://ci.guix.gnu.org/nar/lzip/…-emacs-26.3 \ | lzip -d | guix archive -t
Next: Desarrollo, Previous: Gestión de paquetes, Up: GNU Guix [Contents][Index]
7 Canales
Guix y su colección de paquetes se actualizan ejecutando guix pull
(see Invocación de guix pull). Por defecto guix pull descarga y
despliega el mismo Guix del repositorio oficial de GNU Guix. Esto se
puede personalizar definiendo canales en el archivo
~/.config/guix/channels.scm. Un canal especifica una URL y una rama
de un repositorio Git que será desplegada, y guix pull puede ser
instruido para tomar los datos de uno o más canales. En otras palabras, los
canales se pueden usar para personalizar y para extender Guix,
como vemos a continuación. Guix tiene en cuenta consideraciones de seguridad
e implementa actualizaciones verificadas.
- Especificación de canales adicionales
- Uso de un canal de Guix personalizado
- Replicación de Guix
- Verificación de canales
- Channels with Substitutes
- Creación de un canal
- Módulos de paquetes en un subdirectorio
- Declaración de dependencias de canales
- Especificación de autorizaciones del canal
- URL primaria
- Escribir de noticias del canal
Next: Uso de un canal de Guix personalizado, Up: Canales [Contents][Index]
7.1 Especificación de canales adicionales
You can specify additional channels to pull from. To use a channel,
write ~/.config/guix/channels.scm to instruct guix pull to
pull from it in addition to the default Guix channel(s):
;; Añade variaciones de paquetes sobre los que proporciona Guix. (cons (channel (name 'paquetes-personalizados) (url "https://example.org/paquetes-personalizados.git")) %default-channels)
Fíjese que el fragmento previo es (¡como siempre!) código Scheme; usamos
cons para añadir un canal a la lista de canales a la que la variable
%default-channels hace referencia (see cons and
lists in GNU Guile Reference Manual). Con el archivo en este lugar,
guix pull no solo construye Guix sino también los módulos de
paquetes de su propio repositorio. El resultado en
~/.config/guix/current es la unión de Guix con sus propios módulos de
paquetes:
$ guix describe
Generation 19 Aug 27 2018 16:20:48
guix d894ab8
repository URL: https://git.savannah.gnu.org/git/guix.git
branch: master
commit: d894ab8e9bfabcefa6c49d9ba2e834dd5a73a300
variant-packages dd3df5e
repository URL: https://example.org/variant-packages.git
branch: master
commit: dd3df5e2c8818760a8fc0bd699e55d3b69fef2bb
The output of guix describe above shows that we’re now running
Generation 19 and that it includes both Guix and packages from the
variant-personal-packages channel (see Invocación de guix describe).
Next: Replicación de Guix, Previous: Especificación de canales adicionales, Up: Canales [Contents][Index]
7.2 Uso de un canal de Guix personalizado
El canal llamado guix especifica de dónde debe descargarse el mismo
Guix—sus herramientas de línea de órdenes y su colección de
paquetes—. Por ejemplo, suponga que quiere actualizar de otra copia del
repositorio Guix en example.org, y específicamente la rama
super-hacks, para ello puede escribir en
~/.config/guix/channels.scm esta especificación:
;; Le dice a 'guix pull' que use mi propio repositorio. (list (channel (name 'guix) (url "https://example.org/otro-guix.git") (branch "super-hacks")))
From there on, guix pull will fetch code from the
super-hacks branch of the repository at example.org. The
authentication concern is addressed below (see Verificación de canales).
Next: Verificación de canales, Previous: Uso de un canal de Guix personalizado, Up: Canales [Contents][Index]
7.3 Replicación de Guix
The guix describe command shows precisely which commits were used
to build the instance of Guix we’re using (see Invocación de guix describe).
We can replicate this instance on another machine or at a different point in
time by providing a channel specification “pinned” to these commits that
looks like this:
;; Despliega unas revisiones específicas de mis canales de interés. (list (channel (name 'guix) (url "https://git.savannah.gnu.org/git/guix.git") (commit "d894ab8e9bfabcefa6c49d9ba2e834dd5a73a300")) (channel (name 'paquetes-personalizados) (url "https://example.org/paquetes-personalizados.git") (branch "dd3df5e2c8818760a8fc0bd699e55d3b69fef2bb")))
To obtain this pinned channel specification, the easiest way is to run
guix describe and to save its output in the channels format
in a file, like so:
guix describe -f channels > channels.scm
The resulting channels.scm file can be passed to the -C
option of guix pull (see Invocación de guix pull) or guix
time-machine (see Invocación de guix time-machine), as in this example:
guix time-machine -C channels.scm -- shell python -- python3
Given the channels.scm file, the command above will always fetch the
exact same Guix instance, then use that instance to run the exact
same Python (see Invoking guix shell). On any machine, at any time, it
ends up running the exact same binaries, bit for bit.
Pinned channels address a problem similar to “lock files” as implemented by some deployment tools—they let you pin and reproduce a set of packages. In the case of Guix though, you are effectively pinning the entire package set as defined at the given channel commits; in fact, you are pinning all of Guix, including its core modules and command-line tools. You’re also getting strong guarantees that you are, indeed, obtaining the exact same software.
Esto le proporciona superpoderes, lo que le permite seguir la pista de la procedencia de los artefactos binarios con un grano muy fino, y reproducir entornos de software a su voluntad—un tipo de capacidad de “meta-reproducibilidad”, si lo desea. See Inferiores, para otro modo de tomar ventaja de estos superpoderes.
Next: Channels with Substitutes, Previous: Replicación de Guix, Up: Canales [Contents][Index]
7.4 Verificación de canales
Las órdenes guix pull y guix time-machine
verifican el código obtenido de los canales: se aseguran de que cada
commit que se obtenga se encuentre firmado por una desarrolladora
autorizada. El objetivo es proteger de modificaciones no-autorizadas al
canal que podrían provocar que las usuarias ejecuten código pernicioso.
Como usuaria, debe proporcionar una presentación del canal en su archivo de canales de modo que Guix sepa como verificar su primera revision. La especificación de una canal, incluyendo su introducción, es más o menos así:
(channel
(name 'un-canal)
(url "https://example.org/un-canal.git")
(introduction
(make-channel-introduction
"6f0d8cc0d88abb59c324b2990bfee2876016bb86"
(openpgp-fingerprint
"CABB A931 C0FF EEC6 900D 0CFB 090B 1199 3D9A EBB5"))))
La especificación previa muestra el nombre y la URL del canal. La llamada a
make-channel-introduction especifica que la identificación de este
canal empieza en la revisión 6f0d8cc…, que está firmada por la
clave de OpenPGP que tiene la huella CABB A931….
En el canal principal, llamado guix, obtiene esta información de
manera automática desde su instalación de Guix. Para otros canales, incluya
la presentación del canal proporcionada por sus autoras en su archivo
channels.scm. Asegúrese de obtener la presentación del canal desde
una fuente confiable ya que es la raíz de su confianza.
Si tiene curiosidad sobre los mecanismos de identificación y verificación, ¡siga leyendo!
Next: Creación de un canal, Previous: Verificación de canales, Up: Canales [Contents][Index]
7.5 Channels with Substitutes
When running guix pull, Guix will first compile the definitions of
every available package. This is an expensive operation for which
substitutes (see Sustituciones) may be available. The following snippet
in channels.scm will ensure that guix pull uses the latest
commit with available substitutes for the package definitions: this is done
by querying the continuous integration server at
https://ci.guix.gnu.org.
(use-modules (guix ci)) (list (channel-with-substitutes-available %default-guix-channel "https://ci.guix.gnu.org"))
Note that this does not mean that all the packages that you will install
after running guix pull will have available substitutes. It only
ensures that guix pull will not try to compile package
definitions. This is particularly useful when using machines with limited
resources.
Next: Módulos de paquetes en un subdirectorio, Previous: Channels with Substitutes, Up: Canales [Contents][Index]
7.6 Creación de un canal
Digamos que tiene un montón de variaciones personalizadas de paquetes que piensa que no tiene mucho sentido contribuir al proyecto Guix, pero quiere tener esos paquetes disponibles en su línea de órdenes de manera transparente. Primero debería escribir módulos que contengan esas definiciones de paquete (see Módulos de paquetes), mantenerlos en un repositorio Git, y de esta manera usted y cualquier otra persona podría usarlos como un canal adicional del que obtener paquetes. Limpio, ¿no?
Aviso: Antes de que, querida usuaria, grite—“¡Guau, esto es la caña!”—y publique su canal personal al mundo, nos gustaría compartir algunas palabras de precaución:
- Antes de publicar un canal, por favor considere contribuir sus definiciones de paquete al propio Guix (see Contribuir). Guix como proyecto es abierto a software libre de todo tipo, y los paquetes en el propio Guix están disponibles para todas las usuarias de Guix y se benefician del proceso de gestión de calidad del proyecto.
- Cuando mantiene definiciones de paquete fuera de Guix, nosotras, las desarrolladoras de Guix, consideramos que la carga de la compatibilidad cae de su lado. Recuerde que los módulos y definiciones de paquetes son solo código Scheme que usa varias interfaces programáticas (APIs). Queremos mantener la libertad de cambiar dichas interfaces para seguir mejorando Guix, posiblemente en formas que pueden romper su canal. Nunca cambiamos las interfaces gratuitamente, pero no vamos tampoco a congelar las interfaces.
- Corolario: si está usando un canal externo y el canal se rompe, por favor informe del problema a las autoras del canal, no al proyecto Guix.
¡Ha quedado advertida! Habiendo dicho esto, creemos que los canales externos son una forma práctica de ejercitar su libertad para aumentar la colección de paquetes de Guix y compartir su mejoras, que son pilares básicos del software libre. Por favor, envíenos un correo a guix-devel@gnu.org si quiere hablar sobre esto.
Para crear un canal, cree un repositorio Git que contenga sus propios
módulos de paquetes y haga que esté disponible. El repositorio puede
contener cualquier cosa, pero un canal útil contendrá módulos Guile que
exportan paquetes. Una vez comience a usar un canal, Guix se comportará como
si el directorio raíz del repositorio Git de dicho canal hubiese sido
añadido a la ruta de carga de Guile (see Load Paths in GNU Guile
Reference Manual). Por ejemplo, si su canal contiene un archivo en
mis-paquetes/mis-herramientas.scm que define un módulo, entonces
dicho módulo estará disponible bajo el nombre (mis-paquetes
mis-herramientas), y podrá usarlo como cualquier otro módulo
(see Modules in GNU Guile Reference Manual).
Como autora de un canal, considere adjuntar el material para la identificación a su canal de modo que las usuarias puedan verificarlo. See Verificación de canales, y Especificación de autorizaciones del canal, para obtener información sobre cómo hacerlo.
Next: Declaración de dependencias de canales, Previous: Creación de un canal, Up: Canales [Contents][Index]
7.7 Módulos de paquetes en un subdirectorio
Como autora de un canal, es posible que desee mantener los módulos de su canal en un subdirectorio. Si sus módulos se encuentran en el subdirectorio guix, debe añadir un archivo .guix-channel de metadatos que contenga:
(channel
(version 0)
(directory "guix"))
Next: Especificación de autorizaciones del canal, Previous: Módulos de paquetes en un subdirectorio, Up: Canales [Contents][Index]
7.8 Declaración de dependencias de canales
Las autoras de canales pueden decidir aumentar una colección de paquetes proporcionada por otros canales. Pueden declarar su canal como dependiente de otros canales en el archivo de metadatos .guix-channel, que debe encontrarse en la raíz del repositorio del canal.
Este archivo de metadatos debe contener una expresión-S simple como esta:
(channel
(version 0)
(dependencies
(channel
(name some-collection)
(url "https://example.org/first-collection.git")
;; The 'introduction' bit below is optional: you would
;; provide it for dependencies that can be authenticated.
(introduction
(channel-introduction
(version 0)
(commit "a8883b58dc82e167c96506cf05095f37c2c2c6cd")
(signer "CABB A931 C0FF EEC6 900D 0CFB 090B 1199 3D9A EBB5"))))
(channel
(name some-other-collection)
(url "https://example.org/second-collection.git")
(branch "testing"))))
En el ejemplo previo, este canal se declara como dependiente de otros dos canales, que se obtendrán de manera automática. Los módulos proporcionados por el canal se compilarán en un entorno donde los módulos de todos estos canales declarados estén disponibles.
De cara a la confianza proporcionada y el esfuerzo que supondrá su mantenimiento, debería evitar depender de canales que no controle, y debería intentar minimizar el número de dependencias.
Next: URL primaria, Previous: Declaración de dependencias de canales, Up: Canales [Contents][Index]
7.9 Especificación de autorizaciones del canal
Como hemos visto previamente, Guix se asegura de que el código fuente que obtiene de los canales proviene de desarrolladoras autorizadas. Como autora del canal, es necesario que especifique la lista de desarrolladoras autorizadas en el archivo .guix-authorizations del repositorio Git del canal. Las reglas para la verificación son simples: cada revisión debe firmarse con una de las claves enumeradas en el archivo .guix-authorizations de la revisión o revisiones anteriores14 El archivo .guix-authorizations tiene está estructura básica:
;; Archivo '.guix-authorizations' de ejemplo. (authorizations (version 0) ;versión de formato actual (("AD17 A21E F8AE D8F1 CC02 DBD9 F8AE D8F1 765C 61E3" (name "alicia")) ("CABB A931 C0FF EEC6 900D 0CFB 090B 1199 3D9A EBB5" (name "carlos")) ("2A39 3FFF 68F4 EF7A 3D29 12AF 68F4 EF7A 22FB B2D5" (name "rober"))))
Cada huella va seguida de pares clave/valor opcionales, como en el ejemplo siguiente. Actualmente se ignoran dichos pares.
Estas reglas de verificación dan lugar a un problema “del huevo y la gallina”: ¿cómo se verifica la primera revisión? En relación con esto: ¿cómo se gestionan los canales cuyo repositorio tiene en su historia revisiones sin firmar y carece del archivo .guix-authorizations? ¿Y cómo creamos un nuevo canal separado en base a un canal ya existente?
Channel introductions answer these questions by describing the first commit
of a channel that should be authenticated. The first time a channel is
fetched with guix pull or guix time-machine, the command
looks up the introductory commit and verifies that it is signed by the
specified OpenPGP key. From then on, it authenticates commits according to
the rule above. Authentication fails if the target commit is neither a
descendant nor an ancestor of the introductory commit.
De manera adicional, su canal debe proporcionar todas las claves públicas
que hayan sido mencionadas en .guix-authorizations, almacenadas como
archivos .key, los cuales pueden ser binarios o tener “armadura
ASCII”. De manera predeterminada, esos archivos .key se buscan en la
rama llamada keyring pero puede especificar una rama diferente en
.guix-channel de este modo:
(channel
(version 0)
(keyring-reference "mi-rama-de-claves"))
En resumen, como autora de un canal, hay tres cosas que debe hacer para permitir que las usuarias verifiquen su código:
- Exportar las claves OpenPGP de quienes contribuyan en el presente y quienes
hayan contribuido en el pasado con
gpg --exporty almacenarlas en archivos .key, de manera predeterminada en una rama llamadakeyring(recomendamos que sea una rama huérfana). - Introducir un archivo inicial .guix-authorizations en el repositorio del canal. Hágalo con una revisión firmada (see Acceso al repositorio, para más información sobre cómo firmar revisiones).
- Anuncie la presentación del canal, por ejemplo, en la página web de su canal. La presentación del canal, como hemos visto antes, es el par revisión/clave—es decir, la revisión que introdujo el archivo .guix-authorizations, y la huella de la clave de OpenPGP usada para firmarlo.
Antes de que suba los cambios a su repositorio Git público puede ejecutar
guix git-authenticate para verificar que ha firmado todas las
revisiones que va a subir con una clave autorizada:
guix git authenticate revisión firma
donde revisión y firma son la presentación de su canal.
See Invocación de guix git authenticate, para obtener más detalles.
Publicar un canal firmado requiere disciplina: cualquier error, como una revisión sin firmar o una revisión firmada por una clave no autorizada, evitará que las usuarias obtengan nuevas versiones de su canal—bueno, ¡ese es principalmente el objetivo de la verificación! Preste especial atención a la mezcla de ramas: las revisiones de mezcla se consideran auténticas únicamente en caso de que la clave que firma esté presente en el archivo .guix-authorizations de ambas ramas.
Next: Escribir de noticias del canal, Previous: Especificación de autorizaciones del canal, Up: Canales [Contents][Index]
7.10 URL primaria
Las autoras pueden declarar la URL primaria del repositorio Git de su canal en el archivo .guix-channel de esta manera:
(channel
(version 0)
(url "https://example.org/guix.git"))
This allows guix pull to determine whether it is pulling code from
a mirror of the channel; when that is the case, it warns the user that the
mirror might be stale and displays the primary URL. That way, users cannot
be tricked into fetching code from a stale mirror that does not receive
security updates.
Esta caraterística únicamente tiene sentido en repositorios verificables,
como el canal oficial guix, en el que guix pull se asegura
de verificar la autenticidad del código que obtiene.
Previous: URL primaria, Up: Canales [Contents][Index]
7.11 Escribir de noticias del canal
Las autoras los canales pueden querer ocasionalmente comunicar información a sus usuarias acerca de cambios importantes en el canal. Podrían mandar un correo a todo el mundo, pero esto no es tan conveniente.
En vez de eso, los canales proporcionan un archivo de noticias; cuando
las usuarias de un canal ejecutan guix pull, dicho archivo de
noticias se lee automáticamente y guix pull --news puede mostrar
los anuncios que correspondan a las nuevas revisiones que se han obtenido,
si existen.
Para hacerlo, las autoras del canal deben declarar primero el nombre del archivo de noticias en su archivo .guix-channel:
(channel
(version 0)
(news-file "etc/noticias.txt"))
El archivo de noticias en sí, etc/noticias.txt en este ejemplo, debe ser similar a este:
(channel-news
(version 0)
(entry (tag "the-bug-fix")
(title (en "Fixed terrible bug")
(fr "Oh la la")
(es "Podemos volver a dormir en calma"))
(body (en "@emph{Good news}! It's fixed!")
(eo "Certe ĝi pli bone funkcias nun!")
(es "¡Al fin se ha corregido el error!")))
(entry (commit "bdcabe815cd28144a2d2b4bc3c5057b051fa9906")
(title (en "Added a great package")
(ca "Què vol dir guix?")
(es "Nuevo paquete añadido"))
(body (en "Don't miss the @code{hello} package!")
(es "Atención a la versátil herramienta @code{hello}"))))
Aunque el archivo de noticias use sintaxis de Scheme evite nombrarlo con .scm como extensión o se usará cuando se construya el canal, lo que emitirá un error debido a que no es un módulo válido. También puede mover el módulo del canal a un subdirectorio y almacenar el archivo de noticias en otro directorio.
Este archivo consiste en una lista de entradas de noticias. Cada entrada15 se asocia a una revisión o una etiqueta: describe los cambios llevados a cabo en ella, y posiblemente también en revisiones anteriores. Las usuarias ven las entradas únicamente la primera vez que obtienen la revisión a la que la entrada hace referencia.
El campo del título (title) debe ser un resumen de una línea mientras
que el cuerpo de la noticia (body) puede ser arbitrariamente largo, y
ambos pueden contener marcas de Texinfo (see Overview in GNU
Texinfo). Tanto el título como el cuerpo son una lista de tuplas de
etiqueta de lengua y mensaje, lo que permite a guix pull mostrar
las noticias en la lengua que corresponde a la localización de la usuaria.
Si desea traducir las noticias siguiendo un flujo de trabajo basado en
gettext, puede extraer las cadenas traducibles con xgettext
(see xgettext Invocation in GNU Gettext Utilities). Por
ejemplo, asumiendo que escribe las entradas de noticias primero en inglés,
la siguiente orden crea un archivo PO que contiene las cadenas a traducir:
xgettext -o news.po -l scheme -ken etc/news.txt
En resumen, sí, puede usar su canal como un blog. Pero tenga en cuenta que esto puede que no sea exactamente lo que sus usuarias podrían esperar.
Next: Interfaz programática, Previous: Canales, Up: GNU Guix [Contents][Index]
8 Desarrollo
Si es una desarrolladora de software, Guix le proporciona herramientas que debería encontrar útiles—independientemente del lenguaje en el que desarrolle actualmente. Esto es sobre lo que trata este capítulo.
The guix shell command provides a convenient way to set up one-off
software environments, be it for development purposes or to run a command
without installing it in your profile. The guix pack command
allows you to create application bundles that can be easily
distributed to users who do not run Guix.
- Invoking
guix shell - Invocación de
guix environment - Invocación de
guix pack - La cadena de herramientas de GCC
- Invocación de
guix git authenticate
Next: Invocación de guix environment, Up: Desarrollo [Contents][Index]
8.1 Invoking guix shell
The purpose of guix shell is to make it easy to create one-off
software environments, without changing one’s profile. It is typically used
to create development environments; it is also a convenient way to run
applications without “polluting” your profile.
Nota: The
guix shellcommand was recently introduced to supersedeguix environment(see Invocación deguix environment). If you are familiar withguix environment, you will notice that it is similar but also—we hope!—more convenient.
La sintaxis general es:
guix shell [options] [package…]
The following example creates an environment containing Python and NumPy,
building or downloading any missing package, and runs the python3
command in that environment:
guix shell python python-numpy -- python3
Development environments can be created as in the example below, which spawns an interactive shell containing all the dependencies and environment variables needed to work on Inkscape:
guix shell --development inkscape
Exiting the shell places the user back in the original environment before
guix shell was invoked. The next garbage collection
(see Invocación de guix gc) may clean up packages that were installed in the
environment and that are no longer used outside of it.
As an added convenience, guix shell will try to do what you mean
when it is invoked interactively without any other arguments as in:
guix shell
If it finds a manifest.scm in the current working directory or any of
its parents, it uses this manifest as though it was given via
--manifest. Likewise, if it finds a guix.scm in the same
directories, it uses it to build a development profile as though both
--development and --file were present. In either case, the
file will only be loaded if the directory it resides in is listed in
~/.config/guix/shell-authorized-directories. This provides an easy
way to define, share, and enter development environments.
By default, the shell session or command runs in an augmented
environment, where the new packages are added to search path environment
variables such as PATH. You can, instead, choose to create an
isolated environment containing nothing but the packages you asked
for. Passing the --pure option clears environment variable
definitions found in the parent environment16; passing --container goes one step further by
spawning a container isolated from the rest of the system:
guix shell --container emacs gcc-toolchain
The command above spawns an interactive shell in a container where nothing
but emacs, gcc-toolchain, and their dependencies is
available. The container lacks network access and shares no files other
than the current working directory with the surrounding environment. This
is useful to prevent access to system-wide resources such as /usr/bin
on foreign distros.
This --container option can also prove useful if you wish to run a
security-sensitive application, such as a web browser, in an isolated
environment. For example, the command below launches Ungoogled-Chromium in
an isolated environment, this time sharing network access with the host and
preserving its DISPLAY environment variable, but without even sharing
the current directory:
guix shell --container --network --no-cwd ungoogled-chromium \ --preserve='^DISPLAY$' -- chromium
guix shell defines the GUIX_ENVIRONMENT variable in the
shell it spawns; its value is the file name of the profile of this
environment. This allows users to, say, define a specific prompt for
development environments in their .bashrc (see Bash Startup
Files in The GNU Bash Reference Manual):
if [ -n "$GUIX_ENVIRONMENT" ]
then
export PS1="\u@\h \w [dev]\$ "
fi
... o para explorar el perfil:
$ ls "$GUIX_ENVIRONMENT/bin"
Las opciones disponibles se resumen a continuación.
--checkSet up the environment and check whether the shell would clobber environment variables. It’s a good idea to use this option the first time you run
guix shellfor an interactive session to make sure your setup is correct.For example, if the shell modifies the
PATHenvironment variable, report it since you would get a different environment than what you asked for.Such problems usually indicate that the shell startup files are unexpectedly modifying those environment variables. For example, if you are using Bash, make sure that environment variables are set or modified in ~/.bash_profile and not in ~/.bashrc—the former is sourced only by log-in shells. See Bash Startup Files in The GNU Bash Reference Manual, for details on Bash start-up files.
--development-DCause
guix shellto include in the environment the dependencies of the following package rather than the package itself. This can be combined with other packages. For instance, the command below starts an interactive shell containing the build-time dependencies of GNU Guile, plus Autoconf, Automake, and Libtool:guix shell -D guile autoconf automake libtool
--expression=expr-e exprCrea un entorno para el paquete o lista de paquetes a los que evalúa expr.
Por ejemplo, ejecutando:
guix shell -D -e '(@ (gnu packages maths) petsc-openmpi)'
inicia un shell con el entorno para esta variante específica del paquete PETSc.
Ejecutar:
guix shell -e '(@ (gnu) %base-packages)'
inicia un shell con todos los paquetes básicos del sistema disponibles.
Las órdenes previas usan únicamente la salida predeterminada de los paquetes dados. Para seleccionar otras salidas, tuplas de dos elementos pueden ser especificadas:
guix shell -e '(list (@ (gnu packages bash) bash) "include")'
See
package->development-manifest, for information on how to write a manifest for the development environment of a package.--file=archivo-f archivoCreate an environment containing the package or list of packages that the code within file evaluates to.
Como un ejemplo, archivo puede contener una definición como esta (see Definición de paquetes):
(use-modules (guix) (gnu packages gdb) (gnu packages autotools) (gnu packages texinfo)) ;; Augment the package definition of GDB with the build tools ;; needed when developing GDB (and which are not needed when ;; simply installing it.) (package (inherit gdb) (native-inputs (modify-inputs (package-native-inputs gdb) (prepend autoconf-2.64 automake texinfo))))With the file above, you can enter a development environment for GDB by running:
guix shell -D -f gdb-devel.scm
--manifest=archivo-m archivoCrea un entorno para los paquetes contenidos en el objeto manifest devuelto por el código Scheme en file. Esta opción se puede repetir varias veces, en cuyo caso los manifiestos se concatenan.
Esto es similar a la opción del mismo nombre en
guix package(see --manifest) y usa los mismos archivos de manifiesto.See Writing Manifests, for information on how to write a manifest. See --export-manifest below on how to obtain a first manifest.
--export-manifestWrite to standard output a manifest suitable for --manifest corresponding to given command-line options.
This is a way to “convert” command-line arguments into a manifest. For example, imagine you are tired of typing long lines and would like to get a manifest equivalent to this command line:
guix shell -D guile git emacs emacs-geiser emacs-geiser-guile
Just add --export-manifest to the command line above:
guix shell --export-manifest \ -D guile git emacs emacs-geiser emacs-geiser-guile
... and you get a manifest along these lines:
(concatenate-manifests (list (specifications->manifest (list "git" "emacs" "emacs-geiser" "emacs-geiser-guile")) (package->development-manifest (specification->package "guile"))))You can store it into a file, say manifest.scm, and from there pass it to
guix shellor indeed pretty much anyguixcommand:guix shell -m manifest.scm
Voilà, you’ve converted a long command line into a manifest! That conversion process honors package transformation options (see Opciones de transformación de paquetes) so it should be lossless.
--profile=perfil-p perfilCreate an environment containing the packages installed in profile. Use
guix package(see Invocación deguix package) to create and manage profiles.--pureOlvida las variables de entorno existentes cuando se construye un nuevo entorno, excepto aquellas especificadas con --preserve (véase más adelante). Esto tiene el efecto de crear un entorno en el que las rutas de búsqueda únicamente contienen las entradas del paquete.
--preserve=regexp-E regexpCuando se usa junto a --pure, preserva las variables de entorno que corresponden con regexp—en otras palabras, las pone en una lista de variables de entorno que deben preservarse. Esta opción puede repetirse varias veces.
guix shell --pure --preserve=^SLURM openmpi … \ -- mpirun …
Este ejemplo ejecuta
mpirunen un contexto donde las únicas variables de entorno definidas sonPATH, variables de entorno cuyo nombre empiece con ‘SLURM’, así como las variables “preciosas” habituales (HOME,USER, etc.).--search-pathsMuestra las definiciones de variables de entorno que componen el entorno.
--system=sistema-s sistemaIntenta construir para sistema—por ejemplo,
i686-linux.--container¶-CEjecuta la orden en un contenedor aislado. El directorio actual fuera del contenedor es asociado al interior del contenedor. Adicionalmente, a menos que se fuerce con --user, un directorio de prueba de la usuaria se crea de forma que coincida con el directorio actual de la usuaria, y /etc/passwd se configura adecuadamente.
El proceso lanzado se ejecuta como el usuario actual fuera del contenedor. Dentro del contenedor, tiene el mismo UID y GID que el usuario actual, a menos que se proporcione --user (véase más adelante).
--network-NPara contenedores, comparte el espacio de nombres de red con el sistema anfitrión. Los contenedores creados sin esta opción únicamente tienen acceso a la red local.
--link-profile-PFor containers, link the environment profile to ~/.guix-profile within the container and set
GUIX_ENVIRONMENTto that. This is equivalent to making ~/.guix-profile a symlink to the actual profile within the container. Linking will fail and abort the environment if the directory already exists, which will certainly be the case ifguix shellwas invoked in the user’s home directory.Determinados paquetes se configuran para buscar en ~/.guix-profile archivos de configuración y datos;17 --link-profile permite a estos programas operar de la manera esperada dentro del entorno.
--user=usuaria-u usuariaPara contenedores, usa el nombre de usuaria usuaria en vez de la actual. La entrada generada en /etc/passwd dentro del contenedor contendrá el nombre usuaria; su directorio será /home/usuaria y ningún dato GECOS de la usuaria se copiará. Más aún, el UID y GID dentro del contenedor son 1000. usuaria no debe existir en el sistema.
Adicionalmente, cualquier ruta compartida o expuesta (véanse --share y --expose respectivamente) cuyo destino esté dentro de la carpeta actual de la usuaria será reasociada en relación a /home/usuaria; esto incluye la relación automática del directorio de trabajo actual.
# will expose paths as /home/foo/wd, /home/foo/test, and /home/foo/target cd $HOME/wd guix shell --container --user=foo \ --expose=$HOME/test \ --expose=/tmp/target=$HOME/targetMientras esto limita el escape de la identidad de la usuaria a través de las rutas de sus directorios y cada uno de los campos de usuaria, esto es únicamente un componente útil de una solución de privacidad/anonimato más amplia—no una solución completa.
--no-cwdEl comportamiento predeterminado con contenedores es compartir el directorio de trabajo actual con el contenedor aislado e inmediatamente cambiar a dicho directorio dentro del contenedor. Si no se desea este comportamiento, --no-cwd indica que el directorio actual no se compartirá automáticamente y, en vez de cambiar a dicho directorio, se cambiará al directorio de la usuaria dentro del contenedor. Véase también --user.
--expose=fuente[=destino]--share=fuente[=destino]En contenedores, la --expose expone el sistema de archivos fuente del sistema anfitrión como un sistema de archivos de solo-lectura destino dentro del contenedor. --share de la misma manera expone el sistema de archivos con posibilidad de escritura. Si no se especifica destino, fuente se usa como el punto de montaje en el contenedor.
El ejemplo a continuación lanza una sesión interactiva de Guile en un contenedor donde el directorio principal de la usuaria es accesible en modo solo-lectura a través del directorio /intercambio:
guix shell --container --expose=$HOME=/exchange guile -- guile
--symlink=spec-S specFor containers, create the symbolic links specified by spec, as documented in pack-symlink-option.
--emulate-fhs-FWhen used with --container, emulate a Filesystem Hierarchy Standard (FHS) configuration within the container, providing /bin, /lib, and other directories and files specified by the FHS.
As Guix deviates from the FHS specification, this option sets up the container to more closely mimic that of other GNU/Linux distributions. This is useful for reproducing other development environments, testing, and using programs which expect the FHS specification to be followed. With this option, the container will include a version of glibc that will read /etc/ld.so.cache within the container for the shared library cache (contrary to glibc in regular Guix usage) and set up the expected FHS directories: /bin, /etc, /lib, and /usr from the container’s profile.
--rebuild-cache¶-
In most cases,
guix shellcaches the environment so that subsequent uses are instantaneous. Least-recently used cache entries are periodically removed. The cache is also invalidated, when using --file or --manifest, anytime the corresponding file is modified.The --rebuild-cache forces the cached environment to be refreshed. This is useful when using --file or --manifest and the
guix.scmormanifest.scmfile has external dependencies, or if its behavior depends, say, on environment variables. --root=archivo¶-r archivo-
Hace que archivo sea un enlace simbólico al perfil para este entorno, y lo registra como una raíz del recolector de basura.
Esto es útil si desea proteger su entorno de la recolección de basura, hacerlo “persistente”.
When this option is omitted,
guix shellcaches profiles so that subsequent uses of the same environment are instantaneous—this is comparable to using --root except thatguix shelltakes care of periodically removing the least-recently used garbage collector roots.In some cases,
guix shelldoes not cache profiles—e.g., if transformation options such as --with-latest are used. In those cases, the environment is protected from garbage collection only for the duration of theguix shellsession. This means that next time you recreate the same environment, you could have to rebuild or re-download packages.See Invocación de
guix gc, for more on GC roots.
guix shell also supports all of the common build options that
guix build supports (see Opciones comunes de construcción) as well as
package transformation options (see Opciones de transformación de paquetes).
Next: Invocación de guix pack, Previous: Invoking guix shell, Up: Desarrollo [Contents][Index]
8.2 Invocación de guix environment
The purpose of guix environment is to assist in creating
development environments.
Deprecation warning: The
guix environmentcommand is deprecated in favor ofguix shell, which performs similar functions but is more convenient to use. See Invokingguix shell.Being deprecated,
guix environmentis slated for eventual removal, but the Guix project is committed to keeping it until May 1st, 2023. Please get in touch with us at guix-devel@gnu.org if you would like to discuss it.
La sintaxis general es:
guix environment opciones paquete…
El ejemplo siguiente lanza un nuevo shell preparado para el desarrollo de GNU Guile:
guix environment guile
Si las dependencias necesarias no están construidas todavía, guix
environment las construye automáticamente. El entorno del nuevo shell es
una versión aumentada del entorno en el que guix environment se
ejecutó. Contiene las rutas de búsqueda necesarias para la construcción del
paquete proporcionado añadidas a las variables ya existentes. Para crear un
entorno “puro”, donde las variables de entorno previas no existen, use la
opción --pure18.
Exiting from a Guix environment is the same as exiting from the shell, and
will place the user back in the old environment before guix
environment was invoked. The next garbage collection (see Invocación de guix gc) will clean up packages that were installed from within the environment
and are no longer used outside of it.
guix environment define la variable GUIX_ENVIRONMENT en el
shell que lanza; su valor es el nombre de archivo del perfil para este
entorno. Esto permite a las usuarias, digamos, definir un prompt para
entornos de desarrollo en su .bashrc (see Bash Startup Files in The GNU Bash Reference Manual):
if [ -n "$GUIX_ENVIRONMENT" ]
then
export PS1="\u@\h \w [dev]\$ "
fi
... o para explorar el perfil:
$ ls "$GUIX_ENVIRONMENT/bin"
Adicionalmente, más de un paquete puede ser especificado, en cuyo caso se usa la unión de las entradas de los paquetes proporcionados. Por ejemplo, la siguiente orden lanza un shell donde todas las dependencias tanto de Guile como de Emacs están disponibles:
guix environment guile emacs
A veces no se desea una sesión interactiva de shell. Una orden arbitraria se
puede invocar usando el valor -- para separar la orden del resto de
los parámetros:
guix environment guile -- make -j4
In other situations, it is more convenient to specify the list of packages
needed in the environment. For example, the following command runs
python from an environment containing Python 3 and NumPy:
guix environment --ad-hoc python-numpy python -- python3
Es más, se pueden desear las dependencias de un paquete y también algunos paquetes adicionales que no son dependencias ni en tiempo de construcción ni en el de ejecución, pero son útiles no obstante para el desarrollo. Por esta razón, la opción --ad-hoc es posicional. Los paquetes que aparecen antes de --ad-hoc se interpretan como paquetes cuyas dependencias se añadirán al entorno. Los paquetes que aparecen después se interpretan como paquetes que se añadirán directamente al entorno. Por ejemplo, la siguiente orden crea un entorno de desarrollo Guix que incluye adicionalmente Git y strace:
guix environment --pure guix --ad-hoc git strace
En ocasiones es deseable aislar el entorno tanto como sea posible, para obtener la máxima pureza y reproducibilidad. En particular, cuando se usa Guix en una distribución anfitriona que no es el sistema Guix, es deseable prevenir acceso a /usr/bin y otros recursos del sistema desde el entorno de desarrollo. Por ejemplo, la siguiente orden lanza un REPL Guile en un “contenedor” donde únicamente el almacén y el directorio actual están montados:
guix environment --ad-hoc --container guile -- guile
Nota: La opción --container requiere Linux-libre 3.19 o posterior.
Otro caso de uso típico para los contenedores es la ejecución de
aplicaciones sensibles como navegadores web. Para ejecutar Eolie, debemos
exponer y compartir algunos archivos y directorios; incluimos
nss-certs y exponemos /etc/ssl/certs/ para la identificación
HTTPS; por último preservamos la variable de entorno DISPLAY ya que
las aplicaciones gráficas en el contenedor no se mostrarían sin ella.
guix environment --preserve='^DISPLAY$' --container --network \ --expose=/etc/machine-id \ --expose=/etc/ssl/certs/ \ --share=$HOME/.local/share/eolie/=$HOME/.local/share/eolie/ \ --ad-hoc eolie nss-certs dbus -- eolie
Las opciones disponibles se resumen a continuación.
--checkSet up the environment and check whether the shell would clobber environment variables. See --check, for more info.
--root=archivo¶-r archivo-
Hace que archivo sea un enlace simbólico al perfil para este entorno, y lo registra como una raíz del recolector de basura.
Esto es útil si desea proteger su entorno de la recolección de basura, hacerlo “persistente”.
Cuando se omite esta opción, el entorno se protege de la recolección de basura únicamente por la duración de la sesión
guix environment. Esto significa que la siguiente vez que vuelva a crear el mismo entorno, puede tener que reconstruir o volver a descargar paquetes. See Invocación deguix gc, para más información sobre las raíces del recolector de basura. --expression=expr-e exprCrea un entorno para el paquete o lista de paquetes a los que evalúa expr.
Por ejemplo, ejecutando:
guix environment -e '(@ (gnu packages maths) petsc-openmpi)'
inicia un shell con el entorno para esta variante específica del paquete PETSc.
Ejecutar:
guix environment --ad-hoc -e '(@ (gnu) %base-packages)'
inicia un shell con todos los paquetes básicos del sistema disponibles.
Las órdenes previas usan únicamente la salida predeterminada de los paquetes dados. Para seleccionar otras salidas, tuplas de dos elementos pueden ser especificadas:
guix environment --ad-hoc -e '(list (@ (gnu packages bash) bash) "include")'
--load=archivo-l archivoCrea un entorno para el paquete o la lista de paquetes a la que el código en archivo evalúa.
Como un ejemplo, archivo puede contener una definición como esta (see Definición de paquetes):
(use-modules (guix) (gnu packages gdb) (gnu packages autotools) (gnu packages texinfo)) ;; Augment the package definition of GDB with the build tools ;; needed when developing GDB (and which are not needed when ;; simply installing it.) (package (inherit gdb) (native-inputs (modify-inputs (package-native-inputs gdb) (prepend autoconf-2.64 automake texinfo))))--manifest=archivo-m archivoCrea un entorno para los paquetes contenidos en el objeto manifest devuelto por el código Scheme en file. Esta opción se puede repetir varias veces, en cuyo caso los manifiestos se concatenan.
Esto es similar a la opción del mismo nombre en
guix package(see --manifest) y usa los mismos archivos de manifiesto.See
guix shell --export-manifest, for information on how to “convert” command-line options into a manifest.--ad-hocIncluye todos los paquetes especificados en el entorno resultante, como si un paquete ad hoc hubiese sido definido con ellos como entradas. Esta opción es útil para la creación rápida un entorno sin tener que escribir una expresión de paquete que contenga las entradas deseadas.
Por ejemplo, la orden:
guix environment --ad-hoc guile guile-sdl -- guile
ejecuta
guileen un entorno donde están disponibles Guile y Guile-SDL.Fíjese que este ejemplo solicita implícitamente la salida predeterminada de
guileyguile-sdl, pero es posible solicitar una salida específica—por ejemplo,glib:binsolicita la salidabindeglib(see Paquetes con múltiples salidas).Esta opción puede componerse con el comportamiento predeterminado de
guix environment. Los paquetes que aparecen antes de --ad-hoc se interpretan como paquetes cuyas dependencias se añadirán al entorno, el comportamiento predefinido. Los paquetes que aparecen después se interpretan como paquetes a añadir directamente al entorno.--profile=perfil-p perfilCreate an environment containing the packages installed in profile. Use
guix package(see Invocación deguix package) to create and manage profiles.--pureOlvida las variables de entorno existentes cuando se construye un nuevo entorno, excepto aquellas especificadas con --preserve (véase más adelante). Esto tiene el efecto de crear un entorno en el que las rutas de búsqueda únicamente contienen las entradas del paquete.
--preserve=regexp-E regexpCuando se usa junto a --pure, preserva las variables de entorno que corresponden con regexp—en otras palabras, las pone en una lista de variables de entorno que deben preservarse. Esta opción puede repetirse varias veces.
guix environment --pure --preserve=^SLURM --ad-hoc openmpi … \ -- mpirun …
Este ejemplo ejecuta
mpirunen un contexto donde las únicas variables de entorno definidas sonPATH, variables de entorno cuyo nombre empiece con ‘SLURM’, así como las variables “preciosas” habituales (HOME,USER, etc.).--search-pathsMuestra las definiciones de variables de entorno que componen el entorno.
--system=sistema-s sistemaIntenta construir para sistema—por ejemplo,
i686-linux.--container¶-CEjecuta la orden en un contenedor aislado. El directorio actual fuera del contenedor es asociado al interior del contenedor. Adicionalmente, a menos que se fuerce con --user, un directorio de prueba de la usuaria se crea de forma que coincida con el directorio actual de la usuaria, y /etc/passwd se configura adecuadamente.
El proceso lanzado se ejecuta como el usuario actual fuera del contenedor. Dentro del contenedor, tiene el mismo UID y GID que el usuario actual, a menos que se proporcione --user (véase más adelante).
--network-NPara contenedores, comparte el espacio de nombres de red con el sistema anfitrión. Los contenedores creados sin esta opción únicamente tienen acceso a la red local.
--link-profile-PPara contenedores, enlaza el perfil del entorno a ~/.guix-profile dentro del contenedor y asigna ese valor a
GUIX_ENVIRONMENT. Es equivalente a que ~/.guix-profile sea un enlace al perfil real dentro del contenedor. El enlace fallará e interrumpirá el entorno si el directorio ya existe, lo cual será probablemente el caso siguix environmentse invocó en el directorio de la usuaria.Determinados paquetes se configuran para buscar en ~/.guix-profile archivos de configuración y datos;19 --link-profile permite a estos programas operar de la manera esperada dentro del entorno.
--user=usuaria-u usuariaPara contenedores, usa el nombre de usuaria usuaria en vez de la actual. La entrada generada en /etc/passwd dentro del contenedor contendrá el nombre usuaria; su directorio será /home/usuaria y ningún dato GECOS de la usuaria se copiará. Más aún, el UID y GID dentro del contenedor son 1000. usuaria no debe existir en el sistema.
Adicionalmente, cualquier ruta compartida o expuesta (véanse --share y --expose respectivamente) cuyo destino esté dentro de la carpeta actual de la usuaria será reasociada en relación a /home/usuaria; esto incluye la relación automática del directorio de trabajo actual.
# expondrá las rutas /home/foo/ddt, /home/foo/prueba y /home/foo/objetivo cd $HOME/ddt guix environment --container --user=foo \ --expose=$HOME/prueba \ --expose=/tmp/objetivo=$HOME/objetivoMientras esto limita el escape de la identidad de la usuaria a través de las rutas de sus directorios y cada uno de los campos de usuaria, esto es únicamente un componente útil de una solución de privacidad/anonimato más amplia—no una solución completa.
--no-cwdEl comportamiento predeterminado con contenedores es compartir el directorio de trabajo actual con el contenedor aislado e inmediatamente cambiar a dicho directorio dentro del contenedor. Si no se desea este comportamiento, --no-cwd indica que el directorio actual no se compartirá automáticamente y, en vez de cambiar a dicho directorio, se cambiará al directorio de la usuaria dentro del contenedor. Véase también --user.
--expose=fuente[=destino]--share=fuente[=destino]En contenedores, la --expose expone el sistema de archivos fuente del sistema anfitrión como un sistema de archivos de solo-lectura destino dentro del contenedor. --share de la misma manera expone el sistema de archivos con posibilidad de escritura. Si no se especifica destino, fuente se usa como el punto de montaje en el contenedor.
El ejemplo a continuación lanza una sesión interactiva de Guile en un contenedor donde el directorio principal de la usuaria es accesible en modo solo-lectura a través del directorio /intercambio:
guix environment --container --expose=$HOME=/intercambio --ad-hoc guile -- guile
--emulate-fhs-FFor containers, emulate a Filesystem Hierarchy Standard (FHS) configuration within the container, see the official specification. As Guix deviates from the FHS specification, this option sets up the container to more closely mimic that of other GNU/Linux distributions. This is useful for reproducing other development environments, testing, and using programs which expect the FHS specification to be followed. With this option, the container will include a version of
glibcwhich will read/etc/ld.so.cachewithin the container for the shared library cache (contrary toglibcin regular Guix usage) and set up the expected FHS directories:/bin,/etc,/lib, and/usrfrom the container’s profile.
Además, guix environment acepta todas las opciones comunes de
construcción que permite guix build (see Opciones comunes de construcción)
así como las opciones de transformación de paquetes (see Opciones de transformación de paquetes).
Next: La cadena de herramientas de GCC, Previous: Invocación de guix environment, Up: Desarrollo [Contents][Index]
8.3 Invocación de guix pack
De manera ocasional querrá dar software a gente que (¡todavía!) no tiene la
suerte de usar Guix. Usted les diría que ejecuten guix package -i
algo, pero eso no es posible en este caso. Aquí es donde viene
guix pack.
Nota: Si está buscando formas de intercambiar binarios entre máquinas que ya ejecutan Guix, see Invocación de
guix copy, Invocación deguix publish, y Invocación deguix archive.
La orden guix pack crea un paquete reducido o
empaquetado de software: crea un archivador tar u otro tipo que
contiene los binarios del software en el que está interesada y todas sus
dependencias. El archivo resultante puede ser usado en una máquina que no
tiene Guix, y la gente puede ejecutar exactamente los mismos binarios que
usted tiene con Guix. El paquete en sí es creado de forma reproducible
bit-a-bit, para que cualquiera pueda verificar que realmente contiene los
resultados de construcción que pretende distribuir.
Por ejemplo, para crear un empaquetado que contenga Guile, Emacs, Geiser y todas sus dependencias, puede ejecutar:
$ guix pack guile emacs emacs-geiser … /gnu/store/…-pack.tar.gz
El resultado aquí es un archivador tar que contiene un directorio de
/gnu/store con todos los paquetes relevantes. El archivador
resultante contiene un perfil con los tres paquetes de interés; el
perfil es el mismo que se hubiera creado por guix package -i. Este
es el mecanismo usado para crear el propio archivador de binarios separado
de Guix (see Instalación binaria).
Las usuarias de este empaquetad tendrán que ejecutar /gnu/store/…-profile/bin/guile para ejecutar guile, lo que puede resultar inconveniente. Para evitarlo, puede crear, digamos, un enlace simbólico /opt/gnu/bin al perfil:
guix pack -S /opt/gnu/bin=bin guile emacs emacs-geiser
De este modo, las usuarias pueden escribir alegremente /opt/gnu/bin/guile y disfrutar.
¿Qué pasa se la receptora de su paquete no tiene privilegios de root en su máquina y por lo tanto no puede desempaquetarlo en la raíz del sistema de archivos? En ese caso, lo que usted desea es usar la opción --relocatable (véase a continuación). Esta opción produce binarios reposicionables, significando que pueden ser colocados en cualquier lugar de la jerarquía del sistema de archivos: en el ejemplo anterior, las usuarias pueden desempaquetar el archivador en su directorio de usuaria y ejecutar directamente ./opt/gnu/bin/guile.
De manera alternativa, puede producir un empaquetado en el formato de imagen Docker usando la siguiente orden:
guix pack -f docker -S /bin=bin guile guile-readline
El resultado es un archivador “tar” que puede ser proporcionado a la orden
docker load, seguida de docker run:
docker load < archivo docker run -ti guile-guile-readline /bin/guile
donde archivo es la imagen devuelta por guix pack, y
guile-guile-readline es la “etiqueta de imagen”. Véase la
documentación de Docker para más información.
Otra opción más es producir una imagen SquashFS con la siguiente orden:
guix pack -f squashfs bash guile emacs emacs-geiser
El resultado es una imagen de sistema de archivos SquashFS que puede ser o
bien montada, o bien usada directamente como una imagen contenedora de
sistemas de archivos con el entorno de
ejecución de contenedores Singularity, usando órdenes como
singularity shell o singularity exec.
Varias opciones de la línea de órdenes le permiten personalizar su empaquetado:
--format=formato-f formatoProduce un empaquetado en el formato específico.
Los formatos disponibles son:
tarballEs el formato predeterminado. Produce un archivador que contiene todos los binarios y enlaces simbólicos especificados.
dockerProduce un archivador que sigue la especificación de imágenes Docker. El “nombre de repositorio” como aparece en la salida de la orden
docker imagesse calcula a partir de los nombres de paquete proporcionados en la línea de órdenes o en el archivo de manifiesto.squashfsProduce una imagen SquashFS que contiene todos los binarios y enlaces simbólicos especificados, así como puntos de montaje vacíos para sistemas de archivos virtuales como procfs.
Nota: Singularity necesita que proporcione /bin/sh en la imagen. Por esta razón,
guix pack -f squashfssiempre implica-S /bin=bin. Por tanto, su invocación deguix packdebe siempre comenzar de manera similar a esta:guix pack -f squashfs bash …
Si se olvida del paquete
bash(o similar),singularity runysingularity execfallarán con el mensaje “no existe el archivo o directorio”, lo que no sirve de ayuda.debThis produces a Debian archive (a package with the ‘.deb’ file extension) containing all the specified binaries and symbolic links, that can be installed on top of any dpkg-based GNU(/Linux) distribution. Advanced options can be revealed via the --help-deb-format option. They allow embedding control files for more fine-grained control, such as activating specific triggers or providing a maintainer configure script to run arbitrary setup code upon installation.
guix pack -f deb -C xz -S /usr/bin/hello=bin/hello hello
Nota: Because archives produced with
guix packcontain a collection of store items and because eachdpkgpackage must not have conflicting files, in practice that means you likely won’t be able to install more than one such archive on a given system.Aviso:
dpkgwill assume ownership of any files contained in the pack that it does not know about. It is unwise to install Guix-produced ‘.deb’ files on a system where /gnu/store is shared by other software, such as a Guix installation or other, non-deb packs.
--relocatable-RProduce binarios reposicionables—es decir, binarios que se pueden encontrar en cualquier lugar de la jerarquía del sistema de archivos, y ejecutarse desde allí.
Cuando se proporciona una vez la opción, los binarios resultantes necesitan la implementación de espacios de nombres de usuaria del núcleo Linux; cuando se proporciona dos veces20, los binarios reposicionables usan otras técnicas si los espacios de nombres de usuaria no están disponibles, y funcionan esencialmente en cualquier sitio—véase más adelante las implicaciones.
Por ejemplo, si crea un empaquetado que contiene Bash con:
guix pack -RR -S /mybin=bin bash
... puede copiar ese empaquetado a una máquina que no tiene Guix, y desde su directorio, como una usuaria normal, ejecutar:
tar xf pack.tar.gz ./mibin/sh
En ese shell, si escribe
ls /gnu/store, notará que /gnu/store muestra y contiene todas las dependencias debash, ¡incluso cuando la máquina no tiene el directorio /gnu/store! Esto es probablemente el modo más simple de desplegar software construido en Guix en una máquina no-Guix.Nota: No obstante hay un punto a tener en cuenta: esta técnica descansa en la característica de espacios de nombres de usuaria del núcleo Linux, la cual permite a usuarias no privilegiadas montar o cambiar la raíz. Versiones antiguas de Linux no los implementan, y algunas distribuciones GNU/Linux los desactivan.
Para producir binarios reposicionables que funcionen incluso en ausencia de espacios de nombre de usuaria, proporcione --relocatable o -R dos veces. En ese caso, los binarios intentarán el uso de espacios de nombres de usuaria y usarán otro motor de ejecución si los espacios de nombres no están disponibles. Existe implementación para siguientes motores de ejecución:
defaultIntenta usar espacios de nombres de usuaria y usa PRoot en caso de no estar disponibles (véase a continuación).
performanceIntenta usar espacios de nombres de usuaria y usa Fakechroot en caso de no estar disponibles (véase a continuación).
usernsUsa espacios de nombres de usuaria o aborta el programa si no están disponibles.
prootEjecución a través de PRoot. El programa PRoot proporciona el soporte necesario para la virtualización del sistema de archivos. Lo consigue mediante el uso de la llamada al sistema
ptraceen el programa en ejecución. Esta aproximación tiene la ventaja de funcionar sin soporte especial en el núcleo, pero incurre en una sobrecarga en el tiempo de ejecución cada vez que se realiza una llamada al sistema.fakechrootEjecución a través de Fakechroot. Fakechroot virtualiza los accesos al sistema de archivos interceptando las llamadas a las funciones de la biblioteca de C como
open,stat,exec, etcétera. Al contrario que PRoot, el proceso se somete únicamente a una pequeña sobrecarga. No obstante, no siempre funciona: algunos accesos realizados dentro de la biblioteca de C no se interceptan, ni tampoco los accesos al sistema de archivos a través de llamadas al sistema directas, lo que puede provocar un comportamiento impredecible.
Cuando ejecute un programa recubierto puede solicitar explícitamente uno de los motores de ejecución enumerados previamente proporcionando el valor adecuado a la variable de entorno
GUIX_EXECUTION_ENGINE.--entry-point=ordenUsa orden como el punto de entrada del empaquetado resultante, si el formato de empaquetado lo permite—actualmente
dockerysquashfs(Singularity) lo permiten. orden debe ser una ruta relativa al perfil contenido en el empaquetado.El punto de entrada especifica la orden que herramientas como
docker runosingularity runarrancan de manera automática de forma predeterminada. Por ejemplo, puede ejecutar:guix pack -f docker --entry-point=bin/guile guile
El empaquetado resultante puede cargarse fácilmente y
docker runsin parámetros adicionales lanzarábin/guile:docker load -i pack.tar.gz docker run image-id
--expression=expr-e exprConsidera el paquete al que evalúa expr
Su propósito es idéntico a la opción del mismo nombre en
guix build(see --expression enguix build).--manifest=archivo-m archivoUsa los paquetes contenidos en el objeto manifest devuelto por el código Scheme en archivo. Esta opción puede repetirse varias veces, en cuyo caso los manifiestos se concatenan.
Esto tiene un propósito similar al de la opción del mismo nombre en
guix package(see --manifest) y usa los mismos archivos de manifiesto. Esto le permite definir una colección de paquetes una vez y usarla tanto para crear perfiles como para crear archivos en máquinas que no tienen instalado Guix. Fíjese que puede especificar o bien un archivo de manifiesto o bien una lista de paquetes, pero no ambas.See Writing Manifests, for information on how to write a manifest. See
guix shell --export-manifest, for information on how to “convert” command-line options into a manifest.--system=sistema-s sistemaIntenta construir paquetes para sistema—por ejemplo,
x86_64-linux—en vez del tipo de sistema de la máquina de construcción.--target=tripleta¶Compilación cruzada para la tripleta, que debe ser una tripleta GNU válida, cómo
"aarch64-linux-gnu"(see GNU configuration triplets in Autoconf).--compression=herramienta-C herramientaComprime el archivador resultante usando herramienta—un valor que puede ser
gzip,zstd,bzip2,xz,lzipononepara no usar compresión.--symlink=spec-S specAñade los enlaces simbólicos especificados por spec al empaquetado. Esta opción puede aparecer varias veces.
La forma de spec es
fuente=destino, donde fuente es el enlace simbólico que será creado y destino es el destino del enlace simbólico.Por ejemplo,
-S /opt/gnu/bin=bincrea un enlace simbólico /opt/gnu/bin apuntando al subdirectorio bin del perfil.--save-provenanceAlmacena la información de procedencia para paquetes proporcionados en la línea de órdenes. La información de procedencia incluye la URL y revisión de los canales en uso (see Canales).
La información de procedencia se almacena en el archivo /gnu/store/…-profile/manifest dentro del empaquetado, junto a los metadatos habituales del paquete—el nombre y la versión de cada paquete, sus entradas propagadas, etcétera. Es información útil para la parte receptora del empaquetado, quien de ese modo conoce como se obtuvo (supuestamente) dicho empaquetado.
Esta opción no se usa de manera predeterminada debido a que, como las marcas de tiempo, la información de procedencia no aportan nada al proceso de construcción. En otras palabras, hay una infinidad de URL de canales e identificadores de revisiones que pueden llevar al mismo empaquetado. Almacenar estos metadatos “silenciosos” en la salida puede potencialmente romper la propiedad de reproducibilidad bit a bit entre fuentes y binarios.
--root=archivo¶-r archivoHace que archivo sea un enlace simbólico al empaquetado resultante, y lo registra como una raíz del recolector de basura.
--localstatedir--profile-name=nombreIncluye el “directorio de estado local”, /var/guix, en el empaquetado resultante, y notablemente el perfil /var/guix/profiles/per-user/root/nombre—por defecto nombre es
guix-profile, que corresponde con ~root/.guix-profile./var/guix contiene la base de datos del almacén (see El almacén) así como las raíces del recolector de basura (see Invocación de
guix gc). Proporcionarlo junto al empaquetado significa que el almacén está “completo” y Guix puede trabajar con él; no proporcionarlo significa que el almacén está “muerto”: no se pueden añadir o borrar nuevos elementos después de la extracción del empaquetado.Un caso de uso para esto es el archivador tar autocontenido de binarios de Guix (see Instalación binaria).
--derivation-dImprime el nombre de la derivación que construye el empaquetado.
--bootstrapUsa los binarios del lanzamiento para construir el empaquetado. Esta opción es útil únicamente a las desarrolladoras de Guix.
Además, guix pack acepta todas las opciones comunes de
construcción (see Opciones comunes de construcción) y todas las opciones de
transformación de paquetes (see Opciones de transformación de paquetes).
Next: Invocación de guix git authenticate, Previous: Invocación de guix pack, Up: Desarrollo [Contents][Index]
8.4 La cadena de herramientas de GCC
Si necesita una cadena de herramientas de desarrollo completa para compilar
y enlazar código fuente C o C++, use el paquete gcc-toolchain. Este
paquete proporciona una cadena de herramientas GCC para desarrollo C/C++,
incluyendo el propio GCC, la biblioteca de C GNU (cabeceras y binarios, más
símbolos de depuración de la salida debug), Binutils y un
recubrimiento del enlazador.
El propósito del recubrimiento es inspeccionar las opciones -L y
-l proporcionadas al enlazador, y los correspondientes parámetros
-rpath, y llamar al enlazador real con este nuevo conjunto de
parámetros. Puede instruir al recubrimiento para rechazar el enlace contra
bibliotecas que no se encuentren en el almacén proporcionando el valor
no a la variable de entorno GUIX_LD_WRAPPER_ALLOW_IMPURITIES.
El paquete gfortran-toolchain proporciona una cadena de herramientas
de desarrollo completa de GCC para desarrollo en Fortran. Para otros
lenguajes por favor use ‘guix search gcc toolchain’
(see Invoking guix package).
Previous: La cadena de herramientas de GCC, Up: Desarrollo [Contents][Index]
8.5 Invocación de guix git authenticate
La orden guix git authenticate verifica una revisión de Git
siguiendo las mismas reglas que con los canales
(see verificación de canales). Es decir,
empezando en una revisión dada, se asegura que todas las revisiones
posteriores están firmadas por una clave OpenPGP cuya huella aparece en el
archivo .guix-authorizations de su revisión o revisiones antecesoras.
Encontrará útil esta orden si mantiene un canal. Pero de hecho, este sistema de verificación es útil en un contexto más amplio, por lo que quizá quiera usarlo para repositorios de Git que no estén relacionados con Guix.
La sintaxis general es:
guix git authenticate revisión firma [opciones…]
De manera predeterminada esta orden verifica la copia de trabajo de Git en el directorio actual; no muestra nada y termina con un código de salida cero en caso satisfactorio y con un valor distinto a cero en caso de fallo. revisión denota la primera revisión a partir de la cual la verificación tiene lugar, y firma es la huella de OpenPGP de la clave pública usada para firmar revisión. Juntas forman la “presentación del canal” (see presentación del canal). Las siguientes opciones le permiten controlar con más detalle el proceso.
--repository=directorio-r directorioUsa el repositorio Git en directorio en vez del directorio actual.
--keyring=referencia-k referenciaCarga el anillo de claves desde referencia, la rama de referencia como por ejemplo
origin/keyringomi-anillo-de-claves. La rama debe contener las claves públicas de OpenPGP en archivos .key, binarios o con “armadura ASCII’. De manera predeterminada el anillo de claves se carga de la rama con nombrekeyring.--statsMuestra las estadísticas de firmas de revisiones tras finalizar.
--cache-key=claveLas revisiones verificadas previamente se almacenan en un archivo bajo ~/.cache/guix/authentication. Esta opción fuerza el almacenamiento en el archivo clave de dicho directorio.
--historical-authorizations=archivoDe manera predeterminada, cualquier revisión cuyo antecesor o antecesores carezcan del archivo .guix-authorizations no se considera auténtica. En contraste, esta opción considera las autorizaciones en archivo para cualquier revisión que carezca de .guix-authorizations. El formato de archivo es el mismo que el de .guix-authorizations (see formato de .guix-authorizations).
Next: Utilidades, Previous: Desarrollo, Up: GNU Guix [Contents][Index]
9 Interfaz programática
GNU Guix proporciona viarias interfaces programáticas Scheme (APIs) para definir, construir y consultar paquetes. La primera interfaz permite a las usuarias escribir definiciones de paquetes a alto nivel. Estas definiciones referencian conceptos familiares de empaquetamiento, como el nombre y la versión de un paquete, su sistema de construcción y sus dependencias. Estas definiciones se pueden convertir en acciones concretas de construcción.
Las acciones de construcción son realizadas por el daemon Guix, en delegación de las usuarias. En una configuración estándar, el daemon tiene acceso de escritura al almacén—el directorio /gnu/store—mientras que las usuarias no. En la configuración recomendada el daemon también realiza las construcciones en chroots, bajo usuarias específicas de construcción, para minimizar la interferencia con el resto del sistema.
Las APIs de nivel más bajo están disponibles para interactuar con el daemon y el almacén. Para instruir al daemon para realizar una acción de construcción, las usuarias realmente proporcionan una derivación. Una derivación es una representación de bajo nivel de las acciones de construcción a tomar, y el entorno en el que deberían suceder—las derivaciones son a las definiciones de paquetes lo que es el ensamblador a los programas en C. El término “derivación” viene del hecho de que los resultados de la construcción derivan de ellas.
Este capítulo describe todas estas APIs en orden, empezando por las definiciones de alto nivel de paquetes.
- Módulos de paquetes
- Definición de paquetes
- Definición de variantes de paquetes
- Writing Manifests
- Sistemas de construcción
- Fases de construcción
- Utilidades de construcción
- Search Paths
- El almacén
- Derivaciones
- La mónada del almacén
- Expresiones-G
- Invocación de
guix repl - Using Guix Interactively
Next: Definición de paquetes, Up: Interfaz programática [Contents][Index]
9.1 Módulos de paquetes
Desde un punto de vista programático, las definiciones de paquetes de la
distribución GNU se proporcionan por módulos Guile en el espacio de nombres
(gnu packages …)21 (see Guile modules in GNU Guile Reference Manual). Por ejemplo, el módulo
(gnu packages emacs) exporta una variable con nombre emacs,
que está asociada a un objeto <package> (see Definición de paquetes).
El espacio de nombres de módulos (gnu packages …) se recorre
automáticamente en busca de paquetes en las herramientas de línea de
ordenes. Por ejemplo, cuando se ejecuta guix install emacs, todos los
módulos (gnu packages …) son procesados hasta encontrar uno que
exporte un objeto de paquete cuyo nombre sea emacs. Esta búsqueda de
paquetes se implementa en el módulo (gnu packages).
Las usuarias pueden almacenar definiciones de paquetes en módulos con
nombres diferentes—por ejemplo, (mis-paquetes
emacs)22. Existen dos maneras de
hacer visibles estas definiciones de paquetes a las interfaces de usuaria:
- Mediante la adición del directorio que contiene sus módulos de paquetes a la
ruta de búsqueda con la opción
-Ldeguix packagey otras órdenes (see Opciones comunes de construcción), o usando la variable de entornoGUIX_PACKAGE_PATHdescrita a continuación. - Mediante la definición de un canal y la configuración de
guix pullde manera que se actualice desde él. Un canal es esencialmente un repositorio Git que contiene módulos de paquetes. See Canales, para más información sobre cómo definir y usar canales.
GUIX_PACKAGE_PATH funciona de forma similar a otras variables de rutas
de búsqueda:
- Variable de entorno: GUIX_PACKAGE_PATH
Es una lista separada por dos puntos de directorios en los que se buscarán módulos de paquetes adicionales. Los directorios enumerados en esta variable tienen preferencia sobre los propios módulos de la distribución.
La distribución es auto-contenida y completamente basada en el
lanzamiento inicial: cada paquete se construye basado únicamente en otros
paquetes de la distribución. La raíz de este grafo de dependencias es un
pequeño conjunto de binarios del lanzamiento inicial, proporcionados
por el módulo (gnu packages bootstrap). Para más información sobre el
lanzamiento inicial, see Lanzamiento inicial.
Next: Definición de variantes de paquetes, Previous: Módulos de paquetes, Up: Interfaz programática [Contents][Index]
9.2 Definición de paquetes
La interfaz de alto nivel de las definiciones de paquetes está implementada
en los módulos (guix packages) y (guix build-system). Como un
ejemplo, la definición de paquete, o receta, para el paquete GNU Hello
es como sigue:
(define-module (gnu packages hello) #:use-module (guix packages) #:use-module (guix download) #:use-module (guix build-system gnu) #:use-module (guix licenses) #:use-module (gnu packages gawk)) (define-public hello (package (name "hello") (version "2.10") (source (origin (method url-fetch) (uri (string-append "mirror://gnu/hello/hello-" version ".tar.gz")) (sha256 (base32 "0ssi1wpaf7plaswqqjwigppsg5fyh99vdlb9kzl7c9lng89ndq1i")))) (build-system gnu-build-system) (arguments '(#:configure-flags '("--enable-silent-rules"))) (inputs (list gawk)) (synopsis "Hello, GNU world: An example GNU package") (description "Guess what GNU Hello prints!") (home-page "https://www.gnu.org/software/hello/") (license gpl3+)))
Sin ser una experta en Scheme—pero conociendo un poco de inglés—, la
lectora puede haber supuesto el significado de varios campos aquí. Esta
expresión asocia la variable hello al objeto <package>, que
esencialmente es un registro (see Scheme records in GNU
Guile Reference Manual). Este objeto de paquete puede ser inspeccionado
usando los procedimientos encontrados en el módulo (guix packages);
por ejemplo, (package-name hello)
devuelve—¡sorpresa!—"hello".
Con suerte, puede que sea capaz de importar parte o toda la definición del
paquete de su interés de otro repositorio, usando la orden guix
import (see Invocación de guix import).
En el ejemplo previo, hello se define en un módulo para ella,
(gnu packages hello). Técnicamente, esto no es estrictamente
necesario, pero es conveniente hacerlo: todos los paquetes definidos en
módulos bajo (gnu packages …) se reconocen automáticamente en
las herramientas de línea de órdenes (see Módulos de paquetes).
Hay unos pocos puntos que merece la pena destacar de la definición de paquete previa:
- El campo
sourcedel paquete es un objeto<origin>(see Referencia deorigin, para la referencia completa). Aquí se usa el métodourl-fetchde(guix download), lo que significa que la fuente es un archivo a descargar por FTP o HTTP.El prefijo
mirror://gnuinstruye aurl-fetchpara usar uno de los espejos GNU definidos en(guix download).El campo
sha256especifica el hash SHA256 esperado del archivo descargado. Es obligatorio, y permite a Guix comprobar la integridad del archivo. La forma(base32 …)introduce la representación base32 del hash. Puede obtener esta información conguix download(see Invocación deguix download) yguix hash(see Invocación deguix hash).Cuando sea necesario, la forma
origintambién puede tener un campopatchescon la lista de parches a ser aplicados, y un camposnippetcon una expresión Scheme para modificar el código fuente. -
El campo
build-systemespecifica el procedimiento de construcción del paquete (see Sistemas de construcción). Aquí,gnu-build-systemrepresenta el familiar sistema de construcción GNU, donde los paquetes pueden configurarse, construirse e instalarse con la secuencia de ordenes habitual./configure && make && make check && make install.Cuando comience a empaquetar software no trivial puede que necesite herramientas para manipular estas fases de construcción, manipular archivos, etcétera. See Utilidades de construcción para obtener más información sobre este tema.
- El campo
argumentsespecifica las opciones para el sistema de construcción (see Sistemas de construcción). Aquí son interpretadas porgnu-build-systemcomo una petición de ejecutar configure con la opción --enable-silent-rules.What about these quote (
') characters? They are Scheme syntax to introduce a literal list;'is synonymous withquote. Sometimes you’ll also see`(a backquote, synonymous withquasiquote) and,(a comma, synonymous withunquote). See quoting in GNU Guile Reference Manual, for details. Here the value of theargumentsfield is a list of arguments passed to the build system down the road, as withapply(seeapplyin GNU Guile Reference Manual).La secuencia almohadilla-dos puntos (
#:) define una palabra clave Scheme (see Keywords in GNU Guile Reference Manual), y#:configure-flagses una palabra clave usada para pasar un parámetro nominal al sistema de construcción (see Coding With Keywords in GNU Guile Reference Manual). - The
inputsfield specifies inputs to the build process—i.e., build-time or run-time dependencies of the package. Here, we add an input, a reference to thegawkvariable;gawkis itself bound to a<package>object.Fíjese que no hace falta que GCC, Coreutils, Bash y otras herramientas esenciales se especifiquen como entradas aquí. En vez de eso,
gnu-build-systemse hace cargo de asegurar que están presentes (see Sistemas de construcción).No obstante, cualquier otra dependencia debe ser especificada en el campo
inputs. Las dependencias no especificadas aquí simplemente no estarán disponibles para el proceso de construcción, provocando posiblemente un fallo de construcción.
See Referencia de package, para una descripción completa de los campos
posibles.
Más allá: Intimidated by the Scheme language or curious about it? The Cookbook has a short section to get started that recaps some of the things shown above and explains the fundamentals. See A Scheme Crash Course in GNU Guix Cookbook, for more information.
Una vez la definición de paquete esté en su lugar, el paquete puede ser
construido realmente usando la herramienta de línea de órdenes guix
build (see Invocación de guix build), pudiendo resolver cualquier fallo de
construcción que encuentre (see Depuración de fallos de construcción). Puede volver
a la definición del paquete fácilmente usando la orden guix edit
(see Invocación de guix edit). See Pautas de empaquetamiento, para más
información sobre cómo probar definiciones de paquetes, y Invocación de guix lint, para información sobre cómo comprobar la consistencia del estilo de
una definición.
Por último, see Canales, para información sobre cómo extender la
distribución añadiendo sus propias definiciones de paquetes en un “canal”.
Finalmente, la actualización de la definición con una nueva versión oficial
puede ser automatizada parcialmente por la orden guix refresh
(see Invocación de guix refresh).
Tras el telón, una derivación correspondiente al objeto <package> se
calcula primero mediante el procedimiento package-derivation. Esta
derivación se almacena en un archivo .drv bajo /gnu/store. Las
acciones de construcción que prescribe pueden entonces llevarse a cabo
usando el procedimiento build-derivations (see El almacén).
- Procedimiento Scheme: package-derivation almacén paquete [sistema]
Devuelve el objeto
<derivation>del paquete pra el sistema (see Derivaciones).paquete debe ser un objeto
<package>válido, y sistema debe ser una cadena que denote el tipo de sistema objetivo—por ejemplo,"x86_64-linux"para un sistema GNU x86_64 basado en Linux. almacén debe ser una conexión al daemon, que opera en el almacén (see El almacén).
De manera similar, es posible calcular una derivación que construye de forma cruzada un paquete para otro sistema:
- Procedimiento Scheme: package-cross-derivation almacén paquete plataforma [sistema]
Devuelve el objeto
<derivation>de paquete compilado de forma cruzada desde sistema a plataforma.plataforma debe ser una tripleta GNU válida que identifique al hardware y el sistema operativo deseado, como por ejemplo
"aarch64-linux-gnu"(see Specifying Target Triplets in Autoconf).
Una vez tenga sus definiciones de paquetes puede definir facilmente variantes de dichos paquetes. See Definición de variantes de paquetes para obtener más información sobre ello.
Next: Referencia de origin, Up: Definición de paquetes [Contents][Index]
9.2.1 Referencia de package
Esta sección resume todas las opciones disponibles en declaraciones
package (see Definición de paquetes).
- Tipo de datos: package
Este es el tipo de datos que representa la receta de un paquete.
nameEl nombre del paquete, como una cadena.
versionThe version of the package, as a string. See Versiones numéricas, for guidelines.
sourceUn objeto que determina cómo se debería obtener el código fuente del paquete. La mayor parte del tiempo, es un objeto
origin, que denota un archivo obtenido de Internet (see Referencia deorigin). También puede ser cualquier otro objeto “tipo-archivo” comolocal-file, que denota un archivo del sistema local de archivos (seelocal-file).build-systemEl sistema de construcción que debe ser usado para construir el paquete (see Sistemas de construcción).
arguments(predeterminados:'())The arguments that should be passed to the build system (see Sistemas de construcción). This is a list, typically containing sequential keyword-value pairs, as in this example:
(package (name "example") ;; several fields omitted (arguments (list #:tests? #f ;skip tests #:make-flags #~'("VERBOSE=1") ;pass flags to 'make' #:configure-flags #~'("--enable-frobbing"))))The exact set of supported keywords depends on the build system (see Sistemas de construcción), but you will find that almost all of them honor
#:configure-flags,#:make-flags,#:tests?, and#:phases. The#:phaseskeyword in particular lets you modify the set of build phases for your package (see Fases de construcción).inputs(predeterminadas:'()) ¶native-inputs(predeterminadas:'())propagated-inputs(predeterminadas:'())These fields list dependencies of the package. Each element of these lists is either a package, origin, or other “file-like object” (see Expresiones-G); to specify the output of that file-like object that should be used, pass a two-element list where the second element is the output (see Paquetes con múltiples salidas, for more on package outputs). For example, the list below specifies three inputs:
(list libffi libunistring `(,glib "bin")) ;the "bin" output of GLib
In the example above, the
"out"output oflibffiandlibunistringis used.Compatibility Note: Until version 1.3.0, input lists were a list of tuples, where each tuple has a label for the input (a string) as its first element, a package, origin, or derivation as its second element, and optionally the name of the output thereof that should be used, which defaults to
"out". For example, the list below is equivalent to the one above, but using the old input style:;; Old input style (deprecated). `(("libffi" ,libffi) ("libunistring" ,libunistring) ("glib:bin" ,glib "bin")) ;the "bin" output of GLib
This style is now deprecated; it is still supported but support will be removed in a future version. It should not be used for new package definitions. See Invoking
guix style, on how to migrate to the new style.La distinción entre
native-inputsyinputses necesaria cuando se considera la compilación cruzada. Cuando se compila desde una arquitectura distinta, las dependencias enumeradas eninputsson construidas para la arquitectura objetivo; de modo contrario, las dependencias enumeradas ennative-inputsse construyen para la arquitectura de la máquina de construcción.native-inputsse usa típicamente para enumerar herramientas necesarias en tiempo de construcción, pero no en tiempo de ejecución, como Autoconf, Automake, pkg-config, Gettext o Bison.guix lintpuede informar de probables errores en este área (see Invocación deguix lint).Por último,
propagated-inputses similar ainputs, pero los paquetes especificados se instalarán automáticamente a los perfiles (see el rol de los perfiles en Guix) junto al paquete al que pertenecen (seeguix package, para información sobre cómoguix packagegestiona las entradas propagadas).Por ejemplo esto es necesario cuando se empaqueta una biblioteca C/C++ que necesita cabeceras de otra biblioteca para compilar, o cuando un archivo pkg-config se refiere a otro a través de su campo
Requires.Otro ejemplo donde
propagated-inputses útil es en lenguajes que carecen de la facilidad de almacenar la ruta de búsqueda de tiempo de ejecución de la misma manera que el campoRUNPATHde los archivos ELF; esto incluye Guile, Python, Perl y más. Cuando se empaquetan bibliotecas escritas en estos lenguajes, enumerar enpropagated-inputsen vez de eninputslas dependencias de tiempo de ejecución permite asegurarse de encontrar el código de las bibliotecas de las que dependan en tiempo de ejecución.outputs(predeterminada:'("out"))La lista de nombres de salidas del paquete. See Paquetes con múltiples salidas, para usos típicos de salidas adicionales.
native-search-paths(predeterminadas:'())search-paths(predeterminadas:'())A list of
search-path-specificationobjects describing search-path environment variables honored by the package. See Search Paths, for more on search path specifications.As for inputs, the distinction between
native-search-pathsandsearch-pathsonly matters when cross-compiling. In a cross-compilation context,native-search-pathsapplies exclusively to native inputs whereassearch-pathsapplies only to host inputs.Packages such as cross-compilers care about target inputs—for instance, our (modified) GCC cross-compiler has
CROSS_C_INCLUDE_PATHinsearch-paths, which allows it to pick .h files for the target system and not those of native inputs. For the majority of packages though, onlynative-search-pathsmakes sense.replacement(predeterminado:1.0)Esto debe ser o bien
#fo bien un objeto package que será usado como reemplazo para ete paquete. See injertos, para más detalles.synopsisUna descripción en una línea del paquete.
descriptionA more elaborate description of the package, as a string in Texinfo syntax.
license¶La licencia del paquete; un valor de
(guix licenses), o una lista de dichos valores.home-pageLa URL de la página principal del paquete, como una cadena.
supported-systems(predeterminados:%supported-systems)La lista de sistemas en los que se mantiene el paquete, como cadenas de la forma
arquitectura-núcleo, por ejemplo"x86_64-linux".location(predeterminada: la localización de los fuentes de la formapackage)La localización de las fuentes del paquete. Es útil forzar su valor cuando se hereda de otro paquete, en cuyo caso este campo no se corrige automáticamente.
- Sintaxis Scheme: this-package
Cuando se usa en el ámbito léxico de la definición de un paquete, este identificador resuelve al paquete que se está definiendo.
El ejemplo previo muestra cómo añadir un paquete como su propia entrada nativa cuando se compila de forma cruzada:
(package (name "guile") ;; ... ;; When cross-compiled, Guile, for example, depends on ;; a native version of itself. Add it here. (native-inputs (if (%current-target-system) (list this-package) '())))Es un error hacer referencia a
this-packagefuera de la definición de un paquete.
The following helper procedures are provided to help deal with package inputs.
- Scheme Procedure: lookup-package-input package name
- Scheme Procedure: lookup-package-native-input package name
- Scheme Procedure: lookup-package-propagated-input package name
- Scheme Procedure: lookup-package-direct-input package name
Look up name among package’s inputs (or native, propagated, or direct inputs). Return it if found,
#fotherwise.name is the name of a package depended on. Here’s how you might use it:
(use-modules (guix packages) (gnu packages base)) (lookup-package-direct-input coreutils "gmp") ⇒ #<package gmp@6.2.1 …>
In this example we obtain the
gmppackage that is among the direct inputs ofcoreutils.
Sometimes you will want to obtain the list of inputs needed to
develop a package—all the inputs that are visible when the package
is compiled. This is what the package-development-inputs procedure
returns.
- Scheme Procedure: package-development-inputs package [system] [#:target #f] Return the list of inputs required by
package for development purposes on system. When target is true, return the inputs needed to cross-compile package from system to target, where target is a triplet such as
"aarch64-linux-gnu".Note that the result includes both explicit inputs and implicit inputs—inputs automatically added by the build system (see Sistemas de construcción). Let us take the
hellopackage to illustrate that:(use-modules (gnu packages base) (guix packages)) hello ⇒ #<package hello@2.10 gnu/packages/base.scm:79 7f585d4f6790> (package-direct-inputs hello) ⇒ () (package-development-inputs hello) ⇒ (("source" …) ("tar" #<package tar@1.32 …>) …)
In this example,
package-direct-inputsreturns the empty list, becausehellohas zero explicit dependencies. Conversely,package-development-inputsincludes inputs implicitly added bygnu-build-systemthat are required to buildhello: tar, gzip, GCC, libc, Bash, and more. To visualize it,guix graph hellowould show you explicit inputs, whereasguix graph -t bag hellowould include implicit inputs (see Invocación deguix graph).
Debido a que los paquetes son objetos Scheme normales que capturan un grafo de dependencias completo y se asocian a procedimientos de construcción, habitualmente es útil escribir procedimientos que toman un paquete y devuelven una versión modificada de acuerdo a ciertos parámetros. A continuación se muestran algunos ejemplos:
- Procedimiento Scheme: package-with-c-toolchain paquete cadena
Devuelve una variación de paquete que usa cadena en vez de la cadena de herramientas de construcción de C/C++ de GNU predeterminada. cadena debe ser una lista de entradas (tuplas etiqueta/paquete) que proporcionen una funcionalidad equivalente a la del paquete
gcc-toolchain.El siguiente ejemplo devuelve una variación del paquete
helloque se ha construido con GCC 10.x y el resto de la cadena de herramientas de construcción de GNU (Binutils y la biblioteca de C de GNU) en vez de la cadena de construcción predeterminada:(let ((cadena (specification->package "gcc-toolchain@10"))) ;; El nombre de la entrada debe ser "toolchain". (package-with-c-toolchain hello `(("toolchain" ,cadena))))La cadena de herramientas de construcción es parte de las entradas impícitas de los paquetes—habitualmente no se enumera como parte de los distintos campos de entrada (“inputs”) sino que el sistema de construcción es quién la incorpora. Por lo tanto este procedimiento funciona cambiando el sistema de construcción del paquete de modo que se incorpora cadena en vez de los valores predeterminados. Sistemas de construcción para obtener más información sobre sistemas de construcción.
Previous: Referencia de package, Up: Definición de paquetes [Contents][Index]
9.2.2 Referencia de origin
Esta sección documenta los orígenes. Una declaración de origen
(origin) especifica datos que se deben “producir”—descargandose,
habitualmente—y el hash de su contenido se conoce de antemano. Los
origenes se usan habitualmente para reprensentar el código fuente de los
paquetes (see Definición de paquetes). Por esta razón la forma sintáctica
origin le permite declarar tanto parches para aplicar al código
fuente original como fragmentos de código que para su modificación.
- Tipo de datos: origin
Este es el tipo de datos que representa un origen de código fuente.
uriUn objeto que contiene el URI de las fuentes. El tipo de objeto depende del valor de
method(véase a continuación). Por ejemplo, cuando se usa el método url-fetch de(guix download), los valores adecuados paraurison: una cadena que contiene una URL, o una lista de cadenas.methodA monadic procedure that handles the given URI. The procedure must accept at least three arguments: the value of the
urifield and the hash algorithm and hash value specified by thehashfield. It must return a store item or a derivation in the store monad (see La mónada del almacén); most methods return a fixed-output derivation (see Derivaciones).Los métodos habitualmente usados incluyen
url-fetch, que obtiene datos a partir de una URL, ygit-fetch, que obtiene datos de un repositorio Git (véase a continuación).sha256Un vector de bytes que contiene el hash SHA-256 de las fuentes. Es equivalente a proporcionar un objeto SHA256
content-hashen el campohashdescrito a continuación.hashEl objeto
content-hashde las fuentes—véase a continuación cómo usarcontent-hash.Puede obtener esta información usando
guix download(see Invocación deguix download) oguix hash(see Invocación deguix hash).file-name(predeterminado:#f)El nombre de archivo bajo el que el código fuente se almacenará. Cuando este es
#f, un valor predeterminado sensato se usará en la mayor parte de casos. En caso de que las fuentes se obtengan de una URL, el nombre de archivo de la URL se usará. Para copias de trabajo de sistemas de control de versiones, se recomienda proporcionar el nombre de archivo explícitamente ya que el predeterminado no es muy descriptivo.patches(predeterminados:'())Una lista de nombres de archivos, orígenes u objetos tipo-archivo (see objetos “tipo-archivo”) apuntando a parches que deben ser aplicados a las fuentes.
La lista de parches debe ser incondicional. En particular, no puede depender del valor de
%current-systemo%current-target-system.snippet(predeterminado:#f)Una expresión-G (see Expresiones-G) o expresión-S que se ejecutará en el directorio de fuentes. Esta es una forma conveniente de modificar el software, a veces más que un parche.
patch-flags(predeterminadas:'("-p1"))Una lista de opciones de línea de órdenes que deberían ser pasadas a la orden
patch.patch-inputs(predeterminada:#f)Paquetes o derivaciones de entrada al proceso de aplicación de los parches. Cuando es
#f, se proporciona el conjunto habitual de entradas necesarias para la aplicación de parches, como GNU Patch.modules(predeterminados:'())Una lista de módulos Guile que debe ser cargada durante el proceso de aplicación de parches y mientras se ejecuta el código del campo
snippet.patch-guile(predeterminado:#f)El paquete Guile que debe ser usado durante la aplicación de parches. Cuando es
#fse usa un valor predeterminado.
- Tipo de datos: content-hash valor [algoritmo]
Construye un objeto del hash del contenido para el algoritmo proporcionado, y con valor como su valor. Cuando se omite algoritmo se asume que es
sha256.valor puede ser una cadena literal, en cuyo caso se decodifica en base32, o un vector de bytes.
Las siguientes opciones equivalentes entre sí:
(content-hash "05zxkyz9bv3j9h0xyid1rhvh3klhsmrpkf3bcs6frvlgyr2gwilj") (content-hash "05zxkyz9bv3j9h0xyid1rhvh3klhsmrpkf3bcs6frvlgyr2gwilj" sha256) (content-hash (base32 "05zxkyz9bv3j9h0xyid1rhvh3klhsmrpkf3bcs6frvlgyr2gwilj")) (content-hash (base64 "kkb+RPaP7uyMZmu4eXPVkM4BN8yhRd8BTHLslb6f/Rc=") sha256)
Técnicamente,
content-hashse implementa actualmente con un macro. Realiza comprobaciones de seguridad en tiempo de expansión, cuando es posible, como asegurarse de que valor tiene el tamaño adecuado para algoritmo.
Como se ha visto previamente, la forma exacta en la que un origen hace
referencia a los datos se determina por su campo method. El módulo
(guix download) proporciona el método más común, url-fetch,
descrito a continuación.
- Procedimiento Scheme: url-fetch url algo-hash hash [nombre] [#:executable? #f]
Devuelve una derivación de salida fija que obtiene datos desde url (una cadena o una lista de cadenas indicando URL alternativas), la cual se espera que tenga el hash hash del tipo algo-hash (un símbolo). De manera predeterminada el nombre de archivo es el identificador final de la URL; de manera opcional se puede usar nombre para especificar un nombre de archivo diferente. Cuando executable? es verdadero se proporciona el permiso de ejecución al archivo descargado.
Cuando una de las URL comienza con
mirror://, la parte de la máquina se interpreta como el nombre de un esquema de espejos, obtenido de %mirror-file.De manera alternativa, cuando URL comienza con
file://, devuelve el nombre de archivo del almacén correspondiente.
De igual modo el módulo (guix git-download) define el método de
origen git-fetch, que descarga datos de un repositorio de control de
versiones Git, y el tipo de datos git-reference, que describe el
repositorio y la revisión que se debe obtener.
- Procedimiento Scheme: git-fetch url algo-hash hash
Devuelve una derivación de salida fija que obtiene ref, un objeto
<git-reference>. El hash recursivo de la salida se espera que tenga el valor hash del tipo algo-hash (un símbolo). Se usa nombre para el nombre de archivo, o un nombre genérico si su valor es#f.
- Tipo de datos: git-reference
Este es el tipo de datos que representa una referencia de Git que debe obtener el módulo
git-fetch.urlLa URL del repositorio Git que debe clonarse.
commitThis string denotes either the commit to fetch (a hexadecimal string), or the tag to fetch. You can also use a “short” commit ID or a
git describestyle identifier such asv1.0.1-10-g58d7909c97.recursive?(predeterminado:#f)Este valor booleano indica si se obtienen los sub-modulos de Git de manera recursiva.
El siguiente ejemplo representa la etiqueta
v2.10del repositorio de GNU Hello:(git-reference (url "https://git.savannah.gnu.org/git/hello.git") (commit "v2.10"))Es equivalente a la siguiente referencia, la cual nombra de manera explícita la revisión:
(git-reference (url "https://git.savannah.gnu.org/git/hello.git") (commit "dc7dc56a00e48fe6f231a58f6537139fe2908fb9"))
For Mercurial repositories, the module (guix hg-download) defines the
hg-fetch origin method and hg-reference data type for support
of the Mercurial version control system.
- Scheme Procedure: hg-fetch ref hash-algo hash [name] Return a fixed-output derivation that fetches ref, a
<hg-reference>object. The output is expected to have recursive hash hash of type hash-algo (a symbol). Use name as the file name, or a generic name if#false.
Next: Writing Manifests, Previous: Definición de paquetes, Up: Interfaz programática [Contents][Index]
9.3 Definición de variantes de paquetes
One of the nice things with Guix is that, given a package definition, you can easily derive variants of that package—for a different upstream version, with different dependencies, different compilation options, and so on. Some of these custom packages can be defined straight from the command line (see Opciones de transformación de paquetes). This section describes how to define package variants in code. This can be useful in “manifests” (see Writing Manifests) and in your own package collection (see Creación de un canal), among others!
Como se ha mostrado previamente, los paquetes son objetos de primera clase
del lenguage Scheme. El módulo (guix packages) proporciona la forma
sintáctica package para definir nuevos objetos de paquetes
(see Referencia de package). La forma más fácil de definir una variante de
un paquete es usar la palabra clave inherit junto a
package. Esto le permite heredar de una definición de paquete y
modificar únicamente los campos que desee.
Por ejemplo, a partir de la variable hello, que contiene la
definición de la versión actual de GNU Hello, podría definir de esta
forma una variante para la versión 2.2 (publicada 2006, ¡con solera!):
(use-modules (gnu packages base)) ;para 'hello' (define hello-2.2 (package (inherit hello) (version "2.2") (source (origin (method url-fetch) (uri (string-append "mirror://gnu/hello/hello-" version ".tar.gz")) (sha256 (base32 "0lappv4slgb5spyqbh6yl5r013zv72yqg2pcl30mginf3wdqd8k9"))))))
El ejemplo previo es equivalente a lo que la opción de transformación de
paquetes --with-source realiza. Esencialmente hello-2.2
preserva todos los campos de hello, excepto version y
source, los cuales se modifican. Tenca en cuenta que la variable
original hello todavía está disponible en el módulo (gnu
packages base) sin sufrir ningún cambio. Cuando define un paquete
personalizado como este realmente está añadiendo una nueva definición
de paquete; la orignal sigue disponible.
De igual manera puede definir variantes con un conjunto de dependencias
distinto al del paquete original. Por ejemplo, el paquete gdb
predeterminado depende de guile pero, puesto que es una dependencia
opcional, podría definir una variante que elimina dicha dependencia de este
modo:
(use-modules (gnu packages gdb)) ;for 'gdb' (define gdb-sans-guile (package (inherit gdb) (inputs (modify-inputs (package-inputs gdb) (delete "guile")))))
The modify-inputs form above removes the "guile" package from
the inputs field of gdb. The modify-inputs macro is a
helper that can prove useful anytime you want to remove, add, or replace
package inputs.
- Scheme Syntax: modify-inputs inputs clauses
Modify the given package inputs, as returned by
package-inputs& co., according to the given clauses. Each clause must have one of the following forms:(delete name…)Delete from the inputs packages with the given names (strings).
(prepend package…)Add packages to the front of the input list.
(append package…)Add packages to the end of the input list.
The example below removes the GMP and ACL inputs of Coreutils and adds libcap to the front of the input list:
(modify-inputs (package-inputs coreutils) (delete "gmp" "acl") (prepend libcap))The example below replaces the
guilepackage from the inputs ofguile-rediswithguile-2.2:(modify-inputs (package-inputs guile-redis) (replace "guile" guile-2.2))The last type of clause is
append, to add inputs at the back of the list.
En ciertos casos encontrará útil escribir funciones («procedimientos» en el
vocabulario de Scheme) que devuelven un paquete en base a ciertos
parámetros. Por ejemplo, considere la biblioteca luasocket para el
lenguaje de programación Lua. Se desea crear paquetes de luasocket
para las versiones mayores de Lua. Una forma de hacerlo es definir un
procedimiento que recibe un paquete Lua y devuelve un paquete
luasocket que depende de él:
(define (make-lua-socket name lua) ;; Return a luasocket package built with LUA. (package (name name) (version "3.0") ;; several fields omitted (inputs (list lua)) (synopsis "Socket library for Lua"))) (define-public lua5.1-socket (make-lua-socket "lua5.1-socket" lua-5.1)) (define-public lua5.2-socket (make-lua-socket "lua5.2-socket" lua-5.2))
En este ejemplo se han definido los paquetes lua5.1-socket y
lua5.2-socket llamando a crea-lua-socket con distintos
parámetros. See Procedures in GNU Guile Reference Manual para más
información sobre procedimientos. El hecho de disponer de definiciones
públicas de nivel superior de estos dos paquetes permite que se les haga
referencia desde la línea de órdenes (see Módulos de paquetes).
Estas son variantes muy simples. Para facilitar esta tarea, el módulo
(guix transformations) proporciona una interfaz de alto nivel que se
corresponde directamente con las opciones de transformación de paquetes más
sofisticadas (see Opciones de transformación de paquetes):
- Procedimiento Scheme: options->transformation opciones
Devuelve un procedimiento que, cuando se le proporciona un objeto que construir (paquete, derivación, etc.), aplica las transformaciones especificadas en opciones y devuelve los objetos resultantes. opciones debe ser una lista de pares símbolo/cadena como los siguientes:
((with-branch . "guile-gcrypt=master") (without-tests . "libgcrypt"))Cada símbolo nombra una transformación y la cadena correspondiente es el parámetro de dicha transformación.
Por ejemplo, un manifiesto equivalente a esta orden:
guix build guix \ --with-branch=guile-gcrypt=master \ --with-debug-info=zlib
... sería algo parecido a esto:
(use-modules (guix transformations)) (define transforma ;; El procedimiento de transformación del paquete. (options->transformation '((with-branch . "guile-gcrypt=master") (with-debug-info . "zlib")))) (packages->manifest (list (transforma (specification->package "guix"))))
El procedimiento options->transformation es conveniente, pero quizá
no es tan flexible como pudiese desear. ¿Cómo se ha implementado? Es posible
que ya se haya percatado de que la mayoría de las opciones de transformación
de paquetes van más allá de los cambios superficiales mostrados en los
primeros ejemplos de esta sección: implican reescritura de entradas,
lo que significa que el grafo de dependencias de un paquete se reescribe
sustituyendo entradas específicas por otras.
La reescritura del grafo de dependencias, con el propósito de reemplazar
paquetes del grafo, es implementada por el procedimiento
package-input-rewriting en (guix packages).
- Procedimiento Scheme: package-input-rewriting reemplazos [nombre-reescrito] [#:deep? #t]
Devuelve un procedimiento que, cuando se le pasa un paquete, reemplaza sus dependencias directas e indirectas, incluyendo sus entradas implícitas cuando deep? es verdadero, de acuerdo a reemplazos. reemplazos es una lista de pares de paquetes; el primer elemento de cada par es el paquete a reemplazar, el segundo es el reemplazo.
Opcionalmente, nombre-reescrito es un procedimiento de un parámetro que toma el nombre del paquete y devuelve su nuevo nombre tras la reescritura.
Considere este ejemplo:
(define libressl-en-vez-de-openssl ;; Esto es un procedimiento para reemplazar OPENSSL ;; por LIBRESSL, recursivamente. (package-input-rewriting `((,openssl . ,libressl)))) (define git-con-libressl (libressl-en-vez-de-openssl git))
Aquí primero definimos un procedimiento de reescritura que substituye openssl por libressl. Una vez hecho esto, lo usamos para definir una variante del paquete git que usa libressl en vez de openssl. Esto es exactamente lo que hace la opción de línea de órdenes --with-input (see --with-input).
La siguiente variante de package-input-rewriting puede encontrar
paquetes a reemplazar por su nombre en vez de por su identidad.
- Procedimiento Scheme: package-input-rewriting/spec reemplazos [#:deep? #t]
Devuelve un procedimiento que, proporcionado un paquete, realiza los reemplazos proporcionados sobre todo el grafo del paquete, incluyendo las entradas implícitas a menos que deep? sea falso. reemplazos es una lista de pares de especificación y procedimiento; cada especificación es una especificación de paquete como
"gcc"o"guile@2", y cada procedimiento toma un paquete que corresponda con la especificación y devuelve un reemplazo para dicho paquete.
El ejemplo previo podría ser reescrito de esta forma:
(define libressl-en-vez-de-openssl
;; Reemplaza todos los paquetes llamados "openssl" con LibreSSL.
(package-input-rewriting/spec `(("openssl" . ,(const libressl)))))
La diferencia principal en este caso es que, esta vez, los paquetes se
buscan por su especificación y no por su identidad. En otras palabras,
cualquier paquete en el grafo que se llame openssl será reemplazado.
Un procedimiento más genérico para reescribir el grafo de dependencias de un
paquete es package-mapping: acepta cambios arbitrarios sobre nodos
del grafo.
- Scheme Procedure: package-mapping proc [cortar?] [#:deep? #f]
Devuelve un procedimiento que, dado un paquete, aplica proc a todos los paquetes de los que depende y devuelve el paquete resultante. El procedimiento para la recursión cuando cortar? devuelve verdadero para un paquete dado. Cuando deep? tiene valor verdadero, proc se aplica también a las entradas implícitas.
Next: Sistemas de construcción, Previous: Definición de variantes de paquetes, Up: Interfaz programática [Contents][Index]
9.4 Writing Manifests
guix commands let you specify package lists on the command line.
This is convenient, but as the command line becomes longer and less trivial,
it quickly becomes more convenient to have that package list in what we call
a manifest. A manifest is some sort of a “bill of materials” that
defines a package set. You would typically come up with a code snippet that
builds the manifest, store it in a file, say manifest.scm, and then
pass that file to the -m (or --manifest) option that many
guix commands support. For example, here’s what a manifest for a
simple package set might look like:
;; Manifest for three packages. (specifications->manifest '("gcc-toolchain" "make" "git"))
Once you have that manifest, you can pass it, for example, to guix
package to install just those three packages to your profile
(see -m option of guix package):
guix package -m manifest.scm
... or you can pass it to guix shell (see -m option of guix shell) to spawn an ephemeral
environment:
guix shell -m manifest.scm
... or you can pass it to guix pack in pretty much the same way
(see -m option of guix pack). You can
store the manifest under version control, share it with others so they can
easily get set up, etc.
But how do you write your first manifest? To get started, maybe you’ll want
to write a manifest that mirrors what you already have in a profile. Rather
than start from a blank page, guix package can generate a manifest
for you (see guix package --export-manifest):
# Write to 'manifest.scm' a manifest corresponding to the # default profile, ~/.guix-profile. guix package --export-manifest > manifest.scm
Or maybe you’ll want to “translate” command-line arguments into a
manifest. In that case, guix shell can help
(see guix shell --export-manifest):
# Write a manifest for the packages specified on the command line. guix shell --export-manifest gcc-toolchain make git > manifest.scm
In both cases, the --export-manifest option tries hard to generate a faithful manifest; in particular, it takes package transformation options into account (see Opciones de transformación de paquetes).
Nota: Manifests are symbolic: they refer to packages of the channels currently in use (see Canales). In the example above,
gcc-toolchainmight refer to version 11 today, but it might refer to version 13 two years from now.If you want to “pin” your software environment to specific package versions and variants, you need an additional piece of information: the list of channel revisions in use, as returned by
guix describe. See Replicación de Guix, for more information.
Once you’ve obtained your first manifest, perhaps you’ll want to customize it. Since your manifest is code, you now have access to all the Guix programming interfaces!
Let’s assume you want a manifest to deploy a custom variant of GDB, the GNU Debugger, that does not depend on Guile, together with another package. Building on the example seen in the previous section (see Definición de variantes de paquetes), you can write a manifest along these lines:
(use-modules (guix packages) (gnu packages gdb) ;for 'gdb' (gnu packages version-control)) ;for 'git' ;; Define a variant of GDB without a dependency on Guile. (define gdb-sans-guile (package (inherit gdb) (inputs (modify-inputs (package-inputs gdb) (delete "guile"))))) ;; Return a manifest containing that one package plus Git. (packages->manifest (list gdb-sans-guile git))
Note that in this example, the manifest directly refers to the gdb
and git variables, which are bound to a package object
(see Referencia de package), instead of calling
specifications->manifest to look up packages by name as we did
before. The use-modules form at the top lets us access the core
package interface (see Definición de paquetes) and the modules that define
gdb and git (see Módulos de paquetes). Seamlessly, we’re
weaving all this together—the possibilities are endless, unleash your
creativity!
The data type for manifests as well as supporting procedures are defined in
the (guix profiles) module, which is automatically available to code
passed to -m. The reference follows.
- Data Type: manifest
Data type representing a manifest.
It currently has one field:
entriesThis must be a list of
manifest-entryrecords—see below.
- Data Type: manifest-entry
Data type representing a manifest entry. A manifest entry contains essential metadata: a name and version string, the object (usually a package) for that entry, the desired output (see Paquetes con múltiples salidas), and a number of optional pieces of information detailed below.
Most of the time, you won’t build a manifest entry directly; instead, you will pass a package to
package->manifest-entry, described below. In some unusual cases though, you might want to create manifest entries for things that are not packages, as in this example:;; Manually build a single manifest entry for a non-package object. (let ((hello (program-file "hello" #~(display "Hi!")))) (manifest-entry (name "foo") (version "42") (item (computed-file "hello-directory" #~(let ((bin (string-append #$output "/bin"))) (mkdir #$output) (mkdir bin) (symlink #$hello (string-append bin "/hello")))))))
The available fields are the following:
nameversionName and version string for this entry.
itemA package or other file-like object (see file-like objects).
output(default:"out")Output of
itemto use, in caseitemhas multiple outputs (see Paquetes con múltiples salidas).dependencies(predeterminadas:'())List of manifest entries this entry depends on. When building a profile, dependencies are added to the profile.
Typically, the propagated inputs of a package (see
propagated-inputs) end up having a corresponding manifest entry in among the dependencies of the package’s own manifest entry.search-paths(predeterminadas:'())The list of search path specifications honored by this entry (see Search Paths).
properties(default:'())List of symbol/value pairs. When building a profile, those properties get serialized.
This can be used to piggyback additional metadata—e.g., the transformations applied to a package (see Opciones de transformación de paquetes).
parent(default:(delay #f))A promise pointing to the “parent” manifest entry.
This is used as a hint to provide context when reporting an error related to a manifest entry coming from a
dependenciesfield.
- Scheme Procedure: concatenate-manifests lst
Concatenate the manifests listed in lst and return the resulting manifest.
- Scheme Procedure: package->manifest-entry package [output] [#:properties] Return a manifest entry for the output
of package package, where output defaults to
"out", and with the given properties. By default properties is the empty list or, if one or more package transformations were applied to package, it is an association list representing those transformations, suitable as an argument tooptions->transformation(seeoptions->transformation).The code snippet below builds a manifest with an entry for the default output and the
send-emailoutput of thegitpackage:(use-modules (gnu packages version-control)) (manifest (list (package->manifest-entry git) (package->manifest-entry git "send-email")))
- Scheme Procedure: packages->manifest packages
Return a list of manifest entries, one for each item listed in packages. Elements of packages can be either package objects or package/string tuples denoting a specific output of a package.
Using this procedure, the manifest above may be rewritten more concisely:
(use-modules (gnu packages version-control)) (packages->manifest (list git `(,git "send-email")))
- Scheme Procedure: package->development-manifest package [system] [#:target] Return a manifest for the development inputs
of package for system, optionally when cross-compiling to target. Development inputs include both explicit and implicit inputs of package.
Like the -D option of
guix shell(seeguix shell -D), the resulting manifest describes the environment in which one can develop package. For example, suppose you’re willing to set up a development environment for Inkscape, with the addition of Git for version control; you can describe that “bill of materials” with the following manifest:(use-modules (gnu packages inkscape) ;for 'inkscape' (gnu packages version-control)) ;for 'git' (concatenate-manifests (list (package->development-manifest inkscape) (packages->manifest (list git))))
In this example, the development manifest that
package->development-manifestreturns includes the compiler (GCC), the many supporting libraries (Boost, GLib, GTK, etc.), and a couple of additional development tools—these are the dependenciesguix show inkscapelists.
Last, the (gnu packages) module provides higher-level facilities to
build manifests. In particular, it lets you look up packages by name—see
below.
- Scheme Procedure: specifications->manifest specs
Given specs, a list of specifications such as
"emacs@25.2"or"guile:debug", return a manifest. Specs have the format that command-line tools such asguix installandguix packageunderstand (see Invocación deguix package).As an example, it lets you rewrite the Git manifest that we saw earlier like this:
(specifications->manifest '("git" "git:send-email"))Notice that we do not need to worry about
use-modules, importing the right set of modules, and referring to the right variables. Instead, we directly refer to packages in the same way as on the command line, which can often be more convenient.
Next: Fases de construcción, Previous: Writing Manifests, Up: Interfaz programática [Contents][Index]
9.5 Sistemas de construcción
Cada definición de paquete especifica un sistema de construcción y
parámetros para dicho sistema de construcción (see Definición de paquetes). Este campo build-system representa el procedimiento de
construcción del paquete, así como las dependencias implícitas de dicho
procedimiento de construcción.
Los sistemas de construcción son objetos <build-system>. La interfaz
para crear y manipularlos se proporciona en el módulo (guix
build-system), y otros módulos exportan sistemas de construcción reales.
En su implementación, los sistemas de construcción primero compilan los
objetos package a objetos bag. Una bolsa (traducción de bag) es
como un paquete, pero con menos ornamentos—en otras palabras, una bolsa es
una representación a un nivel más bajo de un paquete, que contiene todas las
entradas de dicho paquete, incluyendo algunas implícitamente añadidas por el
sistema de construcción. Esta representación intermedia se compila entonces
a una derivación (see Derivaciones). EL procedimiento
package-with-c-toolchain es un ejemplo de una forma de cambiar las
entradas implícitas que el sistema de construcción del paquete incluye
(see package-with-c-toolchain).
Los sistemas de construcción aceptan una lista opcional de
parámetros. En las definiciones de paquete, estos son pasados vía
el campo arguments (see Definición de paquetes). Normalmente son
parámetros con palabras clave (see keyword arguments
in Guile in GNU Guile Reference Manual). El valor de estos parámetros
normalmente se evalúa en la capa de construcción—es decir, por un
proceso Guile lanzado por el daemon (see Derivaciones).
El sistema de construcción principal es gnu-build-system, el cual
implementa el procedimiento estándar de construcción para GNU y muchos otros
paquetes. Se proporciona por el módulo (guix build-system gnu).
- Variable Scheme: gnu-build-system
gnu-build-system representa el sistema de construcción GNU y sus variantes (see configuration and makefile conventions in GNU Coding Standards).
In a nutshell, packages using it are configured, built, and installed with the usual
./configure && make && make check && make installcommand sequence. In practice, a few additional steps are often needed. All these steps are split up in separate phases. See Fases de construcción, for more info on build phases and ways to customize them.Además, este sistema de construcción asegura que el entorno “estándar” para paquetes GNU está disponible. Esto incluye herramientas como GCC, libc, Coreutils, Bash, Make, Diffutils, grep y sed (vea el módulo
(guix build system gnu)para una lista completa). A estas las llamamos las entradas implícitas de un paquete, porque las definiciones de paquete no las mencionan.This build system supports a number of keyword arguments, which can be passed via the
argumentsfield of a package. Here are some of the main parameters:#:phasesThis argument specifies build-side code that evaluates to an alist of build phases. See Fases de construcción, for more information.
#:configure-flagsThis is a list of flags (strings) passed to the
configurescript. See Definición de paquetes, for an example.#:make-flagsThis list of strings contains flags passed as arguments to
makeinvocations in thebuild,check, andinstallphases.#:out-of-source?This Boolean,
#fby default, indicates whether to run builds in a build directory separate from the source tree.When it is true, the
configurephase creates a separate build directory, changes to that directory, and runs theconfigurescript from there. This is useful for packages that require it, such asglibc.#:tests?This Boolean,
#tby default, indicates whether thecheckphase should run the package’s test suite.#:test-targetThis string,
"check"by default, gives the name of the makefile target used by thecheckphase.#:parallel-build?#:parallel-tests?These Boolean values specify whether to build, respectively run the test suite, in parallel, with the
-jflag ofmake. When they are true,makeis passed-jn, where n is the number specified as the --cores option ofguix-daemonor that of theguixclient command (see --cores).#:validate-runpath?This Boolean,
#tby default, determines whether to “validate” theRUNPATHof ELF binaries (.soshared libraries as well as executables) previously installed by theinstallphase. See thevalidate-runpathphase, for details.#:substitutable?This Boolean,
#tby default, tells whether the package outputs should be substitutable—i.e., whether users should be able to obtain substitutes for them instead of building locally (see Sustituciones).#:allowed-references#:disallowed-referencesWhen true, these arguments must be a list of dependencies that must not appear among the references of the build results. If, upon build completion, some of these references are retained, the build process fails.
This is useful to ensure that a package does not erroneously keep a reference to some of it build-time inputs, in cases where doing so would, for example, unnecessarily increase its size (see Invocación de
guix size).
Most other build systems support these keyword arguments.
Hay definidos otros objetos <build-system> para implementar otras
convenciones y herramientas usadas por paquetes de software libre. Heredan
la mayor parte de gnu-build-system, y se diferencian principalmente en
el conjunto de entradas implícitamente añadidas al proceso de construcción,
y en la lista de fases ejecutadas. Algunos de estos sistemas de construcción
se enumeran a continuación.
- Variable Scheme: ant-build-system
(guix build-system ant)exporta esta variable. Implementa el procedimiento de construcción de paquetes Java que pueden construirse con la herramienta de construcción Ant.Añade tanto
antcomo el kit de desarrollo Java (JDK), que proporciona el paqueteicedtea, al conjunto de entradas. Se pueden especificar paquetes diferentes con los parámetros#:anty#:jdk, respectivamente.Cuando el paquete original no proporciona un archivo Ant apropiado, el parámetro
#:jar-namepuede usarse para generar un archivo de construcción Ant build.xml mínimo con tareas para construir el archivo jar especificado. En este caso, el parámetro#:source-dirse puede usar para especificar el subdirectorio de fuentes, con “src” como valor predeterminado.The
#:main-classparameter can be used with the minimal ant buildfile to specify the main class of the resulting jar. This makes the jar file executable. The#:test-includeparameter can be used to specify the list of junit tests to run. It defaults to(list "**/*Test.java"). The#:test-excludecan be used to disable some tests. It defaults to(list "**/Abstract*.java"), because abstract classes cannot be run as tests.El parámetro
#:build-targetse puede usar para especificar la tarea Ant que debe ser ejecutada durante la fasebuild. Por defecto se ejecuta la tarea “jar”.
- Variable Scheme: android-ndk-build-system
-
Esta variable es exportada por
(guix build-system android-ndk). Implementa un procedimiento de construcción para paquetes Android NDK (kit de desarrollo nativo) usando un proceso de construcción específico de Guix.El sistema de construcción asume que los paquetes instalan sus archivos de interfaz pública (cabeceras) en el subdirectorio include de la salida
outy sus bibliotecas en el subdirectorio lib de la salidaout".También se asume que la unión de todas las dependencias de un paquete no tiene archivos en conflicto.
En este momento no funciona la compilación cruzada - por lo que las bibliotecas y los archivos de cabecera se asumen que son locales.
- Variable Scheme: asdf-build-system/source
- Variable Scheme: asdf-build-system/sbcl
- Variable Scheme: asdf-build-system/ecl
-
These variables, exported by
(guix build-system asdf), implement build procedures for Common Lisp packages using “ASDF”. ASDF is a system definition facility for Common Lisp programs and libraries.The
asdf-build-system/sourcesystem installs the packages in source form, and can be loaded using any common lisp implementation, via ASDF. The others, such asasdf-build-system/sbcl, install binary systems in the format which a particular implementation understands. These build systems can also be used to produce executable programs, or lisp images which contain a set of packages pre-loaded.El sistema de construcción usa convenciones de nombres. Para paquetes binarios, el paquete debería estar prefijado con la implementación lisp, como
sbcl-paraasdf-build-system/sbcl.Adicionalmente, el paquete de fuentes correspondiente debe etiquetarse usando la misma convención que los paquetes python (vea Módulos Python), usando el prefijo
cl-.In order to create executable programs and images, the build-side procedures
build-programandbuild-imagecan be used. They should be called in a build phase after thecreate-asdf-configurationphase, so that the system which was just built can be used within the resulting image.build-programrequires a list of Common Lisp expressions to be passed as the#:entry-programargument.By default, all the .asd files present in the sources are read to find system definitions. The
#:asd-filesparameter can be used to specify the list of .asd files to read. Furthermore, if the package defines a system for its tests in a separate file, it will be loaded before the tests are run if it is specified by the#:test-asd-fileparameter. If it is not set, the files<system>-tests.asd,<system>-test.asd,tests.asd, andtest.asdwill be tried if they exist.If for some reason the package must be named in a different way than the naming conventions suggest, or if several systems must be compiled, the
#:asd-systemsparameter can be used to specify the list of system names.
- Variable Scheme: cargo-build-system
-
Esta variable se exporta en
(guix build-system cargo). Permite la construcción de paquetes usando Cargo, la herramienta de construcción del lenguaje de programación Rust.Automáticamente añade
rustcycargoal conjunto de entradas. Se puede especificar el uso de un paquete Rust distinto con el parámetro#:rust.Regular cargo dependencies should be added to the package definition similarly to other packages; those needed only at build time to native-inputs, others to inputs. If you need to add source-only crates then you should add them to via the
#:cargo-inputsparameter as a list of name and spec pairs, where the spec can be a package or a source definition. Note that the spec must evaluate to a path to a gzipped tarball which includes aCargo.tomlfile at its root, or it will be ignored. Similarly, cargo dev-dependencies should be added to the package definition via the#:cargo-development-inputsparameter.In its
configurephase, this build system will make any source inputs specified in the#:cargo-inputsand#:cargo-development-inputsparameters available to cargo. It will also remove an includedCargo.lockfile to be recreated bycargoduring thebuildphase. Thepackagephase will runcargo packageto create a source crate for future use. Theinstallphase installs the binaries defined by the crate. Unlessinstall-source? #fis defined it will also install a source crate repository of itself and unpacked sources, to ease in future hacking on rust packages.
- Scheme Variable: chicken-build-system
This variable is exported by
(guix build-system chicken). It builds CHICKEN Scheme modules, also called “eggs” or “extensions”. CHICKEN generates C source code, which then gets compiled by a C compiler, in this case GCC.This build system adds
chickento the package inputs, as well as the packages ofgnu-build-system.The build system can’t (yet) deduce the egg’s name automatically, so just like with
go-build-systemand its#:import-path, you should define#:egg-namein the package’sargumentsfield.For example, if you are packaging the
srfi-1egg:(arguments '(#:egg-name "srfi-1"))Egg dependencies must be defined in
propagated-inputs, notinputsbecause CHICKEN doesn’t embed absolute references in compiled eggs. Test dependencies should go tonative-inputs, as usual.
- Variable Scheme: copy-build-system
Esta variable se exporta en
(guix build-system copy). Permite la construcción de paquetes simples que no necesitan mucha compilación y en su mayor parte dependen únicamente de la copia de archivos en distintas rutas.Añade gran parte de los paquetes de
gnu-build-systemal conjunto de entradas. Por esta razón,copy-build-systemno necesita toda la verborrea que habitualmente requieretrivial-build-system.Para simplificar más aún el proceso de instalación de archivos, se expone un parámetro
#:install-planpara permitir a quien genera el paquete especificar dónde van los distintos archivos. El plan de instalación (#:install-plan) es una lista de(fuente destino [filtro]). Los filtros son opcionales.- Cuando fuente corresponde con un archivo o un directorio sin la barra final, se instala en destino.
- Si destino contiene una barra al final, fuente se instala con su nombre de archivo en la ruta destino.
- En otro caso se instala fuente como destino.
- Cuando fuente es un directorio terminado en una barra, o cuando se usa algún filtro,
la barra al final de destino tiene el significado que se describió
anteriormente.
- Sin filtros, instala todo el contenido de fuente en destino.
- Cuando filtro contiene
#:include,#:include-regexp,#:exclude,#:exclude-regexp, únicamente se seleccionan los archivos instalados dependiendo de los filtros. Cada filtro se especifica como una lista de cadenas.- Con
#:include, se instalan todos los archivos de la ruta cuyo sufijo corresponda con al menos uno de los elementos de la lista proporcionada. - Con
#:include-regexpse instalan todos los archivos cuyas rutas relativas correspondan con al menos una de las expresiones regulares en la lista proporcionada. - Los filtros
#:excludey#:exclude-regexpson complementarios a sus equivalentes inclusivos. Sin opciones#:include, se instalan todos los archivos excepto aquellos que correspondan con los filtros de exclusión. Si se proporcionan tanto inclusiones como exclusiones, las exclusiones tienen efecto sobre los resultados de las inclusiones.
- Con
En todos los casos, las rutas relativas a fuente se preservan dentro de destino.
Ejemplos:
-
("foo/bar" "share/my-app/"): Instala bar en share/my-app/bar. -
("foo/bar" "share/my-app/baz"): Instala bar en share/my-app/baz. -
("foo/" "share/my-app"): Instala el contenido de foo dentro de share/my-app, por ejemplo, instala foo/sub/file en share/my-app/sub/file. -
("foo/" "share/my-app" #:include ("sub/file")): Instala únicamente foo/sub/file en share/my-app/sub/file. -
("foo/sub" "share/my-app" #:include ("file")): Instala foo/sub/file en share/my-app/file.
- Cuando fuente corresponde con un archivo o un directorio sin la barra final, se instala en destino.
- Variable Scheme: clojure-build-system
Esta variable se exporta en
(guix build-system clojure). Implementa un procedimiento de construcción simple para paquetes Clojure usando directamentecompileen Clojure. La compilación cruzada no está disponible todavía.Añade
clojure,icedteayzipal conjunto de entradas. Se pueden especificar paquetes diferentes con los parámetros#:clojure,#:jdky#:zip, respectivamente.Una lista de directorios de fuentes, directorios de pruebas y nombres de jar pueden especificarse con los parámetros
#:source-dirs,#:test-dirsy#:jar-names, respectivamente. El directorio de compilación y la clase principal pueden especificarse con los parámetros#:compile-diry#:main-class, respectivamente. Otros parámetros se documentan más adelante.Este sistema de construcción es una extensión de ant-build-system, pero con las siguientes fases cambiadas:
buildEsta fase llama
compileen Clojure para compilar los archivos de fuentes y ejecutajarpara crear archivadores jar tanto de archivos de fuentes y compilados de acuerdo con las listas de inclusión y exclusión especificadas en#:aot-includey#:aot-exclude, respectivamente. La lista de exclusión tiene prioridad sobre la de inclusión. Estas listas consisten en símbolos que representan bibliotecas Clojure o la palabra clave especial#:allque representa todas las bibliotecas encontradas en los directorios de fuentes. El parámetro#:omit-source?determina si las fuentes deben incluirse en los archivadores jar.checkEsta fase ejecuta las pruebas de acuerdo a las listas de inclusión y exclusión especificadas en
#:test-includey#:test-exclude, respectivamente. Sus significados son análogos a los de#:aot-includey#:aot-exclude, excepto que la palabra clave especial#:alldesigna ahora a todas las bibliotecas Clojure encontradas en los directorios de pruebas. El parámetro#:tests?determina si se deben ejecutar las pruebas.installEsta fase instala todos los archivadores jar construidos previamente.
Además de las previas, este sistema de construcción contiene una fase adicional:
install-docEsta fase instala todos los archivos de nivel superior con un nombre que corresponda con %doc-regex. Una expresión regular diferente se puede especificar con el parámetro
#:doc-regex. Todos los archivos dentro (recursivamente) de los directorios de documentación especificados en#:doc-dirsse instalan también.
- Variable Scheme: cmake-build-system
Esta variable se exporta en
(guix build-system cmake). Implementa el procedimiento de construcción para paquetes que usen la herramienta de construcción CMake.Automáticamente añade el paquete
cmakeal conjunto de entradas. El paquete usado se puede especificar con el parámetro#:cmake.El parámetro
#:configure-flagsse toma como una lista de opciones a pasar acmake. El parámetro#:build-typeespecifica en términos abstractos las opciones pasadas al compilador; su valor predeterminado es"RelWithDebInfo"(quiere decir “modo de entrega con información de depuración”), lo que aproximadamente significa que el código se compila con-O2 -g, lo cual es el caso predeterminado en paquetes basados en Autoconf.
- Variable Scheme: dune-build-system
Esta variable se exporta en
(guix build-system dune). Permite la construcción de paquetes mediante el uso de Dune, una herramienta de construcción para el lenguaje de programación OCaml. Se implementa como una extensión deocaml-build-systemque se describe a continuación. Como tal, se pueden proporcionar los parámetros#:ocamly#:findliba este sistema de construcción.Automáticamente añade el paquete
duneal conjunto de entradas. El paquete usado se puede especificar con el parámetro#:dune.No existe una fase
configuredebido a que los paquetes dune no necesitan ser configurados típicamente. El parámetro#:build-flagsse toma como una lista de opciones proporcionadas a la ordendunedurante la construcción.El parámetro
#:jbuild?puede proporcionarse para usar la ordenjbuilden vez de la más recientedunedurante la construcción de un paquete. Su valor predeterminado es#f.El parámetro
#:packagepuede proporcionarse para especificar un nombre de paquete, lo que resulta útil cuando un paquete contiene múltiples paquetes y únicamente quiere construir uno de ellos. Es equivalente a proporcionar el parámetro-padune.
- Scheme variable: elm-build-system
This variable is exported by
(guix build-system elm). It implements a build procedure for Elm packages similar to ‘elm install’.The build system adds an Elm compiler package to the set of inputs. The default compiler package (currently
elm-sans-reactor) can be overridden using the#:elmargument. Additionally, Elm packages needed by the build system itself are added as implicit inputs if they are not already present: to suppress this behavior, use the#:implicit-elm-package-inputs?argument, which is primarily useful for bootstrapping.The
"dependencies"and"test-dependencies"in an Elm package’s elm.json file correspond topropagated-inputsandinputs, respectively.Elm requires a particular structure for package names: see Paquetes Elm for more details, including utilities provided by
(guix build-system elm).There are currently a few noteworthy limitations to
elm-build-system:- The build system is focused on packages in the Elm sense of the word:
Elm projects which declare
{ "type": "package" }in their elm.json files. Usingelm-build-systemto build Elm applications (which declare{ "type": "application" }) is possible, but requires ad-hoc modifications to the build phases. For examples, see the definitions of theelm-todomvcexample application and theelmpackage itself (because the front-end for the ‘elm reactor’ command is an Elm application). - Elm supports multiple versions of a package coexisting simultaneously under
ELM_HOME, but this does not yet work well withelm-build-system. This limitation primarily affects Elm applications, because they specify exact versions for their dependencies, whereas Elm packages specify supported version ranges. As a workaround, the example applications mentioned above use thepatch-application-dependenciesprocedure provided by(guix build elm-build-system)to rewrite their elm.json files to refer to the package versions actually present in the build environment. Alternatively, Guix package transformations (see Definición de variantes de paquetes) could be used to rewrite an application’s entire dependency graph. - We are not yet able to run tests for Elm projects because neither
elm-test-rsnor the Node.js-basedelm-testrunner has been packaged for Guix yet.
- The build system is focused on packages in the Elm sense of the word:
Elm projects which declare
- Variable Scheme: go-build-system
Esta variable se exporta en
(guix build-system go). Implementa el procedimiento de construcción para paquetes Go usando los mecanismos de construcción de Go estándares.Se espera que la usuaria proporcione un valor para el parámetro
#:import-pathy, en algunos caso,#:unpack-path. La ruta de importación corresponde a la ruta del sistema de archivos esperada por los guiones de construcción del paquete y los paquetes a los que hace referencia, y proporciona una forma de hacer referencia a un paquete Go unívocamente. Está basado típicamente en una combinación de la URI remota del paquete de archivos de fuente y la estructura jerárquica del sistema de archivos. En algunos casos, necesitará desempaquetar el código fuente del paquete en una estructura de directorios diferente a la indicada en la ruta de importación, y#:unpack-pathdebe usarse en dichos casos.Los paquetes que proporcionan bibliotecas Go deben instalar su código fuente en la salida de la construcción. El parámetro
#:install-source?, cuyo valor por defecto es#t, controla si se instalará o no el código fuente. Puede proporcionarse#fen paquetes que proporcionan únicamente archivos ejecutables.Packages can be cross-built, and if a specific architecture or operating system is desired then the keywords
#:goarchand#:gooscan be used to force the package to be built for that architecture and operating system. The combinations known to Go can be found in their documentation.
- Variable Scheme: glib-or-gtk-build-system
Esta variable se exporta en
(guix build-system glib-or-gtk). Está pensada para usarse con paquetes que usan GLib o GTK+.Este sistema de construcción añade las dos fases siguientes a las definidas en gnu-build-system:
glib-or-gtk-wrapLa fase
glib-or-gtk-wrapse asegura de que los programas en bin/ son capaces de encontrar los “esquemas” GLib y los módulos GTK+. Esto se consigue recubriendo los programas en guiones de lanzamiento que proporcionan valores apropiados para las variables de entornoXDG_DATA_DIRSyGTK_PATH.Es posible excluir salidas específicas del paquete del proceso de recubrimiento enumerando sus nombres en el parámetro
#:glib-org-gtk-wrap-excluded-outputs. Esto es útil cuando se sabe que una salida no contiene binarios GLib o GTK+, y cuando empaquetar gratuitamente añadiría una dependencia de dicha salida en GLib y GTK+.glib-or-gtk-compile-schemasLa fase
glib-or-gtk-compile-schemasse asegura que todos los esquemas GSettings o GLib se compilan. La compilación la realiza el programaglib-compile-schemas. Lo proporciona el paqueteglib:binque se importa automáticamente por el sistema de construcción. El paqueteglibque proporcionaglib-compile-schemaspuede especificarse con el parámetro#:glib.
Ambas fases se ejecutan tras la fase
install.
- Variable Scheme: guile-build-system
Este sistema de construcción es para paquetes Guile que consisten exclusivamente en código Scheme y son tan simples que no tienen ni siquiera un archivo Makefile, menos un guión configure. Compila código Scheme usando
guild compile(see Compilation in GNU Guile Reference Manual) e instala los archivos .scm y .go en el lugar correcto. También instala documentación.Este sistema de construcción permite la compilación cruzada usando la opción --target de
guild compile.Los paquetes construidos con
guile-build-systemdeben proporcionar un paquete Guile en su camponative-inputs.
- Variable Scheme: julia-build-system
This variable is exported by
(guix build-system julia). It implements the build procedure used by julia packages, which essentially is similar to running ‘julia -e 'using Pkg; Pkg.add(package)'’ in an environment whereJULIA_LOAD_PATHcontains the paths to all Julia package inputs. Tests are run by calling/test/runtests.jl.The Julia package name and uuid is read from the file Project.toml. These values can be overridden by passing the argument
#:julia-package-name(which must be correctly capitalized) or#:julia-package-uuid.Julia packages usually manage their binary dependencies via
JLLWrappers.jl, a Julia package that creates a module (named after the wrapped library followed by_jll.jl.To add the binary path
_jll.jlpackages, you need to patch the files under src/wrappers/, replacing the call to the macroJLLWrappers.@generate_wrapper_header, adding as a second argument containing the store path the binary.As an example, in the MbedTLS Julia package, we add a build phase (see Fases de construcción) to insert the absolute file name of the wrapped MbedTLS package:
(add-after 'unpack 'override-binary-path (lambda* (#:key inputs #:allow-other-keys) (for-each (lambda (wrapper) (substitute* wrapper (("generate_wrapper_header.*") (string-append "generate_wrapper_header(\"MbedTLS\", \"" (assoc-ref inputs "mbedtls-apache") "\")\n")))) ;; There's a Julia file for each platform, override them all. (find-files "src/wrappers/" "\\.jl$"))))Some older packages that aren’t using Project.toml yet, will require this file to be created, too. It is internally done if the arguments
#:julia-package-nameand#:julia-package-uuidare provided.
- Variable Scheme: maven-build-system
Esta variable se exporta en
(guix build-system maven). Implementa un procedimiento de construcción para paquetes basados en Maven. Maven es una herramienta para Java de gestión de dependencias y ciclo de vida. Las usuarias de Maven especifican las dependencias y módulos en un archivo pom.xml que Maven lee. Cuando Maven no dispone de una de dichas dependencias o módulos en su repositorio, las descarga y las usa para construir el paquete.El sistema de compilación de maven se asegura de que maven no intentará descargar ninguna dependencia ejecutándo maven en modo sin conexión. Maven fallará si falta alguna dependencia. Antes de ejecutar Maven, el archivo pom.xml (y los subproyectos) se modifican para especificar la versión de las dependencias y módulos que corresponden a las versiones disponibles en el entorno de construcción de guix. Las dependencias y los módulos se deben instalar en un repositorio de maven ad hoc en lib/m2, y se enlazan un repositorio real antes de que se ejecute maven. Se le indica a Maven que use ese repositorio para la construcción e instale los artefactos generados allí. Los archivos cambiados se copian del directorio lib/m2 a la salida del paquete.
Puede especificar un archivo pom.xml con el parámetro
#:pom-file, o dejar al sistema de construcción usar el archivo predeterminado pom.xml en las fuentes.En caso de que necesite especificar la versión de una dependencia manualmente puede usar el parámetro
#:local-packages. Toma como valor una lista asociativa donde la clave es el valor del campo “groupId” del paquete y su valor es una lista asociativa donde la clave es el campo “artifactId” del paquete y su valor la versión que quiere forzar en vez de la que se encuentra en pom.xml.Algunos paquetes usan dependencias o módulos que no son útiles en tiempo de ejecución ni en tiempo de construcción en Guix. Puede modificar el archivo pom.xml para eliminarlos usando el parámetro
#:exclude. Su valor es una lista asociativa donde la clave es el valor del campo “groupId” del módulo o dependencia que quiere eliminar, y su valor es una lista de valores del campo “artifactId” que se eliminarán.Puede usar valores distintos para los paquetes
jdkymavencon el parámetro correspondiente,#:jdky#:maven.El parámetro
#:maven-pluginses una lista de módulos de maven usados durante la construcción, con el mismo formato que el campoinputsde la declaración del paquete. Su valor predeterminado es(default-maven-plugins)que también se exporta.
- Scheme Variable: minetest-mod-build-system
This variable is exported by
(guix build-system minetest). It implements a build procedure for Minetest mods, which consists of copying Lua code, images and other resources to the location Minetest searches for mods. The build system also minimises PNG images and verifies that Minetest can load the mod without errors.
- Variable Scheme: minify-build-system
Esta variable se exporta en
(guix build-system minify). Implementa un procedimiento de minificación para paquetes JavaScript simples.Añade
uglify-jsal conjunto de entradas y lo utiliza para comprimir todos los archivos JavaScript en el directorio src. Un paquete de minificación diferente puede especificarse con el parámetro#:uglify-js, pero se espera que el paquete escriba el código minificado en la salida estándar.Cuando los archivos JavaScript de entrada no se encuentran en el directorio src, el parámetro
#:javascript-filespuede usarse para especificar una lista de nombres de archivo que proporcionar al minificador.
- Variable Scheme: ocaml-build-system
Esta variable se exporta en
(guix build-system ocaml). Implementa un procedimiento de construcción para paquetes OCaml, que consiste en seleccionar el conjunto correcto de órdenes a ejecutar para cada paquete. Los paquetes OCaml pueden esperar la ejecución de muchas ordenes diferentes. Este sistema de construcción probará algunas de ellas.Cuando el paquete tiene un archivo setup.ml presente en el nivel superior, se ejecuta
ocaml setup.ml -configure,ocaml setup.ml -buildyocaml setup.ml -install. El sistema de construcción asumirá que este archivo se generó con http://oasis.forge.ocamlcore.org/ OASIS y se encargará de establecer el prefijo y la activación de las pruebas si no se desactivaron. Puede pasar opciones de configuración y construcción con#:configure-flagsy#:build-flags, respectivamente. El parámetro#:test-flagspuede usarse para cambiar el conjunto de opciones usadas para activar las pruebas. El parámetro#:use-make?puede usarse para ignorar este sistema en las fases de construcción e instalación.Cuando el paquete tiene un archivo configure, se asume que es un guión de configuración hecho a mano que necesita un formato de parámetros diferente a los del sistema
gnu-build-system. Puede añadir más opciones con el parámetro#:configure-flags.Cuando el paquete tiene un archivo Makefile (o
#:use-make?es#t), será usado y se pueden proporcionar más opciones para las fases de construcción y e instalación con el parámetro#:make-flags.Por último, algunos paquetes no tienen estos archivos y usan unas localizaciones de algún modo estándares para su sistema de construcción. En este caso, el sistema de construcción ejecutará
ocaml pkg/pkg.mloocaml pkg/build.mly se hará cargo de proporcionar la ruta del módulo findlib necesario. Se pueden pasar opciones adicionales con el parámetro#:build-flags. De la instalación se hace cargoopam-installer. En este caso, el paqueteopamdebe añadirse al camponative-inputsde la definición del paquete.Fíjese que la mayoría de los paquetes OCaml asumen su instalación en el mismo directorio que OCaml, lo que no es el comportamiento deseado en guix. En particular, tratarán de instalar archivos .so en su directorio de módulos, lo que normalmente es aceptable puesto que está bajo el directorio del compilador de OCaml. No obstante, en guix estas bibliotecas no se pueden instalar ahí, por lo que se usa
CAML_LD_LIBRARY_PATH. Esta variable apunta a lib/ocaml/site-lib/stubslibs y allí es donde se deben instalar las bibliotecas .so.
- Variable Scheme: python-build-system
Esta variable se exporta en
(guix build-system python). Implementa el procedimiento más o menos estándar de construcción usado por paquetes Python, que consiste en la ejecución depython setup.py buildypython setup.py install --prefix=/gnu/store/….For packages that install stand-alone Python programs under
bin/, it takes care of wrapping these programs so that theirGUIX_PYTHONPATHenvironment variable points to all the Python libraries they depend on.Se puede especificar el paquete Python usado para llevar a cabo la construcción con el parámetro
#:python. Esta es habitualmente una forma de forzar la construcción de un paquete para una versión específica del intérprete Python, lo que puede ser necesario si el paquete es compatible únicamente con una versión del intérprete.De manera predeterminada guix llama a
setup.pybajo el control desetuptoolsde manera similar a lo realizado porpip. Algunos paquetes no son compatibles con setuptools (y pip), por lo que puede desactivar esta configuración estableciendo el parámetro#:use-setuptoolsa#f.If a
"python"output is available, the package is installed into it instead of the default"out"output. This is useful for packages that include a Python package as only a part of the software, and thus want to combine the phases ofpython-build-systemwith another build system. Python bindings are a common usecase.
- Scheme Variable: pyproject-build-system
This is a variable exported by
guix build-system pyproject. It is based on python-build-system, and adds support for pyproject.toml and PEP 517. It also supports a variety of build backends and test frameworks.The API is slightly different from python-build-system:
-
#:use-setuptools?and#:test-targetis removed. -
#:build-backendis added. It defaults to#falseand will try to guess the appropriate backend based on pyproject.toml. -
#:test-backendis added. It defaults to#falseand will guess an appropriate test backend based on what is available in package inputs. -
#:test-flagsis added. The default is'(). These flags are passed as arguments to the test command. Note that flags for verbose output is always enabled on supported backends.
It is considered “experimental” in that the implementation details are not set in stone yet, however users are encouraged to try it for new Python projects (even those using setup.py). The API is subject to change, but any breaking changes in the Guix channel will be dealt with.
Eventually this build system will be deprecated and merged back into python-build-system, probably some time in 2024.
-
- Variable Scheme: perl-build-system
Esta variable se exporta en
(guix build-system perl). Implementa el procedimiento de construcción estándar para paquetes Perl, lo que o bien consiste en la ejecución deperl Build.PL --prefix=/gnu/store/…, seguido deBuildyBuild install; o en la ejecución deperl Makefile.PL PREFIX=/gnu/store/…, seguida demakeymake install, dependiendo de siBuild.PLoMakefile.PLestán presentes en la distribución del paquete. El primero tiene preferencia si existen tantoBuild.PLcomoMakefile.PLen la distribución del paquete. Esta preferencia puede ser invertida mediante la especificación del valor#ten el parámetro#:make-maker?.La invocación inicial de
perl Makefile.PLoperl Build.PLpasa a su vez las opciones especificadas por los parámetros#:make-maker-flagso#:module-build-flags, respectivamente.El paquete Perl usado puede especificarse con
#:perl.
- Scheme Variable: renpy-build-system
This variable is exported by
(guix build-system renpy). It implements the more or less standard build procedure used by Ren’py games, which consists of loading#:gameonce, thereby creating bytecode for it.It further creates a wrapper script in
bin/and a desktop entry inshare/applications, both of which can be used to launch the game.Which Ren’py package is used can be specified with
#:renpy. Games can also be installed in outputs other than “out” by using#:output.
- Variable Scheme: qt-build-system
Esta variable se exporta en
(guix build-system qt). Está pensado para usarse con aplicaciones que usen Qt o KDE.Este sistema de construcción añade las dos fases siguientes a las definidas en cmake-build-system:
check-setupLa fase
check-setupprepara el entorno para la ejecución de las comprobaciones usadas habitualmente por los programas de pruebas de Qt. Por ahora únicamente proporciona valor a algunas variables de entorno:QT_QPA_PLATFORM=offscreen,DBUS_FATAL_WARNINGS=0yCTEST_OUTPUT_ON_FAILURE=1.Esta fase se añade previamente a la fase
check. Es una fase separada para facilitar el ajuste si fuese necesario.qt-wrapLa fase
qt-wrapbusca las rutas de módulos de Qt5, las rutas de QML y algunas rutas XDG en las entradas y la salida. En caso de que alguna ruta se encuentra, todos los programas en los directorios bin/, sbin/, libexec/ y lib/libexec/ de la salida se envuelven en guiones que definen las variables de entorno necesarias.Es posible excluir salidas específicas del paquete del proceso de recubrimiento enumerando sus nombres en el parámetro
#:qt-wrap-excluded-outputs. Esto es útil cuando se sabe que una salida no contiene binarios que usen Qt, y cuando empaquetar gratuitamente añadiría una dependencia de dicha salida en Qt.Ambas fases se añaden tras la fase
install.
- Variable Scheme: r-build-system
Esta variable se exporta en
(guix build-system r). Implementa el procedimiento de construcción usados por paquetes R, lo que esencialmente es poco más que la ejecución de ‘R CMD INSTALL --library=/gnu/store/…’ en un entorno dondeR_LIBS_SITEcontiene las rutas de todos los paquetes R de entrada. Las pruebas se ejecutan tras la instalación usando la función Rtools::testInstalledPackage.
- Variable Scheme: rakudo-build-system
This variable is exported by
(guix build-system rakudo). It implements the build procedure used by Rakudo for Perl6 packages. It installs the package to/gnu/store/…/NAME-VERSION/share/perl6and installs the binaries, library files and the resources, as well as wrap the files under thebin/directory. Tests can be skipped by passing#fto thetests?parameter.El paquete rakudo en uso puede especificarse con
rakudo. El paquete perl6-tap-harness en uso durante las pruebas puede especificarse con#:prove6o eliminarse proporcionando#fal parámetrowith-prove6?. El paquete perl6-zef en uso durante las pruebas e instalación puede especificarse con#:zefo eliminarse proporcionando#fal parámetrowith-zef?.
- Scheme Variable: rebar-build-system
This variable is exported by
(guix build-system rebar). It implements a build procedure around rebar3, a build system for programs written in the Erlang language.It adds both
rebar3and theerlangto the set of inputs. Different packages can be specified with the#:rebarand#:erlangparameters, respectively.This build system is based on
gnu-build-system, but with the following phases changed:unpackThis phase, after unpacking the source like the
gnu-build-systemdoes, checks for a filecontents.tar.gzat the top-level of the source. If this file exists, it will be unpacked, too. This eases handling of package hosted at https://hex.pm/, the Erlang and Elixir package repository.bootstrapconfigureThere are no
bootstrapandconfigurephase because erlang packages typically don’t need to be configured.buildThis phase runs
rebar3 compilewith the flags listed in#:rebar-flags.checkUnless
#:tests? #fis passed, this phase runsrebar3 eunit, or some other target specified with#:test-target, with the flags listed in#:rebar-flags,installThis installs the files created in the default profile, or some other profile specified with
#:install-profile.
- Variable Scheme: texlive-build-system
Esta variable se exporta en
(guix build-system texlive). Se usa para construir paquetes TeX en modo de procesamiento de lotes con el motor especificado. El sistema de construcción proporciona valor a la variableTEXINPUTSpara encontrar todos los archivos de fuentes TeX en las entradas.Por defecto ejecuta
luatexen todos los archivos que terminan enins. Un motor y formato diferente puede especificarse con el parámetro#:tex-format. Los diferentes objetivos de construcción pueden especificarse con el parámetro#:build-targets, que espera una lista de nombres de archivo. El sistema de construcción añade únicamentetexlive-binytexlive-latex-base(ambos desde(gnu packages tex)a las entradas. Ambos pueden forzarse con los parámetros#:texlive-biny#:texlive-latex-baserespectivamente.El parámetro
#:tex-directoryle dice al sistema de construcción dónde instalar los archivos construidos bajo el árbol texmf.
- Variable Scheme: ruby-build-system
Esta variable se exporta en
(guix build-system ruby). Implementa el procedimiento de construcción de RubyGems usado por los paquetes Ruby, que implica la ejecución degem buildseguida degem install.El campo
sourcede un paquete que usa este sistema de construcción típicamente se refiere a un archivo gem, ya que este es el formato usado por las desarrolladoras Ruby cuando publican su software. El sistema de construcción desempaqueta el archivo gem, potencialmente parchea las fuentes, ejecuta la batería de pruebas, vuelve a empaquetar el archivo gem y lo instala. Adicionalmente, se puede hacer referencia a directorios y archivadores tar para permitir la construcción de archivos gem no publicados desde Git o un archivador tar de publicación de fuentes tradicional.Se puede especificar el paquete Ruby usado mediante el parámetro
#:ruby. Una lista de opciones adicionales pueden pasarse a la ordengemen el parámetro#:gem-flags.
- Variable Scheme: waf-build-system
Esta variable se exporta en
(guix build-system waf). Implementa un procedimiento de construcción alrededor del guiónwaf. Las fases comunes—configure,buildyinstall—se implementan pasando sus nombres como parámetros al guiónwaf.El guión
wafes ejecutado por el intérprete Python. El paquete Python usado para la ejecución puede ser especificado con el parámetro#:python.
- Variable Scheme: scons-build-system
Esta variable se exporta en
(guix build-system scons). Implementa en procedimiento de construcción usado por la herramienta de construcción de software SCons. Este sistema de construcción ejecutasconspara construir el paquete,scons testpara ejecutar las pruebas y despuésscons installpara instalar el paquete.Las opciones adicionales a pasar a
sconsse pueden especificar con el parámetro#:scons-flags. Los objetivos predeterminados de construcción (build) e instalación (install) pueden modificarse con#:build-targetsy#:install-targetsrespectivamente. La versión de Python usada para ejecutar SCons puede especificarse seleccionando el paquete SCons apropiado con el parámetro#:scons.
- Variable Scheme: haskell-build-system
Esta variable se exporta en
(guix build-system haskell). Implementa el procedimiento de construcción Cabal usado por paquetes Haskell, el cual implica la ejecución derunhaskell Setup.hs configure --prefix=/gnu/store/…yrunhaskell Setup.hs build. En vez de instalar el paquete ejecutandorunhaskell Setup.hs install, para evitar el intento de registro de bibliotecas en el directorio de solo-lectura del compilador en el almacén, el sistema de construcción usarunhaskell Setup.hs copy, seguido derunhaskell Setup.hs register. Además, el sistema de construcción genera la documentación del paquete ejecutandorunhaskell Setup.hs haddock, a menos que se pasase#:haddock? #f. Parámetros opcionales de Haddock pueden proporcionarse con la ayuda del parámetro#:haddock-flags. Si el archivoSetup.hsno es encontrado, el sistema de construcción buscaSetup.lhsa su vez.El compilador Haskell usado puede especificarse con el parámetro
#:haskellcuyo valor predeterminado esghc.
- Variable Scheme: dub-build-system
Esta variable se exporta en
(guix build-system dub). Implementa el procedimiento de construcción Dub usado por los paquetes D, que implica la ejecución dedub buildydub run. La instalación se lleva a cabo con la copia manual de los archivos.El compilador D usado puede ser especificado con el parámetro
#:ldccuyo valor predeterminado esldc.
- Variable Scheme: emacs-build-system
Esta variable se exporta en
(guix build-system emacs). Implementa un procedimiento de instalación similar al propio sistema de empaquetado de Emacs (see Packages in The GNU Emacs Manual).Primero crea el archivo
paquete-autoloads.el, tras lo que compila todos los archivos Emacs Lisp. De manera diferente al sistema de paquetes de Emacs, los archivos de documentación Info se mueven al directorio estándar de documentación y se borra el archivo dir. Los archivos del paquete Elisp se instalan directamente en share/emacs/site-lisp.
- Variable Scheme: font-build-system
Esta variable se exporta en
(guix build-system font). Implementa un procedimiento de instalación para paquetes de fuentes donde las proveedoras originales proporcionan archivos de tipografía TrueType, OpenType, etc. precompilados que simplemente necesitan copiarse en su lugar. Copia los archivos de tipografías a las localizaciones estándar en el directorio de salida.
- Variable Scheme: meson-build-system
Esta variable se exporta en
(guix build-system meson). Implementa el procedimiento de construcción para paquetes que usan Meson como su sistema de construcción.It adds both Meson and Ninja to the set of inputs, and they can be changed with the parameters
#:mesonand#:ninjaif needed.Este sistema de construcción es una extensión de gnu-build-system, pero con las siguientes fases cambiadas por otras específicas para Meson:
configureEsta fase ejecuta
mesoncon las opciones especificadas en#:configure-flags. La opción --buildtype recibe el valordebugoptimizedexcepto cuando se especifique algo distinto en#:build-type.buildEsta fase ejecuta
ninjapara construir el paquete en paralelo por defecto, pero esto puede cambiarse con#:parallel-build?.checkThe phase runs ‘meson test’ with a base set of options that cannot be overridden. This base set of options can be extended via the
#:test-optionsargument, for example to select or skip a specific test suite.installEsta fase ejecuta
ninja instally no puede cambiarse.
Aparte de estas, el sistema de ejecución también añade las siguientes fases:
fix-runpathThis phase ensures that all binaries can find the libraries they need. It searches for required libraries in subdirectories of the package being built, and adds those to
RUNPATHwhere needed. It also removes references to libraries left over from the build phase bymeson, such as test dependencies, that aren’t actually required for the program to run.glib-or-gtk-wrapEsta fase es la fase proporcionada por
glib-or-gtk-build-system, y no está activa por defecto. Puede activarse con#:glib-or-gtk.glib-or-gtk-compile-schemasEsta fase es la fase proporcionada por
glib-or-gtk-build-system, y no está activa por defecto. Puede activarse con#:glib-or-gtk.
- Variable Scheme: linux-module-build-system
linux-module-build-system permite la construcción de módulos del núcleo Linux.
Este sistema de construcción es una extensión de gnu-build-system, pero con las siguientes fases cambiadas:
configureEsta fase configura el entorno de modo que el Makefile del núcleo Linux pueda usarse para la construcción del módulo externo del núcleo.
buildEsta fase usa el Makefile del núcleo Linux para construir el módulo externo del núcleo.
installEsta fase usa el Makefile del núcleo Linux para instalar el módulo externo del núcleo.
Es posible y útil especificar el núcleo Linux usado para la construcción del módulo (para ello debe usar el parámetro
#:linuxa través de la formaargumentsen un paquete que uselinux-module-build-system).
- Variable Scheme: node-build-system
Esta variable se exporta en
(guix build-system node). Implementa el procedimiento de construcción usado por Node.js, que implementa una aproximación de la ordennpm install, seguida de una ordennpm test.El paquete Node.js usado para interpretar las órdenes
npmpuede especificarse a través del parámetro#:nodecuyo valor predeterminado esnode.
Por último, para paquetes que no necesiten nada tan sofisticado se proporciona un sistema de construcción “trivial”. Es trivial en el sentido de que no proporciona prácticamente funcionalidad: no incorpora entradas implícitas y no tiene una noción de fases de construcción.
- Variable Scheme: trivial-build-system
Esta variable se exporta en
(guix build-system trivial).Este sistema de construcción necesita un parámetro
#:builder. Este parámetro debe ser una expresión Scheme que construya la(s) salida(s) del paquete—como enbuild-expression->derivation(seebuild-expression->derivation).
- Scheme Variable: channel-build-system
This variable is exported by
(guix build-system channel).This build system is meant primarily for internal use. A package using this build system must have a channel specification as its
sourcefield (see Canales); alternatively, its source can be a directory name, in which case an additional#:commitargument must be supplied to specify the commit being built (a hexadecimal string).The resulting package is a Guix instance of the given channel, similar to how
guix time-machinewould build it.
Next: Utilidades de construcción, Previous: Sistemas de construcción, Up: Interfaz programática [Contents][Index]
9.6 Fases de construcción
Prácticamente todos los sistemas de construcción de paquetes implementan una
noción de fases de construcción: una secuencia de acciones ejecutadas
por el sistema de construcción, cuando usted construya el paquete, que
conducen a la instalación de su producción en el almacén. Una excepción
notable es el sistema de construcción trivial trivial-build-system
(see Sistemas de construcción).
As discussed in the previous section, those build systems provide a standard
list of phases. For gnu-build-system, the main build phases are the
following:
set-pathsDefine search path environment variables for all the input packages, including
PATH(see Search Paths).unpackExtrae el archivador tar de la fuente, y cambia el directorio actual al directorio recién extraído. Si la fuente es realmente un directorio, lo copia al árbol de construcción y entra en ese directorio.
patch-source-shebangsSustituye secuencias “#!” encontradas al inicio de los archivos de fuentes para que hagan referencia a los nombres correctos de archivos del almacén. Por ejemplo, esto cambia
#!/bin/shpor#!/gnu/store/…-bash-4.3/bin/sh.configureEjecuta el guión configure con algunas opciones predeterminadas, como --prefix=/gnu/store/…, así como las opciones especificadas por el parámetro
#:configure-flags.buildEjecuta
makecon la lista de opciones especificadas en#:make-flags. Si el parámetro#:parallel-build?es verdadero (por defecto), construye conmake -j.checkEjecuta
make check, u otro objetivo especificado con#:test-target, a menos que se pasase#:tests? #f. Si el parámetro#:parallel-tests?es verdadero (por defecto), ejecutamake check -j.installEjecuta
make installcon las opciones enumeradas en#:make-flags.patch-shebangsSustituye las secuencias “#!” en los archivos ejecutables instalados.
stripExtrae los símbolos de depuración de archivos ELF (a menos que el valor de
#:strip-binaries?sea falso), y los copia a la salidadebugcuando esté disponible (see Instalación de archivos de depuración).validate-runpathValidate the
RUNPATHof ELF binaries, unless#:validate-runpath?is false (see Sistemas de construcción).This validation step consists in making sure that all the shared libraries needed by an ELF binary, which are listed as
DT_NEEDEDentries in itsPT_DYNAMICsegment, appear in theDT_RUNPATHentry of that binary. In other words, it ensures that running or using those binaries will not result in a “file not found” error at run time. See -rpath in The GNU Linker, for more information onRUNPATH.
Other build systems have similar phases, with some variations. For example,
cmake-build-system has same-named phases but its configure
phases runs cmake instead of ./configure. Others, such as
python-build-system, have a wholly different list of standard
phases. All this code runs on the build side: it is evaluated when
you actually build the package, in a dedicated build process spawned by the
build daemon (see Invocación de guix-daemon).
Las fases de construcción se representan como listas asociativas o “alists” (see Association Lists in GNU Guile Reference Manual) donde cada clave es un símbolo que nombra a la fase y el valor asociado es un procedimiento que acepta un número arbitrario de parámetros. Por convención, estos procedimientos reciben información sobre la construcción en forma de parámetros que usan palabras clave, de los cuales pueden hacer uso o ignorarlos.
Por ejemplo, esta es la forma en la que (guix build gnu-build-system)
define %standard-phases, la variable que contiene su lista asociativa
de fases de construcción23:
;; Las fases de construcción de 'gnu-build-system'. (define* (unpack #:key source #:allow-other-keys) ;; Extracción del archivador tar de las fuentes. (invoke "tar" "xvf" source)) (define* (configure #:key outputs #:allow-other-keys) ;; Ejecución del guión 'configure'. Instalación de la salida ;; en "out". (let ((out (assoc-ref outputs "out"))) (invoke "./configure" (string-append "--prefix=" out)))) (define* (build #:allow-other-keys) ;; Compilación. (invoke "make")) (define* (check #:key (test-target "check") (tests? #true) #:allow-other-keys) ;; Ejecución de la batería de pruebas. (if tests? (invoke "make" test-target) (display "test suite not run\n"))) (define* (install #:allow-other-keys) ;; Instalación de los archivos en el prefijo especificado ;; al guión 'configure'. (invoke "make" "install")) (define %standard-phases ;; La lista de las fases estándar (algunas se omiten por ;; brevedad). Cada elemento es un par símbolo/procedimiento. (list (cons 'unpack unpack) (cons 'configure configure) (cons 'build build) (cons 'check check) (cons 'install install)))
Aquí se muestra como %standard-phases se define como una lista de
pares símbolo/procedimiento (see Pairs in GNU Guile Reference
Manual). El primer par asocia el procedimiento unpack con el símbolo
unpack—un nombre; el segundo par define de manera similar la fase
configure, etcétera. Cuando se construye un paquete que usa
gnu-build-system, con su lista predeterminada de fases, estas fases
se ejecutan de manera secuencial. Puede ver el nombre de cada fase a su
inicio y tras su finalización en el registro de construcción de los paquetes
que construya.
Echemos un vistazo a los propios procedimientos. Cada uno se define con
define*: #:key enumera parámetros con palabras clave que el
procedimiento acepta, con la posibilidad de proporcionar un valor
predeterminado, y #:allow-other-keys especifica que se ignora
cualquier otra palabra clave en los parámetros (see Optional Arguments in GNU Guile Reference Manual).
El procedimiento unpack utiliza el valor proporcionado al parámetro
source, usado por el sistema de construcción usa para proporcionar el
nombre de archivo del archivador de fuentes (o la copia de trabajo del
sistema de control de versiones), e ignora otros parámetros. La fase
configure únicamente tiene en cuenta el parámetro outputs, una
lista asociativa de nombres de salida de paquetes con su nombre de archivo
en el almacén (see Paquetes con múltiples salidas). Para ello se extrae
el nombre de archivo de out, la salida predeterminada, y se lo
proporciona a la orden ./configure como el prefijo de la
instalación (./configure --prefix=out), lo que significa que
make install acabará copiando todos los archivos en dicho
directorio (see configuration and makefile conventions in GNU Coding Standards). Tanto build como install
ignoran todos los parámetros. check utiliza el parámetro
test-target, que especifica el nombre del objetivo del archivo
Makefile que debe ejecutarse para ejecutar las pruebas; se imprime un
mensaje y se omiten las pruebas cuando el parámetro tests? tiene
falso como valor.
Se puede cambiar con el parámetro #:phases la lista de fases usada
por el sistema de construcción para un paquete en particular. El cambio del
conjunto de fases de construcción se realiza mediante la construcción de una
nueva lista asociativa basada en la lista asociativa %standard-phases
descrita previamente. Esto se puede llevar a cabo con procedimientos
estándar para la manipulación de listas asociativas como alist-delete
(see SRFI-1 Association Lists in GNU Guile Reference Manual); no
obstante es más conveniente hacerlo con modify-phases (see modify-phases).
Aquí se encuentra un ejemplo de una definición de paquete que borra la fase
configure de %standard-phases e inserta una nueva fase antes
de la fase build, llamada proporciona-prefijo-en-makefile:
(define-public example
(package
(name "example")
;; other fields omitted
(build-system gnu-build-system)
(arguments
'(#:phases (modify-phases %standard-phases
(delete 'configure)
(add-before 'build 'set-prefix-in-makefile
(lambda* (#:key outputs #:allow-other-keys)
;; Modify the makefile so that its
;; 'PREFIX' variable points to "out".
(let ((out (assoc-ref outputs "out")))
(substitute* "Makefile"
(("PREFIX =.*")
(string-append "PREFIX = "
out "\n")))))))))))
La nueva fase insertada se escribe como un procedimiento anónimo, generado
con lambda*; usa el parámetro outputs visto
anteriormente. See Utilidades de construcción para obtener más información sobre las
funciones auxiliares usadas en esta fase y donde encontrará más ejemplos de
uso de modify-phases.
Tenga en cuenta que las fases de construcción son código que se evalúa
cuando se realiza la construcción real del paquete. Esto explica por qué la
expresión modify-phases al completo se encuentra escapada (viene
precedida de ', un apóstrofe): se ha preparado para una
ejecución posterior. See Expresiones-G para obener una explicación sobre
esta preparación del código para las distintas fases de ejecución y los
distintos estratos de código implicados.
Next: Search Paths, Previous: Fases de construcción, Up: Interfaz programática [Contents][Index]
9.7 Utilidades de construcción
En cuanto empiece a escribir definiciones de paquete no-triviales
(see Definición de paquetes) u otras acciones de construcción
(see Expresiones-G), es probable que empiece a buscar funciones
auxiliares parecidas a las habituales en el intérprete de ordenes—creación
de directorios, borrado y copia recursiva de archivos, manipulación de fases
de construcción, etcétera. El módulo (guix build utils) proporciona
dichos procedimientos auxiliares.
La mayoría de sistemas de construcción cargan (guix build utils)
(see Sistemas de construcción). Por tanto, cuando construya fases de construcción
personalizadas para sus definiciones de paquetes, habitualmente puede asumir
que dichos procedimientos ya han sido incorporados al ámbito de ejecución.
Cuando escriba G-expressions, puede importar (guix build utils) en el
“lado de la construcción” mediante el uso with-imported-modules e
importandolos al ámbito actual con la forma sintáctica use-modules
(see Using Guile Modules in GNU Guile Reference Manual):
(with-imported-modules '((guix build utils)) ; Se importa.
(computed-file "empty-tree"
#~(begin
;; Se añade al ámbito actual.
(use-modules (guix build utils))
;; Se usa su procedimiento 'mkdir-p'.
(mkdir-p (string-append #$output "/a/b/c")))))
El resto de esta sección es la referencia de la mayoría de las
procedimientos de utilidad proporcionados por (guix build utils).
- Tratamiento de nombres de archivo del almacén
- Tipos de archivo
- Manipulación de archivos
- Búsqueda de archivos
- Program Invocation
- Fases de construcción
- Wrappers
9.7.1 Tratamiento de nombres de archivo del almacén
Esta sección documenta procedimientos para el manejo de nombres de archivo del almacén.
- Procedimiento Scheme: %store-directory
Devuelve el nombre del directorio del almacén.
- Procedimiento Scheme: store-file-name? archivo
Devuelve verdadero si archivo está en el almacén.
- Procedimiento Scheme: strip-store-file-name archivo
Elimina /gnu/store y el hash de archivo, un nombre de archivo del almacén. El resultado es habitualmente una cadena
"paquete-versión".
- Procedimiento Scheme: package-name>name+version nombre
Cuando se proporciona nombre, un nombre de paquete como
"foo-0.9.1b", devuelve dos valores:"foo"y"0.9.1b". Cuando la perte de la versión no está disponible, se devuelve nombre y#f. Se considera que el primer guión seguido de un dígito introduce la parte de la versión.
9.7.2 Tipos de archivo
Los siguientes procedimientos tratan con archivos y tipos de archivos.
- Procedimiento Scheme: directory-exists? dir
Devuelve
#tsi dir existe y es un directorio.
- Procedimiento Scheme: executable-file archivo
Devuelve
#tsi archivo existe y es ejecutable.
- Procedimiento Scheme: symbolic-link= archivo
Devuelve
#tsi archivo es enlace simbólico (“symlink”).
- Procedimiento Scheme: elf-file? archivo
- Procedimiento Scheme: ar-file? archivo
- Procedimiento Scheme: gzip-file? archivo
Devuelve
#tsi archivo es, respectivamente, un archivo ELF, un archivadorar(como una biblioteca estática .a), o un archivo comprimido con gzip.
- Procedimiento Scheme: reset-gzip-timestamp archivo [#:keep-mtime? #t]
Si archivo es un archivo gzip, reinicia su marca de tiempo embebida (como con
gzip --no-name) y devuelve un valor verdadero. En otro caso devuelve#f. Cuando keep-mtime? es verdadero, se preserva el tiempo de modificación del archivo.
9.7.3 Manipulación de archivos
Los siguientes procedimientos y macros sirven de ayuda en la creación,
modificación y borrado de archivos. Proporcionan funcionalidades comparables
con las herrambientas comunes del intérprete de órdenes como mkdir
-p, cp -r, rm -r y sed. Sirven de complemento
a la interfaz de sistema de archivos de Guile, la cual es extensa pero de
bajo nivel (see POSIX in GNU Guile Reference Manual).
- Sintaxis Scheme: with-directory-excursion directorio cuerpo…
Ejecuta cuerpo con directorio como el directorio actual del proceso.
Esecialmente este macro cambia el directorio actual a directorio antes de evaluar cuerpo, usando
chdir(see Processes in GNU Guile Reference Manual). Se vuelve al directorio inicial en cuanto se abandone el ámbito dinámico de cuerpo, ya sea a través de su finalización normal o de una salida no-local como pueda ser una excepción.
- Procedimiento Scheme: mkdir-p dir
Crea el directorio dir y todos sus predecesores.
- Procedimiento Scheme: install-file archivo directorio
Crea directorio si no existe y copia archivo allí con el mismo nombre.
- Procedimiento Scheme: make-file-writable archivo
Activa el permiso de escritura en archivo para su propietaria.
- Procedimiento Scheme: copy-recursively fuente destino [#:log (current-output-port)] [#:follow-symlinks? #f] [#:copy-file
copy-file] [#:keep-mtime? #f] [#:keep-permissions? #t] Copy source directory to destination. Follow symlinks if follow-symlinks? is true; otherwise, just preserve them. Call copy-file to copy regular files. When keep-mtime? is true, keep the modification time of the files in source on those of destination. When keep-permissions? is true, preserve file permissions. Write verbose output to the log port.
- Procedimiento Scheme: delete-file-recursively dir [#:follow-mounts? #f]
Borra dir recursivamente, como
rm -rf, sin seguir los enlaces simbólicos. No atraviesa puntos de montaje tampoco, a no ser que follow-mounts? sea verdadero. Informa de los errores, pero no devuelve error por ellos.
- Sintaxis Scheme: substitute archivo ((expreg var-encontrada…) cuerpo…) …
-
Sustituye expreg en archivo con la cadena que devuelve cuerpo. La evaluación de cuerpo se realiza con cada var-encontrada asociada con la subexpresión posicional correspondiente de la expresión regular. Por ejemplo:
(substitute* file (("hello") "good morning\n") (("foo([a-z]+)bar(.*)$" all letters end) (string-append "baz" letters end)))En este ejemplo, cada ver que una línea de archivo contiene
hola, esto se sustituye porbuenos días. Cada vez que una línea del archivo corresponde con la segunda expresión regular,todose asocia con la cadena encontrada al completo,letrastoma el valor de la primera sub-expresión, yfinse asocia con la última.Cuando una de las var-encontrada es
_, no se asocia ninguna variable con la correspondiente subcadena.También puede proporcionarse una lista como archivo, en cuyo caso los nombres de archivo que contenga serán los que se sometan a las sustituciones.
Tenga cuidado con el uso de
$para marcar el final de una línea; la cadena encontrada no contiene el caracter de salto de línea al final.
9.7.4 Búsqueda de archivos
Esta sección documenta procedimientos de búsqueda y filtrado de archivos.
- Procedimiento Scheme: file-name-predicate expreg
Devuelve un predicado que devuelve un valor verdadero cuando el nombre del archivo proporcionado sin la parte del directorio corresponde con expreg.
- Procedimiento Scheme: find-files dir [pred] [#:stat lstat] [#:directories? #f] [#:fail-on-error? #f]
Devuelve una lista ordenada lexicográficamente de los archivos que se encuentran en dir para los cuales pred devuelve verdadero. Se le proporcionan dos parámetros a pred: la ruta absoluta del archivo y su búfer de stat; el predicado predeteminado siempre devuelve verdadero. pred también puede ser una expresión regular, en cuyo caso es equivalente a escribir
(file-name-predicate pred). stat se usa para obtener información del archivo; el uso delstatsignifica que no se siguen los enlaces simbólicos. Si directories? es verdadero se incluyen también los directorios. Si fail-on-error? es verdadero, se emite una excepción en caso de error.
Aquí se pueden encontrar algunos ejemplos en los que se asume que el directorio actual es la raíz del arbol de fuentes de Guix:
;; Enumera todos los archivos regulares en el directorio actual. (find-files ".") ⇒ ("./.dir-locals.el" "./.gitignore" …) ;; Enumera todos los archivos .scm en gnu/services. (find-files "gnu/services" "\\.scm$") ⇒ ("gnu/services/admin.scm" "gnu/services/audio.scm" …) ;; Enumera los archivos ar en el directorio actual. (find-files "." (lambda (file stat) (ar-file? file))) ⇒ ("./libformat.a" "./libstore.a" …)
- Procedimiento Scheme: which programa
Devuelve el nombre de archivo completo para programa tal y como se encuentra en
$PATH, o#fsi no se ha encontrado programa.
- Scheme Procedure: search-input-file inputs name
- Scheme Procedure: search-input-directory inputs name
Return the complete file name for name as found in inputs;
search-input-filesearches for a regular file andsearch-input-directorysearches for a directory. If name could not be found, an exception is raised.Here, inputs must be an association list like
inputsandnative-inputsas available to build phases (see Fases de construcción).
Here is a (simplified) example of how search-input-file is used in a
build phase of the wireguard-tools package:
(add-after 'install 'wrap-wg-quick
(lambda* (#:key inputs outputs #:allow-other-keys)
(let ((coreutils (string-append (assoc-ref inputs "coreutils")
"/bin")))
(wrap-program (search-input-file outputs "bin/wg-quick")
#:sh (search-input-file inputs "bin/bash")
`("PATH" ":" prefix ,(list coreutils))))))
9.7.5 Program Invocation
You’ll find handy procedures to spawn processes in this module, essentially
convenient wrappers around Guile’s system* (see system* in GNU Guile Reference Manual).
- Scheme Procedure: invoke program args…
Invoke program with the given args. Raise an
&invoke-errorexception if the exit code is non-zero; otherwise return#t.The advantage compared to
system*is that you do not need to check the return value. This reduces boilerplate in shell-script-like snippets for instance in package build phases.
- Scheme Procedure: invoke-error? c
Return true if c is an
&invoke-errorcondition.
- Scheme Procedure: invoke-error-program c
- Scheme Procedure: invoke-error-arguments c
- Scheme Procedure: invoke-error-exit-status c
- Scheme Procedure: invoke-error-term-signal c
- Scheme Procedure: invoke-error-stop-signal c
Access specific fields of c, an
&invoke-errorcondition.
- Scheme Procedure: report-invoke-error c [port]
Report to port (by default the current error port) about c, an
&invoke-errorcondition, in a human-friendly way.Typical usage would look like this:
(use-modules (srfi srfi-34) ;for 'guard' (guix build utils)) (guard (c ((invoke-error? c) (report-invoke-error c))) (invoke "date" "--imaginary-option")) -| command "date" "--imaginary-option" failed with status 1
- Scheme Procedure: invoke/quiet program args…
Invoke program with args and capture program’s standard output and standard error. If program succeeds, print nothing and return the unspecified value; otherwise, raise a
&messageerror condition that includes the status code and the output of program.Here’s an example:
(use-modules (srfi srfi-34) ;for 'guard' (srfi srfi-35) ;for 'message-condition?' (guix build utils)) (guard (c ((message-condition? c) (display (condition-message c)))) (invoke/quiet "date") ;all is fine (invoke/quiet "date" "--imaginary-option")) -| 'date --imaginary-option' exited with status 1; output follows: date: unrecognized option '--imaginary-option' Try 'date --help' for more information.
9.7.6 Fases de construcción
(guix build utils) también contiene herramientas para la manipulación
de las fases de construcción usadas por los sistemas de construcción
(see Sistemas de construcción). Las fases de construcción se representan como
listas asociativas o “alists” (see Association Lists in GNU
Guile Reference Manual) donde cada clave es un símbolo que nombra a la
fase, y el valor asociado es un procedimiento (see Fases de construcción).
Tanto el propio Guile como el módulo (srfi srfi-1) proporcionan
herramientas para la manipulación de listas asociativas. El módulo
(guix build utils) complementa estas con herramientas pensadas para
las fases de construcción.
- Sintaxis Scheme: modify-phases fases cláusula…
Modifica fases de manera secuencial com cada indique cada cláusula, que puede tener una de las siguentes formas:
(delete nombre-fase) (replace nombre-fase nueva-fase) (add-before nombre-fase nombre-nueva-fase nueva-fase) (add-after nombre-fase nombre-nueva-fase nueva-fase)
Donde cada nombre-fase y nombre-nueva-fase es una expresión que evalúa aun símbolo, y nueva-fase es una expresión que evalúa a un procedimiento.
El siguiente ejemplo se ha tomado de la definición del paquete
grep. Añade una fase que se ejecuta tras la fase install,
llamada fix-egrep-and-fgrep. Dicha fase es un procedimiento
(lambda* genera procedimientos anónimos) que toma un parámetro de
palabra clave #:outputs e ignora el resto (see Optional
Arguments in GNU Guile Reference Manual para obtener más información
sobre lambda* y los parámetros opcionales y de palabras clave). La
fase usa substitute* para modificar los guiones egrep y
fgrep instalados para que hagan referencia a grep con su ruta
de archivo absoluta:
(modify-phases %standard-phases
(add-after 'install 'fix-egrep-and-fgrep
;; Patch 'egrep' and 'fgrep' to execute 'grep' via its
;; absolute file name instead of searching for it in $PATH.
(lambda* (#:key outputs #:allow-other-keys)
(let* ((out (assoc-ref outputs "out"))
(bin (string-append out "/bin")))
(substitute* (list (string-append bin "/egrep")
(string-append bin "/fgrep"))
(("^exec grep")
(string-append "exec " bin "/grep")))))))
En el siguiente ejemplo se modifican las fases de dos maneras: se elimina la
fase estándar configure, posiblemente porque el paquete no tiene un
guión configure ni nada similar, y la fase install
predeterminada se sustituye por una que copia manualmente el archivo
ejecutable que se debe instalar:
(modify-phases %standard-phases
(delete 'configure) ;no 'configure' script
(replace 'install
(lambda* (#:key outputs #:allow-other-keys)
;; The package's Makefile doesn't provide an "install"
;; rule so do it by ourselves.
(let ((bin (string-append (assoc-ref outputs "out")
"/bin")))
(install-file "footswitch" bin)
(install-file "scythe" bin)))))
9.7.7 Wrappers
It is not unusual for a command to require certain environment variables to be set for proper functioning, typically search paths (see Search Paths). Failing to do that, the command might fail to find files or other commands it relies on, or it might pick the “wrong” ones—depending on the environment in which it runs. Examples include:
- a shell script that assumes all the commands it uses are in
PATH; - a Guile program that assumes all its modules are in
GUILE_LOAD_PATHandGUILE_LOAD_COMPILED_PATH; - a Qt application that expects to find certain plugins in
QT_PLUGIN_PATH.
For a package writer, the goal is to make sure commands always work the same
rather than depend on some external settings. One way to achieve that is to
wrap commands in a thin script that sets those environment variables,
thereby ensuring that those run-time dependencies are always found. The
wrapper would be used to set PATH, GUILE_LOAD_PATH, or
QT_PLUGIN_PATH in the examples above.
To ease that task, the (guix build utils) module provides a couple of
helpers to wrap commands.
- Scheme Procedure: wrap-program program [#:sh sh] [#:rest variables] Make a wrapper for program.
variables should look like this:
'(variable delimiter position list-of-directories)
where delimiter is optional.
:will be used if delimiter is not given.For example, this call:
(wrap-program "foo" '("PATH" ":" = ("/gnu/.../bar/bin")) '("CERT_PATH" suffix ("/gnu/.../baz/certs" "/qux/certs")))will copy foo to .foo-real and create the file foo with the following contents:
#!location/of/bin/bash export PATH="/gnu/.../bar/bin" export CERT_PATH="$CERT_PATH${CERT_PATH:+:}/gnu/.../baz/certs:/qux/certs" exec -a $0 location/of/.foo-real "$@"If program has previously been wrapped by
wrap-program, the wrapper is extended with definitions for variables. If it is not, sh will be used as the interpreter.
- Scheme Procedure: wrap-script program [#:guile guile] [#:rest variables] Wrap the script program
such that variables are set first. The format of variables is the same as in the
wrap-programprocedure. This procedure differs fromwrap-programin that it does not create a separate shell script. Instead, program is modified directly by prepending a Guile script, which is interpreted as a comment in the script’s language.Special encoding comments as supported by Python are recreated on the second line.
Note that this procedure can only be used once per file as Guile scripts are not supported.
Next: El almacén, Previous: Utilidades de construcción, Up: Interfaz programática [Contents][Index]
9.8 Search Paths
Many programs and libraries look for input data in a search path, a list of directories: shells like Bash look for executables in the command search path, a C compiler looks for .h files in its header search path, the Python interpreter looks for .py files in its search path, the spell checker has a search path for dictionaries, and so on.
Search paths can usually be defined or overridden via environment
variables (see Environment Variables in The GNU C Library Reference
Manual). For example, the search paths mentioned above can be changed by
defining the PATH, C_INCLUDE_PATH, PYTHONPATH (or
GUIX_PYTHONPATH), and DICPATH environment variables—you know,
all these something-PATH variables that you need to get right or things
“won’t be found”.
You may have noticed from the command line that Guix “knows” which search
path environment variables should be defined, and how. When you install
packages in your default profile, the file
~/.guix-profile/etc/profile is created, which you can “source” from
the shell to set those variables. Likewise, if you ask guix shell
to create an environment containing Python and NumPy, a Python library, and
if you pass it the --search-paths option, it will tell you about
PATH and GUIX_PYTHONPATH (see Invoking guix shell):
$ guix shell python python-numpy --pure --search-paths export PATH="/gnu/store/…-profile/bin" export GUIX_PYTHONPATH="/gnu/store/…-profile/lib/python3.9/site-packages"
When you omit --search-paths, it defines these environment variables right away, such that Python can readily find NumPy:
$ guix shell python python-numpy -- python3 Python 3.9.6 (default, Jan 1 1970, 00:00:01) [GCC 10.3.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import numpy >>> numpy.version.version '1.20.3'
For this to work, the definition of the python package
declares the search path it cares about and its associated
environment variable, GUIX_PYTHONPATH. It looks like this:
(package
(name "python")
(version "3.9.9")
;; some fields omitted...
(native-search-paths
(list (search-path-specification
(variable "GUIX_PYTHONPATH")
(files (list "lib/python/3.9/site-packages"))))))
What this native-search-paths field says is that, when the
python package is used, the GUIX_PYTHONPATH environment
variable must be defined to include all the
lib/python/3.9/site-packages sub-directories encountered in its
environment. (The native- bit means that, if we are in a
cross-compilation environment, only native inputs may be added to the search
path; see search-paths.) In the NumPy example
above, the profile where python appears contains exactly one such
sub-directory, and GUIX_PYTHONPATH is set to that. When there are
several lib/python/3.9/site-packages—this is the case in package
build environments—they are all added to GUIX_PYTHONPATH, separated
by colons (:).
Nota: Notice that
GUIX_PYTHONPATHis specified as part of the definition of thepythonpackage, and not as part of that ofpython-numpy. This is because this environment variable “belongs” to Python, not NumPy: Python actually reads the value of that variable and honors it.Corollary: if you create a profile that does not contain
python,GUIX_PYTHONPATHwill not be defined, even if it contains packages that provide .py files:$ guix shell python-numpy --search-paths --pure export PATH="/gnu/store/…-profile/bin"This makes a lot of sense if we look at this profile in isolation: no software in this profile would read
GUIX_PYTHONPATH.
Of course, there are many variations on that theme: some packages honor more
than one search path, some use separators other than colon, some accumulate
several directories in their search path, and so on. A more complex example
is the search path of libxml2: the value of the XML_CATALOG_FILES
environment variable is space-separated, it must contain a list of
catalog.xml files (not directories), which are to be found in
xml sub-directories—nothing less. The search path specification
looks like this:
(package
(name "libxml2")
;; some fields omitted
(native-search-paths
(list (search-path-specification
(variable "XML_CATALOG_FILES")
(separator " ")
(files '("xml"))
(file-pattern "^catalog\\.xml$")
(file-type 'regular)))))
Worry not, search path specifications are usually not this tricky.
The (guix search-paths) module defines the data type of search path
specifications and a number of helper procedures. Below is the reference of
search path specifications.
- Data Type: search-path-specification
The data type for search path specifications.
variableThe name of the environment variable for this search path (a string).
filesThe list of sub-directories (strings) that should be added to the search path.
separator(default:":")The string used to separate search path components.
As a special case, a
separatorvalue of#fspecifies a “single-component search path”—in other words, a search path that cannot contain more than one element. This is useful in some cases, such as theSSL_CERT_DIRvariable (honored by OpenSSL, cURL, and a few other packages) or theASPELL_DICT_DIRvariable (honored by the GNU Aspell spell checker), both of which must point to a single directory.file-type(default:'directory)The type of file being matched—
'directoryor'regular, though it can be any symbol returned bystat:type(seestatin GNU Guile Reference Manual).In the libxml2 example above, we would match regular files; in the Python example, we would match directories.
file-pattern(default:#f)This must be either
#for a regular expression specifying files to be matched within the sub-directories specified by thefilesfield.Again, the libxml2 example shows a situation where this is needed.
Some search paths are not tied by a single package but to many packages. To
reduce duplications, some of them are pre-defined in (guix
search-paths).
- Scheme Variable: $SSL_CERT_DIR
- Scheme Variable: $SSL_CERT_FILE
These two search paths indicate where X.509 certificates can be found (see Certificados X.509).
These pre-defined search paths can be used as in the following example:
(package
(name "curl")
;; some fields omitted ...
(native-search-paths (list $SSL_CERT_DIR $SSL_CERT_FILE)))
How do you turn search path specifications on one hand and a bunch of
directories on the other hand in a set of environment variable definitions?
That’s the job of evaluate-search-paths.
- Scheme Procedure: evaluate-search-paths search-paths directories [getenv] Evaluate search-paths, a list of
search-path specifications, for directories, a list of directory names, and return a list of specification/value pairs. Use getenv to determine the current settings and report only settings not already effective.
The (guix profiles) provides a higher-level helper procedure,
load-profile, that sets the environment variables of a profile.
Next: Derivaciones, Previous: Search Paths, Up: Interfaz programática [Contents][Index]
9.9 El almacén
Conceptualmente, el almacén es el lugar donde se almacenan las derivaciones cuya construcción fue satisfactoria—por defecto, /gnu/store. Los subdirectorios en el almacén se denominan elementos del almacén o rutas del almacén en ocasiones. El almacén tiene una base de datos asociada que contiene información como las rutas del almacén a las que referencia cada ruta del almacén, y la lista de elementos válidos del almacén—los resultados de las construcciones satisfactorias. Esta base de datos reside en localstatedir/guix/db, donde localstatedir es el directorio de estado especificado vía --localstatedir en tiempo de configuración, normalmente /var.
El almacén siempre es accedido a través del daemon en delegación de
sus clientes (see Invocación de guix-daemon). Para manipular el almacén, los
clientes se conectan al daemon por un socket de dominio Unix, le envían
peticiones y leen el resultado—esto son llamadas a procedimientos remotos,
o RPC.
Nota: Las usuarias nunca deben modificar archivos directamente bajo el directorio /gnu/store. Esto llevaría a inconsistencias y rompería las premisas de inmutabilidad del modelo funcional de Guix (see Introducción).
See
guix gc --verify, para información sobre cómo comprobar la integridad del almacén e intentar recuperarse de modificaciones accidentales.
El módulo (guix store) proporciona procedimientos para conectarse al
daemon y realizar RPCs. Estos se describen más adelante. Por defecto,
open-connection, y por tanto todas las órdenes guix, se
conectan al daemon local o a la URI especificada en la variable de entorno
GUIX_DAEMON_SOCKET.
- Variable de entorno: GUIX_DAEMON_SOCKET
Cuando se ha definido, el valor de esta variable debe ser un nombre de archivo o una URI designando el punto de conexión del daemon. Cuando es un nombre de archivo, denota un socket de dominio Unix al que conectarse. Además de nombres de archivos, los esquemas de URI aceptados son:
fileunixEstos son equivalentes a los sockets de dominio Unix.
file:///var/guix/daemon-socket/socketes equivalente a /var/guix/daemon-socket/socket.guix¶-
Estas URI denotan conexiones sobre TCP/IP, sin cifrado ni verificación de la máquina remota. La URI debe especificar el nombre de máquina y opcionalmente un número de puerto (por defecto se usa el puerto 44146):
guix://principal.guix.example.org:1234
Esta configuración es apropiada para redes locales, como clusters, donde únicamente los nodos de confianza pueden conectarse al daemon de construcción en
principal.guix.example.org.La opción --listen de
guix-daemonpuede usarse para indicarle que escuche conexiones TCP (see --listen). ssh¶These URIs allow you to connect to a remote daemon over SSH. This feature requires Guile-SSH (see Requisitos) and a working
guilebinary inPATHon the destination machine. It supports public key and GSSAPI authentication. A typical URL might look like this:ssh://carlos@guix.example.org:22
Como con
guix copy, se tienen en cuenta los archivos habituales de configuración del cliente OpenSSH (see Invocación deguix copy).
Esquemas URI adicionales pueden ser aceptados en el futuro.
Nota: La conexión con daemon de construcción remotos se considera experimental en 1.4.0. Por favor, contacte con nosotras para compartir cualquier problema o sugerencias que pueda tener (see Contribuir).
- Procedimiento Scheme: open-connection [uri] [#:reserve-space? #t]
Abre una conexión al daemon a través del socket de dominio Unix apuntado por uri (una cadena). Cuando reserve-space? es verdadero, le indica que reserve un poco de espacio extra en el sistema de archivos de modo que el recolector de basura pueda operar incluso cuando el disco se llene. Devuelve un objeto servidor.
El valor por defecto de uri es
%default-socket-path, que ese la ruta esperada según las opciones proporcionadas aconfigure.
- Procedimiento Scheme: close-connection servidor
Cierra la conexión al servidor.
- Variable Scheme: current-build-output-port
Esta variable está enlazada a un parámetro SRFI-39, que referencia al puerto donde los logs de construcción y error enviados por el daemon deben escribirse.
Los procedimientos que realizan RPCs toman todos como primer parámetro un objeto servidor.
- Procedimiento Scheme: valid-path? servidor ruta
-
Devuelve
#tcuando ruta designa un elemento válido del almacén y#fen otro caso (un elemento no-válido puede existir en el disco pero aun así no ser válido, por ejemplo debido a que es el resultado de una construcción que se interrumpió o falló).Una condición
&store-protocol-errorse eleva si ruta no contiene como prefijo el directorio del almacén (/gnu/store).
- Procedimiento Scheme: add-text-to-store servidor nombre texto [referencias]
Añade texto bajo el archivo nombre en el almacén, y devuelve su ruta en el almacén. referencias es la lista de rutas del almacén a las que hace referencia la ruta del almacén resultante.
- Procedimiento Scheme: build-derivations almacén derivaciones [modo]
Construye derivaciones, una lista de objetos
<derivation>, nombres de archivo .drv, o pares derivación/salida, usando el modo especificado—(build-mode normal)en caso de omisión.
Fíjese que el módulo (guix monads) proporciona una mónada así como
versiones monádicas de los procedimientos previos, con el objetivo de hacer
más conveniente el trabajo con código que accede al almacén (see La mónada del almacén).
Esta sección actualmente está incompleta.
Next: La mónada del almacén, Previous: El almacén, Up: Interfaz programática [Contents][Index]
9.10 Derivaciones
Las acciones de construcción a bajo nivel y el entorno en el que se realizan se representan mediante derivaciones. Una derivación contiene las siguientes piezas de información:
- Las salidas de la derivación—las derivaciones producen al menos un archivo o directorio en el almacén, pero pueden producir más.
- Las entradas de las derivaciones—es decir, sus dependencias de tiempo de construcción—, que pueden ser otras derivaciones o simples archivos en el almacén (parches, guiones de construcción, etc.).
- El tipo de sistema objetivo de la derivación—por ejemplo,
x86_64-linux. - El nombre de archivo del guión de construcción en el almacén, junto a los parámetros que se le deben pasar.
- Una lista de variables de entorno a ser definidas.
Las derivaciones permiten a los clientes del daemon comunicar acciones de
construcción al almacén. Existen en dos formas: como una representación en
memoria, tanto en el lado del cliente como el del daemon, y como archivos en
el almacén cuyo nombre termina en .drv—estos archivos se conocen
como rutas de derivación. Las rutas de derivación se pueden
proporcionar al procedimiento build-derivations para que realice las
acciones de construcción prescritas (see El almacén).
Operaciones como la descarga de archivos y las instantáneas de un control de versiones para las cuales el hash del contenido esperado se conoce previamente se modelan como derivaciones de salida fija. Al contrario que las derivaciones normales, las salidas de una derivación de salida fija son independientes de sus entradas—por ejemplo, la descarga del código fuente produce el mismo resultado independientemente del método de descarga y las herramientas usadas.
Las derivaciones de salida—es decir, los resultados de
construcción—tienen un conjunto de referencias, del que informa la
RPC references o la orden guix gc --references
(see Invocación de guix gc). Las referencias son el conjunto de dependencias
en tiempo de ejecución de los resultados de construcción. Las referencias
son un subconjunto de las entradas de la derivación; el daemon de
construcción calcula este subconjunto de forma automática mediante el
procesado de todos los archivos en las salidas.
El módulo (guix derivations) proporciona una representación de
derivaciones como objetos Scheme, junto a procedimientos para crear y
manipular de otras formas derivaciones. La primitiva de más bajo nivel para
crear una derivación es el procedimiento derivation:
- Procedimiento Scheme: derivation almacén nombre constructor args [#:outputs '("out")] [#:hash #f] [#:hash-algo #f] [#:recursive? #f] [#:inputs '()] [#:env-vars '()] [#:system (%current-system)] [#:references-graphs #f] [#:allowed-references #f] [#:disallowed-references #f] [#:leaked-env-vars #f] [#:local-build? #f] [#:substitutable? #t] [#:properties '()]
Construye una derivación con los parámetros proporcionados, y devuelve el objeto
<derivation>resultante.Cuando se proporcionan hash y hash-algo, una derivación de salida fija se crea—es decir, una cuyo resultado se conoce de antemano, como la descarga de un archivo. Si, además, recursive? es verdadero, entonces la salida fijada puede ser un archivo ejecutable o un directorio y hash debe ser el hash de un archivador que contenga esta salida.
Cuando references-graphs es verdadero, debe ser una lista de pares de nombre de archivo/ruta del almacén. En ese caso, el grafo de referencias de cada ruta del almacén se exporta en el entorno de construcción del archivo correspondiente, en un formato de texto simple.
Cuando allowed-references es verdadero, debe ser una lista de elementos del almacén o salidas a las que puede hacer referencia la salida de la derivación. Del mismo modo, disallowed-references, en caso de ser verdadero, debe ser una lista de cosas a las que las salidas no pueden hacer referencia.
Cuando leaked-env-vars es verdadero, debe ser una lista de cadenas que denoten variables de entorno que se permite “escapar” del entorno del daemon al entorno de construcción. Esto es únicamente aplicable a derivaciones de salida fija—es decir, cuando hash es verdadero. El uso principal es permitir que variables como
http_proxysean pasadas a las derivaciones que descargan archivos.Cuando local-build? es verdadero, declara que la derivación no es una buena candidata para delegación y debe ser construida localmente (see Uso de la facilidad de delegación de trabajo). Este es el caso para pequeñas derivaciones donde los costes de transferencia de datos sobrepasarían los beneficios.
Cuando substitutable? es falso, declara que las sustituciones de la salida de la derivación no deben usarse (see Sustituciones). Esto es útil, por ejemplo, cuando se construyen paquetes que capturan detalles sobre el conjunto de instrucciones de la CPU anfitriona.
properties debe ser una lista asociada que describe “propiedades” de la derivación. Debe mantenerse tal cual, sin interpretar, en la derivación.
Esto es un ejemplo con un guión de shell como constructor, asumiendo que almacén es una conexión abierta al daemon, bash apunta al ejecutable Bash en el almacén:
(use-modules (guix utils) (guix store) (guix derivations)) (let ((constructor ; añade el guión de Bash al almacén (add-text-to-store store "mi-constructor.sh" "echo hola mundo > $out\n" '()))) (derivation almacen "foo" bash `("-e" ,builder) #:inputs `((,bash) (,constructor)) #:env-vars '(("HOME" . "/sindirectorio")))) ⇒ #<derivation /gnu/store/…-foo.drv => /gnu/store/…-foo>
Como puede suponerse, el uso directo de esta primitiva es algo
enrevesado. Una mejor aproximación es escribir guiones de construcción en
Scheme, ¡por supuesto! La mejor forma de hacerlo es escribir el código de
construcción como una “expresión-G”, y pasarla a
gexp->derivation. Para más información, see Expresiones-G.
En otros tiempos, gexp->derivation no existía y la creación de
derivaciones con código de construcción escrito en Scheme se conseguía con
build-expression->derivation, documentada más adelante. Este
procedimiento está ahora obsoleto en favor del procedimiento
gexp->derivation mucho más conveniente.
- Procedimiento Scheme: build-expression->derivation almacén nombre exp [#:system (%current-system)] [#:inputs '()] [#:outputs '("out")] [#:hash #f] [#:hash-algo #f] [#:recursive? #f] [#:env-vars '()] [#:modules '()] [#:references-graphs #f] [#:allowed-references #f] [#:disallowed-references #f] [#:local-build? #f] [#:substitutable? #t] [#:guile-for-build #f]
Devuelve una derivación que ejecuta la expresión Scheme exp como un constructor para la derivación nombre. inputs debe ser una lista de tuplas
(nombre ruta-drv sub-drv); cuando sub-drv se omite, se asume"out". modules es una lista de nombres de módulos Guile de la ruta actual de búsqueda a copiar en el almacén, compilados, y poner a disposición en la ruta de carga durante la ejecución de exp—por ejemplo,((guix build utils) (guix build gnu-build-system)).exp se evalúa en un entorno donde
%outputsestá asociada a una lista de pares salida/ruta, y donde%build-inputsestá asociada a una lista de pares cadena/ruta-de-salida que provienen de inputs. De manera opcional, env-vars es una lista de pares de cadenas que especifican el nombre y el valor de las variables de entorno visibles al constructor. El constructor termina pasando el resultado de exp aexit; por tanto, cuando exp devuelve#f, la construcción se considera fallida.exp se construye usando guile-for-build (una derivación). Cuando guile-for-build se omite o es
#f, el valor del fluido%guile-for-buildse usa en su lugar.Véase el procedimiento
derivationpara el significado de references-graphs, allowed-references, disallowed-references, local-build? y substitutable?.
Aquí está un ejemplo de derivación de salida única que crea un directorio que contiene un archivo:
(let ((constructor '(let ((salida (assoc-ref %outputs "out"))) (mkdir salida) ; crea /gnu/store/…-goo (call-with-output-file (string-append salida "/prueba") (lambda (p) (display '(hola guix) p)))))) (build-expression->derivation almacen "goo" constructor)) ⇒ #<derivation /gnu/store/…-goo.drv => …>
Next: Expresiones-G, Previous: Derivaciones, Up: Interfaz programática [Contents][Index]
9.11 La mónada del almacén
Los procedimientos que operan en el almacén descritos en la sección previa toman todos una conexión abierta al daemon de construcción en su primer parámetro. Aunque el modelo subyacente es funcional, tienen o bien efectos secundarios o dependen del estado actual del almacén.
Lo anterior es inconveniente: la conexión al daemon de construcción tiene que proporcionarse en todas estas funciones, haciendo imposible la composición de funciones que no toman ese parámetro con funciones que sí lo hacen. Lo último puede ser problemático: ya que las operaciones del almacén tienen efectos secundarios y/o dependen del estado externo, deben ser secuenciadas de manera adecuada.
Aquí es donde entra en juego el módulo (guix monads). Este módulo
proporciona un entorno para trabajar con mónadas, y una mónada
particularmente útil para nuestros usos, la mónada del almacén. Las
mónadas son una construcción que permite dos cosas: asociar “contexto” con
valores (en nuestro caso, el contexto es el almacén), y la construcción de
secuencias de computaciones (aquí computaciones incluye accesos al
almacén). Los valores en una mónada—valores que transportan este contexto
adicional—se llaman valores monádicos; los procedimientos que
devuelven dichos valores se llaman procedimientos monádicos.
Considere este procedimiento “normal”:
(define (enlace-sh almacen)
;; Devuelve una derivación que enlaza el ejecutable 'bash'.
(let* ((drv (package-derivation store bash))
(out (derivation->output-path drv))
(sh (string-append out "/bin/bash")))
(build-expression->derivation store "sh"
`(symlink ,sh %output))))
Mediante el uso de (guix monads) y (guix gexp), puede
reescribirse como una función monádica:
(define (enlace-sh)
;; Lo mismo, pero devuelve un valor monádico.
(mlet %store-monad ((drv (package->derivation bash)))
(gexp->derivation "sh"
#~(symlink (string-append #$drv "/bin/bash")
#$output))))
Hay varias cosas a tener en cuenta en la segunda versión: el parámetro
store ahora es implícito y es “hilado en las llamadas a los
procedimientos monádicos package->derivation y
gexp->derivation, y el valor monádico devuelto por
package->derivation es asociado mediante el uso de mlet
en vez de un simple let.
Al final, la llamada a package->derivation puede omitirse ya que
tendrá lugar implícitamente, como veremos más adelante
(see Expresiones-G):
(define (enlace-sh)
(gexp->derivation "sh"
#~(symlink (string-append #$bash "/bin/bash")
#$output)))
La ejecución del procedimiento monádico enlace-para-sh no tiene
ningún efecto. Como alguien dijo una vez, “sales de una mónada como sales
de un edificio en llamas: corriendo” (run en inglés). Por tanto, para salir
de la mónada y obtener el efecto deseado se debe usar run-with-store:
(run-with-store (open-connection) (enlace-sh)) ⇒ /gnu/store/...-enlace-para-sh
Note that the (guix monad-repl) module extends the Guile REPL with
new “commands” to make it easier to deal with monadic procedures:
run-in-store, and enter-store-monad (see Using Guix Interactively). The former is used to “run” a single monadic value
through the store:
scheme@(guile-user)> ,run-in-store (package->derivation hello) $1 = #<derivation /gnu/store/…-hello-2.9.drv => …>
El último entra en un entorno interactivo recursivo, donde todos los valores devueltos se ejecutan automáticamente a través del almacén:
scheme@(guile-user)> ,enter-store-monad store-monad@(guile-user) [1]> (package->derivation hello) $2 = #<derivation /gnu/store/…-hello-2.9.drv => …> store-monad@(guile-user) [1]> (text-file "foo" "Hello!") $3 = "/gnu/store/…-foo" store-monad@(guile-user) [1]> ,q scheme@(guile-user)>
Fíjese que los valores no-monádicos no pueden devolverse en el entorno
interactivo store-monad.
Other meta-commands are available at the REPL, such as ,build to
build a file-like object (see Using Guix Interactively).
Las formas sintácticas principales para tratar con mónadas en general se
proporcionan por el módulo (guix monads) y se describen a
continuación.
- Sintaxis Scheme: with-monad mónada cuerpo ...
Evalúa cualquier forma
>>=oreturnen cuerpo como estando en mónada.
- Sintaxis Scheme: return val
Devuelve el valor monádico que encapsula val.
- Sintaxis Scheme: >>= mval mproc ...
Asocia el valor monádico mval, pasando su “contenido” a los procedimientos monádicos mproc…24. Puede haber un mproc o varios, como en este ejemplo:
(run-with-state (with-monad %state-monad (>>= (return 1) (lambda (x) (return (+ 1 x))) (lambda (x) (return (* 2 x))))) 'un-estado) ⇒ 4 ⇒ un-estado
- Sintaxis Scheme: mlet mónada ((var mval) ...) cuerpo ...
- Sintaxis Scheme: mlet* mónada ((var mval) ...) cuerpo ... Asocia las variables var a los valores monádicos
mval en cuerpo, el cual es una secuencia de expresiones. Como con el operador bind, esto puede pensarse como el “desempaquetado” del valor crudo no-monádico dentro del ámbito del cuerpo. La forma (var -> val) asocia var al valor “normal” val, como en
let. Las operaciones de asociación ocurren en secuencia de izquierda a derecha. La última expresión de cuerpo debe ser una expresión monádica, y su resultado se convertirá en el resultado demletomlet*cuando se ejecute en la mónada.mlet*es amletlo quelet*es alet(see Local Bindings in GNU Guile Reference Manual).
- Sistema Scheme: mbegin mónada mexp ...
Asocia mexp y las siguientes expresiones monádicas en secuencia, devolviendo el resultado de la última expresión. Cada expresión en la secuencia debe ser una expresión monádica.
Esto es similar a
mlet, excepto que los valores devueltos por las expresiones monádicas se ignoran. En ese sentido el funcionamiento es análogo abeginpero aplicado a expresiones monádicas.
- Sistema Scheme: mwhen condición mexp0 mexp* ...
Cuando condición es verdadero, evalúa la secuencia de expresiones monádicas mexp0..mexp* como dentro de
mbegin. Cuando condición es falso, devuelve*unespecified*en la mónada actual. Todas las expresiones en la secuencia deben ser expresiones monádicas.
- Sistema Scheme: munless condición mexp0 mexp* ...
Cuando condición es falso, evalúa la secuencia de expresiones monádicas mexp0..mexp* como dentro de
mbegin. Cuando condición es verdadero, devuelve*unespecified*en la mónada actual. Todas las expresiones en la secuencia deben ser expresiones monádicas.
El módulo (guix monads) proporciona la mónada de estado, que
permite que un valor adicional—el estado—sea hilado a través de
las llamadas a procedimientos monádicos.
- Variable Scheme: %state-monad
La mónada de estado. Procedimientos en la mónada de estado pueden acceder y cambiar el estado hilado.
Considere el siguiente ejemplo. El procedimiento
cuadradodevuelve un valor en la mónada de estado.(define (cuadrado x) (mlet %state-monad ((count (current-state))) (mbegin %state-monad (set-current-state (+ 1 count)) (return (* x x))))) (run-with-state (sequence %state-monad (map cuadrado (iota 3))) 0) ⇒ (0 1 4) ⇒ 3
Cuando se “ejecuta” a través de
%state-monad, obtenemos un valor adicional de estado, que es el número de llamadas acuadrado.
- Procedimiento monádico: current-state
Devuelve el estado actual como un valor monádico.
- Procedimiento monádico: set-current-state valor
Establece el estado actual a valor y devuelve el estado previo como un valor monádico.
- Procedimiento monádico: state-push valor
Apila valor al estado actual, que se asume que es una lista, y devuelve el estado previo como un valor monádico.
- Procedimiento monádico: state-pop
Extrae un valor del estado actual y lo devuelve como un valor monádico. Se asume que el estado es una lista.
- Procedimiento Scheme: run-with-state mval [estado]
Ejecuta un valor monádico mval comenzando con estado como el estado inicial. Devuelve dos valores: el valor resultante y el estado resultante.
La interfaz principal a la mónada del almacén, proporcionada por el módulo
(guix store), es como sigue.
- Variable Scheme: %store-monad
La mónada del almacén—un alias para
%state-monad.Los valores en la mónada del almacén encapsulan los accesos al almacén. Cuando su efecto es necesario, un valor de la mónada del almacén será “evaluado” cuando se proporcione al procedimiento
run-with-store(véase a continuación).
- Procedimiento Scheme: run-with-store almacén mval [#:guile-for-build] [#:system (%current-system)]
Ejecuta mval, un valor monádico en la mónada del almacén, en almacén, una conexión abierta al almacén.
- Procedimiento monádico: text-file nombre texto [referencias]
Devuelve como un valor monádico el nombre absoluto del archivo en el almacén del archivo que contiene ŧexto, una cadena. referencias es una lista de elementos del almacén a los que el archivo de texto referencia; su valor predeterminado es la lista vacía.
- Procedimiento monádico: binary-file nombre datos [referencias]
Devuelve como un valor monádico el nombre absoluto del archivo en el almacén del archivo que contiene datos, un vector de bytes. referencias es una lista de elementos del almacén a los que el archivo binario referencia; su valor predeterminado es la lista vacía.
- Procedimiento monádico: interned-file archivo [nombre] [#:recursive? #t] [#:select? (const #t)]
Devuelve el nombre del archivo una vez internado en el almacén. Usa nombre como su nombre del almacén, o el nombre base de archivo si nombre se omite.
Cuando recursive? es verdadero, los contenidos del archivo se añaden recursivamente; si archivo designa un archivo plano y recursive? es verdadero, sus contenidos se añaden, y sus bits de permisos se mantienen.
Cuando recursive? es verdadero, llama a
(select? archivo stat)por cada entrada del directorio, donde archivo es el nombre absoluto de archivo de la entrada y stat es el resultado delstat; excluyendo las entradas para las cuales select? no devuelve verdadero.El ejemplo siguiente añade un archivo al almacén, bajo dos nombres diferentes:
(run-with-store (open-connection) (mlet %store-monad ((a (interned-file "README")) (b (interned-file "README" "LEGU-MIN"))) (return (list a b)))) ⇒ ("/gnu/store/rwm…-README" "/gnu/store/44i…-LEGU-MIN")
El módulo (guix packages) exporta los siguientes procedimientos
monádicos relacionados con paquetes:
- Procedimiento monádico: package-file paquete [archivo] [#:system (%current-system)] [#:target #f] [#:output "out"]
Devuelve como un valor monádico el nombre absoluto de archivo de archivo dentro del directorio de salida output del paquete. Cuando se omite archivo, devuelve el nombre del directorio de salida output del paquete. Cuando target es verdadero, se usa como una tripleta de compilación cruzada.
Tenga en cuenta que este procedimiento no construye paquete. Por lo tanto, el resultado puede designar o no un archivo existente. Le recomendamos que no use este procedimiento a no ser que sepa qué está haciendo.
- Procedimiento monádico: package->derivation paquete [sistema]
- Procedimiento monádico: package->cross-derivation paquete objetivo [sistema]
Versión monádica de
package-derivationypackage-cross-derivation(see Definición de paquetes).
Next: Invocación de guix repl, Previous: La mónada del almacén, Up: Interfaz programática [Contents][Index]
9.12 Expresiones-G
Por tanto tenemos “derivaciones”, que representan una secuencia de
acciones de construcción a realizar para producir un elemento en el almacén
(see Derivaciones). Estas acciones de construcción se llevan a cabo
cuando se solicita al daemon construir realmente la derivación; se ejecutan
por el daemon en un contenedor (see Invocación de guix-daemon).
No debería ser ninguna sorpresa que nos guste escribir estas acciones de
construcción en Scheme. Cuando lo hacemos, terminamos con dos estratos
de código Scheme25: el “código anfitrión”—código que define
paquetes, habla al daemon, etc.—y el “código de construcción”—código
que realmente realiza las acciones de construcción, como la creación de
directorios, la invocación de make, etcétera (see Fases de construcción).
Para describir una derivación y sus acciones de construcción, típicamente se
necesita embeber código de construcción dentro del código anfitrión. Se
resume en la manipulación de código de construcción como datos, y la
homoiconicidad de Scheme—el código tiene representación directa como
datos—es útil para ello. Pero necesitamos más que el mecanismo normal de
quasiquote en Scheme para construir expresiones de construcción.
El módulo (guix gexp) implementa las expresiones-G, una forma
de expresiones-S adaptada para expresiones de construcción. Las
expresiones-G, o gexps, consiste esencialmente en tres formas
sintácticas: gexp, ungexp y ungexp-splicing (o
simplemente: #~, #$ y #$@), que son comparables a
quasiquote, unquote y unquote-splicing, respectivamente
(see quasiquote in GNU Guile Reference
Manual). No obstante, hay importantes diferencias:
- Las expresiones-G están destinadas a escribirse en un archivo y ser ejecutadas o manipuladas por otros procesos.
- Cuando un objeto de alto nivel como un paquete o una derivación se expande dentro de una expresión-G, el resultado es el mismo que la introducción de su nombre de archivo de salida.
- Las expresiones-G transportan información acerca de los paquetes o derivaciones que referencian, y estas referencias se añaden automáticamente como entradas al proceso de construcción que las usa.
Este mecanismo no se limita a objetos de paquete ni derivación: pueden
definirse compiladores capaces de “bajar el nivel” de otros objetos
de alto nivel a derivaciones o archivos en el almacén, de modo que esos
objetos puedan introducirse también en expresiones-G. Por ejemplo, un tipo
útil de objetos de alto nivel que pueden insertarse en una expresión-G son
los “objetos tipo-archivo”, los cuales facilitan la adición de archivos al
almacén y su referencia en derivaciones y demás (vea local-file y
plain-file más adelante).
Para ilustrar la idea, aquí está un ejemplo de expresión-G:
(define exp-construccion
#~(begin
(mkdir #$output)
(chdir #$output)
(symlink (string-append #$coreutils "/bin/ls")
"enumera-archivos")))
Esta expresión-G puede pasarse a gexp->derivation; obtenemos una
derivación que construye un directorio que contiene exactamente un enlace
simbólico a /gnu/store/…-coreutils-8.22/bin/ls:
(gexp->derivation "la-cosa" exp-construccion)
Como se puede esperar, la cadena "/gnu/store/…-coreutils-8.22"
se sustituye por la referencia al paquete coreutils en el código de
construcción real, y coreutils se marca automáticamente como una
entrada a la derivación. Del mismo modo, #$output (equivalente a
(ungexp output)) se reemplaza por una cadena que contiene el nombre
del directorio de la salida de la derivación.
En un contexto de compilación cruzada, es útil distinguir entre referencias
a construcciones nativas del paquete—que pueden ejecutarse en el
sistema anfitrión—de referencias de compilaciones cruzadas de un
paquete. Para dicho fin, #+ tiene el mismo papel que #$, pero
es una referencia a una construcción nativa del paquete:
(gexp->derivation "vi"
#~(begin
(mkdir #$output)
(mkdir (string-append #$output "/bin"))
(system* (string-append #+coreutils "/bin/ln")
"-s"
(string-append #$emacs "/bin/emacs")
(string-append #$output "/bin/vi")))
#:target "aarch64-linux-gnu")
En el ejemplo previo, se usa la construcción nativa de coreutils, de
modo que ln pueda realmente ejecutarse en el anfitrión; pero se
hace referencia a la construcción de compilación cruzada de emacs.
Otra característica de las expresiones-G son los módulos importados: a
veces deseará ser capaz de usar determinados módulos Guile del “entorno
anfitrión” en la expresión-G, de modo que esos módulos deban ser importados
en el “entorno de construcción”. La forma with-imported-modules le
permite expresarlo:
(let ((build (with-imported-modules '((guix build utils))
#~(begin
(use-modules (guix build utils))
(mkdir-p (string-append #$output "/bin"))))))
(gexp->derivation "directorio-vacio"
#~(begin
#$build
(display "éxito!\n")
#t)))
En este ejemplo, el módulo (guix build utils) se incorpora
automáticamente dentro del entorno de construcción aislado de nuestra
expresión-G, de modo que (use-modules (guix build utils)) funciona
como se espera.
De manera habitual deseará que la clausura del módulo se importe—es
decir, el módulo en sí y todos los módulos de los que depende—en vez del
módulo únicamente; si no se hace, cualquier intento de uso del módulo
fallará porque faltan módulos dependientes. El procedimiento
source-module-closure computa la clausura de un módulo mirando en las
cabeceras de sus archivos de fuentes, lo que es útil en este caso:
(use-modules (guix modules)) ;para 'source-module-closure' (with-imported-modules (source-module-closure '((guix build utils) (gnu build image))) (gexp->derivation "something-with-vms" #~(begin (use-modules (guix build utils) (gnu build image)) …)))
De la misma manera, a veces deseará importar no únicamente módulos puros de
Scheme, pero también “extensiones” como enlaces Guile a bibliotecas C u
otros paquetes “completos”. Si, digamos, necesitase el paquete
guile-json disponible en el lado de construcción, esta sería la forma
de hacerlo:
(use-modules (gnu packages guile)) ;para 'guile-json' (with-extensions (list guile-json) (gexp->derivation "algo-con-json" #~(begin (use-modules (json)) …)))
La forma sintáctica para construir expresiones-G se resume a continuación.
- Sintaxis Scheme: #~exp ¶
- Sintaxis Scheme: (gexp exp)
Devuelve una expresión-G que contiene exp. exp puede contener una o más de las siguientes formas:
#$obj(ungexp obj)Introduce una referencia a obj. obj puede tener uno de los tipos permitidos, por ejemplo un paquete o derivación, en cuyo caso la forma
ungexpse substituye por el nombre de archivo de su salida—por ejemplo,"/gnu/store/…-coreutils-8.22.Si obj es una lista, se recorre y las referencias a objetos permitidos se substituyen de manera similar.
Si obj es otra expresión-G, su contenido se inserta y sus dependencias se añaden a aquellas de la expresión-G que la contiene.
Si obj es otro tipo de objeto, se inserta tal cual es.
#$obj:salida(ungexp obj salida)Como la forma previa, pero referenciando explícitamente la salida de obj—esto es útil cuando obj produce múltiples salidas (see Paquetes con múltiples salidas).
#+obj#+obj:salida(ungexp-native obj)(ungexp-native obj salida)Igual que
ungexp, pero produce una referencia a la construcción nativa de obj cuando se usa en un contexto de compilación cruzada.#$output[:salida](ungexp output [salida])Inserta una referencia a la salida de la derivación salida, o a la salida principal cuando salida se omite.
Esto únicamente tiene sentido para expresiones-G pasadas a
gexp->derivation.#$@lst(ungexp-splicing lst)Lo mismo que la forma previa, pero expande el contenido de la lista lst como parte de la lista que la contiene.
#+@lst(ungexp-native-splicing lst)Lo mismo que la forma previa, pero hace referencia a las construcciones nativas de los objetos listados en lst.
Las expresiones-G creadas por
gexpo#~son objetos del tipogexp?en tiempo de ejecución (véase a continuación).
- Sintaxis Scheme: with-imported-modules módulos cuerpo…
Marca las expresiones-G definidas en el cuerpo… como si requiriesen módulos en su entorno de ejecución.
Cada elemento en módulos puede ser el nombre de un módulo, como
(guix build utils), o puede ser el nombre de un módulo, seguido de una flecha, seguido de un objeto tipo-archivo:`((guix build utils) (guix gcrypt) ((guix config) => ,(scheme-file "config.scm" #~(define-module …))))
En el ejemplo previo, los dos primeros módulos se toman de la ruta de búsqueda, y el último se crea desde el objeto tipo-archivo proporcionado.
Esta forma tiene ámbito léxico: tiene efecto en las expresiones-G definidas en cuerpo…, pero no en aquellas definidas, digamos, en procedimientos llamados por cuerpo….
- Sintaxis Scheme: with-extensions extensiones cuerpo…
Marca que las expresiones definidas en cuerpo… requieren extensiones en su entorno de construcción y ejecución. extensiones es típicamente una lista de objetos de paquetes como los que se definen en el módulo
(gnu packages guile).De manera concreta, los paquetes listados en extensiones se añaden a la ruta de carga mientras se compilan los módulos importados en cuerpo…; también se añaden a la ruta de carga en la expresión-G devuelta por cuerpo….
- Procedimiento Scheme: gexp? obj
Devuelve
#tsi obj es una expresión-G.
Las expresiones-G están destinadas a escribirse en disco, tanto en código que construye alguna derivación, como en archivos planos en el almacén. Los procedimientos monádicos siguientes le permiten hacerlo (see La mónada del almacén, para más información sobre mónadas).
- Procedimiento monádico: gexp->derivation nombre exp [#:system (%current-system)] [#:target #f] [#:graft? #t] [#:hash #f] [#:hash-algo #f] [#:recursive? #f] [#:env-vars '()] [#:modules '()] [#:module-path
%load-path] [#:effective-version "2.2"] [#:references-graphs #f] [#:allowed-references #f] [#:disallowed-references #f] [#:leaked-env-vars #f] [#:script-name (string-append nombre "-builder")] [#:deprecation-warnings #f] [#:local-build? #f] [#:substitutable? #t] [#:properties '()] [#:guile-for-build #f] Devuelve una derivación nombre que ejecuta exp (una expresión-G) con guile-for-build (una derivación) en el sistema system; exp se almacena en un archivo llamado script-name. Cuando target tiene valor verdadero, se usa como tripleta de compilación cruzada para paquetes a los que haga referencia exp.
modules está obsoleto en favor de
with-imported-modules. Su significado es hacer que los módulos modules estén disponibles en el contexto de evaluación de exp; modules es una lista de nombres de módulos Guile buscados en module-path para ser copiados al almacén, compilados y disponibles en la ruta de carga durante la ejecución de exp—por ejemplo,((guix build utils) (gui build gnu-build-system)).effective-version determina la cadena usada cuando se añaden las extensiones de exp (vea
with-extensions) a la ruta de búsqueda—por ejemplo,"2.2".graft? determina si los paquetes a los que exp hace referencia deben ser injertados cuando sea posible.
Cuando references-graphs es verdadero, debe ser una lista de tuplas de una de las formas siguientes:
(nombre-archivo paquete) (nombre-archivo paquete salida) (nombre-archivo derivación) (nombre-archivo derivación salida) (nombre-archivo elemento-almacén)
El lado derecho de cada elemento de references-graphs se convierte automáticamente en una entrada del proceso de construcción de exp. En el entorno de construcción, cada nombre-archivo contiene el grafo de referencias del elemento correspondiente, en un formato de texto simple.
allowed-references debe ser o bien
#fo una lista de nombres y paquetes de salida. En el último caso, la lista denota elementos del almacén a los que el resultado puede hacer referencia. Cualquier referencia a otro elemento del almacén produce un error de construcción. De igual manera con disallowed-references, que enumera elementos a los que las salidas no deben hacer referencia.deprecation-warnings determina si mostrar avisos de obsolescencia durante la compilación de los módulos. Puede ser
#f,#to'detailed.El resto de parámetros funcionan como en
derivation(see Derivaciones).
Los procedimientos local-file, plain-file,
computed-file, program-file y scheme-file a
continuación devuelven objetos tipo-archivo. Esto es, cuando se
expanden en una expresión-G, estos objetos dirigen a un archivo en el
almacén. Considere esta expresión-G:
#~(system* #$(file-append glibc "/sbin/nscd") "-f" #$(local-file "/tmp/mi-nscd.conf"))
El efecto aquí es el “internamiento” de /tmp/mi-nscd.conf mediante
su copia al almacén. Una vez expandida, por ejemplo vía
gexp->derivation, la expresión-G hace referencia a la copia bajo
/gnu/store; por tanto, la modificación o el borrado del archivo en
/tmp no tiene ningún efecto en lo que la expresión-G
hace. plain-file puede usarse de manera similar; se diferencia en que
el contenido del archivo se proporciona directamente como una cadena.
- Procedimiento Scheme: local-file archivo [nombre] [#:recursive? #f] [#:select? (const #t)]
Devuelve un objeto que representa el archivo local archivo a añadir al almacén; este objeto puede usarse en una expresión-G. Si archivo es un nombre de archivo relativo, se busca de forma relativa al archivo fuente donde esta forma aparece; si archivo no es una cadena literal, se buscará de manera relativa al directorio de trabajo durante la ejecución. archivo se añadirá al almacén bajo nombre—de manera predeterminada el nombre de archivo sin los directorios.
Cuando recursive? es verdadero, los contenidos del archivo se añaden recursivamente; si archivo designa un archivo plano y recursive? es verdadero, sus contenidos se añaden, y sus bits de permisos se mantienen.
Cuando recursive? es verdadero, llama a
(select? archivo stat)por cada entrada del directorio, donde archivo es el nombre absoluto de archivo de la entrada y stat es el resultado delstat; excluyendo las entradas para las cuales select? no devuelve verdadero.Esta es la contraparte declarativa del procedimiento monádico
interned-file(seeinterned-file).
- Procedimiento Scheme: plain-file nombre contenido
Devuelve un objeto que representa un archivo de texto llamado nombre con el contenido proporcionado (una cadena o un vector de bytes) para ser añadido al almacén.
Esta es la contraparte declarativa de
text-file.
- Procedimiento Scheme: computed-file nombre gexp [#:local-build? #t] [#:options '()]
Devuelve un objeto que representa el elemento del almacén nombre, un archivo o un directorio computado por gexp. Cuando local-build? tiene valor verdadero (el caso predeterminado), la derivación se construye de manera local. options es una lista de parámetros adicionales proporcionados a
gexp->derivation.Esta es la contraparte declarativa de
gexp->derivation.
- Procedimiento monádico: gexp->script nombre exp [#:guile (default-guile)] [#:module-path %load-path] [#:system
(%current-system)] [#:target #f] Devuelve un guión ejecutable nombre que ejecuta exp usando guile, con los módulos importados por exp en su ruta de búsqueda. Busca los módulos de exp en module-path.
El ejemplo siguiente construye un guión que simplemente invoca la orden
ls:(use-modules (guix gexp) (gnu packages base)) (gexp->script "enumera-archivos" #~(execl #$(file-append coreutils "/bin/ls") "ls"))
Cuando se ejecuta a través del almacén (see
run-with-store), obtenemos una derivación que produce un archivo ejecutable /gnu/store/…-enumera-archivos más o menos así:#!/gnu/store/…-guile-2.0.11/bin/guile -ds !# (execl "/gnu/store/…-coreutils-8.22"/bin/ls" "ls")
- Procedimiento Scheme: program-file nombre exp [#:guile #f] [#:module-path %load-path]
Devuelve un objeto que representa el elemento ejecutable del almacén nombre que ejecuta gexp. guile es el paquete Guile usado para ejecutar el guión. Los módulos importados por gexp se buscan en module-path.
Esta es la contraparte declarativa de
gexp->script.
- Procedimiento monádico: gexp->file nombre exp [#:set-load-path? #t] [#:module-path %load-path] [#:splice? #f] [#:guile (default-guile)]
Devuelve una derivación que construye un archivo nombre que contiene exp. Cuando splice? es verdadero, se considera que exp es una lista de expresiones que deben ser expandidas en el archivo resultante.
Cuando set-load-path es verdadero, emite código en el archivo resultante para establecer
%load-pathy%load-compiled-pathde manera que respeten los módulos importados por exp. Busca los módulos de exp en module-path.El archivo resultante hace referencia a todas las dependencias de exp o a un subconjunto de ellas.
- Procedimiento Scheme: scheme-file nombre exp [#:splice? #f] [#:set-load-path? #t]
Devuelve un objeto que representa el archivo Scheme nombre que contiene exp.
Esta es la contraparte declarativa de
gexp->file.
- Procedimiento monádico: text-file* nombre texto …
Devuelve como un valor monádico una derivación que construye un archivo de texto que contiene todo texto. texto puede ser una lista de, además de cadenas, objetos de cualquier tipo que pueda ser usado en expresiones-G: paquetes, derivaciones, archivos locales, objetos, etc. El archivo del almacén resultante hace referencia a todos ellos.
Esta variante debe preferirse sobre
text-filecuando el archivo a crear haga referencia a elementos del almacén. Esto es el caso típico cuando se construye un archivo de configuración que embebe nombres de archivos del almacén, como este:(define (perfil.sh) ;; Devuelve el nombre de un guión shell en el almacén ;; que establece la variable de entorno 'PATH' (text-file* "perfil.sh" "export PATH=" coreutils "/bin:" grep "/bin:" sed "/bin\n"))En este ejemplo, el archivo /gnu/store/…-perfil.sh resultante hará referencia a coreutils, grep y sed, por tanto evitando que se recolecten como basura durante su tiempo de vida.
- Procedimiento Scheme: mixed-text-file nombre texto …
Devuelve un objeto que representa el archivo del almacén nombre que contiene texto. texto es una secuencia de cadenas y objetos tipo-archivo, como en:
(mixed-text-file "perfil" "export PATH=" coreutils "/bin:" grep "/bin")Esta es la contraparte declarativa de
text-file*.
- Procedimiento Scheme: file-union nombre archivos
Devuelve un
<computed-file>que construye un directorio que contiene todos los archivos. Cada elemento en archivos debe ser una lista de dos elementos donde el primer elemento es el nombre de archivo usado en el nuevo directorio y el segundo elemento es una expresión-G que denota el archivo de destino. Aquí está un ejemplo:(file-union "etc" `(("hosts" ,(plain-file "hosts" "127.0.0.1 localhost")) ("bashrc" ,(plain-file "bashrc" "alias ls='ls --color=auto'"))))Esto emite un directorio
etcque contiene estos dos archivos.
- Procedimiento Scheme: directory-union nombre cosas
Devuelve un directorio que es la unión de cosas, donde cosas es una lista de objetos tipo-archivo que denotan directorios. Por ejemplo:
(directory-union "guile+emacs" (list guile emacs))emite un directorio que es la unión de los paquetes
guileyemacs.
- Procedimientos Scheme: file-append obj sufijo …
Devuelve un objeto tipo-archivo que se expande a la concatenación de obj y sufijo, donde obj es un objeto que se puede bajar de nivel y cada sufijo es una cadena.
Como un ejemplo, considere esta expresión-G:
(gexp->script "ejecuta-uname" #~(system* #$(file-append coreutils "/bin/uname")))El mismo efecto podría conseguirse con:
(gexp->script "ejecuta-uname" #~(system* (string-append #$coreutils "/bin/uname")))Hay una diferencia no obstante: en el caso de
file-append, el guión resultante contiene una ruta absoluta de archivo como una cadena, mientras que en el segundo caso, el guión resultante contiene una expresión(string-append …)para construir el nombre de archivo en tiempo de ejecución.
- Sintaxis Scheme: let-system sistema cuerpo…
- Sintaxis Scheme: let-system (sistema objetivo) cuerpo…
Asocia sistema al sistema objetivo actual—por ejemplo,
"x86_64-linux"—dentro de cuerpo.En el segundo caso, asocia también objetivo al objetivo actual de compilación cruzada—una tripleta de GNU como
"arm-linux-gnueabihf"—o#fsi no se trata de una compilación cruzada.let-systemes útil en el caso ocasional en el que el objeto introducido en la expresión-G depende del sistema objetivo, como en este ejemplo:#~(system* #+(let-system system (cond ((string-prefix? "armhf-" system) (file-append qemu "/bin/qemu-system-arm")) ((string-prefix? "x86_64-" system) (file-append qemu "/bin/qemu-system-x86_64")) (else (error "¡ni idea!")))) "-net" "user" #$image)
- Sintaxis Scheme: with-parameters ((parámetro valor …) exp
Este macro es similar a la forma
parameterizepara parámetros asociados de forma dinámica (see Parameters in GNU Guile Reference Manual). La principal diferencia es que se hace efectivo cuando el objeto tipo-archivo devuelto por exp se baja de nivel a una derivación o un elemento del almacén.Un uso típico de
with-parameterses para forzar el sistema efectivo de cierto objeto:(with-parameters ((%current-system "i686-linux")) coreutils)El ejemplo previo devuelve un objeto que corresponde a la construcción en i686 de Coreutils, independientemente del valor actual de
%current-system.
Por supuesto, además de expresiones-G embebidas en código “anfitrión”, hay
también módulos que contienen herramientas de construcción. Para clarificar
que están destinados para su uso en el estrato de construcción, estos
módulos se mantienen en el espacio de nombres (guix build …).
Internamente, los objetos de alto nivel se bajan de nivel, usando su
compilador, a derivaciones o elementos del almacén. Por ejemplo, bajar de
nivel un paquete emite una derivación, y bajar de nivel un plain-file
emite un elemento del almacén. Esto se consigue usando el procedimiento
monádico lower-object.
- Procedimiento monádico: lower-object obj [sistema] [#:target #f]
Devuelve como un valor en
%store-monadla derivación o elemento del almacén que corresponde a obj en sistema, compilando de manera cruzada para target si target es verdadero. obj debe ser un objeto que tiene asociado un compilador de expresiones-G, como por ejemplo un objeto del tipo<package>.
- Procedure: gexp->approximate-sexp gexp
Sometimes, it may be useful to convert a G-exp into a S-exp. For example, some linters (see Invocación de
guix lint) peek into the build phases of a package to detect potential problems. This conversion can be achieved with this procedure. However, some information can be lost in the process. More specifically, lowerable objects will be silently replaced with some arbitrary object – currently the list(*approximate*), but this may change.
Next: Using Guix Interactively, Previous: Expresiones-G, Up: Interfaz programática [Contents][Index]
9.13 Invocación de guix repl
La orden guix repl lanza una sesión interactiva Guile (REPL)
para la programación interactiva (see Using Guile Interactively in GNU Guile Reference Manual), o para la ejecución de guiones de
Guile. Comparado a simplemente lanzar la orden guile,
guix repl garantiza que todos los módulos Guix y todas sus
dependencias están disponibles en la ruta de búsqueda.
La sintaxis general es:
guix repl opciones [archivo parámetros]
Cuando se proporciona archivo, archivo se ejecuta como un guión de Guile:
guix repl mi-guion.scm
Para proporcionar parámetros al guión, use -- para evitar que se
interpreten como parámetros específicos de guix repl:
guix repl -- mi-guion.scm --input=foo.txt
Pare hacer que un guión sea ejecutable directamente desde el shell, mediante el uso del ejecutable de guix que se encuentre en la ruta de búsqueda de la usuaria, escriba las siguientes dos líneas al inicio del archivo:
#!/usr/bin/env -S guix repl --!#
Without a file name argument, a Guile REPL is started, allowing for interactive use (see Using Guix Interactively):
$ guix repl scheme@(guile-user)> ,use (gnu packages base) scheme@(guile-user)> coreutils $1 = #<package coreutils@8.29 gnu/packages/base.scm:327 3e28300>
Además, guix repl implementa un protocolo del REPL simple legible
por máquinas para su uso por (guix inferior), una facilidad para
interactuar con inferiores, procesos separados que ejecutan una
revisión de Guix potencialmente distinta.
Las opciones disponibles son las siguientes:
--type=tipo-t tipoInicia un REPL del TIPO dado, que puede ser uno de los siguientes:
guileEs el predeterminado, y lanza una sesión interactiva Guile estándar con todas las características.
machineLanza un REPL que usa el protocolo legible por máquinas. Este es el protocolo con el que el módulo
(guix inferior)se comunica.
--listen=destinoPor defecto,
guix repllee de la entrada estándar y escribe en la salida estándar. Cuando se pasa esta opción, en vez de eso escuchará las conexiones en destino. Estos son ejemplos de opciones válidas:--listen=tcp:37146Acepta conexiones locales por el puerto 37146.
--listen=unix:/tmp/socketAcepta conexiones a través del socket de dominio Unix /tmp/socket.
--load-path=directorio-L directorioAñade directorio al frente de la ruta de búsqueda de módulos de paquetes (see Módulos de paquetes).
Esto permite a las usuarias definir sus propios paquetes y hacerlos visibles al guión o a la sesión interactiva.
-qInhibe la carga del archivo ~/.guile. De manera predeterminada, dicho archivo de configuración se carga al lanzar una sesión interactiva de
guile.
Previous: Invocación de guix repl, Up: Interfaz programática [Contents][Index]
9.14 Using Guix Interactively
The guix repl command gives you access to a warm and friendly
read-eval-print loop (REPL) (see Invocación de guix repl). If you’re
getting into Guix programming—defining your own packages, writing
manifests, defining services for Guix System or Guix Home, etc.—you will
surely find it convenient to toy with ideas at the REPL.
If you use Emacs, the most convenient way to do that is with Geiser
(see La configuración perfecta), but you do not have to use Emacs to enjoy the
REPL. When using guix repl or guile in the terminal,
we recommend using Readline for completion and Colorized to get colorful
output. To do that, you can run:
guix install guile guile-readline guile-colorized
... and then create a .guile file in your home directory containing this:
(use-modules (ice-9 readline) (ice-9 colorized)) (activate-readline) (activate-colorized)
The REPL lets you evaluate Scheme code; you type a Scheme expression at the prompt, and the REPL prints what it evaluates to:
$ guix repl scheme@(guix-user)> (+ 2 3) $1 = 5 scheme@(guix-user)> (string-append "a" "b") $2 = "ab"
It becomes interesting when you start fiddling with Guix at the REPL. The
first thing you’ll want to do is to “import” the (guix) module,
which gives access to the main part of the programming interface, and
perhaps a bunch of useful Guix modules. You could type (use-modules
(guix)), which is valid Scheme code to import a module (see Using Guile
Modules in GNU Guile Reference Manual), but the REPL provides the
use command as a shorthand notation (see REPL Commands in GNU Guile Reference Manual):
scheme@(guix-user)> ,use (guix) scheme@(guix-user)> ,use (gnu packages base)
Notice that REPL commands are introduced by a leading comma. A REPL command
like use is not valid Scheme code; it’s interpreted specially by the
REPL.
Guix extends the Guile REPL with additional commands for convenience. Among
those, the build command comes in handy: it ensures that the given
file-like object is built, building it if needed, and returns its output
file name(s). In the example below, we build the coreutils and
grep packages, as well as a “computed file” (see computed-file), and we use the scandir procedure to list the
files in Grep’s /bin directory:
scheme@(guix-user)> ,build coreutils
$1 = "/gnu/store/…-coreutils-8.32-debug"
$2 = "/gnu/store/…-coreutils-8.32"
scheme@(guix-user)> ,build grep
$3 = "/gnu/store/…-grep-3.6"
scheme@(guix-user)> ,build (computed-file "x" #~(mkdir #$output))
building /gnu/store/…-x.drv...
$4 = "/gnu/store/…-x"
scheme@(guix-user)> ,use(ice-9 ftw)
scheme@(guix-user)> (scandir (string-append $3 "/bin"))
$5 = ("." ".." "egrep" "fgrep" "grep")
At a lower-level, a useful command is lower: it takes a file-like
object and “lowers” it into a derivation (see Derivaciones) or a store
file:
scheme@(guix-user)> ,lower grep $6 = #<derivation /gnu/store/…-grep-3.6.drv => /gnu/store/…-grep-3.6 7f0e639115f0> scheme@(guix-user)> ,lower (plain-file "x" "Hello!") $7 = "/gnu/store/…-x"
The full list of REPL commands can be seen by typing ,help guix and
is given below for reference.
- REPL command: build object
Lower object and build it if it’s not already built, returning its output file name(s).
- REPL command: lower object
Lower object into a derivation or store file name and return it.
- REPL command: verbosity level
Change build verbosity to level.
This is similar to the --verbosity command-line option (see Opciones comunes de construcción): level 0 means total silence, level 1 shows build events only, and higher levels print build logs.
- REPL command: run-in-store exp
Run exp, a monadic expresssion, through the store monad. See La mónada del almacén, for more information.
- REPL command: enter-store-monad
Enter a new REPL to evaluate monadic expressions (see La mónada del almacén). You can quit this “inner” REPL by typing
,q.
Next: Foreign Architectures, Previous: Interfaz programática, Up: GNU Guix [Contents][Index]
10 Utilidades
Esta sección describe las utilidades de línea de órdenes de Guix. Algunas de ellas están orientadas principalmente para desarrolladoras y usuarias que escriban definiciones de paquetes nuevas, mientras que otras son útiles de manera más general. Complementan la interfaz programática Scheme de Guix de modo conveniente.
- Invocación de
guix build - Invocación de
guix edit - Invocación de
guix download - Invocación de
guix hash - Invocación de
guix import - Invocación de
guix refresh - Invoking
guix style - Invocación de
guix lint - Invocación de
guix size - Invocación de
guix graph - Invocación de
guix publish - Invocación de
guix challenge - Invocación de
guix copy - Invocación de
guix container - Invocación de
guix weather - Invocación de
guix processes
Next: Invocación de guix edit, Up: Utilidades [Contents][Index]
10.1 Invocación de guix build
La orden guix build construye paquetes o derivaciones y sus
dependencias, e imprime las rutas del almacén resultantes. Fíjese que no
modifica el perfil de la usuaria—este es el trabajo de la orden
guix package (see Invocación de guix package). Por tanto, es útil
principalmente para las desarrolladoras de la distribución.
La sintaxis general es:
guix build opciones paquete-o-derivación…
Como ejemplo, la siguiente orden construye las últimas versiones de Emacs y Guile, muestra sus log de construcción, y finalmente muestra los directorios resultantes:
guix build emacs guile
De forma similar, la siguiente orden construye todos los paquetes disponibles:
guix build --quiet --keep-going \
$(guix package -A | awk '{ print $1 "@" $2 }')
paquete-o-derivación puede ser tanto el nombre de un paquete que se
encuentra en la distribución de software como coreutils o
coreutils@8.20, o una derivación como
/gnu/store/…-coreutils-8.19.drv. En el primer caso, el paquete
de nombre (y opcionalmente versión) correspondiente se busca entre los
módulos de la distribución GNU (see Módulos de paquetes).
De manera alternativa, la opción --expression puede ser usada para especificar una expresión Scheme que evalúa a un paquete; esto es útil para diferenciar entre varios paquetes con el mismo nombre o si se necesitan variaciones del paquete.
Puede haber cero o más opciones. Las opciones disponibles se describen en la subsección siguiente.
- Opciones comunes de construcción
- Opciones de transformación de paquetes
- Opciones de construcción adicionales
- Depuración de fallos de construcción
10.1.1 Opciones comunes de construcción
Un número de opciones que controlan el proceso de construcción son comunes a
guix build y otras órdenes que pueden lanzar construcciones, como
guix package o guix archive. Son las siguientes:
--load-path=directorio-L directorioAñade directorio al frente de la ruta de búsqueda de módulos de paquetes (see Módulos de paquetes).
Esto permite a las usuarias definir sus propios paquetes y hacerlos visibles a las herramientas de línea de órdenes.
--keep-failed-KMantiene los árboles de construcción de las construcciones fallidas. Por tanto, si una construcción falla, su árbol de construcción se mantiene bajo /tmp, en un directorio cuyo nombre se muestra al final del log de construcción. Esto es útil cuando se depuran problemas en la construcción. See Depuración de fallos de construcción, para trucos y consejos sobre cómo depurar problemas en la construcción.
Esta opción implica --no-offload, y no tiene efecto cuando se conecta a un daemon remoto con una URI
guix://(see la variableGUIX_DAEMON_SOCKET).--keep-going-kSeguir adelante cuando alguna de las derivaciones de un fallo durante la construcción; devuelve una única vez todas las construcciones que se han completado o bien han fallado.
El comportamiento predeterminado es parar tan pronto una de las derivaciones especificadas falle.
--dry-run-nNo construye las derivaciones.
--fallbackCuando la sustitución de un binario preconstruido falle, intenta la construcción local de paquetes (see Fallos en las sustituciones).
--substitute-urls=urlsConsidera urls la lista separada por espacios de URLs de fuentes de sustituciones, anulando la lista predeterminada de URLs de
guix-daemon(seeguix-daemon URLs).Significa que las sustituciones puede ser descargadas de urls, mientras que estén firmadas por una clave autorizada por la administradora del sistema (see Sustituciones).
Cuando urls es la cadena vacía, las sustituciones están efectivamente desactivadas.
--no-substitutesNo usa sustituciones para la construcción de productos. Esto es, siempre realiza las construcciones localmente en vez de permitir la descarga de binarios pre-construidos (see Sustituciones).
--no-graftsNo “injerta” paquetes. En la práctica esto significa que las actualizaciones de paquetes disponibles como injertos no se aplican. See Actualizaciones de seguridad, para más información sobre los injertos.
--rounds=nConstruye cada derivación n veces seguidas, y lanza un error si los resultados de las construcciones consecutivas no son idénticos bit-a-bit.
Esto es útil para la detección de procesos de construcción no-deterministas. Los procesos de construcción no-deterministas son un problema puesto que prácticamente imposibilitan a las usuarias la verificación de la autenticidad de binarios proporcionados por terceras partes. See Invocación de
guix challenge, para más sobre esto.Cuando se usa conjuntamente con --keep-failed, la salida que difiere se mantiene en el almacén, bajo /gnu/store/…-check. Esto hace fácil buscar diferencias entre los dos resultados.
--no-offloadNo usa la delegación de construcciones en otras máquinas (see Uso de la facilidad de delegación de trabajo). Es decir, siempre realiza las construcciones de manera local en vez de delegar construcciones a máquinas remotas.
--max-silent-time=segundosCuando la construcción o sustitución permanece en silencio más de segundos, la finaliza e informa de un fallo de construcción.
Por defecto, se respeta la configuración del daemon (see --max-silent-time).
--timeout=segundosDel mismo modo, cuando el proceso de construcción o sustitución dura más de segundos, lo termina e informa un fallo de construcción.
Por defecto, se respeta la configuración del daemon (see --timeout).
-v nivel--verbosity=nivelUse the given verbosity level, an integer. Choosing 0 means that no output is produced, 1 is for quiet output; 2 is similar to 1 but it additionally displays download URLs; 3 shows all the build log output on standard error.
--cores=n-c nPermite usar n núcleos de la CPU para la construcción. El valor especial
0significa usar tantos como núcleos haya en la CPU.--max-jobs=n-M nPermite como máximo n trabajos de construcción en paralelo. See --max-jobs, para detalles acerca de esta opción y la opción equivalente de
guix-daemon.--debug=nivelUsa el nivel de detalle proporcionado en los mensajes procedentes del daemon de construcción. nivel debe ser un entero entre 0 y 5; valores mayores indican una salida más detallada. Establecer un nivel de 4 o superior puede ser útil en la depuración de problemas de configuración con el daemon de construcción.
Tras las cortinas, guix build es esencialmente una interfaz al
procedimiento package-derivation del módulo (guix packages), y
al procedimiento build-derivations del módulo (guix
derivations).
Además de las opciones proporcionadas explícitamente en la línea de órdenes,
guix build y otras órdenes guix que permiten la
construcción respetan el contenido de la variable de entorno
GUIX_BUILD_OPTIONS.
- Variable de entorno: GUIX_BUILD_OPTIONS
Las usuarias pueden definir esta variable para que contenga una lista de opciones de línea de órdenes que se usarán automáticamente por
guix buildy otras órdenesguixque puedan realizar construcciones, como en el ejemplo siguiente:$ export GUIX_BUILD_OPTIONS="--no-substitutes -c 2 -L /foo/bar"
Estas opciones se analizan independientemente, y el resultado se añade a continuación de las opciones de línea de órdenes.
Next: Opciones de construcción adicionales, Previous: Opciones comunes de construcción, Up: Invocación de guix build [Contents][Index]
10.1.2 Opciones de transformación de paquetes
Otro conjunto de opciones de línea de órdenes permitidas por guix
build y también guix package son las opciones de
transformación de paquetes. Son opciones que hacen posible la definición de
variaciones de paquetes—por ejemplo, paquetes construidos con un
código fuente diferente. Es una forma conveniente de crear paquetes
personalizados al vuelo sin tener que escribir las definiciones de las
variaciones del paquete (see Definición de paquetes).
Las opciones de transformación del paquete se preservan con las
actualizaciones: guix upgrade intenta aplicar las opciones de
transformación usadas inicialmente al crear el perfil para actualizar los
paquetes.
Las opciones disponibles se enumeran a continuación. La mayor parte de las ordenes los aceptan, así como la opción --help-transform que enumera todas las opciones disponibles y una sinópsis (estas opciones no se muestran en la salida de --help por brevedad).
--tune[=cpu]Use versions of the packages marked as “tunable” optimized for cpu. When cpu is
native, or when it is omitted, tune for the CPU on which theguixcommand is running.Valid cpu names are those recognized by the underlying compiler, by default the GNU Compiler Collection. On x86_64 processors, this includes CPU names such as
nehalem,haswell, andskylake(see-marchin Using the GNU Compiler Collection (GCC)).As new generations of CPUs come out, they augment the standard instruction set architecture (ISA) with additional instructions, in particular instructions for single-instruction/multiple-data (SIMD) parallel processing. For example, while Core2 and Skylake CPUs both implement the x86_64 ISA, only the latter supports AVX2 SIMD instructions.
The primary gain one can expect from --tune is for programs that can make use of those SIMD capabilities and that do not already have a mechanism to select the right optimized code at run time. Packages that have the
tunable?property set are considered tunable packages by the --tune option; a package definition with the property set looks like this:(package (name "hello-simd") ;; ... ;; This package may benefit from SIMD extensions so ;; mark it as "tunable". (properties '((tunable? . #t))))Other packages are not considered tunable. This allows Guix to use generic binaries in the cases where tuning for a specific CPU is unlikely to provide any gain.
Tuned packages are built with
-march=CPU; under the hood, the -march option is passed to the actual wrapper by a compiler wrapper. Since the build machine may not be able to run code for the target CPU micro-architecture, the test suite is not run when building a tuned package.To reduce rebuilds to the minimum, tuned packages are grafted onto packages that depend on them (see grafts). Thus, using --no-grafts cancels the effect of --tune.
We call this technique package multi-versioning: several variants of tunable packages may be built, one for each CPU variant. It is the coarse-grain counterpart of function multi-versioning as implemented by the GNU tool chain (see Function Multiversioning in Using the GNU Compiler Collection (GCC)).
--with-source=fuente--with-source=paquete=fuente--with-source=paquete@versión=fuenteUsa fuente como la fuente de paquete, y versión como su número de versión. fuente debe ser un nombre de archivo o una URL, como en
guix download(see Invocación deguix download).Cuando se omite paquete, se toma el nombre de paquete especificado en la línea de ordenes que coincide con el nombre base de fuente—por ejemplo, si fuente fuese
/src/guile-2.0.10.tar.gz, el paquete correspondiente seríaguile.Del mismo modo, si se omite versión, la cadena de versión se deduce de đuente; en el ejemplo previo sería
2.0.10.Esta opción permite a las usuarias probar versiones del paquete distintas a las proporcionadas en la distribución. El ejemplo siguiente descarga ed-1.7.tar.gz de un espejo GNU y lo usa como la fuente para el paquete
ed:guix build ed --with-source=mirror://gnu/ed/ed-1.4.tar.gz
As a developer, --with-source makes it easy to test release candidates, and even to test their impact on packages that depend on them:
guix build elogind --with-source=…/shepherd-0.9.0rc1.tar.gz
… o la construcción desde una revisión en un entorno limpio:
$ git clone git://git.sv.gnu.org/guix.git $ guix build guix --with-source=guix@1.0=./guix
--with-input=paquete=reemplazoSubstituye dependencias de paquete por dependencias de reemplazo. paquete debe ser un nombre de paquete, y reemplazo debe ser una especificación de paquete como
guileoguile@1.8.Por ejemplo, la orden siguiente construye Guix, pero substituye su dependencia de la versión estable actual de Guile con una dependencia en la versión antigua de Guile,
guile@2.0:guix build --with-input=guile=guile@2.0 guix
Esta sustitución se realiza de forma recursiva y en profundidad. Por lo que en este ejemplo, tanto
guixcomo su dependenciaguile-json(que también depende deguile) se reconstruyen contraguile@2.0.Se implementa usando el procedimiento Scheme
package-input-rewriting(seepackage-input-rewriting).--with-graft=paquete=reemplazoEs similar a --with-input pero con una diferencia importante: en vez de reconstruir la cadena de dependencias completa, reemplazo se construye y se injerta en los binarios que inicialmente hacían referencia a paquete. See Actualizaciones de seguridad, para más información sobre injertos.
Por ejemplo, la orden siguiente injerta la versión 3.5.4 de GnuTLS en Wget y todas sus dependencias, substituyendo las referencias a la versión de GnuTLS que tienen actualmente:
guix build --with-graft=gnutls=gnutls@3.5.4 wget
Esta opción tiene la ventaja de ser mucho más rápida que la reconstrucción de todo. Pero hay una trampa: funciona si y solo si paquete y reemplazo son estrictamente compatibles—por ejemplo, si proporcionan una biblioteca, la interfaz binaria de aplicación (ABI) de dichas bibliotecas debe ser compatible. Si reemplazo es incompatible de alguna manera con paquete, el paquete resultante puede no ser usable. ¡Úsela con precaución!
--with-debug-info=paqueteConstruye paquete de modo que preserve su información de depuración y lo injerta en los paquetes que dependan de él. Es útil si paquete no proporciona ya información de depuración como una salida
debug(see Instalación de archivos de depuración).Por ejemplo, supongamos que está experimentando un fallo en Inkscape y querría ver qué pasa en GLib, una biblioteca con mucha profundidad en el grafo de dependencias de Inkscape. GLib no tiene una salida
debug, de modo que su depuración es difícil. Afortunadamente puede reconstruir GLib con información de depuración e incorporarla a Inkscape:guix install inkscape --with-debug-info=glib
Únicamente GLib necesita una reconstrucción por lo que esto tarda un tiempo razonable. See Instalación de archivos de depuración para obtener más información.
Nota: Esta opción funciona en su implementación interna proporcionando ‘#:strip-binaries? #f’ al sistema de construcción del paquete en cuestión (see Sistemas de construcción). La mayor parte de sistemas de construcción implementan dicha opción, pero algunos no lo hacen. En este caso caso se emite un error.
De igual modo, si se construye un paquete C/C++ sin la opción
-g(lo que no es habitual que ocurra), la información de depuración seguirá sin estar disponible incluso cuando#:strip-binaries?sea falso.--with-c-toolchain=paquete=cadenaEsta opción cambia la compilación de paquete y todo lo que dependa de él de modo que se constuya con cadena en vez de la cadena de herramientas de construcción para C/C++ de GNU predeterminada.
Considere este ejemplo:
guix build octave-cli \ --with-c-toolchain=fftw=gcc-toolchain@10 \ --with-c-toolchain=fftwf=gcc-toolchain@10
La orden anterior construye una variante de los paquetes
fftwyfftwfusando la versión 10 degcc-toolchainen vez de la cadena de herramientas de construcción predeterminada, y construye una variante de la interfaz de línea de órdenes GNU Octave que hace uso de ellos. El propio paquete de GNU Octave también se construye congcc-toolchain@10.Este otro ejemplo construye la biblioteca Hardware Locality (
hwloc) y los paquetes que dependan de ella hastaintel-mpi-benchmarkscon el compilador de C Clang:guix build --with-c-toolchain=hwloc=clang-toolchain \ intel-mpi-benchmarksNota: There can be application binary interface (ABI) incompatibilities among tool chains. This is particularly true of the C++ standard library and run-time support libraries such as that of OpenMP. By rebuilding all dependents with the same tool chain, --with-c-toolchain minimizes the risks of incompatibility but cannot entirely eliminate them. Choose package wisely.
--with-git-url=paquete=url¶-
Construye paquete desde la última revisión de la rama
masterdel repositorio Git en url. Los submódulos del repositorio Git se obtienen de forma recursiva.Por ejemplo, la siguiente orden construye la biblioteca NumPy de Python contra la última revisión de la rama master de Python en sí:
guix build python-numpy \ --with-git-url=python=https://github.com/python/cpython
Esta opción también puede combinarse con --with-branch o --with-commit (véase más adelante).
Obviamente, ya que se usa la última revisión de la rama proporcionada, el resultado de dicha orden varia con el tiempo. No obstante es una forma conveniente de reconstruir una pila completa de software contra las últimas revisiones de uno o varios paquetes. Esto es particularmente útil en el contexto de integración continua (CI).
Los directorios de trabajo se conservan en caché en ~/.cache/guix/checkouts para agilizar accesos consecutivos al mismo repositorio. Puede desear limpiarla de vez en cuando para ahorrar espacio en el disco.
--with-branch=paquete=ramaConstruye paquete desde la última revisión de rama. Si el campo
sourcede paquete es un origen con el métodogit-fetch(see Referencia deorigin) o un objetogit-checkout, la URL del repositorio se toma de dicho camposource. En otro caso, se debe especificar la URL del repositorio Git mediante el uso de --with-git-url.Por ejemplo, la siguiente orden construye
guile-sqlite3desde la última revisión de su ramamastery, una vez hecho, construyeguix(que depende de él) ycuirass(que depende deguix) en base a esta construcción específica deguile-sqlite3:guix build --with-branch=guile-sqlite3=master cuirass
--with-commit=paquete=revisiónThis is similar to --with-branch, except that it builds from commit rather than the tip of a branch. commit must be a valid Git commit SHA1 identifier, a tag, or a
git describestyle identifier such as1.0-3-gabc123.--with-patch=package=fileAdd file to the list of patches applied to package, where package is a spec such as
python@3.8orglibc. file must contain a patch; it is applied with the flags specified in theoriginof package (see Referencia deorigin), which by default includes-p1(see patch Directories in Comparing and Merging Files).As an example, the command below rebuilds Coreutils with the GNU C Library (glibc) patched with the given patch:
guix build coreutils --with-patch=glibc=./glibc-frob.patch
In this example, glibc itself as well as everything that leads to Coreutils in the dependency graph is rebuilt.
--with-latest=packageSo you like living on the bleeding edge? This option is for you! It replaces occurrences of package in the dependency graph with its latest upstream version, as reported by
guix refresh(see Invocación deguix refresh).It does so by determining the latest upstream release of package (if possible), downloading it, and authenticating it if it comes with an OpenPGP signature.
As an example, the command below builds Guix against the latest version of Guile-JSON:
guix build guix --with-latest=guile-json
There are limitations. First, in cases where the tool cannot or does not know how to authenticate source code, you are at risk of running malicious code; a warning is emitted in this case. Second, this option simply changes the source used in the existing package definitions, which is not always sufficient: there might be additional dependencies that need to be added, patches to apply, and more generally the quality assurance work that Guix developers normally do will be missing.
You’ve been warned! In all the other cases, it’s a snappy way to stay on top. We encourage you to submit patches updating the actual package definitions once you have successfully tested an upgrade (see Contribuir).
--without-tests=paqueteConstruye paquete sin ejecutar su batería de pruebas. Puede ser útil en situaciones en las que quiera omitir una larga batería de pruebas de un paquete intermedio, o si la batería de pruebas no falla de manera determinista. Debe usarse con cuidado, puesto que la ejecución de la batería de pruebas es una buena forma de asegurarse de que el paquete funciona como se espera.
La desactivación de las pruebas conduce a diferentes elementos en el almacén. Por tanto, cuando use esta opción, cualquier objeto que dependa de paquete debe ser reconstruido, como en este ejemplo:
guix install --without-tests=python python-notebook
La orden anterior instala
python-notebooksobre un paquetepythonconstruido sin ejecutar su batería de pruebas. Para hacerlo, también reconstruye todos los paquetes que dependen depython, incluyendo el propiopyhton-notebook.De manera interna, --without-tests depende del cambio de la opción
#:tests?de la fasecheckdel paquete (see Sistemas de construcción). Tenga en cuenta que algunos paquetes usan una fasecheckpersonalizada que no respeta el valor de configuración#:tests? #f. Por tanto, --without-tests no tiene ningún efecto en dichos paquetes.
¿Se pregunta cómo conseguir el mismo efecto usando código Scheme, por ejemplo en su manifiesto, o cómo escribir su propia transformación de paquetes? See Definición de variantes de paquetes para obtener una descripción de la interfaz programática disponible.
Next: Depuración de fallos de construcción, Previous: Opciones de transformación de paquetes, Up: Invocación de guix build [Contents][Index]
10.1.3 Opciones de construcción adicionales
Las opciones de línea de ordenes presentadas a continuación son específicas
de guix build.
--quiet-qConstruye silenciosamente, sin mostrar el registro de construcción; es equivalente a --verbosity=0. Al finalizar, el registro de construcción se mantiene en /var (o similar) y puede recuperarse siempre mediante el uso de la opción --log-file.
--file=archivo-f archivoConstruye el paquete, derivación u otro objeto tipo-archivo al que evalúa el código en archivo (see objetos “tipo-archivo”).
Como un ejemplo, archivo puede contener una definición como esta (see Definición de paquetes):
(use-modules (guix) (guix build-system gnu) (guix licenses)) (package (name "hello") (version "2.10") (source (origin (method url-fetch) (uri (string-append "mirror://gnu/hello/hello-" version ".tar.gz")) (sha256 (base32 "0ssi1wpaf7plaswqqjwigppsg5fyh99vdlb9kzl7c9lng89ndq1i")))) (build-system gnu-build-system) (synopsis "Hello, GNU world: An example GNU package") (description "Guess what GNU Hello prints!") (home-page "http://www.gnu.org/software/hello/") (license gpl3+))
El archivo también puede contener una representación en JSON de una o más definiciones de paquete. Ejecutar
guix build -fen hello.json con el siguiente contenido resultaría en la construcción de los paquetesmyhelloygreeter:[ { "name": "myhello", "version": "2.10", "source": "mirror://gnu/hello/hello-2.10.tar.gz", "build-system": "gnu", "arguments": { "tests?": false } "home-page": "https://www.gnu.org/software/hello/", "synopsis": "Hello, GNU world: An example GNU package", "description": "GNU Hello prints a greeting.", "license": "GPL-3.0+", "native-inputs": ["gettext"] }, { "name": "greeter", "version": "1.0", "source": "https://example.com/greeter-1.0.tar.gz", "build-system": "gnu", "arguments": { "test-target": "foo", "parallel-build?": false, }, "home-page": "https://example.com/", "synopsis": "Greeter using GNU Hello", "description": "This is a wrapper around GNU Hello.", "license": "GPL-3.0+", "inputs": ["myhello", "hello"] } ]--manifest=manifiesto-m manifiestoConstruye todos los paquetes listados en el manifiesto proporcionado (see --manifest).
--expression=expr-e exprConstruye el paquete o derivación a la que evalúa expr.
Por ejemplo, expr puede ser
(@ (gnu packages guile) guile-1.8), que designa sin ambigüedad a esta variante específica de la versión 1.8 de Guile.De manera alternativa, expr puede ser una expresión-G, en cuyo caso se usa como un programa de construcción pasado a
gexp->derivation(see Expresiones-G).Por último, expr puede hacer referencia a un procedimiento mónadico sin parámetros (see La mónada del almacén). El procedimiento debe devolver una derivación como un valor monádico, el cual después se pasa a través de
run-with-store.--source-SConstruye las derivaciones de las fuentes de los paquetes, en vez de los paquetes mismos.
Por ejemplo,
guix build -S gccdevuelve algo como /gnu/store/…-gcc-4.7.2.tar.bz2, el cual es el archivador tar de fuentes de GCC.El archivador tar devuelto es el resultado de aplicar cualquier parche y fragmento de código en el origen (campo
origin) del paquete (see Definición de paquetes).As with other derivations, the result of building a source derivation can be verified using the --check option (see build-check). This is useful to validate that a (potentially already built or substituted, thus cached) package source matches against its declared hash.
Tenga en cuenta que
guix build -Scompila las fuentes únicamente de los paquetes especificados. Esto no incluye las dependencias enlazadas estáticamente y por sí mismas son insuficientes para reproducir los paquetes.--sourcesObtiene y devuelve las fuentes de paquete-o-derivación y todas sus dependencias, de manera recursiva. Esto es útil para obtener una copia local de todo el código fuente necesario para construir los paquetes, le permite construirlos llegado el momento sin acceso a la red. Es una extensión de la opción --source y puede aceptar uno de los siguientes valores opcionales como parámetro:
packageEste valor hace que la opción --sources se comporte de la misma manera que la opción --source.
allConstruye las derivaciones de las fuentes de todos los paquetes, incluyendo cualquier fuente que pueda enumerarse como entrada (campo
inputs). Este es el valor predeterminado.$ guix build --sources tzdata The following derivations will be built: /gnu/store/…-tzdata2015b.tar.gz.drv /gnu/store/…-tzcode2015b.tar.gz.drv
transitiveConstruye las derivaciones de fuentes de todos los paquetes, así como todas las entradas transitivas de los paquetes. Esto puede usarse, por ejemplo, para obtener las fuentes de paquetes para una construcción posterior sin conexión a la red.
$ guix build --sources=transitive tzdata The following derivations will be built: /gnu/store/…-tzcode2015b.tar.gz.drv /gnu/store/…-findutils-4.4.2.tar.xz.drv /gnu/store/…-grep-2.21.tar.xz.drv /gnu/store/…-coreutils-8.23.tar.xz.drv /gnu/store/…-make-4.1.tar.xz.drv /gnu/store/…-bash-4.3.tar.xz.drv …
--system=sistema-s sistemaIntenta la construcción para sistema—por ejemplo,
i686-linux—en vez del tipo de sistema de la máquina de construcción. La ordenguix buildle permite repetir esta opción varias veces, en cuyo caso construye para todos los sistemas especificados; otras ordenes ignoran opciones -s extrañas.Nota: La opción --system es para compilación nativa y no debe confundirse con la compilación cruzada. Véase --target más adelante para información sobre compilación cruzada.
Un ejemplo de uso de esta opción es en sistemas basados en Linux, que pueden emular diferentes personalidades. Por ejemplo, proporcionar la opción --system=i686-linux en un sistema
x86_64-linux, o la opción --system=armhf-linux en un sistemaaarch64-linux, le permite construir paquetes en un entorno de 32-bits completo.Nota: La construcción para un sistema
armhf-linuxestá disponible de manera incondicional en máquinasaarch64-linux, aunque determinadas familias de procesadores aarch64 no lo permitan, notablemente el ThunderX.De manera similar, cuando la emulación transparente con QEMU y
binfmt_miscestá activada (seeqemu-binfmt-service-type), puede construir para cualquier sistema para el que un manejador QEMU debinfmt_miscesté instalado.Las construcciones para un sistema distinto al de la máquina que usa se pueden delegar también a una máquina remota de la arquitectura correcta. See Uso de la facilidad de delegación de trabajo, para más información sobre delegación.
--target=tripleta¶Compilación cruzada para la tripleta, que debe ser una tripleta GNU válida, cómo
"aarch64-linux-gnu"(see GNU configuration triplets in Autoconf).--list-systemsList all the supported systems, that can be passed as an argument to --system.
--list-targetsList all the supported targets, that can be passed as an argument to --target.
--check¶-
Reconstruye paquete-o-derivación, que ya está disponible en el almacén, y emite un error si los resultados de la construcción no son idénticos bit-a-bit.
Este mecanismo le permite comprobar si sustituciones previamente instaladas son genuinas (see Sustituciones), o si el resultado de la construcción de un paquete es determinista. See Invocación de
guix challenge, para más información de referencia y herramientas.Cuando se usa conjuntamente con --keep-failed, la salida que difiere se mantiene en el almacén, bajo /gnu/store/…-check. Esto hace fácil buscar diferencias entre los dos resultados.
--repair¶-
Intenta reparar los elementos del almacén especificados, si están corruptos, volviendo a descargarlos o mediante su reconstrucción.
Esta operación no es atómica y por lo tanto está restringida a
root. --derivations-dDevuelve las rutas de derivación, no las rutas de salida, de los paquetes proporcionados.
--root=archivo¶-r archivo-
Hace que archivo sea un enlace simbólico al resultado, y lo registra como una raíz del recolector de basura.
Consecuentemente, los resultados de esta invocación de
guix buildse protegen de la recolección de basura hasta que archivo se elimine. Cuando se omite esa opción, los resultados son candidatos a la recolección de basura en cuanto la construcción se haya completado. See Invocación deguix gc, para más sobre las raíces del recolector de basura. --log-file¶Devuelve los nombres de archivos o URL de los log de construcción para el paquete-o-derivación proporcionado, o emite un error si no se encuentran los log de construcción.
Esto funciona independientemente de cómo se especificasen los paquetes o derivaciones. Por ejemplo, las siguientes invocaciones son equivalentes:
guix build --log-file $(guix build -d guile) guix build --log-file $(guix build guile) guix build --log-file guile guix build --log-file -e '(@ (gnu packages guile) guile-2.0)'
Si no está disponible un registro local, y a menos que se proporcione --no-substitutes, la orden busca el registro correspondiente en uno de los servidores de sustituciones (como se especificaron con --substitute-urls).
So for instance, imagine you want to see the build log of GDB on
aarch64, but you are actually on anx86_64machine:$ guix build --log-file gdb -s aarch64-linux https://ci.guix.gnu.org/log/…-gdb-7.10
¡Puede acceder libremente a una biblioteca inmensa de log de construcción!
Previous: Opciones de construcción adicionales, Up: Invocación de guix build [Contents][Index]
10.1.4 Depuración de fallos de construcción
Cuando esté definiendo un paquete nuevo (see Definición de paquetes), probablemente se encuentre que dedicando algún tiempo a depurar y afinar la construcción hasta obtener un resultado satisfactorio. Para hacerlo, tiene que lanzar manualmente las órdenes de construcción en un entorno tan similar como sea posible al que el daemon de construcción usa.
To that end, the first thing to do is to use the --keep-failed or
-K option of guix build, which will keep the failed build
tree in /tmp or whatever directory you specified as TMPDIR
(see --keep-failed).
De ahí en adelante, puede usar cd para ir al árbol de la
construcción fallida y cargar el archivo environment-variables, que
contiene todas las definiciones de variables de entorno que existían cuando
la construcción falló. Digamos que está depurando un fallo en la
construcción del paquete foo; una sesión típica sería así:
$ guix build foo -K … build fails $ cd /tmp/guix-build-foo.drv-0 $ source ./environment-variables $ cd foo-1.2
Ahora puede invocar órdenes (casi) como si fuese el daemon y encontrar los errores en su proceso de construcción.
A veces ocurre que, por ejemplo, las pruebas de un paquete pasan cuando las ejecuta manualmente pero fallan cuando el daemon las ejecuta. Esto puede suceder debido a que el daemon construye dentro de contenedores donde, al contrario que en nuestro entorno previo, el acceso a la red no está disponible, /bin/sh no existe, etc. (see Configuración del entorno de construcción).
En esos casos, puede tener que inspeccionar el proceso de construcción desde un contenedor similar al creado por el daemon de construcción:
$ guix build -K foo … $ cd /tmp/guix-build-foo.drv-0 $ guix shell --no-grafts -C -D foo strace gdb [env]# source ./environment-variables [env]# cd foo-1.2
Here, guix shell -C creates a container and spawns a new shell in
it (see Invoking guix shell). The strace gdb part adds the
strace and gdb commands to the container, which you may
find handy while debugging. The --no-grafts option makes sure we
get the exact same environment, with ungrafted packages (see Actualizaciones de seguridad, for more info on grafts).
Para acercarnos más al contenedor usado por el daemon de construcción, podemos eliminar /bin/sh:
[env]# rm /bin/sh
(Don’t worry, this is harmless: this is all happening in the throw-away
container created by guix shell.)
La orden strace probablemente no esté en la ruta de búsqueda, pero
podemos ejecutar:
[env]# $GUIX_ENVIRONMENT/bin/strace -f -o log make check
De este modo, no solo habrá reproducido las variables de entorno que usa el daemon, también estará ejecutando el proceso de construcción en un contenedor similar al usado por el daemon.
Next: Invocación de guix download, Previous: Invocación de guix build, Up: Utilidades [Contents][Index]
10.2 Invocación de guix edit
¡Tantos paquetes, tantos archivos de fuentes! La orden guix edit
facilita la vida de las usuarias y empaquetadoras apuntando su editor al
archivo de fuentes que contiene la definición de los paquetes
especificados. Por ejemplo:
guix edit gcc@4.9 vim
ejecuta el programa especificado en la variable de entorno VISUAL o en
EDITOR para ver la receta de GCC 4.9.3 y la de Vim.
Si está usando una copia de trabajo de Git de Guix (see Construcción desde Git), o ha creado sus propios paquetes en GUIX_PACKAGE_PATH
(see Módulos de paquetes), será capaz de editar las recetas de los
paquetes. En otros casos, podrá examinar las recetas en modo de lectura
únicamente para paquetes actualmente en el almacén.
En vez de GUIX_PACKAGE_PATH, la opción de línea de ordenes
--load-path=directorio (o en versión corta -L
directorio) le permite añadir directorio al inicio de la ruta
de búsqueda de módulos de paquete y hacer visibles sus propios paquetes.
Next: Invocación de guix hash, Previous: Invocación de guix edit, Up: Utilidades [Contents][Index]
10.3 Invocación de guix download
Durante la escritura de una definición de paquete, las desarrolladoras
típicamente tienen que descargar un archivador tar de fuentes, calcular su
hash SHA256 y escribir ese hash en la definición del paquete
(see Definición de paquetes). La herramienta guix download ayuda
con esta tarea: descarga un archivo de la URI proporcionada, lo añade al
almacén e imprime tanto su nombre de archivo en el almacén como su hash
SHA256.
El hecho de que el archivo descargado se añada al almacén ahorra ancho de
banda: cuando el desarrollador intenta construir el paquete recién definido
con guix build, el archivador de fuentes no tiene que descargarse
de nuevo porque ya está en el almacén. También es una forma conveniente de
conservar archivos temporalmente, que pueden ser borrados en un momento dado
(see Invocación de guix gc).
La orden guix download acepta las mismas URI que las usadas en las
definiciones de paquetes. En particular, permite URI mirror://. Las
URI https (HTTP sobre TLS) se aceptan cuando el enlace Guile
con GnuTLS está disponible en el entorno de la usuaria; cuando no está
disponible se emite un error. See how to install the
GnuTLS bindings for Guile in GnuTLS-Guile, para más
información.
guix download verifica los certificados del servidor HTTPS
cargando las autoridades X.509 del directorio al que apunta la variable de
entorno SSL_CERT_DIR (see Certificados X.509), a menos que se use
--no-check-certificate.
Las siguientes opciones están disponibles:
--hash=algoritmo-H algoritmoCalcula el resultado del hash usando el algoritmo proporcionado. See Invocación de
guix hash, para más información.--format=fmt-f fmtEscribe el hash en el formato especificado por fmt. Para más información sobre los valores aceptados en fmt, see Invocación de
guix hash.--no-check-certificateNo valida los certificados X.509 de los servidores HTTPS.
Cuando se usa esta opción, no tiene absolutamente ninguna garantía de que está comunicando con el servidor responsable de la URL auténtico, lo que le hace vulnerables a ataques de interceptación (“man-in-the-middle”).
--output=archivo-o archivoAlmacena el archivo descargado en archivo en vez de añadirlo al almacén.
Next: Invocación de guix import, Previous: Invocación de guix download, Up: Utilidades [Contents][Index]
10.4 Invocación de guix hash
The guix hash command computes the hash of a file. It is
primarily a convenience tool for anyone contributing to the distribution: it
computes the cryptographic hash of one or more files, which can be used in
the definition of a package (see Definición de paquetes).
La sintaxis general es:
guix hash option file ...
Cuando archivo es - (un guión), guix hash calcula el
hash de los datos leídos por la entrada estándar. guix hash tiene
las siguientes opciones:
--hash=algoritmo-H algoritmoCalcula un hash usando el algoritmo especificado,
sha256de manera predeterminada.algorithm must be the name of a cryptographic hash algorithm supported by Libgcrypt via Guile-Gcrypt—e.g.,
sha512orsha3-256(see Hash Functions in Guile-Gcrypt Reference Manual).--format=fmt-f fmtEscribe el hash en el formato especificado por fmt.
Los formatos disponibles son:
base64,nix-base32,base32,base16(se puede usar tambiénhexyhexadecimal).Si no se especifica la opción --format,
guix hashmostrará el hash ennix-base32. Esta representación es la usada en las definiciones de paquetes.--recursive-rThe --recursive option is deprecated in favor of --serializer=nar (see below); -r remains accepted as a convenient shorthand.
--serializer=type-S typeCompute the hash on file using type serialization.
type may be one of the following:
noneThis is the default: it computes the hash of a file’s contents.
narCompute the hash of a “normalized archive” (or “nar”) containing file, including its children if it is a directory. Some of the metadata of file is part of the archive; for instance, when file is a regular file, the hash is different depending on whether file is executable or not. Metadata such as time stamps have no impact on the hash (see Invocación de
guix archive, for more info on the nar format).gitCompute the hash of the file or directory as a Git “tree”, following the same method as the Git version control system.
--exclude-vcs-xCuando se combina con --recursive, excluye los directorios del sistema de control de versiones (.bzr, .git, .hg, etc.).
Como un ejemplo, así es como calcularía el hash de una copia de trabajo Git, lo cual es útil cuando se usa el método
git-fetch(see Referencia deorigin):$ git clone http://example.org/foo.git $ cd foo $ guix hash -x --serializer=nar .
Next: Invocación de guix refresh, Previous: Invocación de guix hash, Up: Utilidades [Contents][Index]
10.5 Invocación de guix import
La orden guix import es útil para quienes desean añadir un paquete
a la distribución con el menor trabajo posible—una demanda legítima. La
orden conoce algunos repositorios de los que puede “importar” metadatos de
paquetes. El resultado es una definición de paquete, o una plantilla de
ella, en el formato que conocemos (see Definición de paquetes).
La sintaxis general es:
guix import importador opciones…
importador especifica la fuente de la que se importan los metadatos del paquete, opciones especifica un identificador de paquete y otras opciones específicas del importador.
Algunos de los importadores dependen de poder ejecutar la orden
gpgv. Para ello, GnuPG debe estar instalado y en $PATH;
ejecute guix install gnupg si es necesario.
Actualmente los “importadores” disponibles son:
gnuImporta los metadatos del paquete GNU seleccionado. Proporciona una plantilla para la última versión de dicho paquete GNU, incluyendo el hash de su archivador tar de fuentes, y su sinopsis y descripción canónica.
Información adicional como las dependencias del paquete y su licencia deben ser deducidas manualmente.
Por ejemplo, la siguiente orden devuelve una definición de paquete para GNU Hello.
guix import gnu hello
Las opciones específicas de línea de ordenes son:
--key-download=políticaComo en
guix refresh, especifica la política de tratamiento de las claves OpenPGP no encontradas cuando se verifica la firma del paquete. See --key-download.
pypi¶Importa metadatos desde el índice de paquetes Python (PyPI). La información se toma de la descripción con formato JSON disponible en
pypi.python.orgy habitualmente incluye toda la información relevante, incluyendo las dependencias del paquete. Para una máxima eficiencia, se recomienda la instalación de la utilidadunzip, de manera que el importador pueda extraer los archivos wheel de Python y obtener datos de ellos.The command below imports metadata for the latest version of the
itsdangerousPython package:guix import pypi itsdangerous
You can also ask for a specific version:
guix import pypi itsdangerous@1.1.0
--recursive-rRecorre el grafo de dependencias del paquete original proporcionado recursivamente y genera expresiones de paquete para todos aquellos paquetes que no estén todavía en Guix.
gem¶Importa metadatos desde RubyGems. La información se extrae de la descripción en formato JSON disponible en
rubygems.orge incluye la información más relevante, incluyendo las dependencias en tiempo de ejecución. Hay algunos puntos a tener en cuenta, no obstante. Los metadatos no distinguen entre sinopsis y descripción, por lo que se usa la misma cadena para ambos campos. Adicionalmente, los detalles de las dependencias no-Ruby necesarias para construir extensiones nativas no está disponible y se deja como ejercicio a la empaquetadora.La siguiente orden importa los meta-datos para el paquete de Ruby
rails:guix import gem rails
You can also ask for a specific version:
guix import gem rails@7.0.4
--recursive-rRecorre el grafo de dependencias del paquete original proporcionado recursivamente y genera expresiones de paquete para todos aquellos paquetes que no estén todavía en Guix.
minetest¶-
Import metadata from ContentDB. Information is taken from the JSON-formatted metadata provided through ContentDB’s API and includes most relevant information, including dependencies. There are some caveats, however. The license information is often incomplete. The commit hash is sometimes missing. The descriptions are in the Markdown format, but Guix uses Texinfo instead. Texture packs and subgames are unsupported.
The command below imports metadata for the Mesecons mod by Jeija:
guix import minetest Jeija/mesecons
The author name can also be left out:
guix import minetest mesecons
--recursive-rRecorre el grafo de dependencias del paquete original proporcionado recursivamente y genera expresiones de paquete para todos aquellos paquetes que no estén todavía en Guix.
cpan¶Importa metadatos desde MetaCPAN. La información se extrae de la descripción en formato JSON disponible a través del API de MetaCPAN e incluye la información más relevante, como las dependencias de otros módulos. La información de la licencia debe ser comprobada atentamente. Si Perl está disponible en el almacén, se usará la utilidad
corelistpara borrar los módulos básicos de la lista de dependencias.La siguiente orden importa los metadatos del módulo Perl Acme::Boolean:
guix import cpan Acme::Boolean
cran¶-
Importa metadatos desde CRAN, el repositorio central para el entorno estadístico y gráfico GNU R.
La información se extrae del archivo DESCRIPTION del paquete.
La siguiente orden importa los metadatos del paquete de R Cairo:
guix import cran Cairo
You can also ask for a specific version:
guix import cran rasterVis@0.50.3
Cuando se añade --recursive, el importador recorrerá el grafo de dependencias del paquete original proporcionado recursivamente y generará expresiones de paquetes para todos aquellos que no estén todavía en Guix.
When --style=specification is added, the importer will generate package definitions whose inputs are package specifications instead of references to package variables. This is useful when generated package definitions are to be appended to existing user modules, as the list of used package modules need not be changed. The default is --style=variable.
Cuando se usa --archive=bioconductor, los metadatos se importan de Bioconductor, un repositorio de paquetes R para el análisis y comprensión de datos genéticos de alto caudal en bioinformática.
La información se extrae del archivo DESCRIPTION contenido en el archivo del paquete.
La siguiente orden importa los metadatos del paquete de R GenomicRanges:
guix import cran --archive=bioconductor GenomicRanges
Por último, también puede importar paquetes de R que no se hayan publicado todavía en CRAN o en Bioconductor siempre que estén en un repositorio git. Use --archive=git seguido de la URL del repositorio git:
guix import cran --archive=git https://github.com/immunogenomics/harmony
texlive¶-
Import TeX package information from the TeX Live package database for TeX packages that are part of the TeX Live distribution.
Information about the package is obtained from the TeX Live package database, a plain text file that is included in the
texlive-binpackage. The source code is downloaded from possibly multiple locations in the SVN repository of the Tex Live project.La siguiente orden importa los metadatos del paquete de TeX
fontspec:guix import texlive fontspec
json¶Importa metadatos de paquetes desde un archivo JSON local. Considere el siguiente ejemplo de definición de paquete en formato JSON:
{ "name": "hello", "version": "2.10", "source": "mirror://gnu/hello/hello-2.10.tar.gz", "build-system": "gnu", "home-page": "https://www.gnu.org/software/hello/", "synopsis": "Hello, GNU world: An example GNU package", "description": "GNU Hello prints a greeting.", "license": "GPL-3.0+", "native-inputs": ["gettext"] }Los nombres de los campos son los mismos que para el registro
<package>(See Definición de paquetes). Las referencias a otros paquetes se proporcionan como listas JSON de cadenas de especificación de paquete entrecomilladas comoguileoguile@2.0.El importador también permite una definición de fuentes más explícita usando los campos comunes de los registros
<origin>:{ … "source": { "method": "url-fetch", "uri": "mirror://gnu/hello/hello-2.10.tar.gz", "sha256": { "base32": "0ssi1wpaf7plaswqqjwigppsg5fyh99vdlb9kzl7c9lng89ndq1i" } } … }La siguiente orden importa los metadatos desde el archivo JSON
hello.jsony devuelve una expresión de “package”:guix import json hello.json
hackage¶Importa metadatos desde el archivo central de paquetes de la comunidad Haskell Hackage. La información se obtiene de archivos Cabal e incluye toda la información relevante, incluyendo las dependencias del paquete.
Las opciones específicas de línea de ordenes son:
--stdin-sLee un archivo Cabal por la entrada estándar.
--no-test-dependencies-tNo incluye las dependencias necesarias únicamente para las baterías de pruebas.
--cabal-environment=alist-e alistalist es una lista asociativa Scheme que define el entorno en el que los condicionales Cabal se evalúan. Los valores aceptados son:
os,arch,imply una cadena que representa el nombre de la condición. El valor asociado a la condición tiene que ser o bien el símbolotrueo bienfalse. Los valores predeterminados asociados a las clavesos,archyimplson ‘linux’, ‘x86_64’ y ‘ghc’, respectivamente.--recursive-rRecorre el grafo de dependencias del paquete original proporcionado recursivamente y genera expresiones de paquete para todos aquellos paquetes que no estén todavía en Guix.
La siguiente orden importa los metadatos de la última versión del paquete Haskell HTTP sin incluir las dependencias de las pruebas y especificando la opción ‘network-uri’ con valor
false:guix import hackage -t -e "'((\"network-uri\" . false))" HTTP
Se puede especificar opcionalmente una versión específica del paquete añadiendo al nombre del paquete una arroba y el número de versión como en el siguiente ejemplo:
guix import hackage mtl@2.1.3.1
stackage¶El importador
stackagees un recubrimiento sobre el dehackage. Toma un nombre de paquete, busca la versión de paquete incluida en una publicación de la versión de mantenimiento extendido (LTS) Stackage y usa el importadorhackagepara obtener sus metadatos. Fíjese que es su decisión seleccionar una publicación LTS compatible con el compilador GHC usado en Guix.Las opciones específicas de línea de ordenes son:
--no-test-dependencies-tNo incluye las dependencias necesarias únicamente para las baterías de pruebas.
--lts-version=versión-l versiónversión es la versión LTS de publicación deseada. Si se omite se usa la última publicación.
--recursive-rRecorre el grafo de dependencias del paquete original proporcionado recursivamente y genera expresiones de paquete para todos aquellos paquetes que no estén todavía en Guix.
La siguiente orden importa los metadatos del paquete Haskell HTTP incluido en la versión de publicación LTS de Stackage 7.18:
guix import stackage --lts-version=7.18 HTTP
elpa¶Importa metadatos desde el repositorio de archivos de paquetes Emacs Lisp (ELPA) (see Packages in The GNU Emacs Manual).
Las opciones específicas de línea de ordenes son:
--archive=repo-a reporepo identifica el repositorio de archivos del que obtener la información. Actualmente los repositorios disponibles y sus identificadores son:
- - GNU, seleccionado con el identificador
gnu. Utilizado de manera predeterminada.Los paquetes de
elpa.gnu.orgestán firmados con una de las claves que contiene el anillo de claves GnuPG en share/emacs/25.1/etc/package-keyring.gpg (o similar) en el paqueteemacs(see ELPA package signatures in The GNU Emacs Manual). - - NonGNU, selected by the
nongnuidentifier. - - MELPA-Stable, seleccionado con el
identificador
melpa-stable. - - MELPA, seleccionado con el identificador
melpa.
- - GNU, seleccionado con el identificador
--recursive-rRecorre el grafo de dependencias del paquete original proporcionado recursivamente y genera expresiones de paquete para todos aquellos paquetes que no estén todavía en Guix.
crate¶Importa metadatos desde el repositorio de paquetes Rust crates.io, como en este ejemplo:
guix import crate blake2-rfc
El importador de crate también le permite especificar una cadena de versión:
guix import crate constant-time-eq@0.1.0
La opciones adicionales incluyen:
--recursive-rRecorre el grafo de dependencias del paquete original proporcionado recursivamente y genera expresiones de paquete para todos aquellos paquetes que no estén todavía en Guix.
elm¶Import metadata from the Elm package repository package.elm-lang.org, as in this example:
guix import elm elm-explorations/webgl
The Elm importer also allows you to specify a version string:
guix import elm elm-explorations/webgl@1.1.3
La opciones adicionales incluyen:
--recursive-rRecorre el grafo de dependencias del paquete original proporcionado recursivamente y genera expresiones de paquete para todos aquellos paquetes que no estén todavía en Guix.
opam¶-
Importa metadatos desde el repositorio de paquetes OPAM usado por la comunidad OCaml.
La opciones adicionales incluyen:
--recursive-rRecorre el grafo de dependencias del paquete original proporcionado recursivamente y genera expresiones de paquete para todos aquellos paquetes que no estén todavía en Guix.
--repoBy default, packages are searched in the official OPAM repository. This option, which can be used more than once, lets you add other repositories which will be searched for packages. It accepts as valid arguments:
- the name of a known repository - can be one of
opam,coq(equivalent tocoq-released),coq-core-dev,coq-extra-devorgrew. - the URL of a repository as expected by the
opam repository addcommand (for instance, the URL equivalent of the aboveopamname would be https://opam.ocaml.org). - the path to a local copy of a repository (a directory containing a packages/ sub-directory).
Repositories are assumed to be passed to this option by order of preference. The additional repositories will not replace the default
opamrepository, which is always kept as a fallback.Also, please note that versions are not compared across repositories. The first repository (from left to right) that has at least one version of a given package will prevail over any others, and the version imported will be the latest one found in this repository only.
- the name of a known repository - can be one of
go¶Import metadata for a Go module using proxy.golang.org.
guix import go gopkg.in/yaml.v2
It is possible to use a package specification with a
@VERSIONsuffix to import a specific version.La opciones adicionales incluyen:
--recursive-rRecorre el grafo de dependencias del paquete original proporcionado recursivamente y genera expresiones de paquete para todos aquellos paquetes que no estén todavía en Guix.
--pin-versionsWhen using this option, the importer preserves the exact versions of the Go modules dependencies instead of using their latest available versions. This can be useful when attempting to import packages that recursively depend on former versions of themselves to build. When using this mode, the symbol of the package is made by appending the version to its name, so that multiple versions of the same package can coexist.
egg¶Import metadata for CHICKEN eggs. The information is taken from PACKAGE.egg files found in the eggs-5-all Git repository. However, it does not provide all the information that we need, there is no “description” field, and the licenses used are not always precise (BSD is often used instead of BSD-N).
guix import egg sourcehut
You can also ask for a specific version:
guix import egg arrays@1.0
La opciones adicionales incluyen:
--recursive-rRecorre el grafo de dependencias del paquete original proporcionado recursivamente y genera expresiones de paquete para todos aquellos paquetes que no estén todavía en Guix.
hexpm¶Import metadata from the hex.pm Erlang and Elixir package repository hex.pm, as in this example:
guix import hexpm stun
The importer tries to determine the build system used by the package.
The hexpm importer also allows you to specify a version string:
guix import hexpm cf@0.3.0
La opciones adicionales incluyen:
--recursive-rRecorre el grafo de dependencias del paquete original proporcionado recursivamente y genera expresiones de paquete para todos aquellos paquetes que no estén todavía en Guix.
La estructura del código de guix import es modular. Sería útil
tener más importadores para otros formatos de paquetes, y su ayuda es
bienvenida aquí (see Contribuir).
Next: Invoking guix style, Previous: Invocación de guix import, Up: Utilidades [Contents][Index]
10.6 Invocación de guix refresh
The primary audience of the guix refresh command is packagers. As
a user, you may be interested in the --with-latest option, which
can bring you package update superpowers built upon guix refresh
(see --with-latest). By
default, guix refresh reports any packages provided by the
distribution that are outdated compared to the latest upstream version, like
this:
$ guix refresh gnu/packages/gettext.scm:29:13: gettext would be upgraded from 0.18.1.1 to 0.18.2.1 gnu/packages/glib.scm:77:12: glib would be upgraded from 2.34.3 to 2.37.0
De manera alternativa, se pueden especificar los paquetes a considerar, en cuyo caso se emite un aviso para paquetes que carezcan de actualizador:
$ guix refresh coreutils guile guile-ssh gnu/packages/ssh.scm:205:2: warning: no updater for guile-ssh gnu/packages/guile.scm:136:12: guile would be upgraded from 2.0.12 to 2.0.13
guix refresh navega por los repositorios oficiales de cada paquete
y determina el número de versión mayor entre las publicaciones
encontradas. La orden sabe cómo actualizar tipos específicos de paquetes:
paquetes GNU, paquetes ELPA, etc.—vea la documentación de --type
más adelante. Hay muchos paquetes, no obstante, para los que carece de un
método para determinar si está disponible una versión oficial posterior. No
obstante, el mecanismo es extensible, ¡no tenga problema en contactar con
nosotras para añadir un método nuevo!
--recursiveConsidera los paquetes especificados, y todos los paquetes de los que dependen.
$ guix refresh --recursive coreutils gnu/packages/acl.scm:40:13: acl would be upgraded from 2.2.53 to 2.3.1 gnu/packages/m4.scm:30:12: 1.4.18 is already the latest version of m4 gnu/packages/xml.scm:68:2: warning: no updater for expat gnu/packages/multiprecision.scm:40:12: 6.1.2 is already the latest version of gmp …
A veces el nombre oficial es diferente al nombre de paquete usado en Guix, y
guix refresh necesita un poco de ayuda. La mayor parte de los
actualizadores utilizan la propiedad upstream-name en las
definiciones de paquetes, que puede usarse para obtener dicho efecto:
(define-public network-manager
(package
(name "network-manager")
;; …
(properties '((upstream-name . "NetworkManager")))))
Cuando se proporciona --update, modifica los archivos de fuentes de
la distribución para actualizar los números de versión y hash de los
archivadores tar de fuentes en las recetas de los paquetes (see Definición de paquetes). Esto se consigue con la descarga del último archivador de
fuentes del paquete y su firma OpenPGP asociada, seguida de la verificación
del archivador descargado y su firma mediante el uso de gpg, y
finalmente con el cálculo de su hash—tenga en cuenta que GnuPG debe estar
instalado y en $PATH; ejecute guix install gnupg si es
necesario.
Cuando la clave pública usada para firmar el archivador no se encuentra en
el anillo de claves de la usuaria, se intenta automáticamente su obtención
desde un servidor de claves públicas; cuando se encuentra, la clave se añade
al anillo de claves de la usuaria; en otro caso, guix refresh
informa de un error.
Se aceptan las siguientes opciones:
--expression=expr-e exprConsidera el paquete al que evalúa expr
Es útil para hacer una referencia precisa de un paquete concreto, como en este ejemplo:
guix refresh -l -e '(@@ (gnu packages commencement) glibc-final)'
Esta orden enumera los paquetes que dependen de la libc “final” (esencialmente todos los paquetes).
--update-uActualiza los archivos fuente de la distribución (recetas de paquetes) en su lugar. Esto se ejecuta habitualmente desde una copia de trabajo del árbol de fuentes de Guix (see Ejecución de Guix antes de estar instalado):
$ ./pre-inst-env guix refresh -s non-core -u
See Definición de paquetes, para más información sobre la definición de paquetes.
--select=[subconjunto]-s subconjuntoSelecciona todos los paquetes en subconjunto, o bien
coreo biennon-core.El subconjunto
corehace referencia a todos los paquetes en el núcleo de la distribución—es decir, paquetes que se usan para construir “todo lo demás”. Esto incluye GCC, libc, Binutils, Bash, etc. Habitualmente, cambiar uno de esos paquetes en la distribución conlleva la reconstrucción de todos los demás. Por tanto, esas actualizaciones son una inconveniencia para las usuarias en términos de tiempo de construcción o ancho de banda usado por la actualización.El subconjunto
non-corehace referencia a los paquetes restantes. Es típicamente útil en casos donde una actualización de paquetes básicos no sería conveniente.--manifest=archivo-m archivoSelect all the packages from the manifest in file. This is useful to check if any packages of the user manifest can be updated.
--type=actualizador-t actualizadorSelecciona únicamente paquetes manejados por actualizador (puede ser una lista separada por comas de actualizadores). Actualmente, actualizador puede ser:
gnuel actualizador de paquetes GNU;
savannahel actualizador para paquetes alojados en Savannah;
sourceforgethe updater for packages hosted at SourceForge;
gnomeel actualizador para paquetes GNOME;
kdeel actualizador para paquetes KDE;
xorgel actualizador para paquetes X.org;
kernel.orgel actualizador para paquetes alojados en kernel.org;
eggthe updater for Egg packages;
elpael actualizador para paquetes ELPA;
cranel actualizador para paquetes CRAN;
bioconductorel actualizador para paquetes R Bioconductor;
cpanel actualizador para paquetes CPAN;
pypiel actualizador para paquetes PyPI.
gemel actualizador para paquetes RubyGems.
githubel actualizador para paquetes GitHub.
hackageel actualizador para paquetes Hackage.
stackageel actualizador para paquetes Stackage.
crateel actualizador para paquetes Crates.
launchpadel actualizador para paquetes Launchpad.
generic-htmla generic updater that crawls the HTML page where the source tarball of the package is hosted, when applicable.
generic-gita generic updater for packages hosted on Git repositories. It tries to be smart about parsing Git tag names, but if it is not able to parse the tag name and compare tags correctly, users can define the following properties for a package.
-
release-tag-prefix: a regular expression for matching a prefix of the tag name. -
release-tag-suffix: a regular expression for matching a suffix of the tag name. -
release-tag-version-delimiter: a string used as the delimiter in the tag name for separating the numbers of the version. -
accept-pre-releases: by default, the updater will ignore pre-releases; to make it also look for pre-releases, set the this property to#t.
(package (name "foo") ;; ... (properties '((release-tag-prefix . "^release0-") (release-tag-suffix . "[a-z]?$") (release-tag-version-delimiter . ":"))))-
Por ejemplo, la siguiente orden únicamente comprueba actualizaciones de paquetes Emacs alojados en
elpa.gnu.orgy actualizaciones de paquetes CRAN:$ guix refresh --type=elpa,cran gnu/packages/statistics.scm:819:13: r-testthat would be upgraded from 0.10.0 to 0.11.0 gnu/packages/emacs.scm:856:13: emacs-auctex would be upgraded from 11.88.6 to 11.88.9
--list-updatersEnumera los actualizadores disponibles y finaliza (vea la opción previa --type).
Para cada actualizador, muestra la fracción de paquetes que cubre; al final muestra la fracción de paquetes cubiertos por todos estos actualizadores.
Además, guix refresh puede recibir uno o más nombres de paquetes,
como en este ejemplo:
$ ./pre-inst-env guix refresh -u emacs idutils gcc@4.8
The command above specifically updates the emacs and idutils
packages. The --select option would have no effect in this case.
You might also want to update definitions that correspond to the packages
installed in your profile:
$ ./pre-inst-env guix refresh -u \
$(guix package --list-installed | cut -f1)
Cuando se considera la actualización de un paquete, a veces es conveniente
conocer cuantos paquetes se verían afectados por la actualización y su
compatibilidad debería comprobarse. Para ello la siguiente opción puede
usarse cuando se proporcionan uno o más nombres de paquete a guix
refresh:
--list-dependent-lEnumera los paquetes de nivel superior dependientes que necesitarían una reconstrucción como resultado de la actualización de uno o más paquetes.
See el tipo
reverse-packagedeguix graph, para información sobre cómo visualizar la lista de paquetes que dependen de un paquete.
Sea consciente de que la opción --list-dependent únicamente aproxima las reconstrucciones necesarias como resultado de una actualización. Más reconstrucciones pueden ser necesarias bajo algunas circunstancias.
$ guix refresh --list-dependent flex Building the following 120 packages would ensure 213 dependent packages are rebuilt: hop@2.4.0 emacs-geiser@0.13 notmuch@0.18 mu@0.9.9.5 cflow@1.4 idutils@4.6 …
La orden previa enumera un conjunto de paquetes que puede ser construido
para comprobar la compatibilidad con una versión actualizada del paquete
flex.
--list-transitiveEnumera todos los paquetes de los que uno o más paquetes dependen.
$ guix refresh --list-transitive flex flex@2.6.4 depends on the following 25 packages: perl@5.28.0 help2man@1.47.6 bison@3.0.5 indent@2.2.10 tar@1.30 gzip@1.9 bzip2@1.0.6 xz@5.2.4 file@5.33 …
La orden previa enumera un conjunto de paquetes que, en caso de cambiar,
causarían la reconstrucción de flex.
Las siguientes opciones pueden usarse para personalizar la operación de GnuPG:
--gpg=ordenUse orden como la orden de GnuPG 2.x. Se busca orden en
PATH.--keyring=archivoUsa archivo como el anillo de claves para claves de proveedoras. archivo debe estar en el formato keybox. Los archivos Keybox normalmente tienen un nombre terminado en .kbx y GNU Privacy Guard (GPG) puede manipular estos archivos (see
kbxutilin Using the GNU Privacy Guard, para información sobre una herramienta para manipular archivos keybox).Cuando se omite esta opción,
guix refreshusa ~/.config/guix/upstream/trustedkeys.kbx como el anillo de claves para las firmas de proveedoras. Las firmas OpenPGP son comprobadas contra claves de este anillo; las claves que falten son descargadas a este anillo de claves también (véase --key-download a continuación).Puede exportar claves de su anillo de claves GPG predeterminado en un archivo keybox usando órdenes como esta:
gpg --export rms@gnu.org | kbxutil --import-openpgp >> mianillo.kbx
Del mismo modo, puede obtener claves de un archivo keybox específico así:
gpg --no-default-keyring --keyring mianillo.kbx \ --recv-keys 3CE464558A84FDC69DB40CFB090B11993D9AEBB5
See --keyring in Using the GNU Privacy Guard, for more information on GPG’s --keyring option.
--key-download=políticaManeja las claves no encontradas de acuerdo a la política, que puede ser una de:
alwaysSiempre descarga las claves OpenPGP no encontradas del servidor de claves, y las añade al anillo de claves GnuPG de la usuaria.
neverNunca intenta descargar claves OpenPGP no encontradas. Simplemente propaga el error.
interactiveCuando se encuentra un paquete firmado por una clave OpenPGP desconocida, pregunta a la usuaria si descargarla o no. Este es el comportamiento predeterminado.
--key-server=direcciónUse dirección como el servidor de claves OpenPGP cuando se importa una clave pública.
--load-path=directorio-L directorioAñade directorio al frente de la ruta de búsqueda de módulos de paquetes (see Módulos de paquetes).
Esto permite a las usuarias definir sus propios paquetes y hacerlos visibles a las herramientas de línea de órdenes.
El actualizador github usa la API de GitHub para consultar nuevas publicaciones. Cuando se usa
repetidamente, por ejemplo al comprobar todos los paquetes, GitHub terminará
rechazando las peticiones siguientes a través de su API. Por defecto se
permiten 60 peticiones por hora a través de su API, y una actualización
completa de todos los paquetes de GitHub en Guix necesita más que eso. La
identificación con GitHub a través del uso de un identificador de su API
(“token”) amplia esos límites. Para usar dicho identificador, establezca
la variable de entorno GUIX_GITHUB_TOKEN al valor obtenido a través de
https://github.com/settings/tokens o de otra manera.
Next: Invocación de guix lint, Previous: Invocación de guix refresh, Up: Utilidades [Contents][Index]
10.7 Invoking guix style
The guix style command helps users and packagers alike style their
package definitions and configuration files according to the latest
fashionable trends. It can either reformat whole files, with the
--whole-file option, or apply specific styling rules to
individual package definitions. The command currently provides the
following styling rules:
- formatting package definitions according to the project’s conventions (see Formato del código);
- rewriting package inputs to the “new style”, as explained below.
The way package inputs are written is going through a transition
(see Referencia de package, for more on package inputs). Until version
1.3.0, package inputs were written using the “old style”, where each input
was given an explicit label, most of the time the package name:
(package
;; …
;; The "old style" (deprecated).
(inputs `(("libunistring" ,libunistring)
("libffi" ,libffi))))
Today, the old style is deprecated and the preferred style looks like this:
Likewise, uses of alist-delete and friends to manipulate inputs is
now deprecated in favor of modify-inputs (see Definición de variantes de paquetes, for more info on modify-inputs).
In the vast majority of cases, this is a purely mechanical change on the
surface syntax that does not even incur a package rebuild. Running
guix style -S inputs can do that for you, whether you’re working
on packages in Guix proper or in an external channel.
La sintaxis general es:
guix style [options] package…
This causes guix style to analyze and rewrite the definition of
package… or, when package is omitted, of all the
packages. The --styling or -S option allows you to select
the style rule, the default rule being format—see below.
To reformat entire source files, the syntax is:
guix style --whole-file file…
Las opciones disponibles se enumeran a continuación.
--dry-run-nShow source file locations that would be edited but do not modify them.
--whole-file-fReformat the given files in their entirety. In that case, subsequent arguments are interpreted as file names (rather than package names), and the --styling option has no effect.
As an example, here is how you might reformat your operating system configuration (you need write permissions for the file):
guix style -f /etc/config.scm
--styling=rule-S ruleApply rule, one of the following styling rules:
formatFormat the given package definition(s)—this is the default styling rule. For example, a packager running Guix on a checkout (see Ejecución de Guix antes de estar instalado) might want to reformat the definition of the Coreutils package like so:
./pre-inst-env guix style coreutils
inputsRewrite package inputs to the “new style”, as described above. This is how you would rewrite inputs of package
whatnotin your own channel:guix style -L ~/my/channel -S inputs whatnot
Rewriting is done in a conservative way: preserving comments and bailing out if it cannot make sense of the code that appears in an inputs field. The --input-simplification option described below provides fine-grain control over when inputs should be simplified.
--list-stylings-lList and describe the available styling rules and exit.
--load-path=directorio-L directorioAñade directorio al frente de la ruta de búsqueda de módulos de paquetes (see Módulos de paquetes).
--expression=expr-e exprStyle the package expr evaluates to.
Por ejemplo, ejecutando:
guix style -e '(@ (gnu packages gcc) gcc-5)'
styles the
gcc-5package definition.--input-simplification=policyWhen using the
inputsstyling rule, with ‘-S inputs’, this option specifies the package input simplification policy for cases where an input label does not match the corresponding package name. policy may be one of the following:silentSimplify inputs only when the change is “silent”, meaning that the package does not need to be rebuilt (its derivation is unchanged).
safeSimplify inputs only when that is “safe” to do: the package might need to be rebuilt, but the change is known to have no observable effect.
alwaysSimplify inputs even when input labels do not match package names, and even if that might have an observable effect.
The default is
silent, meaning that input simplifications do not trigger any package rebuild.
Next: Invocación de guix size, Previous: Invoking guix style, Up: Utilidades [Contents][Index]
10.8 Invocación de guix lint
La orden guix lint sirve para ayudar a las desarrolladoras de
paquetes a evitar errores comunes y usar un estilo consistente. Ejecuta un
número de comprobaciones en un conjunto de paquetes proporcionado para
encontrar errores comunes en sus definiciones. Las comprobaciones
disponibles incluyen (véase --list-checkers para una lista
completa):
synopsisdescriptionValida ciertas reglas tipográficas y de estilo en la descripción y sinopsis de cada paquete.
inputs-should-be-nativeIdentifica entradas que probablemente deberían ser entradas nativas.
sourcehome-pagemirror-urlgithub-urlsource-file-nameProbe
home-pageandsourceURLs and report those that are invalid. Suggest amirror://URL when applicable. If thesourceURL redirects to a GitHub URL, recommend usage of the GitHub URL. Check that the source file name is meaningful, e.g. is not just a version number or “git-checkout”, without a declaredfile-name(see Referencia deorigin).source-unstable-tarballAnaliza la URL
sourcepara determinar si un archivador tar de GitHub se genera de forma automática o es una publicación oficial. Desafortunadamente los archivadores tar de GitHub a veces se regeneran.derivationComprueba que la derivación de los paquetes proporcionados pueden ser calculadas de manera satisfactoria en todos los sistemas implementados (see Derivaciones).
profile-collisionsComprueba si la instalación de los paquetes proporcionados en el perfil provocaría colisiones. Las colisiones se producen cuando se propagan varios paquetes con el mismo nombre pero una versión diferente o un nombre de archivo del almacén. See
propagated-inputs, para más información sobre entradas propagadas.archival¶-
Comprueba si el código fuente del paquete se encuentra archivado en Software Heritage.
Cuando el código fuente que no se encuentra archivado proviene de un sistema de control de versiones26—por ejemplo, se ha obtenido con
git-fetch—, envía a Software Heritage una petición de almacenamiento de manera que se archive cuando sea posible. Esto asegura que las fuentes permanecen disponibles a largo plazo, y que Guix puede usar Software Heritage como respaldo en caso de que el código fuente desapareciese de la máquina que lo almacenaba originalmente. El estado de las peticiones de almacenamiento recientes puede verse en su página web.Cuando el código fuente es un archivo comprimido que se obtiene con
url-fetch, simplemente imprime un mensaje cuando no se encuentra archivado. En el momento de la escritura de este documento, Software Heritage no permite el almacenamiento de archivos comprimidos arbitrarios; estamos trabajando en formas de asegurar que también se archive el código que no se encuentra bajo control de versiones.Software Heritage limita la tasa de peticiones por dirección IP. Cuando se alcanza dicho límite,
guix lintimprime un mensaje y la comprobaciónarchivalno hace nada hasta que dicho límite se reinicie. cve¶-
Informa de vulnerabilidades encontradas en las bases de datos de vulnerabilidades y exposiciones comunes (CVE) del año actual y el pasado publicadas por el NIST de EEUU.
Para ver información acerca de una vulnerabilidad particular, visite páginas como:
- ‘
https://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-YYYY-ABCD’ - ‘
https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-YYYY-ABCD’
donde
CVE-YYYY-ABCDes el identificador CVE—por ejemplo,CVE-2015-7554.Las desarrolladoras de paquetes pueden especificar en las recetas del paquete el nombre y versión en la plataforma común de enumeración (CPE) del paquete cuando el nombre o versión que usa Guix son diferentes, como en este ejemplo:
(package (name "grub") ;; … ;; CPE llama a este paquete "grub2". (properties '((cpe-name . "grub2") (cpe-version . "2.3"))))Algunas entradas en la base de datos CVE no especifican a qué versión del paquete hacen referencia, y por lo tanto “permanecen visibles” para siempre. Las desarrolladoras de paquetes que encuentren alertas CVE y verifiquen que pueden ignorarse, pueden declararlas como en este ejemplo:
(package (name "t1lib") ;; … ;; Estas alertas de CVE no aplican y pueden ignorarse ;; con seguridad. (properties `((lint-hidden-cve . ("CVE-2011-0433" "CVE-2011-1553" "CVE-2011-1554" "CVE-2011-5244"))))) - ‘
formattingAvisa de problemas de formato obvios en el código fuente: espacios en blanco al final de las líneas, uso de tabuladores, etc.
input-labelsReport old-style input labels that do not match the name of the corresponding package. This aims to help migrate from the “old input style”. See Referencia de
package, for more information on package inputs and input styles. See Invokingguix style, on how to migrate to the new style.
La sintaxis general es:
guix lint opciones paquete…
Si no se proporciona ningún paquete en la linea de órdenes, todos los paquetes se comprueban. Las opciones pueden ser cero o más de las siguientes:
--list-checkers-lEnumera y describe todas las comprobaciones disponibles que se ejecutarán sobre los paquetes y finaliza.
--checkers-cÚnicamente activa las comprobaciones especificadas en una lista separada por comas que use los nombres devueltos por --list-checkers.
--exclude-xÚnicamente desactiva las comprobaciones especificadas en una lista separada por comas que use los nombres devueltos por --list-checkers.
--expression=expr-e exprConsidera el paquete al que evalúa expr
This is useful to unambiguously designate packages, as in this example:
guix lint -c archival -e '(@ (gnu packages guile) guile-3.0)'
--no-network-nActiva únicamente las comprobaciones que no dependen del acceso a internet.
--load-path=directorio-L directorioAñade directorio al frente de la ruta de búsqueda de módulos de paquetes (see Módulos de paquetes).
Esto permite a las usuarias definir sus propios paquetes y hacerlos visibles a las herramientas de línea de órdenes.
Next: Invocación de guix graph, Previous: Invocación de guix lint, Up: Utilidades [Contents][Index]
10.9 Invocación de guix size
La orden guix size ayuda a las desarrolladoras de paquetes a
perfilar el uso de disco de los paquetes. Es fácil pasar por encima el
impacto que produce añadir una dependencia adicional a un paquete, o el
impacto del uso de una salida única para un paquete que puede ser dividido
fácilmente (see Paquetes con múltiples salidas). Estos son los problemas
típicos que guix size puede resaltar.
Se le pueden proporcionar una o más especificaciones de paquete como
gcc@4.8 o guile:debug, o un nombre de archivo en el
almacén. Considere este ejemplo:
$ guix size coreutils store item total self /gnu/store/…-gcc-5.5.0-lib 60.4 30.1 38.1% /gnu/store/…-glibc-2.27 30.3 28.8 36.6% /gnu/store/…-coreutils-8.28 78.9 15.0 19.0% /gnu/store/…-gmp-6.1.2 63.1 2.7 3.4% /gnu/store/…-bash-static-4.4.12 1.5 1.5 1.9% /gnu/store/…-acl-2.2.52 61.1 0.4 0.5% /gnu/store/…-attr-2.4.47 60.6 0.2 0.3% /gnu/store/…-libcap-2.25 60.5 0.2 0.2% total: 78.9 MiB
Los elementos del almacén enumerados aquí constituyen la clausura transitiva de Coreutils—es decir, Coreutils y todas sus dependencias, recursivamente—como sería devuelto por:
$ guix gc -R /gnu/store/…-coreutils-8.23
Aquí la salida muestra tres columnas junto a los elementos del almacén. La primera columna, etiquetada “total”, muestra el tamaño en mebibytes (MiB) de la clausura del elemento del almacén—es decir, su propio tamaño sumado al tamaño de todas sus dependencias. La siguiente columna, etiquetada “self”, muestra el tamaño del elemento en sí. La última columna muestra la relación entre el tamaño del elemento en sí frente al espacio ocupado por todos los elementos enumerados.
En este ejemplo, vemos que la clausura de Coreutils ocupa 79 MiB, cuya mayor parte son libc y las bibliotecas auxiliares de GCC para tiempo de ejecución. (Que libc y las bibliotecas de GCC representen una fracción grande de la clausura no es un problema en sí, puesto que siempre están disponibles en el sistema de todas maneras).
Puesto que la orden también acepta nombres de archivo del almacén, comprobar el tamaño del resultado de una construcción es una operación directa:
guix size $(guix system build config.scm)
Cuando los paquetes pasados a guix size están disponibles en el
almacén27 consultando al daemon para determinar sus dependencias, y mide su
tamaño en el almacén, de forma similar a du -ms --apparent-size
(see du invocation in GNU Coreutils).
Cuando los paquetes proporcionados no están en el almacén,
guix size informa en base de las sustituciones disponibles
(see Sustituciones). Esto hace posible perfilar el espacio en disco
incluso de elementos del almacén que no están en el disco, únicamente
disponibles de forma remota.
Puede especificar también varios nombres de paquetes:
$ guix size coreutils grep sed bash store item total self /gnu/store/…-coreutils-8.24 77.8 13.8 13.4% /gnu/store/…-grep-2.22 73.1 0.8 0.8% /gnu/store/…-bash-4.3.42 72.3 4.7 4.6% /gnu/store/…-readline-6.3 67.6 1.2 1.2% … total: 102.3 MiB
En este ejemplo vemos que la combinación de los cuatro paquetes toma 102.3 MiB en total, lo cual es mucho menos que la suma de cada clausura, ya que tienen muchas dependencias en común.
Cuando tenga delante el perfil devuelto por guix size puede
preguntarse cuál es la razón de que cierto paquete aparezca en el
perfil. Para entenderlo puede usar guix graph --path -t references
para mostrar la ruta más corta entre dos paquetes (see Invocación de guix graph).
Las opciones disponibles son:
- --substitute-urls=urls
Usa la información de sustituciones de urls. See la misma opción en
guix build.- --sort=clave
Ordena las líneas de acuerdo a clave, una de las siguientes opciones:
propioel tamaño de cada elemento (predeterminada);
closureel tamaño total de la clausura del elemento.
- --map-file=archivo
Escribe un mapa gráfico del uso del disco en formato PNG en el archivo.
Para el ejemplo previo, el mapa tiene esta pinta:
Esta opción necesita que la biblioteca Guile-Charting esté instalada y visible en la ruta de búsqueda de módulos Guile. Cuando no es el caso,
guix sizeproduce un error al intentar cargarla.- --system=sistema
- -s sistema
Considera paquetes para sistema—por ejemplo,
x86_64-linux.- --load-path=directorio
- -L directorio
Añade directorio al frente de la ruta de búsqueda de módulos de paquetes (see Módulos de paquetes).
Esto permite a las usuarias definir sus propios paquetes y hacerlos visibles a las herramientas de línea de órdenes.
Next: Invocación de guix publish, Previous: Invocación de guix size, Up: Utilidades [Contents][Index]
10.10 Invocación de guix graph
Packages and their dependencies form a graph, specifically a directed
acyclic graph (DAG). It can quickly become difficult to have a mental model
of the package DAG, so the guix graph command provides a visual
representation of the DAG. By default, guix graph emits a DAG
representation in the input format of Graphviz, so its output can be passed directly to the dot command
of Graphviz. It can also emit an HTML page with embedded JavaScript code to
display a “chord diagram” in a Web browser, using the
d3.js library, or emit Cypher queries to construct
a graph in a graph database supporting the
openCypher query language. With
--path, it simply displays the shortest path between two packages.
The general syntax is:
guix graph opciones paquete…
Por ejemplo, la siguiente orden genera un archivo PDF que representa el GAD para GNU Core Utilities, mostrando sus dependencias en tiempo de construcción:
guix graph coreutils | dot -Tpdf > gad.pdf
La salida es algo así:
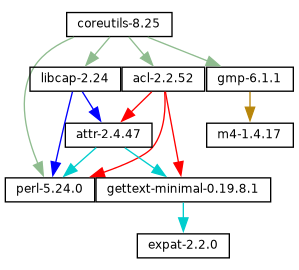
Bonito y pequeño grafo, ¿no?
Puede encontrar más agradable la navegación interactiva del grafo con la
orden xdot (del paquete xdot):
guix graph coreutils | xdot -
¡Pero hay más de un grafo! El grafo previo es conciso: es el grafo de los
objetos package, omitiendo las entradas implícitas como GCC, libc, grep,
etc. Es habitualmente útil tener un grafo conciso así, pero a veces una
puede querer ver más detalles. guix graph implementa varios tipos
de grafos, lo que le permite seleccionar el nivel de detalle:
packageEste es el tipo por defecto usado en el ejemplo previo. Muestra el GAD de objetos package, excluyendo dependencias implícitas. Es conciso, pero deja fuera muchos detalles.
reverse-packageEsto muestra el GAD inverso de paquetes. Por ejemplo:
guix graph --type=reverse-package ocaml
... emite el grafo de paquetes que dependen explícitamente de OCaml (si también tiene interés en casos donde OCaml es una dependencia implícita, véase
reverse-baga continuación).Fíjese que esto puede producir grafos inmensos para los paquetes básicos. Si todo lo que quiere saber es el número de paquetes que dependen de uno determinado, use
guix refresh --list-dependent(see --list-dependent).bag-emergedEste es el GAD del paquete, incluyendo entradas implícitas.
Por ejemplo, la siguiente orden:
guix graph --type=bag-emerged coreutils
... emite este grafo más grande:
En la parte inferior del grafo, vemos todas las entradas implícitas de gnu-build-system (see
gnu-build-system).Ahora bien, fíjese que las dependencias de estas entradas implícitas—es decir, las dependencias del lanzamiento inicial (see Lanzamiento inicial)—no se muestran aquí para mantener una salida concisa.
bagSimilar a
bag-emerged, pero esta vez incluye todas las dependencias del lanzamiento inicial.bag-with-originsSimilar a
bag, pero también muestra los orígenes y sus dependencias.reverse-bagMuestra el GAD inverso de paquetes. Al contrario que
reverse-package, también tiene en cuenta las dependencias implícitas. Por ejemplo:guix graph -t reverse-bag dune
... emite el grafo de tosos los paquetes que dependen de Dune, directa o indirectamente. Ya que Dune es una dependencia implícita de muchos paquetes vía
dune-build-system, esto mostrará un gran número de paquetes, mientras quereverse-packagemostraría muy pocos si muestra alguno.derivationEsta es la representación más detallada: muestra el GAD de derivaciones (see Derivaciones) y elementos simples del almacén. Comparada con las representaciones previas, muchos nodos adicionales son visibles, incluyendo los guiones de construcción, parches, módulos Guile, etc.
Para este tipo de grafo, también es posible pasar un nombre de archivo .drv en vez del nombre del paquete, como en:
guix graph -t derivation $(guix system build -d my-config.scm)
moduleEste es el grafo de los módulos de paquete (see Módulos de paquetes). Por ejemplo, la siguiente orden muestra el grafo para el módulo de paquetes que define el paquete
guile:guix graph -t module guile | xdot -
Todos los tipos previos corresponden a las dependencias durante la construcción. El grafo siguiente representa las dependencias en tiempo de ejecución:
referencesEste es el grafo de referencias de la salida de un paquete, como lo devuelve
guix gc --references(see Invocación deguix gc).Si la salida del paquete proporcionado no está disponible en el almacén,
guix graphintenta obtener la información de dependencias desde las sustituciones.Aquí también puede proporcionar un nombre de archivo del almacén en vez de un nombre de paquete. Por ejemplo, la siguiente orden produce el grafo de referencias de su perfil (¡el cuál puede ser grande!):
guix graph -t references $(readlink -f ~/.guix-profile)
referrersEste es el grafo de referentes de la salida de un paquete, como lo devuelve
guix gc --referrers(see Invocación deguix gc).Depende exclusivamente de información en su almacén. Por ejemplo, supongamos que la versión actual de Inkscape está disponible en 10 perfiles en su máquina;
guix graph -t referrers inkscapemostrará un grafo cuya raíz es Inkscape y con esos 10 perfiles enlazados a ella.Puede ayudar a determinar qué impide que un elemento del almacén sea recolectado.
Habitualmente el grafo del paquete por el que tiene interés no entrará en su
pantall, y en cualquier caso todo lo que quiere saber es por qué
dicho paquete depende de algún paquete que parece no tener relación. La
opción --path le indica a guix graph que muestre la ruta
más corta entre dos paquetes (o derivaciones, o elementos del almacén,
etcétera):
$ guix graph --path emacs libunistring emacs@26.3 mailutils@3.9 libunistring@0.9.10 $ guix graph --path -t derivation emacs libunistring /gnu/store/…-emacs-26.3.drv /gnu/store/…-mailutils-3.9.drv /gnu/store/…-libunistring-0.9.10.drv $ guix graph --path -t references emacs libunistring /gnu/store/…-emacs-26.3 /gnu/store/…-libidn2-2.2.0 /gnu/store/…-libunistring-0.9.10
Sometimes you still want to visualize the graph but would like to trim it so
it can actually be displayed. One way to do it is via the
--max-depth (or -M) option, which lets you specify the
maximum depth of the graph. In the example below, we visualize only
libreoffice and the nodes whose distance to libreoffice is at
most 2:
guix graph -M 2 libreoffice | xdot -f fdp -
Mind you, that’s still a big ball of spaghetti, but at least dot
can render it quickly and it can be browsed somewhat.
Las opciones disponibles son las siguientes:
- --type=tipo
- -t tipo
Produce un grafo de salida de tipo, donde tipo debe ser uno de los valores enumerados previamente.
- --list-types
Enumera los tipos de grafos implementados.
- --backend=motor
- -b motor
Produce un grafo usando el motor seleccionado.
- --list-backends
Enumera los motores de grafos implementados.
Actualmente, los motores disponibles son Graphviz y d3.js.
- --path
Muestra la ruta más corta entre dos nodos del tipo especificado por la opción --type. El ejemplo siguiente muestra la ruta más corta entre
libreofficeyllvmde acuerdo con las referencias delibreoffice:$ guix graph --path -t references libreoffice llvm /gnu/store/…-libreoffice-6.4.2.2 /gnu/store/…-libepoxy-1.5.4 /gnu/store/…-mesa-19.3.4 /gnu/store/…-llvm-9.0.1
- --expression=expr
- -e expr
Considera el paquete al que evalúa expr
Es útil para hacer una referencia precisa de un paquete concreto, como en este ejemplo:
guix graph -e '(@@ (gnu packages commencement) gnu-make-final)'
- --system=sistema
- -s sistema
Muestra el grafo para sistema—por ejemplo,
i686-linux.El grafo de dependencias del paquete es altamente independiente de la arquitectura, pero existen algunas partes dependientes de la arquitectura que esta opción le permite visualizar.
- --load-path=directorio
- -L directorio
Añade directorio al frente de la ruta de búsqueda de módulos de paquetes (see Módulos de paquetes).
Esto permite a las usuarias definir sus propios paquetes y hacerlos visibles a las herramientas de línea de órdenes.
Además de esto, guix graph permite todas las opciones habituales
de transformación de paquetes (see Opciones de transformación de paquetes). Esto
facilita la visualización del efecto de una transformación de reescritura de
grafo como --with-input. Por ejemplo, la siguiente orden muestra el
grafo de git una vez que openssl ha sido reemplazado por
libressl en todos los nodos del grafo:
guix graph git --with-input=openssl=libressl
¡Tantas posibilidades, tanta diversión!
Next: Invocación de guix challenge, Previous: Invocación de guix graph, Up: Utilidades [Contents][Index]
10.11 Invocación de guix publish
El propósito de guix publish es permitir a las usuarias compartir
fácilmente su almacén con otras, quienes pueden usarlo como servidor de
sustituciones (see Sustituciones).
When guix publish runs, it spawns an HTTP server which allows
anyone with network access to obtain substitutes from it. This means that
any machine running Guix can also act as if it were a build farm, since the
HTTP interface is compatible with Cuirass, the software behind the
ci.guix.gnu.org build farm.
Por seguridad, cada sustitución se firma, permitiendo a las receptoras
comprobar su autenticidad e integridad (see Sustituciones). Debido a que
guix publish usa la clave de firma del sistema, que es únicamente
legible por la administradora del sistema, debe iniciarse como root; la
opción --user hace que renuncie a sus privilegios tan pronto como
sea posible.
El par claves de firma debe generarse antes de ejecutar guix
publish, usando guix archive --generate-key (see Invocación de guix archive).
When the --advertise option is passed, the server advertises its availability on the local network using multicast DNS (mDNS) and DNS service discovery (DNS-SD), currently via Guile-Avahi (see Using Avahi in Guile Scheme Programs).
La sintaxis general es:
guix publish opciones…
La ejecución de guix publish sin ningún parámetro adicional
lanzará un servidor HTTP en el puerto 8080:
guix publish
guix publish can also be started following the systemd “socket
activation” protocol (see make-systemd-constructor in The GNU Shepherd Manual).
Una vez el servidor de publicación ha sido autorizado, el daemon puede descargar sustituciones de él. See Obtención de sustiticiones desde otros servidores.
Por defecto, guix publish comprime los archivos al vuelo cuando es
necesario. Este modo “al vuelo” es conveniente ya que no necesita
configuración y está disponible inmediatamente. No obstante, cuando se
proporciona servicio a muchos clientes, se recomienda usar la opción
--cache, que activa el almacenamiento en caché de los archivos
antes de enviarlos a los clientes—véase a continuación para más
detalles. La orden guix weather proporciona una forma fácil de
comprobar lo que proporciona un servidor (see Invocación de guix weather).
Además guix publish también sirve como un espejo de acceso por
contenido a archivos de fuentes a los que los registros origin hacen
referencia (see Referencia de origin). Por ejemplo, si asumimos que
guix publish se ejecuta en example.org, la siguiente URL
devuelve directamente el archivo hello-2.10.tar.gz con el hash SHA256
proporcionado (representado en formato nix-base32, see Invocación de guix hash).
http://example.org/file/hello-2.10.tar.gz/sha256/0ssi1…ndq1i
Obviamente estas URL funcionan solamente para archivos que se encuentran en el almacén; en otros casos devuelven un 404 (“No encontrado”).
Los log de construcción están disponibles desde URL /log como:
http://example.org/log/gwspk…-guile-2.2.3
Cuando guix-daemon está configurado para almacenar comprimidos los
log de construcción, como sucede de forma predeterminada (see Invocación de guix-daemon), las URL /log devuelven los log igualmente comprimidos,
con un Content-Type adecuado y/o una cabecera
Content-Encoding. Recomendamos ejecutar guix-daemon con
--log-compression=gzip ya que los navegadores Web pueden extraer el
contenido automáticamente, lo cual no es el caso con la compresión bzip2.
Las siguientes opciones están disponibles:
--port=puerto-p puertoEscucha peticiones HTTP en puerto.
--listen=direcciónEscucha en la interfaz de red de la dirección. El comportamiento predeterminado es aceptar conexiones de cualquier interfaz.
--user=usuaria-u usuariaCambia los privilegios a los de usuaria tan pronto como sea posible—es decir, una vez el socket del servidor esté abierto y la clave de firma haya sido leída.
--compression[=método[:nivel]]-C [método[:nivel]]Compress data using the given method and level. method is one of
lzip,zstd, andgzip; when method is omitted,gzipis used.Cuando el nivel es cero, desactiva la compresión. El rango 1 a 9 corresponde a distintos niveles de compresión gzip: 1 es el más rápido, y 9 es el mejor (intensivo a nivel de CPU). El valor predeterminado es 3.
Usually,
lzipcompresses noticeably better thangzipfor a small increase in CPU usage; see benchmarks on the lzip Web page. However,lzipachieves low decompression throughput (on the order of 50 MiB/s on modern hardware), which can be a bottleneck for someone who downloads over a fast network connection.The compression ratio of
zstdis between that oflzipand that ofgzip; its main advantage is a high decompression speed.A menos que se use --cache, la compresión ocurre al vuelo y los flujos comprimidos no se almacenan en caché. Por tanto, para reducir la carga en la máquina que ejecuta
guix publish, puede ser una buena idea elegir un nivel de compresión bajo, ejecutarguix publishdetrás de una pasarela con caché o usar --cache. El uso de --cache tiene la ventaja de que permite aguix publishañadir la cabecera HTTPContent-Lengtha sus respuestas.Se puede repetir esta opción, en cuyo caso cada sustitución se comprime usando todos los métodos seleccionados, y todos son anunciados. Esto es útil cuando las usuarias pueden no implementar todos los métodos de compresión: pueden seleccionar el que implementan.
--cache=directorio-c directorioAlmacena en caché los archivos y metadatos (URL
.narinfo) en directorio y únicamente proporciona archivos que están en la caché.Cuando se omite esta opción, los archivos y metadatos se crean al vuelo. Esto puede reducir el ancho de banda disponible, especialmente cuando la compresión está activa, ya que se puede llegar al límite de la CPU. Otra desventaja del modo predeterminado es que la longitud de los archivos no se conoce con anterioridad, por lo que
guix publishno puede añadir la cabecera HTTPContent-Lengtha sus respuestas, lo que a su vez previene que los clientes conozcan la cantidad de datos a descargar.De manera contraria, cuando se usa --cache, la primera petición de un elemento del almacén (a través de una URL
.narinfo) inicia un proceso en segundo plano para cocinar el archivo—calcular su.narinfoy comprimirlo, en caso necesario. Una vez el archivo está alojado en la caché de directorio, las siguientes peticiones obtendrán un resultado satisfactorio y se ofrecerá el contenido directamente desde la caché, lo que garantiza que los clientes obtienen el mejor ancho de banda posible.La primera petción de
.narinfodevuelve no obstante el código 200, en el caso de que el elemento del almacén sea “lo suficientemente pequeño”, es decir que su tamaño sea inferior al límite de bajo el que se ignora la caché—véase la opción --cache-bypass-threshold a continuación. De este modo, los clientes no deben esperar hasta que el archivo se haya cocinado. Con elementos del almacén de mayor tamaño la primera petición.narinfodevuelve el código 404, lo que significa que los clientes deben esperar hasta que el archivo se haya cocinado.El proceso de “cocinado” se realiza por hilos de trabajo. Por defecto, se crea un hilo por núcleo de la CPU, pero puede ser personalizado. Véase --workers a continuación.
Cuando se usa --ttl, las entradas en caché se borran automáticamente cuando hayan expirado.
--workers=NCuando se usa --cache, solicita la creación de N hilos de trabajo para “cocinar” archivos.
--ttl=ttlProduce cabeceras HTTP
Cache-Controlque anuncian un tiempo-de-vida (TTL) de ttl. ttl debe indicar una duración:5dsignifica 5 días,1msignifica un mes, etc.Esto permite a la usuaria de Guix mantener información de sustituciones en la caché durante ttl. No obstante, fíjese que
guix publishno garantiza en sí que los elementos del almacén que proporciona de hecho permanezcan disponibles hasta que ttl expire.Adicionalmente, cuando se usa --cache, las entradas en caché que no hayan sido accedidas en ttl y no tengan un elemento correspondiente en el almacén pueden ser borradas.
--negative-ttl=ttlSimilarly produce
Cache-ControlHTTP headers to advertise the time-to-live (TTL) of negative lookups—missing store items, for which the HTTP 404 code is returned. By default, no negative TTL is advertised.This parameter can help adjust server load and substitute latency by instructing cooperating clients to be more or less patient when a store item is missing.
--cache-bypass-threshold=tamañoCuando se usa en conjunto con la opción --cache, los elementos del almacén cuyo tamaño sea inferior a tamaño están disponibles de manera inmediata, incluso cuando no están todavía en la caché. tamaño es el número de bytes, o se puedem usar sufijos como
Mpara megabytes, etcétera. El valor predeterminado es10M.La opción de omisión de la cache le permite reducir la latencia de publicación a los clientes a expensas de un posible incremento en el uso de E/S y procesador en el lado del servidor: dependiendo de los patrones de acceso de los clientes, dichos elementos del almacén pueden ser cocinados varias veces hasta que una copia se encuentre disponible en la caché.
Incrementar el valor límite puede ser útil para servidores que tengan pocas usuarias, o para garantizar que dichas usuarias obtienen sustituciones incluso con elementos del almacén que no son populares.
--nar-path=rutaUsa ruta como el prefijo para las URL de los archivos “nar” (see archivadores normalizados).
Por defecto, los archivos nar se proporcionan en una URL como
/nar/gzip/…-coreutils-8.25. Esta opción le permite cambiar la parte/narpor ruta.--public-key=archivo--private-key=archivoUsa los archivos específicos como el par de claves pública y privada usadas para firmar los elementos del almacén publicados.
Los archivos deben corresponder al mismo par de claves (la clave privada se usa para la firma y la clave pública simplemente se anuncia en los metadatos de la firma). Deben contener claves en el formato canónico de expresiones-S como el producido por
guix archive --generate-key(see Invocación deguix archive). Por defecto, se usan /etc/guix/signing-key.pub y /etc/guix/signing-key.sec.--repl[=puerto]-r [puerto]Lanza un servidor REPL Guile (see REPL Servers in GNU Guile Reference Manual) en puerto (37146 por defecto). Esto se usa principalmente para la depuración de un servidor
guix publishen ejecución.
Activar guix publish en el sistema Guix consiste en solo una
línea: simplemente instancie un servicio guix-publish-service-type en
el campo services de su declaración del sistema operativo
operating-system (see guix-publish-service-type)
Si en vez de eso ejecuta Guix en una distribución distinta, siga estas instrucciones:
- Si su distribución anfitriona usa el sistema de inicio systemd:
# ln -s ~root/.guix-profile/lib/systemd/system/guix-publish.service \ /etc/systemd/system/ # systemctl start guix-publish && systemctl enable guix-publish - Si su distribución anfitriona usa el sistema de inicio Upstart:
# ln -s ~root/.guix-profile/lib/upstart/system/guix-publish.conf /etc/init/ # start guix-publish
- En otro caso, proceda de forma similar con el sistema de inicio de su distribución.
Next: Invocación de guix copy, Previous: Invocación de guix publish, Up: Utilidades [Contents][Index]
10.12 Invocación de guix challenge
¿Los binarios que proporciona este servidor realmente corresponden al código
fuente que dice construir? ¿Es determinista el proceso de construcción de un
paquete? Estas son las preguntas que la orden guix challenge
intenta responder.
La primera es obviamente una cuestión importante: antes de usar un servidor de sustituciones (see Sustituciones), es importante haber verificado que proporciona los binarios correctos, y por tanto ponerlo a prueba28. La segunda es lo que permite la primera: si las construcciones de los paquetes son deterministas, construcciones independientes deberían emitir el mismo resultado, bit a bit; si el servidor proporciona un binario diferente al obtenido localmente, o bien está corrupto o bien tiene intenciones perniciosas.
Sabemos que el hash que se muestra en los nombres de archivo en
/gnu/store es el hash de todas las entradas del proceso que construyó
el archivo o directorio—compiladores, bibliotecas, guiones de
construcción, etc. (see Introducción). Asumiendo procesos de
construcción deterministas, un nombre de archivo del almacén debe
corresponder exactamente a una salida de construcción. guix
challenge comprueba si existe, realmente, una asociación unívoca comparando
la salida de la construcción de varias construcciones independientes de
cualquier elemento del almacén proporcionado.
La salida de la orden muestra algo así:
$ guix challenge \
--substitute-urls="https://ci.guix.gnu.org https://guix.example.org" \
openssl git pius coreutils grep
updating substitutes from 'https://ci.guix.gnu.org'... 100.0%
updating substitutes from 'https://guix.example.org'... 100.0%
/gnu/store/…-openssl-1.0.2d contents differ:
local hash: 0725l22r5jnzazaacncwsvp9kgf42266ayyp814v7djxs7nk963q
https://ci.guix.gnu.org/nar/…-openssl-1.0.2d: 0725l22r5jnzazaacncwsvp9kgf42266ayyp814v7djxs7nk963q
https://guix.example.org/nar/…-openssl-1.0.2d: 1zy4fmaaqcnjrzzajkdn3f5gmjk754b43qkq47llbyak9z0qjyim
differing files:
/lib/libcrypto.so.1.1
/lib/libssl.so.1.1
/gnu/store/…-git-2.5.0 contents differ:
local hash: 00p3bmryhjxrhpn2gxs2fy0a15lnip05l97205pgbk5ra395hyha
https://ci.guix.gnu.org/nar/…-git-2.5.0: 069nb85bv4d4a6slrwjdy8v1cn4cwspm3kdbmyb81d6zckj3nq9f
https://guix.example.org/nar/…-git-2.5.0: 0mdqa9w1p6cmli6976v4wi0sw9r4p5prkj7lzfd1877wk11c9c73
differing file:
/libexec/git-core/git-fsck
/gnu/store/…-pius-2.1.1 contents differ:
local hash: 0k4v3m9z1zp8xzzizb7d8kjj72f9172xv078sq4wl73vnq9ig3ax
https://ci.guix.gnu.org/nar/…-pius-2.1.1: 0k4v3m9z1zp8xzzizb7d8kjj72f9172xv078sq4wl73vnq9ig3ax
https://guix.example.org/nar/…-pius-2.1.1: 1cy25x1a4fzq5rk0pmvc8xhwyffnqz95h2bpvqsz2mpvlbccy0gs
differing file:
/share/man/man1/pius.1.gz
…
5 store items were analyzed:
- 2 (40.0%) were identical
- 3 (60.0%) differed
- 0 (0.0%) were inconclusive
In this example, guix challenge queries all the substitute servers
for each of the fives packages specified on the command line. It then
reports those store items for which the servers obtained a result different
from the local build (if it exists) and/or different from one another; here,
the ‘local hash’ lines indicate that a local build result was available
for each of these packages and shows its hash.
As an example, guix.example.org always gets a different answer.
Conversely, ci.guix.gnu.org agrees with local builds,
except in the case of Git. This might indicate that the build process of
Git is non-deterministic, meaning that its output varies as a function of
various things that Guix does not fully control, in spite of building
packages in isolated environments (see Características). Most common sources
of non-determinism include the addition of timestamps in build results, the
inclusion of random numbers, and directory listings sorted by inode number.
See https://reproducible-builds.org/docs/, for more information.
Para encontrar cuál es el problema con este binario Git, la aproximación más fácil es ejecutar:
guix challenge git \ --diff=diffoscope \ --substitute-urls="https://ci.guix.gnu.org https://guix.example.org"
Esto invoca automáticamente diffoscope, que muestra información
detallada sobre los archivos que son diferentes.
De manera alternativa, se puede hacer algo parecido a esto (see Invocación de guix archive):
$ wget -q -O - https://ci.guix.gnu.org/nar/lzip/…-git-2.5.0 \ | lzip -d | guix archive -x /tmp/git $ diff -ur --no-dereference /gnu/store/…-git.2.5.0 /tmp/git
This command shows the difference between the files resulting from the local
build, and the files resulting from the build on
ci.guix.gnu.org (see Comparing and Merging
Files in Comparing and Merging Files). The diff
command works great for text files. When binary files differ, a better
option is Diffoscope, a tool that helps
visualize differences for all kinds of files.
Una vez haya realizado este trabajo, puede determinar si las diferencias son
debidas a un procedimiento de construcción no-determinista o a un servidor
con intenciones ocultas. Intentamos duramente eliminar las fuentes de
indeterminismo en los paquetes para facilitar la verificación de
sustituciones, pero por supuesto es un proceso que implica no solo a Guix,
sino a una gran parte de la comunidad del software libre. Entre tanto,
guix challenge es una herramienta para ayudar a afrontar el
problema.
If you are writing packages for Guix, you are encouraged to check whether
ci.guix.gnu.org and other substitute servers obtain the
same build result as you did with:
guix challenge package
La sintaxis general es:
guix challenge options argument…
where argument is a package specification such as guile@2.0 or
glibc:debug or, alternatively, a store file name as returned, for
example, by guix build or guix gc --list-live.
Cuando se encuentra una diferencia entre el hash de un elemento construido localmente y el proporcionado por un servidor de sustituciones; o entre las sustituciones proporcionadas por distintos servidores, esto es mostrado como en el ejemplo previo y el código de salida es 2 (otros valores código de salida distintos de cero denominan otros tipos de error).
La única opción de importancia es:
--substitute-urls=urlsConsidera urls la lista separada por espacios de URL de fuentes de sustituciones con las que realizar la comparación.
--diff=modoMuestra las diferencias encontradas de acuerdo con modo, uno de los siguientes:
simple(el predeterminado)Muestra la lista de archivos que son diferentes.
diffoscope- orden
Invoca Diffoscope y le proporciona los dos directorios cuyo contenido es diferente.
Cuando orden es una ruta absoluta, ejecuta orden en vez de Diffoscope.
noneNo muestra más detalles sobre las diferencias.
Por tanto, a menos que se proporcione --diff=none,
guix challengedescarga los contenidos de los elementos del almacén de los servidores de sustituciones proporcionados para poder compararlos.--verbose-vMuestra detalles sobre coincidencias (contenidos idénticos) además de información sobre las discrepancias.
Next: Invocación de guix container, Previous: Invocación de guix challenge, Up: Utilidades [Contents][Index]
10.13 Invocación de guix copy
La orden guix copy copia elementos del almacén de una máquina al
de otra a través de una conexión de shell seguro (SSH)29. Por ejemplo, la siguiente
orden copia el paquete coreutils, el perfil de la usuaria y todas sus
dependencias a dirección, ingresando en el sistema como usuaria:
guix copy --to=user@host \
coreutils $(readlink -f ~/.guix-profile)
Si alguno de los elementos del almacén a copiar ya están presentes en dirección, no se envían realmente.
La siguiente orden obtiene libreoffice y gimp de
dirección, asumiendo que estén disponibles allí:
guix copy --from=dirección libreoffice gimp
La conexión SSH se establece usando el cliente Guile-SSH, que es compatible con OpenSSH: tiene en cuenta ~/.ssh/known_hosts y ~/.ssh/config, y usa el agente SSH para la identificación.
La clave usada para firmar los elementos enviados debe estar aceptada por la
máquina remota. Del mismo modo, la clave usada por la máquina remota para
firmar los elementos recibidos debe estar en /etc/guix/acl de modo
que sea aceptada por su propio daemon. See Invocación de guix archive, para
más información sobre la verificación de elementos del almacén.
La sintaxis general es:
guix copy [--to=spec|--from=spec] elementos…
Siempre debe especificar una de las siguientes opciones:
--to=spec--from=specEspecifica la máquina a la que mandar o desde la que recibir. spec debe ser una especificación SSH como
example.org,carlos@example.org, orcarlos@example.org:2222.
Los elementos pueden ser tanto nombres de paquetes, como gimp,
como elementos del almacén, como /gnu/store/…-idutils-4.6.
Cuando se especifica el nombre del paquete a enviar, primero se construye si es necesario, a menos que se use --dry-run. Se aceptan las opciones comunes de construcción (see Opciones comunes de construcción).
Next: Invocación de guix weather, Previous: Invocación de guix copy, Up: Utilidades [Contents][Index]
10.14 Invocación de guix container
Nota: En la versión 1.4.0, esta herramienta es experimental. La interfaz está sujeta a cambios radicales en el futuro.
The purpose of guix container is to manipulate processes running
within an isolated environment, commonly known as a “container”, typically
created by the guix shell (see Invoking guix shell) and
guix system container (see Invoking guix system) commands.
La sintaxis general es:
guix container acción opciones…
acción especifica la operación a realizar con el contenedor, y opcines especifica los parámetros específicos del contexto para la acción.
Las siguientes acciones están disponibles:
execEjecute una orden en el contexto de un contenedor en ejecución.
La sintaxis es:
guix container exec pid programa parámetros…
pid especifica el ID del proceso del contenedor en ejecución. programa especifica el nombre del archivo ejecutable dentro del sistema de archivos raíz del contenedor. parámetros son opciones adicionales que se pasarán a programa.
La siguiente orden lanza un shell interactivo de ingreso al sistema dentro de un contenedor del sistema, iniciado por
guix system container, y cuyo ID de proceso es 9001:guix container exec 9001 /run/current-system/profile/bin/bash --login
Fíjese que el pid no puede ser el proceso creador del contenedor. Debe ser el PID 1 del contenedor o uno de sus procesos hijos.
Next: Invocación de guix processes, Previous: Invocación de guix container, Up: Utilidades [Contents][Index]
10.15 Invocación de guix weather
De manera ocasional tendrá un mal día al no estar las sustituciones
disponibles y le toque construir los paquetes a usted misma
(see Sustituciones). La orden guix weather informa de la
disponibilidad de sustituciones en los servidores especificados de modo que
pueda tener una idea sobre cómo será su día hoy. A veces puede ser una
información útil como usuaria, pero es principalmente útil para quienes
ejecuten guix publish (see Invocación de guix publish).
Esta es una ejecución de ejemplo:
$ guix weather --substitute-urls=https://guix.example.org
computing 5,872 package derivations for x86_64-linux...
looking for 6,128 store items on https://guix.example.org..
updating substitutes from 'https://guix.example.org'... 100.0%
https://guix.example.org
43.4% substitutes available (2,658 out of 6,128)
7,032.5 MiB of nars (compressed)
19,824.2 MiB on disk (uncompressed)
0.030 seconds per request (182.9 seconds in total)
33.5 requests per second
9.8% (342 out of 3,470) of the missing items are queued
867 queued builds
x86_64-linux: 518 (59.7%)
i686-linux: 221 (25.5%)
aarch64-linux: 128 (14.8%)
build rate: 23.41 builds per hour
x86_64-linux: 11.16 builds per hour
i686-linux: 6.03 builds per hour
aarch64-linux: 6.41 builds per hour
Como puede ver, informa de la fracción de todos los paquetes para los cuales
hay sustituciones en el servidor—independientemente de que las
sustituciones estén activadas, e independientemente de si la clave de firma
del servidor está autorizada. También informa del tamaño de los archivos
comprimidos (“nar”) proporcionados por el servidor, el tamaño que los
elementos correspondientes del almacén ocupan en el almacén (asumiendo que
la deduplicación está apagada) y el caudal de proceso del servidor. La
segunda parte proporciona estadísticas de integración continua (CI), si el
servidor lo permite. Además, mediante el uso de la opción
--coverage, guix weather puede enumerar sustituciones de
paquetes “importantes” que no se encuentren en el servidor (véase más
adelante).
Para conseguirlo, guix weather consulta los metadatos HTTP(S)
(narinfos) de todos los elementos relevantes del almacén. Como
guix challenge, ignora las firmas en esas sustituciones, lo cual
es inocuo puesto que la orden únicamente obtiene estadísticas y no puede
instalar esas sustituciones.
La sintaxis general es:
guix weather opciones… [paquetes…]
Cuando se omite paquetes, guix weather comprueba la
disponibilidad de sustituciones para todos los paquetes, o para
aquellos especificados con la opción --manifest; en otro caso
considera únicamente los paquetes especificados. También es posible
consultar tipos de sistema específicos con --system. guix
weather termina con un código de salida distinto a cero cuando la fracción
de sustituciones disponibles se encuentra por debajo del 100%.
Las opciones disponibles se enumeran a continuación.
--substitute-urls=urlsurls es la lista separada por espacios de URL de servidores de sustituciones a consultar. Cuando se omite esta opción, el conjunto predeterminado de servidores de sustituciones es el consultado.
--system=sistema-s sistemaConsulta sustituciones para sistema—por ejemplo,
aarch64-linux. Esta opción se puede repetir, en cuyo casoguix weatherconsultará las sustituciones para varios tipos de sistema.--manifest=archivoEn vez de consultar las sustituciones de todos los paquetes, consulta únicamente los especificados en archivo. archivo debe contener un manifiesto, como el usado en la opción
-mdeguix package(see Invocación deguix package).Esta opción puede repetirse varias veces, en cuyo caso los manifiestos se concatenan.
--coverage[=numero]-c [numero]Informa de la cobertura de sustituciones para paquetes: enumera paquetes con al menos número dependientes (cero por omisión) para los cuales no haya sustituciones disponibles. Los paquetes dependientes en sí no se enumeran: si b depende de a y a no tiene sustituciones disponibles, únicamente se muestra a, aunque b normalmente no tenga sustituciones tampoco. El resultado es más o menos así:
$ guix weather --substitute-urls=https://ci.guix.gnu.org https://bordeaux.guix.gnu.org -c 10 computing 8,983 package derivations for x86_64-linux... looking for 9,343 store items on https://ci.guix.gnu.org https://bordeaux.guix.gnu.org... updating substitutes from 'https://ci.guix.gnu.org https://bordeaux.guix.gnu.org'... 100.0% https://ci.guix.gnu.org https://bordeaux.guix.gnu.org 64.7% substitutes available (6,047 out of 9,343) … 2502 packages are missing from 'https://ci.guix.gnu.org https://bordeaux.guix.gnu.org' for 'x86_64-linux', among which: 58 kcoreaddons@5.49.0 /gnu/store/…-kcoreaddons-5.49.0 46 qgpgme@1.11.1 /gnu/store/…-qgpgme-1.11.1 37 perl-http-cookiejar@0.008 /gnu/store/…-perl-http-cookiejar-0.008 …What this example shows is that
kcoreaddonsand presumably the 58 packages that depend on it have no substitutes atci.guix.gnu.org; likewise forqgpgmeand the 46 packages that depend on it.Si es una desarrolladora Guix, o si se encuentra a cargo de esta granja de construcción, probablemente quiera inspeccionar estos paquetes con más detalle: simplemente puede que su construcción falle.
--display-missingMuestra los elementos del almacén para los que faltan las sustituciones.
Previous: Invocación de guix weather, Up: Utilidades [Contents][Index]
10.16 Invocación de guix processes
La orden guix processes puede ser útil a desarrolladoras y
administradoras de sistemas, especialmente en máquinas multiusuaria y en
granjas de construcción: enumera las sesiones actuales (conexiones al
daemon), así como información sobre los procesos envueltos30. A continuación puede verse un ejemplo de la información que
devuelve:
$ sudo guix processes SessionPID: 19002 ClientPID: 19090 ClientCommand: guix shell python SessionPID: 19402 ClientPID: 19367 ClientCommand: guix publish -u guix-publish -p 3000 -C 9 … SessionPID: 19444 ClientPID: 19419 ClientCommand: cuirass --cache-directory /var/cache/cuirass … LockHeld: /gnu/store/…-perl-ipc-cmd-0.96.lock LockHeld: /gnu/store/…-python-six-bootstrap-1.11.0.lock LockHeld: /gnu/store/…-libjpeg-turbo-2.0.0.lock ChildPID: 20495 ChildCommand: guix offload x86_64-linux 7200 1 28800 ChildPID: 27733 ChildCommand: guix offload x86_64-linux 7200 1 28800 ChildPID: 27793 ChildCommand: guix offload x86_64-linux 7200 1 28800
En este ejemplo vemos que guix-daemon tiene tres clientes:
guix environment, guix publish y la herramienta de
integración continua Cuirass; sus identificadores de proceso (PID) se
muestran en el campo ClientPID. El campo SessionPID
proporciona el PID del subproceso de guix-daemon de cada sesión en
particular.
The LockHeld fields show which store items are currently locked by
this session, which corresponds to store items being built or substituted
(the LockHeld field is not displayed when guix processes is
not running as root). Last, by looking at the ChildPID and
ChildCommand fields, we understand that these three builds are being
offloaded (see Uso de la facilidad de delegación de trabajo).
La salida está en formato Recutils por lo que podemos usar la útil orden
recsel para seleccionar sesiones de interés (see Selection
Expressions in GNU recutils manual). Como un ejemplo, la
siguiente orden muestra la línea de órdenes y el PID del cliente que inició
la construcción de un paquete Perl:
$ sudo guix processes | \
recsel -p ClientPID,ClientCommand -e 'LockHeld ~ "perl"'
ClientPID: 19419
ClientCommand: cuirass --cache-directory /var/cache/cuirass …
Additional options are listed below.
--format=formato-f formatoProduce salida en el formato especificado, uno de:
recutilsThe default option. It outputs a set of Session recutils records that include each
ChildProcessas a field.normalizedNormalize the output records into record sets (see Record Sets in GNU recutils manual). Normalizing into record sets allows joins across record types. The example below lists the PID of each
ChildProcessand the associated PID forSessionthat spawned theChildProcesswhere theSessionwas started usingguix build.$ guix processes --format=normalized | \ recsel \ -j Session \ -t ChildProcess \ -p Session.PID,PID \ -e 'Session.ClientCommand ~ "guix build"' PID: 4435 Session_PID: 4278 PID: 4554 Session_PID: 4278 PID: 4646 Session_PID: 4278
Next: Configuración del sistema, Previous: Utilidades, Up: GNU Guix [Contents][Index]
11 Foreign Architectures
You can target computers of different CPU architectures when producing
packages (see Invocación de guix package), packs (see Invocación de guix pack)
or full systems (see Invoking guix system).
GNU Guix supports two distinct mechanisms to target foreign architectures:
- The traditional cross-compilation mechanism.
- The native building mechanism which consists in building using the CPU instruction set of the foreign system you are targeting. It often requires emulation, using the QEMU program for instance.
Next: Native Builds, Up: Foreign Architectures [Contents][Index]
11.1 Cross-Compilation
The commands supporting cross-compilation are proposing the --list-targets and --target options.
The --list-targets option lists all the supported targets that can be passed as an argument to --target.
$ guix build --list-targets The available targets are: - aarch64-linux-gnu - arm-linux-gnueabihf - i586-pc-gnu - i686-linux-gnu - i686-w64-mingw32 - mips64el-linux-gnu - powerpc-linux-gnu - powerpc64le-linux-gnu - riscv64-linux-gnu - x86_64-linux-gnu - x86_64-w64-mingw32
Targets are specified as GNU triplets (see GNU configuration triplets in Autoconf).
Those triplets are passed to GCC and the other underlying compilers possibly involved when building a package, a system image or any other GNU Guix output.
$ guix build --target=aarch64-linux-gnu hello /gnu/store/9926by9qrxa91ijkhw9ndgwp4bn24g9h-hello-2.12 $ file /gnu/store/9926by9qrxa91ijkhw9ndgwp4bn24g9h-hello-2.12/bin/hello /gnu/store/9926by9qrxa91ijkhw9ndgwp4bn24g9h-hello-2.12/bin/hello: ELF 64-bit LSB executable, ARM aarch64 …
The major benefit of cross-compilation is that there are no performance penaly compared to emulation using QEMU. There are however higher risks that some packages fail to cross-compile because few users are using this mechanism extensively.
Previous: Cross-Compilation, Up: Foreign Architectures [Contents][Index]
11.2 Native Builds
The commands that support impersonating a specific system have the --list-systems and --system options.
The --list-systems option lists all the supported systems that can be passed as an argument to --system.
$ guix build --list-systems The available systems are: - x86_64-linux [current] - aarch64-linux - armhf-linux - i586-gnu - i686-linux - mips64el-linux - powerpc-linux - powerpc64le-linux - riscv64-linux $ guix build --system=i686-linux hello /gnu/store/cc0km35s8x2z4pmwkrqqjx46i8b1i3gm-hello-2.12 $ file /gnu/store/cc0km35s8x2z4pmwkrqqjx46i8b1i3gm-hello-2.12/bin/hello /gnu/store/cc0km35s8x2z4pmwkrqqjx46i8b1i3gm-hello-2.12/bin/hello: ELF 32-bit LSB executable, Intel 80386 …
In the above example, the current system is x86_64-linux. The hello package is however built for the i686-linux system.
This is possible because the i686 CPU instruction set is a subset of the x86_64, hence i686 targeting binaries can be run on x86_64.
Still in the context of the previous example, if picking the
aarch64-linux system and the guix build
--system=aarch64-linux hello has to build some derivations, an extra step
might be needed.
The aarch64-linux targeting binaries cannot directly be run on a x86_64-linux system. An emulation layer is requested. The GNU Guix daemon can take advantage of the Linux kernel binfmt_misc mechanism for that. In short, the Linux kernel can defer the execution of a binary targeting a foreign platform, here aarch64-linux, to a userspace program, usually an emulator.
There is a service that registers QEMU as a backend for the
binfmt_misc mechanism (see qemu-binfmt-service-type). On Debian based foreign distributions,
the alternative would be the qemu-user-static package.
If the binfmt_misc mechanism is not setup correctly, the building
will fail this way:
$ guix build --system=armhf-linux hello --check … unsupported-platform /gnu/store/jjn969pijv7hff62025yxpfmc8zy0aq0-hello-2.12.drv aarch64-linux while setting up the build environment: a `aarch64-linux' is required to build `/gnu/store/jjn969pijv7hff62025yxpfmc8zy0aq0-hello-2.12.drv', but I am a `x86_64-linux'…
whereas, with the binfmt_misc mechanism correctly linked with QEMU,
one can expect to see:
$ guix build --system=armhf-linux hello --check /gnu/store/13xz4nghg39wpymivlwghy08yzj97hlj-hello-2.12
The main advantage of native building compared to cross-compiling, is that more packages are likely to build correctly. However it comes at a price: compilation backed by QEMU is way slower than cross-compilation, because every instruction needs to be emulated.
The availability of substitutes for the architecture targeted by the
--system option can mitigate this problem. An other way to work
around it is to install GNU Guix on a machine whose CPU supports the
targeted instruction set, and set it up as an offload machine (see Uso de la facilidad de delegación de trabajo).
Next: Home Configuration, Previous: Foreign Architectures, Up: GNU Guix [Contents][Index]
12 Configuración del sistema
El sistema Guix permite un mecanismo de configuración del sistema completo consistente. Con esto queremos decir que todos los aspectos de la configuración global del sistema—como los servicios disponibles, la zona horaria y la configuración de localización, las cuentas de usuarias—se declaran en un lugar único. Dicha configuración del sistema puede ser instanciada—es decir, hecha efectiva.
Una de las ventajas de poner toda la configuración del sistema bajo el control de Guix es que permite actualizaciones transaccionales del sistema, y hace posible volver a una instanciación previa del sistema, en caso de que haya algún problema con la nueva (see Características). Otra ventaja es que hace fácil replicar exactamente la misma configuración entre máquinas diferentes, o en diferentes momentos, sin tener que utilizar herramientas de administración adicionales sobre las propias herramientas del sistema.
Esta sección describe este mecanismo. Primero nos enfocaremos en el punto de vista de la administradora del sistema—explicando cómo se configura e instancia el sistema. Después mostraremos cómo puede extenderse este mecanismo, por ejemplo para añadir nuevos servicios del sistema.
- Uso de la configuración del sistema
- Referencia de
operating-system - Sistemas de archivos
- Dispositivos traducidos
- Swap Space
- Cuentas de usuaria
- Distribución de teclado
- Localizaciones
- Servicios
- Programas con setuid
- Certificados X.509
- Selector de servicios de nombres
- Disco en RAM inicial
- Configuración del gestor de arranque
- Invoking
guix system - Invoking
guix deploy - Ejecución de Guix en una máquina virtual
- Definición de servicios
Next: Referencia de operating-system, Up: Configuración del sistema [Contents][Index]
12.1 Uso de la configuración del sistema
El sistema operativo se configura proporcionando una declaración
operating-system en un archivo que pueda ser proporcionado a la orden
guix system (see Invoking guix system). Una configuración
simple, con los servicios predeterminados del sistema, el núcleo Linux-Libre
predeterminado, un disco de RAM inicial y un cargador de arranque puede ser
como sigue:
;; This is an operating system configuration template ;; for a "bare bones" setup, with no X11 display server. (use-modules (gnu)) (use-service-modules networking ssh) (use-package-modules screen ssh) (operating-system (host-name "komputilo") (timezone "Europe/Berlin") (locale "en_US.utf8") ;; Boot in "legacy" BIOS mode, assuming /dev/sdX is the ;; target hard disk, and "my-root" is the label of the target ;; root file system. (bootloader (bootloader-configuration (bootloader grub-bootloader) (targets '("/dev/sdX")))) ;; It's fitting to support the equally bare bones ‘-nographic’ ;; QEMU option, which also nicely sidesteps forcing QWERTY. (kernel-arguments (list "console=ttyS0,115200")) (file-systems (cons (file-system (device (file-system-label "my-root")) (mount-point "/") (type "ext4")) %base-file-systems)) ;; This is where user accounts are specified. The "root" ;; account is implicit, and is initially created with the ;; empty password. (users (cons (user-account (name "alice") (comment "Bob's sister") (group "users") ;; Adding the account to the "wheel" group ;; makes it a sudoer. Adding it to "audio" ;; and "video" allows the user to play sound ;; and access the webcam. (supplementary-groups '("wheel" "audio" "video"))) %base-user-accounts)) ;; Globally-installed packages. (packages (cons screen %base-packages)) ;; Add services to the baseline: a DHCP client and ;; an SSH server. (services (append (list (service dhcp-client-service-type) (service openssh-service-type (openssh-configuration (openssh openssh-sans-x) (port-number 2222)))) %base-services)))
Este ejemplo debería ser auto-descriptivo. Algunos de los campos definidos
anteriormente, como host-name y bootloader, son
necesarios. Otros como packages y services, pueden omitirse,
en cuyo caso obtienen un valor por defecto.
Más adelante se muestran los efectos de algunos de los campos más
importantes (see Referencia de operating-system, para detalles acerca de
todos los campos disponibles), y cómo instanciar el sistema operativo
usando guix system.
- Cargador de arranque
- Paquetes visibles globalmente
- Servicios del sistema
- Instanciación del sistema
- La interfaz programática
Cargador de arranque
El campo bootloader describe el método que será usado para arrancar
su sistema. Las máquinas basadas en procesadores Intel pueden arrancar en el
“obsoleto” modo BIOS, como en el ejemplo previo. No obstante, máquinas más
recientes usan la Interfaz Unificada Extensible de Firmware (UEFI)
para arrancar. En ese caso, el capo bootloader debe contener algo
parecido a esto:
(bootloader-configuration
(bootloader grub-efi-bootloader)
(targets '("/boot/efi")))
See Configuración del gestor de arranque, para más información sobre las opciones de configuración disponibles.
Paquetes visibles globalmente
The packages field lists packages that will be globally visible on
the system, for all user accounts—i.e., in every user’s PATH
environment variable—in addition to the per-user profiles (see Invocación de guix package). The %base-packages variable provides all the tools
one would expect for basic user and administrator tasks—including the GNU
Core Utilities, the GNU Networking Utilities, the mg lightweight
text editor, find, grep, etc. The example above adds
GNU Screen to those, taken from the (gnu packages screen) module
(see Módulos de paquetes). The (list package output) syntax can be
used to add a specific output of a package:
(use-modules (gnu packages)) (use-modules (gnu packages dns)) (operating-system ;; ... (packages (cons (list isc-bind "utils") %base-packages)))
Referring to packages by variable name, like isc-bind above, has the
advantage of being unambiguous; it also allows typos and such to be
diagnosed right away as “unbound variables”. The downside is that one
needs to know which module defines which package, and to augment the
use-package-modules line accordingly. To avoid that, one can use the
specification->package procedure of the (gnu packages) module,
which returns the best package for a given name or name and version:
(use-modules (gnu packages)) (operating-system ;; ... (packages (append (map specification->package '("tcpdump" "htop" "gnupg@2.0")) %base-packages)))
Servicios del sistema
El campo services enumera los servicios del sistema disponibles
cuando el sistema arranque (see Servicios). La declaración
operating-system previa especifica que, además de los servicios
básicos, queremos que el daemon de shell seguro OpenSSH espere conexiones
por el puerto 2222 (see openssh-service-type). En su implementación,
openssh-service-type prepara todo para que sshd se inicie con
las opciones de la línea de órdenes adecuadas, posiblemente generando bajo
demanda los archivos de configuración necesarios (see Definición de servicios).
De manera ocasional, en vez de usar los servicios básicos tal y como vienen,
puede querer personalizarlos. Para hacerlo, use modify-services
(see modify-services) para modificar la lista.
Por ejemplo, supongamos que quiere modificar guix-daemon y Mingetty
(el punto de acceso al sistema por consola) en la lista
%base-services (see %base-services). Para
hacerlo, puede escribir lo siguiente en su declaración de sistema operativo:
(define %my-services ;; My very own list of services. (modify-services %base-services (guix-service-type config => (guix-configuration (inherit config) ;; Fetch substitutes from example.org. (substitute-urls (list "https://example.org/guix" "https://ci.guix.gnu.org")))) (mingetty-service-type config => (mingetty-configuration (inherit config) ;; Automatically log in as "guest". (auto-login "guest"))))) (operating-system ;; … (services %mis-servicios))
This changes the configuration—i.e., the service parameters—of the
guix-service-type instance, and that of all the
mingetty-service-type instances in the %base-services list
(see see the cookbook for how to auto-login
one user to a specific TTY in GNU Guix Cookbook)). Observe
how this is accomplished: first, we arrange for the original configuration
to be bound to the identifier config in the body, and then we
write the body so that it evaluates to the desired configuration. In
particular, notice how we use inherit to create a new configuration
which has the same values as the old configuration, but with a few
modifications.
The configuration for a typical “desktop” usage, with an encrypted root partition, a swap file on the root partition, the X11 display server, GNOME and Xfce (users can choose which of these desktop environments to use at the log-in screen by pressing F1), network management, power management, and more, would look like this:
;; This is an operating system configuration template ;; for a "desktop" setup with GNOME and Xfce where the ;; root partition is encrypted with LUKS, and a swap file. (use-modules (gnu) (gnu system nss) (guix utils)) (use-service-modules desktop sddm xorg) (use-package-modules certs gnome) (operating-system (host-name "antelope") (timezone "Europe/Paris") (locale "en_US.utf8") ;; Choose US English keyboard layout. The "altgr-intl" ;; variant provides dead keys for accented characters. (keyboard-layout (keyboard-layout "us" "altgr-intl")) ;; Use the UEFI variant of GRUB with the EFI System ;; Partition mounted on /boot/efi. (bootloader (bootloader-configuration (bootloader grub-efi-bootloader) (targets '("/boot/efi")) (keyboard-layout keyboard-layout))) ;; Specify a mapped device for the encrypted root partition. ;; The UUID is that returned by 'cryptsetup luksUUID'. (mapped-devices (list (mapped-device (source (uuid "12345678-1234-1234-1234-123456789abc")) (target "my-root") (type luks-device-mapping)))) (file-systems (append (list (file-system (device (file-system-label "my-root")) (mount-point "/") (type "ext4") (dependencies mapped-devices)) (file-system (device (uuid "1234-ABCD" 'fat)) (mount-point "/boot/efi") (type "vfat"))) %base-file-systems)) ;; Specify a swap file for the system, which resides on the ;; root file system. (swap-devices (list (swap-space (target "/swapfile")))) ;; Create user `bob' with `alice' as its initial password. (users (cons (user-account (name "bob") (comment "Alice's brother") (password (crypt "alice" "$6$abc")) (group "students") (supplementary-groups '("wheel" "netdev" "audio" "video"))) %base-user-accounts)) ;; Add the `students' group (groups (cons* (user-group (name "students")) %base-groups)) ;; This is where we specify system-wide packages. (packages (append (list ;; for HTTPS access nss-certs ;; for user mounts gvfs) %base-packages)) ;; Add GNOME and Xfce---we can choose at the log-in screen ;; by clicking the gear. Use the "desktop" services, which ;; include the X11 log-in service, networking with ;; NetworkManager, and more. (services (if (target-x86-64?) (append (list (service gnome-desktop-service-type) (service xfce-desktop-service-type) (set-xorg-configuration (xorg-configuration (keyboard-layout keyboard-layout)))) %desktop-services) ;; FIXME: Since GDM depends on Rust (gdm -> gnome-shell -> gjs ;; -> mozjs -> rust) and Rust is currently unavailable on ;; non-x86_64 platforms, we use SDDM and Mate here instead of ;; GNOME and GDM. (append (list (service mate-desktop-service-type) (service xfce-desktop-service-type) (set-xorg-configuration (xorg-configuration (keyboard-layout keyboard-layout)) sddm-service-type)) %desktop-services))) ;; Allow resolution of '.local' host names with mDNS. (name-service-switch %mdns-host-lookup-nss))
Un sistema gráfico con una selección de gestores de ventanas ligeros en vez de entornos de escritorio completos podría ser así:
;; This is an operating system configuration template ;; for a "desktop" setup without full-blown desktop ;; environments. (use-modules (gnu) (gnu system nss)) (use-service-modules desktop) (use-package-modules bootloaders certs emacs emacs-xyz ratpoison suckless wm xorg) (operating-system (host-name "antelope") (timezone "Europe/Paris") (locale "en_US.utf8") ;; Use the UEFI variant of GRUB with the EFI System ;; Partition mounted on /boot/efi. (bootloader (bootloader-configuration (bootloader grub-efi-bootloader) (targets '("/boot/efi")))) ;; Assume the target root file system is labelled "my-root", ;; and the EFI System Partition has UUID 1234-ABCD. (file-systems (append (list (file-system (device (file-system-label "my-root")) (mount-point "/") (type "ext4")) (file-system (device (uuid "1234-ABCD" 'fat)) (mount-point "/boot/efi") (type "vfat"))) %base-file-systems)) (users (cons (user-account (name "alice") (comment "Bob's sister") (group "users") (supplementary-groups '("wheel" "netdev" "audio" "video"))) %base-user-accounts)) ;; Add a bunch of window managers; we can choose one at ;; the log-in screen with F1. (packages (append (list ;; window managers ratpoison i3-wm i3status dmenu emacs emacs-exwm emacs-desktop-environment ;; terminal emulator xterm ;; for HTTPS access nss-certs) %base-packages)) ;; Use the "desktop" services, which include the X11 ;; log-in service, networking with NetworkManager, and more. (services %desktop-services) ;; Allow resolution of '.local' host names with mDNS. (name-service-switch %mdns-host-lookup-nss))
Este ejemplo se refiere al sistema de archivos /boot/efi por su UUID
1234-ABCD. Substituya este UUID con el UUID correcto en su sistema,
como el devuelto por la orden blkid.
See Servicios de escritorio, para la lista exacta de servicios proporcionados
por %desktop-services. See Certificados X.509, para información
sobre el paquete nss-certs usado aquí.
De nuevo, %desktop-services es simplemente una lista de objetos de
servicios. Si desea borrar servicios de aquí, puede hacerlo usando
procedimientos de filtrado de listas (see SRFI-1 Filtering and
Partitioning in GNU Guile Reference Manual). Por ejemplo, la
siguiente expresión devuelve una lista que contiene todos los servicios en
%desktop-services excepto el servicio Avahi:
(remove (lambda (service)
(eq? (service-kind service) avahi-service-type))
%desktop-services)
Alternatively, the modify-services macro can be used:
Instanciación del sistema
Asumiendo que la declaración de operating-system se encuentra en el
archivo mi-configuración-del-sistema.scm, la orden guix
system mi-conf-del-sistema.scm instancia esa configuración, y la convierte
en la entrada predeterminada de GRUB en el arranque (see Invoking guix system).
Nota: We recommend that you keep this my-system-config.scm file safe and under version control to easily track changes to your configuration.
La manera habitual de cambiar la configuración del sistema es actualizar
este archivo y volver a ejecutar guix system reconfigure. Nunca se
deberían tocar los archivos en /etc o ejecutar órdenes que modifiquen
el estado del sistema como useradd o grub-install. De
hecho, debe evitarlo ya que no únicamente anularía su garantía sino que
también le impediría volver a una versión previa de su sistema, en caso de
necesitarlo.
Hablando de vuelta atrás, cada vez que ejecuta guix system
reconfigure se crea una nueva generación del sistema—sin modificar
o borrar generaciones previas. Las generaciones previas tienen una entrada
en el menú del cargador de arranque, lo que permite arrancarlas en caso de
que algo funcionase mal en las últimas generaciones. Tranquilizador, ¿no? La
orden guix system list-generations enumera las generaciones del
sistema disponibles en el disco. Es también posible volver a una versión
previa con las órdenes guix system roll-back y guix
system switch-generation.
Aunque la orden guix system reconfigure no modificará las
generaciones previas, debe tener cuidado cuando la generación actual no es
la última (por ejemplo, después de invocar guix system roll-back),
ya que la operación puede sobreescribir una generación posterior
(see Invoking guix system).
La interfaz programática
A nivel Scheme, el grueso de una declaración operating-system se
instancia con el siguiente procedimiento monádico (see La mónada del almacén):
- Procedimiento monádico: operating-system-derivation so
Devuelve una derivación que construye so, un objeto
operating-system(see Derivaciones).La salida de la derivación es un único directorio que hace referencia a todos los paquetes, archivos de configuración y otros archivos auxiliares necesarios para instanciar so.
Este procedimiento se proporciona por el módulo (gnu system). Junto
con (gnu services) (see Servicios), este módulo contiene los
entresijos del sistema Guix. ¡Asegúrese de echarle un vistazo!
Next: Sistemas de archivos, Previous: Uso de la configuración del sistema, Up: Configuración del sistema [Contents][Index]
12.2 Referencia de operating-system
Esta sección resume todas las opciones disponibles en las declaraciones de
operating-system (see Uso de la configuración del sistema).
- Tipo de datos: operating-system
Este es el tipo de datos que representa la configuración del sistema operativo. Con ello queremos decir toda la configuración global del sistema, no la configuración específica de las usuarias (see Uso de la configuración del sistema).
kernel(predeterminado:linux-libre)El objeto del paquete del núcleo del sistema operativo usado31.
hurd(predeterminado:#f)El objeto del paquete de Hurd iniciado por el núcleo. Cuando se proporciona este campo, produce un sistema operativo GNU/Hurd. En ese caso,
kerneltambién debe contener el paquetegnumach—el micronúcleo sobre el que se ejecuta Hurd.Aviso: Esta característica es experimental y únicamente está implementada para imágenes de disco.
kernel-loadable-modules(predeterminados:'())Una lista de objetos (habitualmente paquetes) desde los que se obtendrán los módulos del núcleo–por ejemplo
(list ddcci-driver-linux).kernel-arguments(predeterminados:%default-kernel-arguments)Lista de cadenas o expresiones-G que representan parámetros adicionales a pasar en la línea de órdenes del núcleo—por ejemplo,
("console=ttyS0").bootloaderEl objeto de configuración del cargador de arranque del sistema. See Configuración del gestor de arranque.
labelEs una etiqueta (una cadena) con la que aparecerá en el menú del cargador de arranque. La etiqueta predeterminada incluye el nombre y la versión del núcleo.
keyboard-layout(predeterminada:#f)This field specifies the keyboard layout to use in the console. It can be either
#f, in which case the default keyboard layout is used (usually US English), or a<keyboard-layout>record. See Distribución de teclado, for more information.Esta distribución de teclado se hace efectiva tan pronto el núcleo haya arrancado. Por ejemplo, la distribución de teclado está en efecto cuando introduzca una contraseña si su sistema de archivos raíz se encuentra en un dispositivo traducido
luks-device-mapping(see Dispositivos traducidos).Nota: Esto no especifica la distribución de teclado usada por el cargador de arranque, ni tampoco la usada por el servidor gráfico. See Configuración del gestor de arranque, para información sobre cómo especificar la distribución de teclado del cargador de arranque. See Sistema X Window, para información sobre cómo especificar la distribución de teclado usada por el sistema de ventanas X.
initrd-modules(predeterminados:%base-initrd-modules) ¶-
La lista de módulos del núcleo Linux que deben estar disponibles en el disco inicial en RAM. See Disco en RAM inicial.
initrd(predeterminado:base-initrd)Un procedimiento que devuelve un disco inicial en RAM para el núcleo Linux. Este campo se proporciona para permitir personalizaciones de bajo nivel y no debería ser necesario para un uso habitual. See Disco en RAM inicial.
firmware(predeterminado:%base-firmware) ¶Lista de paquetes de firmware que pueden ser cargados por el núcleo del sistema operativo.
El valor predeterminado incluye el firmware necesario para dispositivos WiFi basados en Atheros y Broadcom (módulos Linux-libre
ath9kyb43-open, respectivamente). See Consideraciones sobre el hardware, para más información sobre hardware soportado.host-nameEl nombre de la máquina.
hosts-file¶Un objeto tipo-archivo (see objetos “tipo-archivo”) para ser usado como /etc/hosts (see Host Names in The GNU C Library Reference Manual). El predeterminado es un archivo con entradas para
localhosty host-name.mapped-devices(predeterminados:'())Una lista de dispositivos traducidos. See Dispositivos traducidos.
file-systemsUna lista de sistemas de archivos. See Sistemas de archivos.
swap-devices(predeterminados:'()) ¶A list of swap spaces. See Swap Space.
users(predeterminadas:%base-user-accounts)groups(predeterminados:%base-groups)Lista de cuentas de usuaria y grupos. See Cuentas de usuaria.
Si la lista de
usuariascarece de una cuenta de usuaria con UID 0, una cuenta “root” con UID 0 se añade automáticamente.skeletons(predeterminados:(default-skeletons))Una lista de tuplas de nombre de archivo de destino/objeto tipo-archivo (see objetos “tipo-archivo”). Estos son los archivos de esqueleto que se añadirán al directorio de las cuentas de usuaria que se creen.
Por ejemplo, un valor válido puede parecer algo así:
`((".bashrc" ,(plain-file "bashrc" "echo Hola\n")) (".guile" ,(plain-file "guile" "(use-modules (ice-9 readline)) (activate-readline)")))
issue(predeterminado:%default-issue)Una cadena que denota el contenido del archivo /etc/issue, que se muestra cuando las usuarias ingresan al sistema en una consola de texto.
packages(predeterminados:%base-packages)Una lista de paquetes instalados en el perfil global, que es accesible en /run/current-system/profile. Cada elemento debe ser una variable de paquete o una tupla paquete/salida. A continuación se muestra un ejemplo de ambos tipos:
(cons* git ; la salida predeterminada "out" (list git "send-email") ; otra salida de git %base-packages) ; el conjunto predeterminado
El conjunto predeterminado incluye utilidades básicas y es una buena práctica instalar utilidades no-básicas en los perfiles de las usuarias (see Invocación de
guix package).timezone(default:"Etc/UTC")Una cadena que identifica la zona horaria—por ejemplo,
"Europe/Paris".Puede ejecutar la orden
tzselectpara encontrar qué cadena de zona horaria corresponde con su región. Elegir una zona horaria no válida provoca un fallo enguix system.locale(predeterminado:"en_US.utf8")El nombre de la localización predeterminada (see Locale Names in The GNU C Library Reference Manual). See Localizaciones, para más información.
locale-definitions(predeterminadas:%default-locale-definitions)La lista de definiciones de localizaciones a compilar y que puede ser usada en tiempo de ejecución. See Localizaciones.
locale-libcs(predeterminadas:(list glibc))La lista de paquetes GNU libc cuyos datos de localización y herramientas son usadas para las definiciones de localizaciones. See Localizaciones, para consideraciones de compatibilidad que justifican esta opción.
name-service-switch(predeterminado:%default-nss)Configuración del selector de servicios de nombres de libc (NSS)—un objeto
<name-service-switch>. See Selector de servicios de nombres, para detalles.services(predeterminados:%base-services)Una lista de objetos service denotando los servicios del sistema. See Servicios.
essential-services(predeterminados: ...)La lista de “servicios esenciales”—es decir, cosas como instancias de
system-service-typeyhost-name-service-type(see Referencia de servicios), las cuales se derivan de su definición de sistema operativo en sí. Como usuaria nunca debería modificar este campo.pam-services(predeterminados:(base-pam-services)) ¶-
Servicios de los módulos de identificación conectables (PAM) de Linux.
setuid-programs(predeterminados:%setuid-programs)List of
<setuid-program>. See Programas con setuid, for more information.sudoers-file(predeterminado:%sudoers-specification) ¶El contenido de /etc/sudoers como un objeto tipo-archivo (see
local-fileyplain-file).Este archivo especifica qué usuarias pueden usar la orden
sudo, lo que se les permite hacer y qué privilegios pueden obtener. El comportamiento predefinido es que únicamenterooty los miembros del grupowheelpueden usarsudo.
- Tipo de datos: this-operating-system
Cuando se usa en el ámbito léxico de un campo de una definición de sistema operativo, este identificador está enlazado al sistema operativo en definición.
El siguiente ejemplo muestra cómo hacer referencia al sistema operativo en definición en la definición del campo
label:(use-modules (gnu) (guix)) (operating-system ;; ... (label (package-full-name (operating-system-kernel this-operating-system))))
Es un error hacer referencia a
this-operating-systemfuera de una definición de sistema operativo.
Next: Dispositivos traducidos, Previous: Referencia de operating-system, Up: Configuración del sistema [Contents][Index]
12.3 Sistemas de archivos
La lista de sistemas de archivos que deben montarse se especifica en el
campo file-systems de la declaración del sistema operativo
(see Uso de la configuración del sistema). Cada sistema de archivos se
declara usando la forma file-system, como en el siguiente ejemplo:
(file-system
(mount-point "/home")
(device "/dev/sda3")
(type "ext4"))
Como es habitual, algunos de los campos son obligatorios—aquellos mostrados en el ejemplo previo—mientras que otros pueden omitirse. Se describen a continuación.
- Tipo de datos: file-system
Objetos de este tipo representan los sistemas de archivos a montar. Contienen los siguientes campos:
typeEste campo es una cadena que especifica el tipo de sistema de archivos—por ejemplo,
"ext4".mount-pointDesigna la ruta donde el sistema de archivos debe montarse.
deviceNombra la “fuente” del sistema de archivos. Puede ser una de estas tres opciones: una etiqueta de sistema de archivos, un UUID de sistema de archivos o el nombre de un nodo /dev. Las etiquetas y UUID ofrecen una forma de hacer referencia a sistemas de archivos sin codificar su nombre de dispositivo actual32.
Las etiquetas del sistema de archivos se crean mediante el uso del procedimiento
file-system-label, los UUID se crean mediante el uso deuuidy los nodos /dev son simples cadenas. A continuación se proporciona un ejemplo de un sistema de archivos al que se hace referencia mediante su etiqueta, como es mostrada por la ordene2label:(file-system (mount-point "/home") (type "ext4") (device (file-system-label "mi-home")))Los UUID se convierten dede su representación en forma de cadena (como se muestra con la orden
tune2fs -l) mediante el uso de la formauuid33, como sigue:(file-system (mount-point "/home") (type "ext4") (device (uuid "4dab5feb-d176-45de-b287-9b0a6e4c01cb")))Cuando la fuente de un sistema de archivos es un dispositivo traducido (see Dispositivos traducidos), su campo
devicedebe hacer referencia al nombre del dispositivo traducido—por ejemplo, "/dev/mapper/particion-raiz". Esto es necesario para que el sistema sepa que el montaje del sistema de archivos depende del establecimiento de la traducción de dispositivos correspondiente.flags(predeterminadas:'())This is a list of symbols denoting mount flags. Recognized flags include
read-only,bind-mount,no-dev(disallow access to special files),no-suid(ignore setuid and setgid bits),no-atime(do not update file access times),no-diratime(likewise for directories only),strict-atime(update file access time),lazy-time(only update time on the in-memory version of the file inode),no-exec(disallow program execution), andshared(make the mount shared). See Mount-Unmount-Remount in The GNU C Library Reference Manual, for more information on these flags.options(predeterminadas:#f)This is either
#f, or a string denoting mount options passed to the file system driver. See Mount-Unmount-Remount in The GNU C Library Reference Manual, for details.Run
man 8 mountfor options for various file systems, but beware that what it lists as file-system-independent “mount options” are in fact flags, and belong in theflagsfield described above.The
file-system-options->alistandalist->file-system-optionsprocedures from(gnu system file-systems)can be used to convert file system options given as an association list to the string representation, and vice-versa.mount?(predeterminado:#t)Este valor indica si debe montarse el sistema de archivos automáticamente al iniciar el sistema. Cuando se establece como
#f, el sistema de archivos tiene una entrada en /etc/fstab (el cual es leído por la ordenmount) pero no se montará automáticamente.needed-for-boot?(predeterminado:#f)Este valor lógico indica si el sistema de archivos es necesario para el arranque. Si es verdadero, el sistema de archivos se monta al cargar el disco inicial en RAM (initrd). Este es siempre el caso, por ejemplo, para el sistema de archivos raíz.
check?(predeterminado:#t)This Boolean indicates whether the file system should be checked for errors before being mounted. How and when this happens can be further adjusted with the following options.
skip-check-if-clean?(default:#t)When true, this Boolean indicates that a file system check triggered by
check?may exit early if the file system is marked as “clean”, meaning that it was previously correctly unmounted and should not contain errors.Setting this to false will always force a full consistency check when
check?is true. This may take a very long time and is not recommended on healthy systems—in fact, it may reduce reliability!Conversely, some primitive file systems like
fatdo not keep track of clean shutdowns and will perform a full scan regardless of the value of this option.repair(default:'preen)When
check?finds errors, it can (try to) repair them and continue booting. This option controls when and how to do so.If false, try not to modify the file system at all. Checking certain file systems like
jfsmay still write to the device to replay the journal. No repairs will be attempted.If
#t, try to repair any errors found and assume “yes” to all questions. This will fix the most errors, but may be risky.If
'preen, repair only errors that are safe to fix without human interaction. What that means is left up to the developers of each file system and may be equivalent to “none” or “all”.create-mount-point?(predeterminado:#f)Cuando es verdadero, el punto de montaje es creado si no existía previamente.
mount-may-fail?(predeterminado:#f)Cuando tiene valor verdadero indica que el montaje de este sistema de archivos puede fallar pero no debe considerarse un error. Es útil en casos poco habituales; un ejemplo de esto es
efivarfs, un sistema de archivos que únicamente puede montarse en sistemas EFI/UEFI.dependencies(predeterminadas:'())Una lista de objetos
<file-system>o<mapped-device>que representan sistemas de archivos que deben montarse o dispositivos traducidos que se deben abrir antes (y desmontar o cerrar después) que el declarado.Como ejemplo, considere la siguiente jerarquía de montajes: /sys/fs/cgroup es una dependencia de /sys/fs/cgroup/cpu y /sys/fs/cgroup/memory.
Otro ejemplo es un sistema de archivos que depende de un dispositivo traducido, por ejemplo una partición cifrada (see Dispositivos traducidos).
- Procedimiento Scheme: file-system-label str
Este procedimiento devuelve un objeto opaco de etiqueta del sistema de archivos a partir de str, una cadena:
(file-system-label "home") ⇒ #<file-system-label "home">
Las etiquetas del sistema de archivos se usan para hacer referencia a los sistemas de archivos por etiqueta en vez de por nombre de dispositivo. Puede haber encontrado previamente ejemplos en el texto.
El módulo (gnu system file-systems) exporta las siguientes variables
útiles.
- Variable Scheme: %base-file-systems
Estos son los sistemas de archivos esenciales que se necesitan en sistemas normales, como
%pseudo-terminal-file-systemy%immutable-store(véase a continuación). Las declaraciones de sistemas operativos deben contener siempre estos al menos.
- Variable Scheme: %pseudo-terminal-file-systems
El sistema de archivos que debe montarse como /dev/pts. Permite la creación de pseudoterminales a través de
openptyy funciones similares (see Pseudo-Terminals in The GNU C Library Reference Manual). Los pseudoterminales son usados por emuladores de terminales comoxterm.
Este sistema de archivos se monta como /dev/shm y se usa para permitir el uso de memoria compartida entre procesos (see
shm_openin The GNU C Library Reference Manual).
- Variable Scheme: %immutable-store
Este sistema de archivos crea un montaje enlazado (“bind-mount”) de /gnu/store, permitiendo solo el acceso de lectura para todas las usuarias incluyendo a
root. Esto previene modificaciones accidentales por software que se ejecuta comorooto por las administradoras del sistema.El daemon sí es capaz de escribir en el almacén: vuelve a montar /gnu/store en modo lectura-escritura en su propio “espacio de nombres”.
- Variable Scheme: %binary-format-file-system
El sistema de archivos
binfmt_misc, que permite que el manejo de tipos de archivos ejecutables arbitrarios se delegue al espacio de usuaria. Necesita la carga del módulo del núcleobinfmt.ko.
- Variable Scheme: %fuse-control-file-system
El sistema de archivos
fusectl, que permite a usuarias sin privilegios montar y desmontar sistemas de archivos de espacio de usuaria FUSE. Necesita la carga del módulo del núcleofuse.ko.
El módulo (gnu system uuid) proporciona herramientas para tratar con
“identificadores únicos” de sistemas de archivos (UUID).
- Procedimiento Scheme: uuid str [tipo]
Devuelve un objeto opaco de UUID (identificador único) del tipo (un símbolo) procesando str (una cadena):
(uuid "4dab5feb-d176-45de-b287-9b0a6e4c01cb") ⇒ #<<uuid> type: dce bv: …> (uuid "1234-ABCD" 'fat) ⇒ #<<uuid> type: fat bv: …>
tipo puede ser
dce,iso9660,fat,ntfs, o uno de sus sinónimos habitualmente usados para estos tipos.Los UUID son otra forma de hacer referencia de forma inequívoca a sistemas de archivos en la configuración de sistema operativo. Puede haber encontrado previamente ejemplos en el texto.
Up: Sistemas de archivos [Contents][Index]
12.3.1 Sistema de archivos Btrfs
El sistema de archivos Btrfs tiene características especiales, como los subvolúmenes, que merecen una explicación más detallada. La siguiente sección intenta cubrir usos básicos así como usos complejos del sistema de archivos Btrfs con el sistema Guix.
Con el uso más simple se puede describir un sistema de archivos Btrfs puede describirse, por ejemplo, del siguiente modo:
(file-system
(mount-point "/home")
(type "btrfs")
(device (file-system-label "mi-home")))
El ejemplo siguiente es más complejo, ya que usa un subvolumen de Btrfs,
llamado rootfs. El sistema de archivos tiene la etiqueta
mi-btrfs, y se encuentra en un dispositivo cifrado (de aquí la
dependencia de mapped-devices):
(file-system
(device (file-system-label "mi-btrfs"))
(mount-point "/")
(type "btrfs")
(options "subvol=rootfs")
(dependencies mapped-devices))
Algunos cargadores de arranque, por ejemplo GRUB, únicamente montan una
partición Btrfs en su nivel superior durante los momentos iniciales del
arranque, y dependen de que su configuración haga referencia a la ruta
correcta del subvolumen dentro de dicho nivel superior. Los cargadores de
arranque que operan de este modo producen habitualmente su configuración en
un sistema en ejecución donde las particiones Btrfs ya se encuentran
montadas y donde la información de subvolúmenes está disponible. Como un
ejemplo, grub-mkconfig, la herramienta de generación de
configuración que viene con GRUB, lee /proc/self/mountinfo para
determinar la ruta desde el nivel superior de un subvolumen.
El sistema Guix produce una configuración para el cargador de arranque usando la configuración del sistema operativo como su única entrada; por lo tanto es necesario extraer la información del subvolumen en el que se encuentra /gnu/store (en caso de estar en alguno) de la configuración del sistema operativo. Para ilustrar esta situación mejor, considere un subvolumen que se llama ’rootfs’ el cual contiene el sistema de archivos raiz. En esta situación, el cargador de arranque GRUB únicamente vería el nivel superior de la partición de raíz de Btrfs, por ejemplo:
/ (nivel superior)
├── rootfs (directorio del subvolumen)
├── gnu (directorio normal)
├── store (directorio normal)
[...]
Por lo tanto, el nombre del subvolumen debe añadirse al inicio de la ruta al núcleo, los binarios de initrd y otros archivos a los que haga referencia la configuración de GRUB en /gnu/store, para que puedan encontrarse en los momentos iniciales del arranque.
El siguiente ejemplo muestra una jerarquía anidada de subvolúmenes y directorios:
/ (nivel superior)
├── rootfs (subvolumen)
├── gnu (directorio normal)
├── store (subvolumen)
[...]
Este escenario funcionaría sin montar el subvolumen ’store’. Montar ’rootfs’
es suficiente, puesto que el nombre del subvolumen corresponde con el punto
de montaje deseado en la jerarquía del sistema de archivos. Alternativamente
se puede hacer referencia el subvolumen ’store’ proporcionando tanto el
valor /rootfs/gnu/store como el valor rootfs/gnu/store a la
opción subvol.
Por último, un ejemplo más elaborado de subvolúmenes anidados:
/ (nivel superior)
├── root-snapshots (subvolumen)
├── root-current (subvolumen)
├── guix-store (subvolumen)
[...]
Aquí, el subvolumen ’guix-store’ no corresponde con el punto de montaje
deseado, por lo que es necesario montarlo. El subvolumen debe ser
especificado completamente proporcionando su nombre de archivo a la opción
subvol. Para ilustrar este ejemplo, el subvolumen ’guix-store’ puede
montarse en /gnu/store usando una declaración de sistema de archivos
como la siguiente:
(file-system
(device (file-system-label "mi-otro-btrfs"))
(mount-point "/gnu/store")
(type "btrfs")
(options "subvol=root-snapshots/root-current/guix-store,\
compress-force=zstd,space_cache=v2"))
Next: Swap Space, Previous: Sistemas de archivos, Up: Configuración del sistema [Contents][Index]
12.4 Dispositivos traducidos
The Linux kernel has a notion of device mapping: a block device, such
as a hard disk partition, can be mapped into another device, usually
in /dev/mapper/, with additional processing over the data that flows
through it34. A typical example is encryption
device mapping: all writes to the mapped device are encrypted, and all reads
are deciphered, transparently. Guix extends this notion by considering any
device or set of devices that are transformed in some way to create a
new device; for instance, RAID devices are obtained by assembling
several other devices, such as hard disks or partitions, into a new one that
behaves as one partition.
Los dispositivos traducidos se declaran mediante el uso de la forma
mapped-device, definida a continuación; ejemplos más adelante.
- Tipo de datos: mapped-device
Objetos de este tipo representan traducciones de dispositivo que se llevarán a cabo cuando el sistema arranque.
sourceThis is either a string specifying the name of the block device to be mapped, such as
"/dev/sda3", or a list of such strings when several devices need to be assembled for creating a new one. In case of LVM this is a string specifying name of the volume group to be mapped.targetThis string specifies the name of the resulting mapped device. For kernel mappers such as encrypted devices of type
luks-device-mapping, specifying"my-partition"leads to the creation of the"/dev/mapper/my-partition"device. For RAID devices of typeraid-device-mapping, the full device name such as"/dev/md0"needs to be given. LVM logical volumes of typelvm-device-mappingneed to be specified as"VGNAME-LVNAME".targetsThis list of strings specifies names of the resulting mapped devices in case there are several. The format is identical to target.
typeDebe ser un objeto
mapped-device-kind, que especifica cómo source se traduce a target.
- Variable Scheme: luks-device-mapping
Define el cifrado de bloques LUKS mediante el uso de la orden
cryptsetupdel paquete del mismo nombre. Depende del módulodm-cryptdel núcleo Linux.
- Variable Scheme: raid-device-mapping
Define un dispositivo RAID, el cual se ensambla mediante el uso de la orden
mdadmdel paquete del mismo nombre. Requiere la carga del módulo del núcleo Linux para el nivel RAID apropiado, comoraid456para RAID-4, RAID-5 o RAID-6, oraid10para RAID-10.
- Scheme Variable: lvm-device-mapping
This defines one or more logical volumes for the Linux Logical Volume Manager (LVM). The volume group is activated by the
vgchangecommand from thelvm2package.
El siguiente ejemplo especifica una traducción de /dev/sda3 a
/dev/mapper/home mediante el uso de LUKS—la
configuración de claves
unificada de Linux, un mecanismo estándar para cifrado de disco. El
dispositivo /dev/mapper/home puede usarse entonces como el campo
device de una declaración file-system (see Sistemas de archivos).
(mapped-device
(source "/dev/sda3")
(target "home")
(type luks-device-mapping))
De manera alternativa, para independizarse de la numeración de dispositivos, puede obtenerse el UUID LUKS (identificador único) del dispositivo fuente con una orden así:
cryptsetup luksUUID /dev/sda3
y usarlo como sigue:
(mapped-device
(source (uuid "cb67fc72-0d54-4c88-9d4b-b225f30b0f44"))
(target "home")
(type luks-device-mapping))
It is also desirable to encrypt swap space, since swap space may contain sensitive data. One way to accomplish that is to use a swap file in a file system on a device mapped via LUKS encryption. In this way, the swap file is encrypted because the entire device is encrypted. See Swap Space, or See Disk Partitioning, for an example.
Un dispositivo RAID formado por las particiones /dev/sda1 y /dev/sdb1 puede declararse como se muestra a continuación:
(mapped-device
(source (list "/dev/sda1" "/dev/sdb1"))
(target "/dev/md0")
(type raid-device-mapping))
El dispositivo /dev/md0 puede usarse entonces como el campo
device de una declaración file-system (see Sistemas de archivos). Fíjese que no necesita proporcionar el nivel RAID; se selecciona
durante la creación inicial y formato del dispositivo RAID y después se
determina automáticamente.
LVM logical volumes “alpha” and “beta” from volume group “vg0” can be declared as follows:
(mapped-device
(source "vg0")
(targets (list "vg0-alpha" "vg0-beta"))
(type lvm-device-mapping))
Devices /dev/mapper/vg0-alpha and /dev/mapper/vg0-beta can
then be used as the device of a file-system declaration
(see Sistemas de archivos).
Next: Cuentas de usuaria, Previous: Dispositivos traducidos, Up: Configuración del sistema [Contents][Index]
12.5 Swap Space
Swap space, as it is commonly called, is a disk area specifically designated for paging: the process in charge of memory management (the Linux kernel or Hurd’s default pager) can decide that some memory pages stored in RAM which belong to a running program but are unused should be stored on disk instead. It unloads those from the RAM, freeing up precious fast memory, and writes them to the swap space. If the program tries to access that very page, the memory management process loads it back into memory for the program to use.
A common misconception about swap is that it is only useful when small amounts of RAM are available to the system. However, it should be noted that kernels often use all available RAM for disk access caching to make I/O faster, and thus paging out unused portions of program memory will expand the RAM available for such caching.
For a more detailed description of how memory is managed from the viewpoint of a monolithic kernel, See Memory Concepts in The GNU C Library Reference Manual.
The Linux kernel has support for swap partitions and swap files: the former uses a whole disk partition for paging, whereas the second uses a file on a file system for that (the file system driver needs to support it). On a comparable setup, both have the same performance, so one should consider ease of use when deciding between them. Partitions are “simpler” and do not need file system support, but need to be allocated at disk formatting time (logical volumes notwithstanding), whereas files can be allocated and deallocated at any time.
Note that swap space is not zeroed on shutdown, so sensitive data (such as passwords) may linger on it if it was paged out. As such, you should consider having your swap reside on an encrypted device (see Dispositivos traducidos).
- Data Type: swap-space
Objects of this type represent swap spaces. They contain the following members:
targetThe device or file to use, either a UUID, a
file-system-labelor a string, as in the definition of afile-system(see Sistemas de archivos).dependencies(predeterminadas:'())A list of
file-systemormapped-deviceobjects, upon which the availability of the space depends. Note that just like forfile-systemobjects, dependencies which are needed for boot and mounted in early userspace are not managed by the Shepherd, and so automatically filtered out for you.priority(default:#f)Only supported by the Linux kernel. Either
#fto disable swap priority, or an integer between 0 and 32767. The kernel will first use swap spaces of higher priority when paging, and use same priority spaces on a round-robin basis. The kernel will use swap spaces without a set priority after prioritized spaces, and in the order that they appeared in (not round-robin).discard?(default:#f)Only supported by the Linux kernel. When true, the kernel will notify the disk controller of discarded pages, for example with the TRIM operation on Solid State Drives.
Here are some examples:
(swap-space (target (uuid "4dab5feb-d176-45de-b287-9b0a6e4c01cb")))
Use the swap partition with the given UUID. You can learn the UUID of a
Linux swap partition by running swaplabel device, where
device is the /dev file name of that partition.
(swap-space
(target (file-system-label "swap"))
(dependencies mapped-devices))
Use the partition with label swap, which can be found after all the
mapped-devices mapped devices have been opened. Again, the
swaplabel command allows you to view and change the label of a
Linux swap partition.
Here’s a more involved example with the corresponding file-systems
part of an operating-system declaration.
(file-systems (list (file-system (device (file-system-label "root")) (mount-point "/") (type "ext4")) (file-system (device (file-system-label "btrfs")) (mount-point "/btrfs") (type "btrfs")))) (swap-devices (list (swap-space (target "/btrfs/swapfile") (dependencies (filter (file-system-mount-point-predicate "/btrfs") file-systems)))))
Use the file /btrfs/swapfile as swap space, which depends on the file system mounted at /btrfs. Note how we use Guile’s filter to select the file system in an elegant fashion!
Next: Distribución de teclado, Previous: Swap Space, Up: Configuración del sistema [Contents][Index]
12.6 Cuentas de usuaria
Los grupos y cuentas de usuaria se gestionan completamente a través de la
declaración operating-system. Se especifican con las formas
user-account y user-group:
(user-account
(name "alicia")
(group "users")
(supplementary-groups '("wheel" ;permite usar sudo, etc.
"audio" ;tarjeta de sonido
"video" ;dispositivos audivisuales como cámaras
"cdrom")) ;el veterano CD-ROM
(comment "hermana de Roberto"))
Esta es una cuenta que usa un shell diferente y un directorio personalizado (el predeterminado sería "/home/rober"):
(user-account
(name "rober")
(group "users")
(comment "hermano de Alicia")
(shell (file-append zsh "/bin/zsh"))
(home-directory "/home/roberto"))
Durante el arranque o tras la finalización de guix system
reconfigure, el sistema se asegura de que únicamente las cuentas de usuaria
y grupos especificados en la declaración operating-system existen, y
con las propiedades especificadas. Por tanto, la creación o modificación de
cuentas o grupos realizadas directamente invocando órdenes como
useradd se pierden al reconfigurar o reiniciar el sistema. Esto
asegura que el sistema permanece exactamente como se declaró.
- Tipo de datos: user-account
Objetos de este tipo representan cuentas de usuaria. Los siguientes miembros pueden ser especificados:
nameEl nombre de la cuenta de usuaria.
group¶Este es el nombre (una cadena) o identificador (un número) del grupo de usuarias al que esta cuenta pertenece.
supplementary-groups(predeterminados:'())Opcionalmente, esto puede definirse como una lista de nombres de grupo a los que esta cuenta pertenece.
uid(predeterminado:#f)Este es el ID de usuaria para esta cuenta (un número), o
#f. En el último caso, un número es seleccionado automáticamente por el sistema cuando la cuenta es creada.comment(predeterminado:"")Un comentario sobre la cuenta, como el nombre completo de la propietaria.
Note that, for non-system accounts, users are free to change their real name as it appears in /etc/passwd using the
chfncommand. When they do, their choice prevails over the system administrator’s choice; reconfiguring does not change their name.home-directoryEste es el nombre del directorio de usuaria de la cuenta.
create-home-directory?(predeterminado:#t)Indica si el directorio de usuaria de esta cuenta debe ser creado si no existe todavía.
shell(predeterminado: Bash)Esto es una expresión-G denotando el nombre de archivo de un programa que será usado como shell (see Expresiones-G). Por ejemplo, podría hacer referencia al ejecutable de Bash de este modo:
(file-append bash "/bin/bash")... y al ejecutable de Zsh de este otro:
(file-append zsh "/bin/zsh")system?(predeterminado:#f)Este valor lógico indica si la cuenta es una cuenta “del sistema”. Las cuentas del sistema se tratan a veces de forma especial; por ejemplo, los gestores gráficos de inicio no las enumeran.
password(predeterminada:#f)Normalmente debería dejar este campo a
#f, inicializar la contraseña de usuaria comorootcon la ordenpasswd, y entonces dejar a las usuarias cambiarla conpasswd. Las contraseñas establecidas conpasswdson, por supuesto, preservadas entre reinicio y reinicio, y entre reconfiguraciones.Si usted realmente quiere tener una contraseña prefijada para una cuenta, entonces este campo debe contener la contraseña cifrada, como una cadena. Puede usar el procedimiento
cryptpara este fin:(user-account (name "carlos") (group "users") ;; Especifica una contraseña inicial mediante un hash SHA-512. (password (crypt "ContraseñaInicial!" "$6$abc")))Nota: El hash de esta contraseña inicial estará disponible en un archivo en /gnu/store, legible por todas las usuarias, por lo que este método debe usarse con precaución.
See Passphrase Storage in The GNU C Library Reference Manual, para más información sobre el cifrado de contraseñas, y Encryption in GNU Guile Reference Manual, para información sobre el procedimiento de Guile
crypt.
Las declaraciones de grupos incluso son más simples:
(user-group (name "estudiantes"))
- Tipo de datos: user-group
Este tipo es para grupos de usuarias. Hay únicamente unos pocos campos:
nameEl nombre del grupo.
id(predeterminado:#f)El identificador del grupo (un número). Si es
#f, un nuevo número es reservado automáticamente cuando se crea el grupo.system?(predeterminado:#f)Este valor booleano indica si el grupo es un grupo “del sistema”. Los grupos del sistema tienen identificadores numéricos bajos.
password(predeterminada:#f)¿Qué? ¿Los grupos de usuarias pueden tener una contraseña? Bueno, aparentemente sí. A menos que sea
#f, este campo especifica la contraseña del grupo.
Por conveniencia, una variable contiene una lista con todos los grupos de usuarias básicos que se puede esperar:
- Variable Scheme: %base-groups
Esta es la lista de grupos de usuarias básicos que las usuarias y/o los paquetes esperan que estén presentes en el sistema. Esto incluye grupos como “root”, “wheel” y “users”, así como grupos usados para controlar el acceso a dispositivos específicos como “audio”, “disk” y “cdrom”.
- Variable Scheme: %base-user-accounts
Esta es la lista de cuentas de usuaria básicas que los programas pueden esperar encontrar en un sistema GNU/Linux, como la cuenta “nobody”.
Fíjese que la cuenta de “root” no se incluye aquí. Es un caso especial y se añade automáticamente esté o no especificada.
Next: Localizaciones, Previous: Cuentas de usuaria, Up: Configuración del sistema [Contents][Index]
12.7 Distribución de teclado
Para especificar qué hace cada tecla de su teclado, necesita decirle al sistema operativo qué distribución de teclado desea usar. La predeterminada, cuando no se especifica ninguna, es la distribución QWERTY de 105 teclas para PC de teclado inglés estadounidense. No obstante, las personas germano-parlantes habitualmente prefieren la distribución QWERTZ alemana, las franco-parlantes desearán la distribución AZERTY, etcétera; las hackers pueden preferir Dvorak o bépo, y pueden incluso desear personalizar más aún el efecto de determinadas teclas. Esta sección explica cómo hacerlo.
Hay tres componentes que desearán conocer la distribución de su teclado:
- El cargador de arranque puede desear conocer cual es la distribución
de teclado que desea usar (see
keyboard-layout). Esto es útil si desea, por ejemplo, asegurarse de que puede introducir la contraseña de cifrado de su partición raíz usando la distribución correcta. - El núcleo del sistema operativo, Linux, la necesitará de manera que
la consola se configure de manera adecuada (see
keyboard-layout). - El servidor gráfico, habitualmente Xorg, también tiene su propia idea
de distribución de teclado (see
keyboard-layout).
Guix le permite configurar las tres distribuciones por separado pero, afortunadamente, también le permite compartir la misma distribución de teclado para los tres componentes.
Las distribuciones de teclado se representan mediante registros creados con
el procedimiento keyboard-layout de (gnu system keyboard). A
imagen de la extensión de teclado de X (XKB), cada distribución tiene cuatro
atributos: un nombre (habitualmente un código de idioma como “fi” para
finés o “jp” para japonés), un nombre opcional de variante, un nombre
opcional de modelo de teclado y una lista, puede que vacía, de opciones
adicionales. En la mayor parte de los casos el nombre de la distribución es
lo único que le interesará.
- Procedimiento Scheme: keyboard-layout nombre [variante] [#:model] [#:options '()]
Devuelve una distribución de teclado para el nombre y la variante que se proporcionan.
nombre debe ser una cadena como
"fr"; variante debe ser una cadena como"bepo"o"nodeadkeys". Véase el paquetexkeyboard-configpara las opciones válidas.
Estos son algunos ejemplos:
;; La distribución QWERTZ alemana. Se asume un modelo de ;; teclado "pc105" estándar. (keyboard-layout "de") ;; La variante bépo de la distribución francesa. (keyboard-layout "fr" "bepo") ;; La distribución de teclado catalana. (keyboard-layout "es" "cat") ;; Distribución de teclado árabe con "Alt-Shift" para cambiar ;; a la distribución de teclado de EEUU. (keyboard-layout "ar,us" #:options '("grp:alt_shift_toggle")) ;; La distribución de teclado de latinoamérica. Además, ;; la tecla "Bloq Mayús" se usa como una tecla "Ctrl" ;; adicional, y la tecla "Menú" se usa como una tecla ;; "Componer/Compose" para introducir letras acentuadas. (keyboard-layout "latam" #:options '("ctrl:nocaps" "compose:menu")) ;; La distribución rusa para un teclado ThinkPad. (keyboard-layout "ru" #:model "thinkpad") ;; La distribución estadounidense internacional, la cual es ;; la distribución estadounidense junto a teclas muertas para ;; introducir caracteres acentuados. Esta es para un teclado ;; Apple MackBook. (keyboard-layout "us" "intl" #:model "macbook78")
Véase el directorio share/X11/xkb del paquete xkeyboard-config
para una lista completa de implementaciones de distribuciones, variantes y
modelos.
Digamos que desea que su sistema use la distribución de teclado turca a lo largo de todo su sistema—cargador de arranque, consola y Xorg. Así es como sería su configuración del sistema:
;; Usando la distribución turca para el cargador de ;; arranque, la consola y Xorg. (operating-system ;; ... (keyboard-layout (keyboard-layout "tr")) ;for the console (bootloader (bootloader-configuration (bootloader grub-efi-bootloader) (targets '("/boot/efi")) (keyboard-layout keyboard-layout))) ;for GRUB (services (cons (set-xorg-configuration (xorg-configuration ;for Xorg (keyboard-layout keyboard-layout))) %desktop-services)))
En el ejemplo previo, para GRUB y para Xorg, simplemente hemos hecho
referencia al campo keyboard-layout definido previamente, pero
también podíamos haber hecho referencia a una distribución diferente. El
procedimiento set-xorg-configuration comunica la configuración de
Xorg deseada al gestor gráfico de ingreso en el sistema, GDM por omisión.
Hemos tratado cómo especificar la distribución predeterminada del teclado de su sistema cuando arranca, pero también la puede modificar en tiempo de ejecución:
- Si usa GNOME, su panel de configuración tiene una entrada de “Región e Idioma” donde puede seleccionar una o más distribuciones de teclado.
- En Xorg, la orden
setxkbmap(del paquete con el mismo nombre) le permite cambiar la distribución en uso actualmente. Por ejemplo, así es como cambiaría a la distribución Dvorak estadounidense:setxkbmap us dvorak
- La orden
loadkeyscambia la distribución de teclado en efecto en la consola Linux. No obstante, tenga en cuenta queloadkeysno usa la categorización de distribuciones de XKB descrita previamente. La orden a continuación carga la distribución francesa bépo:loadkeys fr-bepo
Next: Servicios, Previous: Distribución de teclado, Up: Configuración del sistema [Contents][Index]
12.8 Localizaciones
Una localización define convenciones culturales para una lengua y
región del mundo particular (see Locales in The GNU C Library
Reference Manual). Cada localización tiene un nombre que típicamente tiene
la forma de lengua_territorio.codificación—por
ejemplo, fr_LU.utf8 designa la localización para la lengua francesa,
con las convenciones culturales de Luxemburgo, usando la codificación UTF-8.
Normalmente deseará especificar la localización predeterminada para la
máquina usando el campo locale de la declaración
operating-system (see locale).
La localización seleccionada es automáticamente añadida a las
definiciones de localización conocidas en el sistema si es necesario,
con su codificación inferida de su nombre—por ejemplo, se asume que
bo_CN.utf8 usa la codificación UTF-8. Definiciones de
localización adicionales pueden ser especificadas en el campo
locale-definitions de operating-system—esto es util, por
ejemplo, si la codificación no puede ser inferida del nombre de la
localización. El conjunto predeterminado de definiciones de localización
incluye algunas localizaciones ampliamente usadas, pero no todas las
disponibles, para ahorrar espacio.
Por ejemplo, para añadir la localización del frisio del norte para Alemania, el valor de dicho campo puede ser:
(cons (locale-definition
(name "fy_DE.utf8") (source "fy_DE"))
%default-locale-definitions)
De mismo modo, para ahorrar espacio, se puede desear que
locale-definitions contenga únicamente las localizaciones que son
realmente usadas, como en:
(list (locale-definition
(name "ja_JP.eucjp") (source "ja_JP")
(charset "EUC-JP")))
Las definiciones de localización compiladas están disponibles en
/run/current-system/locale/X.Y, donde X.Y es la versión de
libc, que es la ruta donde la GNU libc contenida en Guix buscará los
datos de localización. Esto puede ser sobreescrito usando la variable de
entorno LOCPATH (see LOCPATH and locale
packages).
La forma locale-definition es proporcionada por el módulo (gnu
system locale). Los detalles se proporcionan a continuación.
- Tipo de datos: locale-definition
Este es el tipo de datos de una definición de localización.
nameEl nombre de la localización. See Locale Names in The GNU C Library Reference Manual, para más información sobre nombres de localizaciones.
sourceEl nombre de la fuente para dicha localización. Habitualmente es la parte
idioma_territoriodel nombre de localización.charset(predeterminado:"UTF-8")La “codificación de caracteres” o “conjunto de caracteres” para dicha localización, como lo define IANA.
- Variable Scheme: %default-locale-definitions
Una lista de localizaciones UTF-8 usadas de forma común, usada como valor predeterminado del campo
locale-definitionsen las declaracionesoperating-system.Estas definiciones de localizaciones usan la codificación normalizada para el fragmento tras el punto en el nombre (see normalized codeset in The GNU C Library Reference Manual). Por lo que por ejemplo es válido
uk_UA.utf8pero no, digamos,uk_UA.UTF-8.
12.8.1 Consideraciones sobre la compatibilidad de datos de localización
Las declaraciones operating-system proporcionan un campo
locale-libcs para especificar los paquetes GNU libc que se
usarán para compilar las declaraciones de localizaciones
(see Referencia de operating-system). “¿Por qué debo preocuparme?”, puede
preguntarse. Bueno, sucede que el formato binario de los datos de
localización es ocasionalmente incompatible de una versión de libc a otra.
Por ejemplo, un programa enlazado con la versión 2.21 de libc no puede leer
datos de localización producidos con libc 2.22; peor aún, ese programa
aborta en vez de simplemente ignorar los datos de localización
incompatibles35. De manera similar, un programa enlazado con libc 2.22 puede
leer la mayor parte, pero no todo, de los datos de localización de libc 2.21
(específicamente, los datos LC_COLLATE son incompatibles); por tanto
las llamadas a setlocale pueden fallar, pero los programas no
abortarán.
El “problema” con Guix es que las usuarias tienen mucha libertad: pueden elegir cuando e incluso si actualizar el software en sus perfiles, y pueden estar usando una versión de libc diferente de la que la administradora del sistema usó para construir los datos de localización comunes a todo el sistema.
Por suerte, las usuarias sin privilegios también pueden instalar sus propios
datos de localización y definir GUIX_LOCPATH de manera adecuada
(see GUIX_LOCPATH y paquetes de
localizaciones).
No obstante, es mejor si los datos de localización globales del sistema en
/run/current-system/locale se construyen para todas las versiones de
libc realmente en uso en el sistema, de manera que todos los programas
puedan acceder a ellos—esto es especialmente crucial en un sistema
multiusuaria. Para hacerlo, la administradora puede especificar varios
paquetes libc en el campo locale-libcs de operating-system:
(use-package-modules base) (operating-system ;; … (locale-libcs (list glibc-2.21 (canonical-package glibc))))
Este ejemplo llevaría a un sistema que contiene definiciones de localización tanto para libc 2.21 como para la versión actual de libc en /run/current-system/locale.
Next: Programas con setuid, Previous: Localizaciones, Up: Configuración del sistema [Contents][Index]
12.9 Servicios
Una parte importante de la preparación de una declaración
operating-system es listar los servicios del sistema y su
configuración (see Uso de la configuración del sistema). Los servicios del
sistema típicamente son daemon lanzados cuando el sistema arrancha, u otras
acciones necesarias en ese momento—por ejemplo, configurar el acceso de
red.
Guix tiene una definición amplia de “servicio” (see Composición de servicios), pero muchos servicios se gestionan por GNU Shepherd
(see Servicios de Shepherd). En un sistema en ejecución, la orden
herd le permite enumerar los servicios disponibles, mostrar su
estado, arrancarlos y pararlos, o realizar otras acciones específicas
(see Jump Start in The GNU Shepherd Manual). Por ejemplo:
# herd status
La orden previa, ejecutada como root, enumera los servicios
actualmente definidos. La orden herd doc muestra una sinopsis del
servicio proporcionado y sus acciones asociadas:
# herd doc nscd Run libc's name service cache daemon (nscd). # herd doc nscd action invalidate invalidate: Invalidate the given cache--e.g., 'hosts' for host name lookups.
Las ordenes internas start, stop y restart
tienen el efecto de arrancar, parar y reiniciar el servicio,
respectivamente. Por ejemplo, las siguientes órdenes paran el servicio nscd
y reinician el servidor gráfico Xorg:
# herd stop nscd Service nscd has been stopped. # herd restart xorg-server Service xorg-server has been stopped. Service xorg-server has been started.
For some services, herd configuration returns the name of the
service’s configuration file, which can be handy to inspect its
configuration:
# herd configuration sshd /gnu/store/…-sshd_config
Las siguientes secciones documentan los servicios disponibles, comenzando
con los servicios básicos, que pueden ser usados en una declaración
operating-system.
- Servicios base
- Ejecución de tareas programadas
- Rotación del registro de mensajes
- Networking Setup
- Servicios de red
- Actualizaciones no-atendidas
- Sistema X Window
- Servicios de impresión
- Servicios de escritorio
- Servicios de sonido
- Servicios de bases de datos
- Servicios de correo
- Servicios de mensajería
- Servicios de telefonía
- File-Sharing Services
- Servicios de monitorización
- Servicios Kerberos
- Servicios LDAP
- Servicios Web
- Servicios de certificados
- Servicios DNS
- VNC Services
- Servicios VPN
- Sistema de archivos en red
- Samba Services
- Integración continua
- Servicios de gestión de energía
- Servicios de audio
- Servicios de virtualización
- Servicios de control de versiones
- Servicios de juegos
- Servicio PAM Mount
- Servicios de Guix
- Servicios de Linux
- Servicios de Hurd
- Servicios misceláneos
Next: Ejecución de tareas programadas, Up: Servicios [Contents][Index]
12.9.1 Servicios base
El módulo (gnu services base) proporciona definiciones para los
servicios básicos que se esperan en el sistema. Los servicios exportados por
este módulo se enumeran a continuación.
- Variable Scheme: %base-services
Esta variable contiene una lista de servicios básicos (see Tipos de servicios y servicios, para más información sobre los objetos servicio) que se pueden esperar en el sistema: un servicio de ingreso al sistema (mingetty) en cada tty, syslogd, el daemon de la caché del servicio de nombres (nscd), el gestor de dispositivos udev, y más.
Este es el valor predeterminado del campo
servicesde las declaracionesoperating-system. De manera habitual, cuando se personaliza el sistema, es deseable agregar servicios a%base-services, de esta forma:
- Variable Scheme: special-files-service-type
El servicio que establece “archivos especiales” como /bin/sh; una instancia suya es parte de
%base-services.El valor asociado con servicios
special-file-service-typedebe ser una lista de tuplas donde el primer elemento es el “archivo especial” y el segundo elemento es su destino. El valor predeterminado es:`(("/bin/sh" ,(file-append bash "/bin/sh")) ("/usr/bin/env" ,(file-append coreutils "/bin/env")))
If you want to add, say,
/bin/bashto your system, you can change it to:`(("/bin/sh" ,(file-append bash "/bin/sh")) ("/usr/bin/env" ,(file-append coreutils "/bin/env")) ("/bin/bash" ,(file-append bash "/bin/bash")))
Ya que es parte de
%base-services, puede usarmodify-servicespara personalizar el conjunto de archivos especiales (seemodify-services). Pero una forma simple de añadir un archivo especial es usar el procedimientoextra-special-file(véase a continuación).
- Procedimiento Scheme: extra-special-file archivo destino
Usa destino como el “archivo especial” archivo.
Por ejemplo, la adición de las siguientes líneas al campo
servicesde su declaración de sistema operativo genera /usr/bin/env como un enlace simbólico:(extra-special-file "/usr/bin/env" (file-append coreutils "/bin/env"))
- Procedimiento Scheme: host-name-service nombre
Devuelve un servicio que establece el nombre de máquina a nombre.
- Variable Scheme: console-font-service-type
Instala las tipografías proporcionadas en las consolas virtuales (tty) especificados (las tipografías se asocian a cada consola virtual con el núcleo Linux). El valor de este servicio es una lista de pares tty/tipografía. La tipografía puede ser el nombre de alguna de las proporcionadas por el paquete
kbdo cualquier parámetro válido para la ordensetfont, como en este ejemplo:`(("tty1" . "LatGrkCyr-8x16") ("tty2" . ,(file-append font-tamzen "/share/kbd/consolefonts/TamzenForPowerline10x20.psf")) ("tty3" . ,(file-append font-terminus "/share/consolefonts/ter-132n"))) ; para HDPI
- Procedimiento Scheme: login-service config
Devuelve un servicio para ejecutar el ingreso al sistema de acuerdo con config, un objeto
<login-configuration>, que especifica el mensaje del día, entre otras cosas.
- Tipo de datos: login-configuration
Este es el tipo de datos que representa la configuración del ingreso al sistema.
motd¶Un objeto tipo-archivo que contiene el “mensaje del día”.
allow-empty-passwords?(predeterminado:#t)Permite contraseñas vacías por defecto para que las primeras usuarias puedan ingresar en el sistema cuando la cuenta de “root” está recién creada.
- Procedimiento Scheme: mingetty-service config
Devuelve un servicio para ejecutar mingetty de acuerdo con config, un objeto
<mingetty-configuration>, que especifica el tty a ejecutar entre otras cosas.
- Tipo de datos: mingetty-configuration
Este es el tipo de datos que representa la configuración de Mingetty, el cual proporciona la implementación predeterminada de ingreso al sistema en las consolas virtuales.
ttyEl nombre de la consola en la que se ejecuta este Mingetty—por ejemplo,
"tty1".auto-login(predeterminado:#f)Cuando sea verdadero, este campo debe ser una cadena que denote el nombre de usuaria bajo el cual el sistema ingresa automáticamente. Cuando es
#f, se deben proporcionar un nombre de usuaria y una contraseña para ingresar en el sistema.login-program(predeterminado:#f)Debe ser
#f, en cuyo caso se usa el programa predeterminado de ingreso al sistema (loginde las herramientas Shadow), o una expresión-G que determine el nombre del programa de ingreso al sistema.login-pause?(predeterminado:#f)Cuando es
#ten conjunción con auto-login, la usuaria deberá presionar una tecla para lanzar el shell de ingreso al sistema.clear-on-logout?(default:#t)When set to
#t, the screen will be cleared after logout.mingetty(predeterminado: mingetty)El paquete Mingetty usado.
- Procedure Scheme: agetty-service config
Devuelve un servicio para ejecutar agetty de acuerdo con config, un objeto
<agetty-configuration>, que especifica el tty a ejecutar entre otras cosas.
- Tipo de datos: agetty-configuration
Este es el tipo de datos que representa la configuración de agetty, que implementa el ingreso al sistema en las consolas virtuales y serie. Véase la página de manual
agetty(8)para más información.ttyEl nombre de la consola en la que se ejecuta este agetty, como una cadena—por ejemplo,
"ttyS0". Este parámetro es opcional, su valor predeterminado es un puerto serie razonable usado por el núcleo Linux.Para ello, si hay un valor para una opción
agetty.ttyen la línea de órdenes del núcleo, agetty extraerá el nombre del dispositivo del puerto serie de allí y usará dicho valor.Si no y hay un valor para la opción
consolecon un tty en la línea de órdenes de Linux, agetty extraerá el nombre del dispositivo del puerto serie de allí y usará dicho valor.En ambos casos, agetty dejará el resto de configuración de dispositivos serie (tasa de transmisión, etc.) sin modificar—con la esperanza de que Linux haya proporcionado ya los valores correctos.
baud-rate(predeterminado:#f)Una cadena que contenga una lista separada por comas de una o más tasas de transmisión, en orden descendiente.
term(predeterminado:#f)Una cadena que contiene el valor usado para la variable de entorno
TERM.eight-bits?(predeterminado:#f)En caso de ser
#t, se asume que el tty permite el paso de 8 bits, y la detección de paridad está desactivada.auto-login(predeterminado:#f)Cuando se proporciona un nombre de ingreso al sistema, como una cadena, la usuaria especificada ingresará automáticamente sin solicitar su nombre de ingreso ni su contraseña.
no-reset?(predeterminado:#f)En caso de ser
#t, no reinicia los modos de control del terminal (cflags).host(predeterminado:#f)Acepta una cadena que contenga el “nombre_de_máquina_de_ingreso”, que será escrito en el archivo /var/run/utmpx.
remote?(predeterminado:#f)Cuando se fija a
#ten conjunción con host, se añadirá una opción-r"fakehost" a la línea de órdenes del programa de ingreso al sistema especificado en login-program.flow-control?(predeterminado:#f)Cuando es
#t, activa el control de flujo hardware (RTS/CTS).no-issue?(predeterminado:#f)Cuando es
#t, el contenido del archivo /etc/issue no se mostrará antes de presentar el mensaje de ingreso al sistema.init-string(predeterminada:#f)Esto acepta una cadena que se enviará al tty o módem antes de mandar nada más. Puede usarse para inicializar un modem.
no-clear?(predeterminado:#f)Cuando es
#t, agetty no limpiará la pantalla antes de mostrar el mensaje de ingreso al sistema.login-program(predeterminado: (file-append shadow "/bin/login"))Esto debe ser o bien una expresión-g que denote el nombre del programa de ingreso al sistema, o no debe proporcionarse, en cuyo caso el valor predeterminado es
logindel conjunto de herramientas Shadow.local-line(predeterminado:#f)Control the CLOCAL line flag. This accepts one of three symbols as arguments,
'auto,'always, or'never. If#f, the default value chosen by agetty is'auto.extract-baud?(predeterminado:#f)Cuando es
#t, instruye a agetty para extraer la tasa de transmisión de los mensajes de estado producidos por ciertos tipos de módem.skip-login?(predeterminado:#f)Cuando es
#t, no solicita el nombre de la usuaria para el ingreso al sistema. Puede usarse con el campo login-program para usar sistemas de ingreso no estándar.no-newline?(predeterminado:#f)Cuando es
#t, no imprime una nueva línea antes de imprimir el archivo /etc/issue.login-options(predeterminadas:#f)Esta opción acepta una cadena que contenga opciones para proporcionar al programa de ingreso al sistema. Cuando se use con login-program, sea consciente de que una usuaria con malas intenciones podría intentar introducir un nombre que contuviese opciones embebidas que serían procesadas por el programa de ingreso.
login-pause(predeterminada:#f)Cuando es
#t, espera la pulsación de cualquier tecla antes de mostrar el mensaje de ingreso al sistema. Esto puede usarse en conjunción con auto-login para ahorrar memoria lanzando cada shell cuando sea necesario.chroot(predeterminado:#f)Cambia la raíz al directorio especificado. Esta opción acepta una ruta de directorio como una cadena.
hangup?(predeterminado:#f)Usa la llamada del sistema Linux
vhanguppara colgar de forma virtual el terminal especificado.keep-baud?(predeterminado:#f)Cuando es
#t, prueba a mantener la tasa de transmisión existente. Las tasas de transmisión de baud-rate se usan cuando agetty recibe un carácter BREAK.timeout(predeterminado:#f)Cuando sea un valor entero, termina si no se pudo leer ningún nombre de usuaria en timeout segundos.
detect-case?(predeterminado:#f)Cuando es
#t, activa la detección de terminales únicamente con mayúsculas. ESta configuración detectará un nombre de ingreso que contenga únicamente letras mayúsculas como un indicativo de un terminal con letras únicamente mayúsculas y activará las conversiones de mayúscula a minúscula. Tenga en cuenta que esto no permitirá caracteres Unicode.wait-cr?(predeterminado:#f)Cuando es
#t, espera hasta que la usuaria o el modem envíen un carácter de retorno de carro o de salto de línea antes de mostrar /etc/issue o el mensaje de ingreso. Se usa de forma típica junto a la opción init-string.no-hints?(predeterminado:#f)Cuando es
#t, no imprime avisos sobre el bloqueo numérico, las mayúsculas o el bloqueo del desplazamiento.no-hostname?(predeterminado:#f)El nombre de la máquina se imprime de forma predeterminada. Cuando esta opción es
#t, no se mostrará ningún nombre de máquina.long-hostname?(predeterminado:#f)El nombre de máquina se imprime de forma predeterminada únicamente hasta el primer punto. Cuando esta opción es
#t, se muestra el nombre completamente cualificado de la máquina mostrado porgethostnameogetaddrinfo.erase-characters(predeterminado:#f)Esta opción acepta una cadena de caracteres adicionales que deben interpretarse como borrado del carácter anterior cuando la usuaria introduce su nombre de ingreso.
kill-characters(predeterminado:#f)Esta opción acepta una cadena de que debe ser interpretada como “ignora todos los caracteres anteriores” (también llamado carácter “kill”) cuando la usuaria introduce su nombre de ingreso.
chdir(predeterminado:#f)Esta opción acepta, como una cadena, una ruta de directorio que a la que se cambiará antes del ingreso al sistema.
delay(predeterminado:#f)Esta opción acepta, como un entero, el número de segundos a esperar antes de abrir el tty y mostrar el mensaje de ingreso al sistema.
nice(predeterminado:#f)Esta opción acepta, como un entero, el valor “nice” con el que se ejecutará el programa
login.extra-options(predeterminadas:'())Esta opción proporciona una “trampilla de escape” para que la usuaria proporcione parámetros de línea de órdenes adicionales a
agettycomo una lista de cadenas.shepherd-requirement(default:'())The option can be used to provides extra shepherd requirements (for example
'syslogd) to the respective'term-* shepherd service.
- Procedimiento Scheme: kmscon-service-type config
Devuelve un servicio que ejecuta kmscon de acuerdo a config, un objeto
<kmscon-configuration>, que especifica el tty sobre el que se ejecutará, entre otras cosas.
- Tipo de datos: kmscon-configuration
Este es el tipo de datos que representa la configuración de Kmscon, que implementa el ingreso al sistema en consolas virtuales.
virtual-terminalEl nombre de la consola en la que se ejecuta este Kmscon—por ejemplo,
"tty1".login-program(predeterminado:#~(string-append #$shadow "/bin/login"))A gexp denoting the name of the log-in program. The default log-in program is
loginfrom the Shadow tool suite.login-arguments(predeterminados:'("-p"))Una lista de parámetros para proporcionar a
login.auto-login(predeterminado:#f)Cuando se proporciona un nombre de ingreso al sistema, como una cadena, la usuaria especificada ingresará automáticamente sin solicitar su nombre de ingreso ni su contraseña.
hardware-acceleration?(predeterminado: #f)Determina si se usará aceleración hardware.
font-engine(default:"pango")Font engine used in Kmscon.
font-size(default:12)Font size used in Kmscon.
keyboard-layout(predeterminada:#f)If this is
#f, Kmscon uses the default keyboard layout—usually US English (“qwerty”) for a 105-key PC keyboard.Otherwise this must be a
keyboard-layoutobject specifying the keyboard layout. See Distribución de teclado, for more information on how to specify the keyboard layout.kmscon(predeterminado: kmscon)El paquete Kmscon usado.
- Procedimiento Scheme: nscd-service [configuración] [#:glibc glibc] [#:name-services '()]
Devuelve un servicio que ejecuta el daemon de la caché del servicio de nombres (nscd) con la configuración proporcionada—un objeto
<nscd-configuration>. See Selector de servicios de nombres, para un ejemplo.Por conveniencia, el servicio ncsd de Shepherd proporciona las siguientes acciones:
invalidate¶-
Esto invalida la caché dada. Por ejemplo, ejecutar:
herd invalidate nscd hosts
invalida la caché de búsqueda de nombres de máquinas de nscd.
statisticsEjecutar
herd statistics nscdmuestra información del uso nscd y la caché.
- Variable Scheme: %nscd-default-configuration
El valor del
<ncsd-configuration>predeterminado (véase a continuación) usado pornscd-service. Usa los espacios de caché definidos por%nscd-default-caches; véase a continuación.
- Tipo de datos: nscd-configuration
Este tipo de datos representa la configuración del daemon de caché del servicio de nombres (nscd).
name-services(predeterminados:'())Lista de paquetes que indican los servicios de nombres que serán visibles al nscd—por ejemplo,
(list nss-mdns).glibc(predeterminada: glibc)Paquete que denota la biblioteca C de GNU que proporciona la orden
nscd.log-file(predeterminado:"/var/log/nscd.log")Nombre del archivo de registro de nscd. Aquí es donde se almacena la salida de depuración cuando
debug-leveles estrictamente positivo.debug-level(predeterminado:0)Entero que indica el nivel de depuración. Números mayores significan que se registra más salida de depuración.
caches(predeterminado:%nscd-default-caches)Lista de objetos
<nscd-cache>que indican cosas a mantener en caché; véase a continuación.
- Tipo de datos: nscd-cache
Tipo de datos que representa una base de datos de caché de nscd y sus parámetros.
base de datosEs un símbolo que representa el nombre de la base de datos de la que se actúa como caché. Se aceptan los valores
passwd,group,hostsyservices, que designan las bases de datos NSS correspondientes (see NSS Basics in The GNU C Library Reference Manual).positive-time-to-livenegative-time-to-live(predeterminado:20)Un número que representa el número de segundos durante los que una búsqueda positiva o negativa permanece en la caché.
check-files?(predeterminado:#t)Si se comprobará en busca de actualizaciones los archivos que correspondan con database.
Por ejemplo, cuando database es
hosts, la activación de esta opción instruye a nscd para comprobar actualizaciones en /etc/hosts y tenerlas en cuenta.persistent?(predeterminada:#t)Determina si la caché debe almacenarse de manera persistente en disco.
shared?(predeterminado:#t)Determina si la caché debe compartirse entre las usuarias.
max-database-size(predeterminado: 32 MiB)Tamaño máximo en bytes de la caché de la base de datos.
- Variable Scheme: %nscd-default-caches
Lista de objetos
<nscd-cache>usados por omisión pornscd-configuration(véase en la sección previa)Activa el almacenamiento en caché persistente y agresivo de búsquedas de servicios y nombres de máquina. La última proporciona un mejor rendimiento en la búsqueda de nombres de máquina, resilencia en caso de nombres de servidor no confiables y también mejor privacidad—a menudo el resultado de las búsquedas de nombres de máquina está en la caché local, por lo que incluso ni es necesario consultar servidores de nombres externos.
- Tipo de datos: syslog-configuration
Este tipo de datos representa la configuración del daemon syslog.
syslogd(predeterminado:#~(string-append #$inetutils "/libexec/syslogd"))El daemon syslog usado.
config-file(predeterminado:%default-syslog.conf)El archivo de configuración de syslog usado.
- Procedimiento Scheme: syslog-service config
Devuelve un servicio que ejecuta el daemon de syslog de acuerdo a config.
See syslogd invocation in GNU Inetutils, para más información sobre la sintaxis del archivo de configuración.
- Variable Scheme: guix-service-type
El tipo de servicio que ejecuta el daemon de construcción,
guix-daemon(see Invocación deguix-daemon). Su valor debe ser un registroguix-configurationcomo se describe a continuación.
- Tipo de datos: guix-configuration
Este tipo de datos representa la configuración del daemon de construcción de Guix. See Invocación de
guix-daemon, para más información.guix(predeterminado: guix)El paquete Guix usado.
build-group(predeterminado:"guixbuild")El nombre del grupo de las cuentas de usuarias de construcción.
build-accounts(predeterminadas:10)Número de cuentas de usuarias de construcción a crear.
authorize-key?(predeterminado:#t) ¶Whether to authorize the substitute keys listed in
authorized-keys—by default that ofci.guix.gnu.organdbordeaux.guix.gnu.org(see Sustituciones).Cuando
authorize-key?es verdadero, /etc/guix/acl no se puede cambiar a través deguix archive --authorize. En vez de eso debe ajustarguix-configurationcomo desee y reconfigurar el sistema. Esto asegura que la configuración de su sistema operativo es auto-contenida.Nota: Cuando arranque o reconfigure a un sistema donde
authorize-key?sea verdadero, se crea una copia de seguridad del archivo /etc/guix/acl existente como /etc/guix/acl.bak si se determina que el archivo se ha modificado de manera manual. Esto facilita la migración desde versiones anteriores, en las que se permitían las modificaciones directas del archivo /etc/guix/acl.authorized-keys(predeterminadas:%default-authorized-guix-keys)The list of authorized key files for archive imports, as a list of string-valued gexps (see Invocación de
guix archive). By default, it contains that ofci.guix.gnu.organdbordeaux.guix.gnu.org(see Sustituciones). Seesubstitute-urlsbelow for an example on how to change it.use-substitutes?(predeterminado:#t)Determina si se usarán sustituciones.
substitute-urls(predeterminado:%default-substitute-urls)La lista de URLs donde se buscarán sustituciones por defecto.
Suppose you would like to fetch substitutes from
guix.example.orgin addition toci.guix.gnu.org. You will need to do two things: (1) addguix.example.orgtosubstitute-urls, and (2) authorize its signing key, having done appropriate checks (see Autorización de servidores de sustituciones). The configuration below does exactly that:(guix-configuration (substitute-urls (append (list "https://guix.example.org") %default-substitute-urls)) (authorized-keys (append (list (local-file "./guix.example.org-clave.pub")) %default-authorized-guix-keys)))Este ejemplo asume que el archivo ./guix.example.org-clave.pub contiene la clave pública que
guix.example.orgusa para firmar las sustituciones.generate-substitute-key?(default:#t)Whether to generate a substitute key pair under /etc/guix/signing-key.pub and /etc/guix/signing-key.sec if there is not already one.
This key pair is used when exporting store items, for instance with
guix publish(see Invocación deguix publish) orguix archive(see Invocación deguix archive). Generating a key pair takes a few seconds when enough entropy is available and is only done once; you might want to turn it off for instance in a virtual machine that does not need it and where the extra boot time is a problem.max-silent-time(predeterminado:0)timeout(predeterminado:0)El número de segundos de silencio y el número de segundos de actividad respectivamente, tras los cuales el proceso de construcción supera el plazo. Un valor de cero proporciona plazos ilimitados.
log-compression(default:'gzip)El tipo de compresión usado en los log de construcción—o bien
gzip, o bienbzip2onone.discover?(default:#f)Whether to discover substitute servers on the local network using mDNS and DNS-SD.
extra-options(predeterminadas:'())Lista de opciones de línea de órdenes adicionales para
guix-daemon.log-file(predeterminado:"/var/log/guix-daemon.log")Archivo al que se escriben la salida estándar y la salida estándar de error de
guix-daemon.http-proxy(predeterminado:#f)La URL de los proxy HTTP y HTTPS que se usa para la descarga de derivaciones de salida fija y sustituciones.
También es posible cambiar la pasarela del daemon en tiempo te ejecución con la acción
set-http-proxy, la cual lo reinicia:herd set-http-proxy guix-daemon http://localhost:8118
Para desactivar el uso actual de una pasarela ejecute:
herd set-http-proxy guix-daemon
tmpdir(predeterminado:#f)Una ruta de directorio donde
guix-daemonrealiza las construcciones.
- Data Type: guix-extension
-
This data type represents the parameters of the Guix build daemon that are extendable. This is the type of the object that must be used within a guix service extension. See Composición de servicios, for more information.
authorized-keys(predeterminadas:'())A list of file-like objects where each element contains a public key.
substitute-urls(default:'())A list of strings where each element is a substitute URL.
chroot-directories(default:'())A list of file-like objects or strings pointing to additional directories the build daemon can use.
- Procedimiento Scheme: udev-service [#:udev eudev #:rules
'()] Ejecuta udev, que gestiona el contenido del directorio /dev de forma dinámica. Se pueden proporcionar reglas de udev como una lista de archivos a través de la variable rules. Los procedimientos
udev-rule,udev-rules-serviceyfile->udev-rulede(gnu services base)simplifican la creación de dichos archivos de reglas.The
herd rules udevcommand, as root, returns the name of the directory containing all the active udev rules.
- Procedimiento Scheme: udev-rule [nombre-archivo contenido]
Devuelve un archivo de reglas de udev con nombre nombre-archivo que contiene las reglas definidas en el literal contenido.
En el ejemplo siguiente se define una regla para un dispositivo USB que será almacenada en el archivo 90-usb-cosa.rules. Esta regla ejecuta un script cuando se detecta un dispositivo USB con un identificador de producto dado.
(define %regla-ejemplo-udev (udev-rule "90-usb-cosa.rules" (string-append "ACTION==\"add\", SUBSYSTEM==\"usb\", " "ATTR{product}==\"Ejemplo\", " "RUN+=\"/ruta/al/ejecutable\"")))
- Procedimiento Scheme: udev-rules-service [nombre reglas] [#:groups grupos]
Devuelve un servicio que extiende
udev-service-typecon reglas yaccount-service-typecon grupos como grupos del sistema. Esto funciona creando una instancia única del tipo de servicionombre-udev-rules, del cual el servicio devuelto es una instancia.A continuación se muestra cómo se puede usar para extender
udev-service-typecon la regla%regla-ejemplo-udevdefinida previamente.(operating-system ;; … (services (cons (udev-rules-service 'usb-thing %regla-ejemplo-udev) %desktop-services)))
- Procedimiento Scheme: file->udev-rule [nombre-archivo archivo]
Devuelve un archivo de udev con nombre nombre-archivo que contiene las reglas definidas en archivo, un objeto tipo-archivo.
El ejemplo siguiente muestra cómo podemos usar un archivo de reglas existente.
(use-modules (guix download) ;para url-fetch (guix packages) ;para origin …) (define %reglas-android-udev (file->udev-rule "51-android-udev.rules" (let ((version "20170910")) (origin (method url-fetch) (uri (string-append "https://raw.githubusercontent.com/M0Rf30/" "android-udev-rules/" version "/51-android.rules")) (sha256 (base32 "0lmmagpyb6xsq6zcr2w1cyx9qmjqmajkvrdbhjx32gqf1d9is003"))))))
Adicionalmente, las definiciones de paquete Gui pueden ser incluidas en
rules para extender las reglas udev con las definiciones encontradas
bajo su subdirectorio lib/udev/rules.d. En vez del ejemplo previo de
file->udev-rule, podíamos haber usado el paquete
android-udev-rules que existe en Guix en el módulo (gnu packages
android).
El siguiente ejemplo muestra cómo usar el paquete android-udev-rules
para que la herramienta de Android adb pueda detectar dispositivos
sin privilegios de “root”. También detalla como crear el grupo
adbusers, el cual se requiere para el funcionamiento correcto de las
reglas definidas dentro del paquete android-udev-rules. Para crear
tal grupo, debemos definirlo tanto como parte de supplementary-groups
de la declaración de nuestra cuenta de usuaria en user-account, así
como en el parámetro groups del procedimiento
udev-rules-service.
(use-modules (gnu packages android) ;para android-udev-rules (gnu system shadow) ;para user-group …) (operating-system ;; … (users (cons (user-account ;; … (supplementary-groups '("adbusers" ;for adb "wheel" "netdev" "audio" "video"))))) ;; … (services (cons (udev-rules-service 'android android-udev-rules #:groups '("adbusers")) %desktop-services)))
- Variable Scheme: urandom-seed-service-type
Almacena alguna entropía en
%random-seed-filepara alimentar /dev/urandom cuando se reinicia. También intenta alimentar /dev/urandom con /dev/hwrng durante el arranque, si /dev/hwrng existe y se tienen permisos de lectura.
- Variable Scheme: %random-seed-file
Es el nombre del archivo donde algunos bytes aleatorios son almacenados por el servicio urandom-seed-service para alimentar /dev/urandom durante el reinicio. Su valor predeterminado es /var/lib/random-seed.
- Variable Scheme: gpm-service-type
Este es el tipo de servicio que ejecuta GPM, el daemon de ratón de propósito general, que permite el uso del ratón en la consola Linux. GPM permite a las usuarias el uso del ratón en la consola, notablemente la selección, copia y pegado de texto.
El valor para servicios de este tipo debe ser un objeto
gpm-configuration(véase a continuación). Este servicio no es parte de%base-services.
- Tipo de datos: gpm-configuration
Tipo de datos que representa la configuración de GPM.
opciones(predeterminadas:%default-gpm-options)Opciones de línea de órdenes proporcionadas a
gpm. El conjunto predeterminado de opciones instruye agpmpara esperar eventos de ratón en /dev/input/mice. See Command Line in gpm manual, para más información.gpm(predeterminado:gpm)El paquete GPM usado.
- Variable Scheme: guix-publish-service-type
Este es el tipo de servicio para
guix publish(see Invocación deguix publish). Su valor debe ser un objetoguix-publish-configuration, como se describe a continuación.Se asume que /etc/guix ya contiene el par de claves de firma como
guix archive --generate-keylo crea (see Invocación deguix archive). Si no es el caso, el servicio fallará al arrancar.
- Tipo de datos: guix-publish-configuration
Tipo de datos que representa la configuración del servicio
guix publish.guix(predeterminado:guix)El paquete Guix usado.
port(predeterminado:80)El puerto TCP en el que se esperan conexiones.
host(predeterminado:"localhost")La dirección de red (y, por tanto, la interfaz de red) en la que se esperarán conexiones. Use
"0.0.0.0"para aceptar conexiones por todas las interfaces de red.advertise?(default:#f)When true, advertise the service on the local network via the DNS-SD protocol, using Avahi.
This allows neighboring Guix devices with discovery on (see
guix-configurationabove) to discover thisguix publishinstance and to automatically download substitutes from it.compression(default:'(("gzip" 3) ("zstd" 3)))Es una lista de tuplas método de compresión/nivel usadas para la compresión de sustituciones. Por ejemplo, para comprimir todas las sustituciones tanto con lzip a nivel 8 como con gzip a nivel 9, escriba:
'(("lzip" 7) ("gzip" 9))
Level 9 achieves the best compression ratio at the expense of increased CPU usage, whereas level 1 achieves fast compression. See Invocación de
guix publish, for more information on the available compression methods and the tradeoffs involved.Una lista vacía desactiva completamente la compresión.
nar-path(predeterminado:"nar")La ruta URL de la que se pueden obtener “nars”. See --nar-path, para más detalles.
cache(predeterminado:#f)Cuando es
#f, desactiva la caché y genera los archivos bajo demanda. De otro modo, debería ser el nombre de un directorio—por ejemplo,"/var/cache/guix/publish"—dondeguix pubishalmacena los archivos y metadatos en caché listos para ser enviados. See --cache, para más información sobre sus ventajas e inconvenientes.workers(predeterminado:#f)Cuando es un entero, es el número de hilos de trabajo usados para la caché; cuando es
#f, se usa el número de procesadores. See --workers, para más información.cache-bypass-threshold(predeterminado: 10 MiB)Cuando
cachees verdadero, su valor indica el tamaño máximo en bytes de un elemento del almacén hasta el cualguix publishpuede ignorar un fallo de caché y realizar la petición directamente. See --cache-bypass-threshold para obtener más información.ttl(predeterminado:#f)Cuando es un entero, denota el tiempo de vida en segundos de los archivos publicados. See --ttl, para más información.
negative-ttl(default:#f)When it is an integer, this denotes the time-to-live in seconds for the negative lookups. See --negative-ttl, for more information.
- Procedimiento Scheme: rngd-service [#:rng-tools rng-tools] [#:device "/dev/hwrng"]
Devuelve un servicio que ejecuta el programa
rngdde rng-tools para añadir device a la fuente de entropía del núcleo. El servicio emitirá un fallo si device no existe.
- Procedimiento Scheme: pam-limits-service [#:limits
'()] -
Return a service that installs a configuration file for the
pam_limitsmodule. The procedure optionally takes a list ofpam-limits-entryvalues, which can be used to specifyulimitlimits andnicepriority limits to user sessions.Las siguientes definiciones de límites establecen dos límites “hard” y “soft” para todas las sesiones de ingreso al sistema de usuarias pertenecientes al grupo
realtime:(pam-limits-service (list (pam-limits-entry "@realtime" 'both 'rtprio 99) (pam-limits-entry "@realtime" 'both 'memlock 'unlimited)))La primera entrada incrementa la prioridad máxima de tiempo real para procesos sin privilegios; la segunda entrada elimina cualquier restricción sobre el espacio de direcciones que puede bloquearse en memoria. Estas configuraciones se usan habitualmente para sistemas de sonido en tiempo real.
Another useful example is raising the maximum number of open file descriptors that can be used:
(pam-limits-service (list (pam-limits-entry "*" 'both 'nofile 100000)))In the above example, the asterisk means the limit should apply to any user. It is important to ensure the chosen value doesn’t exceed the maximum system value visible in the /proc/sys/fs/file-max file, else the users would be prevented from login in. For more information about the Pluggable Authentication Module (PAM) limits, refer to the ‘pam_limits’ man page from the
linux-pampackage.
- Scheme Variable: greetd-service-type
greetdis a minimal and flexible login manager daemon, that makes no assumptions about what you want to launch.If you can run it from your shell in a TTY, greetd can start it. If it can be taught to speak a simple JSON-based IPC protocol, then it can be a geeter.
greetd-service-typeprovides necessary infrastructure for logging in users, including:-
greetdPAM service - Special variation of
pam-mountto mountXDG_RUNTIME_DIR
Here is example of switching from
mingetty-service-typetogreetd-service-type, and how different terminals could be:(append (modify-services %base-services ;; greetd-service-type provides "greetd" PAM service (delete login-service-type) ;; and can be used in place of mingetty-service-type (delete mingetty-service-type)) (list (service greetd-service-type (greetd-configuration (terminals (list ;; we can make any terminal active by default (greetd-terminal-configuration (terminal-vt "1") (terminal-switch #t)) ;; we can make environment without XDG_RUNTIME_DIR set ;; even provide our own environment variables (greetd-terminal-configuration (terminal-vt "2") (default-session-command (greetd-agreety-session (extra-env '(("MY_VAR" . "1"))) (xdg-env? #f)))) ;; we can use different shell instead of default bash (greetd-terminal-configuration (terminal-vt "3") (default-session-command (greetd-agreety-session (command (file-append zsh "/bin/zsh"))))) ;; we can use any other executable command as greeter (greetd-terminal-configuration (terminal-vt "4") (default-session-command (program-file "my-noop-greeter" #~(exit)))) (greetd-terminal-configuration (terminal-vt "5")) (greetd-terminal-configuration (terminal-vt "6")))))) ;; mingetty-service-type can be used in parallel ;; if needed to do so, do not (delete login-service-type) ;; as illustrated above #| (service mingetty-service-type (mingetty-configuration (tty "tty8"))) |#))-
- Data Type: greetd-configuration
Configuration record for the
greetd-service-type.motdUn objeto tipo-archivo que contiene el “mensaje del día”.
allow-empty-passwords?(predeterminado:#t)Permite contraseñas vacías por defecto para que las primeras usuarias puedan ingresar en el sistema cuando la cuenta de “root” está recién creada.
terminals(default:'())List of
greetd-terminal-configurationper terminal for whichgreetdshould be started.greeter-supplementary-groups(default:'())List of groups which should be added to
greeteruser. For instance:(greeter-supplementary-groups '("seat" "video"))Note that this example will fail if
seatgroup does not exist.
- Data Type: greetd-terminal-configuration
Configuration record for per terminal greetd daemon service.
greetd(default:greetd)The greetd package to use.
config-file-nameConfiguration file name to use for greetd daemon. Generally, autogenerated derivation based on
terminal-vtvalue.log-file-nameLog file name to use for greetd daemon. Generally, autogenerated name based on
terminal-vtvalue.terminal-vt(default: ‘"7"’)The VT to run on. Use of a specific VT with appropriate conflict avoidance is recommended.
terminal-switch(default:#f)Make this terminal active on start of
greetd.default-session-user(default: ‘"greeter"’)The user to use for running the greeter.
default-session-command(default:(greetd-agreety-session))Can be either instance of
greetd-agreety-sessionconfiguration orgexp->scriptlike object to use as greeter.
- Data Type: greetd-agreety-session
Configuration record for the agreety greetd greeter.
agreety(default:greetd)The package with
/bin/agreetycommand.command(default:(file-append bash "/bin/bash"))Command to be started by
/bin/agreetyon successful login.command-args(default:'("-l"))Command arguments to pass to command.
extra-env(default:'())Extra environment variables to set on login.
xdg-env?(default:#t)If true
XDG_RUNTIME_DIRandXDG_SESSION_TYPEwill be set before starting command. One should note that,extra-envvariables are set right after mentioned variables, so that they can be overriden.
- Data Type: greetd-wlgreet-session
Generic configuration record for the wlgreet greetd greeter.
wlgreet(default:wlgreet)The package with the
/bin/wlgreetcommand.command(default:(file-append sway "/bin/sway"))Command to be started by
/bin/wlgreeton successful login.command-args(default:'())Command arguments to pass to command.
output-mode(default:"all")Option to use for
outputModein the TOML configuration file.scale(default:1)Option to use for
scalein the TOML configuration file.background(default:'(0 0 0 0.9))RGBA list to use as the background colour of the login prompt.
headline(default:'(1 1 1 1))RGBA list to use as the headline colour of the UI popup.
prompt(default:'(1 1 1 1))RGBA list to use as the prompt colour of the UI popup.
prompt-error(default:'(1 1 1 1))RGBA list to use as the error colour of the UI popup.
border(default:'(1 1 1 1))RGBA list to use as the border colour of the UI popup.
extra-env(default:'())Extra environment variables to set on login.
- Data Type: greetd-wlgreet-sway-session
Sway-specific configuration record for the wlgreet greetd greeter.
wlgreet-session(default:(greetd-wlgreet-session))A
greetd-wlgreet-sessionrecord for generic wlgreet configuration, on top of the Sway-specificgreetd-wlgreet-sway-session.sway(default:sway)The package providing the
/bin/swaycommand.sway-configuration(default: #f)File-like object providing an additional Sway configuration file to be prepended to the mandatory part of the configuration.
Here is an example of a greetd configuration that uses wlgreet and Sway:
(greetd-configuration ;; We need to give the greeter user these permissions, otherwise ;; Sway will crash on launch. (greeter-supplementary-groups (list "video" "input" "seat")) (terminals (list (greetd-terminal-configuration (terminal-vt "1") (terminal-switch #t) (default-session-command (greetd-wlgreet-sway-session (sway-configuration (local-file "sway-greetd.conf"))))))))
Next: Rotación del registro de mensajes, Previous: Servicios base, Up: Servicios [Contents][Index]
12.9.2 Ejecución de tareas programadas
El módulo (gnu services mcron) proporciona una interfaz a
GNU mcron, un daemon para ejecutar trabajos planificados de antemano
(see GNU mcron). GNU mcron es similar al daemon
tradicional de Unix cron; la principal diferencia es que está
implementado en Scheme Guile, que proporciona mucha flexibilidad cuando se
especifica la planificación de trabajos y sus acciones.
El siguiente ejemplo define un sistema operativo que ejecuta las órdenes
updatedb (see Invoking updatedb in Finding Files) y
guix gc (see Invocación de guix gc) de manera diaria, así como la
orden mkid como una usuaria sin privilegios (see mkid
invocation in ID Database Utilitites). Usa expresiones-g para
introducir definiciones de trabajos que serán proporcionados a mcron
(see Expresiones-G).
(use-modules (guix) (gnu) (gnu services mcron)) (use-package-modules base idutils) (define updatedb-job ;; Run 'updatedb' at 3AM every day. Here we write the ;; job's action as a Scheme procedure. #~(job '(next-hour '(3)) (lambda () (execl (string-append #$findutils "/bin/updatedb") "updatedb" "--prunepaths=/tmp /var/tmp /gnu/store")) "updatedb")) (define trabajo-recolector-basura ;; Recolecta basura 5 minutos después de media noche, ;; todos los días. La acción del trabajo es una orden ;; del shell. #~(job "5 0 * * *" ;sintaxis de Vixie cron "guix gc -F 1G")) (define trabajo-idutils ;; Actualiza el índice de la base de datos como "carlos" a las ;; 12:15 y a las 19:15. Esto se ejecuta desde su directorio. #~(job '(next-minute-from (next-hour '(12 19)) '(15)) (string-append #$idutils "/bin/mkid src") #:user "carlos")) (operating-system ;; … ;; %BASE-SERVICES already includes an instance of ;; 'mcron-service-type', which we extend with additional ;; jobs using 'simple-service'. (services (cons (simple-service 'my-cron-jobs mcron-service-type (list garbage-collector-job updatedb-job idutils-job)) %base-services)))
Tip: When providing the action of a job specification as a procedure, you should provide an explicit name for the job via the optional 3rd argument as done in the
updatedb-jobexample above. Otherwise, the job would appear as “Lambda function” in the output ofherd schedule mcron, which is not nearly descriptive enough!
Para trabajos más complejos definidos en Scheme donde necesita control en el
ámbito global, por ejemplo para introducir una forma use-modules,
puede mover su código a un programa separado usando el procedimiento
program-file del módulo (guix gexp)
(see Expresiones-G). El siguiente ejemplo ilustra este caso.
(define %tarea-alerta-bateria
;; Pita cuando la carga de la batería es inferior a %CARGA-MIN
#~(job
'(next-minute (range 0 60 1))
#$(program-file
"alerta-batería.scm"
(with-imported-modules (source-module-closure
'((guix build utils)))
#~(begin
(use-modules (guix build utils)
(ice-9 popen)
(ice-9 regex)
(ice-9 textual-ports)
(srfi srfi-2))
(define %carga-min 20)
(setenv "LC_ALL" "C") ;Procesado de cadenas en inglés
(and-let* ((entrada (open-pipe*
OPEN_READ
#$(file-append acpi "/bin/acpi")))
(salida (get-string-all entrada))
(m (string-match "Discharging, ([0-9]+)%" output))
(carga (string->number (match:substring m 1)))
((< carga %carga-min)))
(setenv "LC_ALL" "") ;Mensaje de salida traducido
(format #t "aviso: La carga de la batería es baja (~a%)~%"
carga)
(invoke #$(file-append beep "/bin/beep") "-r5")))))))
See mcron job specifications in GNU mcron, para más información sobre las especificaciones de trabajos de mcron. A continuación se encuentra la referencia del servicio mcron.
En un sistema en ejecución puede usar la acción schedule del servicio
para visualizar los siguientes trabajos mcron que se ejecutarán:
# herd schedule mcron
El ejemplo previo enumera las siguientes cinco tareas que se ejecutarán, pero también puede especificar el número de tareas a mostrar:
# herd schedule mcron 10
- Variable Scheme: mcron-service-type
Este es el tipo del servicio
mcron, cuyo valor es un objetomcron-configuration.This service type can be the target of a service extension that provides additional job specifications (see Composición de servicios). In other words, it is possible to define services that provide additional mcron jobs to run.
- Tipo de datos: mcron-configuration
Available
mcron-configurationfields are:mcron(default:mcron) (type: file-like)El paquete mcron usado.
jobs(default:()) (type: list-of-gexps)This is a list of gexps (see Expresiones-G), where each gexp corresponds to an mcron job specification (see mcron job specifications in GNU mcron).
log?(default:#t) (type: boolean)Log messages to standard output.
log-format(default:"~1@*~a ~a: ~a~%") (type: string)(ice-9 format)format string for log messages. The default value produces messages like "‘pid name: message"’ (see Invoking in GNU mcron). Each message is also prefixed by a timestamp by GNU Shepherd.
Next: Networking Setup, Previous: Ejecución de tareas programadas, Up: Servicios [Contents][Index]
12.9.3 Rotación del registro de mensajes
Los archivos de registro como los encontrados en /var/log tienden a
crecer indefinidamente, de modo que es buena idea llevar a cabo una
rotación de vez en cuando—es decir, archivar su contenido en archivos
distintos, posiblemente comprimidos. El módulo (gnu services admin)
proporciona una interfaz con GNU Rot[t]log, una herramienta de rotación
de registros (see GNU Rot[t]log Manual).
Este servicio es parte de %base-services, y por lo tanto se activa de
manera predeterminada, con la configuración predeterminada, para archivos de
registro que se pueden encontrar habitualmente. El siguiente ejemplo muestra
como extenderlo con una rotación adicional, en caso de que deba
hacerlo (habitualmente los servicios que producen archivos de registro ya lo
hacen ellos mismos):
(use-modules (guix) (gnu)) (use-service-modules admin) (define mis-archivos-de-registro ;; Archivos que deseo rotar. '("/var/log/un-archivo.log" "/var/log/otro.log")) (operating-system ;; … (services (cons (simple-service 'rota-mis-cosas rottlog-service-type (list (log-rotation (frequency 'daily) (files mis-archivos-de-registro)))) %base-services)))
- Variable Scheme: rottlog-service-type
Este es el tipo del servicio Rottlog, cuyo valor es un objeto
rottlog-configuration.Otros servicios pueden extenderlo con nuevos objetos
log-rotation(véase a continuación), aumentando de dicho modo el conjunto de archivos a rotar.Este servicio puede definir trabajos de mcron (see Ejecución de tareas programadas) para ejecutar el servicio rottlog.
- Tipo de datos: rottlog-configuration
Tipo de datos que representa la configuración de rottlog.
rottlog(predeterminado:rottlog)El paquete Rottlog usado.
rc-file(predeterminado:(file-append rottlog "/etc/rc"))El archivo de configuración de Rottlog usado (see Mandatory RC Variables in GNU Rot[t]log Manual).
rotations(predeterminadas:%default-rotations)Una lista de objetos
log-rotationcomo se define a continuación.jobsEsta es una lista de expresiones-G donde cada expresión-G corresponde a una especificación de trabajo de mcron (see Ejecución de tareas programadas).
- Tipo de datos: log-rotation
Tipo de datos que representa la rotación de un grupo de archivos de log.
Tomando el ejemplo del manual de Rottlog (see Period Related File Examples in GNU Rot[t]log Manual), una rotación de registros se podría definir de esta manera:
(log-rotation (frequency 'daily) (files '("/var/log/apache/*")) (options '("storedir apache-archives" "rotate 6" "notifempty" "nocompress")))La lista de campos es como sigue:
frequency(predeterminada:'weekly)La frecuencia de rotación de logs, un símbolo.
filesLa lista de archivos o patrones extendidos de archivo a rotar.
options(default:%default-log-rotation-options)The list of rottlog options for this rotation (see Configuration parameters in GNU Rot[t]log Manual).
post-rotate(predeterminado:#f)O bien
#f, o bien una expresión-G que se ejecutará una vez la rotación se haya completado.
- Variable Scheme: %default-rotations
Especifica la rotación semanal de
%rotated-filesy de /var/log/guix-daemon.log.
- Variable Scheme: %rotated-files
La lista de archivos controlados por syslog que deben ser rotados. De manera predeterminada es
'("/var/log/messages" "/var/log/secure" "/var/log/maillog").
Some log files just need to be deleted periodically once they are old,
without any other criterion and without any archival step. This is the case
of build logs stored by guix-daemon under
/var/log/guix/drvs (see Invocación de guix-daemon). The
log-cleanup service addresses this use case. For example,
%base-services (see Servicios base) includes the following:
;; Periodically delete old build logs. (service log-cleanup-service-type (log-cleanup-configuration (directory "/var/log/guix/drvs")))
That ensures build logs do not accumulate endlessly.
- Scheme Variable: log-cleanup-service-type
This is the type of the service to delete old logs. Its value must be a
log-cleanup-configurationrecord as described below.
- Data Type: log-cleanup-configuration
Data type representing the log cleanup configuration
directoryName of the directory containing log files.
expiry(default:(* 6 30 24 3600))Age in seconds after which a file is subject to deletion (six months by default).
schedule(default:"30 12 01,08,15,22 * *")String or gexp denoting the corresponding mcron job schedule (see Ejecución de tareas programadas).
Anonip Service
Anonip is a privacy filter that removes IP address from web server logs. This service creates a FIFO and filters any written lines with anonip before writing the filtered log to a target file.
The following example sets up the FIFO /var/run/anonip/https.access.log and writes the filtered log file /var/log/anonip/https.access.log.
(service anonip-service-type
(anonip-configuration
(input "/var/run/anonip/https.access.log")
(output "/var/log/anonip/https.access.log")))
Configure your web server to write its logs to the FIFO at /var/run/anonip/https.access.log and collect the anonymized log file at /var/web-logs/https.access.log.
- Data Type: anonip-configuration
This data type represents the configuration of anonip. It has the following parameters:
anonip(default:anonip)The anonip package to use.
inputThe file name of the input log file to process. The service creates a FIFO of this name. The web server should write its logs to this FIFO.
outputThe file name of the processed log file.
The following optional settings may be provided:
skip-private?When
#truedo not mask addresses in private ranges.columnA 1-based indexed column number. Assume IP address is in the specified column (default is 1).
replacementReplacement string in case address parsing fails, e.g.
"0.0.0.0".ipv4maskNumber of bits to mask in IPv4 addresses.
ipv6maskNumber of bits to mask in IPv6 addresses.
incrementIncrement the IP address by the given number. By default this is zero.
delimiterLog delimiter string.
regexRegular expression for detecting IP addresses. Use this instead of
column.
Next: Servicios de red, Previous: Rotación del registro de mensajes, Up: Servicios [Contents][Index]
12.9.4 Networking Setup
The (gnu services networking) module provides services to configure
network interfaces and set up networking on your machine. Those services
provide different ways for you to set up your machine: by declaring a static
network configuration, by running a Dynamic Host Configuration Protocol
(DHCP) client, or by running daemons such as NetworkManager and Connman that
automate the whole process, automatically adapt to connectivity changes, and
provide a high-level user interface.
On a laptop, NetworkManager and Connman are by far the most convenient
options, which is why the default desktop services include NetworkManager
(see %desktop-services). For a server, or for
a virtual machine or a container, static network configuration or a simple
DHCP client are often more appropriate.
This section describes the various network setup services available, starting with static network configuration.
- Variable Scheme: static-networking-service-type
This is the type for statically-configured network interfaces. Its value must be a list of
static-networkingrecords. Each of them declares a set of addresses, routes, and links, as shown below.Here is the simplest configuration, with only one network interface controller (NIC) and only IPv4 connectivity:
;; Static networking for one NIC, IPv4-only. (service static-networking-service-type (list (static-networking (addresses (list (network-address (device "eno1") (value "10.0.2.15/24")))) (routes (list (network-route (destination "default") (gateway "10.0.2.2")))) (name-servers '("10.0.2.3")))))
The snippet above can be added to the
servicesfield of your operating system configuration (see Uso de la configuración del sistema). It will configure your machine to have 10.0.2.15 as its IP address, with a 24-bit netmask for the local network—meaning that any 10.0.2.x address is on the local area network (LAN). Traffic to addresses outside the local network is routed via 10.0.2.2. Host names are resolved by sending domain name system (DNS) queries to 10.0.2.3.
- Data Type: static-networking
This is the data type representing a static network configuration.
As an example, here is how you would declare the configuration of a machine with a single network interface controller (NIC) available as
eno1, and with one IPv4 and one IPv6 address:;; Network configuration for one NIC, IPv4 + IPv6. (static-networking (addresses (list (network-address (device "eno1") (value "10.0.2.15/24")) (network-address (device "eno1") (value "2001:123:4567:101::1/64")))) (routes (list (network-route (destination "default") (gateway "10.0.2.2")) (network-route (destination "default") (gateway "2020:321:4567:42::1")))) (name-servers '("10.0.2.3")))
If you are familiar with the
ipcommand of theiproute2package found on Linux-based systems, the declaration above is equivalent to typing:ip address add 10.0.2.15/24 dev eno1 ip address add 2001:123:4567:101::1/64 dev eno1 ip route add default via inet 10.0.2.2 ip route add default via inet6 2020:321:4567:42::1
Run
man 8 ipfor more info. Venerable GNU/Linux users will certainly know how to do it withifconfigandroute, but we’ll spare you that.The available fields of this data type are as follows:
addresseslinks(default:'())routes(default:'())The list of
network-address,network-link, andnetwork-routerecords for this network (see below).name-servers(default:'())The list of IP addresses (strings) of domain name servers. These IP addresses go to /etc/resolv.conf.
provision(default:'(networking))If true, this should be a list of symbols for the Shepherd service corresponding to this network configuration.
requirement(default'())The list of Shepherd services depended on.
- Data Type: network-address
This is the data type representing the IP address of a network interface.
deviceThe name of the network interface for this address—e.g.,
"eno1".valueThe actual IP address and network mask, in CIDR (Classless Inter-Domain Routing) notation, as a string.
For example,
"10.0.2.15/24"denotes IPv4 address 10.0.2.15 on a 24-bit sub-network—all 10.0.2.x addresses are on the same local network.ipv6?Whether
valuedenotes an IPv6 address. By default this is automatically determined.
- Data Type: network-route
This is the data type representing a network route.
destinationThe route destination (a string), either an IP address and network mask or
"default"to denote the default route.source(default:#f)The route source.
device(predeterminado:#f)The device used for this route—e.g.,
"eno2".ipv6?(default: auto)Whether this is an IPv6 route. By default this is automatically determined based on
destinationorgateway.gateway(default:#f)IP address (a string) through which traffic is routed.
- Data Type: network-link
Data type for a network link (see Link in Guile-Netlink Manual).
nameThe name of the link—e.g.,
"v0p0".typeA symbol denoting the type of the link—e.g.,
'veth.argumentsList of arguments for this type of link.
- Scheme Variable: %loopback-static-networking
This is the
static-networkingrecord representing the “loopback device”,lo, for IP addresses 127.0.0.1 and ::1, and providing theloopbackShepherd service.
- Scheme Variable: %qemu-static-networking
This is the
static-networkingrecord representing network setup when using QEMU’s user-mode network stack oneth0(see Using the user mode network stack in QEMU Documentation).
- Variable Scheme: dhcp-client-service-type
This is the type of services that run dhcp, a Dynamic Host Configuration Protocol (DHCP) client.
- Data Type: dhcp-client-configuration
Data type representing the configuration of the DHCP client service.
package(predeterminado:isc-dhcp)DHCP client package to use.
interfaces(default:'all)Either
'allor the list of interface names that the DHCP client should listen on—e.g.,'("eno1").When set to
'all, the DHCP client listens on all the available non-loopback interfaces that can be activated. Otherwise the DHCP client listens only on the specified interfaces.
- Variable Scheme: network-manager-service-type
Este es el tipo de servicio para el servicio NetworkManager. El valor para este tipo de servicio es un registro
network-manager-configuration.Este servicio es parte de
%desktop-services(see Servicios de escritorio).
- Tipo de datos: network-manager-configuration
Tipo de datos que representa la configuración de NetworkManager.
network-manager(predeterminado:network-manager)El paquete de NetworkManager usado.
dns(predeterminado:"default")Modo de procesamiento para DNS, que afecta la manera en la que NetworkManager usa el archivo de configuración
resolv.conf.- ‘default’
NetworkManager actualizará
resolv.confpara reflejar los servidores de nombres proporcionados por las conexiones activas actualmente.- ‘dnsmasq’
NetworkManager ejecutará
dnsmasqcomo una caché local del servicio de nombres, mediante un reenvío condicional si se encuentra conectada a una VPN, y actualiza posteriormenteresolv.confpara apuntar al servidor de nombres local.Con esta configuración puede compartir su conexión de red. Por ejemplo, cuando desee compartir su conexión de red a otro equipo a través de un cable Ethernet, puede abrir
nm-connection-editory configurar el método de la conexión cableada para IPv4 y IPv6 “Compartida con otros equipos” y restablecer la conexión (o reiniciar).También puede configurar una conexión anfitrión-invitado a las máquinas virtuales de QEMU (see Instalación de Guix en una máquina virtual). Con una conexión anfitrión-invitado puede, por ejemplo, acceder a un servidor web que se ejecute en la máquina virtual (see Servicios Web) desde un navegador web en su sistema anfitrión, o conectarse a la máquina virtual a través de SSH (see
openssh-service-type). Para configurar una conexión anfitrión-invitado, ejecute esta orden una única vez:nmcli connection add type tun \ connection.interface-name tap0 \ tun.mode tap tun.owner $(id -u) \ ipv4.method shared \ ipv4.addresses 172.28.112.1/24
Cada vez que arranque su máquina virtual de QEMU (see Ejecución de Guix en una máquina virtual), proporcione -nic tap,ifname=tap0,script=no,downscript=no a
qemu-system-....- ‘none’
NetworkManager no modificará
resolv.conf.
vpn-plugins(predeterminados:'())Esta es la lista de módulos disponibles para redes privadas virtuales (VPN). Un ejemplo es el paquete
network-manager-openvpn, que permite a NetworkManager la gestión de redes VPN a través de OpenVPN.
- Variable Scheme: connman-service-type
Este es el tipo de servicio para la ejecución de Connman, un gestor de conexiones de red.
Su valor debe ser un registro
connman-configurationcomo en este ejemplo:(service connman-service-type (connman-configuration (disable-vpn? #t)))Véase a continuación más detalles sobre
connman-configuration.
- Tipo de datos: connman-configuration
Tipo de datos que representa la configuración de connman.
connman(predeterminado: connman)El paquete connman usado.
disable-vpn?(predeterminado:#f)Cuando es verdadero, desactiva el módulo vpn de connman.
- Variable Scheme: wpa-supplicant-service-type
Este es el tipo de servicio para la ejecución de WPA supplicant, un daemon de identificación necesario para la identificación en redes WiFi o ethernet cifradas.
- Tipo de datos: wpa-supplicant-configuration
Tipo de datos que representa la configuración de WPA Supplicant.
Toma los siguientes parámetros:
wpa-supplicant(predeterminado:wpa-supplicant)El paquete de WPA Supplicant usado.
requirement(predeterminados:'(user-processes loopback syslogd)Lista de servicios que deben iniciarse antes del arranque de WPA Supplicant.
dbus?(predeterminado:#t)Si se escuchan o no peticiones en D-Bus.
pid-file(predeterminado:"/var/run/wpa_supplicant.pid")Dónde se almacena el archivo con el PID.
interface(predeterminado:#f)En caso de proporcionarse un valor, debe especificar el nombre de la interfaz de red que WPA supplicant controlará.
config-file(predeterminado:#f)Archivo de configuración opcional usado.
extra-options(predeterminadas:'())Lista de parámetros adicionales a pasar al daemon en la línea de órdenes.
Some networking devices such as modems require special care, and this is what the services below focus on.
- Variable Scheme: modem-manager-service-type
This is the service type for the ModemManager service. The value for this service type is a
modem-manager-configurationrecord.Este servicio es parte de
%desktop-services(see Servicios de escritorio).
- Tipo de datos: modem-manager-configuration
Tipo de datos que representa la configuración de ModemManager.
modem-manager(predeterminado:modem-manager)El paquete de ModemManager usado.
- Variable Scheme: usb-modeswitch-service-type
This is the service type for the USB_ModeSwitch service. The value for this service type is a
usb-modeswitch-configurationrecord.Cuando se conectan, algunos modem USB (y otros dispositivos USB) se presentan inicialmente como medios de almacenamiento de sólo-lectura y no como un modem. Deben cambiar de modo antes de poder usarse. El tipo de servicio USB_ModeSwitch instala reglas de udev para cambiar automáticamente de modo cuando se conecten estos dispositivos.
Este servicio es parte de
%desktop-services(see Servicios de escritorio).
- Tipo de datos: usb-modeswitch-configuration
Tipo de datos que representa la configuración de USB_ModeSwitch.
usb-modeswitch(predeterminado:usb-modeswitch)El paquete USB_ModeSwitch que proporciona los binarios para el cambio de modo.
usb-modeswitch-data(predeterminado:usb-modeswitch-data)El paquete que proporciona los datos de dispositivos y las reglas de udev usadas por USB_ModeSwitch.
config-file(predeterminado:#~(string-append #$usb-modeswitch:dispatcher "/etc/usb_modeswitch.conf"))Archivo de configuración usado para el gestor de eventos (dispatcher) de USB_ModeSwitch. De manera predeterminada se usa el archivo que viene con USB_ModeSwitch, que deshabilita el registro en /var/log junto a otras configuraciones. Si se proporciona
#fno se usa ningún archivo de configuración.
Next: Actualizaciones no-atendidas, Previous: Networking Setup, Up: Servicios [Contents][Index]
12.9.5 Servicios de red
The (gnu services networking) module discussed in the previous
section provides services for more advanced setups: providing a DHCP service
for others to use, filtering packets with iptables or nftables, running a
WiFi access point with hostapd, running the inetd
“superdaemon”, and more. This section describes those.
- Procedimiento Scheme: dhcpd-service-type
Este tipo define un servicio que ejecuta el daemon DHCP. Para crear un servicio de este tipo debe proporcionar un objeto
<dhcpd-configuration>. Por ejemplo:(service dhcpd-service-type (dhcpd-configuration (config-file (local-file "mi-dhcpd.conf")) (interfaces '("enp0s25"))))
- Tipo de datos: dhcpd-configuration
package(predeterminado:isc-dhcp)The package that provides the DHCP daemon. This package is expected to provide the daemon at sbin/dhcpd relative to its output directory. The default package is the ISC’s DHCP server.
config-file(predeterminado:#f)El archivo de configuración usado. Esta opción es necesaria. Se le proporcionará a
dhcpda través de su opción-cf. Puede ser cualquier objeto “tipo-archivo” (see objetos “tipo-archivo”). Véaseman dhcpd.confpara detalles sobre la sintaxis del archivo de configuración.version(predeterminada:"4")La versión DHCP usada. El servidor DHCP de ISC permite los valores “4”, “6” y “4o6”. Corresponden con las opciones
-4,-6y-4o6del programadhcpd. Véaseman dhcpdpara más detalles.run-directory(predeterminado:"/run/dhcpd")El directorio de ejecución usado. Durante la activación del servicio se creará en caso de no existir.
pid-file(predeterminado:"/run/dhcpd/dhcpd.pid")El archivo de PID usado. Corresponde con la opción
-pfdedhcpd. Véaseman dhcpdpara más detalles.interfaces(predeterminadas:'())Los nombres de las interfaces de red en las que dhcpd debería esperar retransmisiones. Si la lista no está vacía, entonces sus elementos (que deben ser cadenas) se añadirá a la invocación de
dhcpdcuando se inicie el daemon. Puede no ser necesaria la especificación explícita aquí de ninguna interfaz; véaseman dhcpdpara más detalles.
- Variable Scheme: hostapd-service-type
Este es el tipo de servicio que ejecuta el daemon hostapd para configurar puntos de acceso WiFi (IEEE 802.11) y servidores de identificación. Su valor debe ser un registro
hostapd-configurationcomo en este ejemplo:;; Use wlan1 para ejecutar el punto de acceso para "Mi red". (service hostapd-service-type (hostapd-configuration (interface "wlan1") (ssid "Mi red") (channel 12)))
- Tipo de datos: hostapd-configuration
Este tipo de datos representa la configuración del servicio hostapd, y tiene los siguientes campos:
package(predeterminado:hostapd)El paquete hostapd usado.
interface(predeterminado:"wlan0")La interfaz de red en la que se establece el punto de acceso WiFi.
ssidEl SSID (identificador del servicio, del inglés “service set identifier”), una cadena que identifica esta red.
broadcast-ssid?(predeterminado:#t)Determina si se emite este SSID.
channel(predeterminado:1)El canal WiFi usado.
driver(predeterminado:"nl80211")El tipo de controlador de la interfaz.
"nl80211"se usa con todos los controladores de mac80211 de Linux. Use"none"si está construyendo hostapd como un servidor RADIUS independiente que no controla ningún controlador de red cableada o inalámbrica.extra-settings(predeterminado:"")Configuración adicional que se añade literalmente al archivo de configuración de hostapd. Véase https://w1.fi/cgit/hostap/plain/hostapd/hostapd.conf para la referencia del archivo de configuración.
- Variable Scheme: simulated-wifi-service-type
Tipo de servicio que simula una red inalámbrica (“WiFi”), lo que puede ser útil en máquinas virtuales para realizar pruebas. El servicio carga el módulo
mac80211_hwsimdel núcleo Linux e inicia hostapd para crear una red inalámbrica virtual que puede verse enwlan0, de manera predeterminada.El valor de este servicio es un registro
hostapd-configuration.
- Variable Scheme: iptables-service-type
Este es el tipo de servicio para la aplicación de configuración de iptables. iptables es un entorno de trabajo para el filtrado de paquetes implementado por el núcleo Linux. Este servicio permite la configuración de iptables tanto para IPv4 como IPv6. Un ejemplo simple de cómo rechazar todas las conexiones entrantes excepto aquellas al puerto 22 de ssh se muestra a continuación.
(service iptables-service-type (iptables-configuration (ipv4-rules (plain-file "iptables.rules" "*filter :INPUT ACCEPT :FORWARD ACCEPT :OUTPUT ACCEPT -A INPUT -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT -A INPUT -p tcp --dport 22 -j ACCEPT -A INPUT -j REJECT --reject-with icmp-port-unreachable COMMIT ")) (ipv6-rules (plain-file "ip6tables.rules" "*filter :INPUT ACCEPT :FORWARD ACCEPT :OUTPUT ACCEPT -A INPUT -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT -A INPUT -p tcp --dport 22 -j ACCEPT -A INPUT -j REJECT --reject-with icmp6-port-unreachable COMMIT "))))
- Tipo de datos: iptables-configuration
El tipo de datos que representa la configuración de iptables.
iptables(predeterminado:iptables)El paquete iptables que proporciona
iptables-restoreyip6tables-restore.ipv4-rules(predeterminado:%iptables-accept-all-rules)Las reglas de iptables usadas. Se le proporcionarán a
iptables-restore. Puede ser cualquier objeto “tipo-archivo” (see objetos “tipo-archivo”).ipv6-rules(predeterminadas:%iptables-accept-all-rules)Las reglas de ip6tables usadas. Se le proporcionarán a
ip6tables-restore. Puede ser cualquier objeto “tipo-archivo” (see objetos “tipo-archivo”).
- Variable Scheme: nftables-service-type
This is the service type to set up a nftables configuration. nftables is a netfilter project that aims to replace the existing iptables, ip6tables, arptables and ebtables framework. It provides a new packet filtering framework, a new user-space utility
nft, and a compatibility layer for iptables. This service comes with a default ruleset%default-nftables-rulesetthat rejecting all incoming connections except those to the ssh port 22. To use it, simply write:
- Tipo de datos: nftables-configuration
El tipo de datos que representa la configuración de nftables.
package(predeterminado:nftables)El paquete nftables que proporciona
nft.ruleset(predeterminados:%default-nftables-ruleset)El conjunto de reglas de nftables usado. Puede ser cualquier objeto “tipo-archivo” (see objetos “tipo-archivo”).
- Variable Scheme: ntp-service-type
Este es el tipo del servicio que ejecuta el daemon del protocolo de tiempo en red (NTP),
ntpd. El daemon mantendrá el reloj del sistema sincronizado con el de los servidores NTP especificados.El valor de este servicio es un objeto
ntpd-configuration, como se describe a continuación.
- Tipo de datos: ntp-configuration
Este es el tipo de datos para la configuración del servicio NTP.
servers(predeterminados:%ntp-servers)La lista de servidores (registros
<ntp-server>) con los que la herramientantpdse sincronizará. Véase la información sobre el tipo de datosntp-servera continuación.allow-large-adjustment?(predeterminado:#t)Esto determina si se le permite a
ntpdrealizar un ajuste inicial de más de 1000 segundos.ntp(predeterminado:ntp)El paquete NTP usado.
- Variable Scheme: %ntp-servers
Lista de nombres de máquinas usadas como servidores NTP predeterminados. Son servidores del NTP Pool Project.
- Tipo de datos: ntp-server
Tipo de datos que representa la configuración de un servidor NTP.
type(predeterminado:'server)The type of the NTP server, given as a symbol. One of
'pool,'server,'peer,'broadcastor'manycastclient.addressLa dirección del servidor, como una cadena.
optionsNTPD options to use with that specific server, given as a list of option names and/or of option names and values tuples. The following example define a server to use with the options iburst and prefer, as well as version 3 and a maxpoll time of 16 seconds.
(ntp-server (type 'server) (address "miservidor.ntp.server.org") (options `(iburst (version 3) (maxpoll 16) prefer))))
- Procedimiento Scheme: openntpd-service-type
Ejecuta
ntpd, el daemon del protocolo de tiempo en red (NTP), implementado por OpenNTPD. El daemon mantendrá el reloj del sistema sincronizado con el de los servidores proporcionados.(service openntpd-service-type (openntpd-configuration (listen-on '("127.0.0.1" "::1")) (sensor '("udcf0 correction 70000")) (constraint-from '("www.gnu.org")) (constraints-from '("https://www.google.com/"))))
- Variable Scheme: %openntpd-servers
Esta variable es una lista de las direcciones de servidores definidos en
%ntp-servers.
- Tipo de datos: openntpd-configuration
openntpd(predeterminado:(file-append openntpd "/sbin/ntpd"))El ejecutable openntpd usado.
listen-on(predeterminadas:'("127.0.0.1" "::1"))Una lista de direcciones IP o nombres de máquina en los que el daemon ntpd debe escuchar conexiones.
query-from(predeterminadas:'())Una lista de direcciones IP locales que el daemon ntpd debe usar para consultas salientes.
sensor(predeterminados:'())Especifica una lista de dispositivos de sensores de tiempo de ntpd debería usar.
ntpdescuchará cada sensor que realmente exista e ignora los que no. Véase la documentación de las desarrolladoras originales para más información.server(predeterminado:'())Especifica una lista de direcciones IP o nombres de máquina de servidores NTP con los que sincronizarse.
servers(predeterminada:%openntp-servers)Una lista de direcciones IP o nombres de máquina con los que el daemon ntpd se debe sincronizar.
constraint-from(predeterminado:'())ntpdpuede configurarse para que solicite la fecha a través del campo “Date” de servidores HTTPS en los que se confíe a través de TLS. Esta información de tiempo no se usa por precisión pero actúa como una condición verificada, por tanto reduciendo el impacto de ataques mediante la intervención del tráfico con servidores NTP no verificados. Especifica una lista de URL, direcciones IP o nombres de máquina de servidores HTTPS que proporcionarán la condición.constraints-from(predeterminadas:'())Como en constraint-from, proporciona una lista de URL, direcciones IP o nombres de máquina de servidores HTTP para proporcionar la condición. En caso de que el nombre de máquina resuelva en múltiples direcciones IP,
ntpdcalculará la condición mediana de todas ellas.
- Variable Scheme: inetd-service-type
Este servicio ejecuta el daemon
inetd(see inetd invocation in GNU Inetutils).inetdescucha conexiones en sockets de internet, e inicia bajo demanda el programa servidor cuando se realiza una conexión en uno de esos sockets.El valor de este servicio es un objeto
inetd-configuration. El ejemplo siguiente configura el daemoninetdpara proporcionar el servicioechoimplementado por él mismo, así como un servicio smtp que reenvía el tráfico smtp por ssh a un servidorservidor-smtptras la pasarelamáquina:(service inetd-service-type (inetd-configuration (entries (list (inetd-entry (name "echo") (socket-type 'stream) (protocol "tcp") (wait? #f) (user "root")) (inetd-entry (node "127.0.0.1") (name "smtp") (socket-type 'stream) (protocol "tcp") (wait? #f) (user "root") (program (file-append openssh "/bin/ssh")) (arguments '("ssh" "-qT" "-i" "/ruta/de/la/clave_ssh" "-W" "servidor-smtp:25" "usuaria@maquina")))))))A continuación se proporcionan más detalles acerca de
inetd-configuration.
- Tipo de datos: inetd-configuration
Tipo de datos que representa la configuración de
inetd.program(predeterminado:(file-append inetutils "/libexec/inetd"))El ejecutable
inetdusado.entries(predeterminadas:'())Una lista de entradas de servicio de
inetd. Cada entrada debe crearse con el constructorinted-entry.
- Tipo de datos: inetd-entry
Tipo de datos que representa una entrada en la configuración de
inetd. Cada entrada corresponde a un socket en el queinetdescuchará a la espera de peticiones.node(predeterminado:#f)Cadena opcional, una lista separada por comas de direcciones locales que
inetddebería usar cuando se escuche para este servicio. See Configuration file in GNU Inetutils para una descripción completa de todas las opciones.nameUna cadena, el nombre debe corresponder con una entrada en
/etc/services.socket-typePuede ser
'stream,'dgram,'raw,'rdmo'seqpacket.protocolUna cadena, debe corresponder con una entrada en
/etc/protocols.wait?(predeterminado:#t)Si
inetddebe esperar la salida del servidor antes de reiniciar la escucha de nuevas peticiones de servicio.userUna cadena que contiene el nombre (y, opcionalmente, el grupo) de la usuaria como la que se deberá ejecutar el servidor. El nombe de grupo se puede especificar en un sufijo, separado por dos puntos o un punto normal, es decir
"usuaria","usuaria:grupo"o"usuaria.grupo".program(predeterminado:"internal")El programa servidor que recibirá las peticiones, o
"internal"siinetddebería usar un servicio implementado internamente.arguments(predeterminados:'())Una lista de cadenas u objetos “tipo-archivo”, que serán los parámetros del programa servidor, empezando con el parámetro 0, es decir, el nombre del programa en sí mismo. Para los servicios internos de
inetd, esta entrada debe ser'()o'("internal").
See Configuration file in GNU Inetutils, para una información más detallada sobre cada campo de la configuración.
- Scheme Variable: opendht-service-type
This is the type of the service running a OpenDHT node,
dhtnode. The daemon can be used to host your own proxy service to the distributed hash table (DHT), for example to connect to with Jami, among other applications.Importante: When using the OpenDHT proxy server, the IP addresses it “sees” from the clients should be addresses reachable from other peers. In practice this means that a publicly reachable address is best suited for a proxy server, outside of your private network. For example, hosting the proxy server on a IPv4 private local network and exposing it via port forwarding could work for external peers, but peers local to the proxy would have their private addresses shared with the external peers, leading to connectivity problems.
The value of this service is a
opendht-configurationobject, as described below.
- Data Type: opendht-configuration
Available
opendht-configurationfields are:opendht(default:opendht) (type: file-like)The
opendhtpackage to use.peer-discovery?(default:#f) (type: boolean)Whether to enable the multicast local peer discovery mechanism.
enable-logging?(default:#f) (type: boolean)Whether to enable logging messages to syslog. It is disabled by default as it is rather verbose.
debug?(default:#f) (type: boolean)Whether to enable debug-level logging messages. This has no effect if logging is disabled.
bootstrap-host(default:"bootstrap.jami.net:4222") (type: maybe-string)The node host name that is used to make the first connection to the network. A specific port value can be provided by appending the
:PORTsuffix. By default, it uses the Jami bootstrap nodes, but any host can be specified here. It’s also possible to disable bootstrapping by explicitly setting this field to the%unset-valuevalue.port(default:4222) (type: maybe-number)The UDP port to bind to. When left unspecified, an available port is automatically selected.
proxy-server-port(type: maybe-number)Spawn a proxy server listening on the specified port.
proxy-server-port-tls(type: maybe-number)Spawn a proxy server listening to TLS connections on the specified port.
- Variable Scheme: tor-service-type
Este es el tipo para un servicio que ejecuta el daemon de red anónima Tor. El servicio se configura mediante un registro
<tor-configuration>. De manera predeterminada, el daemon Tor se ejecuta como la usuaria sin privilegiostor, que es miembro del grupotor.
- Tipo de datos: tor-configuration
tor(predeterminado:tor)El paquete que proporciona el daemon Tor. Se espera que este paquete proporcione el daemon en bin/tor de manera relativa al directorio de su salida. El paquete predeterminado es la implementación del Proyecto Tor.
config-file(predeterminado:(plain-file "empty" ""))El archivo de configuración usado. Se agregará al final del archivo de configuración predeterminado, y se proporcionará el archivo de configuración resultante a
tora través de su opción-f. Puede ser cualquier objeto “tipo-archivo” (see objetos “tipo-archivo”). Véaseman torpara detalles sobre la sintaxis del archivo de configuración.hidden-services(predeterminados:'())La lista de registros de servicios ocultos
<hidden-service>usados. Para cada servicio oculto que añada en esta lista, se activará la configuración apropiada para su activación en el archivo de configuración predeterminado. Puede crear registros<hidden-service>de manera conveniente mediante el uso del procedimientotor-hidden-servicedescrito a continuación.socks-socket-type(predeterminado:'tcp)El tipo socket predeterminado que Tor debe usar para su socket SOCKS. Debe ser
'tcpi'unix. Si es'tcp, Tor escuchará en el puerto TCP 9050 de la interfaz local (es decir, localhost) de manera predeterminada. Si es'unix, tor escuchará en el socket de dominio de UNIX /var/run/tor/socks-sock, que tendrá permisos de escritura para miembros del grupotor.Si desea personalizar el socket SOCKS de manera más detallada, mantenga
socks-socket-typecon su valor predeterminado de'tcpy useconfig-filepara modificar el valor predeterminado proporcionando su propia opciónSocksPort.control-socket?(default:#f)Whether or not to provide a “control socket” by which Tor can be controlled to, for instance, dynamically instantiate tor onion services. If
#t, Tor will listen for control commands on the UNIX domain socket /var/run/tor/control-sock, which will be made writable by members of thetorgroup.
Define un servicio oculto Tor llamado nombre y que implementa la relación. relación es una lista de tuplas puerto/máquina, como:
'((22 "127.0.0.1:22") (80 "127.0.0.1:8080"))
En este ejemplo, el puerto 22 del servicio oculto se asocia con el puerto 22 local, y el puerto 80 se asocia con el puerto 8080 local.
Esto crea un directorio /var/lib/tor/hidden-services/nombre, donde el archivo hostname contiene el nombre de máquina
.onionpara el servicio oculto.Véase la documentación del proyecto Tor para más información.
El módulo (gnu services rsync) proporciona los siguientes servicios:
Puede ser que desee un daemon rsync si tiene archivos que desee tener disponibles de modo que cualquiera (o simplemente usted) pueda descargar archivos existentes o subir nuevos archivos.
- Variable Scheme: rsync-service-type
Este es el tipo de servicio para el daemon rsync. El valor tipo de servicio es un registro
rsync-configurationcomo en este ejemplo.;; Export two directories over rsync. By default rsync listens on ;; all the network interfaces. (service rsync-service-type (rsync-configuration (modules (list (rsync-module (name "music") (file-name "/srv/zik") (read-only? #f)) (rsync-module (name "movies") (file-name "/home/charlie/movies"))))))
Véase a continuación para detalles sobre
rsync-configuration.
- Tipo de datos: rsync-configuration
Tipo de datos que representa la configuración para
rsync-service.package(predeterminado: rsync)Paquete
rsyncusado.address(predeterminada:#f)IP address on which
rsynclistens for incoming connections. If unspecified, it defaults to listening on all available addresses.port-number(predeterminado:873)Puerto TCP en el que
rsyncescucha conexiones entrantes. Si el puerto es menor a1024,rsyncnecesita iniciarse comoroot, tanto usuaria como grupo.pid-file(predeterminado:"/var/run/rsyncd/rsyncd.pid")Nombre del archivo donde
rsyncescribe su PID.lock-file(predeterminado:"/var/run/rsyncd/rsyncd.lock")Nombre del archivo donde
rsyncescribe su archivo de bloqueo.log-file(predeterminado:"/var/log/rsyncd.log")Nombre del archivo donde
rsyncescribe su archivo de registros.user(predeterminada:"root")Propietaria del proceso
rsync.group(default:"root")Grupo del proceso
rsync.uid(default:"rsyncd")Nombre o ID de usuaria bajo la cual se efectúan las transferencias desde y hacia el módulo cuando el daemon se ejecuta como
root.gid(default:"rsyncd")Nombre o ID de grupo que se usa cuando se accede al módulo.
modules(predeterminados:%default-modules)List of “modules”—i.e., directories exported over rsync. Each element must be a
rsync-modulerecord, as described below.
- Data Type: rsync-module
This is the data type for rsync “modules”. A module is a directory exported over the rsync protocol. The available fields are as follows:
nameThe module name. This is the name that shows up in URLs. For example, if the module is called
music, the corresponding URL will bersync://host.example.org/music.file-nameName of the directory being exported.
comment(predeterminado:"")Comment associated with the module. Client user interfaces may display it when they obtain the list of available modules.
read-only?(default:#t)Whether or not client will be able to upload files. If this is false, the uploads will be authorized if permissions on the daemon side permit it.
chroot?(default:#t)When this is true, the rsync daemon changes root to the module’s directory before starting file transfers with the client. This improves security, but requires rsync to run as root.
timeout(predeterminado:300)Idle time in seconds after which the daemon closes a connection with the client.
The (gnu services syncthing) module provides the following services:
You might want a syncthing daemon if you have files between two or more computers and want to sync them in real time, safely protected from prying eyes.
- Scheme Variable: syncthing-service-type
This is the service type for the syncthing daemon, The value for this service type is a
syncthing-configurationrecord as in this example:(service syncthing-service-type (syncthing-configuration (user "alice")))See below for details about
syncthing-configuration.- Data Type: syncthing-configuration
Data type representing the configuration for
syncthing-service-type.syncthing(default: syncthing)syncthingpackage to use.arguments(default: ’())List of command-line arguments passing to
syncthingbinary.logflags(default: 0)Sum of logging flags, see Syncthing documentation logflags.
user(default: #f)The user as which the Syncthing service is to be run. This assumes that the specified user exists.
group(default: "users")The group as which the Syncthing service is to be run. This assumes that the specified group exists.
home(default: #f)Common configuration and data directory. The default configuration directory is $HOME of the specified Syncthing
user.
Es más, (gnu services ssh) proporciona los siguientes servicios.
- Procedimiento Scheme: lsh-service [#:host-key "/etc/lsh/host-key"] [#:daemonic? #t] [#:interfaces '()] [#:port-number 22] [#:allow-empty-passwords? #f] [#:root-login? #f] [#:syslog-output? #t] [#:x11-forwarding? #t] [#:tcp/ip-forwarding? #t] [#:password-authentication? #t] [#:public-key-authentication? #t] [#:initialize? #t]
Ejecuta el programa
lshdde lsh para escuchar en el puerto port-number. host-key debe designar a un archivo que contiene la clave de la máquina, y que sea legible únicamente por root.Cuando daemonic? es verdadero,
lshdse desligará del terminal de control y registrará su salida con syslogd, a menos que se establezca syslog-output? a falso. Obviamente, esto hace que lsh-dependa de la existencia de un servicio syslogd. Cuando pid-file? es verdadero,lshdescribe su PID al archivo llamado pid-file.Cuando initialize? es verdadero, crea automáticamente una semilla una clave de máquina una vez se active el servicio si no existen todavía. Puede tomar un tiempo prolongado y necesita interacción.
Cuando initialize? es falso, es cuestión de la usuaria la inicialización del generador aleatorio (see lsh-make-seed in LSH Manual), la creación de un par de claves y el almacenamiento de la clave privada en el archivo host-key (see lshd basics in LSH Manual).
Cuando interfaces está vacío, lshd escucha conexiones en todas las interfaces de red; en otro caso, interfaces debe ser una lista de nombres de máquina o direcciones.
allow-empty-passwords? especifica si se aceptará el ingreso al sistema con una contraseña vacía y root-login? especifica si se acepta el ingreso al sistema como root.
El resto de opciones deberían ser autodescriptivas.
- Variable Scheme: openssh-service-type
Este es el tipo para el daemon de shell seguro OpenSSH,
sshd. Su valor debe ser un registroopenssh-configurationcomo en este ejemplo:(service openssh-service-type (openssh-configuration (x11-forwarding? #t) (permit-root-login 'prohibit-password) (authorized-keys `(("alice" ,(local-file "alice.pub")) ("bob" ,(local-file "bob.pub"))))))Véase a continuación detalles sobre
openssh-configuration.Este servicio se puede extender con claves autorizadas adicionales, como en este ejemplo:
(service-extension openssh-service-type (const `(("carlos" ,(local-file "carlos.pub")))))
- Tipo de datos: openssh-configuration
Este es el registro de configuración para
sshdde OpenSSH.openssh(predeterminado: openssh)The OpenSSH package to use.
pid-file(predeterminado:"/var/run/sshd.pid")Nombre del archivo donde
sshdescribe su PID.port-number(predeterminado:22)Puerto TCP en el que
sshdespera conexiones entrantes.max-connections(default:200)Hard limit on the maximum number of simultaneous client connections, enforced by the inetd-style Shepherd service (see
make-inetd-constructorin The GNU Shepherd Manual).permit-root-login(predeterminado:#f)This field determines whether and when to allow logins as root. If
#f, root logins are disallowed; if#t, they are allowed. If it’s the symbol'prohibit-password, then root logins are permitted but not with password-based authentication.allow-empty-passwords?(predeterminado:#f)Cuando es verdadero, las usuarias con contraseñas vacías pueden ingresar en el sistema. Cuando es falso, no pueden.
password-authentication?(predeterminado:#t)Cuando es verdadero, las usuarias pueden ingresar al sistema con su contraseña. En caso falso, tienen otros métodos de identificación.
public-key-authentication?(predeterminado:#t)Cuando es verdadero, las usuarias pueden ingresar en el sistema mediante el uso de clave publica para su identificación. Cuando es falso, las usuarias tienen que usar otros métodos de identificación.
Las claves públicas autorizadas se almacenan en ~/.ssh/authorized_keys. Se usa únicamente por la versión 2 del protocolo.
x11-forwarding?(predeterminado:#f)Cuando verdadero, la retransmisión de conexiones del cliente gráfico X11 está desactivada—en otras palabras, las opciones -X y -Y de
sshfuncionarán.allow-agent-forwarding?(predeterminado:#t)Si se permite la retransmisión del agente de claves.
allow-tcp-forwarding?(predeterminado:#t)Si se permite la retransmisión TCP.
gateway-ports?(predeterminado:#f)Si se permiten los puertos pasarela.
challenge-response-authentication?(predeterminado:#f)Especifica si la identificación mediante respuesta de desafío está permitida (por ejemplo, a través de PAM).
use-pam?(predeterminado:#t)Permite el uso de la interfaz de módulos de identificación conectables (PAM). Si es
#tse activará la identificación PAM mediante el uso dechallenge-response-authentication?ypassword-authentication?, además del procesado de los módulos de cuenta usuaria y de sesión de PAM en todos los tipos de identificación.Debido a que la identificación mediante respuesta de desafío de PAM tiene un rol equivalente a la identificación por contraseña habitualmente, debería desactivar
challenge-response-authentication?opassword-authentication?.print-last-log?(predeterminado:#t)Especifica si
sshddebe imprimir la fecha y hora del último ingreso al sistema de la usuaria cuando una usuaria ingresa interactivamente.subsystems(predeterminados:'(("sftp" "internal-sftp")))Configura subsistemas externos (por ejemplo, el daemon de transmisión de archivos).
Esta es una lista de listas de dos elementos, cada una de las cuales que contienen el nombre del subsistema y una orden (con parámetros opcionales) para ejecutar tras petición del subsistema.
La orden
internal-sftpimplementa un servidor SFTP dentro del mismo proceso. De manera alternativa, se puede especificar la ordensftp-server:(service openssh-service-type (openssh-configuration (subsystems `(("sftp" ,(file-append openssh "/libexec/sftp-server"))))))accepted-environment(predeterminado:'())Una lista de cadenas que describe qué variables de entorno pueden ser exportadas.
Cada cadena obtiene su propia línea. Véase la opción
AcceptEnvenman sshd_config.Este ejemplo permite a clientes ssh exportar la variable
COLORTERM. La establecen emuladores de terminal que implementan colores. Puede usarla en su archivo de recursos del shell para permitir colores en la línea de órdenes y las propias ordenes si esta variable está definida.(service openssh-service-type (openssh-configuration (accepted-environment '("COLORTERM"))))authorized-keys(predeterminadas:'()) ¶-
Esta es la lista de claves autorizadas. Cada elemento de la lista es un nombre de usuaria seguido de uno o más objetos “tipo-archivo” que representan claves públicas SSH. Por ejemplo:
(openssh-configuration (authorized-keys `(("rekado" ,(local-file "rekado.pub")) ("chris" ,(local-file "chris.pub")) ("root" ,(local-file "rekado.pub") ,(local-file "chris.pub")))))registra las claves públicas especificadas para las cuentas
rekado,chrisyroot.Se pueden especificar claves autorizadas adicionales a través de
service-extension.Tenga en cuenta que esto no interfiere con el uso de ~/.ssh/authorized_keys.
generate-host-keys?(default:#t)Whether to generate host key pairs with
ssh-keygen -Aunder /etc/ssh if there are none.Generating key pairs takes a few seconds when enough entropy is available and is only done once. You might want to turn it off for instance in a virtual machine that does not need it because host keys are provided in some other way, and where the extra boot time is a problem.
log-level(predeterminado:'info)Es un símbolo que especifica el nivel de detalle en los registros:
quiet,fatal,error,info,verbose,debug, etc. Véase la página del manual de sshd_config para la lista completa de los nombres de nivel.extra-content(predeterminado:"")Este campo puede usarse para agregar un texto arbitrario al archivo de configuración. Es especialmente útil para configuraciones elaboradas que no se puedan expresar de otro modo. Esta configuración, por ejemplo, generalmente desactivaría el ingreso al sistema como root, pero lo permite para una dirección IP específica:
(openssh-configuration (extra-content "\ Match Address 192.168.0.1 PermitRootLogin yes"))
- Procedimiento Scheme: dropbear-service [config]
Ejecuta el daemon Dropbear SSH con la configuración proporcionada, un objeto
<dropbear-configuration>.Por ejemplo, para especificar un servicio Dropbear que escuche en el puerto 1234, añada esta llama al campo
servicesde su sistema operativo:(dropbear-service (dropbear-configuration (port-number 1234)))
- Tipo de datos: dropbear-configuration
Este tipo de datos representa la configuración del daemon Dropbear SSH.
dropbear(predeterminado: dropbear)El paquete de Dropbear usado.
port-number(predeterminado: 22)Puerto TCP donde el daemon espera conexiones entrantes.
syslog-output?(predeterminado:#t)Determina si se envía la salida a syslog.
pid-file(predeterminado:"/var/run/dropbear.pid")El nombre de archivo del archivo de PID del daemon.
root-login?(predeterminado:#f)Si se permite el ingreso al sistema como
root.allow-empty-passwords?(predeterminado:#f)Si se permiten las contraseñas vacías.
password-authentication?(predeterminado:#t)Determina si se usará identificación basada en contraseña.
- Variable Scheme: autossh-service-type
Tipo del servicio para el programa AutoSSH que ejecuta una copia de
sshy la monitoriza, reiniciando la conexión en caso de que se rompa la conexión o deje de transmitir datos. AutoSSH puede ejecutarse manualmente en la línea de órdenes proporcionando los parámetros al binarioautosshdel paqueteautossh, pero también se puede ejecutar como un servicio de Guix. Este último caso de uso se encuentra documentado aquí.AutoSSH se puede usar para retransmitir tráfico local a una máquina remota usando un túnel SSH, y respeta el archivo de configuración ~/.ssh/config de la cuenta bajo la que se ejecute.
Por ejemplo, para especificar un servicio que ejecute autossh con la cuenta
pinoy retransmita todas las conexiones locales al puerto8081haciaremote:8081usando un túnel SSH, añada esta llamada al camposervicesdel sistema operativo:(service autossh-service-type (autossh-configuration (user "pino") (ssh-options (list "-T" "-N" "-L" "8081:localhost:8081" "remote.net"))))
- Tipo de datos: autossh-configuration
Este tipo de datos representa la configuración del servicio AutoSSH.
user(predeterminado:"autossh")La cuenta de usuaria con la cual se ejecuta el servicio AutoSSH. Se asume que existe dicha cuenta.
poll(predeterminado:600)Especifica el tiempo de comprobación de la conexión en segundos.
first-poll(predeterminado:#f)Especifica cuantos segundos espera AutoSSH antes de la primera prueba de conexión. Tras esta primera prueba las comprobaciones se realizan con la frecuencia definida en
poll. Cuando se proporciona el valor#fla primera comprobación no se trata de manera especial y también usará el valor especificado enpoll.gate-time(predeterminado:30)Especifica cuantos segundos debe estar activa una conexión SSH antes de que se considere satisfactoria.
log-level(predeterminado:1)El nivel de registro, corresponde con los niveles usados por—por lo que
0es el más silencioso y7el que contiene más información.max-start(predeterminado:#f)El número de veces máximo que puede lanzarse (o reiniciarse) SSH antes de que AutoSSH termine. Cuando se proporciona
#f, no existe un máximo por lo que AutoSSH puede reiniciar la conexión indefinidamente.message(predeterminado:"")El mensaje que se añade al mensaje de eco que se envía cuando se prueban las conexiones.
port(predeterminado:"0")Los puertos usados para la monitorización de la conexión. Cuando se proporciona
"0", se desactiva la monitorización. Cuando se proporciona"n"donde n es un entero positivo, los puertos n y n+1 se usan para monitorizar la conexión, de tal modo que el puerto n es el puerto base de monitorización yn+1es el puerto de eco. Cuando se proporciona"n:m"donde n y m son enteros positivos, los puertos n y m se usan para monitorizar la conexión, de tal modo que n es el puerto base de monitorización y m es el puerto de eco.ssh-options(predeterminados:'())Lista de parámetros de línea de órdenes proporcionados a
sshcuando se ejecuta. Las opciones -f y -M están reservadas para AutoSSH y pueden causar un comportamiento indefinido.
- Variable Scheme: webssh-service-type
Tipo para el programa WebSSH que ejecuta un cliente SSH web. WebSSH puede ejecutarse manualmente en la línea de órdenes proporcionando los parámetros al binario
wsshdel paquetewebssh, pero también se puede ejecutar como un servicio de Guix. Este último caso de uso se encuentra documentado aquí.Por ejemplo, para especificar un servicio que ejecute WebSSH en la interfaz de red local sobre el puerto
8888con una política de rechazo predeterminado con una lista de máquinas a las que se les permite explícitamente la conexión, y NGINX como pasarela inversa de este servicio a la escucha de conexiones HTTPS, añada esta llamada al camposervicesde su declaración de sistema operativo:(service webssh-service-type (webssh-configuration (address "127.0.0.1") (port 8888) (policy 'reject) (known-hosts '("localhost ecdsa-sha2-nistp256 AAAA…" "127.0.0.1 ecdsa-sha2-nistp256 AAAA…")))) (service nginx-service-type (nginx-configuration (server-blocks (list (nginx-server-configuration (inherit %webssh-configuration-nginx) (server-name '("webssh.example.com")) (listen '("443 ssl")) (ssl-certificate (letsencrypt-certificate "webssh.example.com")) (ssl-certificate-key (letsencrypt-key "webssh.example.com")) (locations (cons (nginx-location-configuration (uri "/.well-known") (body '("root /var/www;"))) (nginx-server-configuration-locations %webssh-configuration-nginx))))))))
- Tipo de datos: webssh-configuration
Tipo de datos que representa la configuración para
webssh-service.package(predeterminado: webssh)Paquete
websshusado.user-name(predeterminado: "webssh")Nombre o ID de usuaria bajo la cual se efectúan las transferencias desde y hacia el módulo.
group-name(predeterminado: "webssh")Nombre o ID de grupo que se usa cuando se accede al módulo.
address(predeterminada: #f)Dirección IP en la que
websshespera conexiones entrantes.port(predeterminado: 8888)Puerto TCP en el que
websshespera conexiones entrantes.policy(predeterminada: #f)Política de conexión. La política reject necesita que se especifique un valor en known-hosts.
known-hosts(predeterminada: ’())Lista de máquinas a las que se permite realizar conexiones SSH desde
webssh.log-file(predeterminado: "/var/log/webssh.log")Name of the file where
websshwrites its log file.log-level(predeterminado: #f)Nivel de registro.
- Variable Scheme: %facebook-host-aliases
Esta variable contiene una cadena para su uso en /etc/hosts (see Host Names in The GNU C Library Reference Manual). Cada línea contiene una entrada que asocia un nombre de servidor conocido del servicio en línea Facebook—por ejemplo,
www.facebook.com—a la máquina local—127.0.0.1o su equivalente IPv6,::1.Esta variable habitualmente se usa en el campo
hosts-filede una declaraciónoperating-system(see /etc/hosts):(use-modules (gnu) (guix)) (operating-system (host-name "micompu") ;; ... (hosts-file ;; Crea un archivo /etc/hosts file con alias para "localhost" ;; y "micompu", así como los servidores de facebook. (plain-file "hosts" (string-append (local-host-aliases host-name) %facebook-host-aliases))))
Este mecanismo puede impedir a los programas que se ejecutan localmente, como navegadores Web, el acceso a Facebook.
El módulo (gnu services avahi) proporciona la siguiente definición.
- Variable Scheme: avahi-service-type
Es el servicio que ejecuta
avahi-daemon, un servidor mDNS/DNS-SD a nivel del sistema que permite el descubrimiento de servicios y la búsqueda de nombres de máquina “sin configuración” (“zero-configuration”, véase https://avahi.org/). Su valor debe ser un registroavahi-configuration—véase a continuación.Este servicio extiende el daemon de la caché del servicio de nombres (nscd) de manera que pueda resolver nombres de máquina
.localmediante el uso de nss-mds. See Selector de servicios de nombres, para información sobre la resolución de nombres de máquina.De manera adicional, añade el paquete avahi al perfil del sistema de manera que ordenes como
avahi-browseestén disponibles de manera directa.
- Tipo de datos: avahi-configuration
Tipo de datos que representa la configuración de Avahi.
host-name(predeterminado:#f)Si es diferente de
#f, se usa como el nombre de máquina a publicar para esta máquina; en otro caso, usa el nombre actual de la máquina.publish?(predeterminado:#t)Cuando es verdadero, permite la publicación (retransmisión) de nombres de máquina y servicios a través de la red.
publish-workstation?(predeterminado:#t)Cuando es verdadero,
avahi-daemonpublica el nombre de máquina y la dirección IP a través de mDNS en la red local. Para ver los nombres de máquina publicados en su red local, puede ejecutar:avahi-browse _workstation._tcp
wide-area?(predeterminado:#f)Cuando es verdadero, se permite DNS-SD sobre DNS unicast.
ipv4?(predeterminado:#t)ipv6?(predeterminado:#t)Estos campos determinan si usar sockets IPv4/IPv6.
domains-to-browse(predeterminado:'())Esta es la lista de dominios a explorar.
- Variable Scheme: openvswitch-service-type
Este es el tipo del servicio Open vSwitch, cuyo valor debe ser un objeto
openvswitch-configuration.
- Tipo de datos: openvswitch-configuration
Tipo de datos que representa la configuración de Open vSwitch, un switch virtual multicapa que está diseñado para permitir una automatización masiva en la red a través de extensión programática.
package(predeterminado: openvswitch)El objeto paquete de Open vSwitch.
- Variable Scheme: pagekite-service-type
El tipo de servicio para el servicio PageKite, una solución de encaminado para hacer servidores de la red local visibles públicamente, incluso detrás de cortafuegos restrictivos o NAT sin redirección de puertos. El valor para este servicio es un registro
pagekite-configuration.Este es un ejemplo que expone los daemon HTTP y SSH locales:
(service pagekite-service-type (pagekite-configuration (kites '("http:@kitename:localhost:80:@kitesecret" "raw/22:@kitename:localhost:22:@kitesecret")) (extra-file "/etc/pagekite.rc")))
- Tipo de datos: pagekite-configuration
Tipo de datos que representa la configuración de PageKite.
package(predeterminado: pagekite)El objeto paquete de PageKite.
kitename(predeterminado:#f)Nombre de PageKite para la identificación con el servidor de fachada.
kitesecret(predeterminado:#f)Secreto compartido para la comunicación con el servidor. Probablemente debería almacenarlo dentro
extra-fileen vez de aquí.frontend(predeterminado:#f)Conecta al servidor de fachada de PageKite con este nombre en vez de al servicio de pagekite.net.
kites(predeterminados:'("http:@kitename:localhost:80:@kitesecret"))List of service kites to use. Exposes HTTP on port 80 by default. The format is
proto:kitename:host:port:secret.extra-file(predeterminado:#f)Archivo adicional de configuración que debe leerse, el cual se espera que sea creado de forma manual. Úselo para añadir opciones adicionales y gestionar secretos compartidos fuera de banda.
- Scheme Variable: yggdrasil-service-type
The service type for connecting to the Yggdrasil network, an early-stage implementation of a fully end-to-end encrypted IPv6 network.
Yggdrasil provides name-independent routing with cryptographically generated addresses. Static addressing means you can keep the same address as long as you want, even if you move to a new location, or generate a new address (by generating new keys) whenever you want. https://yggdrasil-network.github.io/2018/07/28/addressing.html
Pass it a value of
yggdrasil-configurationto connect it to public peers and/or local peers.Here is an example using public peers and a static address. The static signing and encryption keys are defined in /etc/yggdrasil-private.conf (the default value for
config-file).;; part of the operating-system declaration (service yggdrasil-service-type (yggdrasil-configuration (autoconf? #f) ;; use only the public peers (json-config ;; choose one from ;; https://github.com/yggdrasil-network/public-peers '((peers . #("tcp://1.2.3.4:1337")))) ;; /etc/yggdrasil-private.conf is the default value for config-file ))
# sample content for /etc/yggdrasil-private.conf { # Your public key. Your peers may ask you for this to put # into their AllowedPublicKeys configuration. PublicKey: 64277... # Your private key. DO NOT share this with anyone! PrivateKey: 5c750... }
- Data Type: yggdrasil-configuration
Data type representing the configuration of Yggdrasil.
package(default:yggdrasil)Package object of Yggdrasil.
json-config(default:'())Contents of /etc/yggdrasil.conf. Will be merged with /etc/yggdrasil-private.conf. Note that these settings are stored in the Guix store, which is readable to all users. Do not store your private keys in it. See the output of
yggdrasil -genconffor a quick overview of valid keys and their default values.autoconf?(default:#f)Whether to use automatic mode. Enabling it makes Yggdrasil use adynamic IP and peer with IPv6 neighbors.
log-level(predeterminado:'info)How much detail to include in logs. Use
'debugfor more detail.log-to(default:'stdout)Where to send logs. By default, the service logs standard output to /var/log/yggdrasil.log. The alternative is
'syslog, which sends output to the running syslog service.config-file(default:"/etc/yggdrasil-private.conf")What HJSON file to load sensitive data from. This is where private keys should be stored, which are necessary to specify if you don’t want a randomized address after each restart. Use
#fto disable. Options defined in this file take precedence overjson-config. Use the output ofyggdrasil -genconfas a starting point. To configure a static address, delete everything except these options:-
EncryptionPublicKey -
EncryptionPrivateKey -
SigningPublicKey -
SigningPrivateKey
-
- Scheme Variable: ipfs-service-type
The service type for connecting to the IPFS network, a global, versioned, peer-to-peer file system. Pass it a
ipfs-configurationto change the ports used for the gateway and API.Here’s an example configuration, using some non-standard ports:
(service ipfs-service-type (ipfs-configuration (gateway "/ip4/127.0.0.1/tcp/8880") (api "/ip4/127.0.0.1/tcp/8881")))
- Data Type: ipfs-configuration
Data type representing the configuration of IPFS.
package(default:go-ipfs)Package object of IPFS.
gateway(default:"/ip4/127.0.0.1/tcp/8082")Address of the gateway, in ‘multiaddress’ format.
api(default:"/ip4/127.0.0.1/tcp/5001")Address of the API endpoint, in ‘multiaddress’ format.
- Scheme Variable: keepalived-service-type
This is the type for the Keepalived routing software,
keepalived. Its value must be ankeepalived-configurationrecord as in this example for master machine:(service keepalived-service-type (keepalived-configuration (config-file (local-file "keepalived-master.conf"))))where keepalived-master.conf:
vrrp_instance my-group { state MASTER interface enp9s0 virtual_router_id 100 priority 100 unicast_peer { 10.0.0.2 } virtual_ipaddress { 10.0.0.4/24 } }and for backup machine:
(service keepalived-service-type (keepalived-configuration (config-file (local-file "keepalived-backup.conf"))))where keepalived-backup.conf:
vrrp_instance my-group { state BACKUP interface enp9s0 virtual_router_id 100 priority 99 unicast_peer { 10.0.0.3 } virtual_ipaddress { 10.0.0.4/24 } }
Next: Sistema X Window, Previous: Servicios de red, Up: Servicios [Contents][Index]
12.9.6 Actualizaciones no-atendidas
Guix proporciona un servicio para realizar actualizaciones desatendidas: periodicamente el sistema se reconfigura automáticamente con la última revisión de Guix. El sistema Guix tiene varias propiedades que hacen que las actualizaciones desatendidas sean seguras:
- las actualizaciones son transaccionales (o bien la actualización se lleva a cabo con éxito o bien falla, pero no puede acabar en un estado “intermedio” del sistema);
- el registro de actualizaciones se mantiene—puede acceder a dicho registro
con
guix system list-generations—y puede volver a una generación previa, en caso de que alguna generación no funcione como desee; - el código del canal se verifica de modo que únicamente pueda ejecutar código que ha sido firmado (see Canales);
-
guix system reconfigureevita la instalación de versiones previas, que lo hace inmune a ataques de versión anterior.
Para configurar las actualizaciones desatendidas, añada una instancia de
unattended-upgrade-service-type como la que se muestra a continuación
a la lista de servicios de su sistema operativo:
El valor predeterminado configura actualizaciones semanales: cada domingo a medianoche. No es necesario que proporcione el archivo de configuración de su sistema operativo: el servicio usa /run/current-system/configuration.scm, lo que asegura el uso de su última configuración—see provenance-service-type, para obtener más información sobre este archivo.
Hay varios aspectos que se pueden configurar, en particular la periodicidad
y los servicios (daemon) que se reiniciarán tras completar la
actualización. Cuando la actualización se lleva a cabo satisfactoriamente el
servicio se encarga de borrar las generaciones del sistema cuya antigüedad
es superior a determinado valor, usando guix system
delete-generations. Véase la referencia a continuación para obtener más
detalles.
Para asegurar que las actualizaciones se están levando a cabo realmente,
puede ejecutar guix system describe. Para investigar fallos en las
actualizaciones, visite el archivo de registro de las actualizaciones
desatendidas (véase a continuación).
- Variable Scheme: unattended-upgrade-service-type
Es el tipo de servicio para las actualizaciones desatendidas. Configura un trabajo de mcron (see Ejecución de tareas programadas) que ejecuta
guix system reconfigurea partir de la última versión de los canales especificados.Su valor debe ser un registro
unattended-upgrade-configuration(véase a continuación).
- Tipo de datos: unattended-upgrade-configuration
Este tipo de datos representa la configuración del servicio de actualizaciones desatendidas. Los siguientes campos están disponibles:
schedule(predeterminada:"30 01 * * 0")La planificación de las actualizaciones, expresada en una expresión-G que contiene una planificación de trabajo de mcron (see mcron job specifications in GNU mcron).
channels(predeterminada:#~%default-channels)Esta expresión-G especifica los canales usados para la actualización (see Canales). De manera predeterminada, se usa la última revisión del canal oficial
guix.operating-system-file(predeterminado:"/run/current-system/configuration.scm")Este campo especifica el archivo de configuración del sistema operativo usado. El valor predeterminado reutiliza el archivo de configuración de la configuración actual.
No obstante hay casos en los que no es suficiente hacer referencia a /run/current-system/configuration.scm, por ejemplo porque dicho archivo hace referencia a archivos adicionales (claves públicas de SSH, archivos de configuración adicionales, etcétera) a través de
local-filey construcciones similares. Para estos casos recomendamos una configuración parecida a esta:(unattended-upgrade-configuration (operating-system-file (file-append (local-file "." "config-dir" #:recursive? #t) "/config.scm")))El efecto que esto tiene es la importación del directorio actual al completo en el almacén, y hace referencia a config.scm dentro de dicho directorio. Por lo tanto, los usos de
local-filedentro de config.scm funcionarán como se espera. See Expresiones-G para más información acerca delocal-fileyfile-append.services-to-restart(predeterminados:'(mcron))Este campo especifica los servicios de Shepherd que se reiniciarán cuando se complete una actualización.
Estos servicios se reinician tras completarse la actualización, como ejecutando
herd restart, lo que asegura la ejecución de la última versión—recuerde que de manera predeterminadaguix system reconfigureúnicamente reinicia los servicios que no se están ejecutando en este momento, lo que es una aproximación conservadora: minimiza la disrupción pero mantiene servicios en ejecución con código previo a la actualización.Use
herd statusto find out candidates for restarting. See Servicios, for general information about services. Common services to restart would includentpdandssh-daemon.De manera predeterminada se reinicia el servicio
mcron. Esto asegura que la última versión del trabajo de actualización desatendida será la que se use la próxima vez.system-expiration(predeterminado:(* 3 30 24 3600))Tiempo de expiración en segundos de las generaciones del sistema. Las generaciones del sistema cuya antigüedad sea mayor que esta cantidad de tiempo se borran con
guix system delete-generationscuando se completa una actualización.Nota: El servicio de actualizaciones desatendidas no ejecuta el proceso de recolección de basura. Probablemente quiera añadir su propio trabajo a mcron para ejecutar
guix gcde manera periódica.maximum-duration(predeterminado:3600)Duración máxima en segundos de la actualización; tras pasar este tiempo se aborta la actualización.
Esto es útil principalmente para asegurar que una actualización no reconstruye o vuelve a descargarse “el mundo entero”.
log-file(predeterminado:"/var/log/unattended-upgrade.log")Archivo donde se registran las actualizaciones desatendidas.
Next: Servicios de impresión, Previous: Actualizaciones no-atendidas, Up: Servicios [Contents][Index]
12.9.7 Sistema X Window
El sistema gráfico X Window—específicamente Xorg—se proporciona en el
módulo (gnu services xorg). Fíjese que no existe un procedimiento
xorg-service. En vez de eso, el servidor X se inicia por el
gestor de ingreso al sistema, de manera predeterminada el gestor de
acceso de GNOME (GDM).
GDM por supuesto que permite a las usuarias ingresar al sistema con gestores de ventanas y entornos de escritorio distintos a GNOME; para aquellas que usan GNOME, GDM es necesario para características como el bloqueo automático de pantalla.
Para usar X11, debe instalar al menos un gestor de ventanas—por
ejemplo los paquetes windowmaker o openbox—, preferiblemente
añadiendo el que desee al campo packages de su definición de sistema
operativo (see paquetes del sistema).
GDM also supports Wayland: it can itself use Wayland instead of X11 for its
user interface, and it can also start Wayland sessions. The former is
required for the latter, to enable, set wayland? to #t in
gdm-configuration.
- Variable Scheme: gdm-service-type
Este es el tipo para el gestor de acceso de GNOME (GDM), un programa que gestiona servidores gráficos y maneja de forma gráfica el ingreso al sistema de usuarias. Su valor debe ser un
gdm-configuration(véase a continuación).GDM looks for session types described by the .desktop files in /run/current-system/profile/share/xsessions (for X11 sessions) and /run/current-system/profile/share/wayland-sessions (for Wayland sessions) and allows users to choose a session from the log-in screen. Packages such as
gnome,xfce,i3andswayprovide .desktop files; adding them to the system-wide set of packages automatically makes them available at the log-in screen.Además, se respetan los archivos ~/.xsession. Cuando esté disponible, ~/.xsession debe ser un ejecutable que inicie un gestor de ventanas y/o otros clientes de X.
- Tipo de datos: gdm-configuration
auto-login?(predeterminado:#f)default-user(predeterminado:#f)Cuando
auto-login?es falso, GDM presenta una pantalla de ingreso.Cuando
auto-login?es verdadero, GDM ingresa directamente al sistema comodefault-user.auto-suspend?(default#t)When true, GDM will automatically suspend to RAM when nobody is physically connected. When a machine is used via remote desktop or SSH, this should be set to false to avoid GDM interrupting remote sessions or rendering the machine unavailable.
debug?(predeterminado:#f)Cuando tiene valor verdadero, GDM escribe los mensajes de depuración en su registro.
gnome-shell-assets(predeterminados: ...)Lista de activos de GNOME Shell necesarios para GDM: tema de iconos, fuentes, etc.cc
xorg-configuration(predeterminada:(xorg-configuration))Configuración del servidor gráfico Xorg.
x-session(default:(xinitrc))Guión a ejecutar antes de iniciar una sesión X.
xdmcp?(default:#f)When true, enable the X Display Manager Control Protocol (XDMCP). This should only be enabled in trusted environments, as the protocol is not secure. When enabled, GDM listens for XDMCP queries on the UDP port 177.
dbus-daemon(predeterminado:dbus-daemon-wrapper)El nombre de archivo del ejecutable
dbus-daemon.gdm(predeterminado:gdm)El paquete GDM usado.
wayland?(default:#f)When true, enables Wayland in GDM, necessary to use Wayland sessions.
wayland-session(default:gdm-wayland-session-wrapper)The Wayland session wrapper to use, needed to setup the environment.
- Variable Scheme: slim-service-type
Este es el tipo para el gestor de ingreso al sistema gráfico para X11 SLiM.
Como GDM, SLiM busca tipos de sesión descritos por archivos .desktop y permite a las usuarias la selección de sesión en la pantalla de ingreso al sistema mediante el uso de F1. También respeta los archivos ~/.xsession.
Al contrario que GDM, SLiM no lanza las sesiones de las usuarias en terminales virtuales diferentes al usado para el ingreso, lo que significa que únicamente puede iniciar una sesión gráfica. Si desea ejecutar varias sesiones gráficas de manera simultánea, debe añadir múltiples servicios de SLiM a los servicios de su sistema. El ejemplo siguiente muestra cómo sustituir el servicio GDM predeterminado con dos servicios de SLiM en tty7 y tty8.
(use-modules (gnu services) (gnu services desktop) (gnu services xorg)) (operating-system ;; ... (services (cons* (service slim-service-type (slim-configuration (display ":0") (vt "vt7"))) (service slim-service-type (slim-configuration (display ":1") (vt "vt8"))) (modify-services %desktop-services (delete gdm-service-type)))))
- Tipo de datos: slim-configuration
Tipo de datos que representa la configuración de
slim-service-type.allow-empty-passwords?(predeterminado:#t)Si se permite el ingreso al sistema con contraseñas vacías.
gnupg?(default:#f)If enabled,
pam-gnupgwill attempt to automatically unlock the user’s GPG keys with the login password viagpg-agent. The keygrips of all keys to be unlocked should be written to ~/.pam-gnupg, and can be queried withgpg -K --with-keygrip. Presetting passphrases must be enabled by addingallow-preset-passphrasein ~/.gnupg/gpg-agent.conf.auto-login?(predeterminado:#f)default-user(predeterminado:"")Cuando
auto-login?es falso, SLiM presenta una pantalla de ingreso.Cuando
auto-login?es verdadero, SLiM ingresa en el sistema directamente comodefault-user.theme(predeterminado:%default-slim-theme)theme-name(predeterminado:%default-slim-theme-name)El tema gráfico usado y su nombre.
auto-login-session(predeterminado:#f)Si es verdadero, debe ser el nombre del ejecutable a arrancar como la sesión predeterminada—por ejemplo,
(file-append windowmaker "/bin/windowmaker").Si es falso, se usará una sesión de las descritas en uno de los archivos .desktop disponibles en
/run/current-system/profiley~/.guix-profile.Nota: Debe instalar al menos un gestor de ventanas en el perfil del sistema o en su perfil de usuaria. En caso de no hacerlo, si
auto-login-sessiones falso, no podrá ingresar al sistema.xorg-configuration(predeterminada(xorg-configuration))Configuración del servidor gráfico Xorg.
display(predeterminada:":0")La pantalla en la que se iniciará el servidor gráfico Xorg.
vt(predeterminado:"vt7")El terminal virtual (VT) en el que se iniciará el servidor gráfico Xorg.
xauth(predeterminado:xauth)El paquete XAuth usado.
shepherd(predeterminado:shepherd)El paquete de Shepherd usado para la invocación de
haltyreboot.sessreg(predeterminado:sessreg)El paquete sessreg usado para el registro de la sesión.
slim(predeterminado:slim)El paquete SLiM usado.
- Variable Scheme: %default-theme
- Variable Scheme: %default-theme-name
El tema predeterminado de SLiM y su nombre.
- Variable Scheme: sddm-service-type
Es el tipo del servicio que ejecuta el gestor de entrada SDDM. Su valor es un registro
sddm-configuration(véase a continuación).Este es un ejemplo de su uso:
(service sddm-service-type (sddm-configuration (auto-login-user "alicia") (auto-login-session "xfce.desktop")))
- Tipo de datos: sddm-configuration
Este tipo de datos representa la configuración del gestor de ingreso al sistema SDDM. Los campos disponibles son:
sddm(predeterminado:sddm)El paquete SDDM usado.
display-server(predeterminado: "x11")Selecciona el servidor de pantalla usado para el saludo. Los valores validos son ‘"x11"’ o ‘"wayland"’.
numlock(predeterminado: "on")Son valores válidos ‘"on"’, ‘"off"’ o ‘"none"’.
halt-command(default#~(string-append #$shepherd "/sbin/halt"))Orden a ejecutar para parar el sistema.
reboot-command(predeterminado#~(string-append #$shepherd "/sbin/reboot"))Orden a ejecutar para reiniciar el sistema.
theme(predeterminado "maldives")Tema usado. Los temas predeterminados proporcionados por SDDM son ‘"elarun"’, ‘"maldives"’ o ‘"maya"’.
themes-directory(predeterminado "/run/current-system/profile/share/sddm/themes")Directorio en el que buscar temas.
faces-directory(predeterminado "/run/current-system/profile/share/sddm/faces")Directorio en el que buscar caras.
default-path(predeterminado "/run/current-system/profile/bin")El valor predeterminado del PATH.
minimum-uid(predeterminado: 1000)UID mínimo mostrado en SDDM y al que se le permite el acceso.
maximum-uid(predeterminado: 2000)UID máximo mostrado en SDDM.
remember-last-user?(predeterminado #t)Recuerda la última usuaria.
remember-last-session?(predeterminado #t)Recuerda la última sesión.
hide-users(predeterminado "")Nombres de usuaria a ocultar de la pantalla de inicio de SDDM.
hide-shells(predeterminado#~(string-append #$shadow "/sbin/nologin"))Las usuarias que tengan alguno de los shell enumerados se ocultarán de la pantalla de inicio de SDDM.
session-command(predeterminado#~(string-append #$sddm "/share/sddm/scripts/wayland-session"))Guión a ejecutar antes de iniciar una sesión wayland.
sessions-directory(predeterminado "/run/current-system/profile/share/wayland-sessions")Directorio en el que buscar archivos desktop que inicien sesiones wayland.
xorg-configuration(predeterminada(xorg-configuration))Configuración del servidor gráfico Xorg.
xauth-path(predeterminado#~(string-append #$xauth "/bin/xauth"))Ruta de xauth.
xephyr-path(predeterminado#~(string-append #$xorg-server "/bin/Xephyr"))Ruta de Xephyr.
xdisplay-start(predeterminado#~(string-append #$sddm "/share/sddm/scripts/Xsetup"))Guión a ejecutar tras iniciar xorg-server.
xdisplay-stop(predeterminado#~(string-append #$sddm "/share/sddm/scripts/Xstop"))Guión a ejecutar antes de parar xorg-server.
xsession-command(predeterminado:xinitrc)Guión a ejecutar antes de iniciar una sesión X.
xsessions-directory(predeterminado: "/run/current-system/profile/share/xsessions")Directorio para buscar archivos desktop que inicien sesiones X.
minimum-vt(predeterminado: 7)VT mínimo usado.
auto-login-user(predeterminado "")User account that will be automatically logged in. Setting this to the empty string disables auto-login.
auto-login-session(predeterminado "")The .desktop file name to use as the auto-login session, or the empty string.
relogin?(predeterminado #f)Volver a ingresar en el sistema tras salir.
- Scheme Variable: lightdm-service-type
This is the type of the service to run the LightDM display manager. Its value must be a
lightdm-configurationrecord, which is documented below. Among its distinguishing features are TigerVNC integration for easily remoting your desktop as well as support for the XDMCP protocol, which can be used by remote clients to start a session from the login manager.In its most basic form, it can be used simply as:
A more elaborate example making use of the VNC capabilities and enabling more features and verbose logs could look like:
(service lightdm-service-type (lightdm-configuration (allow-empty-passwords? #t) (xdmcp? #t) (vnc-server? #t) (vnc-server-command (file-append tigervnc-server "/bin/Xvnc" " -SecurityTypes None")) (seats (list (lightdm-seat-configuration (name "*") (user-session "ratpoison"))))))
- Data Type: lightdm-configuration
Available
lightdm-configurationfields are:lightdm(default:lightdm) (type: file-like)The lightdm package to use.
allow-empty-passwords?(default:#f) (type: boolean)Whether users not having a password set can login.
debug?(default:#f) (type: boolean)Enable verbose output.
xorg-configuration(type: xorg-configuration)The default Xorg server configuration to use to generate the Xorg server start script. It can be refined per seat via the
xserver-commandof the<lightdm-seat-configuration>record, if desired.greeters(type: list-of-greeter-configurations)The LightDM greeter configurations specifying the greeters to use.
seats(type: list-of-seat-configurations)The seat configurations to use. A LightDM seat is akin to a user.
xdmcp?(default:#f) (type: boolean)Whether a XDMCP server should listen on port UDP 177.
xdmcp-listen-address(type: maybe-string)The host or IP address the XDMCP server listens for incoming connections. When unspecified, listen on for any hosts/IP addresses.
vnc-server?(default:#f) (type: boolean)Whether a VNC server is started.
vnc-server-command(type: file-like)The Xvnc command to use for the VNC server, it’s possible to provide extra options not otherwise exposed along the command, for example to disable security:
(vnc-server-command (file-append tigervnc-server "/bin/Xvnc" " -SecurityTypes None" ))Or to set a PasswordFile for the classic (unsecure) VncAuth mecanism:
(vnc-server-command (file-append tigervnc-server "/bin/Xvnc" " -PasswordFile /var/lib/lightdm/.vnc/passwd"))The password file should be manually created using the
vncpasswdcommand. Note that LightDM will create new sessions for VNC users, which means they need to authenticate in the same way as local users would.vnc-server-listen-address(type: maybe-string)The host or IP address the VNC server listens for incoming connections. When unspecified, listen for any hosts/IP addresses.
vnc-server-port(default:5900) (type: number)The TCP port the VNC server should listen to.
extra-config(default:()) (type: list-of-strings)Extra configuration values to append to the LightDM configuration file.
- Data Type: lightdm-gtk-greeter-configuration
Available
lightdm-gtk-greeter-configurationfields are:lightdm-gtk-greeter(default:lightdm-gtk-greeter) (type: file-like)The lightdm-gtk-greeter package to use.
assets(default:
(adwaita-icon-theme gnome-themes-extrahicolor-icon-theme)) (type: list-of-file-likes) The list of packages complementing the greeter, such as package providing icon themes.theme-name(default:"Adwaita") (type: string)The name of the theme to use.
icon-theme-name(default:"Adwaita") (type: string)The name of the icon theme to use.
cursor-theme-name(default:"Adwaita") (type: string)The name of the cursor theme to use.
cursor-theme-size(default:16) (type: number)The size to use for the cursor theme.
allow-debugging?(type: maybe-boolean)Set to #t to enable debug log level.
background(type: file-like)The background image to use.
at-spi-enabled?(default:#f) (type: boolean)Enable accessibility support through the Assistive Technology Service Provider Interface (AT-SPI).
a11y-states(default:
(contrast font keyboard reader)) (type: list-of-a11y-states) The accessibility features to enable, given as list of symbols.reader(type: maybe-file-like)The command to use to launch a screen reader.
extra-config(default:()) (type: list-of-strings)Extra configuration values to append to the LightDM GTK Greeter configuration file.
- Data Type: lightdm-seat-configuration
Available
lightdm-seat-configurationfields are:name(type: seat-name)The name of the seat. An asterisk (*) can be used in the name to apply the seat configuration to all the seat names it matches.
user-session(type: maybe-string)The session to use by default. The session name must be provided as a lowercase string, such as
"gnome","ratpoison", etc.type(default:local) (type: seat-type)The type of the seat, either the
localorxremotesymbol.autologin-user(type: maybe-string)The username to automatically log in with by default.
greeter-session(default:
lightdm-gtk-greeter) (type: greeter-session) The greeter session to use, specified as a symbol. Currently, onlylightdm-gtk-greeteris supported.xserver-command(type: maybe-file-like)The Xorg server command to run.
session-wrapper(type: file-like)The xinitrc session wrapper to use.
extra-config(default:()) (type: list-of-strings)Extra configuration values to append to the seat configuration section.
- Tipo de datos: xorg-configuration
This data type represents the configuration of the Xorg graphical display server. Note that there is no Xorg service; instead, the X server is started by a “display manager” such as GDM, SDDM, LightDM or SLiM. Thus, the configuration of these display managers aggregates an
xorg-configurationrecord.modules(predeterminados:%default-xorg-modules)Esta es la lista de paquetes de módulos cargados por el servidor Xorg—por ejemplo,
xf86-video-vesa,xf86-input-keyboard, etcétera.fonts(predeterminadas:%default-xorg-fonts)Es una lista de directorios de tipografías a añadir a la ruta de tipografías del servidor.
drivers(predeterminados:'())Debe ser o bien la lista vacía, en cuyo caso Xorg selecciona el controlador gráfico automáticamente, o una lista de nombres de controladores que se intentarán en el orden especificado—por ejemplo,
("modesetting" "vesa").resolutions(predeterminadas:'())Cuando
resolutionses la lista vacía, Xorg selecciona una resolución de pantalla adecuada. En otro caso, debe ser una lista de resoluciones—por ejemplo,((1024 768) (640 480)).keyboard-layout(predeterminada:#f)Si es
#f, Xorg usa la distribución de teclado predeterminada—normalmente inglés de EEUU (“qwerty”) para un teclado de PC de 105 teclas.En otro caso, debe ser un objeto
keyboard-layoutque especifique la distribución de teclado usada para la ejecución de Xorg. See Distribución de teclado, para más información sobre cómo especificar la distribución de teclado.extra-config(predeterminada:'())Es una lista de cadenas u objetos añadida al final del archivo de configuración. Se usa para proporcionar texto adicional para ser introducido de forma literal en el archivo de configuración.
server(predeterminado:xorg-server)Este es el paquete que proporciona el servidor Xorg.
server-arguments(predeterminados:%default-xorg-server-arguments)Es la lista de parámetros de línea de órdenes que se proporcionarán al servidor X. El valor predeterminado es
-nolisten tcp.
- Procedimiento Scheme: set-xorg-configuration config [tipo-de-servicio-del-gestor-de-pantalla]
-
Le dice al gestor de pantalla (de tipo tipo-de-servicio-del-gestor-de-pantalla) que use config, un registro
<xorg-configuration>.Debido a que la configuración de Xorg se embebe en la configuración del gestor de ingreso en el sistema—por ejemplo,
gdm-configuration—este procedimiento proporciona un atajo para establecer la configuración de Xorg.
- Procedimiento Scheme: xorg-start-command [config]
Devuelve un script
startxen el que los módulos, las tipografías, etcétera, especificadas en config están disponibles. El resultado debe usarse en lugar destartx.Habitualmente el servidor X es iniciado por un gestor de ingreso al sistema.
- Procedimiento Scheme: screen-locker-service paquete [programa]
Añade paquete, un paquete para un bloqueador de sesión o un salvapantallas cuya orden es programa, al conjunto de programas setuid y añade una entrada PAM para él. Por ejemplo:
(screen-locker-service xlockmore "xlock")permite usar el viejo XlockMore.
Next: Servicios de escritorio, Previous: Sistema X Window, Up: Servicios [Contents][Index]
12.9.8 Servicios de impresión
El módulo (gnu services cups) proporciona una definición de servicio
Guix para el servicio de impresión CUPS. Para usar impresoras en un sistema
Guix, añada un servicio cups-service en su definición de sistema
operativo:
- Variable Scheme: cups-service-type
El tipo de servicio para el servidor de impresión CUPS. Su valor debe ser una configuración de CUPS válida (véase a continuación). Para usar la configuración predeterminada, simplemente escriba:
La configuración de CUPS controla los aspectos básicos de su instalación de CUPS: sobre qué interfaces se escuchará, qué hacer si falla un trabajo de impresión, cuanta información registrar, etcétera. Para realmente añadir una impresora, debe visitar la URL http://localhost:631, o usar una herramienta como los servicios de configuración de impresión de GNOME. De manera predeterminada, la configuración de un servicio CUPS generará un certificado auto-firmado en caso de ser necesario, para ofrecer conexiones seguras con el servidor de impresión.
Suppose you want to enable the Web interface of CUPS and also add support
for Epson printers via the epson-inkjet-printer-escpr package and
for HP printers via the hplip-minimal package. You can do that
directly, like this (you need to use the (gnu packages cups) module):
(service cups-service-type
(cups-configuration
(web-interface? #t)
(extensions
(list cups-filters epson-inkjet-printer-escpr hplip-minimal))))
Nota: If you wish to use the Qt5 based GUI which comes with the hplip package then it is suggested that you install the
hplippackage, either in your OS configuration file or as your user.
A continuación se encuentran los parámetros de configuración disponibles. El
tipo de cada parámetro antecede la definición del mismo; por ejemplo,
‘string-list foo’ indica que el parámetro foo debe especificarse
como una lista de cadenas. También existe la posibilidad de especificar la
configuración como una cadena, si tiene un archivo cupsd.conf antiguo
que quiere trasladar a otro sistema; véase el final para más detalles.
Los campos disponibles de cups-configuration son:
- parámetro de
cups-configuration: package cups ¶ El paquete CUPS.
cups-configurationparameter: package-list extensions (default:(list brlaser cups-filters epson-inkjet-printer-escpr foomatic-filters hplip-minimal splix)) ¶Controladores y otras extensiones al paquete CUPS.
- parámetro de
cups-configuration: archivos-conf files-configuration ¶ Configuración sobre dónde escribir los registros, qué directorios usar para las colas de impresión y parámetros de configuración privilegiados relacionados.
Los campos disponibles de
files-configurationson:- parámetro de
files-configuration: ruta-registro access-log ¶ Define el nombre de archivo del registro de acceso. La especificación de un nombre de archivo en blanco desactiva la generación de registros de acceso. El valor
stderrhace que las entradas de registro se envíen al archivo de la salida estándar de error cuando el planificador se ejecute en primer plano, o al daemon de registro del sistema cuando se ejecute en segundo plano. El valorsyslogenvía las entradas de registro al daemon de registro del sistema. El nombre de servidor puede incluirse en los nombres de archivo mediante el uso de la cadena%s, como en/var/log/cups/%s-access_log.El valor predeterminado es ‘"/var/log/cups/access_log"’.
- parámetro de
files-configuration: nombre-archivo cache-dir ¶ Donde CUPS debe almacenar los datos de la caché.
El valor predeterminado es ‘"/var/cache/cups"’.
- parámetro de
files-configuration: string config-file-perm ¶ Especifica los permisos para todos los archivos de configuración que escriba el planficador.
Tenga en cuenta que los permisos para el archivo printers.conf están configurados actualmente de modo que únicamente la usuaria del planificador (habitualmente root) tenga acceso. Se hace de esta manera debido a que las URI de las impresoras a veces contienen información sensible sobre la identificación que no debería conocerse de manera general en el sistema. No hay forma de desactivar esta característica de seguridad.
El valor predeterminado es ‘"0640"’.
- parámetro de
files-configuration: ruta-registro error-log ¶ Define el nombre de archivo del registro de error. La especificación de un nombre de archivo en blanco desactiva la generación de registros de error. El valor
stderrhace que las entradas del registro se envíen al archivo de la salida de error estándar cuando el planificador se ejecute en primer plano, o al daemon de registro del sistema cuando se ejecute en segundo plano. El valorsyslogprovoca que las entradas del registro se envíen al daemon de registro del sistema. El nombre del servidor puede incluirse en los nombres de archivo mediante el uso de la cadena%s, como en/var/log/cups/%s-error_log.El valor predeterminado es ‘"/var/log/cups/error_log"’.
- parámetro de
files-configuration: string fatal-errors ¶ Especifica qué errores son fatales, los cuales provocan la salida del planificador. El tipo de cadenas son:
noneNingún error es fatal.
allTodos los errores a continuación son fatales.
browseLos errores de la inicialización de exploración son fatales, por ejemplo las conexiones fallidas al daemon DNS-SD.
configLos errores de sintaxis en el archivo de configuración son fatales.
listenLos errores de escucha o de puertos son fatales, excepto fallos IPv6 en la red local o en direcciones
any.logLos errores de creación o escritura en el archivo de registros son fatales.
permissionsLa mala configuración de los permisos de los archivos al inicio son fatales, por ejemplo certificados TLS compartidos y archivos de claves con permisos de escritura para todo el mundo.
El valor predeterminado es ‘"all -browse"’.
- parámetro de
files-configuration: boolean file-device? ¶ Especifica si el pseudo-dispositivo del archivo puede usarse para nuevas colas de impresión. Siempre se permite la URI file:///dev/null.
El valor predeterminado es ‘#f’
- parámetro de
files-configuration: string group ¶ Especifica el nombre de grupo o ID usado para la ejecución de programas externos.
El valor predeterminado es ‘"lp"’.
files-configurationparameter: string log-file-group ¶Specifies the group name or ID that will be used for log files.
Defaults to ‘"lpadmin"’.
- parámetro de
files-configuration: string log-file-perm ¶ Especifica los permisos para todos los archivos de registro que el planificador escriba.
El valor predeterminado es ‘"0644"’.
- parámetro de
files-configuration: ruta-registro page-log ¶ Define el nombre de archivo del registro de páginas. La especificación de un nombre de archivo en blanco desactiva la generación de registro de páginas. El valor
stderrhace que las entradas del registro se envíen al archivo de la salida de error cuando el planificador se ejecute en primer plano, o al daemon de registro del sistema cuando se ejecuten en segundo plano. El valorsyslogprovoca que las entradas del registro se envíen al daemon de registro del sistema. El nombre del servidor puede incluirse en los nombres de archivo mediante el uso de la cadena%s, como en/var/log/cups/%s-page_log.El valor predeterminado es ‘"/var/log/cups/page_log"’.
- parámetro de
files-configuration: string remote-root ¶ Especifica el nombre de la usuaria asociado con accesos sin identificación por parte de clientes que digan ser la usuaria root. La usuaria predeterminada es
remroot.El valor predeterminado es ‘"remroot"’.
- parámetro de
files-configuration: nombre-archivo request-root ¶ Especifica el directorio que contiene los trabajos de impresión y otros datos de peticiones HTTP.
El valor predeterminado es ‘"/var/spool/cups"’.
- parámetro de
files-configuration: aislamiento sandboxing ¶ Especifica el nivel de seguridad del aislamiento (sandbox) que se aplica sobre los filtros de impresión, motores y otros procesos lanzados por el planificador; o bien
relaxedo bienstrict. Esta directiva únicamente tiene uso actualmente en macOS.El valor predeterminado es ‘strict’.
- parámetro de
files-configuration: nombre-archivo server-keychain ¶ Especifica la localización de los certificados TLS y las claves privadas. CUPS buscará claves públicas y privadas en este directorio: un archivo .crt para certificados codificados con PEM y los correspondientes archivo .key para las claves privadas codificadas con PEM.
El valor predeterminado es ‘"/etc/cups/ssl"’.
- parámetro de
files-configuration: nombre-archivo server-root ¶ Especifica el directorio que contiene los archivos de configuración del servidor.
El valor predeterminado es ‘"/etc/cups"’.
- parámetro de
files-configuration: boolean sync-on-close? ¶ Especifica si el planificador llama fsync(2) tras la escritura de los archivos de configuración o estado.
El valor predeterminado es ‘#f’
- parámetro de
files-configuration: cadenas-separadas-por-espacios system-group ¶ Especifica el o los grupos usados para la identificación del grupo
@SYSTEM.
- parámetro de
files-configuration: nombre-archivo temp-dir ¶ Especifica el directorio donde se escriben los archivos temporales.
El valor predeterminado es ‘"/var/spool/cups/tmp"’.
- parámetro de
files-configuration: string user ¶ Especifica el nombre de usuaria o ID usado para la ejecución de programas externos.
El valor predeterminado es ‘"lp"’.
- parámetro de
files-configuration: string set-env ¶ Establece el valor de la variable de entorno especificada que se proporcionará a los procesos lanzados.
El valor predeterminado es ‘"variable value"’.
- parámetro de
- parámetro de
cups-configuration: nivel-registro-acceso access-log-level ¶ Especifica el nivel de registro para el archivo AccessLog. El nivel
configregistra la adición, borrado o modificación de impresoras y clases, y el acceso y modificación de los archivos de configuración. El nivelactionsregistra cuando los trabajos de impresión se envían, mantienen a la espera, liberan, modifican o cancelan, además de todas las condiciones deconfig. El nivelallregistra todas las peticiones.El valor predeterminado es ‘actions’.
- parámetro de
cups-configuration: boolean auto-purge-jobs? ¶ Especifica si se purgan los datos del histórico de trabajos de manera automática cuando ya no son necesarios para las cuotas.
El valor predeterminado es ‘#f’
- parámetro de
cups-configuration: lista-cadenas-separada-comas browse-dns-sd-sub-types ¶ Especifica una lista de subtipos de DNS-SD anunciados por cada impresora compartida. Por ejemplo, ‘"_cups" "_print"’ le dirá a los clientes de red que se implementa tanto la compartición con CUPS como IPP Everywhere.
El valor predeterminado es ‘"_cups"’.
- parámetro de
cups-configuration: protocolos browse-local-protocols ¶ Especifica qué protocolos deben usarse para compartir las impresoras locales.
El valor predeterminado es ‘dnssd’.
- parámetro de
cups-configuration: boolean browse-web-if? ¶ Especifica si se anuncia la interfaz web de CUPS.
El valor predeterminado es ‘#f’
- parámetro de
cups-configuration: boolean browsing? ¶ Especifica si se anuncian las impresoras compartidas.
El valor predeterminado es ‘#f’
- parámetro de
cups-configuration: string classification ¶ Especifica la clasificación de seguridad del servidor. Se puede usar cualquier nombre válido para anunciar la identificación del nivel de seguridad, incluyendo ‘"classified"’, ‘"confidential"’, ‘"secret"’, ‘"topsecret"’ y ‘"unclassified"’, o el anuncio puede omitirse para desactivar las funciones de impresión segura.
El valor predeterminado es ‘""’.
- parámetro de
cups-configuration: boolean classify-override? ¶ Especifica si las usuarias pueden modificar la clasificación (página de portada) de trabajos de impresión individuales mediante el uso de la opción
job-sheets.El valor predeterminado es ‘#f’
- parámetro de
cups-configuration: tipo-id-pred default-auth-type ¶ Especifica el tipo de identificación usado por omisión.
El valor predeterminado es ‘Basic’.
- parámetro de
cups-configuration: cifrado-pred default-encryption ¶ Especifica si se usará cifrado para peticiones con identificación.
El valor predeterminado es ‘Required’.
- parámetro de
cups-configuration: string default-language ¶ Especifica el idioma predeterminado usado para el texto y contenido de la web.
El valor predeterminado es ‘"en"’.
- parámetro de
cups-configuration: cadena default-paper-size ¶ Especifica el tamaño predeterminado del papel para colas de impresión nuevas. ‘"Auto"’ usa el valor predeterminado de la localización, mientras que ‘"None"’ especifica que no hay un tamaño de papel predeterminado. Los nombres de tamaños específicos habitualmente son ‘"Letter"’ o ‘"A4"’36.
El valor predeterminado es ‘"Auto"’.
- parámetro de
cups-configuration: string default-policy ¶ Especifica la política de acceso usada por omisión.
El valor predeterminado es ‘"default"’.
Especifica si las impresoras locales se comparten de manera predeterminada.
El valor predeterminado es ‘#t’
- parámetro de
cups-configuration: entero-no-negativo dirty-clean-interval ¶ Especifica el retraso para la actualización de los archivos de configuración y estado, en segundo. Un valor de 0 hace que la actualización se lleve a cabo tan pronto sea posible, en algunos milisegundos habitualmente.
El valor predeterminado es ‘30’.
- parámetro de
cups-configuration: política-error error-policy ¶ Especifica qué hacer cuando ocurra un error. Los valores posibles son
abort-job, que descartará el trabajo de impresión fallido;retry-job, que intentará llevar de nuevo a cabo el trabajo en un momento posterior;retry-current-job, que reintenta el trabajo que falló de manera inmediata; ystop-printer, que para la impresora.El valor predeterminado es ‘stop-printer’.
- parámetro de
cups-configuration: entero-no-negativo filter-limit ¶ Especifica el coste máximo de filtros que se ejecutan de manera concurrente, lo que puede usarse para minimizar problemas de recursos de disco, memoria y procesador. Un límite de 0 desactiva la limitación del filtrado. Una impresión media con una impresora no-PostScript necesita una limitación del filtrado de 200 más o menos. Una impresora PostScript necesita cerca de la mitad (100). Establecer un límite por debajo de estos valores limitará de forma efectiva al planificador a la ejecución de un único trabajo de impresión en cualquier momento.
El valor predeterminado es ‘0’.
- parámetro de
cups-configuration: entero-no-negativo filter-nice ¶ Especifica la prioridad de planificación de los filtros que se ejecuten para la impresión de un trabajo. El valor de “nice” va desde 0, la mayor prioridad, a 19, la menor prioridad.
El valor predeterminado es ‘0’.
- parámetro de
cups-configuration: búsqueda-nombres-máquina host-name-lookups ¶ Especifica si se realizarán las búsquedas inversas en las conexiones de clientes. La opción
doubleinstruye acupsdpara que verifique que el nombre de máquina al que resuelve la dirección corresponde con la dirección devuelta por dicho nombre de máquina. Las búsquedas dobles también evitan que clientes con direcciones sin registrar se conecten a su servidor. Configure esta opción con#todoubleúnicamente si es absolutamente necesario.El valor predeterminado es ‘#f’
- parámetro de
cups-configuration: entero-no-negativo job-kill-delay ¶ Especifica el número de segundos a esperar antes de terminar los filtros y el motor asociados con un trabajo cancelado o puesto en espera.
El valor predeterminado es ‘30’.
- parámetro de
cups-configuration: entero-no-negativo job-retry-interval ¶ Especifica el intervalo entre los reintentos de trabajos en segundos. Se usa de manera habitual en colas de fax pero también puede usarse con colas de impresión normales cuya política de error sea
retry-joboretry-current-job.El valor predeterminado es ‘30’.
- parámetro de
cups-configuration: entero-no-negativo job-retry-limit ¶ Especifica el número de reintentos que se llevan a cabo con los trabajos. De manera habitual se usa con colas de fax pero también puede usarse con colas de impresión normal cuya política de error sea
retry-joboretry-current-job.El valor predeterminado es ‘5’.
- parámetro de
cups-configuration: boolean keep-alive? ¶ Especifica si se permiten conexiones “keep-alive” de HTTP.
El valor predeterminado es ‘#t’
- parámetro de
cups-configuration: entero-no-negativo limit-request-body ¶ Especifica el tamaño máximo de los archivos de impresión, peticiones IPP y datos de formularios HTTP. Un límite de 0 desactiva la comprobación del límite.
El valor predeterminado es ‘0’.
- parámetro de
cups-configuration: lista-cadenas-multilínea listen ¶ Escucha a la espera de conexiones en las interfaces especificadas. Se aceptan valores con la forma dirección:puerto, donde dirección es o bien una dirección IPv6 entre corchetes, una dirección IPv4 o
*para indicar todas las direcciones. Los valores también pueden ser nombres de archivo de sockets de dominio de UNIX locales. La directiva “Listen” es similar a la directiva “Port”, pero le permite la restricción del acceso a interfaces o redes específicas.
- parámetro de
cups-configuration: entero-no-negativo listen-back-log ¶ Especifica el número de conexiones pendientes permitidas. Habitualmente afecta de manera exclusiva a servidores con mucha carga de trabajo que han alcanzado el límite de clientes “MaxClients”, pero también puede ser provocado por grandes números de conexiones simultaneas. Cuando se alcanza el límite, el sistema operativo rechaza conexiones adicionales hasta que el planificador pueda aceptar las pendientes.
El valor predeterminado es ‘128’.
- parámetro de
cups-configuration: lista-location-access-control location-access-controls ¶ Especifica un conjunto adicional de controles de acceso.
Los campos disponibles de
location-access-controlsson:- parámetro de
location-access-controls: nombre-archivo path ¶ Especifica la ruta URI sobre la que el control de acceso tendrá efecto.
- parámetro de
location-access-controls: lista-access-control access-controls ¶ Controles de acceso para todos los accesos a esta ruta, en el mismo formato que
access-controlsdeoperation-access-control.El valor predeterminado es ‘()’.
- parámetro de
location-access-controls: lista-method-access-control method-access-controls ¶ Controles de acceso para accesos con métodos específicos para esta ruta.
El valor predeterminado es ‘()’.
Los campos disponibles de
method-access-controlsson:- parámetro de
method-access-controls: boolean reverse? ¶ Si es
#t, los controles de acceso son efectivos con todos los métodos excepto los métodos listados. En otro caso, son efectivos únicamente con los métodos listados.El valor predeterminado es ‘#f’
- parámetro de
method-access-controls: lista-métodos methods ¶ Métodos con los cuales este control de acceso es efectivo.
El valor predeterminado es ‘()’.
- parámetro de
method-access-controls: lista-control-acceso access-controls ¶ Directivas de control de acceso, como una lista de cadenas. Cada cadena debe ser una directiva, como ‘"Order allow,deny"’.
El valor predeterminado es ‘()’.
- parámetro de
- parámetro de
- parámetro de
cups-configuration: entero-no-negativo log-debug-history ¶ Especifica el número de mensajes de depuración que se retienen para el registro si sucede un error en un trabajo de impresión. Los mensajes de depuración se registran independientemente de la configuración de “LogLevel”.
El valor predeterminado es ‘100’.
- parámetro de
cups-configuration: nivel-registro log-level ¶ Especifica el nivel de depuración del archivo “ErrorLog”. El valor
noneinhibe todos los registros mientras quedebug2registra todo.El valor predeterminado es ‘info’
- parámetro de
cups-configuration: formato-tiempo-registro log-time-format ¶ Especifica el formato de la fecha y el tiempo en los archivos de registro. El valor
standardregistra con segundos completos mientras queusecsregistra con microsegundos.El valor predeterminado es ‘standard’.
- parámetro de
cups-configuration: entero-no-negativo max-clients ¶ Especifica el número de clientes simultáneos máximo que son admitidos por el planificador.
El valor predeterminado es ‘100’.
- parámetro de
cups-configuration: entero-no-negativo max-clients-per-host ¶ Especifica el número de clientes simultáneos máximo que se permiten desde una única dirección.
El valor predeterminado es ‘100’.
- parámetro de
cups-configuration: entero-no-negativo max-copies ¶ Especifica el número de copias máximo que una usuaria puede imprimir con cada trabajo.
El valor predeterminado es ‘9999’.
- parámetro de
cups-configuration: entero-no-negativo max-hold-time ¶ Especifica el tiempo máximo que un trabajo puede permanecer en el estado de espera
indefiniteantes de su cancelación. Un valor de 0 desactiva la cancelación de trabajos en espera.El valor predeterminado es ‘0’.
- parámetro de
cups-configuration: entero-no-negativo max-jobs ¶ Especifica el número de trabajos simultáneos máximo permitido. El valor 0 permite un número ilimitado de trabajos.
El valor predeterminado es ‘500’.
- parámetro de
cups-configuration: entero-no-negativo max-jobs-per-printer ¶ Especifica el número de trabajos simultáneos máximo que se permite por impresora. Un valor de 0 permite hasta “MaxJobs” por impresora.
El valor predeterminado es ‘0’.
- parámetro de
cups-configuration: entero-no-negativo max-jobs-per-user ¶ Especifica el número de trabajos simultáneos máximo que se permite por usuaria. Un valor de 0 permite hasta “MaxJobs” por usuaria.
El valor predeterminado es ‘0’.
- parámetro de
cups-configuration: entero-no-negativo max-job-time ¶ Especifica el tiempo de duración de la impresión máximo que un trabajo puede tomar antes de ser cancelado, en segundos. El valor 0 desactiva la cancelación de trabajos “atascados”.
El valor predeterminado es ‘10800’.
- parámetro de
cups-configuration: entero-no-negativo max-log-size ¶ Especifica el tamaño máximo de los archivos de registro antes de su rotación, en bytes. El valor 0 desactiva la rotación de registros.
El valor predeterminado es ‘1048576’.
- parámetro de
cups-configuration: entero-no-negativo multiple-operation-timeout ¶ Especifica el tiempo máximo permitido entre archivos en un trabajo de impresión con múltiples archivos, en segundos.
Defaults to ‘900’.
- parámetro de
cups-configuration: string page-log-format ¶ Especifica el formato de las líneas PageLog. Las secuencias de caracteres que comiencen con el signo de porcentaje (‘%’) se reemplazan con la información correspondiente, mientras que el resto de caracteres se copia de manera literal. Se reconocen las siguientes secuencias:
- ‘%%’
inserta literalmente un símbolo de porcentaje
- ‘%{nombre}’
inserta el valor del atributo IPP especificado
- ‘%C’
inserta el número de copias para la página actual
- ‘%P’
inserta el número de página actual
- ‘%T’
inserta la fecha y hora actuales en el formato común de registro
- ‘%j’
introduce el ID del trabajo
- ‘%p’
inserta el nombre de impresora
- ‘%u’
inserta el nombre de usuaria
La cadena vacía desactiva el registro de página. La cadena
%p %u %j %T %P %C %{job-billing} %{job-originating-host-name} %{job-name} %{media} %{sides}crea un registro de página con los elementos estándar.El valor predeterminado es ‘""’.
- parámetro de
cups-configuration: variables-entorno environment-variables ¶ Proporciona la o las variables de entorno especificadas a los procesos iniciados; una lista de cadenas.
El valor predeterminado es ‘()’.
- parámetro de
cups-configuration: lista-policy-configuration policies ¶ Especifica las políticas de control de acceso con nombre.
Los campos disponibles de
policy-configurationson:- parámetro de
policy-configuration: string name ¶ El nombre de la política.
- parámetro de
policy-configuration: string job-private-access ¶ Specifies an access list for a job’s private values.
@ACLmaps to the printer’s requesting-user-name-allowed or requesting-user-name-denied values.@OWNERmaps to the job’s owner.@SYSTEMmaps to the groups listed for thesystem-groupfield of thefiles-configuration, which is reified into thecups-files.conf(5)file. Other possible elements of the access list include specific user names, and@groupto indicate members of a specific group. The access list may also be simplyallordefault.El valor predeterminado es ‘"@OWNER @SYSTEM"’.
- parámetro de
policy-configuration: string job-private-values ¶ Especifica la lista de valores de trabajos a hacer privados, o bien
all,default, onone.El valor predeterminado es ‘"job-name job-originating-host-name job-originating-user-name phone"’.
- parámetro de
policy-configuration: string subscription-private-access ¶ Specifies an access list for a subscription’s private values.
@ACLmaps to the printer’s requesting-user-name-allowed or requesting-user-name-denied values.@OWNERmaps to the job’s owner.@SYSTEMmaps to the groups listed for thesystem-groupfield of thefiles-configuration, which is reified into thecups-files.conf(5)file. Other possible elements of the access list include specific user names, and@groupto indicate members of a specific group. The access list may also be simplyallordefault.El valor predeterminado es ‘"@OWNER @SYSTEM"’.
- parámetro de
policy-configuration: string subscription-private-values ¶ Especifica la lista de valores de trabajos a hacer privados, o bien
all,default, onone.El valor predeterminado es ‘"notify-events notify-pull-method notify-recipient-uri notify-subscriber-user-name notify-user-data"’.
- parámetro de
policy-configuration: lista-operation-access-control access-controls ¶ Control de acceso para operaciones de IPP.
El valor predeterminado es ‘()’.
- parámetro de
- parámetro de
cups-configuration: boolean-o-entero-no-negativo preserve-job-files ¶ Especifica si los archivos del trabajo (documentos) se preservan tras la impresión de un trabajo. Si se especifica un valor numérico, los archivos del trabajo se preservan durante el número indicado de segundos tras la impresión. En otro caso, el valor booleano determina la conservación de manera indefinida.
El valor predeterminado es ‘86400’.
- parámetro de
cups-configuration: boolean-o-entero-no-negativo preserve-job-history ¶ Especifica si la historia del trabajo se preserva tras la impresión de un trabajo. Si se especifica un valor numérico, la historia del trabajo se conserva tras la impresión el número de segundos indicado. Si es
#t, la historia del trabajo se conserva hasta que se alcance el límite de trabajos “MaxJobs”.El valor predeterminado es ‘#t’
- parámetro de
cups-configuration: entero-no-negativo reload-timeout ¶ Especifica el tiempo a esperar hasta la finalización del trabajo antes de reiniciar el planificador.
El valor predeterminado es ‘30’.
- parámetro de
cups-configuration: string rip-cache ¶ Especifica la cantidad máxima de memoria usada durante la conversión de documentos en imágenes para una impresora.
El valor predeterminado es ‘"128m"’.
- parámetro de
cups-configuration: string server-admin ¶ Especifica la dirección de correo electrónico de la administradora del servidor.
El valor predeterminado es ‘"root@localhost.localdomain"’.
- parámetro de
cups-configuration: lista-nombres-máquina-o-* server-alias ¶ La directiva ServerAlias se usa para la validación de la cabecera HTTP Host cuando los clientes se conecten al planificador desde interfaces externas. El uso del nombre especial
*puede exponer su sistema a ataques basados en el navegador web de reenlazado DNS ya conocidos, incluso cuando se accede a páginas a través de un cortafuegos. Si el descubrimiento automático de nombres alternativos no funcionase, le recomendamos enumerar cada nombre alternativo con una directiva ServerAlias en vez del uso de*.El valor predeterminado es ‘*’.
- parámetro de
cups-configuration: string server-name ¶ Especifica el nombre de máquina completamente cualificado del servidor.
El valor predeterminado es ‘"localhost"’.
- parámetro de
cups-configuration: server-tokens server-tokens ¶ Especifica qué información se incluye en la cabecera Server de las respuestas HTTP.
Nonedesactiva la cabecera Server.ProductOnlyproporcionaCUPS.MajorproporcionaCUPS 2.MinorproporcionaCUPS 2.0.MinimapproporcionaCUPS 2.0.0.OSproporcionaCUPS 2.0.0 (uname)donde uname es la salida de la ordenuname.FullproporcionaCUPS 2.0.0 (uname) IPP/2.0.El valor predeterminado es ‘Minimal’.
- parámetro de
cups-configuration: lista-cadenas-multilínea ssl-listen ¶ Escucha en las interfaces especificadas a la espera de conexiones cifradas. Se aceptan valores con la forma dirección:puerto, siendo dirección o bien una dirección IPv6 entre corchetes, o bien una dirección IPv4, o bien
*que representa todas las direcciones.El valor predeterminado es ‘()’.
- parámetro de
cups-configuration: opciones-ssl ssl-options ¶ Determina las opciones de cifrado. De manera predeterminada, CUPS permite únicamente el cifrado mediante TLS v1.0 o superior mediante el uso de modelos de cifrado de conocida seguridad. La seguridad se reduce cuando se usan opciones
Allowy se aumenta cuando se usan opcionesDeny. La opciónAllowRC4permite el cifrado RC4 de 128 bits, necesario para algunos clientes antiguos que no implementan los modelos más modernos. La opciónAllowSSL3desactiva SSL v3.0, necesario para algunos clientes antiguos que no implementan TLS v1.0. La opciónDenyCBCdesactiva todos los modelos de cifrado CBC. La opciónDenyTLS1.0desactiva TLS v1.0—esto fuerza la versión mínima del protocolo a TLS v1.1.El valor predeterminado es ‘()’.
- parámetro de
cups-configuration: boolean strict-conformance? ¶ Especifica si el planificador exige que los clientes se adhieran de manera estricta a las especificaciones IPP.
El valor predeterminado es ‘#f’
- parámetro de
cups-configuration: entero-no-negativo timeout ¶ Especifica el plazo de las peticiones HTTP, en segundos.
Defaults to ‘900’.
- parámetro de
cups-configuration: boolean web-interface? ¶ Especifica si se debe activar la interfaz web.
El valor predeterminado es ‘#f’
En este punto probablemente esté pensando, “querido manual de Guix, me
gusta todo esto, pero... ¡¿cuando se acaban las opciones de
configuración?!”. De hecho ya terminan. No obstante, hay un punto más:
puede ser que ya tenga un archivo cupsd.conf que desee usar. En ese
caso, puede proporcionar un objeto opaque-cups-configuration como la
configuración de cups-service-type.
Los campos disponibles de opaque-cups-configuration son:
- parámetro de
opaque-cups-configuration: paquete cups ¶ El paquete CUPS.
- parámetro de
opaque-cups-configuration: string cupsd.conf ¶ El contenido de
cupsd.conf, como una cadena.
- parámetro de
opaque-cups-configuration: string cups-files.conf ¶ El contenido del archivo
cups-files.conf, como una cadena.
Por ejemplo, si el contenido de sus archivos cupsd.conf y
cups-files.conf estuviese en cadenas del mismo nombre, podría
instanciar un servicio CUPS de esta manera:
(service cups-service-type
(opaque-cups-configuration
(cupsd.conf cupsd.conf)
(cups-files.conf cups-files.conf)))
Next: Servicios de sonido, Previous: Servicios de impresión, Up: Servicios [Contents][Index]
12.9.9 Servicios de escritorio
El módulo (gnu services desktop) proporciona servicios que son útiles
habitualmente en el contexto de una configuración de “escritorio”—es
decir, en una máquina que ejecute un servidor gráfico, posiblemente con
interfaces gráficas, etcétera. También define servicios que proporcionan
entornos de escritorio específicos como GNOME, Xfce o MATE.
Para simplificar las cosas, el módulo define una variable que contiene el conjunto de servicios que las usuarias esperarían de manera habitual junto a un entorno gráfico y de red:
- Variable Scheme: %desktop-services
Es una lista de servicios que se construye en base a
%base-servicesy añade o ajusta servicios para una configuración de “escritorio” típica.En particular, añade un gestor de ingreso al sistema gráfico (see
gdm-service-type), herramientas para el bloqueo de la pantalla, una herramienta de gestión de redes (seenetwork-manager-service-type) y gestión de modem (seemodem-manager-service-type), servicios de gestión de la energía y el color, el gestor de asientos e ingresos al sistemaelogind, el servicio de privilegios Polkit, el servicio de geolocalización GeoClue, el daemon AccountsService que permite a las usuarias autorizadas el cambio de contraseñas del sistema, un cliente NTP (see Servicios de red), el daemon Avahi y configura el servicio del selector de servicios de nombres para que pueda usarnss-mdns(see mDNS).
La variable %desktop-services puede usarse como el campo
services de una declaración operating-system
(see services).
De manera adicional, los procedimientos gnome-desktop-service-type,
xfce-desktop-service, mate-desktop-service-type,
lxqt-desktop-service-type y enlightenment-desktop-service-type
pueden añadir GNOME, Xfce, MATE y/o Enlightenment al sistema. “Añadir
GNOME” significa que servicios a nivel de sistema como las herramientas de
ayuda para el ajuste de la intensidad de luz de la pantalla y de gestión de
energía se añaden al sistema, extendiendo polkit y dbus de
manera apropiada, y permitiendo a GNOME operar con privilegios elevados en
un número de interfaces del sistema de propósito especial. Además, la
adición de un servicio generado por gnome-desktop-service-type añade
el metapaquete GNOME al perfil del sistema. Del mismo modo, la adición del
servicio Xfde no añade únicamente el metapaquete xfce al perfil del
sistema, sino que también le proporciona al gestor de archivos Thunar la
posibilidad de abrir una ventana de gestión de archivos en “modo root”, si
la usuaria se identifica mediante la contraseña de administración a través
de la interfaz gráfica estándar polkit. “Añadir MATE” significa que
polkit y dbus se extienden de manera apropiada, permitiendo a
MATE operar con privilegios elevados en un número de interfaces del sistema
de propósito especial. De manera adicional, la adición de un servicio de
tipo mate-desktop-service-type añade el metapaquete MATE al perfil
del sistema. “Añadir Enlightenment” significa que dbus se extiende
de manera apropiada y varios ejecutables de Enlightenment se marcan como
“setuid”, para permitir el funcionamiento esperado del sistema bloqueo de
pantalla de Enlightenment entre otras funcionalidades.
The desktop environments in Guix use the Xorg display server by default. If
you’d like to use the newer display server protocol called Wayland, you need
to enable Wayland support in GDM (see wayland-gdm). Another solution is
to use the sddm-service instead of GDM as the graphical login
manager. You should then select the “GNOME (Wayland)” session in SDDM.
Alternatively you can also try starting GNOME on Wayland manually from a TTY
with the command “XDG_SESSION_TYPE=wayland exec dbus-run-session
gnome-session“. Currently only GNOME has support for Wayland.
- Variable Scheme: gnome-desktop-service-type
Es el tipo del servicio que añade el entorno de escritorio GNOME. Su valor es un objeto
gnome-desktop-configuration(véase a continuación).Este servicio añade el paquete
gnomeal perfil del sistema, y extiende polkit con las acciones degnome-settings-daemon.
- Tipo de datos: gnome-desktop-configuration
Registro de configuración para el entorno de escritorio GNOME.
gnome(predeterminado:gnome)El paquete GNOME usado.
- Variable Scheme: xfce-desktop-service-type
Este es el tipo de un servicio para ejecutar el entorno de escritorio https://xfce.org. Su valor es un objeto
xfce-desktop-configuration(véase a continuación).Este servicio añade el paquete
xfceal perfil del sistema, y extiende polkit con la capacidad dethunarpara manipular el sistema de archivos como root dentro de una sesión de usuaria, tras la identificación de la usuaria con la contraseña de administración.Note that
xfce4-paneland its plugin packages should be installed in the same profile to ensure compatibility. When using this service, you should add extra plugins (xfce4-whiskermenu-plugin,xfce4-weather-plugin, etc.) to thepackagesfield of youroperating-system.
- Tipo de datos: xfce-desktop-configuration
Registro de configuración para el entorno de escritorio Xfce.
xfce(predeterminado:xfce)El paquete Xfce usado.
- Variable Scheme: mate-desktop-service-type
Es el tipo del servicio que ejecuta el entorno de escritorio MATE. Su valor es un objeto
mate-desktop-configuration(véase a continuación).Este servicio añade el paquete
mateal perfil del sistema, y extiende polkit con acciones demate-settings-daemon.
- Tipo de datos: mate-desktop-configuration
Registro de configuración para el entorno de escritorio MATE.
mate(predeterminado:mate)El paquete MATE usado.
- Variable Scheme: lxqt-desktop-service-type
This is the type of the service that runs the LXQt desktop environment. Its value is a
lxqt-desktop-configurationobject (see below).Este servicio añade el paquete
lxqtal perfil del sistema.
- Tipo de datos: lxqt-desktop-configuration
Registro de configuración para el entorno de escritorio LXQt.
lxqt(predeterminado:lxqt)El paquete LXQT usado.
- Variable Scheme: enlightenment-desktop-service-type
Devuelve un servicio que añade el paquete
enlightenmental perfil del sistema, y extiende dbus con acciones deefl.
- Tipo de datos: enlightenment-desktop-service-configuration
enlightenment(predeterminado:enlightenment)El paquete enlightenment usado.
Debido a que los servicios de escritorio GNOME, Xfce y MATE incorporan
tantos paquetes, la variable %desktop-services no incluye ninguno de
manera predeterminada. Para añadir GNOME, Xfce o MATE, simplemente use
cons junto a %desktop-services en el campo services de
su declaración operating-system:
(use-modules (gnu)) (use-service-modules desktop) (operating-system ... ;; cons* añade elementos a la lista proporcionada en el último ;; parámetro. (services (cons* (service gnome-desktop-service-type) (service xfce-desktop-service) %desktop-services)) ...)
Una vez realizado, estos entornos de escritorio se encontrarán como opciones disponibles en la ventana del gestor gráfico de ingreso al sistema.
Las definiciones de servicio incluidas realmente en %desktop-services
y proporcionadas por (gnu services dbus) y (gnu services
desktop) se describen a continuación.
- Scheme Procedure: dbus-service [#:dbus dbus] [#:services '()] [#:verbose?] Return a service that runs the ``system bus'', using
dbus, with support for services. When verbose? is true, it causes the ‘DBUS_VERBOSE’ environment variable to be set to ‘1’; a verbose-enabled D-Bus package such as
dbus-verboseshould be provided as dbus in this scenario. The verbose output is logged to /var/log/dbus-daemon.log.D-Bus es una herramienta para la facilitación de intercomunicación entre procesos. Su bus del sistema se usa para permitir la comunicación entre y la notificación de eventos a nivel de sistema a los servicios.
services debe ser una lista de paquetes que proporcionen un directorio etc/dbus-1/system.d que contenga archivos de configuración y políticas adicionales de D-Bus. Por ejemplo, para permitir a avahi-daemon el uso del bus del sistema, services debe tener el valor
(list avahi).
- Procedimiento Scheme: elogind-service [#:config config]
Devuelve un servicio que ejecuta el daemon de gestión de ingreso al sistema y de asientos
elogind. Elogind expone una interfaz D-Bus que puede usarse para conocer las usuarias que han ingresado en el sistema, conocer qué tipo de sesiones tienen abiertas, suspender el sistema o inhibir su suspensión, reiniciar el sistema y otras tareas.Elogind maneja la mayor parte de los eventos a nivel de sistema de alimentación de su máquina, por ejemplo mediante la suspensión del sistema cuando se cierre la tapa, o mediante el apagado al pulsar la tecla correspondiente.
El parámetro config especifica la configuración de elogind, y debería resultar en una invocación
(elogind-configuration (parámetro valor)...). Los parámetros disponibles y sus valores predeterminados son:kill-user-processes?#fkill-only-users()kill-exclude-users("root")inhibit-delay-max-seconds5handle-power-keypoweroffhandle-suspend-keysuspendhandle-hibernate-keyhibernatehandle-lid-switchsuspendhandle-lid-switch-dockedignorehandle-lid-switch-external-power*unspecified*power-key-ignore-inhibited?#fsuspend-key-ignore-inhibited?#fhibernate-key-ignore-inhibited?#flid-switch-ignore-inhibited?#tholdoff-timeout-seconds30idle-actionignoreidle-action-seconds(* 30 60)runtime-directory-size-percent10runtime-directory-size#fremove-ipc?#tsuspend-state("mem" "standby" "freeze")suspend-mode()hibernate-state("disk")hibernate-mode("platform" "shutdown")hybrid-sleep-state("disk")hybrid-sleep-mode("suspend" "platform" "shutdown")
- Procedimiento Scheme: accountsservice-service [#:accountsservice accountsservice]
Devuelve un servicio que ejecuta AccountsService, un servicio del sistema para la enumeración de cuentas disponibles, el cambio de sus contraseñas, etcétera. AccountsService se integra con PolicyKit para permitir a las usuarias sin privilegios la adquisición de la capacidad de modificar la configuración de su sistema. Véase la página web de AccountsService para más información.
El parámetro accountsservice es el paquete
accountsserviceque se expondrá como un servicio.
- Procedimiento Scheme: polkit-service [#:polkit polkit]
Devuelve un servicio que ejecuta el servicio de gestión de privilegios Polkit, que permite a las administradoras del sistema la concesión de permisos sobre operaciones privilegiadas de manera estructurada. Mediante las consultas al servicio Polkit, un componente del sistema con privilegios puede conocer cuando debe conceder capacidades adicionales a usuarias ordinarias. Por ejemplo, se le puede conceder la capacidad a una usuaria ordinaria de suspender el sistema si la usuaria ingresó de forma local.
- Variable Scheme: polkit-wheel-service
Servicio que añade a las usuarias del grupo
wheelcomo administradoras del servicio Polkit. Esto hace que se solicite su propia contraseña a las usuarias del grupowheelcuando realicen acciones administrativas en vez de la contraseña deroot, de manera similar al comportamiento desudo.
- Variable Scheme: upower-service-type
Servicio que ejecuta https://upower.freedesktop.org/,
upowerd, un monitor a nivel de sistema de consumo de energía y niveles de batería, con las opciones de configuración proporcionadas.Implementa la interfaz D-Bus
org.freedesktop.UPower, y se usa de forma notable en GNOME.
- Tipo de datos: upower-configuration
Tipo de datos que representa la configuración de UPower.
upower(predeterminado: upower)Paquete usado para
upower.watts-up-pro?(predeterminado:#f)Permite el uso del dispositivo Watts Up Pro.
poll-batteries?(predeterminado:#t)Usa el servicio de consulta del núcleo para los cambios en niveles de batería.
ignore-lid?(predeterminado:#f)Ignora el estado de la tapa, puede ser útil en caso de ser incorrecto un dispositivo determinado.
use-percentage-for-policy?(default:#t)Whether to use a policy based on battery percentage rather than on estimated time left. A policy based on battery percentage is usually more reliable.
percentage-low(default:20)Cuando
use-percentaje-for-policy?es#t, determina el porcentaje en el que la carga de la batería se considera baja.percentage-critical(default:5)Cuando
use-percentaje-for-policy?es#t, determina el porcentaje en el que la carga de la batería se considera crítica.percentage-action(predeterminado:2)Cuando
use-percentaje-for-policy?es#t, determina el porcentaje en el que se tomará la acción.time-low(predeterminado:1200)Cuando
use-percentaje-for-policy?es#t, determina el tiempo restante en segundos con el que carga de la batería se considera baja.time-critical(predeterminado:300)Cuando
use-percentaje-for-policy?es#t, determina el tiempo restante en segundos con el que carga de la batería se considera crítica.time-action(predeterminado:120)Cuando
use-percentaje-for-policy?es#t, determina el tiempo restante en segundos con el que se tomará la acción.critical-power-action(predeterminada:'hybrid-sleep)La acción tomada cuando se alcanza
percentage-actionotime-action(dependiendo de la configuración deuse-percentage-for-policy?).Los valores posibles son:
-
'power-off -
'hibernate -
'hybrid-sleep.
-
- Procedimiento Scheme: udisks-service [#:udisks udisks]
Devuelve un servicio para UDisks, un daemon de gestión de discos que proporciona interfaces de usuaria con notificaciones y formas de montar/desmontar discos. Los programas que se comunican con UDisk incluyen la orden
udisksctl, parte de UDisks, y la utilidad “Discos” de GNOME. Tenga en cuenta que Udisks depende de la ordenmount, de modo que únicamente será capaz de usar utilidades para sistemas de archivos instaladas en el perfil del sistema. Si quiere, por ejemplo, poder montar sistemas de archivos NTFS en modo lectura/escritura, debe instalarntfs-3gen su sistema operativo.
- Variable Scheme: colord-service-type
Devuelve un servicio que ejecuta
colord, un servicio del sistema con una interfaz D-Bus para la gestión de perfiles de dispositivos de entrada y salida como la pantalla y el escáner. Se usa de forma notable por parte de la herramienta gráfica de “Gestión de color” de GNOME. Véase la página web de colord para más información.
- Scheme Variable: sane-service-type
This service provides access to scanners via SANE by installing the necessary udev rules. It is included in
%desktop-services(see Servicios de escritorio) and relies by default onsane-backends-minimalpackage (see below) for hardware support.
- Scheme Variable: sane-backends-minimal
The default package which the
sane-service-typeinstalls. It supports many recent scanners.
- Scheme Variable: sane-backends
This package includes support for all scanners that
sane-backends-minimalsupports, plus older Hewlett-Packard scanners supported byhplippackage. In order to use this on a system which relies on%desktop-services, you may usemodify-services(seemodify-services) as illustrated below:(use-modules (gnu)) (use-service-modules … desktop) (use-package-modules … scanner) (define %my-desktop-services ;; List of desktop services that supports a broader range of scanners. (modify-services %desktop-services (sane-service-type _ => sane-backends))) (operating-system … (services %my-desktop-services))
- Procedimiento Scheme: geoclue-application-name [#:allowed? #t] [#:system? #f] [#:users '()]
Devuelve una configuración que permite a una aplicación el acceso a los datos de posicionamiento de GeoClue. nombre es el Desktop ID de la aplicación, sin la parte
.desktop. Si el valor de allowed? es verdadero, la aplicación tendrá acceso a la información de posicionamiento de manera predeterminada. El valor booleano system? indica si una aplicación es un componente de sistema o no. Por último, users es una lista de UID de todas las usuarias para las que esta aplicación tiene permitido el acceso de información. Una lista de usuarias vacía significa que se permiten todas las usuarias.
- Variable Scheme: %standard-geoclue-applications
La lista estándar de configuraciones de GeoClue de aplicaciones conocidas, proporcionando autoridad a la utilidad de fecha y hora de GNOME para obtener la localización actual para ajustar la zona horaria, y permitiendo que los navegadores Icecat y Epiphany puedan solicitar información de localización. Tanto IceCat como Epiphany solicitan permiso a la usuaria antes de permitir a una página web conocer la ubicación de la usuaria.
- Procedimiento Scheme: geoclue-service [#:colord colord] [#:whitelist '()] [#:wifi-geolocation-url
"https://location.services.mozilla.com/v1/geolocate?key=geoclue"] [#:submit-data? #f] [#:wifi-submission-url "https://location.services.mozilla.com/v1/submit?key=geoclue"] [#:submission-nick "geoclue"] [#:applications %standard-geoclue-applications] Devuelve un servicio que ejecuta el servicio de posicionamiento GeoClue. Proporciona una interfaz D-Bus que permite a las aplicaciones solicitar una posición física de la usuaria, y de manera opcional añadir información a bases de datos de posicionamiento en línea. Véase la página web de GeoClue para obtener más información.
- Procedimiento Scheme: bluetooth-service [#:bluez bluez] [#:auto-enable? #f]
Devuelve un servicio que ejecuta el daemon
bluetoothdque gestiona todos los dispositivos Bluetooth y proporciona cierto número de interfaces D-Bus. Cuando auto-enable? es verdadero, el controlador bluetooth tendrá alimentación automáticamente tras el arranque, lo que puede ser útil si se posee un teclado o un ratón bluetooth.Las usuarias necesitan la pertenencia al grupo
lppara el acceso al servicio D-Bus.
- Scheme Variable: bluetooth-service-type
This is the type for the Linux Bluetooth Protocol Stack (BlueZ) system, which generates the /etc/bluetooth/main.conf configuration file. The value for this type is a
bluetooth-configurationrecord as in this example:See below for details about
bluetooth-configuration.
- Data Type: bluetooth-configuration
Data type representing the configuration for
bluetooth-service.bluez(default:bluez)bluezpackage to use.name(default:"BlueZ")Default adapter name.
class(default:#x000000)Default device class. Only the major and minor device class bits are considered.
discoverable-timeout(default:180)How long to stay in discoverable mode before going back to non-discoverable. The value is in seconds.
always-pairable?(default:#f)Always allow pairing even if there are no agents registered.
pairable-timeout(default:0)How long to stay in pairable mode before going back to non-discoverable. The value is in seconds.
device-id(default:#f)Use vendor id source (assigner), vendor, product and version information for DID profile support. The values are separated by ":" and assigner, VID, PID and version.
Los valores posibles son:
-
#fto disable it, -
"assigner:1234:5678:abcd", where assigner is eitherusb(default) orbluetooth.
-
reverse-service-discovery?(default:#t)Do reverse service discovery for previously unknown devices that connect to us. For BR/EDR this option is really only needed for qualification since the BITE tester doesn’t like us doing reverse SDP for some test cases, for LE this disables the GATT client functionally so it can be used in system which can only operate as peripheral.
name-resolving?(default:#t)Enable name resolving after inquiry. Set it to
#fif you don’t need remote devices name and want shorter discovery cycle.debug-keys?(default:#f)Enable runtime persistency of debug link keys. Default is false which makes debug link keys valid only for the duration of the connection that they were created for.
controller-mode(default:'dual)Restricts all controllers to the specified transport.
'dualmeans both BR/EDR and LE are enabled (if supported by the hardware).Los valores posibles son:
-
'dual -
'bredr -
'le
-
multi-profile(default:'off)Enables Multi Profile Specification support. This allows to specify if system supports only Multiple Profiles Single Device (MPSD) configuration or both Multiple Profiles Single Device (MPSD) and Multiple Profiles Multiple Devices (MPMD) configurations.
Los valores posibles son:
-
'off -
'single -
'multiple
-
fast-connectable?(default:#f)Permanently enables the Fast Connectable setting for adapters that support it. When enabled other devices can connect faster to us, however the tradeoff is increased power consumptions. This feature will fully work only on kernel version 4.1 and newer.
privacy(default:'off)Default privacy settings.
-
'off: Disable local privacy -
'network/on: A device will only accept advertising packets from peer devices that contain private addresses. It may not be compatible with some legacy devices since it requires the use of RPA(s) all the time -
'device: A device in device privacy mode is only concerned about the privacy of the device and will accept advertising packets from peer devices that contain their Identity Address as well as ones that contain a private address, even if the peer device has distributed its IRK in the past
and additionally, if controller-mode is set to
'dual:-
'limited-network: Apply Limited Discoverable Mode to advertising, which follows the same policy as to BR/EDR that publishes the identity address when discoverable, and Network Privacy Mode for scanning -
'limited-device: Apply Limited Discoverable Mode to advertising, which follows the same policy as to BR/EDR that publishes the identity address when discoverable, and Device Privacy Mode for scanning.
-
just-works-repairing(default:'never)Specify the policy to the JUST-WORKS repairing initiated by peer.
Possible values:
-
'never -
'confirm -
'always
-
temporary-timeout(default:30)How long to keep temporary devices around. The value is in seconds.
0disables the timer completely.refresh-discovery?(default:#t)Enables the device to issue an SDP request to update known services when profile is connected.
experimental(default:#f)Enables experimental features and interfaces, alternatively a list of UUIDs can be given.
Possible values:
-
#t -
#f -
(list (uuid <uuid-1>) (uuid <uuid-2>) ...).
List of possible UUIDs:
-
d4992530-b9ec-469f-ab01-6c481c47da1c: BlueZ Experimental Debug, -
671b10b5-42c0-4696-9227-eb28d1b049d6: BlueZ Experimental Simultaneous Central and Peripheral, -
"15c0a148-c273-11ea-b3de-0242ac130004: BlueZ Experimental LL privacy, -
330859bc-7506-492d-9370-9a6f0614037f: BlueZ Experimental Bluetooth Quality Report, -
a6695ace-ee7f-4fb9-881a-5fac66c629af: BlueZ Experimental Offload Codecs.
-
remote-name-request-retry-delay(default:300)The duration to avoid retrying to resolve a peer’s name, if the previous try failed.
page-scan-type(default:#f)BR/EDR Page scan activity type.
page-scan-interval(default:#f)BR/EDR Page scan activity interval.
page-scan-window(default:#f)BR/EDR Page scan activity window.
inquiry-scan-type(default:#f)BR/EDR Inquiry scan activity type.
inquiry-scan-interval(default:#f)BR/EDR Inquiry scan activity interval.
inquiry-scan-window(default:#f)BR/EDR Inquiry scan activity window.
link-supervision-timeout(default:#f)BR/EDR Link supervision timeout.
page-timeout(default:#f)BR/EDR Page timeout.
min-sniff-interval(default:#f)BR/EDR minimum sniff interval.
max-sniff-interval(default:#f)BR/EDR maximum sniff interval.
min-advertisement-interval(default:#f)LE minimum advertisement interval (used for legacy advertisement only).
max-advertisement-interval(default:#f)LE maximum advertisement interval (used for legacy advertisement only).
multi-advertisement-rotation-interval(default:#f)LE multiple advertisement rotation interval.
scan-interval-auto-connect(default:#f)LE scanning interval used for passive scanning supporting auto connect.
scan-window-auto-connect(default:#f)LE scanning window used for passive scanning supporting auto connect.
scan-interval-suspend(default:#f)LE scanning interval used for active scanning supporting wake from suspend.
scan-window-suspend(default:#f)LE scanning window used for active scanning supporting wake from suspend.
scan-interval-discovery(default:#f)LE scanning interval used for active scanning supporting discovery.
scan-window-discovery(default:#f)LE scanning window used for active scanning supporting discovery.
scan-interval-adv-monitor(default:#f)LE scanning interval used for passive scanning supporting the advertisement monitor APIs.
scan-window-adv-monitor(default:#f)LE scanning window used for passive scanning supporting the advertisement monitor APIs.
scan-interval-connect(default:#f)LE scanning interval used for connection establishment.
scan-window-connect(default:#f)LE scanning window used for connection establishment.
min-connection-interval(default:#f)LE default minimum connection interval. This value is superseded by any specific value provided via the Load Connection Parameters interface.
max-connection-interval(default:#f)LE default maximum connection interval. This value is superseded by any specific value provided via the Load Connection Parameters interface.
connection-latency(default:#f)LE default connection latency. This value is superseded by any specific value provided via the Load Connection Parameters interface.
connection-supervision-timeout(default:#f)LE default connection supervision timeout. This value is superseded by any specific value provided via the Load Connection Parameters interface.
autoconnect-timeout(default:#f)LE default autoconnect timeout. This value is superseded by any specific value provided via the Load Connection Parameters interface.
adv-mon-allowlist-scan-duration(default:300)Allowlist scan duration during interleaving scan. Only used when scanning for ADV monitors. The units are msec.
adv-mon-no-filter-scan-duration(default:500)No filter scan duration during interleaving scan. Only used when scanning for ADV monitors. The units are msec.
enable-adv-mon-interleave-scan?(default:#t)Enable/Disable Advertisement Monitor interleave scan for power saving.
cache(default:'always)GATT attribute cache.
Los valores posibles son:
-
'always: Always cache attributes even for devices not paired, this is recommended as it is best for interoperability, with more consistent reconnection times and enables proper tracking of notifications for all devices -
'yes: Only cache attributes of paired devices -
'no: Never cache attributes.
-
key-size(default:0)Minimum required Encryption Key Size for accessing secured characteristics.
Los valores posibles son:
-
0: Don’t care -
7 <= N <= 16
-
exchange-mtu(default:517)Exchange MTU size. Possible values are:
-
23 <= N <= 517
-
att-channels(default:3)Number of ATT channels. Possible values are:
-
1: Disables EATT -
2 <= N <= 5
-
session-mode(default:'basic)AVDTP L2CAP signalling channel mode.
Los valores posibles son:
-
'basic: Use L2CAP basic mode -
'ertm: Use L2CAP enhanced retransmission mode.
-
stream-mode(default:'basic)AVDTP L2CAP transport channel mode.
Los valores posibles son:
-
'basic: Use L2CAP basic mode -
'streaming: Use L2CAP streaming mode.
-
reconnect-uuids(default:'())The ReconnectUUIDs defines the set of remote services that should try to be reconnected to in case of a link loss (link supervision timeout). The policy plugin should contain a sane set of values by default, but this list can be overridden here. By setting the list to empty the reconnection feature gets disabled.
Possible values:
-
'() -
(list (uuid <uuid-1>) (uuid <uuid-2>) ...).
-
reconnect-attempts(default:7)Defines the number of attempts to reconnect after a link lost. Setting the value to 0 disables reconnecting feature.
reconnect-intervals(default:'(1 2 4 8 16 32 64))Defines a list of intervals in seconds to use in between attempts. If the number of attempts defined in reconnect-attempts is bigger than the list of intervals the last interval is repeated until the last attempt.
auto-enable?(default:#f)Defines option to enable all controllers when they are found. This includes adapters present on start as well as adapters that are plugged in later on.
resume-delay(default:2)Audio devices that were disconnected due to suspend will be reconnected on resume. resume-delay determines the delay between when the controller resumes from suspend and a connection attempt is made. A longer delay is better for better co-existence with Wi-Fi. The value is in seconds.
rssi-sampling-period(default:#xFF)Default RSSI Sampling Period. This is used when a client registers an advertisement monitor and leaves the RSSISamplingPeriod unset.
Los valores posibles son:
-
#x0: Report all advertisements -
N = #xXX: Report advertisements every N x 100 msec (range: #x01 to #xFE) -
#xFF: Report only one advertisement per device during monitoring period.
-
- Variable Scheme: gnome-keyring-service-type
Es el tipo del servicio que añade el entorno de escritorio el anillo de claves de GNOME. Su valor es un objeto
gnome-keyring-configuration(véase a continuación).Este servicio añade el paquete
gnome-keyringal perfil del sistema y extiende PAM con entradas que usanpam_gnome_keyring.so, las cuales desbloquean el anillo de claves del sistema de la usuaria cuando ingrese en el sistema o cambie su contraseña con passwd.
- Tipo de datos: gnome-keyring-configuration
Registro de configuración para el servicio del anillo de claves de GNOME.
keyring(predeterminado:gnome-keyring)El paquete GNOME keyring usado.
pam-servicesUna lista de pares
(servicio . tipo)que denotan los servicios de PAM que deben extenderse, donde servicio es el nombre de un servicio existente que debe extenderse y tipo esloginopasswd.Si se proporciona
login, añade un campo opcionalpam_gnome_keyring.soal bloque de identificación sin parámetros y al bloque de sesión conauto_start. Si se proporcionapasswd, añade un campo opcionalpam_gnome_keyring.soal bloque de contraseña sin parámetros.De manera predeterminada, este campo contiene “gdm-password” con el valor
loginy “passwd” tiene valorpasswd.
- Scheme Variable: seatd-service-type
seatd is a minimal seat management daemon.
Seat management takes care of mediating access to shared devices (graphics, input), without requiring the applications needing access to be root.
(append (list ;; make sure seatd is running (service seatd-service-type)) ;; normally one would want %base-services %base-services)seatdoperates over a UNIX domain socket, withlibseatproviding the client side of the protocol. Applications that acquire access to the shared resources viaseatd(e.g.sway) need to be able to talk to this socket. This can be achieved by adding the user they run under to the group owningseatd’s socket (usually “seat”), like so:(user-account (name "alice") (group "users") (supplementary-groups '("wheel" ; allow use of sudo, etc. "seat" ; seat management "audio" ; sound card "video" ; video devices such as webcams "cdrom")) ; the good ol' CD-ROM (comment "Bob's sister"))Depending on your setup, you will have to not only add regular users, but also system users to this group. For instance, some greetd greeters require graphics and therefore also need to negotiate with seatd.
- Data Type: seatd-configuration
Configuration record for the seatd daemon service.
seatd(default:seatd)The seatd package to use.
group(default: ‘"seat"’)Group to own the seatd socket.
socket(default: ‘"/run/seatd.sock"’)Where to create the seatd socket.
logfile(default: ‘"/var/log/seatd.log"’)Log file to write to.
loglevel(default: ‘"error"’)Log level to output logs. Possible values: ‘"silent"’, ‘"error"’, ‘"info"’ and ‘"debug"’.
Next: Servicios de bases de datos, Previous: Servicios de escritorio, Up: Servicios [Contents][Index]
12.9.10 Servicios de sonido
El módulo (gnu services sound) proporciona un servicio para la
configuración del sistema ALSA (arquitectura avanzada de sonido de Linux),
el cual establece PulseAudio como el controlador de ALSA preferido para
salida de sonido.
- Variable Scheme: alsa-service-type
Es el tipo para el sistema ALSA (Arquitectura de sonido avanzada de Linux), que genera el archivo de configuración /etc/asound.conf. El valor para este tipo es un registro
alsa-configurationcomo en el ejemplo:Véase a continuación más detalles sobre
alsa-configuration.
- Tipo de datos: alsa-configuration
Tipo de datos que representa la configuración para
alsa-service.alsa-plugins(predeterminados: alsa-plugins)El paquete
alsa-pluginsusado.pulseaudio?(predeterminado: #t)Determina si las aplicaciones ALSA deben usar el servidor de sonido PulseAudio de manera transparente.
El uso de PulseAudio le permite la ejecución de varias aplicaciones que produzcan sonido al mismo tiempo y su control individual mediante
pavucontrol, entre otras opciones.extra-options(predeterminado: "")Cadena a añadir al final del archivo /etc/asound.conf.
Las usuarias individuales que deseen forzar la configuración de ALSA en el sistema para sus cuentas pueden hacerlo con el archivo ~/.asoundrc:
# En guix tenemos que especificar la ruta absoluta del módulo.
pcm_type.jack {
lib "/home/alicia/.guix-profile/lib/alsa-lib/libasound_module_pcm_jack.so"
}
# Redirección de ALSA a jack:
# <http://jackaudio.org/faq/routing_alsa.html>.
pcm.rawjack {
type jack
playback_ports {
0 system:playback_1
1 system:playback_2
}
capture_ports {
0 system:capture_1
1 system:capture_2
}
}
pcm.!default {
type plug
slave {
pcm "rawjack"
}
}
Véase https://www.alsa-project.org/main/index.php/Asoundrc para obtener más detalles.
- Variable Scheme: pulseaudio-service-type
Tipo de servicio del servidor de sonido PulseAudio. Existe para permitir los cambios a nivel de sistema de la configuración predeterminada a través de
pulseaudio-configuration, véase a continuación.Aviso: Este servicio hace que se ignoren los archivos de configuración de cada usuaria. Si desea que PulseAudio respete los archivos de configuración en ~/.config/pulse tiene que eliminar del entorno (con
unset) las variablesPULSE_CONFIGyPULSE_CLIENTCONFIGen su archivo ~/.bash_profile.Aviso: Este servicio no asegura en sí que el paquete
pulseaudioexista en su máquina. Únicamente añade los archivos de configuración, como se detalla a continuación. En el caso (ciertamente poco probable), de que se encuentre si un paquete pulseaudiopulseaudio, considere activarlo a través del tipoalsa-service-typemostrado previamente.
- Tipo de datos: pulseaudio-configuration
Tipo de datos que representa la configuración para
pulseaudio-service.client-conf(predeterminada:'())List of settings to set in client.conf. Accepts a list of strings or symbol-value pairs. A string will be inserted as-is with a newline added. A pair will be formatted as “key = value”, again with a newline added.
daemon-conf(predeterminada:'((flat-volumes . no)))Lista de opciones de configuración de daemon.conf, con el mismo formato que client-conf.
script-file(predeterminado:(file-append pulseaudio "/etc/pulse/default.pa"))Script file to use as default.pa. In case the
extra-script-filesfield below is used, an.includedirective pointing to /etc/pulse/default.pa.d is appended to the provided script.extra-script-files(default:'())A list of file-like objects defining extra PulseAudio scripts to run at the initialization of the
pulseaudiodaemon, after the mainscript-file. The scripts are deployed to the /etc/pulse/default.pa.d directory; they should have the ‘.pa’ file name extension. For a reference of the available commands, refer toman pulse-cli-syntax.system-script-file(predeterminado:(file-append pulseaudio "/etc/pulse/system.pa"))Archivo del guión usado como system.pa
The example below sets the default PulseAudio card profile, the default sink and the default source to use for a old SoundBlaster Audigy sound card:
(pulseaudio-configuration (extra-script-files (list (plain-file "audigy.pa" (string-append "\ set-card-profile alsa_card.pci-0000_01_01.0 \ output:analog-surround-40+input:analog-mono set-default-source alsa_input.pci-0000_01_01.0.analog-mono set-default-sink alsa_output.pci-0000_01_01.0.analog-surround-40\n")))))Note that
pulseaudio-service-typeis part of%desktop-services; if your operating system declaration was derived from one of the desktop templates, you’ll want to adjust the above example to modify the existingpulseaudio-service-typeviamodify-services(seemodify-services), instead of defining a new one.
- Variable Scheme: ladspa-service-type
Este servicio proporciona valor a la variable LADSPA_PATH, de manera que los programas que lo tengan en cuenta, por ejemplo PulseAudio, puedan cargar módulos LADSPA.
El siguiente ejemplo configura el servicio para permitir la activación de los módulos del paquete
swh-plugins:(service ladspa-service-type (ladspa-configuration (plugins (list swh-plugins))))Véase http://plugin.org.uk/ladspa-swh/docs/ladspa-swh.html para obtener más detalles.
Next: Servicios de correo, Previous: Servicios de sonido, Up: Servicios [Contents][Index]
12.9.11 Servicios de bases de datos
El módulo (gnu services databases) proporciona los siguientes
servicios.
PostgreSQL
El ejemplo siguiente describe un servicio PostgreSQL con su configuración predeterminada.
(service postgresql-service-type
(postgresql-configuration
(postgresql postgresql-10)))
Si los servicios fallan al arrancar puede deberse a que ya se encuentra presente otro cluster incompatible en data-directory. Puede modificar el valor (o, si no necesita más dicho cluster, borrar data-directory), y reiniciar el servicio.
La identificación de pares se usa de manera predeterminada y la cuenta de
usuaria postgres no tiene intérprete predeterminado, lo que evita la
ejecución directa de órdenes psql bajo dicha cuenta. Para usar
psql, puede ingresar temporalmente al sistema como postgres
usando un intérprete de órdenes, crear una cuenta de administración de
PostgreSQL con el mismo nombre de una de las usuarias del sistema y, tras
esto, crear la base de datos asociada.
sudo -u postgres -s /bin/sh createuser --interactive createdb $MI_CUENTA_DE_USUARIA # Sustituir por el valor apropiado.
- Tipo de datos: postgresql-configuration
Tipo de datos que representa la configuración de
postgresql-service-type.postgresqlEl paquete PostgreSQL usado para este servicio.
port(predeterminado:5432)Puerto en el que debe escuchar PostgreSQL.
locale(predeterminado:"en_US.utf8")Localización predeterminada cuando se crea el cluster de la base de datos.
config-file(predeterminado:(postgresql-config-file))The configuration file to use when running PostgreSQL. The default behaviour uses the postgresql-config-file record with the default values for the fields.
log-directory(default:"/var/log/postgresql")The directory where
pg_ctloutput will be written in a file named"pg_ctl.log". This file can be useful to debug PostgreSQL configuration errors for instance.data-directory(predeterminado:"/var/lib/postgresql/data")Directorio en el que se almacenan los datos.
extension-packages(predeterminado:'()) ¶Las extensiones adicionales se cargan de paquetes enumerados en extension-packages. Las extensiones están disponibles en tiempo de ejecución. Por ejemplo, para crear una base de datos geográfica con la extensión
postgis, una usuaria podría configurar el servicio postgresql-service como en este ejemplo:(use-package-modules databases geo) (operating-system ... ;; postgresql es necesario para ejecutar `psql' pero no se necesita ;; postgis para un funcionamiento correcto. (packages (cons* postgresql %base-packages)) (services (cons* (service postgresql-service-type (postgresql-configuration (postgresql postgresql-10) (extension-packages (list postgis)))) %base-services)))
Una vez hecho, la extensión estará visible y podrá inicializar una base de datos geográfica de este modo:
psql -U postgres > create database pruebapostgis; > \connect pruebapostgis; > create extension postgis; > create extension postgis_topology;
No es necesaria la adición de este campo para extensiones incluidas en la distribución oficial37 como hstore o dblink, puesto que ya pueden cargarse en postgresql. Este campo únicamente es necesario para extensiones proporcionadas por otros paquetes.
- Tipo de datos: postgresql-config-file
Data type representing the PostgreSQL configuration file. As shown in the following example, this can be used to customize the configuration of PostgreSQL. Note that you can use any G-expression or filename in place of this record, if you already have a configuration file you’d like to use for example.
(service postgresql-service-type (postgresql-configuration (config-file (postgresql-config-file (log-destination "stderr") (hba-file (plain-file "pg_hba.conf" " local all all trust host all all 127.0.0.1/32 md5 host all all ::1/128 md5")) (extra-config '(("session_preload_libraries" "auto_explain") ("random_page_cost" 2) ("auto_explain.log_min_duration" "100 ms") ("work_mem" "500 MB") ("logging_collector" #t) ("log_directory" "/var/log/postgresql")))))))log-destination(predeterminado:"syslog")The logging method to use for PostgreSQL. Multiple values are accepted, separated by commas.
hba-file(predeterminado:%default-postgres-hba)Nombre de archivo o expresión-G para la configuración de identificación basada en nombres de máquina.
ident-file(predeterminado:%default-postgres-ident)Nombre de archivo o expresión-G para la configuración de asociación de nombres de usuaria.
socket-directory(default:"/var/run/postgresql")Specifies the directory of the Unix-domain socket(s) on which PostgreSQL is to listen for connections from client applications. If set to
""PostgreSQL does not listen on any Unix-domain sockets, in which case only TCP/IP sockets can be used to connect to the server.By default, the
#falsevalue means the PostgreSQL default value will be used, which is currently ‘/tmp’.extra-config(predeterminada:'())Claves y valores adicionales que se incluirán en el archivo de configuración de PostgreSQL. Cada entrada en la lista debe ser una lista cuyo primer elemento sea la clave y los elementos restantes son los valores.
The values can be numbers, booleans or strings and will be mapped to PostgreSQL parameters types
Boolean,String,Numeric,Numeric with UnitandEnumerateddescribed here.
- Scheme Variable: postgresql-role-service-type
This service allows to create PostgreSQL roles and databases after PostgreSQL service start. Here is an example of its use.
(service postgresql-role-service-type (postgresql-role-configuration (roles (list (postgresql-role (name "test") (create-database? #t))))))This service can be extended with extra roles, as in this example:
(service-extension postgresql-role-service-type (const (postgresql-role (name "alice") (create-database? #t))))
- Data Type: postgresql-role
PostgreSQL manages database access permissions using the concept of roles. A role can be thought of as either a database user, or a group of database users, depending on how the role is set up. Roles can own database objects (for example, tables) and can assign privileges on those objects to other roles to control who has access to which objects.
nameThe role name.
permissions(default:'(createdb login))The role permissions list. Supported permissions are
bypassrls,createdb,createrole,login,replicationandsuperuser.create-database?(default:#f)Whether to create a database with the same name as the role.
- Data Type: postgresql-role-configuration
Data type representing the configuration of postgresql-role-service-type.
host(default:"/var/run/postgresql")The PostgreSQL host to connect to.
log(default:"/var/log/postgresql_roles.log")File name of the log file.
roles(default:'())The initial PostgreSQL roles to create.
MariaDB/MySQL
- Scheme Variable: mysql-service-type
This is the service type for a MySQL or MariaDB database server. Its value is a
mysql-configurationobject that specifies which package to use, as well as various settings for themysqlddaemon.
- Tipo de datos: mysql-configuration
Data type representing the configuration of mysql-service-type.
mysql(predeterminado: mariadb)Objeto de paquete del servidor de bases de datos MySQL, puede ser tanto mariadb como mysql.
Para MySQL, se mostrará una contraseña de root temporal durante el tiempo de activación. Para MariaDB, la contraseña de root está vacía.
bind-address(predeterminada:"127.0.0.1")The IP on which to listen for network connections. Use
"0.0.0.0"to bind to all available network interfaces.port(predeterminado:3306)Puerto TCP en el que escucha el servidor de bases de datos a la espera de conexiones entrantes.
socket(default:"/run/mysqld/mysqld.sock")Socket file to use for local (non-network) connections.
extra-content(predeterminado:"")Additional settings for the my.cnf configuration file.
extra-environment(default:#~'())List of environment variables passed to the
mysqldprocess.auto-upgrade?(default:#t)Whether to automatically run
mysql_upgradeafter starting the service. This is necessary to upgrade the system schema after “major” updates (such as switching from MariaDB 10.4 to 10.5), but can be disabled if you would rather do that manually.
Memcached
- Variable Scheme: memcached-service-type
Este es el tipo de servicio para el servicio Memcached, que proporciona caché distribuida en memoria. El valor para este tipo de servicio es un objeto
memcached-configuration.
- Tipo de datos: memcached-configuration
Tipo de datos que representa la configuración de memcached.
memcached(predeterminado:memcached)El paquete de Memcached usado.
interfaces(predeterminadas:'("0.0.0.0"))Interfaces de red por las que se esperan conexiones.
tcp-port(predeterminado:11211)Port on which to accept connections.
udp-port(predeterminado:11211)Puerto en el que se deben aceptar conexiones UDP, el valor 0 desactiva la escucha en un socket UDP.
additional-options(predeterminadas:'())Opciones de línea de órdenes adicionales que se le proporcionarán a
memcached.
Redis
- Variable Scheme: redis-service-type
Es el tipo de servicio para el almacén de clave/valor Redis, cuyo valor es un objeto
redis-configuration.
- Tipo de datos: redis-configuration
Tipo de datos que representa la configuración de redis.
redis(predeterminado:redis)El paquete Redis usado.
bind(predeterminada:"127.0.0.1")La interfaz de red en la que se escucha.
port(predeterminado:6379)Puerto en el que se aceptan conexiones, el valor 0 desactiva la escucha en un socket TCP.
working-directory(predeterminado:"/var/lib/redis")Directorio en el que se almacena los archivos de base de datos y relacionados.
Next: Servicios de mensajería, Previous: Servicios de bases de datos, Up: Servicios [Contents][Index]
12.9.12 Servicios de correo
El módulo (gnu services mail) proporciona definiciones de servicios
Guix para servicios de correo electrónico: servidores IMAP, POP3 y LMTP, así
como agentes de transporte de correo (MTA). ¡Muchos acrónimos! Estos
servicios se detallan en las subsecciones a continuación.
Servicio Dovecot
- Procedimiento Scheme: dovecot-service [#:config (dovecot-configuration)]
Devuelve un servicio que ejecuta el servidor de correo IMAP/POP3/LMTP Dovecot.
Habitualmente Dovecot no necesita mucha configuración; el objeto de
configuración predeterminado creado por (dovecot-configuration) es
suficiente si su correo se entrega en ~/Maildir. Un certificado
auto-firmado se generará para las conexiones protegidas por TLS, aunque
Dovecot también escuchará en puertos sin cifrar de manera
predeterminada. Existe un amplio número de opciones no obstante, las cuales
las administradoras del correo puede que deban cambiar, y como en el caso de
otros servicios, Guix permite a la administradora del sistema la
especificación de dichos parámetros a través de una interfaz Scheme
uniforme.
Por ejemplo, para especificar que el correo se encuentra en
maildir:~/.correo, se debe instanciar el servicio de Dovecot de esta
manera:
(dovecot-service #:config
(dovecot-configuration
(mail-location "maildir:~/.correo")))
A continuación se encuentran los parámetros de configuración disponibles. El
tipo de cada parámetro antecede la definición del mismo; por ejemplo,
‘string-list foo’ indica que el parámetro foo debe especificarse
como una lista de cadenas. También existe la posibilidad de especificar la
configuración como una cadena, si tiene un archivo dovecot.conf
antiguo que quiere trasladar a otro sistema; véase el final para más
detalles.
Los campos disponibles de dovecot-configuration son:
- parámetro de
dovecot-configuration: package dovecot ¶ El paquete dovecot.
- parámetro de
dovecot-configuration: lista-cadenas-separada-comas listen ¶ Una lista de direcciones IP o nombres de máquina donde se escucharán conexiones. ‘*’ escucha en todas las interfaces IPv4, ‘::’ escucha en todas las interfaces IPv6. Si desea especificar puertos distintos a los predefinidos o algo más complejo, personalice los campos de dirección y puerto del ‘inet-listener’ de los servicios específicos en los que tenga interés.
- parámetro de
dovecot-configuration: lista-protocol-configuration protocols ¶ Lista de protocolos que se desea ofrecer. Los protocolos disponibles incluyen ‘imap’, ‘pop3’ y ‘lmtp’.
Los campos disponibles de
protocol-configurationson:- parámetro de
protocol-configuration: string name ¶ El nombre del protocolo.
- parámetro de
protocol-configuration: string auth-socket-path ¶ Ruta del socket de UNIX del servidor de identificación maestro para la búsqueda de usuarias. Se usa por parte de imap (para usuarias compartidas) y lda. Su valor predeterminado es ‘"/var/run/dovecot/auth-userdb"’.
protocol-configurationparameter: boolean imap-metadata? ¶Whether to enable the
IMAP METADATAextension as defined in RFC 5464, which provides a means for clients to set and retrieve per-mailbox, per-user metadata and annotations over IMAP.If this is ‘#t’, you must also specify a dictionary via the
mail-attribute-dictsetting.El valor predeterminado es ‘#f’
protocol-configurationparameter: space-separated-string-list managesieve-notify-capabilities ¶Which NOTIFY capabilities to report to clients that first connect to the ManageSieve service, before authentication. These may differ from the capabilities offered to authenticated users. If this field is left empty, report what the Sieve interpreter supports by default.
El valor predeterminado es ‘()’.
protocol-configurationparameter: space-separated-string-list managesieve-sieve-capability ¶Which SIEVE capabilities to report to clients that first connect to the ManageSieve service, before authentication. These may differ from the capabilities offered to authenticated users. If this field is left empty, report what the Sieve interpreter supports by default.
El valor predeterminado es ‘()’.
- parámetro de
protocol-configuration: list-cadenas-separada-espacios mail-plugins ¶ Lista separada por espacios de módulos a cargar.
- parámetro de
protocol-configuration: entero-no-negativo mail-max-userip-connections ¶ Número máximo de conexiones IMAP permitido para una usuaria desde cada dirección IP. ATENCIÓN: El nombre de usuaria es sensible a las mayúsculas. Su valor predeterminado es ‘10’.
- parámetro de
- parámetro de
dovecot-configuration: lista-service-configuration services ¶ Lista de servicios activados. Los servicios disponibles incluyen ‘imap’, ‘imap-login’, ‘pop3’, ‘pop3-login’, ‘auth’ y ‘lmtp’.
Los campos disponibles de
service-configurationson:- parámetro de
service-configuration: string kind ¶ El tipo del servicio. Entre los valores aceptados se incluye
director,imap-login,pop3-login,lmtp,imap,pop3,auth,auth-worker,dict,tcpwrap,quota-warningo cualquier otro.
- parámetro de
service-configuration: lista-listener-configuration listeners ¶ Procesos de escucha para el servicio. Un proceso de escucha es un objeto
unix-listener-configuration, un objetofifo-listener-configurationo un objetoinet-listener-configuration. Su valor predeterminado es ‘()’.Los campos disponibles de
unix-listener-configurationson:- parámetro de
unix-listener-configuration: string path ¶ Ruta al archivo, relativa al campo
base-dir. También se usa como nombre de la sección.
- parámetro de
unix-listener-configuration: string mode ¶ Modo de acceso del socket. Su valor predeterminado es ‘"0600"’.
- parámetro de
unix-listener-configuration: string user ¶ Usuaria que posee el socket. Su valor predeterminado es ‘""’.
- parámetro de
unix-listener-configuration: string group ¶ Grupo que posee el socket. Su valor predeterminado es ‘""’.
Los campos disponibles de
fifo-listener-configurationson:- parámetro de
fifo-listener-configuration: string path ¶ Ruta al archivo, relativa al campo
base-dir. También se usa como nombre de la sección.
- parámetro de
fifo-listener-configuration: string mode ¶ Modo de acceso del socket. Su valor predeterminado es ‘"0600"’.
- parámetro de
fifo-listener-configuration: string user ¶ Usuaria que posee el socket. Su valor predeterminado es ‘""’.
- parámetro de
fifo-listener-configuration: string group ¶ Grupo que posee el socket. Su valor predeterminado es ‘""’.
Los campos disponibles de
inet-listener-configurationson:- parámetro de
inet-listener-configuration: string protocol ¶ El protocolo con el que se esperan las conexiones.
- parámetro de
inet-listener-configuration: string address ¶ La dirección en la que se escuchará, o vacío para escuchar en todas las direcciones. Su valor predeterminado es ‘""’.
- parámetro de
inet-listener-configuration: entero-no-negativo port ¶ El puerto en el que esperarán conexiones.
- parámetro de
inet-listener-configuration: boolean ssl? ¶ Si se usará SSL para este servicio; ‘yes’ (sí), ‘no’ o ‘required’ (necesario). Su valor predeterminado es ‘#t’.
- parámetro de
- parámetro de
service-configuration: entero-no-negativo client-limit ¶ Número máximo de conexiones simultáneas por cliente por proceso. Una vez se reciba este número de conexiones, la siguiente conexión entrante solicitará a Dovecot el inicio de un nuevo proceso. Si se proporciona el valor 0, se usa
default-client-limit.El valor predeterminado es ‘0’.
- parámetro de
service-configuration: entero-no-negativo service-count ¶ Número de conexiones a manejar antes de iniciar un nuevo proceso. Habitualmente los únicos valores útiles son 0 (ilimitadas) o 1. 1 es más seguro, pero 0 es más rápido. <doc/wiki/LoginProcess.txt>. Su valor predeterminado es ‘1’.
- parámetro de
service-configuration: entero-no-negativo process-limit ¶ Número máximo de procesos que pueden existir para este servicio. Si se proporciona el valor 0, se usa
default-process-limit.El valor predeterminado es ‘0’.
- parámetro de
service-configuration: entero-no-negativo process-min-avail ¶ Número de procesos que siempre permanecerán a la espera de más conexiones. Su valor predeterminado es ‘0’.
- parámetro de
service-configuration: entero-no-negativo vsz-limit ¶ Si proporciona ‘service-count 0’, probablemente necesitará incrementar este valor. Su valor predeterminado es ‘256000000’.
- parámetro de
- parámetro de
dovecot-configuration: dict-configuration dict ¶ Configuración de Dict, como la creada por el constructor
dict-configuration.Los campos disponibles de
dict-configurationson:- parámetro de
dict-configuration: campos-libres entries ¶ Una lista de pares clave-valor que este diccionario debe incorporar. Su valor predeterminado es ‘()’.
- parámetro de
- parámetro de
dovecot-configuration: lista-passdb-configuration passdbs ¶ Una lista de configuraciones de passdb, cada una creada por el constructor
passdb-configuration.Los campos disponibles de
passdb-configurationson:- parámetro de
passdb-configuration: string driver ¶ El controlador que passdb debe usar. Entre los valores aceptados se incluye ‘pam’, ‘passwd’, ‘shadow’, ‘bsdauth’ y ‘static’. Su valor predeterminado es ‘"pam"’.
- parámetro de
passdb-configuration: lista-cadenas-separada-espacios args ¶ Lista de parámetros separados por espacios para proporcionar al controlador passdb. Su valor predeterminado es ‘""’.
- parámetro de
- parámetro de
dovecot-configuration: lista-userdb-configuration userdbs ¶ Lista de configuraciones userdb, cada una creada por el constructor
userdb-configuration.Los campos disponibles de
userdb-configurationson:- parámetro de
userdb-configuration: string driver ¶ El controlador que userdb debe usar. Entre los valores aceptados se incluye ‘passwd’ y ‘static’. Su valor predeterminado es ‘"passwd"’.
- parámetro de
userdb-configuration: lista-cadenas-separada-espacios args ¶ Lista separada por espacios de parámetros usados para el controlador userdb. Su valor predeterminado es ‘""’.
- parámetro de
userdb-configuration: parámetros-libres override-fields ¶ Sustituye los valores de campos de passwd. Su valor predeterminado es ‘()’.
- parámetro de
- parámetro de
dovecot-configuration: plugin-configuration plugin-configuration ¶ Configuración del módulo, creada por el constructor
plugin-configuration.
- parámetro de
dovecot-configuration: lista-namespace-configuration namespaces ¶ Lista de espacios de nombres. Cada elemento de la lista debe crearse con el constructor
namespace-configuration.Los campos disponibles de
namespace-configurationson:- parámetro de
namespace-configuration: string name ¶ Nombre para este espacio de nombres.
- parámetro de
namespace-configuration: string type ¶ Tipo del espacio de nombres: ‘private’, ‘shared’ o ‘public’. Su valor predeterminado es ‘"private"’.
- parámetro de
namespace-configuration: string separator ¶ Hierarchy separator to use. You should use the same separator for all namespaces or some clients get confused. ‘/’ is usually a good one. The default however depends on the underlying mail storage format. Defaults to ‘""’.
- parámetro de
namespace-configuration: string prefix ¶ Prefix required to access this namespace. This needs to be different for all namespaces. For example ‘Public/’. Defaults to ‘""’.
- parámetro de
namespace-configuration: string location ¶ Localización física de la bandeja de correo. En el mismo formato que la localización del correo, que también es su valor predeterminado. Su valor predeterminado es ‘""’.
- parámetro de
namespace-configuration: boolean inbox? ¶ Únicamente puede existir una bandeja de entrada (INBOX), y esta configuración define qué espacio de nombres la posee. Su valor predeterminado es ‘#f’.
If namespace is hidden, it’s not advertised to clients via NAMESPACE extension. You’ll most likely also want to set ‘list? #f’. This is mostly useful when converting from another server with different namespaces which you want to deprecate but still keep working. For example you can create hidden namespaces with prefixes ‘~/mail/’, ‘~%u/mail/’ and ‘mail/’. Defaults to ‘#f’.
- parámetro de
namespace-configuration: boolean list? ¶ Show the mailboxes under this namespace with the LIST command. This makes the namespace visible for clients that do not support the NAMESPACE extension. The special
childrenvalue lists child mailboxes, but hides the namespace prefix. Defaults to ‘#t’.
- parámetro de
namespace-configuration: boolean subscriptions? ¶ El espacio de nombres maneja sus propias subscripciones. Si es
#f, el espacio de nombres superior las maneja. El prefijo vacío siempre debe tener este valor como#t. Su valor predeterminado es ‘#t’.
- parámetro de
namespace-configuration: lista-mailbox-configuration mailboxes ¶ Lista de bandejas de correo predefinidas en este espacio de nombres. Su valor predeterminado es ‘()’.
Los campos disponibles de
mailbox-configurationson:- parámetro de
mailbox-configuration: string name ¶ Nombre de esta bandeja de correo.
- parámetro de
mailbox-configuration: string auto ¶ Con ‘create’ se crea de forma automática esta bandeja de correo. Con ‘subscribe’ se crea y se suscribe a la bandeja de correo. Su valor predeterminado es ‘"no"’.
- parámetro de
mailbox-configuration: lista-cadenas-separada-espacios special-use ¶ Lista de atributos
SPECIAL-USEde IMAP como se especifican en el RFC 6154. Entre los valores aceptados se incluye\All,\Archive,\Drafts,\Flagged,\Junk,\Senty\Trash. Su valor predeterminado es ‘()’.
- parámetro de
- parámetro de
- parámetro de
dovecot-configuration: nombre-archivo base-dir ¶ Directorio base donde se almacenan los datos de tiempo de ejecución. Su valor predeterminado es ‘"/var/run/dovecot/"’.
- parámetro de
dovecot-configuration: string login-greeting ¶ Mensaje de saludo para clientes. Su valor predeterminado es ‘"Dovecot ready."’.
- parámetro de
dovecot-configuration: lista-cadenas-separada-espacios login-trusted-networks ¶ Lista de rangos de red en los que se confía. Las conexiones desde estas IP tienen permitido forzar sus direcciones IP y puertos (para el registro y las comprobaciones de identidad). ‘disable-plaintext-auth’ también se ignora en estas redes. Habitualmente aquí se especificarían los servidores proxy IMAP. Su valor predeterminado es ‘()’.
- parámetro de
dovecot-configuration: lista-cadenas-separada-espacios login-access-sockets ¶ Lista de sockets para la comprobación de acceso al sistema (por ejemplo tcpwrap). Su valor predeterminado es ‘()’.
- parámetro de
dovecot-configuration: boolean verbose-proctitle? ¶ Muestra títulos de procesamiento más detallados (en la postdata). Actualmente muestra el nombre de la usuaria y su dirección IP. Es útil para ver quién está usando procesos IMAP realmente (por ejemplo bandejas de correo compartidas o si el mismo identificador numérico de usuaria se usa para varias cuentas). Su valor predeterminado es ‘#f’.
- parámetro de
dovecot-configuration: boolean shutdown-clients? ¶ Determina si se deben finalizar todos los procesos cuando el proceso maestro de Dovecot termine su ejecución. El valor
#fsignifica que Dovecot puede actualizarse sin forzar el cierre de las conexiones existentes (aunque esto puede ser un problema si la actualización se debe, por ejemplo, a la corrección de una vulnerabilidad). Su valor predeterminado es ‘#t’.
- parámetro de
dovecot-configuration: entero-no-negativo doveadm-worker-count ¶ Si no es cero, ejecuta las ordenes del correo a través de este número de conexiones al servidor doveadm, en vez de ejecutarlas directamente en el mismo proceso. Su valor predeterminado es ‘0’.
- parámetro de
dovecot-configuration: string doveadm-socket-path ¶ Socket UNIX o máquina:puerto usados para la conexión al servidor doveadm. Su valor predeterminado es ‘"doveadm-server"’.
- parámetro de
dovecot-configuration: lista-cadenas-separada-espacios import-environment ¶ Lista de variables de entorno que se preservan al inicio de Dovecot y se proporcionan a los procesos iniciados. También puede proporcionar pares clave=valor para proporcionar siempre dicha configuración específica.
- parámetro de
dovecot-configuration: boolean disable-plaintext-auth? ¶ Desactiva la orden LOGIN y todas las otras identificaciones en texto plano a menos que se use SSL/TLS (capacidad LOGINDISABLED). Tenga en cuenta que si la IP remota coincide con la IP local (es decir, se ha conectado desde la misma máquina), la conexión se considera segura y se permite la identificación en texto plano. Véase también la configuración ssl=required. Su valor predeterminado es ‘#t’.
- parámetro de
dovecot-configuration: entero-no-negativo auth-cache-size ¶ Tamaño de la caché de identificaciones (por ejemplo, ‘#e10e6’. 0 significa que está desactivada. Tenga en cuenta que bsdauth, PAM y vpopmail necesitan un valor en ‘cache-key’ para que se use la caché. Su valor predeterminado es ‘0’.
- parámetro de
dovecot-configuration: string auth-cache-ttl ¶ Tiempo de vida de los datos almacenados en caché. Los registros de caché no se usan tras su expiración, *excepto* si la base de datos principal devuelve un fallo interno. También se intentan manejar los cambios de contraseña de manera automática: si la identificación previa de la usuaria fue satisfactoria, pero no esta última, la caché no se usa. En estos momentos únicamente funciona con identificación en texto plano. Su valor predeterminado es ‘"1 hour"’.
- parámetro de
dovecot-configuration: string auth-cache-negative-ttl ¶ Tiempo de vida para fallos de búsqueda en la caché (usuaria no encontrada, la contraseña no coincide). 0 desactiva completamente su almacenamiento en caché. Su valor predeterminado es ‘"1 hour"’.
- parámetro de
dovecot-configuration: lista-cadenas-separada-espacios auth-realms ¶ Lista de dominios para los mecanismos de identificación de SASL que necesite. Puede dejarla vacía si no desea permitir múltiples dominios. Muchos clientes simplemente usarán el primero de la lista, por lo que debe mantener el dominio predeterminado en primera posición. Su valor predeterminado es ‘()’.
- parámetro de
dovecot-configuration: string auth-default-realm ¶ Dominio predeterminado usado en caso de no especificar ninguno. Esto se usa tanto en dominios SASL y como al añadir @dominio al nombre de usuaria en los ingresos al sistema a través de texto en claro. Su valor predeterminado es ‘""’.
- parámetro de
dovecot-configuration: string auth-username-chars ¶ Lista de caracteres permitidos en los nombres de usuaria. Si el nombre de usuaria proporcionado contiene un carácter no enumerado aquí, el login falla automáticamente. Es únicamente una comprobación adicional para asegurarse de que las usuarias no pueden explotar ninguna potencial vulnerabilidad con el escape de comillas en bases de datos SQL/LDAP. Si desea permitir todos los caracteres, establezca este valor a la cadena vacía. Su valor predeterminado es ‘"abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ01234567890.-_@"’.
- parámetro de
dovecot-configuration: string auth-username-translation ¶ Traducciones de caracteres de nombres de usuaria antes de que se busque en las bases de datos. El valor contiene series de caracteres "original -> transformado". Por ejemplo ‘#@/@’ significa que ‘#’ y ‘/’ se traducen en ‘@’. Su valor predeterminado es ‘""’.
- parámetro de
dovecot-configuration: string auth-username-format ¶ Formato proporcionado al nombre de usuaria antes de buscarlo en las bases de datos. Puede usar variables estándar aquí, por ejemplo %Lu transformará el nombre a minúsculas, %n eliminará el fragmento del dominio si se proporcionó, o ‘%n-AT-%d’ cambiaría ‘@’ en ‘-AT-’. Esta traducción se realiza tras los cambios de ‘auth-username-translation’. Su valor predeterminado es ‘"%Lu"’.
- parámetro de
dovecot-configuration: string auth-master-user-separator ¶ Si desea permitir que usuarias maestras ingresen mediante la especificación del nombre de usuaria maestra dentro de la cadena de nombre de usuaria normal (es decir, sin usar el mecanismo para ello implementado por SASL), puede especificar aquí el carácter separador. El formato es entonces <usuaria><separador><usuaria maestra>. UW-IMAP usa ‘*’ como separador, por lo que esa puede ser una buena elección. Su valor predeterminado es ‘""’.
- parámetro de
dovecot-configuration: string auth-anonymous-username ¶ Usuaria usada para las usuarias que ingresen al sistema con el mecanismo de SASL ANONYMOUS. Su valor predeterminado es ‘"anonymous"’.
- parámetro de
dovecot-configuration: entero-no-negativo auth-worker-max-count ¶ Número máximo de procesos de trabajo dovecot-auth. Se usan para la ejecución de consultas bloqueantes a passdb y userdb (por ejemplo MySQL y PAM). Se crean y destruyen bajo demanda de manera automática. Su valor predeterminado es ‘30’.
- parámetro de
dovecot-configuration: string auth-gssapi-hostname ¶ Nombre de máquina usado en los nombres de GSSAPI principales. Por omisión se usa el nombre devuelto por gethostname(). Use ‘$ALL’ (con comillas) para permitir todas las entradas keytab. Su valor predeterminado es ‘""’.
- parámetro de
dovecot-configuration: string auth-krb5-keytab ¶ Keytab de Kerberos usado para el mecanismo GSSAPI. Si no se especifica ninguno, se usa el predeterminado del sistema (habitualmente /etc/krb5.keytab). Puede ser necesario cambiar el servicio auth para que se ejecute como root y tenga permisos de lectura sobre este archivo. Su valor predeterminado es ‘""’.
- parámetro de
dovecot-configuration: boolean auth-use-winbind? ¶ Se identifica con NTLM y GSS-SPNEGO mediante el uso del daemon winbind de Samba y la herramienta auxiliar ‘ntlm-auth’. <doc/wiki/Authentication/Mechanisms/Winbind.txt>. Su valor predeterminado es ‘#f’.
- parámetro de
dovecot-configuration: nombre-archivo auth-winbind-helper-path ¶ Ruta al binario de la herramienta auxiliar ‘ntlm-auth’ de Samba. Su valor predeterminado es ‘"/usr/bin/ntlm_auth"’.
- parámetro de
dovecot-configuration: string auth-failure-delay ¶ Tiempo de espera antes de responder a identificaciones fallidas. Su valor predeterminado es ‘"2 secs"’.
- parámetro de
dovecot-configuration: boolean auth-ssl-require-client-cert? ¶ Es necesario un certificado de cliente SSL válido o falla la identificación. Su valor predeterminado es ‘#f’.
- parámetro de
dovecot-configuration: boolean auth-ssl-username-from-cert? ¶ Toma el nombre de usuaria del certificado de cliente SSL, mediante el uso de
X509_NAME_get_text_by_NID(), que devuelve el nombre común (CommonName) del nombre de dominio (DN) del sujeto del certificado. Su valor predeterminado es ‘#f’.
- parámetro de
dovecot-configuration: lista-cadenas-separada-espacios auth-mechanisms ¶ Lista de mecanismos de identificación deseados. Los mecanismos permitidos son: ‘plain’, ‘login’, ‘digest-md5’, ‘cram-md5’, ‘ntlm’, ‘rpa’, ‘apop’, ‘anonymous’, ‘gssapi’, ‘otp’, ‘key’, and ‘gss-spnego’. ATENCIÓN: Véase también la opción de configuración ‘disable-plaintext-auth’.
- parámetro de
dovecot-configuration: lista-cadenas-separada-espacios director-servers ¶ Lista de IP o nombres de máquina de los servidores directores, incluyendo este mismo. Los puertos se pueden especificar como ip:puerto. El puerto predeterminado es el mismo que el usado por el servicio director ‘inet-listener’. Su valor predeterminado es ‘()’.
- parámetro de
dovecot-configuration: lista-cadenas-separada-espacios director-mail-servers ¶ Lista de IP o nombres de máquina de los servidores motores de correo. Se permiten también rangos, como 10.0.0.10-10.0.0.30. Su valor predeterminado es ‘()’.
- parámetro de
dovecot-configuration: string director-user-expire ¶ Por cuanto tiempo se redirige a las usuarias a un servidor específico tras pasar ese tiempo sin conexiones. Su valor predeterminado es ‘"15 min"’.
- parámetro de
dovecot-configuration: string director-username-hash ¶ Cómo se traduce el nombre de usuaria antes de aplicar el hash. Entre los valores útiles se incluye %Ln si la usuaria puede ingresar en el sistema con o sin @dominio, %Ld si las bandejas de correo se comparten dentro del dominio. Su valor predeterminado es ‘"%Lu"’.
- parámetro de
dovecot-configuration: string log-path ¶ Archivo de registro usado para los mensajes de error. ‘syslog’ los envía a syslog, ‘"/dev/stderr"’ a la salida de error estándar. Su valor predeterminado es ‘"syslog"’.
- parámetro de
dovecot-configuration: string info-log-path ¶ Archivo de registro usado para los mensajes informativos. Por omisión se usa ‘log-path’. Su valor predeterminado es ‘""’.
- parámetro de
dovecot-configuration: string debug-log-path ¶ Archivo de registro usado para los mensajes de depuración. Por omisión se usa ‘info-log-path’. Su valor predeterminado es ‘""’.
- parámetro de
dovecot-configuration: string syslog-facility ¶ Subsistema de syslog (facility) usado si se envía el registro a syslog. De manera habitual, si desea que no se use ‘mail’, se usará local0..local7. Otros subsistemas estándar también están implementados. Su valor predeterminado es ‘"mail"’.
- parámetro de
dovecot-configuration: boolean auth-verbose? ¶ Registra los intentos de identificación infructuosos y las razones por los que fallaron. Su valor predeterminado es ‘#f’.
- parámetro de
dovecot-configuration: string auth-verbose-passwords ¶ En caso de no coincidir la contraseña, registra la contraseña que se intentó. Los valores aceptados son “no”, “plain” y “sha1”. “sha1” puede ser útil para diferenciar intentos de descubrir la contraseña por fuerza bruta frente a una usuaria simplemente intentando la misma contraseña una y otra vez. También puede recortar el valor a n caracteres mediante la adición de ":n" (por ejemplo “sha1:6”). Su valor predeterminado es ‘"no"’.
- parámetro de
dovecot-configuration: boolean auth-debug? ¶ Registros aún más detallados para facilitar la depuración. Muestra, por ejemplo, las consultas SQL. Su valor predeterminado es ‘#f’.
- parámetro de
dovecot-configuration: boolean auth-debug-passwords? ¶ En caso de no coincidir la contraseña, registra las contraseñas y esquema usadas de manera que el problema se pueda depurar. La activación de este valor también provoca la activación de ‘auth-debug’. Su valor predeterminado es ‘#f’.
- parámetro de
dovecot-configuration: boolean mail-debug? ¶ Permite la depuración de los procesos de correo. Puede ayudarle a comprender los motivos en caso de que Dovecot no encuentre sus correos. Su valor predeterminado es ‘#f’.
- parámetro de
dovecot-configuration: boolean verbose-ssl? ¶ Muestra los errores a nivel de protocolo SSL. Su valor predeterminado es ‘#f’.
- parámetro de
dovecot-configuration: string log-timestamp ¶ Prefijo de cada línea registrada en el archivo. Los códigos % tienen el formato de strftime(3). Su valor predeterminado es ‘"\"%b %d %H:%M:%S \""’.
- parámetro de
dovecot-configuration: lista-cadenas-separada-espacios login-log-format-elements ¶ Lista de elementos que se desea registrar. Los elementos que tengan valor de variable no-vacía se unen para la formación de una cadena separada por comas.
- parámetro de
dovecot-configuration: string login-log-format ¶ Formato del registro de ingresos al sistema. %s contiene la cadena ‘login-log-format-elements’, %$ contiene los datos que se desean registrar. Su valor predeterminado es ‘"%$: %s"’.
- parámetro de
dovecot-configuration: string mail-log-prefix ¶ Prefijo de los registros de procesos de correo. Véase doc/wiki/Variables.txt para obtener una lista de variables que puede usar. Su valor predeterminado es ‘"\"%s(%u)<%{pid}><%{session}>: \""’.
- parámetro de
dovecot-configuration: string deliver-log-format ¶ Formato usado para el registro de las entregas de correo. Puede usar las variables:
%$Mensaje de estado de entrega (por ejemplo: ‘saved to INBOX’)
%mMessage-ID
%sAsunto
%fDe (dirección)
%pTamaño físico
%wTamaño virtual.
El valor predeterminado es ‘"msgid=%m: %$"’.
- parámetro de
dovecot-configuration: string mail-location ¶ Localización de las bandejas de correo de las usuarias. El valor predeterminado está vacío, lo que significa que Dovecot intenta encontrar las bandejas de correo de manera automática. Esto no funciona si la usuaria no tiene todavía ningún correo, por lo que debe proporcionarle a Dovecot la ruta completa.
Si usa mbox, proporcionar una ruta al archivo de la bandeja entrada “INBOX” (por ejemplo /var/mail/%u) no es suficiente. También debe proporcionarle a Dovecot la ruta de otras bandejas de correo. Este es el llamado directorio de correo raíz, y debe ser la primera ruta proporcionada en la opción ‘mail-location’.
Existen algunas variables especiales que puede usar, por ejemplo:
- ‘%u’
nombre de usuaria
- ‘%n’
parte de la usuaria en usuaria@dominio, idéntica a %u si no existe dominio
- ‘%d’
parte del dominio en usuaria@dominio, vacía si no existe dominio
- ‘%h’
directorio de la usuaria
Véase doc/wiki/Variables.txt para obtener una lista completa. Algunos ejemplos:
- ‘maildir:~/Correo’
- ‘mbox:~/correo:INBOX=/var/mail/%u’
- ‘mbox:/var/mail/%d/%1n/%n:INDEX=/var/indexes/%d/%1n/%’
El valor predeterminado es ‘""’.
- parámetro de
dovecot-configuration: string mail-uid ¶ Usuaria del sistema y grupo que realizan el acceso al correo. Si se usan varias, userdb puede forzar su valor al devolver campos uid o gid. Se pueden usar tanto identificadores numéricos como nominales. <doc/wiki/UserIds.txt>. Su valor predeterminado es ‘""’.
- parámetro de
dovecot-configuration: string mail-gid ¶ -
El valor predeterminado es ‘""’.
- parámetro de
dovecot-configuration: string mail-privileged-group ¶ Grupo para permitir de forma temporal operaciones privilegiadas. Actualmente esto se usa únicamente con la bandeja de entrada (INBOX), cuando su creación inicial o el bloqueo con archivo .lock falle. Habitualmente se le proporciona el valor ‘"mail"’ para tener acceso a /var/mail. Su valor predeterminado es ‘""’.
- parámetro de
dovecot-configuration: string mail-access-groups ¶ Proporciona acceso a estos grupos suplementarios a los procesos de correo. Habitualmente se usan para configurar el acceso a bandejas de correo compartidas. Tenga en cuenta que puede ser peligroso establecerlos si las usuarias pueden crear enlaces simbólicos (por ejemplo si se configura el grupo ‘mail’ aquí,
ln -s /var/mail ~/mail/varpuede permitir a una usuaria borrar las bandejas de correo de otras usuarias, oln -s /bandeja/compartida/secreta ~/mail/mibandejapermitiría su lectura). Su valor predeterminado es ‘""’.
dovecot-configurationparameter: string mail-attribute-dict ¶The location of a dictionary used to store
IMAP METADATAas defined by RFC 5464.The IMAP METADATA commands are available only if the “imap” protocol configuration’s
imap-metadata?field is ‘#t’.El valor predeterminado es ‘""’.
- parámetro de
dovecot-configuration: boolean mail-full-filesystem-access? ¶ Allow full file system access to clients. There’s no access checks other than what the operating system does for the active UID/GID. It works with both maildir and mboxes, allowing you to prefix mailboxes names with e.g. /path/ or ~user/. Defaults to ‘#f’.
- parámetro de
dovecot-configuration: boolean mmap-disable? ¶ No usa
mmap()en absoluto. Es necesario si almacena índices en sistemas de archivos compartidos (NFS o sistemas de archivos en cluster). Su valor predeterminado es ‘#f’.
- parámetro de
dovecot-configuration: boolean dotlock-use-excl? ¶ Confía en el correcto funcionamiento de ‘O_EXCL’ para la creación de archivos de bloqueo dotlock. NFS implementa ‘O_EXCL’ desde la versión 3, por lo que debería ser seguro usarlo hoy en día de manera predeterminada. Su valor predeterminado es ‘#t’.
- parámetro de
dovecot-configuration: string mail-fsync ¶ Cuando se usarán las llamadas fsync() o fdatasync():
optimizedCuando sea necesario para evitar la perdida de datos importantes
alwaysÚtil con, por ejemplo, NFS, donde las escrituras con
write()se aplazanneverNunca se usa (mejor rendimiento, pero los fallos pueden producir pérdida de datos)
Su valor predeterminado es ‘"optimized"’.
- parámetro de
dovecot-configuration: boolean mail-nfs-storage? ¶ Mail storage exists in NFS. Set this to yes to make Dovecot flush NFS caches whenever needed. If you’re using only a single mail server this isn’t needed. Defaults to ‘#f’.
- parámetro de
dovecot-configuration: boolean mail-nfs-index? ¶ Mail index files also exist in NFS. Setting this to yes requires ‘mmap-disable? #t’ and ‘fsync-disable? #f’. Defaults to ‘#f’.
- parámetro de
dovecot-configuration: string lock-method ¶ Método de bloqueo para los archivos de índice. Las alternativas son fcntl, flock y dotlock. Dotlock utiliza técnicas que pueden provocar un consumo de E/S mayor que otros métodos de bloqueo. Usuarias de NFS: flock no funciona, recuerde que se debe cambiar ‘mmap-disable’. Su valor predeterminado es ‘"fcntl"’.
- parámetro de
dovecot-configuration: nombre-archivo mail-temp-dir ¶ Directorio en el que LDA/LMTP almacena de manera temporal correos entrantes de de más de 128 kB. Su valor predeterminado es ‘"/tmp"’.
- parámetro de
dovecot-configuration: entero-no-negativo first-valid-uid ¶ Rango de UID aceptado para las usuarias. Principalmente es para asegurarse de que las usuarias no pueden ingresar en el sistema como un daemon u otras usuarias del sistema. Tenga en cuenta que el binario de dovecot tiene código que impide el ingreso al sistema como root y no puede llevarse a cabo incluso aunque ‘first-valid-uid’ tenga el valor 0. Su valor predeterminado es ‘500’.
- parámetro de
dovecot-configuration: entero-no-negativo last-valid-uid ¶ -
El valor predeterminado es ‘0’.
- parámetro de
dovecot-configuration: entero-no-negativo first-valid-gid ¶ Rango de GID aceptado para las usuarias. Las usuarias que no posean GID válido como ID primario de grupo no tienen permitido el ingreso al sistema. Si la usuaria es miembro de grupos suplementarios con GID no válido, no se activan dichos grupos. Su valor predeterminado es ‘1’.
- parámetro de
dovecot-configuration: entero-no-negativo last-valid-gid ¶ -
El valor predeterminado es ‘0’.
- parámetro de
dovecot-configuration: entero-no-negativo mail-max-keyword-length ¶ Longitud máxima permitida para nombres de palabras clave del correo. El límite actúa únicamente en la creación de nuevas palabras clave. Su valor predeterminado es ‘50’.
- parámetro de
dovecot-configuration: lista-archivos-sep-dos-puntos valid-chroot-dirs ¶ Lista de directorios bajo los que se permite realizar la llamada al sistema chroot a procesos de correo (es decir, /var/mail permitiría realizar la llamada también en /var/mail/sub/directorio). Esta configuración no afecta a la configuración de ‘login-chroot’, ‘mail-chroot’ o la de chroot para identificación. En caso de estar vacía, se ignora ‘"/./"’ en los directorios de usuarias. AVISO: Nunca añada directorios que las usuarias locales puedan modificar, puesto que podría permitir vulnerar el control de acceso como “root”. Habitualmente esta opción se activa únicamente si no permite a las usuarias acceder a un intérprete de órdenes. <doc/wiki/Chrooting.txt>. Su valor predeterminado es ‘()’.
- parámetro de
dovecot-configuration: string mail-chroot ¶ Directorio predeterminado de la llamada al sistema chroot para los procesos de correo. El valor puede forzarse para usuarias específicas en la base de datos proporcionando ‘/./’ en el directorio de la usuaria (por ejemplo, ‘/home/./usuaria’ llama a chroot con /home). Tenga en cuenta que habitualmente no es necesario llamar a chroot, Dovecot no permite a las usuarias el acceso a archivos más allá de su directorio de correo en cualquier caso. Si sus directorios de usuaria contienen el directorio de chroot como prefijo, agregue ‘/.’ al final de ‘mail-chroot’. <doc/wiki/Chrooting.txt>. Su valor predeterminado es ‘""’.
- parámetro de
dovecot-configuration: nombre-archivo auth-socket-path ¶ Ruta al socket de UNIX al servidor maestro de identificación para la búsqueda de usuarias. Se usa por parte de imap (para usuarias compartidas) y lda. Su valor predeterminado es ‘"/var/run/dovecot/auth-userdb"’.
- parámetro de
dovecot-configuration: nombre-archivo mail-plugin-dir ¶ Directorio en el que se buscarán módulos de correo. Su valor predeterminado es ‘"/usr/lib/dovecot"’.
- parámetro de
dovecot-configuration: lista-cadena-separada-espacios mail-plugins ¶ Lista de módulos cargados en todos los servicios. Los módulos específicos para IMAP, LDA, etc. se añaden en esta lista en sus propios archivos .conf. Su valor predeterminado es ‘()’.
- parámetro de
dovecot-configuration: entero-no-negativo mail-cache-min-mail-count ¶ El número mínimo de correos en una bandeja antes de que las actualizaciones se realicen en un archivo de caché. Permite optimizar el comportamiento de Dovecot para reducir la tasa de escritura en el disco, lo que produce un aumento de la tasa de lectura. Su valor predeterminado es ‘0’.
- parámetro de
dovecot-configuration: string mailbox-idle-check-interval ¶ Cuando se ejecute la orden IDLE, la bandeja de correo se comprueba de vez en cuando para comprobar si existen nuevos correos o se han producido otros cambios. Esta configuración define el tiempo mínimo entre dichas comprobaciones. Dovecot también puede usar dnotify, inotify y kqueue para recibir información inmediata sobre los cambios que ocurran. Su valor predeterminado es ‘"30 secs"’.
- parámetro de
dovecot-configuration: boolean mail-save-crlf? ¶ Save mails with CR+LF instead of plain LF. This makes sending those mails take less CPU, especially with sendfile() syscall with Linux and FreeBSD. But it also creates a bit more disk I/O which may just make it slower. Also note that if other software reads the mboxes/maildirs, they may handle the extra CRs wrong and cause problems. Defaults to ‘#f’.
- parámetro de
dovecot-configuration: boolean maildir-stat-dirs? ¶ De manera predeterminada la orden LIST devuelve todas las entradas en maildir cuyo nombre empiece en punto. La activación de esta opción hace que Dovecot únicamente devuelva las entradas que sean directorios. Esto se lleva a cabo llamando a stat() con cada entrada, lo que causa mayor E/S del disco. (En sistemas que proporcionen valor a ‘dirent->d_type’ esta comprobación no tiene coste alguno y se realiza siempre independientemente del valor configurado aquí). Su valor predeterminado es ‘#f’.
- parámetro de
dovecot-configuration: boolean maildir-copy-with-hardlinks? ¶ Cuando se copia un mensaje, se usan enlaces duros cuando sea posible. Esto mejora mucho el rendimiento, y es difícil que produzca algún efecto secundario. Su valor predeterminado es ‘#t’.
- parámetro de
dovecot-configuration: boolean maildir-very-dirty-syncs? ¶ Asume que Dovecot es el único MUA que accede a maildir: Recorre el directorio cur/ únicamente cuando cambie su mtime de manera inesperada o cuando no se pueda encontrar el correo de otra manera. Su valor predeterminado es ‘#f’.
- parámetro de
dovecot-configuration: lista-cadena-separada-espacios mbox-read-locks ¶ Qué métodos de bloqueo deben usarse para el bloque de mbox. Hay cuatro disponibles:
dotlockCrea un archivo <bandeja>.lock. Esta es la solución más antigua y más segura con NFS. Si desea usar un directorio como /var/mail/, las usuarias necesitarán acceso de escritura a dicho directorio.
dotlock-tryLo mismo que dotlock, pero si se produce un fallo debido a los permisos o a que no existe suficiente espacio en disco, simplemente se omite el bloqueo.
fcntlUse este a ser posible. Funciona también con NFS si se usa lockd.
flockPuede no existir en todos los sistemas. No funciona con NFS.
lockfPuede no existir en todos los sistemas. No funciona con NFS.
Puede usar múltiples métodos de bloqueo; en ese caso el orden en el que se declaran es importante para evitar situaciones de bloqueo mutuo en caso de que otros MTA/MUA usen también múltiples métodos de bloqueo. Algunos sistemas operativos no permiten el uso de varios de ellos de manera simultánea.
- parámetro de
dovecot-configuration: lista-cadena-separada-espacios mbox-write-locks ¶
- parámetro de
dovecot-configuration: string mbox-lock-timeout ¶ Tiempo máximo esperado hasta el bloqueo (de todos los archivos) antes de interrumpir la operación. Su valor predeterminado es ‘"5 mins"’.
- parámetro de
dovecot-configuration: string mbox-dotlock-change-timeout ¶ Si existe el archivo dotlock pero la bandeja no se ha modificado de ninguna manera, ignora el archivo de bloqueo tras este tiempo. Su valor predeterminado es ‘"2 mins"’.
- parámetro de
dovecot-configuration: boolean mbox-dirty-syncs? ¶ Cuando el archivo mbox cambie de manera inesperada, se tiene que leer completamente para encontrar los cambios. Si es grande puede tardar bastante tiempo. Deido a que el cambio habitualmente es un nuevo correo añadido al final, sería más rápido únicamente leer los correos nuevos. Si se activa esta opción, Dovecot hace esto pero de todos modos vuelve a leer el archivo mbox al completo cuando algo en la bandeja no se encuentra como se esperaba. La única desventaja real de esta configuración es que si otro MUA cambia las opciones de los mensajes, Dovecot no tiene constancia de ello de manera inmediata. Tenga en cuenta que una sincronización completa se lleva a cabo con las órdenes SELECT, EXAMINE, EXPUNGE y CHECK. Su valor predeterminado es ‘#t’.
- parámetro de
dovecot-configuration: boolean mbox-very-dirty-syncs? ¶ Como ‘mbox-dirty-syncs’, pero no realiza sincronizaciones completas tampoco con las órdenes SELECT, EXAMINE, EXPUNGE o CHECK. Si se configura este valor, ‘mbox-dirty-syncs’ se ignora. Su valor predeterminado es ‘#f’.
- parámetro de
dovecot-configuration: boolean mbox-lazy-writes? ¶ Retrasa la escritura de las cabeceras de mbox hasta que se realice una escritura completa sincronizada (con las órdenes EXPUNGE y CHECK, y al cerrar la bandeja de correo). Es útil especialmente con POP3, donde el cliente habitualmente borra todos los correos. La desventaja es que nuestros cambios no son visibles para otros MUA de manera inmediata. Su valor predeterminado es ‘#t’.
- parámetro de
dovecot-configuration: entero-no-negativo mbox-min-index-size ¶ Si el tamaño del archivo mbox es menor que este valor (por ejemplo, 100k), no escribe archivos de índice. Si el archivo de índice ya existe, todavía se usa para la lectura, pero no se actualiza. Su valor predeterminado es ‘0’.
- parámetro de
dovecot-configuration: entero-no-negativo mdbox-rotate-size ¶ Tamaño máximo del archivo dbox hasta su rotación. Su valor predeterminado es ‘10000000’.
- parámetro de
dovecot-configuration: string mdbox-rotate-interval ¶ Antigüedad máxima del archivo dbox hasta que se produce su rotación. Habitualmente en días. El día comienza a medianoche, por lo que 1d = hoy, 2d = ayer, etcétera. 0 = comprobación desactivada. Su valor predeterminado es ‘"1d"’.
- parámetro de
dovecot-configuration: boolean mdbox-preallocate-space? ¶ Cuando se crean nuevos archivos mdbox, reserva inmediatamente un tamaño de ‘mbox-rotate-size’. Actualmente esta configuración funciona únicamente en Linux con determinados sistemas de archivos (ext4, xfs). Su valor predeterminado es ‘#f’.
- parámetro de
dovecot-configuration: string mail-attachment-dir ¶ sdbox y mdbox permiten el almacenamiento de adjuntos en archivos externos, lo que permite también su almacenamiento único. Otros motores no lo permiten por el momento.
AVISO: Esta característica todavía no se ha probado mucho. Su uso queda bajo su propia responsabilidad.
Directorio raíz donde almacenar los adjuntos de los correos. Se desactiva en caso de estar vacío. Su valor predeterminado es ‘""’.
- parámetro de
dovecot-configuration: entero-no-negativo mail-attachment-min-size ¶ Los adjuntos de menor tamaño que este valor no se almacenan externamente. También es posible la escritura de un módulo que deshabilite el almacenamiento externo de adjuntos específicos. Su valor predeterminado es ‘128000’.
- parámetro de
dovecot-configuration: string mail-attachment-fs ¶ Motor del sistema de archivos usado para el almacenamiento de adjuntos:
posixDovecot no lleva a cabo el SiS (aunque esto puede ayudar a la deduplicación del propio sistema de archivos)
sis posixSiS con comparación inmediata byte-por-byte durante el almacenamiento.
sis-queue posixSiS mediante comparación retrasada y deduplicación.
El valor predeterminado es ‘"sis posix"’.
- parámetro de
dovecot-configuration: string mail-attachment-hash ¶ Formato del hash usado en los archivos adjuntos. Puede añadir cualquier texto y variables:
%{md4},%{md5},%{sha1},%{sha256},%{sha512},%{size}. Las variables pueden reducirse, por ejemplo%{sha256:80}devuelve únicamente los primeros 80 bits. Su valor predeterminado es ‘"%{sha1}"’.
- parámetro de
dovecot-configuration: entero-no-negativo default-process-limit ¶ -
El valor predeterminado es ‘100’.
- parámetro de
dovecot-configuration: entero-no-negativo default-client-limit ¶ -
El valor predeterminado es ‘1000’.
- parámetro de
dovecot-configuration: entero-no-negativo default-vsz-limit ¶ Límite predeterminado del tamaño de memoria virtual (VSZ) para procesos del servicio. Esta principalmente orientado a la captura y parada de procesos que pierden memoria antes de que utilicen toda la disponible. Su valor predeterminado es ‘256000000’.
- parámetro de
dovecot-configuration: string default-login-user ¶ Usuaria de ingreso al sistema para los procesos de ingreso al sistema. Es la usuaria en la que menos se confía en el sistema Dovecot. No debería tener acceso a nada en absoluto. Su valor predeterminado es ‘"dovenull"’.
- parámetro de
dovecot-configuration: string default-internal-user ¶ Usuaria interna usada por procesos sin privilegios. Debería ser distinta a la usuaria de ingreso, de modo que los procesos de ingreso al sistema no interfieran con otros procesos. Su valor predeterminado es ‘"dovecot"’.
- parámetro de
dovecot-configuration: string ssl? ¶ Si se permite SSL/TLS: ‘yes’ (sí), ‘no’, ‘required’ (necesario). <doc/wiki/SSL.txt>. Su valor predeterminado es ‘"required"’.
- parámetro de
dovecot-configuration: string ssl-cert ¶ Certificado X.509 de SSL/TLS codificado con PEM (clave pública). Su valor predeterminado es ‘"</etc/dovecot/default.pem"’.
- parámetro de
dovecot-configuration: string ssl-key ¶ Clave privada de SSL/TLS codificada con PEM. La clave se abre antes de renunciar a los privilegios de root, por lo que debe mantenerse legible únicamente para root. Su valor predeterminado es ‘"</etc/dovecot/private/default.pem"’.
- parámetro de
dovecot-configuration: string ssl-key-password ¶ Si el archivo de la clave está protegido por contraseña, introduzca dicha contraseña aquí. De manera alternativa, puede proporcionarla al iniciar dovecot con el parámetro -p. Como este archivo es habitualmente legible por todo el mundo, puede que desee desplazar esta opción a un archivo diferente. Su valor predeterminado es ‘""’.
- parámetro de
dovecot-configuration: string ssl-ca ¶ Certificado usado como autoridad de certificación de confianza codificado en PEM. Configure este valor únicamente si tiene intención de usar ‘ssl-verify-client-cert? #t’. El archivo debe contener el archivo de la o las AC seguido de las CRL correspondientes (por ejemplo, ‘ssl-ca </etc/ssl/certs/ca.pem’). Su valor predeterminado es ‘""’.
- parámetro de
dovecot-configuration: boolean ssl-require-crl? ¶ Es necesario que la comprobación de CRL sea satisfactoria para certificados de clientes.. Su valor predeterminado es ‘#t’.
- parámetro de
dovecot-configuration: boolean ssl-verify-client-cert? ¶ Solicita al cliente el envío de un certificado. Si también desea que sea un requisito, proporcione ‘auth-ssl-require-client-cert? #t’ en la sección de identificación. Su valor predeterminado es ‘#f’.
- parámetro de
dovecot-configuration: string ssl-cert-username-field ¶ Cual es el campo del certificado que determina el nombre de usuaria. “commonName” y “x500UniqueIdentifier” son las opciones habituales. También tendrá proporcionar ‘auth-ssl-username-from-cert? #t’. Su valor predeterminado es ‘"commonName"’.
- parámetro de
dovecot-configuration: string ssl-min-protocol ¶ Versión mínima aceptada del protocolo SSL. Su valor predeterminado es ‘"TLSv1"’.
- parámetro de
dovecot-configuration: string ssl-cipher-list ¶ Protocolos de cifrado de SSL usados. Su valor predeterminado es ‘"ALL:!kRSA:!SRP:!kDHd:!DSS:!aNULL:!eNULL:!EXPORT:!DES:!3DES:!MD5:!PSK:!RC4:!ADH:!LOW@STRENGTH"’.
- parámetro de
dovecot-configuration: string ssl-crypto-device ¶ Dispositivo de cifrado de SSL usado, ejecute "openssl engine" para obtener los valores aceptados. Su valor predeterminado es ‘""’.
- parámetro de
dovecot-configuration: string postmaster-address ¶ Dirección usada cuando se notifiquen correos rechazados. %d expande al dominio receptor. Su valor predeterminado es ‘"postmaster@%d"’.
- parámetro de
dovecot-configuration: string hostname ¶ Nombre de máquina usado en diversas partes de los correos enviados (por ejemplo, en Message-Id) y en las respuestas LMTP. Su valor predeterminado es <el nombre real de la máquina>@dominio. Su valor predeterminado es ‘""’.
- parámetro de
dovecot-configuration: boolean quota-full-tempfail? ¶ Si la usuaria supera la cuota, devuelve un fallo temporal en vez de rechazar el correo. Su valor predeterminado es ‘#f’.
- parámetro de
dovecot-configuration: nombre-archivo sendmail-path ¶ Binario usado para el envío de correos. Su valor predeterminado es ‘"/usr/sbin/sendmail"’.
- parámetro de
dovecot-configuration: string submission-host ¶ Si no está vacío, envía el correo a través de esta máquina[:puerto] SMTP en vez de usar sendmail Su valor predeterminado es ‘""’.
- parámetro de
dovecot-configuration: string rejection-subject ¶ Asunto: cabecera usada en el rechazo de correos. Puede usar las mismas variables que las indicadas en ‘rejection-reason’ a continuación. Su valor predeterminado es ‘"Rejected: %s"’.
- parámetro de
dovecot-configuration: string rejection-reason ¶ Mensaje de error legible por personas para el rechazo de correos. Puede usar variables:
%nCRLF
%rrazón
%sasunto original
%treceptora
El valor predeterminado es ‘"Your message to <%t> was automatically rejected:%n%r"’.
- parámetro de
dovecot-configuration: string recipient-delimiter ¶ Carácter delimitador entre la parte local y el detalle en las direcciones de correo. Su valor predeterminado es ‘"+"’.
- parámetro de
dovecot-configuration: string lda-original-recipient-header ¶ Cabecera de donde se obtiene la dirección receptora original (la dirección de SMTP RCPT TO:) en caso de no estar disponible en otro lugar. El parámetro -a de dovecot-lda reemplaza este valor. Una cabecera usada para esto de manera común es X-Original-To. Su valor predeterminado es ‘""’.
- parámetro de
dovecot-configuration: boolean lda-mailbox-autocreate? ¶ ¿Se debe crear una bandeja de correo no existente de manera automática al almacenar un correo? Su valor predeterminado es ‘#f’.
- parámetro de
dovecot-configuration: boolean lda-mailbox-autosubscribe? ¶ ¿También Se deben crear suscripciones de manera automática a las bandejas de correo creadas? Su valor predeterminado es ‘#f’.
- parámetro de
dovecot-configuration: entero-no-negativo imap-max-line-length ¶ Longitud máxima de la línea de órdenes de IMAP. Algunos clientes generan líneas de órdenes muy largas con bandejas de correo enormes, por lo que debe incrementarlo si recibe los errores “Too long argument” (parámetro demasiado largo) o "IMAP command line too large" (línea de órdenes de IMAP demasiado grande). Su valor predeterminado es ‘64000’.
- parámetro de
dovecot-configuration: string imap-logout-format ¶ Formato de la cadena de IMAP de salida del sistema:
%inúmero total de bytes leídos del cliente
%onúmero total de bytes enviados al cliente.
Véase doc/wiki/Variables.txt para obtener una lista completa de todas las variables que puede usar. Su valor predeterminado es ‘"in=%i out=%o deleted=%{deleted} expunged=%{expunged} trashed=%{trashed} hdr_count=%{fetch_hdr_count} hdr_bytes=%{fetch_hdr_bytes} body_count=%{fetch_body_count} body_bytes=%{fetch_body_bytes}"’.
- parámetro de
dovecot-configuration: string imap-capability ¶ Fuerza el valor de la respuesta de IMAP CAPABILITY. Si el valor comienza con ’+’, añade las capacidades especificadas sobre las predeterminadas (por ejemplo, +XFOO XBAR). Su valor predeterminado es ‘""’.
- parámetro de
dovecot-configuration: string imap-idle-notify-interval ¶ Durante cuanto tiempo se espera entre notificaciones "OK Still here" cuando el cliente se encuentre en estado IDLE. Su valor predeterminado es ‘"2 mins"’.
- parámetro de
dovecot-configuration: string imap-id-send ¶ Nombres y valores de campos de identificación (ID) que se enviarán a los clientes. El uso de * como un valor hace que Dovecot utilice el valor predeterminado. Los siguientes campos tienen actualmente valores predeterminados: name, version, os, os-version, support-url, support-email. Su valor predeterminado es ‘""’.
- parámetro de
dovecot-configuration: string imap-id-log ¶ Campos de identificación (ID) enviados para su registro por cliente.
*significa todos. Su valor predeterminado es ‘""’.
- parámetro de
dovecot-configuration: lista-cadena-separada-espacios imap-client-workarounds ¶ Soluciones temporales para varios errores de clientes:
delay-newmailEnvía notificaciones de nuevo correo EXISTS/RECENT únicamente en respuesta a ordenes NOOP o CHECK. Algunos clientes las ignoran en otro caso, por ejemplo OSX Mail (<v2.1). Outlook Express tiene problemas mayores no obstante, sin esto puede mostrar a la usuaria errores "Message no longer in server". Tenga en cuenta que OE6 también falla con esta solución temporal si la sincronización se establece como "Headers Only".
tb-extra-mailbox-sepThunderbird se confunde de algún modo con LAYOUT=fs (mbox y dbox) y añade sufijos ‘/’ adicionales a los nombres de las bandejas de correo. Esta opción hace que Dovecot ignore el carácter ‘/’ adicional en vez de tratarlo como un nombre de bandeja de correo no válido.
tb-lsub-flagsMuestra las opciones \Noselect para respuestas LSUB con LAYOUT=fs (por ejemplo mbox). Esto permite a Thunderbird ser consciente de que no se pueden seleccionar y mostrarlas en gris, en vez de únicamente mostrar después el mensaje de error "no seleccionable".
El valor predeterminado es ‘()’.
- parámetro de
dovecot-configuration: string imap-urlauth-host ¶ Máquina permitida en las URL URLAUTH enviadas por el cliente. "*" permite todas. Su valor predeterminado es ‘""’.
¡Miau! Muchas opciones de configuración. Lo bueno es que Guix tiene una interfaz completa al lenguage de configuración de Dovecot. Esto no permite únicamente declarar configuraciones de forma bonita, sino que también ofrece capacidades reflexivas: las usuarias pueden escribir código en Scheme para inspeccionar y transformar configuraciones.
No obstante, puede ser que únicamente desee usar un archivo
dovecot.conf existente. En ese caso, puede proporcionar un objeto
opaque-dovecot-configuration como parámetro #:config a
dovecot-service. Como su nombre en inglés indica, una configuración
opaca no tiene gran capacidad reflexiva.
Los campos disponibles de opaque-dovecot-configuration son:
- parámetro de
opaque-dovecot-configuration: package dovecot ¶ El paquete dovecot.
- parámetro de
opaque-dovecot-configuration: string string ¶ El contenido de
dovecot.conf, como una cadena.
Por ejemplo, si su dovecot.conf fuese simplemente la cadena vacía,
podría instanciar un servicio dovecot de esta manera:
(dovecot-service #:config
(opaque-dovecot-configuration
(string "")))
Servicio OpenSMTPD
- Variable Scheme: opensmtpd-service-type
Es el tipo del servicio OpenSMTPD, cuyo valor debe ser un objeto
opensmtpd-configurationcomo en este ejemplo:(service opensmtpd-service-type (opensmtpd-configuration (config-file (local-file "./mi-smtpd.conf"))))
- Tipo de datos: opensmtpd-configuration
Tipo de datos que representa la configuración de opensmtpd.
package(predeterminado: opensmtpd)El objeto paquete del servidor SMTP OpenSMTPD.
config-file(default:%default-opensmtpd-config-file)Objeto “tipo-archivo” del archivo de configuración de OpenSMTPD usado. De manera predeterminada escucha en la interfaz de red local, y pone a disposición de usuarias y daemon de la máquina local el servicio de correo, así como el envío de correo a servidores remotos. Ejecute
man smtpd.confpara obtener más información.setgid-commands?(default:#t)Make the following commands setgid to
smtpqso they can be executed:smtpctl,sendmail,send-mail,makemap,mailq, andnewaliases. See Programas con setuid, for more information on setgid programs.
Servicio Exim
- Variable Scheme: exim-service-type
Este es el tipo del agente de transferencia de correo (MTA) Exim, cuyo valor debe ser un objeto
exim-configurationcomo en este ejemplo:(service exim-service-type (exim-configuration (config-file (local-file "./mi-exim.conf"))))
Para usar un servicio exim-service-type debe tener también un
servicio mail-aliases-service-type presente en su declaración
operating-system (incluso aunque no exista ningún alias).
- Tipo de datos: exim-configuration
Tipo de datos que representa la configuración de exim.
package(predeterminado: exim)El objeto paquete del servidor Exim.
config-file(predeterminado:#f)File-like object of the Exim configuration file to use. If its value is
#fthen use the default configuration file from the package provided inpackage. The resulting configuration file is loaded after setting theexim_userandexim_groupconfiguration variables.
Servicio Getmail
- Variable Scheme: getmail-service-type
El tipo del receptor de correo Getmail, cuyo valor debe ser un objeto
getmail-configuration.
Los campos disponibles de getmail-configuration son:
- parámetro de
getmail-configuration: símbolo name ¶ Un símbolo que identifique el servicio getmail.
El valor predeterminado es ‘"unset"’.
- parámetro de
getmail-configuration: package package ¶ El paquete getmail usado.
- parámetro de
getmail-configuration: string user ¶ Usuaria que ejecuta getmail.
El valor predeterminado es ‘"getmail"’.
- parámetro de
getmail-configuration: string group ¶ Grupo que ejecuta getmail.
El valor predeterminado es ‘"getmail"’.
- parámetro de
getmail-configuration: string directory ¶ El directorio usado para getmail.
El valor predeterminado es ‘"/var/lib/getmail/default"’.
- parámetro de
getmail-configuration: getmail-configuration-file rcfile ¶ El archivo de configuración de getmail usado.
Los campos disponibles de
getmail-configuration-fileson:- parámetro de
getmail-configuration-file: getmail-retriever-configuration retriever ¶ De qué cuenta de correo obtener el correo, y cómo acceder a dicha cuenta.
Los campos disponibles de
getmail-retriever-configurationson:- parámetro de
getmail-retriever-configuration: string type ¶ El controlador que userdb debe usar. Entre los valores aceptados se incluye ‘passwd’ y ‘static’.
El valor predeterminado es ‘"SimpleIMAPSSLRetriever"’.
- parámetro de
getmail-retriever-configuration: string server ¶ Usuaria que ejecutará el servidor de correo.
El valor predeterminado es ‘unset’.
- parámetro de
getmail-retriever-configuration: string username ¶ Usuaria que ejecutará el servidor de correo.
El valor predeterminado es ‘unset’.
- parámetro de
getmail-retriever-configuration: entero-no-negativo port ¶ Número de puerto al que conectarse.
El valor predeterminado es ‘#f’
- parámetro de
getmail-retriever-configuration: string password ¶ Sustituye los valores de campos de passwd.
El valor predeterminado es ‘""’.
- parámetro de
getmail-retriever-configuration: list password-command ¶ Sustituye los valores de campos de passwd.
El valor predeterminado es ‘()’.
- parámetro de
getmail-retriever-configuration: string keyfile ¶ Archivo de claves con formato PEM usado para la negociación TLS.
El valor predeterminado es ‘""’.
- parámetro de
getmail-retriever-configuration: string certfile ¶ Archivo de certificado con formato PEM usado para la negociación TLS.
El valor predeterminado es ‘""’.
- parámetro de
getmail-retriever-configuration: string ca-certs ¶ Certificados de autoridad de certificación (CA) usados.
El valor predeterminado es ‘""’.
- parámetro de
getmail-retriever-configuration: parameter-alist extra-parameters ¶ Parámetros adicionales del receptor de correo.
El valor predeterminado es ‘()’.
- parámetro de
- parámetro de
getmail-configuration-file: getmail-destination-configuration destination ¶ Qué hacer con los mensajes obtenidos.
Los campos disponibles de
getmail-destination-configurationson:- parámetro de
getmail-destination-configuration: string type ¶ Tipo de destino del correo. Entre los valores válidos se incluye ‘Maildir’, ‘Mboxrd’ y ‘MDA_external’.
El valor predeterminado es ‘unset’.
- parámetro de
getmail-destination-configuration: string-or-filelike path ¶ Opción de ruta para el destino del correo. El comportamiento depende del tipo seleccionado.
El valor predeterminado es ‘""’.
- parámetro de
getmail-destination-configuration: parameter-alist extra-parameters ¶ Parámetros adicionales del destino.
El valor predeterminado es ‘()’.
- parámetro de
- parámetro de
getmail-configuration-file: getmail-options-configuration options ¶ Configuración de getmail.
Los campos disponibles de
getmail-options-configurationson:- parámetro de
getmail-options-configuration: entero-no-negativo verbose ¶ If set to ‘0’, getmail will only print warnings and errors. A value of ‘1’ means that messages will be printed about retrieving and deleting messages. If set to ‘2’, getmail will print messages about each of its actions.
El valor predeterminado es ‘1’.
- parámetro de
getmail-options-configuration: boolean read-all ¶ Si es verdadero, getmail obtendrá todos los mensajes disponibles. En otro caso, únicamente recupera mensajes que no se hayan visto previamente.
El valor predeterminado es ‘#t’
- parámetro de
getmail-options-configuration: boolean delete ¶ Si se proporciona un valor verdadero, los mensajes se borrarán del servidor tras su recuperación y entrega posterior satisfactoria. En otro caso, los mensajes permanecerán en el servidor.
El valor predeterminado es ‘#f’
- parámetro de
getmail-options-configuration: entero-no-negativo delete-after ¶ Getmail borrará los mensajes tras este número de días después de haberlos visto, si han sido entregados. Esto significa que los mensajes se mantendrán en el servidor este número de días tras entregarlos. El valor ‘0’ desactiva esta característica.
El valor predeterminado es ‘0’.
- parámetro de
getmail-options-configuration: entero-no-negativo delete-bigger-than ¶ Borra los mensajes de tamaño mayor que estos bytes tras recibirlos, incluso si las opciones “delete” y “delete-after” están desactivadas. El valor ‘0’ desactiva esta característica.
El valor predeterminado es ‘0’.
- parámetro de
getmail-options-configuration: entero-no-negativo max-bytes-per-session ¶ Obtiene mensajes hasta este número de bytes en total antes de cerrar la sesión con el servidor. El valor ‘0’ desactiva esta característica.
El valor predeterminado es ‘0’.
- parámetro de
getmail-options-configuration: entero-no-negativo max-message-size ¶ No obtiene mensajes con mayor tamaño que este número de bytes. El valor ‘0’ desactiva esta característica.
El valor predeterminado es ‘0’.
- parámetro de
getmail-options-configuration: boolean delivered-to ¶ Si es verdadero, getmail añadirá una cabecera “Delivered-To” a los mensajes.
El valor predeterminado es ‘#t’
- parámetro de
getmail-options-configuration: boolean received ¶ Si es verdadero, getmail añadirá una cabecera “Received” a los mensajes.
El valor predeterminado es ‘#t’
- parámetro de
getmail-options-configuration: string message-log ¶ Getmail generará un registro de sus acciones en el archivo nombrado. El valor ‘""’ desactiva esta característica.
El valor predeterminado es ‘""’.
- parámetro de
getmail-options-configuration: boolean message-log-syslog ¶ Si es verdadero, getmail registrará sus acciones a través del registro del sistema.
El valor predeterminado es ‘#f’
- parámetro de
getmail-options-configuration: boolean message-log-verbose ¶ Si es verdadero, getmail registrará información sobre los mensajes que no se hayan podido recuperar y la razón para no hacerlo, así como líneas de inicio y fin informativas.
El valor predeterminado es ‘#f’
- parámetro de
getmail-options-configuration: parameter-alist extra-parameters ¶ Opciones adicionales a incluir.
El valor predeterminado es ‘()’.
- parámetro de
- parámetro de
- parámetro de
getmail-configuration: lista idle ¶ Una lista de bandejas de correo en las que getmail debe esperar en el servidor nuevas notificaciones de correo. Esto depende de que el servidor implemente la extensión IDLE.
El valor predeterminado es ‘()’.
- parámetro de
getmail-configuration: lista environment-variables ¶ Variables de entorno proporcionadas a getmail.
El valor predeterminado es ‘()’.
Servicios de alias de correo
- Variable Scheme: mail-aliases-service-type
Este es el tipo del servicio que proporciona
/etc/aliases, donde se especifica cómo entregar el correo a las usuarias de este sistema.(service mail-aliases-service-type '(("postmaster" "rober") ("rober" "rober@example.com" "rober@example2.com")))
The configuration for a mail-aliases-service-type service is an
association list denoting how to deliver mail that comes to this system.
Each entry is of the form (alias addresses ...), with alias
specifying the local alias and addresses specifying where to deliver
this user’s mail.
The aliases aren’t required to exist as users on the local system. In the
above example, there doesn’t need to be a postmaster entry in the
operating-system’s user-accounts in order to deliver the
postmaster mail to bob (which subsequently would deliver mail
to bob@example.com and bob@example2.com).
daemon de IMAP3 de GNU Mailutils
- Variable Scheme: imap4d-service-type
Es el tipo del daemon IMAP4 de GNU Mailutils (see imap4d in GNU Mailutils Manual), cuyo valor debe ser un objeto
imap4d-configurationcomo en este ejemplo:(service imap4d-service-type (imap4d-configuration (config-file (local-file "imap4d.conf"))))
- Tipo de datos: imap4d-configuration
Tipo de datos que representa la configuración de
imap4d.package(predeterminado:mailutils)El paquete que proporciona
imap4d.config-file(predeterminado:%default-imap4d-config-file)Objeto “tipo-archivo” con el archivo de configuración usado, de manera predeterminada escucha en el puerto TCP 143 de
localhost. See Conf-imap4d in GNU Mailutils Manual, para más detalles.
Radicale Service
- Scheme Variable: radicale-service-type
This is the type of the Radicale CalDAV/CardDAV server whose value should be a
radicale-configuration.
- Data Type: radicale-configuration
Data type representing the configuration of
radicale.package(default:radicale)The package that provides
radicale.config-file(default:%default-radicale-config-file)File-like object of the configuration file to use, by default it will listen on TCP port 5232 of
localhostand use thehtpasswdfile at /var/lib/radicale/users with no (plain) encryption.
Next: Servicios de telefonía, Previous: Servicios de correo, Up: Servicios [Contents][Index]
12.9.13 Servicios de mensajería
El módulo (gnu services messaging) proporciona definiciones de
servicios Guix para servicios de mensajería. Actualmente proporciona los
siguientes servicios:
Servicio Prosody
- Variable Scheme: prosody-service-type
Este es el tipo para el servidor de comunicaciones XMPP Prosody. Su valor debe ser un registro
prosody-configurationcomo en este ejemplo:(service prosody-service-type (prosody-configuration (modules-enabled (cons* "groups" "mam" %default-modules-enabled)) (int-components (list (int-component-configuration (hostname "conference.ejemplo.net") (plugin "muc") (mod-muc (mod-muc-configuration))))) (virtualhosts (list (virtualhost-configuration (domain "ejemplo.net"))))))Véase a continuación detalles acerca de
prosody-configuration.
De manera predeterminada, Prosody no necesita demasiada
configuración. Únicamente un campo virtualhost es necesario:
especifica el dominio en el que se desea que Prosody proporcione el
servicio.
Puede realizar varias comprobaciones preliminares sobre la configuración
generada con la orden prosodyctl check.
Prosodyctl también le ayudará con la importación de certificados del
directorio letsencrypt de modo que la usuaria prosody puede
acceder a ellos. Véase https://prosody.im/doc/letsencrypt.
prosodyctl --root cert import /etc/letsencrypt/live
The available configuration parameters follow. Each parameter definition is
preceded by its type; for example, ‘string-list foo’ indicates that the
foo parameter should be specified as a list of strings. Types
starting with maybe- denote parameters that won’t show up in
prosody.cfg.lua when their value is left unspecified.
También existe la posibilidad de especificar la configuración como una
cadena, por si tiene un archivo prosody.cfg.lua antiguo que desea
transportar desde otro sistema; véase más detalles al final.
El tipo file-object designa o bien un objeto “tipo-archivo”
(see objetos “tipo-archivo”) o un nombre de archivo.
Los campos disponibles de prosody-configuration son:
- parámetro de
prosody-configuration: package prosody ¶ El paquete Prosody.
- parámetro de
prosody-configuration: nombre-archivo data-path ¶ Ruta del directorio de almacenamiento de datos de Prosody. Véase https://prosody.im/doc/configure. Su valor predeterminado es ‘"/var/lib/prosody"’.
- parámetro de
prosody-configuration: lista-file-object plugin-paths ¶ Directorios de módulos adicionales. Los módulos se buscan en orden en todas las rutas especificadas. Véase https://prosody.im/doc/plugins_directory. Su valor predeterminado es ‘()’.
- parámetro de
prosody-configuration: nombre-archivo certificates ¶ Cada máquina virtual y componente necesitan un certificado de manera que los clientes y servidores puedan verificar su identidad de manera segura. Prosody cargará de manera automática certificados/claves del directorio especificado aquí. Su valor predeterminado es ‘"/etc/prosody/certs"’.
- parámetro de
prosody-configuration: lista-string admins ¶ Es una lista de cuentas con permisos de administración en el servidor. Tenga en cuenta que debe crear las cuentas de manera separada. Véase https://prosody.im/doc/admins y https://prosody.im/doc/creating_accounts. Ejemplo:
(admins '("usuaria1@example.com" "usuaria2@example.net"))Su valor predeterminado es ‘()’.
- parámetro de
prosody-configuration: boolean use-libevent? ¶ Activa el uso de libevent para mejorar el rendimiento bajo altas cargas de trabajo. Véase https://prosody.im/doc/libevent. Su valor predeterminado es ‘#f’.
- parámetro de
prosody-configuration: lista-módulos modules-enabled ¶ La lista de módulos de Prosody cargada durante el arranque. Busca en el archivo de módulos
mod_nombremodulo.lua, por lo que asegúrese de que también exista. La documentación de los módulos puede encontrarse en: https://prosody.im/doc/modules. Su valor predeterminado es ‘("roster" "saslauth" "tls" "dialback" "disco" "carbons" "private" "blocklist" "vcard" "version" "uptime" "time" "ping" "pep" "register" "admin_adhoc")’.
- parámetro de
prosody-configuration: lista-string modules-disabled ¶ ‘"offline"’, ‘"c2s"’ y ‘"s2s"’ se cargan de manera automática, pero puede desactivarlos si los añade a esta lista. Su valor predeterminado es ‘()’.
- parámetro de
prosody-configuration: file-object groups-file ¶ Ruta a un archivo de texto donde se definan los grupos compartidos. Si esta ruta está vacía, ‘mod_groups’ no hace nada. Véase https://prosody.im/doc/modules/mod_groups. Su valor predeterminado es ‘"/var/lib/prosody/sharedgroups.txt"’.
- parámetro de
prosody-configuration: boolean allow-registration? ¶ Desactiva la creación de cuentas de manera predeterminada, por seguridad. Véase https://prosody.im/doc/creating_accounts. Su valor predeterminado es ‘#f’.
- parámetro de
prosody-configuration: maybe-ssl-configuration ssl ¶ Estas opciones de configuración están relacionadas con SSL/TLS. La mayor parte no se proporcionan para usar los valores predeterminados de Prosody. Si no entiende completamente estas opciones, no las añada a su configuración, es fácil aumentar la vulnerabilidad de su servidor si las usa. Véase https://prosody.im/doc/advanced_ssl_config.
Los campos disponibles de
ssl-configurationson:- parámetro de
ssl-configuration: maybe-string protocol ¶ Determina el inicio del protocolo usado (handshake).
- parámetro de
ssl-configuration: maybe-nombre-archivo key ¶ Ruta a su archivo de clave privada.
- parámetro de
ssl-configuration: maybe-nombre-archivo certificate ¶ Ruta al archivo de su certificado.
- parámetro de
ssl-configuration: file-object capath ¶ Ruta al directorio que contiene los certificados raíz en los que desea que Prosody confíe al verificar los certificados de servidores remotos. Su valor predeterminado es ‘"/etc/ssl/certs"’.
- parámetro de
ssl-configuration: maybe-file-object cafile ¶ Ruta al archivo que contiene los certificados raíz en los que desea que Prosody confíe. Es similar a
capathpero con todos los certificados concatenados en el mismo archivo.
- parámetro de
ssl-configuration: maybe-lista-string verify ¶ Una lista de opciones de verificación (son de manera prácticamente directa las opciones de
set_verify()de OpenSSL).
- parámetro de
ssl-configuration: maybe-lista-string options ¶ A list of general options relating to SSL/TLS. These map to OpenSSL’s
set_options(). For a full list of options available in LuaSec, see the LuaSec source.
- parámetro de
ssl-configuration: maybe-entero-no-negativo depth ¶ Cómo de larga puede ser la cadena de autoridades de certificación a comprobar cuando se busque un certificado de confianza.
- parámetro de
ssl-configuration: maybe-string ciphers ¶ Una cadena de algoritmos de cifrado de OpenSSL. Selecciona que algoritmos ofrecerá Prosody a los clientes, y en qué orden.
- parámetro de
ssl-configuration: maybe-nombre-archivo dhparam ¶ Una ruta a un archivo que contenga parámetros para el intercambio de claves Diffie-Hellman. Puede crear un archivo de este tipo con:
openssl dhparam -out /etc/prosody/certs/dh-2048.pem 2048
- parámetro de
ssl-configuration: maybe-string curve ¶ Curva para el protocolo Diffie-Hellman de curva elíptica. El valor predeterminado de Prosody es ‘"secp384r1"’.
- parámetro de
ssl-configuration: maybe-string-list verifyext ¶ Una lista de opciones de verificación adicionales.
- parámetro de
ssl-configuration: maybe-string password ¶ Contraseña para claves privadas cifradas.
- parámetro de
- parámetro de
prosody-configuration: boolean c2s-require-encryption? ¶ Determina si se fuerza que todas las conexiones cliente-servidor vayan cifradas o no. Véase https://prosody.im/doc/modules/mod_tls. Su valor predeterminado es ‘#f’.
- parámetro de
prosody-configuration: lista-string disable-sasl-mechanisms ¶ Conjunto de mecanismos que no se ofrecerán nunca. Véase https://prosody.im/doc/modules/mod_saslauth. Su valor predeterminado es ‘("DIGEST-MD5")’.
- parámetro de
prosody-configuration: boolean s2s-require-encryption? ¶ Determina si se fuerza que todas las conexiones servidor-servidor vayan cifradas o no. Véase https://prosody.im/doc/modules/mod_tls. Su valor predeterminado es ‘#f’.
- parámetro de
prosody-configuration: boolean s2s-secure-auth? ¶ Determina si el cifrado y la identificación mediante certificado son necesarias. Esto proporciona una seguridad ideal, pero necesita que los servidores con los que se comunique permitan cifrado y tengan presentes certificados válidos en los que se tenga confianza. Véase https://prosody.im/doc/s2s#security. Su valor predeterminado es ‘#f’.
- parámetro de
prosody-configuration: lista-string s2s-insecure-domains ¶ Many servers don’t support encryption or have invalid or self-signed certificates. You can list domains here that will not be required to authenticate using certificates. They will be authenticated using DNS. See https://prosody.im/doc/s2s#security. Defaults to ‘()’.
- parámetro de
prosody-configuration: lista-string s2s-secure-domains ¶ Aún en el caso de mantener
s2s-secure-auth?, puede exigir certificados válidos para algunos dominios especificando una lista aquí. Véase https://prosody.im/doc/s2s#security. Su valor predeterminado es ‘()’.
- parámetro de
prosody-configuration: string authentication ¶ Selecciona el motor de identificación usado. La implementación predeterminada almacena las contraseñas en texto claro y usa el almacenamiento de datos configurado en Prosody para los datos de identificación. Si no confía en su servidor le recomendamos que visite https://prosody.im/doc/modules/mod_auth_internal_hashed para obtener información sobre el motor de almacenamiento tras hash. Véase también https://prosody.im/doc/authentication. Su valor predeterminado es ‘"internal_plain"’.
- parámetro de
prosody-configuration: maybe-string log ¶ Determina las opciones del registro. La configuración avanzada del registro no está implementada todavía para el servicio Prosody. Véase https://prosody.im/doc/logging. Su valor predeterminado es ‘"*syslog"’.
- parámetro de
prosody-configuration: nombre-archivo pidfile ¶ Archivo en el que se escribirá el PID. Véase https://prosody.im/doc/modules/mod_posix. Su valor predeterminado es ‘"/var/run/prosody/prosody.pid"’.
- parámetro de
prosody-configuration: maybe-entero-no-negativo http-max-content-size ¶ Tamaño máximo permitido del cuerpo (body) HTTP (en bytes)
- parámetro de
prosody-configuration: maybe-string http-external-url ¶ Algunos módulos exponen sus propias URL de diversas maneras. Esta URL se construye en base al protocolo, máquina y puerto usados. Si Prosody se encuentra tras un proxy, se usara
http-external-urlcomo URL pública. Véase https://prosody.im/doc/http#external_url.
- parámetro de
prosody-configuration: lista-virtualhost-configuration virtualhosts ¶ Una máquina (host) en Prosody es un dominio en el que se pueden crear cuentas de usuaria. Por ejemplo, si desea que sus usuarias tengan direcciones como ‘"juan.herrero@example.com"’ necesitará añadir una máquina ‘"example.com"’. Todas las opciones en esta lista son efectivas únicamente en esa máquina.
Nota: The name virtual host is used in configuration to avoid confusion with the actual physical host that Prosody is installed on. A single Prosody instance can serve many domains, each one defined as a VirtualHost entry in Prosody’s configuration. Conversely a server that hosts a single domain would have just one VirtualHost entry.
Véase https://prosody.im/doc/configure#virtual_host_settings.
Los campos disponibles de
virtualhost-configurationson:todos estos campos de
prosody-configuration:admins,use-libevent?,modules-enabled,modules-disabled,groups-file,allow-registration?,ssl,c2s-require-encryption?,disable-sasl-mechanisms,s2s-require-encryption?,s2s-secure-auth?,s2s-insecure-domains,s2s-secure-domains,authentication,log,http-max-content-size,http-external-url,raw-content, además de:- parámetro de
virtualhost-configuration: string domain ¶ Dominio en el que desea que Prosody proporcione servicio.
- parámetro de
- parámetro de
prosody-configuration: lista-int-component-configuration int-components ¶ Los componentes son servicios adicionales en un servidor que están disponibles a los clientes, habitualmente en un subdominio del servidor principal (como por ejemplo ‘"micomponente.example.com"’). Algunos ejemplos de componentes pueden ser los servidores de salas de conversación, los directorios de usuarias o las pasarelas a otros protocolos.
Los componentes internos se implementan con módulos específicos de Prosody. Para añadir un componente interno, simplemente rellene el campo del nombre de máquina, y el módulo que desea usar para el componente.
Véase https://prosody.im/doc/components. Su valor predeterminado es ‘()’.
Los campos disponibles de
int-component-configurationson:todos estos campos de
prosody-configuration:admins,use-libevent?,modules-enabled,modules-disabled,groups-file,allow-registration?,ssl,c2s-require-encryption?,disable-sasl-mechanisms,s2s-require-encryption?,s2s-secure-auth?,s2s-insecure-domains,s2s-secure-domains,authentication,log,http-max-content-size,http-external-url,raw-content, además de:- parámetro de
int-component-configuration: string hostname ¶ Nombre de máquina del componente.
- parámetro de
int-component-configuration: string plugin ¶ Módulo que desea usar para el componente.
- parámetro de
int-component-configuration: maybe-mod-muc-configuration mod-muc ¶ Multi-user chat (MUC) es el módulo de Prosody que permite la creación de salas de conversación/conferencias para usuarias XMPP.
Información general sobre la configuración y el uso de las salas de conversación multi-usuaria puede encontrarse en la documentación “Chatrooms” (https://prosody.im/doc/chatrooms), que debería leer si no conoce las salas de conversación de XMPP.
Véase también https://prosody.im/doc/modules/mod_muc.
Los campos disponibles de
mod-muc-configurationson:- parámetro de
mod-muc-configuration: string name ¶ El nombre devuelto en las respuestas de descubrimiento de servicios. Su valor predeterminado es ‘"Prosody Chatrooms"’.
- parámetro de
mod-muc-configuration: string-o-boolean restrict-room-creation ¶ Si es ‘#t’, únicamente se permitirá a las administradoras la creación de nuevas salas de conversación. En otro caso cualquiera puede crear una sala. El valor ‘"local"’ restringe la creación a usuarias en el dominio superior del servicio. Por ejemplo ‘usuaria@example.com’ puede crear grupos en ‘rooms.example.com’. El valor ‘"admin"’ restringe el servicio a las administradoras únicamente. Su valor predeterminado es ‘#f’.
- parámetro de
mod-muc-configuration: entero-no-negativo max-history-messages ¶ Número máximo de mensajes históricos que se enviarán a quien se acabe de unir a la sala. Su valor predeterminado es ‘20’.
- parámetro de
- parámetro de
- parámetro de
prosody-configuration: lista-ext-component-configuration ext-components ¶ Los componentes externos usan XEP-0114, el cual se implementa en la mayor parte de componentes independientes. Para añadir un componente externo, simplemente rellene el campo de nombre de máquina (hostname). Véase httos://prosody.im/doc/components. Su valor predeterminado es ‘()’.
Los campos disponibles de
ext-component-configurationson:todos estos campos de
prosody-configuration:admins,use-libevent?,modules-enabled,modules-disabled,groups-file,allow-registration?,ssl,c2s-require-encryption?,disable-sasl-mechanisms,s2s-require-encryption?,s2s-secure-auth?,s2s-insecure-domains,s2s-secure-domains,authentication,log,http-max-content-size,http-external-url,raw-content, además de:- parámetro de
ext-component-configuration: string component-secret ¶ Contraseña usada por el componente para el ingreso al sistema.
- parámetro de
ext-component-configuration: string hostname ¶ Nombre de máquina del componente.
- parámetro de
- parámetro de
prosody-configuration: lista-entero-no-negativo component-ports ¶ Puerto o puertos en los que prosody escucha conexiones de componentes. Su valor predeterminado es ‘(5347)’.
- parámetro de
prosody-configuration: string component-interface ¶ Interfaz en la que Prosody escucha conexiones de componentes. Su valor predeterminado es ‘"127.0.0.1"’.
- parámetro de
prosody-configuration: maybe-raw-content raw-content ¶ Contenido que se añadirá directamente al archivo de configuración.
Puede ser que únicamente desee usar un archivo prosody.cfg.lua ya
creado. En ese caso, puede proporcionar un registro
opaque-prosody-configuration como el valor de
prosody-service-type. Como su nombre en inglés indica, una
configuración opaca no tiene gran capacidad reflexiva. Los campos
disponibles de opaque-prosody-configuration son:
- parámetro de
opaque-prosody-configuration: package prosody ¶ El paquete prosody.
- parámetro de
opaque-prosody-configuration: string prosody.cfg.lua ¶ El contenido usado para
prosody.cfg.lua.
Por ejemplo, si su prosody.cfg.lua es simplemente la cadena vacía,
podría instanciar el servicio de Prosody de esta manera:
(service prosody-service-type
(opaque-prosody-configuration
(prosody.cfg.lua "")))
Servicio BitlBee
BitlBee es una pasarela que proporciona una interfaz IRC a una variedad de protocolos como XMPP.
- Variable Scheme: bitlbee-service-type
Este es el tipo de servicio para el daemon de pasarela IRC BitlBee. Su valor es un
bitlbee-configuration(véase a continuación).Para que BitlBee escuche en el puerto 6667 de localhost, añada esta línea a sus servicios:
- Tipo de datos: bitlbee-configuration
Esta es la configuración para BitlBee, con los siguientes campos:
interface(predeterminada:"127.0.0.1")port(predeterminado:6667)Escucha en la interfaz de red correspondiente a la dirección IP especificada en interface, en el puerto port.
Cuando interface es
127.0.0.1, únicamente se permite la conexión de clientes locales; cuando es0.0.0.0, las conexiones pueden venir de cualquier interfaz de red.bitlbee(predeterminado:bitlbee)El paquete BitlBee usado.
plugins(predeterminados:'())Lista de paquetes de módulos usados—por ejemplo,
bitlbee-discord.extra-settings(predeterminado:"")Fragmento de configuración añadido tal cual al archivo de configuración de BitlBee.
Servicio Quassel
Quassel es un cliente IRC distribuido, lo que significa que uno o más clientes se pueden conectar y desconectar del núcleo central.
- Variable Scheme: quassel-service-type
Es el tipo de servicio del daemon del motor IRC de Quassel. Su valor es un
quassel-configuration(véase a continuación).
- Tipo de datos: quassel-configuration
Es la configuración para Quassel, con los siguientes campos:
quassel(predeterminado:quassel)El paquete Quassel usado.
interface(predeterminada:"::,0.0.0.0")port(predeterminado:4242)Escucha en la o las interfaces de red que correspondan con las direcciones IPv4 o IPv6 delimitadas por comas especificadas en interface, en el puerto port.
loglevel(predeterminado:"Info")El nivel de registro deseado. Los valores aceptados son Debug, Info, Warning y Error.
Next: File-Sharing Services, Previous: Servicios de mensajería, Up: Servicios [Contents][Index]
12.9.14 Servicios de telefonía
The (gnu services telephony) module contains Guix service definitions
for telephony services. Currently it provides the following services:
Jami
This section describes how to configure a Jami server that can be used to host video (or audio) conferences, among other uses. The following example demonstrates how to specify Jami account archives (backups) to be provisioned automatically:
(service jami-service-type
(jami-configuration
(accounts
(list (jami-account
(archive "/etc/jami/unencrypted-account-1.gz"))
(jami-account
(archive "/etc/jami/unencrypted-account-2.gz"))))))
When the accounts field is specified, the Jami account files of the service found under /var/lib/jami are recreated every time the service starts.
Jami accounts and their corresponding backup archives can be generated using
the jami or jami-gnome Jami clients. The accounts should not
be password-protected, but it is wise to ensure their files are only
readable by ‘root’.
The next example shows how to declare that only some contacts should be allowed to communicate with a given account:
(service jami-service-type
(jami-configuration
(accounts
(list (jami-account
(archive "/etc/jami/unencrypted-account-1.gz")
(peer-discovery? #t)
(rendezvous-point? #t)
(allowed-contacts
'("1dbcb0f5f37324228235564b79f2b9737e9a008f"
"2dbcb0f5f37324228235564b79f2b9737e9a008f")))))))
In this mode, only the declared allowed-contacts can initiate
communication with the Jami account. This can be used, for example, with
rendezvous point accounts to create a private video conferencing space.
To put the system administrator in full control of the conferences hosted on their system, the Jami service supports the following actions:
# herd doc jami list-actions (list-accounts list-account-details list-banned-contacts list-contacts list-moderators add-moderator ban-contact enable-account disable-account)
The above actions aim to provide the most valuable actions for moderation
purposes, not to cover the whole Jami API. Users wanting to interact with
the Jami daemon from Guile may be interested in experimenting with the
(gnu build jami-service) module, which powers the above Shepherd
actions.
The add-moderator and ban-contact actions accept a contact
fingerprint (40 characters long hash) as first argument and an
account fingerprint or username as second argument:
# herd add-moderator jami 1dbcb0f5f37324228235564b79f2b9737e9a008f \ f3345f2775ddfe07a4b0d95daea111d15fbc1199 # herd list-moderators jami Moderators for account f3345f2775ddfe07a4b0d95daea111d15fbc1199: - 1dbcb0f5f37324228235564b79f2b9737e9a008f
In the case of ban-contact, the second username argument is optional;
when omitted, the account is banned from all Jami accounts:
# herd ban-contact jami 1dbcb0f5f37324228235564b79f2b9737e9a008f # herd list-banned-contacts jami Banned contacts for account f3345f2775ddfe07a4b0d95daea111d15fbc1199: - 1dbcb0f5f37324228235564b79f2b9737e9a008f
Banned contacts are also stripped from their moderation privileges.
The disable-account action allows to completely disconnect an account
from the network, making it unreachable, while enable-account does
the inverse. They accept a single account username or fingerprint as first
argument:
# herd disable-account jami f3345f2775ddfe07a4b0d95daea111d15fbc1199 # herd list-accounts jami The following Jami accounts are available: - f3345f2775ddfe07a4b0d95daea111d15fbc1199 (dummy) [disabled]
The list-account-details action prints the detailed parameters of
each accounts in the Recutils format, which means the recsel
command can be used to select accounts of interest (see Selection
Expressions in GNU recutils manual). Note that period characters
(‘.’) found in the account parameter keys are mapped to underscores
(‘_’) in the output, to meet the requirements of the Recutils format.
The following example shows how to print the account fingerprints for all
accounts operating in the rendezvous point mode:
# herd list-account-details jami | \ recsel -p Account.username -e 'Account.rendezVous ~ "true"' Account_username: f3345f2775ddfe07a4b0d95daea111d15fbc1199
The remaining actions should be self-explanatory.
The complete set of available configuration options is detailed below.
- Data Type: jami-configuration
Available
jami-configurationfields are:libjami(default:libjami) (type: package)The Jami daemon package to use.
dbus(default:dbus-for-jami) (type: package)The D-Bus package to use to start the required D-Bus session.
nss-certs(default:nss-certs) (type: package)The nss-certs package to use to provide TLS certificates.
enable-logging?(default:#t) (type: boolean)Whether to enable logging to syslog.
debug?(default:#f) (type: boolean)Whether to enable debug level messages.
auto-answer?(default:#f) (type: boolean)Whether to force automatic answer to incoming calls.
accounts(type: maybe-jami-account-list)A list of Jami accounts to be (re-)provisioned every time the Jami daemon service starts. When providing this field, the account directories under /var/lib/jami/ are recreated every time the service starts, ensuring a consistent state.
- Data Type: jami-account
Available
jami-accountfields are:archive(type: string-or-computed-file)The account archive (backup) file name of the account. This is used to provision the account when the service starts. The account archive should not be encrypted. It is highly recommended to make it readable only to the ‘root’ user (i.e., not in the store), to guard against leaking the secret key material of the Jami account it contains.
allowed-contacts(type: maybe-account-fingerprint-list)The list of allowed contacts for the account, entered as their 40 characters long fingerprint. Messages or calls from accounts not in that list will be rejected. When left specified, the configuration of the account archive is used as-is with respect to contacts and public inbound calls/messaging allowance, which typically defaults to allow any contact to communicate with the account.
moderators(type: maybe-account-fingerprint-list)The list of contacts that should have moderation privileges (to ban, mute, etc. other users) in rendezvous conferences, entered as their 40 characters long fingerprint. When left unspecified, the configuration of the account archive is used as-is with respect to moderation, which typically defaults to allow anyone to moderate.
rendezvous-point?(type: maybe-boolean)Whether the account should operate in the rendezvous mode. In this mode, all the incoming audio/video calls are mixed into a conference. When left unspecified, the value from the account archive prevails.
peer-discovery?(type: maybe-boolean)Whether peer discovery should be enabled. Peer discovery is used to discover other OpenDHT nodes on the local network, which can be useful to maintain communication between devices on such network even when the connection to the Internet has been lost. When left unspecified, the value from the account archive prevails.
bootstrap-hostnames(type: maybe-string-list)A list of hostnames or IPs pointing to OpenDHT nodes, that should be used to initially join the OpenDHT network. When left unspecified, the value from the account archive prevails.
name-server-uri(type: maybe-string)The URI of the name server to use, that can be used to retrieve the account fingerprint for a registered username.
Mumble server
This section describes how to set up and run a Mumble server (formerly known as Murmur).
- Data Type: mumble-server-configuration
The service type for the Mumble server. An example configuration can look like this:
(service mumble-server-service-type (mumble-server-configuration (welcome-text "Welcome to this Mumble server running on Guix!") (cert-required? #t) ;disallow text password logins (ssl-cert "/etc/letsencrypt/live/mumble.example.com/fullchain.pem") (ssl-key "/etc/letsencrypt/live/mumble.example.com/privkey.pem")))After reconfiguring your system, you can manually set the mumble-server
SuperUserpassword with the command that is printed during the activation phase.Se recomienda el registro de una cuenta de usuaria normal de Mumble y la concesión de permisos de administración o moderación. Puede usar el cliente
mumblepara ingresar como una nueva usuaria normal, registrarse usted misma, y salir del sistema. En el siguiente paso ingrese en el sistema con el nombreSuperUser, use la contraseña deSuperUserque fue establecida con anterioridad, y conceda los permisos de administración o moderación a su usuaria de nombre creada anteriormente y cree algunos canales.Available
mumble-server-configurationfields are:package(predeterminado:mumble)Package that contains
bin/mumble-server.user(default:"mumble-server")User who will run the Mumble-Server server.
group(default:"mumble-server")Group of the user who will run the mumble-server server.
port(predeterminado:64738)Puerto en el que escucha el servidor.
welcome-text(predeterminado:"")Mensaje de bienvenida enviado a clientes tras su conexión.
server-password(predeterminada:"")Contraseña que debe introducirse para poder conectarse.
max-users(predeterminados:100)Número máximo de usuarias que pueden estar conectadas a la vez al servidor.
max-user-bandwidth(predeterminado:#f)Tráfico de voz máximo que una usuaria puede mandar por segundo.
database-file(default:"/var/lib/mumble-server/db.sqlite")Nombre de archivo de la base de datos sqlite. La usuaria del servicio se convertirá en propietaria del directorio.
log-file(default:"/var/log/mumble-server/mumble-server.log")Nombre de archivo del archivo de registro. La usuaria del servicio se convertirá en propietaria del directorio.
autoban-attempts(predeterminados:10)Número máximo de ingresos al sistema que una usuaria puede llevar a cabo en
autoban-timeframesin bloquearse su acceso duranteautoban-time.autoban-timeframe(predeterminado:120)Marco de tiempo del bloqueo automático en segundos.
autoban-time(predeterminado:300)Duración en segundos del periodo que permanecerá bloqueado un cliente cuando viole los límites de bloqueo automático.
opus-threshold(predeterminado:100)Porcentaje de clientes que tienen que permitir opus antes de cambiar al algoritmo de sonido opus.
channel-nesting-limit(predeterminado:10)Cual puede ser el nivel de recursión de los canales.
channelname-regex(predeterminado:#f)Una cadena en forma de expresión regular Qt que deben cumplir los nombres de canal.
username-regex(predeterminado:#f)Una cadena en forma de expresión regular Qt que deben cumplir los nombres de usuaria.
text-message-length(predeterminado:5000)Número máximo de bytes que una usuaria puede enviar en un mensaje de texto.
image-message-length(predeterminado:(* 128 1024))Número máximo de bytes que una usuaria puede enviar en un mensaje de imagen.
cert-required?(predeterminado:#f)If it is set to
#tclients that use weak password authentication will not be accepted. Users must have completed the certificate wizard to join.remember-channel?(predeterminado:#f)Should mumble-server remember the last channel each user was in when they disconnected and put them into the remembered channel when they rejoin.
allow-html?(predeterminado:#f)Si se permite html en mensajes de texto, comentarios de usuaria y descripciones de canal.
allow-ping?(predeterminado:#f)Setting to true exposes the current user count, the maximum user count, and the server’s maximum bandwidth per client to unauthenticated users. In the Mumble client, this information is shown in the Connect dialog.
Desactivar esta opción impedirá la escucha pública en el servidor.
bonjour?(predeterminado:#f)Si el servidor debe anunciarse a sí mismo en la red local a través del protocolo “bonjour”.
send-version?(predeterminado:#f)Should the mumble-server server version be exposed in ping requests.
log-days(predeterminado:31)Mumble also stores logs in the database, which are accessible via RPC. The default is 31 days of months, but you can set this setting to 0 to keep logs forever, or -1 to disable logging to the database.
obfuscate-ips?(predeterminado:#t)Si las IP registradas deben ofuscarse para proteger la privacidad de las usuarias.
ssl-cert(predeterminado:#f)Nombre del archivo del certificado SSL/TLS usado para conexiones cifradas.
(ssl-cert "/etc/letsencrypt/live/example.com/fullchain.pem")ssl-key(predeterminada:#f)Ruta de archivo de la clave privada de ssl usada para las conexiones cifradas.
(ssl-key "/etc/letsencrypt/live/example.com/privkey.pem")ssl-dh-params(predeterminado:#f)Nombre del archivo codificado con PEM con parámetros Diffie-Hellman para el cifrado SSL/TLS. De manera alternativa puede establecer su valor a
"@ffdhe2048","@ffdhe3072","@ffdhe4096","@ffdhe6144"o"@ffdhe8192"para usar los parámetros contenidos en el RFC 7919.ssl-ciphers(predeterminado:#f)La opción
ssl-ciphersselecciona los protocolos de cifrado disponibles para su uso en SSL/TLS.Esta opción se especifica mediante el uso de la notación de listas de prot. de cifrado de OpenSSL.
It is recommended that you try your cipher string using ’openssl ciphers <string>’ before setting it here, to get a feel for which cipher suites you will get. After setting this option, it is recommend that you inspect your Mumble server log to ensure that Mumble is using the cipher suites that you expected it to.
Nota: Changing this option may impact the backwards compatibility of your Mumble-Server server, and can remove the ability for older Mumble clients to be able to connect to it.
public-registration(predeterminado:#f)Must be a
<mumble-server-public-registration-configuration>record or#f.Puede registrar de manera opcional su servidor en la lista pública de servidores que el cliente
mumblemuestra al inicio. No puede registrar su servidor si tiene establecida una contraseña para el servidor (server-password), o estableceallow-pingcomo#f.Puede tomar algunas horas hasta que se muestre en la lista pública.
file(predeterminado:#f)Forma opcional alternativa de forzar el valor de esta configuración.
- Data Type: mumble-server-public-registration-configuration
Configuration for public registration of a mumble-server service.
nameThis is a display name for your server. Not to be confused with the hostname.
passwordA password to identify your registration. Subsequent updates will need the same password. Don’t lose your password.
urlDebe ser un enlace
http://ohttps://a su página web.hostname(predeterminado:#f)De manera predeterminada su servidor se enumerará por sus direcciones IP. Si se usa esta opción, en vez de eso se enlazará a través de este nombre de máquina.
Deprecation notice: Due to historical reasons, all of the above
mumble-server-procedures are also exported with themurmur-prefix. It is recommended that you switch to usingmumble-server-going forward.
Next: Servicios de monitorización, Previous: Servicios de telefonía, Up: Servicios [Contents][Index]
12.9.15 File-Sharing Services
The (gnu services file-sharing) module provides services that assist
with transferring files over peer-to-peer file-sharing networks.
Transmission Daemon Service
Transmission is a flexible BitTorrent
client that offers a variety of graphical and command-line interfaces. A
transmission-daemon-service-type service provides Transmission’s
headless variant, transmission-daemon, as a system service,
allowing users to share files via BitTorrent even when they are not logged
in.
- Scheme Variable: transmission-daemon-service-type
The service type for the Transmission Daemon BitTorrent client. Its value must be a
transmission-daemon-configurationobject as in this example:(service transmission-daemon-service-type (transmission-daemon-configuration ;; Restrict access to the RPC ("control") interface (rpc-authentication-required? #t) (rpc-username "transmission") (rpc-password (transmission-password-hash "transmission" ; desired password "uKd1uMs9")) ; arbitrary salt value ;; Accept requests from this and other hosts on the ;; local network (rpc-whitelist-enabled? #t) (rpc-whitelist '("::1" "127.0.0.1" "192.168.0.*")) ;; Limit bandwidth use during work hours (alt-speed-down (* 1024 2)) ; 2 MB/s (alt-speed-up 512) ; 512 kB/s (alt-speed-time-enabled? #t) (alt-speed-time-day 'weekdays) (alt-speed-time-begin (+ (* 60 8) 30)) ; 8:30 am (alt-speed-time-end (+ (* 60 (+ 12 5)) 30)))) ; 5:30 pm
Once the service is started, users can interact with the daemon through its
Web interface (at http://localhost:9091/) or by using the
transmission-remote command-line tool, available in the
transmission package. (Emacs users may want to also consider the
emacs-transmission package.) Both communicate with the daemon
through its remote procedure call (RPC) interface, which by default is
available to all users on the system; you may wish to change this by
assigning values to the rpc-authentication-required?,
rpc-username and rpc-password settings, as shown in the
example above and documented further below.
The value for rpc-password must be a password hash of the type
generated and used by Transmission clients. This can be copied verbatim
from an existing settings.json file, if another Transmission client
is already being used. Otherwise, the transmission-password-hash and
transmission-random-salt procedures provided by this module can be
used to obtain a suitable hash value.
- Scheme Procedure: transmission-password-hash password salt
Returns a string containing the result of hashing password together with salt, in the format recognized by Transmission clients for their
rpc-passwordconfiguration setting.salt must be an eight-character string. The
transmission-random-saltprocedure can be used to generate a suitable salt value at random.
- Scheme Procedure: transmission-random-salt
Returns a string containing a random, eight-character salt value of the type generated and used by Transmission clients, suitable for passing to the
transmission-password-hashprocedure.
These procedures are accessible from within a Guile REPL started with the
guix repl command (see Invocación de guix repl). This is useful
for obtaining a random salt value to provide as the second parameter to
‘transmission-password-hash‘, as in this example session:
$ guix repl scheme@(guix-user)> ,use (gnu services file-sharing) scheme@(guix-user)> (transmission-random-salt) $1 = "uKd1uMs9"
Alternatively, a complete password hash can generated in a single step:
scheme@(guix-user)> (transmission-password-hash "transmission"
(transmission-random-salt))
$2 = "{c8bbc6d1740cd8dc819a6e25563b67812c1c19c9VtFPfdsX"
The resulting string can be used as-is for the value of rpc-password,
allowing the password to be kept hidden even in the operating-system
configuration.
Torrent files downloaded by the daemon are directly accessible only to users
in the “transmission” user group, who receive read-only access to the
directory specified by the download-dir configuration setting (and
also the directory specified by incomplete-dir, if
incomplete-dir-enabled? is #t). Downloaded files can be moved
to another directory or deleted altogether using
transmission-remote with its --move and
--remove-and-delete options.
If the watch-dir-enabled? setting is set to #t, users in the
“transmission” group are able also to place .torrent files in the
directory specified by watch-dir to have the corresponding torrents
added by the daemon. (The trash-original-torrent-files? setting
controls whether the daemon deletes these files after processing them.)
Some of the daemon’s configuration settings can be changed temporarily by
transmission-remote and similar tools. To undo these changes, use
the service’s reload action to have the daemon reload its settings
from disk:
# herd reload transmission-daemon
The full set of available configuration settings is defined by the
transmission-daemon-configuration data type.
- Data Type: transmission-daemon-configuration
The data type representing configuration settings for Transmission Daemon. These correspond directly to the settings recognized by Transmission clients in their settings.json file.
Available transmission-daemon-configuration fields are:
transmission-daemon-configurationparameter: package transmission ¶The Transmission package to use.
transmission-daemon-configurationparameter: non-negative-integer stop-wait-period ¶The period, in seconds, to wait when stopping the service for
transmission-daemonto exit before killing its process. This allows the daemon time to complete its housekeeping and send a final update to trackers as it shuts down. On slow hosts, or hosts with a slow network connection, this value may need to be increased.El valor predeterminado es ‘10’.
transmission-daemon-configurationparameter: string download-dir ¶The directory to which torrent files are downloaded.
Defaults to ‘"/var/lib/transmission-daemon/downloads"’.
transmission-daemon-configurationparameter: boolean incomplete-dir-enabled? ¶If
#t, files will be held inincomplete-dirwhile their torrent is being downloaded, then moved todownload-dironce the torrent is complete. Otherwise, files for all torrents (including those still being downloaded) will be placed indownload-dir.El valor predeterminado es ‘#f’
transmission-daemon-configurationparameter: maybe-string incomplete-dir ¶The directory in which files from incompletely downloaded torrents will be held when
incomplete-dir-enabled?is#t.El valor predeterminado es ‘disabled’.
transmission-daemon-configurationparameter: umask umask ¶The file mode creation mask used for downloaded files. (See the
umaskman page for more information.)Defaults to ‘18’.
transmission-daemon-configurationparameter: boolean rename-partial-files? ¶When
#t, “.part” is appended to the name of partially downloaded files.El valor predeterminado es ‘#t’
transmission-daemon-configurationparameter: preallocation-mode preallocation ¶The mode by which space should be preallocated for downloaded files, one of
none,fast(orsparse) andfull. Specifyingfullwill minimize disk fragmentation at a cost to file-creation speed.Defaults to ‘fast’.
transmission-daemon-configurationparameter: boolean watch-dir-enabled? ¶If
#t, the directory specified bywatch-dirwill be watched for new .torrent files and the torrents they describe added automatically (and the original files removed, iftrash-original-torrent-files?is#t).El valor predeterminado es ‘#f’
transmission-daemon-configurationparameter: maybe-string watch-dir ¶The directory to be watched for .torrent files indicating new torrents to be added, when
watch-dir-enabledis#t.El valor predeterminado es ‘disabled’.
transmission-daemon-configurationparameter: boolean trash-original-torrent-files? ¶When
#t, .torrent files will be deleted from the watch directory once their torrent has been added (seewatch-directory-enabled?).El valor predeterminado es ‘#f’
transmission-daemon-configurationparameter: boolean speed-limit-down-enabled? ¶When
#t, the daemon’s download speed will be limited to the rate specified byspeed-limit-down.El valor predeterminado es ‘#f’
transmission-daemon-configurationparameter: non-negative-integer speed-limit-down ¶The default global-maximum download speed, in kilobytes per second.
El valor predeterminado es ‘100’.
transmission-daemon-configurationparameter: boolean speed-limit-up-enabled? ¶When
#t, the daemon’s upload speed will be limited to the rate specified byspeed-limit-up.El valor predeterminado es ‘#f’
transmission-daemon-configurationparameter: non-negative-integer speed-limit-up ¶The default global-maximum upload speed, in kilobytes per second.
El valor predeterminado es ‘100’.
transmission-daemon-configurationparameter: boolean alt-speed-enabled? ¶When
#t, the alternate speed limitsalt-speed-downandalt-speed-upare used (in place ofspeed-limit-downandspeed-limit-up, if they are enabled) to constrain the daemon’s bandwidth usage. This can be scheduled to occur automatically at certain times during the week; seealt-speed-time-enabled?.El valor predeterminado es ‘#f’
transmission-daemon-configurationparameter: non-negative-integer alt-speed-down ¶The alternate global-maximum download speed, in kilobytes per second.
El valor predeterminado es ‘50’.
transmission-daemon-configurationparameter: non-negative-integer alt-speed-up ¶The alternate global-maximum upload speed, in kilobytes per second.
El valor predeterminado es ‘50’.
transmission-daemon-configurationparameter: boolean alt-speed-time-enabled? ¶When
#t, the alternate speed limitsalt-speed-downandalt-speed-upwill be enabled automatically during the periods specified byalt-speed-time-day,alt-speed-time-beginandalt-time-speed-end.El valor predeterminado es ‘#f’
transmission-daemon-configurationparameter: day-list alt-speed-time-day ¶The days of the week on which the alternate-speed schedule should be used, specified either as a list of days (
sunday,monday, and so on) or using one of the symbolsweekdays,weekendsorall.Defaults to ‘all’.
transmission-daemon-configurationparameter: non-negative-integer alt-speed-time-begin ¶The time of day at which to enable the alternate speed limits, expressed as a number of minutes since midnight.
Defaults to ‘540’.
transmission-daemon-configurationparameter: non-negative-integer alt-speed-time-end ¶The time of day at which to disable the alternate speed limits, expressed as a number of minutes since midnight.
Defaults to ‘1020’.
transmission-daemon-configurationparameter: string bind-address-ipv4 ¶The IP address at which to listen for peer connections, or “0.0.0.0” to listen at all available IP addresses.
El valor predeterminado es ‘"0.0.0.0"’.
transmission-daemon-configurationparameter: string bind-address-ipv6 ¶The IPv6 address at which to listen for peer connections, or “::” to listen at all available IPv6 addresses.
Defaults to ‘"::"’.
transmission-daemon-configurationparameter: boolean peer-port-random-on-start? ¶If
#t, when the daemon starts it will select a port at random on which to listen for peer connections, from the range specified (inclusively) bypeer-port-random-lowandpeer-port-random-high. Otherwise, it listens on the port specified bypeer-port.El valor predeterminado es ‘#f’
transmission-daemon-configurationparameter: port-number peer-port-random-low ¶The lowest selectable port number when
peer-port-random-on-start?is#t.Defaults to ‘49152’.
transmission-daemon-configurationparameter: port-number peer-port-random-high ¶The highest selectable port number when
peer-port-random-on-startis#t.Defaults to ‘65535’.
transmission-daemon-configurationparameter: port-number peer-port ¶The port on which to listen for peer connections when
peer-port-random-on-start?is#f.Defaults to ‘51413’.
transmission-daemon-configurationparameter: boolean port-forwarding-enabled? ¶If
#t, the daemon will attempt to configure port-forwarding on an upstream gateway automatically using UPnP and NAT-PMP.El valor predeterminado es ‘#t’
transmission-daemon-configurationparameter: encryption-mode encryption ¶The encryption preference for peer connections, one of
prefer-unencrypted-connections,prefer-encrypted-connectionsorrequire-encrypted-connections.Defaults to ‘prefer-encrypted-connections’.
transmission-daemon-configurationparameter: maybe-string peer-congestion-algorithm ¶The TCP congestion-control algorithm to use for peer connections, specified using a string recognized by the operating system in calls to
setsockopt. When left unspecified, the operating-system default is used.Note that on GNU/Linux systems, the kernel must be configured to allow processes to use a congestion-control algorithm not in the default set; otherwise, it will deny these requests with “Operation not permitted”. To see which algorithms are available on your system and which are currently permitted for use, look at the contents of the files tcp_available_congestion_control and tcp_allowed_congestion_control in the /proc/sys/net/ipv4 directory.
As an example, to have Transmission Daemon use the TCP Low Priority congestion-control algorithm, you’ll need to modify your kernel configuration to build in support for the algorithm, then update your operating-system configuration to allow its use by adding a
sysctl-service-typeservice (or updating the existing one’s configuration) with lines like the following:(service sysctl-service-type (sysctl-configuration (settings ("net.ipv4.tcp_allowed_congestion_control" . "reno cubic lp"))))The Transmission Daemon configuration can then be updated with
(peer-congestion-algorithm "lp")and the system reconfigured to have the changes take effect.
El valor predeterminado es ‘disabled’.
transmission-daemon-configurationparameter: tcp-type-of-service peer-socket-tos ¶The type of service to request in outgoing TCP packets, one of
default,low-cost,throughput,low-delayandreliability.Defaults to ‘default’.
transmission-daemon-configurationparameter: non-negative-integer peer-limit-global ¶The global limit on the number of connected peers.
Defaults to ‘200’.
transmission-daemon-configurationparameter: non-negative-integer peer-limit-per-torrent ¶The per-torrent limit on the number of connected peers.
El valor predeterminado es ‘50’.
transmission-daemon-configurationparameter: non-negative-integer upload-slots-per-torrent ¶The maximum number of peers to which the daemon will upload data simultaneously for each torrent.
Defaults to ‘14’.
transmission-daemon-configurationparameter: non-negative-integer peer-id-ttl-hours ¶The maximum lifespan, in hours, of the peer ID associated with each public torrent before it is regenerated.
Defaults to ‘6’.
transmission-daemon-configurationparameter: boolean blocklist-enabled? ¶When
#t, the daemon will ignore peers mentioned in the blocklist it has most recently downloaded fromblocklist-url.El valor predeterminado es ‘#f’
transmission-daemon-configurationparameter: maybe-string blocklist-url ¶The URL of a peer blocklist (in P2P-plaintext or eMule .dat format) to be periodically downloaded and applied when
blocklist-enabled?is#t.El valor predeterminado es ‘disabled’.
transmission-daemon-configurationparameter: boolean download-queue-enabled? ¶If
#t, the daemon will be limited to downloading at mostdownload-queue-sizenon-stalled torrents simultaneously.El valor predeterminado es ‘#t’
transmission-daemon-configurationparameter: non-negative-integer download-queue-size ¶The size of the daemon’s download queue, which limits the number of non-stalled torrents it will download at any one time when
download-queue-enabled?is#t.El valor predeterminado es ‘5’.
transmission-daemon-configurationparameter: boolean seed-queue-enabled? ¶If
#t, the daemon will be limited to seeding at mostseed-queue-sizenon-stalled torrents simultaneously.El valor predeterminado es ‘#f’
transmission-daemon-configurationparameter: non-negative-integer seed-queue-size ¶The size of the daemon’s seed queue, which limits the number of non-stalled torrents it will seed at any one time when
seed-queue-enabled?is#t.El valor predeterminado es ‘10’.
transmission-daemon-configurationparameter: boolean queue-stalled-enabled? ¶When
#t, the daemon will consider torrents for which it has not shared data in the pastqueue-stalled-minutesminutes to be stalled and not count them against itsdownload-queue-sizeandseed-queue-sizelimits.El valor predeterminado es ‘#t’
transmission-daemon-configurationparameter: non-negative-integer queue-stalled-minutes ¶The maximum period, in minutes, a torrent may be idle before it is considered to be stalled, when
queue-stalled-enabled?is#t.El valor predeterminado es ‘30’.
transmission-daemon-configurationparameter: boolean ratio-limit-enabled? ¶When
#t, a torrent being seeded will automatically be paused once it reaches the ratio specified byratio-limit.El valor predeterminado es ‘#f’
transmission-daemon-configurationparameter: non-negative-rational ratio-limit ¶The ratio at which a torrent being seeded will be paused, when
ratio-limit-enabled?is#t.Defaults to ‘2.0’.
transmission-daemon-configurationparameter: boolean idle-seeding-limit-enabled? ¶When
#t, a torrent being seeded will automatically be paused once it has been idle foridle-seeding-limitminutes.El valor predeterminado es ‘#f’
transmission-daemon-configurationparameter: non-negative-integer idle-seeding-limit ¶The maximum period, in minutes, a torrent being seeded may be idle before it is paused, when
idle-seeding-limit-enabled?is#t.El valor predeterminado es ‘30’.
transmission-daemon-configurationparameter: boolean dht-enabled? ¶Enable the distributed hash table (DHT) protocol, which supports the use of trackerless torrents.
El valor predeterminado es ‘#t’
transmission-daemon-configurationparameter: boolean lpd-enabled? ¶Enable local peer discovery (LPD), which allows the discovery of peers on the local network and may reduce the amount of data sent over the public Internet.
El valor predeterminado es ‘#f’
transmission-daemon-configurationparameter: boolean pex-enabled? ¶Enable peer exchange (PEX), which reduces the daemon’s reliance on external trackers and may improve its performance.
El valor predeterminado es ‘#t’
transmission-daemon-configurationparameter: boolean utp-enabled? ¶Enable the micro transport protocol (uTP), which aims to reduce the impact of BitTorrent traffic on other users of the local network while maintaining full utilization of the available bandwidth.
El valor predeterminado es ‘#t’
transmission-daemon-configurationparameter: boolean rpc-enabled? ¶If
#t, enable the remote procedure call (RPC) interface, which allows remote control of the daemon via its Web interface, thetransmission-remotecommand-line client, and similar tools.El valor predeterminado es ‘#t’
transmission-daemon-configurationparameter: string rpc-bind-address ¶The IP address at which to listen for RPC connections, or “0.0.0.0” to listen at all available IP addresses.
El valor predeterminado es ‘"0.0.0.0"’.
transmission-daemon-configurationparameter: port-number rpc-port ¶The port on which to listen for RPC connections.
Defaults to ‘9091’.
transmission-daemon-configurationparameter: string rpc-url ¶The path prefix to use in the RPC-endpoint URL.
Defaults to ‘"/transmission/"’.
transmission-daemon-configurationparameter: boolean rpc-authentication-required? ¶When
#t, clients must authenticate (seerpc-usernameandrpc-password) when using the RPC interface. Note this has the side effect of disabling host-name whitelisting (seerpc-host-whitelist-enabled?.El valor predeterminado es ‘#f’
transmission-daemon-configurationparameter: maybe-string rpc-username ¶The username required by clients to access the RPC interface when
rpc-authentication-required?is#t.El valor predeterminado es ‘disabled’.
transmission-daemon-configurationparameter: maybe-transmission-password-hash rpc-password ¶The password required by clients to access the RPC interface when
rpc-authentication-required?is#t. This must be specified using a password hash in the format recognized by Transmission clients, either copied from an existing settings.json file or generated using thetransmission-password-hashprocedure.El valor predeterminado es ‘disabled’.
transmission-daemon-configurationparameter: boolean rpc-whitelist-enabled? ¶When
#t, RPC requests will be accepted only when they originate from an address specified inrpc-whitelist.El valor predeterminado es ‘#t’
transmission-daemon-configurationparameter: string-list rpc-whitelist ¶The list of IP and IPv6 addresses from which RPC requests will be accepted when
rpc-whitelist-enabled?is#t. Wildcards may be specified using ‘*’.Defaults to ‘("127.0.0.1" "::1")’.
transmission-daemon-configurationparameter: boolean rpc-host-whitelist-enabled? ¶When
#t, RPC requests will be accepted only when they are addressed to a host named inrpc-host-whitelist. Note that requests to “localhost” or “localhost.”, or to a numeric address, are always accepted regardless of these settings.Note also this functionality is disabled when
rpc-authentication-required?is#t.El valor predeterminado es ‘#t’
transmission-daemon-configurationparameter: string-list rpc-host-whitelist ¶The list of host names recognized by the RPC server when
rpc-host-whitelist-enabled?is#t.El valor predeterminado es ‘()’.
transmission-daemon-configurationparameter: message-level message-level ¶The minimum severity level of messages to be logged (to /var/log/transmission.log) by the daemon, one of
none(no logging),error,infoanddebug.El valor predeterminado es ‘info’
transmission-daemon-configurationparameter: boolean start-added-torrents? ¶When
#t, torrents are started as soon as they are added; otherwise, they are added in “paused” state.El valor predeterminado es ‘#t’
transmission-daemon-configurationparameter: boolean script-torrent-done-enabled? ¶When
#t, the script specified byscript-torrent-done-filenamewill be invoked each time a torrent completes.El valor predeterminado es ‘#f’
transmission-daemon-configurationparameter: maybe-file-object script-torrent-done-filename ¶A file name or file-like object specifying a script to run each time a torrent completes, when
script-torrent-done-enabled?is#t.El valor predeterminado es ‘disabled’.
transmission-daemon-configurationparameter: boolean scrape-paused-torrents-enabled? ¶When
#t, the daemon will scrape trackers for a torrent even when the torrent is paused.El valor predeterminado es ‘#t’
transmission-daemon-configurationparameter: non-negative-integer cache-size-mb ¶The amount of memory, in megabytes, to allocate for the daemon’s in-memory cache. A larger value may increase performance by reducing the frequency of disk I/O.
Defaults to ‘4’.
transmission-daemon-configurationparameter: boolean prefetch-enabled? ¶When
#t, the daemon will try to improve I/O performance by hinting to the operating system which data is likely to be read next from disk to satisfy requests from peers.El valor predeterminado es ‘#t’
Next: Servicios Kerberos, Previous: File-Sharing Services, Up: Servicios [Contents][Index]
12.9.16 Servicios de monitorización
Servicio Tailon
Tailon es una aplicación web para la visualización y búsqueda en archivos de registro.
El ejemplo siguiente configura el servicio con los valores
predeterminados. Por omisión, se puede acceder a Tailon en el puerto 8080
(http://localhost:8080).
(service tailon-service-type)
El ejemplo siguiente personaliza más la configuración de Tailon, añadiendo
sed a la lista de órdenes permitidas.
(service tailon-service-type
(tailon-configuration
(config-file
(tailon-configuration-file
(allowed-commands '("tail" "grep" "awk" "sed"))))))
- Tipo de datos: tailon-configuration
Tipo de datos que representa la configuración de Tailon. Este tipo tiene los siguientes parámetros:
config-file(predeterminado:(tailon-configuration-file))The configuration file to use for Tailon. This can be set to a tailon-configuration-file record value, or any gexp (see Expresiones-G).
Por ejemplo, para usar un archivo local, se puede usar la función
local-file:(service tailon-service-type (tailon-configuration (config-file (local-file "./mi-tailon.conf"))))package(predeterminado:tailon)El paquete tailon usado.
- Tipo de datos: tailon-configuration-file
Tipo de datos que representa las opciones de configuración de Tailon. Este tipo tiene los siguientes parámetros:
files(predeterminados:(list "/var/log"))List of files to display. The list can include strings for a single file or directory, or a list, where the first item is the name of a subsection, and the remaining items are the files or directories in that subsection.
bind(predeterminado:"localhost:8080")Dirección y puerto al que Tailon debe asociarse.
relative-root(predeterminado:#f)Ruta URL usada por Tailon, use
#fpara no usar una ruta.allow-transfers?(predeterminado:#t)Permite la descarga de archivos de registro en la interfaz web.
follow-names?(predeterminado:#t)Permite la lectura de archivos todavía no existentes.
tail-lines(predeterminado:200)Número de líneas a leer inicialmente de cada archivo.
allowed-commands(predeterminadas:(list "tail" "grep" "awk"))Commands to allow running. By default,
sedis disabled.debug?(predeterminado:#f)Proporcione el valor
#tendebug?para mostrar mensajes de depuración.wrap-lines(predeterminado:#t)Initial line wrapping state in the web interface. Set to
#tto initially wrap lines (the default), or to#fto initially not wrap lines.http-auth(predeterminado:#f)HTTP authentication type to use. Set to
#fto disable authentication (the default). Supported values are"digest"or"basic".users(predeterminado:#f)If HTTP authentication is enabled (see
http-auth), access will be restricted to the credentials provided here. To configure users, use a list of pairs, where the first element of the pair is the username, and the 2nd element of the pair is the password.(tailon-configuration-file (http-auth "basic") (users '(("usuaria1" . "contraseña1") ("usuaria2" . "contraseña2"))))
Servicio Darkstat
Darkstat es un programa de interceptación de paquetes que captura el tráfico de la red, calcula estadísticas sobre su uso y proporciona informes a través de HTTP.
- Variable: Variable Scheme darkstat-service-type
Este es el tipo de servicio del servicio darkstat, su valor debe ser un registro
darkstat-configurationcomo en este ejemplo:(service darkstat-service-type (darkstat-configuration (interface "eno1")))
- Tipo de datos: darkstat-configuration
Tipo de datos que representa la configuración de
darkstat.package(predeterminado:darkstat)El paquete darkstat usado.
interfaceCaptura el tráfico en la interfaz de red especificada.
port(predeterminado:"667")Asocia la interfaz web al puerto especificado.
bind-address(predeterminada:"127.0.0.1")Asocia la interfaz web a la dirección especificada.
base(predeterminada:"/")Specify the path of the base URL. This can be useful if
darkstatis accessed via a reverse proxy.
Servicio del exportador de nodos Prometheus
El “exportador de nodos” Prometheus pone a disposición del sistema de monitorización Prometheus las estadísticas de hardware y el sistema operativo proporcionadas por el núcleo Linux. Este servicio debe desplegarse en todos los nodos físicos y máquinas virtuales, donde la monitorización de estas estadísticas sea deseable.
- Variable: Variable Scheme prometheus-node-exporter-service-type
This is the service type for the prometheus-node-exporter service, its value must be a
prometheus-node-exporter-configuration.(service prometheus-node-exporter-service-type)
- Tipo de datos: prometheus-node-exporter-configuration
Tipo de datos que representa la configuración de
node_exporter.package(predeterminado:go-github-com-prometheus-node-exporter)El paquete prometheus-node-exporter usado.
web-listen-address(predeterminada:":9100")Asocia la interfaz web a la dirección especificada.
textfile-directory(default:"/var/lib/prometheus/node-exporter")This directory can be used to export metrics specific to this machine. Files containing metrics in the text format, with the filename ending in
.promshould be placed in this directory.extra-options(predeterminadas:'())Extra options to pass to the Prometheus node exporter.
Servidor Zabbix
Zabbix is a high performance monitoring system that can collect data from a variety of sources and provide the results in a web-based interface. Alerting and reporting is built-in, as well as templates for common operating system metrics such as network utilization, CPU load, and disk space consumption.
This service provides the central Zabbix monitoring service; you also need
zabbix-front-end-service-type to configure
Zabbix and display results, and optionally zabbix-agent-service-type on machines that should be monitored
(other data sources are supported, such as Prometheus Node Exporter).
- Variable: Scheme variable zabbix-server-service-type
This is the service type for the Zabbix server service. Its value must be a
zabbix-server-configurationrecord, shown below.
- Data Type: zabbix-server-configuration
Los campos disponibles de
zabbix-server-configurationson:zabbix-server(default:zabbix-server) (type: file-like)El paquete zabbix-server.
user(default:"zabbix") (type: string)Usuaria que ejecutará el servidor Zabbix.
group(default:"zabbix") (type: group)Grupo que ejecutará el servidor Zabbix.
db-host(default:"127.0.0.1") (type: string)El nombre de máquina de la base de datos.
db-name(default:"zabbix") (type: string)Nombre de la base de datos.
db-user(default:"zabbix") (type: string)Usuaria de la base de datos.
db-password(default:"") (type: string)Contraseña de la base de datos. Por favor, en vez de esto use
include-filesconDBPassword=SECRETdentro de un archivo especificado.db-port(default:5432) (type: number)Puerto de la base de datos.
log-type(default:"") (type: string)Especifica donde se escriben los mensajes de registro:
-
system- syslog. -
file- archivo especificado con el parámetrolog-file. -
console- salida estándar.
-
log-file(default:"/var/log/zabbix/server.log") (type: string)Nombre del archivo de registro para el parámetro
filedelog-type.pid-file(default:"/var/run/zabbix/zabbix_server.pid") (type: string)Nombre del archivo de PID.
ssl-ca-location(default:"/etc/ssl/certs/ca-certificates.crt") (type: string)La localización de los archivos de autoridades de certificación (CA) para la verificación de certificados SSL de los servidores.
ssl-cert-location(default:"/etc/ssl/certs") (type: string)Localización de los certificados SSL de los clientes.
extra-options(default:"") (type: extra-options)Opciones adicionales que se añadirán al final del archivo de configuración de Zabbix.
include-files(default:()) (type: include-files)Puede incluir archivos individuales o todos los archivos en un directorio en el archivo de configuración.
Agente Zabbix
The Zabbix agent gathers information about the running system for the Zabbix monitoring server. It has a variety of built-in checks, and can be extended with custom user parameters.
- Variable: Scheme variable zabbix-agent-service-type
This is the service type for the Zabbix agent service. Its value must be a
zabbix-agent-configurationrecord, shown below.
- Data Type: zabbix-agent-configuration
Los campos disponibles de
zabbix-agent-configurationson:zabbix-agent(default:zabbix-agentd) (type: file-like)El paquete zabbix-agent.
user(default:"zabbix") (type: string)Usuaria que ejecutará el agente Zabbix.
group(default:"zabbix") (type: group)Grupo que ejecutará el agente Zabbix.
hostname(default:"") (type: string)Nombre de máquina único y sensible a mayúsculas que es necesario para la comprobaciones activas y debe corresponder con el nombre de máquina configurado en el servidor.
log-type(default:"") (type: string)Especifica donde se escriben los mensajes de registro:
-
system- syslog. -
file- file specified withlog-fileparameter. -
console- salida estándar.
-
log-file(default:"/var/log/zabbix/agent.log") (type: string)Nombre del archivo de registro para el parámetro
filedelog-type.pid-file(default:"/var/run/zabbix/zabbix_agent.pid") (type: string)Nombre del archivo de PID.
server(default:("127.0.0.1")) (type: list)Lista de direcciones IP, opcionalmente en notación CIDR, o nombres de máquina de servidores y proxy Zabbix. Se aceptarán conexiones entrantes únicamente desde las máquinas proporcionadas aquí.
server-active(default:("127.0.0.1")) (type: list)Lista de pares IP:puerto (o máquina:puerto) de servidores Zabbix y servidores Zabbix para las comprobaciones activas. Si no se especifica un puerto, se usa el puerto predeterminado. Si no se especifica este parámetro, las comprobaciones activas se desactivan.
extra-options(default:"") (type: extra-options)Opciones adicionales que se añadirán al final del archivo de configuración de Zabbix.
include-files(default:()) (type: include-files)Puede incluir archivos individuales o todos los archivos en un directorio en el archivo de configuración.
Motor de visualización de Zabbix
The Zabbix front-end provides a web interface to Zabbix. It does not need to run on the same machine as the Zabbix server. This service works by extending the PHP-FPM and NGINX services with the configuration necessary for loading the Zabbix user interface.
- Variable: Scheme variable zabbix-front-end-service-type
This is the service type for the Zabbix web frontend. Its value must be a
zabbix-front-end-configurationrecord, shown below.
- Data Type: zabbix-front-end-configuration
Los campos disponibles de
zabbix-front-end-configurationson:zabbix-server(default:zabbix-server) (type: file-like)The Zabbix server package to use.
nginx(default:()) (type: list)List of
nginx-server-configurationblocks for the Zabbix front-end. When empty, a default that listens on port 80 is used.db-host(default:"localhost") (type: string)El nombre de máquina de la base de datos.
db-port(default:5432) (type: number)Puerto de la base de datos.
db-name(default:"zabbix") (type: string)Nombre de la base de datos.
db-user(default:"zabbix") (type: string)Usuaria de la base de datos.
db-password(default:"") (type: string)Contraseña de la base de datos. Por favor, en vez de esto use
db-secret-file.db-secret-file(default:"") (type: string)Archivo secreto que se añadirá al final del archivo zabbix.conf.php. Este archivo contiene las credenciales usadas por el motor de visualización de Zabbix. Se espera que usted lo cree manualmente.
zabbix-host(default:"localhost") (type: string)Nombre de máquina del servidor Zabbix.
zabbix-port(default:10051) (type: number)Puerto del servidor Zabbix.
Next: Servicios LDAP, Previous: Servicios de monitorización, Up: Servicios [Contents][Index]
12.9.17 Servicios Kerberos
El módulo (gnu services kerberos) proporciona servicios relacionados
con el protocolo de identificación Kerberos.
Servicio Krb5
Los programas que usan una biblioteca cliente de Kerberos habitualmente esperan un archivo de configuración en la ruta /etc/krb5.conf. Este servicio genera dicho archivo desde una definición proporcionada en la declaración de sistema operativo. Esto no causa el inicio de ningún daemon.
Este servicio no crea ningún archivo “keytab”—debe crearlos
explícitamente usted. Se ha comprobado que este servicio funciona con la
biblioteca de cliente mit-krb5 del MIT. No se han probado otras
implementaciones.
- Variable Scheme: krb5-service-type
Un tipo de servicio para clientes Kerberos 5.
Este es un ejemplo de su uso:
(service krb5-service-type
(krb5-configuration
(default-realm "EXAMPLE.COM")
(allow-weak-crypto? #t)
(realms (list
(krb5-realm
(name "EXAMPLE.COM")
(admin-server "groucho.example.com")
(kdc "karl.example.com"))
(krb5-realm
(name "ARGRX.EDU")
(admin-server "kerb-admin.argrx.edu")
(kdc "keys.argrx.edu"))))))
Este ejemplo proporciona una configuración de cliente Kerberos 5 que:
- Reconoce dos dominios, sean: “EXAMPLE.COM” y “ARGRX.EDU”, los cuales tienen distintos servidores administrativos y centros de distribución de claves;
- El valor predeterminado será “EXAMPLE.COM” si no se especifica el dominio explícitamente por parte del cliente.
- Acepta servicios cuyos únicos tipos de cifrado implementados se sabe que son débiles.
Los tipos krb5-realm y krb5-configuration contienen muchos
campos. Aquí se describen únicamente los más habitualmente usados. Para
obtener una lista complete y una explicación detallada de cada campo, véase
la documentación de
krb5.conf.
- Tipo de datos: krb5-realm
-
nameEste campo es una cadena que identifica el nombre del dominio. Una convención habitual es el uso del nombre completo de DNS de su organización, convertido a mayúsculas.
admin-serverEste campo es una cadena que identifica la máquina donde se ejecuta el servidor administrativo.
kdcEste campo es una cadena que identifica el centro de distribución de claves para el dominio.
- Tipo de datos: krb5-configuration
-
allow-weak-crypto?(predeterminado:#f)Si esta opción es
#tse aceptarán los servicios que únicamente ofrezcan algoritmos de cifrado que se conozca que son débiles.default-realm(predeterminado:#f)Este campo debe ser una cadena que identifique el dominio predeterminado de Kerberos para los clientes. Debería proporcionar el nombre de su dominio Kerberos. Si este valor es
#f, el dominio debe especificarse en cada principal de Kerberos cuando se invoquen programas comokinit.realmsDebe ser una lista no vacía de objetos
krb5-realm, accesibles por los clientes. Normalmente, uno de ellos tendrá un camponameque corresponda con el campodefault-realm.
Servicio krb5 de PAM
El servicio pam-krb5 le permite la identificación para el ingreso al
sistema y la gestión de contraseñas mediante Kerberos. Este servicio es
necesario si desea que aplicaciones que permiten PAM lleven a cabo la
identificación de usuarias mediante el uso de Kerberos.
- Variable Scheme: pam-krb5-service-type
Un tipo de servicio para el módulo PAM de Kerberos 5.
- Tipo de datos: pam-krb5-configuration
Tipo de datos que representa la configuración del módulo PAM de Kerberos 5. Este tipo tiene los siguientes parámetros:
pam-krb5(predeterminado:pam-krb5)El paquete pam-krb5 usado.
minimum-uid(predeterminado:1000)El ID de usuaria mínimo con el que se permitirán los intentos de identificación con Kerberos. El proceso de identificación de las cuentas locales con valores menores fallará de manera silenciosa.
Next: Servicios Web, Previous: Servicios Kerberos, Up: Servicios [Contents][Index]
12.9.18 Servicios LDAP
El módulo (gnu services authentication) proporciona el tipo
nslcd-service-type, que puede usarse para la identificación a través
de un servidor LDAP. Además de la configuración del servicio en sí, puede
desear añadir ldap como servicio de nombres en el selector de
servicios de nombres (NSS). See Selector de servicios de nombres para información
detallada.
Aquí se encuentra una declaración simple de sistema operativo con la
configuración predeterminada de nslcd-service-type y una
configuración del selector de servicios de nombre que consulta en último
lugar al servicios de nombres ldap:
(use-service-modules authentication) (use-modules (gnu system nss)) ... (operating-system ... (services (cons* (service nslcd-service-type) (service dhcp-client-service-type) %base-services)) (name-service-switch (let ((services (list (name-service (name "db")) (name-service (name "files")) (name-service (name "ldap"))))) (name-service-switch (inherit %mdns-host-lookup-nss) (password services) (shadow services) (group services) (netgroup services) (gshadow services)))))
Los campos disponibles de nslcd-configuration son:
- parámetro de
nslcd-configuration: package nss-pam-ldapd ¶ El paquete
nss-pam-ldapdusado.
- parámetro de
nslcd-configuration: maybe-number threads ¶ El número de hilos a iniciar que pueden gestionar peticiones y realizar consultas en LDAP. Cada hilo abre una conexión separada al servidor LDAP. Se inician 5 hilos de manera predeterminada.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: string uid ¶ Especifica el id de usuaria con el que debe ejecutarse el daemon.
El valor predeterminado es ‘"nslcd"’.
- parámetro de
nslcd-configuration: string gid ¶ Especifica el id de grupo con el que debe ejecutarse el daemon.
El valor predeterminado es ‘"nslcd"’.
- parámetro de
nslcd-configuration: opción-registro log ¶ This option controls the way logging is done via a list containing SCHEME and LEVEL. The SCHEME argument may either be the symbols ‘none’ or ‘syslog’, or an absolute file name. The LEVEL argument is optional and specifies the log level. The log level may be one of the following symbols: ‘crit’, ‘error’, ‘warning’, ‘notice’, ‘info’ or ‘debug’. All messages with the specified log level or higher are logged.
El valor predeterminado es ‘("/var/log/nslcd" info)’.
- parámetro de
nslcd-configuration: lista uri ¶ La lista de URI de servidores LDAP. Normalmente, únicamente se usará el primer servidor y los siguientes se usan en caso de fallo.
El valor predeterminado es ‘"ldap://localhost:389/"’.
- parámetro de
nslcd-configuration: maybe-string ldap-version ¶ La versión del protocolo LDAP usada. El valor predeterminado usa la versión máxima implementada por la biblioteca LDAP.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-string binddn ¶ Especifica el nombre distinguido con el que enlazarse en el servidor de directorio para las búsquedas. El valor predeterminado se enlaza de forma anónima.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-string bindpw ¶ Especifica las credenciales usadas para el enlace. Esta opción tiene utilidad únicamente cuando se usa con binddn.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-string rootpwmoddn ¶ Especifica el nombre distinguido usado cuando la usuaria root intenta modificar la contraseña de una usuaria mediante el módulo de PAM.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-string rootpwmodpw ¶ Especifica las credenciales con las que enlazarse si la usuaria root intenta cambiar la contraseña de una usuaria. Esta opción tiene utilidad únicamente cuando se usa con rootpwmoddn.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-string sasl-mech ¶ Especifica el mecanismo de SASL usado cuando se realice la identificación con SASL.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-string sasl-realm ¶ Especifica el dominio de SASL usado cuando se realice la identificación con SASL.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-string sasl-authcid ¶ Especifica la identidad de verificación usada cuando se realice la identificación con SASL.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-string sasl-authzid ¶ Especifica la identidad de autorización usada cuando se realice la identificación con SASL.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-boolean sasl-canonicalize? ¶ Determina si el nombre de máquina del servidor LDAP debe transformarse a su forma canónica. Si se activa, la librería LDAP realizará una búsqueda inversa de nombre de máquina. De manera predeterminada, se delega en la biblioteca la decisión de realizar esta comprobación o no.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-string krb5-ccname ¶ Establece el nombre para la caché de credenciales GSS-API de Kerberos.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: string base ¶ El directorio de búsqueda base.
El valor predeterminado es ‘"dc=example,dc=com"’.
- parámetro de
nslcd-configuration: opción-de-ámbito scope ¶ Especifica el ámbito de búsqueda (subtree, oneleve, base o children). El ámbito predeterminado es subtree; el ámbito base casi nunca es útil para búsquedas del servicio de nombres; el ámbito children no está implementado en todos los servidores.
El valor predeterminado es ‘(subtree)’.
- parámetro de
nslcd-configuration: maybe-deref-option deref ¶ Especifica la política para seguir las referencias de los alias. La política predeterminada es nunca seguir las referencias de los alias.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-boolean referrals ¶ Especifica si el seguimiento automático de referencias debe activarse. El seguimiento de referencias es comportamiento predeterminado.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: lista-asociación-entrada maps ¶ Esta opción permite que se busquen atributos personalizados en vez de los atributos predeterminados de RFC 2307. Es una lista de asociaciones, de las que cada una consiste en el nombre de la asociación, el atributo de RFC 2307 al que corresponde y la expresión de búsqueda del atributo en la forma que esté disponible en el directorio.
El valor predeterminado es ‘()’.
- parámetro de
nslcd-configuration: lista-asociación-entrada filters ¶ Una lista de filtros que consiste en el nombre de una asociación a la que se aplica el filtro y una expresión de filtrado de búsqueda de LDAP.
El valor predeterminado es ‘()’.
- parámetro de
nslcd-configuration: maybe-number bind-timelimit ¶ Especifica el tiempo límite usado en segundos durante la conexión al servidor de directorio. El valor predeterminado son 10 segundos.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-number timelimit ¶ Especifica el tiempo límite (en segundos) durante el que se esperará una respuesta del servidor LDAP. Un valor de cero, por omisión, hace que se espere de manera indefinida hasta que las búsquedas se completen.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-number idle-timelimit ¶ Especifica el periodo de inactividad (en segundos) tras el cual se cerrará la conexión con el servidor LDAP. El valor predeterminado no cierra las conexiones por inactividad.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-number reconnect-sleeptime ¶ Especifica en número de segundos que se dormirá cuando falle la conexión a todos los servidores LDAP. De manera predeterminada se espera un segundo entre el primer fallo y el primer reintento.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-number reconnect-retrytime ¶ Especifica el tiempo tras el cual el servidor LDAP se considera no disponible de manera permanente. Una vez se alcance este tiempo, los reintentos se realizarán una vez en cada periodo de tiempo igual al especificado. El valor predeterminado es 10 segundos.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-ssl-option ssl ¶ Determina si se usa SSL/TLS o no (el comportamiento predeterminado es no hacerlo). Si se especifica ’start-tls, se usa StartTLS en vez de la transmisión del protocolo LDAP en crudo sobre SSL.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-tls-reqcert-option tls-reqcert ¶ Especifica las comprobaciones que se deben realizar con un certificado proporcionado por el servidor. El significado de los valores se describe en la página de manual de ldap.conf(5).
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-string tls-cacertdir ¶ Especifica el directorio que contiene los certificados X.509 para la identificación de pares. Este parámetro se ignora si se usa GnuTLS.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-string tls-cacertfile ¶ Especifica la ruta al certificado X.509 para la identificación de pares.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-string tls-randfile ¶ Especifica la ruta de la fuente de entropía. Este parámetro se ignora si se usa GnuTLS.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-string tls-ciphers ¶ Especifica como una cadena los algoritmos de cifrado usados para TLS.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-string tls-cert ¶ Especifica la ruta al archivo que contiene el certificado local para la identificación de clientes con TLS.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-string tls-key ¶ Especifica la ruta al archivo que contiene la clave privada para la identificación de clientes con TLS.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-number pagesize ¶ Proporcione un valor superior a 0 para solicitar al servidor LDAP que proporcione los resultados divididos en páginas de acuerdo con el RFC2696. El valor predeterminado (0) no solicita resultados divididos en páginas.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-ignore-users-option nss-initgroups-ignoreusers ¶ Esta opción previene las búsquedas de pertenencia a grupos a través de LDAP sobre las usuarias especificadas. De manera alternativa, se puede usar el valor ’all-local. Con dicho valor nslcd construye al inicio una lista completa de usuarias que no se encuentren en LDAP.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-number nss-min-uid ¶ Esta opción hace que se ignoren las usuarias de LDAP con un identificador numérico inferior al valor especificado.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-number nss-uid-offset ¶ Esta opción especifica un desplazamiento que se añade a todos los identificadores numéricos de usuaria de LDAP. Puede usarse para evitar colisiones de identificadores con usuarias locales.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-number nss-gid-offset ¶ Esta opción especifica un desplazamiento que se añade a todos los identificadores numéricos de grupos de LDAP. Puede usarse para evitar colisiones de identificadores con grupos locales.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-boolean nss-nested-groups ¶ Cuando se activa esta opción, un grupo puede contener como atributo la pertenencia a otro grupo. Los miembros de grupos anidados se devuelven en el grupo superior y los grupos superiores se devuelven cuando se busquen los grupos de una usuaria específica. El valor predeterminado determina que no se realicen búsquedas adicionales para grupos anidados.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-boolean nss-getgrent-skipmembers ¶ Cuando se activa esta opción, la lista de miembros de un grupo no se obtiene en las búsquedas de grupos. Las búsquedas que busquen los grupos de los que una usuaria es miembro continuarán funcionando de manera que probablemente a la usuaria se le asignen los grupos correctos durante el ingreso al sistema.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-boolean nss-disable-enumeration ¶ Cuando se activa esta opción, las funciones que provocan la carga de todas las entradas usuaria/grupo del directorio no tendrán éxito al realizarlo. Esto puede reducir de forma dramática la carga del servidor LDAP cuando existe un gran número de usuarias y/o grupos. Esta opción no se recomienda para la mayoría de las configuraciones.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-string validnames ¶ Esta opción puede usarse para especificar cómo se verifican en el sistema los nombres de usuaria y grupo. Este patrón se usa para comprobar todos los nombres de usuarias y grupos que se soliciten y proporcionen a través de LDAP.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-boolean ignorecase ¶ Especifica si se realizarán las búsquedas sin diferenciar mayúsculas y minúsculas o no. Su activación puede abrir puntos vulnerables que permitan la omisión de las comprobaciones de autorización e introducir vulnerabilidades que permitan el envenenamiento de la caché de nscd, lo que puede provocar la denegación del servicio.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-boolean pam-authc-ppolicy ¶ Esta opción determina si los controles de la política de contraseñas se solicitan y manejan desde el servidor LDAP cuando se realice la identificación de usuarias.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-string pam-authc-search ¶ De manera predeterminada nslcd realiza una búsqueda LDAP con las credenciales de la usuaria tras la orden BIND (identificación) para asegurarse de que la opción BIND fue satisfactoria. La búsqueda predeterminada es una simple comprobación de la existencia del DN de la usuaria. Se puede especificar un filtro de búsqueda que se usará en vez de dicha búsqueda. Debe devolver al menos una entrada.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-string pam-authz-search ¶ Esta opción permite la configuración detallada de las comprobaciones de autorización que deben realizarse. El filtro de búsqueda especificado es ejecutado, y si cualquier entrada corresponde se permite el acceso, el cual se deniega en caso contrario.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: maybe-string pam-password-prohibit-message ¶ Si se proporciona esta opción, se denegará la modificación de contraseñas a través de pam_ldap y en vez de ello el mensaje especificado se presentará a la usuaria. El mensaje puede usarse para redirigir a la usuaria a un medio alternativo para el cambio de su contraseña.
El valor predeterminado es ‘disabled’.
- parámetro de
nslcd-configuration: lista pam-services ¶ Lista de nombres de servicio de PAM para los que la identificación de LDAP debería ser suficiente.
El valor predeterminado es ‘()’.
Next: Servicios de certificados, Previous: Servicios LDAP, Up: Servicios [Contents][Index]
12.9.19 Servicios Web
El módulo (gnu services web) proporciona el servidor HTTP Apache, el
servidor web nginx y también un recubrimiento del daemon de fastcgi.
Servidor HTTP Apache
- Variable Scheme: httpd-service-type
Tipo de servicio para el servidor Apache HTTP (httpd). El valor para este tipo de servicio es un registro
httpd-configuration.Un ejemplo de configuración simple se proporciona a continuación.
(service httpd-service-type (httpd-configuration (config (httpd-config-file (server-name "www.example.com") (document-root "/srv/http/www.example.com")))))Otros servicios también pueden extender el tipo
httpd-service-typepara añadir su contribución a la configuración.(simple-service 'servidor-www.example.com httpd-service-type (list (httpd-virtualhost "*:80" (list (string-join '("ServerName "www.example.com" "DocumentRoot /srv/http/www.example.com") "\n")))))
Los detalles de los tipos de registro httpd-configuration,
httpd-module, httpd-config-file y httpd-virtualhost se
proporcionan a continuación.
- Tipo de datos: httpd-configuration
Este tipo de datos representa la configuración del servicio httpd.
package(predeterminado:httpd)El paquete httpd usado.
pid-file(predeterminado:"/var/run/httpd")El archivo pid usado por el servicio de Shepherd.
config(predeterminado:(httpd-config-file))The configuration file to use with the httpd service. The default value is a
httpd-config-filerecord, but this can also be a different G-expression that generates a file, for example aplain-file. A file outside of the store can also be specified through a string.
- Tipo de datos: httpd-module
Este es el tipo de datos que representa un módulo para el servicio httpd.
nameEl nombre del módulo.
fileThe file for the module. This can be relative to the httpd package being used, the absolute location of a file, or a G-expression for a file within the store, for example
(file-append mod-wsgi "/modules/mod_wsgi.so").
- Variable Scheme: %default-httpd-modules
Una lista de objetos
httpd-modulepredeterminados.
- Tipo de datos: httpd-config-file
Este tipo de datos representa un archivo de configuración para el servicio httpd.
modules(predeterminados:%default-httpd-modules)The modules to load. Additional modules can be added here, or loaded by additional configuration.
Por ejemplo, para manejar las peticiones de archivos PHP, puede usar el módulo
mod_proxy_fcgide Apache junto conphp-fpm-service-type:(service httpd-service-type (httpd-configuration (config (httpd-config-file (modules (cons* (httpd-module (name "modulo_proxy") (file "modules/mod_proxy.so")) (httpd-module (name "module_proxy_fcgi") (file "modules/mod_proxy_fcgi.so")) %default-httpd-modules)) (extra-config (list "\ <FilesMatch \\.php$> SetHandler \"proxy:unix:/var/run/php-fpm.sock|fcgi://localhost/\" </FilesMatch>")))))) (service php-fpm-service-type (php-fpm-configuration (socket "/var/run/php-fpm.sock") (socket-group "httpd")))
server-root(predeterminado:httpd)The
ServerRootin the configuration file, defaults to the httpd package. Directives includingIncludeandLoadModuleare taken as relative to the server root.server-name(predeterminado:#f)El campo
ServerName(nombre del servidor) en el archivo de configuración, el cual se usa para especificar el esquema de peticiones, nombre de máquina y puerto que el servidor usa para su propia identificación.This doesn’t need to be set in the server config, and can be specified in virtual hosts. The default is
#fto not specify aServerName.document-root(predeterminado:"/srv/http")La raíz (
DocumentRoot) desde la que se proporcionan los archivos.listen(predeterminado:'("80"))The list of values for the
Listendirectives in the config file. The value should be a list of strings, when each string can specify the port number to listen on, and optionally the IP address and protocol to use.pid-file(predeterminado:"/var/run/httpd")The
PidFileto use. This should match thepid-fileset in thehttpd-configurationso that the Shepherd service is configured correctly.error-log(predeterminado:"/var/log/httpd/error_log")El archivo
ErrorLogen el que el servidor registrará los errores.user(predeterminada:"httpd")La usuaria como la que el servidor responderá a las peticiones.
group(predeterminado:"httpd")El grupo como el que el servidor responderá a las peticiones.
extra-config(predeterminadas:(list "TypesConfig etc/httpd/mime.types"))Una lista de cadenas y expresiones-G que se añadirán al final del archivo de configuración.
Los valores con los que se extiende el servicio se añaden al final de esta lista.
- Tipo de datos: httpd-virtualhost
Este tipo de datos representa un bloque de configuración de máquina virtual del servicio httpd.
Se deben añadir a la configuración adicional extra-config del servicio httpd-service.
(simple-service 'servidor-www.example.com httpd-service-type (list (httpd-virtualhost "*:80" (list (string-join '("ServerName "www.example.com" "DocumentRoot /srv/http/www.example.com") "\n")))))addresses-and-portsLas direcciones y puertos de la directiva
VirtualHost.contentsEl contenido de la directiva
VirtualHost; debe ser una lista de cadenas y expresiones-G.
NGINX
- Variable Scheme: nginx-service-type
Tipo de servicio para el servidor web NGinx. El valor para este tipo de servicio es un registro
<nginx-configuration>.Un ejemplo de configuración simple se proporciona a continuación.
(service nginx-service-type (nginx-configuration (server-blocks (list (nginx-server-configuration (server-name '("www.example.com")) (root "/srv/http/www.example.com"))))))Además de añadiendo bloques de servidor a la configuración del servicio de manera directa, este servicio puede extenderse con otros servicios para añadir bloques de servidor, como en este ejemplo:
(simple-service 'mi-servidor-adicional nginx-service-type (list (nginx-server-configuration (root "/srv/http/sitio-adicional") (try-files (list "$uri" "$uri/index.html")))))
Durante su inicio, nginx no ha leído todavía su archivo de
configuración, por lo que usa un archivo predeterminado para registrar los
mensajes de error. Si se produce algún fallo al cargar su archivo de
configuración, allí es donde se registran los mensajes de error. Tras la
carga del archivo de configuración, el archivo de registro de errores
predeterminado cambia al especificado allí. En nuestro caso, los mensajes de
error durante el inicio se pueden encontrar en
/var/run/nginx/logs/error.log, y tras la configuración en
/var/log/nginx/error.log. La segunda ruta puede cambiarse con las
opciones de configuración log-directory.
- Tipo de datos: nginx-configuration
This data type represents the configuration for NGinx. Some configuration can be done through this and the other provided record types, or alternatively, a config file can be provided.
nginx(predeterminado:nginx)El paquete nginx usado.
shepherd-requirement(default:'())This is a list of symbols naming Shepherd services the nginx service will depend on.
This is useful if you would like
nginxto be started after a back-end web server or a logging service such as Anonip has been started.log-directory(predeterminado:"/var/log/nginx")Directorio en el que NGinx escribirá los archivos de registro.
run-directory(predeterminado:"/var/run/nginx")Directorio en el que NGinx crea el archivo de PID, y escribe archivos temporales.
server-blocks(predeterminados:'())Una lista de bloques de servidor que se crearán en el archivo de configuración generado; los elementos deben ser del tipo
<nginx-server-configuration>.El ejemplo siguiente configura NGinx para proporcionar
www.example.coma partir del directorio/srv/http/www.example.com, sin usar HTTPS.(service nginx-service-type (nginx-configuration (server-blocks (list (nginx-server-configuration (server-name '("www.example.com")) (root "/srv/http/www.example.com"))))))upstream-blocks(predeterminados:'())Una lista de bloques upstream creada en el archivo de configuración generado, los elementos deben ser del tipo
<nginx-upstream-configuration>.La configuración de proveedores a través de
upstream-blockspuede ser útil al combinarse conlocationen los registros<nginx-server-configuration>. El siguiente ejemplo crea la configuración de un servidor con una configuración de ruta, que hará de intermediaria en las peticiones a la configuración de proveedores, que delegarán las peticiones en dos servidores.(service nginx-service-type (nginx-configuration (server-blocks (list (nginx-server-configuration (server-name '("www.example.com")) (root "/srv/http/www.example.com") (locations (list (nginx-location-configuration (uri "/ruta1") (body '("proxy_pass http://servidor-proxy;")))))))) (upstream-blocks (list (nginx-upstream-configuration (name "servidor-proxy") (servers (list "servidor1.example.com" "servidor2.example.com")))))))file(predeterminado:#f)Si se proporciona un archivo de configuración con file, se usará este, en vez de generar un archivo de configuración a partir de los parámetros
log-directory,run-directory,server-blocksyupstream-blocksproporcionados. Para conseguir un funcionamiento adecuado, estos parámetros deben corresponder con el contenido de file, lo que asegura que los directorios se hayan creado durante la activación del servicio.Esto puede ser útil si ya dispone de un archivo de configuración, o no es posible hacer lo que necesita con el resto de opciones del registro nginx-configuration.
server-names-hash-bucket-size(predeterminado:#f)Tamaño del cubo para las tablas hash de los nombres de servidor, cuyo valor predeterminado es
#fpara que se use el tamaño de la línea de caché de los procesadores.server-names-hash-bucket-max-size(predeterminado:#f)Tamaño máximo del cubo para las tablas hash de nombres de servidor.
modules(predeterminados:'())Lista de módulos dinámicos de nginx cargados. Debe ser una lista de nombres de archivo de módulos cargables, como en este ejemplo:
(modules (list (file-append nginx-accept-language-module "\ /etc/nginx/modules/ngx_http_accept_language_module.so") (file-append nginx-lua-module "\ /etc/nginx/modules/ngx_http_lua_module.so")))lua-package-path(predeterminada:'())Lista de paquetes de lua para nginx cargados. Debe ser una lista de nombres de archivo de módulos cargables, como en este ejemplo:
(lua-package-path (list lua-resty-core lua-resty-lrucache lua-resty-signal lua-tablepool lua-resty-shell))lua-package-cpath(predeterminada:'())Lista de paquetes C de lua para nginx cargados. Debe ser una lista de nombres de archivo de módulos cargables, como en este ejemplo:
(lua-package-cpath (list lua-resty-signal))global-directives(predeterminadas:'((events . ())))Lista asociativa de directivas globales para el nivel superior de la configuración de nginx. Los valores en sí mismos pueden ser listas asociativas.
(global-directives `((worker_processes . 16) (pcre_jit . on) (events . ((worker_connections . 1024)))))extra-content(predeterminado:"")Contenido adicional para el bloque
http. Debe ser una cadena o una expresión-G que evalúe a una cadena.
- Tipo de datos: nginx-server-configuration
Tipo de datos que representa la configuración de un bloque de servidor nginx. Este tipo tiene los siguientes parámetros:
listen(predeterminadas:'("80" "443 ssl"))Cada directiva
listenestablece la dirección y el puerto para IP, o la ruta para un socket de dominio de UNIX sobre el que el servidor acepta peticiones. Se puede especificar tanto dirección y puerto como únicamente la dirección o únicamente el puerto. Una dirección puede ser también un nombre de máquina, por ejemplo:'("127.0.0.1:8000" "127.0.0.1" "8000" "*:8000" "localhost:8000")
server-name(predeterminados:(list 'default))Una lista de nombres de servidor que este servidor representa.
'defaultrepresenta el servidor predeterminado para conexiones que no correspondan a otro servidor.root(predeterminada:"/srv/http")Raíz del sitio web que nginx proporcionará.
locations(predeterminado:'())Una lista de registros nginx-location-configuration o nginx-named-location-configuration usados dentro de este bloque de servidor.
index(predeterminado:(list "index.html"))Archivos de índice buscados cuando los clientes solicitan un directorio. Si no se encuentra ninguno, Nginx enviará la lista de archivos del directorio.
try-files(predeterminado:'())Una lista de archivos cuya existencia se comprueba en el orden especificado.
nginxusará el primer archivo que encuentre para procesar la petición.ssl-certificate(predeterminado:#f)Lugar donde se encuentra el certificado para conexiones seguras. Proporcione
#fsi no dispone de un certificado o no desea usar HTTPS.ssl-certificate-key(predeterminado:#f)Lugar donde se encuentra la clave privada para conexiones seguras. Proporcione
#fsi no dispone de una clave o no desea usar HTTPS.server-tokens?(predeterminado:#f)Determina si el servidor debe añadir su configuración a las respuestas.
raw-content(predeterminado:'())Una lista de líneas que se añadirán literalmente al bloque del servidor.
- Tipo de datos: nginx-upstream-configuration
Tipo de datos que representa la configuración de un bloque
upstreamde nginx. Este tipo tiene los siguientes parámetros:nameNombre para este grupo de servidores.
serversEspecifica las direcciones de los servidores en el grupo. Las direcciones se pueden proporcionar mediante direcciones IP (por ejemplo ‘127.0.0.1’), nombres de dominio (por ejemplo ‘maquina1.example.com’) o rutas de socket de UNIX mediante el prefijo ‘unix:’. El puerto predeterminado para las direcciones IP o nombres de dominio es el 80, y se puede proporcionar un puerto de manera explícita.
extra-contentA string or list of strings to add to the upstream block.
- Tipo de datos: nginx-location-configuration
Tipo de datos que representa la configuración de un bloque
locationde nginx. Este tipo tiene los siguientes parámetros:uriURI a la que corresponde este bloque de location.
bodyBody of the location block, specified as a list of strings. This can contain many configuration directives. For example, to pass requests to a upstream server group defined using an
nginx-upstream-configurationblock, the following directive would be specified in the body ‘(list "proxy_pass http://upstream-name;")’.
- Tipo de datos: nginx-named-location-configuration
Tipo de datos que representa la configuración de un bloque de localización con nombre de nginx. Los bloques de localizaciones con nombre se usan para la redirección de peticiones, y no se usan para el procesamiento regular de peticiones. Este tipo tiene los siguientes parámetros:
nameNombre que identifica este bloque de dirección
location.bodySee cuerpo de nginx-location-configuration, como el cuerpo de los bloques de localizaciones con nombre puede usarse de manera similar al
cuerpo de nginx-location-configuration. Una restricción es que el cuerpo de una localización con nombre no puede contener bloques de localizaciones.
Caché Varnish
Varnish es un servidor de caché rápida que se coloca entre aplicaciones web y usuarios finales. Redirige peticiones a los clientes y almacena en caché las URL a las que se accede de manera que múltiples peticiones al mismo recurso únicamente creen una petición al motor.
- Variable Scheme: varnish-service-type
Tipo de servicio para el daemon Varnish.
- Tipo de datos: varnish-configuration
Tipo de datos que representa la configuración del servicio
varnish. Este tipo tiene los siguientes parámetros:package(predeterminado:varnish)El paquete Varnish usado.
name(predeterminado:"default")Un nombre para esta instancia de Varnish. Varnish creará un directorio en /var/varnish con este nombre y mantendrá allí los archivos temporales. Si el nombre comienza con una barra, se interpreta como un nombre absoluto de directorio.
Proporcione el parámetro
-na otros programas de Varnish para que se conecten a la instancia de dicho nombre, por ejemplovarnishncsa -n default.backend(predeterminado:"localhost:8080")Motor usado. Esta opción no tiene efecto si se usa
vcl.vcl(predeterminado: #f)El programa VCL (lenguaje de configuración de Varnish) ejecutado. Si se proporciona
#f, Varnish llevará a cabo las redirecciones al motor (backend) usando la configuración predeterminada. En otro caso debe ser un objeto “tipo-archivo” con sintaxis válida para VCL.Por ejemplo, para proporcionar un espejo de www.gnu.org con VCL podría escribir algo parecido a esto:
(define %espejo-gnu (plain-file "gnu.vcl" "vcl 4.1; backend gnu { .host = \"www.gnu.org\"; }")) (operating-system ;; … (services (cons (service varnish-service-type (varnish-configuration (listen '(":80")) (vcl %espejo-gnu))) %base-services)))
La configuración de una instancia de Varnish ya en ejecución se puede inspeccionar y cambiar mediante el uso de la orden
varnishadm.Consulte la guía de usuaria de Varnish y el libro de Varnish para obtener la documentación completa de Varnish y su lenguaje de configuración.
listen(predeterminada:'("localhost:80"))Lista de direcciones en las que Varnish escucha.
storage(predeterminado:'("malloc,128m"))Lista de motores de almacenamiento que estarán disponibles en VCL.
parameters(predeterminados:'())Lista de parámetros de tiempo de ejecución con la forma
'(("parámetro" . "valor")).extra-options(predeterminadas:'())Parámetros adicionales a proporcional al proceso
varnishd.
Patchwork
Patchwork es un sistema de seguimiento de parches. Puede recolectar parches enviados a listas de correo y mostrarlos en una interfaz web.
- Variable Scheme: patchwork-service-type
Tipo de servicio para Patchwork.
El siguiente ejemplo muestra un servicio mínimo para Patchwork, para el
dominio patchwork.example.com.
(service patchwork-service-type
(patchwork-configuration
(domain "patchwork.example.com")
(settings-module
(patchwork-settings-module
(allowed-hosts (list domain))
(default-from-email "patchwork@patchwork.example.com")))
(getmail-retriever-config
(getmail-retriever-configuration
(type "SimpleIMAPSSLRetriever")
(server "imap.example.com")
(port 993)
(username "patchwork")
(password-command
(list (file-append coreutils "/bin/cat")
"/etc/getmail-patchwork-imap-password"))
(extra-parameters
'((mailboxes . ("Parches"))))))))
Existen tres registros para la configuración del servicio de Patchwork. El
registro <patchwork-configuration> está relacionado con la
configuración de Patchwork dentro del servicio HTTPD.
El campo settings-module dentro del registro
<patchwork-configuration> puede rellenarse con un registro
<patchwork-settings-module>, que describe un módulo de configuración
generado dentro del almacén de Guix.
En el campo database-configuration dentro del registro
<patchwork-settings-module>, debe usarse
<patchwork-database-configuration>.
- Tipo de datos: patchwork-configuration
Tipo de datos que representa la configuración del servicio Patchwok. Este tipo tiene los siguientes parámetros:
patchwork(predeterminado:patchwork)El paquete Patchwork usado.
domainDominio usado por Patchwork, se usa en el servicio HTTPD como “virtual host”.
settings-moduleThe settings module to use for Patchwork. As a Django application, Patchwork is configured with a Python module containing the settings. This can either be an instance of the
<patchwork-settings-module>record, any other record that represents the settings in the store, or a directory outside of the store.static-path(predeterminada:"/static/")Ruta bajo la cual el servicio HTTPD proporciona archivos estáticos.
getmail-retriever-configThe getmail-retriever-configuration record value to use with Patchwork. Getmail will be configured with this value, the messages will be delivered to Patchwork.
- Tipo de datos: patchwork-settings-module
Tipo de datos que representa un módulo de configuración de Patchwork. Algunas de estas opciones están directamente relacionadas con Patchwork, pero otras son relativas a Django, el entorno web usado Patchwork, o la biblioteca Django Rest Framework. Este tipo tiene los siguientes parámetros:
database-configuration(predeterminada:(patchwork-database-configuration))La configuración de la conexión a la base de datos usada para Patchwork. Véase el tipo de registro
<patchwork-database-configuration>para más información.secret-key-file(predeterminado:"/etc/patchwork/django-secret-key")Patchwork, como una aplicación web Django, usa una clave secreta para firmar criptográficamente valores. Este archivo debe contener un valor único e impredecible.
Si este archivo no existe, el servicio de Shepherd patchwork-setup lo creará y rellenará con un valor aleatorio.
Esta configuración está relacionada con Django.
allowed-hostsA list of valid hosts for this Patchwork service. This should at least include the domain specified in the
<patchwork-configuration>record.Esta es una opción de configuración de Django.
default-from-emailLa dirección de correo desde de la que Patchwork debe enviar el correo de manera predeterminada.
Esta es una opción de configuración de Patchwork.
static-url(predeterminada:#f)The URL to use when serving static assets. It can be part of a URL, or a full URL, but must end in a
/.Si se usa el valor predeterminado, se usará el valor de
static-pathdel registro<patchwork-configuration>.Esta es una opción de configuración de Django.
admins(predeterminadas:'())Direcciones de correo electrónico a las que enviar los detalles de los errores que ocurran. Cada valor debe ser una lista que contenga dos elementos, el nombre y la dirección de correo electrónico en dicho orden.
Esta es una opción de configuración de Django.
debug?(predeterminado:#f)Determina si se ejecuta Patchwork en modo de depuración. Si se proporciona
#t, se mostrarán mensajes de error detallados.Esta es una opción de configuración de Django.
enable-rest-api?(predeterminado:#t)Determina si se activa el API REST de Patchwork.
Esta es una opción de configuración de Patchwork.
enable-xmlrpc?(predeterminado:#t)Determina si se activa el API XML RPC.
Esta es una opción de configuración de Patchwork.
force-https-links?(predeterminado:#t)Determina si se usan enlaces HTTPS en las páginas de Patchwork.
Esta es una opción de configuración de Patchwork.
extra-settings(predeterminado:"")Código adicional que colocar al final del módulo de configuración de Patchwork.
- Tipo de datos: patchwork-database-configuration
Tipo de datos que representa la configuración de base de datos de Patchwork.
engine(predeterminado:"django.db.backends.postgresql_psycopg2")Motor de base de datos usado.
name(predeterminado:"patchwork")Nombre de la base de datos usada.
user(predeterminada:"httpd")Usuaria usada para la conexión a la base de datos.
password(predeterminada:"")Contraseña usada para la conexión a la base de datos.
host(predeterminada:"")Máquina usada para la conexión a la base de datos.
port(predeterminado:"")Puerto en el que se conecta a la base de datos.
Mumi
Mumi es una interfaz web al gestor de incidencias Debbugs, de manera predeterminada apunta a la instancia de GNU. Mumi es un servidor web, pero también obtiene e indexa los correos recibidos de Debbugs.
- Variable Scheme: mumi-service-type
El tipo de servicio para Mumi.
- Tipo de datos: mumi-configuration
Tipo de datos que representa la configuración del servicio Mumi. Este tipo tiene los siguientes campos:
mumi(predeterminado:mumi)El paquete Mumi usado.
mailer?(predeterminado:#true)Determina si se activa o desactiva el componente de correo
mailer.mumi-configuration-senderLa dirección de correo usada como remitente para los comentarios.
mumi-configuration-smtpUna URI para las opciones de configuración de SMTP de Mailutils. Puede ser algo parecido a
sendmail:///ruta/de/bin/msmtpo cualquier otra URI implementada por Mailutils. See SMTP Mailboxes in GNU Mailutils.
FastCGI
FastCGI es una interfaz entre la presentación (front-end) y el motor (back-end) de un servicio web. Es en cierto modo una característica antigua; los nuevos servicios web generalmente únicamente se comunican con HTTP entre ambas partes. No obstante, existe cierto número de servicios de motor como PHP o el acceso HTTP optimizado para repositorios Git que usan FastCGI, por lo que debemos incluirlo en Guix.
Para usar FastCGI debe configurar el servidor web de entrada38 (por ejemplo, ngnix) para delegar un subconjunto de
sus peticiones al motor fastcgi, que escucha en un puerto TCP local o en un
socket de UNIX. Existe un programa de intermediación llamado fcgiwrap
que se posiciona entre el proceso del motor y el servidor web. El servidor
indica el programa del motor usado, proporcionando dicha información al
proceso fcgiwrap.
- Variable Scheme: fcgiwrap-service-type
El tipo de servicio para la pasarela FastCGI
fcgiwrap.
- Tipo de datos: fcgiwrap-configuration
Tipo de datos que representa la configuración del servicio
fcgiwrap. Este tipo tiene los siguientes parámetros:package(predeterminado:fcgiwrap)El paquete fcgiwrap usado.
socket(predeterminado:tcp:127.0.0.1:9000)El socket donde el proceso
fcgiwrapdeba escuchar, como una cadena. Los valores adecuados para socket socket incluyenunix:/ruta/al/socket/unix,tcp:dirección.ip.con.puntos:puertoandtcp6:[dirección_ipv6]:puerto.user(predeterminado:fcgiwrap)group(predeterminado:fcgiwrap)Los nombres de usuaria y grupo, como cadenas, con los que se ejecutará el proceso
fcgiwrap. El serviciofastcgise asegura, en caso de solicitar específicamente el uso de nombres de usuaria o grupofcgiwrap, que la usuaria y/o grupo correspondientes se encuentren presentes en el sistema.Es posible configurar un servicio web proporcionado por FastCGI para que el servidor de fachada proporcione la información de identificación HTTP al motor, y para permitir que
fcgiwrapse ejecute en el proceso del motor como la usuaria local correspondiente. Para activar esta funcionalidad en el motor, ejecutefcgiwrapmediante la usuaria y gruporoot. Tenga en cuenta de que esta funcionalidad debe configurarse del mismo modo en el servidor de fachada.
PHP-FPM
PHP-FPM (FastCGI Process Manager) es una implementación alternativa de FastCGI en PHP con algunas características adicionales útiles para sitios de cualquier tamaño.
Estas características incluyen:
- Lanzamiento adaptativo de procesos
- Estadísticas básicas (similares a mod_status de Apache)
- Gestión avanzada de procesos con parada/arranque coordinados
- Capacidad de iniciar procesos de trbajo con diferentes uid/gid/chroor/entorno y diferentes php.ini (reemplaza a safe_mode)
- Registro a través de la salida estándar y de error
- Reinicio de emergencia en caso de destrucción accidental de la caché de opcode
- Posibilidad de subida acelerada
- Posibilidad de un "slowlog"
- Mejoras a FastCGI, como fastcgi_finish_request() - una función especial para terminar una petición y enviar todos los datos mientras que se continua haciendo una tarea de alto consumo de tiempo (conversión de datos audiovisuales, procesamiento de estadísticas, etcétera).
... y muchas más.
- Variable Scheme: php-fpm-service-type
Un tipo de servicio para
php-fpm.
- Tipo de datos: php-fpm-configuration
Tipo de datos para la configuración del servicio php-fpm.
php(predeterminado:php)El paquete php usado.
socket(predeterminado:(string-append "/var/run/php" (version-major (package-version php)) "-fpm.sock"))La dirección desde la que FastCGI acepta peticiones. Las sintaxis válidas son:
"dir.ecc.ión.ip:puerto"Escucha con un socket TCP en la dirección especificada en un puerto específico.
"puerto"Escucha en un socket TCP en todas las direcciones sobre un puerto específico.
"/ruta/a/socket/unix"Escucha en un socket Unix.
user(predeterminada:php-fpm)Usuaria que poseerá los procesos de trabajo de php.
group(predeterminado:php-fpm)Grupo de los procesos de trabajo.
socket-user(predeterminado:php-fpm)Usuaria que puede comunicarse con el socket de php-fpm.
socket-group(predeterminado:nginx)Grupo que puede comunicarse con el socket de php-fpm.
pid-file(predeterminado:(string-append "/var/run/php" (version-major (package-version php)) "-fpm.pid"))El identificador de proceso del proceso de php-fpm se escribe en este archivo cuando se ha iniciado el servicio.
log-file(predeterminado:(string-append "/var/log/php" (version-major (package-version php)) "-fpm.log"))Registro del proceso maestro de php-fpm.
process-manager(predeterminado:(php-fpm-dynamic-process-manager-configuration))Configuración detallada para el gestor de procesos php-fpm. Debe ser uno de los siguientes tipos:
<php-fpm-dynamic-process-manager-configuration><php-fpm-static-process-manager-configuration><php-fpm-on-demand-process-manager-configuration>
display-errors(predeterminado#f)Determina si los errores y avisos de php deben enviarse a los clientes para que se muestren en sus navegadores. Esto es útil para la programación local con php, pero un riesgo para la seguridad de sitios públicos, ya que los mensajes de error pueden revelar contraseñas y datos personales.
timezone(predeterminado:#f)Especifica el parámetro
php_admin_value[date.timezone].workers-logfile(predeterminado(string-append "/var/log/php" (version-major (package-version php)) "-fpm.www.log"))Este archivo registrará las salidas por
stderrde los procesos de trabajo de php. Puede proporcionarse#fpara desactivar el registro.file(predeterminado#f)Sustituye opcionalmente la configuración al completo. Puede usar la función
mixed-text-fileo una ruta absoluta de un archivo para hacerlo.php-ini-file(predeterminado:#f)Sustituye opcionalmente la configuración predeterminada de php. Puede ser cualquier objeto “tipo-archivo” (see file-like objects). Puede usar la función
mixed-text-fileo una ruta absoluta de un archivo para hacerlo.Para el desarrollo local es útil proporcionar valores mayores para los plazos y límites de memoria de los procesos php lanzados. Esto puede obtenerse con el siguiente fragmento de la configuración de sistema operativo:
(define %php-ini-local (plain-file "php.ini" "memory_limit = 2G max_execution_time = 1800")) (operating-system ;; … (services (cons (service php-fpm-service-type (php-fpm-configuration (php-ini-file %php-ini-local))) %base-services)))
Consulte las directivas principales de php.ini para obtener una documentación extensa de las directivas aceptables en el archivo php.ini.
- Tipo de datos: php-fpm-dynamic-process-manager-configuration
Data Type for the
dynamicphp-fpm process manager. With thedynamicprocess manager, spare worker processes are kept around based on its configured limits.max-children(predeterminados:5)Número máximo de procesos de trabajo.
start-servers(predeterminados:2)Cuantos procesos de trabajo deben ejecutarse al inicio.
min-spare-servers(predeterminado:1)Cuantos procesos de trabajo deben mantenerse disponibles como mínimo.
max-spare-servers(predeterminados:3)Cuantos procesos de trabajo deben mantenerse disponibles como máximo.
- Tipo de datos: php-fpm-static-process-manager-configuration
Tipo de datos para el gestor de procesos
staticde php-fpm. Con el gestor de procesosstatic, se crea un número fijo de procesos de trabajo.max-children(predeterminados:5)Número máximo de procesos de trabajo.
- Tipo de datos: php-fpm-on-demand-process-manager-configuration
Tipo de datos para el gestor de procesos
on-demandde php-fpm. Con el gestor de procesoson-demand, se crean procesos de trabajo únicamente cuando se reciben peticiones.max-children(predeterminados:5)Número máximo de procesos de trabajo.
process-idle-timeout(predeterminado:10)El tiempo en segundos tras el cual un proceso sin peticiones será eliminado.
- Procedimiento Scheme: nginx-php-location [#:nginx-package nginx] [socket (string-append "/var/run/php" (version-major (package-version php)) "-fpm.sock")]
Función auxiliar para añadir php a una configuración
nginx-server-configurationrápidamente.
Una configuración simple de servicios para nginx con php puede ser más o menos así:
(services (cons* (service dhcp-client-service-type)
(service php-fpm-service-type)
(service nginx-service-type
(nginx-server-configuration
(server-name '("example.com"))
(root "/srv/http/")
(locations
(list (nginx-php-location)))
(listen '("80"))
(ssl-certificate #f)
(ssl-certificate-key #f)))
%base-services))
El generadores de avatares de gato es un servicio simple para demostrar el
uso de php-fpm en Nginx. Se usa para generar un avatar de gato desde
una semilla, por ejemplo el hash de la dirección de correo de la usuaria.
- Procedimiento Scheme: cat-avatar-generator-service [#:cache-dir "/var/cache/cat-avatar-generator"] [#:package
cat-avatar-generator] [#:configuration (nginx-server-configuration)] Devuelve una configuración de nginx-server-configuration que hereda de
configuration. Extiende la configuración de nginx para añadir un bloque de servidor que proporcionapackage, una versión de cat-avatar-generator. Durante su ejecución, cat-avatar-generator podrá usarcache-dircomo su directorio de caché.
Una configuración simple para cat-avatar-generator puede ser más o menos así:
(services (cons* (cat-avatar-generator-service
#:configuration
(nginx-server-configuration
(server-name '("example.com"))))
...
%base-services))
Hpcguix-web
El programa hpcguix-web es una interfaz web personalizable para buscar paquetes de Guix, diseñado inicialmente para usuarias de clusters de computación de alto rendimiento (HPC).
- Variable Scheme: hpcguix-web-service-type
El tipo de servicio para
hpcguix-web.
- Tipo de datos: hpcguix-web-configuration
El tipo de datos para la configuración del servicio hpcguix-web.
specsUna expresión-G (see Expresiones-G) que especifica la configuración del servicio hpcguix-web. Los elementos principales en esta especificación son:
title-prefix(predeterminado:"hpcguix | ")El prefijo del título de la página.
guix-command(predeterminada:"guix")La orden
guix.package-filter-proc(predeterminado:(const #t))Un procedimiento que especifica cómo filtrar los paquetes mostrados.
package-page-extension-proc(predeterminado:(const '()))Paquete de extensión para
hpcguix-web.menu(predeterminadas:'())Entradas adicionales en el menú de la página.
channels(predeterminados:%default-channels)Lista de canales desde los que se construye la lista de paquetes (see Canales).
package-list-expiration(predeterminado:(* 12 3600))El tiempo de expiración, en segundos, tras el cual la lista de paquetes se reconstruye desde las últimas instancias de los canales proporcionados.
Véase el repositorio de hpcguix-web para un ejemplo completo.
package(predeterminado:hpcguix-web)El paquete hpcguix-web usado.
address(default:"127.0.0.1")The IP address to listen to.
port(default:5000)The port number to listen to.
Una declaración típica del servicio hpcguix-web es más o menos así:
(service hpcguix-web-service-type
(hpcguix-web-configuration
(specs
#~(define site-config
(hpcweb-configuration
(title-prefix "Guix-HPC - ")
(menu '(("/about" "ABOUT"))))))))
Nota: El servicio hpcguix-web actualiza periódicamente la lista de paquetes que publica obteniendo canales con Git. Para ello, necesita acceder a certificados X.509 de manera que pueda validar los servidores Git durante la comunicación con HTTPS, y asume que /etc/ssl/certs contiene dichos certificados.
Por lo tanto, asegúrese de añadir
nss-certsu otro paquete de certificados al campopackagesde su configuración. Certificados X.509, para más información sobre certificados X.509.
gmnisrv
El programa gmnisrv es un servidor simple del protocolo Gemini.
- Variable Scheme: gmnisrv-service-type
Es el tipo del servicio gmnisrv, cuyo valor debe ser un objeto
gmniserv-configurationcomo en este ejemplo:(service gmnisrv-service-type (gmnisrv-configuration (config-file (local-file "./mi-gmnisrv.ini"))))
- Tipo de datos: gmnisrv-configuration
Tipo de datos que representa la configuración de gmnisrv.
package(predeterminado: gmnisrv)El objeto paquete del servidor gmnisrv.
config-file(predeterminado:%default-gmnisrv-config-file)Objeto tipo-archivo del archivo de configuración de gmnisrv usado. La configuración predeterminada escucha en el puerto 1965 y proporciona archivos desde /srv/gemini. Los certificados se almacenan en /var/lib/gemini/certs. Puede ejecutar las ordenes
man gmnisrvyman gmnisrv.inipara obtener más información.
Agate
The Agate (GitHub page over HTTPS) program is a simple Gemini protocol server written in Rust.
- Scheme Variable: agate-service-type
This is the type of the agate service, whose value should be an
agate-service-typeobject, as in this example:(service agate-service-type (agate-configuration (content "/srv/gemini") (cert "/srv/cert.pem") (key "/srv/key.rsa")))The example above represents the minimal tweaking necessary to get Agate up and running. Specifying the path to the certificate and key is always necessary, as the Gemini protocol requires TLS by default.
To obtain a certificate and a key, you could, for example, use OpenSSL, running a command similar to the following example:
openssl req -x509 -newkey rsa:4096 -keyout key.rsa -out cert.pem \ -days 3650 -nodes -subj "/CN=example.com"Of course, you’ll have to replace example.com with your own domain name, and then point the Agate configuration towards the path of the generated key and certificate.
- Data Type: agate-configuration
Data type representing the configuration of Agate.
package(default:agate)The package object of the Agate server.
content(default: "/srv/gemini")The directory from which Agate will serve files.
cert(default:#f)The path to the TLS certificate PEM file to be used for encrypted connections. Must be filled in with a value from the user.
key(predeterminada:#f)The path to the PKCS8 private key file to be used for encrypted connections. Must be filled in with a value from the user.
addr(default:'("0.0.0.0:1965" "[::]:1965"))A list of the addresses to listen on.
hostname(predeterminado:#f)The domain name of this Gemini server. Optional.
lang(default:#f)RFC 4646 language code(s) for text/gemini documents. Optional.
silent?(default:#f)Set to
#tto disable logging output.serve-secret?(default:#f)Set to
#tto serve secret files (files/directories starting with a dot).log-ip?(default:#t)Whether or not to output IP addresses when logging.
user(default:"agate")Owner of the
agateprocess.group(default:"agate")Owner’s group of the
agateprocess.log-file(default: "/var/log/agate.log")The file which should store the logging output of Agate.
Next: Servicios DNS, Previous: Servicios Web, Up: Servicios [Contents][Index]
12.9.20 Servicios de certificados
El módulo (gnu services certbot) proporciona un servicio para la
obtención automática de un certificado TLS válido de la autoridad de
certificación Let’s Encrypt. Estos certificados pueden usarse para
proporcionar contenido de forma segura sobre HTTPS u otros protocolos
basados en TLS, con el conocimiento de que el cliente podrá verificar la
autenticidad del servidor.
Let’s Encrypt provides the certbot
tool to automate the certification process. This tool first securely
generates a key on the server. It then makes a request to the Let’s Encrypt
certificate authority (CA) to sign the key. The CA checks that the request
originates from the host in question by using a challenge-response protocol,
requiring the server to provide its response over HTTP. If that protocol
completes successfully, the CA signs the key, resulting in a certificate.
That certificate is valid for a limited period of time, and therefore to
continue to provide TLS services, the server needs to periodically ask the
CA to renew its signature.
El servicio certbot automatiza este proceso: la generación inicial de la clave, la petición inicial de certificación al servicio Let’s Encrypt, la integración del desafío/respuesta en el servidor web, la escritura del certificado en disco, las renovaciones periódicas automáticas y el despliegue de tareas asociadas con la renovación (por ejemplo la recarga de servicios y la copia de claves con diferentes permisos).
Certbot se ejecuta dos veces al día, en un minuto aleatorio dentro de la hora. No hará nada hasta que sus certificados estén pendientes de renovación o sean revocados, pero su ejecución regular propociona a su servicio la oportunidad de permanecer en línea en caso de que se produzca una revocación iniciada por Let’s Encrypt por alguna razón.
Mediante el uso de este servicio, usted acepta el acuerdo de suscripción ACME, que se puede encontrar aquí: https://acme-v01.api.letsencrypt.org/directory.
- Variable Scheme: certbot-service-type
Un tipo de servicio para el cliente de Let’s Encrypt
certbot. Su valor debe ser un registrocertbot-configurationcomo en este ejemplo:(define %procedimiento-de-despliegue-nginx (program-file "procedimiento-de-despliegue-nginx" #~(let ((pid (call-with-input-file "/var/run/nginx/pid" read))) (kill pid SIGHUP)))) (service certbot-service-type (certbot-configuration (email "foo@example.net") (certificates (list (certificate-configuration (domains '("example.net" "www.example.net")) (deploy-hook %procedimiento-de-despliegue-nginx)) (certificate-configuration (domains '("bar.example.net")))))))
Véase a continuación los detalles de
certbot-configuration.
- Tipo de datos: certbot-configuration
Tipo de datos que representa la configuración del servicio
certbot. Este tipo tiene los siguientes parámetros:package(predeterminado:certbot)El paquete certbot usado.
webroot(predeterminado:/var/www)Directorio desde el que se proporcionan los archivos de desafío/respuesta de Let’s Encrypt.
certificates(predeterminados:())Una lista de configuraciones
certificates-configurationpara los cuales se generan certificados y se solicitan firmas. Cada certificado tiene un nombre (name) y varios dominios (domains).email(predeterminado:#f)Dirección de correo electrónico opcional usada para el registro y el contacto de recuperación. Se recomienda que proporcione un valor ya que le permite recibir importantes notificaciones acerca de la cuenta y los certificados emitidos.
server(predeterminada:#f)URL opcional del servidor ACME. Esta configuración cambia el valor predeterminado de certbot, que es el servidor de Let’s Encrypt.
rsa-key-size(predeterminado:2048)Tamaño de la clave RSA.
default-location(predeterminada: véase a continuación)La configuración
nginx-location-configurationpredeterminada. Debido a quecertbotnecesita proporcionar desafíos y respuestas, necesita ser capaz de ejecutar un servidor web. Se lleva a cabo extendiendo el servicio webnginxcon una configuraciónnginx-server-configurationque escucha en los dominios domains en el puerto 80, y que contiene una configuraciónnginx-location-configurationpara el subespacio de rutas URI/.well-known/usado por Let’s Encrypt. See Servicios Web, para más información sobre estos tipos de datos de configuración de nginx.Las peticiones a otras rutas URL se compararán contra la dirección predeterminada
default-location, la cual, en caso de estar presente, se añade a todas las configuracionesnginx-server-configuration.De manera predeterminada, la dirección predeterminada
default-locationemitirá una redirecciónhttp://dominio/...ahttps://dominio/..., lo que le permite definir qué proporcionará en su sitio web a través dehttps.Proporcione
#fpara no emitir una dirección predeterminada.
- Tipo de datos: certificate-configuration
Tipo de datos que representa la configuración de un certificado. Este tipo tiene los siguientes parámetros:
name(predeterminado: vea a continuación)Este nombre se usa por Certbot para su mantenimiento interno y en las rutas de archivos; no afecta al contenido del certificado en sí mismo. Para ver los nombres de certificados, ejecute
certbot certificates.Su valor predeterminado es el primer dominio proporcionado.
domains(predeterminado:())El primer dominio proporcionado será el sujeto del nombre común (CN) del certificado, y todos los dominios serán nombres alternativos (Subject Alternative Names) en el certificado.
challenge(predeterminado:#f)El tipo de desafío que debe ejecutar certbot. Si se especifica
#f, el valor por omisión es desafío HTTP. Si se especifica un valor, el valor por omisión es el módulo manual (véaseauthentication-hook,cleanup-hooky la documentación en https://certbot.eff.org/docs/using.html#hooks), y concede permiso a Let’s Encrypt para registrar la IP pública de la máquina que realiza la petición.csr(default:#f)File name of Certificate Signing Request (CSR) in DER or PEM format. If
#fis specified, this argument will not be passed to certbot. If a value is specified, certbot will use it to obtain a certificate, instead of using a self-generated CSR. The domain-name(s) mentioned indomains, must be consistent with the domain-name(s) mentioned in CSR file.authentication-hook(predeterminado:#t)Orden ejecutada en un shell una vez por cada desafío de certificado que debe contestarse. Durante su ejecución, la variable del shell
$CERTBOT_DOMAINcontiene el dominio que se está validando,$CERTBOT_VALIDATIONcontiene la cadena de validación y$CERTBOT_TOKENcontiene el nombre de archivo del recurso solicitado cuando se realiza el desafío HTTP-01.cleanup-hook(predeterminado:#f)Orden ejecutada en un shell una vez por cada desafío de certificado que haya sido contestado por
auth-hook. Durante su ejecución, las variables del shell disponibles en el scriptauth-hooktodavía están disponibles, y adicionalmente$CERTBOT_AUTH_OUTPUTcontendrá la salida estándar que produjoauth-hook.deploy-hook(predeterminado:#f)Orden ejecutada en un shell una vez por cada certificado emitido satisfactoriamente. Durante su ejecución, la variable del shell
$RENEWED_LINEAGEapuntará al subdirectorio live de configuración (por ejemplo, ‘"/etc/letsencrypt/live/example.com"’) que contiene las nuevas claves y certificados; la variable del shell$RENEWED_DOMAINScontendrá una lista delimitada por espacios de certificados de dominio renovados (por ejemplo, ‘"example.com www.example.com"’).
Para cada configuración certificate-configuration, el certificado se
almacena /etc/letsencrypt/live/name/fullchain.pem y la clave se
almacena en /etc/letsencrypt/live/name/privkey.pem.
Next: VNC Services, Previous: Servicios de certificados, Up: Servicios [Contents][Index]
12.9.21 Servicios DNS
El módulo (gnu services dns) proporciona servicios relacionados con
el sistema de nombres de dominio (DNS). Proporciona un servicio de
servidor para el alojamiento de un servidor autorizado DNS para
múltiples zonas, esclavo o maestro. Este servicio usa
Knot DNS. Y también un servidor de caché y
reenvío de DNS para la red local, que usa
dnsmasq.
Servicio Knot
Esta es una configuración de ejemplo de un servidor de autoridad para dos zonas, una maestra y otra esclava:
(define-zone-entries example.org.zone ;; Name TTL Class Type Data ("@" "" "IN" "A" "127.0.0.1") ("@" "" "IN" "NS" "ns") ("ns" "" "IN" "A" "127.0.0.1")) (define master-zone (knot-zone-configuration (domain "example.org") (zone (zone-file (origin "example.org") (entries example.org.zone))))) (define slave-zone (knot-zone-configuration (domain "plop.org") (dnssec-policy "default") (master (list "plop-master")))) (define plop-master (knot-remote-configuration (id "plop-master") (address (list "208.76.58.171")))) (operating-system ;; ... (services (cons* (service knot-service-type (knot-configuration (remotes (list plop-master)) (zones (list master-zone slave-zone)))) ;; ... %base-services)))
- Variable Scheme: knot-service-type
Este es el tipo de datos para el servidor DNS Knot.
Knot DNS es un servidor de autoridad de DNS, lo que significa que puede servir múltiples zonas, es decir, nombres de dominio que compraría a una autoridad de registro de nombres. Este servidor no es un resolvedor, lo que significa que sólo puede resolver nombres para los que tiene autoridad. Este servidor puede configurarse para servir zonas como servidor maestro o como servidor esclavo con una granularidad al nivel de zona. Las zonas esclavas obtendrán sus datos de los servidores maestros, y las proporcionarán como un servidor de autoridad. Desde el punto de vista de un resolvedor, no hay diferencia entre servidor maestro y esclavo.
Los siguientes tipos de datos se usan para configurar el servidor DNS Knot:
- Tipo de datos: knot-key-configuration
Tipo de datos que representa una clave. Este tipo tiene los siguientes parámetros:
id(predeterminado:"")An identifier for other configuration fields to refer to this key. IDs must be unique and must not be empty.
algorithm(predeterminado:#f)El algoritmo usado. Debe seleccionarse entre
#f,'hmac-md5,'hmac-sha1,'hmac-sha224,'hmac-sha256,'hmac-sha384y'hmac-sha512.secret(predeterminado:"")La clave secreta en sí.
- Tipo de datos: knot-acl-configuration
Tipo de datos que representa una configuración de lista de control de acceso (ACL). Este tipo tiene los siguientes parámetros:
id(predeterminado:"")An identifier for other configuration fields to refer to this key. IDs must be unique and must not be empty.
address(predeterminada:'())Lista ordenada de direcciones IP, subredes o rangos de red representadas como cadenas. La búsqueda debe corresponder con alguna. El valor vacío significa que la comprobación de correspondencia de la dirección no es necesaria.
key(predeterminada:'())Lista ordenada de referencias a claves representadas como cadenas. La cadena debe corresponder con un ID de clave definido en
knot-key-configuration. Ninguna clave significa que la comprobación de claves no es necesaria para este control de acceso (ACL).action(predeterminada:'())An ordered list of actions that are permitted or forbidden by this ACL. Possible values are lists of zero or more elements from
'transfer,'notifyand'update.deny?(predeterminado:#f)Cuando es verdadero, este ACL define restricciones. Las acciones enumeradas no se permiten. Cuando es falso, las acciones enumeradas se permiten.
- Tipo de datos: zone-entry
Tipo de datos que representa una entrada de registro en un archivo de zona. Este tipo tiene los siguientes parámetros:
name(predeterminado:"@")El nombre del registro.
"@"hace referencia al origen de la zona. Los nombres son relativos al origen de la zona. Por ejemplo, en la zonaexample.org,"ns.example.org"en realidad hace referencia ans.example.org.example.org. Los nombres que terminan en un punto se consideran absolutos, lo que significa que"ns.example.org."hace referencia ans.example.org.ttl(predeterminado:"")El tiempo de vida (TTL) de este registro. Si no se proporciona, se usa el TTL predeterminado.
class(predeterminada:"IN")La clase del registro. Actualmente Knot implementa únicamente
"IN"y parcialmente"CH".type(predeterminado:"A")El tipo del registro. Los tipos comunes incluyen A (dirección IPv4), AAAA (dirección IPv6), NS (servidor de nombres39) y MX (pasarela de correo40). Otros muchos tipos distintos se encuentran definidos.
data(predeterminados:"")Los datos que contiene el registro. Por ejemplo, una dirección IP asociada con un registro A, o un nombre de dominio asociado con un registro NS. Recuerde que los nombres de dominio son relativos al origen a menos que terminen con punto.
- Tipo de datos: zone-file
Tipo de datos que representa el contenido de un archivo de zona. Este tipo tiene los siguientes parámetros:
entries(predeterminadas:'())La lista de entradas. El registro SOA se genera automáticamente, por lo que no necesita ponerlo en la lista de entradas. Esta lista probablemente debería contener una entrada apuntando a su servidor DNS de autoridad. En vez de usar una lista de entradas directamente, puede usar
define-zone-entriespara definir un objeto que contenga la lista de entradas más fácilmente, que posteriormente puede proporcionar en el campoentriesdel archivozone-file.origin(predeterminado:"")El nombre de su zona. Este parámetro no puede estar vacío.
ns(predeterminado:"ns")El dominio de su servidor DNS primario de autoridad. El nombre es relativo al origen, a menos que termine en punto. Es obligatorio que este servidor DNS primario corresponda con un registro NS en la zona y que esté asociado a una dirección IP en la lista de entradas.
mail(predeterminado:"hostmaster")Dirección de correo a través de la cual la gente puede contactar con usted, como propietaria de la zona. Se traduce a
<mail>@<origin>.serial(predeterminado:1)Número serie de la zona. Como se usa para tener constancia de los cambios tanto en servidores esclavos como en resolvedores, es obligatorio que nunca decremente. Incremente su valor siempre que haga cambios en su zona.
refresh(predeterminado:(* 2 24 3600))La frecuencia con la que los servidores esclavos realizarán una transferencia de zona. Este valor es un número de segundos. Puede calcularse con multiplicaciones o con
(string->duration).retry(predeterminado:(* 15 60))El periodo tras el cual un servidor esclavo reintentará el contacto con su maestro cuando falle al intentarlo la primera vez.
expiry(predeterminado:(* 14 24 3600))Tiempo de vida (TTL) predeterminado de los registros. Los registros existentes se consideran correctos durante al menos este periodo de tiempo. Tras este periodo, los resolvedores invalidarán su caché y comprobarán de nuevo que todavía exista.
nx(predeterminado:3600)Default TTL of inexistent records. This delay is usually short because you want your new domains to reach everyone quickly.
- Tipo de datos: knot-remote-configuration
Tipo de datos que representa una configuración remota. Este tipo tiene los siguientes parámetros:
id(predeterminado:"")An identifier for other configuration fields to refer to this remote. IDs must be unique and must not be empty.
address(predeterminada:'())Una lista ordenada de direcciones IP de destino. Las direcciones se prueban en secuencia. Opcionalmente se puede proporcionar el puerto con el separador @. Por ejemplo:
(list "1.2.3.4" "2.3.4.5@53"). El puerto predeterminado es el 53.via(predeterminada:'())An ordered list of source IP addresses. An empty list will have Knot choose an appropriate source IP. An optional port can be given with the @ separator. The default is to choose at random.
key(predeterminada:#f)Referencia a una clave, esto es una cadena que contiene el identificador de una clave definida en el campo
knot-key-configuration.
- Tipo de datos: knot-keystore-configuration
Tipo de datos que representa un almacén de claves para alojar claves de dnssec. Este tipo tiene los siguientes parámetros:
id(predeterminado:"")El identificador del almacén de claves. No debe estar vacío.
backend(predeterminado:'pem)El motor en el que se almacenan las claves. Puede ser
'pemo'pkcs11.config(predeterminada:"/var/lib/knot/keys/keys")La cadena de configuración del motor. Un ejemplo para PKCS#11 es:
"pkcs11:token=knot;pin-value=1234 /gnu/store/.../lib/pkcs11/libsofthsm2.so". La cadena representa una ruta en el sistema de archivos para el motor pem.
- Tipo de datos: knot-policy-configuration
Tipo de datos que representa una política de dnssec. El DNS Knot es capaz de firmar automáticamente sus zonas. Puede generar y gestionar sus claves de manera automática o usar las claves que usted genere.
Dnssec se implementa habitualmente usando dos claves: una clave para firma de claves (KSK) que se usa para firmar la segunda, y una clave para firma de zona (ZSK) que se usa para firmar la zona. Para establecer la confianza, la KSK necesita estar presente en la zona padre (habitualmente un dominio de nivel superior). Si su entidad de registro permite dnssec, debe mandarle el hash de su KSK de manera que puedan añadir un registro DS en su zona. No es automático y debe realizarse cada vez que cambie su KSK.
La política también define el tiempo de vida de las claves. Habitualmente, la ZSK puede cambiarse fácilmente y usa funciones criptográficas más débiles (usa parámetros de menor magnitud) para firmar los registros rápidamente, ya que cambian habitualmente. No obstante, la KSK requiere interacción manual con la entidad de registro, por lo que se cambia menos habitualmente y usa parámetros más fuertes debido a que únicamente firma un registro.
Este tipo tiene los siguientes parámetros:
id(predeterminado:"")El identificador de la política. No debe estar vacío.
keystore(predeterminado:"default")Referencia a un almacén de claves, es decir una cadena que contiene el identificador de un almacén de claves definido en un campo de
knot-keystore-configuration. El identificador predeterminado"default"implica el uso del almacén de claves predeterminado (una base de datos kasp que se configura para este servicio).manual?(predeterminado:#f)Si la gestión de claves es manual o automática.
single-type-signing?(predeterminado:#f)Cuando sea
#t, usa el esquema de firma de tipo único (Single-Type Signing Scheme).algorithm(predeterminado:"ecdsap256sha256")Algoritmo para las claves de firma y las firmas emitidas.
ksk-size(predeterminado:256)The length of the KSK. Note that this value is correct for the default algorithm, but would be unsecure for other algorithms.
zsk-size(predeterminado:256)The length of the ZSK. Note that this value is correct for the default algorithm, but would be unsecure for other algorithms.
dnskey-ttl(predeterminado:'default)El valor del tiempo de vida (TTL) de los registros DNSKEY añadidos al “apex” de la zona. El valor especial
'defaultsignifica el mismo valor que el TTL del SOA de la zona.zsk-lifetime(predeterminado:(* 30 24 3600))El periodo entre la publicación de la ZSK y el inicio del siguiente ciclo de renovación.
propagation-delay(predeterminado:(* 24 3600))Retraso adicional añadido por cada paso del ciclo de renovación de clave. Este valor debe ser suficientemente alto para cubrir la propagación de datos del servidor maestro a todos los esclavos.
rrsig-lifetime(predeterminado:(* 14 24 3600))Periodo de validez para las nuevas firmas emitidas.
rrsig-refresh(predeterminado:(* 7 24 3600))Periodo de antelación con el que se realiza el refresco de la firma antes de una expiración de la misma.
nsec3?(predeterminado:#f)Si es
#t, se usa NSEC3 en vez de NSEC.nsec3-iterations(predeterminado:5)Número de ejecuciones adicionales de la operación de hash.
nsec3-salt-length(predeterminado:8)La longitud del campo “salt” en octetos, que se añade al nombre de la propietaria original antes de ejecutar la operación de hash.
nsec3-salt-lifetime(predeterminado:(* 30 24 3600))El periodo de validez de los campos “salt” que se generen.
- Tipo de datos: knot-zone-configuration
Tipo de datos que representa una zona ofrecida por Knot. Este tipo tiene los siguientes parámetros:
domain(predeterminado:"")El dominio ofrecido con esta configuración. No debe estar vacío.
file(predeterminado:"")El archivo donde se almacena esta zona. Este parámetro se ignora para zonas maestras. Vacío significa la ruta predeterminada que depende del nombre del dominio.
zone(predeterminado:(zone-file))El contenido del archivo de zona. Este parámetro se ignora para zonas esclavas. Debe contener un registro de archivo de zona.
master(predeterminado:'())Lista de maestros remotos. Cuando está vacía, esta zona es maestra. Cuando tiene contenido, esta zona es esclava. Es una lista de identificadores remotos.
ddns-master(predeterminado:#f)Maestro principal. Cuando está vacío, apunta de manera predeterminada al primer maestro en la lista de maestros.
notify(predeterminado:'())Una lista de identificadores remotos de esclavos.
acl(predeterminado:'())Lista de identificadores acl.
semantic-checks?(predeterminado:#f)Cuando es verdadero, añade más comprobaciones semánticas a la zona.
zonefile-sync(predeterminado:0)El retraso entre una modificación en memoria y en disco. 0 significa sincronización inmediata.
zonefile-load(predeterminado:#f)La forma en la que los contenidos del archivo de zona se aplican durante la carga de la zona. Los valores posibles son:
-
#fpara obtener el valor predeterminado de Knot, -
'nonepara no usar el archivo de zona en absoluto, -
'differencepara calcular la diferencia entre los contenidos disponibles actualmente y los contenidos de la zona y los aplica a los contenidos actuales de la zona actual, -
'difference-no-seriales igual que'difference, pero ignora el código serie SOA en el archivo de zona, mientras que el servidor se hace cargo de él de manera automática. -
'wholepara cargar los contenidos de la zona del archivo de zona.
-
journal-content(predeterminado:'())La forma en la que se usa el diario para almacenar la zona y sus cambios. Los posibles valores son
'nonepara no usarlo en absoluto,'changespara almacenar los cambios y'allpara almacenar los contenidos.#fproporciona un valor a esta opción, por lo que se usa el valor predeterminado de Knot.max-journal-usage(predeterminado:#f)Tamaño máximo del diario en disco.
#fno proporciona un valor a esta opción, por lo que se usa el valor predeterminado de Knot.max-journal-depth(predeterminado:#f)Tamaño máximo de la historia.
#fproporciona un valor a esta opción, por lo que se usa el valor predeterminado de Knot.max-zone-size(predeterminado:#f)Tamaño máximo del archivo de zona. Este límite se usa para transferencias entrantes y actualizaciones.
#fno proporciona un valor a esta opción, por lo que se usa el valor predeterminado de Knot.dnssec-policy(predeterminado:#f)Una referencia a un registro de
knot-policy-configuration, o el nombre especial"default". Si el valor es#f, no se realiza firma dnssec en esta zona.serial-policy(predeterminado:'increment)Una política entre
'incrementy'unixtime.
- Tipo de datos: knot-configuration
Tipo de datos que representa la configuración Knot. Este tipo tiene los siguientes parámetros:
knot(predeterminado:knot)El paquete Knot.
run-directory(predeterminado:"/var/run/knot")El directorio de ejecución. Este directorio se usará para los archivos de PID y de sockets.
includes(predeterminada:'())Una lista de cadenas u objetos “tipo-archivo” que denota otros archivos que deben incluirse al inicio del archivo de configuración.
Puede usarse para gestionar secretos en un canal separado. Por ejemplo, las claves secretas pueden almacenarse en un archivo fuera de banda no gestionado por Guix, y por tanto no visible en /gnu/store—por ejemplo, puede almacenar su configuración de clave secreta en /etc/knot/secrets.conf e incluir este archivo en la lista
includes.Se puede generar una clave secreta tsig (para nsupdate y transferencias de zona) con la orden keymgr del paquete knot. Tenga en cuenta que el paquete no se instala automáticamente con el servicio. El ejemplo siguiente muestra como generar una clave tsig nueva:
keymgr -t misecreto > /etc/knot/secrets.conf chmod 600 /etc/knot/secrets.conf
Tenga también en cuenta que la clave generada se llamará misecreto, de modo que ese nombre es el que debe usarse en el campo key del registro
knot-acl-configurationy en otros lugares que hagan referencia a esa clave.También puede usarse para añadir configuración no implementada por esta interfaz.
listen-v4(predeterminada:"0.0.0.0")La dirección IP en la que escuchar.
listen-v6(predeterminada:"::")La dirección IP en la que escuchar.
listen-port(predeterminado:53)El puerto en el que escuchar.
keys(predeterminada:'())La lista de configuraciones knot-key-configuration usadas por esta configuración.
acls(predeterminado:'())La lista de configuraciones knot-acl-configuration usadas por esta configuración.
remotes(predeterminada:'())La lista de configuraciones knot-remote-configuration usadas por esta configuración.
zones(predeterminada:'())La lista de configuraciones knot-zone-configuration usadas por esta configuración.
Servicio de resolución de Knot
- Variable Scheme: knot-resolver-service-type
El tipo del servicio de resolución de knot, cuyo valor debe ser un objeto
knot-resolver-configurationcomo en este ejemplo:(service knot-resolver-service-type (knot-resolver-configuration (kresd-config-file (plain-file "kresd.conf" " net.listen('192.168.0.1', 5353) user('knot-resolver', 'knot-resolver') modules = { 'hints > iterate', 'stats', 'predict' } cache.size = 100 * MB "))))Para más información, véase su manual.
- Tipo de datos: knot-resolver-configuration
Tipo de datos que representa la configuración de knot-resolver.
package(predeterminado: knot-resolver)El objeto paquete de la resolución de DNS de knot.
kresd-config-file(predeterminado: %kresd.conf)Objeto “tipo-archivo” con el archivo de configuración de kresd usado, de manera predeterminada escucha en
127.0.0.1y::1.garbage-collection-interval(predeterminado: 1000)Número de milisegundos tras los que
kres-cache-gcrealiza una limpieza periódica de la caché.
Servicio Dnsmasq
- Variable Scheme: dnsmasq-service-type
Es el tipo del servicio dnsmasq, cuyo valor debe ser un objeto
dnsmasq-configurationcomo en este ejemplo:(service dnsmasq-service-type (dnsmasq-configuration (no-resolv? #t) (servers '("192.168.1.1"))))
- Tipo de datos: dnsmasq-configuration
Tipo de datos que representa la configuración de dnsmasq.
package(predeterminado: dnsmasq)El objeto paquete del servidor dnsmasq.
no-hosts?(predeterminado:#f)Cuando es verdadero, no lee los nombres de máquina en /etc/hosts.
port(predeterminado:53)El puerto sobre el que se escucha. Proporcionar el valor cero deshabilita las respuestas DNS completamente, dejando las funciones DHCP y/o TFTP únicamente.
local-service?(predeterminado:#t)Acepta peticiones DNS únicamente de máquinas cuya dirección esté en una subred local, es decir, subred para la que existe una interfaz en el servidor.
listen-addresses(predeterminadas:'())Escucha en las direcciones IP proporcionadas.
resolv-file(predeterminado:"/etc/resolv.conf")Archivo en el que se obtienen las direcciones IP de los servidores de nombres desde los que se obtienen datos.
no-resolv?(predeterminado:#f)Cuando tiene valor verdadero, no se lee resolv-file.
forward-private-reverse-lookup?(default:#t)When false, all reverse lookups for private IP ranges are answered with "no such domain" rather than being forwarded upstream.
query-servers-in-order?(default:#f)When true, dnsmasq queries the servers in the same order as they appear in servers.
servers(predeterminados:'())Especifica directamente la dirección IP de los servidores proveedores.
addresses(predeterminado:'())Cada entrada especifica una dirección IP devuelta por cualquiera de las máquinas en los dominios proporcionados. Las búsquedas dentro de los dominios nunca se redirigen y siempre se devuelve la dirección IP especificada.
Es útil para redirigir máquinas localmente, como en este ejemplo:
(service dnsmasq-service-type (dnsmasq-configuration (addresses '(; Redirecciona a un servidor web local. "/example.org/127.0.0.1" ; Redirecciona un dominio a una IP específica. "/subdomain.example.org/192.168.1.42"))))Tenga en cuenta que las reglas en el archivo /etc/hosts tienen precedencia sobre esto.
cache-size(predeterminado:150)Establece el tamaño de la caché de dnsmasq. Proporcionar el valor cero desactiva el almacenamiento en caché.
negative-cache?(predeterminado:#t)Cuando es falso, desactiva la caché negativa.
cpe-id(default:#f)If set, add a CPE (Customer-Premises Equipment) identifier to DNS queries which are forwarded upstream.
tftp-enable?(predeterminado:#f)Determina si se activa el servidor TFTP incluido.
tftp-no-fail?(predeterminado:#f)Si es verdadero, dnsmasq no falla si el servidor TFTP no se ha podido arrancar.
tftp-single-port?(predeterminado:#f)Determina si se un único puerto para TFTP.
tftp-secure?(predeterminado:#f)Si es verdadero, únicamente los archivos propiedad de la cuenta que ejecuta el proceso dnsmasq están accesibles.
Si se ejecuta dnsmasq como “root”, se aplican diferentes reglas:
tftp-secure?no tiene efecto, únicamente los archivos que tengan permiso de lectura global el mundo serán accesibles.tftp-max(predeterminado:#f)Cuando se proporciona un valor indica el número máximo de conexiones simultáneas permitidas.
tftp-mtu(predeterminado:#f)Si se proporciona un valor, establece el tamaño de la unidad de transmisión de mensajes (MTU) para los paquetes TFTP a dicho valor.
tftp-no-blocksize?(predeterminado:#f)Si es verdadero, impide al servidor TFTP la negociación del tamaño del bloque con un cliente.
tftp-lowercase?(predeterminado:#f)Determina si se convierten a minúsculas todos los nombres de archivo en peticiones TFTP.
tftp-port-range(predeterminado:#f)Si se proporciona un valor, este establece el rango (
"<inicio>,<fin>") de puertos dinámicos (uno por cliente) usados.tftp-root(predeterminado:/var/empty,lo)Look for files to transfer using TFTP relative to the given directory. When this is set, TFTP paths which include ‘..’ are rejected, to stop clients getting outside the specified root. Absolute paths (starting with ‘/’) are allowed, but they must be within the TFTP-root. If the optional interface argument is given, the directory is only used for TFTP requests via that interface.
tftp-unique-root(predeterminado:#f)Si se proporciona un valor, añade la dirección IP o hardware del cliente TFTP como un componente de la ruta tras el final de
tftp-root. Es válido únicamente si se proporciona una raíz para TFTP y el directorio existe. El valor predeterminado añade la dirección IP (en el formato estándar de cuatro cifras separadas por puntos).For instance, if --tftp-root is ‘/tftp’ and client ‘1.2.3.4’ requests file myfile then the effective path will be /tftp/1.2.3.4/myfile if /tftp/1.2.3.4 exists or /tftp/myfile otherwise. When ‘=mac’ is specified it will append the MAC address instead, using lowercase zero padded digits separated by dashes, e.g.: ‘01-02-03-04-aa-bb’. Note that resolving MAC addresses is only possible if the client is in the local network or obtained a DHCP lease from dnsmasq.
Servicio ddclient
El servicio de ddclient descrito a continuación ejecuta el daemon ddclient, que se encarga de actualizar automáticamente entradas DNS para proveedores de servicio como Dyn.
El ejemplo siguiente muestra como instanciar el servicio con su configuración predeterminada.
(service ddclient-service-type)
Fíjese que ddclient necesita acceder a las credenciales que se almacenan en
un archivo de secretos, de manera predeterminada
/etc/ddclient/secrets (véase secret-file a continuación). Se
espera que genere este archivo manualmente, “fuera de banda” (puede
incluir este archivo en la configuración del servicio, por ejemplo mediante
el uso de plain-file, pero sera legible por todo el mundo a través de
/gnu/store). Véase los ejemplos en el directorio
share/ddclient del paquete ddclient.
Los campos disponibles de ddclient-configuration son:
- parámetro de
ddclient-configuration: package ddclient ¶ El paquete ddclient.
- parámetro de
ddclient-configuration: integer daemon ¶ Periodo tras el cual ddclient reintentará la comprobación de IP y de nombre de dominio.
El valor predeterminado es ‘300’.
- parámetro de
ddclient-configuration: boolean syslog ¶ Usa syslog para la salida.
El valor predeterminado es ‘#t’
- parámetro de
ddclient-configuration: string mail ¶ Envía por correo a la usuaria.
El valor predeterminado es ‘"root"’.
- parámetro de
ddclient-configuration: string mail-failure ¶ Envía por correo las actualizaciones fallidas a la usuaria.
El valor predeterminado es ‘"root"’.
- parámetro de
ddclient-configuration: string pid ¶ El archivo de PID de ddclient.
El valor predeterminado es ‘"/var/run/ddclient/ddclient.pid"’.
- parámetro de
ddclient-configuration: boolean ssl ¶ Permite el uso de SSL.
El valor predeterminado es ‘#t’
- parámetro de
ddclient-configuration: string user ¶ Especifica el nombre de usuaria o ID usado para la ejecución del programa ddclient.
El valor predeterminado es ‘"ddclient"’.
- parámetro de
ddclient-configuration: string group ¶ Grupo de la usuaria que ejecutará el servidor ddclient.
El valor predeterminado es ‘"ddclient"’.
- parámetro de
ddclient-configuration: string secret-file ¶ Archivo secreto que se añadirá al final del archivo ddclient.conf. Este archivo contiene las credenciales usadas por ddclient. Se espera que usted lo cree manualmente.
El valor predeterminado es ‘"/etc/ddclient/secrets.conf"’.
- parámetro de
ddclient-configuration: lista extra-options ¶ Opciones adicionales a agregar al final del archivo ddclient.conf.
El valor predeterminado es ‘()’.
Next: Servicios VPN, Previous: Servicios DNS, Up: Servicios [Contents][Index]
12.9.22 VNC Services
The (gnu services vnc) module provides services related to
Virtual Network Computing (VNC), which makes it possible to locally
use graphical Xorg applications running on a remote machine. Combined with
a graphical manager that supports the X Display Manager Control
Protocol, such as GDM (see gdm) or LightDM (see lightdm), it is
possible to remote an entire desktop for a multi-user environment.
Xvnc
Xvnc is a VNC server that spawns its own X window server; which means it can
run on headless servers. The Xvnc implementations provided by the
tigervnc-server and turbovnc aim to be fast and efficient.
- Variable: Scheme Variable xvnc-service-type
-
The
xvnc-server-typeservice can be configured via thexvnc-configurationrecord, documented below. A second virtual display could be made available on a remote machine via the following configuration:
(service xvnc-service-type
(xvnc-configuration (display-number 10)))
As a demonstration, the xclock command could then be started on
the remote machine on display number 10, and it could be displayed locally
via the vncviewer command:
# Start xclock on the remote machine. ssh -L5910:localhost:5910 -- guix shell xclock -- env DISPLAY=:10 xclock # Access it via VNC. guix shell tigervnc-client -- vncviewer localhost:5910
The following configuration combines XDMCP and Inetd to allow multiple users to concurrently use the remote system, login in graphically via the GDM display manager:
(operating-system
[...]
(services (cons*
[...]
(service xvnc-service-type (xvnc-configuration
(display-number 5)
(localhost? #f)
(xdmcp? #t)
(inetd? #t)))
(modify-services %desktop-services
(gdm-service-type config => (gdm-configuration
(inherit config)
(auto-suspend? #f)
(xdmcp? #t)))))))
A remote user could then connect to it by using the vncviewer
command or a compatible VNC client and start a desktop session of their
choosing:
vncviewer remote-host:5905
Aviso: Unless your machine is in a controlled environment, for security reasons, the
localhost?configuration of thexvnc-configurationrecord should be left to its default#tvalue and exposed via a secure means such as an SSH port forward. The XDMCP port, UDP 177 should also be blocked from the outside by a firewall, as it is not a secure protocol and can expose login credentials in clear.
- Data Type: xvnc-configuration
Available
xvnc-configurationfields are:xvnc(default:tigervnc-server) (type: file-like)The package that provides the Xvnc binary.
display-number(default:0) (type: number)The display number used by Xvnc. You should set this to a number not already used a Xorg server.
geometry(default:"1024x768") (type: string)The size of the desktop to be created.
depth(default:24) (type: color-depth)The pixel depth in bits of the desktop to be created. Accepted values are 16, 24 or 32.
port(type: maybe-port)The port on which to listen for connections from viewers. When left unspecified, it defaults to 5900 plus the display number.
ipv4?(default:#t) (type: boolean)Use IPv4 for incoming and outgoing connections.
ipv6?(default:#t) (type: boolean)Use IPv6 for incoming and outgoing connections.
password-file(type: maybe-string)The password file to use, if any. Refer to vncpasswd(1) to learn how to generate such a file.
xdmcp?(default:#f) (type: boolean)Query the XDMCP server for a session. This enables users to log in a desktop session from the login manager screen. For a multiple users scenario, you’ll want to enable the
inetd?option as well, so that each connection to the VNC server is handled separately rather than shared.inetd?(default:#f) (type: boolean)Use an Inetd-style service, which runs the Xvnc server on demand.
frame-rate(default:60) (type: number)The maximum number of updates per second sent to each client.
security-types(default:("None")) (type: security-types)The allowed security schemes to use for incoming connections. The default is "None", which is safe given that Xvnc is configured to authenticate the user via the display manager, and only for local connections. Accepted values are any of the following: ("None" "VncAuth" "Plain" "TLSNone" "TLSVnc" "TLSPlain" "X509None" "X509Vnc")
localhost?(default:#t) (type: boolean)Only allow connections from the same machine. It is set to #true by default for security, which means SSH or another secure means should be used to expose the remote port.
log-level(default:30) (type: log-level)The log level, a number between 0 and 100, 100 meaning most verbose output. The log messages are output to syslog.
extra-options(default:()) (type: strings)This can be used to provide extra Xvnc options not exposed via this <xvnc-configuration> record.
Next: Sistema de archivos en red, Previous: VNC Services, Up: Servicios [Contents][Index]
12.9.23 Servicios VPN
The (gnu services vpn) module provides services related to
virtual private networks (VPNs).
Bitmask
- Scheme Variable: bitmask-service-type
A service type for the Bitmask VPN client. It makes the client available in the system and loads its polkit policy. Please note that the client expects an active polkit-agent, which is either run by your desktop-environment or should be run manually.
OpenVPN
It provides a client service for your machine to connect to a VPN, and a server service for your machine to host a VPN.
- Procedimiento Scheme: openvpn-client-service [#:config (openvpn-client-configuration)]
-
Devuelve un servicio que ejecuta
openvpn, un daemon VPN, como cliente.
- Procedimiento Scheme: openvpn-server-service [#:config (openvpn-server-configuration)]
-
Devuelve un servicio que ejecuta
openvpn, un daemon VPN, como servidor.Pueden ejecutarse simultáneamente.
- Data Type: openvpn-client-configuration
Los campos disponibles de
openvpn-client-configurationson:openvpn(default:openvpn) (type: file-like)El paquete OpenVPN.
pid-file(default:"/var/run/openvpn/openvpn.pid") (type: string)El archivo de pid de OpenVPN.
proto(default:udp) (type: proto)El protocolo (UDP o TCP) usado para la apertura del canal entre clientes y servidores.
dev(default:tun) (type: dev)El tipo de dispositivo usado para representar la conexión VPN.
ca(default:"/etc/openvpn/ca.crt") (type: maybe-string)La autoridad de certificación contra la que se comprueban las conexiones.
cert(default:"/etc/openvpn/client.crt") (type: maybe-string)El certificado de la máquina en la que se ejecuta el daemon. Debe estar firmado por la autoridad proporcionada en
ca.key(default:"/etc/openvpn/client.key") (type: maybe-string)La clave de la máquina en la que se ejecuta el daemon. Debe ser la clave cuyo certificado es
cert.comp-lzo?(default:#t) (type: boolean)Determina si se usa el algoritmo de compresión lzo.
persist-key?(default:#t) (type: boolean)No vuelve a leer los archivos de claves tras la señal SIGUSR1 o –ping-restart.
persist-tun?(default:#t) (type: boolean)No cierra y reabre el dispositivo TUN/TAP o ejecuta los guiones de parada e inicio tras el reinicio provocado por SIGUSR1 o –ping-restart.
fast-io?(default:#f) (type: boolean)(Experimental) Optimiza las escrituras de E/S de TUN/TAP/UDP evitando llamar poll/epoll/select antes de la operación de escritura (
write).verbosity(default:3) (type: number)Nivel de detalle en los mensajes.
tls-auth(default:#f) (type: tls-auth-client)Añade una capa adicional de verificación HMAC sobre el canal de control TLS para protección contra ataques de denegación de servicio (DoS).
auth-user-pass(type: maybe-string)Activa la identificación con el servidor mediante el uso de usuaria/contraseña. La opción es un archivo que contiene en dos líneas el nombre de usuaria y la contraseña. No use un objeto tipo-archivo, ya que se añadiría al almacén y sería legible para cualquier usuaria.
verify-key-usage?(default:#t) (type: key-usage)Si se comprueba que el certificado del servidor tenga la extensión de uso de servidor.
bind?(default:#f) (type: bind)Asociación a un número específico de puerto local.
resolv-retry?(default:#t) (type: resolv-retry)Reintentos de resolución de la dirección del servidor.
remote(default:()) (type: openvpn-remote-list)Una lista de servidores remotos a los que conectarse.
- Data Type: openvpn-remote-configuration
Los campos disponibles de
openvpn-remote-configurationson:name(default:"my-server") (type: string)Nombre del servidor.
port(default:1194) (type: number)Puerto en el que escucha el servidor.
- Data Type: openvpn-server-configuration
Los campos disponibles de
openvpn-server-configurationson:openvpn(default:openvpn) (type: file-like)El paquete OpenVPN.
pid-file(default:"/var/run/openvpn/openvpn.pid") (type: string)El archivo de pid de OpenVPN.
proto(default:udp) (type: proto)El protocolo (UDP o TCP) usado para la apertura del canal entre clientes y servidores.
dev(default:tun) (type: dev)El tipo de dispositivo usado para representar la conexión VPN.
ca(default:"/etc/openvpn/ca.crt") (type: maybe-string)La autoridad de certificación contra la que se comprueban las conexiones.
cert(default:"/etc/openvpn/client.crt") (type: maybe-string)El certificado de la máquina en la que se ejecuta el daemon. Debe estar firmado por la autoridad proporcionada en
ca.key(default:"/etc/openvpn/client.key") (type: maybe-string)La clave de la máquina en la que se ejecuta el daemon. Debe ser la clave cuyo certificado es
cert.comp-lzo?(default:#t) (type: boolean)Determina si se usa el algoritmo de compresión lzo.
persist-key?(default:#t) (type: boolean)No vuelve a leer los archivos de claves tras la señal SIGUSR1 o –ping-restart.
persist-tun?(default:#t) (type: boolean)No cierra y reabre el dispositivo TUN/TAP o ejecuta los guiones de parada e inicio tras el reinicio provocado por SIGUSR1 o –ping-restart.
fast-io?(default:#f) (type: boolean)(Experimental) Optimiza las escrituras de E/S de TUN/TAP/UDP evitando llamar poll/epoll/select antes de la operación de escritura (
write).verbosity(default:3) (type: number)Nivel de detalle en los mensajes.
tls-auth(default:#f) (type: tls-auth-server)Añade una capa adicional de verificación HMAC sobre el canal de control TLS para protección contra ataques de denegación de servicio (DoS).
port(default:1194) (type: number)Especifica el número de puerto en el que escucha el servidor.
server(default:"10.8.0.0 255.255.255.0") (type: ip-mask)Una IP y una máscara que especifiquen la subred dentro de la red virtual.
server-ipv6(default:#f) (type: cidr6)La especificación de una subred IPv6 dentro de la red virtual en notación CIDR.
dh(default:"/etc/openvpn/dh2048.pem") (type: string)El archivo de parámetros Diffie-Hellman.
ifconfig-pool-persist(default:"/etc/openvpn/ipp.txt") (type: string)El archivo que registra IP de clientes.
redirect-gateway?(default:#f) (type: gateway)Cuando sea verdadero, el servidor actuará como una pasarela para sus clientes.
client-to-client?(default:#f) (type: boolean)Cuando es verdadero, se permite la comunicación entre clientes dentro de la VPN.
keepalive(default:(10 120)) (type: keepalive)Hace que se envíen mensajes tipo-ping en ambas direcciones a través del enlace de modo que cada extremo conozca si el otro extremo no está disponible.
keepalivenecesita un par. El primer elemento es el periodo de envío de ping, y el segundo elemento es el plazo máximo antes de considerar que el otro extremo no está disponible.max-clients(default:100) (type: number)Número máximo de clientes.
status(default:"/var/run/openvpn/status") (type: string)El archivo de estado. Este archivo muestra un pequeño informe sobre la conexión actual. Su contenido se borra y se reescribe cada minuto.
client-config-dir(default:()) (type: openvpn-ccd-list)Lista de configuración para algunos clientes.
strongSwan
Currently, the strongSwan service only provides legacy-style configuration with ipsec.conf and ipsec.secrets files.
- Scheme Variable: strongswan-service-type
A service type for configuring strongSwan for IPsec VPN (Virtual Private Networking). Its value must be a
strongswan-configurationrecord as in this example:(service strongswan-service-type (strongswan-configuration (ipsec-conf "/etc/ipsec.conf") (ipsec-secrets "/etc/ipsec.secrets")))
- Data Type: strongswan-configuration
Data type representing the configuration of the StrongSwan service.
strongswanThe strongSwan package to use for this service.
ipsec-conf(default:#f)The file name of your ipsec.conf. If not
#f, then this andipsec-secretsmust both be strings.ipsec-secrets(default#f)The file name of your ipsec.secrets. If not
#f, then this andipsec-confmust both be strings.
Wireguard
- Scheme Variable: wireguard-service-type
A service type for a Wireguard tunnel interface. Its value must be a
wireguard-configurationrecord as in this example:(service wireguard-service-type (wireguard-configuration (peers (list (wireguard-peer (name "my-peer") (endpoint "my.wireguard.com:51820") (public-key "hzpKg9X1yqu1axN6iJp0mWf6BZGo8m1wteKwtTmDGF4=") (allowed-ips '("10.0.0.2/32")))))))
- Data Type: wireguard-configuration
Data type representing the configuration of the Wireguard service.
wireguardThe wireguard package to use for this service.
interface(default:"wg0")The interface name for the VPN.
addresses(default:'("10.0.0.1/32"))The IP addresses to be assigned to the above interface.
port(default:51820)The port on which to listen for incoming connections.
dns(default:#f)The DNS server(s) to announce to VPN clients via DHCP.
private-key(default:"/etc/wireguard/private.key")The private key file for the interface. It is automatically generated if the file does not exist.
peers(default:'())The authorized peers on this interface. This is a list of wireguard-peer records.
pre-up(default:'())The script commands to be run before setting up the interface.
post-up(default:'())The script commands to be run after setting up the interface.
pre-down(default:'())The script commands to be run before tearing down the interface.
post-down(default:'())The script commands to be run after tearing down the interface.
table(default:"auto")The routing table to which routes are added, as a string. There are two special values:
"off"that disables the creation of routes altogether, and"auto"(the default) that adds routes to the default table and enables special handling of default routes.
- Data Type: wireguard-peer
Data type representing a Wireguard peer attached to a given interface.
nameThe peer name.
endpoint(default:#f)The optional endpoint for the peer, such as
"demo.wireguard.com:51820".public-keyThe peer public-key represented as a base64 string.
allowed-ipsA list of IP addresses from which incoming traffic for this peer is allowed and to which incoming traffic for this peer is directed.
keep-alive(default:#f)An optional time interval in seconds. A packet will be sent to the server endpoint once per time interval. This helps receiving incoming connections from this peer when you are behind a NAT or a firewall.
Next: Samba Services, Previous: Servicios VPN, Up: Servicios [Contents][Index]
12.9.24 Sistema de archivos en red
El módulo (gnu services nfs) proporciona los siguientes servicios,
que se usan habitualmente en relación con el montado o la exportación de
árboles de directorios como sistemas de archivos en red (NFS).
Mientras que es posible usar los componentes individuales de forma conjunta
para proporcionar un servicio del sistema de archivos en red NFS,
recomendamos la configuración de un servidor NFS mediante
nfs-service-type.
Servicio NFS
El servicio NFS se hace cargo de configurar todos los servicios de componentes de NFS, la configuración del núcleo de sistemas de archivos e instala los archivos de configuración en las rutas que NFS espera.
- Variable Scheme: nfs-service-type
Este es el tipo de datos para un servidor NFS completo.
- Tipo de datos: nfs-configuration
Este tipo de datos representa la configuración del servicio NFS y todos sus subsistemas.
Tiene los siguientes parámetros:
nfs-utils(predeterminado:nfs-utils)El paquete nfs-utils usado.
nfs-versions(predeterminadas:'("4.2" "4.1" "4.0"))Si se proporciona como valor una lista de cadenas, el daemon
rpc.nfsdse limitará a la implementación de las versiones del protocolo NFS proporcionadas.exports(predeterminada:'())Una lista de directorios que el servidor NFS debe exportar. Cada entrada es una lista que consiste en dos elementos: un nombre de directorio y una cadena que contiene todas las opciones. Este es un ejemplo en el que el directorio /exportado se proporciona a todos los clientes NFS en modo de solo-lectura:
(nfs-configuration (exports '(("/exportado" "*(ro,insecure,no_subtree_check,crossmnt,fsid=0)"))))rpcmountd-port(predeterminado:#f)El puerto de red que el daemon
rpc.mountddebe usar.rpcstatd-port(predeterminado:#f)El puerto de red que el daemon
rpc.statddebe usar.rpcbind(predeterminado:rpcbind)El paquete rpcbind usado.
idmap-domain(predeterminado:"localdomain")El nombre de dominio local de NFSv4.
nfsd-port(predeterminado:2049)El puerto de red que el daemon
nfsddebe usar.nfsd-threads(predeterminado:8)Número de hilos usados en el daemon
nfsd.nfsd-tcp?(predeterminado:#t)Determina si el daemon
nfsddebe escuchar en un puerto TCP.nfsd-udp?(predeterminado:#f)Determina si el daemon
nfsddebe escuchar en un puerto UDP.pipefs-directory(predeterminado:"/var/lib/nfs/rpc_pipefs")El directorio donde el sistema de archivos pipefs debe montarse.
debug(predeterminada:'()")Una lista de subsistemas para los cuales debe activarse la salida de depuración. Es una lista de símbolos. Cualquiera de estos símbolos son válidos:
nfsd,nfs,rpc,idmap,statdomountd.
Si no necesita un servicio NFS completo o prefiere construirlo por su cuenta puede usar los componentes individuales que se documentan a continuación.
Servicio RPC Bind
El servicio RPC Bind proporciona una forma de asociar números de programa con direcciones universales. Muchos servicios relacionados con NFS usan esta característica. De ahí que se inicie automáticamente cuando un servicio dependiente se inicia.
- Variable Scheme: rpcbind-service-type
Un tipo de servicio para el daemon de asignación de puertos RPC.
- Tipo de datos: rpcbind-configuration
Tipo de datos que representa la configuración del servicio RPC Bind. Este tipo tiene los siguientes parámetros:
rpcbind(predeterminado:rpcbind)El paquete rpcbind usado.
warm-start?(predeterminado:#t)Si este parámetro es
#t, el daemon leerá el archivo de estado durante el arranche, por tanto recargando la información del estado almacenada por la instancia previa.
Pseudo-sistema de archivos pipefs
El sistema de archivos pipefs se usa para transferir datos relacionados con NFS entre el núcleo y los programas de espacio de usuaria.
- Variable Scheme: pipefs-service-type
Un tipo de servicio para el pseudo-sistema de archivos pipefs.
- Tipo de datos: pipefs-configuration
Tipo de datos que representa la configuración del servicio del pseudo-sistema de archivos pipefs. Este tipo tiene los siguientes parámetros:
mount-point(predeterminado:"/var/lib/nfs/rpc_pipefs")El directorio al que se debe asociar el sistema de archivos.
Servicio del daemon GSS
El daemon sistema de seguridad global (GSS) proporciona fuertes
garantías de seguridad para protocolos basados en RPC. Antes de intercambiar
peticiones RPC el cliente debe establecer un contexto de
seguridad. Habitualmente esto se lleva a cabo con el uso de la orden
kinito automáticamente durante el ingreso al sistema mediante el
uso de servicios PAM (see Servicios Kerberos).
- Variable Scheme: gss-service-type
Un tipo de servicio para el daemon del sistema de seguridad global (GSS).
- Tipo de datos: gss-configuration
Tipo de datos que representa la configuración del servicio del daemon GSS. Este tipo tiene los siguientes parámetros:
nfs-utils(predeterminado:nfs-utils)Paquete en el que se encuentra la orden
rpc.gssd.pipefs-directory(predeterminado:"/var/lib/nfs/rpc_pipefs")El directorio donde el sistema de archivos pipefs debe montarse.
Servicio del daemon IDMAP
El servicio del daemon idmap proporciona una asociación entre identificadores de usuaria y nombres de usuaria. Habitualmente es necesario para acceder sistemas de archivos montados con NFSv4.
- Variable Scheme: idmap-service-type
Un tipo de servicio para el daemon de asociación de identidades (IDMAP).
- Tipo de datos: idmap-configuration
Tipo de datos que representa la configuración del servicio del daemon IDMAP. Este tipo tiene los siguientes parámetros:
nfs-utils(predeterminado:nfs-utils)Paquete en el que se encuentra la orden
rpc.idmapd.pipefs-directory(predeterminado:"/var/lib/nfs/rpc_pipefs")El directorio donde el sistema de archivos pipefs debe montarse.
domain(predeterminado:#f)El nombre de dominio local de NFSv4. Debe ser una cadena o
#f. Si es#fel daemon usará el nombre de dominio totalmente cualificado de la máquina.verbosity(predeterminado:0)El nivel de información de los mensajes del daemon.
Next: Integración continua, Previous: Sistema de archivos en red, Up: Servicios [Contents][Index]
12.9.25 Samba Services
The (gnu services samba) module provides service definitions for
Samba as well as additional helper services. Currently it provides the
following services.
Samba
Samba provides network shares for folders and printers using the SMB/CIFS protocol commonly used on Windows. It can also act as an Active Directory Domain Controller (AD DC) for other hosts in an heterougenious network with different types of Computer systems.
- Variable: Scheme variable samba-service-type
-
The service type to enable the samba services
samba,nmbd,smbdandwinbindd. By default this service type does not run any of the Samba daemons; they must be enabled individually.Below is a basic example that configures a simple, anonymous (unauthenticated) Samba file share exposing the /public directory.
Tip: The /public directory and its contents must be world readable/writable, so you’ll want to run ‘chmod -R 777 /public’ on it.
Caution: Such a Samba configuration should only be used in controlled environments, and you should not share any private files using it, as anyone connecting to your network would be able to access them.
(service samba-service-type (samba-configuration (enable-smbd? #t) (config-file (plain-file "smb.conf" "\ [global] map to guest = Bad User logging = syslog@1 [public] browsable = yes path = /public read only = no guest ok = yes guest only = yes\n"))))
- Data Type: samba-service-configuration Configuration record for the
Samba suite.
package(default:samba)The samba package to use.
config-file(predeterminado:#f)The config file to use. To learn about its syntax, run ‘man smb.conf’.
enable-samba?(default:#f)Enable the
sambadaemon.enable-smbd?(default:#f)Enable the
smbddaemon.enable-nmbd?(default:#f)Enable the
nmbddaemon.enable-winbindd?(default:#f)Enable the
winbindddaemon.
Web Service Discovery Daemon
The WSDD (Web Service Discovery daemon) implements the Web Services Dynamic Discovery protocol that enables host discovery over Multicast DNS, similar to what Avahi does. It is a drop-in replacement for SMB hosts that have had SMBv1 disabled for security reasons.
- Scheme Variable: wsdd-service-type
Service type for the WSD host daemon. The value for this service type is a
wsdd-configurationrecord. The details for thewsdd-configurationrecord type are given below.
- Data Type: wsdd-configuration
This data type represents the configuration for the wsdd service.
package(default:wsdd)The wsdd package to use.
ipv4only?(default:#f)Only listen to IPv4 addresses.
ipv6only(default:#f)Only listen to IPv6 addresses. Please note: Activating both options is not possible, since there would be no IP versions to listen to.
chroot(predeterminado:#f)Chroot into a separate directory to prevent access to other directories. This is to increase security in case there is a vulnerability in
wsdd.hop-limit(default:1)Limit to the level of hops for multicast packets. The default is 1 which should prevent packets from leaving the local network.
interface(default:'())Limit to the given list of interfaces to listen to. By default wsdd will listen to all interfaces. Except the loopback interface is never used.
uuid-device(default:#f)The WSD protocol requires a device to have a UUID. Set this to manually assign the service a UUID.
domain(predeterminado:#f)Notify this host is a member of an Active Directory.
host-name(predeterminado:#f)Manually set the hostname rather than letting
wsddinherit this host’s hostname. Only the host name part of a possible FQDN will be used in the default case.preserve-case?(default:#f)By default
wsddwill convert the hostname in workgroup to all uppercase. The opposite is true for hostnames in domains. Setting this parameter will preserve case.workgroup(default: "WORKGROUP")Change the name of the workgroup. By default
wsddreports this host being member of a workgroup.
Next: Servicios de gestión de energía, Previous: Samba Services, Up: Servicios [Contents][Index]
12.9.26 Integración continua
Cuirass is a continuous integration tool for Guix. It can be used both for development and for providing substitutes to others (see Sustituciones).
El módulo (gnu services cuirass) proporciona el siguiente servicio.
- Procedimiento Scheme: cuirass-service-type
El tipo del servicio Cuirass. Su valor debe ser un objeto
cuirass-configuration, como se describe a continuación.
To add build jobs, you have to set the specifications field of the
configuration. For instance, the following example will build all the
packages provided by the my-channel channel.
(define %cuirass-specs #~(list (specification (name "my-channel") (build '(channels my-channel)) (channels (cons (channel (name 'my-channel) (url "https://my-channel.git")) %default-channels))))) (service cuirass-service-type (cuirass-configuration (specifications %especificacion-de-cuirass)))
To build the linux-libre package defined by the default Guix channel,
one can use the following configuration.
(define %cuirass-specs #~(list (specification (name "my-linux") (build '(packages "linux-libre"))))) (service cuirass-service-type (cuirass-configuration (specifications %especificacion-de-cuirass)))
The other configuration possibilities, as well as the specification record itself are described in the Cuirass manual (see Specifications in Cuirass).
Mientras que la información de los trabajos de construcción se encuentra
directamente en las especificaciones, la configuración global del proceso
cuirass está accesible en otros campos de
cuirass-configuration.
- Tipo de datos: cuirass-configuration
Tipo de datos que representa la configuración de Cuirass.
cuirass(predeterminado:cuirass)El paquete Cuirass usado.
log-file(predeterminado:"/var/log/cuirass.log")Localización del archivo de registro.
web-log-file(predeterminado:"/var/log/cuirass-web.log")Localización del archivo de registro usado por la interfaz web.
cache-directory(predeterminado:"/var/cache/cuirass")Localización de la caché del repositorio.
user(predeterminado:"cuirass")Propietaria del proceso
cuirass.group(predeterminado:"cuirass")Grupo propietario del proceso
cuirass.interval(predeterminado:60)Número de segundos entre las consulta de repositorios seguida de los trabajos de Cuirass.
parameters(default:#f)Read parameters from the given parameters file. The supported parameters are described here (see Parameters in Cuirass).
remote-server(default:#f)A
cuirass-remote-server-configurationrecord to use the build remote mechanism or#fto use the default build mechanism.database(default:"dbname=cuirass host=/var/run/postgresql")Use database as the database containing the jobs and the past build results. Since Cuirass uses PostgreSQL as a database engine, database must be a string such as
"dbname=cuirass host=localhost".port(predeterminado:8081)Número de puerto usado por el servidor HTTP.
host(predeterminado:"localhost")Escucha en la interfaz de red de la dirección host. El comportamiento predeterminado es aceptar conexiones desde la red local.
specifications(predeterminada:#~'())A gexp (see Expresiones-G) that evaluates to a list of specifications records. The specification record is described in the Cuirass manual (see Specifications in Cuirass).
use-substitutes?(predeterminado:#f)Permite el uso de sustituciones para evitar la construcción desde las fuentes de todas las dependencias de un trabajo.
one-shot?(predeterminado:#f)Evalúa las especificaciones y construye las derivaciones solo una vez.
fallback?(predeterminado:#f)Cuando la sustitución de un binario preconstruido falle, se intentará la construcción local de los paquetes.
extra-options(predeterminadas:'())Opciones adicionales proporcionadas a los procesos de Cuirass.
Cuirass remote building
Cuirass supports two mechanisms to build derivations.
- Using the local Guix daemon. This is the default build mechanism. Once the build jobs are evaluated, they are sent to the local Guix daemon. Cuirass then listens to the Guix daemon output to detect the various build events.
- Using the remote build mechanism. The build jobs are not submitted to the local Guix daemon. Instead, a remote server dispatches build requests to the connect remote workers, according to the build priorities.
To enable this build mode a cuirass-remote-server-configuration
record must be passed as remote-server argument of the
cuirass-configuration record. The
cuirass-remote-server-configuration record is described below.
This build mode scales way better than the default build mode. This is the build mode that is used on the GNU Guix build farm at https://ci.guix.gnu.org. It should be preferred when using Cuirass to build large amount of packages.
- Data Type: cuirass-remote-server-configuration
Data type representing the configuration of the Cuirass remote-server.
backend-port(default:5555)The TCP port for communicating with
remote-workerprocesses using ZMQ. It defaults to5555.log-port(default:5556)The TCP port of the log server. It defaults to
5556.publish-port(default:5557)The TCP port of the publish server. It defaults to
5557.log-file(default:"/var/log/cuirass-remote-server.log")Localización del archivo de registro.
cache(default:"/var/cache/cuirass/remote")Use cache directory to cache build log files.
trigger-url(default:#f)Once a substitute is successfully fetched, trigger substitute baking at trigger-url.
publish?(predeterminado:#t)If set to false, do not start a publish server and ignore the
publish-portargument. This can be useful if there is already a standalone publish server standing next to the remote server.public-keyprivate-keyUsa los archivos específicos como el par de claves pública y privada usadas para firmar los elementos del almacén publicados.
At least one remote worker must also be started on any machine of the local network to actually perform the builds and report their status.
- Data Type: cuirass-remote-worker-configuration
Data type representing the configuration of the Cuirass remote-worker.
cuirass(predeterminado:cuirass)El paquete Cuirass usado.
workers(default:1)Start workers parallel workers.
server(predeterminada:#f)Do not use Avahi discovery and connect to the given
serverIP address instead.systems(default:(list (%current-system)))Only request builds for the given systems.
log-file(default:"/var/log/cuirass-remote-worker.log")Localización del archivo de registro.
publish-port(default:5558)The TCP port of the publish server. It defaults to
5558.substitute-urls(predeterminado:%default-substitute-urls)La lista de URLs donde se buscarán sustituciones por defecto.
public-keyprivate-keyUsa los archivos específicos como el par de claves pública y privada usadas para firmar los elementos del almacén publicados.
Laminar
Laminar is a lightweight and modular Continuous Integration service. It doesn’t have a configuration web UI instead uses version-controllable configuration files and scripts.
Laminar encourages the use of existing tools such as bash and cron instead of reinventing them.
- Scheme Procedure: laminar-service-type
The type of the Laminar service. Its value must be a
laminar-configurationobject, as described below.All configuration values have defaults, a minimal configuration to get Laminar running is shown below. By default, the web interface is available on port 8080.
- Data Type: laminar-configuration
Data type representing the configuration of Laminar.
laminar(default:laminar)The Laminar package to use.
home-directory(default:"/var/lib/laminar")The directory for job configurations and run directories.
bind-http(default:"*:8080")The interface/port or unix socket on which laminard should listen for incoming connections to the web frontend.
bind-rpc(default:"unix-abstract:laminar")The interface/port or unix socket on which laminard should listen for incoming commands such as build triggers.
title(default:"Laminar")The page title to show in the web frontend.
keep-rundirs(default:0)Set to an integer defining how many rundirs to keep per job. The lowest-numbered ones will be deleted. The default is 0, meaning all run dirs will be immediately deleted.
archive-url(default:#f)The web frontend served by laminard will use this URL to form links to artefacts archived jobs.
base-url(default:#f)Base URL to use for links to laminar itself.
Next: Servicios de audio, Previous: Integración continua, Up: Servicios [Contents][Index]
12.9.27 Servicios de gestión de energía
Daemon TLP
El módulo (gnu services pm) proporciona una definición de servicio
Guix para la herramienta de gestión de energía de Linux TLP.
TLP activa varios modos de ahorro de energía en el núcleo y en espacio de
usuaria. Al contrario que upower-service, no es una herramienta de
monitorización pasiva, puesto que aplicará una nueva configuración
personalizada cada vez que se detecte una nueva fuente de
energía/alimentación. Puede encontrar más información en
la página de TLP.
- Variable Scheme: tlp-service-type
EL tipo de servicio para la herramienta TLP. La configuración predeterminada está optimizada para la vida de la batería en la mayoría de los sistemas, pero puede modificarla al completo con las opciones que desee proporcionando un objeto
tlp-configurationválido:(service tlp-service-type (tlp-configuration (cpu-scaling-governor-on-ac (list "performance")) (sched-powersave-on-bat? #t)))
Each parameter definition is preceded by its type; for example,
‘boolean foo’ indicates that the foo parameter should be
specified as a boolean. Types starting with maybe- denote parameters
that won’t show up in TLP config file when their value is left unset, or is
explicitly set to the %unset-value value.
Los campos disponibles de tlp-configuration son:
- parámetro de
tlp-configuration: package tlp ¶ El paquete TLP.
- parámetro de
tlp-configuration: boolean tlp-enable? ¶ Proporcione un valor verdadero si desea activar TLP.
El valor predeterminado es ‘#t’
- parámetro de
tlp-configuration: string tlp-default-mode ¶ Modo predeterminado cuando no se puede detectar una fuente de alimentación. Las alternativas son AC (corriente alterna) y BAT (batería).
El valor predeterminado es ‘"AC"’ (corriente alterna).
- parámetro de
tlp-configuration: entero-no-negativo disk-idle-secs-on-ac ¶ Número de segundos que el núcleo Linux debe esperar desde que el disco se queda en espera, antes de sincronizar en corriente alterna (AC).
El valor predeterminado es ‘0’.
- parámetro de
tlp-configuration: entero-no-negativo disk-idle-secs-on-bat ¶ Igual que
disk-idle-acpero en modo BAT (batería).El valor predeterminado es ‘2’.
- parámetro de
tlp-configuration: entero-no-negativo max-lost-work-secs-on-ac ¶ Periodicidad de la evacuación de las páginas sucias, expresada en segundos.
El valor predeterminado es ‘15’.
- parámetro de
tlp-configuration: entero-no-negativo max-lost-work-secs-on-bat ¶ Igual que
max-lost-work-secs-on-acpero en modo BAT (batería).El valor predeterminado es ‘60’.
- parámetro de
tlp-configuration: maybe-lista-cadena-separada-espacios cpu-scaling-governor-on-ac ¶ Gobernador de escalado de frecuencia del procesador en modo de corriente alterna (AC). Con el controlador intel_pstate, las alternativas son “powersave” (ahorro de energía) y “performance” (rendimiento). Con el controlador acpi-cpufreq, las alternativas son “ondemand” (bajo demanda), “powersave”, “performance” y “conservative” (conservativo).
El valor predeterminado es ‘disabled’.
- parámetro de
tlp-configuration: maybe-lista-cadena-separada-espacios cpu-scaling-governor-on-bat ¶ Igual que
max-lost-work-secs-on-acpero en modo BAT (batería).El valor predeterminado es ‘disabled’.
- parámetro de
tlp-configuration: maybe-entero-no-negativo cpu-scaling-min-freq-on-ac ¶ Establece la frecuencia mínima disponible para el controlador de escalado en AC.
El valor predeterminado es ‘disabled’.
- parámetro de
tlp-configuration: maybe-entero-no-negativo cpu-scaling-max-freq-on-ac ¶ Establece la frecuencia máxima disponible para el controlador de escalado en AC.
El valor predeterminado es ‘disabled’.
- parámetro de
tlp-configuration: maybe-entero-no-negativo cpu-scaling-min-freq-on-bat ¶ Establece la frecuencia mínima disponible para el controlador de escalado en BAT.
El valor predeterminado es ‘disabled’.
- parámetro de
tlp-configuration: maybe-entero-no-negativo cpu-scaling-max-freq-on-bat ¶ Establece la frecuencia máxima disponible para el controlador de escalado en BAT.
El valor predeterminado es ‘disabled’.
- parámetro de
tlp-configuration: maybe-entero-no-negativo cpu-min-perf-on-ac ¶ Limita el estado-P mínimo para controlar la disipación de potencia del procesador en modo AC. Los valores se indican como un porcentaje de rendimiento disponible.
El valor predeterminado es ‘disabled’.
- parámetro de
tlp-configuration: maybe-entero-no-negativo cpu-max-perf-on-ac ¶ Limita el estado-P máximo para controlar la disipación de potencia del procesador en modo AC. Los valores se indican como un porcentaje de rendimiento disponible.
El valor predeterminado es ‘disabled’.
- parámetro de
tlp-configuration: maybe-entero-no-negativo cpu-min-perf-on-bat ¶ Igual que
cpu-min-perf-on-acpero en modo BAT (batería).El valor predeterminado es ‘disabled’.
- parámetro de
tlp-configuration: maybe-entero-no-negativo cpu-max-perf-on-bat ¶ Igual que
cpu-max-perf-on-acpero en modo BAT (batería).El valor predeterminado es ‘disabled’.
- parámetro de
tlp-configuration: maybe-boolean cpu-boost-on-ac? ¶ Activa la característica “turbo boost” del procesador en modo AC (corriente alterna).
El valor predeterminado es ‘disabled’.
- parámetro de
tlp-configuration: maybe-boolean cpu-boost-on-bat? ¶ Igual que
cpu-boost-on-acpero en modo BAT (batería).El valor predeterminado es ‘disabled’.
- parámetro de
tlp-configuration: boolean sched-powersave-on-ac? ¶ Permite al núcleo Linux minimizar el número de núcleos/hyper-thread del procesador usados bajo condiciones de baja carga.
El valor predeterminado es ‘#f’
- parámetro de
tlp-configuration: boolean sched-powersave-on-bat? ¶ Igual que
sched-powersave-on-ac?pero en modo BAT (batería).El valor predeterminado es ‘#t’
- parámetro de
tlp-configuration: boolean nmi-watchdog? ¶ Activa el proceso guardián (watchdog) NMI del núcleo Linux.
El valor predeterminado es ‘#f’
- parámetro de
tlp-configuration: maybe-string phc-controls ¶ Para núcleos Linux con el parche PHC aplicado, cambia los voltajes del procesador. Un valor de ejemplo sería ‘"F:V F:V F:V F:V"’.
El valor predeterminado es ‘disabled’.
- parámetro de
tlp-configuration: string energy-perf-policy-on-ac ¶ Set CPU performance versus energy saving policy on AC. Alternatives are performance, normal, powersave.
El valor predeterminado es ‘"performance"’.
- parámetro de
tlp-configuration: string energy-perf-policy-on-bat ¶ Igual que
energy-perf-policy-acpero en modo BAT (batería).El valor predeterminado es ‘"powersave"’.
- parámetro de
tlp-configuration: lista-cadena-separada-espacios disks-devices ¶ Dispositivos de disco duro.
- parámetro de
tlp-configuration: lista-cadena-separada-espacios disk-apm-level-on-ac ¶ Nivel de APM (gestión avanzada de energía) del disco duro.
- parámetro de
tlp-configuration: lista-cadena-separada-espacios disk-apm-level-on-bat ¶ Igual que
disk-apm-batpero en modo BAT (batería).
- parámetro de
tlp-configuration: maybe-lista-cadena-separada-espacios disk-spindown-timeout-on-ac ¶ Plazo para la parada rotacional del disco duro. Se debe especificar un valor por cada disco duro declarado.
El valor predeterminado es ‘disabled’.
- parámetro de
tlp-configuration: maybe-lista-cadena-separada-espacios disk-spindown-timeout-on-bat ¶ Igual que
disk-spindown-timeout-on-acpero en modo BAT (batería).El valor predeterminado es ‘disabled’.
- parámetro de
tlp-configuration: maybe-lista-cadena-separada-espacios disk-iosched ¶ Selecciona el planificador de E/S para dispositivos de disco. Se debe especificar un valor por cada disco duro declarado. Ejemplos de alternativas son “cfq”, “deadline” y “noop”.
El valor predeterminado es ‘disabled’.
- parámetro de
tlp-configuration: string sata-linkpwr-on-ac ¶ Nivel de gestión agresiva de energía del enlace (ALPM) de SATA. Las alternativas son “min_power” (energía mínima), “medium_power” (energía media) y “max_performance” (máximo rendimiento).
El valor predeterminado es ‘"max_performance"’.
- parámetro de
tlp-configuration: string sata-linkpwr-on-bat ¶ Igual que
sata-linkpwr-acpero en modo BAT (batería).El valor predeterminado es ‘"min_power"’.
- parámetro de
tlp-configuration: maybe-string sata-linkpwr-blacklist ¶ Excluye los dispositivos SATA especificados de la gestión de energía del enlace.
El valor predeterminado es ‘disabled’.
- parámetro de
tlp-configuration: maybe-on-off-boolean ahci-runtime-pm-on-ac? ¶ Activa la gestión de energía de tiempo de ejecución para controladores AHCI y discos en modo AC.
El valor predeterminado es ‘disabled’.
- parámetro de
tlp-configuration: maybe-on-off-boolean ahci-runtime-pm-on-bat? ¶ Igual que
ahci-runtime-pm-on-acpero en modo BAT (batería).El valor predeterminado es ‘disabled’.
- parámetro de
tlp-configuration: entero-no-negativo ahci-runtime-pm-timeout ¶ Segundos de inactividad antes de suspender el disco.
El valor predeterminado es ‘15’.
- parámetro de
tlp-configuration: string pcie-aspm-on-ac ¶ Nivel de gestión de energía de estado activo de PCI Express. Las alternativas son “default” (predeterminado), “performance” (rendimiento) y “powersave” (ahorro de energía).
El valor predeterminado es ‘"performance"’.
- parámetro de
tlp-configuration: string pcie-aspm-on-bat ¶ Igual que
pcie-aspm-acpero en modo BAT (batería).El valor predeterminado es ‘"powersave"’.
tlp-configurationparameter: maybe-non-negative-integer start-charge-thresh-bat0 ¶Percentage when battery 0 should begin charging. Only supported on some laptops.
El valor predeterminado es ‘disabled’.
tlp-configurationparameter: maybe-non-negative-integer stop-charge-thresh-bat0 ¶Percentage when battery 0 should stop charging. Only supported on some laptops.
El valor predeterminado es ‘disabled’.
tlp-configurationparameter: maybe-non-negative-integer start-charge-thresh-bat1 ¶Percentage when battery 1 should begin charging. Only supported on some laptops.
El valor predeterminado es ‘disabled’.
tlp-configurationparameter: maybe-non-negative-integer stop-charge-thresh-bat1 ¶Percentage when battery 1 should stop charging. Only supported on some laptops.
El valor predeterminado es ‘disabled’.
- parámetro de
tlp-configuration: string radeon-power-profile-on-ac ¶ Nivel de velocidad de reloj de gráficos Radeon. Las alternativas son “low” (bajo), “mid” (medio), “high” (alto), “auto” (automático) y “default” (predeterminado).
El valor predeterminado es ‘"high"’.
- parámetro de
tlp-configuration: string radeon-power-profile-on-bat ¶ Igual que
radeon-power-acpero en modo BAT (batería).El valor predeterminado es ‘"low"’.
- parámetro de
tlp-configuration: string radeon-dpm-state-on-ac ¶ Método de gestión de energía dinámica (DPM) de Radeon. Las alternativas son “battery” (batería) y “performance” (rendimiento).
El valor predeterminado es ‘"performance"’.
- parámetro de
tlp-configuration: string radeon-dpm-state-on-bat ¶ Igual que
radeon-dpm-state-acpero en modo BAT (batería).El valor predeterminado es ‘"battery"’.
- parámetro de
tlp-configuration: string radeon-dpm-perf-level-on-ac ¶ Nivel de rendimiento del DPM de Radeon. Las alternativas son “auto” (automático), “low” (bajo) y “high” (alto).
El valor predeterminado es ‘"auto"’.
- parámetro de
tlp-configuration: string radeon-dpm-perf-level-on-bat ¶ Igual que
radeon-dpm-perf-acpero en modo BAT (batería).El valor predeterminado es ‘"auto"’.
- parámetro de
tlp-configuration: on-off-boolean wifi-pwr-on-ac? ¶ Modo de ahorro de energía de Wifi.
El valor predeterminado es ‘#f’
- parámetro de
tlp-configuration: on-off-boolean wifi-pwr-on-bat? ¶ Igual que
wifi-power-ac?pero en modo BAT (batería).El valor predeterminado es ‘#t’
- parámetro de
tlp-configuration: y-n-boolean wol-disable? ¶ Desactiva el encendido desde la red local (wake on LAN).
El valor predeterminado es ‘#t’
- parámetro de
tlp-configuration: entero-no-negativo sound-power-save-on-ac ¶ Duración en segundos del plazo antes de activar el ahorro de energía de audio en dispositivos Intel HDA y AC97. El valor 0 desactiva el ahorro de energía.
El valor predeterminado es ‘0’.
- parámetro de
tlp-configuration: entero-no-negativo sound-power-save-on-bat ¶ Igual que
sound-powersave-acpero en modo BAT (batería).El valor predeterminado es ‘1’.
- parámetro de
tlp-configuration: y-n-boolean sound-power-save-controller? ¶ Desactiva el controlador en modo de ahorro de energía en dispositivos Intel HDA.
El valor predeterminado es ‘#t’
- parámetro de
tlp-configuration: boolean bay-poweroff-on-bat? ¶ Activa las unidades ópticas en UltraBay/MediaBay en modo BAT. La unidad puede volver a alimentarse liberando (y reinsertando) la palanca de eyección o presionando el botón de eyección de disco en modelos más modernos.
El valor predeterminado es ‘#f’
- parámetro de
tlp-configuration: string bay-device ¶ Nombre de la unidad de dispositivos ópticos a apagar.
El valor predeterminado es ‘"sr0"’.
- parámetro de
tlp-configuration: string runtime-pm-on-ac ¶ Gestión de energía en tiempo de ejecución para dispositivos de bus PCI(e). Las alternativas son “on” y “auto”.
El valor predeterminado es ‘"on"’.
- parámetro de
tlp-configuration: string runtime-pm-on-bat ¶ Igual que
runtime-pm-acpero en modo BAT (batería).El valor predeterminado es ‘"auto"’.
- parámetro de
tlp-configuration: boolean runtime-pm-all? ¶ Gestión de energía en tiempo de ejecución (Runtime Power Management) para todos los dispositivos del bus PCI(e), excepto los excluidos.
El valor predeterminado es ‘#t’
- parámetro de
tlp-configuration: maybe-lista-cadena-separada-espacios runtime-pm-blacklist ¶ Excluye las direcciones de dispositivo PCI(e) especificadas de la gestión de energía en tiempo de ejecución (Runtime Power Management).
El valor predeterminado es ‘disabled’.
- parámetro de
tlp-configuration: lista-cadena-separada-espacios runtime-pm-driver-blacklist ¶ Excluye los dispositivos PCI(e) asignados a los controladores especificados de la gestión de energía en tiempo de ejecución (Runtime Power Management).
- parámetro de
tlp-configuration: boolean usb-autosuspend? ¶ Permite la suspensión automática de USB.
El valor predeterminado es ‘#t’
- parámetro de
tlp-configuration: maybe-string usb-blacklist ¶ Excluye los dispositivos especificados de la suspensión automática de USB.
El valor predeterminado es ‘disabled’.
- parámetro de
tlp-configuration: boolean usb-blacklist-wwan? ¶ Excluye los dispositivos WWAN de la suspensión automática de USB.
El valor predeterminado es ‘#t’
- parámetro de
tlp-configuration: maybe-string usb-whitelist ¶ Incluye los dispositivos especificados en la suspensión automática de USB, incluso cuando están excluidos por el controlador o a través de
usb-blacklist-wwan?.El valor predeterminado es ‘disabled’.
- parámetro de
tlp-configuration: maybe-boolean usb-autosuspend-disable-on-shutdown? ¶ Activa la suspensión automática de USB antes del apagado.
El valor predeterminado es ‘disabled’.
- parámetro de
tlp-configuration: boolean restore-device-state-on-startup? ¶ Restablece el estado de los dispositivos de radio (bluetooth, wifi, wwan) previo al apagado durante el arranque del sistema.
El valor predeterminado es ‘#f’
Daemon Thermald
El módulo (gnu services pm) proporciona una interfaz con thermald, un
servicio de escalado de frecuencia de la CPU que ayuda a prevenir el
sobrecalentamiento.
- Variable Scheme: thermald-service-type
Este es el tipo de servicio para thermald, el daemon Thermal de Linux, que es responsable del control del estado térmico de los procesadores y la prevención del sobrecalentamiento.
- Tipo de datos: thermald-configuration
Tipo de datos que representa la configuración de
thermald-service-type.adaptive?(default:#f)Use DPTF (Dynamic Power and Thermal Framework) adaptive tables when present.
ignore-cpuid-check?(predeterminado:#f)Ignora la comprobación de cpuid durante la comprobación de procesadores permitidos.
thermald(predeterminado: thermald)El objeto paquete de thermald.
Next: Servicios de virtualización, Previous: Servicios de gestión de energía, Up: Servicios [Contents][Index]
12.9.28 Servicios de audio
El módulo (gnu services audio) proporciona un servicio para iniciar
MPD (el daemon de reproducción de música).
Daemon de reproducción de música (MPD)
El daemon de reproducción de música (MPD) es un servicio que puede reproducir música mientras se controla desde la máquina local o sobre una red por una multitud de clientes.
El siguiente ejemplo muestra como se puede ejecutar mpd como
"rober" en el puerto 6666. Usa pulseaudio para su salida.
(service mpd-service-type
(mpd-configuration
(user "rober")
(port "6666")))
- Variable Scheme: mpd-service-type
El tipo de servicio para
mpd.
- Tipo de datos: mpd-configuration
Tipo de datos que representa la configuración de
mpd.user(predeterminada:"mpd")Usuaria que ejecuta mpd.
music-dir(predeterminado:"~/Music")El directorio para buscar archivos de música.
playlist-dir(predeterminado:"~/.mpd/playlists")El directorio para almacenar listas de reproducción.
db-file(predeterminado:"~/.mpd/tag_cache")La localización de la base de datos de música.
state-file(predeterminado:"~/.mpd/state")La localización del archivo que almacena el estado actual de MPD.
sticker-file(predeterminado:"~/.mpd/sticker.sql")La localización de la base de datos de pegatinas.
port(predeterminado:"6600")Puerto sobre el que se ejecuta mpd.
address(predeterminada:"any")Dirección a la que mpd se asociará. Para usar un socket de dominio de Unix puede especificarse una ruta absoluta.
outputs(predeterminadas:"(list (mpd-output))")Las salidas de audio que MPD puede usar. De manera predeterminada es una salida de audio única usando pulseaudio.
- Tipo de datos: mpd-output
Tipo de datos que representa una salida de audio de
mpd.name(predeterminado:"MPD")Nombre de la salida de audio.
type(predeterminado:"pulse")Tipo de la salida de audio.
enabled?(predeterminado:#t)Especifica si esta salida de audio se activa cuando se inicia MPD. De manera predeterminada se activan todas las salidas de audio. Esta es la configuración predeterminada cuando no existe un archivo de estado; con un archivo de estado se restaura el estado anterior.
tags?(predeterminado:#t)Si se proporciona el valor
#fMPD no envia etiquetas a esta salida. Es útil únicamente para módulos de salida que pueden recibir etiquetas, por ejemplo el módulo de salidahttpd.always-on?(predeterminado:#f)If set to
#t, then MPD attempts to keep this audio output always open. This may be useful for streaming servers, when you don’t want to disconnect all listeners even when playback is accidentally stopped.mixer-typeEste campo acepta un símbolo que especifica que mezclador debe usarse para esta salida de audio: el mezclador
hardware, el mezcladorsoftware, el mezcladornull(permite manejar el volumen pero sin ningún efecto; puede usarse para implementar un mezclador externo) o ningún mezclador (none).extra-options(predeterminadas:'())Una lista asociativa de símbolos de opción con valores de cadenas que se añadirán al final de la configuración de las salidas de audio.
El ejemplo siguiente muestra una configuración de mpd que proporciona
una salida de retransmisión de audio por HTTP.
(service mpd-service-type
(mpd-configuration
(outputs
(list (mpd-output
(name "streaming")
(type "httpd")
(mixer-type 'null)
(extra-options
`((encoder . "vorbis")
(port . "8080"))))))))
Next: Servicios de control de versiones, Previous: Servicios de audio, Up: Servicios [Contents][Index]
12.9.29 Servicios de virtualización
El módulo (gnu services virtualization) proporciona servicios para
los daemon libvirt y virtlog, así como otros servicios relacionados con la
virtualización.
Daemon de Libvirt
libvirtd is the server side daemon component of the libvirt
virtualization management system. This daemon runs on host servers and
performs required management tasks for virtualized guests.
- Variable Scheme: libvirt-service-type
Este es el tipo para el daemon de libvirt. Su valor debe ser un objeto
libvirt-configuration.(service libvirt-service-type (libvirt-configuration (unix-sock-group "libvirt") (tls-port "16555")))
Los campos disponibles de libvirt-configuration son:
- parámetro de
libvirt-configuration: package libvirt ¶ Paquete libvirt.
- parámetro de
libvirt-configuration: boolean listen-tls? ¶ Opción para la escucha de conexiones seguras TLS en el puerto TCP/IP público. Debe haberse proporcionado valor a
listenpara que tenga algún efecto.Es necesario configurar una autoridad de certificación (CA) y emitir certificados de servidor antes de usar esta característica.
El valor predeterminado es ‘#t’
- parámetro de
libvirt-configuration: boolean listen-tcp? ¶ Escucha de conexiones TCP sin cifrar en el puerto TCP/IP público. Debe haberse proporcionado valor a
listenpara que tenga algún efecto.El uso del socket TCP necesita de manera predeterminada identificación SASL. Únicamente se permiten mecanismos SASL que implementen cifrado de datos. Estos son DIGEST_MD5 y GSSAPI (Kerberos5).
El valor predeterminado es ‘#f’
- parámetro de
libvirt-configuration: string tls-port ¶ Puerto en el que se aceptan conexiones seguras. Puede ser un número de puerto o un nombre de servicio.
El valor predeterminado es ‘"16514"’.
- parámetro de
libvirt-configuration: string tcp-port ¶ Puerto en el que se aceptan conexiones inseguras. Puede ser un número de puerto o un nombre de servicio.
El valor predeterminado es ‘"16509"’.
- parámetro de
libvirt-configuration: string listen-addr ¶ Dirección IP o nombre de máquina usado para las conexiones de clientes.
El valor predeterminado es ‘"0.0.0.0"’.
- parámetro de
libvirt-configuration: boolean mdns-adv? ¶ Opción que determina el anuncio mDNS del servicio libvirt.
De manera alternativa puede desactivarse para todos los servicios en una máquina parando el daemon Avahi.
El valor predeterminado es ‘#f’
- parámetro de
libvirt-configuration: string mdns-name ¶ Nombre predeterminado del anuncio mDNS. Debe ser único en la red de distribución inmediata.
El valor predeterminado es ‘"Virtualization Host <hostname>"’.<
- parámetro de
libvirt-configuration: string unix-sock-group ¶ Grupo propietario del socket de dominio de UNIX. Puede usarse para permitir a un conjunto de usuarias “de confianza” acceso a las funcionalidades de gestión sin convertirse en root.
El valor predeterminado es ‘"root"’.
- parámetro de
libvirt-configuration: string unix-sock-ro-perms ¶ Permisos del socket UNIX de sólo lectura41. Se usa únicamente para monitorizar el estado de las máquinas virtuales.
El valor predeterminado es ‘"0777"’.
- parámetro de
libvirt-configuration: string unix-sock-rw-perms ¶ Permisos del socket UNIX de lectura/escritura42. El valor predeterminado únicamente permite acceso a root. Si PolicyKit se encuentra activo en el socket, el valor predeterminado cambiará para permitir acceso universal (es decir, 0777).
El valor predeterminado es ‘"0770"’.
- parámetro de
libvirt-configuration: string unix-sock-admin-perms ¶ Permisos del socket UNIX de administración. El valor predeterminado únicamente permite acceso a la propietaria (root), no lo cambie a menos que esté completamente segura de a quién expone el acceso.
El valor predeterminado es ‘"0777"’.
- parámetro de
libvirt-configuration: string unix-sock-dir ¶ Directorio en el que los sockets se encuentran/crean.
El valor predeterminado es ‘"/var/run/libvirt"’.
- parámetro de
libvirt-configuration: string auth-unix-ro ¶ Esquema de identificación para los sockets de solo-lectura de UNIX. Los permisos predeterminados del socket permiten la conexión de cualquier usuaria.
El valor predeterminado es ‘"polkit"’.
- parámetro de
libvirt-configuration: string auth-unix-rw ¶ Esquema de identificación para los sockets de lectura/escritura de UNIX. Los permisos predeterminados del socket permiten la conexión únicamente a root. Si se activó en la compilación de libvirt la interoperabilidad con PolicyKit, el valor predeterminado es usar la identificación “policykit”.
El valor predeterminado es ‘"polkit"’.
- parámetro de
libvirt-configuration: string auth-tcp ¶ Esquema de identificación para los sockets TCP. Si no activa SASL, todo el tráfico TCP estará en texto plano. No lo haga más allá de un escenario de desarrollo/pruebas.
El valor predeterminado es ‘"sasl"’.
- parámetro de
libvirt-configuration: string auth-tls ¶ Esquema de identificación para los sockets TLS. Los sockets TLS ya se encuentran cifrados gracias a la capa TLS, y una identificación limitada se realiza con los certificados.
También es posible hacer uso de cualquier mecanismo de identificación SASL proporcionando “sasl” en esta opción.
El valor predeterminado es ‘"none"’.
- parámetro de
libvirt-configuration: lista-opcional access-drivers ¶ Esquema de la API de control de acceso.
De manera predeterminada una usuaria identificada puede acceder a todas las API. Los controladores de acceso pueden incluir restricciones de acceso sobre ello.
El valor predeterminado es ‘()’.
- parámetro de
libvirt-configuration: string key-file ¶ Ruta del archivo con la clave del servidor. Si se proporciona una cadena vacía, no se carga ninguna clave privada.
El valor predeterminado es ‘""’.
- parámetro de
libvirt-configuration: string cert-file ¶ Ruta del archivo con la clave del servidor. Si se proporciona una cadena vacía, no se carga ningún certificado.
El valor predeterminado es ‘""’.
- parámetro de
libvirt-configuration: string ca-file ¶ Ruta del archivo con la clave del servidor. Si se proporciona una cadena vacía, no se carga ningún certificado de CA.
El valor predeterminado es ‘""’.
- parámetro de
libvirt-configuration: string crl-file ¶ Ruta de la lista de revocaciones de certificado. Si se proporciona una cadena vacía, no se carga ninguna lista.
El valor predeterminado es ‘""’.
- parámetro de
libvirt-configuration: boolean tls-no-sanity-cert ¶ Desactiva la verificación de los propios certificados del servidor.
Cuando libvirtd arranca, realiza algunas comprobaciones básicas sobre sus propios certificados.
El valor predeterminado es ‘#f’
- parámetro de
libvirt-configuration: boolean tls-no-verify-cert ¶ Desactiva la verificación de certificados de clientes.
La verificación de certificados de cliente es el mecanismo primario de identificación. Se rechazará cualquier cliente que no presente un certificado firmado por la autoridad de certificación (CA).
El valor predeterminado es ‘#f’
- parámetro de
libvirt-configuration: lista-opcional tls-allowed-dn-list ¶ Lista de nombres distinguidos (DN) x509 permitidos.
El valor predeterminado es ‘()’.
- parámetro de
libvirt-configuration: lista-opcional sasl-allowed-usernames ¶ Lista de nombres de usuaria SASL permitidos. El formato para el nombre de la usuaria depende del mecanismo de identificación SASL.
El valor predeterminado es ‘()’.
- parámetro de
libvirt-configuration: string tls-priority ¶ Cambia el valor de la cadena de prioridad de TLS predeterminada en tiempo de compilación. El valor predeterminado habitualmente es ‘"NORMAL"’ a menos que se cambiase en tiempo de compilación. Proporcione este valor únicamente si desea que libvirt se desvíe de la configuración global predeterminada.
El valor predeterminado es ‘"NORMAL"’.
- parámetro de
libvirt-configuration: integer max-clients ¶ Número máximo de conexiones concurrentes de clientes permitidas en todos los sockets combinados.
El valor predeterminado es ‘5000’.
- parámetro de
libvirt-configuration: integer max-queued-clients ¶ Longitud máxima de la cola de conexiones a la espera de ser aceptadas por el daemon. Fíjese que algunos protocolos que implementan la retransmisión pueden obedecer esto de manera que un intento posterior de conexión tenga éxito.
El valor predeterminado es ‘1000’.
- parámetro de
libvirt-configuration: integer max-anonymous-clients ¶ Longitud máxima de la cola de clientes aceptados pero no identificados todavía. Proporcione el valor cero para desactivar esta característica.
El valor predeterminado es ‘20’.
- parámetro de
libvirt-configuration: integer min-workers ¶ Número de procesos de trabajo que se lanzarán inicialmente.
El valor predeterminado es ‘5’.
- parámetro de
libvirt-configuration: integer max-workers ¶ Número máximo de hilos de trabajo.
Si el número de clientes excede
min-workers, se lanzan más hilos, hasta el límitemax-workers. Habitualmente se desea quemax-workerssea igual al número máximo de clientes permitido.El valor predeterminado es ‘20’.
- parámetro de
libvirt-configuration: integer prio-workers ¶ Número de procesos de trabajo prioritarios. Si todos los hilos de trabajo del conjunto previo se encuentran bloqueados, algunas llamadas marcadas como de alta prioridad (notablemente domainDestroy) pueden ejecutarse en este conjunto de hilos.
El valor predeterminado es ‘5’.
- parámetro de
libvirt-configuration: integer max-requests ¶ Límite global total de llamadas RPC concurrentes.
El valor predeterminado es ‘20’.
- parámetro de
libvirt-configuration: integer max-client-requests ¶ Límite de peticiones concurrentes desde una única conexión de cliente. Para evitar que un cliente monopolice el servidor esto debe ser una pequeña fracción de los parámetros globales “max_requests” y “max_workers”.
El valor predeterminado es ‘5’.
- parámetro de
libvirt-configuration: integer admin-min-workers ¶ Igual que
min-workerspero para la interfaz de administración.El valor predeterminado es ‘1’.
- parámetro de
libvirt-configuration: integer admin-max-workers ¶ Igual que
max-workerspero para la interfaz de administración.El valor predeterminado es ‘5’.
- parámetro de
libvirt-configuration: integer admin-max-clients ¶ Igual que
max-clientspero para la interfaz de administración.El valor predeterminado es ‘5’.
- parámetro de
libvirt-configuration: integer admin-max-queued-clients ¶ Igual que
max-queued-clientspero para la interfaz de administración.El valor predeterminado es ‘5’.
- parámetro de
libvirt-configuration: integer admin-max-client-requests ¶ Igual que
max-client-requestspero para la interfaz de administración.El valor predeterminado es ‘5’.
- parámetro de
libvirt-configuration: integer log-level ¶ Nivel de registro. 4 errores, 3 avisos, 2 información, 1 depuración.
El valor predeterminado es ‘3’.
- parámetro de
libvirt-configuration: string log-filters ¶ Filtros del registro.
Un filtro permite la selección de un nivel de registro diferente para una categoría dada de registros. El formato del filtro es uno de los siguientes:
- x:nombre
- x:+nombre
donde
nombrees una cadena contra la que se compara la categoría proporcionada en la llamadaVIR_LOG_INIT()al principio de cada archivo de fuentes de libvirt, por ejemplo ‘"remote"’, ‘"qemu"’ o ‘"util.json"’ (el nombre en el filtro puede ser una subcadena del nombre completo de la categoría, para aceptar múltiples categorías con nombres similares), el prefijo opcional ‘"+"’ indica a libvirt que registre la pila de llamadas en cada mensaje con el nombre correspondiente, yxes el nivel mínimo de los mensajes que deben registrarse:- 1: DEBUG (depuración)
- 2: INFO (información)
- 3: WARNING (aviso)
- 4: ERROR
Se pueden definir en una única sentencia múltiples filtros, únicamente hace falta separarlos por espacios.
El valor predeterminado es ‘"3:remote 4:event"’.
- parámetro de
libvirt-configuration: string log-outputs ¶ Salidas de log.
Una salida es uno de esos lugares para almacenar información de logging. El formato para una salida puede ser:
x:stderrla salida va a stderr
x:syslog:nombreusa syslog para la salida y usa el nombre proporcionado como identificador
x:file:ruta_archivoencamina la salida a un archivo, con la ruta proporcionada
x:journaldusa el sistema de logging journald
En todos los casos el prefijo x es el nivel mínimo, que actúa como filtro
- 1: DEBUG (depuración)
- 2: INFO (información)
- 3: WARNING (aviso)
- 4: ERROR
Se pueden definir salidas múltiples, únicamente deben separarse por espacios.
El valor predeterminado es ‘"3:stderr"’.
- parámetro de
libvirt-configuration: integer audit-level ¶ Permite la alteración del uso del sistema de auditoría.
- 0: desactiva la auditoría
- 1: activa la auditoría, únicamente si está activado en la máquina
- 2: activa la auditoría, y sale si está desactivada en la máquina.
El valor predeterminado es ‘1’.
- parámetro de
libvirt-configuration: boolean audit-logging ¶ Envía los mensajes de auditoría a través de la infraestructura de registro de libvirt.
El valor predeterminado es ‘#f’
- parámetro de
libvirt-configuration: string-opcional host-uuid ¶ Host UUID. UUID must not have all digits be the same.
El valor predeterminado es ‘""’.
- parámetro de
libvirt-configuration: string host-uuid-source ¶ Fuente de lectura del UUID de la máquina anfitriona.
-
smbios: obtiene el UUID dedmidecode -s system-uuid -
machine-id: obtiene el UUID de/etc/machine-id
Si
dmidecodeno proporciona un UUID válido, se generará un UUID temporal.El valor predeterminado es ‘"smbios"’.
-
- parámetro de
libvirt-configuration: integer keepalive-interval ¶ Un mensaje “keepalive” se envía al cliente tras
keepalive_intervalsegundos de inactividad para comprobar si el cliente todavía responde. Si se proporciona el valor -1, libvirtd nunca enviará peticiones “keepalive”; no obstante los clientes todavía pueden mandarlas y el daemon enviará las respuestas.El valor predeterminado es ‘5’.
- parámetro de
libvirt-configuration: integer keepalive-count ¶ Número máximo de mensajes “keepalive” que se permite enviar a un cliente sin obtener respuesta antes de considerar que se ha roto la conexión.
En otras palabras, la conexión se cierra automáticamente tras
keepalive_interval * (keepalive_count + 1)segundos tras la última recepción de un mensaje desde el cliente. Cuandokeepalive_counttiene valor 0, las conexiones se cerrarán automáticamente traskeepalive-intervalsegundos de inactividad sin mandar ningún mensaje “keepalive”.El valor predeterminado es ‘5’.
- parámetro de
libvirt-configuration: integer admin-keepalive-interval ¶ Igual que la opción anterior pero para la interfaz de administración.
El valor predeterminado es ‘5’.
- parámetro de
libvirt-configuration: integer admin-keepalive-count ¶ Igual que la opción anterior pero para la interfaz de administración.
El valor predeterminado es ‘5’.
- parámetro de
libvirt-configuration: integer ovs-timeout ¶ Plazo máximo para las llamadas a Open vSwitch.
La utilidad
ovs-vsctlse usa para la configuración y su opción de plazo máximo (timeout) tiene un valor de 5 segundos de manera predeterminada para evitar que esperas potencialmente infinitas bloqueen libvirt.El valor predeterminado es ‘5’.
Daemon Virtlog
El servicio virtlogd es un daemon del que se compone el lado servidor de libvirt cuya finalidad es la gestión del registro de las consolas de las máquinas virtuales.
This daemon is not used directly by libvirt client applications, rather it
is called on their behalf by libvirtd. By maintaining the logs in a
standalone daemon, the main libvirtd daemon can be restarted without
risk of losing logs. The virtlogd daemon has the ability to
re-exec() itself upon receiving SIGUSR1, to allow live upgrades
without downtime.
- Variable Scheme: virtlog-service-type
Este es el tipo del daemon virtlog. Su valor debe ser un objeto
virtlog-configuration.(service virtlog-service-type (virtlog-configuration (max-clients 1000)))
- Variable:
libvirtparameter package libvirt ¶ Paquete libvirt.
- parámetro de
virtlog-configuration: integer log-level ¶ Nivel de registro. 4 errores, 3 avisos, 2 información, 1 depuración.
El valor predeterminado es ‘3’.
- parámetro de
virtlog-configuration: string log-filters ¶ Filtros del registro.
Un filtro permite la selección de un nivel de registro diferente para una categoría dada de registros. El formato del filtro es uno de los siguientes:
- x:nombre
- x:+nombre
donde
nombrees una cadena contra la que se compara la categoría proporcionada en la llamadaVIR_LOG_INIT()al principio de cada archivo de fuentes de libvirt, por ejemplo "remote", "qemu" o "util.json" (el nombre en el filtro puede ser una subcadena del nombre completo de la categoría, para aceptar múltiples categorías con nombres similares), el prefijo opcional "+" indica a libvirt que registre la pila de llamadas en cada mensaje con el nombre correspondiente, yxes el nivel mínimo de los mensajes que deben registrarse:- 1: DEBUG (depuración)
- 2: INFO (información)
- 3: WARNING (aviso)
- 4: ERROR
Se pueden definir en una única sentencia múltiples filtros, únicamente hace falta separarlos por espacios.
El valor predeterminado es ‘"3:remote 4:event"’.
- parámetro de
virtlog-configuration: string log-outputs ¶ Salidas de log.
Una salida es uno de esos lugares para almacenar información de logging. El formato para una salida puede ser:
x:stderrla salida va a stderr
x:syslog:nombreusa syslog para la salida y usa el nombre proporcionado como identificador
x:file:ruta_archivoencamina la salida a un archivo, con la ruta proporcionada
x:journaldusa el sistema de logging journald
En todos los casos el prefijo x es el nivel mínimo, que actúa como filtro
- 1: DEBUG (depuración)
- 2: INFO (información)
- 3: WARNING (aviso)
- 4: ERROR
Se pueden definir salidas múltiples, únicamente deben separarse por espacios.
El valor predeterminado es ‘"3:stderr"’.
- parámetro de
virtlog-configuration: integer max-clients ¶ Número máximo de conexiones concurrentes de clientes permitidas en todos los sockets combinados.
El valor predeterminado es ‘1024’.
- parámetro de
virtlog-configuration: integer max-size ¶ Tamaño máximo del archivo antes de pasar al siguiente.
El valor predeterminado es ‘2MB’.
- parámetro de
virtlog-configuration: integer max-backups ¶ Número máximo de archivos de backup que se deben mantener.
El valor predeterminado es ‘3’.
Emulación transparente con QEMU
qemu-binfmt-service-type proporciona la capacidad de emular
transparentemente programas binarios construidos para arquitecturas
diferentes—por ejemplo, le permite ejecutar de manera transparente un
programa de ARMv7 en una máquina x86_64. Esto se consigue mediante la
combinación del emulador QEMU y la
característica binfmt_misc del núcleo Linux. Esta característica
únicamente le permite emular GNU/Linux en una arquitectura diferente, pero
más adelante puede ver como implementar también GNU/Hurd.
- Variable Scheme: qemu-binfmt-service-type
Este es el tipo del servicio de emulación transparente QEMU/binfmt. Su valor debe ser un objeto
qemu-binfmt-configuration, que especifica el paquete QEMU usado así como las arquitecturas que se desean emular:(service qemu-binfmt-service-type (qemu-binfmt-configuration (platforms (lookup-qemu-platforms "arm" "aarch64"))))En este ejemplo se activa la emulación transparente para las plataformas ARM y aarch64. La ejecución de
herd stop qemu-binfmtla desactiva, y la ejecución deherd start qemu-binfmtla vuelve a activar (see theherdcommand in The GNU Shepherd Manual).
- Tipo de datos: qemu-binfmt-configuration
Esta es la configuración para el servicio
qemu-binfmt.platforms(predeterminadas:'())Lista de plataformas de QEMU emuladas. Cada elemento debe ser un objeto de plataforma como los devueltos por
lookup-qemu-platforms(véase a continuación).Por ejemplo, supongamos que está en una máquina x86_64 y tiene este servicio:
(service qemu-binfmt-service-type (qemu-binfmt-configuration (platforms (lookup-qemu-platforms "arm"))))Puede ejecutar:
guix build -s armhf-linux inkscape
and it will build Inkscape for ARMv7 as if it were a native build, transparently using QEMU to emulate the ARMv7 CPU. Pretty handy if you’d like to test a package build for an architecture you don’t have access to!
qemu(predeterminado:qemu)El paquete QEMU usado.
- Procedimiento Scheme: lookup-qemu-platforms plataformas…
Devuelve la lista de objetos de plataforma de QEMU que corresponden a plataformas…. plataformas debe ser una lista de cadenas que correspondan con nombres de plataforma, como
"arm","sparc","mips64el", etcétera.
- Procedimiento Scheme: qemu-platform? obj
Devuelve verdadero si obj es un objeto de plataforma.
- Procedimiento Scheme: qemu-platform-name plataforma
Devuelve el nombre de plataforma—una cadena como
"arm".
QEMU Guest Agent
The QEMU guest agent provides control over the emulated system to the host.
The qemu-guest-agent service runs the agent on Guix guests. To
control the agent from the host, open a socket by invoking QEMU with the
following arguments:
qemu-system-x86_64 \ -chardev socket,path=/tmp/qga.sock,server=on,wait=off,id=qga0 \ -device virtio-serial \ -device virtserialport,chardev=qga0,name=org.qemu.guest_agent.0 \ ...
This creates a socket at /tmp/qga.sock on the host. Once the guest
agent is running, you can issue commands with socat:
$ guix shell socat -- socat unix-connect:/tmp/qga.sock stdio
{"execute": "guest-get-host-name"}
{"return": {"host-name": "guix"}}
See QEMU guest agent documentation for more options and commands.
- Scheme Variable: qemu-guest-agent-service-type
Service type for the QEMU guest agent service.
- Data Type: qemu-guest-agent-configuration
Configuration for the
qemu-guest-agentservice.qemu(predeterminado:qemu-minimal)El paquete QEMU usado.
device(default:"")File name of the device or socket the agent uses to communicate with the host. If empty, QEMU uses a default file name.
Hurd en una máquina virtual
El servicio hurd-vm implementa la ejecución de GNU/Hurd en una
máquina virtual (VM), llamado childhurd. Este servicio está destinado
para su uson GNU/Linux y la configuración de sistema operativo de GNU/Hurd
se compila de manera cruzada. La máquina virtual es un servicio de Shepherd
al que se puede hacer referencia a través de los nombres hurd-vm y
childhurd y se puede controlar mediante órdenes como las siguientes:
herd start hurd-vm herd stop childhurd
Cuando el servicio se encuentra en ejecución, puede ver su consola a través de una conexión con un cliente VNC, por ejemplo con:
guix shell tigervnc-client -- vncviewer localhost:5900
La configuración predeterminada (véase hurd-vm-configuration a
continuación) lanza un servidor del intérprete de órdenes seguro (SSH) en su
sistema GNU/Hurd, el cual QEMU (el emulador de máquina virtual) redirige al
puerto 10222 de la máquina anfitriona. Por tanto se puede conectar a Hurd a
través de SSH con:
ssh root@localhost -p 10022
childhurd es volátil y carece de estado: comienza con un sistema de archivos
raíz creado de cero cada vez que lo reinicia. No obstante de manera
predeterminada todos los archivos en la ruta /etc/childhurd de la
máquina anfitriona se copian al sistema de archivos raíz de childhurd cuando
arranca. Esto permite que configure “secretos” dentro de la máquina
virtual: claves de SSH de la máquina, claves de sustituciones autorizadas,
etcétera—véase la explicación de secret-root a continuación.
- Variable Scheme: hurd-vm-service-type
El tipo del servicio que ejecuta Hurd en una máquina virtual. Su valor debe ser un objeto
hurd-vm-configuration, que especifica el sistema operativo (see Referencia deoperating-system) y el tamaño del disco para la máquina virtual de Hurd, el paquete de QEMU usado así como las opciones de ejecución.Por ejemplo:
(service hurd-vm-service-type (hurd-vm-configuration (disk-size (* 5000 (expt 2 20))) ;5G (memory-size 1024))) ;1024MiB
crearía una imagen de disco suficientemente grande para construir GNU Hello, con algo de memoria adicional.
- Tipo de datos: hurd-vm-configuration
Tipo de datos que representa la configuración de
hurd-vm-service-type.os(predeterminado: %hurd-vm-operating-system)El sistema operativo instanciado. El valor predeterminado es un sistema mínimo con un daemon del intérprete de comandos seguro OpenSSH configurado de forma permisiva asociado al puerto 2222 (see
openssh-service-type).qemu(predeterminado:qemu-minimal)El paquete QEMU usado.
image(predeterminado: hurd-vm-disk-image)El procedimiento usado para construir la imagen de disco construida a partir de esta configuración.
disk-size(predeterminado:'guess)El tamaño de la imagen de disco.
memory-size(predeterminado:512)El tamaño de la memoria de la máquina virtual en mebibytes.
options(predeterminadas:'("--snapshot"))Opciones adicionales para ejecutar QEMU.
id(predeterminado:#f)Si se proporciona un valor, debe ser un entero positivo no nulo usado para parametrizar las instancias Childhurd. Se añade al nombre del servicio, por ejemplo
childhurd1.net-options(predeterminado: hurd-vm-net-options)El procedimiento usado para producir la lista de opciones de red para QEMU.
De manera predeterminada produce
'("--device" "rtl8139,netdev=net0" "--netdev" (string-append "user,id=net0," "hostfwd=tcp:127.0.0.1:secrets-port-:1004," "hostfwd=tcp:127.0.0.1:ssh-port-:2222," "hostfwd=tcp:127.0.0.1:vnc-port-:5900"))
con los siguientes puertos redirigidos:
secrets-port:
(+ 11004 (* 1000 ID))ssh-port:(+ 10022 (* 1000 ID))vnc-port:(+ 15900 (* 1000 ID))secret-root(predeterminado: /etc/childhurd)El directorio raíz que contiene los secretos fuera-de-banda que serán instalados en childhurd cuando se ejecute. Los childhurd son volátiles lo que significa que cada arranque los secretos como las claves de SSH de la máquina y la clave de firma de Guix se regeneran.
Si el directorio /etc/childhurd no existe, el servicio
secret-serviceque se ejecuta en childhurd recibirá una lista vacía de secretos.De manera predeterminada el servicio crea /etc/childhurd con los siguientes secretos no volátiles, a no ser que ya existan:
/etc/childhurd/etc/guix/acl /etc/childhurd/etc/guix/signing-key.pub /etc/childhurd/etc/guix/signing-key.sec /etc/childhurd/etc/ssh/ssh_host_ed25519_key /etc/childhurd/etc/ssh/ssh_host_ecdsa_key /etc/childhurd/etc/ssh/ssh_host_ed25519_key.pub /etc/childhurd/etc/ssh/ssh_host_ecdsa_key.pub
Estos archivos se envían automáticamente a la máquina virtual de Hurd cuando arranca, incluyendo sus permisos.
Tener todos estos archivos en un único lugar significa que únicamente faltan un par de detalles para permitir a la máquina anfitriona delegar las construcciones de
i586-gnuen childhurd:- Autorizar la clave de childhurd en la máquina anfitriona de modo que esta
acepte las construcciones que provengan de childhurd, lo que puede hacerse
de este modo:
guix archive --authorize < \ /etc/childhurd/etc/guix/signing-key.pub
- Añadir childhurd a /etc/guix/machines.scm (see Uso de la facilidad de delegación de trabajo).
Estamos trabajando para que esto se haga de forma automática—¡póngase en contacto con nosotras a través de guix-devel@gnu.org para hablar sobre ello!
- Autorizar la clave de childhurd en la máquina anfitriona de modo que esta
acepte las construcciones que provengan de childhurd, lo que puede hacerse
de este modo:
Tenga en cuenta que la imagen de la máquina virtual es volátil, es decir,
los contenidos se pierden cuando se para. Si desea una imagen que mantenga
el estado puede modificar la configuración de image y options
sin la opción --snapshot usando algo parecido a esto:
(service hurd-vm-service-type
(hurd-vm-configuration
(image (const "/no/almacen/y/perm/escritura/hurd.img"))
(options '())))
Ganeti
Nota: Este servicio se considera experimental. Las opciones de configuración pueden cambiar de manera incompatible con versiones previas, y no todas las características han sido probadas en profundidad. Se recomienda a quienes usen este servicio que compartan su experiencia en guix-devel@gnu.org.
Ganeti es un sistema de gestión de máquinas virtuales. Está diseñado para
mantener máquinas virtuales ejecutándose en un cluster de servidores incluso
en casos de fallos de hardware, y para facilitar las tareas de mantenimiento
y recuperación. Consiste en múltiples servicios que se describen a lo largo
de esta sección. Además del servicio de Ganeti, necesitará el servicio
OpenSSH (see openssh-service-type), y
actualizar el archivo /etc/hosts (see hosts-file) con el nombre del cluster y su dirección (o usar un
servidor DNS).
Todos los nodos que participan en el cluster de Ganeti deben tener la misma
configuración de Ganeti y en el archivo /etc/hosts. A continuación se
encuentra un ejemplo de configuración para un nodo del cluster de Ganeti que
implementa varios motores de almacenamiento, e instala los proveedores
de sistema operativo debootstrap y guix:
(use-package-modules virtualization) (use-service-modules base ganeti networking ssh) (operating-system ;; … (host-name "nodo1") (hosts-file (plain-file "hosts" (format #f " 127.0.0.1 localhost ::1 localhost 192.168.1.200 ganeti.example.com 192.168.1.201 nodo1.example.com nodo1 192.168.1.202 nodo2.example.com nodo2 "))) ;; Install QEMU so we can use KVM-based instances, and LVM, DRBD and Ceph ;; in order to use the "plain", "drbd" and "rbd" storage backends. (packages (append (map specification->package '("qemu" "lvm2" "drbd-utils" "ceph" ;; Add the debootstrap and guix OS providers. "ganeti-instance-guix" "ganeti-instance-debootstrap")) %base-packages)) (services (append (list (service static-networking-service-type (list (static-networking (addresses (list (network-address (device "eth0") (value "192.168.1.201/24")))) (routes (list (network-route (destination "default") (gateway "192.168.1.254")))) (name-servers '("192.168.1.252" "192.168.1.253"))))) ;; Ganeti uses SSH to communicate between nodes. (service openssh-service-type (openssh-configuration (permit-root-login 'prohibit-password))) (service ganeti-service-type (ganeti-configuration ;; Esta lista especifica las rutas del ;; sistema de archivos permitidas para el ;; almacenamiento de imágenes de máquinas ;; viruales. (file-storage-paths '("/srv/ganeti/almacenamiento")) ;; Esta variable configura una única ;; "variación" tanto para Debootstrap como ;; Guix que funciona con KVM. (os %default-ganeti-os)))) %base-services)))
Users are advised to read the Ganeti administrators guide to learn about the various cluster options and day-to-day operations. There is also a blog post describing how to configure and initialize a small cluster.
- Variable Scheme: ganeti-service-type
Tipo de servicio que incluye todos los distintos servicios que los nodos Ganeti deben ejecutar.
Su valor es un objeto
ganeti-configurationque define usado para las operaciones de línea de órdenes, así como la configuración para varios daemon. Las rutas de almacenamiento permitidas y los sistemas operativos disponibles para hospedar también se configuran a través de este tipo de datos.
- Tipo de datos: ganeti-configuration
El servicio
ganetiproporciona las siguientes opciones de configuración:ganeti(predeterminado:ganeti)El paquete
ganetiusado. Dicho paquete se instala en el perfil del sistema y hace que las órdenesgnt-cluster,gnt-instance, etcétera, estén disponibles. Tenga en cuenta que el valor especificado aquí no afecta a otros servicios ya que cada uno hace referencia a su paqueteganetiespecífico (véase a continuación).noded-configuration(predeterminado:(ganeti-noded-configuration))confd-configuration(predeterminado:(ganeti-confd-configuration))wconfd-configuration(predeterminado:(ganeti-wconfd-configuration))luxid-configuration(predeterminado:(ganeti-luxid-configuration))rapi-configuration(predeterminado:(ganeti-rapi-configuration))kvmd-configuration(predeterminado:(ganeti-kvmd-configuration))mond-configuration(predeterminado:(ganeti-mond-configuration))metad-configuration(predeterminado:(ganeti-metad-configuration))watcher-configuration(predeterminado:(ganeti-watcher-configuration))cleaner-configuration(predeterminado:(ganeti-cleaner-configuration))-
Estas opciones controlan los distintos daemon y trabajos de cron que se distribuyen con Ganeti. Los posibles valores se describen en detalle a continuación. Para modificar el valor de un elemento de la configuración se debe usar el tipo de configuración para dicho servicio:
(service ganeti-service-type (ganeti-configuration (rapi-configuration (ganeti-rapi-configuration (interface "eth1")))) (watcher-configuration (ganeti-watcher-configuration (rapi-ip "10.0.0.1")))) file-storage-paths(predeterminada:'())Lista de directorios permitidos para el motor de almacenamiento de archivos.
os(predeterminado:%default-ganeti-os)Lista de registros
<ganeti-os>.
En esencia
ganeti-service-typees una abreviación para declara cada uno de los servicios individualmente:(service ganeti-noded-service-type) (service ganeti-confd-service-type) (service ganeti-wconfd-service-type) (service ganeti-luxid-service-type) (service ganeti-kvmd-service-type) (service ganeti-mond-service-type) (service ganeti-metad-service-type) (service ganeti-watcher-service-type) (service ganeti-cleaner-service-type)
Además de una extensión del servicio
etc-service-typeque configura el motor de almacenamiento de archivos y las variantes de sistema operativo.
- Tipo de datos: ganeti-os
Tipo de datos adecuado para proporcionarse como parámetro
osdeganeti-configuration. Tiene los siguientes parámetros:nameNombre para este proveedor de sistema operativo. Solo se usa para especificar dónde termina la configuración. Proporcionar el valor “debootstrap” indica la creación de /etc/ganeti/instance-debootstrap.
extension(default:#f)The file extension for variants of this OS type. For example .conf or .scm. It will be appended to the variant file name if set.
variants(predeterminadas:'())This must be either a list of
ganeti-os-variantobjects for this OS, or a “file-like” object (see file-like objects) representing the variants directory.To use the Guix OS provider with variant definitions residing in a local directory instead of declaring individual variants (see guix-variants below), you can do:
(ganeti-os (name "guix") (variants (local-file "ganeti-guix-variants" #:recursive? #true)))Note that you will need to maintain the variants.list file (see
ganeti-os-interface(7)) manually in this case.
- Tipo de datos: ganeti-os-variant
Tipo de datos que representa una variante de SO Ganeti. Este tipo tiene los siguientes parámetros:
nameEl nombre de esta variación.
configurationUn archivo de configuración para esta variación.
- Variable Scheme: %default-debootstrap-hooks
Esta variable contiene extensiones (“hook”) para la configuración de la red y el cargador de arranque GRUB.
- Variable Scheme: %default-debootstrap-extra-pkgs
Esta variable contiene una lista de paquetes adecuada para una máquina completamente virtualizada.
- Tipo de datos: debootstrap-configuration
-
Este tipo de datos crea archivos de configuración adecuados para la orden de generación de sistemas operativos debootstrap.
hooks(predeterminada:%default-debootstrap-hooks)Cuando no es
#fdebe ser una expresión-G que especifique el directorio con los guiones que deberán ejecutarse cuando se instale el sistema operativo. También puede ser una lista de pares(nombre . obj-tipo-archivo). Por ejemplo:`((99-hola-mundo . ,(plain-file "#!/bin/sh\necho '¡Hola mundo!'")))
Esto crea un directorio con un ejecutable que se llama
99-hola-mundoy se ejecuta cada vez que se instale esta variación. Si se proporciona#f, se usarán los archivos del directorio /etc/ganeti/instance-debootstrap/hooks, si existe alguno.proxy(predeterminado:#f)Valor opcional de la pasarela HTTP usada.
mirror(predeterminado:#f)El servidor espejo de Debian. Habitualmente es algo como
http://ftp.no.debian.org/debian. El valor predeterminado cambia dependiendo de la distribución.arch(predeterminada:#f)La arquitectura de dpkg. Proporcione
armhfpara generar con debootstrap una instancia de ARMv7 en una máquina AArch64. El valor predeterminado corresponde a la arquitectura del sistema en uso.suite(predeterminada:"stable")Si se proporciona debe ser el identificador de una entrega o “suite” de distribución de Debian, como por ejemplo
busterofocal. Si se proporciona#f, se usael valor predeterminado del proveedor de sistema operativo.extra-pkgs(predeterminados:%default-debootstrap-extra-pkgs)Lista de paquetes adicionales que dpkg instala junto al sistema mínimo.
components(predeterminado:#f)Si se proporciona un valor debe ser una lista de “componentes” de repositorio de Debian. Por ejemplo
'("main" "contrib").generate-cache?(predeterminado:#t)Determina si se almacena en caché de manera automática el archivo de debootstrap que se haya generado.
clean-cache(predeterminado:14)Descarta el contenido de la caché tras este número de días. Use
#fpara no descartar contenido de la caché nunca.partition-style(predeterminado:'msdos)Tipo de partición creado. Cuando se proporciona un valor debe ser
'msdos,'noneo una cadena.partition-alignment(predeterminada:2048)Alineación de la partición en sectores.
- Procedimiento Scheme: debootstrap-variant nombre configuración
Procedimiento auxiliar que crea un registro
ganeti-os-variant. Toma dos parámetros: un nombre y un objetodebootstrap-configuration.
- Procedimiento Scheme: debootstrap-os variantes…
Procedimiento auxiliar que crea un registro
ganeti-os. Toma como parámetro una lista de variaciones creada condebootstrap-variant.
- Procedimiento Scheme: guix-variant nombre configuración
Procedimiento auxiliar que crea un registro
ganeti-os-variantpara ser usado por el proveedor de sistema operativo Guix. Toma como parámetros un nombre y una expresión-G que devuelve un objeto “tipo-archivo” (see objetos “tipo-archivo”) que contiene configuración para el sistema Guix.
- Procedimiento Scheme: guix-os variantes…
Procedimiento auxiliar que crea un registro
ganeti-os. Toma como parámetros una lista de variaciones producida porguix-variant.
- Variable Scheme: %default-debootstrap-variants
Variable de conveniencia para que el proveedor debootstrap funcione “automágicamente” sin que quienes lo usan tengan que declarar variaciones manualmente. Contiene una única variación de debootstrap con la configuración predeterminada:
(list (debootstrap-variant "default" (debootstrap-configuration)))
- Variable Scheme: %default-guix-variants
Variable de conveniencia para que el proveedor de sistema operativo Guix funcione sin ninguna configuración adicional. Crea una máquina virtual que tiene un servidor SSH, consola serie y autoriza las claves de SSH de las máquinas de Ganeti.
(list (guix-variant "default" (file-append ganeti-instance-guix "/share/doc/ganeti-instance-guix/examples/dynamic.scm")))
Se pueden implementar proveedores de SO no disponibles en Guix mediante la
extensión de los registros ganeti-os y ganeti-os-variant de
manera apropiada. Por ejemplo:
(ganeti-os
(name "personalizado")
(extension ".conf")
(variants
(list (ganeti-os-variant
(name "cosa")
(configuration (plain-file "archivo" "Esto va bien"))))))
Este ejemplo crearía
/etc/ganeti/instance-personalizado/variants/cosa.conf, el cual apunta
a un archivo en el almacén cuyo contenido es esto va bien. También se
crearía /etc/ganeti/instance-personalizado/variants/variants.list con
el contenido cosa.
Obviamente es posible que esto no funcione con todos los proveedores de sistema operativo existentes. Si está interfaz le está limitando en su implementación, por favor, contacte con guix-devel@gnu.org.
El resto de esta sección documenta los distintos servicios incluidos en
ganeti-service-type.
- Variable Scheme: ganeti-noded-service-type
ganeti-nodedes el daemon responsable de las funciones específicas del nodo dentro del sistema Ganeti. El valor de este servicio debe ser un objetoganeti-noded-configuration.
- Tipo de datos: ganeti-noded-configuration
Esta es la configuración para el servicio
ganeti-noded.ganeti(predeterminado:ganeti)El paquete
ganetiusado para este servicio.port(predeterminado:1811)Puerto TCP en el que escucha el daemon del nodo a la espera de peticiones a través de la red.
address(predeterminado:"0.0.0.0")La dirección de red a la que el daemon se enlaza. La dirección predeterminada significa que el daemon se enlaza a todas las direcciones disponibles.
interface(predeterminado:#f)En caso de proporcionarse un valor, debe especificar el nombre de la interfaz de red (por ejemplo,
eth0a la que el daemon se enlaza.max-clients(predeterminado:20)Establece un límite en el número máximo de conexiones simultaneas de clientes que el daemon manejará. Las conexiones que excedan dicho número se aceptan, pero no se envía respuesta hasta que hayan cerrado suficientes conexiones.
ssl?(predeterminado:#t)Determina si se usa SSL/TLS para cifrar las comunicaciones a través de la red. El cluster proporciona automáticamente el certificado y se puede rotar con
gnt-cluster renew-crypto.ssl-key(predeterminado: "/var/lib/ganeti/server.pem")Puede usarse para proporcionar una clave de cifrado específica para comunicaciones TLS.
ssl-cert(predeterminado: "/var/lib/ganeti/server.pem")Puede usarse para proporcionar un certificado específico para comunicaciones TLS.
debug?(predeterminado:#f)Cuando es verdadero, el daemon almacena registros adicionales con propósitos de depuración. Tenga en cuenta que esto puede exponer detalles de cifrado en los archivos de registro, por lo que debe usarse con precaución.
- Variable Scheme: ganeti-confd-service-type
ganeti-confdresponde a las consultas relacionadas con la configuración del cluster Ganeti. El propósito de este daemon es tener una forma rápida y con alta disponibilidad de consultar los valores de configuración del cluster. Se activa de manera automática en todas las máquinas candidatas de ser coordinadoras. El valor de este servicio debe ser un objetoganeti-confd-configuration.
- Tipo de datos: ganeti-confd-configuration
Esta es la configuración para el servicio
ganeti-confd.ganeti(predeterminado:ganeti)El paquete
ganetiusado para este servicio.port(predeterminado:1814)El puerto UDP en el que esperarán peticiones a través de la red.
address(predeterminado:"0.0.0.0")Dirección de red a la que el daemon se asocia.
debug?(predeterminado:#f)Cuando es verdadero, el daemon almacena registros adicionales con propósitos de depuración.
- Variable Scheme: ganeti-wconfd-service-type
ganeti-wconfdes el daemon que proporciona una autoridad de conocimiento sobre la configuración del cluster y es la única entidad que puede aceptar cambios sobre ella. Todos las trabajos que necesiten modificar la configuración deben hacerlo enviando las peticiones adecuadas a este daemon. Únicamente se ejecuta en el nodo coordinador y se desactiva automáticamente en otros nodos.El valor de este servicio debe ser un objeto
ganeti-wconfd-configuration.
- Tipo de datos: ganeti-wconfd-configuration
Esta es la configuración para el servicio
ganeti-wconfd.ganeti(predeterminado:ganeti)El paquete
ganetiusado para este servicio.no-voting?(predeterminado:#f)El daemon se negará a arrancar si la mayoría de los nodos del cluster no coinciden en que se está ejecutando en el nodo coordinador. Proporcione
#tpara arrancar incluso cuando no se puede alcanzar dicha mayoría (peligroso, úsese con precaución).debug?(predeterminado:#f)Cuando es verdadero, el daemon almacena registros adicionales con propósitos de depuración.
- Variable Scheme: ganeti-luxid-service-type
ganeti-luxides un daemon que responde a las peticiones relacionadas con la configuración del estado actual del cluster Ganeti. De manera adicional, es el daemon que tiene el control sobre la cola de trabajos de Ganeti. Los trabajos se pueden emitir a través de este daemon y éste los planifica y arranca.Recibe un objeto
ganeti-luxid-configuration.
- Tipo de datos: ganeti-luxid-configuration
This is the configuration for the
ganeti-luxidservice.ganeti(predeterminado:ganeti)El paquete
ganetiusado para este servicio.no-voting?(predeterminado:#f)El daemon se negará a arrancar si no puede verificar que la mayoría de los nodos del cluster creen que éste se está ejecutando en el nodo coordinador. Proporcione
#tpara ignorar dichas comprobaciones y arrancar en cualquier caso (puede ser peligroso).debug?(predeterminado:#f)Cuando es verdadero, el daemon almacena registros adicionales con propósitos de depuración.
- Variable Scheme: ganeti-rapi-service-type
ganeti-rapiproporciona una API remota para cluster de Ganeti. Se ejecuta en el nodo coordinador y se puede usar para realizar programática acciones en el cluster a través de un protocolo de llamada de procedimientos remotos (RPC) basado en JSON.Most query operations are allowed without authentication (unless require-authentication? is set), whereas write operations require explicit authorization via the /var/lib/ganeti/rapi/users file. See the Ganeti Remote API documentation for more information.
El valor de este servicio debe ser un objeto
ganeti-rapi-configuration.
- Tipo de datos: ganeti-rapi-configuration
Configuración para el servicio
ganeti-rapi.ganeti(predeterminado:ganeti)El paquete
ganetiusado para este servicio.require-authentication?(predeterminado:#f)Determina si se requiere identificación incluso para operaciones únicamente de lectura.
port(predeterminado:5080)El puerto TCP en el que esperarán peticiones de la API.
address(predeterminado:"0.0.0.0")La dirección de red a la que se asocia el servicio. De manera predeterminada el servicio se asocia a todas las direcciones configuradas.
interface(predeterminado:#f)Si se proporciona un valor, debe especificar el nombre de la interfaz de red, como por ejemplo
eth0, a la que el daemon se asocia.max-clients(predeterminado:20)Número máximo de conexiones simultaneas de clientes que se manejan. Las conexiones que excedan dicho número se aceptan, pero no se envía respuesta hasta que hayan cerrado suficientes conexiones.
ssl?(predeterminado:#t)Determina si se usa cifrado SSL/TLS en el puerto de la API remota.
ssl-key(predeterminado: "/var/lib/ganeti/server.pem")Puede usarse para proporcionar una clave de cifrado específica para comunicaciones TLS.
ssl-cert(predeterminado: "/var/lib/ganeti/server.pem")Puede usarse para proporcionar un certificado específico para comunicaciones TLS.
debug?(predeterminado:#f)Cuando es verdadero, el daemon almacena registros adicionales con propósitos de depuración. Tenga en cuenta que esto puede exponer detalles de cifrado en los archivos de registro, por lo que debe usarse con precaución.
- Variable Scheme: ganeti-kvmd-service-type
ganeti-kvmdes responsable de determinar si una instancia KVM determinada ha sido apagada por una usuaria o una administradora. Normalmente Ganeti reiniciará una instancia que no se haya parado a través de Ganeti. Si la opción del clusteruser_shutdownes verdadera, este daemon monitoriza el puertoQMPque proporciona QEMU y escucha eventos de apagado en él, y marca la instancia como USER_down en vez de ERROR_down cuando el daemon la apaga de manera adecuada.Recibe un objeto
ganeti-kvmd-configuration.
- Tipo de datos: ganeti-kvmd-configuration
-
ganeti(predeterminado:ganeti)El paquete
ganetiusado para este servicio.debug?(predeterminado:#f)Cuando es verdadero, el daemon almacena registros adicionales con propósitos de depuración.
- Variable Scheme: ganeti-mond-service-type
ganeti-mondes un daemon opcional que proporciona la funcionalidad de monitorización de Ganeti. Es responsable de la ejecución de los recolectores de datos y la publicación de la información obtenida a través de una interfaz HTTP.Recibe un objeto
ganeti-mond-configuration.
- Tipo de datos: ganeti-mond-configuration
-
ganeti(predeterminado:ganeti)El paquete
ganetiusado para este servicio.port(predeterminado:1815)Puerto en el que el daemon espera conexiones.
address(predeterminado:"0.0.0.0")La dirección de red a la que se asocia el daemon. De manera predeterminada se asocia a todas las interfaces disponibles.
debug?(predeterminado:#f)Cuando es verdadero, el daemon almacena registros adicionales con propósitos de depuración.
- Variable Scheme: ganeti-metad-service-type
ganeti-metades un daemon opcional que se puede usar para proporcionar información del cluster a instancias o guiones de instalación de sistema operativo.Recibe un objeto
ganeti-metad-configuration.
- Tipo de datos: ganeti-metad-configuration
-
ganeti(predeterminado:ganeti)El paquete
ganetiusado para este servicio.port(predeterminado:80)Puerto en el que el daemon espera conexiones.
address(predeterminada:#f)Si se proporciona un valor el daemon se asociará únicamente a esta dirección. Si no se proporciona valor el comportamiento depende de la configuración del cluster.
debug?(predeterminado:#f)Cuando es verdadero, el daemon almacena registros adicionales con propósitos de depuración.
- Variable Scheme: ganeti-watcher-service-type
ganeti-watcheres un guión diseñado para su ejecución periódica en la que comprueba el estado la salud del cluster. Reinicia automáticamente las instancias que se han parado sin el consentimiento de Ganeti, y repara los enlaces DRBD en caso de que un nodo se haya reiniciado. También archiva los trabajos antiguos del cluster y reinicia los daemon de Ganeti si no se están ejecutando. Si se ha proporcionado valor al parámetro del clusterensure_node_health, este proceso también apagará las instancias y dispositivos DRBD si el nodo que las ejecute se ha declarado fuera de línea por alguna de las máquinas candidatas de coordinación conocidas.Se puede pausar en todos los nodos con
gnt-cluster watcher pause.Este servicio toma como valor un objeto
ganeti-watcher-configuration.
- Tipo de datos: ganeti-watcher-configuration
-
ganeti(predeterminado:ganeti)El paquete
ganetiusado para este servicio.schedule(predeterminado:'(next-second-from (next-minute (range 0 60 5))))Cada cuanto se ejecuta el guión. El valor predeterminado es cada 5 minutos.
rapi-ip(predeterminada:#f)Esta opción se debe especificar únicamente si el daemon de API remota se ha configurado para usar una interfaz o dirección de red concreta. De manera predeterminada se usa la dirección del cluster.
job-age(predeterminados:(* 6 3600))Archiva los trabajos del cluster cuya antigüedad sea mayor que el el número de segundos proporcionado. El valor predeterminado son 6 horas. Esto mantiene la lista proporcionada
gnt-job listdentro de límites gestionables.verify-disks?(predeterminado:#t)Si es
#f, el proceso de vigilancia (“watcher”) no intentará reparar los enlaces de DRBD rotos de manera automática. Esto significa que quienes administren el sistema deberán usargnt-cluster verify-disksmanualmente para realizar dicha tarea.debug?(predeterminado:#f)Cuando es
#t, el guión registra información adicional para facilitar la depuración.
- Variable Scheme: ganeti-cleaner-service-type
ganeti-cleaneres un guión diseñado para su ejecución periódica en la que elimina archivos antiguos del cluster. Este tipo de servicio controla dos trabajos de cron: uno para el nodo coordinador que elimina de manera permanente trabajos antiguos del cluster, y otro para todos los nodos que elimina certificados X509 y claves que hayan expirado así como información desactualizada deganeti-watcher. Como todos los servicios de Ganeti, se puede incluir también en los nodos que no son coordinadores y se desactivará por si mismo si es necesario.Recibe un objeto
ganeti-cleaner-configuration.
- Tipo de datos: ganeti-cleaner-configuration
-
ganeti(predeterminado:ganeti)El paquete
ganetiusado para la ordengnt-cleaner.master-schedule(predeterminado:"45 1 * * *")Cada cuanto se ejecuta el trabajo principal de limpieza. El valor predeterminado representa su ejecución una vez al día, a las 01:45:00.
node-schedule(predeterminada:"45 2 * * *")La frecuencia del trabajo de limpieza del nodo. El valor predeterminado es una vez al día, a las 02:45:00.
Next: Servicios de juegos, Previous: Servicios de virtualización, Up: Servicios [Contents][Index]
12.9.30 Servicios de control de versiones
El módulo (gnu services version-control) proporciona un servicio para
permitir el acceso remoto a repositorios Git locales. Existen tres opciones:
el servicio git-daemon-service, que proporciona acceso a repositorios
a través del protocolo inseguro basado en TCP git://, la extensión
del servidor web nginx para redirigir algunas peticiones al motor
git-http-backend, o una interfaz web proporcionada por el servicio
cgit-service-type.
- Procedimiento Scheme: git-daemon-service [#:config (git-daemon-configuration)]
-
Devuelve un servicio que ejecuta
git daemon, un servidor TCP simple para exponer repositorios con el protocolo Git para acceso anónimo.El parámetro opcional config debe ser un objeto
<git-daemon-configuration>, de manera predeterminada permite acceso de solo lectura a los repositorios exportados43 bajo /srv/git.
- Tipo de datos: git-daemon-configuration
Tipo de datos que representa la configuración para
git-daemon-service.package(predeterminado:git)El objeto paquete del sistema distribuido de control de versiones Git.
export-all?(predeterminado:#f)Determina si se permite el acceso a todos los repositorios Git, incluso si no tienen el archivo git-daemon-export-ok.
base-path(predeterminado: /srv/git)Determina si se traducirán todas las rutas de las peticiones como relativas a la ruta proporcionada. Si se encuentra en ejecución el daemon de git con
(base-path "/srv/git"en example.com, al realizar la solicitud de ‘git://example.com/hello.git’, el daemon de git interpretará la ruta como /srv/git/hello.git.user-path(predeterminado:#f)Determina si se permite el uso de la notación
~useren las peticiones. Si se especifica una cadena vacía, una peticione de ‘git://máquina/~alicia/algo’ se tomará como una petición de acceso al repositorioalgoen el directorio de la usuariaalicia. Si se especifica(user-path "ruta"), la misma petición se traducirá en una petición de acceso al repositorio ruta/algo en el directorio de la usuariaalicia.listen(predeterminadas:'())Determina si se debe escuchar en direcciones IP o nombres de máquina específicos, de manera predeterminada escucha en cualquiera.
port(predeterminado:#f)Determina si se escucha en un puerto alternativo, cuyo valor predeterminado es 9418.
whitelist(predeterminada:'())Si no está vacío, únicamente permite el acceso a esta lista de directorios.
extra-options(predeterminadas:'())Opciones adicionales que se proporcionan a
git daemon, para obtener más información le rogamos que ejecuteman git-daemon.
El protocolo git:// carece de verificación. Cuando se obtienen datos
de un repositorio a través del protocolo git://, no puede tener plena
confianza en que los datos que reciba procedan realmente de la máquina que
ha indicado, y su conexión puede estar sujeta a interceptaciones. Es mejor
usar un transporte verificado y cifrado, como https. Aunque Git le
permite servir repositorios usando servidores web poco sofisticados basados
en archivos, existe un protocolo más rápido implementado en el programa
git-http-backend. Este programa es el motor de un servicio web de Git
adecuado. Está diseñado para ejecutarse tras una pasarela FastCGI. See Servicios Web, para más información sobre la ejecución del daemon
fcgiwrap necesario.
Guix tiene un tipo de datos de configuración distinto para proporcionar repositorios Git sobre HTTP.
- Tipo de datos: git-http-configuration
Data type representing the configuration for a future
git-http-service-type; can currently be used to configure Nginx throughgit-http-nginx-location-configuration.package(predeterminado: git)El objeto paquete del sistema distribuido de control de versiones Git.
git-root(predeterminada: /srv/git)Directorio que contiene los repositorios Git que se expondrán al mundo.
export-all?(predeterminado:#f)Determina si se expondrá el acceso a todos los repositorios en git-root, incluso si no contienen el archivo git-daemon-export-ok.
uri-path(predeterminada: ‘/git/’)Prefijo de la ruta del acceso de Git. Con el prefijo predeterminado ‘/git/’, ‘
http://servidor/git/repositorio.git’ se traducirá en/srv/git/repositorio.git. Las peticiones cuyas rutas URI no comiencen con dicho prefijo no se pasan a esta instancia de Git.fcgiwrap-socket(predeterminado:127.0.0.1:9000)Socket en el que el daemon
fcgiwrapescucha. See Servicios Web.
No existe actualmente git-http-service-type; en vez de eso puede
crear una configuración nginx-location-configuration desde
git-http-configuration y añadir dicha configuración al servidor web.
- Procedimiento Scheme: git-http-nginx-location-configuration [config=(git-http-configuration)]
Calcula una configuración
nginx-location-configurationque corresponde con la configuración http de Git proporcionada. Un ejemplo de definición de servicio nginx que ofrece el directorio predeterminado /srv/git sobre HTTPS podría ser:(service nginx-service-type (nginx-configuration (server-blocks (list (nginx-server-configuration (listen '("443 ssl")) (server-name "git.mi-maquina.org") (ssl-certificate "/etc/letsencrypt/live/git.mi-maquina.org/fullchain.pem") (ssl-certificate-key "/etc/letsencrypt/live/git.mi-maquina.org/privkey.pem") (locations (list (git-http-nginx-location-configuration (git-http-configuration (uri-path "/"))))))))))This example assumes that you are using Let’s Encrypt to get your TLS certificate. See Servicios de certificados. The default
certbotservice will redirect all HTTP traffic ongit.my-host.orgto HTTPS. You will also need to add anfcgiwrapproxy to your system services. See Servicios Web.
Servicio Cgit
Cgit es un servidor de fachada para repositiorios Git escrito en C.
El ejemplo siguiente configura el servicio con los valores
predeterminados. Por omisión, se puede acceder a Cgit en el puerto 80
(http://localhost:80).
(service cgit-service-type)
El tipo file-object designa o bien un objeto “tipo-archivo”
(see objetos “tipo-archivo”), o bien una cadena.
Los campos disponibles de cgit-configuration son:
- parámetro de
cgit-configuration: package package ¶ El paquete CGIT.
- parámetro de
cgit-configuration: lista-nginx-server-configuration nginx ¶ Configuración de NGINX.
- parámetro de
cgit-configuration: file-object about-filter ¶ Especifica una orden que se llamará para dar formato al contenido de las páginas “about” (tanto al nivel superior como cada repositorio).
El valor predeterminado es ‘""’.
- parámetro de
cgit-configuration: string agefile ¶ Especifica una ruta, relativa a cada ruta de repositorio, que puede usarse para especificar una fecha y hora de la revisión más reciente del repositorio.
El valor predeterminado es ‘""’.
- parámetro de
cgit-configuration: file-object auth-filter ¶ Especifica una orden que se invocará para la validación de acceso al repositorio.
El valor predeterminado es ‘""’.
- parámetro de
cgit-configuration: string branch-sort ¶ Opción que, cuando tiene valor ‘age’, activa la ordenación por fecha en la lista de referencias de ramas, y cuando tiene valor ‘name’ activa la ordenación por nombre de rama.
El valor predeterminado es ‘"name"’.
- parámetro de
cgit-configuration: string cache-root ¶ Ruta usada para el almacenamiento de las entradas de caché de cgit.
El valor predeterminado es ‘"/var/cache/cgit"’.
- parámetro de
cgit-configuration: integer cache-static-ttl ¶ Número que especifica el tiempo de vida, en minutos, de la versión en caché de las páginas del repositiorio accedidas mediante un hash SHA1 fijo.
El valor predeterminado es ‘-1’.
- parámetro de
cgit-configuration: integer cache-dynamic-ttl ¶ Número que especifica el tiempo de vida, en minutos, de la versión en caché de las páginas del repositorio accedidas sin un hash SHA1 fijo.
El valor predeterminado es ‘5’.
- parámetro de
cgit-configuration: integer cache-repo-ttl ¶ Número que especifica el tiempo de vida, en minutos, de la versión en caché de la página de resumen del repositorio.
El valor predeterminado es ‘5’.
- parámetro de
cgit-configuration: integer cache-root-ttl ¶ Número que especifica el tiempo de vida, en minutos, de la versión en caché de la página del índice de repositorios.
El valor predeterminado es ‘5’.
- parámetro de
cgit-configuration: integer cache-scanrc-ttl ¶ Número que especifica el tiempo de vida, en minutos, para el resultado de la búsqueda en una ruta para repositorios Git.
El valor predeterminado es ‘15’.
- parámetro de
cgit-configuration: integer cache-about-ttl ¶ Número que especifica el tiempo de vida, en minutos, de la versión en caché de la página de información del repositorio.
El valor predeterminado es ‘15’.
- parámetro de
cgit-configuration: integer cache-snapshot-ttl ¶ Número que especifica el tiempo de vida, en minutos, de la versión en caché de las instantáneas.
El valor predeterminado es ‘5’.
- parámetro de
cgit-configuration: integer cache-size ¶ El número máximo de entradas en la caché de cgit. Cuando el valor es ‘0’, se desactiva el almacenamiento en caché.
El valor predeterminado es ‘0’.
- parámetro de
cgit-configuration: boolean case-sensitive-sort? ¶ Ordena los elementos en la lista del repositorio diferenciando las mayúsculas.
El valor predeterminado es ‘#t’
- parámetro de
cgit-configuration: lista clone-prefix ¶ Lista de prefijos comunes que, cuando se combinen con la URL de un repositorio, generan una URL que permite el clonado del repositorio.
El valor predeterminado es ‘()’.
- parámetro de
cgit-configuration: lista clone-url ¶ Lista de plantillas
clone-url.El valor predeterminado es ‘()’.
- parámetro de
cgit-configuration: file-object commit-filter ¶ Orden ejecutada para el formato de mensajes de revisión.
El valor predeterminado es ‘""’.
- parámetro de
cgit-configuration: string commit-sort ¶ Opción que, cuando tiene valor ‘date’, activa la ordenación estricta por fecha en el registro histórico de revisiones, y cuando tiene valor ‘topo’ activa la ordenación estricta topológica.
El valor predeterminado es ‘"git log"’.
- parámetro de
cgit-configuration: file-object css ¶ URL que especifica el documento css incluido en todas las páginas de cgit.
El valor predeterminado es ‘"/share/cgit/cgit.css"’.
- parámetro de
cgit-configuration: file-object email-filter ¶ Especifica una orden que se llamará para dar formato a los nombres y las direcciones de correo electrónico de las revisoras, autoras y etiquetadoras con el que se representarán en varios lugares de la interfaz cgit.
El valor predeterminado es ‘""’.
- parámetro de
cgit-configuration: boolean embedded? ¶ Opción que, cuando tiene valor ‘#t’, hace que cgit genere un fragmento HTML adecuado para embeberse en otras páginas HTML.
El valor predeterminado es ‘#f’
- parámetro de
cgit-configuration: boolean enable-commit-graph? ¶ Opción que, cuando tiene el valor ‘#t’, hace que cgit imprima un grafo histórico de la revisión de arte ASCII a la izquierda de los mensajes de revisión en la página del histórico del repositorio.
El valor predeterminado es ‘#f’
- parámetro de
cgit-configuration: boolean enable-filter-overrides? ¶ Opción que, cuando tiene valor ‘#t’, permite que todas las configuraciones de filtros se sustituyan en los archivos cgitrc específicos del repositorio.
El valor predeterminado es ‘#f’
- parámetro de
cgit-configuration: boolean enable-follow-links? ¶ Opción que, cuando tiene valor ‘#t’, permite a las usuarias seguir un archivo en la vista de registro (log).
El valor predeterminado es ‘#f’
- parámetro de
cgit-configuration: boolean enable-http-clone? ¶ Si se proporciona ‘#t’, cgit actuará como un simple servidor HTTP para los clones de Git.
El valor predeterminado es ‘#t’
- parámetro de
cgit-configuration: boolean enable-index-links? ¶ Opción que, cuando tiene valor ‘#t’, hace que cgit genere enlaces adicionales "summary" (resumen), "commit" (revisión) y "tree" (árbol) para cada repositorio en el índice de repositorios.
El valor predeterminado es ‘#f’
- parámetro de
cgit-configuration: boolean enable-index-owner? ¶ Opción que, cuando tiene valor ‘#t’, hace que cgit muestre la propietaria de cada repositorio en el índice del repositorios.
El valor predeterminado es ‘#t’
- parámetro de
cgit-configuration: boolean enable-log-filecount? ¶ Opción que, cuando se proporciona el valor ‘#t’, hace que cgit imprima el número de archivos modificados por cada revisión en la página de registro histórico del repositorio ("log").
El valor predeterminado es ‘#f’
- parámetro de
cgit-configuration: boolean enable-log-linecount? ¶ Opción que, cuando se proporciona el valor ‘#t’, hace que cgit imprima el número de líneas añadidas y eliminadas en cada revisión en la página de registro histórico ("log").
El valor predeterminado es ‘#f’
- parámetro de
cgit-configuration: boolean enable-remote-branches? ¶ Opción que, cuando se proporciona el valor ‘#t’, hace que cgit muestre ramas remotas en las vistas de resumen ("summary") y de referencias ("refs").
El valor predeterminado es ‘#f’
- parámetro de
cgit-configuration: boolean enable-subject-links? ¶ Opción que, cuando se proporciona el valor
1, hace que cgit use el asunto de la revisión previa como texto del enlace cuando se generen enlaces a revisiones previas en la vista de la revisión.El valor predeterminado es ‘#f’
- parámetro de
cgit-configuration: boolean enable-html-serving? ¶ Opción que, cuando se proporciona el valor ‘#t’, hace que cgit use el asunto de la revisión previa como texto del enlace cuando se generen enlaces a revisiones previas en la vista de la revisión.
El valor predeterminado es ‘#f’
- parámetro de
cgit-configuration: boolean enable-tree-linenumbers? ¶ Opción que, cuando se proporciona el valor ‘#t’, hace que cgit genere enlaces de números de línea para los archivos (blob) de texto plano impresos en la vista de árbol.
El valor predeterminado es ‘#t’
- parámetro de
cgit-configuration: boolean enable-git-config? ¶ Opción que, cuando tiene valor ‘#f’, permite que cgit use la configuración de Git para fijar el valor de cualquier opción específica del repositorio.
El valor predeterminado es ‘#f’
- parámetro de
cgit-configuration: file-object favicon ¶ URL usada para icono de los enlaces a cgit.
El valor predeterminado es ‘"/favicon.ico"’.
El contenido del archivo especificado con esta opción se incluirá literalmente en la parte inferior de todas las páginas (es decir, sustituye al mensaje estándar "generated by...").
El valor predeterminado es ‘""’.
- parámetro de
cgit-configuration: string head-include ¶ El contenido del archivo especificado con esta opción se incluirá literalmente en la sección HEAD de HTML en todas las páginas.
El valor predeterminado es ‘""’.
- parámetro de
cgit-configuration: string header ¶ El contenido del archivo especificado con esta opción se incluirá literalmente en la parte superior de todas las páginas.
El valor predeterminado es ‘""’.
- parámetro de
cgit-configuration: file-object include ¶ Nombre de un archivo de configuración que debe incluirse antes de procesar el resto del archivo de configuración actual.
El valor predeterminado es ‘""’.
- parámetro de
cgit-configuration: string index-header ¶ El contenido del archivo especificado en esta opción se incluirá literalmente sobre el índice de repositorios.
El valor predeterminado es ‘""’.
- parámetro de
cgit-configuration: string index-info ¶ El contenido del archivo especificado con esta opción se incluirá de manera literal bajo la cabecera en la página de índice del repositorio.
El valor predeterminado es ‘""’.
- parámetro de
cgit-configuration: boolean local-time? ¶ Opción que, cuando tiene valor ‘#t’, hace que cgit imprima las fechas de revisión y etiqueta en la zona horaria del servidor.
El valor predeterminado es ‘#f’
- parámetro de
cgit-configuration: file-object logo ¶ URL que especifica la fuente de una imagen usada como logo en todas las páginas de cgit.
El valor predeterminado es ‘"/share/cgit/cgit.png"’.
- parámetro de
cgit-configuration: string logo-link ¶ URL que se carga al pulsar la imagen del logo de cgit.
El valor predeterminado es ‘""’.
- parámetro de
cgit-configuration: file-object owner-filter ¶ Orden que se ejecuta para dar formato a la columna de propietaria (Owner) de la página principal.
El valor predeterminado es ‘""’.
- parámetro de
cgit-configuration: integer max-atom-items ¶ Número de elementos a mostrar en la vista de “atom feeds”.
El valor predeterminado es ‘10’.
- parámetro de
cgit-configuration: integer max-commit-count ¶ Número de entradas a mostrar por página en la vista del registro histórico ("log").
El valor predeterminado es ‘50’.
- parámetro de
cgit-configuration: integer max-message-length ¶ Número de caracteres del mensaje de la revisión a mostrar en la vista del registro histórico ("log").
El valor predeterminado es ‘80’.
- parámetro de
cgit-configuration: integer max-repo-count ¶ Especifica el número de entradas a mostrar por página en la página de índice de repositorios.
El valor predeterminado es ‘50’.
- parámetro de
cgit-configuration: integer max-repodesc-length ¶ Especifica el número máximo de caracteres mostrados en la descripción del repositorio en la página del índice de repositorios.
El valor predeterminado es ‘80’.
- parámetro de
cgit-configuration: integer max-blob-size ¶ Especifica el tamaño máximo de un archivo (blob) para mostrarlo en HTML en kilobytes.
El valor predeterminado es ‘0’.
- parámetro de
cgit-configuration: string max-stats ¶ Periodo estadístico máximo. Son valores aceptados ‘week’, ‘month’, ‘quarter’ and ‘year’.
El valor predeterminado es ‘""’.
- parámetro de
cgit-configuration: mimetype-alist mimetype ¶ Tipo MIME para la extensión de archivo especificada.
El valor predeterminado es ‘((gif "image/gif") (html "text/html") (jpg "image/jpeg") (jpeg "image/jpeg") (pdf "application/pdf") (png "image/png") (svg "image/svg+xml"))’.
- parámetro de
cgit-configuration: file-object mimetype-file ¶ Especifica el archivo usado para la búsqueda automática de tipos MIME.
El valor predeterminado es ‘""’.
- parámetro de
cgit-configuration: string module-link ¶ Texto que se usará como la cadena de formato para un enlace cuando un submódulo se imprime en el listado del directorio.
El valor predeterminado es ‘""’.
- parámetro de
cgit-configuration: boolean nocache? ¶ Si se proporciona el valor ‘#t’, se desactiva la caché.
El valor predeterminado es ‘#f’
- parámetro de
cgit-configuration: boolean noplainemail? ¶ Si se proporciona ‘#t’, se desactiva la impresión de direcciones de correo completas de las autoras.
El valor predeterminado es ‘#f’
- parámetro de
cgit-configuration: boolean noheader? ¶ Opción que, cuando tiene valor ‘#t’, hace que cgit omita la cabecera estándar en todas las páginas.
El valor predeterminado es ‘#f’
- parámetro de
cgit-configuration: lista-proyectos project-list ¶ Una lista de subdirectorios dentro de
repository-directory, relativa a él, que debe cargarse como repositorios Git. La lista vacía significa que se cargarán todos los subdirectorios.El valor predeterminado es ‘()’.
- parámetro de
cgit-configuration: file-object readme ¶ Texto usado como valor predeterminado para
cgit-repo-readme.El valor predeterminado es ‘""’.
- parámetro de
cgit-configuration: boolean remove-suffix? ¶ Si se proporciona
#tyrepository-directoryestá activo, si se encuentra algún repositorio con el sufijo.git, se elimina dicho sufijo de la URL y del nombre.El valor predeterminado es ‘#f’
- parámetro de
cgit-configuration: integer renamelimit ¶ Número máximo de archivos considerados durante la detección de renombrados.
El valor predeterminado es ‘-1’.
- parámetro de
cgit-configuration: string repository-sort ¶ La forma de ordenar los repositorios de cada sección.
El valor predeterminado es ‘""’.
- parámetro de
cgit-configuration: lista-robots robots ¶ Texto usado como contenido de la meta-etiqueta
robots.El valor predeterminado es ‘("noindex" "nofollow")’.
- parámetro de
cgit-configuration: string root-desc ¶ Texto impreso bajo la cabecera en la página de índice del repositorio.
El valor predeterminado es ‘"a fast webinterface for the git dscm"’.<
- parámetro de
cgit-configuration: string root-readme ¶ El contenido del archivo especificado con esta opción se incluirá de manera literal tras el enlace de información del repositorio (“about”) en la página de índice del repositorio.
El valor predeterminado es ‘""’.
- parámetro de
cgit-configuration: string root-title ¶ Texto impreso como cabecera en la página de índice del repositorio.
El valor predeterminado es ‘""’.
Si se proporciona ‘#t’ y repository-directory está activo, repository-directory recorrerá recursivamente los directorios cuyos nombres comiencen por punto. En otro caso, repository-directory no tendrá en cuenta dichos directorios, considerados ocultos (“hidden”). Tenga en cuenta que esto no incluye al directorio .git en repositorios con una copia de trabajo.
El valor predeterminado es ‘#f’
- parámetro de
cgit-configuration: lista snapshots ¶ Texto que especifica el conjunto predeterminado de formatos de instantánea para los que cgit genera enlaces.
El valor predeterminado es ‘()’.
- parámetro de
cgit-configuration: directorio-repositorio repository-directory ¶ Nombre del directorio en el que se buscarán repositorios (representa
scan-path).El valor predeterminado es ‘"/srv/git"’.
- parámetro de
cgit-configuration: string section ¶ Nombre actual de la sección de repositorios - todos los repositorios definidos tras esta opción heredarán el nombre actual de sección.
El valor predeterminado es ‘""’.
- parámetro de
cgit-configuration: string section-sort ¶ Opción que, cuando tiene valor ‘1’, ordenará las secciones en el listado de repositorios por nombre.
El valor predeterminado es ‘""’.
- parámetro de
cgit-configuration: integer section-from-path ¶ Número que, si se define antes de repository-directory, especifica cuantos elementos de ruta de cada ruta de repositorio se usarán como nombre de sección predeterminado.
El valor predeterminado es ‘0’.
- parámetro de
cgit-configuration: boolean side-by-side-diffs? ¶ Si se proporciona el valor ‘#t’ se muestran las diferencias lado a lado en vez de usar el formato universal de manera predeterminada.
El valor predeterminado es ‘#f’
- parámetro de
cgit-configuration: file-object source-filter ¶ Especifica la orden que se ejecutará para dar formato a los archivos (blob) de texto plano en la vista de árbol.
El valor predeterminado es ‘""’.
- parámetro de
cgit-configuration: integer summary-branches ¶ Especifica el número de ramas mostradas en la vista resumen (“summary”) del repositorio.
El valor predeterminado es ‘10’.
- parámetro de
cgit-configuration: integer summary-log ¶ Especifica el número de entradas del registro mostradas en la vista resumen (“summary”) del repositorio.
El valor predeterminado es ‘10’.
Especifica el número que etiquetas que se mostrarán en la vista resumen (“summary”) del repositorio.
El valor predeterminado es ‘10’.
- parámetro de
cgit-configuration: string strict-export ¶ Nombre de archivo que, en caso de especificarse, debe estar presente en el repositiorio para que se permita el acceso de cgit a dicho repositorio.
El valor predeterminado es ‘""’.
- parámetro de
cgit-configuration: string virtual-root ¶ URL que, en caso de especificarse, se usará como raíz de todos los enlaces de cgit.
El valor predeterminado es ‘"/"’.
- parámetro de
cgit-configuration: lista-repository-cgit-configuration repositories ¶ Lista de registros cgit-repo usados con la configuración.
El valor predeterminado es ‘()’.
Los campos disponibles de
repository-cgit-configurationson:- parámetro de
repository-cgit-configuration: repo-list snapshots ¶ Una máscara de los formatos de instantánea para este repositorio para los que cgit genera enlaces, restringida por la opción de configuración global
snapshots.El valor predeterminado es ‘()’.
- parámetro de
repository-cgit-configuration: repo-file-object source-filter ¶ Sustituye al valor predeterminado de
source-filter.El valor predeterminado es ‘""’.
- parámetro de
repository-cgit-configuration: repo-string url ¶ La URL relativa usada para el acceso al repositorio.
El valor predeterminado es ‘""’.
- parámetro de
repository-cgit-configuration: repo-file-object about-filter ¶ Sustituye al valor predeterminado de
about-filter.El valor predeterminado es ‘""’.
- parámetro de
repository-cgit-configuration: repo-string branch-sort ¶ Cuando se proporciona el valor ‘age’, activa la ordenación por fecha en la lista de referencias de ramas, y cuando se proporciona ‘name’ se activa la ordenación por nombre de rama.
El valor predeterminado es ‘""’.
- parámetro de
repository-cgit-configuration: repo-list clone-url ¶ Una lista de URL que se pueden usar para clonar el repositorio.
El valor predeterminado es ‘()’.
- parámetro de
repository-cgit-configuration: repo-file-object commit-filter ¶ Sustituye al valor predeterminado de
commit-filter.El valor predeterminado es ‘""’.
- parámetro de
repository-cgit-configuration: repo-string commit-sort ¶ Opción que, cuando tiene valor ‘date’, activa la ordenación estricta por fecha en el registro histórico de revisiones, y cuando tiene valor ‘topo’ activa la ordenación estricta topológica.
El valor predeterminado es ‘""’.
- parámetro de
repository-cgit-configuration: repo-string defbranch ¶ Nombre de la rama predeterminada de este repositorio. Si no existe dicha rama en el repositorio, se usará como predeterminado el primer nombre de rama encontrado (tras su ordenación). De manera predeterminada, la rama a la que apunta HEAD, o “master” si no existe un valor adecuado para HEAD.
El valor predeterminado es ‘""’.
- parámetro de
repository-cgit-configuration: repo-string desc ¶ El valor a mostrar como descripción del repositorio.
El valor predeterminado es ‘""’.
- parámetro de
repository-cgit-configuration: repo-string homepage ¶ El valor a mostrar como página web principal del repositorio.
El valor predeterminado es ‘""’.
- parámetro de
repository-cgit-configuration: repo-file-object email-filter ¶ Sustituye al valor predeterminado de
email-filter.El valor predeterminado es ‘""’.
- parámetro de
repository-cgit-configuration: maybe-repo-boolean enable-commit-graph? ¶ Esta opción se puede usar para forzar el valor de la opción de configuración global
enable-commit-graph?.El valor predeterminado es ‘disabled’.
- parámetro de
repository-cgit-configuration: maybe-repo-boolean enable-log-filecount? ¶ Esta opción se puede usar para forzar el valor de la opción de configuración global
enable-log-filecount?.El valor predeterminado es ‘disabled’.
- parámetro de
repository-cgit-configuration: maybe-repo-boolean enable-log-linecount? ¶ Esta opción se puede usar para forzar el valor de la opción de configuración global
enable-log-linecount?.El valor predeterminado es ‘disabled’.
- parámetro de
repository-cgit-configuration: maybe-repo-boolean enable-remote-branches? ¶ Opción que, cuando se proporciona el valor ‘#t’, hace que cgit muestre ramas remotas en las vistas de resumen ("summary") y de referencias ("refs").
El valor predeterminado es ‘disabled’.
- parámetro de
repository-cgit-configuration: maybe-repo-boolean enable-subject-links? ¶ Esta opción se puede usar para forzar el valor de la opción de configuración global
enable-subject-links?.El valor predeterminado es ‘disabled’.
- parámetro de
repository-cgit-configuration: maybe-repo-boolean enable-html-serving? ¶ Esta opción se puede usar para forzar el valor de la opción de configuración global
enable-html-serving?.El valor predeterminado es ‘disabled’.
- parámetro de
repository-cgit-configuration: repo-boolean hide? ¶ Opción que, cuando tiene valor ‘#t’, oculta el repositorio en el índice.
El valor predeterminado es ‘#f’
- parámetro de
repository-cgit-configuration: repo-boolean ignore? ¶ Opción que, cuando tiene valor ‘#t’, ignora el repositorio.
El valor predeterminado es ‘#f’
- parámetro de
repository-cgit-configuration: repo-file-object logo ¶ URL que especifica la fuente de una imagen que se usará como logo en las páginas de este repositorio.
El valor predeterminado es ‘""’.
- parámetro de
repository-cgit-configuration: repo-string logo-link ¶ URL que se carga al pulsar la imagen del logo de cgit.
El valor predeterminado es ‘""’.
- parámetro de
repository-cgit-configuration: repo-file-object owner-filter ¶ Sustituye al valor predeterminado de
owner-filter.El valor predeterminado es ‘""’.
- parámetro de
repository-cgit-configuration: repo-string module-link ¶ Texto que se usará como la cadena de formato de un enlace cuando un submódulo se imprima en el listado de un directorio. Los parámetros para la cadena de formato son la ruta y el SHA1 de la revisión del submódulo.
El valor predeterminado es ‘""’.
- parámetro de
repository-cgit-configuration: ruta-enlace-módulo module-link ¶ Texto que se usará como la cadena de formato de un enlace cuando un submódulo con la ruta de subdirectorio especificada se imprima en el listado de un directorio.
El valor predeterminado es ‘()’.
- parámetro de
repository-cgit-configuration: repo-string max-stats ¶ Sustituye al máximo periodo estadístico predeterminado.
El valor predeterminado es ‘""’.
- parámetro de
repository-cgit-configuration: repo-string name ¶ El valor a mostrar como nombre del repositorio.
El valor predeterminado es ‘""’.
- parámetro de
repository-cgit-configuration: repo-string owner ¶ Un valor usado para identificar a la propietaria del repositorio.
El valor predeterminado es ‘""’.
- parámetro de
repository-cgit-configuration: repo-string path ¶ La ruta absoluta al directorio del repositorio.
El valor predeterminado es ‘""’.
- parámetro de
repository-cgit-configuration: repo-string readme ¶ Una ruta (relativa al repositorio) que especifica un archivo que será incluido literalmente como página de información (“About”) de este repositorio.
El valor predeterminado es ‘""’.
- parámetro de
repository-cgit-configuration: repo-string section ¶ Nombre actual de la sección de repositorios - todos los repositorios definidos tras esta opción heredarán el nombre actual de sección.
El valor predeterminado es ‘""’.
- parámetro de
repository-cgit-configuration: repo-list extra-options ¶ Opciones adicionales a agregar al final del archivo cgitrc.
El valor predeterminado es ‘()’.
- parámetro de
- parámetro de
cgit-configuration: lista extra-options ¶ Opciones adicionales a agregar al final del archivo cgitrc.
El valor predeterminado es ‘()’.
No obstante, puede ser que únicamente desee usar un archivo cgitrc
existente. En ese caso, puede proporcionar opaque-cgit-configuration
como un registro a cgit-service-type. Como su nombre en inglés
indica, una configuración opaca no tiene gran capacidad reflexiva.
Los campos disponibles de opaque-cgit-configuration son:
- parámetro de
opaque-cgit-configuration: package cgit ¶ El paquete cgit.
- parámetro de
opaque-cgit-configuration: string string ¶ El contenido de
cgitrc, como una cadena.
Por ejemplo, si su cgitrc es simplemente la cadena vacía, puede
instanciar un servicio cgit de esta manera:
(service cgit-service-type
(opaque-cgit-configuration
(cgitrc "")))
Servicio Gitolite
Gitolite es una herramienta para el almacenamiento de repositorios Git en un servidor central.
Gitolite puede manejar múltiples repositorios y usuarias, y permite una configuración flexible de los permisos de las usuarias sobre los repositorios.
El siguiente ejemplo configuraría Gitolite con la usuaria predeterminada
git y la clave pública SSH proporcionada.
(service gitolite-service-type
(gitolite-configuration
(admin-pubkey (plain-file
"sunombre.pub"
"ssh-rsa AAAA... guix@example.com"))))
Gitolite se configura a través de un repositorio de administración especial
que puede clonar, por ejemplo, si configuró Gitolite en example.org,
ejecutaría la siguiente orden para clonar el repositorio de administración.
git clone git@example.com:gitolite-admin
Cuando se activa el servicio Gitolite, la clave admin-pubkey
proporcionada se insertará en el directorio keydir en el repositorio
gitolite-admin. Si esto resultase en un cambio en el repositorio, la
revisión se almacenaría con el mensaje “gitolite setup by GNU Guix”.
- Tipo de datos: gitolite-configuration
Tipo de datos que representa la configuración de
gitolite-service-type.package(predeterminado: gitolite)Gitolite package to use. There are optional Gitolite dependencies that are not included in the default package, such as Redis and git-annex. These features can be made available by using the
make-gitoliteprocedure in the(gnu packages version-control) module to produce a variant of Gitolite with the desired additional dependencies.The following code returns a package in which the Redis and git-annex programs can be invoked by Gitolite’s scripts:
(use-modules (gnu packages databases) (gnu packages haskell-apps) (gnu packages version-control)) (make-gitolite (list redis git-annex))user(predeterminada: git)Usuaria usada por Gitolite. Esta será la usuaria a la que se conectará cuando acceda a Gitolite a través de SSH.
group(predeterminado: git)Grupo usado por Gitolite.
home-directory(predeterminado: "/var/lib/gitolite")Directorio en el que se almacenará la configuración y repositorios de Gitolite.
rc-file(predeterminado: (gitolite-rc-file))Un objeto “tipo-archivo” (see objetos “tipo-archivo”), que representa la configuración de Gitolite.
admin-pubkey(predeterminada: #f)Un objeto “tipo-archivo” (see objetos “tipo-archivo”) usado para la configuración de Gitolite. Se insertará en el directorio keydir dentro del repositorio gitolite-admin.
Para especificar la clave SSH como una cadena, use la función
plain-file.(plain-file "sunombre.pub" "ssh-rsa AAAA... guix@example.com")
- Tipo de datos: gitolite-rc-file
Tipo de datos que representa el archivo RC de Gitolite.
umask(predeterminada:#o0077)Controla los permisos que Gitolite establece en los repositorios y sus contenidos.
A value like
#o0027will give read access to the group used by Gitolite (by default:git). This is necessary when using Gitolite with software like cgit or gitweb.local-code(default:"$rc{GL_ADMIN_BASE}/local")Allows you to add your own non-core programs, or even override the shipped ones with your own.
Please supply the FULL path to this variable. By default, directory called "local" in your gitolite clone is used, providing the benefits of versioning them as well as making changes to them without having to log on to the server.
unsafe-pattern(default:#f)An optional Perl regular expression for catching unsafe configurations in the configuration file. See Gitolite’s documentation for more information.
When the value is not
#f, it should be a string containing a Perl regular expression, such as ‘"[`~#\$\&()|;<>]"’, which is the default value used by gitolite. It rejects any special character in configuration that might be interpreted by a shell, which is useful when sharing the administration burden with other people that do not otherwise have shell access on the server.git-config-keys(predeterminadas:"")Gitolite allows you to set git config values using the ‘config’ keyword. This setting allows control over the config keys to accept.
roles(predeterminados:'(("READERS" . 1) ("WRITERS" . )))Establece los nombres de rol que se permite usar a las usuarias que ejecuten la orden perms.
enable(predeterminados:'("help" "desc" "info" "perms" "writable" "ssh-authkeys" "git-config" "daemon" "gitweb"))Esta configuración controla las órdenes y características activadas dentro de Gitolite.
Gitile Service
Gitile is a Git forge for viewing public git repository contents from a web browser.
Gitile works best in collaboration with Gitolite, and will serve the public repositories from Gitolite by default. The service should listen only on a local port, and a webserver should be configured to serve static resources. The gitile service provides an easy way to extend the Nginx service for that purpose (see NGINX).
The following example will configure Gitile to serve repositories from a custom location, with some default messages for the home page and the footers.
(service gitile-service-type
(gitile-configuration
(repositories "/srv/git")
(base-git-url "https://myweb.site/git")
(index-title "My git repositories")
(intro '((p "This is all my public work!")))
(footer '((p "This is the end")))
(nginx-server-block
(nginx-server-configuration
(ssl-certificate
"/etc/letsencrypt/live/myweb.site/fullchain.pem")
(ssl-certificate-key
"/etc/letsencrypt/live/myweb.site/privkey.pem")
(listen '("443 ssl http2" "[::]:443 ssl http2"))
(locations
(list
;; Allow for https anonymous fetch on /git/ urls.
(git-http-nginx-location-configuration
(git-http-configuration
(uri-path "/git/")
(git-root "/var/lib/gitolite/repositories")))))))))
In addition to the configuration record, you should configure your git repositories to contain some optional information. First, your public repositories need to contain the git-daemon-export-ok magic file that allows Git to export the repository. Gitile uses the presence of this file to detect public repositories it should make accessible. To do so with Gitolite for instance, modify your conf/gitolite.conf to include this in the repositories you want to make public:
repo foo
R = daemon
In addition, Gitile can read the repository configuration to display more information on the repository. Gitile uses the gitweb namespace for its configuration. As an example, you can use the following in your conf/gitolite.conf:
repo foo
R = daemon
desc = A long description, optionally with <i>HTML</i>, shown on the index page
config gitweb.name = The Foo Project
config gitweb.synopsis = A short description, shown on the main page of the project
Do not forget to commit and push these changes once you are satisfied. You may need to change your gitolite configuration to allow the previous configuration options to be set. One way to do that is to add the following service definition:
(service gitolite-service-type
(gitolite-configuration
(admin-pubkey (local-file "key.pub"))
(rc-file
(gitolite-rc-file
(umask #o0027)
;; Allow to set any configuration key
(git-config-keys ".*")
;; Allow any text as a valid configuration value
(unsafe-patt "^$")))))
- Data Type: gitile-configuration
Data type representing the configuration for
gitile-service-type.package(default: gitile)Gitile package to use.
host(predeterminado:"localhost")The host on which gitile is listening.
port(default:8080)The port on which gitile is listening.
database(default:"/var/lib/gitile/gitile-db.sql")The location of the database.
repositories(default:"/var/lib/gitolite/repositories")The location of the repositories. Note that only public repositories will be shown by Gitile. To make a repository public, add an empty git-daemon-export-ok file at the root of that repository.
base-git-urlThe base git url that will be used to show clone commands.
index-title(default:"Index")The page title for the index page that lists all the available repositories.
intro(default:'())The intro content, as a list of sxml expressions. This is shown above the list of repositories, on the index page.
footer(default:'())The footer content, as a list of sxml expressions. This is shown on every page served by Gitile.
nginx-server-blockAn nginx server block that will be extended and used as a reverse proxy by Gitile to serve its pages, and as a normal web server to serve its assets.
You can use this block to add more custom URLs to your domain, such as a
/git/URL for anonymous clones, or serving any other files you would like to serve.
Next: Servicio PAM Mount, Previous: Servicios de control de versiones, Up: Servicios [Contents][Index]
12.9.31 Servicios de juegos
El servicio de La batalla por Wesnoth
La batalla por Wesnoth es un juego de estrategia táctica, de fantasía y basado en turnos, con varias campañas de una jugadora, y partidas para múltiples jugadoras (tanto en red como localmente).
- Variable: Variable Scheme wesnothd-service-type
Tipo de servicio para el servicio wesnothd. Su valor debe ser un objeto
wesnothd-configuration. Puede instanciarlo de esta manera para ejecutar wesnothd con la configuración predeterminada:(service wesnothd-service-type)
- Tipo de datos: wesnothd-configuration
Tipo de datos que representa la configuración de
wesnothd.package(predeterminado:wesnoth-server)El paquete del servidor wesnoth usado.
port(predeterminado:15000)Número de puerto usado por el servidor.
Next: Servicios de Guix, Previous: Servicios de juegos, Up: Servicios [Contents][Index]
12.9.32 Servicio PAM Mount
El módulo (gnu services pam-mount) proporciona un servicio que
permite a las usuarias montar volúmenes cuando ingresen al sistema. Debe ser
capaz de montar cualquier formato de volumen que el sistema permita.
- Variable: Variable Scheme pam-mount-service-type
Tipo de servicio para la implementación de PAM Mount.
- Tipo de datos: pam-mount-configuration
Tipo de datos que representa la configuración de PAM Mount.
Toma los siguientes parámetros:
rulesLas reglas de configuración que se usarán para generar /etc/security/pam_mount.conf.xml.
Las reglas de configuración son elementos SXML (see SXML in GNU Guile Reference Manual), y las reglas predeterminadas no incluyen el montado de ningún dispositivo para ningún usuario en el ingreso al sistema:
`((debug (@ (enable "0"))) (mntoptions (@ (allow ,(string-join '("nosuid" "nodev" "loop" "encryption" "fsck" "nonempty" "allow_root" "allow_other") ",")))) (mntoptions (@ (require "nosuid,nodev"))) (logout (@ (wait "0") (hup "0") (term "no") (kill "no"))) (mkmountpoint (@ (enable "1") (remove "true"))))
Algunos elementos
volumedeben añadirse de manera automática para montar volúmenes en el ingreso. El siguiente ejemplo permite a la usuariaaliciamontar su directorioHOMEcifrado y permite al usuariorobermontar la partición donde almacena sus datos:(define reglas-pam-mount `((debug (@ (enable "0"))) (volume (@ (user "alicia") (fstype "crypt") (path "/dev/sda2") (mountpoint "/home/alicia"))) (volume (@ (user "rober") (fstype "auto") (path "/dev/sdb3") (mountpoint "/home/rober/data") (options "defaults,autodefrag,compress"))) (mntoptions (@ (allow ,(string-join '("nosuid" "nodev" "loop" "encryption" "fsck" "nonempty" "allow_root" "allow_other") ",")))) (mntoptions (@ (require "nosuid,nodev"))) (logout (@ (wait "0") (hup "0") (term "no") (kill "no"))) (mkmountpoint (@ (enable "1") (remove "true"))))) (service pam-mount-service-type (pam-mount-configuration (rules reglas-pam-mount)))
La lista completa de opciones posibles se puede encontrar en la página de
mande pam_mount.conf.
Next: Servicios de Linux, Previous: Servicio PAM Mount, Up: Servicios [Contents][Index]
12.9.33 Servicios de Guix
Coordinador de construcciones de Guix
El coordinador de construcciones de Guix ayuda en la distribución de las construcciones de derivaciones entre máquinas que ejecuten un agente. El daemon de construcción se usa todavía para la construcción de las derivaciones, pero el coordinador de construcciones de Guix gestiona su lanzamiento y trabaja con los resultados.
The Guix Build Coordinator consists of one coordinator, and one or more connected agent processes. The coordinator process handles clients submitting builds, and allocating builds to agents. The agent processes talk to a build daemon to actually perform the builds, then send the results back to the coordinator.
Existe un guión para ejecutar el componente de coordinación del servicio de coordinación de construcciones de Guix, pero el servicio de Guix utiliza un guión Guile personalizado en vez de este, para mejorar la integración con las expresiones-G usadas en la configuración.
- Variable: Variable Scheme guix-build-coordinator-service-type
Tipo de servicio para la coordinación de construcciones de Guix. Su valor debe ser un objeto
guix-build-coordinator-configuration.
- Tipo de datos: guix-build-coordinator-configuration
Tipo de datos que representa la configuración del servicio de coordinación de construcciones de Guix.
package(predeterminado:guix-build-coordinator)El paquete del servicio de coordinación de construcciones de Guix usado.
user(predeterminado:"guix-build-coordinator")Usuaria del sistema que ejecuta el servicio.
group(predeterminado:"guix-build-coordinator")Grupo del sistema que ejecuta el servicio.
database-uri-string(predeterminada:"sqlite:///var/lib/guix-build-coordinator/guix_build_coordinator.db")URI usada para la conexión a la base de datos.
agent-communication-uri(predeterminada:"http://0.0.0.0:8745")La URI que describe cómo escuchar peticiones de los procesos agentes.
client-communication-uri(predeterminada:"http://127.0.0.1:8746")La URI que describe cómo escuchar peticiones de los clientes. La interfaz para los clientes permite la emisión de construcciones y no implementa identificación actualmente, por lo que tenga cuidado cuando configure este valor.
allocation-strategy(predeterminada:#~basic-build-allocation-strategy)Una expresión-G para la estrategia de reservas usada. Es un procedimiento que recibe la ruta del almacén como un parámetro y rellena la planificación de reservas en la base de datos.
hooks(predeterminada: ’())Una lista asociativa de procedimientos de extensión44. Proporcionan una forma de ejecutar código arbitrario tras ciertos eventos, como inicio del procesamiento del resultado de una construcción.
parallel-hooks(default: ’())Hooks can be configured to run in parallel. This parameter is an association list of hooks to do in parallel, where the key is the symbol for the hook and the value is the number of threads to run.
guile(predeterminado:guile-3.0-latest)El paquete Guile con el que se ejecuta la coordinación de construcciones de Guix.
- Variable: Variable Scheme guix-build-coordinator-agent-service-type
Tipo de servicio para un agente del coordinador de construcciones de Guix. Su valor debe ser un objeto
guix-build-coordinator-agent-configuration.
- Tipo de datos: guix-build-coordinator-agent-configuration
Tipo de datos que representa la configuración de un agente del coordinador de construcciones de Guix.
package(default:guix-build-coordinator/agent-only)El paquete del servicio de coordinación de construcciones de Guix usado.
user(predeterminado:"guix-build-coordinator-agent")Usuaria del sistema que ejecuta el servicio.
coordinator(predeterminado:"http://localhost:8745")URI usada para la conexión al nodo coordinador.
authenticationRecord describing how this agent should authenticate with the coordinator. Possible record types are described below.
systems(predeterminado:#f)Los sistemas para los cuales este agente debe obtener construcciones. Los procesos agente usan el sistema sobre el que se ejecuten como valor predeterminado.
max-parallel-builds(predeterminado:1)El número de construcciones que se ejecutan en paralelo.
max-allocated-builds(default:#f)The maximum number of builds this agent can be allocated.
max-1min-load-average(default:#f)Load average value to look at when considering starting new builds, if the 1 minute load average exceeds this value, the agent will wait before starting new builds.
This will be unspecified if the value is
#f, and the agent will use the number of cores reported by the system as the max 1 minute load average.derivation-substitute-urls(default:#f)Identificadores URL a partir de los cuales se intentará obtener sustituciones para derivaciones, si las derivaciones no están ya disponibles.
non-derivation-substitute-urls(default:#f)Identificadores URL a partir de los cuales se intentará obtener sustituciones para las entradas de las construcciones, si los elementos de entrada del almacén no están ya disponibles.
- Data Type: guix-build-coordinator-agent-password-auth
Data type representing an agent authenticating with a coordinator via a UUID and password.
uuidEl identificador UUID del agente. Debe ser generado por el proceso de coordinación, almacenarse en la base de datos de coordinación, y usarse por parte del agente en cuestión.
passwordThe password to use when connecting to the coordinator.
- Data Type: guix-build-coordinator-agent-password-file-auth
Data type representing an agent authenticating with a coordinator via a UUID and password read from a file.
uuidEl identificador UUID del agente. Debe ser generado por el proceso de coordinación, almacenarse en la base de datos de coordinación, y usarse por parte del agente en cuestión.
password-fileUn archivo que contiene la contraseña usada para la conexión a la máquina coordinadora.
- Data Type: guix-build-coordinator-agent-dynamic-auth
Data type representing an agent authenticating with a coordinator via a dynamic auth token and agent name.
agent-nameName of an agent, this is used to match up to an existing entry in the database if there is one. When no existing entry is found, a new entry is automatically added.
tokenDynamic auth token, this is created and stored in the coordinator database, and is used by the agent to authenticate.
- Data Type: guix-build-coordinator-agent-dynamic-auth-with-file
Data type representing an agent authenticating with a coordinator via a dynamic auth token read from a file and agent name.
agent-nameName of an agent, this is used to match up to an existing entry in the database if there is one. When no existing entry is found, a new entry is automatically added.
token-fileFile containing the dynamic auth token, this is created and stored in the coordinator database, and is used by the agent to authenticate.
El paquete del coordinador de construcciones de Guix contiene un guión para consultar a una instancia del servicio de datos de Guix derivaciones que deben construirse, y envía dichas derivaciones al proceso de coordinación. El siguiente tipo de servicio sirve de asistencia para ejecución de dicho guión. Se trata de una herramienta adicional que resultar de utilidad cuando se construyan derivaciones contenidas dentro de una instancia del servicio de datos de Guix.
- Variable: Variable Scheme guix-build-coordinator-queue-builds-service-type
Tipo de servicio para el guión
guix-build-coordinator-queue-builds-from-guix-data-service. Su valor debe ser un objetoguix-build-coordinator-queue-builds-configuration.
- Tipo de datos: guix-build-coordinator-queue-builds-configuration
Tipo de datos que representa las opciones de la cola de construcciones del guión del servicio de dados de Guix.
package(predeterminado:guix-build-coordinator)El paquete del servicio de coordinación de construcciones de Guix usado.
user(predeterminada:"guix-build-coordinator-queue-builds")Usuaria del sistema que ejecuta el servicio.
coordinator(default:"http://localhost:8746")URI usada para la conexión al nodo coordinador.
systems(predeterminado:#f)Los sistemas para los que se obtienen derivaciones que construir.
systems-and-targets(predeterminado:#f)Una lista asociativa que contiene pares de sistema y objetivo para los que obtener derivaciones que construir.
guix-data-service(predeterminado:"https://data.guix.gnu.org")La instancia del servicio de datos de Guix a la que se consulta para conocer las derivaciones que deben construirse.
guix-data-service-build-server-id(default:#f)The Guix Data Service build server ID corresponding to the builds being submitted. Providing this speeds up the submitting of builds as derivations that have already been submitted can be skipped before asking the coordinator to build them.
processed-commits-file(predeterminado:"/var/cache/guix-build-coordinator-queue-builds/processed-commits")Archivo en el que se registran las revisiones que se han procesado, para evitar procesarlas de nuevo innecesariamente si se reinicia el servicio.
Servicio de datos de Guix
El servicio de datos de Guix procesa, almacena y proporciona datos acerca de GNU Guix. Esto incluye información sobre paquetes, derivaciones y avisos de “lint”.
Los datos se almacenan en una base de datos PostgreSQL, y están disponibles a través de una interfaz web.
- Variable: Variable Scheme guix-data-service-type
Tipo de servicio para el servicio de datos de Guix. Su valor debe ser un objeto
guix-data-service-configuration. El servicio opcionalmente extiende el servicio getmail, puesto que la lista de correo guix-commits se usa para conocer los cambios del repositorio git de Guix.
- Tipo de datos: guix-data-service-configuration
Tipo de datos que representa la configuración del servicio de datos de Guix.
package(predeterminado:guix-data-service)El paquete del servicio de datos de Guix usado.
user(usuaria:"guix-data-service")Usuaria del sistema que ejecuta el servicio.
group(predeterminado:"guix-data-service")Grupo del sistema que ejecuta el servicio.
port(predeterminado:8765)El puerto al que se asociará el servicio web.
host(predeterminada:"127.0.0.1")El nombre de máquina al que se asociará el servicio web.
getmail-idle-mailboxes(predeterminado:#f)Si se proporciona un valor, es la lista de bandejas de correo en las cuales la configuración debe indicar su lectura al servicio getmail.
commits-getmail-retriever-configuration(predeterminado:#f)Si se proporciona un valor, es el objeto
getmail-retriever-configurationcon el que se configura getmail para obtener recibir el correo de la lista guix-commits.extra-options(predeterminadas: ’())Opciones de línea de órdenes adicionales para
guix-data-service.extra-process-jobs-options(predeterminadas: ’())Opciones de línea de órdenes adicionales para
guix-data-service-process-jobs.
Nar Herder
The Nar Herder is a utility for managing a collection of nars.
- Variable: Scheme Variable nar-herder-type
Service type for the Guix Data Service. Its value must be a
nar-herder-configurationobject. The service optionally extends the getmail service, as the guix-commits mailing list is used to find out about changes in the Guix git repository.
- Data Type: nar-herder-configuration
Tipo de datos que representa la configuración del servicio de datos de Guix.
package(default:nar-herder)The Nar Herder package to use.
user(default:"nar-herder")Usuaria del sistema que ejecuta el servicio.
group(default:"nar-herder")Grupo del sistema que ejecuta el servicio.
port(default:8734)Número de puerto usado por el servidor.
host(predeterminada:"127.0.0.1")The host to bind the server to.
mirror(predeterminado:#f)Optional URL of the other Nar Herder instance which should be mirrored. This means that this Nar Herder instance will download it’s database, and keep it up to date.
database(default:"/var/lib/nar-herder/nar_herder.db")Location for the database. If this Nar Herder instance is mirroring another, the database will be downloaded if it doesn’t exist. If this Nar Herder instance isn’t mirroring another, an empty database will be created.
database-dump(default:"/var/lib/nar-herder/nar_herder_dump.db")Location of the database dump. This is created and regularly updated by taking a copy of the database. This is the version of the database that is available to download.
storage(default:#f)Optional location in which to store nars.
storage-limit(default:"none")Limit in bytes for the nars stored in the storage location. This can also be set to “none” so that there is no limit.
When the storage location exceeds this size, nars are removed according to the nar removal criteria.
storage-nar-removal-criteria(default:'())Criteria used to remove nars from the storage location. These are used in conjunction with the storage limit.
When the storage location exceeds the storage limit size, nars will be checked against the nar removal criteria and if any of the criteria match, they will be removed. This will continue until the storage location is below the storage limit size.
Each criteria is specified by a string, then an equals sign, then another string. Currently, only one criteria is supported, checking if a nar is stored on another Nar Herder instance.
ttl(predeterminado:#f)Produce cabeceras HTTP
Cache-Controlque anuncian un tiempo-de-vida (TTL) de ttl. ttl debe indicar una duración:5dsignifica 5 días,1msignifica un mes, etc.This allows the user’s Guix to keep substitute information in cache for ttl.
negative-ttl(default:#f)Similarly produce
Cache-ControlHTTP headers to advertise the time-to-live (TTL) of negative lookups—missing store items, for which the HTTP 404 code is returned. By default, no negative TTL is advertised.log-level(default:'DEBUG)Log level to use, specify a log level like
'INFOto stop logging individual requests.
Next: Servicios de Hurd, Previous: Servicios de Guix, Up: Servicios [Contents][Index]
12.9.34 Servicios de Linux
Servicio Early OOM
Early OOM, también conocido como Earlyoom, es un daemon minimalista de gestión del llenado de la memoria45 que se ejecuta en espacio de usuaria y proporciona una alternativa al gestor del propio núcleo con una respuesta más inmediata y más configurable. Es útil para prevenir que el sistema no responda cuando se queda sin memoria.
- Variable Scheme: earlyoom-service-type
Tipo de servicio para el servicio
earlyoom, el daemon Early OOM. Su valor debe ser un objetoearlyoom-configuration, descrito a continuación. El servicio se puede instanciar con su configuración predeterminada de esta manera:
- Tipo de datos: earlyoom-configuration
Esta es el registro de configuración para el servicio
earlyoom-service-type.earlyoom(predeterminado: earlyoom)El paquete Earlyoom usado.
minimum-available-memory(predeterminado:10)El límite inferior de memoria disponible, en porcentaje.
minimum-free-swap(predeterminado:10)El límite inferior de memoria de intercambio libre, en porcentaje.
prefer-regexp(predeterminado:#f)Una expresión regular (como cadena) que corresponda con los nombres de los procesos que preferiblemente deban pararse.
avoid-regexp(predeterminado:#f)Una expresión regular (como cadena) que corresponda con los nombres de los procesos que no deban pararse.
memory-report-interval(predeterminado:0)Intervalo en segundos con el cual se imprime el informe de memoria. No está activo de manera predeterminada.
ignore-positive-oom-score-adj?(predeterminado:#f)Valor booleano que indica si se deben ignoran los ajustes positivos realizados en /proc/*/oom_score_adj.
show-debug-messages?(predeterminado:#f)Valor booleano que indica si los mensajes de depuración deben imprimirse. Los registros se almacenan en /var/log/earlyoom.log.
send-notification-command(predeterminada:#f)Puede usarse para proporcionar una orden personalizada para el envío de notificaciones.
Servicio de carga de módulos del núcleo
The kernel module loader service allows one to load loadable kernel modules
at boot. This is especially useful for modules that don’t autoload and need
to be manually loaded, as is the case with ddcci.
- Variable Scheme: kernel-module-loader-service-type
Tipo de servicio para la carga de módulos del núcleo durante el arranque con
modprobe. Su valor debe ser una lista de cadenas que representan nombres de módulo. Por ejemplo, la carga de los controladores proporcionados porddcci-driver-linuxen modo de depuración proporcionando algunos parámetros para el módulo puede realizarse de la siguiente manera:(use-modules (gnu) (gnu services)) (use-package-modules linux) (use-service-modules linux) (define ddcci-config (plain-file "ddcci.conf" "options ddcci dyndbg delay=120")) (operating-system ... (services (cons* (service kernel-module-loader-service-type '("ddcci" "ddcci_backlight")) (simple-service 'ddcci-config etc-service-type (list `("modprobe.d/ddcci.conf" ,ddcci-config))) %base-services)) (kernel-loadable-modules (list ddcci-driver-linux)))
Rasdaemon Service
The Rasdaemon service provides a daemon which monitors platform RAS (Reliability, Availability, and Serviceability) reports from Linux kernel trace events, logging them to syslogd.
Reliability, Availability and Serviceability is a concept used on servers meant to measure their robustness.
Relability is the probability that a system will produce correct outputs:
- Generally measured as Mean Time Between Failures (MTBF), and
- Enhanced by features that help to avoid, detect and repair hardware faults
Availability is the probability that a system is operational at a given time:
- Generally measured as a percentage of downtime per a period of time, and
- Often uses mechanisms to detect and correct hardware faults in runtime.
Serviceability is the simplicity and speed with which a system can be repaired or maintained:
- Generally measured on Mean Time Between Repair (MTBR).
Among the monitoring measures, the most usual ones include:
- CPU – detect errors at instruction execution and at L1/L2/L3 caches;
- Memory – add error correction logic (ECC) to detect and correct errors;
- I/O – add CRC checksums for transferred data;
- Storage – RAID, journal file systems, checksums, Self-Monitoring, Analysis and Reporting Technology (SMART).
By monitoring the number of occurrences of error detections, it is possible to identify if the probability of hardware errors is increasing, and, on such case, do a preventive maintenance to replace a degraded component while those errors are correctable.
For detailed information about the types of error events gathered and how to make sense of them, see the kernel administrator’s guide at https://www.kernel.org/doc/html/latest/admin-guide/ras.html.
- Scheme Variable: rasdaemon-service-type
Service type for the
rasdaemonservice. It accepts arasdaemon-configurationobject. Instantiating likewill load with a default configuration, which monitors all events and logs to syslogd.
- Data Type: rasdaemon-configuration
The data type representing the configuration of
rasdaemon.record?(default:#f)-
A boolean indicating whether to record the events in an SQLite database. This provides a more structured access to the information contained in the log file. The database location is hard-coded to /var/lib/rasdaemon/ras-mc_event.db.
Servicio de dispositivo Zram
El servicio de dispositivo Zram proporciona un dispositivo comprimido de intercambio en la memoria del sistema. La documentación del núcleo Linux contiene más información sobre dispositivos zram.
- Variable Scheme: zram-device-service-type
Este servicio crea el dispositivo de bloques zram, le proporciona el formato de la memoria de intercambio y lo activa. El valor del servicio es un registro
zram-device-configuration.- Tipo de datos: zram-device-configuration
Este tipo de datos representa la configuración del servicio zram-device.
size(predeterminado:"1G")Es la cantidad de espacio que desea proporcionar al dispositivo zram. Acepta una cadena y puede ser el número de bytes o usar un sufijo, como por ejemplo
"512M"o1024000.compression-algorithm(predeterminado:'lzo)Algoritmo de compresión que desea usar. Es difícil enumerar todas las opciones de compresión posibles, pero las más habituales entre las implementadas por el núcleo Linux Libre usado por Guix incluyen
'lzo,'lz4y'zstd.memory-limit(predeterminado:0)Cantidad máxima de memoria que el dispositivo zram puede usar. Proporcionar el valor ’0’ desactiva el límite. Mientras que generalmente se espera que la compresión tenga una relación con los datos sin comprimir de 2:1, es posible que se escriban datos en la memoria de intercambio que no se pueden comprimir más, y esta es una forma de limitar cuanta memoria puede usarse. Acepta una cadena y puede ser un número de bytes o un usar sufijo, por ejemplo
"2G".priority(default#f)This is the priority of the swap device created from the zram device. See Swap Space for a description of swap priorities. You might want to set a specific priority for the zram device, otherwise it could end up not being used much for the reasons described there.
Next: Servicios misceláneos, Previous: Servicios de Linux, Up: Servicios [Contents][Index]
12.9.35 Servicios de Hurd
- Variable Scheme: hurd-console-service-type
Este servicio inicia el cliente de consola
VGAen Hurd.El valor de este servicio es un registro
hurd-console-configuration.
- Tipo de datos: hurd-console-configuration
Este tipo de datos representa la configuración del servicio hurd-console-service.
hurd(predeterminado: hurd)El paquete de Hurd usado.
- Variable Scheme: hurd-getty-service-type
Este servicio inicia una interfaz de teletipo (“tty”) mediante el uso del programa
gettyde Hurd.El valor del servicio es un registro
hurd-getty-configuration.
- Tipo de datos: hurd-getty-configuration
Este tipo de datos representa la configuración del servicio hurd-getty-service.
hurd(predeterminado: hurd)El paquete de Hurd usado.
ttyEl nombre de la consola en la que se ejecuta este Getty—por ejemplo,
"tty1".baud-rate(predeterminado:38400)Un entero que especifica la tasa de transmisión de interfaz de teletipo.
Previous: Servicios de Hurd, Up: Servicios [Contents][Index]
12.9.36 Servicios misceláneos
Servicio de huella dactilar
El módulo (gnu services authentication) proporciona un servicio DBus
para leer e identificar huellas dactilares mediante un sensor de huellas.
- Variable Scheme: fprintd-service-type
El tipo de servicio para
fprintd, que proporciona la capacidad de lectura de huellas dactilares.
Servicios de control del sistema
El módulo (gnu services sysctl) proporciona servicios para configurar
parámetros del núcleo durante el arranque.
- Variable Scheme: sysctl-service-type
El tipo de servicio para
sysctl, que modifica parámetros del núcleo bajo /proc/sys. Para activar el encaminamiento de tráfico IPv4 se puede instanciar de esta manera:(service sysctl-service-type (sysctl-configuration (settings '(("net.ipv4.ip_forward" . "1")))))Since
sysctl-service-typeis used in the default lists of services,%base-servicesand%desktop-services, you can usemodify-servicesto change its configuration and add the kernel parameters that you want (seemodify-services).(modify-services %base-services (sysctl-service-type config => (sysctl-configuration (settings (append '(("net.ipv4.ip_forward" . "1")) %default-sysctl-settings)))))
- Tipo de datos: sysctl-configuration
Tipo de datos que representa la configuración de
sysctl.sysctl(predeterminado:(file-append procps "/sbin/sysctl")El ejecutable
sysctlusado.settings(default:%default-sysctl-settings)Una lista asociativa que especifica parámetros del núcleo y sus valores.
- Scheme Variable: %default-sysctl-settings
An association list specifying the default
sysctlparameters on Guix System.
Servicio del daemon de tarjetas inteligentes PC/SC
The (gnu services security-token) module provides the following
service to run pcscd, the PC/SC Smart Card Daemon.
pcscd is the daemon program for pcsc-lite and the MuscleCard
framework. It is a resource manager that coordinates communications with
smart card readers, smart cards and cryptographic tokens that are connected
to the system.
- Variable Scheme: pcscd-service-type
Tipo de servicio para el servicio
pcscd. Su valor debe ser un objetopcscd-configuration. Puede instanciarlo de esta manera para ejecutar pcscd con la configuración predeterminada:
- Tipo de datos: pcscd-configuration
Tipo de datos que representa la configuración de
pcscd.pcsc-lite(predeterminado:pcsc-lite)El paquete pcsc-lite que proporciona pcscd.
usb-drivers(predeterminado:(list ccid))List of packages that provide USB drivers to pcscd. Drivers are expected to be under pcsc/drivers in the store directory of the package.
Servicio Lirc
El módulo (gnu services lirc) proporciona el siguiente servicio.
- Procedimiento Scheme: lirc-service [#:lirc lirc] [#:device #f] [#:driver #f] [#:config-file #f] [#:extra-options '()]
Devuelve un servicio que ejecuta LIRC, un daemon que decodifica señales infrarrojas de dispositivos de control remoto.
De manera opcional, se pueden especificar device, driver y config-file (nombre del archivo de configuración) may be specified. Véase el manual de
lircdpara obtener más detalles.Por último, extra-options es una lista de opciones adicionales para la línea de órdenes proporcionada a
lircd.
Servicio Spice
El módulo (gnu services spice) proporciona el siguiente servicio.
- Procedimiento Scheme: spice-vdagent-service [#:spice-vdagent]
Devuelve un servicio que ejecuta VDAGENT, un daemon que permite compartir el portapapeles con una máquina virtual y la configuración de la resolución de la pantalla de la máquina virtual cuando la ventana de la consola gráfica cambia de tamaño.
Servicio inputattach
El servicio inputattach permite el uso de dispositivos de entrada como tabletas Wacom, pantallas táctiles, o joysticks con el servidor gráfico Xorg.
- Variable Scheme: inputattach-service-type
Tipo de un servicio que ejecuta
inputattachcon un dispositivo y reenvía los eventos que produzca.
- Tipo de datos: inputattach-configuration
device-type(predeterminado:"wacom")Tipo del dispositivo al que conectarse. Ejecute
inputattach --help, del paqueteinputattach, para ver la lista de tipos de dispositivo implementados.device(predeterminado:"/dev/ttyS0")El nombre de archivo para la conexión al dispositivo.
baud-rate(predeterminado:#f)Tasa de transmisión usada para las conexiones serie. Debe ser un número o
#f.log-file(predeterminado:#f)Si es verdadero, debe ser el nombre de un archivo en el que registrar los mensajes.
Servicio de diccionario
El módulo (gnu services dict) proporciona el servicio siguiente:
- Variable Scheme: dicod-service-type
Tipo de servicio que ejecuta el daemon
dicod, una implementación del servidor DICT (see Dicod in GNU Dico Manual).
- Procedimiento Scheme: dicod-service [#:config (dicod-configuration)]
Devuelve un servicio que ejecuta el daemon
dicod, una implementación del servidor DICT (see Dicod in GNU Dico Manual).El parámetro opcional config especifica la configuración para
dicod, que debe ser un objeto<dicod-configuration>, de manera predeterminada proporciona el diccionario colaborativo internacional de Inglés de GNU.Puede añadir
open localhosten su archivo ~/.dico para hacer quelocalhostsea el servidor predeterminado de su clientedico(see Initialization File in GNU Dico Manual).
- Tipo de datos: dicod-configuration
Tipo de datos que representa la configuración de dicod.
dico(predeterminado: dico)El objeto paquete del servidor de diccionario GNU Dico.
interfaces(predeterminada: ’("localhost"))Es la lista de direcciones IP y puertos, y posiblemente nombres de archivo de sockets, en los que se debe escuchar (see
listendirective in GNU Dico Manual).handlers(predeterminados: ’())Lista de objetos
<dicod-handler>que identifican los controladores (instancias de módulos).databases(predeterminada: (list %dicod-database:gcide))Lista de objetos
<dicod-database>que identifican los diccionarios proporcionados.
- Tipo de datos: dicod-handler
Tipo de datos que representa un controlador de diccionario (instancia de un módulo).
nameNombre del controlador (instancia de un módulo).
module(predeterminado: #f)Nombre del módulo del controlador de dicod (instancia). Si es
#f, el módulo tiene el mismo nombre que el controlador. (see Modules in GNU Dico Manual).optionsLista de cadenas o expresiones-G que representan los parámetros al módulo de control
- Tipo de datos: dicod-database
Tipo de datos que representa una base de datos de diccionario.
nameNombre de la base de datos, será usada en las órdenes DICT.
handlerNombre del controlador de dicod (instancia de un módulo) usado por esta base de datos (see Handlers in GNU Dico Manual).
complex?(predeterminado: #f)Determina si se usará la configuración compleja. La configuración compleja necesita un objeto
<dicod-handler>, que no es necesario en otro caso.optionsLista de cadenas o expresiones-g que representan los parámetros para la base de datos (see Databases in GNU Dico Manual).
- Variable Scheme: %dicod-database:gcide
Un objeto
<dicod-service>que ofrece el diccionario internacional colaborativo de inglés de GNU usando el paquetegcide.
A continuación se encuentra un ejemplo de configuración de
dicod-service.
(dicod-service #:config
(dicod-configuration
(handlers (list (dicod-handler
(name "wordnet")
(module "dictorg")
(options
(list #~(string-append "dbdir=" #$wordnet))))))
(databases (list (dicod-database
(name "wordnet")
(complex? #t)
(handler "wordnet")
(options '("database=wn")))
%dicod-database:gcide))))
Servicio Docker
El módulo (gnu services docker) proporciona los siguientes servicios.
- Variable Scheme: docker-service-type
-
Este es el tipo del servicio que ejecuta Docker, un daemon que puede ejecutar empaquetados de aplicaciones (a los que a veces nos referimos como “contenedores”) en entornos aislados.
- Tipo de datos: docker-configuration
Este es el tipo de datos que representa la configuración de Docker y Containerd.
docker(default:docker)El paquete de daemon de Docker usado.
docker-cli(default:docker-cli)El paquete de cliente de Docker usado.
containerd(predeterminado: containerd)El paquete Containerd usado.
proxy(predeterminado: docker-libnetwork-cmd-proxy)La pasarela de espacio de usuario para red de Docker usada.
enable-proxy?(predeterminado:#t)Activa o desactiva el uso de la pasarela de espacio de usuario para red de Docker.
debug?(predeterminado:#f)Activa o desactiva la salida de depuración.
enable-iptables?(predeterminado:#t)Activa o desactiva la adición de reglas para iptables.
environment-variables(default:())List of environment variables to set for
dockerd.This must be a list of strings where each string has the form ‘key=value’ as in this example:
(list "LANGUAGE=eo:ca:eu" "TMPDIR=/tmp/dockerd")
- Variable Scheme: singularity-service-type
Tipo de servicio que le permite ejecutar Singularity, una herramienta tipo-Docker para crear y ejecutar aplicaciones empaquetadas (también conocidas como “contenedores”). El valor para este servicio es el paquete de Singularity usado.
El servicio no instala un daemon; en vez de ello, instala programas auxiliares con con el bit setuid de root (see Programas con setuid) de modo que usuarias sin privilegios puedan ejecutar
singularity runy ordenes similares.
Servicio Auditd
El módulo (gnu services auditd) proporciona el servicio siguiente:
- Variable Scheme: auditd-service-type
-
Este es el tipo del servicio que ejecuta auditd, un daemon que recolecta información relevante a la seguridad en su sistema.
Ejemplos de cosas que se pueden recolectar:
- Acceso a archivos
- Llamadas al sistema
- Órdenes invocadas
- Intentos fallidos de ingreso en el sistema
- Activaciones de filtros en el cortafuegos
- Accesos de red
Puede usarse
auditctldel paqueteauditpara añadir o eliminar eventos a recolectar (hasta el siguiente reinicio). Para hacer permanente la recolección de dichos eventos, introduzca los parámetros de la línea de órdenes de auditctl en un archivo llamado audit.rules del directorio de configuración (véase a continuación). También se puede usaraureportdel paqueteauditpara ver un informe de todos los eventos registrados. El daemon audit habitualmente registra los eventos en el archivo /var/log/audit.
- Tipo de datos: auditd-configuration
Este es el tipo de datos que representa la configuración de auditd.
audit(predeterminado:audit)El paquete audit usado.
configuration-directory(predeterminado:%default-auditd-configuration-directory)Directorio que contiene el archivo de configuración para el paquete audit, cuyo nombre debe ser
auditd.conf, y de manera opcional reglas de audit que se instanciarán en el arranque.
servicio R-Shiny
El módulo (gnu services science) proporciona el siguiente servicio.
- Variable Scheme: rshiny-service-type
-
Tipo de servicio usado para ejecutar una aplicación web creada con
r-shiny. Este servicio proporciona el valor adecuado a la variable de entornoR_LIBS_USERy ejecuta el guión proporcionado para llamar arunApp.- Tipo de datos: rshiny-configuration
Este es el tipo de datos que representa la configuración del rshiny.
package(predeterminado:r-shiny)El paquete usado.
binary(default"rshiny")Nombre del binario o del guión en el directorio
paquete/bin/ejecutado cuando se arranca este servicio.La manera habitual de crear este archivo es la siguiente:
… (let* ((out (assoc-ref %outputs "out")) (targetdir (string-append out "/share/" ,name)) (app (string-append out "/bin/" ,name)) (Rbin (search-input-file %build-inputs "/bin/Rscript"))) ;; … (mkdir-p (string-append out "/bin")) (call-with-output-file app (lambda (port) (format port "#!~a library(shiny) setwd(\"~a\") runApp(launch.browser=0, port=4202)~%\n" Rbin targetdir))))
Servicio Nix
El módulo (gnu services nix) proporciona el siguiente servicio.
- Variable Scheme: nix-service-type
-
Tipo del servicio que ejecuta el daemon de construcción del gestor de paquetes Nix. Este es un ejemplo de cómo usarlo:
(use-modules (gnu)) (use-service-modules nix) (use-package-modules package-management) (operating-system ;; … (packages (append (list nix) %base-packages)) (services (append (list (service nix-service-type)) %base-services)))
Tras
guix system reconfigure, configure Nix para su usuaria:- Añada un canal Nix y lance una actualización. Véase la guía del gestor de paquetes Nix.
- Cree un enlace simbólico a su perfil y active el perfil de Nix:
$ ln -s "/nix/var/nix/profiles/per-user/$USER/profile" ~/.nix-profile $ source /run/current-system/profile/etc/profile.d/nix.sh
- Tipo de datos: nix-configuration
Este tipo de datos representa la configuración del daemon de Nix.
nix(predeterminado:nix)El paquete Nix usado.
sandbox(predeterminado:#t)Especifica si las construcciones se ejecutan en un entorno aislado (“sandbox”) de manera predeterminada.
build-sandbox-items(predeterminada:'())Lista de cadenas u objetos añadida al final del campo
build-sandbox-itemsen el archivo de configuración.extra-config(predeterminada:'())Es una lista de cadenas u objetos añadida al final del archivo de configuración. Se usa para proporcionar texto adicional para ser introducido de forma literal en el archivo de configuración.
extra-options(predeterminadas:'())Opciones de línea de órdenes adicionales para
nix-service-type.
Fail2Ban service
fail2ban scans log files
(e.g. /var/log/apache/error_log) and bans IP addresses that show
malicious signs – repeated password failures, attempts to make use of
exploits, etc.
fail2ban-service-type service type is provided by the (gnu
services security) module.
This service type runs the fail2ban daemon. It can be configured in
various ways, which are:
- Basic configuration
The basic parameters of the Fail2Ban service can be configured via its
fail2banconfiguration, which is documented below.- User-specified jail extensions
The
fail2ban-jail-servicefunction can be used to add new Fail2Ban jails.- Shepherd extension mechanism
Service developers can extend the
fail2ban-service-typeservice type itself via the usual service extension mechanism.
- Scheme Variable: fail2ban-service-type
-
This is the type of the service that runs
fail2bandaemon. Below is an example of a basic, explicit configuration:(append (list (service fail2ban-service-type (fail2ban-configuration (extra-jails (list (fail2ban-jail-configuration (name "sshd") (enabled? #t)))))) ;; There is no implicit dependency on an actual SSH ;; service, so you need to provide one. (service openssh-service-type)) %base-services)
- Scheme Procedure: fail2ban-jail-service svc-type jail
Extend svc-type, a
<service-type>object with jail, afail2ban-jail-configurationobject.Por ejemplo:
(append (list (service ;; The 'fail2ban-jail-service' procedure can extend any service type ;; with a fail2ban jail. This removes the requirement to explicitly ;; extend services with fail2ban-service-type. (fail2ban-jail-service openssh-service-type (fail2ban-jail-configuration (name "sshd") (enabled? #t))) (openssh-configuration ...))))
Below is the reference for the different jail-service-type
configuration records.
- Data Type: fail2ban-configuration
Available
fail2ban-configurationfields are:fail2ban(default:fail2ban) (type: package)The
fail2banpackage to use. It is used for both binaries and as base default configuration that is to be extended with<fail2ban-jail-configuration>objects.run-directory(default:"/var/run/fail2ban") (type: string)The state directory for the
fail2bandaemon.jails(default:()) (type: list-of-fail2ban-jail-configurations)Instances of
<fail2ban-jail-configuration>collected from extensions.extra-jails(default:()) (type: list-of-fail2ban-jail-configurations)Instances of
<fail2ban-jail-configuration>explicitly provided.extra-content(default:()) (type: text-config)Extra raw content to add to the end of the jail.local file, provided as a list of file-like objects.
- Data Type: fail2ban-ignore-cache-configuration
Available
fail2ban-ignore-cache-configurationfields are:key(type: string)Cache key.
max-count(type: integer)Cache size.
max-time(type: integer)Cache time.
- Data Type: fail2ban-jail-action-configuration
Available
fail2ban-jail-action-configurationfields are:name(type: string)Action name.
arguments(default:()) (type: list-of-arguments)Action arguments.
- Data Type: fail2ban-jail-configuration
Available
fail2ban-jail-configurationfields are:name(type: string)Required name of this jail configuration.
enabled?(default:#t) (type: boolean)Whether this jail is enabled.
backend(type: maybe-symbol)Backend to use to detect changes in the
log-path. The default is ’auto. To consult the defaults of the jail configuration, refer to the /etc/fail2ban/jail.conf file of thefail2banpackage.max-retry(type: maybe-integer)The number of failures before a host get banned (e.g.
(max-retry 5)).max-matches(type: maybe-integer)The number of matches stored in ticket (resolvable via tag
<matches>) in action.find-time(type: maybe-string)The time window during which the maximum retry count must be reached for an IP address to be banned. A host is banned if it has generated
max-retryduring the lastfind-timeseconds (e.g.(find-time "10m")). It can be provided in seconds or using Fail2Ban’s "time abbreviation format", as described inman 5 jail.conf.ban-time(type: maybe-string)The duration, in seconds or time abbreviated format, that a ban should last. (e.g.
(ban-time "10m")).ban-time-increment?(type: maybe-boolean)Whether to consider past bans to compute increases to the default ban time of a specific IP address.
ban-time-factor(type: maybe-string)The coefficient to use to compute an exponentially growing ban time.
ban-time-formula(type: maybe-string)This is the formula used to calculate the next value of a ban time.
ban-time-multipliers(type: maybe-string)Used to calculate next value of ban time instead of formula.
ban-time-max-time(type: maybe-string)The maximum number of seconds a ban should last.
ban-time-rnd-time(type: maybe-string)The maximum number of seconds a randomized ban time should last. This can be useful to stop “clever” botnets calculating the exact time an IP address can be unbanned again.
ban-time-overall-jails?(type: maybe-boolean)When true, it specifies the search of an IP address in the database should be made across all jails. Otherwise, only the current jail of the ban IP address is considered.
ignore-self?(type: maybe-boolean)Never ban the local machine’s own IP address.
ignore-ip(default:()) (type: list-of-strings)A list of IP addresses, CIDR masks or DNS hosts to ignore.
fail2banwill not ban a host which matches an address in this list.ignore-cache(type: maybe-fail2ban-ignore-cache-configuration)Provide cache parameters for the ignore failure check.
filter(type: maybe-fail2ban-jail-filter-configuration)The filter to use by the jail, specified via a
<fail2ban-jail-filter-configuration>object. By default, jails have names matching their filter name.log-time-zone(type: maybe-string)The default time zone for log lines that do not have one.
log-encoding(type: maybe-symbol)The encoding of the log files handled by the jail. Possible values are:
'ascii,'utf-8and'auto.log-path(default:()) (type: list-of-strings)The file names of the log files to be monitored.
action(default:()) (type: list-of-fail2ban-jail-actions)A list of
<fail2ban-jail-action-configuration>.extra-content(default:()) (type: text-config)Extra content for the jail configuration, provided as a list of file-like objects.
- Data Type: fail2ban-jail-filter-configuration
Available
fail2ban-jail-filter-configurationfields are:name(type: string)Filter to use.
mode(type: maybe-string)Mode for filter.
Next: Certificados X.509, Previous: Servicios, Up: Configuración del sistema [Contents][Index]
12.10 Programas con setuid
Some programs need to run with elevated privileges, even when they are
launched by unprivileged users. A notorious example is the passwd
program, which users can run to change their password, and which needs to
access the /etc/passwd and /etc/shadow files—something
normally restricted to root, for obvious security reasons. To address that,
passwd should be setuid-root, meaning that it always runs
with root privileges (see How Change Persona in The GNU C Library
Reference Manual, for more info about the setuid mechanism).
The store itself cannot contain setuid programs: that would be a security issue since any user on the system can write derivations that populate the store (see El almacén). Thus, a different mechanism is used: instead of changing the setuid or setgid bits directly on files that are in the store, we let the system administrator declare which programs should be entrusted with these additional privileges.
The setuid-programs field of an operating-system declaration
contains a list of <setuid-program> denoting the names of programs to
have a setuid or setgid bit set (see Uso de la configuración del sistema).
For instance, the mount.nfs program, which is part of the
nfs-utils package, with a setuid root can be designated like this:
(setuid-program
(program (file-append nfs-utils "/sbin/mount.nfs")))
And then, to make mount.nfs setuid on your system, add the
previous example to your operating system declaration by appending it to
%setuid-programs like this:
(operating-system
;; Some fields omitted...
(setuid-programs
(append (list (setuid-program
(program (file-append nfs-utils "/sbin/mount.nfs"))))
%setuid-programs)))
- Data Type: setuid-program
This data type represents a program with a setuid or setgid bit set.
programA file-like object having its setuid and/or setgid bit set.
setuid?(default:#t)Whether to set user setuid bit.
setgid?(default:#f)Whether to set group setgid bit.
user(default:0)UID (integer) or user name (string) for the user owner of the program, defaults to root.
group(default:0)GID (integer) goup name (string) for the group owner of the program, defaults to root.
Un conjunto predeterminado de programas con el bit setuid se define en la
variable %setuid-programs del módulo (gnu system).
- Variable Scheme: %setuid-programs
A list of
<setuid-program>denoting common programs that are setuid-root.La lista incluye órdenes como
passwd,ping,suysudo.
Para su implementación, los programas con setuid reales se crean en el directorio /run/setuid-programs durante la activación del sistema. Los archivos en este directorio hacen referencia a los binarios “reales”, que están en el almacén.
Next: Selector de servicios de nombres, Previous: Programas con setuid, Up: Configuración del sistema [Contents][Index]
12.11 Certificados X.509
En las conexiones HTTPS a servidores Web (esto es, HTTP sobre el mecanismo de seguridad de la capa de transporte, TLS) se envía a los programas clientes un certificado X.509 que el cliente puede usar para autentificar al servidor. Para hacerlo, los clientes verifican que el certificado del servidor está firmado por una de las llamadas autoridades de certificación (AC, CA en inglés). Pero para verificar la firma de una AC, los clientes deben haber obtenido previamente el certificado de dicha AC.
Los navegadores Web como GNU IceCat incluyen su propio conjunto de certificados de AC, de manera que pueden verificar las firmas independientemente.
No obstante, a la mayor parte de otros programas que pueden comunicarse a
través de HTTPS—wget, git, w3m, etc.—se
les debe informar de dónde pueden encontrar los certificados de CA.
En Guix, esto se lleva a cabo mediante la adición de un paquete que
proporcione certificados en el campo packages de la declaración
operating-system (see Referencia de operating-system). Guix incluye
un paquete de este tipo, nss-certs, compuesto por un conjunto de
certificados de CA proporcionados como parte de los servicios de seguridad
de red de Mozilla (NSS).
Fíjese que no es parte de %base-packages, por lo que debe ser
añadido explícitamente. El directorio /etc/ssl/certs, donde la mayor
parte de las aplicaciones y bibliotecas buscarán los certificados de manera
predeterminada, enlaza a los certificados instalados de manera global.
Las usuarias sin privilegios, incluyendo a usuarias de Guix en una
distribución distinta, pueden también instalar su propio paquete de
certificados en su perfil. Es necesario definir cierto número de variables
de entorno de manera que las aplicaciones y bibliotecas sepan dónde
encontrarlos. Por ejemplo, la biblioteca OpenSSL inspecciona las variables
SSL_CERT_DIR y SSL_CERT_FILE. Algunas aplicaciones añaden sus
variables de entorno propias; por ejemplo, el sistema de control de
versiones Git inspecciona el empaquetado de certificados al que apunta la
variable de entorno GIT_SSL_CAINFO. Por tanto, en el caso típico se
debe ejecutar algo parecido a esto:
guix install nss-certs export SSL_CERT_DIR="$HOME/.guix-profile/etc/ssl/certs" export SSL_CERT_FILE="$HOME/.guix-profile/etc/ssl/certs/ca-certificates.crt" export GIT_SSL_CAINFO="$SSL_CERT_FILE"
Como otro ejemplo, R necesita que la variable de entorno
CURL_CA_BUNDLE apunte al empaquetado de certificados, de manera que se
debe ejecutar algo parecido a esto:
guix install nss-certs export CURL_CA_BUNDLE="$HOME/.guix-profile/etc/ssl/certs/ca-certificates.crt"
Para otras aplicaciones puede tener que buscar la variable de entorno necesaria en la documentación relevante.
Next: Disco en RAM inicial, Previous: Certificados X.509, Up: Configuración del sistema [Contents][Index]
12.12 Selector de servicios de nombres
El módulo (gnu system nss) proporciona una interfaz con el archivo de
configuración del selector de servicios de nombres o NSS
(see NSS Configuration File in The GNU C Library Reference
Manual). En resumen, NSS es un mecanismo que permite la extensión de libc
con nuevos métodos de búsqueda de “nombres”, lo que incluye nombres de
máquinas, nombres de servicios, cuentas de usuaria y más (see System Databases and Name Service Switch in The GNU C
Library Reference Manual).
La configuración de NSS especifica, para cada base de datos del sistema, que
método de búsqueda debe ser usado, y cómo los varios métodos se enlazan
entre sí—por ejemplo, bajo qué circunstancias NSS deberá probar con el
siguiente método en la lista. La configuración de NSS se proporciona en el
campo name-service-switch de las declaraciones
operating-system (see name-service-switch).
Como ejemplo, la siguiente declaración configura NSS para que use el
motor
nss-mdns, que permite las búsquedas de nombres de máquinas sobre DNS
multicast (mDNS) para nombres de máquinas terminados en .local:
(name-service-switch
(hosts (list %files ;primero, comprueba /etc/hosts
;; Si lo anterior no funcionó, prueba
;; con 'mdns_minimal'.
(name-service
(name "mdns_minimal")
;; 'mdns_minimal' tiene autoridad sobre
;; '.local'. Cuando devuelve 'not-found,
;; no es necesario intentarlo con los
;; métodos siguientes.
(reaction (lookup-specification
(not-found => return))))
;; Si no, usa DNS.
(name-service
(name "dns"))
;; Finalmente, prueba con 'mdns' "al completo".
(name-service
(name "mdns")))))
No se preocupe: la variable %mdns-host-lookup-nss (véase a
continuación) contiene esta configuración, de manera que no tiene que
escribirla si todo lo que desea es que funcione la búsqueda de nombres de
máquina en .local.
Fíjese que, en este caso, además de establecer el valor de
name-service-switch en la declaración operating-system, es
necesario también usar el servicio avahi-service-type
(see avahi-service-type) o
%desktop-services, donde está incluido. Esto permite el acceso a
nss-mdsn desde el daemon de la caché del servicio de nombres
(see nscd-service).
Por conveniencia, las siguientes variables proporcionan configuraciones NSS típicas.
- Variable Scheme: %default-nss
Esta es la configuración predeterminada del selector de servicios de nombres, un objeto
name-service-switch.
- Variable Scheme: %mdns-host-lookup-nss
Esta es la configuración del selector de servicios de nombres que permite la búsqueda de nombres de máquinas por DNS multicast (mDNS) para nombres de máquinas terminados en
.local.
La referencia de la configuración del selector de servicios de nombres se
proporciona a continuación. Tiene una asociación directa con el formato del
archivo de configuración de la biblioteca C, por lo que se recomienda el
manual de la biblioteca C para obtener más información (see NSS
Configuration File in The GNU C Library Reference Manual). En
comparación con el formato del archivo de configuración del NSS de libc, no
solo tiene solo la ventaja de la cálida sensación proporcionada por la
adición de paréntesis que tanto nos gustan, sino que también tiene
comprobaciones estáticas: conocerá los errores sintácticos y tipográficos
con la ejecución de guix system.
- Tipo de datos: name-service-switch
-
El tipo de datos que representa la configuración del selector de servicios de nombres (NSS). Cada campo a continuación representa una de las bases de datos del sistema admitidas.
aliasesethersgroupgshadowhostsinitgroupsnetgroupnetworkspasswordpublic-keyrpcservicesshadowThe system databases handled by the NSS. Each of these fields must be a list of
<name-service>objects (see below).
- Tipo de datos: name-service
-
Este es el tipo de datos que representa un servicio de nombres real y la acción de búsqueda asociada.
nameUna cadena que denota el nombre de servicio (see Services in the NSS configuration in The GNU C Library Reference Manual).
Fíjese que los servicios de nombres enumerados aquí deben ser visibles para nscd. Esto se consigue mediante la adición del parámetro
#:name-servicesanscd-servicecon la lista de paquetes que proporcionan los servicios de nombres necesarios (seenscd-service).reactionUna acción especificada mediante el uso del macro
lookup-specification(see Actions in the NSS configuration in The GNU C Library Reference Manual). Por ejemplo:
Next: Configuración del gestor de arranque, Previous: Selector de servicios de nombres, Up: Configuración del sistema [Contents][Index]
12.13 Disco en RAM inicial
Para el propósito del arranque inicial, se le proporciona al núcleo Linux-libre un disco inicial en RAM, o initrd. Un initrd contiene un sistema de archivos raíz temporal así como un guión de inicialización. Este último es responsable del montaje del sistema de archivos raíz real, así como de la carga de cualquier módulo del núcleo que pueda ser necesario para esta tarea.
El campo initrd-modules de una declaración operating-system le
permite especificar qué módulos del núcleo Linux-libre deben estar
disponibles en el initrd. En particular, aquí es donde se debe enumerar los
módulos que controlen realmente el disco duro donde su partición raíz se
encuentre—aunque el valor predeterminado de initrd-modules debería
cubrir la mayor parte de casos de uso. Por ejemplo, en caso de necesitar el
módulo megaraid_sas además de los módulos predeterminados para poder
acceder a sistema de archivos raíz, se podría escribir:
(operating-system
;; …
(initrd-modules (cons "megaraid_sas" %base-initrd-modules)))
- Variable Scheme: %base-initrd-modules
Esta es la lista de módulos del núcleo que se incluyen en el initrd predeterminado.
Más allá, si necesita personalizaciones de un nivel más bajo, el campo
initrd de una declaración operating-system le permite
especificar qué initrd desea usar. El módulo (gnu system
linux-initrd) proporciona tres formas de construir un initrd: el
procedimiento de alto nivel base-initrd y los procedimientos de bajo
nivel raw-initrd y expression->initrd.
El procedimiento base-initrd está pensado para cubrir la mayor parte
de usos comunes. Por ejemplo, si desea añadir algunos módulos del núcleo que
deben cargarse durante el arranque, puede definir el campo initrd de
la declaración de sistema operativo de esta forma:
(initrd (lambda (sistemas-de-archivos . resto)
;; Crea un initrd estándar pero configura la red
;; con los parámetros que QEMU espera por omisión.
(apply base-initrd sistemas-de-archivos
#:qemu-networking? #t
resto)))
El procedimiento base-initrd también maneja casos de uso comunes que
implican el uso del sistema en un anfitrión QEMU, o como un sistema “live”
con un sistema de archivos raíz volátil.
The base-initrd procedure is built from raw-initrd procedure.
Unlike base-initrd, raw-initrd doesn’t do anything high-level,
such as trying to guess which kernel modules and packages should be included
to the initrd. An example use of raw-initrd is when a user has a
custom Linux kernel configuration and default kernel modules included by
base-initrd are not available.
El disco inicial en RAM producido por base-initrd o raw-initrd
inspecciona varias opciones proporcionadas por la línea de órdenes al núcleo
Linux (esto es, argumentos pasados a través de la orden linux de
GRUB, o de la opción -append de QEMU), notablemente:
gnu.load=bootIndica al disco de RAM inicial que cargue arranque, un archivo que contiene un programa Scheme, una vez haya montado el sistema de archivos raíz.
Guix usa esta opción para proporcionar el control a un programa de arranque que ejecuta los programas de activación de servicios y lanza GNU Shepherd, el sistema de inicialización.
root=rootMonta raíz como el sistema de archivos raíz. raíz puede ser un nombre de dispositivo como
/dev/sda1, una etiqueta del sistema de archivos o un UUID del sistema de archivos. Si no se proporciona se usa el nombre del sistema de archivos raíz de la declaración del sistema operativo.rootfstype=typeSet the type of the root file system. It overrides the
typefield of the root file system specified via theoperating-systemdeclaration, if any.rootflags=optionsSet the mount options of the root file system. It overrides the
optionsfield of the root file system specified via theoperating-systemdeclaration, if any.fsck.mode=modeWhether to check the root file system for errors before mounting it. mode is one of
skip(never check),force(always check), orautoto respect the root<file-system>object’scheck?setting (see Sistemas de archivos) and run a full scan only if the file system was not cleanly shut down.autois the default if this option is not present or if mode is not one of the above.fsck.repair=levelThe level of repairs to perform automatically if errors are found in the root file system. level is one of
no(do not write to root at all if possible),yes(repair as much as possible), orpreento repair problems considered safe to repair automatically.preenis the default if this option is not present or if level is not one of the above.gnu.system=systemHace que /run/booted-system y /run/current-system apunten a sistema.
modprobe.blacklist=módulos…¶-
Indica al disco inicial en RAM así como a la orden
modprobe(del paquete kmod) que deben negarse a cargar módulos. módulos debe ser una lista separada por comas de nombres de módulos—por ejemplo,usbkbd,9pnet. gnu.replInicia una sesión interactiva (REPL) desde el disco inicial en RAM antes de que intente cargar los módulos del núcleo y del montaje del sistema de archivos raíz. Nuestro departamento comercial lo llama arranca-en-Guile. Como amante de Scheme, lo adorará. See Using Guile Interactively in GNU Guile Reference Manual, para más información sobre sesiones interactivas Guile.
Una vez conocidas todas las características que proporcionan los discos
iniciales en RAM que producen base-initrd y raw-initrd, a
continuación veremos cómo usarlas y personalizarlos más aún.
- Procedimiento Scheme: raw-initrd sistemas-de-archivos [#:linux-modules '()] [#:pre-mount #t] [#:mapped-devices '()] [#:keyboard-layout #f] [#:helper-packages '()] [#:qemu-networking? #f]
[#:volatile-root? #f] Return a derivation that builds a raw initrd. file-systems is a list of file systems to be mounted by the initrd, possibly in addition to the root file system specified on the kernel command line via root. linux-modules is a list of kernel modules to be loaded at boot time. mapped-devices is a list of device mappings to realize before file-systems are mounted (see Dispositivos traducidos). pre-mount is a G-expression to evaluate before realizing mapped-devices. helper-packages is a list of packages to be copied in the initrd. It may include
e2fsck/staticor other packages needed by the initrd to check the root file system.Cuando su valor es verdadero, keyboard-layout es un registro
<keyboard-layout>que denota la distribución de teclado en consola deseada. Esto se realiza previamente a que los dispositivos configurados en mapped-devices se inicien y antes de que los sistemas de archivos en file-systems se monten, de manera que, en caso de que la usuaria tuviese que introducir una contraseña o usar la sesión interactiva, esto suceda usando la distribución de teclado deseada.Cuando qemu-networking? es verdadero, configura la red con los parámetros QEMU estándar. Cuando virtio? es verdadero, carga módulos adicionales para que la imagen en RAM pueda ser usada como un sistema virtualizado por QEMU con controladores paravirtualizados de E/S.
Cuando volatile-root? es verdadero, el sistema de archivos raíz tiene permisos de escritura pero cualquier cambio realizado se perderá.
- Procedimiento Scheme: base-initrd sistemas-de-archivos [#:mapped-devices '()] [#:keyboard-layout #f] [#:qemu-networking? #f]
[#:volatile-root? #f] [#:linux-modules ’()] Return as a file-like object a generic initrd, with kernel modules taken from linux. file-systems is a list of file-systems to be mounted by the initrd, possibly in addition to the root file system specified on the kernel command line via root. mapped-devices is a list of device mappings to realize before file-systems are mounted.
Cuando su valor es verdadero, keyboard-layout es un registro
<keyboard-layout>que denota la distribución de teclado en consola deseada. Esto se realiza previamente a que los dispositivos configurados en mapped-devices se inicien y antes de que los sistemas de archivos en file-systems se monten, de manera que, en caso de que la usuaria tuviese que introducir una contraseña o usar la sesión interactiva, esto suceda usando la distribución de teclado deseada.qemu-networking? y volatile-root? funcionan como en
raw-initrd.El initrd incorpora automáticamente todos los módulos del núcleo necesarios para sistemas-de-archivos y para las opciones proporcionadas. Módulos del núcleo adicionales pueden proporcionarse a través de linux-modules. Se añadirán al initrd y se cargarán en tiempo de arranque en el orden que aparezcan.
No es necesario decir que los initrd que producimos y usamos embeben un
Guile enlazado estáticamente, y que el programa de inicialización es un
programa Guile. Esto proporciona mucha flexibilidad. El procedimiento
expression->initrd construye un initrd de ese tipo, una vez
proporcionado el programa a ejecutar en dicho initrd.
- Procedimiento Scheme: expression->initrd exp [#:guile %guile-static-stripped] [#:name "guile-initrd"] Return as a
file-like object a Linux initrd (a gzipped cpio archive) containing guile and that evaluates exp, a G-expression, upon booting. All the derivations referenced by exp are automatically copied to the initrd.
Next: Invoking guix system, Previous: Disco en RAM inicial, Up: Configuración del sistema [Contents][Index]
12.14 Configuración del gestor de arranque
El sistema operativo permite varios cargadores de arranque. El cargador de
arranque se configura mediante el uso de la declaración
bootloader-configuration. Todos los campos de esta estructura son
independientes del cargador de arranque excepto uno, bootloader, que
indica el cargador de arranque a configurar e instalar.
Algunos de los cargadores de arranque no inspeccionan todos los campos de
bootloader-configuration. Por ejemplo, el cargador de arranque
extlinux no permite temas y por lo tanto ignora el campo theme.
- Tipo de datos: bootloader-configuration
El tipo de una declaración de configuración del cargador de arranque.
bootloader¶-
The bootloader to use, as a
bootloaderobject. For nowgrub-bootloader,grub-efi-bootloader,grub-efi-netboot-bootloader,grub-efi-removable-bootloader,extlinux-bootloaderandu-boot-bootloaderare supported.Los cargadores de arranque se describen en los módulos
(gnu bootloader …). En particular,(gnu bootloader u-boot)contiene definiciones de cargadores de arranque para un amplio rango de sistemas ARM y AArch64, mediante el uso del cargador de arranque U-Boot.grub-efi-bootloaderpermite el arranque en sistemas modernos que usan la interfaz extendida de firmware unificada (UEFI). Es el que debería ser usado si la imagen de instalación contiene un directorio /sys/firmware/efi cuando la arranca en su sistema.grub-bootloaderpermite el arranque en máquinas basadas en Intel en modo “antiguo” BIOS.grub-efi-netboot-bootloaderallows you to boot your system over network through TFTP. In combination with an NFS root file system this allows you to build a diskless Guix system.The installation of the
grub-efi-netboot-bootloadergenerates the content of the TFTP root directory attargets(seetargets), to be served by a TFTP server. You may want to mount your TFTP server directories onto thetargetsto move the required files to the TFTP server automatically.Si tiene pensado usar también un sistema de archivos raíz NFS (en realidad si monta el almacén desde un directorio compartido con NFS) el servidor TFTP también debe proporcionar el archivo /boot/grub/grub.cfg y otros archivos desde el almacén (como las imágenes de fondo de GRUB, el núcleo (see
kernel) y el disco en RAM para el arranque (seeinitrd)). GRUB accederá a todos estos archivos del almacén a través de TFTP con su ruta del almacén habitual, como por ejemplo tftp://tftp-server/gnu/store/…-initrd/initrd.cpio.gz.Two symlinks are created to make this possible. For each target in the
targetsfield, the first symlink is ‘target’/efi/Guix/boot/grub/grub.cfg pointing to ../../../boot/grub/grub.cfg, where ‘target’ may be /boot. In this case the link is not leaving the served TFTP root directory, but otherwise it does. The second link is ‘target’/gnu/store and points to ../gnu/store. This link is leaving the served TFTP root directory.The assumption behind all this is that you have an NFS server exporting the root file system for your Guix system, and additionally a TFTP server exporting your
targetsdirectories—usually a single /boot—from that same root file system for your Guix system. In this constellation the symlinks will work.For other constellations you will have to program your own bootloader installer, which then takes care to make necessary files from the store accessible through TFTP, for example by copying them into the TFTP root directory to your
targets.It is important to note that symlinks pointing outside the TFTP root directory may need to be allowed in the configuration of your TFTP server. Further the store link exposes the whole store through TFTP. Both points need to be considered carefully for security aspects.
Además de lo expresado anteriormente—
grub-efi-netboot-bootloader, los servidores TFTP y NFS—también necesitará un servidor DHCP configurado correctamente para hacer posible el arranque a través de la red. Para esto únicamente podemos recomendarle por el momento que busque información sobre PXE (Preboot eXecution Environment).grub-efi-removable-bootloaderallows you to boot your system from removable media by writing the GRUB file to the UEFI-specification location of /EFI/BOOT/BOOTX64.efi of the boot directory, usually /boot/efi. This is also useful for some UEFI firmwares that “forget” their configuration from their non-volatile storage. Likegrub-efi-bootloader, this can only be used if the /sys/firmware/efi directory is available.Nota: This will overwrite the GRUB file from any other operating systems that also place their GRUB file in the UEFI-specification location; making them unbootable.
targetsThis is a list of strings denoting the targets onto which to install the bootloader.
The interpretation of targets depends on the bootloader in question. For
grub-bootloader, for example, they should be device names understood by the bootloaderinstallercommand, such as/dev/sdaor(hd0)(see Invoking grub-install in GNU GRUB Manual). Forgrub-efi-bootloaderandgrub-efi-removable-bootloaderthey should be mount points of the EFI file system, usually /boot/efi. Forgrub-efi-netboot-bootloader,targetsshould be the mount points corresponding to TFTP root directories served by your TFTP server.menu-entries(predeterminadas:())Una lista posiblemente vacía de objetos
menu-entry(véase a continuación), que indican entradas que deben aparecer en el menú del cargador de arranque, además de la entrada del sistema actual y la entrada que apunta a generaciones previas del sistema.default-entry(predeterminada:0)El índice de la entrada del menú de arranque por omisión. El índice 0 es para la entrada del sistema actual.
timeout(predeterminado:5)El número de segundos que se esperará entrada por el teclado antes de arrancar. El valor 0 indica que se debe arrancar de forma inmediata, y -1 que se debe esperar indefinidamente.
keyboard-layout(predeterminada:#f)Si es
#f, el menú del cargador de arranque (si existe) usa la distribución de teclado predeterminada, habitualmente inglés estadounidense (“qwerty”).En otro caso, debe ser un objeto
keyboard-layout(see Distribución de teclado).Nota: Esta opción se ignora actualmente por todos los cargadores de arranque menos
grubygrub-efi.theme(predeterminado: #f)El objeto del tema del cargador de arranque que describe el tema usado. Si no se proporciona ningún tema, algunos cargadores de arranque pueden usar un tema por omisión, lo cual es cierto en GRUB.
terminal-outputs(predeterminadas:'(gfxterm))Los terminales de salida que se usarán para el menú de arranque, como una lista de símbolos. GRUB acepta los valores:
console,serial,serial_{0-3},gfxterm,vga_text,mda_text,morseypkmodem. Este campo corresponde con la variableGRUB_TERMINAL_OUTPUT(see Simple configuration in GNU GRUB manual).terminal-inputs(predeterminadas:'())Los terminales de entrada que se usarán para el menú de arranque, como una lista de símbolos. Para GRUB, el valor predeterminado es el terminal nativo de la plataforma determinado en tiempo de ejecución. GRUB acepta los valores:
console,serial,serial{0-3},at_keyboardyusb_keyboard. Este campo corresponde a la variable GRUBGRUB_TERMINAL_INPUT(see Simple configuration in GNU GRUB manual).serial-unit(predeterminada:#f)La unidad serie usada por el cargador de arranque, como un entero del 0 al 3. Para GRUB, se selecciona en tiempo de ejecución; actualmente GRUB selecciona 0 lo que corresponde a COM1 (see Serial terminal in GNU GRUB manual).
serial-speed(predeterminada:#f)La velocidad de la interfaz serie, como un entero. Para GRUB, el valor predeterminado se selecciona en tiempo de ejecución, actualmente GRUB selecciona 9600 bps (see Serial terminal in GNU GRUB manual).
device-tree-support?(default:#t)Whether to support Linux device tree files loading.
This option in enabled by default. In some cases involving the
u-bootbootloader, where the device tree has already been loaded in RAM, it can be handy to disable the option by setting it to#f.
Si desease listar entradas adicionales para el menú de arranque a través del
campo menu-entries mostrado previamente, deberá crearlas con la forma
menu-entry. Por ejemplo, imagine que desea ser capaz de arrancar otra
distribución (¡difícil de imaginar!), puede definir una entrada de menú de
esta forma:
(menu-entry
(label "La otra distribución")
(linux "/boot/old/vmlinux-2.6.32")
(linux-arguments '("root=/dev/sda2"))
(initrd "/boot/old/initrd"))
Los detalles se encuentran a continuación.
El tipo de una entrada en el menú del cargador de arranque.
labelLa etiqueta a mostrar en el menú—por ejemplo,
"GNU".linux(predeterminado:#f)La imagen del núcleo Linux a arrancar, por ejemplo:
(file-append linux-libre "/bzImage")Con GRUB, también es posible especificar un dispositivo explícitamente mediante el uso de la convención de nombres de dispositivo de GRUB (see Naming convention in GNU GRUB manual), por ejemplo:
"(hd0,msdos1)/boot/vmlinuz"
Si se especifica el dispositivo explícitamente como en el ejemplo anterior, el campo
devicese ignora completamente.linux-arguments(predeterminados:())La lista de parámetros extra de línea de órdenes para el núcleo Linux—por ejemplo,
("console=ttyS0").initrd(predeterminado:#f)Una expresión-G o una cadena que contiene el nombre de archivo del disco inicial en RAM usado (see Expresiones-G).
device(predeterminado:#f)El dispositivo donde se encuentran el núcleo y el initrd—es decir, para GRUB, raíz de esta entrada de menú (see root in GNU GRUB manual).
Puede ser una etiqueta de sistema de archivos (una cadena), un UUID de sistema de archivos (un vector de bytes, see Sistemas de archivos), o
#f, en cuyo caso el cargador de arranque buscará el dispositivo que contenga el archivo especificado por el campolinux(see search in GNU GRUB manual). No debe ser un nombre de dispositivo del SO como /dev/sda1.multiboot-kernel(predeterminado:#f)El núcleo a arrancar en modo Multiboot (see multiboot in GNU GRUB manual). Cuando se proporciona este campo, se genera una entrada Multiboot en el menú. Por ejemplo:
(file-append mach "/boot/gnumach")multiboot-arguments(predeterminados:())Lista de parámetros adicionales que se proporcionan al núcleo Multiboot en la línea de órdenes.
multiboot-modules(predeterminados:())Lista de ordenes para cargar módulos de Multiboot. Por ejemplo:
(list (list (file-append hurd "/hurd/ext2fs.static") "ext2fs" …) (list (file-append libc "/lib/ld.so.1") "exec" …))chain-loader(default:#f)A string that can be accepted by
grub’schainloaderdirective. This has no effect if eitherlinuxormultiboot-kernelfields are specified. The following is an example of chainloading a different GNU/Linux system.(bootloader (bootloader-configuration ;; … (menu-entries (list (menu-entry (label "GNU/Linux") (device (uuid "1C31-A17C" 'fat)) (chain-loader "/EFI/GNULinux/grubx64.efi"))))))
De momento únicamente GRUB permite el uso de temas. Los temas de GRUB se
crean mediante el uso de grub-theme, todavía no documentado
completamente.
- Tipo de datos: grub-theme
Tipo de datos que representa la configuración de un tema de GRUB.
gfxmode(predeterminado:'("auto"))El modo gráfico
gfxmodede GRUB configurado (una lista de cadenas con resoluciones de pantalla, see gfxmode in GNU GRUB manual).
- Procedimiento Scheme: grub-theme
Devuelve el tema predeterminado de GRUB que usa el sistema operativo si no se especifica el campo
themeen el registrobootloader-configuration.Viene con una bonita imagen de fondo que muestra los logos de GNU y Guix.
Por ejemplo, para usar una resolución distinta de la predeterminada, puede usar algo como esto:
(bootloader
(bootloader-configuration
;; …
(theme (grub-theme
(inherit (grub-theme))
(gfxmode '("1024x786x32" "auto"))))))
Next: Invoking guix deploy, Previous: Configuración del gestor de arranque, Up: Configuración del sistema [Contents][Index]
12.15 Invoking guix system
Una vez haya escrito la declaración de sistema operativo como se ha visto en
la sección previa, puede instanciarse mediante el uso de la orden
guix system. Su sinopsis es:
guix system opciones… acción archivo
archivo debe ser el nombre de un archivo que contenga una declaración
operating-system. acción especifica cómo se instancia el
sistema operativo. Actualmente se permiten los siguientes valores:
searchMuestra las definiciones de tipos de servicio disponibles que corresponden con las expresiones regulares proporcionadas, ordenadas por relevancia:
$ guix system search console name: console-fonts location: gnu/services/base.scm:806:2 extends: shepherd-root description: Install the given fonts on the specified ttys (fonts are per + virtual console on GNU/Linux). The value of this service is a list of + tty/font pairs. The font can be the name of a font provided by the `kbd' + package or any valid argument to `setfont', as in this example: + + '(("tty1" . "LatGrkCyr-8x16") + ("tty2" . (file-append + font-tamzen + "/share/kbd/consolefonts/TamzenForPowerline10x20.psf")) + ("tty3" . (file-append + font-terminus + "/share/consolefonts/ter-132n"))) ; for HDPI relevance: 9 name: mingetty location: gnu/services/base.scm:1190:2 extends: shepherd-root description: Provide console login using the `mingetty' program. relevance: 2 name: login location: gnu/services/base.scm:860:2 extends: pam description: Provide a console log-in service as specified by its + configuration value, a `login-configuration' object. relevance: 2 …Como con
guix package --search, el resultado se obtiene en formatorecutils, lo que facilita el filtrado de la salida (see GNU recutils databases in GNU recutils manual).editEdit or view the definition of the given service types.
For example, the command below opens your editor, as specified by the
EDITORenvironment variable, on the definition of theopensshservice type:guix system edit openssh
reconfigureConstruye el sistema operativo descrito en archivo, lo activa, y se constituye como estado actual46.
Nota: Es altamente recomendable ejecutar
guix pullantes de la primera ejecución deguix system reconfigure(see Invocación deguix pull). No hacerlo puede ocasionar que se obtenga una versión más antigua de Guix una vez quereconfigurese haya completado.Lleva a efecto toda la configuración especificada en archivo: cuentas de usuaria, servicios del sistema, lista de paquetes global, programas con setuid, etc. La orden inicia los servicios del sistema especificados en archivo que no estén actualmente en ejecución; si un servicio se encuentra en ejecución esta orden prepara su actualización durante la próxima parada (por ejemplo, con
herd stop Xoherd restart X).Esta orden crea una nueva generación cuyo número es el sucesor de la siguiente generación (como lo muestra
guix system list-generations). Si esa generación ya existe, será sobreescrita. Este comportamiento es el mismo que el deguix package(see Invocación deguix package).También añade una entrada al cargador de arranque para la nueva configuración del sistema operativo—en caso de que no se proporcione la opción --no-bootloader. Con GRUB, mueve las entradas de configuraciones antiguas a un submenú, permitiendo la selección de una generación previa del sistema en tiempo de arranque en caso necesario.
Tras la finalización, el nuevo sistema se despliega en /run/current-system. Este directorio contiene metadatos de procedencia: la lista de canales usados (see Canales) y el archivo en sí, cuando esté disponible. Puede visualizar dichos metadatos con la siguiente orden:
guix system describe
Esta información es útil en caso de que desee inspeccionar posteriormente cómo se construyó está generación en particular. De hecho, asumiendo que archivo es autocontenido, puede construir de nuevo la generación n de su sistema operativo con:
guix time-machine \ -C /var/guix/profiles/system-n-link/channels.scm -- \ system reconfigure \ /var/guix/profiles/system-n-link/configuration.scm
¡Puede pensar en ello como una especie de control de versiones incorporado en Guix! Su sistema no es únicamente un artefacto binario: transporta sus propias fuentes con él. See
provenance-service-type, para más información sobre el seguimiento de procedencia.De manera predeterminada,
reconfigureevita que instale una version anterior en su sistema operativo, lo que podría (re)introducir fallos de seguridad y también provocar problemas con servicios que mantienen estado como los sistemas de gestión de bases de datos. Puede modificar este comportamiento con el parámetro --allow-downgrades.switch-generation¶Cambia a una generación existente del sistema. Esta acción cambia atómicamente el perfil del sistema a la generación del sistema especificada. También redistribuye las entradas de sistema del menú de arranque existentes. Marca como predeterminada la entrada de la generación de sistema especificada y mueve las entradas de otras generaciones a un submenú, si el cargador de arranque lo permite. La próxima vez que se arranque el sistema, se usará la generación de sistema especificada.
El cargador de arranque en sí no se reinstala durante esta orden. Por tanto, el cargador de arranque instalado se usa con un archivo de configuración actualizado.
La generación deseada puede especificarse explícitamente con su numero de generación. Por ejemplo, la siguiente invocación cambiaría a la generación 7 del sistema:
guix system switch-generation 7
La generación deseada puede especificarse también de forma relativa a la generación actual con la forma
+No-N, donde+3significa “3 generaciones después de la generación actual”, y-1significa “1 generación antes de la generación actual”. Cuando se especifica un valor negativo como-1debe ir precedido de--para evitar que se analice como una opción. Por ejemplo:guix system switch-generation -- -1
Actualmente, el efecto de la invocación de esta acción es únicamente cambiar el perfil del sistema a una generación existente y redistribuir las entradas del menú de arranque. Para realmente empezar a usar la generación deseada del sistema, debe reiniciar tras esta acción. En el futuro, se actualizará para hacer lo mismo que
reconfigure, como activación y desactivación de servicios.Esta acción fallará si la generación especificada no existe.
roll-back¶Cambia a la generación de sistema previa. Tras el siguiente arranque del sistema, usará la generación de sistema precedente. Es la operación inversa de
reconfigure, y es equivalente a la invocación deswitch-generationcon-1como parámetro.Actualmente, como con
switch-generation, debe reiniciar tras la ejecución de esta acción para realmente empezar a usar la generación de sistema precedente.delete-generations¶-
Elimina generaciones del sistema, haciendo posible su recolección con la basura (see Invocación de
guix gc, para información sobre como llevar a cabo la “recolección de basura”).Esto funciona del mismo modo que ‘guix package --delete-generations’ (see --delete-generations). Sin parámetros, se eliminan todas las generaciones del sistema excepto la actual:
guix system delete-generations
You can also select the generations you want to delete. The example below deletes all the system generations that are more than two months old:
guix system delete-generations 2m
La ejecución de esta orden reinstala automáticamente el cargador de arranque con una lista de entradas del menú actualizada—por ejemplo, el submenú de generaciones antiguas en GRUB no mostrará las generaciones que hayan sido borradas.
buildConstruye la derivación del sistema operativo, que incluye todos los archivos de configuración y programas necesarios para el arranque y la ejecución del sistema. Esta acción no instala nada en realidad.
initConstruye el directorio dado con todos los archivos necesarios para ejecutar el sistema operativo especificado en archivo. Esto es útil para la instalación inicial de Guix. Por ejemplo:
guix system init mi-configuración-del-so.scm /mnt
copia a /mnt todos los elementos del almacén necesarios para la configuración especificada en mi-configuración-del-so.scm. Esto incluye los archivos de configuración, paquetes y demás. También crea otros archivos esenciales necesarios para la correcta operación del sistema—por ejemplo, los directorios /etc, /var y /run, y el archivo /bin/sh.
This command also installs bootloader on the targets specified in my-os-config, unless the --no-bootloader option was passed.
vm¶-
Build a virtual machine (VM) that contains the operating system declared in file, and return a script to run that VM.
Nota: La acción
vmy otras presentadas a continuación pueden usar la funcionalidad KVM del núcleo Linux-libre. Específicamente, si la máquina permite la virtualización hardware, debe cargarse el correspondiente módulo KVM del núcleo, debe existir el nodo del dispositivo /dev/kvm y tanto la propia usuaria como las usuarias de construcción del daemon deben tener acceso de lectura y escritura al mismo (see Configuración del entorno de construcción).Los parámetros proporcionados al guión se pasan a QEMU como en el siguiente ejemplo, que activa la red y solicita 1 GiB de RAM para la máquina emulada:
$ /gnu/store/…-run-vm.sh -m 1024 -smp 2 -nic user,model=virtio-net-pci
It’s possible to combine the two steps into one:
$ $(guix system vm my-config.scm) -m 1024 -smp 2 -nic user,model=virtio-net-pci
La VM comparte su almacén con el sistema anfitrión.
By default, the root file system of the VM is mounted volatile; the --persistent option can be provided to make it persistent instead. In that case, the VM disk-image file will be copied from the store to the
TMPDIRdirectory to make it writable.Sistemas de archivos adicionales pueden compartirse entre la máquina anfitriona y la virtual mediante el uso de las opciones --share y --expose: la primera especifica un directorio a compartir con acceso de escritura, mientras que la última proporciona solo acceso de lectura al directorio compartido.
El siguiente ejemplo crea una máquina virtual en la que el directorio de la usuaria es accesible en modo solo-lecture, y donde el directorio /intercambio esta asociado de forma lectura-escritura con $HOME/tmp en el sistema anfitrión:
guix system vm mi-configuración.scm \ --expose=$HOME --share=$HOME/tmp=/intercambio
En GNU/Linux, lo predeterminado es arrancar directamente el núcleo; esto posee la ventaja de necesitar únicamente una pequeña imagen del disco raíz pequeña ya el el almacén de la anfitriona puede montarse.
The --full-boot option forces a complete boot sequence, starting with the bootloader. This requires more disk space since a root image containing at least the kernel, initrd, and bootloader data files must be created.
The --image-size option can be used to specify the size of the image.
The --no-graphic option will instruct
guix systemto spawn a headless VM that will use the invoking tty for IO. Among other things, this enables copy-pasting, and scrollback. Use the ctrl-a prefix to issue QEMU commands; e.g. ctrl-a h prints a help, ctrl-a x quits the VM, and ctrl-a c switches between the QEMU monitor and the VM. image¶The
imagecommand can produce various image types. The image type can be selected using the --image-type option. It defaults toefi-raw. When its value isiso9660, the --label option can be used to specify a volume ID withimage. By default, the root file system of a disk image is mounted non-volatile; the --volatile option can be provided to make it volatile instead. When usingimage, the bootloader installed on the generated image is taken from the providedoperating-systemdefinition. The following example demonstrates how to generate an image that uses thegrub-efi-bootloaderbootloader and boot it with QEMU:image=$(guix system image --image-type=qcow2 \ gnu/system/examples/lightweight-desktop.tmpl) cp $image /tmp/my-image.qcow2 chmod +w /tmp/my-image.qcow2 qemu-system-x86_64 -enable-kvm -hda /tmp/my-image.qcow2 -m 1000 \ -bios $(guix build ovmf)/share/firmware/ovmf_x64.binWhen using the
efi-rawimage type, a raw disk image is produced; it can be copied as is to a USB stick, for instance. Assuming/dev/sdcis the device corresponding to a USB stick, one can copy the image to it using the following command:# dd if=$(guix system image my-os.scm) of=/dev/sdc status=progress
La orden
--list-image-typesmuestra todos los tipos de imagen disponibles.When using the
qcow2image type, the returned image is in qcow2 format, which the QEMU emulator can efficiently use. See Ejecución de Guix en una máquina virtual, for more information on how to run the image in a virtual machine. Thegrub-bootloaderbootloader is always used independently of what is declared in theoperating-systemfile passed as argument. This is to make it easier to work with QEMU, which uses the SeaBIOS BIOS by default, expecting a bootloader to be installed in the Master Boot Record (MBR).When using the
dockerimage type, a Docker image is produced. Guix builds the image from scratch, not from a pre-existing Docker base image. As a result, it contains exactly what you define in the operating system configuration file. You can then load the image and launch a Docker container using commands like the following:image_id="$(docker load < guix-system-docker-image.tar.gz)" container_id="$(docker create $image_id)" docker start $container_id
Esta orden arranca un contenedor Docker nuevo a partir de la imagen especificada. El sistema Guix se arrancará de la manera habitual, lo que implica el inicio de cualquier servicio que se haya definido en la configuración del sistema operativo. Puede iniciar una sesión de shell interactiva en el contenedor mediante el uso de
docker exec:docker exec -ti $container_id /run/current-system/profile/bin/bash --login
Dependiendo de lo que ejecute en el contenedor Docker, puede ser necesario proporcionar permisos adicionales al contenedor. Por ejemplo, si pretende construir software mediante el uso de Guix dentro del contenedor Docker, puede tener que proporcionar la opción --privileged a
docker create.Por último, la opción --network afecta a
guix system docker-image: produce una imagen donde la red supuestamente se comparte con el sistema anfitrión, y por lo tanto no contiene servicios como nscd o NetworkManager.containerDevuelve un guión de la ejecución del sistema operativo declarado en archivo dentro de un contenedor. Los contenedores son un conjunto de mecanismos de aislamiento ligeros que proporciona el núcleo Linux-libre. Los contenedores necesitan sustancialmente menos recursos que máquinas virtuales completas debido a que el núcleo, los objetos compartidos y otros recursos pueden compartirse con el sistema anfitrión; esto también significa que proporcionan un menor aislamiento.
En este momento, el guión debe ejecutarse como root para permitir más de una única usuaria y grupo. El contenedor comparte su almacén con la máquina anfitriona.
Como con la acción
vm(see guix system vm), sistemas de archivos adicionales a compartir entre la máquina anfitriona y el contenedor pueden especificarse mediante el uso de las opciones --share y --expose:guix system container mi-configuración.scm \ --expose=$HOME --share=$HOME/tmp=/intercambio
The --share and --expose options can also be passed to the generated script to bind-mount additional directories into the container.
Nota: Esta opción requiere Linux-libre 3.19 o posterior.
opciones puede contener cualquiera de las opciones de construcción comunes (see Opciones comunes de construcción). Además, opciones puede contener una de las siguientes:
- --expression=expr
- -e expr
Considera el sistema operativo al cual evalúa expr. Es una alternativa a la especificación de un archivo que evalúe a un sistema operativo. Se usa para la generación de la imagen de instalación de Guix (see Construcción de la imagen de instalación).
- --system=sistema
- -s sistema
Intenta la construcción para sistema en vez de para el tipo de la máquina anfitriona. Funciona como en
guix build(see Invocación deguix build).- --target=tripleta
Compilación cruzada para la tripleta, que debe ser una tripleta GNU válida, cómo
"aarch64-linux-gnu"(see GNU configuration triplets in Autoconf).- --derivation
- -d
Devuelve el nombre de archivo de la derivación del sistema operativo proporcionado sin construir nada.
- --save-provenance
Como se ha mostrado previamente,
guix system inityguix system reconfiguresiempre almacenan información de procedencia a través de un servicio dedicado (seeprovenance-service-type). No obstante, otras órdenes no hacen esto de manera predeterminada. Si desea, digamos, crear una imagen de máquina virtual que contenga información de procedencia, puede ejecutar:guix system image -t qcow2 --save-provenance config.scm
De este modo, la imagen resultante “embeberá sus propias fuentes” de manera efectiva en forma de metadatos en /run/current-system. Con dicha información se puede reconstruir la imagen para asegurarse de que realmente contiene lo que dice contener; o se puede usar para derivar una variante de la imagen.
- --image-type=tipo
- -t tipo
For the
imageaction, create an image with given type.When this option is omitted,
guix systemuses theefi-rawimage type.--file-system-type=iso9660 produce una imagen ISO-9660, que puede ser grabada en CD y DVD.
- --image-size=tamaño
For the
imageaction, create an image of the given size. size may be a number of bytes, or it may include a unit as a suffix (see size specifications in GNU Coreutils).Cuando se omite esta opción,
guix systemcalcula una estimación del tamaño de la imagen en función del tamaño del sistema declarado en archivo.- --network
- -N
Con la acción
container, permite a los contenedores acceder a la red de la máquina anfitriona, es decir, no crea un espacio de nombres de red.- --root=archivo
- -r archivo
Hace que archivo sea un enlace simbólico al resultado, y lo registra como una raíz del recolector de basura.
- --skip-checks
Omite las comprobaciones de seguridad previas a la instalación.
Por omisión,
guix system inityguix system reconfigurerealizan comprobaciones de seguridad: se aseguran de que los sistemas de archivos que aparecen en la declaraciónoperating-systemrealmente existen (see Sistemas de archivos) y que cualquier módulo del núcleo Linux que pudiese necesitarse durante el arranque se encuentre eninitrd-modules(see Disco en RAM inicial). El uso de esta opción omite todas estas comprobaciones.- --allow-downgrades
Indica a
guix system reconfigureque permita la instalación de versiones más antiguas.De manera predeterminada
reconfigureevita que instale una versión más antigua. Esto se consigue comparando la información de procedencia en su sistema operativo (mostrada porguix system describe) con aquella de la ordenguix(mostrada porguix describe). Si las revisiones deguixno son descendientes de las usadas en su sistema,guix system reconfiguretermina con un error. Proporcionar la opción --allow-downgrades le permite evitar estas comprobaciones.Nota: Asegúrese de entender las implicaciones de seguridad antes de usar la opción --allow-downgrades.
- --on-error=estrategia
Aplica estrategia cuando ocurre un error durante la lectura de archivo. estrategia puede ser uno de los siguientes valores:
nothing-specialInforma concisamente del error y termina la ejecución. Es la estrategia predeterminada.
backtraceDel mismo modo, pero también muestra la secuencia de llamadas.
debugInforma del error y entra en el depurador de Guile. A partir de ahí, puede ejecutar órdenes como
,btpara obtener la secuencia de llamadas,,localspara mostrar los valores de las variables locales, e inspeccionar el estado del programa de forma más general. See Debug Commands in GNU Guile Reference Manual, para una lista de órdenes de depuración disponibles.
Una vez haya construido, configurado, reconfigurado y re-reconfigurado su instalación de Guix, puede encontrar útil enumerar las generaciones del sistema operativo disponibles en el disco—y que puede seleccionar en el menú de arranque:
describeDescribe the running system generation: its file name, the kernel and bootloader used, etc., as well as provenance information when available.
The
--list-installedflag is available, with the same syntax that is used inguix package --list-installed(see Invocación deguix package). When the flag is used, the description will include a list of packages that are currently installed in the system profile, with optional filtering based on a regular expression.Nota: The running system generation—referred to by /run/current-system—is not necessarily the current system generation—referred to by /var/guix/profiles/system: it differs when, for instance, you chose from the bootloader menu to boot an older generation.
It can also differ from the booted system generation—referred to by /run/booted-system—for instance because you reconfigured the system in the meantime.
list-generationsMuestra un resumen de cada generación del sistema operativo disponible en el disco, de manera legible por humanos. Es similar a la opción --list-generations de
guix package(see Invocación deguix package).De manera opcional, se puede especificar un patrón, con la misma sintaxis que la usada en
guix package --list-generations, para restringir la lista de generaciones mostradas. Por ejemplo, la siguiente orden muestra generaciones que tienen hasta 10 días de antigüedad:$ guix system list-generations 10d
The
--list-installedflag may also be specified, with the same syntax that is used inguix package --list-installed. This may be helpful if trying to determine when a package was added to the system.
¡La orden guix system tiene aún más que ofrecer! Las siguientes
ordenes le permiten visualizar cual es la relación entre los servicios del
sistema:
extension-graphEmit to standard output the service extension graph of the operating system defined in file (see Composición de servicios, for more information on service extensions). By default the output is in Dot/Graphviz format, but you can choose a different format with --graph-backend, as with
guix graph(see --backend):La orden:
$ guix system extension-graph archivo | xdot -
muestra las relaciones de extensión entre los servicios.
Nota: The
dotprogram is provided by thegraphvizpackage.shepherd-graphEmit to standard output the dependency graph of shepherd services of the operating system defined in file. See Servicios de Shepherd, for more information and for an example graph.
Again, the default output format is Dot/Graphviz, but you can pass --graph-backend to select a different one.
Next: Ejecución de Guix en una máquina virtual, Previous: Invoking guix system, Up: Configuración del sistema [Contents][Index]
12.16 Invoking guix deploy
Ya hemos visto como usar declaraciones operating-system para
gestionar la configuración de una máquina de manera local. Supongamos no
obstante que necesita configurar múltiples máquinas—quizá esté gestionando
un servicio en la web que se componga de varios servidores. guix
deploy le permite usar las mismas declaraciones operating-system
para gestionar múltiples máquinas remotas como un único “despliegue”
lógico.
Nota: La funcionalidad descrita en esta sección está todavía en desarrollo y sujeta a cambios. Puede ponerse en contacto con nosotras a través de guix-devel@gnu.org.
guix deploy archivo
Dicha invocación llevará a cabo en las máquinas el despliegue al cual el archivo evalúe. Como ejemplo, archivo puede contener una definición como esta:
;; Este es un despliegue de Guix con una configuración en ;; mínima ("en los huesos"), sin servidor gráfico X11, ;; en una máquina con un daemon SSH escuchando en ;; localhost:2222. Una configuración como esta puede ser ;; apropiada para máquinas virtuales con puertos redirigidos ;; a la interfaz local de la máquina anfitriona. (use-service-modules networking ssh) (use-package-modules bootloaders) (define %system (operating-system (host-name "gnu-deployed") (timezone "Etc/UTC") (bootloader (bootloader-configuration (bootloader grub-bootloader) (targets '("/dev/vda")) (terminal-outputs '(console)))) (file-systems (cons (file-system (mount-point "/") (device "/dev/vda1") (type "ext4")) %base-file-systems)) (services (append (list (service dhcp-client-service-type) (service openssh-service-type (openssh-configuration (permit-root-login #t) (allow-empty-passwords? #t)))) %base-services)))) (list (machine (operating-system %sistema) (environment managed-host-environment-type) (configuration (machine-ssh-configuration (host-name "localhost") (system "x86_64-linux") (user "alicia") (identity "./id_rsa") (port 2222)))))
El archivo debe evaluar a una lista de objetos machine. Este ejemplo,
durante el despliegue, creará una nueva generación en el sistema remoto que
implemente la declaración operating-system
%system. environment y configuration especifican cómo
debe aprovisionarse la máquina—es decir, cómo se crean y gestionan los
recursos computacionales. El ejemplo previo no crea ningún recurso, ya que
'managed-host es una máquina que ya está ejecutando el sistema Guix y
está disponible a través de la red. Este es un caso particularmente simple;
un despliegue más complejo puede implicar, por ejemplo, el arranque de
máquinas virtuales a través de un proveedor de servidores privados virtuales
(VPS). En dicho caso se usaría un tipo distinto en environment.
Tenga en cuenta que primero debe generar un par de claves en la máquina
coordinadora para permitir al daemon exportar archivos firmados de archivos
en el almacén (see Invocación de guix archive), aunque este paso se realiza
de manera automática en el sistema Guix:
# guix archive --generate-key
Cada máquina de destino debe autorizar a la clave de la máquina maestra para que acepte elementos del almacén que reciba de la coordinadora:
# guix archive --authorize < clave-publica-coordinadora.txt
La usuaria proporcionada en user, en este ejemplo, especifica la
cuenta de la usuaria con la que ingresar en el sistema para realizar el
despliegue. Su valor predeterminado es root, pero el ingreso al
sistema como root a través de SSH en algunos casos puede no estar
permitido. Para solventar este problema, guix deploy puede
ingresar al sistema como una usuaria sin privilegios y ejecutar sudo
para escalar privilegios. Esto funciona únicamente si sudo está
instalado en el sistema remoto y se puede invocar de manera no interactiva
como user. Es decir: la línea de sudoers que permite a la
usuaria user la capacidad de usar sudo debe contener la
etiqueta NOPASSWD. Esto se puede conseguir con el siguiente fragmento
de la configuración de sistema operativo:
(use-modules ... (gnu system)) ;para %sudoers-specification (define %usuaria "nombre") (operating-system ... (sudoers-file (plain-file "sudoers" (string-append (plain-file-content %sudoers-specification) (format #f "~a ALL = NOPASSWD: ALL~%" %usuaria)))))
Para obtener más información sobre el formato del archivo sudoers
consulte man sudoers.
Once you’ve deployed a system on a set of machines, you may find it useful
to run a command on all of them. The --execute or -x
option lets you do that; the example below runs uname -a on all
the machines listed in the deployment file:
guix deploy file -x -- uname -a
One thing you may often need to do after deployment is restart specific services on all the machines, which you can do like so:
guix deploy file -x -- herd restart service
The guix deploy -x command returns zero if and only if the command
succeeded on all the machines.
Below are the data types you need to know about when writing a deployment file.
- Tipo de datos: machine
Tipo de datos que representa una máquina individual en un despliegue heterogéneo de Guix.
operating-systemEl objeto de la configuración de sistema operativo a desplegar.
environmentUn objeto
environment-typeque describe como debe aprovisionarse la máquina.configuration(predeterminado:#f)Un objeto que describe la configuración para el entorno (
environment) de la máquina. Sienvironmenttiene una configuración predeterminada, puede usarse#f. No obstante, si se usa#fpara un entorno sin configuración predeterminada se emitirá un error.
- Tipo de datos: machine-ssh-configuration
Tipo de datos que representa los parámetros del cliente SSH para una máquina con un entorno (
environment) de tipo gestionado (managed-host-environment-type).host-namebuild-locally?(predeterminado:#t)Si es falso, las derivaciones del sistema se construirán en la máquina sobre la que se realiza el despliegue.
systemEl tipo de sistema que describe la arquitectura de la máquina sobre la que se realiza el despliegue—por ejemplo,
"x86_64-linux".authorize?(predeterminado:#t)Si es verdadero, la clave de firma de la máquina coordinadora debe añadirse al anillo de claves del control de acceso (ACL) de la máquina remota.
port(predeterminado:22)user(predeterminada:"root")identity(predeterminada:#f)Cuando se especifica, indica la ruta al archivo que contiene la clave privada de SSH para la identificación con la máquina remota.
host-key(predeterminada:#f)Esta debería ser la clave SSH de la máquina, que puede ser más o menos así:
ssh-ed25519 AAAAC3Nz… root@example.org
Cuando
host-keyes#f, el servidor se identifica con el archivo ~/.ssh/known_hosts, igual que hace el clientesshde OpenSSH.allow-downgrades?(predeterminado:#f)Determina si se permiten instalaciones de versiones potencialmente anteriores.
Al igual que
guix system reconfigure,guix deploycompara la revisión del canal desplegada actualmente en la máquina remota (como muestraguix system describe) con aquella que se esté usando en ese momento (como muestraguix describe) para determinar si las revisiones que se despliegan son descendientes de aquellas en uso. Cuando no es el caso y el valor deallow-downgrades?es falso, emite un error. Esto le permite no instalar accidentalmente una versión anterior en máquinas remotas.safety-checks?(default:#t)Whether to perform “safety checks” before deployment. This includes verifying that devices and file systems referred to in the operating system configuration actually exist on the target machine, and making sure that Linux modules required to access storage devices at boot time are listed in the
initrd-modulesfield of the operating system.These safety checks ensure that you do not inadvertently deploy a system that would fail to boot. Be careful before turning them off!
- Tipo de datos: digital-ocean-configuration
Tipo de datos que representa el Droplet que debe crearse para la máquina con
environmentdigital-ocean-environment-type.ssh-keyThe path to the SSH private key to use to authenticate with the remote host. In the future, this field may not exist.
tagsA list of string “tags” that uniquely identify the machine. Must be given such that no two machines in the deployment have the same set of tags.
regionDescriptor (slug) de región de Digital Ocean, como
"nyc3".sizeDescriptor (slug) de tamaño de Digital Ocean, como
"s-1vcpu-1gb"enable-ipv6?Determina si droplet debe crearse con capacidad de usar redes IPv6 o no.
Next: Definición de servicios, Previous: Invoking guix deploy, Up: Configuración del sistema [Contents][Index]
12.17 Ejecución de Guix en una máquina virtual
To run Guix in a virtual machine (VM), one can use the pre-built Guix VM image distributed at https://ftp.gnu.org/gnu/guix/guix-system-vm-image-1.4.0.x86_64-linux.qcow2. This image is a compressed image in QCOW format. You can pass it to an emulator such as QEMU (see below for details).
Esta imagen arranca en el entorno gráfico Xfce y contiene algunas
herramientas usadas de forma común. Puede instalar más software en la imagen
mediante la ejecución de guix package en un terminal
(see Invocación de guix package). También puede reconfigurar el sistema en
base a su archivo de configuración inicial, disponible como
/run/current-system/configuration.scm (see Uso de la configuración del sistema).
Instead of using this pre-built image, one can also build their own image
using guix system image (see Invoking guix system).
If you built your own image, you must copy it out of the store (see El almacén) and give yourself permission to write to the copy before you can use
it. When invoking QEMU, you must choose a system emulator that is suitable
for your hardware platform. Here is a minimal QEMU invocation that will
boot the result of guix system image -t qcow2 on x86_64 hardware:
$ qemu-system-x86_64 \ -nic user,model=virtio-net-pci \ -enable-kvm -m 2048 \ -device virtio-blk,drive=myhd \ -drive if=none,file=guix-system-vm-image-1.4.0.x86_64-linux.qcow2,id=myhd
Aquí está el significado de cada una de esas opciones:
qemu-system-x86_64Esto especifica la plataforma hardware a emular. Debe corresponder con el anfitrión.
-nic user,model=virtio-net-pciActiva la pila de red en espacio de usuaria sin privilegios. El SO anfitrión puede acceder a la máquina virtualizada pero no al revés. Este es el modo más simple de poner la máquina en red.
modelespecifica que dispositivo de red emular:virtio-net-pcies un dispositivo especial para sistemas operativos virtualizados y recomendado para la mayor parte de usos. Asumiendo que su plataforma de hardware es x86_64, puede obtener una lista de adaptadores de red disponibles ejecutandoqemu-system-x86_64 -nic model=help.-enable-kvmSi su sistema tiene extensiones de virtualización por hardware, la activación de la implementación de máquinas virtuales (KVM) del núcleo Linux hará que la ejecución sea más rápida.
-m 2048RAM disponible para el sistema operativo virtualizado, en mebibytes. El valor predeterminado es 128 MiB, que puede ser insuficiente para algunas operaciones.
-device virtio-blk,drive=midiscoCrea un dispositivo
virtio-blkllamado “midisco”.virtio-blkes un mecanismo de “paravirtualización” de dispositivos de bloques que permite a QEMU obtener un mejor rendimiento que se emulase una unidad de disco completa. Véase la documentación de QEMU y KVM para más información.-drive if=none,file=/tmp/imagen-qemu,id=midiscoUsa nuestra imagen QCOW, el archivo /tmp/imagen-qemu, como almacenamiento físico para la unidad “midisco”.
The default run-vm.sh script that is returned by an invocation of
guix system vm does not add a -nic user flag by
default. To get network access from within the vm add the
(dhcp-client-service) to your system definition and start the VM
using $(guix system vm config.scm) -nic user. An important caveat
of using -nic user for networking is that ping will not
work, because it uses the ICMP protocol. You’ll have to use a different
command to check for network connectivity, for example guix
download.
12.17.1 Conexión a través de SSH
Para activar SSH dentro de una máquina virtual debe añadir un servidor SSH
como (openssh-service-type) en su máquina virtual (see openssh-service-type). Además debe que redirigir el puerto
SSH, el 22 por omisión, a la máquina anfitriona. Puede hacerlo con
$(guix system vm config.scm) -nic user,model=virtio-net-pci,hostfwd=tcp::10022-:22
Para conectarse a la máquina virtual puede ejecutar
ssh -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no -p 10022 localhost
La -p indica a ssh el puerto al que se debe
conectar. -o UserKnownHostsFile=/dev/null evita que ssh
se queje cada vez que modifique su archivo config.scm y la orden
-o StrictHostKeyChecking=no evita que tenga que autorizar la
conexión a una máquina desconocida cada vez que se conecte.
Nota: If you find the above ‘hostfwd’ example not to be working (e.g., your SSH client hangs attempting to connect to the mapped port of your VM), make sure that your Guix System VM has networking support, such as by using the
dhcp-client-service-typeservice type.
12.17.2 Uso de virt-viewer con Spice
Como alternativa al cliente gráfico predeterminado de qemu puede
usar remote-viewer del paquete virt-viewer. Para
conectarse proporcione la opción -spice
port=5930,disable-ticketing a qemu. Véase la sección previa para
más información sobre cómo hacer esto.
Spice also allows you to do some nice stuff like share your clipboard with
your VM. To enable that you’ll also have to pass the following flags to
qemu:
-device virtio-serial-pci,id=virtio-serial0,max_ports=16,bus=pci.0,addr=0x5 -chardev spicevmc,name=vdagent,id=vdagent -device virtserialport,nr=1,bus=virtio-serial0.0,chardev=vdagent,\ name=com.redhat.spice.0
También deber añadir a su definición de sistema el servicio
(spice-vdagent-service) (see servicio
Spice).
Previous: Ejecución de Guix en una máquina virtual, Up: Configuración del sistema [Contents][Index]
12.18 Definición de servicios
Las secciones anteriores muestran los servicios disponibles y cómo se pueden
combinar en una declaración operating-system. ¿Pero cómo las
definimos en primer lugar? ¿Y qué es un servicio en cualquier caso?
- Composición de servicios
- Tipos de servicios y servicios
- Referencia de servicios
- Servicios de Shepherd
- Complex Configurations
Next: Tipos de servicios y servicios, Up: Definición de servicios [Contents][Index]
12.18.1 Composición de servicios
Definimos un servicio como, de manera genérica, algo que extiende la
funcionalidad del sistema operativo. Habitualmente un servicio es un
proceso—un daemon—iniciado cuando el sistema arranca: un servidor
de shell seguro, un servidor Web, el daemon de construcción de Guix, etc. A
veces un servicio es un daemon cuya ejecución puede ser iniciada por otro
daemon—por ejemplo, un servidor FTP iniciado por inetd o un
servicio D-Bus activado por dbus-daemon. De manera ocasional, un
servicio no se puede asociar a un daemon. Por ejemplo, el servicio
“account” recopila cuentas de usuaria y se asegura que existen cuando el
sistema se ejecuta; el servicio “udev” recopila reglas de gestión de
dispositivos y los pone a disposición del daemon eudev; el servicio
/etc genera el contenido del directorio /etc del sistema.
Los servicios de Guix se conectan a través de extensiones. Por
ejemplo, el servicio de shell seguro extiende Shepherd—el sistema
de inicio, el cual se ejecuta como PID 1—proporcionando las líneas de
órdenes para arrancar y parar el daemon de shell seguro (see lsh-service); el servicio UPower extiende el servicio
D-Bus proporcionando su especificación .service, y extiende el
servicio udev al que proporciona reglas de gestión de dispositivos
(see upower-service); el servicio del daemon de
Guix extiende Shepherd proporcionando las líneas de órdenes para arrancar y
parar el daemon, y extiende el servicio de cuentas proporcionando una lista
de cuentas de usuarias de construcción que necesita (see Servicios base).
Al fin y al cabo, los servicios y sus relaciones de “extensión” forman un grafo acíclico dirigido (GAD). Si representamos los servicios como cajas y las extensiones como flechas, un sistema típico puede proporcionar algo de este estilo:
En la base, podemos ver el servicio del sistema, el cual produce el
directorio que contiene todo lo necesario para ejecutar y arrancar el
sistema, como es devuelto por la orden guix system
build. See Referencia de servicios, para aprender acerca de otros servicios
mostrados aquí. See la orden guix system
extension-graph, para información sobre cómo generar esta representación
para una definición particular de sistema operativo.
Técnicamente, las desarrolladoras pueden definir tipos de servicio para expresar estas relaciones. Puede haber cualquier número de servicios de un tipo dado en el sistema—por ejemplo, un sistema que ejecuta dos instancias del shell seguro GNU (lsh) tiene dos instancias de lsh-service-type, con parámetros diferentes.
La siguiente sección describe la interfaz programática para tipos de servicio y servicios.
Next: Referencia de servicios, Previous: Composición de servicios, Up: Definición de servicios [Contents][Index]
12.18.2 Tipos de servicios y servicios
Un tipo de servicio es un nodo en el GAD descrito
previamente. Empecemos con un ejemplo simple, el tipo de servicio para el
daemon de construcción Guix (see Invocación de guix-daemon):
(define guix-service-type
(service-type
(name 'guix)
(extensions
(list (service-extension shepherd-root-service-type guix-shepherd-service)
(service-extension account-service-type guix-accounts)
(service-extension activation-service-type guix-activation)))
(default-value (guix-configuration))))
Define tres cosas:
- Un nombre, cuyo único propósito es facilitar la inspección y la depuración.
- Una lista de extensiones de servicio, donde cada extensión designa el
tipo de servicio a extender y un procedimiento que, dados los parámetros del
servicio, devuelve una lista de objetos para extender el servicio de dicho
tipo.
Cada tipo de servicio tiene al menos una extensión de servicio. La única excepción es el tipo de servicio de arranque, que es el último servicio.
- De manera opcional, un valor predeterminado para instancias de este tipo.
En este ejemplo, guix-service-type extiende tres servicios:
shepherd-root-service-typeEl procedimiento
guix-shepherd-servicedefine cómo se extiende el servicio de Shepherd. Es decir, devuelve un objeto<shepherd-service>que define cómo se arranca y paraguix-daemon(see Servicios de Shepherd).account-service-typeguix-accountscrea la implementación de esta extensión para este servicio, la cual devuelve una lista de objetosuser-groupyuser-accountque representan las cuentas de usuarias de construcción (see Invocación deguix-daemon).activation-service-typeAquí
guix-activationes un procedimiento que devuelve una expresión-G, que es un fragmento de código a ejecutar en “tiempo de activación”—por ejemplo, cuando el servicio se arranca.
Un servicio de este tipo se puede instanciar de esta manera:
(service guix-service-type
(guix-configuration
(build-accounts 5)
(extra-options '("--gc-keep-derivations"))))
El segundo parámetro a la forma service es un valor que representa
los parámetros de esta instancia específica del
servicio. See guix-configuration, para
información acerca del tipo de datos guix-configuration. Cuando se
omite el valor, se usa el valor predeterminado por guix-service-type:
guix-service-type es bastante simple puesto que extiende otros
servicios pero no es extensible a su vez.
El tipo de servicio para un servicio extensible puede tener esta forma:
(define udev-service-type
(service-type (name 'udev)
(extensions
(list (service-extension shepherd-root-service-type
udev-shepherd-service)))
(compose concatenate) ;concatena la lista de reglas
(extend (lambda (config rules)
(match config
(($ <udev-configuration> udev initial-rules)
(udev-configuration
(udev udev) ;el paquete udev usado
(rules (append initial-rules rules)))))))))
Este es el tipo de servicio para el
daemon de gestión de
dispositivos eudev. En comparación con el ejemplo previo, además de una
extensión de shepherd-root-service-type, podemos ver dos nuevos
campos:
composeEste es el procedimiento para componer la lista de extensiones en servicios de este tipo.
Los servicios pueden extender el servicio udev proporcionandole una lista de reglas; componemos estas extensiones mediante una simple concatenación.
extendEste procedimiento define cómo el valor del servicio se extiende con la composición de la extensión.
Las extensiones de udev se componen en una lista de reglas, pero el valor del servicio udev es en sí un registro
<udev-configuration>. Por tanto aquí extendemos el registro agregando la lista de reglas que contiene al final de la lista de reglas que se contribuyeron.descriptionEs una cadena que proporciona una descripción del tipo de servicio. Dicha cadena puede contener lenguaje de marcado Texinfo (see Overview in GNU Texinfo). La orden
guix system searchbusca estas cadenas y las muestra (see Invokingguix system).
Puede haber únicamente una instancia de un tipo de servicio extensible como
udev-service-type. Si hubiese más, las especificaciones
service-extension serían ambiguas.
¿Todavía aquí? La siguiente sección proporciona una referencia de la interfaz programática de los servicios.
Next: Servicios de Shepherd, Previous: Tipos de servicios y servicios, Up: Definición de servicios [Contents][Index]
12.18.3 Referencia de servicios
Ya hemos echado un vistazo a los tipos de servicio (see Tipos de servicios y servicios). Esta sección proporciona referencias sobre cómo manipular
servicios y tipos de servicio. Esta interfaz se proporciona en el módulo
(gnu services).
- Procedimiento Scheme: service tipo [valor]
Devuelve un nuevo servicio de tipo, un objeto
<service-type>(véase a continuación). valor puede ser cualquier objeto; representa los parámetros de esta instancia de servicio particular.Cuando se omite valor, se usa el valor predeterminado especificado por tipo; si type no especifica ningún valor, se produce un error.
Por ejemplo, esto:
es equivalente a esto:
En ambos casos el resultado es una instancia de
openssh-service-typecon la configuración predeterminada.
- Procedimiento Scheme: service? obj
Devuelve verdadero si obj es un servicio.
- Procedimiento Scheme: service-kind servicio
Devuelve el tipo de servicio—es decir, un objeto
<service-type>.
- Procedimiento Scheme: service-value servicio
Devuelve el valor asociado con servicio. Representa sus parámetros.
Este es un ejemplo de creación y manipulación de un servicio:
(define s (service nginx-service-type (nginx-configuration (nginx nginx) (log-directory log-directory) (run-directory run-directory) (file config-file)))) (service? s) ⇒ #t (eq? (service-kind s) nginx-service-type) ⇒ #t
La forma modify-services proporciona una manera fácil de cambiar los
parámetros de algunos servicios de una lista como %base-services
(see %base-services). Evalúa a una lista de
servicios. Por supuesto, siempre puede usar operaciones estándar sobre
listas como map y fold para hacerlo (see List
Library in GNU Guile Reference Manual); modify-services
proporciona simplemente una forma más concisa para este patrón común.
- Sintaxis Scheme: modify-services servicios (tipo variable => cuerpo) …
-
Modifica los servicios listados en servicios de acuerdo a las cláusulas proporcionadas. Cada cláusula tiene la forma:
(tipo variable => cuerpo)
donde tipo es un tipo de servicio—por ejemplo,
guix-service-type—y variable es un identificador que se asocia dentro del cuerpo a los parámetros del servicio—por ejemplo, una instanciaguix-configuration—del servicio original de dicho ŧipo.El cuerpo deve evaluar a los nuevos parámetros del servicio, que serán usados para configurar el nuevo servicio. Este nuevo servicio reemplaza el original en la lista resultante. Debido a que los parámetros de servicio de un servicio se crean mediante el uso de
define-record-type*, puede escribir un breve cuerpo que evalúe a los nuevos parámetros del servicio mediante el uso de la característicainheritque proporcionadefine-record-type*para heredar los valores antiguos.Clauses can also have the following form:
(delete type)Such a clause removes all services of the given type from services.
See Uso de la configuración del sistema, para ejemplos de uso.
A continuación se procede con la interfaz programática de los tipos de
servicios. Es algo que debe conocer para escribir definiciones de nuevos
servicios, pero no es cuando busque formas de personalizar su declaración
operating-system.
- Tipo de datos: service-type
-
Esta es la representación de un tipo de servicio (see Tipos de servicios y servicios).
nameEs un símbolo, usado únicamente para simplificar la inspección y la depuración.
extensionsUna lista no vacía de objetos
<service-extension>(véase a continuación).compose(predeterminado:#f)Si es
#f, entonces el tipo de servicio denota servicios que no pueden extenderse—es decir, servicios que no pueden recibir “valores” de otros servicios.En otro caso, debe ser un procedimiento de un único parámetro. El procedimiento es invocado en
fold-servicesy se le proporciona una lista de valores recibidos de las extensiones. Puede devolver un valor único.extend(predeterminado:#f)Si es
#f, los servicios de este tipo no pueden extenderse.En otro caso, debe ser un procedimiento que acepte dos parámetros:
fold-serviceslo invoca, proporcionandole el valor inicial del servicio como el primer parámetro y el resultado de aplicarcomposea los valores de las extensiones como segundo parámetro. Debe devolver un valor que es un parámetro válido para la instancia del servicio.descriptionUna cadena, que posiblemente usa el lenguaje de marcas Texinfo, que describe en un par de frases el servicio. Esta cadena permite la búsqueda del servicio a través de
guix system search(see Invokingguix system).default-value(predeterminado:&no-default-value)El valor predeterminado asociado a instancias de este tipo de servicio. Esto permite a las usuarias usar
servicesin su segundo parámetro:(service tipo)El servicio devuelto en este caso tiene el valor predeterminado especificado por tipo.
See Tipos de servicios y servicios, para ejemplos.
- Procedimiento Scheme: service-extension tipo-deseado calcula
-
Devuelve una nueva extensión para servicios del tipo tipo-deseado. calcula debe ser un procedimiento de un único parámetro: es llamado en
fold-services, proporcionandole el valor asociado con el servicio que proporciona la extensión; debe devolver un valor válido para el servicio deseado.
- Procedimiento Scheme: service-extension? obj
Devuelve verdadero si obj es una expresión-G.
De manera ocasional, puede desear simplemente extender un servicio
existente. Esto implica la creación de un nuevo tipo de servicio y la
especificación de la extensión deseada, lo cual puede ser engorroso; el
procedimiento simple-service proporciona un atajo para ello.
- Procedimiento Scheme: simple-service nombre deseado valor
Devuelve un servicio que extiende deseado con valor. Esto funciona creando una instancia única del tipo de servicio nombre, de la cual el servicio devuelto es una instancia.
Por ejemplo, esto extiende mcron (see Ejecución de tareas programadas) con una tarea adicional:
(simple-service 'mi-tarea-mcron mcron-service-type #~(job '(next-hour (3)) "guix gc -F 2G"))
En el núcleo de la abstracción de los servicios se encuentra el
procedimiento fold-services, que es responsable de la “compilación”
de una lista de servicios en un único directorio que contiene todo lo
necesario para arrancar y ejecutar el sistema—el directorio mostrado por
la orden guix system build (see Invoking guix system). En
esencia, propaga las extensiones de servicios a través del grafo de
servicios, actualizando los parámetros de cada nodo en el camino, hasta que
alcanza el nodo raíz.
- Procedimiento Scheme: fold-services servicios [#:target-type system-service-type]
Recorre servicios propagando sus extensiones hasta la raíz del tipo target-type; devuelve el servicio raíz tratado de la manera apropiada.
Por último, el módulo (gnu services) también define varios tipos
esenciales de servicios, algunos de los cuales se enumeran a continuación.
- Variable Scheme: system-service-type
Esta es la raíz del grafo de servicios. Produce el directorio del sistema como lo devuelve la orden
guix system build.
- Variable Scheme: boot-service-type
El tipo del “servicio de arranque”, que produce un guión de arranque. El guión de arranque es lo que ejecuta el disco inicial en RAM cuando se arranca.
- Variable Scheme: etc-service-type
El tipo del servicio /etc. Este servicio se usa para crear los archivos en /etc y puede extenderse proporcionandole pares nombre/archivo como estas:
(list `("issue" ,(plain-file "issue" "¡Bienvenida!\n")))En este ejemplo, el efecto sería la adición de un archivo /etc/issue que apunte al archivo proporcionado.
- Variable Scheme: setuid-program-service-type
Type for the “setuid-program service”. This service collects lists of executable file names, passed as gexps, and adds them to the set of setuid and setgid programs on the system (see Programas con setuid).
- Variable Scheme: profile-service-type
Tipo del servicio que genera el perfil del sistema—es decir, los programas en /run/current-system/profile. Otros servicios pueden extenderlo proporcionandole listas de paquetes a añadir al perfil del sistema.
- Variable Scheme: provenance-service-type
Es el tipo del servicio que registra los metadatos de procedencia en el sistema mismo. Crea varios archivos en /run/current-system:
- channels.scm
Es un “archivo de canales” que se le puede proporcionar a
guix pull -Coguix time-machine -C, y que describe los canales usados para construir el sistema, si dicha información estaba disponible (see Canales).- configuration.scm
Est es el archivo que se proporciona como valor para el servicio
provenance-service-type. De manera predeterminada,guix system reconfigureproporciona automáticamente el archivo de configuración del SO que recibió en la línea de órdenes.- provenance
Contiene la misma información que los otros dos archivos, pero en un formato que se puede procesar más fácilmente.
En general, estas dos piezas de información (canales y el archivo de configuración) son suficientes para reproducir el sistema operativo “desde las fuentes”.
Advertencias: Esta información es necesaria para reconstruir su sistema operativo, pero no siempre es suficiente. En particular, configuration.scm en sí es insuficiente si no está autocontenido—si hace referencia a módulos externos de Guile o a archivos adicionales. Si desea que configuration.scm sea autocontenido, le recomendamos que los módulos o archivos a los que haga referencia sean parte de un canal.
Además, la proveniencia de los metadatos es “silenciosa” en el sentido de que no cambia los bits que contiene su sistema, excepto por los bits de los metadatos en sí. Dos configuraciones de SO diferentes o conjuntos de canales pueden llevar al mismo sistema, bit a bit; cuando se usa
provenance-service-type, estos dos sistemas tendrán distintos metadatos y por lo tanto distintos nombres de archivo en el almacén, lo que hace no tan trivial dicha comparación.Este servicio se añade automáticamente a la configuración de su sistema operativo cuando usa
guix system reconfigure,guix system initoguix deploy.
- Scheme Variable: linux-loadable-module-service-type
Type of the service that collects lists of packages containing kernel-loadable modules, and adds them to the set of kernel-loadable modules.
This service type is intended to be extended by other service types, such as below:
(simple-service 'installing-module linux-loadable-module-service-type (list module-to-install-1 module-to-install-2))This does not actually load modules at bootup, only adds it to the kernel profile so that it can be loaded by other means.
Next: Complex Configurations, Previous: Referencia de servicios, Up: Definición de servicios [Contents][Index]
12.18.4 Servicios de Shepherd
El módulo (gnu services shepherd) proporciona una forma de definir
servicios gestionados por GNU Shepherd, que es el sistema de
inicio—el primer proceso que se inicia cuando el sistema arranca, también
conocido como PID 1 (see Introduction in The GNU Shepherd
Manual).
Los servicios en Shepherd pueden depender de otros servicios. Por ejemplo, el daemon SSH puede tener que arrancarse tras el arranque del daemon syslog, lo cual a su vez puede suceder únicamente tras el montaje de todos los sistemas de archivos. El sistema operativo simple definido previamente (see Uso de la configuración del sistema) genera un grafo de servicios como este:
En realidad puede generar dicho grafo para cualquier definición de sistema
operativo mediante el uso de la orden guix system shepherd-graph
(see guix system shepherd-graph).
%shepherd-root-service es un objeto de servicio que representa el
PID 1, del tipo shepherd-root-service-type; puede ser extendido
proporcionandole listas de objetos <shepherd-service>.
- Tipo de datos: shepherd-service
El tipo de datos que representa un servicio gestionado por Shepherd.
provisionUna lista de símbolos que indican lo que proporciona el servicio.
Esto son nombres que pueden proporcionarse a
herd start,herd statusy órdenes similares (see Invoking herd in The GNU Shepherd Manual). See theprovidesslot in The GNU Shepherd Manual, para más detalles.requirement(predeterminada:'())Lista de símbolos que indican los servicios Shepherd de los que este depende.
one-shot?(predeterminado:#f)Si este servicio es one-shot. Los servicios “one-shot” finalizan inmediatamente después de que su acción
startse complete. See Slots of services in The GNU Shepherd Manual, para más información.respawn?(predeterminado:#t)Indica si se debe reiniciar el servicio cuando se para, por ejemplo cuando el proceso subyacente muere.
startstop(predeterminado:#~(const #f))Los campos
startystophacen referencia a las características de Shepherd de arranque y parada de procesos respectivamente (see Service De- and Constructors in The GNU Shepherd Manual). Se proporcionan como expresiones-G que se expandirán en el archivo de configuración de Shepherd (see Expresiones-G).actions(predeterminadas:'()) ¶Esta es la lista de objetos
shepherd-action(véase a continuación) que definen las acciones permitidas por el servicio, además de las acciones estándarstartystop. Las acciones que se listan aquí estarán disponibles como ordenes deherd:herd acción servicio [parámetros…]
auto-start?(predeterminado:#t)Determina si Shepherd debe iniciar este servicio de manera automática. Si es
#fel servicio debe iniciarse manualmente conherd start.documentaciónUna cadena de documentación, que se mostrará al ejecutar:
herd doc nombre-del-servicio
donde nombre-del-servicio es uno de los símbolos en
provision(see Invoking herd in The GNU Shepherd Manual).modules(predeterminados:%default-modules)Esta es la lista de módulos que deben estar dentro del ámbito cuando
startystopson evaluados.
The example below defines a Shepherd service that spawns syslogd,
the system logger from the GNU Networking Utilities (see syslogd in GNU Inetutils):
(let ((config (plain-file "syslogd.conf" "…")))
(shepherd-service
(documentation "Run the syslog daemon (syslogd).")
(provision '(syslogd))
(requirement '(user-processes))
(start #~(make-forkexec-constructor
(list #$(file-append inetutils "/libexec/syslogd")
"--rcfile" #$config)
#:pid-file "/var/run/syslog.pid"))
(stop #~(make-kill-destructor))))
Key elements in this example are the start and stop fields:
they are staged code snippets that use the
make-forkexec-constructor procedure provided by the Shepherd and its
dual, make-kill-destructor (see Service De- and Constructors in The GNU Shepherd Manual). The start field will have
shepherd spawn syslogd with the given option; note that
we pass config after --rcfile, which is a configuration file
declared above (contents of this file are omitted). Likewise, the
stop field tells how this service is to be stopped; in this case, it
is stopped by making the kill system call on its PID. Code staging
is achieved using G-expressions: #~ stages code, while #$
“escapes” back to host code (see Expresiones-G).
- Tipo de datos: shepherd-action
Este es el tipo de datos que define acciones adicionales implementadas por un servicio Shepherd (vea previamente).
nameSímbolo que nombra la acción.
documentaciónEsta es una cadena de documentación para la acción. Puede verse ejecutando:
herd doc servicio action acción
procedureDebe ser una expresión-G que evalúa a un procedimiento de al menos un parámetro, el cual es el “valor de ejecución” del servicio (see Slots of services in The GNU Shepherd Manual).
El siguiente ejemplo define una acción llamada
di-holaque saluda amablemente a la usuaria:(shepherd-action (name 'di-hola) (documentation "¡Di hola!") (procedure #~(lambda (running . args) (format #t "¡Hola, compa! parámetros: ~s\n" args) #t)))Asumiendo que esta acción se añade al servicio
ejemplo, puede ejecutar:# herd di-hola ejemplo ¡Hola, compa! parámetros: () # herd di-hola ejemplo a b c ¡Hola, compa! parámetros: ("a" "b" "c")Esta, como puede ver, es una forma un tanto sofisticada de decir hola. See Service Convenience in The GNU Shepherd Manual, para más información sobre acciones.
- Scheme Procedure: shepherd-configuration-action
Return a
configurationaction to display file, which should be the name of the service’s configuration file.It can be useful to equip services with that action. For example, the service for the Tor anonymous router (see
tor-service-type) is defined roughly like this:(let ((torrc (plain-file "torrc" …))) (shepherd-service (provision '(tor)) (requirement '(user-processes loopback syslogd)) (start #~(make-forkexec-constructor (list #$(file-append tor "/bin/tor") "-f" #$torrc) #:user "tor" #:group "tor")) (stop #~(make-kill-destructor)) (actions (list (shepherd-configuration-action torrc))) (documentation "Run the Tor anonymous network overlay.")))Thanks to this action, administrators can inspect the configuration file passed to
torwith this shell command:cat $(herd configuration tor)
This can come in as a handy debugging tool!
- Variable Scheme: shepherd-root-service-type
El tipo de servicio para el “servicio raíz” de Shepherd—es decir, PID 1.
This is the service type that extensions target when they want to create shepherd services (see Tipos de servicios y servicios, for an example). Each extension must pass a list of
<shepherd-service>. Its value must be ashepherd-configuration, as described below.
- Data Type: shepherd-configuration
This data type represents the Shepherd’s configuration.
shepherd (default:shepherd)The Shepherd package to use.
services (default:'())A list of
<shepherd-service>to start. You should probably use the service extension mechanism instead (see Servicios de Shepherd).
The following example specifies the Shepherd package for the operating system:
(operating-system
;; ...
(services (append (list openssh-service-type))
;; ...
%desktop-services)
;; ...
;; Use own Shepherd package.
(essential-services
(modify-services (operating-system-default-essential-services
this-operating-system)
(shepherd-root-service-type config => (shepherd-configuration
(inherit config)
(shepherd my-shepherd))))))
- Variable Scheme: %shepherd-root-service
Este servicio representa el PID 1.
Previous: Servicios de Shepherd, Up: Definición de servicios [Contents][Index]
12.18.5 Complex Configurations
Some programs might have rather complex configuration files or formats, and
to make it easier to create Scheme bindings for these configuration files,
you can use the utilities defined in the (gnu services configuration)
module.
The main utility is the define-configuration macro, which you will
use to define a Scheme record type (see Record Overview in GNU
Guile Reference Manual). The Scheme record will be serialized to a
configuration file by using serializers, which are procedures that
take some kind of Scheme value and returns a G-expression
(see Expresiones-G), which should, once serialized to the disk, return a
string. More details are listed below.
- Scheme Syntax: define-configuration name clause1 clause2 ... Create a record type named
namethat contains the fields found in the clauses.
A clause can have one of the following forms:
(field-name (type default-value) documentation) (field-name (type default-value) documentation serializer) (field-name (type) documentation) (field-name (type) documentation serializer)
field-name is an identifier that denotes the name of the field in the generated record.
type is the type of the value corresponding to field-name; since Guile is untyped, a predicate procedure—
type?—will be called on the value corresponding to the field to ensure that the value is of the correct type. This means that if say, type ispackage, then a procedure namedpackage?will be applied on the value to make sure that it is indeed a<package>object.default-value is the default value corresponding to the field; if none is specified, the user is forced to provide a value when creating an object of the record type.
documentation is a string formatted with Texinfo syntax which should provide a description of what setting this field does.
serializer is the name of a procedure which takes two arguments, the first is the name of the field, and the second is the value corresponding to the field. The procedure should return a string or G-expression (see Expresiones-G) that represents the content that will be serialized to the configuration file. If none is specified, a procedure of the name
serialize-typewill be used.A simple serializer procedure could look like this:
(define (serialize-boolean field-name value) (let ((value (if value "true" "false"))) #~(string-append #$field-name #$value)))In some cases multiple different configuration records might be defined in the same file, but their serializers for the same type might have to be different, because they have different configuration formats. For example, the
serialize-booleanprocedure for the Getmail service would have to be different from the one for the Transmission service. To make it easier to deal with this situation, one can specify a serializer prefix by using theprefixliteral in thedefine-configurationform. This means that one doesn’t have to manually specify a custom serializer for every field.(define (foo-serialize-string field-name value) …) (define (bar-serialize-string field-name value) …) (define-configuration foo-configuration (label (string) "The name of label.") (prefix foo-)) (define-configuration bar-configuration (ip-address (string) "The IPv4 address for this device.") (prefix bar-))
However, in some cases you might not want to serialize any of the values of the record, to do this, you can use the
no-serializationliteral. There is also thedefine-configuration/no-serializationmacro which is a shorthand of this.
- Scheme Syntax: define-maybe type
Sometimes a field should not be serialized if the user doesn’t specify a value. To achieve this, you can use the
define-maybemacro to define a “maybe type”; if the value of a maybe type is left unset, or is set to the%unset-valuevalue, then it will not be serialized.When defining a “maybe type”, the corresponding serializer for the regular type will be used by default. For example, a field of type
maybe-stringwill be serialized using theserialize-stringprocedure by default, you can of course change this by specifying a custom serializer procedure. Likewise, the type of the value would have to be a string, or left unspecified.(define-maybe string) (define (serialize-string field-name value) …) (define-configuration baz-configuration (name ;; If set to a string, the `serialize-string' procedure will be used ;; to serialize the string. Otherwise this field is not serialized. maybe-string "The name of this module."))
Like with
define-configuration, one can set a prefix for the serializer name by using theprefixliteral.(define-maybe integer (prefix baz-)) (define (baz-serialize-integer field-name value) …)
There is also the
no-serializationliteral, which when set means that no serializer will be defined for the “maybe type”, regardless of whether its value is set or not.define-maybe/no-serializationis a shorthand for specifying theno-serializationliteral.(define-maybe/no-serialization symbol) (define-configuration/no-serialization test-configuration (mode maybe-symbol "Docstring."))
- (Scheme: Procedure) maybe-value-set? value
Predicate to check whether a user explicitly specified the value of a maybe field.
- Scheme Procedure: serialize-configuration configuration fields Return a G-expression that contains the values corresponding to
the fields of configuration, a record that has been generated by
define-configuration. The G-expression can then be serialized to disk by using something likemixed-text-file.
- Scheme Procedure: empty-serializer field-name value
A serializer that just returns an empty string. The
serialize-packageprocedure is an alias for this.
Once you have defined a configuration record, you will most likely also want to document it so that other people know to use it. To help with that, there are two procedures, both of which are documented below.
- Scheme Procedure: generate-documentation documentation documentation-name Generate a Texinfo fragment from the docstrings in
documentation, a list of
(label fields sub-documentation ...). label should be a symbol and should be the name of the configuration record. fields should be a list of all the fields available for the configuration record.sub-documentation is a
(field-name configuration-name)tuple. field-name is the name of the field which takes another configuration record as its value, and configuration-name is the name of that configuration record.sub-documentation is only needed if there are nested configuration records. For example, the
getmail-configurationrecord (see Servicios de correo) accepts agetmail-configuration-filerecord in one of itsrcfilefield, therefore documentation forgetmail-configuration-fileis nested ingetmail-configuration.(generate-documentation `((getmail-configuration ,getmail-configuration-fields (rcfile getmail-configuration-file)) …) 'getmail-configuration)documentation-name should be a symbol and should be the name of the configuration record.
- Scheme Procedure: configuration->documentation
configuration-symbol Take configuration-symbol, the symbol corresponding to the name used when defining a configuration record with
define-configuration, and print the Texinfo documentation of its fields. This is useful if there aren’t any nested configuration records since it only prints the documentation for the top-level fields.
As of right now, there is no automated way to generate documentation for
configuration records and put them in the manual. Instead, every time you
make a change to the docstrings of a configuration record, you have to
manually call generate-documentation or
configuration->documentation, and paste the output into the
doc/guix.texi file.
Below is an example of a record type created using
define-configuration and friends.
(use-modules (gnu services) (guix gexp) (gnu services configuration) (srfi srfi-26) (srfi srfi-1)) ;; Turn field names, which are Scheme symbols into strings (define (uglify-field-name field-name) (let ((str (symbol->string field-name))) ;; field? -> is-field (if (string-suffix? "?" str) (string-append "is-" (string-drop-right str 1)) str))) (define (serialize-string field-name value) #~(string-append #$(uglify-field-name field-name) " = " #$value "\n")) (define (serialize-integer field-name value) (serialize-string field-name (number->string value))) (define (serialize-boolean field-name value) (serialize-string field-name (if value "true" "false"))) (define (serialize-contact-name field-name value) #~(string-append "\n[" #$value "]\n")) (define (list-of-contact-configurations? lst) (every contact-configuration? lst)) (define (serialize-list-of-contact-configurations field-name value) #~(string-append #$@(map (cut serialize-configuration <> contact-configuration-fields) value))) (define (serialize-contacts-list-configuration configuration) (mixed-text-file "contactrc" #~(string-append "[Owner]\n" #$(serialize-configuration configuration contacts-list-configuration-fields)))) (define-maybe integer) (define-maybe string) (define-configuration contact-configuration (name (string) "The name of the contact." serialize-contact-name) (phone-number maybe-integer "The person's phone number.") (email maybe-string "The person's email address.") (married? (boolean) "Whether the person is married.")) (define-configuration contacts-list-configuration (name (string) "The name of the owner of this contact list.") (email (string) "The owner's email address.") (contacts (list-of-contact-configurations '()) "A list of @code{contact-configuation} records which contain information about all your contacts."))
A contacts list configuration could then be created like this:
(define my-contacts
(contacts-list-configuration
(name "Alice")
(email "alice@example.org")
(contacts
(list (contact-configuration
(name "Bob")
(phone-number 1234)
(email "bob@gnu.org")
(married? #f))
(contact-configuration
(name "Charlie")
(phone-number 0000)
(married? #t))))))
After serializing the configuration to disk, the resulting file would look like this:
[owner] name = Alice email = alice@example.org [Bob] phone-number = 1234 email = bob@gnu.org is-married = false [Charlie] phone-number = 0 is-married = true
Next: Documentación, Previous: Configuración del sistema, Up: GNU Guix [Contents][Index]
13 Home Configuration
Guix supports declarative configuration of home environments by
utilizing the configuration mechanism described in the previous chapter
(see Definición de servicios), but for user’s dotfiles and packages. It works
both on Guix System and foreign distros and allows users to declare all the
packages and services that should be installed and configured for the user.
Once a user has written a file containing home-environment record,
such a configuration can be instantiated by an unprivileged user with
the guix home command (see Invoking guix home).
Nota: La funcionalidad descrita en esta sección está todavía en desarrollo y sujeta a cambios. Puede ponerse en contacto con nosotras a través de guix-devel@gnu.org.
The user’s home environment usually consists of three basic parts: software,
configuration, and state. Software in mainstream distros are usually
installed system-wide, but with GNU Guix most software packages can be
installed on a per-user basis without needing root privileges, and are thus
considered part of the user’s home environment. Packages on their own
are not very useful in many cases, because often they require some
additional configuration, usually config files that reside in
XDG_CONFIG_HOME (~/.config by default) or other directories.
Everything else can be considered state, like media files, application
databases, and logs.
Using Guix for managing home environments provides a number of advantages:
- All software can be configured in one language (Guile Scheme), this gives users the ability to share values between configurations of different programs.
- A well-defined home environment is self-contained and can be created in a declarative and reproducible way—there is no need to grab external binaries or manually edit some configuration file.
- After every
guix home reconfigureinvocation, a new home environment generation will be created. This means that users can rollback to a previous home environment generation so they don’t have to worry about breaking their configuration. - It is possible to manage stateful data with Guix Home, this
includes the ability to automatically clone Git repositories on the initial
setup of the machine, and periodically running commands like
rsyncto sync data with another host. This functionality is still in an experimental stage, though.
Next: Configuring the Shell, Up: Home Configuration [Contents][Index]
13.1 Declaring the Home Environment
The home environment is configured by providing a home-environment
declaration in a file that can be passed to the guix home command
(see Invoking guix home). The easiest way to get started is by
generating an initial configuration with guix home import:
guix home import ~/src/guix-config
The guix home import command reads some of the “dot files” such
as ~/.bashrc found in your home directory and copies them to the
given directory, ~/src/guix-config in this case; it also reads the
contents of your profile, ~/.guix-profile, and, based on that, it
populates ~/src/guix-config/home-configuration.scm with a Home
configuration that resembles your current configuration.
A simple setup can include Bash and a custom text configuration, like in the example below. Don’t be afraid to declare home environment parts, which overlaps with your current dot files: before installing any configuration files, Guix Home will back up existing config files to a separate place in the home directory.
Nota: It is highly recommended that you manage your shell or shells with Guix Home, because it will make sure that all the necessary scripts are sourced by the shell configuration file. Otherwise you will need to do it manually. (see Configuring the Shell).
(use-modules (gnu home) (gnu home services) (gnu home services shells) (gnu services) (gnu packages admin) (guix gexp)) (home-environment (packages (list htop)) (services (list (service home-bash-service-type (home-bash-configuration (guix-defaults? #t) (bash-profile (list (plain-file "bash-profile" "\ export HISTFILE=$XDG_CACHE_HOME/.bash_history"))))) (simple-service 'test-config home-xdg-configuration-files-service-type (list `("test.conf" ,(plain-file "tmp-file.txt" "the content of ~/.config/test.conf")))))))
The packages field should be self-explanatory, it will install the
list of packages into the user’s profile. The most important field is
services, it contains a list of home services, which are the
basic building blocks of a home environment.
There is no daemon (at least not necessarily) related to a home service, a home service is just an element that is used to declare part of home environment and extend other parts of it. The extension mechanism discussed in the previous chapter (see Definición de servicios) should not be confused with Shepherd services (see Servicios de Shepherd). Using this extension mechanism and some Scheme code that glues things together gives the user the freedom to declare their own, very custom, home environments.
Once the configuration looks good, you can first test it in a throw-away “container”:
guix home container config.scm
The command above spawns a shell where your home environment is running. The shell runs in a container, meaning it’s isolated from the rest of the system, so it’s a good way to try out your configuration—you can see if configuration bits are missing or misbehaving, if daemons get started, and so on. Once you exit that shell, you’re back to the prompt of your original shell “in the real world”.
Once you have a configuration file that suits your needs, you can reconfigure your home by running:
guix home reconfigure config.scm
This “builds” your home environment and creates ~/.guix-home pointing to it. Voilà!
Nota: Make sure the operating system has elogind, systemd, or a similar mechanism to create the XDG run-time directory and has the
XDG_RUNTIME_DIRvariable set. Failing that, the on-first-login script will not execute anything, and processes like user Shepherd and its descendants will not start.
Next: Home Services, Previous: Declaring the Home Environment, Up: Home Configuration [Contents][Index]
13.2 Configuring the Shell
This section is safe to skip if your shell or shells are managed by Guix Home. Otherwise, read it carefully.
There are a few scripts that must be evaluated by a login shell to activate
the home environment. The shell startup files only read by login shells
often have profile suffix. For more information about login shells
see Invoking Bash in The GNU Bash Reference Manual and see
Bash Startup Files in The GNU Bash Reference Manual.
The first script that needs to be sourced is setup-environment, which
sets all the necessary environment variables (including variables declared
by the user) and the second one is on-first-login, which starts
Shepherd for the current user and performs actions declared by other home
services that extends home-run-on-first-login-service-type.
Guix Home will always create ~/.profile, which contains the following lines:
HOME_ENVIRONMENT=$HOME/.guix-home . $HOME_ENVIRONMENT/setup-environment $HOME_ENVIRONMENT/on-first-login
This makes POSIX compliant login shells activate the home environment. However, in most cases this file won’t be read by most modern shells, because they are run in non POSIX mode by default and have their own *profile startup files. For example Bash will prefer ~/.bash_profile in case it exists and only if it doesn’t will it fallback to ~/.profile. Zsh (if no additional options are specified) will ignore ~/.profile, even if ~/.zprofile doesn’t exist.
To make your shell respect ~/.profile, add . ~/.profile or
source ~/.profile to the startup file for the login shell. In case
of Bash, it is ~/.bash_profile, and in case of Zsh, it is
~/.zprofile.
Nota: This step is only required if your shell is not managed by Guix Home. Otherwise, everything will be done automatically.
Next: Invoking guix home, Previous: Configuring the Shell, Up: Home Configuration [Contents][Index]
13.3 Home Services
A home service is not necessarily something that has a daemon and is
managed by Shepherd (see Jump Start in The GNU Shepherd
Manual), in most cases it doesn’t. It’s a simple building block of the
home environment, often declaring a set of packages to be installed in the
home environment profile, a set of config files to be symlinked into
XDG_CONFIG_HOME (~/.config by default), and environment
variables to be set by a login shell.
There is a service extension mechanism (see Composición de servicios) which
allows home services to extend other home services and utilize capabilities
they provide; for example: declare mcron jobs (see GNU Mcron) by extending Scheduled User’s Job Execution; declare daemons by
extending Managing User Daemons; add commands, which will be invoked
on by the Bash by extending home-bash-service-type.
A good way to discover available home services is using the guix
home search command (see Invoking guix home). After the required home
services are found, include its module with the use-modules form
(see Using Guile Modules in The GNU Guile Reference
Manual), or the #:use-modules directive (see Creating Guile Modules in The GNU Guile Reference Manual) and declare
a home service using the service function, or extend a service type
by declaring a new service with the simple-service procedure from
(gnu services).
- Essential Home Services
- Shells
- Scheduled User’s Job Execution
- Power Management Home Services
- Managing User Daemons
- Secure Shell
- Desktop Home Services
- Guix Home Services
Next: Shells, Up: Home Services [Contents][Index]
13.3.1 Essential Home Services
There are a few essential home services defined in (gnu services),
they are mostly for internal use and are required to build a home
environment, but some of them will be useful for the end user.
- Scheme Variable: home-environment-variables-service-type
The service of this type will be instantiated by every home environment automatically by default, there is no need to define it, but someone may want to extend it with a list of pairs to set some environment variables.
(list ("ENV_VAR1" . "value1") ("ENV_VAR2" . "value2"))The easiest way to extend a service type, without defining a new service type is to use the
simple-servicehelper from(gnu services).(simple-service 'some-useful-env-vars-service home-environment-variables-service-type `(("LESSHISTFILE" . "$XDG_CACHE_HOME/.lesshst") ("SHELL" . ,(file-append zsh "/bin/zsh")) ("USELESS_VAR" . #f) ("_JAVA_AWT_WM_NONREPARENTING" . #t)))If you include such a service in you home environment definition, it will add the following content to the setup-environment script (which is expected to be sourced by the login shell):
export LESSHISTFILE=$XDG_CACHE_HOME/.lesshst export SHELL=/gnu/store/2hsg15n644f0glrcbkb1kqknmmqdar03-zsh-5.8/bin/zsh export _JAVA_AWT_WM_NONREPARENTING
Nota: Make sure that module
(gnu packages shells)is imported withuse-modulesor any other way, this namespace contains the definition of thezshpackage, which is used in the example above.The association list (see Association Lists in The GNU Guile Reference manual) is a data structure containing key-value pairs, for
home-environment-variables-service-typethe key is always a string, the value can be a string, string-valued gexp (see Expresiones-G), file-like object (see file-like object) or boolean. For gexps, the variable will be set to the value of the gexp; for file-like objects, it will be set to the path of the file in the store (see El almacén); for#t, it will export the variable without any value; and for#f, it will omit variable.
- Scheme Variable: home-profile-service-type
The service of this type will be instantiated by every home environment automatically, there is no need to define it, but you may want to extend it with a list of packages if you want to install additional packages into your profile. Other services, which need to make some programs available to the user will also extend this service type.
The extension value is just a list of packages:
(list htop vim emacs)The same approach as
simple-service(see simple-service) forhome-environment-variables-service-typecan be used here, too. Make sure that modules containing the specified packages are imported withuse-modules. To find a package or information about its module useguix search(see Invocación deguix package). Alternatively,specification->packagecan be used to get the package record from string without importing related module.
There are few more essential services, but users are not expected to extend them.
- Scheme Variable: home-service-type
The root of home services DAG, it generates a folder, which later will be symlinked to ~/.guix-home, it contains configurations, profile with binaries and libraries, and some necessary scripts to glue things together.
- Scheme Variable: home-run-on-first-login-service-type
The service of this type generates a Guile script, which is expected to be executed by the login shell. It is only executed if the special flag file inside
XDG_RUNTIME_DIRhasn’t been created, this prevents redundant executions of the script if multiple login shells are spawned.It can be extended with a gexp. However, to autostart an application, users should not use this service, in most cases it’s better to extend
home-shepherd-service-typewith a Shepherd service (see Servicios de Shepherd), or extend the shell’s startup file with the required command using the appropriate service type.
- Scheme Variable: home-files-service-type
The service of this type allows to specify a list of files, which will go to ~/.guix-home/files, usually this directory contains configuration files (to be more precise it contains symlinks to files in /gnu/store), which should be placed in $XDG_CONFIG_DIR or in rare cases in $HOME. It accepts extension values in the following format:
`((".sway/config" ,sway-file-like-object) (".tmux.conf" ,(local-file "./tmux.conf")))
Each nested list contains two values: a subdirectory and file-like object. After building a home environment ~/.guix-home/files will be populated with apropiate content and all nested directories will be created accordingly, however, those files won’t go any further until some other service will do it. By default a
home-symlink-manager-service-type, which creates necessary symlinks in home folder to files from ~/.guix-home/files and backs up already existing, but clashing configs and other things, is a part of essential home services (enabled by default), but it’s possible to use alternative services to implement more advanced use cases like read-only home. Feel free to experiment and share your results.
- Scheme Variable: home-xdg-configuration-files-service-type
The service is very similiar to
home-files-service-type(and actually extends it), but used for defining files, which will go to ~/.guix-home/files/.config, which will be symlinked to $XDG_CONFIG_DIR byhome-symlink-manager-service-type(for example) during activation. It accepts extension values in the following format:`(("sway/config" ,sway-file-like-object) ;; -> ~/.guix-home/files/.config/sway/config ;; -> $XDG_CONFIG_DIR/sway/config (by symlink-manager) ("tmux/tmux.conf" ,(local-file "./tmux.conf")))
- Scheme Variable: home-activation-service-type
The service of this type generates a guile script, which runs on every
guix home reconfigureinvocation or any other action, which leads to the activation of the home environment.
- Scheme Variable: home-symlink-manager-service-type
The service of this type generates a guile script, which will be executed during activation of home environment, and do a few following steps:
- Reads the content of files/ directory of current and pending home environments.
- Cleans up all symlinks created by symlink-manager on previous activation. Also, sub-directories, which become empty also will be cleaned up.
- Creates new symlinks the following way: It looks files/ directory
(usually defined with
home-files-service-type,home-xdg-configuration-files-service-typeand maybe some others), takes the files from files/.config/ subdirectory and put respective links inXDG_CONFIG_DIR. For example symlink for files/.config/sway/config will end up in $XDG_CONFIG_DIR/sway/config. The rest files in files/ outside of files/.config/ subdirectory will be treated slightly different: symlink will just go to $HOME. files/.some-program/config will end up in $HOME/.some-program/config. - If some sub-directories are missing, they will be created.
- If there is a clashing files on the way, they will be backed up.
symlink-manager is a part of essential home services and is enabled and used by default.
Next: Scheduled User’s Job Execution, Previous: Essential Home Services, Up: Home Services [Contents][Index]
13.3.2 Shells
Shells play a quite important role in the environment initialization process, you can configure them manually as described in section Configuring the Shell, but the recommended way is to use home services listed below. It’s both easier and more reliable.
Each home environment instantiates home-shell-profile-service-type,
which creates a ~/.profile startup file for all POSIX-compatible
shells. This file contains all the necessary steps to properly initialize
the environment, but many modern shells like Bash or Zsh prefer their own
startup files, that’s why the respective home services
(home-bash-service-type and home-zsh-service-type) ensure that
~/.profile is sourced by ~/.bash_profile and
~/.zprofile, respectively.
Shell Profile Service
- Data Type: home-shell-profile-configuration
Available
home-shell-profile-configurationfields are:profile(default:()) (type: text-config)home-shell-profileis instantiated automatically byhome-environment, DO NOT create this service manually, it can only be extended.profileis a list of file-like objects, which will go to ~/.profile. By default ~/.profile contains the initialization code which must be evaluated by the login shell to make home-environment’s profile available to the user, but other commands can be added to the file if it is really necessary. In most cases shell’s configuration files are preferred places for user’s customizations. Extend home-shell-profile service only if you really know what you do.
Bash Home Service
- Data Type: home-bash-configuration
Available
home-bash-configurationfields are:package(default:bash) (type: package)The Bash package to use.
guix-defaults?(default:#t) (type: boolean)Add sane defaults like reading /etc/bashrc and coloring the output of
lsto the top of the .bashrc file.environment-variables(default:()) (type: alist)Association list of environment variables to set for the Bash session. The rules for the
home-environment-variables-service-typeapply here (see Essential Home Services). The contents of this field will be added after the contents of thebash-profilefield.aliases(default:()) (type: alist)Association list of aliases to set for the Bash session. The aliases will be defined after the contents of the
bashrcfield has been put in the .bashrc file. The alias will automatically be quoted, so something like this:'(("ls" . "ls -alF"))
turns into
alias ls="ls -alF"
bash-profile(default:()) (type: text-config)List of file-like objects, which will be added to .bash_profile. Used for executing user’s commands at start of login shell (In most cases the shell started on tty just after login). .bash_login won’t be ever read, because .bash_profile always present.
bashrc(default:()) (type: text-config)List of file-like objects, which will be added to .bashrc. Used for executing user’s commands at start of interactive shell (The shell for interactive usage started by typing
bashor by terminal app or any other program).bash-logout(default:()) (type: text-config)List of file-like objects, which will be added to .bash_logout. Used for executing user’s commands at the exit of login shell. It won’t be read in some cases (if the shell terminates by exec’ing another process for example).
You can extend the Bash service by using the home-bash-extension
configuration record, whose fields must mirror that of
home-bash-configuration (see home-bash-configuration). The
contents of the extensions will be added to the end of the corresponding
Bash configuration files (see Bash Startup Files in The GNU Bash
Reference Manual.
For example, here is how you would define a service that extends the Bash
service such that ~/.bash_profile defines an additional environment
variable, PS1:
(define bash-fancy-prompt-service
(simple-service 'bash-fancy-prompt
home-bash-service-type
(home-bash-extension
(environment-variables
'(("PS1" . "\\u \\wλ "))))))
You would then add bash-fancy-prompt-service to the list in the
services field of your home-environment. The reference of
home-bash-extension follows.
- Data Type: home-bash-extension
Available
home-bash-extensionfields are:environment-variables(default:()) (type: alist)Additional environment variables to set. These will be combined with the environment variables from other extensions and the base service to form one coherent block of environment variables.
aliases(default:()) (type: alist)Additional aliases to set. These will be combined with the aliases from other extensions and the base service.
bash-profile(default:()) (type: text-config)Additional text blocks to add to .bash_profile, which will be combined with text blocks from other extensions and the base service.
bashrc(default:()) (type: text-config)Additional text blocks to add to .bashrc, which will be combined with text blocks from other extensions and the base service.
bash-logout(default:()) (type: text-config)Additional text blocks to add to .bash_logout, which will be combined with text blocks from other extensions and the base service.
Zsh Home Service
- Data Type: home-zsh-configuration
Available
home-zsh-configurationfields are:package(default:zsh) (type: package)The Zsh package to use.
xdg-flavor?(default:#t) (type: boolean)Place all the configs to $XDG_CONFIG_HOME/zsh. Makes ~/.zshenv to set
ZDOTDIRto $XDG_CONFIG_HOME/zsh. Shell startup process will continue with $XDG_CONFIG_HOME/zsh/.zshenv.environment-variables(default:()) (type: alist)Association list of environment variables to set for the Zsh session.
zshenv(default:()) (type: text-config)List of file-like objects, which will be added to .zshenv. Used for setting user’s shell environment variables. Must not contain commands assuming the presence of tty or producing output. Will be read always. Will be read before any other file in
ZDOTDIR.zprofile(default:()) (type: text-config)List of file-like objects, which will be added to .zprofile. Used for executing user’s commands at start of login shell (In most cases the shell started on tty just after login). Will be read before .zlogin.
zshrc(default:()) (type: text-config)List of file-like objects, which will be added to .zshrc. Used for executing user’s commands at start of interactive shell (The shell for interactive usage started by typing
zshor by terminal app or any other program).zlogin(default:()) (type: text-config)List of file-like objects, which will be added to .zlogin. Used for executing user’s commands at the end of starting process of login shell.
zlogout(default:()) (type: text-config)List of file-like objects, which will be added to .zlogout. Used for executing user’s commands at the exit of login shell. It won’t be read in some cases (if the shell terminates by exec’ing another process for example).
Next: Power Management Home Services, Previous: Shells, Up: Home Services [Contents][Index]
13.3.3 Scheduled User’s Job Execution
The (gnu home services mcron) module provides an interface to
GNU mcron, a daemon to run jobs at scheduled times (see GNU mcron). The information about system’s mcron is applicable
here (see Ejecución de tareas programadas), the only difference for home
services is that they have to be declared in a home-environment
record instead of an operating-system record.
- Scheme Variable: home-mcron-service-type
This is the type of the
mcronhome service, whose value is anhome-mcron-configurationobject. It allows to manage scheduled tasks.This service type can be the target of a service extension that provides additional job specifications (see Composición de servicios). In other words, it is possible to define services that provide additional mcron jobs to run.
- Data Type: home-mcron-configuration
Available
home-mcron-configurationfields are:mcron(default:mcron) (type: file-like)El paquete mcron usado.
jobs(default:()) (type: list-of-gexps)This is a list of gexps (see Expresiones-G), where each gexp corresponds to an mcron job specification (see mcron job specifications in GNU mcron).
log?(default:#t) (type: boolean)Log messages to standard output.
log-format(default:"~1@*~a ~a: ~a~%") (type: string)(ice-9 format)format string for log messages. The default value produces messages like "‘pid name: message"’ (see Invoking in GNU mcron). Each message is also prefixed by a timestamp by GNU Shepherd.
Next: Managing User Daemons, Previous: Scheduled User’s Job Execution, Up: Home Services [Contents][Index]
13.3.4 Power Management Home Services
The (gnu home services pm) module provides home services pertaining
to battery power.
- Scheme Variable: home-batsignal-service-type
Service for
batsignal, a program that monitors battery levels and warns the user through desktop notifications when their battery is getting low. You can also configure a command to be run when the battery level passes a point deemed “dangerous”. This service is configured with thehome-batsignal-configurationrecord.
- Data Type: home-batsignal-configuration
Data type representing the configuration for batsignal.
warning-level(default:15)The battery level to send a warning message at.
warning-message(default:#f)The message to send as a notification when the battery level reaches the
warning-level. Setting to#fuses the default message.critical-level(default:5)The battery level to send a critical message at.
critical-message(default:#f)The message to send as a notification when the battery level reaches the
critical-level. Setting to#fuses the default message.danger-level(default:2)The battery level to run the
danger-commandat.danger-command(default:#f)The command to run when the battery level reaches the
danger-level. Setting to#fdisables running the command entirely.full-level(default:#f)The battery level to send a full message at. Setting to
#fdisables sending the full message entirely.full-message(default:#f)The message to send as a notification when the battery level reaches the
full-level. Setting to#fuses the default message.batteries(default:'())The batteries to monitor. Setting to
'()tries to find batteries automatically.poll-delay(default:60)The time in seconds to wait before checking the batteries again.
icon(default:#f)A file-like object to use as the icon for battery notifications. Setting to
#fdisables notification icons entirely.notifications?(default:#t)Whether to send any notifications.
notifications-expire?(default:#f)Whether notifications sent expire after a time.
notification-command(default:#f)Command to use to send messages. Setting to
#fsends a notification throughlibnotify.ignore-missing?(default:#f)Whether to ignore missing battery errors.
Next: Secure Shell, Previous: Power Management Home Services, Up: Home Services [Contents][Index]
13.3.5 Managing User Daemons
The (gnu home services shepherd) module supports the definitions of
per-user Shepherd services (see Introduction in The GNU
Shepherd Manual). You extend home-shepherd-service-type with new
services; Guix Home then takes care of starting the shepherd daemon
for you when you log in, which in turns starts the services you asked for.
- Scheme Variable: home-shepherd-service-type
The service type for the userland Shepherd, which allows one to manage long-running processes or one-shot tasks. User’s Shepherd is not an init process (PID 1), but almost all other information described in (see Servicios de Shepherd) is applicable here too.
This is the service type that extensions target when they want to create shepherd services (see Tipos de servicios y servicios, for an example). Each extension must pass a list of
<shepherd-service>. Its value must be ahome-shepherd-configuration, as described below.
- Data Type: home-shepherd-configuration
This data type represents the Shepherd’s configuration.
shepherd (default:shepherd)The Shepherd package to use.
auto-start? (default:#t)Whether or not to start Shepherd on first login.
services (default:'())A list of
<shepherd-service>to start. You should probably use the service extension mechanism instead (see Servicios de Shepherd).
Next: Desktop Home Services, Previous: Managing User Daemons, Up: Home Services [Contents][Index]
13.3.6 Secure Shell
The OpenSSH package includes a client, the
ssh command, that allows you to connect to remote machines using
the SSH (secure shell) protocol. With the (gnu home services
ssh) module, you can set up OpenSSH so that it works in a predictable
fashion, almost independently of state on the local machine. To do that,
you instantiate home-openssh-service-type in your Home configuration,
as explained below.
- Scheme Variable: home-openssh-service-type
This is the type of the service to set up the OpenSSH client. It takes care of several things:
- providing a ~/.ssh/config file based on your configuration so that
sshknows about hosts you regularly connect to and their associated parameters; - providing a ~/.ssh/authorized_keys, which lists public keys that the
local SSH server,
sshd, may accept to connect to this user account; - optionally providing a ~/.ssh/known_hosts file so that ssh can authenticate hosts you connect to.
Here is an example of a service and its configuration that you could add to the
servicesfield of yourhome-environment:(service home-openssh-service-type (home-openssh-configuration (hosts (list (openssh-host (name "ci.guix.gnu.org") (user "charlie")) (openssh-host (name "chbouib") (host-name "chbouib.example.org") (user "supercharlie") (port 10022)))) (authorized-keys (list (local-file "alice.pub")))))The example above lists two hosts and their parameters. For instance, running
ssh chbouibwill automatically connect tochbouib.example.orgon port 10022, logging in as user ‘supercharlie’. Further, it marks the public key in alice.pub as authorized for incoming connections.The value associated with a
home-openssh-service-typeinstance must be ahome-openssh-configurationrecord, as describe below.- providing a ~/.ssh/config file based on your configuration so that
- Data Type: home-openssh-configuration
This is the datatype representing the OpenSSH client and server configuration in one’s home environment. It contains the following fields:
hosts(default:'())A list of
openssh-hostrecords specifying host names and associated connection parameters (see below). This host list goes into ~/.ssh/config, whichsshreads at startup.known-hosts(default:*unspecified*)This must be either:
-
*unspecified*, in which casehome-openssh-service-typeleaves it up tosshand to the user to maintain the list of known hosts at ~/.ssh/known_hosts, or - a list of file-like objects, in which case those are concatenated and emitted as ~/.ssh/known_hosts.
The ~/.ssh/known_hosts contains a list of host name/host key pairs that allow
sshto authenticate hosts you connect to and to detect possible impersonation attacks. By default,sshupdates it in a TOFU, trust-on-first-use fashion, meaning that it records the host’s key in that file the first time you connect to it. This behavior is preserved whenknown-hostsis set to*unspecified*.If you instead provide a list of host keys upfront in the
known-hostsfield, your configuration becomes self-contained and stateless: it can be replicated elsewhere or at another point in time. Preparing this list can be relatively tedious though, which is why*unspecified*is kept as a default.-
authorized-keys(predeterminadas:'())This must be a list of file-like objects, each of which containing an SSH public key that should be authorized to connect to this machine.
Concretely, these files are concatenated and made available as ~/.ssh/authorized_keys. If an OpenSSH server,
sshd, is running on this machine, then it may take this file into account: this is whatsshddoes by default, but be aware that it can also be configured to ignore it.
- Data Type: openssh-host
Available
openssh-hostfields are:name(type: string)Name of this host declaration.
host-name(type: maybe-string)Host name—e.g.,
"foo.example.org"or"192.168.1.2".address-family(type: address-family)Address family to use when connecting to this host: one of
AF_INET(for IPv4 only),AF_INET6(for IPv6 only), or*unspecified*(allowing any address family).identity-file(type: maybe-string)The identity file to use—e.g.,
"/home/charlie/.ssh/id_ed25519".port(type: maybe-natural-number)TCP port number to connect to.
user(type: maybe-string)User name on the remote host.
forward-x11?(default:#f) (type: boolean)Whether to forward remote client connections to the local X11 graphical display.
forward-x11-trusted?(default:#f) (type: boolean)Whether remote X11 clients have full access to the original X11 graphical display.
forward-agent?(default:#f) (type: boolean)Whether the authentication agent (if any) is forwarded to the remote machine.
compression?(default:#f) (type: boolean)Whether to compress data in transit.
proxy-command(type: maybe-string)The command to use to connect to the server. As an example, a command to connect via an HTTP proxy at 192.0.2.0 would be:
"nc -X connect -x 192.0.2.0:8080 %h %p".host-key-algorithms(type: maybe-string-list)The list of accepted host key algorithms—e.g.,
'("ssh-ed25519").accepted-key-types(type: maybe-string-list)The list of accepted user public key types.
extra-content(default:"") (type: raw-configuration-string)Extra content appended as-is to this
Hostblock in ~/.ssh/config.
Next: Guix Home Services, Previous: Secure Shell, Up: Home Services [Contents][Index]
13.3.7 Desktop Home Services
The (gnu home services desktop) module provides services that you may
find useful on “desktop” systems running a graphical user environment such
as Xorg.
- Scheme Variable: home-redshift-service-type
This is the service type for Redshift, a program that adjusts the display color temperature according to the time of day. Its associated value must be a
home-redshift-configurationrecord, as shown below.A typical configuration, where we manually specify the latitude and longitude, might look like this:
(service home-redshift-service-type (home-redshift-configuration (location-provider 'manual) (latitude 35.81) ;northern hemisphere (longitude -0.80))) ;west of Greenwich
- Data Type: home-redshift-configuration
Available
home-redshift-configurationfields are:redshift(default:redshift) (type: file-like)Redshift package to use.
location-provider(default:geoclue2) (type: symbol)Geolocation provider—
'manualor'geoclue2. In the former case, you must also specify thelatitudeandlongitudefields so Redshift can determine daytime at your place. In the latter case, the Geoclue system service must be running; it will be queried for location information.adjustment-method(default:randr) (type: symbol)Color adjustment method.
daytime-temperature(default:6500) (type: integer)Daytime color temperature (kelvins).
nighttime-temperature(default:4500) (type: integer)Nighttime color temperature (kelvins).
daytime-brightness(type: maybe-inexact-number)Daytime screen brightness, between 0.1 and 1.0, or left unspecified.
nighttime-brightness(type: maybe-inexact-number)Nighttime screen brightness, between 0.1 and 1.0, or left unspecified.
latitude(type: maybe-inexact-number)Latitude, when
location-provideris'manual.longitude(type: maybe-inexact-number)Longitude, when
location-provideris'manual.dawn-time(type: maybe-string)Custom time for the transition from night to day in the morning—
"HH:MM"format. When specified, solar elevation is not used to determine the daytime/nighttime period.dusk-time(type: maybe-string)Likewise, custom time for the transition from day to night in the evening.
extra-content(default:"") (type: raw-configuration-string)Extra content appended as-is to the Redshift configuration file. Run
man redshiftfor more information about the configuration file format.
- Scheme Variable: home-dbus-service-type
This is the service type for running a session-specific D-Bus, for unprivileged applications that require D-Bus to be running.
- Data Type: home-dbus-configuration
The configuration record for
home-dbus-service-type.dbus(default:dbus)The package providing the
/bin/dbus-daemoncommand.
Previous: Desktop Home Services, Up: Home Services [Contents][Index]
13.3.8 Guix Home Services
The (gnu home services guix) module provides services for
user-specific Guix configuration.
- Scheme Variable: home-channels-service-type
This is the service type for managing $XDG_CONFIG_HOME/guix/channels.scm, the file that controls the channels received on
guix pull(see Canales). Its associated value is a list ofchannelrecords, defined in the(guix channels)module.Generally, it is better to extend this service than to directly configure it, as its default value is the default guix channel(s) defined by
%default-channels. If you configure this service directly, be sure to include a guix channel. See Especificación de canales adicionales and Uso de un canal de Guix personalizado for more details.A typical extension for adding a channel might look like this:
(simple-service 'variant-packages-service home-channels-service-type (list (channel (name 'variant-packages) (url "https://example.org/variant-packages.git"))))
Previous: Home Services, Up: Home Configuration [Contents][Index]
13.4 Invoking guix home
Once you have written a home environment declaration (see Declaring the Home Environment, it can be instantiated using the guix
home command. The synopsis is:
guix home options… action file
file must be the name of a file containing a home-environment
declaration. action specifies how the home environment is
instantiated, but there are few auxiliary actions which don’t instantiate
it. Currently the following values are supported:
searchDisplay available home service type definitions that match the given regular expressions, sorted by relevance:
$ guix home search shell name: home-shell-profile location: gnu/home/services/shells.scm:100:2 extends: home-files description: Create `~/.profile', which is used for environment initialization of POSIX compliant login shells. + This service type can be extended with a list of file-like objects. relevance: 6 name: home-fish location: gnu/home/services/shells.scm:640:2 extends: home-files home-profile description: Install and configure Fish, the friendly interactive shell. relevance: 3 name: home-zsh location: gnu/home/services/shells.scm:290:2 extends: home-files home-profile description: Install and configure Zsh. relevance: 1 name: home-bash location: gnu/home/services/shells.scm:508:2 extends: home-files home-profile description: Install and configure GNU Bash. relevance: 1 …
As for
guix search, the result is written inrecutilsformat, which makes it easy to filter the output (see GNU recutils databases in GNU recutils manual).containerSpawn a shell in an isolated environment—a container—containing your home as specified by file.
For example, this is how you would start an interactive shell in a container with your home:
guix home container config.scm
This is a throw-away container where you can lightheartedly fiddle with files; any changes made within the container, any process started—all this disappears as soon as you exit that shell.
As with
guix shell, several options control that container:- --network
- -N
Enable networking within the container (it is disabled by default).
- --expose=fuente[=destino]
- --share=fuente[=destino]
As with
guix shell, make directory source of the host system available as target inside the container—read-only if you pass --expose, and writable if you pass --share (see --expose and --share).
Additionally, you can run a command in that container, instead of spawning an interactive shell. For instance, here is how you would check which Shepherd services are started in a throw-away home container:
guix home container config.scm -- herd status
The command to run in the container must come after
--(double hyphen).editEdit or view the definition of the given Home service types.
For example, the command below opens your editor, as specified by the
EDITORenvironment variable, on the definition of thehome-mcronservice type:guix home edit home-mcron
reconfigureBuild the home environment described in file, and switch to it. Switching means that the activation script will be evaluated and (in basic scenario) symlinks to configuration files generated from
home-environmentdeclaration will be created in ~. If the file with the same path already exists in home folder it will be moved to ~/timestamp-guix-home-legacy-configs-backup, where timestamp is a current UNIX epoch time.Nota: It is highly recommended to run
guix pullonce before you runguix home reconfigurefor the first time (see Invocación deguix pull).This effects all the configuration specified in file. The command starts Shepherd services specified in file that are not currently running; if a service is currently running, this command will arrange for it to be upgraded the next time it is stopped (e.g. by
herd stop serviceorherd restart service).This command creates a new generation whose number is one greater than the current generation (as reported by
guix home list-generations). If that generation already exists, it will be overwritten. This behavior mirrors that ofguix package(see Invocación deguix package).Upon completion, the new home is deployed under ~/.guix-home. This directory contains provenance meta-data: the list of channels in use (see Canales) and file itself, when available. You can view the provenance information by running:
guix home describe
This information is useful should you later want to inspect how this particular generation was built. In fact, assuming file is self-contained, you can later rebuild generation n of your home environment with:
guix time-machine \ -C /var/guix/profiles/per-user/USER/guix-home-n-link/channels.scm -- \ home reconfigure \ /var/guix/profiles/per-user/USER/guix-home-n-link/configuration.scm
You can think of it as some sort of built-in version control! Your home is not just a binary artifact: it carries its own source.
switch-generation¶Switch to an existing home generation. This action atomically switches the home profile to the specified home generation.
The target generation can be specified explicitly by its generation number. For example, the following invocation would switch to home generation 7:
guix home switch-generation 7
La generación deseada puede especificarse también de forma relativa a la generación actual con la forma
+No-N, donde+3significa “3 generaciones después de la generación actual”, y-1significa “1 generación antes de la generación actual”. Cuando se especifica un valor negativo como-1debe ir precedido de--para evitar que se analice como una opción. Por ejemplo:guix home switch-generation -- -1
Esta acción fallará si la generación especificada no existe.
roll-back¶Switch to the preceding home generation. This is the inverse of
reconfigure, and it is exactly the same as invokingswitch-generationwith an argument of-1.delete-generations¶-
Delete home generations, making them candidates for garbage collection (see Invocación de
guix gc, for information on how to run the “garbage collector”).This works in the same way as ‘guix package --delete-generations’ (see --delete-generations). With no arguments, all home generations but the current one are deleted:
guix home delete-generations
You can also select the generations you want to delete. The example below deletes all the home generations that are more than two months old:
guix home delete-generations 2m
buildBuild the derivation of the home environment, which includes all the configuration files and programs needed. This action does not actually install anything.
describeDescribe the current home generation: its file name, as well as provenance information when available.
To show installed packages in the current home generation’s profile, the
--list-installedflag is provided, with the same syntax that is used inguix package --list-installed(see Invocación deguix package). For instance, the following command shows a table of all the packages with “emacs” in their name that are installed in the current home generation’s profile:guix home describe --list-installed=emacs
list-generationsList a summary of each generation of the home environment available on disk, in a human-readable way. This is similar to the --list-generations option of
guix package(see Invocación deguix package).De manera opcional, se puede especificar un patrón, con la misma sintaxis que la usada en
guix package --list-generations, para restringir la lista de generaciones mostradas. Por ejemplo, la siguiente orden muestra generaciones que tienen hasta 10 días de antigüedad:guix home list-generations 10d
The
--list-installedflag may also be specified, with the same syntax that is used inguix home describe. This may be helpful if trying to determine when a package was added to the home profile.importGenerate a home environment from the packages in the default profile and configuration files found in the user’s home directory. The configuration files will be copied to the specified directory, and a home-configuration.scm will be populated with the home environment. Note that not every home service that exists is supported (see Home Services).
$ guix home import ~/guix-config guix home: '/home/alice/guix-config' populated with all the Home configuration files
And there’s more! guix home also provides the following
sub-commands to visualize how the services of your home environment relate
to one another:
extension-graphEmit to standard output the service extension graph of the home environment defined in file (see Composición de servicios, for more information on service extensions). By default the output is in Dot/Graphviz format, but you can choose a different format with --graph-backend, as with
guix graph(see --backend):La orden:
guix home extension-graph file | xdot -
muestra las relaciones de extensión entre los servicios.
shepherd-graphEmit to standard output the dependency graph of shepherd services of the home environment defined in file. See Servicios de Shepherd, for more information and for an example graph.
Again, the default output format is Dot/Graphviz, but you can pass --graph-backend to select a different one.
opciones puede contener cualquiera de las opciones de construcción comunes (see Opciones comunes de construcción). Además, opciones puede contener una de las siguientes:
- --expression=expr
- -e expr
Consider the home-environment expr evaluates to. This is an alternative to specifying a file which evaluates to a home environment.
- --allow-downgrades
Instruct
guix home reconfigureto allow system downgrades.Just like
guix system,guix home reconfigure, by default, prevents you from downgrading your home to older or unrelated revisions compared to the channel revisions that were used to deploy it—those shown byguix home describe. Using --allow-downgrades allows you to bypass that check, at the risk of downgrading your home—be careful!
Next: Platforms, Previous: Home Configuration, Up: GNU Guix [Contents][Index]
14 Documentación
In most cases packages installed with Guix come with documentation. There
are two main documentation formats: “Info”, a browsable hypertext format
used for GNU software, and “manual pages” (or “man pages”), the linear
documentation format traditionally found on Unix. Info manuals are accessed
with the info command or with Emacs, and man pages are accessed
using man.
Puede buscar documentación de software instalado en su sistema por palabras clave. Por ejemplo, la siguiente orden busca información sobre “TLS” en manuales Info:
$ info -k TLS "(emacs)Network Security" -- STARTTLS "(emacs)Network Security" -- TLS "(gnutls)Core TLS API" -- gnutls_certificate_set_verify_flags "(gnutls)Core TLS API" -- gnutls_certificate_set_verify_function …
The command below searches for the same keyword in man pages47:
$ man -k TLS SSL (7) - OpenSSL SSL/TLS library certtool (1) - GnuTLS certificate tool …
Estas búsquedas son completamente locales en su máquina de modo que tiene la garantía de que la documentación que encuentre corresponde con lo que está realmente instalado, puede acceder a ella sin conexión a la red, y se respeta su privacidad.
Una vez tenga estos resultados, puede ver la documentación relevante mediante la ejecución de, digamos:
$ info "(gnutls)Core TLS API"
o:
$ man certtool
Los manuales Info contienen secciones e índices, así como enlaces como
aquellos encontrados en páginas Web. El lector info (see Info reader in Stand-alone GNU Info) y su contraparte en Emacs
(see Misc Help in The GNU Emacs Manual) proporcionan
combinaciones de teclas intuitivas para la navegación en los
manuales. See Getting Started in Info: An Introduction, para una
introducción a la navegación en Info.
Next: Creating System Images, Previous: Documentación, Up: GNU Guix [Contents][Index]
15 Platforms
The packages and systems built by Guix are intended, like most computer
programs, to run on a CPU with a specific instruction set, and under a
specific operating system. Those programs are often also targeting a
specific kernel and system library. Those constraints are captured by Guix
in platform records.
Next: Supported Platforms, Up: Platforms [Contents][Index]
15.1 platform Reference
The platform data type describes a platform: an ISA (instruction set architecture), combined with an operating system and
possibly additional system-wide settings such as the ABI (application binary interface).
- Data Type: platform
This is the data type representing a platform.
targetThis field specifies the platform’s GNU triplet as a string (see GNU configuration triplets in Autoconf).
systemThis string is the system type as it is known to Guix and passed, for instance, to the --system option of most commands.
It usually has the form
"cpu-kernel", where cpu is the target CPU and kernel the target operating system kernel.It can be for instance
"aarch64-linux"or"armhf-linux". You will encounter system types when you perform native builds (see Native Builds).linux-architecture(default:#false)This optional string field is only relevant if the kernel is Linux. In that case, it corresponds to the ARCH variable used when building Linux,
"mips"for instance.glibc-dynamic-linkerThis field is the name of the GNU C Library dynamic linker for the corresponding system, as a string. It can be
"/lib/ld-linux-armhf.so.3".
Previous: platform Reference, Up: Platforms [Contents][Index]
15.2 Supported Platforms
The (guix platforms …) modules export the following variables,
each of which is bound to a platform record.
- Scheme Variable: armv7-linux
Platform targeting ARM v7 CPU running GNU/Linux.
- Scheme Variable: aarch64-linux
Platform targeting ARM v8 CPU running GNU/Linux.
- Scheme Variable: mips64-linux
Platform targeting MIPS little-endian 64-bit CPU running GNU/Linux.
- Scheme Variable: powerpc-linux
Platform targeting PowerPC big-endian 32-bit CPU running GNU/Linux.
- Scheme Variable: powerpc64le-linux
Platform targeting PowerPC little-endian 64-bit CPU running GNU/Linux.
- Scheme Variable: riscv64-linux
Platform targeting RISC-V 64-bit CPU running GNU/Linux.
- Scheme Variable: i686-linux
Platform targeting x86 CPU running GNU/Linux.
- Scheme Variable: x86_64-linux
Platform targeting x86 64-bit CPU running GNU/Linux.
- Scheme Variable: i686-mingw
Platform targeting x86 CPU running Windows, with run-time support from MinGW.
- Scheme Variable: x86_64-mingw
Platform targeting x86 64-bit CPU running Windows, with run-time support from MinGW.
- Scheme Variable: i586-gnu
Platform targeting x86 CPU running GNU/Hurd (also referred to as “GNU”).
Next: Instalación de archivos de depuración, Previous: Platforms, Up: GNU Guix [Contents][Index]
16 Creating System Images
When it comes to installing Guix System for the first time on a new machine,
you can basically proceed in three different ways. The first one is to use
an existing operating system on the machine to run the guix system
init command (see Invoking guix system). The second one, is to produce
an installation image (see Construcción de la imagen de instalación). This is a
bootable system which role is to eventually run guix system init.
Finally, the third option would be to produce an image that is a direct
instantiation of the system you wish to run. That image can then be copied
on a bootable device such as an USB drive or a memory card. The target
machine would then directly boot from it, without any kind of installation
procedure.
The guix system image command is able to turn an operating system
definition into a bootable image. This command supports different image
types, such as efi-raw, iso9660 and docker. Any modern
x86_64 machine will probably be able to boot from an iso9660
image. However, there are a few machines out there that require specific
image types. Those machines, in general using ARM processors, may
expect specific partitions at specific offsets.
This chapter explains how to define customized system images and how to turn them into actual bootable images.
Next: Instantiate an Image, Up: Creating System Images [Contents][Index]
16.1 image Reference
The image record, described right after, allows you to define a
customized bootable system image.
- Data Type: image
This is the data type representing a system image.
name(default:#false)The image name as a symbol,
'my-iso9660for instance. The name is optional and it defaults to#false.formatThe image format as a symbol. The following formats are supported:
-
disk-image, a raw disk image composed of one or multiple partitions. -
compressed-qcow2, a compressed qcow2 image composed of one or multiple partitions. -
docker, a Docker image. -
iso9660, an ISO-9660 image. -
tarball, a tar.gz image archive. -
wsl2, a WSL2 image.
-
platform(default:#false)The
platformrecord the image is targeting (see Platforms),aarch64-linuxfor instance. By default, this field is set to#falseand the image will target the host platform.size(default:'guess)The image size in bytes or
'guess. The'guesssymbol, which is the default, means that the image size will be inferred based on the image content.operating-systemThe image’s
operating-systemrecord that is instanciated.partition-table-type(default:'mbr)The image partition table type as a symbol. Possible values are
'mbrand'gpt. It default to'mbr.partitions(default:'())The image partitions as a list of
partitionrecords (seepartitionReference).compression?(default:#true)Whether the image content should be compressed, as a boolean. It defaults to
#trueand only applies to'iso9660image formats.volatile-root?(default:#true)Whether the image root partition should be made volatile, as a boolean.
This is achieved by using a RAM backed file system (overlayfs) that is mounted on top of the root partition by the initrd. It defaults to
#true. When set to#false, the image root partition is mounted as read-write partition by the initrd.shared-store?(default:#false)Whether the image’s store should be shared with the host system, as a boolean. This can be useful when creating images dedicated to virtual machines. When set to
#false, which is the default, the image’soperating-systemclosure is copied to the image. Otherwise, when set to#true, it is assumed that the host store will be made available at boot, using a9pmount for instance.shared-network?(default:#false)Whether to use the host network interfaces within the image, as a boolean. This is only used for the
'dockerimage format. It defaults to#false.substitutable?(default:#true)Whether the image derivation should be substitutable, as a boolean. It defaults to
true.
Up: image Reference [Contents][Index]
16.1.1 partition Reference
In image record may contain some partitions.
- Data Type: partition
This is the data type representing an image partition.
size(default:'guess)The partition size in bytes or
'guess. The'guesssymbol, which is the default, means that the partition size will be inferred based on the partition content.offset(default:0)The partition’s start offset in bytes, relative to the image start or the previous partition end. It defaults to
0which means that there is no offset applied.file-system(default:"ext4")The partition file system as a string, defaulting to
"ext4". The supported values are"vfat","fat16","fat32"and"ext4".file-system-options(default:'())The partition file system creation options that should be passed to the partition creation tool, as a list of strings. This is only supported when creating
"ext4"partitions.See the
"extended-options"man page section of the"mke2fs"tool for a more complete reference.labelThe partition label as a mandatory string,
"my-root"for instance.uuid(default:#false)The partition UUID as an
uuidrecord (see Sistemas de archivos). By default it is#false, which means that the partition creation tool will attribute a random UUID to the partition.flags(predeterminadas:'())The partition flags as a list of symbols. Possible values are
'bootand'esp. The'bootflags should be set if you want to boot from this partition. Exactly one partition should have this flag set, usually the root one. The'espflag identifies a UEFI System Partition.initializer(default:#false)The partition initializer procedure as a gexp. This procedure is called to populate a partition. If no initializer is passed, the
initialize-root-partitionprocedure from the(gnu build image)module is used.
Next: image-type Reference, Previous: image Reference, Up: Creating System Images [Contents][Index]
16.2 Instantiate an Image
Let’s say you would like to create an MBR image with three distinct partitions:
- The ESP (EFI System Partition), a partition of 40 MiB at offset 1024 KiB with a vfat file system.
- an ext4 partition of 50 MiB data file, and labeled “data”.
- an ext4 bootable partition containing the
%simple-osoperating-system.
You would then write the following image definition in a my-image.scm
file for instance.
(use-modules (gnu) (gnu image) (gnu tests) (gnu system image) (guix gexp)) (define MiB (expt 2 20)) (image (format 'disk-image) (operating-system %simple-os) (partitions (list (partition (size (* 40 MiB)) (offset (* 1024 1024)) (label "GNU-ESP") (file-system "vfat") (flags '(esp)) (initializer (gexp initialize-efi-partition))) (partition (size (* 50 MiB)) (label "DATA") (file-system "ext4") (initializer #~(lambda* (root . rest) (mkdir root) (call-with-output-file (string-append root "/data") (lambda (port) (format port "my-data")))))) (partition (size 'guess) (label root-label) (file-system "ext4") (flags '(boot)) (initializer (gexp initialize-root-partition))))))
Note that the first and third partitions use generic initializers
procedures, initialize-efi-partition and initialize-root-partition
respectively. The initialize-efi-partition installs a GRUB EFI loader that
is loading the GRUB bootloader located in the root partition. The
initialize-root-partition instantiates a complete system as defined by the
%simple-os operating-system.
You can now run:
guix system image my-image.scm
to instantiate the image definition. That produces a disk image
which has the expected structure:
$ parted $(guix system image my-image.scm) print … Model: (file) Disk /gnu/store/yhylv1bp5b2ypb97pd3bbhz6jk5nbhxw-disk-image: 1714MB Sector size (logical/physical): 512B/512B Partition Table: msdos Disk Flags: Number Start End Size Type File system Flags 1 1049kB 43.0MB 41.9MB primary fat16 esp 2 43.0MB 95.4MB 52.4MB primary ext4 3 95.4MB 1714MB 1619MB primary ext4 boot
The size of the boot partition has been inferred to 1619MB so
that it is large enough to host the %simple-os operating-system.
You can also use existing image record definitions and inherit from
them to simplify the image definition. The (gnu system image)
module provides the following image definition variables.
- Scheme Variable: efi-disk-image
A MBR disk-image composed of two partitions: a 64 bits ESP partition and a ROOT boot partition. This image can be used on most
x86_64andi686machines, supporting BIOS or UEFI booting.
- Scheme Variable: efi32-disk-image
Same as
efi-disk-imagebut with a 32 bits EFI partition.
- Scheme Variable: iso9660-image
An ISO-9660 image composed of a single bootable partition. This image can also be used on most
x86_64andi686machines.
- Scheme Variable: docker-image
A Docker image that can be used to spawn a Docker container.
Using the efi-disk-image we can simplify our previous image
declaration this way:
(use-modules (gnu) (gnu image) (gnu tests) (gnu system image) (guix gexp) (ice-9 match)) (define MiB (expt 2 20)) (define data (partition (size (* 50 MiB)) (label "DATA") (file-system "ext4") (initializer #~(lambda* (root . rest) (mkdir root) (call-with-output-file (string-append root "/data") (lambda (port) (format port "my-data"))))))) (image (inherit efi-disk-image) (operating-system %simple-os) (partitions (match (image-partitions efi-disk-image) ((esp root) (list esp data root)))))
This will give the exact same image instantiation but the
image declaration is simpler.
Next: Image Modules, Previous: Instantiate an Image, Up: Creating System Images [Contents][Index]
16.3 image-type Reference
The guix system image command can, as we saw above, take a file
containing an image declaration as argument and produce an actual
disk image from it. The same command can also handle a file containing an
operating-system declaration as argument. In that case, how is the
operating-system turned into an image?
That’s where the image-type record intervenes. This record defines
how to transform an operating-system record into an image
record.
- Data Type: image-type
This is the data type representing an image-type.
nameThe image-type name as a mandatory symbol,
'efi32-rawfor instance.constructorThe image-type constructor, as a mandatory procedure that takes an
operating-systemrecord as argument and returns animagerecord.
There are several image-type records provided by the (gnu
system image) and the (gnu system images …) modules.
- Scheme Variable: efi-raw-image-type
Build an image based on the
efi-disk-imageimage.
- Scheme Variable: efi32-raw-image-type
Build an image based on the
efi32-disk-imageimage.
- Scheme Variable: qcow2-image-type
Build an image based on the
efi-disk-imageimage but with thecompressed-qcow2image format.
- Scheme Variable: iso-image-type
Build a compressed image based on the
iso9660-imageimage.
- Scheme Variable: uncompressed-iso-image-type
Build an image based on the
iso9660-imageimage but with thecompression?field set to#false.
- Scheme Variable: docker-image-type
Build an image based on the
docker-imageimage.
- Scheme Variable: raw-with-offset-image-type
Build an MBR image with a single partition starting at a
1024KiBoffset. This is useful to leave some room to install a bootloader in the post-MBR gap.
- Scheme Variable: pinebook-pro-image-type
Build an image that is targeting the Pinebook Pro machine. The MBR image contains a single partition starting at a
9MiBoffset. Theu-boot-pinebook-pro-rk3399-bootloaderbootloader will be installed in this gap.
- Scheme Variable: rock64-image-type
Build an image that is targeting the Rock64 machine. The MBR image contains a single partition starting at a
16MiBoffset. Theu-boot-rock64-rk3328-bootloaderbootloader will be installed in this gap.
- Scheme Variable: novena-image-type
Build an image that is targeting the Novena machine. It has the same characteristics as
raw-with-offset-image-type.
- Scheme Variable: pine64-image-type
Build an image that is targeting the Pine64 machine. It has the same characteristics as
raw-with-offset-image-type.
- Scheme Variable: hurd-image-type
Build an image that is targeting a
i386machine running the Hurd kernel. The MBR image contains a single ext2 partitions with specificfile-system-optionsflags.
- Scheme Variable: hurd-qcow2-image-type
Build an image similar to the one built by the
hurd-image-typebut with theformatset to'compressed-qcow2.
- Scheme Variable: wsl2-image-type
Build an image for the WSL2 (Windows Subsystem for Linux 2). It can be imported by running:
wsl --import Guix ./guix ./wsl2-image.tar.gz wsl -d Guix
So, if we get back to the guix system image command taking an
operating-system declaration as argument. By default, the
efi-raw-image-type is used to turn the provided
operating-system into an actual bootable image.
To use a different image-type, the --image-type option can be
used. The --list-image-types option will list all the supported
image types. It turns out to be a textual listing of all the
image-types variables described just above (see Invoking guix system).
Previous: image-type Reference, Up: Creating System Images [Contents][Index]
16.4 Image Modules
Let’s take the example of the Pine64, an ARM based machine. To be able to produce an image targeting this board, we need the following elements:
- An
operating-systemrecord containing at least an appropriate kernel (linux-libre-arm64-generic) and bootloaderu-boot-pine64-lts-bootloader) for the Pine64. - Possibly, an
image-typerecord providing a way to turn anoperating-systemrecord to animagerecord suitable for the Pine64. - An actual
imagethat can be instantiated with theguix system imagecommand.
The (gnu system images pine64) module provides all those elements:
pine64-barebones-os, pine64-image-type and
pine64-barebones-raw-image respectively.
The module returns the pine64-barebones-raw-image in order for users
to be able to run:
guix system image gnu/system/images/pine64.scm
Now, thanks to the pine64-image-type record declaring the
'pine64-raw image-type, one could also prepare a
my-pine.scm file with the following content:
(use-modules (gnu system images pine64)) (operating-system (inherit pine64-barebones-os) (timezone "Europe/Athens"))
to customize the pine64-barebones-os, and run:
$ guix system image --image-type=pine64-raw my-pine.scm
Note that there are other modules in the gnu/system/images directory
targeting Novena, Pine64, PinebookPro and Rock64
machines.
Next: Using TeX and LaTeX, Previous: Creating System Images, Up: GNU Guix [Contents][Index]
17 Instalación de archivos de depuración
Los programas binarios, como los producidos por los compiladores GCC por ejemplo, se escriben típicamente en el formato ELF, con una sección que contiene información de depuración. La información de depuración es lo que permite que el depurador, GDB, asocie código binario a código fuente; es necesaria para depurar un programa compilado en condiciones adecuadas.
Este capítulo explica cómo usar la información de depuración separada cuando los paquetes la proporcionan, y cómo reconstruir paquetes con información de depuración cuando esta falte.
Next: Reconstrucción de la información para depuración, Up: Instalación de archivos de depuración [Contents][Index]
17.1 Información separada para depuración
The problem with debugging information is that is takes up a fair amount of disk space. For example, debugging information for the GNU C Library weighs in at more than 60 MiB. Thus, as a user, keeping all the debugging info of all the installed programs is usually not an option. Yet, space savings should not come at the cost of an impediment to debugging—especially in the GNU system, which should make it easier for users to exert their computing freedom (see Distribución GNU).
Afortunadamente, las utilidades binarias GNU (Binutils) y GDB proporcionan un mecanismo que permite a las usuarias obtener lo mejor de ambos mundos: la información de depuración puede extraerse de los binarios y almacenarse en archivos separados. GDB es capaz entonces de cargar la información de depuración desde esos archivos, cuando estén disponibles (see Separate Debug Files in Debugging with GDB).
La distribución GNU toma ventaja de este hecho almacenando la información de
depuración en el subdirectorio lib/debug de una salida separada del
paquete llamada debug (see Paquetes con múltiples salidas). Las
usuarias pueden elegir si instalan la salida debug de un paquete
cuando la necesitan. Por ejemplo, la siguiente orden instala la información
de depuración para la biblioteca C de GNU y para GNU Guile.
guix install glibc:debug guile:debug
Se debe decir entonces a GDB que busque los archivos de depuración en el
perfil de la usuaria, proporcionando un valor a la variable
debug-file-directory (considere hacerlo en el archivo
~/.gdbinit, see Startup in Debugging with GDB):
(gdb) set debug-file-directory ~/.guix-profile/lib/debug
A partir de ese momento GDB obtendrá la información de depuración de los archivos .debug dentro de la carpeta ~/.guix-profile/lib/debug.
Below is an alternative GDB script which is useful when working with other profiles. It takes advantage of the optional Guile integration in GDB. This snippet is included by default on Guix System in the ~/.gdbinit file.
guile
(use-modules (gdb))
(execute (string-append "set debug-file-directory "
(or (getenv "GDB_DEBUG_FILE_DIRECTORY")
"~/.guix-profile/lib/debug")))
end
Además, probablemente desee que GDB sea capaz de mostrar el código fuente
que está depurando. Para hacerlo, tiene que desempaquetar el código fuente
del paquete de su interés (obtenido con guix build --source,
see Invocación de guix build) e indicar a GDB cual es el directorio de
fuentes mediante el uso de la orden directory (see directory in Debugging with GDB).
El mecanismo de la salida debug en Guix se implementa por el sistema
de construcción gnu-build-system (see Sistemas de construcción). Ahora mismo
necesita una activación explícita—la información de depuración está
disponible únicamente para paquetes con definiciones que declaren
explícitamente una salida debug. Para comprobar si un paquete tiene
una salida debug, use guix package --list-available
(see Invocación de guix package).
Siga leyendo para ver cómo tratar con paquetes que carezcan de la salida
debug.
Previous: Información separada para depuración, Up: Instalación de archivos de depuración [Contents][Index]
17.2 Reconstrucción de la información para depuración
Como vimos anteriormente, algunos paquetes, pero no todos, proporcionan
información de depuración en una salida llamada debug. ¿Qué puede
hacer cuando dicha información de depuración no está disponible? La opción
--with-debug-info proporciona una solución para ello: le permite
reconstruir uno o más paquetes para los que la información de depuración no
esté disponible—y únicamente esos—e injertarlos en la aplicación que
esté depurando. Por lo tanto, aunque no es tan rápido como instalar una
salida debug, no tiene un coste elevado.
Vamos a ilustrarlo con un ejemplo. Supongamos que está sufriendo un error en
Inkscape y desearía que está pasando en GLib, una biblioteca que se
encuentra enraizada profundamente en su grafo de dependencias. Además GLib
no tiene una salida debug y la pila de llamadas que GDB muestra es
completamente deprimente:
(gdb) bt
#0 0x00007ffff5f92190 in g_getenv ()
from /gnu/store/…-glib-2.62.6/lib/libglib-2.0.so.0
#1 0x00007ffff608a7d6 in gobject_init_ctor ()
from /gnu/store/…-glib-2.62.6/lib/libgobject-2.0.so.0
#2 0x00007ffff7fe275a in call_init (l=<optimized out>, argc=argc@entry=1, argv=argv@entry=0x7fffffffcfd8,
env=env@entry=0x7fffffffcfe8) at dl-init.c:72
#3 0x00007ffff7fe2866 in call_init (env=0x7fffffffcfe8, argv=0x7fffffffcfd8, argc=1, l=<optimized out>)
at dl-init.c:118
Para hacer frente a esta situación debe instalar Inkscape enlazado con una variante de GLib que contenga información de depuración:
guix install inkscape --with-debug-info=glib
Esta vez la depuración será mucho más agradable:
$ gdb --args sh -c 'exec inkscape'
…
(gdb) b g_getenv
Function "g_getenv" not defined.
Make breakpoint pending on future shared library load? (y or [n]) y
Breakpoint 1 (g_getenv) pending.
(gdb) r
Starting program: /gnu/store/…-profile/bin/sh -c exec\ inkscape
…
(gdb) bt
#0 g_getenv (variable=variable@entry=0x7ffff60c7a2e "GOBJECT_DEBUG") at ../glib-2.62.6/glib/genviron.c:252
#1 0x00007ffff608a7d6 in gobject_init () at ../glib-2.62.6/gobject/gtype.c:4380
#2 gobject_init_ctor () at ../glib-2.62.6/gobject/gtype.c:4493
#3 0x00007ffff7fe275a in call_init (l=<optimized out>, argc=argc@entry=3, argv=argv@entry=0x7fffffffd088,
env=env@entry=0x7fffffffd0a8) at dl-init.c:72
…
¡Así mejor!
Tenga en cuenta que puede haber paquetes en los que la opción --with-debug-info no tenga el efecto deseado. See --with-debug-info para obtener más información.
Next: Actualizaciones de seguridad, Previous: Instalación de archivos de depuración, Up: GNU Guix [Contents][Index]
18 Using TeX and LaTeX
Guix provides packages for the TeX, LaTeX, ConTeXt, LuaTeX, and related typesetting systems, taken from the TeX Live distribution. However, because TeX Live is so huge and because finding your way in this maze is tricky, we thought that you, dear user, would welcome guidance on how to deploy the relevant packages so you can compile your TeX and LaTeX documents.
TeX Live currently comes in two flavors in Guix:
- The “monolithic”
texlivepackage: it comes with every single TeX Live package (more than 7,000 of them), but it is huge (more than 4 GiB for a single package!). - The “modular”
texlive-packages: you installtexlive-base, which provides core functionality and the main commands—pdflatex,dvips,luatex,mf, etc.—together with individual packages that provide just the features you need—texlive-listingsfor thelistingspackage,texlive-hyperrefforhyperref,texlive-beamerfor Beamer,texlive-pgffor PGF/TikZ, and so on.
We recommend using the modular package set because it is much less resource-hungry. To build your documents, you would use commands such as:
guix shell texlive-base texlive-wrapfig \ texlive-hyperref texlive-cm-super -- pdflatex doc.tex
You can quickly end up with unreasonably long command lines though. The solution is to instead write a manifest, for example like this one:
(specifications->manifest
'("rubber"
"texlive-base"
"texlive-wrapfig"
"texlive-microtype"
"texlive-listings" "texlive-hyperref"
;; PGF/TikZ
"texlive-pgf"
;; Additional fonts.
"texlive-cm-super" "texlive-amsfonts"
"texlive-times" "texlive-helvetic" "texlive-courier"))
You can then pass it to any command with the -m option:
guix shell -m manifest.scm -- pdflatex doc.tex
See Writing Manifests, for more on manifests. In the future, we plan to
provide packages for TeX Live collections—“meta-packages” such
as fontsrecommended, humanities, or langarabic that
provide the set of packages needed in this particular domain. That will
allow you to list fewer packages.
The main difficulty here is that using the modular package set forces you to
select precisely the packages that you need. You can use guix
search, but finding the right package can prove to be tedious. When a
package is missing, pdflatex and similar commands fail with an
obscure message along the lines of:
doc.tex: File `tikz.sty' not found. doc.tex:7: Emergency stop.
or, for a missing font:
kpathsea: Running mktexmf phvr7t ! I can't find file `phvr7t'.
How do you determine what the missing package is? In the first case, you’ll find the answer by running:
$ guix search texlive tikz name: texlive-pgf version: 59745 …
In the second case, guix search turns up nothing. Instead, you
can search the TeX Live package database using the tlmgr
command:
$ guix shell texlive-base -- tlmgr info phvr7t
tlmgr: cannot find package phvr7t, searching for other matches:
Packages containing `phvr7t' in their title/description:
Packages containing files matching `phvr7t':
helvetic:
texmf-dist/fonts/tfm/adobe/helvetic/phvr7t.tfm
texmf-dist/fonts/tfm/adobe/helvetic/phvr7tn.tfm
texmf-dist/fonts/vf/adobe/helvetic/phvr7t.vf
texmf-dist/fonts/vf/adobe/helvetic/phvr7tn.vf
tex4ht:
texmf-dist/tex4ht/ht-fonts/alias/adobe/helvetic/phvr7t.htf
The file is available in the TeX Live helvetic package, which is
known in Guix as texlive-helvetic. Quite a ride, but we found it!
There is one important limitation though: Guix currently provides a subset
of the TeX Live packages. If you stumble upon a missing package, you can
try and import it (see Invocación de guix import):
guix import texlive package
La opciones adicionales incluyen:
--recursive-rRecorre el grafo de dependencias del paquete original proporcionado recursivamente y genera expresiones de paquete para todos aquellos paquetes que no estén todavía en Guix.
Nota: TeX Live packaging is still very much work in progress, but you can help! See Contribuir, for more information.
Next: Lanzamiento inicial, Previous: Using TeX and LaTeX, Up: GNU Guix [Contents][Index]
19 Actualizaciones de seguridad
De manera ocasional, vulnerabilidades importantes de seguridad se descubren
en los paquetes de software y deben aplicarse parches. Las desarrolladoras
de Guix tratan de seguir las vulnerabilidades conocidas y aplicar parches
tan pronto como sea posible en la rama master de Guix (todavía no
proporcionamos una rama “estable” que contenga únicamente actualizaciones
de seguridad). La herramienta guix lint ayuda a las
desarrolladoras a encontrar versiones vulnerables de paquetes de software en
la distribución:
$ guix lint -c cve gnu/packages/base.scm:652:2: glibc@2.21: probablemente vulnerable a CVE-2015-1781, CVE-2015-7547 gnu/packages/gcc.scm:334:2: gcc@4.9.3: probablemente vulnerable a CVE-2015-5276 gnu/packages/image.scm:312:2: openjpeg@2.1.0: probablemente vulnerable a CVE-2016-1923, CVE-2016-1924 …
See Invocación de guix lint, para más información.
Guix sigue una disciplina funcional de gestión de paquetes (see Introducción), lo que implica que, cuando se cambia un paquete, todos los paquetes que dependen de él deben ser reconstruidos. Esto puede ralentizar de manera significativa el despliegue de correcciones en paquetes básicos como libc o Bash, ya que básicamente la distribución al completo debe reconstruirse. El uso de binarios preconstruidos ayuda (see Sustituciones), pero el despliegue aún puede tomar más tiempo del deseado.
Para afrontar esto, Guix implementa injertos, un mecanismo que permite un rápido despliegue de actualizaciones críticas sin los costes asociados con una reconstrucción completa de la distribución. La idea es reconstruir únicamente el paquete que hace falta parchear, y entonces “injertarlo” en los paquetes explícitamente instalados por la usuaria y que previamente hacían referencia al paquete original. El coste de realizar un injerto es menor que una reconstrucción completa de la cadena de dependencias.
Por ejemplo, supongamos que es necesario incorporar una actualización de
seguridad en Bash. Las desarrolladoras de Guix proporcionarán una definición
de paquete para la versión “corregida” de Bash, digamos bash-fixed,
de la manera habitual (see Definición de paquetes). Una vez hecho, la
definición original del paquete es aumentada con un campo replacement
que apunta al paquete que contiene la corrección del error:
(define bash
(package
(name "bash")
;; …
(replacement bash-fixed)))
De ahí en adelante, cualquier paquete que dependa directa o indirectamente
de Bash—como informa de ello guix gc --requisites
(see Invocación de guix gc)—que se instale se “reescribe” automáticamente
para hacer referencia a bash-fixed en vez de bash. Este
proceso de injerto toma un tiempo proporcional al tamaño del paquete,
normalmente menos de un minuto para un paquete “medio” en una máquina
reciente. El injertado es recursivo: cuando una dependencia indirecta
requiere un injerto, el injerto se “propagará” hasta el paquete que la
usuaria esté instalando.
Actualmente, la longitud del nombre y la versión del injerto y aquella del
paquete que reemplaza (bash-fixed y bash en el ejemplo previo)
debe ser igual. Esta restricción viene principalmente del hecho de que el
injertado funciona mediante la aplicación de parches en archivos, incluyendo
archivos binarios, directamente. Otras restricciones pueden ser aplicables:
por ejemplo, durante la adición de un injerto a un paquete que proporciona
una biblioteca compartida, la biblioteca compartida y su reemplazo deben
tener el mismo SONAME y deben ser compatibles a nivel binario.
La opción de línea de órdenes --no-grafts le permite anular voluntariamente el proceso de injerto (see --no-grafts). Por tanto, la orden:
guix build bash --no-grafts
devuelve el nombre de archivo del almacén de la versión original de Bash, mientras que:
guix build bash
devuelve el nombre de archivo del almacén de la versión “corregida”, reemplazo de Bash. Esto le permite distinguir entre las dos variantes de Bash.
Para verificar a qué Bash hace referencia su perfil al completo, puede
ejecutar (see Invocación de guix gc):
guix gc -R $(readlink -f ~/.guix-profile) | grep bash
… y compare los nombres de archivo del almacén que obtendrá con los ejemplos previos. Del mismo modo, para una generación completa del sistema Guix:
guix gc -R $(guix system build my-config.scm) | grep bash
Por último, para comprobar qué versión de Bash están usando los procesos en
ejecución, puede usar la orden lsof:
lsof | grep /gnu/store/.*bash
Next: Transportar a una nueva plataforma, Previous: Actualizaciones de seguridad, Up: GNU Guix [Contents][Index]
20 Lanzamiento inicial
Bootstrapping in our context refers to how the distribution gets built “from nothing”. Remember that the build environment of a derivation contains nothing but its declared inputs (see Introducción). So there’s an obvious chicken-and-egg problem: how does the first package get built? How does the first compiler get compiled?
It is tempting to think of this question as one that only die-hard hackers may care about. However, while the answer to that question is technical in nature, its implications are wide-ranging. How the distribution is bootstrapped defines the extent to which we, as individuals and as a collective of users and hackers, can trust the software we run. It is a central concern from the standpoint of security and from a user freedom viewpoint.
El sistema GNU está compuesto principalmente de código C, con libc en su
base. El sistema de construcción GNU en sí asume la disponibilidad del shell
Bourne y las herramientas de línea de órdenes proporcionadas por GNU
Coreutils, Awk, Findutils, ‘sed’ y ‘grep’. Además, los programas de
construcción—programas que ejecutan ./configure, make,
etc.—están escritos en Scheme Guile
(see Derivaciones). Consecuentemente, para ser capaz de construir
cualquier cosa, desde cero, Guix depende en binarios preconstruidos de
Guile, GCC, Binutils, libc y otros paquetes mencionados anteriormente—los
binarios del lanzamiento inicial.
Estos binarios del lanzamiento inicial se “dan por supuestos”, aunque se pueden volver a crear en caso de ser necesario (see Preparación para usar los binarios del lanzamiento inicial).
- El lanzamiento inicial a partir de la semilla binaria reducida
- Preparación para usar los binarios del lanzamiento inicial
- Construcción de las herramientas de construcción
- Construir los binarios de lanzamiento
- Reducción del conjunto de binarios de lanzamiento
Next: Preparación para usar los binarios del lanzamiento inicial, Up: Lanzamiento inicial [Contents][Index]
20.1 El lanzamiento inicial a partir de la semilla binaria reducida
Guix—al igual que otras distribuciones de GNU/Linux—se lanza inicialmente desde un conjunto de binarios de manera tradicional: un shell Bourne, herramientas de línea de órdenes que proporcionan GNU Coreutils, Awk, Findutils, ‘sed’ y ‘grep’ y Guile, GCC, Binutils y la biblioteca de C de GNU (see Lanzamiento inicial). Habitualmente dichos binarios se “dan por hecho”.
El dar por hecho estos binarios significa que consideramos que son una “semilla” correcta y fiable para la construcción del sistema completo. En esta asunción yace un problema: el tamaño combinado de dichos binarios necesarios para el lanzamiento inicial es de alrededor de 250MB (see Bootstrappable Builds in GNU Mes). Auditar o incluso la inspeccionar de dichos binarios es prácticamente imposible.
En i686-linux y x86_64-linux, Guix basa su lanzamiento inicial
en una “semilla binaria reducida”48.
El lanzamiento inicial basado en la semilla binaria reducida elimina las
herramientas más críticas—desde una perspectiva de confianza—de los
binarios del lanzamiento inicial: GCC, Binutils y la biblioteca de C de GNU
se sustituyen por: bootstrap-mescc-tools (un pequeño ensamblador y
enlazador) y bootstrap-mes (un pequeño intérprete de Scheme, un
compilador de C escrito en Scheme y la biblioteca de C de Mes, construida
para TinyCC y para GCC).
Mediante el uso de estas nuevas semillas binarias, los paquetes Binutils, GCC, y la biblioteca de C de GNU “que faltan” se construyen desde las fuentes. De aquí en adelante se prosigue con el proceso del lanzamiento inicial más tradicional. Esta aproximación redujo el tamaño de los binarios del lanzamiento inicial a cerca de 145MB en la versión 1.1 de Guix.
El siguiente paso que Guix ha tomado es sustituir el intérprete de órdenes y sus utilidades con implementaciones en el dialecto Guile de Scheme, el lanzamiento inicial basado únicamente en Scheme. Gash (see Gash in The Gash manual) es un intérprete de órdenes compatible con POSIX que sustituye a Bash, y viene con Gash Utils que contiene reemplazos minimalistas de Awk, las GNU Core Utilities, Grep, Gzip, Sed y Tar. El resto de semillas binarias del lanzamiento inicial que se han eliminado se construyen ahora desde las fuentes.
Building the GNU System from source is currently only possible by adding
some historical GNU packages as intermediate steps49. As Gash and Gash Utils mature, and
GNU packages become more bootstrappable again (e.g., new releases of GNU Sed
will also ship as gzipped tarballs again, as alternative to the hard to
bootstrap xz-compression), this set of added packages can hopefully
be reduced again.
A continuación se encuentra el grafo de dependencias generado para
gcc-core-mesboot0, el compilador del lanzamiento inicial usado para
el lanzamiento inicial tradicional del resto del sistema Guix.
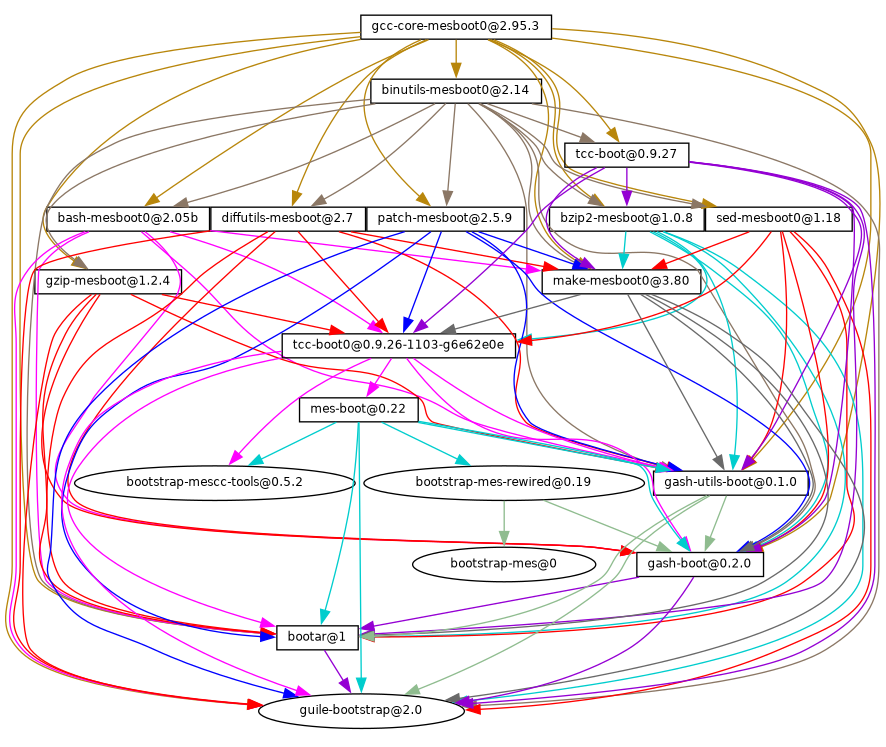
The only significant binary bootstrap seeds that remain50 are a Scheme interpreter and a Scheme compiler: GNU Mes and GNU Guile51.
Esta reducción adicional ha llevado el tamaño de la semilla de binarios
inicial a cerca de los 60MB para i686-linux y x86_64-linux.
Se está trabajando en eliminar todos los binarios de nuestra pila de
software libre del lanzamiento inicial, en pos de un lanzamiento inicial
basado completamente en fuentes. También se está trabajando en proporcionar
estos lanzamientos iniciales a las arquitecturas arm-linux y
aarch64-linux y a Hurd.
Si tiene interés, puede unirse a ‘#bootstrappable’ en la red de IRC de Freenode o participar en las discusiones a través de bug-mes@gnu.org o gash-devel@nongnu.org.
Previous: El lanzamiento inicial a partir de la semilla binaria reducida, Up: Lanzamiento inicial [Contents][Index]
20.2 Preparación para usar los binarios del lanzamiento inicial
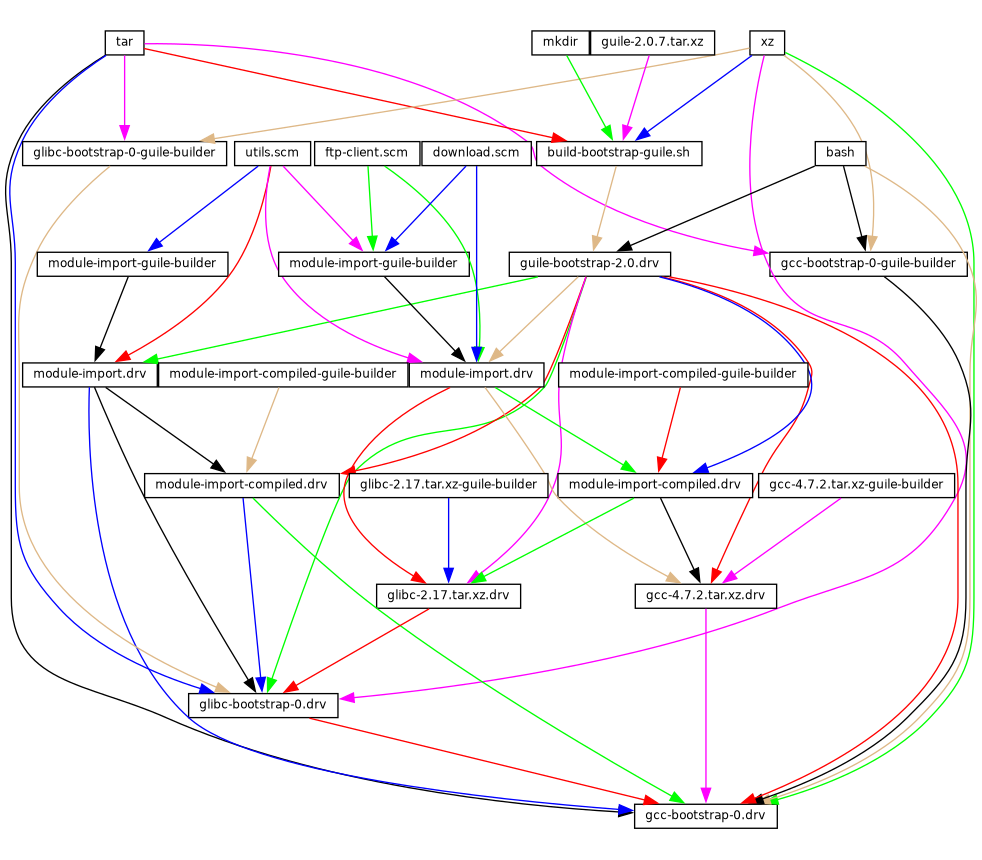
La figura previa muestra el auténtico inicio del grafo de dependencias de la
distribución, correspondiente a las definiciones de paquete del módulo
(gnu packages bootstrap). Un gráfico similar puede generarse con
guix graph (see Invocación de guix graph), más o menos así:
guix graph -t derivation \ -e '(@@ (gnu packages bootstrap) %bootstrap-gcc)' \ | dot -Tps > gcc.ps
o, para la semilla binaria aún más reducida del lanzamiento inicial
guix graph -t derivation \ -e '(@@ (gnu packages bootstrap) %bootstrap-mes)' \ | dot -Tps > mes.ps
En este nivel de detalle, las cosas son ligeramente complejas. Primero,
Guile en sí consiste en un ejecutable ELF, junto a muchas fuentes y archivos
compilados Scheme que se cargan dinámicamente durante la ejecución. Esto se
almacena en el archivador tar guile-2.0.7.tar.xz mostrado en este
grafo. Este archivador es parte de la distribución de “fuentes” de Guix, y
se inserta en el almacén con add-to-store (see El almacén).
¿Pero cómo escribimos una derivación que extraiga este archivador y lo añada
al almacén? Para resolver este problema, la derivación
guile-bootstrap-2.0.drv—la primera en construirse—usa bash
como su constructor, que ejecuta build-bootstrap-guile.sh, que a su
vez llama a tar para extraer el archivador. Por tanto, bash,
tar, xz y mkdir son binarios enlazados estáticamente,
también parte de la distribución de fuentes de Guix, cuyo único propósito es
permitir la extracción del archivador de Guile.
Una vez queguile-bootstrap-2.0.drv se ha construido, tenemos un Guile
funcional que se puede usar para ejecutar los programas de construcción
siguientes. Su primera tarea es descargar los archivadores qu contienen los
otros binarios preconstruidos—esto es lo que las derivaciones
.tar.xz.drv hacen. Módulos Guix como ftp-client.scm se usan
para este propósito. Las derivaciones module-import.drv importan esos
módulos en un directorio del almacén, manteniendo la distribución de
carpetas. Las derivaciones module-import-compiled.drv compilan esos
módulos, y los escriben en un directorio con la distribución de carpetas
correcta. Esto corresponde al parámetro #:modules de
build-expression->derivation (see Derivaciones).
Finalmente, los archivadores tar son extraídos por las derivaciones
gcc-bootstrap-0.drv, glibc-bootstrap-0.drv, or
bootstrap-mes-0.drv y bootstrap-mescc-tools-0.drv, hasta el
punto en el que disponemos de una cadena de herramientas C funcional.
Construcción de las herramientas de construcción
El lanzamiento inicial está completo cuando tenemos una cadena de
herramientas completa que no depende en las herramientas preconstruidas del
lanzamiento inicial descritas previamente. Este requisito de no-dependencia
se verifica comprobando si los archivos de la cadena de herramientas final
contienen referencias a directorios de /gnu/store de las entradas del
lanzamiento. El proceso que lleva a esta cadena de herramientas “final” es
descrito por las definiciones de paquetes encontradas en el módulo
(gnu packages commencement).
La orden guix graph nos permite “distanciarnos” en comparación
con el grafo previo, mirando al nivel de objetos de paquetes en vez de
derivaciones individuales—recuerde que un paquete puede traducirse en
varias derivaciones, típicamente una derivación para descargar sus fuentes,
una para construir los módulos Guile que necesita y uno para realmente
construir el paquete de las fuentes. La orden:
guix graph -t bag \
-e '(@@ (gnu packages commencement)
glibc-final-with-bootstrap-bash)' | xdot -
muestra el grafo de dependencias que lleva a la biblioteca C “final”52, mostrado a continuación.
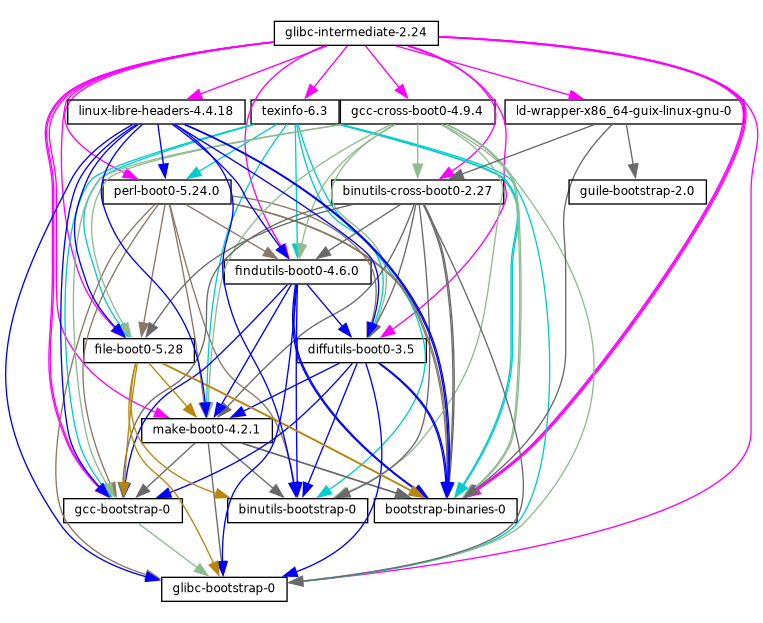
La primera herramienta que se construye con los binarios del lanzamiento
inicial es GNU Make—marcado como make-boot0 en el grafo—,
que es un pre-requisito para todos los paquetes siguientes. Una vez hecho se
construyen Findutils y Diffutils.
Después viene la primera fase de Binutils y GCC, construidas como herramientas pseudo-cruzadas—es decir, con --target igual a --host. Se usan para construir libc. Gracias a este truco de compilación cruzada, se garantiza que esta libc no tendrá ninguna referencia a la cadena de herramientas inicial.
Posteriormente se construyen las herramientas Binutils y GCC (no mostradas
previamente) finales. GCC usa ld de la construcción final de
Binutils y enlazan los programas contra la libc recién construía. Esta
cadena de herramientas se usa para construir otros paquetes usados por Guix
y el sistema de construcción GNU: Guile, Bash, Coreutils, etc.
¡Y voilà! En este punto tenemos un conjunto completo de herramientas de
construcción esperadas por el sistema de construcción GNU. Están en la
variable %final-inputs del módulo (gnu packages commencement),
y se usan implícitamente por cualquier paquete que use
gnu-build-system (see gnu-build-system).
Construir los binarios de lanzamiento
Debido a que la cadena de herramientas final no depende de los binarios de
lanzamiento, estos rara vez necesitan ser actualizados. No obstante, es útil
tener una forma automatizada de producirlos en caso de que se dé una
actualización, y esto es lo que proporciona el módulo (gnu packages
make-bootstrap).
La siguiente orden construye los archivadores que contienen los binarios de lanzamiento (Binutils, GCC, glibc para el lanzamiento inicial tradicional y linux-libre-headers, bootstrap-mescc-tools y bootstrap-mes para el lanzamiento inicial basado en la semilla binaria reducida, y Guile y un archivador que contiene una mezcla de Coreutils y otras herramientas básicas de línea de órdenes):
guix build bootstrap-tarballs
Los archivadores “tar” generados son aquellos a cuya referencia debe
encontrarse en el módulo (gnu packages bootstrap) mencionado al
inicio de esta sección.
¿Todavía aquí? Entonces quizá se habrá empezado a preguntar: ¿cuándo llegamos a un punto fijo? ¡Esa es una pregunta interesante! La respuesta es desconocida, pero si pudiese investigar más a fondo (y tiene unos recursos computacionales y de almacenamiento significativos para hacerlo) háganoslo saber.
Reducción del conjunto de binarios de lanzamiento
Nuestros binarios de lanzamiento actualmente incluyen GCC, GNU Libc, Guile, etc. ¡Eso es mucho código binario! ¿Por qué es eso un problema? Es un problema porque esos grandes fragmentos de código binario no son auditables en la práctica, lo que hace difícil establecer qué código fuente los produjo. Cada binario no-auditable también nos deja vulnerables a puertas traseras en los compiladores, como describió Ken Thompson en su publicación de 1984 Reflections on Trusting Trust.
Esto se mitiga por el hecho de que nuestros binarios de lanzamiento fueron generados por una revisión anterior de Guix. No obstante, esto no posee el nivel de transparencia que obtenemos en el resto del grado de dependencias de los paquetes, donde Guix siempre nos da una asociación de fuente-a-binario. Por lo tanto, nuestro objetivo es reducir el conjunto de binarios de lanzamiento al mínimo posible.
El sitio web Bootstrappable.org enumera proyectos en activo realizándolo. Uno de ellos está a punto de sustituir el GCC de lanzamiento con una secuencia de ensambladores, interpretes y compiladores de complejidad incremental, que pueden ser construidos desde las fuentes empezando con un código ensamblador simple y auditable.
Nuestro primer logro de importancia es la sustitución de GCC, la biblioteca de C de GNU y Binutils por MesCC-Tools (un enlazador hexadecimal y un macro-ensamblador) y Mes (see GNU Mes Reference Manual in GNU Mes, un intérprete de Scheme y compilador de C en Scheme). Ni MesCC-Tools ni Mes pueden lanzarse inicialmente a sí mismas completamente todavía y por lo tanto se inyectan como semillas binarias. A esto es lo que llamamos la semilla binaria reducida del lanzamiento inicial, ¡ya que ha reducido a la mitad el tamaño de nuestros binarios del lanzamiento inicial! También ha eliminado el binario del compilador de C; los paquetes de Guix en i686-linux y x86_64-linux se generan a partir de un lanzamiento inicial sin ningún binario que sea un compilador de C.
Se está trabajando en hacer que MesCC-Tools y Mes puedan lanzarse inicialmente de manera completa, y también se buscan otros binarios para el lanzamiento inicial. ¡Su ayuda es bienvenida!
Next: Contribuir, Previous: Lanzamiento inicial, Up: GNU Guix [Contents][Index]
21 Transportar a una nueva plataforma
Como se explicó previamente, la distribución GNU es autocontenida, lo cual
se consigue dependiendo de unos “binarios del lanzamiento inicial”
preconstruidos (see Lanzamiento inicial). Estos binarios son específicos para
un núcleo del sistema operativo, arquitectura de la CPU e interfaz binaria
de aplicaciones (ABI). Por tanto, para transportar la distribución a una
nueva plataforma que no está soportada todavía, se deben construir estos
binarios del lanzamiento inicial, y actualizar el módulo (gnu packages
bootstrap) para usarlos en dicha plataforma.
Por suerte, Guix puede compilar de forma cruzada esos binarios del lanzamiento inicial. Cuando todo va bien, y asumiendo que la cadena de herramientas GNU soporta para la plataforma deseada, esto puede ser tan simple como ejecutar una orden así:
guix build --target=armv5tel-linux-gnueabi bootstrap-tarballs
For this to work, it is first required to register a new platform as defined
in the (guix platform) module. A platform is making the connection
between a GNU triplet (see GNU configuration
triplets in Autoconf), the equivalent system in Nix
notation, the name of the glibc-dynamic-linker, and the corresponding
Linux architecture name if applicable (see Platforms).
Once the bootstrap tarball are built, the (gnu packages bootstrap)
module needs to be updated to refer to these binaries on the target
platform. That is, the hashes and URLs of the bootstrap tarballs for the
new platform must be added alongside those of the currently supported
platforms. The bootstrap Guile tarball is treated specially: it is expected
to be available locally, and gnu/local.mk has rules to download it
for the supported architectures; a rule for the new platform must be added
as well.
En la práctica puede haber algunas complicaciones. Primero, puede ser que la
tripleta extendida GNU que especifica un ABI (como el sufijo eabi
previamente) no es reconocida por todas las herramientas GNU. Típicamente,
glibc reconoce algunas de ellas, mientras que GCC usa una opción de
configuración extra --with-abi (vea gcc.scm para ejemplos de
como manejar este caso). En segundo lugar, algunos de los paquetes
necesarios pueden fallar en su construcción para dicha plataforma. Por
último, los binarios generados pueden estar defectuosos por alguna razón.
Next: Reconocimientos, Previous: Transportar a una nueva plataforma, Up: GNU Guix [Contents][Index]
22 Contribuir
Este proyecto es un esfuerzo colaborativo, y ¡necesitamos su ayuda para que
crezca! Por favor, contacte con nosotros en guix-devel@gnu.org y en
#guix en la red IRC Libera Chat. Estamos abiertos a ideas, informes
de errores, parches y cualquier cosa que pueda ser de ayuda para el
proyecto. Especialmente se agradece ayuda con la creación de paquetes
(see Pautas de empaquetamiento).
Queremos proporcionar un entorno cálido, amistoso y libre de acoso, para que cualquiera pueda contribuir al máximo de sus capacidades. Para este fin nuestro proyecto usa un “Acuerdo de Contribución”, que fue adaptado de https://contributor-coventant.org. Se puede encontrar una versión local en el archivo CODE-OF-CONDUCT del árbol de fuentes.
Las contribuidoras no están obligadas a usar su nombre legal en los parches ni en la comunicación on-line; pueden usar cualquier nombre o seudónimo de su elección.
- Construcción desde Git
- Ejecución de Guix antes de estar instalado
- La configuración perfecta
- Pautas de empaquetamiento
- Estilo de codificación
- Envío de parches
- Seguimiento de errores y parches
- Acceso al repositorio
- Actualizar el paquete Guix
- Writing Documentation
- Traduciendo Guix
Next: Ejecución de Guix antes de estar instalado, Up: Contribuir [Contents][Index]
22.1 Construcción desde Git
Si quiere picar en el mismo Guix se recomienda usar la última versión del repositorio Git:
git clone https://git.savannah.gnu.org/git/guix.git
¿Cómo se puede asegurar de que ha obtenido una copia auténtica del
repositorio? Para ello ejecute guix git authenticate,
proporcionando la revisión y la huella de OpenPGP de la presentación
del canal (see Invocación de guix git authenticate):
git fetch origin keyring:keyring guix git authenticate 9edb3f66fd807b096b48283debdcddccfea34bad \ "BBB0 2DDF 2CEA F6A8 0D1D E643 A2A0 6DF2 A33A 54FA"
Esta orden termina con un código de salida cero cuando al finalizar correctamente; o imprime un mensaje de error y sale con un código de salida distinto a cero en otro caso.
Como puede ver, nos encontramos ante el problema del huevo y la gallina: es necesario haber instalado Guix. Durante la instalación habitual del sistema Guix (see Instalación del sistema) o Guix sobre otra distribución (see Instalación binaria) debería verificar la firma de OpenPGP del medio de instalación. Este paso es el primer eslabón de la cadena de confianza.
El modo más fácil de preparar un entorno de desarrollo para Guix es, por supuesto, ¡usando Guix! Las siguientes órdenes inician un nuevo intérprete donde todas las dependencias y las variables de entorno apropiadas están listas para picar código en Guix:
guix shell -D guix --pure
See Invoking guix shell, para más información sobre este comando.
Si no puede usar Guix para construir Guix desde una copia de trabajo, son necesarios los paquetes siguientes además de los mencionados en las instrucciones de instalación (see Requisitos).
En Guix se pueden añadir dependencias adicionales ejecutando en su lugar
guix shell:
guix shell -D guix help2man git strace --pure
From there you can generate the build system infrastructure using Autoconf and Automake:
./bootstrap
Si se produce un error como el siguiente:
configure.ac:46: error: possibly undefined macro: PKG_CHECK_MODULES
probablemente significa que Autoconf no pudo encontrar el archivo pkg.m4, que proporciona pkg-config. Asegúrese de que pkg.m4 está disponible. Lo mismo aplica para el conjunto de macros guile.m4 que proporciona Guile. Por ejemplo, si ha instalado Automake en /usr/local, no va a buscar archivos .m4 en /usr/share. En ese caso tiene que ejecutar la siguiente orden:
export ACLOCAL_PATH=/usr/share/aclocal
See Macro Search Path in The GNU Automake Manual para más información.
Entonces, ejecute:
./configure --localstatedir=/var
... where /var is the normal localstatedir value (see El almacén, for information about this). Note that you will probably not run
make install at the end (you don’t have to) but it’s still
important to pass the right localstatedir.
Finalmente, puede construir Guix y, si se siente inclinado a ello, ejecutar los tests (see Ejecución de la batería de pruebas):
make make check
If anything fails, take a look at installation instructions (see Instalación) or send a message to the mailing list.
De aquí en adelante, puede identificar todos las revisiones incluidas en su copia ejecutando:
make authenticate
La primera ejecución puede tardar varios minutos, pero las ejecuciones siguientes son más rápidas.
O, cuando la configuración de su repositorio local Git no corresponda con la
predeterminada, puede proporcionar la referencia de la rama keyring a
través de la variable GUIX_GIT_KEYRING. El ejemplo siguiente asume
que tiene configurado un servidor remoto de git llamado ‘miremoto’ que
apunta al repositorio oficial:
make authenticate GUIX_GIT_KEYRING=miremoto/keyring
Nota: Se recomienda que ejecute
make authenticatetras cada ejecución degit pull. Así se asegura de que está recibiendo cambios válidos del repositorio.
Después de actualizar el repositorio, make podría fallar con un
error similar al del ejemplo siguiente:
error: fallo al cargar 'gnu/packages/dunst.scm': ice-9/eval.scm:293:34: En el procedimiento abi-check: #<record-type <origin>>: registro ABI erróneo; se necesita recompilación
Esto significa que uno de los tipos de registro que Guix define (en este
ejemplo, el registro origin) ha cambiado, y todo guix necesita ser
recompilado para tener en cuenta ese cambio. Para ello, ejecute
make clean-go seguido de make.
Next: La configuración perfecta, Previous: Construcción desde Git, Up: Contribuir [Contents][Index]
22.2 Ejecución de Guix antes de estar instalado
Para mantener un entorno de trabajo estable, encontrará útil probar los cambios hechos en su copia de trabajo local sin instalarlos realmente. De esa manera, puede distinguir entre su sombrero de “usuaria final” y el traje de “harapos”.
Para dicho fin, todas las herramientas de línea de comandos pueden ser
usadas incluso si no ha ejecutado make install. Para hacerlo, primero
necesita tener un entorno con todas las dependencias disponibles
(see Construcción desde Git) y entonces añada al inicio de cada orden
./pre-inst-env (el guión pre-inst-env se encuentra en la
raíz del árbol de compilación de Guix; se genera ejecutando
./bootstrap seguido de ./configure). A modo de ejemplo
puede ver a continuación cómo construiría el paquete hello que se
encuentre definido en su directorio de trabajo (esto asume que guix
daemon se esté ejecutando en su sistema; no es un problema que la versión
sea diferente):
$ ./pre-inst-env guix build hello
De manera similar, un ejemplo de una sesión de Guile con los módulos Guix disponibles:
$ ./pre-inst-env guile -c '(use-modules (guix utils)) (pk (%current-system))'
;;; ("x86_64-linux")
… and for a REPL (see Using Guix Interactively):
$ ./pre-inst-env guile
scheme@(guile-user)> ,use(guix)
scheme@(guile-user)> ,use(gnu)
scheme@(guile-user)> (define serpientes
(fold-packages
(lambda (paquete lst)
(if (string-prefix? "python"
(package-name paquete))
(cons paquete lst)
lst))
'()))
scheme@(guile-user)> (length serpientes)
$1 = 361
Si modifica el código del daemon o código auxiliar, o si
guix-daemon no se está ejecutando todavía en su sistema, puede
ejecutarlo desde el árbol de construción53:
$ sudo -E ./pre-inst-env guix-daemon --build-users-group=guixbuild
El guión pre-inst-env proporciona valor a todas las variables de
entorno necesarias para permitirlo, incluyendo PATH y
GUILE_LOAD_PATH.
Fíjese que la orden ./pre-inst-env guix pull no actualiza
el árbol de fuentes local; simplemente actualiza el enlace
~/.config/guix/latest (see Invocación de guix pull). Ejecute
git pull si quiere actualizar su árbol de fuentes local.
A veces, especialmente si ha actualizado recientemente su repositorio, la
ejecución de ./pre-inst-env imprimirá un mensaje similar al
siguiente ejemplo:
;;; nota: archivo fuente /home/user/projects/guix/guix/progress.scm ;;; más reciente que el compilado /home/user/projects/guix/guix/progress.go
Esto es sólo una nota y se puede ignorar con seguridad. Puede deshacerse
del mensaje ejecutando make -j4. Hasta que lo haga, Guile se
ejecutará ligeramente más lento porque interpretará el código en lugar de
utilizar archivos de objetos Guile preparados (.go).
Puede ejecutar make automáticamente mientras trabaja utilizando
watchexec del paquete watchexec. Por ejemplo, para
construir de nuevo cada vez que actualice un archivo de paquete, ejecute
‘watchexec -w gnu/packages -- make -j4’.
Next: Pautas de empaquetamiento, Previous: Ejecución de Guix antes de estar instalado, Up: Contribuir [Contents][Index]
22.3 La configuración perfecta
La configuración perfecta para hackear en Guix es básicamente la configuración perfecta para hacerlo en Guile (see Using Guile in Emacs in Guile Reference Manual). Primero, necesita más que un editor, necesita Emacs, con su potencia aumentada gracias al maravilloso Geiser. Para conseguir esta configuración ejecute:
guix install emacs guile emacs-geiser emacs-geiser-guile
Geiser permite desarrollo incremental e interactivo dentro de Emacs: compilación y evaluación de código dentro de los buffers, acceso a documentación en línea (docstrings), completado dependiente del contexto, M-. para saltar a la definición de un objeto, una consola interactiva (REPL) para probar su código, y más (see Introduction in Geiser User Manual). Para desarrollar Guix adecuadamente, asegúrese de aumentar la ruta de carga de Guile (load-path) para que encuentre los archivos fuente de su copia de trabajo:
;; Suponiendo que la copia de trabajo de Guix está en ~/src/guix. (with-eval-after-load 'geiser-guile (add-to-list 'geiser-guile-load-path "~/src/guix"))
Para realmente editar el código, Emacs tiene un modo para Scheme muy limpio. Pero además de eso, no debe perderse Paredit. Provee de facilidades para operar directamente en el árbol sintáctico como elevar una expresión-S o recubrirla, embeber o expulsar la siguiente expresión-S, etc.
We also provide templates for common git commit messages and package definitions in the etc/snippets directory. These templates can be used to expand short trigger strings to interactive text snippets. If you use YASnippet, you may want to add the etc/snippets/yas snippets directory to the yas-snippet-dirs variable. If you use Tempel, you may want to add the etc/snippets/tempel/* path to the tempel-path variable in Emacs.
;; Suponiendo que el checkout de Guix está en ~/src/guix. ;; Configuración de yasnippet (with-eval-after-load 'yasnippet (add-to-list 'yas-snippet-dirs "~/src/guix/etc/snippets/yas")) ;; Tempel configuration (con-eval-after-load 'tempel ;; Asegúrese de que tempel-path es una lista -- también puede ser una cadena. (unless (listp 'tempel-path) (setq tempel-path (list tempel-path)) (add-to-list 'tempel-path "~/src/guix/etc/snippets/tempel/*"))
Los fragmentos de mensajes de la revisión dependen de
Magit para mostrar los archivos preparados. En la
edición del mensaje de la revisión teclee add seguido de TAB
(el tabulador) para insertar la plantilla del mensaje de la revisión de
adición de un paquete; teclee update seguido de TAB para
insertar una plantilla de actualización de un paquete; teclee https
seguido de TAB para insertar una plantilla para cambiar la URI de la
página de un paquete a HTTPS.
El fragmento principal para scheme-mode es activado al teclear
package... seguido de TAB. Este fragmento también inserta el
lanzador origin... que puede ser expandido de nuevo. El fragmento
origin puede a su vez insertar otros identificadores de lanzado
terminando en ..., que pueden ser expandidos de nuevo.
También proporcionamos herramientas para la inserción y actualización automática del copyright en etc/copyright.el. Puede proporcionar su nombre completo, correo electrónico y cargar el archivo.
(setq user-full-name "Alicia Díaz") (setq user-mail-address "alicia@correo.org") ;; Se asume que la copia trabajo de guix está en ~/src/guix. (load-file "~/src/guix/etc/copyright.el")
Para insertar el aviso de copyright en la línea actual invoque M-x
guix-copyright.
Para actualizar el aviso de copyright debe especificar una expresión regular
de nombres en la variable copyright-names-regexp.
(setq copyright-names-regexp
(format "%s <%s>" user-full-name user-mail-address))
Puede comprobar si su copyright está actualizado evaluando M-x
copyright-update. Si desea hacerlo de manera automática tras guardar un
archivo añada (add-hook 'after-save-hook 'copyright-update) en Emacs.
Next: Estilo de codificación, Previous: La configuración perfecta, Up: Contribuir [Contents][Index]
22.4 Pautas de empaquetamiento
La distribución GNU es reciente y puede no disponer de alguno de sus paquetes favoritos. Esta sección describe cómo puede ayudar a hacer crecer la distribución.
Los paquetes de software libre habitualmente se distribuyen en forma de archivadores de código fuente—típicamente archivos tar.gz que contienen todos los archivos fuente. Añadir un paquete a la distribución significa esencialmente dos cosas: añadir una receta que describe cómo construir el paquete, la que incluye una lista de otros paquetes necesarios para la construcción, y añadir metadatos del paquete junto a dicha receta, como la descripción y la información de licencias.
En Guix toda esta información está contenida en definiciones de paquete. Las definiciones de paquete proporcionan una vista de alto nivel del paquete. Son escritas usando la sintaxis del lenguaje de programación Scheme; de hecho, definimos una variable por cada paquete enlazada a su definición y exportamos esa variable desde un módulo (see Módulos de paquetes). No obstante, un conocimiento profundo de Scheme no es un pre-requisito para la creación de paquetes. Para más información obre las definiciones de paquetes, see Definición de paquetes.
Una vez que una definición de paquete está en su lugar, almacenada en un
archivo del árbol de fuentes de Guix, puede probarse usando la orden
guix build (see Invocación de guix build). Por ejemplo, asumiendo
que el nuevo paquete se llama gnuevo, puede ejecutar esta orden desde
el árbol de construcción de Guix (see Ejecución de Guix antes de estar instalado):
./pre-inst-env guix build gnuevo --keep-failed
El uso de --keep-failed facilita la depuración de errores de
construcción ya que proporciona acceso al árbol de la construcción
fallida. Otra opción útil de línea de órdenes para la depuración es
--log-file, para acceder al log de construcción.
Si el paquete resulta desconocido para la orden guix, puede ser
que el archivo fuente contenga un error de sintaxis, o no tenga una cláusula
define-public para exportar la variable del paquete. Para encontrar
el problema puede cargar el módulo desde Guile para obtener más información
sobre el error real:
./pre-inst-env guile -c '(use-modules (gnu packages gnuevo))'
Once your package builds correctly, please send us a patch (see Envío de parches). Well, if you need help, we will be happy to help you too. Once the patch is committed in the Guix repository, the new package automatically gets built on the supported platforms by our continuous integration system.
Users can obtain the new package definition simply by running guix
pull (see Invocación de guix pull). When ci.guix.gnu.org
is done building the package, installing the package automatically downloads
binaries from there (see Sustituciones). The only place where human
intervention is needed is to review and apply the patch.
- Libertad del software
- Nombrado de paquetes
- Versiones numéricas
- Sinopsis y descripciones
snippetsfrente a fases- Paquetes Emacs
- Módulos Python
- Módulos Perl
- Paquetes Java
- Crates de Rust
- Paquetes Elm
- Tipos de letra
Next: Nombrado de paquetes, Up: Pautas de empaquetamiento [Contents][Index]
22.4.1 Libertad del software
El sistema operativo GNU se ha desarrollado para que las usuarias puedan ejercitar su libertad de computación. GNU es software libre, lo que significa que las usuarias tienen las cuatro libertades esenciales: para ejecutar el programa, para estudiar y modificar el programa en la forma de código fuente, para redistribuir copias exactas y para distribuir versiones modificadas. Los paquetes encontrados en la distribución GNU contienen únicamente software que proporciona estas cuatro libertades.
Además, la distribución GNU sigue las directrices de distribución de software libre. Entre otras cosas, estas directrices rechazan firmware no-libre, recomendaciones de software no-libre, y tienen en cuenta formas de tratar con marcas registradas y patentes.
Algunos paquetes originales, que serían de otra manera software libre,
contienen un subconjunto pequeño y opcional que viola estas directrices, por
ejemplo debido a que ese subconjunto sea en sí código no-libre. Cuando esto
sucede, las partes indeseadas son eliminadas con parches o fragmentos de
código en la forma origin del paquete (see Definición de paquetes). De
este modo, guix build --source devuelve las fuentes “liberadas” en
vez de la versión original de las fuentes.
Next: Versiones numéricas, Previous: Libertad del software, Up: Pautas de empaquetamiento [Contents][Index]
22.4.2 Nombrado de paquetes
Un paquete tiene actualmente dos nombre asociados con él. Primero el nombre
de la Variable Scheme, seguido de define-public. Por este
nombre, el paquete se puede conocer por este nombre en el código Scheme, por
ejemplo como entrada a otro paquete. El segundo es la cadena en el campo
nombre de la definición de paquete. Este nombre es el utilizado por
los comandos de administración de paquetes como guix package y
guix build.
Ambos normalmente son iguales y corresponden a la conversión a minúsculas
del nombre de proyecto elegido por sus creadoras, con los guiones bajos
sustituidos por guiones. Por ejemplo, GNUnet está disponible como
gnunet, y SDL_net como sdl-net.
Una excepción notable a esta regla es cuando el nombre del proyecto es un
sólo carácter o si existe un proyecto más antiguo mantenido con el mismo
nombre —sin importar si ha sido empaquetado para Guix. Utilice el sentido
común para hacer que estos nombre no sean ambiguos y tengan significado. Por
ejemplo, el paquete de Guix para la shell llamado “s” hacia arriba es
s-shell y not s. No dude en pedir inspiración a sus
compañeros hackers.
No añadimos prefijos lib para paquetes de bibliotecas, a menos que
sean parte del nombre oficial del proyecto. Pero vea Módulos Python y
Módulos Perl para reglas especiales que conciernen a los módulos de
los lenguajes Python y Perl.
Los nombres de paquetes de tipografías se manejan de forma diferente, see Tipos de letra.
Next: Sinopsis y descripciones, Previous: Nombrado de paquetes, Up: Pautas de empaquetamiento [Contents][Index]
22.4.3 Versiones numéricas
Normalmente empaquetamos únicamente la última versión de un proyecto dado de
software libre. Pero a veces, por ejemplo para versiones de bibliotecas
incompatibles, se necesitan dos (o más) versiones del mismo paquete. Estas
necesitan nombres diferentes para las variables Scheme. Usamos el nombre
como se define en Nombrado de paquetes para la versión más reciente; las
versiones previas usan el mismo nombre, añadiendo un - y el prefijo
menor del número de versión que permite distinguir las dos versiones.
El nombre dentro de la definición de paquete es el mismo para todas las versiones de un paquete y no contiene ningún número de versión.
Por ejemplo, las versiones 2.24.20 y 3.9.12 de GTK+ pueden empaquetarse como sigue:
(define-public gtk+ (package (name "gtk+") (version "3.9.12") ...)) (define-public gtk+-2 (package (name "gtk+") (version "2.24.20") ...))
Si también deseásemos GTK+3.8.2, se empaquetaría como
De manera ocasional, empaquetamos instantáneas del sistema de control de
versiones (VCS) de las desarrolladoras originales en vez de publicaciones
formales. Esto debería permanecer como algo excepcional, ya que son las
desarrolladoras originales quienes deben clarificar cual es la entrega
estable. No obstante, a veces es necesario. Por tanto, ¿qué deberíamos poner
en el campo version?
Claramente, tenemos que hacer visible el identificador de la revisión en el
VCS en la cadena de versión, pero también debemos asegurarnos que la cadena
de versión incrementa monotónicamente de manera que guix package
--upgrade pueda determinar qué versión es más moderna. Ya que los
identificadores de revisión, notablemente en Git, no incrementan
monotónicamente, añadimos un número de revisión que se incrementa cada vez
que actualizamos a una nueva instantánea. La versión que resulta debería ser
así:
2.0.11-3.cabba9e ^ ^ ^ | | `-- ID de revisión original | | | `--- revisión del paquete Guix | última versión de publicación
It is a good idea to strip commit identifiers in the version field
to, say, 7 digits. It avoids an aesthetic annoyance (assuming aesthetics
have a role to play here) as well as problems related to OS limits such as
the maximum shebang length (127 bytes for the Linux kernel). There are
helper functions for doing this for packages using git-fetch or
hg-fetch (see below). It is best to use the full commit identifiers
in origins, though, to avoid ambiguities. A typical package
definition may look like this:
(define mi-paquete
(let ((commit "c3f29bc928d5900971f65965feaae59e1272a3f7")
(revision "1")) ;Revisión Guix del paquete
(package
(version (git-version "0.9" revision commit))
(source (origin
(method git-fetch)
(uri (git-reference
(url "git://example.org/mi-paquete.git")
(commit commit)))
(sha256 (base32 "1mbikn…"))
(file-name (git-file-name name version))))
;; …
)))
- Scheme Procedure: git-version VERSION REVISION COMMIT
Return the version string for packages using
git-fetch.(git-version "0.2.3" "0" "93818c936ee7e2f1ba1b315578bde363a7d43d05") ⇒ "0.2.3-0.93818c9"
- Scheme Procedure: hg-version VERSION REVISION CHANGESET
Devuelve la cadena de versión de los paquetes utilizando
hg-fetch. Funciona de la misma manera quegit-version.
Next: snippets frente a fases, Previous: Versiones numéricas, Up: Pautas de empaquetamiento [Contents][Index]
22.4.4 Sinopsis y descripciones
Como hemos visto previamente, cada paquete en GNU Guix incluye una
sinopsis y una descripción (see Definición de paquetes). Las sinopsis y
descripciones son importantes: son en lo que guix package --search
busca, y una pieza crucial de información para ayudar a las usuarias a
determinar si un paquete dado cubre sus necesidades. Consecuentemente, las
empaquetadoras deben prestar atención a qué se incluye en ellas.
Las sinopsis deben empezar con mayúscula y no deben terminar con punto. No deben empezar con un artículo que habitualmente no aporta nada; por ejemplo, se prefiere “Herramienta para chiribizar” sobre “Una herramienta que chiribiza archivos”. La sinopsis debe decir qué es el paquete—por ejemplo, “Utilidades básicas GNU (archivos, texto, intérprete de consola)”—o para qué se usa—por ejemplo, la sinopsis de GNU grep es “Imprime líneas aceptadas por un patrón”.
Tenga en cuenta que las sinopsis deben tener un claro significado para una audiencia muy amplia. Por ejemplo, “Manipula la alineación en el formato SAM” puede tener sentido para una investigadora de bioinformática con experiencia, pero puede ser de poca ayuda o incluso llevar a confusión a una audiencia no-especializada. Es una buena idea proporcionar una sinopsis que da una idea del dominio de aplicación del paquete. En ese ejemplo, esto podría ser algo como “Manipula la alineación de secuencias de nucleótidos”, lo que con suerte proporcionará a la usuaria una mejor idea sobre si esto es lo que está buscando.
Las descripciones deben tener entre cinco y diez líneas. Use frases completas, y evite usar acrónimos sin introducirlos previamente. Por favor evite frases comerciales como “líder mundial”, “de potencia industrial” y “siguiente generación”, y evite superlativos como “el más avanzado”—no son útiles para las usuarias que buscan un paquete e incluso pueden sonar sospechosas. En vez de eso, intente ceñirse a los hechos, mencionando casos de uso y características.
Descriptions can include Texinfo markup, which is useful to introduce
ornaments such as @code or @dfn, bullet lists, or hyperlinks
(see Overview in GNU Texinfo). However you should be careful
when using some characters for example ‘@’ and curly braces which are
the basic special characters in Texinfo (see Special Characters in GNU Texinfo). User interfaces such as guix show take
care of rendering it appropriately.
Synopses and descriptions are translated by volunteers at Weblate so that as many users as possible can read them in their native language. User interfaces search them and display them in the language specified by the current locale.
Para permitir a xgettext extraerlas como cadenas traducibles, las
sinopsis y descripciones deben ser cadenas literales. Esto significa
que no puede usar string-append o format para construir estas
cadenas:
(package
;; …
(synopsis "Esto es traducible")
(description (string-append "Esto " "*no*" " es traducible.")))
La traducción requiere mucho trabajo, por lo que, como empaquetadora, le rogamos que ponga incluso más atención a sus sinopsis y descripciones ya que cada cambio puede suponer trabajo adicional para las traductoras. Para ayudarlas, es posible hacer recomendaciones o instrucciones insertando comentarios especiales como este (see xgettext Invocation in GNU Gettext):
;; TRANSLATORS: "X11 resize-and-rotate" should not be translated. (description "ARandR is designed to provide a simple visual front end for the X11 resize-and-rotate (RandR) extension. …")
Next: Paquetes Emacs, Previous: Sinopsis y descripciones, Up: Pautas de empaquetamiento [Contents][Index]
22.4.5 snippets frente a fases
La frontera entre el uso de un fragmento de código para la modificación de
un origen (snippet) frente a una fase de construcción puede ser
ténue. Los fragmentos de código para el origen se usan habitualmente para
eliminar archivos no deseados, como bibliotecas incluidas, fuentes no
libres, o simplemente para aplicar sustituciones simples. Las fuentes que
derivan de un origen deben producir unas fuentes capaces de compilar en
cualquier sistema que permita el paquete original (es decir, actuar como la
fuente correspondiente). En particular, los snippet del campo
origin no deben incluir elementos del almacén en las fuentes; esos
parches deben llevarse a cabo en las fases de construcción. Véase el
registro origin para obtener más información (see Referencia de origin).
Next: Módulos Python, Previous: snippets frente a fases, Up: Pautas de empaquetamiento [Contents][Index]
22.4.6 Paquetes Emacs
Los paquetes Emacs deberían usar preferentemente el sistema de construcción
de Emacs (see emacs-build-system), por uniformidad y por los beneficios
que proporcionan sus fases de construcción, tales como la autogeneración del
fichero de autocargas y la compilación de bytes de las fuentes. Debido a
que no hay una forma estandarizada de ejecutar un conjunto de pruebas para
los paquetes Emacs, las pruebas están deshabilitadas por defecto. Cuando
un conjunto de pruebas está disponible, debe ser habilitado estableciendo el
argumento #:tests? a #true. Por defecto, el comando para
ejecutar la prueba es make check, pero se puede especificar
cualquier comando mediante el argumento #:test-command. El
argumento #:test-command espera una lista que contenga un comando y
sus argumentos, para ser invocado durante la fase check.
Las dependencias de Elisp de los paquetes de Emacs se proporcionan
normalmente como propagated-inputs cuando se requieren en tiempo de
ejecución. En cuanto a otros paquetes, las dependencias de construcción o
de prueba deben especificarse como native-inputs.
Los paquetes de Emacs a veces dependen de directorios de recursos que deben
instalarse junto con los archivos de Elisp. El argumento #:include
puede utilizarse para este fin, especificando una lista de expresiones
regulares que deben coincidir. La mejor práctica cuando se utiliza el
argumento #:include es ampliar en lugar de anular su valor por
defecto (accesible a través de la variable %default-include). Como
ejemplo, un paquete de extensión de yasnippet suele incluir un directorio
snippets, que podría copiarse en el directorio de instalación
utilizando:
#:include (cons "^snippets/" %default-include)
When encountering problems, it is wise to check for the presence of the
Package-Requires extension header in the package main source file,
and whether any dependencies and their versions listed therein are
satisfied.
Next: Módulos Perl, Previous: Paquetes Emacs, Up: Pautas de empaquetamiento [Contents][Index]
22.4.7 Módulos Python
Actualmente empaquetamos Python 2 y Python 3, bajo los nombres de variable
Scheme python-2 y python como se explica en Versiones numéricas. Para evitar confusiones y conflictos de nombres con otros
lenguajes de programación, parece deseable que el nombre de paquete para un
módulo Python contenga la palabra python.
Algunos módulos son compatibles únicamente con una versión de Python, otros
con ambas. Si el paquete Foo se compila únicamente con Python 3, lo llamamos
python-foo. Si se compila con Python 2, lo llamamos
python2-foo. Los paquetes deben añadirse cuando sean necesarios; no
añadimos la variante de Python 2 del paquete a menos que vayamos a usarla.
Si un proyecto ya contiene la palabra python, la eliminamos; por
ejemplo, el módulo python-dateutil se empaqueta con los nombres
python-dateutil y python2-dateutil. Si el nombre del proyecto
empieza con py (por ejemplo pytz), este se mantiene y el
prefijo es el especificado anteriormente..
Nota: Currently there are two different build systems for Python packages in Guix: python-build-system and pyproject-build-system. For the longest time, Python packages were built from an informally specified setup.py file. That worked amazingly well, considering Python’s success, but was difficult to build tooling around. As a result, a host of alternative build systems emerged and the community eventually settled on a formal standard for specifying build requirements. pyproject-build-system is Guix’s implementation of this standard. It is considered “experimental” in that it does not yet support all the various PEP-517 build backends, but you are encouraged to try it for new Python packages and report any problems. It will eventually be deprecated and merged into python-build-system.
22.4.7.1 Especificación de dependencias
Dependency information for Python packages is usually available in the package source tree, with varying degrees of accuracy: in the pyproject.toml file, the setup.py file, in requirements.txt, or in tox.ini (the latter mostly for test dependencies).
Su misión, cuando escriba una receta para un paquete Python, es asociar
estas dependencias con el tipo apropiado de “entrada” (see inputs). Aunque el importador de pypi normalmente hace un
buen trabajo (see Invocación de guix import), puede querer comprobar la
siguiente lista para determinar qué dependencia va dónde.
- We currently package Python with
setuptoolsandpipinstalled per default. This is about to change, and users are encouraged to usepython-toolchainif they want a build environment for Python.guix lintwill warn ifsetuptoolsorpipare added as native-inputs because they are generally not necessary. - Las dependencias Python requeridas en tiempo de ejecución van en
propagated-inputs. Típicamente están definidas con la palabra claveinstall_requiresen setup.py, o en el archivo requirements.txt. - Python packages required only at build time—e.g., those listed under
build-system.requiresin pyproject.toml or with thesetup_requireskeyword in setup.py—or dependencies only for testing—e.g., those intests_requireor tox.ini—go intonative-inputs. The rationale is that (1) they do not need to be propagated because they are not needed at run time, and (2) in a cross-compilation context, it’s the “native” input that we’d want.Ejemplos son las bibliotecas de pruebas
pytest,mockynose. Por supuesto, si alguno de estos paquetes también se necesita en tiempo de ejecución, necesita ir enpropagated-inputs. - Todo lo que no caiga en las categorías anteriores va a
inputs, por ejemplo programas o bibliotecas C requeridas para construir los paquetes Python que contienen extensiones C. - Si un paquete Python tiene dependencias opcionales (
extras_require), queda en su mano decidir si las añade o no, en base a la relación utilidad/sobrecarga (seeguix size).
Next: Paquetes Java, Previous: Módulos Python, Up: Pautas de empaquetamiento [Contents][Index]
22.4.8 Módulos Perl
Los programas ejecutables Perl se nombran como cualquier otro paquete,
mediante el uso del nombre oficial en minúsculas. Para paquetes Perl que
contienen una única clase, usamos el nombre en minúsculas de la clase,
substituyendo todas las ocurrencias de :: por guiones y agregando el
prefijo perl-. Por tanto la clase XML::Parser se convierte en
perl-xml-parser. Los módulos que contienen varias clases mantienen su
nombre oficial en minúsculas y también se agrega perl- al
inicio. Dichos módulos tienden a tener la palabra perl en alguna
parte de su nombre, la cual se elimina en favor del prefijo. Por ejemplo,
libwww-perl se convierte en perl-libwww.
Next: Crates de Rust, Previous: Módulos Perl, Up: Pautas de empaquetamiento [Contents][Index]
22.4.9 Paquetes Java
Los programas Java ejecutables se nombran como cualquier otro paquete, mediante el uso del nombre oficial en minúsculas.
Para evitar confusión y colisiones de nombres con otros lenguajes de
programación, es deseable que el nombre del paquete para un paquete Java
contenga el prefijo java-. Si el proyecto ya tiene la palabra
java, eliminamos esta; por ejemplo, el paquete ngsjaga se
empaqueta bajo el nombre java-ngs.
Para los paquetes Java que contienen una clase única o una jerarquía
pequeña, usamos el nombre de clase en minúsculas, substituyendo todas las
ocurrencias de . por guiones y agregando el prefijo java-. Por
tanto la clase apache.commons.cli se convierte en el paquete
java-apache-commons-cli.
Next: Paquetes Elm, Previous: Paquetes Java, Up: Pautas de empaquetamiento [Contents][Index]
22.4.10 Crates de Rust
Los programas Rust ejecutables se nombran como cualquier otro paquete, mediante el uso del nombre oficial en minúsculas.
Para evitar colisiones en el espacio de nombres añadimos rust- como
prefijo al resto de paquetes de Rust. El nombre debe cambiarse a letras
minúsculas cuando sea apropiado y los guiones deben mantenerse.
In the rust ecosystem it is common for multiple incompatible versions of a
package to be used at any given time, so all package definitions should have
a versioned suffix. The versioned suffix is the left-most non-zero digit
(and any leading zeros, of course). This follows the “caret” version
scheme intended by Cargo. Examples rust-clap-2,
rust-rand-0.6.
Debido a la dificultad a la hora de reusar paquetes de rust como entradas
pre-compiladas de otros paquetes, el sistema de construcción de Cargo
(see cargo-build-system) presenta las palabras
clave #:cargo-inputs y cargo-development-inputs como
parámetros del sistema de construcción. Puede servir de ayuda pensar en
estos parámetros de manera similar a propagated-inputs y
native-inputs. Las dependencias de rust de dependencies y
build-dependencies deben proporcionarse a través de
#:cargo-inputs, y dev-dependencies deben proporcionarse a
través de #:cargo-development-inputs. Si un paquete de Rust se enlaza
con otras bibliotecas deben proporcionarse como habitualmente en
inputs y otros campos relacionados.
Se debe tener cuidado a la hora de asegurar que se usan las versiones
correctas de las dependencias; para ello intentamos no evitar la ejecución
de pruebas o la construcción completa con #:skip-build? cuando sea
posible. Por supuesto, no siempre es posible, ya que el paquete puede
desarrollarse para un sistema operativo distinto, depender de
características del compilador de Rust que se construye a diario (Nightly),
o la batería de pruebas puede haberse atrofiado desde su lanzamiento.
Next: Tipos de letra, Previous: Crates de Rust, Up: Pautas de empaquetamiento [Contents][Index]
22.4.11 Paquetes Elm
Elm applications can be named like other software: their names need not mention Elm.
Packages in the Elm sense (see elm-build-system under Sistemas de construcción) are required use names of the format
author/project, where both the author and the
project may contain hyphens internally, and the author sometimes
contains uppercase letters.
To form the Guix package name from the upstream name, we follow a convention
similar to Python packages (see Módulos Python), adding an elm-
prefix unless the name would already begin with elm-.
In many cases we can reconstruct an Elm package’s upstream name
heuristically, but, since conversion to a Guix-style name involves a loss of
information, this is not always possible. Care should be taken to add the
'upstream-name property when necessary so that ‘guix import elm’
will work correctly (see Invocación de guix import). The most notable
scenarios when explicitly specifying the upstream name is necessary are:
- When the author is
elmand the project contains one or more hyphens, as withelm/virtual-dom; and - When the author contains hyphens or uppercase letters, as with
Elm-Canvas/raster-shapes—unless the author iselm-explorations, which is handled as a special case, so packages likeelm-explorations/markdowndo not need to use the'upstream-nameproperty.
The module (guix build-system elm) provides the following utilities
for working with names and related conventions:
- Scheme procedure: elm-package-origin elm-name version hash Returns a Git origin using the repository naming and tagging
regime required for a published Elm package with the upstream name elm-name at version version with sha256 checksum hash.
Por ejemplo:
(package (name "elm-html") (version "1.0.0") (source (elm-package-origin "elm/html" version (base32 "15k1679ja57vvlpinpv06znmrxy09lbhzfkzdc89i01qa8c4gb4a"))) ...)
- Scheme procedure: elm->package-name elm-name
Returns the Guix-style package name for an Elm package with upstream name elm-name.
Note that there is more than one possible elm-name for which
elm->package-namewill produce a given result.
- Scheme procedure: guix-package->elm-name package
Given an Elm package, returns the possibly-inferred upstream name, or
#fthe upstream name is not specified via the'upstream-nameproperty and can not be inferred byinfer-elm-package-name.
- Scheme procedure: infer-elm-package-name guix-name
Given the guix-name of an Elm package, returns the inferred upstream name, or
#fif the upstream name can’t be inferred. If the result is not#f, supplying it toelm->package-namewould produce guix-name.
Previous: Paquetes Elm, Up: Pautas de empaquetamiento [Contents][Index]
22.4.12 Tipos de letra
Para tipografías que no se instalan generalmente por una usuaria para propósitos tipográficos, o que se distribuyen como parte de un paquete de software más grande, seguimos las reglas generales de empaquetamiento de software; por ejemplo, esto aplica a las tipografías distribuidas como parte del sistema X.Org o las tipografías que son parte de TeX Live.
Para facilitar a las usuarias la búsqueda de tipografías, los nombres para otros paquetes que contienen únicamente tipografías se construyen como sigue, independientemente del nombre de paquete oficial.
El nombre de un paquete que contiene únicamente una familia tipográfica
comienza con font-; seguido por el nombre de la tipografía y un guión
si la tipografía es conocida, y el nombre de la familia tipográfica, donde
los espacios se sustituyen por guiones (y como es habitual, todas las letras
mayúsculas se transforman a minúsculas). Por ejemplo, la familia de
tipografías Gentium de SIL se empaqueta bajo el nombre de
font-sil-gentium.
Para un paquete que contenga varias familias tipográficas, el nombre de la
colección se usa en vez del nombre de la familia tipográfica. Por ejemplo,
las tipografías Liberation consisten en tres familias: Liberation Sans,
Liberation Serif y Liberation Mono. Estas se podrían empaquetar por separado
bajo los nombres font-liberation-sans, etcétera; pero como se
distribuyen de forma conjunta bajo un nombre común, preferimos empaquetarlas
conjuntamente como font-liberation.
En el caso de que varios formatos de la misma familia o colección
tipográfica se empaqueten de forma separada, una forma corta del formato,
precedida por un guión, se añade al nombre del paquete. Usamos -ttf
para tipografías TrueType, -otf para tipografías OpenType y
-type1 para tipografías Tipo 1 PostScript.
Next: Envío de parches, Previous: Pautas de empaquetamiento, Up: Contribuir [Contents][Index]
22.5 Estilo de codificación
En general nuestro código sigue los Estándares de codificación GNU (see GNU Coding Standards). No obstante, no dicen mucho de Scheme, así que aquí están algunas reglas adicionales.
Next: Módulos, Up: Estilo de codificación [Contents][Index]
22.5.1 Paradigma de programación
El código scheme en Guix está escrito en un estilo puramente funcional. Una
excepción es el código que incluye entrada/salida, y procedimientos que
implementan conceptos de bajo nivel, como el procedimiento memoize.
Next: Tipos de datos y reconocimiento de patrones, Previous: Paradigma de programación, Up: Estilo de codificación [Contents][Index]
22.5.2 Módulos
Los módulos Guile que están destinados a ser usados en el lado del
constructor deben encontrarse en el espacio de nombres (guix build
…). No deben hacer referencia a otros módulos Guix o GNU. No
obstante, no hay problema en usar un módulo del lado del constructor en un
módulo “del lado del cliente”.
Los módulos que tratan con el sistema GNU más amplio deben estar en el
espacio de nombres (gnu …) en vez de en (guix …).
Next: Formato del código, Previous: Módulos, Up: Estilo de codificación [Contents][Index]
22.5.3 Tipos de datos y reconocimiento de patrones
La tendencia en el Lisp clásico es usar listas para representar todo, y
recorrerlas “a mano” usando car, cdr, cadr y
compañía. Hay varios problemas con este estilo, notablemente el hecho de que
es difícil de leer, propenso a errores y una carga para informes adecuados
de errores de tipado.
Guix code should define appropriate data types (for instance, using
define-record-type*) rather than abuse lists. In addition, it should
use pattern matching, via Guile’s (ice-9 match) module, especially
when matching lists (see Pattern Matching in GNU Guile Reference
Manual); pattern matching for records is better done using
match-record from (guix records), which, unlike match,
verifies field names at macro-expansion time.
Previous: Tipos de datos y reconocimiento de patrones, Up: Estilo de codificación [Contents][Index]
22.5.4 Formato del código
Cuando escribimos código Scheme, seguimos la sabiduría común entre las programadoras Scheme. En general, seguimos las Reglas de estilo Lisp de Riastradh. Este documento resulta que también describe las convenciones más usadas en el código Guile. Está lleno de ideas y bien escrito, así que recomendamos encarecidamente su lectura.
Algunas formas especiales introducidas en Guix, como el macro
substitute* tienen reglas de indentación especiales. Estas están
definidas en el archivo .dir-locals.el, el cual Emacs usa
automáticamente. Fíjese que además Emacs-Guix proporciona el modo
guix-devel-mode que indenta y resalta adecuadamente el código de Guix
(see Development in The Emacs-Guix Reference Manual).
Si no usa Emacs, por favor asegúrese de que su editor conoce esas reglas. Para indentar automáticamente una definición de paquete también puede ejecutar:
./pre-inst-env guix style package
See Invoking guix style, for more information.
Si está editando código con Vim, le recomendamos ejecutar :set
autoindent para que el código se indente automáticamente mientras
escribe. Adicionalmente,
paredit.vim puede ayudar a manejar todos estos paréntesis.
Requerimos que todos los procedimientos del nivel superior tengan una cadena
de documentación. Este requisito puede relajarse para procedimientos simples
privados en el espacio de nombres (guix build …) no obstante.
Los procedimientos no deben tener más de cuatro parámetros posicionales. Use parámetros con palabras clave para procedimientos que toman más de cuatro parámetros.
Next: Seguimiento de errores y parches, Previous: Estilo de codificación, Up: Contribuir [Contents][Index]
22.6 Envío de parches
Development is done using the Git distributed version control system. Thus,
access to the repository is not strictly necessary. We welcome
contributions in the form of patches as produced by git format-patch
sent to the guix-patches@gnu.org mailing list (see Submitting
patches to a project in Git User Manual). Contributors are encouraged
to take a moment to set some Git repository options (see Configuring Git) first, which can improve the readability of patches. Seasoned Guix
developers may also want to look at the section on commit access
(see Acceso al repositorio).
This mailing list is backed by a Debbugs instance, which allows us to keep
track of submissions (see Seguimiento de errores y parches). Each message sent
to that mailing list gets a new tracking number assigned; people can then
follow up on the submission by sending email to
ISSUE_NUMBER@debbugs.gnu.org, where ISSUE_NUMBER is the
tracking number (see Envío de una serie de parches).
Le rogamos que escriba los mensajes de revisiones en formato ChangeLog (see Change Logs in GNU Coding Standards); puede comprobar la historia de revisiones en busca de ejemplos.
Antes de enviar un parche que añade o modifica una definición de un paquete, por favor recorra esta lista de comprobaciones:
- Si las autoras del paquete software proporcionan una firma criptográfica
para el archivo de la versión, haga un esfuerzo para verificar la
autenticidad del archivo. Para un archivo de firma GPG separado esto puede
hacerse con la orden
gpg --verify. - Dedique algún tiempo a proporcionar una sinopsis y descripción adecuadas para el paquete. See Sinopsis y descripciones, para algunas directrices.
- Ejecute
guix lint paquete, donde paquete es el nombre del paquete nuevo o modificado, y corrija cualquier error del que informe (see Invocación deguix lint). - Run
guix style packageto format the new package definition according to the project’s conventions (see Invokingguix style). - Asegúrese de que el paquete compile en su plataforma, usando
guix build package. - We recommend you also try building the package on other supported
platforms. As you may not have access to actual hardware platforms, we
recommend using the
qemu-binfmt-service-typeto emulate them. In order to enable it, add thevirtualizationservice module and the following service to the list of services in youroperating-systemconfiguration:(service qemu-binfmt-service-type (qemu-binfmt-configuration (platforms (lookup-qemu-platforms "arm" "aarch64"))))Una vez hecho esto, reconfigure su sistema.
You can then build packages for different platforms by specifying the
--systemoption. For example, to build the "hello" package for the armhf or aarch64 architectures, you would run the following commands, respectively:guix build --system=armhf-linux --rounds=2 hello guix build --system=aarch64-linux --rounds=2 hello
-
Asegúrese de que el paquete no usa copias empaquetadas de software ya
disponible como paquetes separados.
A veces, paquetes incluyen copias embebidas del código fuente de sus dependencias para conveniencia de las usuarias. No obstante, como distribución, queremos asegurar que dichos paquetes efectivamente usan la copia que ya tenemos en la distribución si hay ya una. Esto mejora el uso de recursos (la dependencia es construida y almacenada una sola vez), y permite a la distribución hacer cambios transversales como aplicar actualizaciones de seguridad para un software dado en un único lugar y que afecte a todo el sistema—algo que esas copias embebidas impiden.
- Take a look at the profile reported by
guix size(see Invocación deguix size). This will allow you to notice references to other packages unwillingly retained. It may also help determine whether to split the package (see Paquetes con múltiples salidas), and which optional dependencies should be used. In particular, avoid addingtexliveas a dependency: because of its extreme size, use thetexlive-tinypackage ortexlive-unionprocedure instead. - For important changes, check that dependent packages (if applicable) are not
affected by the change;
guix refresh --list-dependent packagewill help you do that (see Invocación deguix refresh).En base al número de paquetes dependientes y, por tanto, del tamaño de la reconstrucción inducida, los revisiones van a ramas separadas, según estas líneas:
- 300 paquetes dependientes o menos
rama
master(cambios no disruptivos).- entre 300 y 1.800 paquetes dependientes
stagingbranch (non-disruptive changes). This branch is intended to be merged inmasterevery 6 weeks or so. Topical changes (e.g., an update of the GNOME stack) can instead go to a specific branch (say,gnome-updates). This branch is not expected to be buildable or usable until late in its development process.- más de 1.800 paquetes dependientes
core-updatesbranch (may include major and potentially disruptive changes). This branch is intended to be merged inmasterevery 6 months or so. This branch is not expected to be buildable or usable until late in its development process.
All these branches are tracked by our build farm and merged into
masteronce everything has been successfully built. This allows us to fix issues before they hit users, and to reduce the window during which pre-built binaries are not available.When we decide to start building the
stagingorcore-updatesbranches, they will be forked and renamed with the suffix-frozen, at which time only bug fixes may be pushed to the frozen branches. Thecore-updatesandstagingbranches will remain open to accept patches for the next cycle. Please ask on the mailing list or IRC if unsure where to place a patch. -
Compruebe si el proceso de construcción de un paquete es determinista. Esto
significa típicamente comprobar si una construcción independiente del
paquete ofrece exactamente el mismo resultado que usted obtuvo, bit a bit.
Una forma simple de hacerlo es construyendo el mismo paquete varias veces seguidas en su máquina (see Invocación de
guix build):guix build --rounds=2 mi-paquete
Esto es suficiente una clase común de problemas de no-determinismo, como las marcas de tiempo o salida generada aleatoriamente en el resultado de la construcción.
Another option is to use
guix challenge(see Invocación deguix challenge). You may run it once the package has been committed and built byci.guix.gnu.orgto check whether it obtains the same result as you did. Better yet: Find another machine that can build it and runguix publish. Since the remote build machine is likely different from yours, this can catch non-determinism issues related to the hardware—e.g., use of different instruction set extensions—or to the operating system kernel—e.g., reliance onunameor /proc files. - Cuando escriba documentación, por favor use construcciones neutrales de género para referirse a la gente54, como singular “they”, “their”, “them” y demás.
- Compruebe que su parche contiene únicamente un conjunto relacionado de
cambios. Agrupando cambios sin relación dificulta y ralentiza la revisión.
Ejemplos de cambios sin relación incluyen la adición de varios paquetes, o una actualización de un paquete junto a correcciones a ese paquete.
- Please follow our code formatting rules, possibly running
guix stylescript to do that automatically for you (see Formato del código). - Cuando sea posible, use espejos en la URL de las fuentes (see Invocación de
guix download). Use URL fiables, no generadas. Por ejemplo, los archivos de GitHub no son necesariamente idénticos de una generación a la siguiente, así que en este caso es normalmente mejor clonar el repositorio. No use el camponameen la URL: no es muy útil y si el nombre cambia, la URL probablemente estará mal. - Comprueba si Guix se puede construir correctamente (see Construcción desde Git) y trata los avisos, especialmente aquellos acerca del uso de símbolos sin definición.
- Asegúrese de que sus cambios no rompen Guix y simule
guix pullcon:guix pull --url=/ruta/a/su/copia --profile=/tmp/guix.master
When posting a patch to the mailing list, use ‘[PATCH] …’ as a
subject, if your patch is to be applied on a branch other than
master, say core-updates, specify it in the subject like
‘[PATCH core-updates] …’.
You may use your email client or the git send-email command
(see Envío de una serie de parches). We prefer to get patches in plain text
messages, either inline or as MIME attachments. You are advised to pay
attention if your email client changes anything like line breaks or
indentation which could potentially break the patches.
Expect some delay when you submit your very first patch to guix-patches@gnu.org. You have to wait until you get an acknowledgement with the assigned tracking number. Future acknowledgements should not be delayed.
When a bug is resolved, please close the thread by sending an email to ISSUE_NUMBER-done@debbugs.gnu.org.
Next: Envío de una serie de parches, Up: Envío de parches [Contents][Index]
22.6.1 Configuring Git
If you have not done so already, you may wish to set a name and email that
will be associated with your commits (see Telling Git your name in Git User Manual). If you wish to use a
different name or email just for commits in this repository, you can use
git config --local, or edit .git/config in the repository
instead of ~/.gitconfig.
We provide some default settings in etc/git/gitconfig which modify how patches are generated, making them easier to read and apply. These settings can be applied by manually copying them to .git/config in your checkout, or by telling Git to include the whole file:
git config --local include.path ../etc/git/gitconfig
From then on, any changes to etc/git/gitconfig would automatically take effect.
Since the first patch in a series must be sent separately (see Envío de una serie de parches), it can also be helpful to tell git format-patch to
handle the e-mail threading instead of git send-email:
git config --local format.thread shallow git config --local sendemail.thread no
Next: Teams, Previous: Configuring Git, Up: Envío de parches [Contents][Index]
22.6.2 Envío de una serie de parches
Single Patches
The git send-email command is the best way to send both single
patches and patch series (see Multiple Patches) to the Guix mailing
list. Sending patches as email attachments may make them difficult to
review in some mail clients, and git diff does not store commit
metadata.
Nota: The
git send-emailcommand is provided by thesend-emailoutput of thegitpackage, i.e.git:send-email.
The following command will create a patch email from the latest commit, open it in your EDITOR or VISUAL for editing, and send it to the Guix mailing list to be reviewed and merged:
$ git send-email -1 -a --base=auto --to=guix-patches@gnu.org
Tip: To add a prefix to the subject of your patch, you may use the --subject-prefix option. The Guix project uses this to specify that the patch is intended for a branch or repository other than the
masterbranch of https://git.savannah.gnu.org/cgit/guix.git.git send-email -1 -a --base=auto \ --subject-prefix='PATCH core-updates' \ --to=guix-patches@gnu.org
The patch email contains a three-dash separator line after the commit message. You may “annotate” the patch with explanatory text by adding it under this line. If you do not wish to annotate the email, you may drop the -a flag (which is short for --annotate).
The --base=auto flag automatically adds a note at the bottom of the patch of the commit it was based on, making it easier for maintainers to rebase and merge your patch.
If you need to send a revised patch, don’t resend it like this or send a
“fix” patch to be applied on top of the last one; instead, use
git commit -a or git rebase
to modify the commit, and use the
ISSUE_NUMBER@debbugs.gnu.org address and the -v flag
with git send-email.
$ git commit -a
$ git send-email -1 -a --base=auto -v REVISION \
--to=ISSUE_NUMBER@debbugs.gnu.org
You can find out ISSUE_NUMBER either by searching on the mumi interface at issues.guix.gnu.org for the name of your patch or reading the acknowledgement email sent automatically by Debbugs in reply to incoming bugs and patches, which contains the bug number.
Notifying Teams
The etc/teams.scm script may be used to notify all those who may be
interested in your patch of its existence (see Teams). Use
etc/teams.scm list-teams to display all the teams, decide which
team(s) your patch relates to, and use etc/teams.scm cc to output
various git send-email flags which will notify the appropriate
team members, or use etc/teams.scm cc-members to detect the
appropriate teams automatically.
Multiple Patches
While git send-email alone will suffice for a single patch, an
unfortunate flaw in Debbugs means you need to be more careful when sending
multiple patches: if you send them all to the guix-patches@gnu.org
address, a new issue will be created for each patch!
When sending a series of patches, it’s best to send a Git “cover letter”
first, to give reviewers an overview of the patch series. We can create a
directory called outgoing containing both our patch series and a
cover letter called 0000-cover-letter.patch with git
format-patch.
$ git format-patch -NUMBER_COMMITS -o outgoing \
--cover-letter --base=auto
We can now send just the cover letter to the guix-patches@gnu.org address, which will create an issue that we can send the rest of the patches to.
$ git send-email outgoing/0000-cover-letter.patch -a \
--to=guix-patches@debbugs.gnu.org \
$(etc/teams.scm cc-members ...)
$ rm outgoing/0000-cover-letter.patch # we don't want to resend it!
Ensure you edit the email to add an appropriate subject line and blurb before sending it. Note the automatically generated shortlog and diffstat below the blurb.
Once the Debbugs mailer has replied to your cover letter email, you can send the actual patches to the newly-created issue address.
$ git send-email outgoing/*.patch \
--to=ISSUE_NUMBER@debbugs.gnu.org \
$(etc/teams.scm cc-members ...)
$ rm -rf outgoing # we don't need these anymore
Thankfully, this git format-patch dance is not necessary to send
an amended patch series, since an issue already exists for the patchset.
$ git send-email -NUMBER_COMMITS \
-vREVISION --base=auto \
--to ISSUE_NUMBER@debbugs.gnu.org
If need be, you may use --cover-letter -a to send another cover letter, e.g. for explaining what’s changed since the last revision, and these changes are necessary.
Previous: Envío de una serie de parches, Up: Envío de parches [Contents][Index]
22.6.3 Teams
There are several teams mentoring different parts of the Guix source code. To list all those teams, you can run from a Guix checkout:
$ ./etc/teams.scm list-teams id: mentors name: Mentors description: A group of mentors who chaperone contributions by newcomers. members: + Christopher Baines <mail@cbaines.net> + Ricardo Wurmus <rekado@elephly.net> + Mathieu Othacehe <othacehe@gnu.org> + jgart <jgart@dismail.de> + Ludovic Courtès <ludo@gnu.org> …
You can run the following command to have the Mentors team put in CC
of a patch series:
$ git send-email --to ISSUE_NUMBER@debbugs.gnu.org $(./etc/teams.scm cc mentors) *.patch
The appropriate team or teams can also be inferred from the modified files. For instance, if you want to send the two latest commits of the current Git repository to review, you can run:
$ guix shell -D guix [env]$ git send-email --to ISSUE_NUMBER@debbugs.gnu.org $(./etc/teams.scm cc-members HEAD~2 HEAD) *.patch
Next: Acceso al repositorio, Previous: Envío de parches, Up: Contribuir [Contents][Index]
22.7 Seguimiento de errores y parches
This section describes how the Guix project tracks its bug reports and patch submissions.
Next: Debbugs User Interfaces, Up: Seguimiento de errores y parches [Contents][Index]
22.7.1 The Issue Tracker
El seguimiento de los informes de errores y los envíos de parches se realiza
con una instancia de Debbugs en https://bugs.gnu.org. Los informes de
errores se abren para el “paquete” guix (en la jerga de Debbugs),
enviando un correo a bug-guix@gnu.org, mientras que para los envíos
de parches se usa el paquete guix-patches enviando un correo a
guix-patches@gnu.org (see Envío de parches).
Next: Debbugs Usertags, Previous: The Issue Tracker, Up: Seguimiento de errores y parches [Contents][Index]
22.7.2 Debbugs User Interfaces
Hay disponible una interfaz web (¡en realidad dos interfaces web!) para la navegación por las incidencias:
- https://issues.guix.gnu.org proporciona una agradable interfaz 55 paranavegar por los informes de errores y parches, y para participar en las discusiones;
- https://bugs.gnu.org/guix muestra informes de errores;
- https://bugs.gnu.org/guix-patches muestra parches enviados.
Para ver los hilos relacionados con la incidencia número n, visite
‘https://issues.guix.gnu.org/n’ o
‘https://bugs.gnu.org/n’.
Si usa Emacs, puede encontrar más conveniente la interacción con las incidencias mediante debbugs.el, que puede instalar con:
guix install emacs-debbugs
Por ejemplo, para enumerar todos las incidencias abiertas en
guix-patches pulse:
C-u M-x debbugs-gnu RET RET guix-patches RET n y
See Debbugs User Guide, para más información sobre esta útil herramienta.
Previous: Debbugs User Interfaces, Up: Seguimiento de errores y parches [Contents][Index]
22.7.3 Debbugs Usertags
Debbugs provides a feature called usertags that allows any user to tag any bug with an arbitrary label. Bugs can be searched by usertag, so this is a handy way to organize bugs56.
For example, to view all the bug reports (or patches, in the case of
guix-patches) tagged with the usertag powerpc64le-linux for
the user guix, open a URL like the following in a web browser:
https://debbugs.gnu.org/cgi-bin/pkgreport.cgi?tag=powerpc64le-linux;users=guix.
For more information on how to use usertags, please refer to the documentation for Debbugs or the documentation for whatever tool you use to interact with Debbugs.
In Guix, we are experimenting with usertags to keep track of
architecture-specific issues. To facilitate collaboration, all our usertags
are associated with the single user guix. The following usertags
currently exist for that user:
powerpc64le-linuxThe purpose of this usertag is to make it easy to find the issues that matter most for the
powerpc64le-linuxsystem type. Please assign this usertag to bugs or patches that affectpowerpc64le-linuxbut not other system types. In addition, you may use it to identify issues that for some reason are particularly important for thepowerpc64le-linuxsystem type, even if the issue affects other system types, too.reproducibilidadFor issues related to reproducibility. For example, it would be appropriate to assign this usertag to a bug report for a package that fails to build reproducibly.
If you’re a committer and you want to add a usertag, just start using it
with the guix user. If the usertag proves useful to you, consider
updating this section of the manual so that others will know what your
usertag means.
Next: Actualizar el paquete Guix, Previous: Seguimiento de errores y parches, Up: Contribuir [Contents][Index]
22.8 Acceso al repositorio
Everyone can contribute to Guix without having commit access (see Envío de parches). However, for frequent contributors, having write access to the repository can be convenient. As a rule of thumb, a contributor should have accumulated fifty (50) reviewed commits to be considered as a committer and have sustained their activity in the project for at least 6 months. This ensures enough interactions with the contributor, which is essential for mentoring and assessing whether they are ready to become a committer. Commit access should not be thought of as a “badge of honor” but rather as a responsibility a contributor is willing to take to help the project.
The following sections explain how to get commit access, how to be ready to push commits, and the policies and community expectations for commits pushed upstream.
22.8.1 Applying for Commit Access
When you deem it necessary, consider applying for commit access by following these steps:
- Encuentre tres personas que contribuyan al proyecto que puedan
respaldarle. Puede ver la lista de personas que contribuyen en
https://savannah.gnu.org/project/memberlist.php?group=guix. Cada una
de ellas deberá enviar un correo confirmando el respaldo a
guix-maintainers@gnu.org (un alias privado para el colectivo de
personas que mantienen el proyecto), firmado con su clave OpenPGP.
Se espera que dichas personas hayan tenido algunas interacciones con usted en sus contribuciones y sean capaces de juzgar si es suficientemente familiar con las prácticas del proyecto. No es un juicio sobre el valor de su trabajo, por lo que un rechazo debe ser interpretado más bien como un “habrá que probar de nuevo más adelante”.
- Envíe un correo a guix-maintainers@gnu.org expresando su intención,
enumerando a las tres contribuidoras que respaldan su petición, firmado con
su clave OpenPGP que usará para firmar las revisiones, y proporcionando su
huella dactilar (véase a continuación). Véase
https://emailselfdefense.fsf.org/es/ para una introducción a la
criptografía de clave pública con GnuPG.
Configure GnuPG de modo que no use el algorítmo de hash SHA1 nunca para las firmas digitales, el cual se sabe que no es seguro desde 2019, añadiendo, por ejemplo, la siguiente línea en ~/.gnupg/gpg.conf (see GPG Esoteric Options in The GNU Privacy Guard Manual):
digest-algo sha512
- Las personas que mantienen el proyecto decidirán en última instancia si conceder o no el acceso de escritura, habitualmente siguiendo las recomendaciones de las personas de referencia proporcionadas.
-
Una vez haya conseguido acceso, en caso de hacerlo, por favor envíe un
mensaje a guix-devel@gnu.org para notificarlo, de nuevo firmado con
la clave OpenPGP que vaya a usar para firmar las revisiones (hágalo antes de
subir su primera revisión). De esta manera todo el mundo puede enterarse y
asegurarse de que controla su clave OpenPGP.
Importante: Antes de que suba alguna revisión por primera vez, quienes mantienen Guix deben:
- añadir su clave OpenPGP a la rama
keyring; - añadir su firma OpenPGP al archivo .guix-authorizations de la(s) rama(s) a las que vaya a subir código.
- añadir su clave OpenPGP a la rama
- Asegúrese de leer el resto de esta sección y... ¡a disfrutar!
Nota: Quienes mantienen el proyecto están encantadas de proporcionar acceso al repositorio a personas que han contribuido durante algún tiempo y tienen buen registro—¡no sea tímida y no subestime su trabajo!
No obstante, tenga en cuenta que el proyecto está trabajando hacia la automatización de la revisión de parches y el sistema de mezclas, lo que, como consecuencia, puede hacer necesario que menos gente tenga acceso de escritura al repositorio principal. ¡Seguiremos informando!
Todas las revisiones que se suban al repositorio central de Savannah deben
estar firmadas por una clave OpenPGP, y la clave pública debe subirse a su
cuenta de usuaria en Savannah y a servidores públicos de claves, como
keys.openpgp.org. Para configurar que Git firme automáticamente las
revisiones ejecute:
git config commit.gpgsign true # Substitute the fingerprint of your public PGP key. git config user.signingkey CABBA6EA1DC0FF33
To check that commits are signed with correct key, use:
make authenticate
You can prevent yourself from accidentally pushing unsigned or signed with the wrong key commits to Savannah by using the pre-push Git hook located at etc/git/pre-push:
cp etc/git/pre-push .git/hooks/pre-push
It additionally calls make check-channel-news to be sure
news.scm file is correct.
22.8.2 Commit Policy
Si obtiene acceso, por favor asegúrese de seguir la política descrita a continuación (el debate sobre dicha política puede llevarse a cabo en guix-devel@gnu.org).
Los parches no triviales deben enviarse siempre a guix-patches@gnu.org (los parches triviales incluyen la corrección de errores tipográficos, etcétera). Esta lista de correo rellena la base de datos de seguimiento de parches (see Seguimiento de errores y parches).
Para los parches que únicamente añaden un nuevo paquete, y uno simple, está
bien subirlos directamente, si tiene confianza en ello (lo que significa que
lo ha construido de manera correcta en un entorno chroot, y ha hecho un
auditado razonable de derechos de copia y licencias). Lo mismo puede ser
dicho de las actualizaciones de paquetes, excepto actualizaciones que
desencadenen muchas reconstrucciones (por ejemplo, la actualización de
GnuTLS o GLib). Tenemos una lista de correo para las notificaciones de
revisiones (guix-commits@gnu.org), de manera que la gente pueda
enterarse. Antes de subir los cambios, asegúrese de ejecutar git pull
--rebase.
Cuando suba un commit en nombre de alguien, por favor añada una línea de
Signed-off-by al final del mensaje de la revisión—por ejemplo con
git am --signoff. Esto mejora el seguimiento sobre quién hizo qué.
Cuando añada entradas de noticias del canal (see Writing Channel News), compruebe que tienen el formato correcto con la siguiente órden antes de subir los cambios al repositorio:
make check-channel-news
Para cualquier otra cosa, envíe un mensaje a guix-patches@gnu.org y deje tiempo para que sea revisado, sin subir ningún cambio (see Envío de parches). Si no recibe ninguna respuesta después de dos semanas y tiene confianza en ello, está bien subir el cambio.
Esta última parte está sujeta a revisión, para permitir a individualidades que suban cambios que no puedan generar controversia directamente en partes con las que estén familiarizadas.
22.8.3 Addressing Issues
Peer review (see Envío de parches) and tools such as guix
lint (see Invocación de guix lint) and the test suite (see Ejecución de la batería de pruebas) should catch issues before they are pushed. Yet, commits that
“break” functionality might occasionally go through. When that happens,
there are two priorities: mitigating the impact, and understanding what
happened to reduce the chance of similar incidents in the future. The
responsibility for both these things primarily lies with those involved, but
like everything this is a group effort.
Some issues can directly affect all users—for instance because they make
guix pull fail or break core functionality, because they break
major packages (at build time or run time), or because they introduce known
security vulnerabilities.
The people involved in authoring, reviewing, and pushing such commit(s) should be at the forefront to mitigate their impact in a timely fashion: by pushing a followup commit to fix it (if possible), or by reverting it to leave time to come up with a proper fix, and by communicating with other developers about the problem.
If these persons are unavailable to address the issue in time, other committers are entitled to revert the commit(s), explaining in the commit log and on the mailing list what the problem was, with the goal of leaving time to the original committer, reviewer(s), and author(s) to propose a way forward.
Once the problem has been dealt with, it is the responsibility of those involved to make sure the situation is understood. If you are working to understand what happened, focus on gathering information and avoid assigning any blame. Do ask those involved to describe what happened, do not ask them to explain the situation—this would implicitly blame them, which is unhelpful. Accountability comes from a consensus about the problem, learning from it and improving processes so that it’s less likely to reoccur.
22.8.4 Commit Revocation
In order to reduce the possibility of mistakes, committers will have their Savannah account removed from the Guix Savannah project and their key removed from .guix-authorizations after 12 months of inactivity; they can ask to regain commit access by emailing the maintainers, without going through the vouching process.
Maintainers57 may also revoke an individual’s commit rights, as a last resort, if cooperation with the rest of the community has caused too much friction—even within the bounds of the project’s code of conduct (see Contribuir). They would only do so after public or private discussion with the individual and a clear notice. Examples of behavior that hinders cooperation and could lead to such a decision include:
- repeated violation of the commit policy stated above;
- repeated failure to take peer criticism into account;
- breaching trust through a series of grave incidents.
When maintainers resort to such a decision, they notify developers on guix-devel@gnu.org; inquiries may be sent to guix-maintainers@gnu.org. Depending on the situation, the individual may still be welcome to contribute.
22.8.5 Helping Out
Una última cosa: el proyecto sigue adelante porque las contribuidoras no solo suben sus cambios, sino que también ofrecen su tiempo revisando y subiendo cambios de otras personas. Como contribuidora, también se agradece que use su experiencia y derechos de escritura en el repositorio para ayudar a otras personas que quieren contribuir.
Next: Writing Documentation, Previous: Acceso al repositorio, Up: Contribuir [Contents][Index]
22.9 Actualizar el paquete Guix
A veces es deseable actualizar el propio paquete guix (el paquete
definido en (gnu packages package-management), por ejemplo para poner
a disposición del tipo de servicio guix-service-type nuevas
características disponibles en el daemon. Para simplificar esta tarea se
puede usar la siguiente orden:
make update-guix-package
El objetivo de make update-guix-package usa la última revisión
(commit en inglés) de HEAD en su copia local de Guix, calcula el hash
correspondiente a las fuentes de Guix en dicho commit y actualiza los campos
commit, revision y el hash de la definción del paquete
guix.
Para validar que la actualización del hash del paquete guix es
correcta y que se puede construir de manera satisfactoria se puede ejecutar
la siguiente orden en el directorio de su copia de trabajo local de Guix:
./pre-inst-env guix build guix
Para prevenir de actualizaciones accidentales del paquete guix a una
revisión a la que otras personas no puedan hacer referencia se comprueba que
dicha revisión se haya publicado ya en el repositorio git de Guix alojado en
Savannah.
This check can be disabled, at your own peril, by setting the
GUIX_ALLOW_ME_TO_USE_PRIVATE_COMMIT environment variable. When this
variable is set, the updated package source is also added to the store.
This is used as part of the release process of Guix.
Next: Traduciendo Guix, Previous: Actualizar el paquete Guix, Up: Contribuir [Contents][Index]
22.10 Writing Documentation
Guix is documented using the Texinfo system. If you are not yet familiar with it, we accept contributions for documentation in most formats. That includes plain text, Markdown, Org, etc.
Documentation contributions can be sent to guix-patches@gnu.org. Prepend ‘[DOCUMENTATION]’ to the subject.
When you need to make more than a simple addition to the documentation, we prefer that you send a proper patch as opposed to sending an email as described above. See Envío de parches for more information on how to send your patches.
To modify the documentation, you need to edit doc/guix.texi and doc/contributing.texi (which contains this documentation section), or doc/guix-cookbook.texi for the cookbook. If you compiled the Guix repository before, you will have many more .texi files that are translations of these documents. Do not modify them, the translation is managed through Weblate. See Traduciendo Guix for more information.
To render documentation, you must first make sure that you ran
./configure in your source tree (see Ejecución de Guix antes de estar instalado). After that you can run one of the following commands:
- ‘make doc/guix.info’ to compile the Info manual.
You can check it with
info doc/guix.info. - ‘make doc/guix.html’ to compile the HTML version. You can point your browser to the relevant file in the doc/guix.html directory.
- ‘make doc/guix-cookbook.info’ for the cookbook Info manual.
- ‘make doc/guix-cookbook.html’ for the cookbook HTML version.
Previous: Writing Documentation, Up: Contribuir [Contents][Index]
22.11 Traduciendo Guix
Writing code and packages is not the only way to provide a meaningful contribution to Guix. Translating to a language you speak is another example of a valuable contribution you can make. This section is designed to describe the translation process. It gives you advice on how you can get involved, what can be translated, what mistakes you should avoid and what we can do to help you!
Guix is a big project that has multiple components that can be translated. We coordinate the translation effort on a Weblate instance hosted by our friends at Fedora. You will need an account to submit translations.
Some of the software packaged in Guix also contain translations. We do not
host a translation platform for them. If you want to translate a package
provided by Guix, you should contact their developers or find the
information on their website. As an example, you can find the homepage of
the hello package by typing guix show hello. On the
“homepage” line, you will see https://www.gnu.org/software/hello/ as
the homepage.
Many GNU and non-GNU packages can be translated on the Translation Project. Some projects with multiple components have their own platform. For instance, GNOME has its own platform, Damned Lies.
Guix has five components hosted on Weblate.
-
guixcontains all the strings from the Guix software (the guided system installer, the package manager, etc), excluding packages. -
packagescontains the synopsis (single-sentence description of a package) and description (longer description) of packages in Guix. -
websitecontains the official Guix website, except for blog posts and multimedia content. -
documentation-manualcorresponds to this manual. -
documentation-cookbookis the component for the cookbook.
General Directions
Once you get an account, you should be able to select a component from the guix project, and select a language. If your language does not appear in the list, go to the bottom and click on the “Start new translation” button. Select the language you want to translate to from the list, to start your new translation.
Like lots of other free software packages, Guix uses GNU Gettext for its translations, with which translatable strings are extracted from the source code to so-called PO files.
Even though PO files are text files, changes should not be made with a text editor but with PO editing software. Weblate integrates PO editing functionality. Alternatively, translators can use any of various free-software tools for filling in translations, of which Poedit is one example, and (after logging in) upload the changed file. There is also a special PO editing mode for users of GNU Emacs. Over time translators find out what software they are happy with and what features they need.
On Weblate, you will find various links to the editor, that will show various subsets (or all) of the strings. Have a look around and at the documentation to familiarize yourself with the platform.
Translation Components
In this section, we provide more detailed guidance on the translation process, as well as details on what you should or should not do. When in doubt, please contact us, we will be happy to help!
- guix
Guix is written in the Guile programming language, and some strings contain special formatting that is interpreted by Guile. These special formatting should be highlighted by Weblate. They start with
~followed by one or more characters.When printing the string, Guile replaces the special formatting symbols with actual values. For instance, the string ‘ambiguous package specification `~a'’ would be substituted to contain said package specification instead of
~a. To properly translate this string, you must keep the formatting code in your translation, although you can place it where it makes sense in your language. For instance, the French translation says ‘spécification du paquet « ~a » ambiguë’ because the adjective needs to be placed in the end of the sentence.If there are multiple formatting symbols, make sure to respect the order. Guile does not know in which order you intended the string to be read, so it will substitute the symbols in the same order as the English sentence.
As an example, you cannot translate ‘package '~a' has been superseded by '~a'’ by ‘'~a' superseeds package '~a'’, because the meaning would be reversed. If foo is superseded by bar, the translation would read ‘'foo' superseeds package 'bar'’. To work around this problem, it is possible to use more advanced formatting to select a given piece of data, instead of following the default English order. See Formatted Output in GNU Guile Reference Manual, for more information on formatting in Guile.
- paquetes
-
Package descriptions occasionally contain Texinfo markup (see Sinopsis y descripciones). Texinfo markup looks like ‘@code{rm -rf}’, ‘@emph{important}’, etc. When translating, please leave markup as is.
The characters after “@” form the name of the markup, and the text between “{” and “}” is its content. In general, you should not translate the content of markup like
@code, as it contains literal code that do not change with language. You can translate the content of formatting markup such as@emph,@i,@itemize,@item. However, do not translate the name of the markup, or it will not be recognized. Do not translate the word after@end, it is the name of the markup that is closed at this position (e.g.@itemize ... @end itemize). - documentation-manual and documentation-cookbook
-
The first step to ensure a successful translation of the manual is to find and translate the following strings first:
-
version.texi: Translate this string asversion-xx.texi, wherexxis your language code (the one shown in the URL on weblate). -
contributing.texi: Translate this string ascontributing.xx.texi, wherexxis the same language code. -
Top: Do not translate this string, it is important for Texinfo. If you translate it, the document will be empty (missing a Top node). Please look for it, and registerTopas its translation.
Translating these strings first ensure we can include your translation in the guix repository without breaking the make process or the
guix pullmachinery.The manual and the cookbook both use Texinfo. As for
packages, please keep Texinfo markup as is. There are more possible markup types in the manual than in the package descriptions. In general, do not translate the content of@code,@file,@var,@value, etc. You should translate the content of formatting markup such as@emph,@i, etc.The manual contains sections that can be referred to by name by
@ref,@xrefand@pxref. We have a mechanism in place so you do not have to translate their content. If you keep the English title, we will automatically replace it with your translation of that title. This ensures that Texinfo will always be able to find the node. If you decide to change the translation of the title, the references will automatically be updated and you will not have to update them all yourself.When translating references from the cookbook to the manual, you need to replace the name of the manual and the name of the section. For instance, to translate
@pxref{Defining Packages,,, guix, GNU Guix Reference Manual}, you would replaceDefining Packageswith the title of that section in the translated manual only if that title is translated. If the title is not translated in your language yet, do not translate it here, or the link will be broken. Replaceguixwithguix.xxwherexxis your language code.GNU Guix Reference Manualis the text of the link. You can translate it however you wish. -
- website
-
The website pages are written using SXML, an s-expression version of HTML, the basic language of the web. We have a process to extract translatable strings from the source, and replace complex s-expressions with a more familiar XML markup, where each markup is numbered. Translators can arbitrarily change the ordering, as in the following example.
#. TRANSLATORS: Defining Packages is a section name #. in the English (en) manual. #: apps/base/templates/about.scm:64 msgid "Packages are <1>defined<1.1>en</1.1><1.2>Defining-Packages.html</1.2></1> as native <2>Guile</2> modules." msgstr "Pakete werden als reine <2>Guile</2>-Module <1>definiert<1.1>de</1.1><1.2>Pakete-definieren.html</1.2></1>."
Note that you need to include the same markups. You cannot skip any.
In case you make a mistake, the component might fail to build properly with your language, or even make guix pull fail. To prevent that, we have a process in place to check the content of the files before pushing to our repository. We will not be able to update the translation for your language in Guix, so we will notify you (through weblate and/or by email) so you get a chance to fix the issue.
Outside of Weblate
Currently, some parts of Guix cannot be translated on Weblate, help wanted!
-
guix pullnews can be translated in news.scm, but is not available from Weblate. If you want to provide a translation, you can prepare a patch as described above, or simply send us your translation with the name of the news entry you translated and your language. See Escribir de noticias del canal, for more information about channel news. - Guix blog posts cannot currently be translated.
- The installer script (for foreign distributions) is entirely in English.
- Some of the libraries Guix uses cannot be translated or are translated outside of the Guix project. Guile itself is not internationalized.
- Other manuals linked from this manual or the cookbook might not be translated.
Conditions for Inclusion
There are no conditions for adding new translations of the guix and
guix-packages components, other than they need at least one
translated string. New languages will be added to Guix as soon as
possible. The files may be removed if they fall out of sync and have no
more translated strings.
Given that the web site is dedicated to new users, we want its translation to be as complete as possible before we include it in the language menu. For a new language to be included, it needs to reach at least 80% completion. When a language is included, it may be removed in the future if it stays out of sync and falls below 60% completion.
The manual and cookbook are automatically added in the default compilation target. Every time we synchronize translations, developers need to recompile all the translated manuals and cookbooks. This is useless for what is essentially the English manual or cookbook. Therefore, we will only include a new language when it reaches 10% completion in the component. When a language is included, it may be removed in the future if it stays out of sync and falls below 5% completion.
Translation Infrastructure
Weblate is backed by a git repository from which it discovers new strings to translate and pushes new and updated translations. Normally, it would be enough to give it commit access to our repositories. However, we decided to use a separate repository for two reasons. First, we would have to give Weblate commit access and authorize its signing key, but we do not trust it in the same way we trust guix developers, especially since we do not manage the instance ourselves. Second, if translators mess something up, it can break the generation of the website and/or guix pull for all our users, independently of their language.
For these reasons, we use a dedicated repository to host translations, and we synchronize it with our guix and artworks repositories after checking no issue was introduced in the translation.
Developers can download the latest PO files from weblate in the Guix
repository by running the make download-po command. It will
automatically download the latest files from weblate, reformat them to a
canonical form, and check they do not contain issues. The manual needs to
be built again to check for additional issues that might crash Texinfo.
Before pushing new translation files, developers should add them to the make machinery so the translations are actually available. The process differs for the various components.
- New po files for the
guixandpackagescomponents must be registered by adding the new language to po/guix/LINGUAS or po/packages/LINGUAS. - New po files for the
documentation-manualcomponent must be registered by adding the file name toDOC_PO_FILESin po/doc/local.mk, the generated %D%/guix.xx.texi manual toinfo_TEXINFOSin doc/local.mk and the generated %D%/guix.xx.texi and %D%/contributing.xx.texi toTRANSLATED_INFOalso in doc/local.mk. - New po files for the
documentation-cookbookcomponent must be registered by adding the file name toDOC_COOKBOOK_PO_FILESin po/doc/local.mk, the generated %D%/guix-cookbook.xx.texi manual toinfo_TEXINFOSin doc/local.mk and the generated %D%/guix-cookbook.xx.texi toTRANSLATED_INFOalso in doc/local.mk. - New po files for the
websitecomponent must be added to theguix-artworkrepository, in website/po/. website/po/LINGUAS and website/po/ietf-tags.scm must be updated accordingly (see website/i18n-howto.txt for more information on the process).
Next: Licencia de documentación libre GNU, Previous: Contribuir, Up: GNU Guix [Contents][Index]
23 Reconocimientos
Guix está basado en el gestor de paquetes Nix, que fue diseñado e implementado por Eelco Dolstra, con contribuciones de otra gente (véase el archivo nix/AUTHORS en Guix). Nix fue pionero en la gestión de paquetes funcional, y promovió características sin precedentes, como las actualizaciones y reversiones de paquetes transaccionales, perfiles por usuaria y un proceso de compilación referencialmente transparente. Sin este trabajo, Guix no existiría.
Las distribuciones de software basadas en Nix, Nixpkgs y NixOS, también han sido una inspiración para Guix.
GNU Guix en sí es un trabajo colectivo con contribuciones de un número de gente. Mire el archivo AUTHORS en Guix para más información sobre esa gente maja. El archivo THANKS enumera personas que han ayudado informando de errores, se han encargado de infraestructura, han proporcionando arte y temas, han realizado sugerencias, y más—¡gracias!
Next: Índice de conceptos, Previous: Reconocimientos, Up: GNU Guix [Contents][Index]
Appendix A Licencia de documentación libre GNU
Copyright © 2000, 2001, 2002, 2007, 2008 Free Software Foundation, Inc. https://fsf.org/ Everyone is permitted to copy and distribute verbatim copies of this license document, but changing it is not allowed.
- PREAMBLE
The purpose of this License is to make a manual, textbook, or other functional and useful document free in the sense of freedom: to assure everyone the effective freedom to copy and redistribute it, with or without modifying it, either commercially or noncommercially. Secondarily, this License preserves for the author and publisher a way to get credit for their work, while not being considered responsible for modifications made by others.
This License is a kind of “copyleft”, which means that derivative works of the document must themselves be free in the same sense. It complements the GNU General Public License, which is a copyleft license designed for free software.
We have designed this License in order to use it for manuals for free software, because free software needs free documentation: a free program should come with manuals providing the same freedoms that the software does. But this License is not limited to software manuals; it can be used for any textual work, regardless of subject matter or whether it is published as a printed book. We recommend this License principally for works whose purpose is instruction or reference.
- APPLICABILITY AND DEFINITIONS
This License applies to any manual or other work, in any medium, that contains a notice placed by the copyright holder saying it can be distributed under the terms of this License. Such a notice grants a world-wide, royalty-free license, unlimited in duration, to use that work under the conditions stated herein. The “Document”, below, refers to any such manual or work. Any member of the public is a licensee, and is addressed as “you”. You accept the license if you copy, modify or distribute the work in a way requiring permission under copyright law.
A “Modified Version” of the Document means any work containing the Document or a portion of it, either copied verbatim, or with modifications and/or translated into another language.
A “Secondary Section” is a named appendix or a front-matter section of the Document that deals exclusively with the relationship of the publishers or authors of the Document to the Document’s overall subject (or to related matters) and contains nothing that could fall directly within that overall subject. (Thus, if the Document is in part a textbook of mathematics, a Secondary Section may not explain any mathematics.) The relationship could be a matter of historical connection with the subject or with related matters, or of legal, commercial, philosophical, ethical or political position regarding them.
The “Invariant Sections” are certain Secondary Sections whose titles are designated, as being those of Invariant Sections, in the notice that says that the Document is released under this License. If a section does not fit the above definition of Secondary then it is not allowed to be designated as Invariant. The Document may contain zero Invariant Sections. If the Document does not identify any Invariant Sections then there are none.
The “Cover Texts” are certain short passages of text that are listed, as Front-Cover Texts or Back-Cover Texts, in the notice that says that the Document is released under this License. A Front-Cover Text may be at most 5 words, and a Back-Cover Text may be at most 25 words.
A “Transparent” copy of the Document means a machine-readable copy, represented in a format whose specification is available to the general public, that is suitable for revising the document straightforwardly with generic text editors or (for images composed of pixels) generic paint programs or (for drawings) some widely available drawing editor, and that is suitable for input to text formatters or for automatic translation to a variety of formats suitable for input to text formatters. A copy made in an otherwise Transparent file format whose markup, or absence of markup, has been arranged to thwart or discourage subsequent modification by readers is not Transparent. An image format is not Transparent if used for any substantial amount of text. A copy that is not “Transparent” is called “Opaque”.
Examples of suitable formats for Transparent copies include plain ASCII without markup, Texinfo input format, LaTeX input format, SGML or XML using a publicly available DTD, and standard-conforming simple HTML, PostScript or PDF designed for human modification. Examples of transparent image formats include PNG, XCF and JPG. Opaque formats include proprietary formats that can be read and edited only by proprietary word processors, SGML or XML for which the DTD and/or processing tools are not generally available, and the machine-generated HTML, PostScript or PDF produced by some word processors for output purposes only.
The “Title Page” means, for a printed book, the title page itself, plus such following pages as are needed to hold, legibly, the material this License requires to appear in the title page. For works in formats which do not have any title page as such, “Title Page” means the text near the most prominent appearance of the work’s title, preceding the beginning of the body of the text.
The “publisher” means any person or entity that distributes copies of the Document to the public.
A section “Entitled XYZ” means a named subunit of the Document whose title either is precisely XYZ or contains XYZ in parentheses following text that translates XYZ in another language. (Here XYZ stands for a specific section name mentioned below, such as “Acknowledgements”, “Dedications”, “Endorsements”, or “History”.) To “Preserve the Title” of such a section when you modify the Document means that it remains a section “Entitled XYZ” according to this definition.
The Document may include Warranty Disclaimers next to the notice which states that this License applies to the Document. These Warranty Disclaimers are considered to be included by reference in this License, but only as regards disclaiming warranties: any other implication that these Warranty Disclaimers may have is void and has no effect on the meaning of this License.
- VERBATIM COPYING
You may copy and distribute the Document in any medium, either commercially or noncommercially, provided that this License, the copyright notices, and the license notice saying this License applies to the Document are reproduced in all copies, and that you add no other conditions whatsoever to those of this License. You may not use technical measures to obstruct or control the reading or further copying of the copies you make or distribute. However, you may accept compensation in exchange for copies. If you distribute a large enough number of copies you must also follow the conditions in section 3.
You may also lend copies, under the same conditions stated above, and you may publicly display copies.
- COPYING IN QUANTITY
If you publish printed copies (or copies in media that commonly have printed covers) of the Document, numbering more than 100, and the Document’s license notice requires Cover Texts, you must enclose the copies in covers that carry, clearly and legibly, all these Cover Texts: Front-Cover Texts on the front cover, and Back-Cover Texts on the back cover. Both covers must also clearly and legibly identify you as the publisher of these copies. The front cover must present the full title with all words of the title equally prominent and visible. You may add other material on the covers in addition. Copying with changes limited to the covers, as long as they preserve the title of the Document and satisfy these conditions, can be treated as verbatim copying in other respects.
If the required texts for either cover are too voluminous to fit legibly, you should put the first ones listed (as many as fit reasonably) on the actual cover, and continue the rest onto adjacent pages.
If you publish or distribute Opaque copies of the Document numbering more than 100, you must either include a machine-readable Transparent copy along with each Opaque copy, or state in or with each Opaque copy a computer-network location from which the general network-using public has access to download using public-standard network protocols a complete Transparent copy of the Document, free of added material. If you use the latter option, you must take reasonably prudent steps, when you begin distribution of Opaque copies in quantity, to ensure that this Transparent copy will remain thus accessible at the stated location until at least one year after the last time you distribute an Opaque copy (directly or through your agents or retailers) of that edition to the public.
It is requested, but not required, that you contact the authors of the Document well before redistributing any large number of copies, to give them a chance to provide you with an updated version of the Document.
- MODIFICATIONS
You may copy and distribute a Modified Version of the Document under the conditions of sections 2 and 3 above, provided that you release the Modified Version under precisely this License, with the Modified Version filling the role of the Document, thus licensing distribution and modification of the Modified Version to whoever possesses a copy of it. In addition, you must do these things in the Modified Version:
- Use in the Title Page (and on the covers, if any) a title distinct from that of the Document, and from those of previous versions (which should, if there were any, be listed in the History section of the Document). You may use the same title as a previous version if the original publisher of that version gives permission.
- List on the Title Page, as authors, one or more persons or entities responsible for authorship of the modifications in the Modified Version, together with at least five of the principal authors of the Document (all of its principal authors, if it has fewer than five), unless they release you from this requirement.
- State on the Title page the name of the publisher of the Modified Version, as the publisher.
- Preserve all the copyright notices of the Document.
- Add an appropriate copyright notice for your modifications adjacent to the other copyright notices.
- Include, immediately after the copyright notices, a license notice giving the public permission to use the Modified Version under the terms of this License, in the form shown in the Addendum below.
- Preserve in that license notice the full lists of Invariant Sections and required Cover Texts given in the Document’s license notice.
- Include an unaltered copy of this License.
- Preserve the section Entitled “History”, Preserve its Title, and add to it an item stating at least the title, year, new authors, and publisher of the Modified Version as given on the Title Page. If there is no section Entitled “History” in the Document, create one stating the title, year, authors, and publisher of the Document as given on its Title Page, then add an item describing the Modified Version as stated in the previous sentence.
- Preserve the network location, if any, given in the Document for public access to a Transparent copy of the Document, and likewise the network locations given in the Document for previous versions it was based on. These may be placed in the “History” section. You may omit a network location for a work that was published at least four years before the Document itself, or if the original publisher of the version it refers to gives permission.
- For any section Entitled “Acknowledgements” or “Dedications”, Preserve the Title of the section, and preserve in the section all the substance and tone of each of the contributor acknowledgements and/or dedications given therein.
- Preserve all the Invariant Sections of the Document, unaltered in their text and in their titles. Section numbers or the equivalent are not considered part of the section titles.
- Delete any section Entitled “Endorsements”. Such a section may not be included in the Modified Version.
- Do not retitle any existing section to be Entitled “Endorsements” or to conflict in title with any Invariant Section.
- Preserve any Warranty Disclaimers.
If the Modified Version includes new front-matter sections or appendices that qualify as Secondary Sections and contain no material copied from the Document, you may at your option designate some or all of these sections as invariant. To do this, add their titles to the list of Invariant Sections in the Modified Version’s license notice. These titles must be distinct from any other section titles.
You may add a section Entitled “Endorsements”, provided it contains nothing but endorsements of your Modified Version by various parties—for example, statements of peer review or that the text has been approved by an organization as the authoritative definition of a standard.
You may add a passage of up to five words as a Front-Cover Text, and a passage of up to 25 words as a Back-Cover Text, to the end of the list of Cover Texts in the Modified Version. Only one passage of Front-Cover Text and one of Back-Cover Text may be added by (or through arrangements made by) any one entity. If the Document already includes a cover text for the same cover, previously added by you or by arrangement made by the same entity you are acting on behalf of, you may not add another; but you may replace the old one, on explicit permission from the previous publisher that added the old one.
The author(s) and publisher(s) of the Document do not by this License give permission to use their names for publicity for or to assert or imply endorsement of any Modified Version.
- COMBINING DOCUMENTS
You may combine the Document with other documents released under this License, under the terms defined in section 4 above for modified versions, provided that you include in the combination all of the Invariant Sections of all of the original documents, unmodified, and list them all as Invariant Sections of your combined work in its license notice, and that you preserve all their Warranty Disclaimers.
The combined work need only contain one copy of this License, and multiple identical Invariant Sections may be replaced with a single copy. If there are multiple Invariant Sections with the same name but different contents, make the title of each such section unique by adding at the end of it, in parentheses, the name of the original author or publisher of that section if known, or else a unique number. Make the same adjustment to the section titles in the list of Invariant Sections in the license notice of the combined work.
In the combination, you must combine any sections Entitled “History” in the various original documents, forming one section Entitled “History”; likewise combine any sections Entitled “Acknowledgements”, and any sections Entitled “Dedications”. You must delete all sections Entitled “Endorsements.”
- COLLECTIONS OF DOCUMENTS
You may make a collection consisting of the Document and other documents released under this License, and replace the individual copies of this License in the various documents with a single copy that is included in the collection, provided that you follow the rules of this License for verbatim copying of each of the documents in all other respects.
You may extract a single document from such a collection, and distribute it individually under this License, provided you insert a copy of this License into the extracted document, and follow this License in all other respects regarding verbatim copying of that document.
- AGGREGATION WITH INDEPENDENT WORKS
A compilation of the Document or its derivatives with other separate and independent documents or works, in or on a volume of a storage or distribution medium, is called an “aggregate” if the copyright resulting from the compilation is not used to limit the legal rights of the compilation’s users beyond what the individual works permit. When the Document is included in an aggregate, this License does not apply to the other works in the aggregate which are not themselves derivative works of the Document.
If the Cover Text requirement of section 3 is applicable to these copies of the Document, then if the Document is less than one half of the entire aggregate, the Document’s Cover Texts may be placed on covers that bracket the Document within the aggregate, or the electronic equivalent of covers if the Document is in electronic form. Otherwise they must appear on printed covers that bracket the whole aggregate.
- TRANSLATION
Translation is considered a kind of modification, so you may distribute translations of the Document under the terms of section 4. Replacing Invariant Sections with translations requires special permission from their copyright holders, but you may include translations of some or all Invariant Sections in addition to the original versions of these Invariant Sections. You may include a translation of this License, and all the license notices in the Document, and any Warranty Disclaimers, provided that you also include the original English version of this License and the original versions of those notices and disclaimers. In case of a disagreement between the translation and the original version of this License or a notice or disclaimer, the original version will prevail.
If a section in the Document is Entitled “Acknowledgements”, “Dedications”, or “History”, the requirement (section 4) to Preserve its Title (section 1) will typically require changing the actual title.
- TERMINATION
You may not copy, modify, sublicense, or distribute the Document except as expressly provided under this License. Any attempt otherwise to copy, modify, sublicense, or distribute it is void, and will automatically terminate your rights under this License.
However, if you cease all violation of this License, then your license from a particular copyright holder is reinstated (a) provisionally, unless and until the copyright holder explicitly and finally terminates your license, and (b) permanently, if the copyright holder fails to notify you of the violation by some reasonable means prior to 60 days after the cessation.
Moreover, your license from a particular copyright holder is reinstated permanently if the copyright holder notifies you of the violation by some reasonable means, this is the first time you have received notice of violation of this License (for any work) from that copyright holder, and you cure the violation prior to 30 days after your receipt of the notice.
Termination of your rights under this section does not terminate the licenses of parties who have received copies or rights from you under this License. If your rights have been terminated and not permanently reinstated, receipt of a copy of some or all of the same material does not give you any rights to use it.
- FUTURE REVISIONS OF THIS LICENSE
The Free Software Foundation may publish new, revised versions of the GNU Free Documentation License from time to time. Such new versions will be similar in spirit to the present version, but may differ in detail to address new problems or concerns. See https://www.gnu.org/copyleft/.
Each version of the License is given a distinguishing version number. If the Document specifies that a particular numbered version of this License “or any later version” applies to it, you have the option of following the terms and conditions either of that specified version or of any later version that has been published (not as a draft) by the Free Software Foundation. If the Document does not specify a version number of this License, you may choose any version ever published (not as a draft) by the Free Software Foundation. If the Document specifies that a proxy can decide which future versions of this License can be used, that proxy’s public statement of acceptance of a version permanently authorizes you to choose that version for the Document.
- RELICENSING
“Massive Multiauthor Collaboration Site” (or “MMC Site”) means any World Wide Web server that publishes copyrightable works and also provides prominent facilities for anybody to edit those works. A public wiki that anybody can edit is an example of such a server. A “Massive Multiauthor Collaboration” (or “MMC”) contained in the site means any set of copyrightable works thus published on the MMC site.
“CC-BY-SA” means the Creative Commons Attribution-Share Alike 3.0 license published by Creative Commons Corporation, a not-for-profit corporation with a principal place of business in San Francisco, California, as well as future copyleft versions of that license published by that same organization.
“Incorporate” means to publish or republish a Document, in whole or in part, as part of another Document.
An MMC is “eligible for relicensing” if it is licensed under this License, and if all works that were first published under this License somewhere other than this MMC, and subsequently incorporated in whole or in part into the MMC, (1) had no cover texts or invariant sections, and (2) were thus incorporated prior to November 1, 2008.
The operator of an MMC Site may republish an MMC contained in the site under CC-BY-SA on the same site at any time before August 1, 2009, provided the MMC is eligible for relicensing.
ADDENDUM: How to use this License for your documents
To use this License in a document you have written, include a copy of the License in the document and put the following copyright and license notices just after the title page:
Copyright (C) year your name. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.3 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the section entitled ``GNU Free Documentation License''.
If you have Invariant Sections, Front-Cover Texts and Back-Cover Texts, replace the “with…Texts.” line with this:
with the Invariant Sections being list their titles, with
the Front-Cover Texts being list, and with the Back-Cover Texts
being list.
If you have Invariant Sections without Cover Texts, or some other combination of the three, merge those two alternatives to suit the situation.
If your document contains nontrivial examples of program code, we recommend releasing these examples in parallel under your choice of free software license, such as the GNU General Public License, to permit their use in free software.
Next: Índice programático, Previous: Licencia de documentación libre GNU, Up: GNU Guix [Contents][Index]
Índice de conceptos
| Jump to: | .
/
A B C D E F G H I J K L M N O P Q R S T U V W X Z Ú |
|---|
| Jump to: | .
/
A B C D E F G H I J K L M N O P Q R S T U V W X Z Ú |
|---|
Previous: Índice de conceptos, Up: GNU Guix [Contents][Index]
Índice programático
| Jump to: | #
$
%
'
(
,
>
`
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z |
|---|
| Jump to: | #
$
%
'
(
,
>
`
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z |
|---|